
Abstract
BACKGROUND:
In the process of medical images acquisition, the unknown mixed noise will affect image quality. However, the existing denoising methods usually focus on the known noise distribution.
OBJECTIVE:
In order to remove the unknown real noise in low-dose CT images (LDCT), a two-step deep learning framework is proposed in this study, which is called Noisy Generation-Removal Network (NGRNet).
METHODS:
Firstly, the output results of L0 Gradient Minimization are used as the labels of a dental CT image dataset to form a pseudo-image pair with the real dental CT images, which are used to train the noise generation network to estimate real noise distribution. Then, for the lung CT images of the LIDC/IDRI database, we migrate the real noise to the noise-free lung CT images, to construct a new almost-real noisy images dataset. Since dental images and lung images are all CT images, this migration can be achieved. The denoising network is trained to realize the denoising of real LDCT for dental images by using this dataset but can extend for any low-dose CT images.
RESULTS:
To prove the effectiveness of our NGRNet, we conduct experiments on lung CT images with synthetic noise and tooth CT images with real noise. For synthetic noise image datasets, experimental results show that NGRNet is superior to existing denoising methods in terms of visual effect and exceeds 0.13dB in the peak signal-to-noise ratio (PSNR). For real noisy image datasets, the proposed method can achieve the best visual denoising effect.
CONCLUSIONS:
The proposed method can retain more details and achieve impressive denoising performance.
Introduction
In modern medicine, medical images highlight the subtle lesions, which have a direct impact on the analysis and diagnosis results. In recent years, more and more dental Computed Tomography (CT) imaging technology has been applied in the diagnosis and treatment of oral cavities and teeth. However, in the process of generating CT images, various interference effects, such as transmission medium errors, electronic and photometric anomalies, are often encountered. The dental images with low-dose CT (LDCT) usually contain unknown mixed noise, which can cause fuzzy and indistinct boundary phenomena, reducing the quality of CT images, and increasing the difficulty of diagnosis. Image denoising methods can remove the noise interference caused in the imaging formation process, and can restore the detail of features. Therefore, the research works of removing the noise in LDCT images, in general, and dental images with LDCT, in particular, have great importance [1]. In this paper, we mainly focus on the problem of restoring real noise in CT images.
Most of the traditional denoising methods are based on filters, prior models, differential equations, variational methods, e.g., Mean filtering [2], median filtering [3], Gaussian filtering [4], Wiener filtering [5], the denoising method based on total variation [6] and wavelet transform [7], etc. Among them, the linear filter represented by the mean filter is prone to over smoothing, and the median filter is effective in removing salt and pepper noise, but it is not ideal for other distribution noise. Wiener filter is suitable for the stationary stochastic process, but not for the non-stationary stochastic process. The denoising method based on total variation can produce false edges when the noise level is high, which affects the denoising effect. The medical image denoising method based on wavelet transform is widely used, but it is difficult to distinguish tiny details and noise in the feature space after wavelet transform, so the denoised image’s edge and details are easily blurred. Although traditional denoising methods can remove image noise, they still ignore the details of image features, and it is difficult to capture the complete contour information. So, the denoised results may not be suitable for some applications which need high accuracy, such as in medical image processing, remote sensing, and so on. Budes et al. [8] firstly constructed a filter named non-local mean filter (NLM) based on block similarity and global patch similarity, which greatly improved the effect of image denoising. And Dabov et al. [9] proposed a Sparse 3-D Transform-Domain Collaborative Filtering (BM3D) for image denoising, and BM3D achieved a good denoising effect.
In recent years, with the development of deep learning, image denoising algorithms based on deep learning are also proposed and widely applied in many kinds of fields. Yan et al. proposed a denoising network, named BM3Dnet, based on BM3D [10]. Xu et al. [11] used a convolutional neural network (CNN) to deal with the problem of natural image denoising. The neural network model can converge more quickly in the training process, to reduce the computational complexity and obtain better results than the best denoising method at that time. Zhang et al. [12] improved the traditional denoising neural network and proposed the feedforward denoising convolutional neural network named DnCNN which predicted the residual noise to achieve denoising effect. DnCNN further improved the effect of Gaussian denoising at a specific noise level with uniform distribution, but it performs poorly in dealing with non-uniformly distributed noise. For the case of non-uniform noise distribution, Zhang et al. [13] proposed FFDNet, which used a noise estimation map as input to generalize Gaussian noise into more complex real noise and achieved good results. Aiming at the problem of blind denoising, Guo et al. [14] proposed a convolution blind denoising network (CBDNet) based on the noise level map of FFDNet. Using a more realistic noise model, the noise level map can be obtained through five layers of Fully Convolutional Networks (FCN) to achieve blind denoising to a certain extent. Zhu et al. [15] proposed a CNN-based recursive information distillation network (RIDNet) to remove noise in color images. The variational denoising network (VDN) proposed by Yue et al. [16] can estimate the noise while removing noise in a noisy image. The generated model in VDN has good generalization ability and can deal with the denoising problems with different distributions. In recent studies, Zamir et al. [17] proposed a multi-stage architecture, named as MPRNet. MPRNet adopts the multi-stage method to decompose complex tasks into simpler sub-tasks and gradually learn the degraded information of images to complete restoration. Chen et al. [18] proposed the Half Instance Normalization Network (HINet), which used instance normalization as the building block to improve network performance for the first time. Although the image denoising methods based on deep learning can remove the simulated noise well, they still have many drawbacks, as follows: firstly, the traditional methods based on deep learning are often good at removing the known distribution noise, but not good at removing the real noise; secondly, the image denoising methods based on deep learning mostly rely on a large amount of data for end-to-end training network framework. However, for the denoising task of real dental CT images, different CT scanners often produce different real noise, and it is difficult to obtain the corresponding real noise-free image as ground truth.
Inspired by the previous study on the learning noise distribution of Generative Adversarial Networks (GAN), we propose a two-step framework for blind denoising of medical images, named Noisy Generation-removal Network (NGRNet). Using the advantages of GAN, the real noise distribution of CT images can be learned. In the proposed framework, there are two sub-networks, namely noise generation network and noise removal network. In the pre-treatment stage, the output results of L0 Gradient Minimization (L0 filter) are used as the labels of dental CT images, and to produce the real dental noisy images, which are used to train the noise generation network to estimate the real noise distribution. In the noise generation network, the real noise distribution learned is transferred to noise-free lung CT to generate noise over lung CT images, and a new almost-real noisy images dataset is constructed. The denoising network was trained to realize the denoising of real dental images with LDCT by using this dataset. Figure 1(a) shows the noisy dental images with LDCT, and Fig. 1(b) shows the denoising result of NGRNet, which shows their visual differences.

