
Abstract
The prevalence of violence against women and children is concerning, and the initial step is to raise awareness of this issue. Certain forms of detection based techniques are not frequently regarded both socially and culturally permissible. Designing and implementing effective approaches in secondary and supplementary avoidance simultaneously depends on the characterization and assessment. Given the greater incidence of instances and mortalities resulting developing an early detection system is essential. Consequently, violence against women and children is a problem of human health of pandemic proportions. As a result, the focus of this survey is to analyze the existing methods used to identify violence in photos or films. Here, 50 research papers are reviewed and their techniques employed, dataset, evaluation metrics, and publication year are analyzed. The study reviews the potential future research areas by examining the difficulties in identifying violence against women and children in literary works for researchers to overcome in order to produce better results.
Keywords
Introduction
Vision input data are frequently employed in the 24/7 surveillance environment of today to autonomously monitor activities and communicate them to functional areas for corrective action. Deep approaches have produced incredibly accurate results in many computer vision issues, ranging from object recognition to complicated activity detection and perception. Autonomous monitoring is a recent topic and enterprise for computer vision scientists. The success of computer vision techniques is mostly attributable to the overwhelming need for computerized video empirical techniques for large-scale operations such as video indexing and retrieval, video summarization, action and activity identification, and video categorization. Due to its applications in security, medical healthcare, and sports, action and activity detection has attracted a lot of study interest in the area of video categorization. One of the main categories for classifying videos is violence detection (VD), which focuses on identifying patterns in violent and destructive events in an input video. The term “VD” refers to the selection or extraction of anomalous patterns from typical monitoring clips that may happen for either a brief or a very long time. Early discovery helps in either preventing or decreasing the residual damage to people’s lives and their property by starting preventative measures including alerting the closest relevant departments for quick responses. Violence is any abnormally cruel human action, including hitting, harming, destroying, and wounding others. An essential function of a VD system is to identify and report any unusual behaviour that deviates from a normal pattern of behaviour [38,44].
In addition to being a sign of sex inequality, violence against women also keeps a power imbalance in place. Violence may occasionally be intentionally used by those who commit it as a means of subordination. For instance, intimate partner violence is frequently used to enforce and show that a male is the leader of the home or relationship. The subordination of women may not be the perpetrator’s express goal in other types of violence, but it is nonetheless a result of those actions [60]. A number of psychiatric illnesses, such as depression, adversarial rebellious diagnosis, and violence against others, as well as developmental delays and academic failure, are all risks for children who witness intimate partner abuse. Children who are subjected to physical or sexual abuse are more likely to experience individual abuse as adults [39]. The films from surveillance cameras are investigated systematically through violence detection techniques (VDT) and data analysis. These sensors and other surveillance tools have been deployed in a variety of locations for public safety during the past few years, including educational facilities, hospitals, banks, markets, roadways, and so forth to keep an eye on people’s movements. Surveillance involves examining people’s actions to determine whether they are questionable or not. It is extremely difficult to notice unusual behaviour around the clock or to locate it in vast databases of movie clips. Various approaches have been devised to identify people’s interactions in the real world for this goal. These techniques aid in identifying suspicious activity in surveillance films [40,48].
Three categories of VDT are employed, including VDT, which uses machine learning, VDT [40]. In this new era of automation, deep learning plays a critical role in computer vision for object detection. To solve the issues with typical hand-crafted feature extraction architectures, deep learning offers strong tools that can learn semantics and high-level deep features [29]. For managing such massive amounts of data, Deep Neural Networks (DNNs) and Deep Learning (DL) techniques [31,47] are more dependable. To automatically recover attributes from images and utilize these features for predictions, a convolutional DNN incorporates convolutional layers, pooling layers, and fully connected layers in various ways [12,49]. Six separate modules of machine learning are applied to the recorded movies, cutting the frames in accordance with the mobility sensor, mean calculation of magnitude change vector, optical flow calculation and violence sketch generation. To get a conclusion on violent occurrences, various machine learning approaches are used in conjunction with the violent flow descriptors for each movie. Support vector machine (SVM), Random Forest (RF), and Bagging Trees are among the machine learning approaches utilized here [45,51]. Using supervised learning, the SVM method is utilized to resolve classification issues. In SVM, we plot information on the subspace of characteristics and distinguish between two groups. Due to its robustness and consideration of nominal attributes, SVM is a commonly utilized strategy in computer vision. It is employed for problems involving binary categorization based on kernel [40,46].
The major aim of this research is to evaluate several strategies pertaining to VD against women and children. On the basis of the categorization of this investigation, existing techniques are divided into deep learning, machine learning, SVM, vision and audio, video, hybrid, and multitasking. This outline of research is employed by the deliberation of classification of methods, datasets, evaluation metrics and publication year. Accordingly, accuracy is deliberated as an assessment estimation for VD against women and children. The drawbacks acquired in investigation papers are distinctly described in the research gaps spotted segment. Thus, the research gap segment is deliberated as stimulation for the effective construction of a novel framework of VD against women and children.
The investigation is displayed as follows: Section 2 exhibits the segment of approaches for VD, and Section 3 explains the research gaps attained from the VD techniques. Section 4 describes an evaluation of VD in regard to datasets employed, evaluation metrics, and publication year. Finally, Section 5 indicates the conclusion of the investigation.
Motivation
This segment demonstrated the review of several conventional approaches to Violence detection techniques by investigating their pros and cons that help the investigators to accumulate an effectual mechanism for VD techniques against women and children.
