
Abstract
BACKGROUND:
The construction industry is an important productive sector worldwide. However, the industry is also responsible for high numbers of work-related accidents, which highlights the necessity for improving safety management on construction sites. In parallel, technological applications such as machine learning (ML) are used in many productive sectors, including construction, and have proved significant in process optimizations and decision-making. Thus, advanced studies are required to comprehend the best way of using this technology to enhance construction site safety.
OBJECTIVE:
This research developed a systematic literature review using ten scientific databases to retrieve relevant publications and fill the knowledge gaps regarding ML applications in construction accident prevention.
METHODS:
This study examined 73 scientific articles through bibliometric research and descriptive analysis.
RESULTS:
The results showed the publications timeline and the most recurrent journals, authors, institutions, and countries-regions. In addition, the review discovered information about the developed models, such as the research goals, the ML methods used, and the data features. The research findings revealed that USA and China are the leading countries regarding publications. Also, Support Vector Machine – SVM was the most used ML method. Furthermore, most models used textual data as a source, generally related to inspection reports and accident narratives. The data approach was usually related to facts before an accident (proactive data).
CONCLUSION:
The review highlighted improvement proposals for future works and provided insights into the application of ML in construction safety management.
Introduction
Construction is one of the most relevant productive sectors worldwide and highly participates in the countries’ economies. However, the sector is responsible for thousands of work-related accidents yearly [1]. According to the International Labour Organization – ILO [2], at least 60,000 fatal accidents occur annually on construction sites, representing one fatal accident every ten minutes. Also, the Occupational Safety and Health Administration – OSHA statistics about the United States show 1.061 deaths in construction in 2019, representing 20% of worker fatalities in private industries [3]. Other countries present the same pattern of construction accident rates, such as China, the United Kingdom, Singapore, Australia, and South Korea [4].
The high number of accidents in construction indicates that the activities development is not effective enough to guarantee Health and Safety (HS) conditions for the workers. Therefore, improving safety management in construction sites is fundamental. Furthermore, the causes of work-related accidents are usually known and potentially evitable. Thus, it is necessary to comprehensively and precisely monitor the HS aspects of the workers and work environment to understand the general factors that generate the accidents/ incidents. Hence, it is possible planning specific strategies and apply measures that eliminate or reduce the activities’ risks [5].
Over the years, researchers have adopted different technologies to analyze and transform data into useful information, from basic statistics to high-level automated computational techniques [6]. One of the current techniques is machine learning (ML), which consists of the computer’s capacity to obtain knowledge from the data. The technology uses various algorithms that iteratively learn from data to improve, describe information, and even predict results [7]. Therefore, ML techniques can reveal and discuss potential patterns and trends. Also, the methods can discover relevant predictions for workplace safety management [8, 9].
Precise models of accident risk prediction can help construction managers identify potential risks in the initial stage, providing the ahead application of adequate safety measures and specific workers’ training [10]. In addition, recognition models based on ML can contribute to workplace inspection assistance, safety warning anticipation, activities monitoring, and even productive analysis [11]. These systems can collaborate with the decision-making on construction sites and, consequently, more effective safety management.
Although the high potential in resolving safety problems offered by this technology, ML applications remain discrete in construction accident prevention. Also, understanding the best way to use these methods for safety process optimization requires advanced studies [12–14]. Therefore, this study aimed to identify the ML applications developed for accident prevention in construction. For this purpose, a literature review presented the main methods, features, goals, and trends.
Materials and methods
Bibliometric research
The first step of the research consisted of investigating the scientific publications related to the proposed subject. This phase analyzed quantitatively the articles found in international databases. The process followed the guidelines of the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement [15] into three steps: planning, execution, and summarization of the results.
Initially, the planning phase developed the research protocol, which specified the necessary information for the review. The protocol defined the research objective, guiding questions, keywords, limitations, selection criteria, and databases.
The authors selected ten scientific databases to retrieve relevant publications capable of answering this central question: Association for Computing Machinery (ACM) Digital Library, American Society of Civil Engineering (ASCE) Library, Compendex (Engineering Village), EBSCO Information Services, Institute of Electrical and Electronics Engineers Xplore (IEEE), Science Direct, Scopus, SpringerLink, Taylor & Francis Online, Wiley Online Library. The databases’ selection criteria considered the cover period, the number of titles, and the relevance to the field of study of each database.
After the libraries’ selection, the PICo strategy [16] supported the development of the research guiding question. To the acronym Population (P), the review considered the construction sector; in the Interest (I), the ML applications; in the Context (Co), work-related accidents prevention. Thus, the study established the keywords and the search terms for the retrieval process: “Construction Industry”, “Machine Learning”, and “Accident Prevention”; and the synonyms “Construction”, “Civil Engineering”, “Deep Learning”, “Data Science”, “Learning System”, “Learning Algorithms”, and “Injury Prevention”.
