
Abstract
BACKGROUND:
The morbidity of breast cancer has been increased in these years and ranked the first of all female diseases. Computer-aided diagnosis techniques for mammograms can help radiologists find early breast lesions. In mammograms, the degree of malignancy of the tumor is not only related to its morphology and texture features, but also closely related to the density of the tumor. However, in the current research on breast masses detection and diagnosis, people usually use the fusion feature of morphology and texture but neglect density, or only the density feature is considered. Therefore, this paper proposes a method to detect and diagnose the breast mass using fused features with density.
METHODS:
In this paper, we first propose a method based on sub-region clustering to detect the breast mass. The breast region is divided into sub-regions of equal size, and each sub-region is extracted based on local density feature, after that, an Unsupervised ELM (US-ELM) is used for clustering to complete the mass detection. Second, the feature model is constructed based on the mass. This model is composed of the mass region density feature, morphology feature and texture feature. And Genetic Algorithm is used for feature selection, and the optimized feature model is formed. Finally, ELM is used to diagnose benign or malignant mass.
RESULTS:
An experiment on the real dataset of 480 mammograms in Northeast China shows that our proposed method can effectively improve the detection and diagnosis accuracy of breast masses, where we obtained 0.9184 precision in detection of breast masses and 0.911 accuracy in diagnosis of breast masses.
CONCLUSIONS:
We have proposed a mass detection system, which achieves better detection accuracy performance than the existing state-of-art algorithm. We also propose a mass diagnosis system based on the fused features with density, which is more efficient than other feature model and classifier on the same dataset.
Keywords
Introduction
According to the statistics from American Cancer Society (ACS), the morbidity of breast cancer ranks first in the incidence of female malignancy [21]. However, early detection and timely treatment are the most effective ways to prolong the survival time of breast cancer patients [28]. As the most common method of breast cancer early diagnosis, mammography is widely used in clinical practice [22]. Therefore, radiologists always need to read many images and spend lots of time, but there is still a high missing rate of 15% – 30% [20]. Hence, in order to improve the accuracy of diagnosis results and reduce image reading time of radiologists, Computer-aided Diagnosis (CAD) is developed in mammograms [25]. Computer-aided Diagnosis of breast mass consists of two key steps: the accurate detection and the accurate diagnosis. The purpose of the first step is to assist radiologists to find and detect suspicious masses, that is, to precisely segment breast mass regions. The purpose of the second step is to assist radiologists to diagnose the suspected mass, that is, to accurately determine the quality of the mass.
Mammography has natural advantages due to the imaging principle, which can show density differences of tissues more clearly. As the breast mass is often denser than the normal glandular tissue [29], density quantitative analysis of the mammary gland tissue in mammograms brings a chance of detecting breast mass region. In addition, researches indicate that the density of breast masses is closely related to the possibility of breast cancer, and dense breast tissue may have much higher cancer risk than low-density tissue [31]. Therefore, extracting and analyzing breast density feature is expected to further improve the mass diagnosis accuracy.
Background
The accuracy of computer-aided detection (CADe) affects the accuracy of computer-aided diagnosis (CADx), so lots of work is carried out to solve the segmentation problems. In general, these segmentation algorithms can be summarized into three categories: region-based segmentation algorithms [6, 30], edge-based segmentation algorithms [2], and threshold-based segmentation algorithms [10]. Region-based segmentation algorithms divide the breast region into small areas and the maximum gray value is used as the seed point [30]. In [6], a watershed semi-automated mass segmentation method is introduced, where a transfer function is used to obtain the mass area. In [2], a method is proposed to use the discrete active contour model to complete the breast mass segmentation. Hu et al. [10] propose a combination of local and global threshold of the mass segmentation method, which is a threshold-based segmentation method.
In CAD, feature modeling and optimizing is very important. Wang et al. [27] constructs a model based on texture features and geometry features of unilateral mammary gland. The experimental results in [8] show that the image features can be used to express the image, and the feature model can improve the classification accuracy to a certain extent. Bosch et al. [14] proposes a multi-scale invariant feature model. There are often redundant features with strong correlations in the feature model, so it is necessary to select better feature vectors from the extracted features to improve the learning effect and classification accuracy. At present, the widely used feature selection methods include Impact Value Selection (IVS) [7], Sequential Forward Selection (SFS) [18] and Genetic Algorithm Selection (GAS) [15] and so on.