Literature survey
This research considers various approaches designed for violence prediction, which are explicated in this section. The categorization of violence detection techniques is described in Fig. 1. Here, various approaches namely, deep learning, machine learning, support vector machines and other approaches devised for the prediction of violence. The difficulties associated with these approaches are examined to affirm the researchers to construct a novel framework for violence detection techniques against women and children.
Categorization of violence detection techniques
This research focuses on different existing violence detection approaches that can be classified into six groups:

Categorization of violence detection techniques.
This section describes DL techniques employed for detecting violence.
Khan et al. [30] designed a violence detection scheme for movies. Characteristic support from each report was then chosen depending on saliency after the entire film was initially interlaced into shots. Then, in order to categorize violent and nonviolent movie scenes, these chosen frames are transmitted from a lightweight deep learning model that has been refined using a transfer learning approach. To create a film that was free of violence so that both children and individuals who are afraid of violence may see all the non-violent parts were eventually combined into a single segment. This strategy underwent analysis and offered quick and precise detection. It was unsuccessful in improving the effectiveness of violence detection in complex circumstances by using sequential learning parameters, namely, long short-term memory (LSTM) with convolutional neural networks (CNNs).
Shoaib and Sayed [50] developed an ensemble of Mask Region-based Convolutional Neural Networks (Mask RCNN) and LSTM based Recurrent Neural Network (RNN) was used to create a deep neural network model for recognizing the violent activities of a single person. In contrast, to remove the secular source of data, the key-point positions and ground control of persons in a picture are first chosen utilizing the targeted region. To better understand and increase accuracy, it was used with the LSTM approach to obtain the spatio-temporal system used for the discharged behaviour. Using our own unique custom dataset, the assessment was analyzed of various algorithms for identifying violent attitudes in videos. The technique performed well and achieved computational efficiency.
Sivanaiah et al. [54] introduced a CNN model that was utilized to detect violence from the image content. The technique for detecting misogynous text and visual content was first described. The system created by the team TECHSSN then employs a CNN model for picture data with the aid of Multimedia Automatic Misogyny Identification and transformer models to detect misogynous material from text (MAMI). The context offered by the other modality may be vital to further improving the performance of this system, however, memes convey misogynistic material using a combination of text and picture cues, thus training these models independently may miss it.
Haque et al. [24] designed a new Deep Convolutional Neural Network (DCNN) model that we call BrutNet. The BrutNet was initially built to work on patterns across numerous supports of a movie or clips of temporal length. Convolutional layers were then taken into account for each support of the time-grouped layer in order to acquire the picture aspect set and the scheme of that particular frame. In order to acquire a collection of 512 features for each frame, the model then cryptic the source from 4D to 2D. The GRU layer then extracts the temporal properties of these frames as a 1D vector, which was then refined by a number of serried layers. Thus, the content was classified as either violent or not violent in a binary manner.
Constantin and Ionescu [16] devised a Two-Stage Vision Transformer based (2SViT) system for the detection of violent scenes. While the second level analyses sequences of successive frames, it represents a Temporal Transformer. The first stage was devoted to interpreting spatial features, and forming a spatial transformer. A multilayer perceptron classification, which makes up the last layers of the design, takes data from the Temporal Transformer’s last levels and carries out the classification. Finally, the detection of violent scenes using Transformer topologies was successful. In order to evaluate a set of popular, an audio processing branch was supposed to be included in the system, but the approach that was developed did not contain this.
Sernani et al. [43] developed the architecture of three deep learning-based models for violence detection in videos. In order to establish an inception of metrics for the AIRTLab dataset determine precision metrics on the three devised approaches two of which were based on transfer learning and one of which was evaluated from scratch, and then we validate the devised dataset’s ability to test the robustness to false positives. The testing showed that the majority of the classification mistakes relate to the assignment of non-violent video, supporting the suggested dataset’s architecture. The research next shows a comparison between the suggested models and approaches depending on well-known pre-trained 2D CNNs in order to show the relevance of the presented approaches.
Subramani et al. [55] introduced an approach for multi-class identification from Domestic violence (DV) social media posts with existing Deep Learning approaches for the support of domestic violence crisis support (DVCS) groups. The initial strategy involved developing a model “gold standard” database from networks with multi-class annotation. It then conducted numerous tests with a variety of deep learning architectures, generated context descriptors for better performance and information retrieval, and finally created visualizations to make it easier to analyze the networks and explain the results. Additionally, the empirical data on a ground control database has produced predictions of classes accurately.
Wang et al. [59] established deep learning as an approach for the automatic identification of DV victims in critical need. The perpetrators of this situation must be immediately discovered in order for the DV Crisis Service (DVCS) to provide satisfactory service. Social media’s accessibility has made it possible for DV victims to tell their experiences and obtain support from the public, which provides a chance for DVCS to directly participate with and assist DV victims. However, individually browsing through the enormous array of postings takes a significant amount of time and is unproductive. Finally, statistical findings on a ground truth database surpassed conventional machine learning methods with an accuracy of up to 94%.
Magdy et al. [35] designed Violence 4D in surveillance using 4D convolutional neural networks for detection. To obtain an interest in RGB supports, the approach first uses the dense optical flow and resnet50 as its backbone. Four-dimensional ResNet was gradationally combined with existing 3D CNNs for long-term modeling because video four-dimensional convolution neural networks inhibit document inter-clip interactions, which can enhance the interpretation functionality of three-dimensional CNN at the clip level. Four sources for violent and nonviolent videos that were frequently used for VD were subjected to the designed approach. Based on the statistics, it was able to achieve improved test accuracy.
