
Abstract
Lung cancer is the most lethal and severe illness in existence. However, lung cancer patients may live longer if they receive early detection and treatment. In the medical field, the best imaging technique is CT scan imaging as it is more complex for doctors to identify cancer and interpret from CT scan images. Consequently, the computer-aided diagnosis (CAD) is more useful for doctors to find out cancerous nodules. To identify lung cancer, a number of CAD techniques utilising machine learning (ML) and image processing are used nowadays. The goal of this study is to present a novel method for detecting lung cancer that entails four main steps: (i) Pre-processing, (ii) Segmentation, (iii) Feature extraction, and (iv) Classification. ”The input image is first put through a pre-processing step in which the CLAHE model is used to pre-process the image. The segmentation phase of the pre-processed images is then initiated, and it makes use of a modified Level set segmentation method. The retrieved features from the segmented images include statistical features, colour features, and texture features (GLCM, GLRM, and LBP). The Layer Fused Conventional Neural Network (LF-CNN) is then utilised to classify these features in the end. Particularly, layer-wise modification is carried out, and along with that, the LF-CNN is trained by the Modified Cat swarm Optimization (MCSO) Algorithm via selecting optimal weights. The accepted scheme is then compared to the current models in terms of several metrics, including recall, FNR, MCC, FDR, Threat score, FPR, precision, FOR, accuracy, specificity, NPV, FMS, and sensitivity.
Nomenclature
multidimensional Region-based Fully Convolutional Network Linear Regression Computed Tomography Linear Discriminant Analysis Computer-Aided Design Deep Learning k-Nearest Neighbor Convolutional Neural Networks Decision Tree Computer-Aided Detection Serological Analysis of Recombinant cDNA Expression Libraries Probability Density Function Enzyme-Linked Immune Sorbent Assay Improved Profuse Clustering Technique Support Vector Machine Improved Deep Neural Network Tumor-Associated Antigens Cancer Imaging Archive Region of Interest Contrast Limited Adaptive Histogram Equalization Position-Sensitive Score Maps Multi-Layer Fusion Region Proposal Network World Health Organization Area Under Curve Contrast Limited Histogram Equalization Deep Learning with Instantaneously Trained Neural Networks Cumulative Density Function Signed Distance Function Modified Cat Swarm Optimization Grey Level Runlength Matrix Local Binary Pattern Layer Fused Conventional Neural Network Grey Level Co-ocurrence Matrix Seeking Memory Pool False Discovery Rate Counts of Dimension to Change Self-Position Considering False Discovery Rate F-Measure Matthews Correlation Coefficient False Positive Rate Whale Optimization Algorithm Deep Belief Network Seeking Range of the selected Dimension Mixture Ratio False Negative Rate Net Predictive Value Moth Flame Optimization False Omission Rate
Introduction
The leading cause of death all over the world during the year 2018 is 9.6 million, as per the report of WHO [21,24]. Moreover, lung cancer causes the uppermost mortality rates. The clinical reports indicated that early lung cancer treatment would increase the survival rate [30]. Consequently, the early detection of lung cancer is investigated extensively around the world by different research groups and medical corporations. However, it is more complex because it arises and illustrates symptoms only at the final stage [55]. Still, it is believed that the probability and mortality rate are lowered through the early detection and treatment of the disease. Nowadays, lung cancer is signified as the post deadliest disease, which poses a great threat to humans due to the spreading of smoke, the high rates of air pollution, and the more complex treatment [6]. Therefore, the early detection of lung cancer in the medical field is a major concern of scientists. The most excellent imaging approach is reliable for lung cancer diagnosis using CT images as it discloses every unsuspected and suspected lung nodules [19].
CT images outperformed traditional radiography for screening the lungs as it produces detailed high-resolution images and showed the early-stage lesion that is too small to be detected through traditional X-ray [31]. The growing body of medical data is also beneficial for healthcare practitioners who want to raise the standard of care [48]. Many governments now consider improving individualized healthcare to be one of their major responsibilities [33]. In addition, CT is widely used for detecting different lung diseases like pulmonary edema, pneumonia, lung cancer, and pneumoconiosis [50]. It is regarded as the most challenging task by radiologists owing to the large amount of information generated through the CT scan [14]. Consequently, CAD systems are required for helping radiologists during the evaluation and analysis of CT scans. Furthermore, the CAD system analyzes the medical images in different steps such as preprocessing step for enhancing the image quality and noise reduction, and then the segmentation step for differentiating the ROI in the image [4,28]. Following the segmentation procedure, several features such as textural, statistical, and geometrical attributes are extracted. The evaluation or classification step is performed for evaluating and diagnosing the ROI based on extracted features [43]. Several models have been employed in previous research to construct prediction models to improve forecast accuracy [17].