After extracting breast mass feature, it is necessary to use the machine learning method to classify the benign and malignant masses. Monica Di et al. [19] perform early Alzheimer’s disease by simulation based on BP neural network. Liu et al. [17] use SVM as a classifier to judge the benign and malignant masses. Anitha et al. [1] propose an improved SVM classifier, combining the regression method to effectively improve the classification accuracy. In 2005, Huang et al. [12] propose ELM as a single-hidden Layer Feed-forward Neural Networks (SLFNs), which randomly generate input weights and hidden bias, with less human intervention, better generalization ability, and faster learning speed. US-ELM is developed on the basis of ELM, and US-ELM has as good performance as ELM in computational efficiency and machine learning ability. And US-ELM can also solve the data relationship problem in the unlabeled dataset and can solve the multi-clustering problem more accurately [11].
Material
In this paper, an image dataset composed of 480 mammograms is applied, including 240 Craniocaudal (CC) and 240 Mediolateral Oblique (MLO) images. These images are from 120 patients and every patient has 4 mammograms, including left CC, left MLO, right CC and right MLO. In this dataset, 246 mammograms have masses, including 130 malignant images and 116 benign images, and others are normal. All of the mammograms have pathological diagnosis report showing normal, benign or malignant category, and experienced radiologists also mark the mass location, so these images can be used as our gold-standard dataset. Also, these images are taken by the Senographe 2000D Full digital mammography camera. And the dataset covers all women patients from a certain hospital in Northeast China from the year 2005 to 2007, and the patients are women between 32 to 74 years old.
Methods
Mass detection and diagnosis framework
In order to realize breast mass detection and diagnosis, we propose a breast mass detection method based on US-ELM using sub-region density clustering, and establish a model of local density feature. After extract features, feature selection is operated, and then, ELM method is used to diagnose the benign and malignant masses. The process framework of our proposed method, breast mass detection (BMDe) and breast mass diagnosis (BMDx), is shown in Fig. 1. In the process of detection, the sub-region of the breast is first divided, and then the density features are extracted in each sub-region. Then, US-ELM is used for sub-region clustering to complete breast mass detection. In the process of diagnosis, the fusion feature modeling is carried out firstly. This model includes the global density features of the tumor, as well as the geometry features and texture features. Then, the genetic algorithm is used to select the feature, and then, the optimized feature vector is obtained. ELM is used to classify the benign and malignant masses.

Breast mass detection and diagnosis framework.
In the process of mass detection, this paper presents a mass detection method based on US-ELM using sub-region density clustering (BMDe). Mass detection actually is the process of confirming whether a region is the mass or not. According to document [29], the mass tissue is often denser than the gland tissue. Therefore, the whole area of the mammary gland is first segmented into multiple sub-regions, and then the density features of each sub-region are extracted. Later, clustering is carried out based on density features to detect the breast mass. This mass detecting process includes three steps, including sub-region division, density feature extraction from each sub-region, and clustering based on US-ELM.
Sub-region division
Sub-region division is a prerequisite for extracting sub-region density features and clustering. And before that, image preprocessing and contour acquisition are necessary. The purpose of image preprocessing is to reduce the noise of mammograms and to increase the difference between regions. The purpose of boundary acquisition is to obtain the mammary gland region in mammograms.
Image preprocessing.
Image preprocessing includes image denoising and enhancing. For image denoising, We use a transform method in space domain, namely adaptive median filter denoising algorithm [4]. The method first uses the scanning window to obtain median pixel values from small to large values, and then common median filter method is used to replace noise points with the median value. This method can eliminate the noise and keep images details well. For image enhancement, we use contrast enhancement method [24]. First, the gray scale of the image is divided into higher and lower parts. Then the range of the two parts is reduced, so that the contrast of the region of interest is enhanced. The contrast, before and after the pre-processing, is shown in Fig. 2 (a) and (b).