Jain and Vishwakarma [27] introduced state-of-the-art research in the field of violence detection using CNN. The several CNN variations were described after a brief summary of CNN and its features. We have offered an in-depth analysis of the pros and cons of the various CNNs used for violence detection in videos. In addition, the main widely used datasets were examined that were freely viewable, as well as their properties and the assessment criteria applied to those databases, in order to test the devised approaches. CNN has had a great deal of success, but there are still many problems that need to be looked into deeper.
Annapragada et al. [8] developed a natural language processing (NLP) and deep learning approach to identify child abuse from pediatric electronic medical records. Deep learning methodologies to categorize induced concussion to children were devised utilizing the segments of the electronic health care information prior to consultation to a CAP team in regards to recreating an atmosphere in which child physical violence was not frequently included in the diagnostic process. The use of deep learning approaches to NLP of the complimentary practitioner annotations in electronic health records could be used as a computer-aided detection algorithm to identify patients with a high risk of violence for consultation with skilled CAP doctors. It may also offer the possibility to recognize children at risk for violence consciously and instantaneously. The best performing NLP technique used in these assessments, BOW-TFIDF had an average accuracy score, ROC-AUC.
Castorena et al. [13] devised a deep Neural Network (DNN) for Gender-Based Violence Detection on Twitter Messages. Initially, CountVectorizer, TfidfVectorizer, and HashingVectorizer were employed as the feature extraction techniques, while a DL multilayer perceptron was used as the classifier. The fundamental contribution of this research was that, in dissimilarity to the majority of splitting approaches, the set of data was only a little pre-processed. Only some parts of speech which appear repeatedly in literature and are believed do not assist prejudiced statements on Twitter were removed from the original messages after being turned into a numerical vector based on word frequency. Last but not least, this initiative helps address the much-needed problem of female violence in Mexico.
Azimi et al. [11] developed a methodology for real-time “Signal for Help” detection based on two lightweight CNN architectures, each specialized in hand gesture categorization and hand palm identification. Initially, the first video dataset was produced utilizing depicting the “Signal for Help” hand movement for identification and categorization technologies because there isn’t one already available. The classification network was developed using the freely searchable Gesture database and quite well with the “Signal for Help” dataset utilizing transfer learning, but the hand-prection job was based on a pre-trained network. Finally, it made sure that the tiny size and high productivity were ideal for embedded applications and devices with limited resources.
Kumar et al. [32] developed a deep learning approach for the identification of Arabic misogyny from tweets. BERT, an ensemble-based framework, and a dynamic model on dense neural networks were some of the methods. The use of character-level features from Arabic tweets demonstrated encouraging results in the recognition of sexism and the characterization of abusive behaviour from the tweets, it was discovered. The established and improved BERT model has the highest accuracy for the job of identifying sexism.
Gunale and Mukherji [22] developed a novel HOME FAST (Histogram of Orientation, Magnitude, and Entropy with Fast Accelerated Segment Test) spatiotemporal feature extraction approach based on optical flow information to capture anomalies. Here, a framework for producing relevant features based on cuboids’ direction, motion, volatility, and feature values was provided in the spatiotemporal domain. To determine the AUC, a formative evaluation of the UCSD, Avenue, and LV recognizable databases was conducted. The Peds2 scenario’s performance in the presented design surpassed the Peds1 scenario’s efficacy on the UCSD dataset. This analysis shows that HOME-FAST deep learning surpassed all other preceding attributes in terms of performance. For the Avenue and LV data sources, the designed approach’s accuracy increased when compared to recently utilized current approaches. Despite the fact that the suggested strategy performed better on the unusual cases, there were significant false alarms in the public areas.
This section describes machine learning approaches for violence detection.
Tamilarasi and Rani [57] designed the Diagnosis of Crime Rate against Women using k-fold cross-validation through Machine Learning Algorithms, which introduced six distinct categories such as KNN and decision trees, Naive Baves, Linear Regression Classification and Regression Tree (CART) and support vector machine (SVM) using similar characteristics on crime data which were tested for reliability. This research’s main purpose was to evaluate the applicability and scalability of ML algorithms in predictive analysis. In the end, it was determined that the KNN technique was more effective than previous ML algorithms. However, it was not possible to improve precision by using various cross-validation procedures.
Alzyout et al. [5] devised a Sentiment Analysis of Arabic Tweets about Violence against Women using Machine Learning. Using a Twitter API, first gathered tweets in Arabic dialect from every Arab country as data, and then cleaned the data to use it in the categorization stage. The machine learning strategies that were investigated in this case were SVM, K-Nearest-Neighbor, Decision Trees, and Naive Bayes. In the end, the suggested technique demonstrated that the SVM algorithm had the better results, while the Naive Bayes algorithm obtained the worst results, and SVM generated higher accuracy with high effectiveness. However, there was no increase in the amount of tweets utilized in the analysis.
Amrit et al. [6] developed a decision support system for identifying child abuse based on structural and free-text data. A thorough analysis of ML techniques revealed that the complementary content can be utilized to flag potential exploitation. We employed relevant patterns found in both organized and unstructured data to build Random Forest and SVM algorithms. By merging both structured and unstructured information with a classification algorithm, we were able to maximize the AUC meter, which we determined to be the most appropriate evaluation statistic. The established approach demonstrated the viability and benefits of using machine learning techniques for decision support linked to children’s health; however, it did not incorporate more information from other pertinent organizations.
Zhou et al. [63] introduced a novel method to detect violence sequences. The distribution of optical flow fields was used to first categorise the movement parts. Second, it was thought that two distinct low-level traits might be extracted from the movement sections to describe the behaviours and display aggressive behaviours. The suggested low-level features were the Local Histogram of Oriented Gradient (LHOG) descriptor and the Local Histogram of Optical Flow (LHOF) descriptor. They were both taken, from respective RGB and optical flow images. Thirdly, each video clip’s specific-length vector was constructed after the features were coded using the Bag of Words (BoW) model to omit extraneous information. SVM was used to eventually classify the video-level vectors, and experiments on three challenging databases demonstrate that the created prediction methodology was superior to the preceding methods.