CAD systems are divided into 2 groups deep-learnable and classical systems. Further, the classical CADe systems are started usually through the extracted lung regions, and then it uses the shape, texture features, and intensity taken from the lung regions for detecting lung cancer [5,51]. Additionally, deep-learnable CADe algorithms are used to address the shortcomings of lung cancer diagnosis. The DL techniques [16,39] and CNN [7,10,40,46] are the most important approaches used for the analysis of medical images and in computer vision applications. The DL techniques [37,38,47] are used for extracting the data features efficiently that determine the current problem through many layers-networks [9,53]. One of the most successful DL medical image analyzers is the CNNs [18]. Optimization difficulties present a challenge in terms of minimizing or maximizing an objective function [27]. Even though the innovations in pulmonary cancer are unsteady and slow based on survival rate; DL approaches [13,15] provides promising outcomes and thru these detection systems, the lung cancer death rate is declined.
The following list of the model’s main contributions:
Suggests using a CNN layer that has been fused for the final prediction of lung cancer images.
Exposes the Modified Cat Swarm Optimization (MCSO) Method for determining the best weights for training a LF-CNN model.
Section 2 of this essay presents a review of lung cancer detection. Section 3 gives an overview of the intended work. Pre-processing via CLAHE model and segmentation process via modified level set algorithm is presented by Section 4. The process of extracting texture, statistical, and colour information is described in Section 5. The categorisation of lung cancer is shown in Section 6 using a modified cat swarm optimisation approach and a CNN that has been tuned for training. The outcome and discussion are described in Section 7. Section 8 completes the essay at last.
Literature review
Related works
In 2019, Sori et al. [45] has examined the multi-path CNN for the detection of lung cancer. Moreover, the deep CNN architecture was implemented that differs from the conventionally used computer vision framework for solving these issues. Moreover, the suspicious nodule was produced along with the U-Net’s modified version and then the produced nodules act as the input data in the adopted model. Further, the adopted scheme was the multi-path CNN that exploited both the global contextual features and the local features to detect lung cancer automatically. The retraining phase system was implemented, which permits tackling the issues oriented to image labels imbalance. Furthermore, when compared to the conventional methods, the experimental results of both the standard type have produced improved detection outcomes.
In 2019, Mesut et al. [49] have developed the low redundancy high relevance feature selection approach on chest CT images with CNNs for the detection of lung cancer. Furthermore, lung cancer identification was recognized by VGG-16 deep learning, AlexNet, and LeNet schemes. Moreover, the classification and the feature extraction process were performed by the CNNs. Separate from either the final fully-connected layer of this method, the features obtained were used as the inputs to LDA, CNN, LR, SVM, softmax classifiers, and DT. An image augmentation approaches like horizontal turning, zooming, filling, and cutting was applied during the training for increasing the success rate of classification. Last but not least, the simulation outcomes of the accepted model have demonstrated higher classification accuracy, higher sensitivity, higher specificity, time consumed, and reduced memory usage.
In 2020, Shakeel et al. [41] have designed a novel machine learning technique and optimized image processing for predicting lung cancer. The collected images were determined by applying the multilevel brightness-preserving model that removes the noise, maximizes the quality of the lung image, and examines each pixel effectively. The affected region was segmented through an IDNN which segments the region based on the network layers and extracts different features from the noise-removed lung CT image. Furthermore, the simulation outcomes of the suggested model have increased F-score for predicting lung cancer and decreased mean absolute error, logarithmic loss, and precision.
In 2020, Masood et al. [23] has implemented an improved mRFCN based automated decision support scheme for lung nodule classification and detection. Moreover, the mRFCN was used for feature extraction with the new mLRPN and PSSM as a helping hand of image classification. Further, the median intensity projection was applied from CT scans and deconvolutional layer to leverage 3D information that was introduced for adopting the proposed mLRPN to select the potential ROI. The model that has been provided has generated positive experimental results with a more promising detection performance than other existing methods with respect to sensitivity and classification accuracy.
In 2020, Zhan et al. [54] has suggested a new application in lung cancer diagnosis based on conformal prediction. Moreover, the nonconformity measurement was performed on the basics of KNN. High accuracy of the proposed model has been attained through the conformal predictors of 1NN and 3NN respectively in the offline prediction that outperforms the simple KNN predictors. In addition, the conformal predictors provided more confidence and credibility information for predicting the patient’s severity. Further, the experimental results of the adopted approach have proven higher overall sensitivity, maximum prediction accuracy, and better credibility.
In 2021, Feng et al. [44] has introduced the “denoising first two-path CNN” (i.e.), DFD-Net for addressing its complexity. In addition, the implemented model consists of detection part and denoising in an end-to-end manner. Moreover, the “residual learning denoising approach (i.e.) DR-Net” was utilized during the preprocessing stage for removing the noises. Furthermore, a two-path CNN has taken the denoised image as input through DR-Net for lung cancer detection. A retraining technique was proposed for overcoming the problems linked to the imbalance of image labels. And last, the model’s simulation results affords the receptive field size effect balance, more representative features, reduce noise in an image, and effortlessly flexibility to the discrepancy between the size and shape of the nodule.