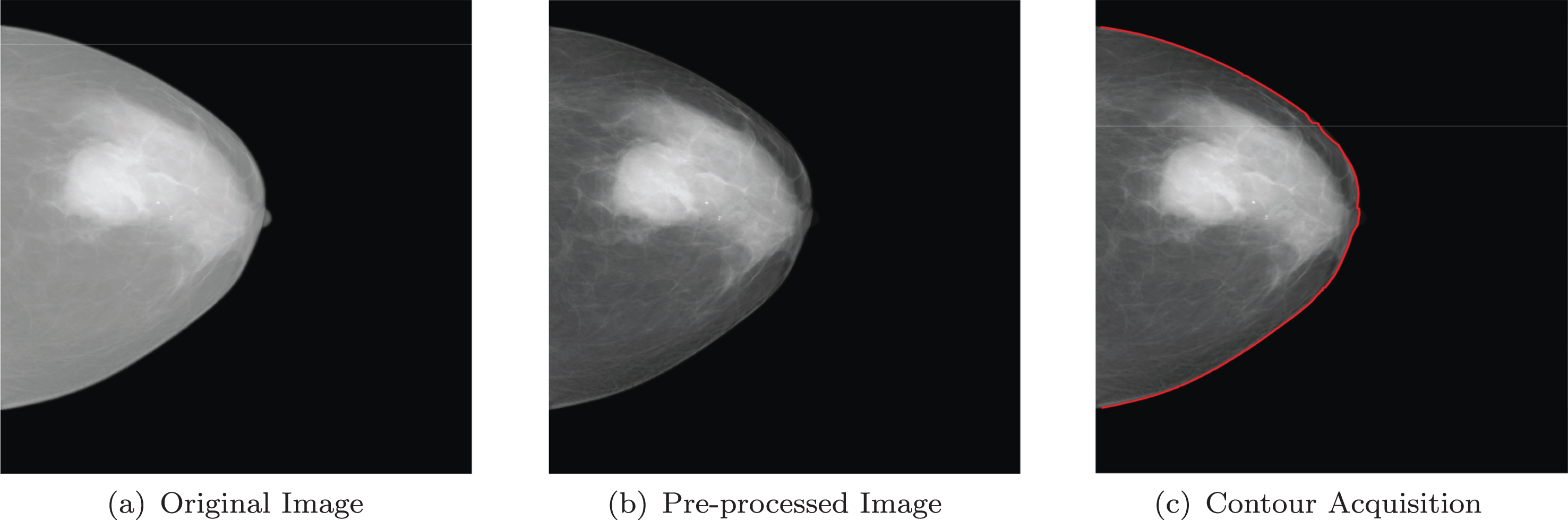
A Demonstration for image pre-processing and contour acquisition.
After preprocessing, it is necessary to obtain the breast contour, which is the range of sub-region division. In this paper, the edge detection algorithm is used for contour acquisition. Since the information contained in edge pixels is obviously different from the information contained in background regions, and the edges have a first order differential maximum or minimum extremum because of a step change [9]. Canny [13] operator is a first-order differential multi-scale edge detector, which has better edge connectivity, so we use Canny operator for edge detection. The contour acquisition result is shown in Fig. 2 (b) and (c).
Sub-region division.
The main purpose of sub-region division is to divide the breast region into several sub-regions of equal size in order to extract the local features from each sub-region. And we will use a sliding window method to achieve this goal.
First, the sliding range is determined. Because the breast mass must be inside the breast area, we define a smallest rectangular area, which contains breast tissue, as the sliding range. The breast tissue contour is the boundary. (x1, y1), (x2, y2), (x3, y3) and (x4, y4), are the coordinates of the rectangular vertices, clockwise from the upper left corner to the bottom right corner.
Then, a 32 × 32 pixels square area is used as a sliding window to slide within this rectangular area. The window starts from the upper left corner, (x1, y1), in row-major order of rectangular area S, and the sliding step is always 32 pixels. When the four vertices are all outside the S region, the row is ended and the next line continues to slide. Sliding along the line in this way, and sliding stops until the last line of sliding window contains (x3, y3) and the four vertices are not all outside the S region. Fig. 3 shows a mammogram, where the red lines represent the boundary of the mammary gland; the gray ones represent the mass; the pink ones represent the rectangular region S; the four vertices of S are (x1, y1), (x2, y2), (x3, y3) and (x4, y4); the sliding window is represented by the 32 × 32 pixels black square area in the upper left corner; the step length is 32 pixels; the window slides in the direction of the arrow. Thus, the sub-region is the area of the sliding window at each step, and then, local density feature is extracted in these sub-regions.