Jaiswal and Mohod [28] devised a unique technique of violent video classification, which relies on the fusion of low-level features taken from single frames of video because utilizing the entire film as input could introduce noise and redundancy into the learning process. To utilize low-level aspects and combine them by developing an approach utilizing a supervised learning strategy that employs adaptive boosting, in order to accomplish the objective of classifying violent videos as a categorical classification. Additionally, it was assessed using three different data sources that were primarily utilized to classify violent videos for the study. And when given the goal of separating violent and non-violent clips across a broad spectrum of violent data, including both crowded scenes and non-crowded scenes, it demonstrates cutting-edge classification capacity.
Escobar-Linero et al. [19] introduced a novel application of machine learning techniques to predict the decision of victims of IPV to withdraw from prosecution. In order to demonstrate the excellent assessment of ML techniques against non-linear source information, three distinct ML methods, including SVM, artificial neural network, and random forest, have been evaluated and evaluated with the exact database. Using the smallest and most useful set of input characteristics, this step seeks to select the model that best categorizes victim disengagement. Results have demonstrated that an ANN-based classifier was the most effective method for determining which variables were the most relevant and for improving accuracy.
Ye et al. [61] established a video-based school violence-detecting algorithm. It begins by employing the KNN (K-Nearest Neighbor) method to recognize peripheral moving targets, after which the targets were preprocessed using structural analysis techniques. Then, in order to enhance the constrained rectangular support of specific things, it developed a constricted rectangular framework cooperating method. Additionally, the feature dimension was reduced using the Relief-F and Wrapper methods, and SVM was employed as the classifier. Fivefold cross-validation was also carried out. A two-layer (DT-SVM) Decision Tree-SVM classifier was devised to further enhance recognition performance. Boxplots were used to identify several characteristics of the DT layer that can differentiate among typical daily activities and physical violence and between typical day-to-day commotions and physical violence. Finally, accuracy and precision reached their peak, demonstrating a noticeable improvement.
This section describes SVM based techniques for Violence detection
Chen et al. [14] developed an effective method for automatically detecting violent scenes in digital movies. The digital movie input video was initially divided into a number of scenes. Some aspects of the action scene were extracted and fed into the SVM for categorization based on the film making properties of the scene. In contrast, to assess whether an action scene has violent material, the face, blood, and motion information were finally combined. Tests have shown that the established approach was reasonably successful in identifying the majority of violent sequences. Compared to existing techniques this approach was simple and effectual.
Zhang et al. [62] introduced a Gaussian Model of Optical Flow (GMOF) to extract candidate violence regions, n order to identify places of potential violence that deviate from the crowd’s typical behaviour in the scenario. The first step in the VD process was to densely sample the candidate violence locations within each video volume. We also suggest a brand-new descriptor, Orientation Histogram of Optical Flow (OHOF), which was given into a linear SVM for categorization and can be utilized to differentiate violent from nonviolent cases. The advantages of this research included its quickness, robustness against a cluttered background, and adoption of crowd behaviour.
This section explains video-based approaches for violence detection.
Jahlan and Elrefaei [26] developed a novel method to detect violence using a fusion technique of two significantly different convolutional neural networks (CNNs) which were AlexNet and SqueezeNet networks. To recover stronger and richer characteristics from a video in its eventual concealed state, each system was preceded by a distinct Convolution Long Short Term Memory (ConvLSTM). In the end, characteristics were categorized using a softmax filter and several convent layers. Three common benchmark datasets were used to assess the method’s performance in terms of classification accuracies.
Saad et al. [41] established a violence prediction pruning system from movies and videos using two Markovian models. The first approach predicts whether or not the retrieved attitudes were violent, while the second model analyzes the obtained values from video sequences. Additionally, facial expressions from the videos were recovered, and face Cascade Classifiers, and machine learning classifiers were utilized to categorize them into the emotions of fear, sadness, anger, and happiness. To estimate the possibility of violence in text, however, it employed the Text2Emotion program. Upon testing the models using the gathered movie data source, they proved consistent assessment and astounding accuracy in detecting violent emotional scenes. A prediction method for removing objectionable material from movies and videos was consequently created.
Sandhiya et al. [42] devised a women abuse detection method in the surveillance video system. It begins with gender detection utilizing CNNs to determine whether there were male and female individuals in the area. The three strategies were then utilized to determine the abusive action. To eliminate noise artifacts, the subject sector was first identified using the noise removal approach, and then the topology filter was implemented. Second, the motion vector estimation with the Combined Local-Global method with Total Variation (CLG-TV). Thirdly, the Motion Co-occurrence Characteristic was used to examine the features of the motion vectors created during the abuse action detection (MCF). Finally, the developed method demonstrated that it accurately detects women.
Teja et al. [58] introduced Haar Cascade for Man-on-Man Brutality Identification on Video data. First, a machine learning method was employed to retrain interpolation pictures for the subsequent frames. Second, the angles and magnitudes of the interpolation characteristics were retrieved. After that, motion co-occurrence characteristics based on momentum and inclination were computed by taking into account both recent and historic motion vectors. The results produced in several videos utilizing the suggested method had a high success rate. Fighting clips with high rates were prejudiced against. This approach can put an end to conflicts, aggression, and other problems. This lessens aggression and improves the ability to spot confrontations before they start.