In 2019, Mohamed et al. [42] examined the improvement in the quality of lung image and lung cancer diagnosis by lowering the misclassification. The DITNN and the IPCT approach were used for predicting lung cancer through lung CT images. Furthermore, the CIA dataset, which consists of 5043 DICOM file images divided into 2043 test images and 3000 training images, was used to gather the lung CT scans. Finally, the suggested model successfully predicts cancer with improved accuracy and a lower classification error.
In 2019, Lu et al. [32] have suggested the TAAs identification and their equivalent autoantibodies in LC that expanded the vision of cancer immunity. The objective of the proposed model has screened the new TAAs from the healthy population to distinguish LC. Moreover, the Oncomine database was utilized for identifying the potential genes in cancer progression and 35 genes encrypt LC-associated TAAs was recognized by SEREX. The ELISA in sera was used for testing the Auto-antibodies in the verification set and validation set from 1379 participants. Ultimately, the accepted model’s output has a high AUC, the highest sensitivity, and the highest specificity.
In 2021, Priya et al. [34] have deployed a learning rate-modified convolutional neural network algorithm based on BAT optimization presented in this research. Additionally, the input picture is deconstructed with assistance from the Discrete Wavelet Transform to enhance the proposed classification performance (DWT). With, the image is divided into four subbands; in this instance, the Low (LL) band image was taken into consideration. After that, two sets of segmentation results are split into training and testing groups. The publicly accessible LIDC-IDRI dataset was used to validate the proposed approach. A convolutional neural network is used to study them, and a quickly trained neural network for LC prediction is also applied. In the end, a MATLAB tool is used to determine the system’s effectiveness.
In 2021 Xin et al. [22] have deployed a brand-new convolutional neural network. For greater network accuracy and optimal organization, the marine predator’s algorithm is also applied. Finally, the technique was fixed to RIDER dataset as well as outcomes were evaluated against those of a few pre-trained deep networks, includes CNN ResNet-18, GoogLeNet, AlexNet, and VGG-19. The end results showed that the proposed approach outperformed the compared strategies.
Review on existing lung cancer detection schemes: features and challenges
Review on existing lung cancer detection schemes: features and challenges
The review of lung cancer detection is shown in Table 1. At first, the Multi-path CNN model was deployed in [45], which presents more flexibility, better accuracy, improved specificity, and higher recall; however, the additional feature does not give any significant improvement in the results. Wang-Scheme was exploited in [49] that offers higher classification accuracy, better sensitivity, higher specificity, time-consumption, and lower memory usage, but the super pixel approach was not examined in this dataset. Moreover, the IDNN model was deployed in [41] provide better recall, maximum accuracy, increased precision, improved F1 score, and higher specificity. Nevertheless, the adopted method does not have a single gradient function. Likewise, mRFCN based automated decision support system was exploited in [23], which offers high sensitivity, maximum low error rate, and higher classification accuracy. However, the detection of some micronodules (i.e.), less than 3 mm in diameter was not focused. KNN approach was exploited in [54] that have higher overall sensitivity, maximum prediction accuracy, and better credibility; however, different approaches of nonconformity measurement in conformal predictions were not applied. In addition, DFD – the net model was introduced in [44], which offers low noise, easily adaptable, high specificity, better recall, and maximum accuracy. However, the greater or same accuracy value was not obtained with the denoised images in the proposed approach. IPCT and DITNN approach was suggested in [42] that offers better accuracy, and minimum classification error. However, it does not require manually extracted features in the proposed model. Finally, the ELISA test was implemented in [32], which offers better AUC, maximum sensitivity, and higher specificity, but the differences in autoantibodies were not observed in the different cancers. Such limitations are taken into account to effectively diagnose lung cancer in the current work.
The likelihood of receiving effective therapy for lung disease will much depend on the timing of the diagnosis. Lung cancer can be diagnosed with the help of imaging, radiographs, & CT scans, in addition to biopsy, bronchoscopy, and evaluation of the breast mucosa. Numerous research have been done so far to identify and describe lung diseases. A specialist doctor may have difficulty distinguishing nodules from veins, wounds, etc. because of the removal of the lungs, the high number of radiographic images taken of them, and their complex and uneven structure. The fundamental principle is to employ the machine rather than leave the diagnosis to it since it improves the work’s sensitivity and lowers the rate of positive error. The processing time is high and it cannot diagnose the disease early. The prediction model is used in this study to address the shortcomings of the current methodology.
Overview of the proposed work: An architectural description
This research aims to present an unique method for detecting lung cancer that includes 4 critical stages: “(i) Pre-processing (ii) Segmentation (iii) Feature extraction and (iv) Classification”. At first, the input image is subjected to the CLAHE model to preprocess it. The segmentation phase is then applied to the previously processed images, where the image gets segmented using a modified Level set segmentation algorithm. From the segmented images, texture features (GLCM, GLRM, and LBP), statistical features (mean, mode, median, skewness, kurtosis, correlation, and entropy), and color features was get extracted. Additionally, the LF receives these qualities as input. -CNN for final classification. Particularly, the layer-wise modification is carried out, and along with that the MCSO Model is trained the LF-CNN by choosing the best weights. The recommended model’s overall structure is depicted in Fig. 1.

