
Abstract
Testing and debugging have been the most significant steps of software development since it is tricky for engineers to create error-free software. Software testing takes place after coding with the goal of finding flaws. If errors are found, debugging would be done to identify the source of the errors so that they may be fixed. Detecting as well as locating defects are thus two essential stages in the creation of software. We have created a unique approach with the following two working phases to generate a minimized test suite that is capable of both detecting and localizing faults. In the initial test suite minimization process, the cases were generated and minimized based on the objectives such as D-score and coverage by the utilization of the proposed Blue Monkey Customized Black Widow (BMCBW) algorithm. After this test suite minimization, the fault validation is done which includes the process of fault detection and localization. For this fault validation, we have utilized an improved Long Short-Term Memory (LSTM). At 90% of the learning rate the accuracy of the presented work is 0.97%, 2.20%, 2.52%, 0.97% and 2.81% is better than the other extant models like AOA, COOT, BES, BMO and BWO methods. The results obtained proved that our Blue Monkey Customized Black Widow Optimization-based fault detection and localization approach can provide superior outcomes.
Keywords
Nomenclature
Additional Greedy Method call Sequence Archimedes Optimization Algorithm Average fault Detection capability Branch Coverage Bald eagle Search Algorithm Bidirectional Gated Recurrent Unit Blue Monkey Customized Black Widow Blue Monkey Optimization Black Widow Optimization Cross Entropy Convolutional Neural Network Cannibalism Rate Deep Belief Network Differential Evolution Deep Neural Network False Detection Rate Genetic Algorithm Long Short-Term Memory Mutant Based Fault Localization Mathew’s Correlation Co-efficient Multi-Objective Particle Swarm Optimization Non-dominated Sorting Genetic Algorithm II Opposition Based Learning Principal Component Analysis Particle Swarm Optimization Rectified Linear Unit Recurrent Neural Network Statement-Based Fault Localization Software Complexity Statement Coverage Software Development Life Cycle System Under Test Support Vector Machine Test Case Prioritization
Introduction
Software testing is one of the most labor-intensive and crucial phases of the software development life cycle. It is very labor-intensive and expensive work and accounts for approximately 50–60% of the cost of software development. Software testing plays a crucial role in the software development life cycle (SDLC). There are two approaches for the testing work manual testing and automated testing [17]. Software testing is done to detect faults. Testing of software is done to find faults. If a fault is there then it needs to be detected, located, and then resolved. Fault detection means testing the system under test (SUT) for finding faults whereas fault localization means locating the suspicious lines which were the cause of occurred fault [11,18].
Fault detection is done under two conditions; software development and when changes are made to the existing software. While fault localization requires information that aids in precisely finding the problems, fault detection requires test information that aids in early fault detection [4,12]. For dealing with modification in the existing software, regression testing is done. To minimize the effort while regression testing, test cases may be minimized, selected, or prioritized. Further, optimization techniques may also be used to minimize test cases based on considered adequacy criteria like code coverage, mutation coverage, fault history coverage, execution time, etc. Various approaches have been proposed for fault detection while regression testing where optimization techniques such as Genetic algorithm with diversity, NSGA-II, MOPSO, Harmony search, etc. have been used [8,9,16,24].
On the other hand, fault localization needs test cases that carry the maximum diagnostic information. Statement-based (SBFL) and mutant-based (MBFL) techniques are widely used for locating faults. In SBFL techniques suspiciousness of each line is calculated using the pass/fail and statement coverage information of test cases whereas in MBFL techniques, pass/fail and killed-mutant coverage information by test cases is used. MBFL techniques have better fault localization accuracy as compared to SBFL techniques [7,25,29]. For fault localization, if all test cases are used for calculating the suspiciousness value of code then a lot of effort would be required. Thus, optimization techniques may be used with fault localization techniques to reduce the required effort [13,15,22]. While reducing test cases for fault localization one must tread caution because test reduction may remove test cases that carry the maximum diagnostic information. The resolution for this problem is to use offline techniques of fault localization in combination with fault detection techniques. These techniques do not require pass/fail information of test cases. A reduced test suite obtained by the combination of these techniques would be available before regression testing and thus it may help for both fault detection and localization. As the minimization of test cases is done for each task, a combined approach may be proposed which minimizes test cases for both detecting and locating faults [5,14,19,28]. A combined approach was developed for minimizing test cases for both detecting and locating faults. In their approach test cases have been minimized based on the maximization of code coverage and a number of partitions of code. After creating an individual set of test cases for each detecting and locating faults, integration of these sets is done to get test cases that are appropriate for both instead of individual activity [2,21,23,31]. All these works have been done to integrate the detection and localization of faults. In our paper, we have developed an optimization-dependent fault detection and localization approach which contains the following contributions.
