
Abstract
BACKGROUND AND OBJECTIVE:
Since low-dose computed tomography (LDCT) images typically have higher noise that may affect accuracy of disease diagnosis, the objective of this study is to develop and evaluate a new artifact-assisted feature fusion attention (AAFFA) network to extract and reduce image artifact and noise in LDCT images.
METHODS:
In AAFFA network, a feature fusion attention block is constructed for local multi-scale artifact feature extraction and progressive fusion from coarse to fine. A multi-level fusion architecture based on skip connection and attention modules is also introduced for artifact feature extraction. Specifically, long-range skip connections are used to enhance and fuse artifact features with different depth levels. Then, the fused shallower features enter channel attention for better extraction of artifact features, and the fused deeper features are sent into pixel attention for focusing on the artifact pixel information. Besides, an artifact channel is designed to provide rich artifact features and guide the extraction of noise and artifact features. The AAPM LDCT Challenge dataset is used to train and test the network. The performance is evaluated by using both visual observation and quantitative metrics including peak signal-noise-ratio (PSNR), structural similarity index (SSIM) and visual information fidelity (VIF).
RESULTS:
Using AAFFA network improves the averaged PSNR/SSIM/VIF values of AAPM LDCT images from 43.4961, 0.9595, 0.3926 to 48.2513, 0.9859, 0.4589, respectively.
CONCLUSIONS:
The proposed AAFFA network is able to effectively reduce noise and artifacts while preserving object edges. Assessment of visual quality and quantitative index demonstrates the significant improvement compared with other image denoising methods.
Keywords
Introduction
X-ray computed tomography (CT) is a critical non-invasive imaging modality which is widely used to detect pulmonary nodules, tumors and bone fractures in diagnostic applications. However, the potential radiation risk has attracted more public concerns due to X-rays passing through the body [1]. The risk is much higher especially for children and those adults who need multiple CT scans. Considering the advantages of CT scanning which clearly show the shape and density of the lesion, it is necessary to discuss how to lower the radiation to patients. One of the feasible approaches is to decrease X-ray current levels. However, the low-dose CT images often suffer from noticeable artifacts, noise and other visible quality degradation [2], which easily cause misdiagnosis and missed diagnosis of early lesions. Due to the directionality, multi-scale and uneven density of artifacts, how to effectively remove the artifacts and noise is still a challenging problem.
There are three commonly used techniques for obtaining high quality CT images: iterative reconstruction approaches, sinograms restoration methods and image space denoising algorithms. Iterative reconstruction approaches are to directly obtain the reconstructed image from projection data through an iterative process where the prior information is often used as the penalty term of the objective function to suppress noise and preserve edges, such as sparse representation prior [3], dictionary learning prior [4]. Sinograms restoration methods aim at removing the noise of projection data, mainly including iterative denoising methods [5, 6] and nonlinear filters [7]. Iterative reconstruction and sinograms restoration methods are limited by original projection data, which is generally not available for many commercial CT scanners [8]. For image space denoising algorithm, it does not depend on the original projection data and directly processes low-dose CT (LDCT) images, including traditional denoising technique and deep learning algorithms. Traditional denoising technique mainly include some filter-based denoising methods, such as block-matching 3D (BM3D) algorithm [9].
At present, deep learning methods have become the mainstream methods for removing artifacts and noise and are the focus of this paper. Denoising networks based on deep learning are usually trained in a supervised mode, pairing LDCT images and normal-dose CT (NDCT) images (or difference images LDCT-NDCT). The existing network structures mainly include basic convolutional neural networks (CNNs) [10–12], residual CNNs [13] and generative adversarial networks (GANs) [14–19]. As the early application of CNN in LDCT, such as image-domain CNN [10] and wavelet-domain CNN [11], the training capacity of these networks are still limited. In [12], considering multiple scanning geometries and dose levels simultaneously, parameter-dependent framework obtains competing performance compared with the network with specific geometry and dose level. Based on the structures of autoencoders and residual CNN, a residual encoder-decoder CNN (RED-CNN) was presented, obtaining promising quantitative results [13].