Regarding the research limitations, the retrieval considered publications only in English until July/2021. As the exclusion criteria, the investigation excluded the papers: duplicated; not published in journals; about reviews; without access; without the search terms in the title, abstract, and keywords; without the performance of ML applications; not about the construction industry; without the focus in accident prevention. Also, the inclusion criteria considered the articles about ML applications in accident prevention and about safety performance in construction, documents that could answer the research question. After establishing the research guidelines, Table 1 shows the research protocol.
Research protocol
Research protocol
The research execution comprehended three steps: identifying publications in databases, selecting studies, and extracting studies.
The identification phase consisted of applying the search terms in the selected scientific databases to retrieve relevant papers for the review. Initially, the search in the databases identified 832 papers. After the retrieval, the authors downloaded the results of each database and used Excel to organize the data and apply the selection criteria to refine the results. Then, the authors excluded 133 duplicated studies and 699 documents passed for the selection step.
In the selection phase, the reviewers analyzed the titles, abstracts, and keywords of the papers, applied the selection criteria, and selected the adherent articles for the entire reading. Thus, the reviewers excluded 592 papers for the reasons: of not being published in journals (87); about reviews (7); without access (4); without the search terms in the title, abstract, and keywords (332); without the performance of ML applications (31); not about the construction industry (59); without the focus in accident prevention (72).
After this process, the research accepted 107 papers for the entire reading. However, the review excluded 34 other studies by the selection criteria: without the performance of ML applications (18), not about the construction industry (10), and without the focus on accident prevention (6). In the end, the extraction step included 73 articles to analyze and extract information about ML applications in construction accident prevention.