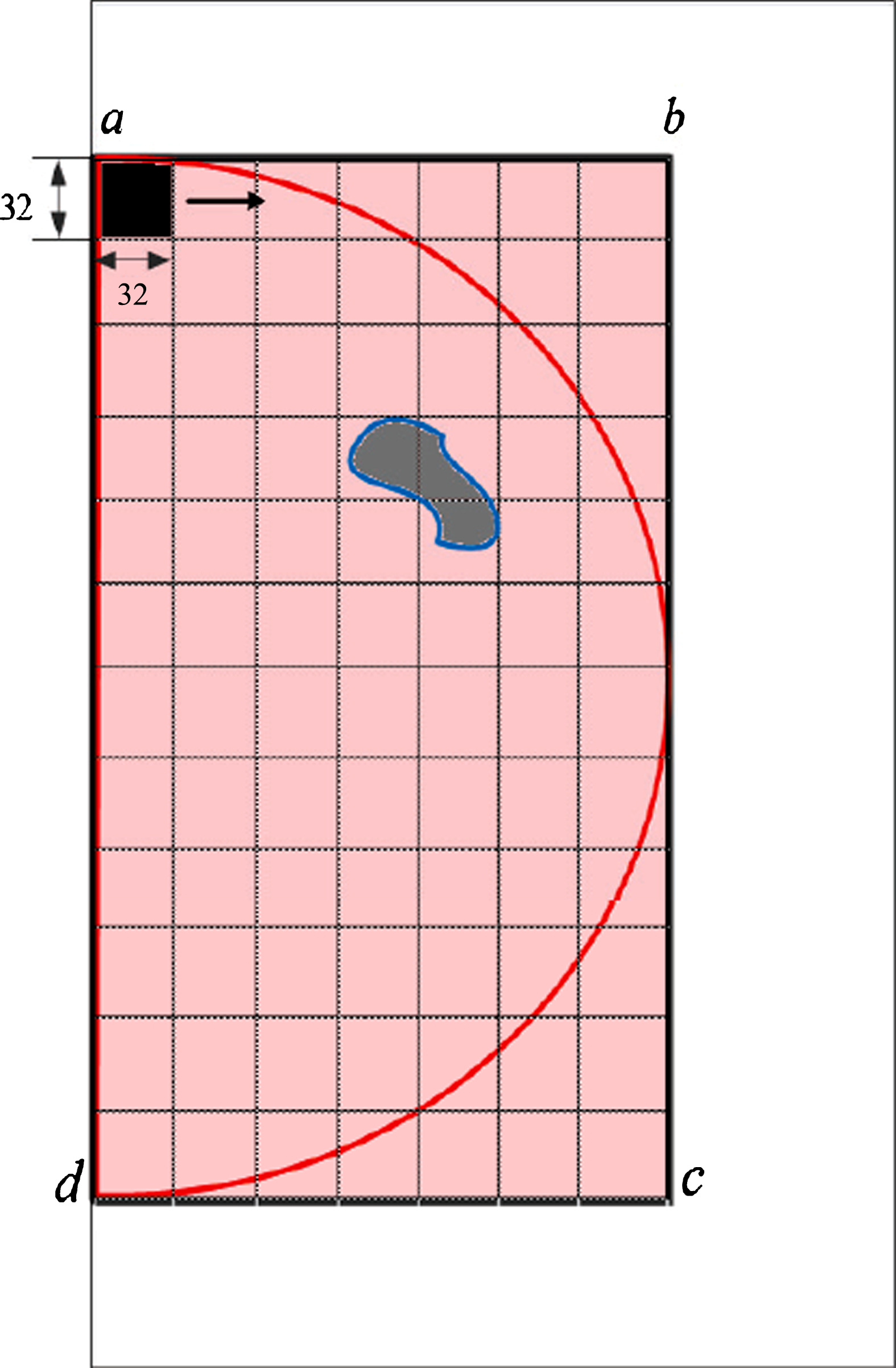
An Example of the sliding window.
Here, we choose the square slide window and try the size of 2 n × 2 n during the experiment. And after comparison, we find 25 × 25 can get better results with less time and more clearly visual effects. Thus, we set 32 × 32 as the slide window size.
Since the density of the mass and the glandular tissue in mammograms is different, we can distinguish the mass region by local density feature of the sub-region. In mammograms, the mass region is usually dense and bright, but the normal tissue is usually sparse. And there are also some normal dense regions due to lots of fibro-glandular tissues (We call it dense region without mass.). In this section, we first analyze the density difference between these three regions. Then, we quantify the density feature based on these differences, and this density feature will be used to distinguish whether a sub-region is a mass region.