Ciampi et al. [15] designed the Bus Violence benchmark, the first extensive compilation of video footage for detecting violence on mass transportation, in which some performers acted out violent scenarios inside a public vehicle under various backdrops and lighting circumstances. Additionally, we evaluate the effectiveness of a number of cutting-edge video violence detectors that have been pre-trained using databases for general VD on this recently developed. The obtained mediocre assessment highlights the challenges in extrapolating widely used approaches, demonstrating the need for this fresh set of labelled data that will help them become more specialized in this novel situation.
Liu et al. [33] developed a C3D (Convolutional 3D) neural network based on Artificial Intelligent Interpretation of Surveillance Video Sequences for violence detection. It was first executed behaviour and emotion recognition independently before fusing the results of the recognition. An enhanced fusion method was designed to address the vote power issue, and it reached average detection performance on the video dataset when paired with the Finnish emotional information. Even though the sources employed differ, it was still possible to compare the suggested method to the previous works in a straightforward manner. In terms of recognition accuracy, the suggested strategy outperforms the majority of the earlier research. Additionally, when compared to the current fusion rule, the new feature algorithm can increase the identification precision. It was not done to compare skeleton-based identification algorithms for VD with body-based ones, though.
Das et al. [18] devised a novel method was developed to identify violence in different circumstances. First, several samples from each video clip were chosen utilizing image elimination and smoothing methods, and then lower-level characteristics were extracted using the Histogram of Oriented Gradient (HOG) method. Finally, for classification purposes, Naive Bayes, Linear Discriminant Analysis (LDA), Random Forest, Support Vector Machine (SVM), and K-Nearest Neighbors (KNN) were employed. The Random Forest classifier enables the system to reach the best overall accuracy. Finally, compared to the previously developed approaches, the benchmark dataset exhibited notable accuracy and improvement. However, deep learning-based technology was not put into use.
Singh et al. [53] established a fine-grained approach, referred as KidsGUARD, to detect sparsely present child-unsafe content. To begin with, use an LSTM-based autoencoder to learn efficient video approximations of video characteristics discovered through the use of VGG16 CNN. For the purpose of identifying sparse child-safe video content, encoded video delineation was given into an LSTM. A dataset of video clips that had been explicitly filtered for child-unsafe content was then generated in order to evaluate this approach. Additionally, it was found that deep learning outperformed standard video encoding methods based on Fisher Vector (FV) and Vector of Locally Aggregated Descriptors in identifying even sparsely dispersed child harmful video content by attaining a high recall at high precision (VLAD).
Mabrouk and Zagrouba [34] introduced a new feature that describes violence in video based on interest points, detected in both space and time domains, and optical flow information. The optical flow magnitude and inclination determined throughout spatiotemporal points were assessed as a bivariate distribution (STIP). The bivariate kernel density estimation method was employed to calculate the probability. To develop an SVM-based binary classifier, we created a descriptor called Distribution of Magnitude and Orientation of Local Interest Frame (DiMOLIF). On two conventional functions for VD in both congested and uncluttered scenarios, investigations were undertaken. Achieved results demonstrate that it was beneficial and surpassed the most recent classifiers.
Febin et al. [20] developed a cascaded method of violence detection based on motion boundary SIFT (MoBSIFT) and movement filtering. The majority of the aggressive behaviours were initially removed from the surveillance videos that used a movement filtering technique that utilizes a temporal variation. Only the filtered frames may therefore be eligible for feature extraction after that. The mobility boundary distribution was also recovered and integrated with the scale-invariant feature transform (SIFT) and optical flow feature histogram to form the MoBSIFT descriptor. Finally, the MoBSIFT’s high tolerance for camera movements demonstrated how accurate it was compared to other approaches already in use. Additionally, it has been demonstrated that using MoBSIFT and movement filtering reduces time complexity.
This section explains hybrid-based approaches for violence detection.
Jahlan and Elrefaei [25] developed LSTM convolution and autonomous robot neural architecture search network was used to retrieve spatiotemporal features from the video. Max and typical convolution layers were incorporated to encapsulate richer attributes, and the component was reduced using linear racially discriminatory evaluation to destroy inessential aspects, culminating in algorithms that perform well in low proportions. The Random Forest, SVM, and K-Nearest Neighbor classifiers are three ML techniques that have been devised and tested for diagnosis. To create unified information from the datasets of hockey, movies, and violent flow that contains both violent and nonviolent scenes. Three sources of data namely; hockey, movie, and violent flow theater violent flow database in regards to detection accuracy as well as a consolidated database were used to judge the effectualness of the established approach.
Asad et al. [10] designed a novel method to detect violent activities in videos, using fused spatial feature maps, based on CNN and LSTM units. The local and overall difference in patterns among the frames was produced by combining the multi-frame characteristics with spatial information. The reliability of learning these coupled spatial features has been greatly enhanced by adding supplementary residual layer blocks in addition to the pre-trained network. The LSTM layer block employed unit dimensional properties of two input supports to learn the temporal relationships in the input frame sequence. The suggested methods were evaluated on three common datasets, including a hockey brawl, a violent crowd, and BEHAVE. The investigation results demonstrate a notable enhancement in assessment when balanced with cutting-edge violence detection techniques.
Mumtaz et al. [37] introduced a novel deep learning-based violence detection framework. The extensively utilized BD-LSTM structure will be used after recovering dimensional aspects utilizing a specialized generator for the best frame resemblance prospects. To eliminate or reduce false alarms in the VD domain, the detected violence was examined using control charts, a well-known process optimization technique. Even though there has been extensive investigation assistance employing spatio-temporal modelling methodologies for VD accuracy, their performance was constrained in terms of practical viability.