An example of Dental CT image denoising. (a) the original LDCT image. (b) the denoising result of the proposed method.
The remainder of this paper is organized as follows. In section 2, we introduce L0 Gradient Minimization and summarize the existing noise synthesis algorithms based on GAN and the real noise denoising algorithms. In section 3, we introduce our network framework in detail. In Section 4, the experimental results and comparisons with related denoising methods are presented.
The main contributions of this work are summarized as follows: Aiming at the blind denoising problem of dental images with LDCT without ground truth, a pseudo-noise-free images dataset for dental CT images is constructed by using the output results of the L0 filter as labels. Labels output by the L0 filter can keep the main structures of dental images while removing unimportant details to ensure that the network can learn noise better. The learning ability of GAN is used to learn the distribution of real noise and transfer the learned real noise to the dataset of clean lung CT images. The almost-real noisy dataset for lung CT dataset is constructed. This dataset includes the label required by the supervised methods and enables the network to learn real noise. In addition, for a limited dental dataset, the dataset can be expanded by this method. We apply the residual dense block of Super-Resolution Image Reconstruction to construct the noise removal network and introduced an attention module to further improve the noise reduction performance.
L0 gradient minimization
The role of image smoothing is to retain significant image edges while removing unimportant details. Traditional filtering methods not only remove the details of the image but also punish the large edges in the image, resulting in the significant edge weakening or disappearing. Li X et al. [19] proposed an L0 minimum norm image smoothing filter by mathematically associating with the L0 norm. This kind of filter does not depend on local features but is a global smoothing filter based on sparse strategy. By increasing the L0 gradient, the L0 filter can maintain the smooth effect and improve the prominent edge effect at the same time. In addition, the controllable low amplitude structure can be eliminated, and the main structure of the image can be represented.
Noise generation method based on GAN
Because traditional deep learning method often relies on large-scale annotated data, the collection and annotation of dataset need a lot of computation cost, which is a key problem restricting the further development of the deep learning denoising method. To synthesize more training data pairs, some scholars proposed several image generation methods based on GAN. GAN is usually composed of two networks, i.e., generator and discriminator. The generator can generate real data as much as possible, and the discriminator can improve the ability to identify real data and false data as much as possible. In the process of training, the two sub-networks learn against each other, which makes the data generated by the network closer to the real data distribution. Different from the classical GAN, the grouped residual dense network (GRDN) [20] takes both real data and false data as the input of the discriminator, which makes the discriminator compare the two data more clearly, to simulate more real noise. GAN-CNN-based blind denoiser (GCBD) [21] directly uses GAN to learn the real noise distribution, extracts approximate noise blocks from a given real noise image, and then uses these blocks to train GAN for noise modeling and noise data generation. The traditional denoising framework infers the posterior distribution of potential noise-free images from noisy images, while the dual adversarial network (DANet) [22] proposed a framework to denoising by learning the joint distribution of noisy and noise-free images. It maps the noise image to a noise-free image through the denoiser, then maps the noise-free image to the noise image through the generator, and finally optimizes the denoiser and discriminator by using the antagonism effect of the discriminator. The framework of DANet can deal with both denoising and noise generation tasks at the same time.
Denoising method for real noise
The denoising algorithms based on convolutional neural networks can achieve favorable results in denoising simulated noise, but for real noise removal, these methods are often inadequate. The reason for this phenomenon is that the noise in the real world is more complex than simulated noise distribution. To reduce the complexity of neural networks, U-Net [23] increased the acceptance domain by reducing the resolution of features, and then reused features by using the cascade of matching resolution levels to minimize the information loss caused by up-down scaling. DNDH [24] was a further improvement on the hierarchical structure of U-Net, which realized a single model to deal with different levels of noise based on the pre-training model and adopted the methods of self-integration and model integration to further improve the model effect, to improve the image denoising performance. To solve the problem that it is difficult to simulate the real image, CBDNet simulated the real noise for the first time and trained the sub-net for noise estimation. AINDNet [25] improved the estimator of noise data based on CBDNet, used the multi-scale method of up and downsampling to get the estimated noise sub-net, and proposed a new transfer learning to reduce the difference between the training set and the test set, to train a real noise reduction network with good generalization ability. VDN [16] was for blind image denoising problem, explicitly modeled the generation of noise, noise estimation at the same time of denoising, and avoided the overfitting problem of the deep learning model. So, VDN generation model has good generalization ability, and it can not only perform well for the noise that does not appear in the test set but also deal with the denoising problem under different distributions. There are many effective methods of image real noise removal based on deep learning, while they are usually unable to deal with the case of lacking ground truth. To solve this problem, in our proposed framework, the output results of L0 Gradient Minimization are used as the labels of dental CT images to form a pair of dental images (noisy and noise-free version), which are used to train the noise generation network to estimate the real noise distribution. Then, the learned distribution of real noise is transferred to a dataset of noise-free lung CT images to generate noise over them, and a new almost-real noisy dataset is constructed.
Proposed method
Because the collected CT images of teeth contain real noise, the noise distribution is different, and there is no corresponding noise-free image. The goal of our work is to design and train a blind denoising network that removes the real noise in images. Inspired by DANet [22] and RDN [26], the proposed framework we designed makes full use of the learning ability of GAN network. In our framework, GAN is used to estimate the noise distribution of each input dental CT image, and the learned real noise distribution is transferred to the lung CT image, to build a new set of images for the training dataset, and then the supervised training can be used to learn the denoising network. In this section, we first describe the overall network structure of our framework and then introduce the noise generation network and noise removal network respectively.
Overview
As an important pre-processing step in computer vision tasks, the existing denoising methods follow a noise model as follows,
Therefore, our denoising algorithm can adopt the mean square error as a loss function which aims to reduce the distance between the noise-free image
Figure 2 shows the training process of NGRNet. It also shows that our network is composed of two sub-networks, i.e., noise generation network and noise removal network. We will describe these two networks in detail in sections 3.3 and 3.4, respectively.

The training process of our network. In the noise generation network, we input the degraded image and the filtering result of dental CT to learn the real noise map. We transfer the noise map to the unpaired clean image to synthesize the pseudo-degraded image of lung CT. Thus, a set of cleaning-real noise data pairs of lung CT are constructed. This data pair is used as the training dataset of noise removal network for subsequent supervised learning.
