
Abstract
BACKGROUND:
Coronary computed tomography angiography (CCTA) is a noninvasive imaging modality to detect and diagnose coronary artery disease. Due to the limitations of equipment and the patient’s physiological condition, some CCTA images collected by 64-slice spiral computed tomography (CT) have motion artifacts in the right coronary artery, left circumflex coronary artery and other positions.
OBJECTIVE:
To perform coronary artery motion artifact correction on clinical CCTA images collected by Siemens 64-slice spiral CT and evaluate the artifact correction method.
METHODS:
We propose a novel method based on the generative adversarial network (GAN) to correct artifacts of CCTA clinical images. We use CCTA clinical images collected by 64-slice spiral CT as the original dataset. Pairs of regions of interest (ROIs) cropped from original dataset or images with and without motion artifacts are used to train the dual-zone GAN. When predicting the CCTA images, the network inputs only the clinical images with motion artifacts.
RESULTS:
Experiments show that this network effectively corrects CCTA motion artifacts. Regardless of ROIs or images, the peak signal to noise ratio (PSNR), structural similarity (SSIM), mean square error (MSE) and mean absolute error (MAE) of the generated images are greatly improved compared to those of the input data. In addition, based on scores from physicians, the average score for the coronary artery artifact correction of the output images is higher.
CONCLUSIONS:
This study demonstrates that the dual-zone GAN has the excellent ability to correct motion artifacts in the coronary arteries and maintain the overall characteristics of CCTA clinical images.
Keywords
Introduction
Coronary computed tomography angiography (CCTA) is a noninvasive clinical imaging technology for detecting and diagnosing coronary artery diseases that can clearly reveal the coronary arteries [1], which helps in assessing the degree of vascular stenosis and the characteristics of atherosclerotic plaques. Through the application of this method, clinicians can complete the pre-examination of coronary artery disease in groups of high-risk patients, which is highly significant for the early detection and treatment of the disease. It has gradually become an important examination method for screening suspected coronary artery disease. At present, retrospective electrocardiogram (ECG) gating technology is mostly used in clinical coronary computed tomography (CT) examinations. Retrospective gating, a highly overlapping scanning method, acquires images continually throughout the cardiac cycle and simply pieces together images from the desired phase (typically diastole for anatomic imaging) after the entire scan is completed. During the patient’s examination, if the heart rate is out of the range of the retrospective ECG gated scan, the retrospective ECG gating technology cannot reconstruct CCTA images that can be used for clinical diagnosis.
In recent years, artificial intelligence techniques, the most prominent of which are convolutional neural network (CNN) models, have made substantial progress in imaging fields. These models have progressed from the initial introduction of CNNs through classic CNN model proposals such as AlexNet [2], VGG [3], ResNet [4], and DenseNet [5] to ever more complex CNN structures derived from classic CNNs. Simultaneously, another technological breakthrough in the field of deep learning is the emergence of generative adversarial networks (GANs) [6]. GANs are unsupervised learning methods that can generate high-quality images, generate text, and fulfill other potential use cases. A GAN is composed of two networks: a generator and discriminator. These two networks compete during the training process to continuously optimize the network parameters and generate high-quality images. Kuang Gong et al. proposed a deep neural network to denoise positron emission tomography (PET) images using perceptual loss and mean squared error (MSE) loss [7]. Yang Lei et al. proposed CycleGAN to accurately estimate the diagnostic quality of PET images using only one-eighth of the photon counts previously required [8]. Chih-Chieh Liu generated PET images with a higher signal-to-noise ratio (SNR) using the 3U-net model and magnetic resonance imaging (MRI) images [9]. Zhanli Hu et al. proposed the Wasserstein GAN to directly reconstruct PET images [10]. To remove artifacts from CT images, Wei-an Lin proposed a dual-domain network that reduces metal artifacts by simultaneously performing refining operations in the sinogram and image domains [11]. Binyu Zhao proposed a reused convolutional network to remove metal artifacts from CT images [12]. Shipeng Xie proposed a conditional GAN to remove artifacts introduced by limited-angle CT [13] and proposed the FFRN model to remove artifacts from different anatomical regions of sparse-angle CT images [14]. For low-dose CT images, Hu Chen proposed a residual encoder-decoder CNN [15]. Eunhee Kang proposed a deep CNN to perform wavelet domain denoising in low-dose CT images [16]. Dufan Wu proposed a novel iterative CT reconstruction method based on priors learned by artificial neural networks [17]. Wei Yang proposed a residual convolutional network to remove artifacts from low-dose CT images [18]. Qingsong Yang proposed a GAN with Wasserstein distance and perceptual loss to denoise low-dose CT images while simultaneously maintaining critical information [19]. Qihang Chen proposed a multiscale feature-sensing network to enhance the quality of low-dose dental CT images under different downsampling methods [20]. Zhiyuan Huang proposed a cycle-consistent GAN with an attention mechanism and designed multiple loss functions [21]. Zhenxing Huang proposed an adaptive dose-aware network to explore the influence of dose-level differences to improve image quality performance [22] and proposed an attribute-augmented Wasserstein GAN model using anatomical prior information to estimate high-resolution CT images [23]. The above studies showed that GANs and CNNs can generate high-quality images for the medical field. In the medical imaging field, compared with conventional denoising methods, deep learning methods have the advantages of compressing motion blur and artifacts and reducing processing time. Moreover, deep learning, as a supplement to conventional methods, can provide radiologists with more choices. For example, if deep learning-based methods can effectively remove motion artifacts in CCTA images, radiologists can choose to use prospective ECG gating technology with a lower radiation dose instead of retrospective ECG gating technology.
The method based on deep learning is a new method among the methods for removing artifacts. Lossau has conducted deep research on the removal of motion artifacts from CCTA images. To evaluate the diagnostic reliability and image quality of CCTA images, he proposed a method for identifying and quantifying coronary artery motion artifacts based on deep learning, which is better than manual identification and quantification [24]. In the same year, Lossau proposed an iterative motion compensation method assisted by deep learning methods [25]. The CNN he proposed is used to estimate the coronary artery motion vector with the plaque analysis method in CT data. The trained CNN is integrated into an iterative motion compensation pipeline that includes distance-weighted motion vector extrapolation. The alternating motion estimation and compensation of the CCTA images gradually corrects motion artifacts. In the abovementioned research, the deep learning method is used as an auxiliary tool of conventional denoising methods to identify motion artifacts and evaluate the motion vectors of motion artifacts, rather than a new method to directly remove motion artifacts in CCTA images.
In this study, we propose a CCTA motion artifact correction network called the dual-zone cycle GAN to directly correct the motion artifacts in the coronary arteries and conduct a subjective and objective quantitative evaluation of the network to verify its effectiveness. This network quickly generates coronary artery features while preserving the image details of CCTA images. The main contributions of this study are as follows: a) the dual-zone GAN uses the corresponding pairs of patches or images with and without coronary artery artifacts as training data during training. During the test, only patches or images with artifacts are needed to directly remove the motion artifacts of the coronary arteries in the CCTA images. b) We use multiple loss functions such as perceptual loss, mean square error, and kernel loss to maintain the overall characteristics of the image, locally enhance image details, remove motion artifacts, and finally improve network stability. c) We provide applicable quantitative and qualitative evaluations to prove the effectiveness of the proposed method to remove motion artifacts.
This manuscript is divided into five main sections. Section I provides an introduction. Section II explains the proposed dual-zone cycle GAN architecture, describes the CCTA data and presents the quantitative evaluation indicators. Section III reports the experimental results, section IV provides a discussion, and section V provides a conclusion.
Material and methods
Methods
Proposed model
The network proposed in this paper improves on the structure of the LIR network, which is an unsupervised neural network denoising method. To adapt LIR to the needs of coronary motion artifact correction, we changed the calculation of the loss function to make it a supervised GAN model. This network is a GAN nested within a GAN. In the general GAN model, the generator and discriminator are general CNNs. We call the GAN nested in the GAN the son-GAN, and the nesting GAN is called the father-GAN. In our proposed model, the generator is a dual-zone GAN. As the father-GAN, the dual-zone GAN is composed of two son-GANs, AD and CD. AD and CD themselves are least-squares GANs (LSGANs), and their own generators and discriminators compete to optimize and converge. In the dual-zone cycle GAN, the dual-zone GAN is its generator. The generator and discriminator of the dual-zone cycle GAN compete to optimize and converge. In fact, its optimization of the generator actually optimizes the two son-GANs of the generator. This optimization method makes the two son-GANs more stable and the convergence faster.
The dual-zone cycle GAN is an improved version of the LIR [26] that includes CD, AD and a content discriminator (DIS cont ). The two domains are each composed of a generator and discriminator; each single domain also contains a small LSGAN [27].
The artifact domain (AD) contains a generator and a discriminator. The generator includes a feature encoder (E a ), an artifact encoder (E art ) and a feature decoder (D a ). E a and E art generate feature images and artifact feature images from CCTA images, respectively, while D a is used to decode the artifact feature images and feature images in the AD to generate CCTA images with artifacts. The clean domain also contains a generator and discriminator. The generator includes a feature encoder (E b ) and feature decoder (D b ). E b extracts feature images from CCTA images, while D b reconstructs the CCTA images and maintains the image details in the feature images generated by Ea _ cont in the AD.
In the dual-zone cycle GAN, DIS
cont
is used as a discriminator against the generative network, and it should be trained first during the training process. DIS
cont
constrains the features from both the clean domain and artifact domain so that the two encoders for the generators in different domains generate similar feature images. We use least-squares loss as the loss function calculated with the following formula:
where y represents CCTA images with clear coronary artery features, and x represents CCTA images with artifacts. Feature images generated from artifact images are labeled with a 0, while feature images generated from clean images are labeled with a 1. DIS cont represents the processing by the content discriminator.
Each single zone of the generator of the dual-zone cycle GAN is a complete GAN. Therefore, when training the generator of the cycle GAN, the discriminators in the two zones should be trained first. The total loss of the discriminators in the dual domains includes the loss of the content discriminator. The discriminators of the two domains distinguish the feature images generated by E
a
and E
b
The loss function formula is as follows:
When training the discriminators for the generators in different zones, we combine Eqs. (1), (2), and (3); thus, the total loss function of the discriminators is as follows:
where GAN is the weight to calculate the loss of the discriminators, and loss dis b and loss dis a represent the losses of the clean domain and artifact domain discriminators, respectively.
The generators in the different zones are trained last in the proposed framework, and they are also the most complex and most constrained. Therefore, we next analyze the method and meaning of the loss functions used by the generators in the two domains to optimize the network from different aspects.