The data were treated by one reviewer and checked by the others in the entire process of research execution, including assessing the risk of bias. All the discrepancies were resolved through discussion. The execution process was based on the PRISMA flow diagram [15] and illustrated in Fig. 1.
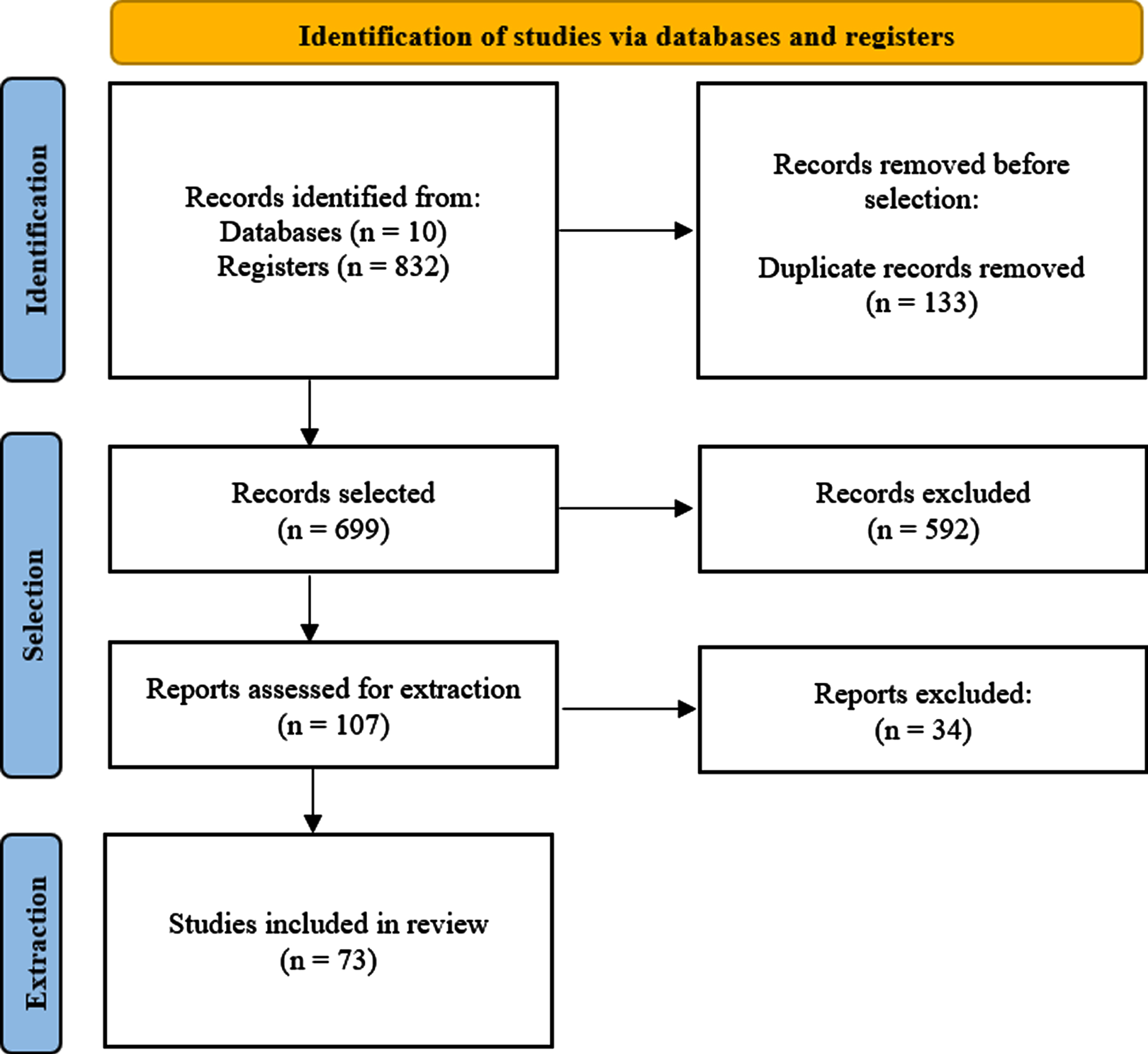
PRISMA flow diagram.
With the articles extracted, a summarization of the results showed information about the timeline of the papers, the journals more recurrent, the authors, institutions, and countries/regions with more publications, and the keywords more used in the articles.
In addition to the bibliometric results, the descriptive analysis brought other relevant information to the research. This step presented an overview of ML applications in construction safety based on the studies’ extracted. Thus, the analysis considered information such as the studies’ goals, the ML methods, and the data features, such as data collection method, data type, and approaches.
Results and discussion
Bibliometric research
The bibliometric results regarding the timeline analysis, the review showed that the first article on the subject was published in 1995 [17] to verify the ML feasibility in obtaining knowledge about work-related accident data. After twelve years without publications related, from 2008, the number of articles started a growing curve. Especially in 2016, there was a peak of publications, from 1 (2015) to 10. Another highlighted year is 2020, with 18 articles regarding the subject. This review considered publications until July/2021, but the number of studies until that passed the total in 2019, which also shows an increasing tendency.
The analysis also identified the scientific journals where the studies were published (Fig. 2). In total, 26 high-impact journals appeared; the highlighted one was the Automation in Construction, with 19 article publications. Other journals, such as “Journal of Construction Engineering and Management” and “Safety Science” were also highlighted, with 11 and 6 articles each.
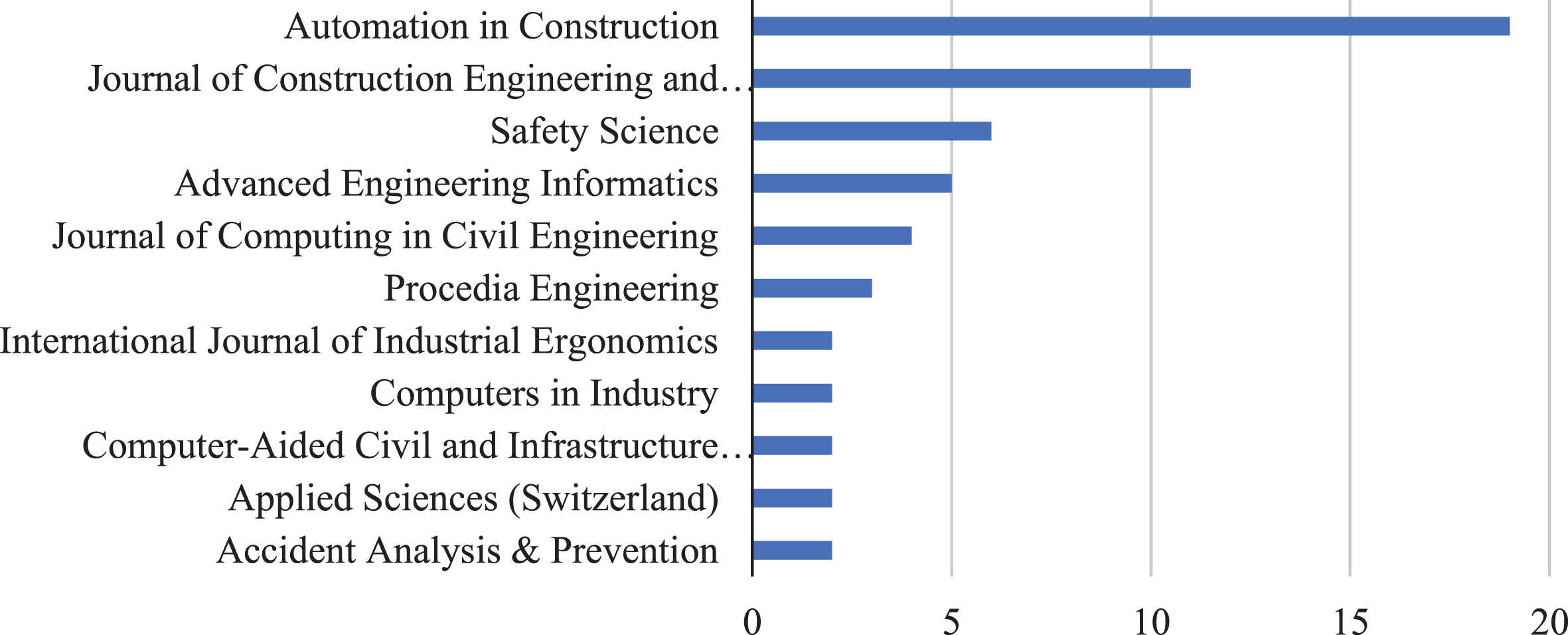
Journals with more publications.