Meanwhile, GAN has gained a lot of attention due to its training mode, which is trained with an alternate training process. Wolterink et al. applied GAN network to remove noise in cardiac CT images, which achieved a better performance than CNN with the help of an adversarial discriminator [14]. In [15], a GAN with Wasserstein distance was proposed to improve the stability of GAN and visual similarity to NDCT images. Shan et al. utilized three-dimensional CNN model as a generator to integrate spatial information for improving the image quality [16]. Then, they used different loss functions for training structurally sensitive multi-scale generative adversarial net to improve the image quality [17]. Based on residual encoder-decoder blocks, a modularized adaptive processing neural network (MAP-NN) was proposed for LDCT progressively denoising [18]. In [19], Huang et al. used dual-domain U-Net-based discriminators to learn global and local differences between the denoised and label images for improving the global denoising effect and enhancing the edge. These networks have significantly improved the performance of LDCT denoising, but there is still some room for improvement.
Most models extract CT image features in fixed-size receptive field across the feature layer. Due to multi-scale and uneven distribution of streak artifacts in LDCT images, fixed-size receptive field may limit the representation ability of the models. Convolution operation with different receptive fields can capture different scales contextual information. Gholizadeh-Ansari et al. utilized dilated convolutions with different dilated factors to extract different scale artifact features of LDCT images, which not only expanded the receptive field of convolution operation but also could not increase the number of parameters [20]. However, inappropriate integration of dilated convolutions may cause grid-like artifacts. To solve the problem, we design a local multi-scale feature extraction and fusion attention block to extract and fuse multi-scale artifact features, which includes multi-path dilated convolutions, residual blocks (RBs) and attention mechanism. Multi-path dilated convolutions are used to extract local multi-scale artifact features and RBs for better multi-scale feature fusion. Attention mechanisms are used to further optimize fused features. In [20], to improve edge extraction capabilities of CNN, a four-kernel Sobel edge detection layer was concatenated with the input image and sent into the network for LDCT denoising. In [21], a trainable Sobel edge enhancement module was used to enrich the input information. The ability to extract artifact features in residual networks has a great influence on network performance.
Inspired by [20, 21], we design an artifact branch to provide rich artifact features and strengthen the effect of artifact information to the backbone network. Besides, long-range skip connections are often introduced to fuse features with different depth levels. In [22], the features at three different depth levels were concatenated through long-range skip connections and then sent to channel attention (CA) and pixel attention (PA) successively. However, the series connection can cause the performance of attention decrease. There are two reasons: (1) the two attention models need the activation function Sigmoid to obtain the normalized weight and perform dot multiplication with the input, which makes the output response weaker. (2) the way of connection will make the pixel values of the final output features smaller. In [23], considering the difference of different depth features and based on the opinion that low-level features can preserve ample edge information, Zhang et al. designed an edge guidance module by utilizing the information at the top of early layers for medical image segmentation. This shows that the shallow features consist of rich edge information. As such, we send the shallower information to CA for concerns about artifact channels, and the deeper features to PA to focus on the artifact pixel information, and then connect the two results in parallel.
The rest of this paper is organized as follows. Related works are placed in the second section. Detail parts of the AAFFA network are presented in the third section. Experimental results and ablation study are given in the fourth section. The last section is the conclusion and discussion.
Related works
In addition to low-dose CT denoising, our work is also related to feature fusion and attention mechanisms. In this section, we introduce them.
Feature fusion
Feature fusion is often used to enrich the features for better image recognition. Some researchers have designed different network blocks to fuse features with different depth levels through dense connection [24]. In [22], Qin et al. fused multi-level features by connecting group residual blocks to avoid the loss of shallower features as the network deepens. These blocks only used convolutional kernel with single size and didn’t take the local multi-scale feature in each layer into consideration. In [25], three densely connected blocks based on different sizes convolutional kernels was applied to capture multi-scale features of LDCT images. In [26], Bao et al. concatenated local multi-scale features from the dilated spatial pyramid pooling for real image denoising. However, feature fusion by directly concatenating multi-channel different scales features makes merged features produce inconsistencies. Res2Net module constructed hierarchical connections within a residual block to aggregate features from a variety of different receptive fields [27]. In our paper, a progressive fusion module is constructed to achieve the consistency of multi-scale feature fusion.
