
Abstract
The automatic classification of breast cancer pathological images has important clinical application value. However, to develop the classification algorithm using the artificially extracted image features faces several challenges including the requirement of professional domain knowledge to extract and compute highiquality image features, which are often time-consuming, laborious, and difficult. For overcoming these challenges, this study developed and applied an improved deep convolutional neural network model to perform automatic classification of breast cancer using pathological images. Specifically, in this study, data enhancement and migration learning methods are used to effectively avoid the overfitting problems with deep learning models when they are limited by training image sample size. Experimental results show that a 91% recognition rate or accuracy when applying this improved deep learning model to a publicly available dataset of BreaKHis. Comparing with other previously used models, the new model yields good robustness and generalization.
Keywords
Introduction
With the rapid development in the recent years, deep learning technology has been widely used in computer vision and machine learning problems. Many experiments have demonstrated the high and improved performance of applying deep learning methods to variety of scientific and engineering applications [1, 2]. As a result, the deep learning technology has also been applied to medicine fields [3–5], which include segmentation of different regions of interest depicting on medical images (i.e., knee cartilage [6], infant brain [7], prostate [8] and adipose tissue [9]), diagnosis of AD and MCI [10], classification of breast tumors [11], lung nodule detection [12] and diagnosis [13], identification of local lung disease patterns [14], classification between epithelium and stroma [15] and quantification of hepatic steatosis in histologic images [16].
Cancer is one of the major killers that threaten human health and life. Wherein, breast cancer is the most common cancer among women. According to data that were published by the International Agency for Research on Cancer (IARC) under the World Health Organization (WHO) in 2014 [17], breast cancer is the second leading cause of female deaths, and its incidence is rising year by year and younger. Clinically, compared with X-ray, molybdenum target, nuclear magnetic resonance and other images, pathological images are the most important criteria for doctors to final diagnose breast cancer. Accurate classification of pathological images is an important basis for doctors to formulate optimal treatment plans. The current classification based on artificial pathological images is not only time consuming and laborious, but also the results of diagnosis are easily affected by many subjective human factors. With the aid of Computer-Aided Diagnosis (CAD), the classification of benign and malignant pathological images can not only improve the diagnosis efficiency, but also provide doctors with more objective and accurate diagnosis results. Therefore, it has important clinical application value.
Automatic classification of pathological images of breast cancer is a very challenging task. First, due to the characteristics of pathological images: subtle differences among images, overlapping of cells, uneven color distribution, etc., these have brought great difficulties to image classification. Second, due to the lack of large, open, tagged datasets, it has brought some difficulties to the algorithm research. Despite this, researchers have conducted many studies in the automatic classification of pathological images of breast cancer and made a series of important research progresses. It mainly focuses on the following two aspects:
In order to address challenges and problems described above, this study aims to explore a modified deep learning model to avoid the complexity and limitations of artificial feature extraction in which automatic classification of breast cancer pathological images are achieved, at the same time, advanced data enhancement methods and migration-fine-tuning learn are used to prevent overfitting of the deep learning algorithm on small training image sample sets, and the recognition rate of images is improved to meet high standards of clinical needs.
Materials and methods
Deep learning can be viewed as a multi-layered artificial neural network [28]. By constructing a neural network model with multiple hidden layers, low-level features are transformed through layer-by-layer non-linear feature combinations, more abstract high-level feature representations are formed, the distributed representation of data is found [29]. As one of the most commonly used deep learning models, convolutional neural networks directly use 2D or 3D images as the input of the network, it avoids the complex feature extraction process in traditional machine learning algorithms. Compared with fully connected neural networks, the characteristics of local concatenation weight sharing and downsampling reduce the number of network parameters, it also reduce the computational complexity, there are a high degree of invariability to the translation, scaling, rotation, and other changes of the image. Figure 1 shows the characteristic learning process of deep convolutional neural networks. The model can only learn some low-level features such as edges, textures, and colors from the original image. As the number of layers deepens, the model can learn more abstractly and contain rich semantic information with high-level features.