An optimization-based approach that integrated the activities of both fault detection and localization is developed in this work.
In order to develop a minimized test suite having the ability to both detect and locate faults, we have introduced a novel BMCBW algorithm, which maximizes the D-score and coverage.
In order to provide effective fault detection and localization we have introduced an improved LSTM, which utilizes leaky RELU as its activation function.
This essay has been set up as follows: Section 2 describes recent research on software fault localization or detection. Section 3 provides a detailed explanation of the proposed optimization-based fault detection and classification approach. Section 4 explains the findings of this study. Section 5 concludes this work. The next section provides references for this work.
Literature review
Some recent works which are related to software fault detection have been described below.
In 2020, Jianlei Chi et al. [6] claimed that TCP (Test Case Prioritization) could be effectively guided by dynamic function call sequences. The same collection of functions and statements may execute in vastly different ways. In order to forecast fault detection capacity, mapping software behaviors to unit-based (function/statement) coverage may not be sufficient. A new strategy (Additional Greedy method Call sequence) extends the original additional greedy coverage algorithm in TCP techniques using dynamic relation-dependent coverage as a measurement. Results demonstrate that AGC achieves the greatest mean APFD value and outperforms previous techniques on large programs in terms of bug detection capability. As the program got bigger, the performance shows a growing tendency.
In 2020, Tiantian Wang et al. [26] suggested a method for fault localization that examines the context of failure propagation and locates suspect statements by comparing the execution status and structural semantics of the defective program and a sample program. Code variation and failure propagation were lessened by the interactive study of value sequences and structure semantics. When there were enough sample programs, the experimental results demonstrated that the approach can efficiently identify suspicious statements and offer assistance for fault repair.
In 2020, Manju Khari et al. [17] suggested a statistical model for understanding the numerous aspects that affect the testing cost, quality, and effort. Here the project duration, Software Complexity (SC), testing tools, and automated test suite creation were examined while contrasting it with the entire software test automation, with the goal of determining how much automation influences the cost, quality, and effort in practice. Additionally, the data showed that SC had a very minimal impact on both cost and effort.
In 2021, Anu Bajaj et al. [3] suggested a discrete cuckoo search algorithm for test case prioritization. The order of the test cases was a concern of the prioritization problem. To further balance the trade-off between exploration and exploitation, the genetic algorithm’s mutation operator was added to the cuckoo search algorithm. In-depth comparisons are made between the suggested algorithms, current cutting-edge algorithms, and the baseline method using four case examples.
In 2021, N. Gokilavani et al. [10] used a dataset with 12,486 test cases from the Firefox bugs report as their starting point. Dealing with such a large number of test cases might take all of the time and resources, which was detrimental to the proposed job. The dataset was go through pre-processing in order to eliminate any undesirable information from problem reports, such as assertions in some circumstances. Then, using the PCA approach, necessary features were chosen, and dimensionality reduction was used to establish the attributes for grouping and prioritization. The agglomerative K-means clustering technique was used following the feature selection procedure to create clustered groups. The ranking algorithm prioritizes the test cases in the clusters after the clustering procedure. By examining the priority ranking for clusters, the sum of the distinct faults discovered based on the number of test cases, the adjacency matrix between test cases, and the fault detection rate, the performance of this work was examined and cross-verified.
In 2021, Namita Panda et al. [20] suggested a technique called Requirement-based test scenario prioritizing to-order test scenarios centered on requirements gathered from end users for creating software applications, the author. The functional requirements were gathered and given some weight based on many considerations. The requirements gathered from the end users were used to create test scenarios. The suggested strategy was assessed using the average percentage of fault detection metric and is discovered to be very effective in prioritizing early test scenario defects and fault detection.
In 2021, Xi Xiao et al. [27] proposed ALBFL, a novel neural ranking model that integrated static and dynamic information, in order to improve the capability of identifying software defects with statement granularity. ALBFL achieves outstanding fault localization accuracy. A transformer encoder was used by ALBFL to first understand the semantic aspects of the source code. It then makes use of a self-attention layer to combine both static and dynamic characteristics. Finally, a LambdaRank model was fed with the integrated features so that it may list the questionable claims in descending order based on their ranking scores.