Attention mechanism
The attention mechanism has been widely used to improve the performance gains of CNNs [28–30]. The well-known Squeeze-and-Excitation (SE) module, also called channel attention (CA), obtains different weights for channel features according to their importance by using global average pooling and SE mechanism [28]. The pixel attention (PA) is to give a spatial attention map of every input feature, increasing the weights of important pixels and suppress the weights of unimportant pixels [22]. In [29], a dual attention mechanism was used to adaptively adjust local features and global channel weight for scene segmentation, where non-local attention module connects with CA module in parallel. Recently, attention mechanism is also applied for low-dose CT denoising [30], where a 3D self-attention module was used to obtain a large scope of spatial information within CT slices and between CT slices, improving the network performance. Inspired by references [22, 29], we also use dual attention mechanism to focus on the pixel features and the differences between channels.
Methods
Let X ∈ Rm×n denotes a LDCT image, Y ∈ Rm×n is a NDCT image corresponding to X. The purpose of noise reduction is to find a function G, such that
To make the network easy to train, we let the model learn the difference between LDCT and NDCT image. The structure of the AAFFA is shown in Fig. 1(a). The backbone network has three stages: preliminary feature extraction of the input image (achieved by feature extraction and fusion block (FEFB)), extraction of noise and artifact features (enclosed by the blue box) and reconstruction of noise and artifact (enclosed by the purple box). The artifact channel, shown in pink, is embedded as a branch of the network AAFFA to provide rich noise and artifact features for better extraction of artifact and noise features in the second stage.
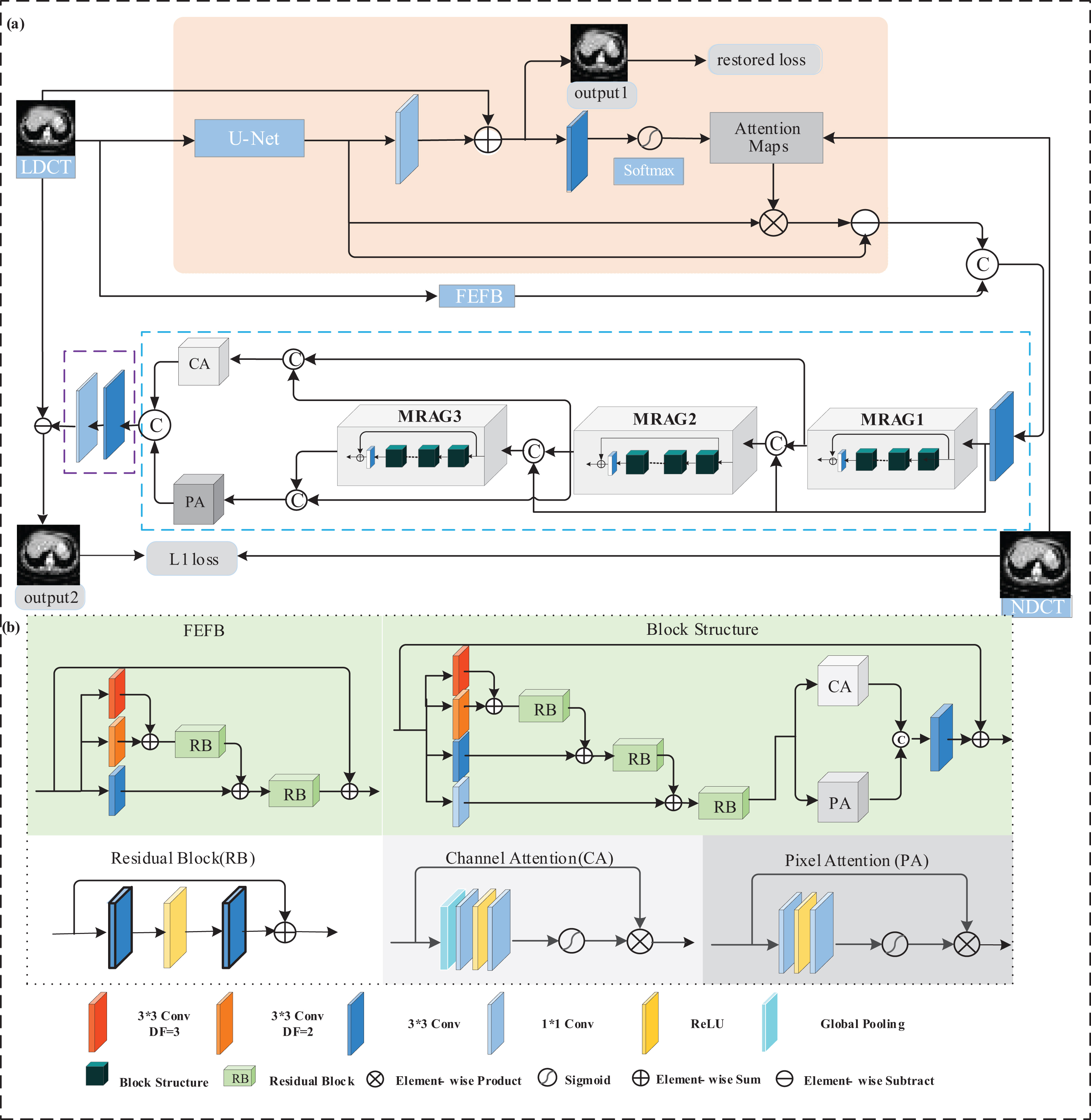
The structure of the proposed network AAFFA. (a) the overall denoising network (b) the module details.