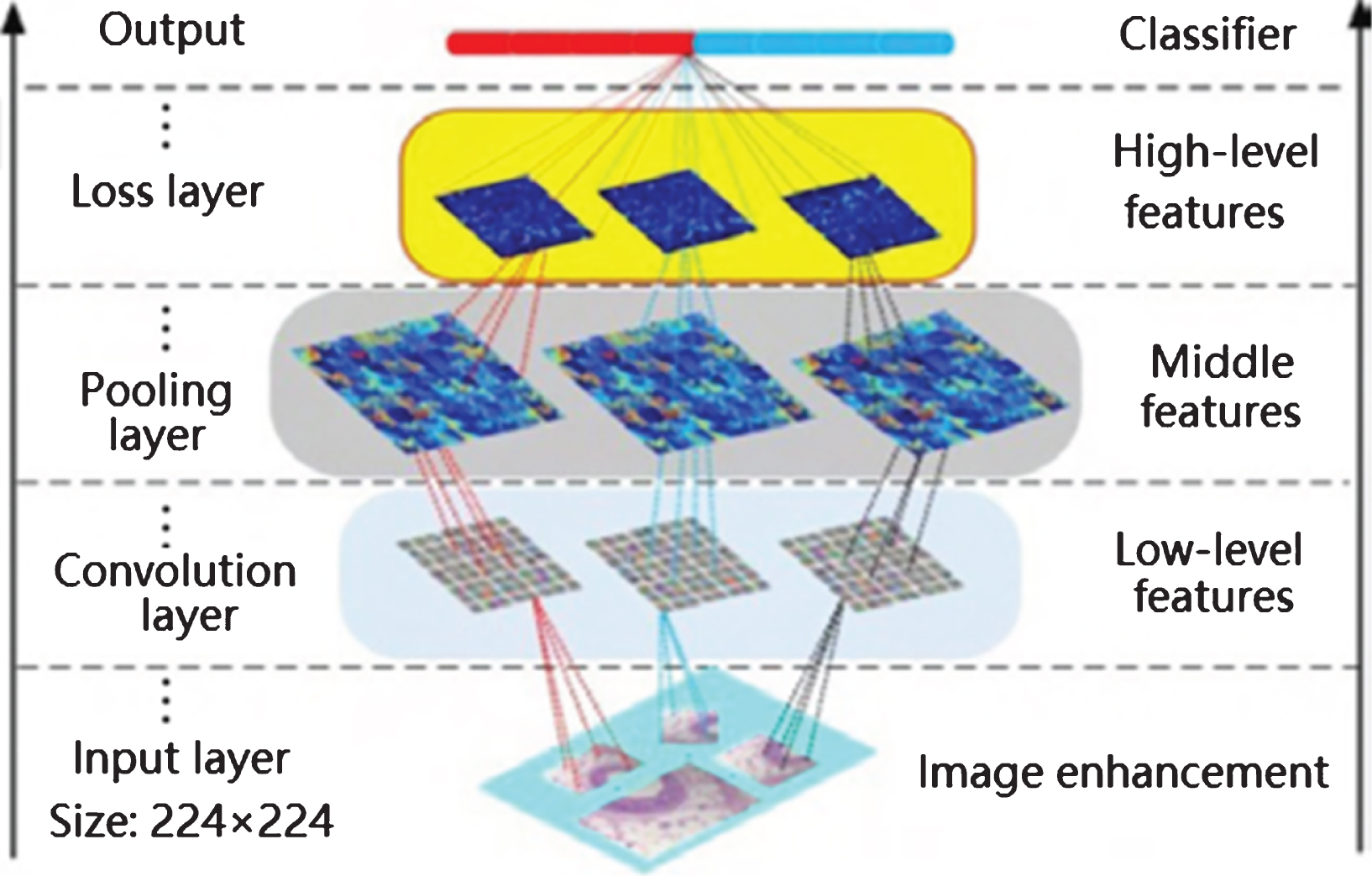
Convolutional neural network feature learning visualization process.