In 2022, Neha Gupta et al. [11] developed a code and mutant coverage-based multi-objective strategy to create a reduced test suite capable of both identifying and locating problems. The NSGA-II method had been used to optimize test cases. Results on projects from the Defects4j repository show that the suggested approach could provide minimized test suites with the ability to detect 95.16 percent of faults and locate all detected faults with fault localization scores nearly equal to those of the full test suite
Also, some of the features and limitations of this described publication were given in Table 1.
Review of the existing works
Review of the existing works
The main drawbacks of the existing approaches includes: fault localisation is not good, failure to defect the faults, risk of requirements, computational time is more, the performance of cluster based technique is affected. If test suite reduction can be integrated for both activities, then less effort will be required by testers. Although many methods have been developed to provide efficient faults detection and localization, the average test suit reduction rate should be further improved. As a result, using the suggested method eliminates the problems with existing models that were previously discussed. As a consequence, we have developed a novel fault detection and localization approach which is described below.
Proposed methodology on test suite optimization under multi-objective constraints
Software is tested with the goal of identifying faults. If there is a fault, it has to be found, identified, and then fixed. Since fault localization, as well as detection, are related processes, combining the two is challenging. While fault localization necessitates data to assist in precisely finding the flaws, fault detection depends on test data that aids in early fault detection. However, one thing that all tasks have in common is the need for test data. We have developed a method an optimization-based approach that has the following two working phases. Firstly, test suite minimization helps in getting a reduced test suite. It aids in testing that the changes done in the software have not affected the non-modified part of the software. This has been determined with respect to multi-objective functions like coverage and D-Score. To solve this optimization issue, we have introduced a new hybrid optimization algorithm termed BMCBW that combines black widow optimization and blue monkey optimization. After that fault validation is conducted by the utilization of improved LSTM and the architecture of our developed work has given in Fig. 1.

Architectural diagram of proposed BMCBW-based fault validation.
A proper test suite’s execution is a laborious task. By choosing, limiting, or ranking test cases, the testing complexity can be decreased. There are two phases in this test suite minimization procedure. The project will first be used as input for the process of creating test cases. The test suite reduction will be carried out after the generation of test cases. This test case reduction assists in obtaining a reduced test suite. It assists in verifying that the software updates have not adversely impacted the unmodified portion of the software. In our work, we have used the BMCBW algorithm for test case minimization where the coverage and D-score get optimized. The detailed description of two objectives such as coverage and D-score has been described below.
Utilizing the diversity-aware mutation adequacy criteria, the D-score has been determined. When all mutants can be identified from one another, the count of unique d-vectors created by a test suite exceeds the maximum count of unique d-vectors. D-score maximization attempts to maximize the D-score using the lowest count test cases. The range of the D-score is [0–1]. Therefore, 1 is the highest ideal value for the D-score which is symbolized as DS. The preceding Eq. (4) is employed to determine the D-score for a test suite
We have used two types of coverages which were described below.
Statement coverage maximization Finding the smallest test suite that can maximize the statement coverage value is the goal of statement coverage maximization. Equation (6) defines the statement coverage metric (SC) that measures the proportion of statements that are covered by a subset test suite. T.
Branch coverage maximization Finding the lowest test suite that can maximize the utility of branch coverage is the goal of branch coverage maximization. Branch coverage refers to the idea that the test suite under consideration should execute all branches of each and every control structure in the program. In Eq. (5), the term BC is specified as the proportion of branches that the subset test suite has covered. T. B stands for the programme D branches that Test suite T covers, and
Proposed BMCBW algorithm for solving optimization problem
After the test case generation, the test suite minimization will be done using the optimization of our proposed BMCBW algorithm, which is the hybridization of both Black Widow Optimization and Blue Monkey Optimization. Here the BWO’s cannibalism phase position updation can be done using the BMO’s updation function. Our developed BMCBW can provide early convergence and have the ability to provide competitive and promising results.
Objective function as well as solution encoding In order to optimize or maximize the D-score, statement as well as branch coverages we have utilized BMCBW which has the following objective function.
Solution encoding Our BMCBW maximizes the D-score, statement as well as branch coverages in order to get the minimized test suite and the solution provided as input to the optimization are Branch coverage, Statement coverage, and D-score with population size as 10, problem size as 1000 and epoch as 50 respectively.