Accattoli et al. [2] a solution based on a 3D Convolutional Neural Network that can effectively detect fights, aggressive motions and violence scenes in live video streams. At first, C3D permits the extraction of motion characteristics without the need for any previous knowledge in order to estimate the aspect descriptors of the movies. After that, a linear SVM was given these attributes as information to classify videos as violent or peaceful. Finally, it surpassed other legislature algorithms in terms of accuracy in databases for both individual and group battles. However, augmenting the administration by enhancing the load capacity of the system did not lead to real-time violence detection.
Al-Garadi et al. [3] introduced an effective natural language processing (NLP) model to identify Intimate partner violence (IPV) reporting tweets automatically. The NLP pipeline demonstrated competence on line with that of humans and was particularly unaffected by terms with racial or gender implications. The developed methodology will establish the framework for creating and implementing evidence-based interventions, and support for IPV victims, and assuredly allow us to manipulate the IPV issue including almost real-time through social media by recognizing IPV victims on Twitter. In the IPV-report class, the structural model acquired a categorization F1 score of 0.76, whereas in the non-IPV-report class, it received a score of 0.97.
Andrade-Segarra and Le [7] established to perform the identification of cyberbullying based on the Spanish language for Ecuadorian Twitter accounts, it was decided to evaluate an RNN + LSTM neural network and a BERT model using sentiment analysis. The RNN + LSTM model, achieved an equilibrium between implementation time and precision. The BERT model also appears to be better than its counterpart when assessing statements that were not explicitly offensive, outperforming it by 20%. Finally, it was found that the trained approaches were reliable enough to detect whether an account contains reviews related to cyberbullying in its content as well as the proportions.
This section explains about multi task-based approaches for violence detection.
Ta et al. [56] introduced MT-DNN, a multitask learning network, to identify aggressive and violent events in tweets based Detection of Aggressive and Violent Incidents from Social Media in Spanish (DA-VINCIS). Initially, prior to the training phase, several preparatory processes were used to remove or standardize undesirable aspects in tweets and reverse interpretation in four languages to maximize the allocation of categorization. Our retraining was created with subtasks that were binary evaluations that correlated to violent categories. In both subtasks, the approach produced the best F1, precision, and recall.
Khatri and Abdellatif [31] established a multi-modal strategy for measuring the Gender-Based Violence Index (GBVI) that uses satellite imagery to determine the presence of green canopies as well as major pollutants sensors to predict violence before it occurs in a specific community. With the GBVI, organizations and individuals, whose basic aim were peace and prosperity, will have a tool for properly assessing the gaps and inconsistencies in laws and policies that were explicitly targeted at women in systems of oppression.
This section explains vision and audio-based approaches for violence detection.
Hammami and Alhammami [23] developed a machine-learning model for detecting violence against children. Initially, there were originally 12 classes that corresponded to all descriptions of the operations that were documented. The experience curve of the new violent or non-violent classes must then be constructed as a function of amount of training data in order to uphold the aspects and gain insight into the best probabilistic. The classification methods had the best detection rates in the fastest amount of time when tested using both K-NN and Random Forest. Additionally, the feature evaluation process was redone, this time relying on the new output classes rather than the foremost names of action classes. The feature selection procedure consists of two steps: scheme-independent and scheme-dependent. The accuracy percentage for distinguishing violent or nonviolent content then appeared to be 99.03%.
Singh et al. [52] devised an efficient framework to detect violence in sensitive areas using feasible computer vision and machine learning techniques. It gathers video streams of people’s influence and employs motion tracking, which differentiates temporal information based on the existence of distant vehicles, to provide violence-related attributes. It estimates the optical flow for every element in the support in order to find the violent flow descriptors. To recognize violent processes, various machine learning approaches were used with these violent flow descriptors. Various machine learning algorithms were examined and differentiated for the planning phase. The combination of workable strategies was also tested for increasing accuracy and decreasing mistake rate. Finally, the results of the developed technique on various datasets were quite positive for developing a real-time application. However, cloud computing underside can be utilized to process video streams.
Anwar et al. [9] introduced a novel information fusion method for detecting the degree of violent actions in conversations that extracts and merges multi-level features from verbal, vocal, and text data as heterogeneity sources of information. Four distinct kinds of data from the raw audio signals were integrated by the multilevel multi-model fusion framework, including embeddings formed by the BERT and Bi-long short-term memory (LSTM) models, the outcome of a 2D CNN adapted to the Melfrequency Cepstrum (MFCC), and the outcome of the audio Time-Domain dense layer. The implanting was then transmitted to three-layer FC networks as a conjugated step after that. The designed approach knowledge of the characteristics that employs a combination of multi-level characteristics from many modalities results in greater performance instead of using just one with F1 Score.
This section describes other approaches for violence detection.
Alhammami and Hammami [4] introduced an FPGA-based IP for recognizing the most common violent actions against children (VACR IP). In order to maintain the confidentiality of individuals inside their homes or schools, VACR IP only permits skeleton joint data as a source. Initially, utilizing a counter and a registered de multiplexer, serially accepting the incoming skeletal joints data and moulding it into parallel frames. Following that, the block that calculates features employs the newly acquired data to carry out the necessary functions. Additionally, in a 1-NN classifier, any k-dimensional Euclidean distance can be computed and employed in the categorization array by increasing the old structure. After that, the blocks were synchronized and FIFO blocks were used to hold intermediate values in places where delayed functions arrive after rapid functions.