Regarding the number of authorships, the review identified 273 authors, 13% with more than one article. The highlight was to the authors Hallowell, M. R., Li, H., Luo, X. e Tixier, A. J. -P., with four publications each. Figure 3 shows the authors with more than three publications on the subject.
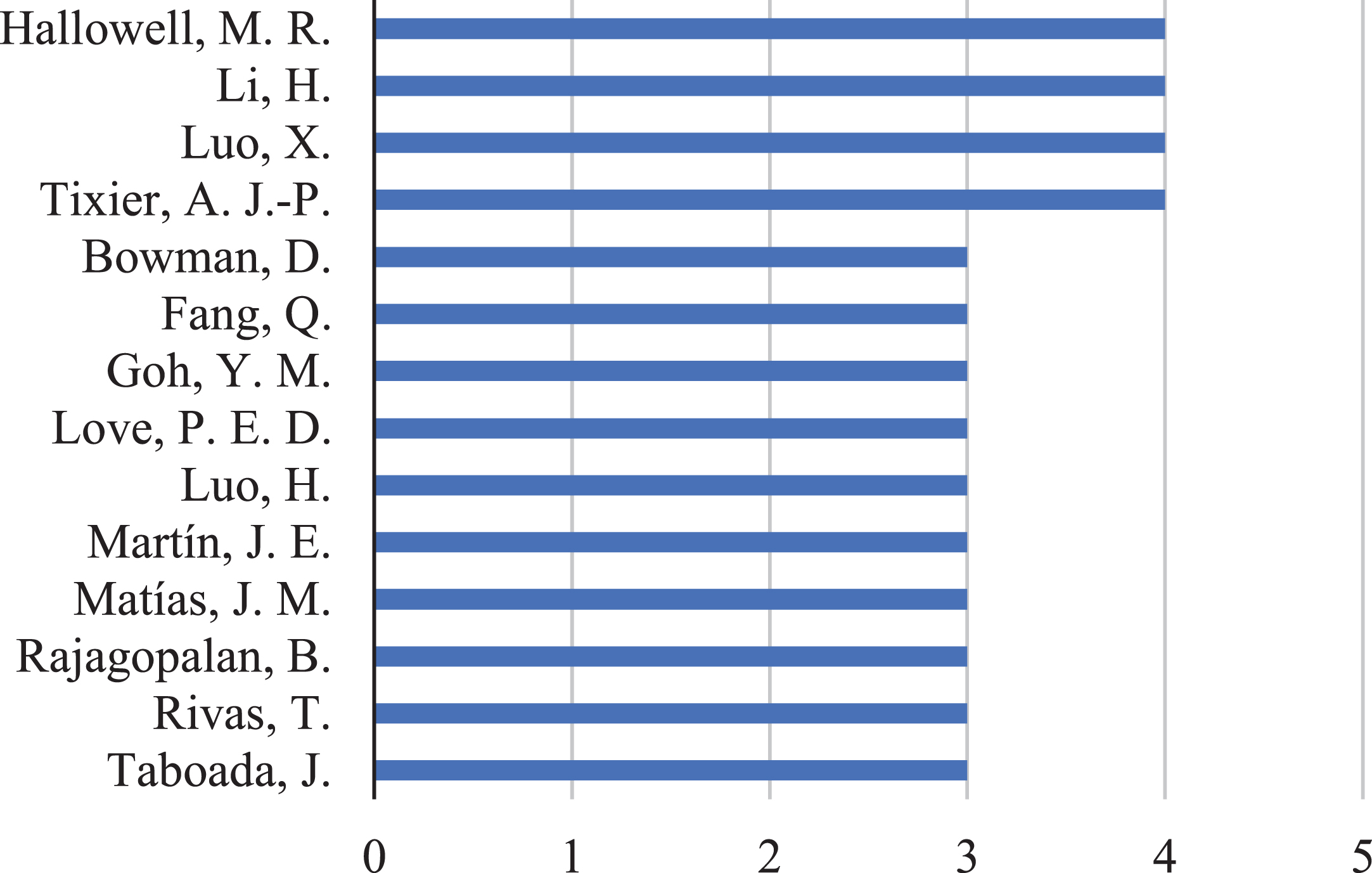
Authors with more than three publications.