In the AD, CCTA images containing artifacts are processed by E
a
and Ea _ art, and we obtain the feature images and artifact feature images. The two feature images generate images with artifacts through D
a
; thus, we can calculate the reconstruction loss between the generated images and real CCTA images as follows:
In the clean domain, the CCTA images with clean coronary artery features pass through E
b
and D
b
, and the output consists of clean generated images. Then, we can calculate the reconstruction loss between the generated images and the clean CCTA images as follows:
To promote the convergence of the encoders in different domains, we use kernel loss functions [28]. These loss functions are as follows:
where x represents the CCTA images with artifacts, and y represents the clean CCTA images.
As mentioned earlier, each domain contains a complete small GAN. Confrontation occurs between the generator and discriminator in each domain, and the adversarial loss of the generator promotes the convergence of that domain. The loss function is as follows:
Simultaneously, to accelerate internal convergence of the generator of a single domain, we designed a constraint for the generator. After reconstructing the CCTA images from the feature images, we use perceptual loss [29] to calculate the loss between the generated images and CCTA images to help maintain the image characteristics. We adopt a VGG-19 network as the feature extractor. VGG-19 includes 16 convolutional layers, 4 pooling layers, and 3 fully connected layers. Here, we need only the first 20 layers of the network as feature extractors. VGG-19 was designed to process color images, but the CCTA images we use during training are grayscale images that first must be converted into three-channel images, mimicking color images. Then, we obtain the extracted features from the VGG-19. The perceptual loss is as follows:
where x represents the CCTA images both with and without artifacts. VGG(x) represents the ground truth features, while VGG(G(z)) represents the reconstructed image features.
Although the basic features of CCTA images can be extracted and included by the generators, the image details and visual quality must be improved at the pixel level. We use MSE loss to improve the image quality at the pixel level. The formula for the MSE loss function is as follows:
In this way, we complete the first round of training and obtain the generated images
During the cycle process, several constraints are set for the encoders and decoders of the two domains, including the kernel loss and cycle consistency loss functions. The kernel loss of the cycle process is as follows:
Simultaneously, the consistency loss formula is as follows:
where
In summary, during the generator training for the dual zones, by combining Eqs. (5) to (20), the total loss function formula is as follows:
where GAN, K, VGG, REC, E cyc , REC cyc and MSE are all weight parameters used to control the least squares loss, adversarial loss, kernel loss, perceptual loss, reconstruction loss, cycle kernel loss and cycle consistency loss, respectively.
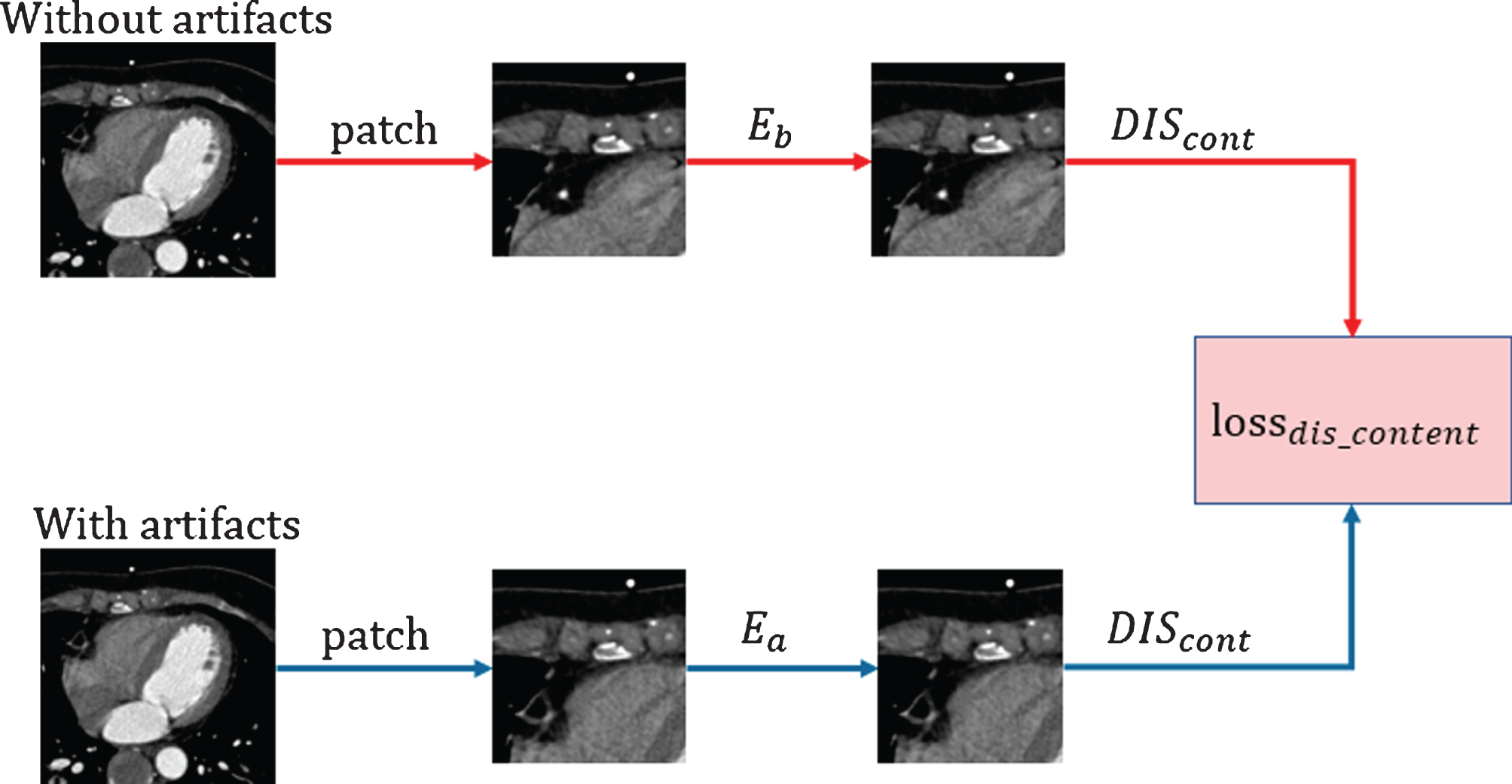
The training process of the content discriminator.
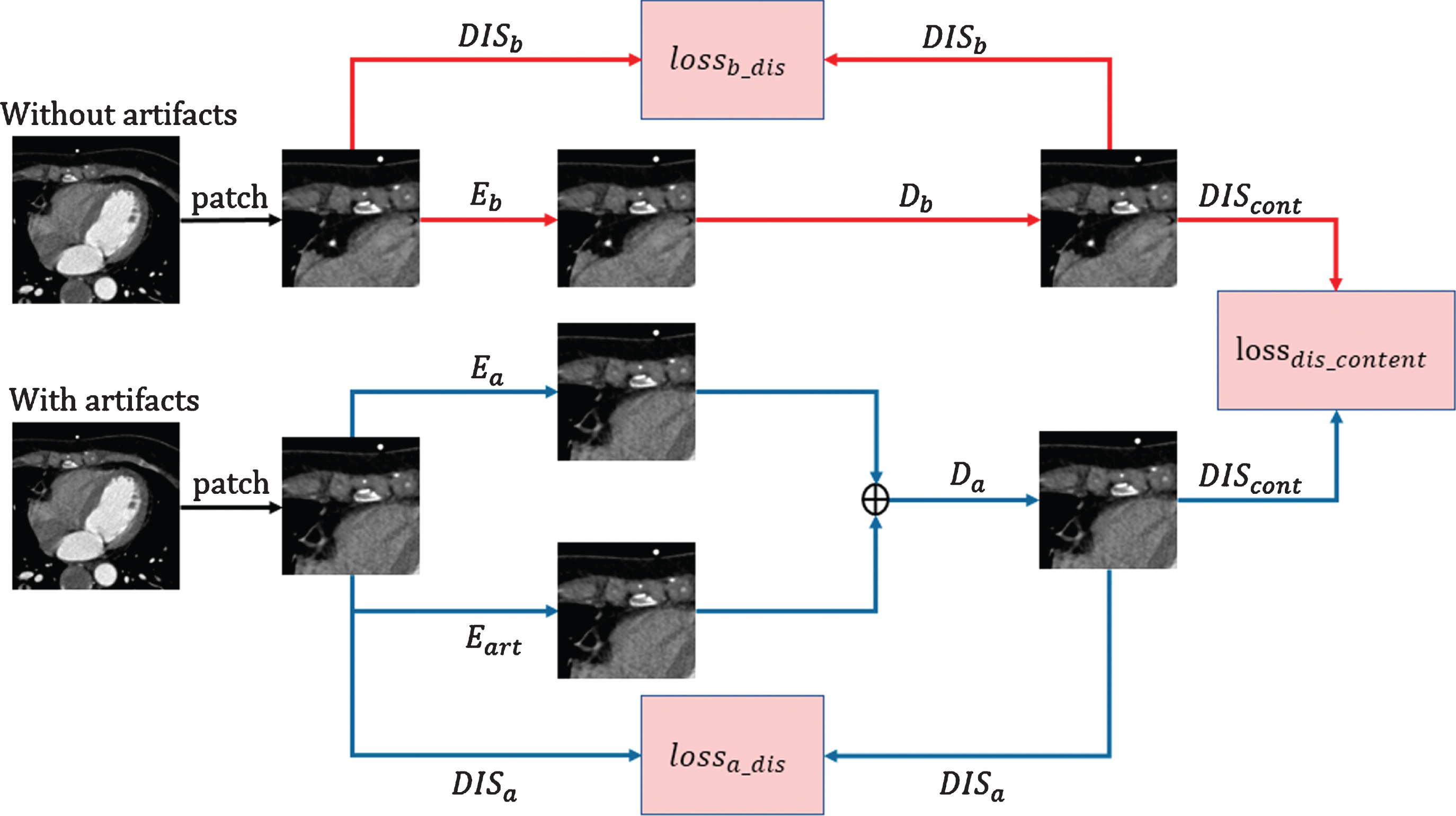
The dual-zone discriminator training process.