The general structure of the suggested model.
The input image ‘
CLAHE model
An adaptive contrast histogram equalization approach is known as the CLAHE, where it enhances the contrast of the image by applying it to tiny data regions known as tiles rather than the whole image. The resulting adjacent tiles are then stitched back flawlessly by the bilinear interpolation. Further, the contrasts in the homogeneous region are limited as it avoids noise amplification.
The CLAHE model applies the histogram equalization for every contextual region. The partition B is attained through the CLAHE [11] via 5 phases. The supplied image is first divided into identically sized, tiny blocks. The larger histograms is minimized by calculating the clip point in each block. The clip point estimation is determined as in Eq. (3).
In Eq. (3), β denotes the clip point,
Modified levelset segmentation
The preprocessed image
In Eq. (4), the d value is the minimum distance between d point on the curve and the surface. The entire curve’s evolutional process and its point are given in Eq. (5). The Level Set movement formula is determined in Eq. (6).
In Eq. (6), F indicates the speed function, in which the function is associated with the characteristics of the developing surface and image. The implementation F depends on the ideal value of zero and the image information on the target edge while applying it for segmentation. Due to its irrelevancy and stability with topology, the Level set method displayed a large advantage for solving the issues of corner point production, combing and curve breaking, etc. Consequently, it is used in a wide range. Moreover, it is required to remain the developing level set function near to signed distance function while implementing the level set method.
The energy function includes an external and an internal energy term, correspondingly. The external energy term
In Eq. (7),
In Eq. (8),
In Eq. (9),
The length
Where
Where,
Feature extraction process: Texture, statistical, and color features
From the segmented regions, the texture features (GLCM, GLRM, LBP), statistical features (Mean, mode, median, entropy, correlation, skewness, and kurtosis), and color features are extracted.
Texture features
LBP The LBP [29] has computational simplicity and higher discriminative power. Additionally, the LBP operator labels each image pixel to decimal integers. During the labelling process, each imaging pixel is calculated with its surrounding pixels by subtracting the centre pixel value. Further, it encodes any negative values that are produced as 0, and it encodes the positive and 0 values as 1. The binary numbers created by concatenating all the binary digits in a clockwise motion starting from the top-left are known as LBP codes. All the many local representations that are combined to produce the global description are built using the texture descriptor. Additionally, based on the capacity to distinguish between these textured objects, the characteristics are retrieved. In Eq. (14),
GLCM features [
35
] The GLCM is an approach used to extract the 2nd order statistical texture features by the intensity values of statistical distributions that combines the image at various positions close to each other. Regardless of the number of task, an image’s statistics are divided into first, second, and high order categories. Higher order statistics are superior conceptually but are not developed due to computing complexity. Information about the surface’s internal structure and relationship to its surroundings is included in the texture features. Additionally, the texture-based capabilities of GLCM consist of “Energy, correlation, contrast, homogeneity, dissimilarity, ASM, GLCM-mean, GLCM-std, GLCM-max, GLCM-entropy, GLCM-skew, and GLCM-kurtosis”. The extracted 12 GLCM-based feature was displayed as
GLRM features [
36
] The texture is considered as a grey intensity pixel pattern in a certain direction from the reference pixels. Additionally, the GRLM is a matrices from which the texture analysis extracts the texture features. With the result of a comparable grey level for the scatter of pixels, GLRM calculates in which direction the pixels will move. The Run length is defined as the number of neighbouring pixels in a particular direction that have a similar grey intensity. The number of elements with an intensity in a certain direction is included in the 2D matrix of GLRM. Likewise, a texture-based GLRM features include “SRE, LRE, GLN, GLNN, RLN, RLNN, RP, LGLRE, HGLRE, SRLGLE, SRLHGLE, LRLGLE, LRHGLE, and GLV”. The extracted 14 GLRM features are denoted as
Statistical features
Along with the texture features, the statistical feature including mean, mode, median, entropy, kurtosis, skewness, & moment are also extracted. The size of statistical features is represented as
Mean (Average) [
3
] The process in which the sum of all values divided by the sum of some values is known to be the mean value. The mean was signified as
In Eq. (16), V represents the observed value,
Mode The “most frequent value in the dataset” is the mode. One of the most used “central tendency measures” (that is, used with “nominal data” that have entirely arbitrary class assignments) is this one. The mode was displayed as
Median The method used to arrange a dataset’s middle value in ascending order. When there are two middle elements in a dataset, the median is defined as the mean of the two middle values. A median was displayed as
In Eq. (17),
Entropy [
2
] Entropy is considered as the average level of a random variable with “information”, “surprise”, or “uncertainty” inherent to the possible variable’s resultant of the information theory. Sometimes, the information entropy was said to be Shannon entropy. Consider, V was discrete random variable having handed resultant
Moment [
1
] The central moment is the probability distribution moment with the random variable in probability theory and statistics. It is the anticipated mean value of a particular integer power deviation of something like the random variable. various moments from either the quantities of one set by the characteristics of the probability distribution.