The analysis also considered the relationship between the authors, institutions, and countries/regions. Thus, the USA was the first, representing around 30% of the total authorship. The second country with more research on the subject was China, with approximately 25% of authorship. The countries represented more than half (53%) of the authors. Other countries such as South Korea, Spain, Taiwan, and the region of Hong Kong also appear in the authorship with a participation percentage varying from 5 to 10%.
Regarding the institutions, the analysis found 81 total. The University of Huazhong in Chine had more publications (6) and authors (21). Also, the University of Vigo in Spain and the Hong Kong Polytechnic University in China had 12 and 11 authorships. Figure 4 shows the number of institutions and authors per country/region.
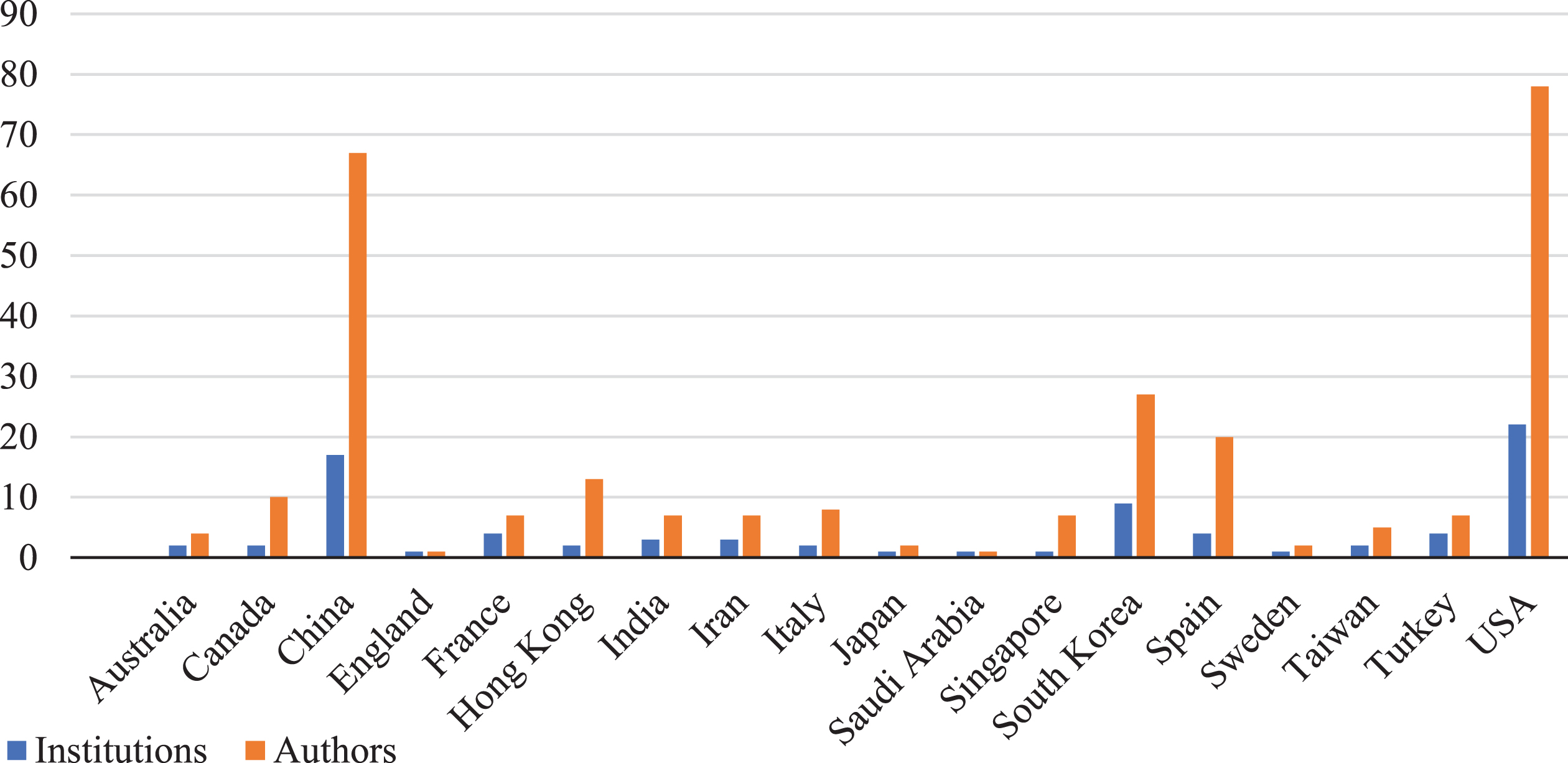
The number of institutions and authors per country/region.