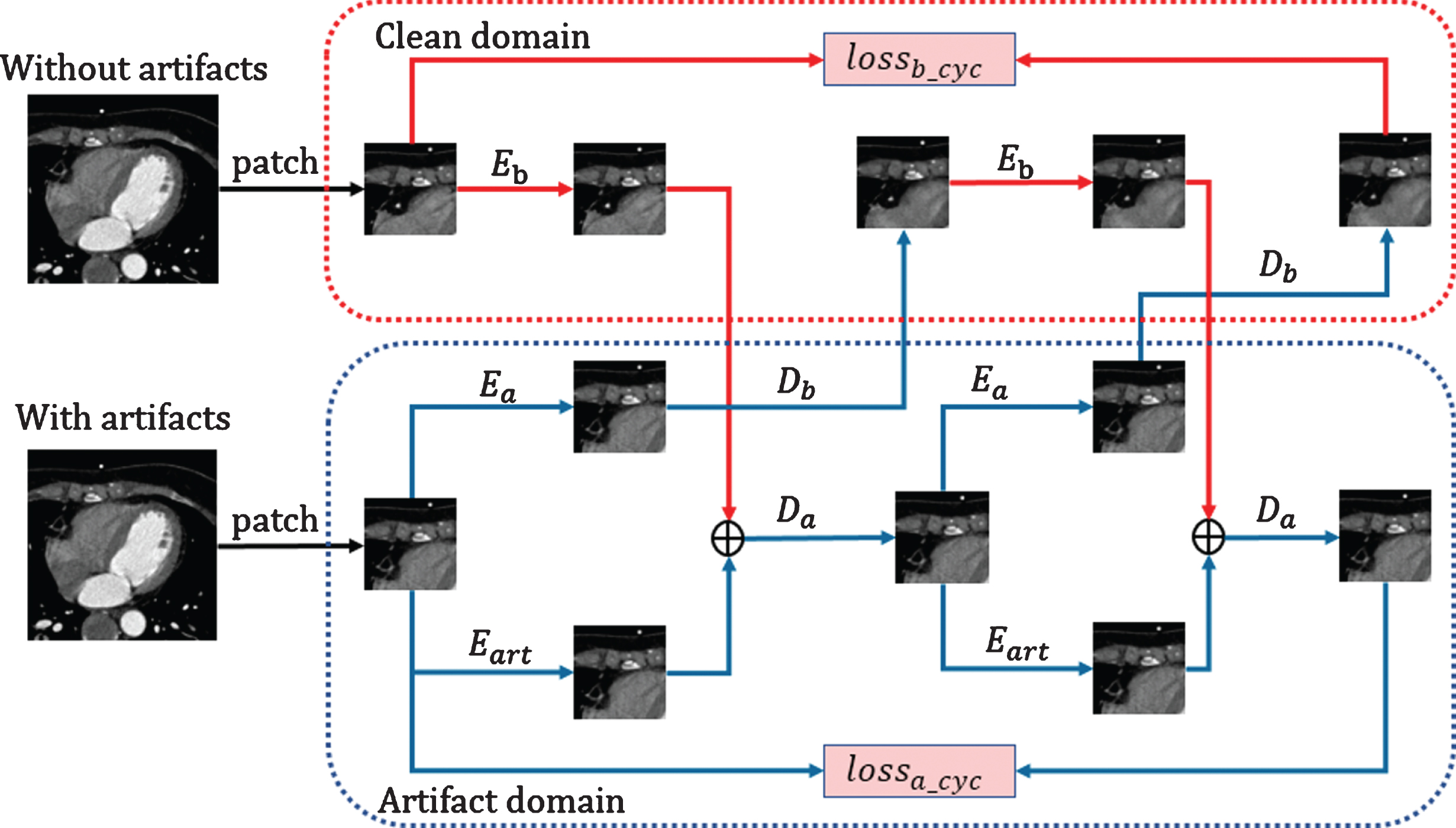
The training process of the dual-zone generative neural network.
The structure of the dual-zone cycle GAN is shown in Fig. 4. We divide the entire framework into two domains and a content discriminator. The two domains are the clear domain (CD) and AD. The AD contains a generator and discriminator, and the generator further incudes a feature encoder, an artifact encoder and a feature decoder. The feature encoder (E a ) learns the features of the CCTA images with artifacts and generates feature images from these images. The artifact encoder (E art ) learns the artifact features of CCTA images with artifacts and generates artifact feature images from the images. The decoder (D a ) of the AD reconstructs the images with artifacts from the joint feature images and the feature images generated by the encoders in the AD.
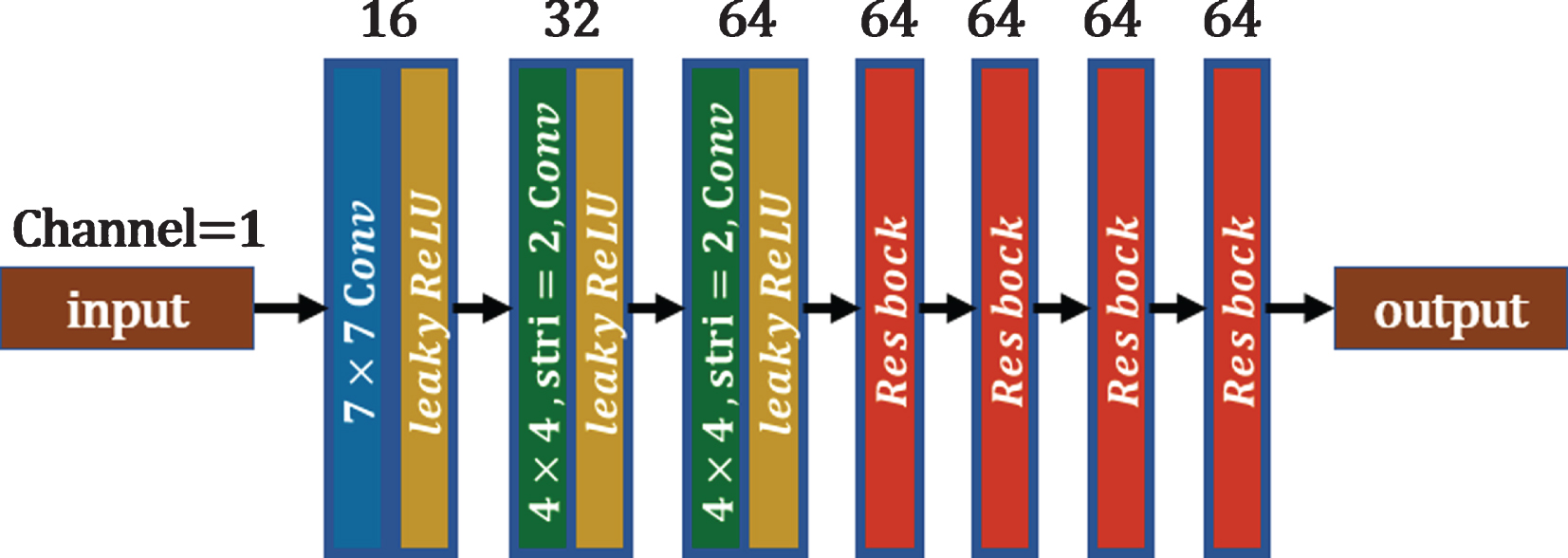
The content encoder of dual zones.
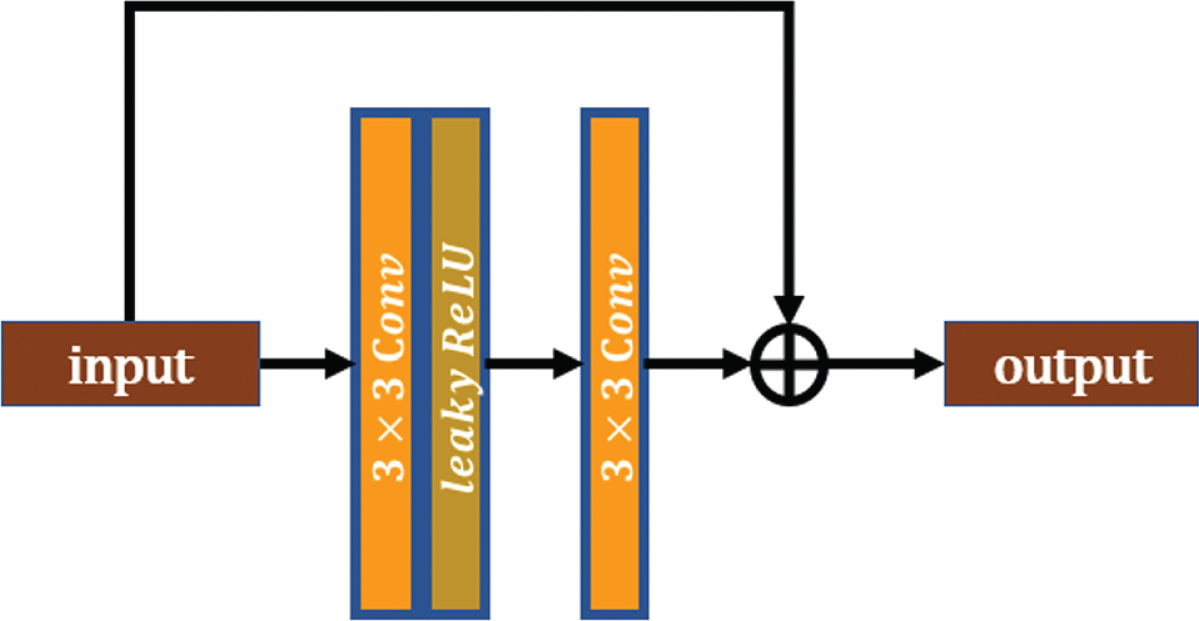
The residual block of the cycle generative adversarial network.
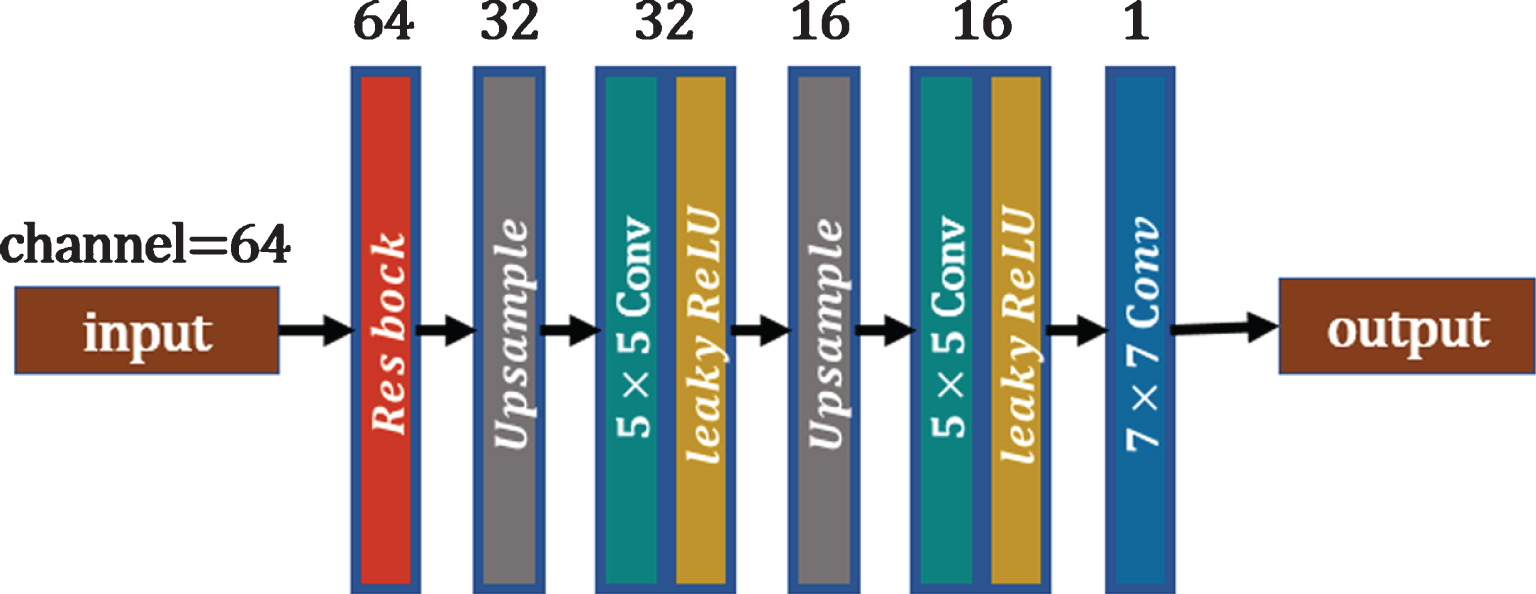
The decoder of the clear domain.