Skewness “It is a symmetry measure or the lack of symmetry exactly. A data set or distribution is symmetric only if it is similar to the left and right of the center point”. Skewness
Here Eq. (20),
Kurtosis “It is a measure that identifies whether the data are light-tailed or heavy-tailed and related to the normal distribution”. Low kurtosis data sets tend to have fewer outliers or lower tails. Therefore, datasets having higher kurtosis are more likely to have outliers or heavy tails. Kurtosis
The standard deviation is calculated through the
Color features
Color is the straight-forward and significant feature in which humans distinguish while it views an image. Moreover, the human vision scheme is highly susceptible to gray levels to color information, therefore color is used as the 1st candidate. RGB color space is an important one for computer images since the computer display uses the primary color mixing such as blue, green, and red for displaying any apparent color. Furthermore, the RGB color feature consists of 3 bands. Each band includes 32 numbers of bins while applying the histogram. In addition, the frequency of min, max color, standard deviation, mean, and the median is calculated using these color features. At last, the extracted color features involve 111 features and it is represented as
The final indication of the retrieved features is
Lung cancer classification: CNN with modified cat swarm optimization-based training
Optimized LF-CNN model
The extracted features
In CNN, Eq. (27) displayed loss function.
Pooling layer “In CNN, the pooling layer has performed the down sampling operations with the results obtained from the convolutional layers. Also, the 2 renowned pooling types consist of max pooling and average pooling. The max pooling has attained the higher value; but, the average value is observed in the average pooling”.
Fully connected layer “It works within the flattened inputs. Normally, the results acquired from the pooling layer are provided as the input of a fully connected layer and thus the inputs are linked to all layers. The fully connected layer in the CNN structure occurs at its edges”.
As per the proposed LF-CNN are as follows: multi-resolution and multiple layers are used such as multi-size, multi-shape, and multi-angle for region proposal generation. In the proposed LF-CNN, the 3 same sets of layers like “convolutional layer, relu layer, and pooling layer” are considered as 1 set of layers and it is fused with another similar set of the layer. The fused sets of layers are combined with the fully connected layer. The faster LF-CNN suggested is used to improve the original RPN in order to get beyond the traditional CNN’s object detection-focused limitations. As 3D convolution layers substitute the 2D convolution layers in the standard type, it is expected to perform better than resnet. The CT images were performs through the adopted scheme to view the CT data volumes. Here, the number of each pixel in CT is specified through the less CT volume. Table 2 depicts the CNN hyper-parameters.
CNN hyper parameters
CNN hyper parameters
As previously stated, the suggested MCSO model optimises the LF-CNN weights. The recommended MCSO method’s input solution is shown in Fig. 2. In this, N displays weights in overall. The suggested model’s primary purpose is to maximise accuracy

Solution encoding.
Although, the existing CSO [12] method avoids trapping in the local optima and improves the accuracy; still, it has poor tracking accuracy, slow tracking speed, and precocity convergence. The MCSO approach is used in this study to avoid this issue. Normally, the self-improvement in the existing optimization models [16,37–39,47] makes the algorithm even stronger for solving the optimization issues. The “seeking mode” and “tracking mode” are two main sub that make up the major two cat behaviours according to CSO. Moreover, all cat with its position includes every dimension velocities, fitness value, and M dimensions; it represents the fitness function based on the cat’s accommodation, and the flag for Cat identification is being done in a searching or tracing mode. The ideal situation the cat could achieve at the completion of the iterations is also the final answer.
Seeking Mode In CSO, the seeking mode is used for modeling the cat’s situation (i.e.), seeking the next position, looking around, and resting for moving. In this mode, the 4 important factors such as SMP, SRD, CDC, and SPC are used.
SMP: For each cat, the SMP is used to describe the seeking memory size that specifies the points required through the cat. From the memory pool, the cat has picked the point.
SRD: For the chosen dimensions, the SRD declared the MR. Choosing a dimension to alter in the searching mode, an difference between the novel and the previous value isnot in the out of the range.
CDC: It reveals the number of varied dimensions. In the seeking mode, this factor plays significant roles.
SPC: It considers the already standing cat with a Boolean variable that decides the point as one of the candidates for moving. Whether the SPC value is false or true; does not influence the SMP value.
Moreover, the seeking mode mechanism is determined in five major steps:
If the fitness function would identify the minimum solution
Tracing Mode This mode is modeled based on the tracing behavior of the cat to the targets. The cat moves in the tracing mode for every dimension based on its velocities. The tracing mode action is determined in 3 steps:
In Eq. (30),
Additionally, according to the suggested model, the Cauchy’s mutation is employed to modify the answer. The chosen MCSO model’s pseudo-code is depicted in Algorithm 1.