The keywords used in the articles generated a word cloud presented in Fig. 5. The review identified 230 keywords, and the most recurrent term seen was Machine Learning, followed by Construction Safety, Deep Learning, and Safety.

Word cloud from WordArt.
Safety management and ML model goals
Work-related accidents in construction are responsible for thousands of deaths by year worldwide. The major causes of the events are generally related to falls (trips, slips, and falls from high elevations), struck-by, caught in-between, and electrocution [6, 18–21].
Operations involving machines and equipment generate thousands of struck-by and caught in-between accidents annually. Moreover, these operations are considered hazardous when executed on construction sites. In this context, researchers developed ML models to avoid collisions between workers and machines by detecting and monitoring entities and trajectory prediction [22–25].
Regarding the fall accidents, some studies tried to collaborate with the height-work safety by developing models of near-miss events recognition, some with the capacity to identify hazardous elements and vulnerable workers [20, 26]. Other research created tools to detect fall protection equipment (PPE, guardrail, scaffolding, and others), safety normative fall protection compliance checking, and detect workers’ unsafe actions [18, 28].
Furthermore, researchers developed solutions to identify the dependency relations between different variables that originate fall accidents [29, 30] and to predict the severity risks of falls [31] and the scaffolding fall risks [32]. Also, Bonifazi et al. [33] created a platform to identify fall occurrences and establish their causes and severity. The information input could activate warning signs and organize/enable rescue management plans. In addition, Sakhakarmi, Park, and Cho [34] proposed a model to classify scaffolding failure cases and predict safety conditions reliably based on strain data sets from scaffolding columns.
The necessity to guarantee adequate ergonomic conditions for workers in safety activities generated ML models to recognize and monitor corporal posture and workload information. Thus, some studies focused on unsafe actions recognition through human action modeling and classification systems using motion capture data [35–37]. In this respect, Yu et al. [38] developed an integrated model to provide detailed automated ergonomic evaluations of construction workers. The proposed method, combined with an ergonomic risk punctuation module based on the Rapid Entire Body Assessment – REBA risk score, identified the high-risk activities and the adequate rest schedule for each service or worker.
Additionally, Alwasel et al. [39] developed a study to classify work poses between groups of masons during standard concrete wall construction. Afterward, the investigation continued by Ryu et al. [40], which identified with high accuracy that masons more experienced adopt postures ergonomically safer and are more productive, indicating less energy use and lost movements.
Whereas an injury is rarely or never the result of one risk factor but a combination of them, understanding the causal factors involved in an accident is essential to offer guidance on effective accident prevention measures [41, 42]. Thus, by manipulating accident data to deduct and systematize significant variables, ML models can discover hidden patterns related to risks and injuries and rationally approach and predict some construction safety problems [43, 44].
In this regard, many researchers developed models to analyze construction data to classify and identify general factors that affect work-related injury incidence [6, 45–49]. For example, Fan [50] designed a tool to identify the relationships between defects and their occurrence probabilities, establish the hierarchical relation and determine the priority in safety management. Furthermore, Zhong et al. [51] conceived a model to identify implicit topics in construction safety-related textual description registers. The tool demonstrated hazard recurrence patterns automatically and reliably.
Other studies were more specific and developed simulation models to understand, for example, the relation between project safety status and the increase in rent search [52]. Additional research utilized data analysis models to classify construction accident reports [53–56], classify works by the project safety risk [57] and determine the construction site’s risk level [58].
Furthermore, forecasting is a significant issue for OHS because it can provide an opportunity to reveal problems before their occurrence [41]. Regarding this, some studies created tools to predict accident risks [10, 60], workers’ fatigue levels [61], incident outcomes [41, 62], fatal accident risks [63] and injury outcomes [9].