Comparing the commonly used deep convolutional neural network models such as LeNet [30], AlexNet [31], and VGG [32], GoogLeNet won the championship in the ILSVRC14 contest [33], it was selected as the infrastructure of this model. The model has a total of 22 layers. It mainly includes input layer, 2 common convolution layers, 9 Inception layers and several pooled layers. Among them, each Inception layer contains 6 convolution layers and 1 pool layer. All convolutions, including the Inception structure, use the ReLU function. Through the Inception structure, the model reduces the number of parameters and reduces the computational complexity while increasing the width of the network. The loss of the gradient return is ensured by adding two loss at different depths.
Network architecture design
Where, l denotes the number of layers, k ij denotes the convolution kernel that connects the feature map j of the first layer and the feature map i of the l-th layer, Ml-1 denotes the input feature map selected by the layer-1, and * denotes a convolution operation, b denotes offset, and f(×) denotes a nonlinear activation function.
In this model, the convolution kernel size of common convolutional layers is set to 7×7 and 3×3 respectively, the stride is 2, The size and stride value of each Inception layer convolution kernel are set according to the model, and all the convolutions use the ReLU function.
Softmax classifier is used in this study for feature recognition. The Softmax classifier is a generalization of the logistic model for multi-classification problems, the target variables are classified into multiple classes. Suppose there are N input images {x
i
, y
i
}
N
i
=
1
, each image is marked by {y
i
∈ {1, 2, ⋯ , k} , k ⩾ 2}, it is for a total of k class, k = 2 in this paper. For a given test image x
i
, the hypothesis function is used to estimate the probability value p (y
i
= j |x
i
) for each class j. Assume that the function h
θ
(x
i
) is the formula (2):
In the formula,
The loss function of the Softmax classifier is the formula (3):
Wherein, 1{y i = j} is indicative function. Its value rules are as follows: 1{expression is true} = 1, 1 {false expression} = 0. Finally, the error function is minimized by the random gradient descent method.
The lack of large-scale training data is one of the major challenges in the application of CNN to medical image classification, because the training of CNN parameters requires large-scale labeled samples in order to prevent over-fitting, it is difficult and costly to obtain large-scale medical images, especially medical images marked by professional doctors. In this paper, based on the breast cancer pathological dataset BreaKHis [21], two solutions are adopted. One is data enhancement [28]. The affine transform method is used to enhance the BreaKHis dataset. The dataset is expanded by 14 times mainly by rotating the image 90°/180°/270°, scaling according to 0.8, mirroring in the horizontal and vertical directions, and a combination of these operations. The second is migration learning [33]. Through pre-training on the existing large-scale datasets, the initialization parameters of the model are obtained, then it is migrated to the target dataset for fine-tuning training. Migration learning can learn some basic features, such as colors, edge features, etc., the classification of the target dataset are helped in the pre-training dataset, thereby the classification performance of the model is improved. In this paper, the model is pre-trained on ImageNet (containing more than 1.2 million natural images and more than 1,000 different categories), and then the model parameters are transferred to BreakHis for fine-tuning training. Cancer deep learning detection framework is in Fig. 2.