BWO is indeed an optimization technique that draws inspiration from nature and may address a variety of technical and scientific issues because of its simplicity and adaptability. The proposed approach begins with an initial spider’s initial population so that every spider signifies a potential solution. In pairings, these initial spiders attempt to generate the next generation. The female black widow consumes the male either during or following mating. Then she discharges the sperm she has saved in her sperm thecae into the egg sacs. Spiderlings emerge from the egg sacs as earlier as 11 days after getting laid. From a few days to one week, they live on the same maternal web, at which period sibling cannibalism can be seen. After then, they fly away in the wind.
Initial population The problem variable’s value must take the shape of an adequate structure for resolving the current problem before an optimization problem can be solved. This structure is referred to as a “chromosome” as well as a “particle position,” etc, in GA and PSO terminology. However, the black widow optimization method (BWO) refers to it as a “widow.” A Black widow spider has been employed in the Black widow Optimization Algorithm (BWO) to represent each possible solution to a problem. The ratings of the variables causing the problem are displayed on each Black Widow spider. This structure should be regarded as an array in an attempt to resolve benchmark functions.
A widow is indeed an array of
The values of the variables
A candidate widow matrix having size
Our BMCBW uses chaotic OBL in our work to generate a solution. In certain optimization issues, opposition behavior learning (OBL) has shown to be a successful approach to differential evolution (ODE). The computation time is proportional to how far the guess is from the ideal result. By examining the opposite solution concurrently, we can increase the likelihood that we will begin with a closer (best) option. Therefore, the guess or opposing guess that is closest to the solution might be picked as the first solution. Probability theory states that in 50% of circumstances, the guess was farther to the solution than the opposite guess; in these situations, beginning with the opposite guess might speed up convergence. For that reason, we have used chaotic OBL in our population initialization phase, and is expressed in the following eqn. (5)
Where
Procreate The pairings begin to mate independently of one another in an attempt to generate the next generation. This is similar to how it happens in nature, as each pair mates in its own web, apart from the others. In the actual world, each pairing produces about 1000 eggs, although some of the spider offspring do survive and are stronger. Now, in this procedure, in order to generate children, an array termed alpha must also be formed along with a widow array that comprises random numbers. Then, utilizing the preceding equation (equation (1)), offspring were created, that has
Repeat this operation for
Cannibalism Here, cannibalism takes three distinct forms. The first one involves a female black widow eating her husband after or during mating, which is known as sexual cannibalism. We could distinguish between males and females using this algorithm based on their fitness levels. Sibling cannibalism is also another type when the stronger spiderlings consume their weaker siblings. In this technique, the number of survivors is calculated based on a cannibalism rating (CR). The third type of cannibalism is rarely seen in which the young spiders consume their mother. To identify whether spiderlings are strong or weak, we utilize the fitness value.
Our BMCBW algorithm utilizes the following modified BMO equation (7) in place of conventional cannibalism phase updation.
Monkey’s power rate gets represented by Rate, while the monkey’s position gets symbolized by y. A random among 0–1 get represented by r and q symbolized by
The conventional position updation formula of BMO is expressed in the following eqn. (8).
Mutation During this stage, we choose an arbitrary sample of Mutep people from the population. Two components in the array are arbitrarily switched by each of the selected solutions. The mutation rate is utilized to compute mute.
Three stop criteria were considered: a fixed count of iterations, discovering that the best widow’s fitness value has not changed after a lot of iterations, and achieving the desired accuracy level.
Finally, our BMCBW algorithm has utilized Cauchy’s mutation in our work to increase the searching ability, and provide an optimal solution.

Blue Monkey Customized Black Widow Optimization
After optimization, the test suite is minimized. The faulty test cases are reduced from the test suite.
After test suite minimization, we carried out the fault validation using our improved LSTM. Fault validation is a very costly and time-consuming technique for debugging programs. As a result, there is a strong need for automated fault localization and detection approaches that may help programmers locate and identify issues with minimal to no human involvement. In response, we’ve introduced an enhanced LSTM to deliver a powerful fault validation. Below is a full description of the fault validation methodology.