Density difference analysis
Tissues with Different density will present bright or dark, and gray-level histograms are also different. We crop different regions from the mammograms for analysis, as shown in Fig. 4. (a) shows the original image and the sub-regions of size 32 × 32, where (a-1) is the dense region without mass, (a-2) is the true mass region, (a-3) is the normal region (sparse region). The gray-level histograms are shown in (b), (c) and (d).

Density comparison of different sub-regions.
Comparing (d) with (b) and (c), the mean value of the sparse region histogram is obviously smaller than the dense region, and the sparse region histogram is more concentrated distribution. Then, comparing (b) and (c), we find that for the dense region, the mean value of mass region histogram is larger than dense region without mass. And the mass region histogram distributes more concentratedly. Since the histograms are different in mean value and skewness, density feature can be obtained by quantifying histograms.
Because gray-level histograms of mass region, dense region without mass and sparse region are different, we describe mammary gland density feature based on the gray-level histograms. The density feature set includes density mean, density variance, density skewness, density kurtosis, gray-level density variance, gray-level density skewness, and gray-level density kurtosis [16], which are described as follows:
Density Mean: The Density mean is the average value of sub-regions, which reflects the distribution of the image density in each sub-region. The formula is Eq. (1). Where, L is the grey-level of pixels in a sub-region, z i is the number of pixels of grey-level i and p (z i ) is the percentage that the number of pixels of grey-level i for the number of all pixels.
Density Variance: The density variance describes the variation of the pixel density in the sub-region, which is used to extract the variance of the pixels in each sub-region. The formula is Eq. (2). Where, m is the gray-level mean of pixels in the sub-region.
Density Skewness: The density skewness describes the symmetry of the sub-region image density distribution, which is used to extract the skew of the pixels in each sub-region. The formula is Eq. (3).
Density Kurtosis: The density kurtosis describes the relative flatness of the sub-region image density distribution, which is used to extract the kurtosis of the pixels in each sub-region. The formula is Eq. (4).
Gray-level Density Variance: The gray-level density variance describes the variation of the gray density of the image in the sub-region, which is used to extract the variance of the gray-level density of each sub-region. The formula is Eq. (5). Where, the gray-level density of the pixels in the sub-region is calculated as the Eq. (6).
Gray-level Density Skewness: The gray-level density skewness describes the symmetry of the gray-level density distribution of the image in the sub-region. It is used to extract the gray-level skew of the image in each sub-region. The formula is as follows Eq. (7).
Gray-level Density Kurtosis: The gray-level density kurtosis is the kurtosis of the gray-level density of the image in the sub-region. It is used to extract the kurtosis of the gray-level density of the image in each sub-region. The formula is Eq. (8).
After extracting the seven density features above, a US-ELM based clustering of density features is carried out. The two clustering groups are the regions of breast mass and non-mass. Because the regions of mass have higher average pixel values, we can use that to determine the tumor areas and detect them.
US-ELM algorithm for clustering is shown in Algorithm 1. The input is the local density feature vector D, and the output is the clustering result. Firstly, the Laplace transform matrix L is constructed from the input density feature vector D, and then the hidden layer node parameters (ω i , b i ) are randomly generated to calculate the hidden layer node output matrix H. Next, comparing the number of hidden nodes and input nodes, the output weight β is calculated by different formulas. Fourthly, by using the Laplacian matrix L, the hidden layer output matrix H and the output weight β, the embedding matrix E is obtained. Finally, regarding each row in the matrix E as a point, the clustering result is obtained by the k-means method.
ELM based diagnosis using fused features with density
After finishing breast mass detection by sub-region density clustering, we also propose a breast mass diagnosis method based on ELM using fused features with density (BMDx). Especially, since we have already got the mass region by detection, diagnosis is performed on the whole breast mass region. Firstly, morphology, texture and density features are extracted from the whole mass region, and a fusion feature model (fused features with density) is built. Then, the model is optimized by feature selection. Finally, ELM is used to classify benign or malignant mass.
Fusion feature modeling
According to the radiologists’ clinical experience, in addition to the density of the tumor, the geometry and texture features are also considered. The geometry features, such as the roughness, size and shape of the mass, is important to distinguish the mass quality. Texture is a common visual phenomenon, which can reflect the color pattern, surface roughness and the gray-level direction, so it can be used as an effective feature to classify masses. Therefore, the feature model considers the density features, geometry features and texture features together. The feature vectors are shown in Eq. (9).
The feature vectors of density, geometry and texture features are shown in Eqs. (10, 11, 12), respectively. Furthermore, the 7 global density features, 8 geometry features, and 11 texture features are described in detail below.