Ferdinando et al. [21] established Violence Detection (VITEC) as a potential structure to help heterogeneous experts combat violence it gathered information to identify recent instances of physical assault using sensors attached to a young person’s body and CCTV cameras. Efficacy can be defined system depending on the victim’s perspective and a supplementary prediction structure that relies on the witness’ perspective to build up this system. The principal agents utilize physiological and cognitive information gathered from young people to detect violence. Although there hasn’t been much progress in the study of VD from the victim’s perspective, developments in mathematics, signal processing techniques, computer technology, and sensor enhancement suggest that it was not inconceivable.
Abburi et al. [1] developed a neural network for this sexism detection and categorization that, with the use of recurrent components, may merge representations acquired using the RoBERT a model and language features like Empath, Hurtlex, and Perspective API. Initially, the domain-specific transformer model was constructed utilizing unlabeled data. The technique demonstrated how external knowledge representations ingested into the neural framework contributed to enhancing performance. All of the developed approach’s variations surpass a number of thresholds for deep learning and conventional machine learning. Our investigation revealed that our suggested method was also useful for identifying and categorizing postings on Gab.com where the use of offensive content was not prohibited.
Constantin et al. [17] designed a common evaluation framework for Violent Scenes Detection (VSD) in Hollywood and YouTube videos. By adding a substantial database, the VSD96, with over 96 hours of clips in a diverse range of genres, evaluations at varying degrees of detail, annotations of intermediate thoughts, several pre-computed multi-modal terms, and more than 230 system output findings as inception. This was the most extensive database specifically developed for the VSD task that was currently available, and it was thoroughly tested via the MediaEval comparison campaigns. By evaluating the capabilities and development of current systems, we also present a thorough study of the essential elements of VSD algorithms. Finally, the potential was analyzed for an ad-hoc late processing technique to surpass existing performance. On the VSD96 database, investigations were conducted.
Mensa et al. [36] developed the Violence Detection System (VIDES), aimed at providing the categorization computed through a neural-network-based classifier with explanations. The word embeddings that compensate the source to the VIDES system were plagued with typos, abbreviations, acronyms, and other grammatical errors that make it difficult for typical NLP techniques to elaborate on them. As aforementioned, we have given the system spaces to fill out that describe a violent incident that has already been provided to the neural model in the specific employment of semantic role assignment. The VIDES system uses word embeddings, super sense tags, and PoS filtering algorithms to execute a hybrid phase of information extraction to justify why a source of data was classified as a violence-related injury. This method demonstrated to have promising outcomes, even if improvements could be made, specifically for some different types of data.
This section reveals an identified issue on investigation as well as gaps skilled by previous VD techniques against women and children are designated below:
The research issues encountered by the DL method are illustrated as follows. A deep learning method developed in [30] for VD was unable to utilize other domains which include monitoring in smart urban, and minimized the length of the aspects by introducing embedded vision technologies for violence detection. In [50], it was feasible to handle more complex data, such as numerous people occupying a large number of obscured areas was not accomplished whereas in [24], it failed to address with more optimized layers and training with enhanced computational resources and more comprehensive AVDC dataset and also the devised deep learning method in [13], was unable to confront mainly to limit the amount of manual work to define the GBV texts and to screening more sophisticated deep learning models in order to increase the performance of the classifier, including more advanced natural language processing approaches.
The research problems encountered by the ML-based method are instantiated as follows. The machine learning-based strategy was employed in [57] to enhance performance, but it was not expanded to include various validation data techniques for increased precision or to prevent violence against women. The approach taken in [5], which involved using additional tweets for the research, was not recommended and also intended to create our own Lexicon to make the process of classifying data easier and incorporate more deep learning approaches. While the long-term impacts of the automated identification of child abuse were not examined, this method [6] was not expanded for other health risks to children’s development or for weighting evidence in accordance with its temporal distance from the present instant. The obtained approach was not compared to other deep learning methods in [28], notably those that extract spatiotemporal features from video and estimate the viability of the current method for more general action identification tasks for other fields in computer vision.
The research problems encountered by the vision and audio-based approach are instantiated as follows. While the audio-based method was not recommended in [9] for the use of edge computing embedded in unobtrusive wearable devices can help society to live a better and safer life, and the implementation and experimental evaluation of such wearable systems was not focused, the incorporation of additional sensing technologies, the vision-based method developed in [52] was unable to integrate the face detection module to identify the people involved in the violent act.
The research problem confronted by the hybrid-based method is illustrated as, in [2], Implementing a multiclass classifier was not included in the hybrid technique because it focused on improving accuracy, optimizing implementation to use the system for real-time violence detection, and categorizing various violent actions.
The research problems encountered by other methods are instantiated as follows. By exploiting the capability to duplicate VACR IP in accordance with the number of the Kinect sensors and processing in parallel with just one FPGA system, it was unsuccessful in constructing a fog-based system that can accept multiple Kinect sensors that were close to each other, like in a school or a hospital. The method in [36] did not look into generalizing the results to other domains or to further medical applications. In theory, the provided technology may be used in numerous situations in regards to generating clarification of several types of output from neural models, even though some constituents of the pipeline depend on a particular area of knowledge customized to the application demands.
The research problem confronted by the multitasking-based method is illustrated as; the elaboration and validation could not be done using the methodology used in [31].
Analysis and discussion
This section encapsulates an evaluation as well as a discussion of VD against women and children by exerting various research papers attested by the classification of approaches, year of publication, datasets exerted and analysis metrics.