Pseudo code of proposed MCSO model
Simulation procedure
The findings of the chosen lung cancer detection with the MCSO+LF-CNN scheme were tested against other traditional models before being implemented in Python. For the experimentation purpose, we have collected datasets:
Convergence analysis
Figure 4 shows the convergence analysis of a chosen MCSO+LF-CNN approach compared to other existing schemes for various iterations ranging from 0 to 50. It is evident from the graph that now the cost function progressively grows as the number of iterations rises. Additionally, at iteration 50, the suggested MCSO+LF-CNN technique achieved a maximum cost values (∼0.92) in comparison to other conventional models (objective is depicted as the maximisation of accuracy). This has demonstrated that the suggested model achieves the lowest loss when determining the signs of disease. According to Fig. 4, the performance of the suggested MCSO+LF-CNN approach is 1.20 percent, 0.76 percent, and 1.6 percent better than the conventional methods WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN, respectively, at the 30th iteration. According to the convergence analysis graph, using MCSO+LF-CNN approach has produced better results.
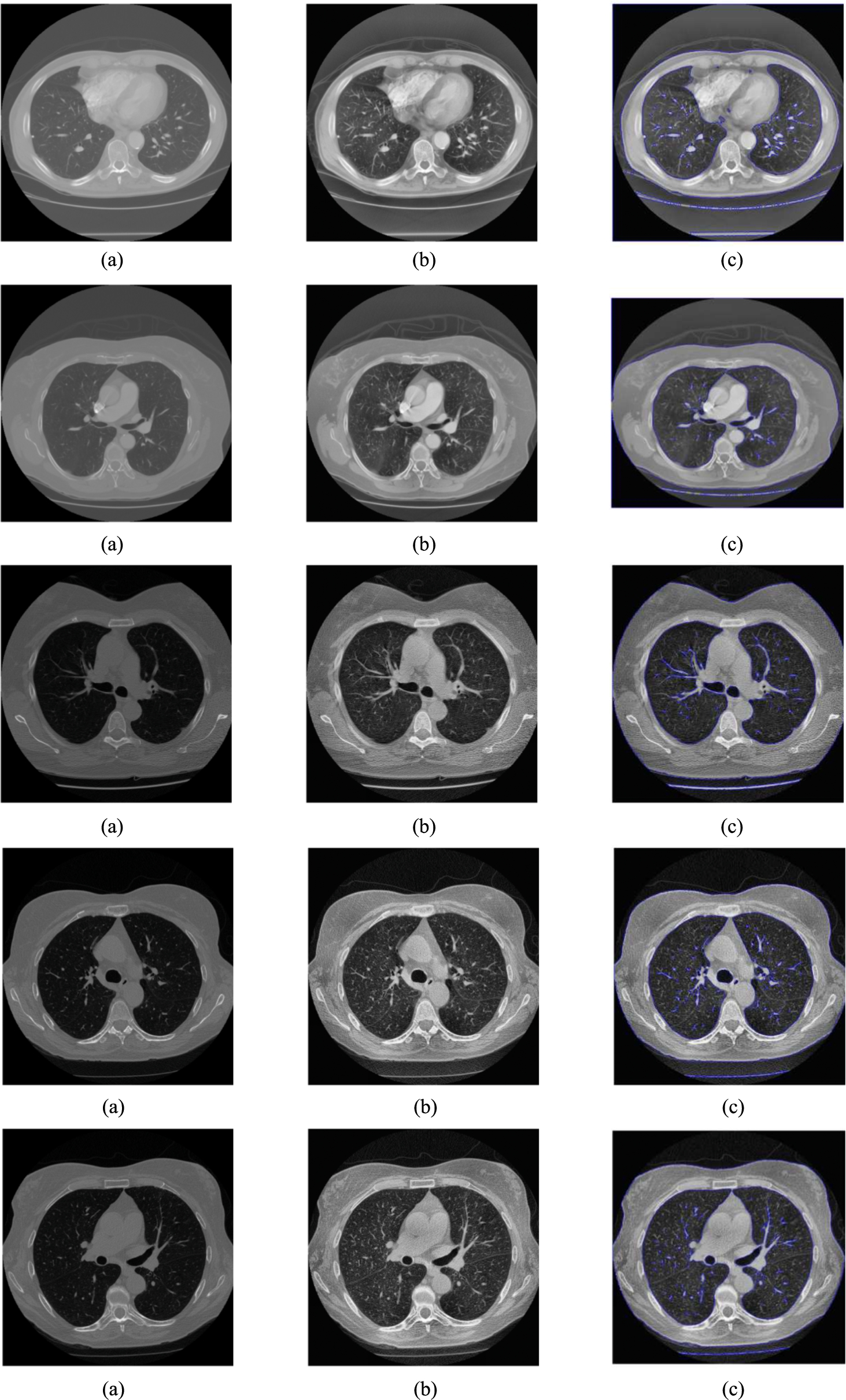
Sample images of dataset showing (a) input images (b) pre-processed images (c) level set segmentation images.