In Eq. (10), the density features of the 7 sub-regions d1, d2, d3, d4, d5, d6, d7 of the mass are the density mean, density variance, density skewness, density kurtosis, gray-level density variance, gray-level density skewness and gray-level density kurtosis [16]. The above features are shown in Table 1, where the meaning of each parameter is as shown in Section 4.2.2.
Density features
Density features
In Eq. (11), g1, g2, g3, g4, g5, g6, g7, g8 are the 8 geometry features, which are the roundness, entropy of standardized radius, variance of standardized radius, ratio of area, G-roughness, circularity, length-width ratio and squareness [27]. The above features are shown in Table 2. A is the area of mass and P is the girth of edge; p k is the probability of standardized histogram; N is the number of edge points; d i is the average standardized radius of edge points; μ R is the average distance from the center of gravity to the boundary point. σ R is the mean square deviation distance from the center of gravity to the boundary point; H ROI and W ROI are the length and width of the circumscribed rectangle of the mass; A MER is the smallest rectangular area surrounding a mass.
Geometry features
Geometry features
In Eq. (12), t1, t2, t3, t4, t5 are the 5 texture features based on Gray-level Co-occurrence Matrix (GLCM) [16], which are inverse difference moment, entropy, energy, correlation coefficient, G-contrast [26]. And t6, t7, t8, t9, t10, t11 are the 6 texture features proposed by Tamura et al. [23], including coarseness, contrast (T-contrast), directionality, line-likeness, regularity and T-roughness. The above features are shown in Table 3. P (i, j) is the element of row i and column j of GLCM; μ x , μ y , δ x , δ y are the average and variance of rows and columns of P; m and n are the length and width of the image and S best (i, j) is the best window size; μ is the statistical mean of whole image pixel and σ is the statistical variance of whole image pixel; n p is the number of peaks in the histogram, p is the peak in the histogram H D , ω p is the range of quantization values that p contains and φ p is the quantization value in the maximum histogram value of ω p ; P Dd is the distance point of local co-occurrence matrix of n × n; r is a normalization factor; σ x is the standard deviation of t x ; t6 is the coarseness and t7 is the T-contrast.
Texture features
Texture features
There are 26 features in the fusion feature model. Among these features, there may be a strong correlation, which can affect the machine learning ability and reduce the accuracy of the diagnosis. Therefore, it is necessary to optimize the fusion feature model. Genetic Algorithm Selection (GAS) [27] is a stochastic search algorithm that mimics the natural selection and genetic process to find the most adaptive individual, ie finding the optimal diagnostic accuracy of the feature model. GAS [15] has the characteristics of parallel processing data, wide application and easy implementation, so this algorithm is used to select the existing features and optimize. The GAS algorithm is shown in Algorithm 2.
Diagnosis of breast mass
After optimization, the feature model is used to diagnose breast masses. ELM includes training and diagnosis processes. During the training process, the input includes the fusion feature of the mass and the pathological diagnosis result. In the diagnosis process, the input is the fusion feature of the mass to be diagnosed.
Feature extraction.
Before the training and diagnosis, the fusion feature F is extracted from mammograms. The feature extraction algorithm is shown in Algorithm 3. This algorithm is performed on all A images in the image dataset, until the optimized fusion feature F is extracted separately, which is used for subsequent training and diagnosis of ELM.
ELM training.
The optimized fusion feature F of the mass area in T training images are obtained by Algorithm 3. Pathological diagnosis result P and optimized fusion feature F are used as the training data, and then, ELM training process can be carried out. In addition to the training data, the ELM training process also needs the hidden layer node number L, in order to randomly generate hidden layer node parameters (ω i , b i ). The ELM training algorithm is shown in Algorithm 4.
ELM diagnosis.
During the ELM training process, the parameters ω, b and β of the classifier are first obtained. Then, the diagnosis of breast mass is carried out to determine the benign and malignant cases. D images are operated by Algorithm 3, in order to obtain the optimized fusion feature F of the masses as the input data of the ELM diagnosis. ELM Diagnosis Algorithm is shown in Algorithm 5.
Experiments and Results
In this paper, we validate the effectiveness of the methods including the detection method based on sub-region density clustering of US-ELM (BMDe) and the diagnosis method based on the ELM using a density feature fusion (BMDx) on a real dataset. In this chapter, the experimental setting is first introduced. Then, the experimental scheme and parameter setting are introduced. Then, the evaluation methods of the experimental results are described. Finally, the experimental results of each experiment are listed and analysis.