The CD also contains a generator and discriminator. The generator is composed of a feature encoder (E b ) and a decoder (D b ). The feature encoder learns the features of CCTA images without artifacts, and the decoder is used to generate clean images from the feature images provided by the AD encoder.
In the above two domains, E a and E b are identical and called the content encoders. The size of the input images is 256 × 256. Each content encoder is composed of a convolutional layer, two downsampling layers and four residual blocks. Each convolutional layer has a leaky rectified linear unit (lReLU) activation function. In the content encoder, the first layer of the convolution kernel is 7 × 7, the stride is 1, and the number of channels is 16. The downsampling process uses a convolution layer with a kernel size of 4×4 and a stride of 2, and the number of channels doubles after each convolution. As shown in the figure, the residual block contains two convolutional layers with a convolution kernel size of 3×3 and a stride of 1. The first layer is followed by the lReLU activation function, but the second layer is not.
In the above two domains, D a and D b differ in the number of input channels. We call D a and D b the feature decoders. As shown in Fig. 7, the feature decoder takes as input a feature image with a size of 64×64×64, which passes through a residual block, two upsampling layers and three convolutional layers. The network finally outputs a series of patches with a size of 256×256. After each upsampling operation, a convolutional layer with a convolution kernel of 5×5 is used to extract the image features. The last layer of convolution, which is used to generate images, is a convolution layer with a convolution kernel of 1×1 and no activation function. Finally, the number of input channels in D b is 64, while the number of input channels of D a is 128—twice the number of input channels in D b .
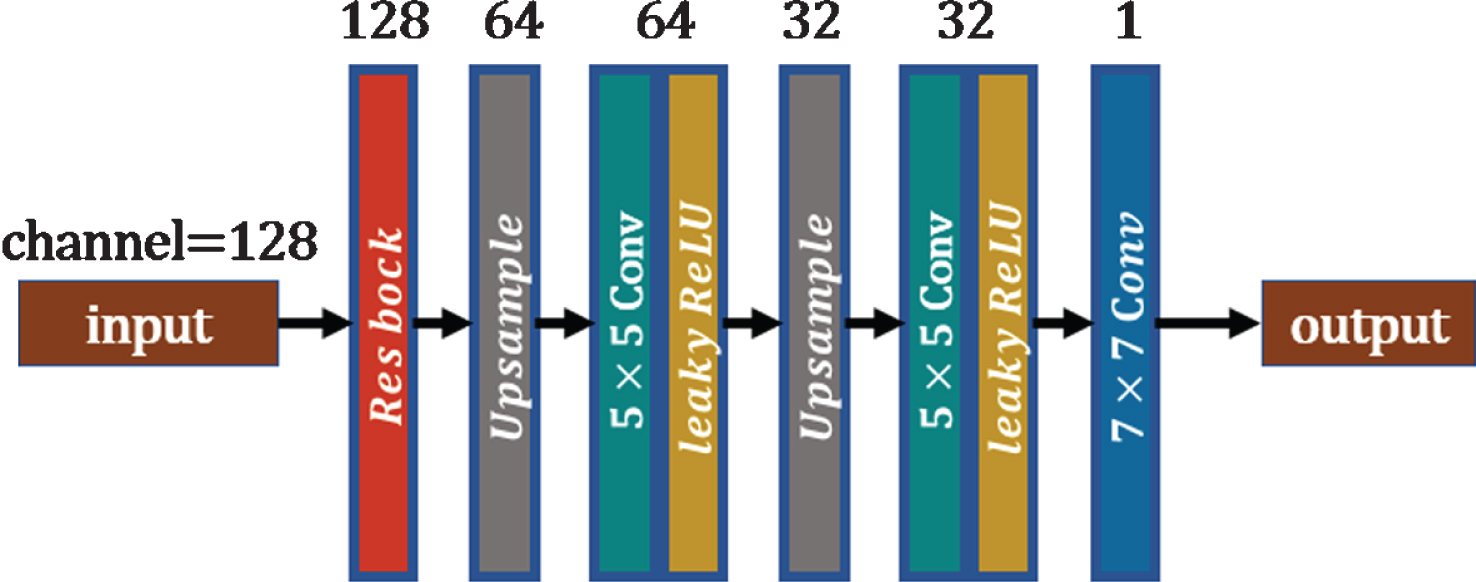
The decoder of the artifact domain.
In addition, a special encoder exists in the AD, called E art , as well as an artifact encoder, which is used to extract the artifact features of the CCTA images with artifacts. As shown in Fig. 8, this encoder contains two convolution kernel layers and two downsampling layers. The size of the convolution kernel of the first convolution layer is 7×7; the next two convolution kernels are 4×4, and the stride is 2. The final convolution kernel is a 1×1 convolution layer. The input images are the same as those for E a . The downsampling multiples of E a , E b and E art should be consistent.
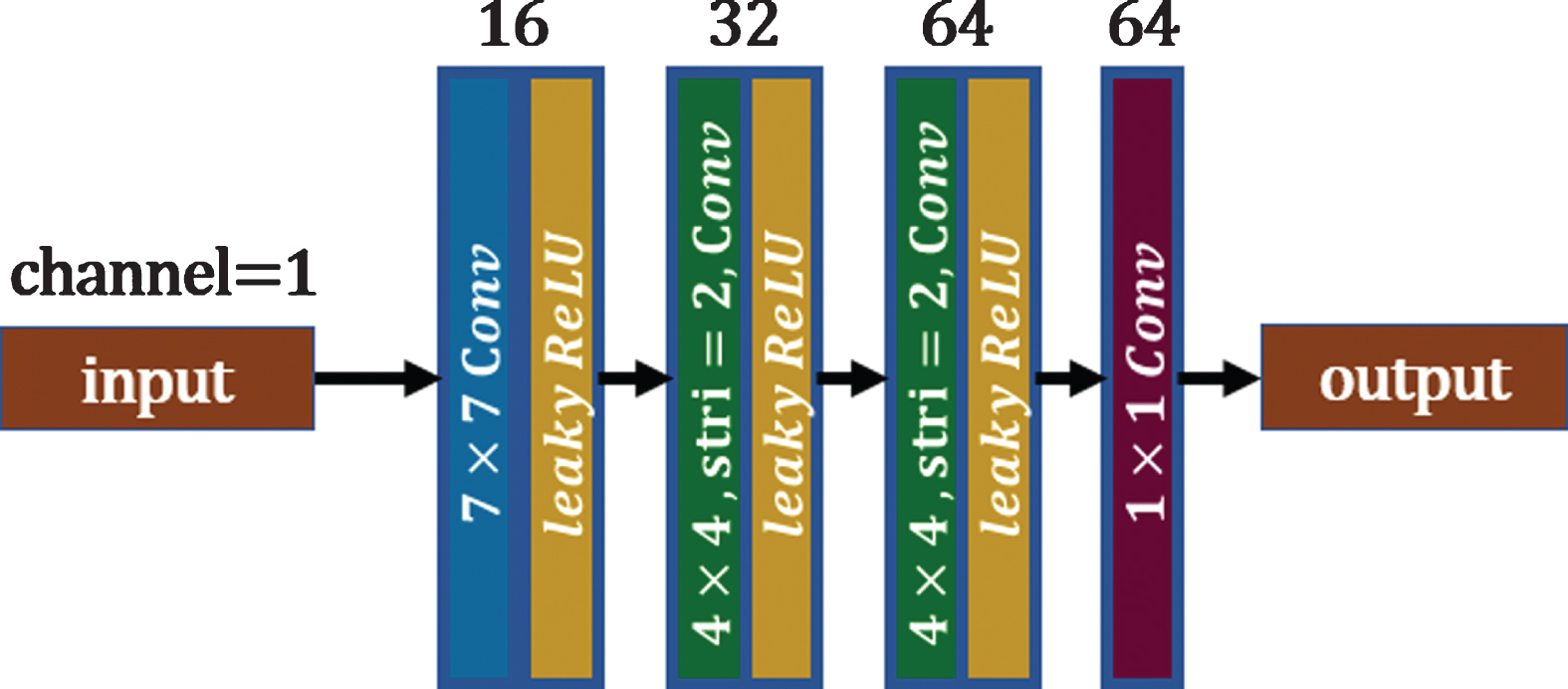
The artifact encoder of the artifact domain.
The discriminators in the two domains compete against the corresponding generators, mutually promoting convergence. The structures of the discriminators in each domain are identical. As shown in Fig. 9, the discriminator contains four downsampling layers, an average pooling layer and a convolutional layer. The number of channels in the input images is 1. The downsampling layer is a convolutional layer with a convolution kernel size of 3×3, stride of 2, and channel size of 16. The last convolution layer has a convolution kernel of 1×1 and 1 output channel. Except for the last layer, all convolutional layers are followed by the lReLU activation function.