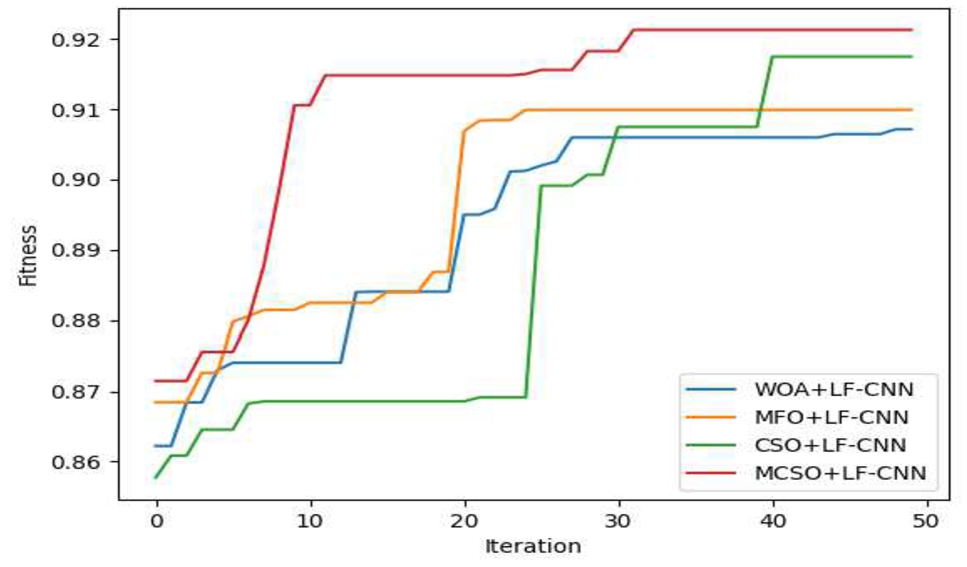
Convergence analysis of adopted MCSO+LF-CNN scheme over other conventional methods.
Table 3 compares the adopted MCSO+LF-CNN model’s overall performance analysis to those of other conventional models for specific training percentages and accuracy measures. From the table, it can be shown that the suggested MCSO+LF-CNN model outperforms other current schemes including DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, & CSO+LF-CNN for nearly all training percentages. Similar to existing standard systems like DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN, the suggested MCSO+LF-CNN method achieved 5.32%, 3.58%, 3.04%, 2.22%, 2.06%, and 1.41% greater accuracy values for train percentage 90. Additionally, Table 3 shows that the suggested MCSO+LF-CNN model outperforms other conventional models including DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN by achieving maximum accuracies (
Overall effectiveness of implemented and current programmes for various training percentages
Overall effectiveness of implemented and current programmes for various training percentages
With regard to several positive, negative, and other metrics, the performance study of the MCSO+LF-CNN algorithm is compared to certain other current systems including DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN. Figures 5, 6, and 7 display the related results in terms of positive, negative, and other metrics. Visual examination of the results reveals that the suggested effort demonstrates the highest quality results. By changing the training % from 40, 50, 60, 70, 80, and 90, respectively, all these evaluations are conducted. It is clear from looking at the proposed work’s correctness that it performed better for every adjustment in the learning percentage. Moreover, the accuracy (in Fig. 5 (a)) of adopted work at 90th training percentage is 92.94, which was superior than old models like DBN = 87.89, SVM = 87.9007, CNN = 88.419, WOA+LF-CNN = 90.3768, MFO+LF-CNN = 90.864, and CSO+LF-CNN = 91.826. In addition, the MCSO+LF-CNN model attains higher sensitivity as 92.89 at 90th training percentage, which is 5.08%, 4.85%, 4.52%, 3.16%, 1.94%, and 1.50% superior to the old approaches include DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN, accordingly. And presented work was attained the highest precision having specificity at 97% and 97% at the 90th training percentage, respectively. At last, the presented design exhibited significantly improved lung cancer identification. A presented design effectiveness is due to two factors: the model’s training remains hopeful, and layer fusion allows the model to be effective in identifying lung cancer with minimum loss.

Performance analysis of the adopted MCSO+LF-CNN schemes over other traditional schemes for (a) accuracy (b) sensitivity (c) specificity (d) precision.
Figure 6 depicts the negative metrics of the adopted and traditional models, including FPR, FNR, FDR, and FOR. A number of training percentages increases while the negative measures decrease, and as a result, an outstanding performance was recorded by the presented system. In comparison to other systems like DBN = 44.9967, SVM = 44.34, CNN = 37.206, WOA+LF-CNN = 30.7171, MFO+LF-CNN = 30.7171, and CSO+LF-CNN = 29.65, the FOR of the suggested work at the 80th training percentage is 19.78, that are the lowest value. Furthermore, at the 90th training percentage, the FPR and FDR of the MCSO+LF-CNN technique outperformed those of other systems including DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN. At training percentage = 80, the MCSO+LF-CNN approach had achieved a minimal FNR value of 8, which is 4.57%, 2.42%, 1.49%, 1.49%, 1.21%, and 1.12% better than other standard design such as DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN. Since the presented design had attained a least error measures; it’s much more significant for lung cancer identification.