In the first stage of the backbone, the low-level features of LDCT images are extracted by FEFB. Then the low-level features and the features from the artifact channel are concatenated and sent into a convolutional layer and multi-scale residual attention groups (MRAGs) successively, where the multi-scale artifacts and noise features are gradually extracted from coarse to fine, and from shallow to deep. In our study, the number of MRAGs is set to 3. Long-range skip connections are introduced to enhance the inputs of MRAGs and to fuse the outputs of MRAGs. CA is used to focus on the information of artifact outline of the fused shallower features, and PA is applied for re-correction pixel information of the fused deeper features. The adjusted features are concatenated and sent into the reconstruction stage, where two convolutional layers are used, one 3 × 3 convolution for extracting the fused features, the other 1 × 1 convolution for reconstructing the noise and artifact image.
As shown in pink in Fig. 1, a U-net network is introduced to extract artifact and noise features Ta of input image. However, these feature images may contain the tissue structure features of the human body. In order to provide effective artifacts and noise information for the backbone network, we adopt a structure attention mechanism to remove tissue structure information in Ta. In this mechanism, 1 × 1 convolution is used to get an artifact image from Ta and the input image is subtracted from the artifact image to get an output with less artifacts and noise, which can be expressed as
Then 3 × 3 convolution is used to extract features of the output. The structure attention map is obtained by the softmax normalization operation on the feature images, that is
Perform element-wise product with Ta to get the structure component that are of concern. Finally, the processed artifact features T
b
are obtained by subtracting the structure component from Ta,
In residual networks, the extraction of artifacts and noise feature plays a vital role. Some of the existing methods did not consider the multi-scale characteristics of artifacts, which is prone to artifact residual phenomenon. The proposed contextualized FEFB can obtain multi-scale artifact features from coarse to fine. As shown in Fig. 1(b), three-path dilated convolutions with different dilation factors are introduced to increase receptive field sizes and extract local multi-scale features. RBs are used to gradually aggregate different scales features ensuring the consistency of multi-scale feature fusion.
Multi-scale residual attention group (MRAG)
Residual groups MRAG1, MRAG2 and MRAG3 (shown in Fig. 1(a)) are composed of a series of blocks with the same structure and a 3 × 3 convolution layer. The block structure is shown in Fig. 1(b), which includes different scale feature fusion and attention mechanism. Unlike FEFB, the block adds deep integration by 1×1 convolution, which can reserve the feature scale of the previous layer. In addition, the block introduces CA and PA, which are shown in Fig. 1(b). CA is constituted by the global pooling and two 1 × 1 convolution layers with two activation functions Relu and Sigmoid followed. PA removes the global pooling in CA and get a weight map of the same size as the input feature map.
Loss functions
The setting of loss function has a great impact on the recovery of LDCT images. Recent studies suggest that although L2 loss can achieve high image quality metric, it may generate blurry images and suffer from loss of details which are critical for clinical diagnosis [15]. Compared with L2 loss, L1 loss may tolerate small differences between two contrasted images and alleviate fuzzy phenomenon. So we use L1 loss.