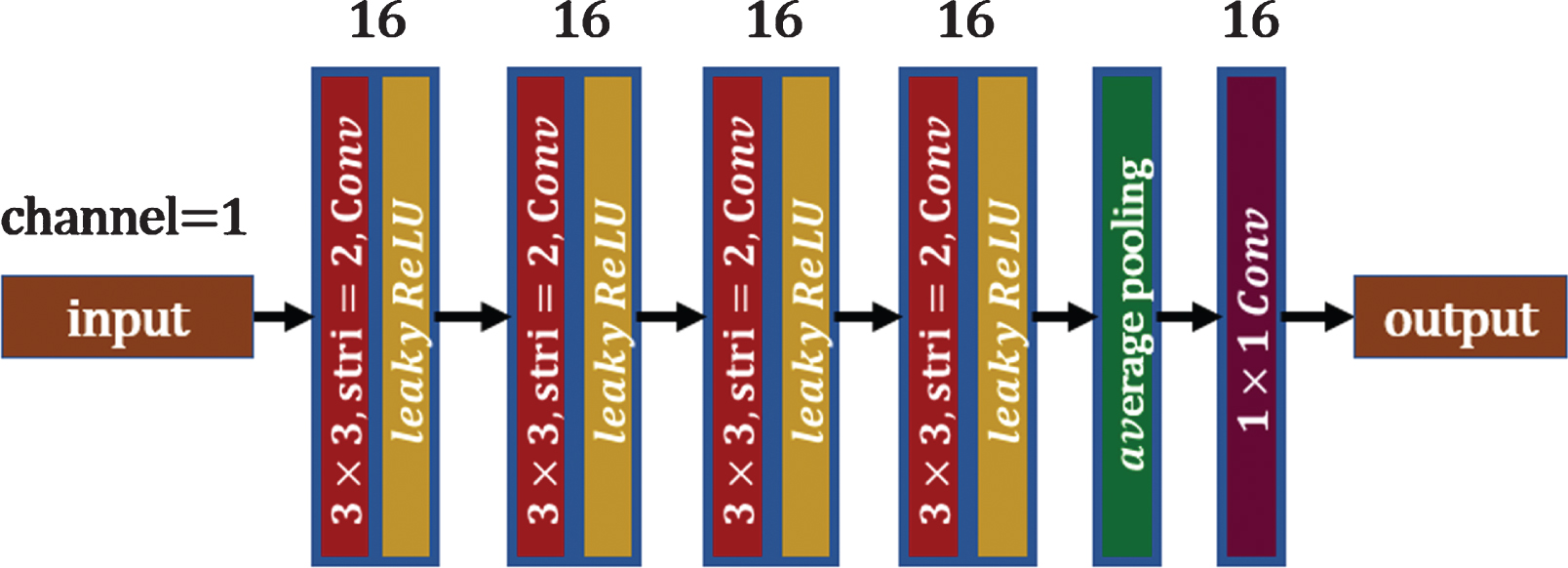
The dual-zone discriminator.
The framework includes a content discriminator, which is used to stabilize the feature generator of the framework, ensuring that E a and E b remain relatively consistent during the training process. As shown in Fig. 10, this discriminator contains four downsampling layers and a convolutional layer. The downsampling layers are convolutional layers with convolution kernel sizes of 3×3, strides of 2, 32 channels, and lReLU activation functions. The last layer is a convolutional layer with a convolution kernel size of 1×1 and 16 output channels.
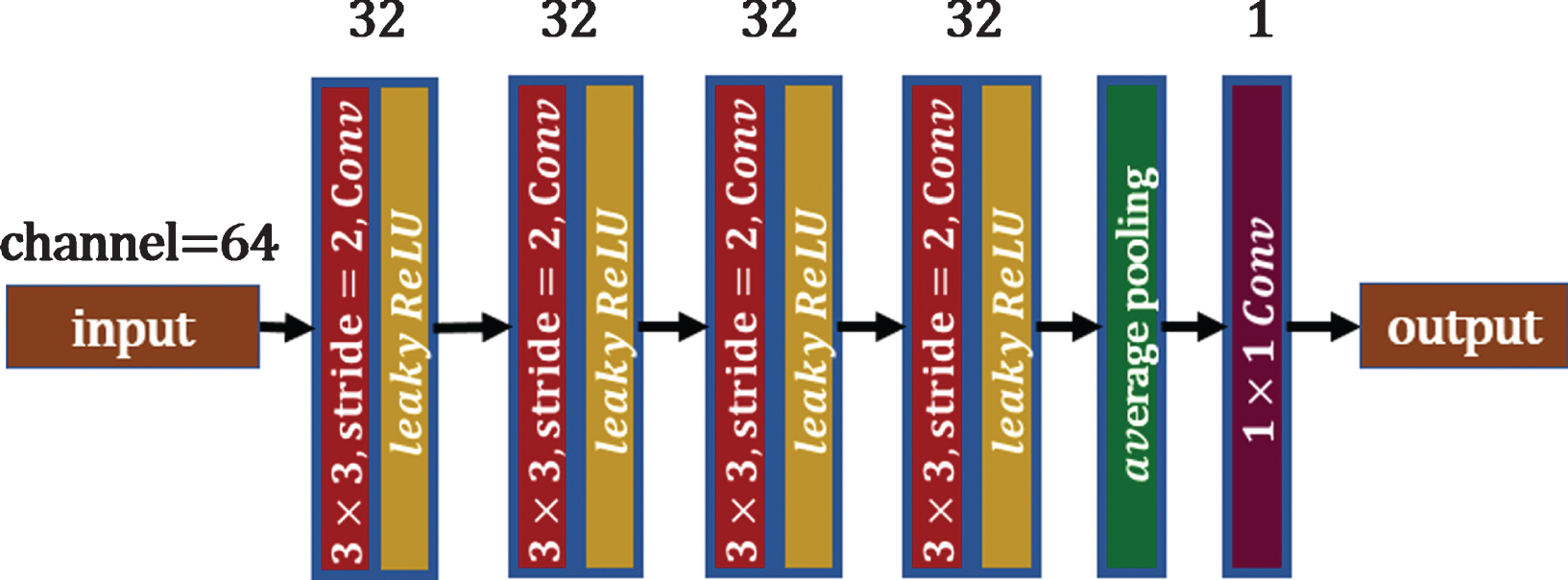
The content discriminator of the dual-zone cycle generative adversarial network.
To evaluate the image quality, we use three metrics in our experiments. The first is the structural similarity index (SSIM), an image quality evaluation standard that conforms to human perception. SSIM is a perception-based model that treats image degradation as a perceived change in structural information, which incorporates important perception phenomena, including brightness masking and contrast masking terms. Structural information is the effect of pixels having a strong interdependence, especially when the pixels are very close spatially. These dependencies carry important information about the structure of objects in the visual scene. In this study, SSIM is used not only to monitor whether the GAN is stable during training but also to evaluate the suppression effect of the cardiac motion artifacts of the entire reconstructed image. SSIM is defined as follows:
where x and y represent the CCTA images generated by the framework and CCTA clinical images, respectively; μ x and σ x are the mean and variance of the reconstructed images, respectively; μy and σy are the mean and variance of the real image, respectively; and σxy is the covariance of the covariance values of μy and σy. C1 = K1*L, C2 = K2*L, and L represents the dynamic range of the images. Empirically, K1 and K2 are set to 0.01 and 0.03, respectively, and L is set to 1.
The second metric is the peak signal-to-noise ratio (PSNR). PSNR is an engineering term for the ratio between the maximum possible power of a signal and the power of the corrupting noise. It is commonly used to measure the quality of reconstruction images. We use this metric to evaluate the correlation between the input data and ground truth data or between the generated data and ground truth data. It is defined as follows:
where y max is the maximum intensity value of the ground truth image, and m is the total number of image pixels.
The third metric is based on the 15-segment method proposed by the American Heart Association (AHA). Based on the quality of the coronary artery images, the score ranges from one to five. Five means no motion artifacts and obvious noise; four indicates slight motion artifacts and noise; three means that there are some motion artifacts and noise, but they do not affect the evaluation of the lumen; two means that the motion artifacts are relatively serious, and the noise is large, which affects the evaluation of the lumen; one indicates significant motion artifacts, and the lumen cannot be evaluated. The images generated in this study were evaluated and compared by two radiologists from Wuhan University Zhongnan Hospital Department of Radiology. If the scores are inconsistent, they are agreed upon through negotiation.
Patient data study
The CCTA clinical images used in this study are clinical images collected by radiologists from Wuhan University Zhongnan Hospital Department of Radiology from December 2019 to October 2020. The 64-slice Siemens spiral CT reconstructed four phases of images, of which two phases are at diastolic phase and two are at systolic phase, through retrospective ECG gated scanning. To avoid changes in the overall structure, we chose two phases that are in the same systolic or diastolic period as the training data. In the two phases of systole or diastole, the phase of the reconstructed image with motion artifacts is used as the input data, and the phase of the reconstructed image without motion artifacts is used as the ground truth data. The images with and without right coronary artery motion artifacts are shown in Fig. 11. The dataset contains CCTA images with motion artifacts and CCTA images with clear coronary artery characteristics, comprising 6,830 pairs of 2D CCTA images. Because the amount of data was too small, we enhanced the existing data by flipping the images vertically and horizontally and reversing the center symmetry, which tripled the amount of data, providing 27,320 total images.
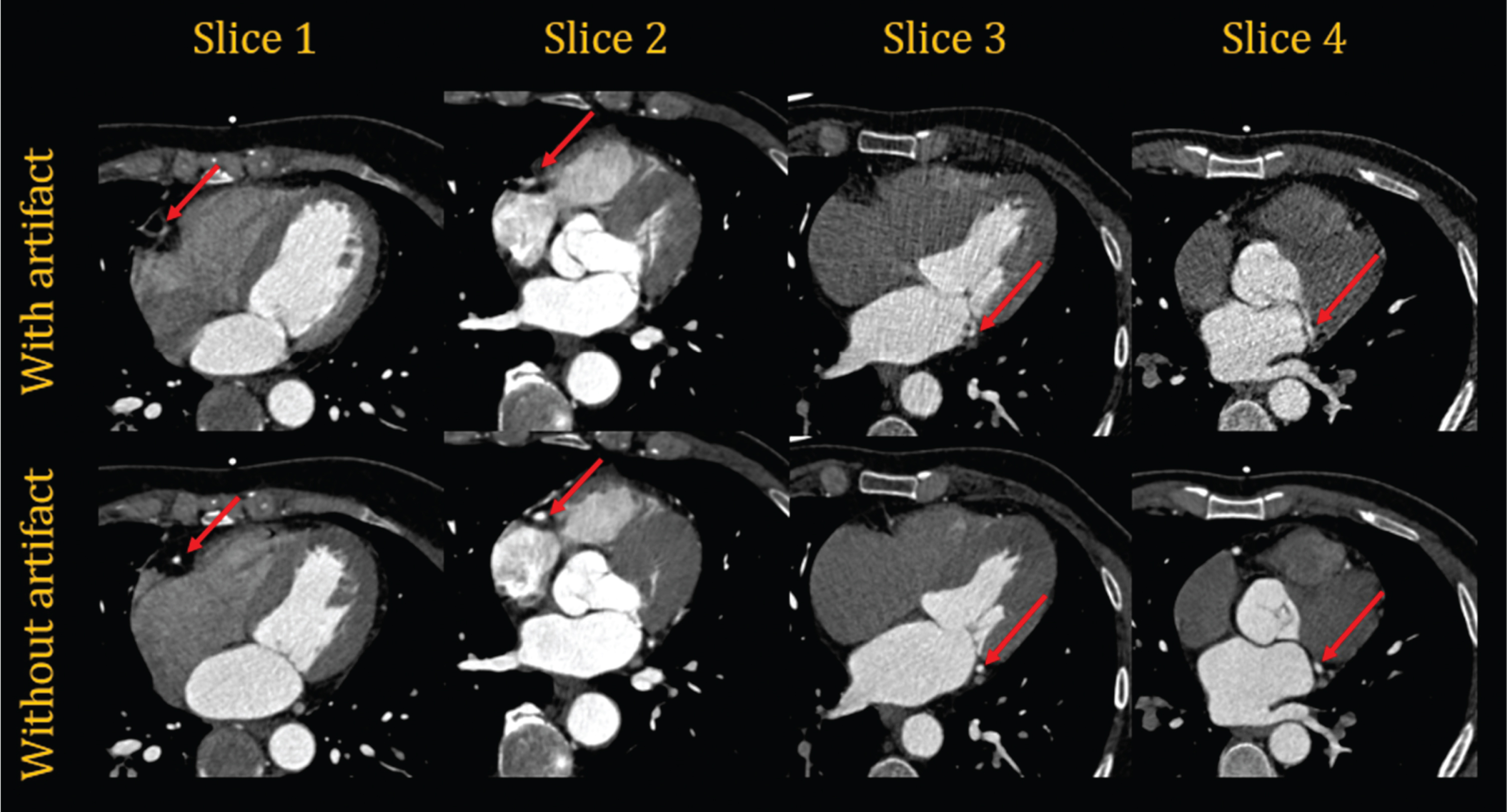
Motion artifacts of different coronary arteries in CCTA images. The images with the right coronary artery motion artifact shown in the first two columns are two pairs of CCTA images from two patients, and the images with the left circumflex coronary artery motion artifact shown in the second two columns are two pairs of CCTA images from two other patients.