Detection scheme and parameters
In the experiment of breast mass detection, the method BMDe proposed in this paper is used. Another 3 common methods are used for comparison, including Watershed Algorithm (WA) [6], Multi-thresholds Segmentation Algorithm (MSA) [10] and Region Grow Algorithm (RGA) [30]. In order to compare clearly, BMDe and another 3 methods are used to segment the same image, and the manually segmentation from radiologists are used as the standard.
Also, US-ELM is used during detection, and parameters include the hidden layer node number L and cluster number k. The number of hidden layer nodes is set to 1000 by pre-tests, and the activation function S selects the sigmoid function. Since we use US-ELM to cluster into 2 classes based on local density feature, k value is set to 2.
Detection evaluation indicators
In the detection of breast masses, we use Precision and Recall to evaluate the accuracy. Also, in order to compare the segmentation methods mentioned in Section 5.1, we choose another 5 indicators, including Misclassified Error (ME), Area Overlap Metric (AOM), Area Over-segmentation Measure (AVM), Area Under-segmentation Measure (AUM) and Combination Measure (CM).
Detection evaluation indicators and the formulas are shown in Table 4, where TP (True Positive) is the number of masses which are successfully detection; FN (False Negative) is the number of masses which are not successfully detection; FP (False Positive) is the number of non-masses which are detected as the masses; S A is the area of target region segmented by the algorithm; S B is the area of the exact segmentation region (In this experiment, S B is the area of the mass region marked by experienced radiologists); α, β, λ are weights. Because CM is overall consideration of AOM, AVM and AUM, α, β, and λ are set as equivalent and the values of them are 1/3 in this paper. Especially for BMDe method, the mass is obtained by clustering the windows. And then, we smooth the mass area according to convex hull [3], and the outer points of sub-region clustering results are connected to form a convex polygon.
Evaluation indices of detection
Evaluation indices of detection
In the diagnosis of breast masses, the feature models and classifiers are validated, respectively. In the verification of the feature models, the results of mass diagnosis under five feature vector models are compared, respectively. The five feature vector models are: 1. geometry features + texture features (GT) model; 2. geometry features + density features (GD) model; 3. texture features + density features (TD) model; 4. geometry features + texture features + density features (GTD) model; 5. (GTD*) model, which is an GAS optimized GTD model. In the verification of the classifier, the results of mass diagnosis based on three classifiers are compared, respectively. The three classifiers are: 1. BP, 2. SVM, 3. ELM. The specific experimental scheme and simplified identification are shown in Table 5.
Diagnosis experimental schemes
Diagnosis experimental schemes
In the diagnosis of breast mass, five feature vector models are tested using BP, SVM and ELM classifiers. The parameters involved in the genetic selection algorithm used in the feature selection optimization process have the initial number of features N, the genetic algebra G and the individual fitness threshold S. In the experiment, N is 26, G is 100 and S is 80% based on experience. In the case of mass diagnosis based on BP, the parameters involved are the activation function S, the error tolerance limit e and the hidden layer node number L. In the experiment, the sigmoid function is chosen as the activation function S, and the error tolerance limit e is set to 1e-4. Under the five different feature models, the numbers of hidden nodes are 10, 11, 13, 12 and 11. In the experiment based on SVM, there are three parameters, including kernel function R, the penalty coefficient c and the kernel function parameter g. Furthermore, the RBF is selected as the R, c is set to 0.5, and g is set to 0.0206 by our pre-tests. In the case of mass-based diagnosis experiments based on ELM, the parameters involved are the activation function S, and the hidden layer node number L. In the experiment, the selected activation function is sigmoid, and the number of hidden nodes is set to 1000 by pre-tests. The choose of kernel functions in SVM have an enormous impact on the classification performance. RBF kernel function based SVM is considered classical, so we directly use it in our method.
Accuracy, Sensitivity, Specificity, True Positive Ratio (TP Ratio), True Negative Ratio (TN Ratio) and Area Under ROC (AUC) are used to evaluate diagnosis results. Diagnosis evaluation indicators and formulas are shown in Table 6. In order to get universal results, cross-validation [5] is used. In the experiment, we use 8-fold cross-validation to get the evaluation indicators. Among these 6 indicators, the larger the value, the more accurate the diagnosis is. In Table 6, TP (True Positive) is the number of malignant masses that can be accurately diagnosed; TN (True Negative) is the number of benign masses that can be accurately diagnosed; FN (False Negative) is the number of malignant masses that cannot be accurately diagnosed; FP (False Positive) is the number of benign masses that cannot be accurately diagnosed; x i is the abscissa value of i in ROC; y i is the ordinate value of i in ROC.