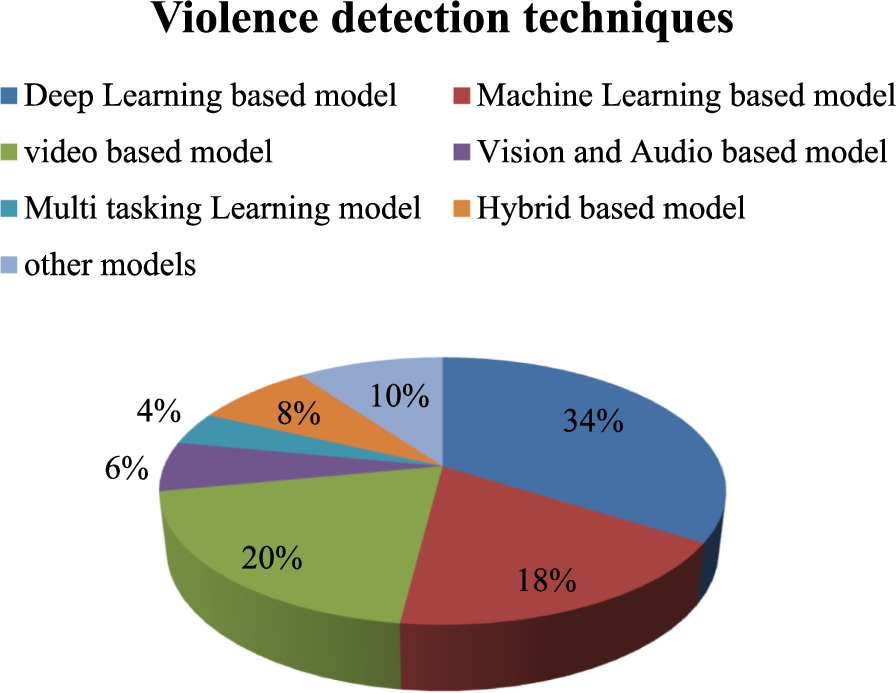
Analysis based on methods for VD.
This section illuminates an inquiry by employing several VD techniques against women and children. Approaches proposed for VD are divulged in Fig. 2. Figure 2 is distinguished as 17 of papers employed for deep learning, 9 of papers employed for machine learning and 10 of papers for video-based approaches. Likewise, 3 of the papers were based on vision and audio methods, 4 of the papers were based on hybrid techniques, Moreover, 2 of the papers were based on multi-tasking learning and 5 of the papers based on other techniques. Therefore, from these approaches, deep learning approaches are the most utilized methods for VD.
Analysis utilizing year of publication
This section explains an evaluation employing years of publication where 50 research papers elaborate on VD techniques against women and children. An analysis utilizing the year of publication is delivered in Table 1. A total of 50 investigation papers were inquired, and more papers were revealed in 2022.
An analysis employing year of publication for VD
An analysis employing year of publication for VD
This section elaborates on an evaluation implemented regarding datasets exerted by existing researches. Figure 4 elucidates manifold databases employed for VD methods against women and children. Commonly, exerted datasets in VD methods against women and children are Hockey, Crowded, Movies dataset, Twitter dataset, video dataset, violent flow dataset, DV dataset, BEHAVE and CAVIER dataset, violence dataset, From Fig. 3 shown below, it is comprehensible that the recurring guided dataset is Hockey fight dataset.

An analysis based upon diverse datasets employed for VD methods against women and children.
An analysis employing performance metrics is depicted in this section. The evaluation metrics, include Accuracy, F1-score, Precision, Recall, F-measure, detection rate, Recognition rate, Loss, test accuracy, sensitivity, specificity, ROC AUC, MAP @ 100 and MAP and Equal Error Rate. From Table 2, it is understood that 33 papers acquired accuracy, 8 papers acquired precision, 9 papers acquired Recall, 14 papers acquired F1-score and 9 papers acquired Area Under Cover (AUC). In this study, accuracy is the most frequently utilized evaluation metric.
Analysis utilizing evaluation metrics
Analysis utilizing evaluation metrics
An analysis in terms of metrics data is depicted in beneath. Here, estimation by means of accuracy is divulged.
An analysis utilizing accuracy
An analysis utilizing accuracy is described in Table 3. Moreover, in Table 3 the outline by means of accuracy is described by six groups, such as 71%–75%, 76%–80%, 81%–85%, 86%–90%, 91%–95% and 96%–100%. The research papers [2,20,21,23,25–27,30,33,37,50,52,61,63] acquired in the range of 96%–100%, research papers [7,11,19,28,41] acquired in the range of 91%–95%, research papers [8,32,34] acquired in the range of 86%–90%, research papers [3,6,58,62] acquired in the range of 81%–85%, research papers [5,13,15] acquired in the range of 76%–80% and research paper [1] acquired in the range of 71%–75%.
An analysis utilizing accuracy
An analysis utilizing accuracy
In this research, various violence detection techniques are contemplated. All explorations are collected from 50 investigated papers and hence the collected papers are classified in regards to assorted techniques, like deep learning, machine learning, multi-task learning, hybrid-based methods, video-based, vision and audio-based techniques. Moreover, manifold sources were utilized for mustering investigation papers in this outlook. Here, investigation papers collected are examined and issues skilled by existing investigations are expounded. Furthermore, these research adjutants investigations for enhancing approaches correlated to violence detection against women and children by pondering various drawbacks and problems specified. In addition, an evaluation is considered to systematize methods, analysis metrics, publication year and datasets utilized. From this assessment, it is evidently attained that deep learning methods are frequently employed techniques in more explored papers. Similarly, the most utilized datasets in explored papers are hockey fights and 2022 papers are mostly utilized in this research. Moreover, accuracy, precision and recall are frequently exerted assessment metrics and accuracy is often employed in analysis metrics with the greatest value.