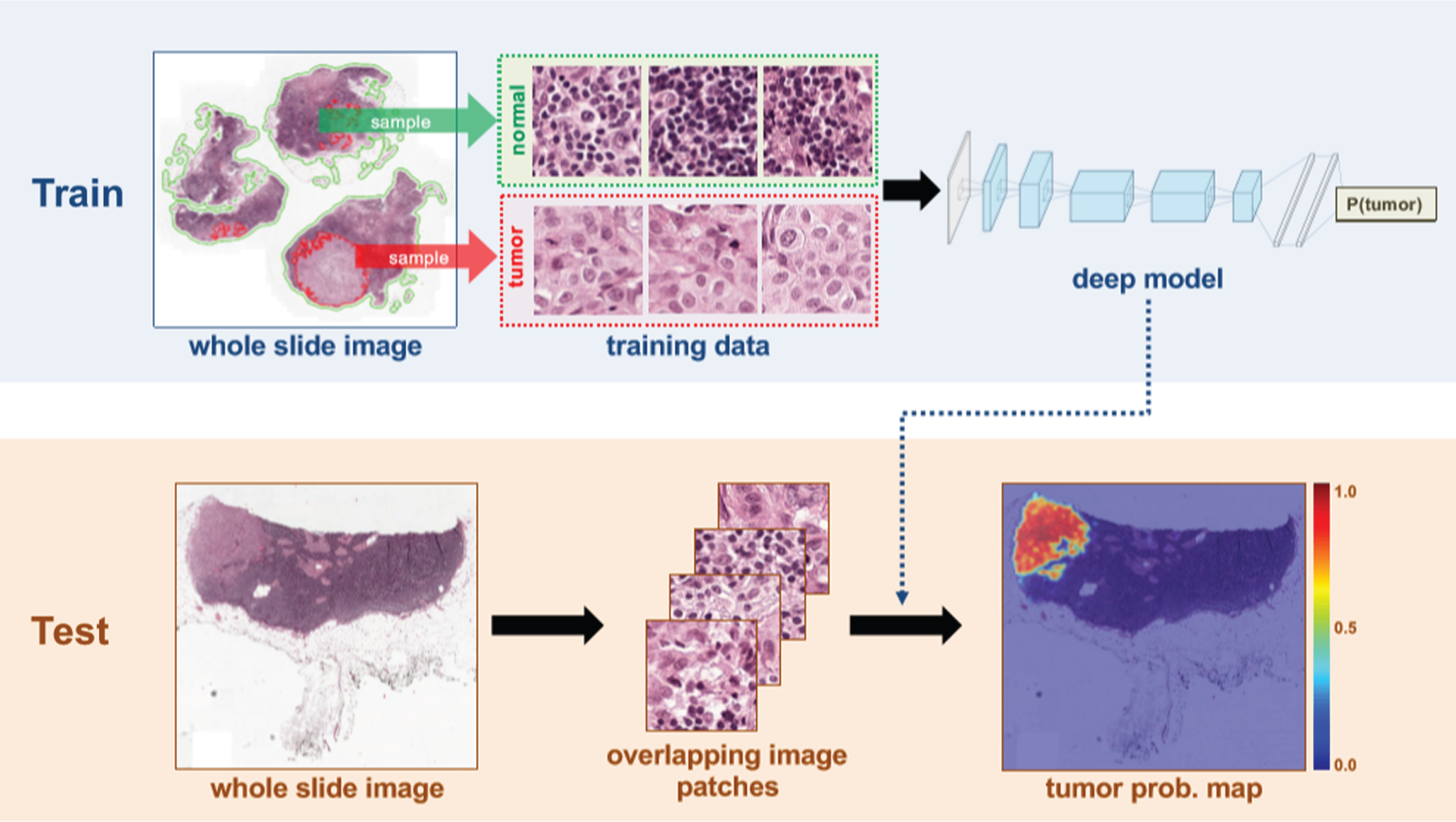
Cancer deep learning detection framework.
Dataset
The open dataset BreaKHis is used in this article [21], a dataset of 7909 breast cancer histopathology images were acquired on 82 patients, which is now publicly available from https://web.inf.ufpr.br/vri/databases/breast-cancer-histopathological-database-breakhis/. The dataset includes both benign and malignant images. The task associated with this dataset is the automated classification of these images in two classes, which would be a valuable computer-aided diagnosis tool for the clinician. the 7909 annotated breast cancer pathology images are from 82 patients with 2480 benign tumor images and 5429 malignant tumor images. Each pathology image was taken at four different magnifications (40X, 100X, 200X and 400X, which corresponds to the objective lens with magnification power of 4X, 10X, 20X and 40X.), and the fixed size was 700×460 pixels. The pattern was RGB three-channel images (24-bit color, 8 bits per channel). Table 1 shows the specific distribution of benign tumor and malignant tumor images with different magnifications [21].
Specific distributions of benign and malignant tumor images at different magnifications
Specific distributions of benign and malignant tumor images at different magnifications
To reduce computation time and to focus the analysis on regions of the slide most likely to contain cancer metastasis, the tissue is first identified within the whole slide images and background white space is excluded. To achieve this, a threshold is adopted based segmentation method to automatically detect the background region. In particular, the original image is first transferred from the RGB color space to the HSV color space, then the optimal threshold values in each channel are computed using the Otsu algorithm, and the final mask images are generated by combining the masks from H and S channels. The enhanced dataset has been expanded 14 times, which contains more than 110,000 pathological images of breast cancer. In order to fully retain image contours and global feature information, the entire slice image is used as a network input.