In artifact channel, the quality of artifact information has a great influence on the backbone network. It depends on the artifact features and structure attention mechanism. So, to improve the ability of extracting artifact and tissue structure features, we propose a Ls loss to constrain the output of the U-net network,
By combining (5) and (6), we get a total loss function, which is expressed as
Dataset and experimental settings
To validate the performance of the proposed network AAFFA in LDCT image restoration, we use a clinical dataset, which has been authorized by Mayo Clinic for “The 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge” [31]. The dataset includes 3mm thickness normal-dose abdominal CT images that were taken from 10 anonymous patients and the corresponding quarter-dose CT images that were simulated by inserting Poisson noise into the projection data of normal-dose CT images for each case to reach a noise level corresponding to 25% of the normal-dose. Each patient has approximately 250 slices per scan. There are 2,378 pairs with size of 512×512 in the dataset. We perform two trainings, each of which selects two patient CT image sets from the Mayo dataset as test sets and the rest as training sets. In order to better extract artifact features from the U-net network, we use larger image patches with size of 256×256 as input. The experiment about the size of image patch is placed in the experimental section.
Before the image patches are sent into the network, the CT Hounsfield Unit scale is normalized to [0,1]. We compare the effect of our network with the existing baseline denoising methods BM3D [9], RED-CNN [13], DRL-E [20], WGAN-VGG [15], CPCE-2D [16] and MAP-NN [18]. BM3D is a traditional rather than CNN-based denoising method. RED-CNN, DRL-E, WGAN-VGG, CPCE-2D and MAP-NN are all CNN-based denoising method for LDCT image denoising. RED-CNN is a residual encoder and decoder network with L2 loss. DRL-E is a CNN with dilated convolutions, shortcut connections, and the edge detection layer. WGAN-VGG is a perceptual-loss-based GAN with Wasserstein distance. CPCE-2D is a 2D conveying path-based convolutional encoder-decoder network within the GAN framework. MAP-NN is an end-to-process mapping GAN, which allows radiologists to optimize the denoising depth in a task-specific fashion.
In addition, to estimate the effect of multi-scale fusion of AAFFA, it is necessary to compare FFA [22] with ours. FFA is a feature fusion attention network for image dehazing, which contains a multi-level fusion mechanism without local multi-scale fusion and artifact channels. And the way of multi-level integration of FFA and AAFFA is also different. FFA performs a simple cascade of features at different levels, while AAFFA performs a gradual cascade from shallow to deep.
The Adam optimization algorithm is used for all network training. The hyper-parameters for Adam are set as β1 = 0.5, β2 = 0.999, and the learning rate is 1 × 10-4. The batch size is 1 and the number of blocks in the residual groups are set to 8 due to memory limitations. The U-net network has 9 layers, and the number of channels is 32, 64, 128, 256, 512, 512, 256, 128, 64 respectively. The hyper-parameter λ in the loss function is set to 0.01 according to the quantitative value of PSNR and SSIM. For comparison with other network-based methods, in our process the step of training is set to 4×105. The network is implemented on NVIDIA GeForce GTX 1080 GPU.

Visual comparison of different methods on an abdominal LDCT image with low-attenuation lesions.
Qualitative assessment
In the part, we visually compare the denoising performance of different algorithms. For a better comparison visually, we select 3 representative LDCT images, which are shown in Figs. 2(a)–4(a). Figure 2(a) is an abdominal LDCT image with obvious horizontal streak artifacts and noises, Fig. 3(a) is an abdominal LDCT image that contains low-attenuation lesions, and in Fig. 4(a) there are rich tissue structure details. And (b)-(i) in Figs. 2–4 are the processed results of different methods. Regions-of-interests (ROIs) marked by rectangles have also been magnified in the corresponding position. The display windows for all figures are in [–160, 240] HU.