Improved LSTM
A group of neural networks that process sequential information were called recurrent neural networks (RNNs). The standard recurrent neural network (RNN) can be enhanced by the LSTM model, which also provides a gated unit mechanism to partially prevent gradient disappearance. The LSTM model has been successfully used to the field of time series prediction due to its capability for processing time series data. Many professionals and academics are searching for different ways to enhance the LSTM model. A gated RNN that successfully addresses the issue of long-term dependency is the Long Short-Term Memory (LSTM) network. The second sigmoid function as well as the tanh function referred to as the input gate, decide what information needs to be updated. The output gate, or third sigmoid function, chooses which data is output. The following are indeed the updated formulas:
Where the forget, input, and output gates, respectively, are
Because of this, some papers use RELU rather than sigmoid functions. RELU is non-linear and offers the benefit of exhibiting no backpropagation errors, and it also builds models for bigger neural networks faster than Sigmoids do. In comparison to tan h or sigmoid functions, ReLU also exhibits a greater convergence rate on applications.ReLU is not zero-centered and isn’t differentiable at zero but is differentiable everywhere else. These are some of ReLU’s other disadvantages. Another problem with ReLU would be the Dying ReLU problem, in which some ReLU Neurons primarily die for all inputs and are still inactive regardless of what input is provided. In this case, no gradient flows, and if a huge count of dead neurons is present in a neural network, performance would be impacted. This can be fixed while using what is defined as Leaky ReLU, where the slope is altered and thereby causing a leak and enhancing the range of ReLU [1].
An improvement over the ReLU Activation function is the employment of Leaky ReLU. It possesses all of the ReLU’s characteristics and will never have a dead ReLU issue. Leaky ReLU has a little negative slope, so instead of firing completely for large gradients, the neurons actually provide some value, which also greatly improves the efficiency of the layer. As a response, our improved LSTM uses the leaky RELU function instead of using the sigmoid function.
Consequently, we have evaluated the cross-entropy loss in our improved LSTM. Cross-entropy loss is used when adjusting model weights during training.
The goal of this cross-entropy loss is to reduce the loss; that is, the less the loss, the more accurate the model. The cross-entropy loss of a flawless model is zero.
In order to offer accurate fault validation while lowering loss, our improved LSTM employs the following eqn (15) rather than the standard cross entropy eqn (14).
The count of scalar values in the model output has been denoted by output size, while
Here r is a random number.
Finally, software faults were detected and localized by our improved LSTM as output.
Results and discussion
PYTHON was used to implement the proposed work based on Software Fault Detection and Localization. The effectiveness of the proposed Blue Monkey Customized Black Widow algorithm (BMCBW) work is measured over the traditional methods including, Archimedes Optimization Algorithm (AOA), Bald Eagle Search (BES), Black Widow Optimization (BWO), COOT and Blue Monkey Optimization (BMO). The execution was done with respect to Accuracy, MCC, FDR, F1-measure, Specificity, and so on, by varying the learning percentage to 60, 70, 80, and 90. Additionally, the Fault Localization score, Fault Detection score, and Coverage score (Statement coverage, Bran coverage, and D-metrics) had been evaluated.
Performance analysis on measure
In comparison to the existing approaches, the created BMCBW method performs better in terms of accuracy, precision, MCC and F-Measure. Consequently, the outcomes are exposed in Fig. 2. For all the measures in the graph, the developed technique has yielded superior results than the distinguished methods. Particularly, at the 90% of learning percentage, the proposed method reached the maximum detection accuracy of 94.12%, surpassing the extant methods such as AOA is 93.21%, COOT is 92.09%, BES is 91.80%, BMO is 93.21% and BWO is 91.54%, respectively. Similarly, 93.96% of detection accuracy has been obtained by the proposed work, in the 60, 70, and 80 learning percentages.