In the BreaKHis dataset, both breast tumors benign and malignant can be sorted into different types based on the way the tumoral cells look under the microscope. Various types/subtypes of breast tumors can have different prognoses and treatment implications. The dataset currently contains four histological distinct types of benign breast tumors: adenosis (A), fibroadenoma (F), phyllodes tumor (PT), and tubular adenona (TA); and four malignant tumors (breast cancer): carcinoma (DC), lobular carcinoma (LC), mucinous carcinoma (MC) and papillary carcinoma (PC). Figure 3 shows a slide of breast malignant tumor (stained with HE) in different magnification factors.
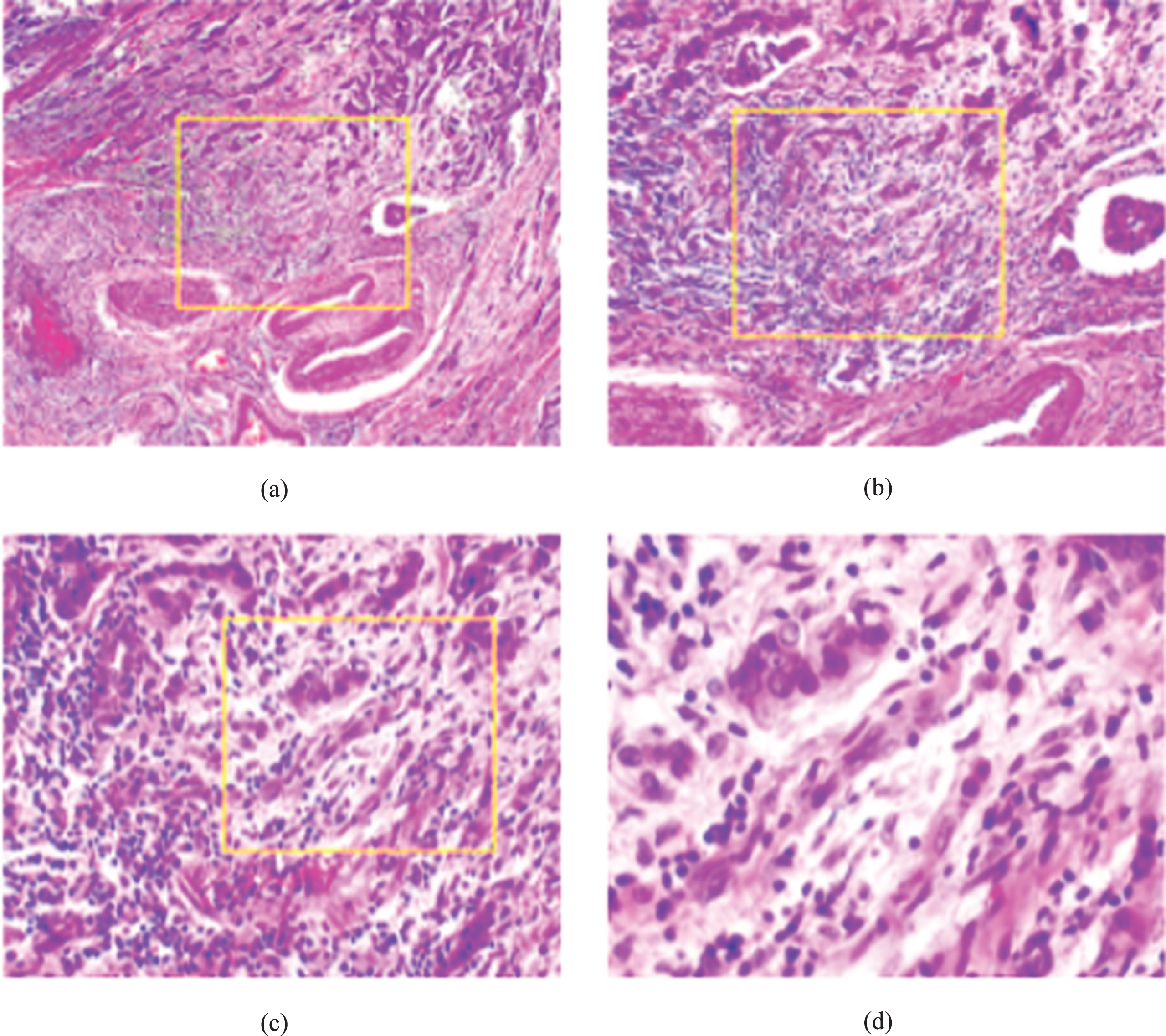
A slide of breast malignant tumor (stained with HE) seen in different magnification factors: (a) 40X, (b) 100X, (c) 200X, and (d) 400X. The highlighted rectangle (added manually for illustrative purposes only) is the area of interest selected by the pathologist and will be detailed in the next higher magnification.