Since the dental CT image contains less texture information, we use the L0 filter [19] to smooth the dental image and use it as the ground truth of the training dataset. We denote by I the result of L0 filter, then the gradient measure in the x and y directions can be expressed as
The L0 filter operation can be defined as follows
Because the objective function is quadratic, the global minimum can be solved by gradient descent. Since the convolution operation of the objective function is carried out, we accelerate the diagonalization transformation of derivative operators after the fast Fourier transform and obtain Equation 9
Problem 10 can be spatially decomposed by estimating both h and v separately. The solution of Equation 10 can be shown as follows
The model of DANet [22] is adopted in our noise generation network, which is different from the traditional method of inferring the posterior distribution of potential noise-free images from noise images, this network learns the joint distribution of clean-noise image pairs. The network contains a denoiser, a generator, and a discriminator, and the network framework is shown in Fig. 3. In the noise generation network, the encoder-decoder architecture of U-Net [23] is adopted. It captures semantic information in the up-sampling process, precisely locates in the down-sampling process, and then recovers some features lost in the up-sampling process through a features map. In the discriminator, we adopt the discriminator structure in [27, 28], including five stride step convolution layers to reduce the feature size, and a fully connected layer to fuse extracted features.

Dual adversarial framework.
In this framework, input the image pairs (I, Y) which we have built. In the denoising task, a noisy image Y is mapped to an estimated noise-free image I
D
by the denoiser, and this process can be represented by pseudo joint distribution as p
D
(I
D
,Y), where (ID,Y) is considered as an example of the pseudo joint distribution sampling, it can be expressed as follows
In the noise-generating task, the filtered image I is mapped to the noise image Y
G
by the generator to obtain another pair (I,Y
G
). We introduce a potential variable Z, which can be easily set as an isotropic Gaussian distribution N(0,Λ), where Λ is diagonal matrix. Then, the generation process from I to Y
G
is represented by pseudo joint distribution as follows
Through the antagonistic effect of the discriminator, the denoiser and generator are trained effectively, so that the two pairs of pseudo images can better approximate the joint distribution p(I,Y). In the DANet, there is an antithetical regularization relationship between the denoiser and the generator, which keeps interaction in each iteration, to enhance each other’s ability to remove and generate noise. The adversarial loss can be expressed as follows
Most supervised denoising methods are based on the given training dataset, which contains the noise image and its corresponding noise-free image. Our denoising method also belongs to supervised learning, but the difference is that our training data is the clean-real noise image data pair which is constructed by a noise generation network. Our noise removal network is divided into three stages. Firstly, in the stage of extracting shallow noise, the convolutional block attention module [29] is used to calibrate the channel importance of input noise. In the second stage, residual dense block (RDB) [26] as a building module is used to learn the concatenated multi-layer features with local residuals. Finally, in the global feature fusion stage, hierarchical features are used globally. The structure of the denoising network is shown in Fig. 4.