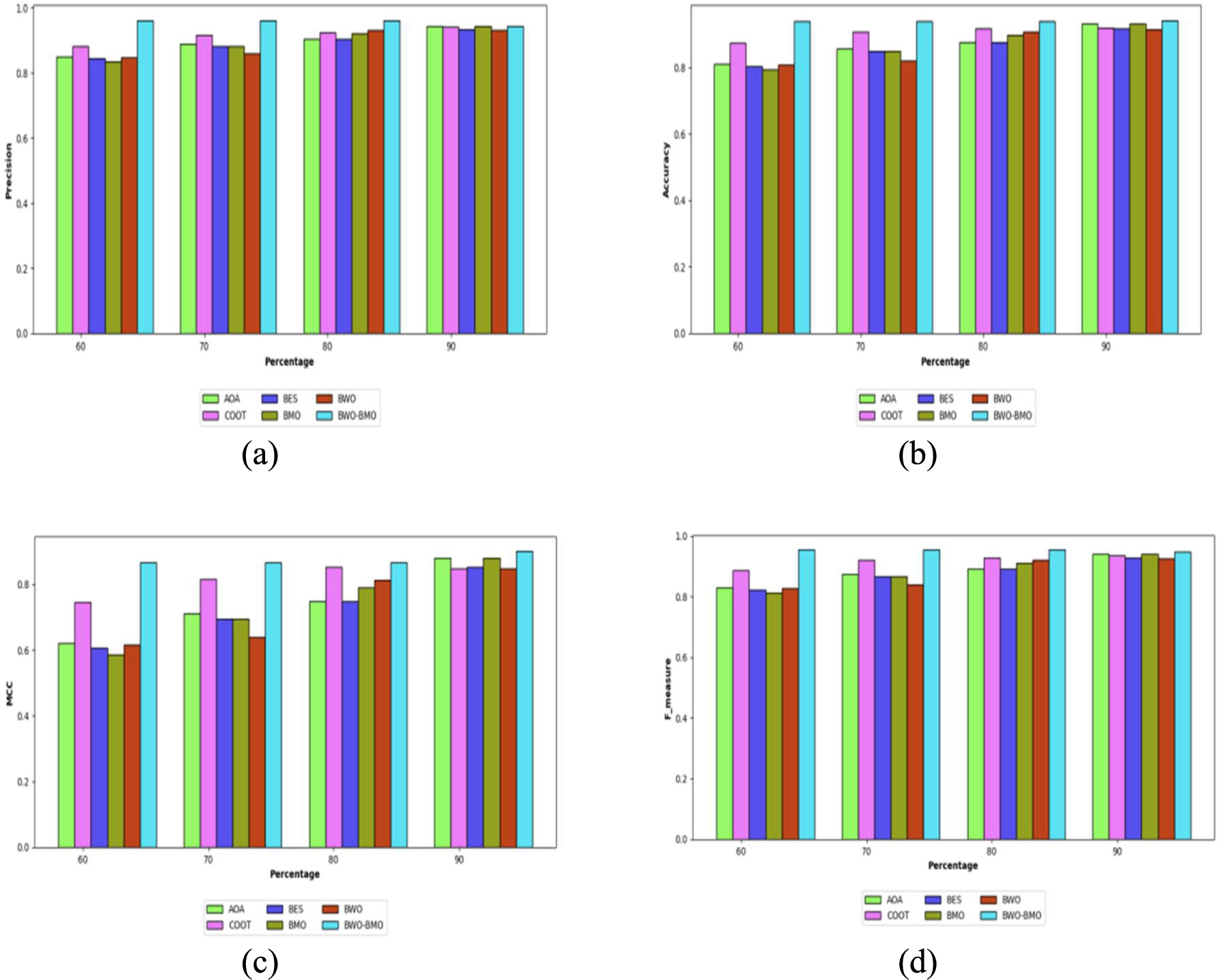
Analysis using the proposed BMCBW method over the conventional schemes regarding (a) accuracy, (b) precision, (c) MCC, (d) F-meaure.
In a similar manner, the precision of the developed method is 96.03%, in the 70% of learning percentage, which is considerably higher than the established schemes such as AOA (89.02%), COOT (91.60%), BES (88.33%), BMO (88.34%) and BWO (85.91%). These outcomes indicate that the proposed BMCBW model is more effective to make the accurate detection of software faults when compared to other conventional models. This is due to the effect of optimization logic in training the model to make the detection more precise.
Figure 2 highlights the effectiveness of the proposed BMCBW model is assessed over the conventional methods (AOA, BES, BWO, COOT, and BMO), regarding other measures like F-measure, MCC Here, the proposed method has accomplished better values than the established methodologies. The MCC attained by the developed strategy at 90% of the learning rate is 90.02%, though it is higher than those attained by the proposed method at the other learning rates.
In the 60% of the learning rate, the recommended method generated an F-measure of 95.40%, while models like AOA, COOT, BES, BMO, and BWO obtained very low F-measure of 83%, 88.7%, 82.27%, 81.26%, and 82.77%, respectively Altogether, this assessment proves that the proposed BMCBW approach improves the performance for detecting the software fault more than the conventional models.
The convergence study of the proposed work is compared to the existing schemes for different iterations (10, 20, 30, 40, and 50) and is analyzed in Fig. 3. While investigating the results, it can be noticed that the proposed method has achieved the least error rate compared to other distinguished schemes, namely AOA, BES, BWO, COOT, and BMO, respectively.