For the classification of medical images, the classification performance of the model can be evaluated from two aspects: patient level and image level. The recognition rate is calculated from the patient level, so that N
np
is the number of pathological images per patient, N
rp
is the number of images correctly classified by each patient, and N
p
is the total number of patients, there is formula (4):
Regardless of the patient level, when the recognition rate is only calculated from the image level, let N
all
represent the number of pathological images in the verification set and test set, and N
r
represents the number of images in which the image was correctly classified. The recognition rate at the image level can be expressed as a formula (5):
Pre- and post-enhancement datasets were randomly divided into three parts: training set is 50%, validation set is 25%, and test set is 25%. Among them, the training set is used for model training and parameter learning; the verification set is used to optimize the model, the model is tested during the training process, and the parameters are automatically fine-tuned according to the test results; The test set is used to test model recognition and generalization capabilities. In order to ensure the model’s ability to generalize unknown data, datasets do not cross each other. The result is the average of 10 randomly assigned dataset experiments.
To verify the effectiveness of migration learning, two training strategies are used: random initialization training and migration are used for fine tuning training. To verify the effectiveness of the data enhancement, two training strategies were applied to the pre-enhancement and post-enhancement datasets, respectively.
Experimental tools and time consumption
This model is trained on Lenovo ThinkStation, Intel i7 CPU, NVIDIA Quadro K2200GPU. The Caffe framework is used [34], the average training time is about 50 minutes on the pre-enhanced dataset and about 10 hours 16 minutes on the enhanced dataset. The average test time is about 0.053 s. The data enhancement algorithm is implemented by Matlab 2016a.
Experimental results
In order to test the performance of the method of this paper, we choose to compare with the methods which were used in the same dataset BreaKHis [21]. The experimental results are shown in Table 2. In this table, the optimal results in the corresponding literature are selected, and the comparison is made from the image level and the patient level. In the table, AlexNet is the network model which was adopted by Spanhol et al. in [26], and the results are the optimal classification results after adopting different fusion strategies. PFTAS + QDA/SVM/RF is the method which was used in [21]. PTFAS (Parameter-Free Threshold Adjacency Statistics) method is used in feature extraction, and then three kinds of machine learning methods QDA (Quadratic Discriminant Analysis), SVM and RF (Random Forests) are used for classification; Single-Task CNN is an independent CNN algorithm of the literature based on magnification [27]. From Table 2, we can see that the recognition rate of this method is higher than that of other methods at the image level or the patient level, and the classification results are almost the same at about 91% for different magnification images. It shows that this method can extract more distinguishing features, so the recognition rate is higher, and it has better robustness and generalization.