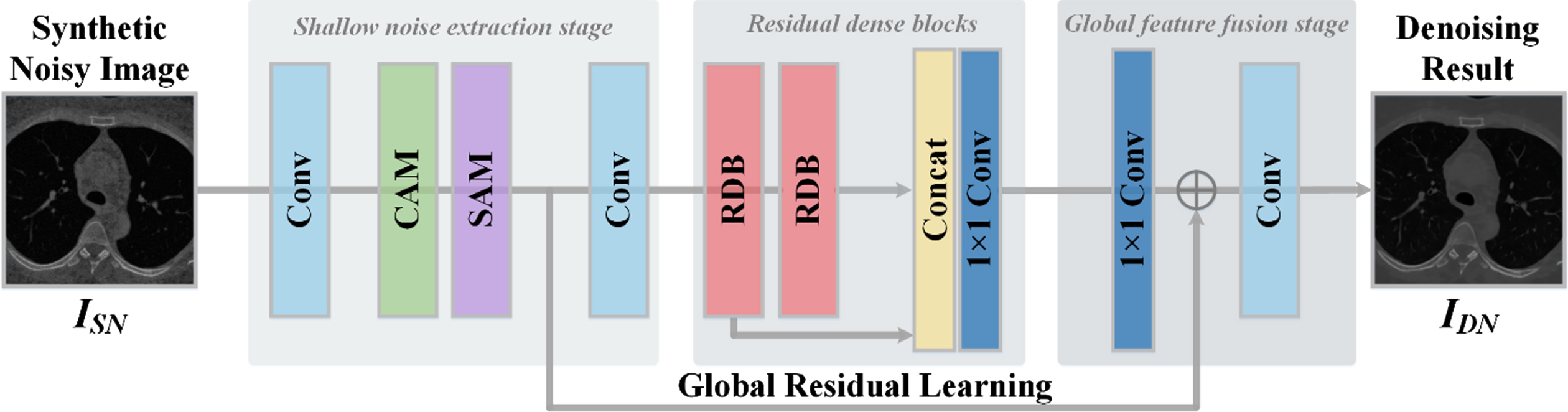
The architecture of the proposed noise removal network.
As shown in Fig. 4, the shallow noise extraction part consists of two convolution layers, Channel Attention Module (CAM) is shown in Fig. 5(a), and Spatial Attention Module (SAM) is shown in Fig. 5(b). Y
DN
is the output of the noise removal network. The pseudo-degraded image
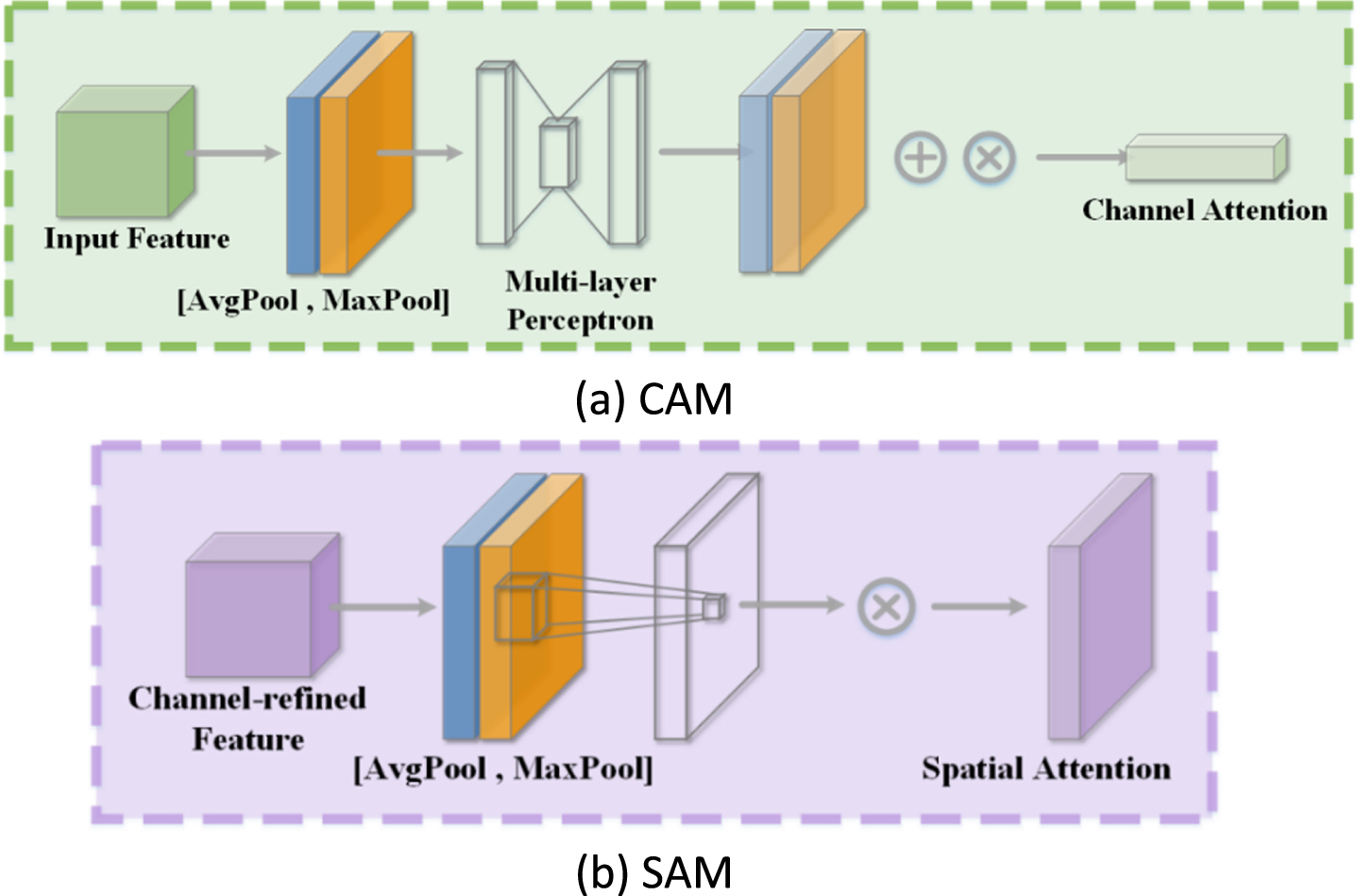
The architecture of Convolutional Block Attention Module.
CAM includes the average pooling output layer and maximum pooling output layer. These Two pooling layers are used to aggregate the spatial information of feature mapping and generate two different features spatial context descriptors, i.e.,
Different from CAM, SAM applies average pooling and maximum pooling operations along the channel axis to highlight the information area. Two descriptors are also generated by operation
Through the above two sequential sub-modules, the intermediate features are adaptively refined, and the output is defined as F CS in the shallow noise extraction stage. In the next stage, we use a residual dense block (RDB) as shown in Fig. 6 to learn more about noise.
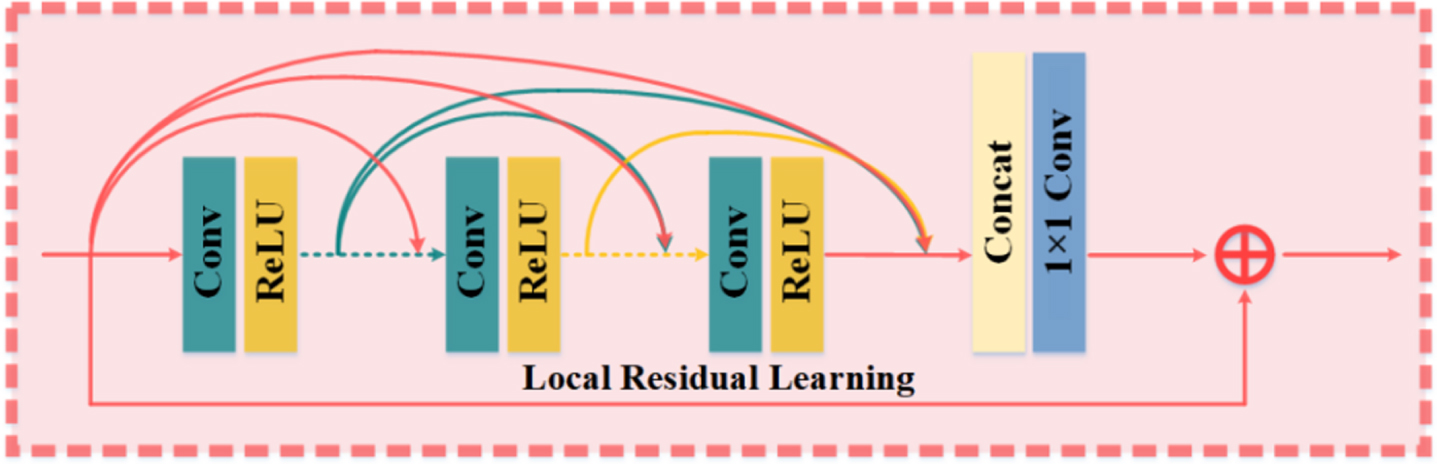
The architecture of RDB.
Each RDB consists of three parts, i.e., dense connection layer, local feature fusion, and local residual learning. The dense connection layer includes K convolution layers and Relu activation function. We concatenate the output features of these layers and then fuse multi-channel features operation by 1×1 convolution operation. Finally, we use local residual learning for further features fusing. F
CS
is an input of RDB, the above process can be expressed as follows,
Experimental setting
Dataset
For the noise generation network, 720 low-dose CT (LDCT) dental scans provided by SHDMU (Stomatological Hospital of Dalian Medical University, China) and their corresponding L0 filter results are selected for training. To improve the overall performance, we also use the data enhancement method during the training.
The LoDoPaB-CT dataset of the LIDC/IDRI database [30] contains 280 ground_truth_train_XXX.hdf5 files and 28 ground_truth_test_XXX.hdf5 files. Each HDF5 file can be extracted to 128 images and stored in PNG format. Note that both the ground_truth_train_xxx.hdf5 and the ground_truth_test_XXX.hdf5 contain noise-free images. So, we can take a part of them as ground truth for training and testing our model.
We selected 16 first ground_truth_train_xxx.hdf5 files (i.e., 2048 lung CT images) as the training set, and first 3 ground_truth_test_XXX. hdf5 files (equivalent to 384 images, but only 300 images are randomly selected) as the test set. Therefore, 2348 (2048 + 300) pieces of lung CT ground truth are sent into the noise generation network to generate synthetic noise images. These lung CT images are multiple scans from several patients. These images are also LDCT [31]. Because they are all CT images, the migration of dental images to lung images can be completed. Among them, 2048 pieces of synthetic noise images and the corresponding ground truth images are combined to construct the training set of the noise removal network. The remaining 300 synthetic noise images are used for testing. Since synthetic noise images have corresponding ground truth images, our denoising method can be verified in terms of qualitative scores. Finally, dental images with LDCT are input into the network as the test set to verify the removal effect of real noise.