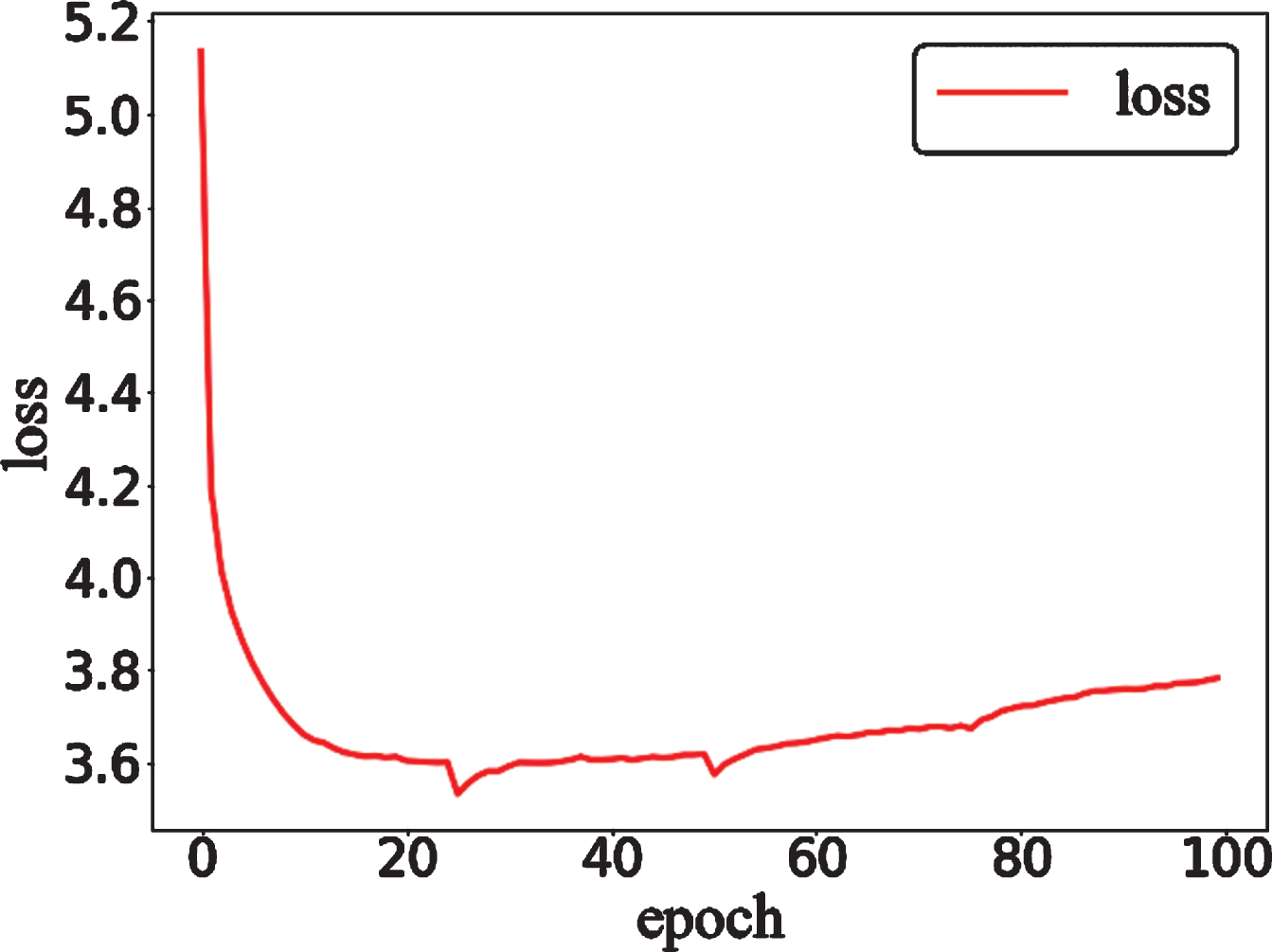
The loss curves for the training process in the cycle generative adversarial network.
The format of the CCTA image is DICOM, and the default size of the pixel matrix is 512×512. We use RadiAnt DICOM Viewer to export DICOM images to BMP images with a size of 512×512. We have two plans. The first is to input the entire input image and ground truth image into the network for training. The second is to extract the ROIs from the same position of the input image and ground truth image and input them into the network for training. Based on the motion trajectory of the right coronary artery in the BMP image, a 256×256 ROI is used to cover it. The ROIs occupy a quarter of the original clinical image, which is enough to cover the trajectory of a single coronary artery. The input ROIs and label ROIs are from input images and ground truth images, respectively. In the above two plans, due to the characteristics of the PyTorch library itself, the network does not need to change anything, including the parameters and frameworks.
In this study, we used a series of CCTA clinical images with motion artifacts as input images and CCTA clinical images with clear coronary artery characteristics as target images. To fully use the dataset, we divided the CCTA clinical images into a training dataset and validation dataset. We used 80% of the image pairs to train the model and the remaining 20% to verify the effect of the images generated by the GAN.
In the dual-zone cycle GAN, the content discriminator acts as the discriminator of the entire framework, while GANs in the dual region act as the framework generators. Therefore, during the training process of the dual-zone cycle GAN, we train the content discriminator and dual domain discriminators separately. In each epoch, the content discriminator is trained three times, while the generators and discriminators in each of the dual domains are trained once. This framework uses the Adam optimizer to conduct optimization training. The hyperparameters of the model, including the learning rate, are set to the default values in PyTorch. The batch size is set to 10, and the network is trained for 48 h with patches on an NVIDIA GeForce RTX 2080Ti GPU, with ten days required to train for the images with the size of 512×512. The GANs are used to control adversarial losses between the generators and discriminators in the dual domains and adversarial loss between the generator and content discriminator of the framework. K and K cyc control the kernel loss, which causes the generators in the dual domains to converge faster. VGG controls the perceptual loss to ensure that the generators in the dual domains maintain the features of the CCTA images. REC and REC cyc are used to control the reconstruction loss, ensuring that the generators in the dual domains converge stably. The MSE controls the MSE loss to improve the edge information and pixel characteristics of the generated images. In our framework, GAN, K, K cyc , VGG, REC, REC cyc and MSE are set to 1, 0.0001, 0.0001, 2, 0.0001, 0.0001 and 2, respectively.
The proposed method is implemented using the PyTorch Python library on a personal workstation equipped with an E5-2687W CPU @ 3.00 GHz and a NVIDIA GeForce RTX 2080Ti GPU.
Results
To evaluate the performance of the dual-zone GAN in CCTA motion artifact correction, we select four pairs of data from the test dataset as a reference to assess whether the network can maintain the main characteristics and monitor the network during the training process. The SSIM curves for the four pairs of data during the training process are shown in Fig. 13. The curves for the four images rise rapidly before twenty epochs, steadily rises between twenty epochs and forty epochs, and stabilize after forty epochs. After forty epochs, a slight upward trend remains. The loss curve of the network is shown in Fig. 14. Since LSGAN is used as the nested framework, the value of the loss function rises after reaching its lowest point. In this study, we used two schemes to train the network. The first plan was to extract 256×256 ROIs in the right coronary artery before training and use them as training data to train the network. The second plan was to train the network using CCTA images with a size of 512×512 as training data. After network training, we used the test dataset to test and evaluate the network. Table 1 lists the mean and variance of the PSNR, SSIM, MSE, and mean absolute error (MAE) of the input and the output, which are divided into two types: ROIs (256×256) and whole images (512×512). The data in the table show that the quality of the generated images improved regardless of whether the extracted image or entire image was used. The data in Table 1 show that it is better to use the originally sized image as the training data.