Performance analysis of the adopted MCSO+LF-CNN schemes over other traditional schemes for (a) FPR (b) FNR (c) FDR (d) FOR.
Figure 7 shows the study of additional measures for the adopted and current models, including NPV, Recall, MCC, FMS, and threat score. In addition at the 80th training percentage, the recall of the MCSO+LF-CNN model is 5.08%, 4.85%, 4.52%, 3.16%, 1.94%, and 1.50% better than existing schemes includes DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN, etc. Additionally, the suggested work’s FMS at the 90th training percentage is 93.96, which is superior to the models already in use like DBN = 89.667, SVM = 89.709, CNN = 89.838, WOA+LF-CNN = 91.60, MFO+LF-CNN = 91.938947, and CSO+LF-CNN = 92.714864. Likewise, the adopted MCSO+LF-CNN model attains a maximum NPV as 92.524% at the 90th training percentage. Additionally, MCC, threat score of the suggested design is higher. As a result, it is clear from the assessment that the suggested MCSO+LF-CNN system has the greatest result, and is hence said to be much more appropriate for lung cancer detection.

Performance analysis of the adopted MCSO+LF-CNN schemes over other traditional schemes for (a) NPV (b) FMS (c) MCC (d) recall (e) threat score.
Table 4 compares the statistical correctness of the proposed MCSO+LF-CNN technique to that of other industry-standard technologies. The suggested work is run numerous times, and the best results are compiled in Table 4 due to the stochastic nature of meta-heuristic algorithms. Its mean performance of a MCSO+LF-CNN is 91.57753086, which represents the best result. It performs better than other models like the DBN, SVM, CNN, WOA, MFO, and CSO+LF-CNN, which have mean performances of 89.114, 89.530, 90.103, and 83.215, respectively. In this study, the suggested LF-CNN is used to improve the original RPN in order to get over the classic CNN’s object detection-focused limitations. The location and the object’s orientation are not encoded by the conventional CNN. The proposed model is encouraged to be superior than the resnet as it replaces the 2D with 3D convolution layers. For optimally tuning the weight in LF-CNN proposes the MCSO overcomes the drawback of poor tracking accuracy, slow tracking speed, and precocity convergence. Thus the proposed method (LF-CNN+MCSO) provides better performance than the conventional method.
Consequently, the proposed model’s improvement has been successfully validated.
Discussion
Section 3 analyses the effectiveness of the proposed research’s ideal LF-CNN and compares the outcomes with those of other existing techniques like DBN, SVM, CNN, etc. The accuracy, precision, F-measure, and other error measures are analyzed. From the results, we attained presented design outperforms another methods because of layer-fused CNN architecture. As per the proposed LF-CNN are as follow: multi-resolution and the multiple layers are used such as multi-size, multi-shape and multi-angle for region proposal generation. In the proposed LF-CNN, the 3 same set of layers like “convolutional layer, relulayer, and pooling layer” are considered as 1 set of layer and it is fused with another similar set of layer. The fused sets of layers are combined with the fully connected layer. The Multiple layers and multiple resolutions of the fusion process accurately predict the cancer regions. In this study, the recommended LF-CNN is used to improve the original RPN in order to get over the classic CNN’s object detection-focused limitations. The location & the object’s orientation are not encoded by the conventional CNN. The proposed model is encouraged to be superior to the resnet as it replaces the 2D with 3D convolution layers. For optimally tuning the weight in LF-CNN proposes the MCSO overcomes the drawback of poor tracking accuracy, slow tracking speed, and precocity convergence. Thus the proposed method (LF-CNN+MCSO) provides better performance than the conventional method.
Statistical analysis of Dataset2 with respect to accuracy
Statistical analysis of Dataset2 with respect to accuracy
The new deep learning-assisted lung cancer detection methodology presented in this paper contains 4 main phases: “(i) Pre-processing (ii) Segmentation (iii) Feature extraction and (iv) Classification”. In this study, the proposed LF-CNN is used to improve the original RPN to get over the limitations of the conventional CNN that is intended for object detection. Traditional CNNs do not encode the object’s position or orientation. As it substitutes 2D for 3D convolution layers, the suggested model is expected to outperform the resnet. The MCSO is a solution that the LF-CNN suggests to solve the drawbacks of poor tracking precision, sluggish tracking speed, and premature convergence while setting the weights optimum. Finally, the accepted scheme was calculated in comparison to the previous models using various measures, including recall, FNR, MCC, FDR, Threat score, FPR, precision, FOR, accuracy, specificity, NPV, FMS, & sensitivity, if appropriate. As seen in the graph, the adopted MCSO+LF-CNN model outperformed other current models including DBN, SVM, CNN, WOA+LF-CNN, MFO+LF-CNN, and CSO+LF-CNN in terms of accuracy by 12.69%, 11.15%, 10.32%, 6.64%, 5.69%, and 4.86%. As a result, the output was effectively categorized.