Baseline algorithm
We use several existing image denoising algorithms, DnCNN [12], FFDNet [13], DANet [22], and RDN [26] as the baseline. To be fair, all the codes used are open-source codes, and the parameters are set under the guidance of the corresponding literature. DnCNN and FFDNet are popular deep learning based models for image denoising, and the proposed method closely relates to DANet and RDN, so DnCNN, FFDNet, DANet, and RDN are selected as the baseline.
Evaluation metric
For the dental images without ground truth, we introduced AKLD (Average KL Divergence) [22] in the noise generation task to compare the similarity between the generated and the real noisy images. In the noise removal task, visual quality is the main measurement standard of dental images. In addition, we further introduce the perception-based image quality evaluator (PIQE) [32] as the blind image quality evaluation index. For the lung CT with ground truth, we choose peak signal-to-noise ratio (PSNR) and the structural similarity index method (SSIM) as the objective performance of our algorithm.
To make the paper clearer, we briefly explain two less commonly used evaluation metrics. The smaller the AKLD value is, the more similar the generated noise image is to the real noise image.
In the noise generation network, both the denoiser and the generator adopt the architecture of U-Net [23], including four encoder blocks ([Conv + ReLU]×2 + Average pooling), three decoder blocks (Transpose Conv + [Conv + ReLU]×2), and symmetric skip connection under each scale. The discriminator contains five stride convolutional layers and one fully-connected layer. We train 50 epochs, the batch size is set as 16, the learning rate of generator and denoiser is set as 1e-4, and the learning rate of the discriminator is set as 2e-4.
In the noise removal network, we use two RDBS. The kernel of local and global feature fusion is 1×1, and the size of other convolutional layers is 3×3. During the training process, the batch size is set to 16, the learning rate is set to 1e-4, and train epochs –800.
Our network framework is based on the PyTorch platform, and all experiments are implemented on a workstation with NVIDIA Titan X GPU, and Core (TM) i7-7700K CPU.
Comparison of data preparation
Before comparing the denoising algorithm, Fig. 7 shows the output results of L0 Gradient Minimization [19]. To better show the detail of the L0 filter keeping the edge, we also provide visual comparisons of enlarged details. The dental CT images smoothed by the L0 filter retain very fine edges while removing noise. For a small main structure, the edge details can also be well maintained. The filtering result is used as the label to eliminate other influencing factors as much as possible so that we can estimate the real noise distribution more accurately.
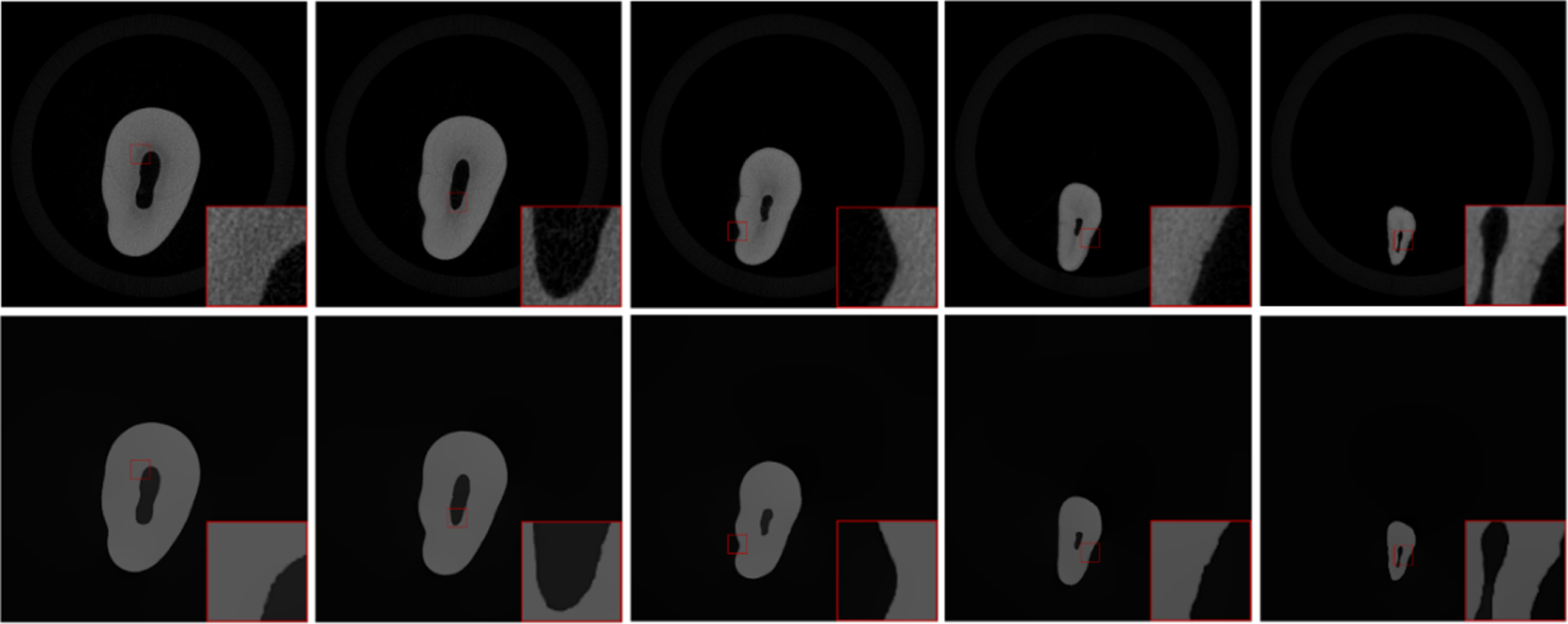
Dental images with LDCT (the first line) and the results of L0 Filter (the second line).
Since dental CT has no ground truth, to show the synthetic effect, we synthesized the noise image on the L0 filter result. Figure 8 shows a model performance change curve with AKLD as its reference index. Figure 9 compares our synthetic noise with real noise. The left half is the dental image with LDCT, and the right half is the synthesized noise image. Our estimated noise is very similar to the real noise.

AKLD results in different training epochs.