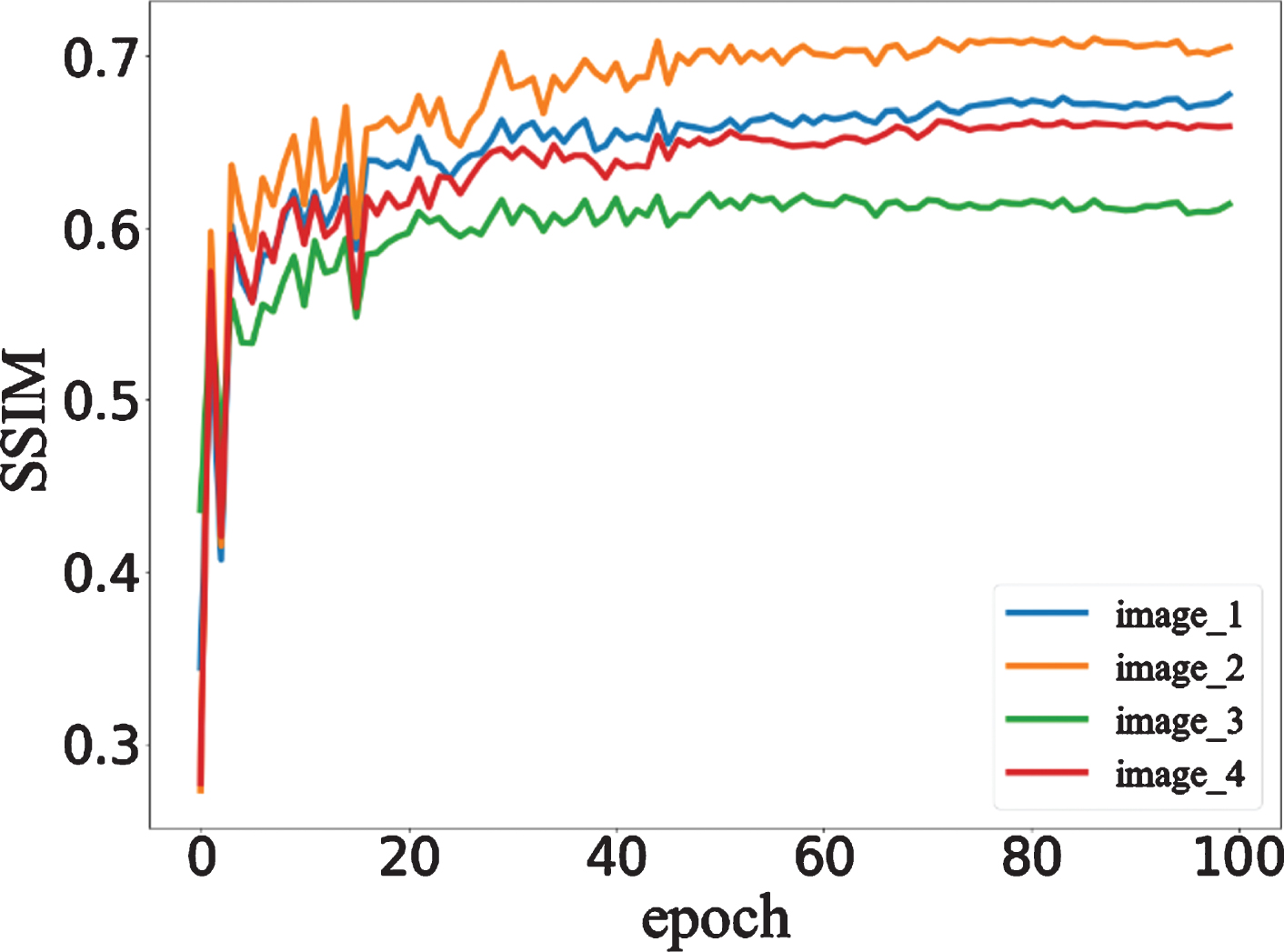
The SSIM curves for images from 4 patients in the test set among the patient dataset.
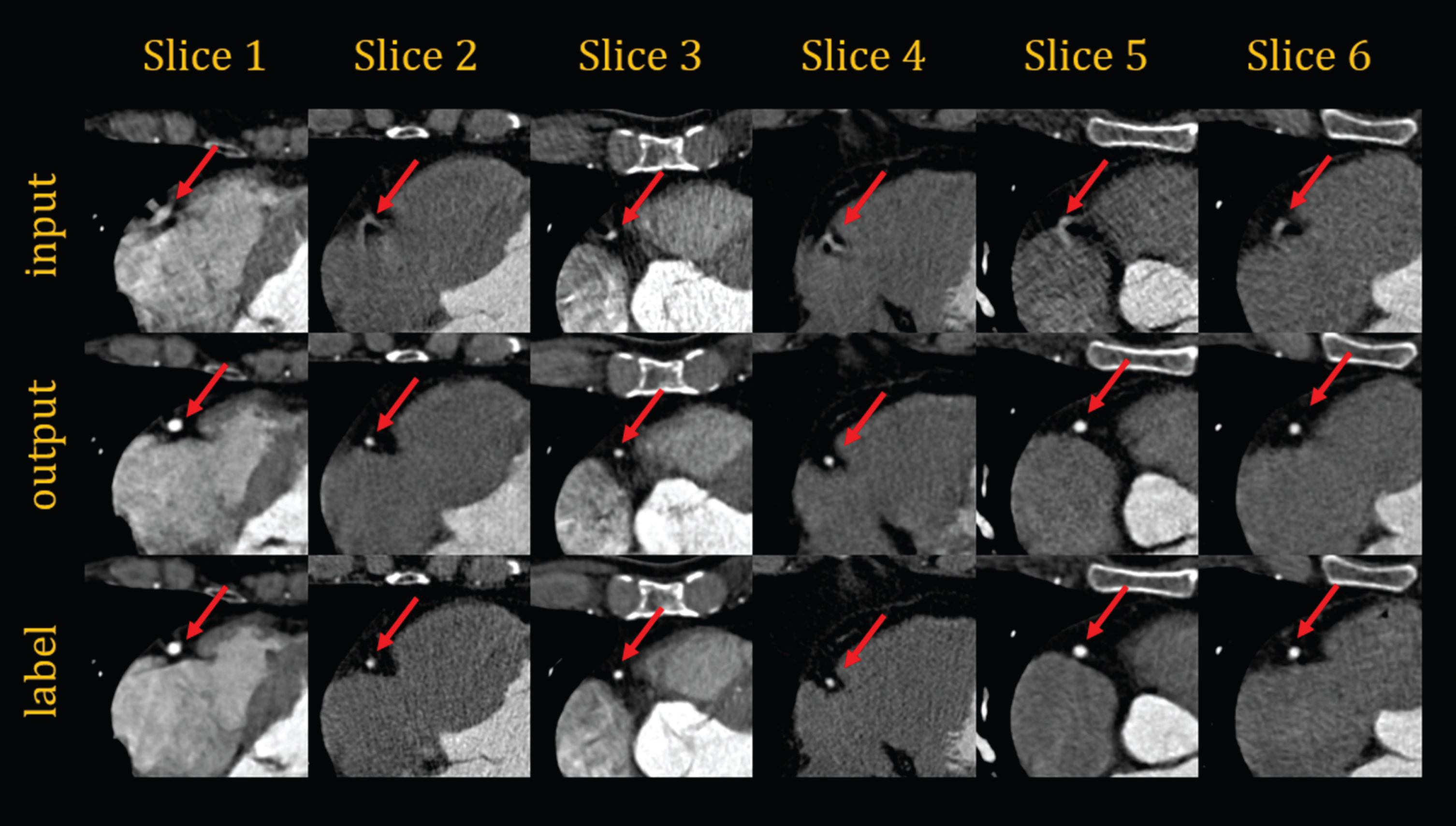
The ROIs of the right coronary artery from 6 patients in the second plan.
Quantitative comparison of image quality indicators for input and output images
When evaluating the effect of CCTA motion artifacts corrected by the framework, it is not reasonable to rely on SSIM and PSNR as the sole evaluation criteria. SSIM and PSNR are used as standard evaluation metrics for overall images, but they cannot evaluate model quality at local image areas. When evaluating the correction effect of coronary artery motion artifacts, radiologists score the coronary artery motion artifacts based on the fifteen coronary artery segments proposed by the AHA. With the first plan, the average score is 3.47, and the standard deviation is 0.87. With the second plan, the average score is 3.16, and the standard deviation is 1.11. With the first plan, a coronary artery score greater than or equal to 4 accounts for approximately 0.54, while with the second plan, the ratio is approximately 0.42.
The above metrics show that the correction effect of coronary artery motion artifacts in the test dataset exhibits good performance. However, we also must compare the input images, generated images, and ground truth images. In evaluating the network with ROIs (256×256) as the training data, we selected six sets of data from six patients, as shown in Fig. 14. In evaluating the network that uses the entire image as training data, we select twelve sets of images from twelve different patients. Among them, six groups show the location of the right coronary artery as shown in Fig. 15, and the other six groups show the location of the left circumflex coronary artery as shown in Fig. 16. The images shown in the above figure all have a size of 256×256 cropped at the corresponding position of sets of images. As in Figs. 14, 15 and 16, the first line shows the ROIs with motion artifacts. The second line shows the ROIs generated by the framework from the input images after motion artifact removal. The third line shows the ROIs of the CCTA clinical images with clear coronary artery features. In the figures, the coronary features of the ROIs are marked with red arrows. In addition, six sets of entire images from six patients are shown in Fig. 17 as in the above figures.

The area of the right coronary artery cropped from the images in the first plan; the images are from six patients.
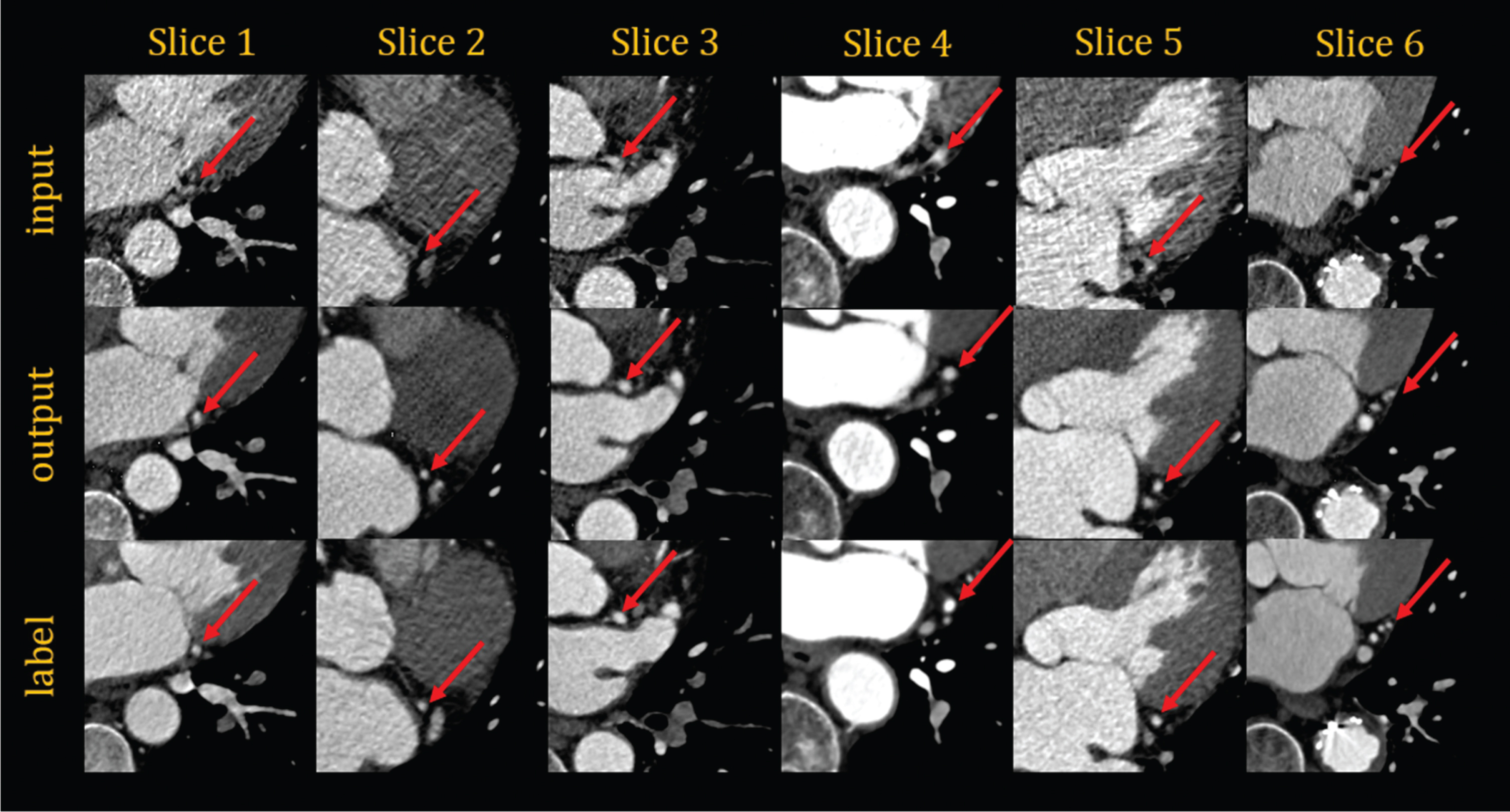
The area of the left circumflex coronary artery cropped from the images in the first plan; the images are from six patients.