The workplace inspection is essential in safety management promotion to verify if the activities have safe and efficient execution. However, due to the dynamic and temporary character of the construction sites, they can be challenging to be monitored [23, 48]. Thus, there is a need to employ tools that automatically recognize and monitor entities in the workplace, such as workers, materials, and equipment/machines [20].
Regarding this, many studies developed recognition models that used computational techniques to recognize the correct use of PPE [64] and the colors of safety helmets [65–67], the detection and movement of workers and activities [11, 69], and sound detection of accidents/hazards [70]. Additionally, the need to reduce time, cost, and error probability in safety inspection reports promote the development of models to automate the compliance verification process [71] and classify near-misses information presented in safety reports [12].
Also, safety training increases knowledge and awareness of HS in the workplace [72]. Therefore, workers’ qualifications are fundamental to construction safety maintenance. In this context, Mariscal et al. [73] developed a Machine Learning model to understand the influence of employee training and information on the probability of accident rates. The results showed that a worker’s chance of suffering an accident could double if the information about the workplace risks is insufficient. In addition to this, it is necessary to identify if the safety culture is absorbed. Thus, Singh e Misra [74] developed a model to assess the workers‘ perceptions to address the issue.
ML methods and data features
According to Fan [50], the use of ML depends on the type of problems addressed, and method selection is closely related to the data collected. Therefore, this review intent to find the data features, such as types, approaches, and data collection methods, and the ML approaches/methods used in the research.
The analysis identified two learning approaches, the supervised and the unsupervised. The supervised approach uses algorithms to generalize knowledge from labeled data to predict other (unlabeled). In unsupervised learning, algorithms learn the underlying relationships from not labeled data and group cases with similar features [75]. In general, the studies analyzed used classification and regression models (supervised learning) and clustering, generalization, and association models (unsupervised learning).
Among the algorithms observed in the research, the SVM was the most recurrent (35%), presented in 26 studies. The classifier showed high performance or better results when compared to other algorithms in cases of classification of construction accident narratives [53], contractual clauses [71], and levels of risk perceived by workers [76], and also in activities recognition [77] and accident predictions [34]. Other algorithms were also recurrent in research, such as isolated or ensemble decision trees (Decision Tree – DT, Boosted Tree – BT, Random Forest – RF, Classification and Regression Tree – CART), other classifiers such as K-Nearest Kneighbor – KNN and Naive Bayes – NB, and deep learning models such as Convolutional Neural Network – CNN. Figure 6 shows the ML methods found in the review.

ML methods of the publications.
Although the good results of isolated algorithms, the ML methods combination can obtain promising outcomes, especially related to the precision achieved. Moreover, complex problems and voluminous data require ML technologies combination for problem-solving [50]. In this regard, Ayhan and Tokdemir [62] used a clustering method with an ANN to create an accident prediction model, obtaining high performance.
Regarding the type of data, the record of an accident in the construction industry is usually in text format and reported through standardized questionnaires or free-text documents, which generates a large amount of text data with rich narratives of the events. Therefore, processing these texts can benefit the identification, analysis, and assessment of safety risks in the construction. This issue becomes evident in the literature due to the number of proposed methods for analyzing textual data [14].
The analysis found six types of data used in the models: textual, images, videos, mechanical, biomechanical, and mixed data. About half of the research (52%) used text data in ML models’ development, such as accident narratives [55, 63], questionnaires with the workers [59, 78], hazardous situations narratives [51], inspections narratives [50, 57], and others. Furthermore, 23% of the research used images of workers, materials, machines/equipment, activities, and hazardous situations [22, 79]. Some other studies used biomechanical data (14%) regarding workers’ physiological and motion data, mechanical data (3%) about structure strain data, videos (3%) about activities and safety situations records, and mixed data (5%) regarding more than one type of data.
Moreover, the analysis of the data approach followed the proactive and reactive safety approaches [13]. The reactive approach considered the data obtained after an unsafe event (accident data, injuries incidence data, number of lost workdays). On the other hand, the proactive approach considered the data obtained before an incident, used to prevent them from occurring (inspection reports, images/videos of hazardous situations). Thus, the review found that 60% of the publication used proactive data in models’ development, while 37% used a reactive approach and 3% used both.
The mechanical and biomechanical data are one type of proactive approach identified in the review. One example is seen in Park et al. [80] that developed a method to automatically control the position of hydraulic excavators through mechanical data from the machines and ANNs, which obtained satisfactory tracking results. Also, Lim et al. [81] created a model to identify slip and trip events at construction sites by extracting and analyzing workers’ energy variation data.