Convergence analysis of the proposed BMCBW methodology versus conventional methods.
Here, the BMO algorithm has exhibited the worst performance in the initial (0th) iteration. The error rate keeps decreasing from iteration 5 to 50 for both the proposed work and other existing models. Nevertheless, the adopted method has recorded the lowest error rate of (∼) 28.78, at the final 50th iteration. Thus, the betterment of the adopted BMCBW model is proved.
For each algorithm, the fault detection and fault not detection score has been calculated and it is presented in Fig. 4. A higher value of fault detection score and a lower value of fault not detected score have the ability to detect the software fault. According to the fault not detected analysis, the proposed strategy generated the highest score for fault detected, as it detected 248 out of 250, which is superior to AOA (210), COOT (145), BES (230), BMO (132) and BWO (243), respectively.
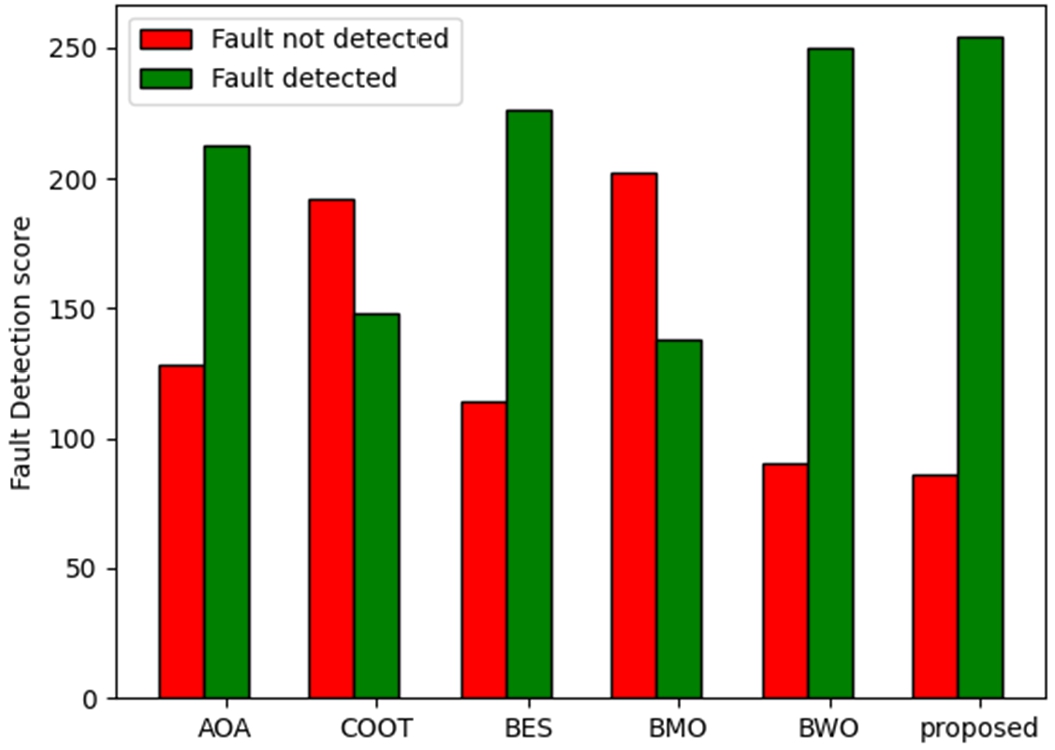
Analysis using the proposed BMCBW method over the conventional schemes regarding fault detection score.
On examining the fault detected score, the other established AOA, COOT, BES, BMO, and BWO methods gained the highest score of 124, 189, 112, 192, and 63, whilst the proposed method acquired the lowest fault detected score of 60. Thus, it may be concluded that the proposed BMCBW strategy is suitable for detecting software faults.
Performance analysis on fault localization score of the complete test case for the proposed method and for the traditional methods is shown in Fig. 5. The optimum method for locating and detecting software faults is a model with a high fault localization score.

Analysis using the proposed BMCBW method over the conventional schemes regarding fault localization score.
In the 35th test case, the proposed method recorded the highest fault localization score of 97.25%, this is significantly better than the CNN (87.42%) method. Similarly, the recommended approach acquired the highest fault localization of 98.84%, in the 85th test case. The experimental results show that the proposed BMCBW method fault localization score is preferable to the conventional methodologies.