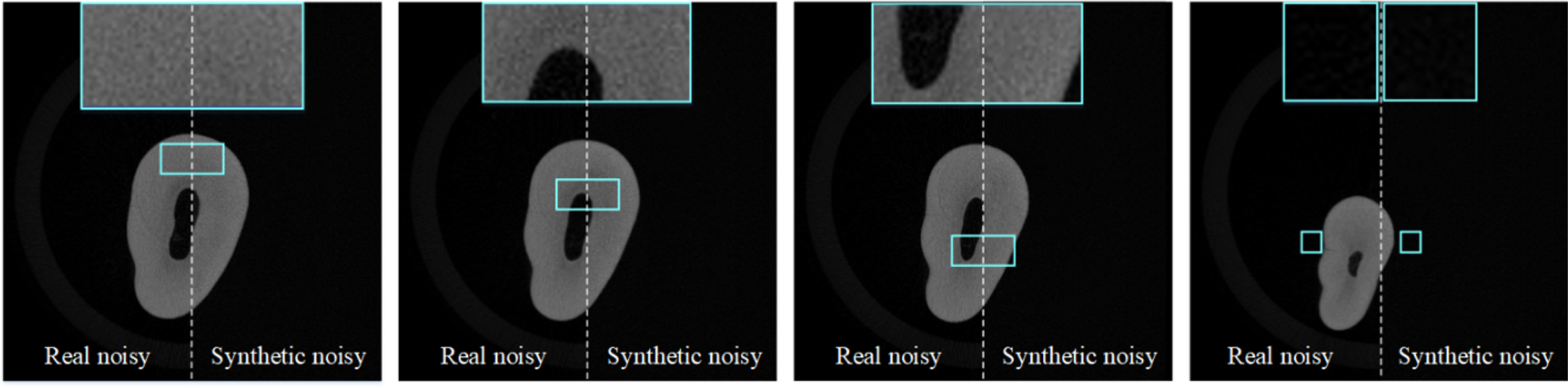
Comparison of dental CT effect among four groups. For each image, the left side of the dotted line is the real noise image, and the right side is the synthetic noise image.
The effect of transfer on lung CT is shown in Fig. 10, with the first line of the noise-free image and the second line of synthesized noise image.
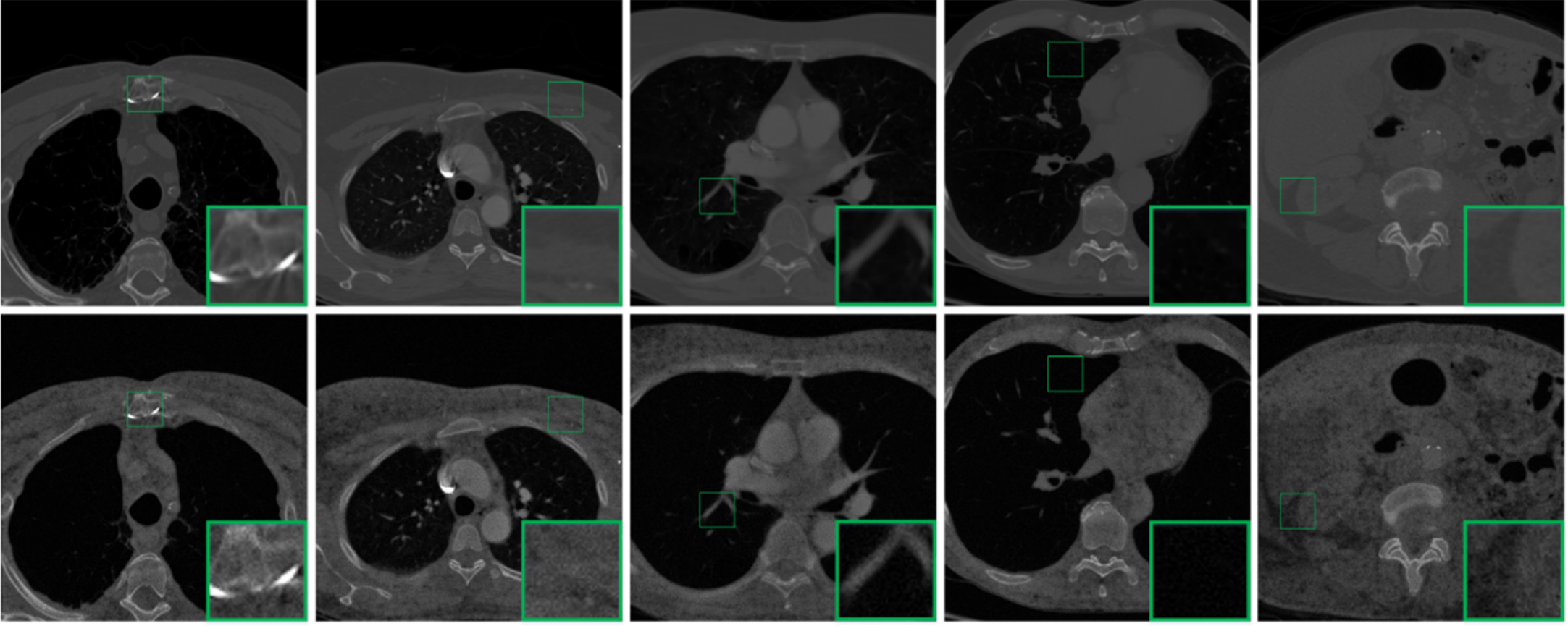
Lung CT: noise-free images (the first line) and synthetic noisy images (the second line).
The denoising experiment is divided into two parts, which are the experiment on the synthetic noise image and the experiment on the real noise image. Since the synthetic noise image has corresponding ground truth, we can use PSNR and SSIM for evaluation. For the noisy image, the visual quality is the main measurement standard since there is no ground truth.
To verify the effectiveness of NGRNet, an experiment is carried out on the synthetic noise image. As shown in Fig. 11 and Fig. 12, two groups of denoising results are presented respectively, and our method is compared with four denoising methods. From the comparison of visual observation, we can see that our algorithm can obtain a good visual effect, and the denoising effect is better. In addition, we also give the PSNR and SSIM values of each image, and it shows that our method is superior to other methods in terms of qualitative scoring.