Evaluation indices of diagnosis
Evaluation indices of diagnosis
In this section, our proposed methods, BMDe and BMDx, are compared with other common methods to analyze the experimental results. BMDe is compared to three common segmentation method, including WA, MSA and RGA. And BMDx is compared using different kinds of classifiers and feature models. Especially, we use 246 images for diagnosis (There are 246 images with masses in our dataset.).
Analysis of detection results
During detection, the BMDe proposed in this paper is compared with another 3 common segmentation methods. Fig. 5 is demonstration of different segmentation methods. A further comparison of these 4 methods is shown in Table 7 and Fig. 6 based on Detection Evaluation Indicators. The results show that BMDe method has higher precision and recall, and ME value is smaller, and CM value is larger. Thus, BMDe has a better performance when detection.

Demonstration of different segmentation methods.
Evaluation indicators of detection

Evaluation indicators of detection.
According to the Diagnosis experimental schemes in Table 5, the accuracy, sensitivity, specificity, TP Ratio, TN Ratio and AUC are analyzed based on 3 kinds of classifiers and 5 kinds of feature models. The results are shown in Table 8.
The results based on BP, SVM and ELM, are shown in Fig. 7, 8 and 9. The results show that, whatever classifiers we use, the optimized feature model (GTD*) can get better results.
For 5 feature models of GT, GD, TD, GTD and GTD*, the ROC results are shown in Fig. 10– 14. The results show that, whatever feature models we use, ELM classifier can get better results.
Therefore, the optimized fusion feature model based on ELM classifier is optimal in breast mass diagnosis.
Evaluation indicators of diagnosis
Evaluation indicators of diagnosis

Comparison of evaluation indexes based on BP.

Comparison of evaluation indexes based on SVM.

Comparison of evaluation indexes based on ELM.

ROC result of GT feature model.

ROC result of GD feature model.

ROC result of TD feature model.

ROC result of GTD feature model.

ROC result of GTD* feature model.
In order to improve the accuracy of computer-aided breast mass detection and diagnosis, this paper proposes a method of computer-aided breast mass detection and diagnosis. The main contributions of our work are as follows: A mass detection method based on US-ELM using sub-region density clustering is proposed, simply as BMDe. This method can reach 0.9184 precision in mass detection. A mass diagnosis method based on ELM using fused features with density is proposed, simply as BMDe. This method can reach 0.911 accuracy in mass diagnosis. These two methods are operated on the real mammograms from Northeast China. We compare them with other common methods, and the results show that the proposed method, BMDe and BMDe, have obvious advantages in multiple indicators.
In this paper, local density feature is used in breast mass detection, and global optimized fusion feature model is used to diagnose benign or malignant breast masses. First, computer-aided detection of breast masses is achieved using sub-region density clustering based on US-ELM. Then, fused feature with density is used to realize the computer-aided diagnosis based on ELM. Finally, the methods of breast mass detection and diagnosis are performed on the real mammograms from Northeast China. The experiments show that, comparing with Watershed Algorithm, Multi-thresholds Segmentation Algorithm and Region Grow Algorithm, BMDe proposed has obvious advantages in precision and other indicators. And comparing with double fusion feature model (GT, GD, TD) and the three fusion feature model (GTD), the optimized three fusion feature model (GTD*) has obvious advantages in the mass diagnosis. Comparing to SVM and BP, ELM classifier performs better.
Disclosure statement
The work described has not been published previously in any form. All authors declare that they have no competing interests. There are no financial or personal relationships with other people or organisations that could inappropriately influence our work.
Funding
This research was partially supported by the National Natural Science Foundation of China (Nos. 61472069, 61402089, and U1401256), the China Postdoctoral Science Foundation (No. 2018M641705), the Fundamental Research Funds for the Central Universities (Nos. N161602003, N161904001, and N160601001), the Fund of Acoustics Science and Technology Laboratory of Harbin Engineering University, and the Open Program of Neusoft Research of Intelligent Healthcare Technology, Co. Ltd. (No. NRIHTOP1802).