An important and often limiting factor for the success of the models is the amount of data used. For example, Sakhakarmi, Park, and Cho [34] showed that the accuracy rate considerably increased when there was an addition in the amount of data used to train the model. To address this problem, other authors focused on making databases available to assist in the algorithms’ training, such as Xiao and Kang [82], that created a database with 10,000 images of machines used in construction environments to train object detection algorithms.
Another relevant factor influencing the models’ results is the data collection method. Thus, the review analyzed the publication and found three groups: archival, research, experiment, and mixed. The findings show that around 45% of the studies used archival data for the models’ development, corresponding to data collected before the analysis in electronic databases such as governmental agencies’ reports. Also, 26% of the research used simulation data on construction sites and laboratories, while 22% used data from surveys usually collected in construction companies. Another 7% utilized more than one method of data collection.
Using primary data can be an option for many applications. However, it can cause inconvenience due to the errors in the collection that take time to standardize. Thus, secondary data may offer an advantage, especially if the data comes from reliable vehicles, such as government official agencies. Regarding this, many studies analyzed and predicted outcomes from historical cases of accidents obtained from official databases of Taiwan [46], the USA [6, 10], and China [9].
Although the significant results found by the ML models, some authors reported problems in the development, such as the lack of structured data and classification labels, incomplete data sets, and others. However, some solutions can contribute to more reliable results, such as uniformity of the data and the use of ontology tools in data pre-processing [44, 56].
One example observed is verified in Zhang et al. [55], where the authors used data mining techniques and NLP to assess construction accident reports. The method presented the benefit of not needing classified data, which reduced plenty of manual work. Also, the model is ideal for extracting patterns from a small number of documents with similar grammatical structures.
Other research also used ontological tools and NLP to analyze unstructured data. For example, Tixier et al. [1] created a tool to scan accident reports fast and automatically with high precision. Chin, Lin, and Hsieh [83] designed an ontological classification model for construction safety to collaborate with work-related risk assessment. In addition, to manage the incomplete datasets problem, Dutta et al. [84] developed a data fusion model.
Additionally, further factors can contribute to achieving higher accuracy in the models: use reactive and proactive data combined to consider accidents and incidents before an event; merge data types, such as images, videos, audios, and textual information; use a combination of ML methods in the models; and others.
Another aspect observed in the research that can pave future works is using technologies integrated into the models, such as Building Information Modeling – BIM, Big Data, and Internet of Things – IoT. These technologies can obtain and assess more data, including real-time data, to generate strong models [7, 54]. Using associated technologies can collaborate to more precise and detailed outcomes, predicting unsafe events and reducing the number of accidents on construction sites.
Limitations
The present study has some limitations, such as the year of publications, which considered only papers up to July 2021, excluding other recent relevant studies that could also be relevant to the research. Another limitation of this review was the language selected, studies in English, which could eliminate other suitable papers published in different languages. Although the search terms strategy adopted and the use of many synonyms, the chosen keywords were another factor that limited the review. Therefore, other relevant studies may have been out of this research. Also, the scientific databases selected and the fact that this review only selected papers published in journals may have been other limiting factors to this review.
Conclusions
The high number of accidents in the construction industry highlights the necessity of improving safety management in the workplace. In this context, ML models are capable of collaborating with accident prevention. Thus, this study aimed to find relevant publications through a literature review capable of filling the knowledge gaps and providing insights into the development of ML models.
By analyzing 73 relevant articles, the bibliometric results showed that ML in construction accident prevention is a recent topic with a growing trend for the coming years. However, the developed countries seem to invest more than the developing ones. An example of this is the lack of research in African and Central/South American countries, which can highlight the discrepancy in investments in construction safety between these places.
The descriptive analysis of the publications found that researchers are focused on developing ML models to address many construction safety problems. For example, control the main accident risks in the sector, like falls and collisions, through detecting and monitoring workers, materials, safety conditions, and equipment/machines in the construction sites. Also, many developed ML models focused on manipulating data to classify and identify patterns and relations between variables that originate accidents and incidents in construction, some particular to predict the accidents risks, accidents outcomes, the severity of risks, safety conditions, and entities’ trajectories.
Therefore, with the comprehension and improvement of those applications, the processes of risk identification/assessment, control measures application, and work monitoring can effectively provide adequate health and safety conditions to the construction workers, reducing the number of incidents and the costs involved in the events.
Ethical approval
Not applicable.
Informed consent
Not applicable.
Conflict of interest
The authors declare that they have no conflict of interest.
Footnotes
Acknowledgments
The authors would like to thank CAPES and the Polytechnique School of Pernambuco for the support.
Funding
The authors report no funding.