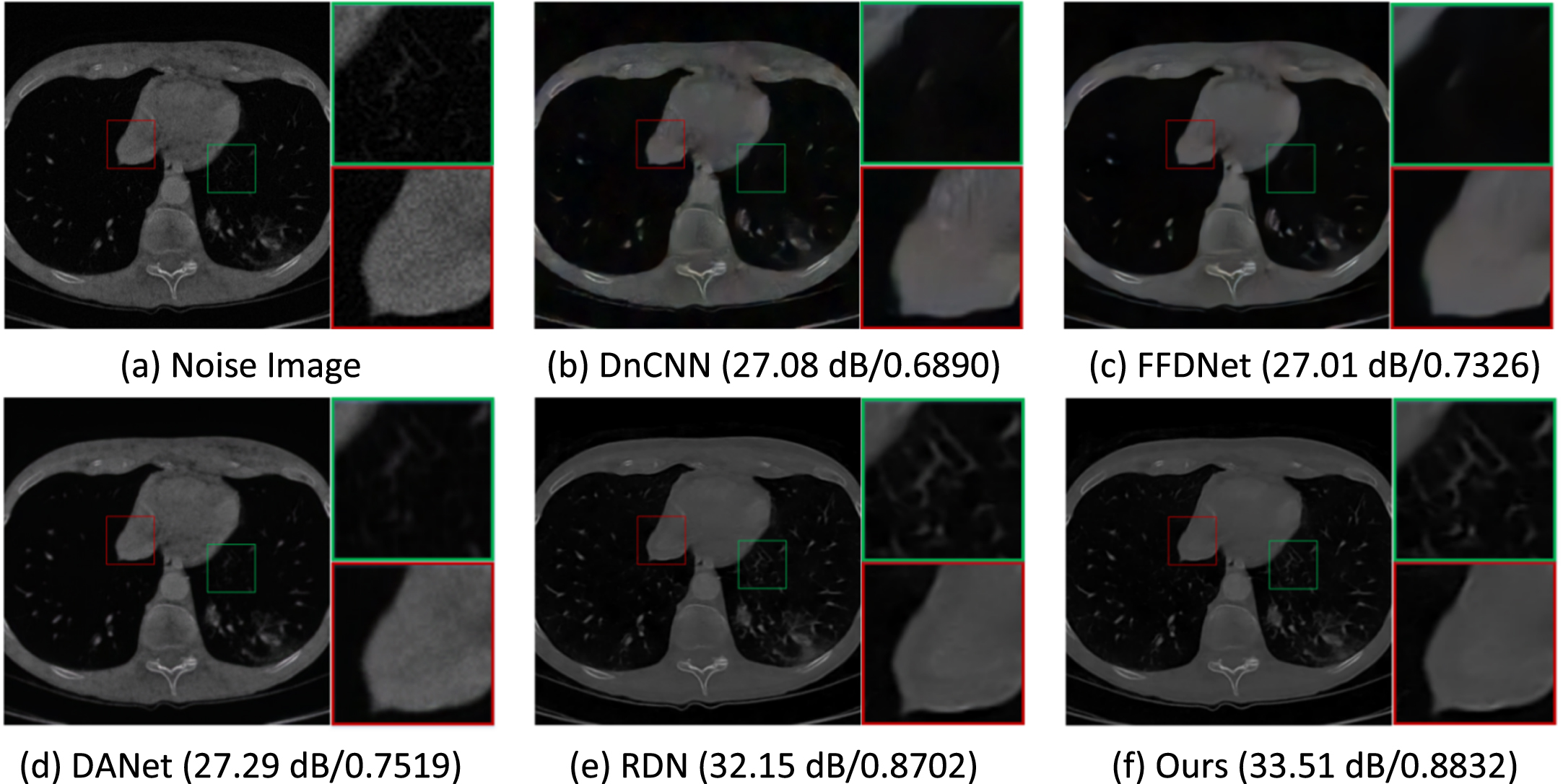
The first group of denoising results of different methods.
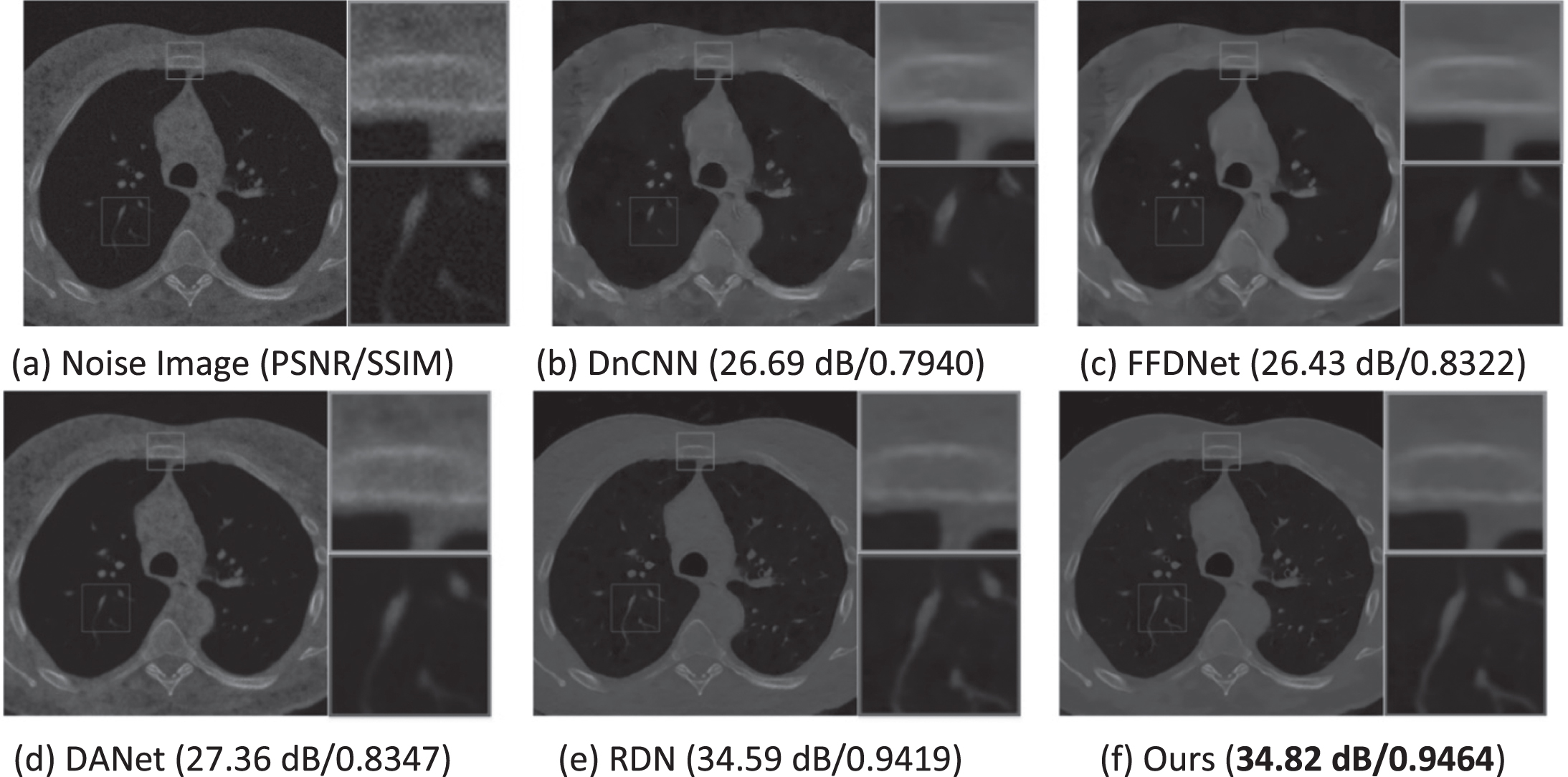
Another group of denoising results of different methods.