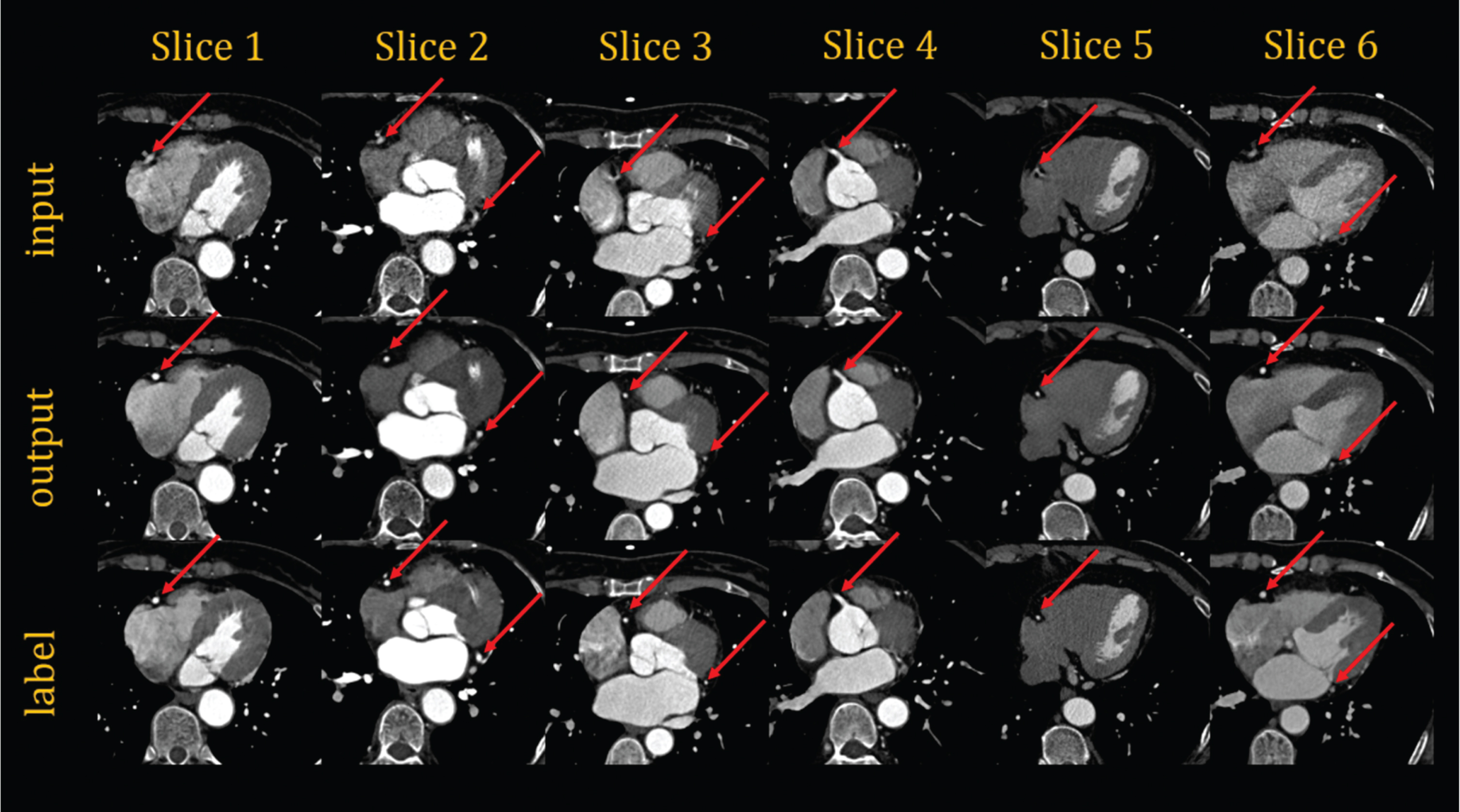
The whole images from six patients in the first plan.
In this study, we propose a dual-zone cycle GAN for removing CCTA coronary artery motion artifacts. The network proposed in this study refers to the structure of the LIR network. We changed the unsupervised learning network to a supervised learning network and added the MSE loss function to the original framework. This network is a GAN nested within a GAN. The nested GAN has better convergence and stability than the general GAN. Moreover, we use multiple loss functions to constrain the adversarial generation network. Perceptual loss, MSE, and kernel loss are used to maintain the overall characteristics of the image, strengthen the detailed information of the image, and promote network convergence and improve network stability, respectively. With reference to other methods that use deep learning to correct coronary motion artifacts, we extract ROIs from the original CCTA pixel matrixes as training data. We also use the original CCTA pixel matrixes as the training data of the network. In the test results, it is obvious that inputting original image pixel matrixes is better than inputting pixel matrix ROIs in the overall characteristic image metrics. Moreover, after injection back into the original image matrix, the texture and overall characteristics of ROI do not match the original image, such as the edge of the heart.
At present, there is no objective evaluation standard for the image evaluation of coronary artery motion artifacts, and the score is generally based on the 15-segment method proposed by AHA. The score is evaluated and scored by experienced radiologists on the right coronary artery, left circumflex coronary artery and other local locations. This evaluation index may be biased due to the subjective factors of the radiologists. Nevertheless, this evaluation index is still the most convincing evaluation of coronary arteries. In the physician evaluation scores, the average score of the first plan is 0.3 higher than that of the second plan, and the standard deviation is smaller. In addition, a score greater than or equal to four is a good evaluation of the correction effect of coronary artery artifacts, which means that there are slight motion artifacts and noises, but they do not affect the diagnosis. In the first plan, this number is 10% higher than in the second plan. We can speculate that when using the original pixel matrix as input, the network can not only learn the mapping from the coronary arteries to the coronary arteries from the images but also learn the mapping from the heart to the coronary arteries. In the above description, we have reached a conclusion that using the original image matrixes as training data is better than extracting ROIs as training data for motion artifact correction.
The above experimental results show that the dual-zone GAN can effectively remove the coronary artery motion artifacts from the CCTA clinical images, maintain the overall characteristics of the images and improve the local details of the images. Compared with conventional motion correction methods, the dual-zone cycle GAN requires many more clinical images. However, the deep-learning method is simpler in operation and faster in processing time. It takes only approximately 0.1 s to process an image. Compared with the method proposed by Philips Research, the dual-zone cycle GAN is directly used to correct coronary artery motion artifacts on clinical images instead of assisting conventional methods to correct coronary artery motion artifacts. For retrospective ECG gating, this GAN is only a supplementary method for correcting coronary artery motion artifacts. It is a post-processing method that does not have any impact on the CCTA scanning process, and it corrects coronary artery motion artifacts on the clinical images obtained after image reconstruction. In theory, it can also perform motion artifact correction of clinical images of prospective ECG-gated scans. If it proves to be effective, this network combined with prospective ECG gating technology can provide stable and reliable clinical images. Compared with that used in retrospective ECG gating technology, it can reduce the radiation dose significantly. However, at present we have no relevant data to confirm that it is indeed effective for prospective ECG-gated clinical images.
Although the method we proposed has many advantages, it still has three limitations. First, though we increased the overall number of data points through image augmentation techniques, the number of training samples is still insufficient. Second, the method is effective in removing motion artifacts from CCTA images. However, it is limited by the computer hardware; if the number of channels in the convolutional layers and the batch size were increased, the effect of removing artifacts would be further improved. Third, we did not use the clinical images from prospective ECG gated scanning to verify whether it can correct motion artifacts in clinical images obtained by prospective ECG gating. Finally, we propose a GAN for correction of coronary artery motion artifacts, but whether it is suitable for calcification artifacts, stent artifacts, and other artifact corrections is not yet known. Therefore, in our future work, we will consider correcting motion artifacts on coronary images with calcification and stents. In other words, we will consider the correction of coronary artery motion artifacts in more complex situations to meet clinical needs.
Conclusion
In general, this paper proposes a dual-zone cycle GAN used to directly remove CCTA coronary motion artifacts. The framework is based on improvements to the LIR, a change from unsupervised learning to supervised learning, and the addition of MSE loss to enhance image details. The experimental results show that the dual-zone cycle GAN can remove different degrees of motion artifacts from CCTA coronary arteries and that it performs well for restoring coronary artery features. In future work, this framework may be used for other types of medical image processing, such as analyzing low-dose PET images to generate high-dose PET images. However, because PET and CCTA have different image characteristics, the relevant parameters would need to be modified based on the actual conditions. Moreover, when removing motion artifacts from CCTA images, it is necessary to pay close attention to the details of CCTA images and maintain the main image characteristics.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (32022042, 81871441), the Shenzhen Excellent Technological Innovation Talent Training Project of China (RCJC20200714114436080), the Natural Science Foundation of Guangdong Province in China (2020A1515010733), the Shenzhen International Cooperation Research Project of China (GJHZ20180928115824168), the Guangdong International Science and Technology Cooperation Project of China (2018A050506064), the Guangdong Special Support Program of China (2017TQ04R395), Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province in China (2020B1212060051).
Conflict of interest
We declare that we have no commercial or associative interests that represent a conflict of interest in connection with the submitted work.