Comparison of patient-level and image-level recognition rates with other methods at different magnifications (%)
Comparison of patient-level and image-level recognition rates with other methods at different magnifications (%)
On the pre-enhanced and post-enhanced datasets, the initial training and migration are randomized, the fine-tuned training were performed. The experimental results are shown in Fig. 4, and comparisons were made from the image level and the patient level. The results in Fig. 4 show that there is little difference between the image level and the patient level; after the data is enhanced, the recognition rate has been greatly improved both when the training was initiated at random and during the migration-fine tuning training (See the blue and red curves in Fig. 4). The red curve confirms the effectiveness of the data enhancement method; after adopting migration learning, the recognition rate has also been improved both on the metadata and on the enhanced data (see the blue and green curves in Fig. 4). The effectiveness of migration learning has also been improved. It shows that this method can effectively avoid overfitting problems which are caused by lack of training sample sets. The model is used to learn some features during pre-training on ImageNet, and these features help the classification of images.
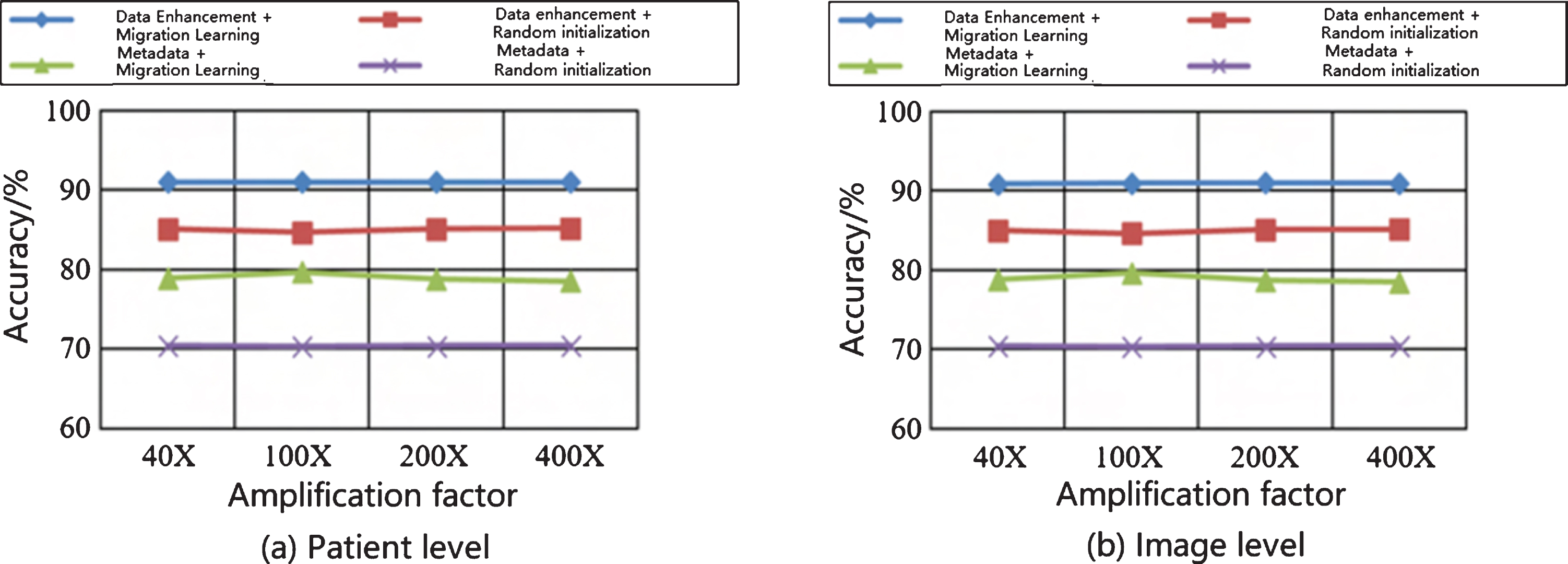
The classification results of two training strategies before and after data enhancement.
In this study the feasibility of automatic classification of breast cancer using pathological images is investigated based on deep learning. Specifically, deep learning is used to automatically detect metastatic cancer in breast cancer pathological images. Key aspects of our system include the use of the latest deep learning model architecture, careful design of post-processing methods based on adenocarcinoma pathological image classification and lesion-based detection tasks.