Lung CT images contain many fine textures. Compared with other methods, our method can recover more image details. In Table 1, for 300 lung CT images with synthetic noise, we compare the PSNR score and SSIM score of our method with other image denoising methods. In Table 1, our algorithm has obtained some advantages compared with other algorithms on PSNR and SSIM.
The PSNR and SSIM scores of our method and other methods for 300 lung CT images
Experiments on the real noise image and measures by visual effects. Figure 13 shows the original image with noise, and the denoising results of the four networks and our network. By comparison, our method can achieve a better denoising effect.
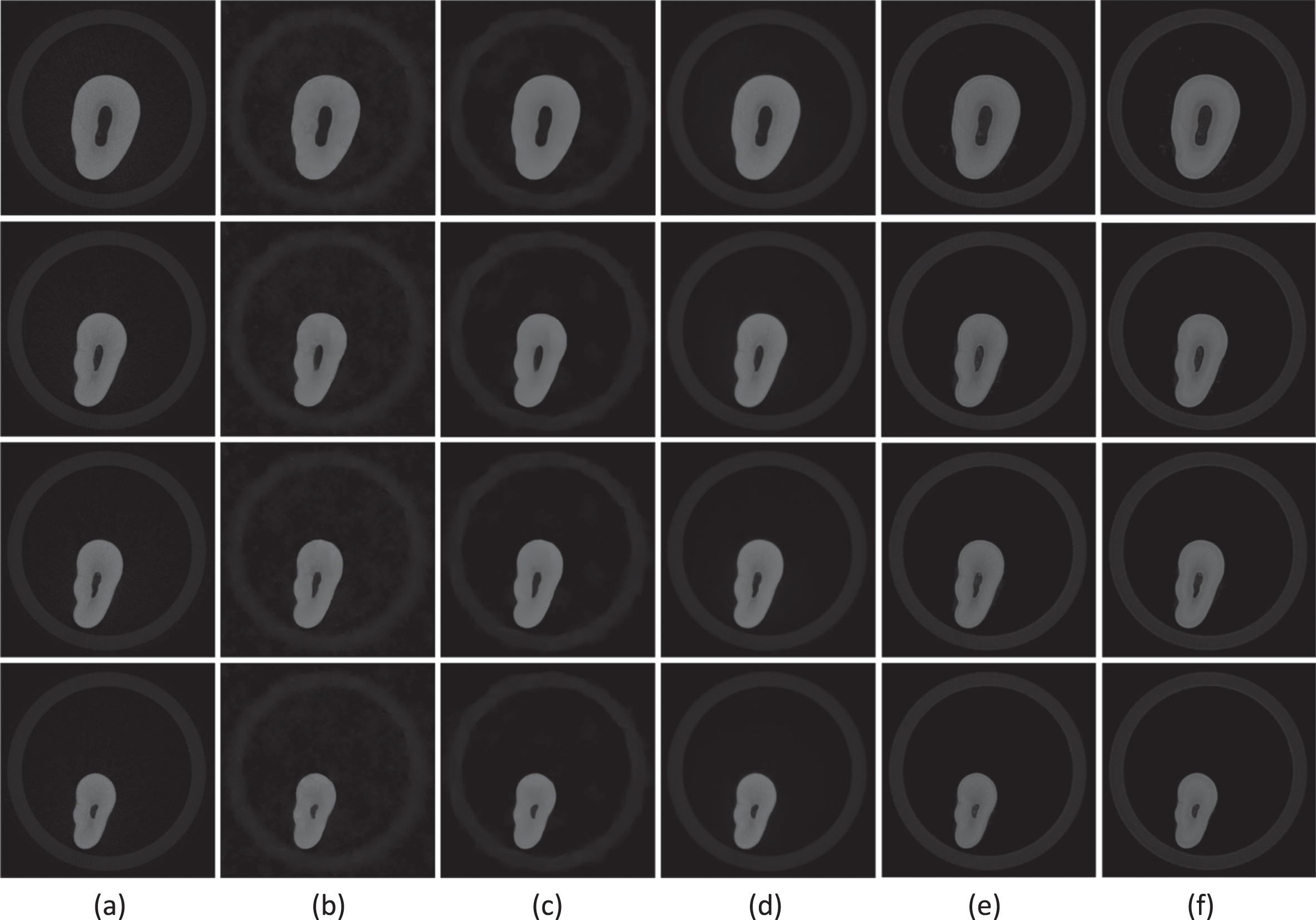
The denoised result images: (a) input, (b) DnCNN, (c) FFDNet, (d) DANet, (e) RDN, (f) Ours.
To better display the denoising details in the experimental results, we provide a magnified image. Figure 14 shows the comparison of the denoising effects of our method with the other four methods. Dental CT images are characterized by obvious edges. Through comparison, we can find that all five methods can remove the noise on the dental images with LDCT to some extent, but our method can retain the edge details of dental CT images to the maximum extent while removing the noise.

The visual quality results of enlarged the dental images with LDCT.
Because the dataset of dental images does not have the ground truth, it is impossible to evaluate the PSNR and SSIM. In this case, we use PIQE, the blind image quality assessment, to evaluate image quality. PIQE values are provided as in Table 2. As we can see that PIQE score of the proposed method is the lowest, which means the image quality of the proposed method is better than others.
The PIQE score for dental image
In this paper, a two-step framework blind denoising method for low-dose dental CT images is proposed, which can learn the real noise from unknown noise intensity. The framework consists of two networks, noise generation network and noise removal network. The noise generation network can simulate real noise. By inputting a noise-free image into the generation network, the corresponding noise image can be obtained. Therefore, supervised learning is constructed, and a noise removal network is used to denoise the real noisy CT images. Experimental results show that the proposed method can retain more details and achieve impressive denoising performance. At present, our method targets real and synthetic noises of medical images, and noise training of natural images will be added in future work to further verify the universality of our method. Since our framework contains two networks, the model is a little inefficient in terms of runtime, so we will further improve the model to achieve miniaturization of model parameters.
Footnotes
Acknowledgments
This work is supported by General project of Liaoning Provincial Department of Education, China, No. LJKZ0986; Postdoctoral Science Foundation, No. 2019M651123; Science and Technology Innovation Fund (Youth Science and Technology Star) of Dalian, China, No. 2018RQ65; receiver: Dr. Bo Fu.
This work is supported by the National Natural Science Foundation of China (NSFC) Grant No.61976109, China; Liaoning Provincial Key Laboratory Special Fund; Dalian Key Laboratory Special Fund. Dr. Yonggong Ren.
This research was funded by University of Economics Ho Chi Minh City, Vietnam. Fund receiver: Dr. Dang Ngoc Hoang Thanh.