Statistical analysis with regards to error
Due to the stochastic character of the optimization process, it is repeatedly run to determine the final outcomes in terms of statistical analysis. Therefore, the outcomes are assessed by using five different case scenarios including Standard Deviation, Mean, Median, Maximum, and Minimum. Consequently, the generated outcomes are illustrated in Table 2. Additionally, the outcomes revealed that the proposed BMCBW strategy recorded the lowest error rate than the other approaches. In accordance with the median case scenario analysis, the proposed method recorded the lowest error rate as 27.98154, while the other methods including AOA, COOT, BES, BMO, and BWO attained the highest error value of 28.00349, 28.07923, 28.00381, 28.05237 and 28.04152.
Likewise, while analyzing the maximum scenario analysis, the established methods (AOA, COOT, BES, BMO, and BWO) attained the highest error values, whereas the developed method maintained the lowest error rate of 28.15635. Moreover, examining the minimum and mean case analysis, the suggested BMCBW approach yielded the least error value of 27.98154 and 27.99438.
Classifier comparison
Table 3 represents the classifier comparison of the developed method computed over the existing approaches like NSGA II [11], DNN [27], DBN, CNN, SVM, Bi-GRU, and LSTM by using various types of metrics. The suggested method accomplished the best values for accuracy and other positive measures as well as obtained lesser negative values. The detection accuracy of the proposed technique is 93.96%, which is preferable than the extant methods such as NSGA II = 91.19%, DNN = 81.01%, DBN = 88.65%, CNN = 77.21%, SVM = 83.72%, Bi-GRU = 78.21% and LSTM = 91.24%. Based on the FPR analysis, 0.07622 is the FPR for the proposed method, this is better than the conventional models like NSGA II, DNN, DBN, CNN, SVM, Bi-GRU, and LSTM. Similarly, the NPV of the proposed model achieves superior outcomes (90%) than other existing models like NSGA II (88.49%), DNN (73.68%), DBN (85.16%), CNN (72.83%), SVM (79.77%), Bi-GRU (73.85%) and LSTM (91%), respectively. Thereby, the improvement of the adopted BMCBW model is proved over other traditional classifiers concerning different metrics.
Analysis on coverage
Table 4 tabulated the Statement coverage, Branch coverage, and D-metrics analysis for the developed BMCBW method and for the extant methods. Based on the statement coverage analysis, the models like AOA, COOT, BES, BMO, and BWO recorded the lowest statement coverage of 54.686, 55.60938, 55.21006, 55.3643, and 55.29655, even though the recommended model obtained the highest statement coverage of 78.37. Likewise, for the Branch coverage and D-metrics, the adopted strategy attained the highest value of branch coverage (60) and D-metrics (0.8). Therefore, the presented BMCBW method is able to detect and localize the software fault such that they have Maximal branch and Statement coverage as well as D-metrics.
Table 5 shows that the time complexity analysis compares the proposed BMCBW model to the currently used approaches, including AOA, COOT, BES, BMO, and BWO. In comparison to the other schemes, the created BMCBW models’ computational time has reached the lowest value. Moreover, the proposed model is 14.9%, 8.9%, 22.9%, 2.5% and 3.52% lower than the existing models such as AOA, COOT, BES, BMO, and BWO. This demonstrates that the proposed BMCBW model is computationally efficient.
Analysis of computation time
Analysis of computation time
Fault detection, as well as localization, are essential operations that need test case information. In general, the software is vast and needs an enormous test suite for testing. Both of these operations involve the minimization of test cases. If test suite minimization can be integrated into both tasks, testers will need to put in less effort. In order to develop a minimized test suite having the ability to both detect and locate faults we have developed a novel technique that has the following two working phases. In the initial test suite minimization process, the test cases were generated and minimized based on the objectives such as D-score and coverage by the utilization of a hybrid algorithm termed BMCBW. After this test suite minimization, the fault validation was done which includes the process of fault detection and localization. For this fault validation, we have utilized an improved Long Short-Term Memory (LSTM). Deep neural networks will be used in multi fault localization in our upcoming work, and their efficacy will be assessed. We will continue researching the viability of using more deep learning models for the localization of software faults in the interim. The results obtained proved that our Blue Monkey Customized Black Widow (BMCBW) based fault detection and localization approach can provide superior outcomes in the task of software fault detection and localization.