Historically, methodological pathological image analysis in digital pathology has focused on low-level image analysis tasks (such as color normalization, nuclear segmentation, and feature extraction), followed by use of classic machine learning methods to build classification models, which include use of regression, support vector machine and random forest. Generally, these algorithms take as input a relatively small set of image features (about tens). Based on this framework, a method has been developed for automatically extracting a moderately high-dimensional image feature set (about thousands) from a histopathological image, and then building a relatively simple linearity using a method designed to reduce the number of dimensions Classification models, such as sparse regression.
Since 2012, deep learning-based methods have consistently shown best-in-class performance in major computer vision competitions, such as the ImageNet Large-scale Visual Recognition Competition (ILSVRC). Deep learning-based methods have also recently shown promise in pathology. Contrary to the type of machine learning methods used in digital pathology in the past, in deep learning-based methods, there are often no discrete human steps for object detection, object segmentation, and feature extraction. Instead, deep learning algorithms take only images and image labels (such as 1 or 0) as inputs and learn very high-dimensional and complex model parameter sets under the supervision of only image labels.
A unique characteristic of this study is that we established a deep learning network architecture for breast cancer pathological images and obtained classification performance close to human level on the test dataset. Importantly, the mistakes made by our deep learning system are not closely related to the mistakes made by human pathologists. Therefore, although pathologists are currently better than deep learning systems alone, combining deep learning with pathologists can greatly reduce the pathologist’s error rate. Generally, these results show that integrating deep learning-based methods into the workflow of diagnostic pathologists can promote the repeatability, accuracy and clinical value of pathological diagnosis.
Success of developing and applying similar automatic classification models can have significant impact in future clinical practice since cancer is a huge public health problem in the world. According to data from the International Cancer Research Agency (IARC), a part of the World Health Organization (WHO), 8.2 million people died of cancer in 2012, and 27 million new cancer cases are expected to occur by 2030. Among cancer types, breast cancer (BC) is the second most common cancer in women (except skin cancer). In addition, BC has a very high mortality rate compared to other types of cancer. Even in the face of recent advances in understanding the molecular biology of BC progression and the discovery of new related molecular markers, histopathological analysis remains the most widely used method for BC diagnosis. Despite the significant advances in diagnostic imaging technology, pathologists perform a final BC diagnosis (including staging and staging) by visually examining histological samples under a microscope.
Recent advances in image processing and machine learning technology can be assisted by computer-aided detection and/or diagnosis (CAD / CADX) systems to help pathologists improve the efficiency of diagnosis from objectivity and consistency. Histopathological image classification includes different histopathological patterns, corresponding to the non-cancerous or cancerous state of the tissue being analyzed. Auto-assisted diagnosis of cancer is the primary goal of image analysis systems. The main challenge with such systems is the inherent complexity of processing histopathological images.
Deep learning is mainly a multilayer neural network. The multi-layer neural network has a better effect than the convolutional neural network. At present, the effect is better on image and audio signals, but the effect on natural language processing is not shown. From the perspective of statistics, deep learning is to predict the distribution of data, learn a model from the data, and then use this model to predict new data. This requires that test data and training data must be the same distribution. From the perspective of Inception, deep learning is simulating the working mechanism of the human brain.
In this study, a deeper and more complex deep learning model is used to avoid the complexity and limitations of the manual extraction of features, it is used to achieve automatic classification of breast cancer pathological images. At the same time, the advanced data enhancement methods and migration are used for fine tune learning, the depth learning algorithm trains over-fitting overfitting is prevented on small sample sets, the recognition rate of the image is increased, the high standards of clinical needs are meet.
In summary, this article presents a new study of applying an improved deep learning method or model to achieve automatic classification of breast cancer using pathological images. The deep convolutional neural network model has a deeper and more complex structure with fewer parameters and higher accuracy. It can avoid the complexity and limitations of human extraction features. The data enhancement and migration learning methods are used effectively to avoid the overfitting problems that the deep learning algorithm is prone to when the sample size is insufficient. Experiments show that this method improves the recognition rate and it has good robustness and generalization. It has potential to meet the more demanding clinical needs in the pathology laboratories.
Footnotes
Acknowledgments
This work is sponsored by the Scientific Research Project (No. 19B329) of Hunan Provincial Education Department, China.