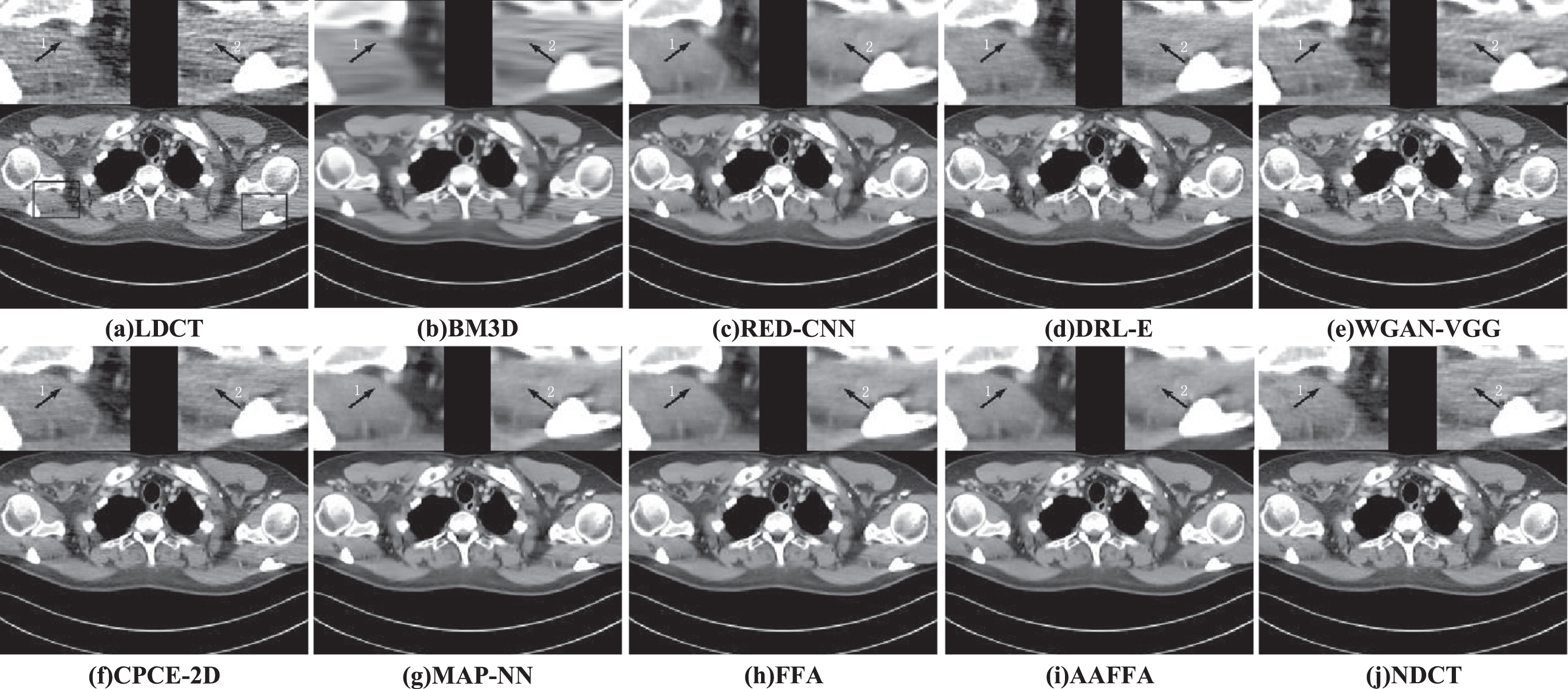
Visual comparison of different methods on an abdominal image with obvious artifacts and noise.
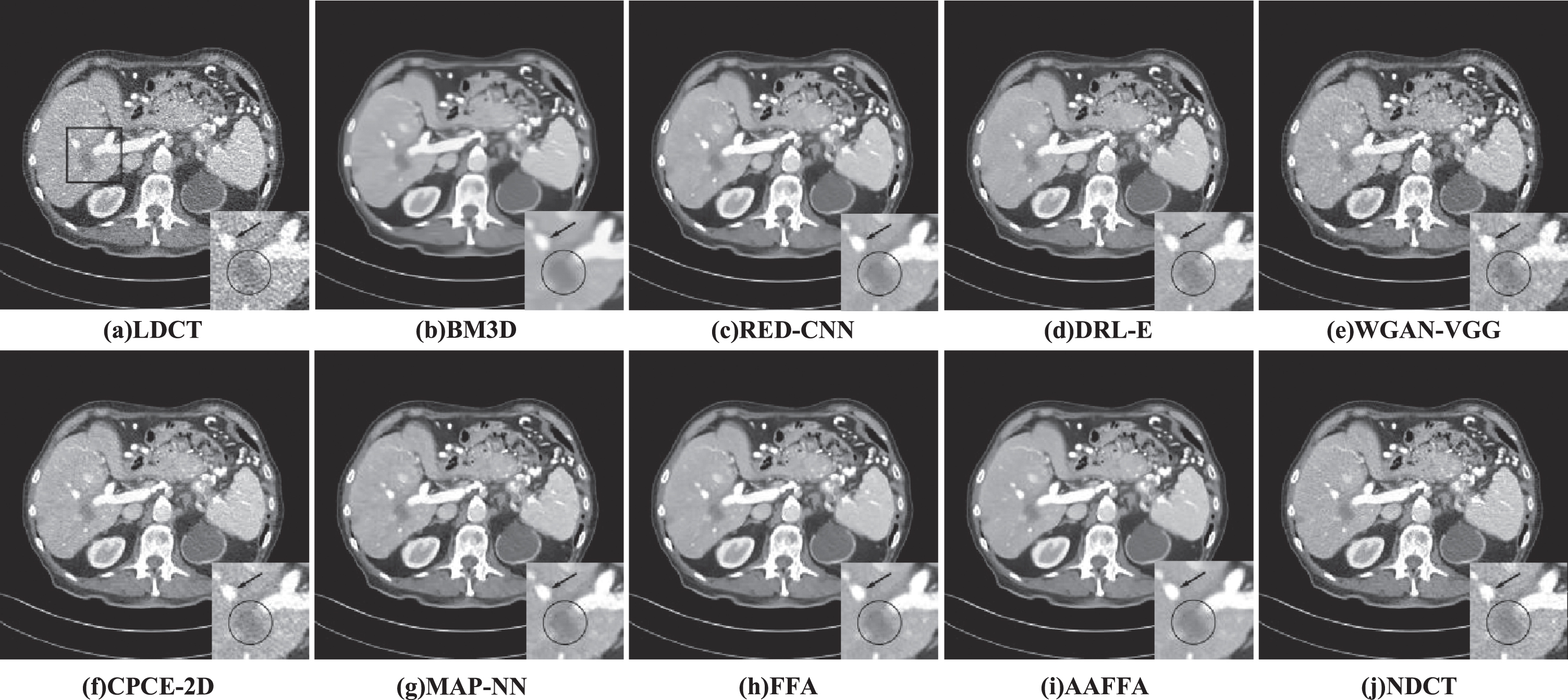
Visual comparison of different methods on an abdominal image with rich tissue structure details.
From the processed images in Figs. 2(b)–(i)–4(b)–(i), we see that all algorithms can suppress noise and artifacts to some extent with the NDCT images as reference in Figs. 2(j)–4(j). However, compared with CNN-based approaches, the BM3D method causes waxy artifacts and over-smoothing in the processed image, which is caused by the uneven distribution of noise in LDCT images, which makes it difficult to effectively remove the noise by traditional denoising mode. The processed images by RED-CNN are a bit blurry (marked by the arrows in Figs. 2(c) and 4(c)) and some details are lost (marked by the arrow in Fig. 3(c)). In DRL-E, dilated convolutions were used to extract different scale artifact components. But dilated convolutions cause grid-like artifacts (as shown in Figs. 2(d)-4(d)). The processed images by the WGAN-VGG algorithm are shown in Figs. 2(e)-4(e), from which we find that WGAN-VGG improves the visual effect of the MSE-based network and avoids over smoothing, but there are still some residual artifacts (marked by the arrow 1 in Fig. 2(e)) and some structures are destroyed, which can be seen from Fig. 4(e). The obtained images by CPCE-2D are close to corresponding NDCT images. However, there are some residual artifacts in the obtained images by CPCE-2D, which can be seen from Figs. 2(f)-4(f). The visual effect of the images by MAP-NN is better than WGAN. But from Fig. 4(g), we can observe some false artifacts. Compared with RED-CNN, DRL-E, WGAN-VGG, CPCE-2D and MAP-NN, the result images of FFA and the proposed network AAFFA have a significant improvement in artifact removal and detail preservation.
These two networks contain CA and PA attention mechanism and multi-level feature fusion, which make the network have a better detail preservation ability (as shown in (h)-(i) of Figs. 2–4). Apart from the multi-level fusion and attention mechanism, the proposed AAFFA has multi-scale feature extraction and fusion mechanism and an artifact channel, which extract the multi-scale artifact features and provide rich artifact information for the backbone network respectively. They are conducive to the removal of noise and artifacts (shown by the arrow 1 in Fig. 2(i)) and detail preservation (shown by the arrow 2 in Fig. 2(i) and the arrow in Fig. 3(i)). The contrast of low-attenuation lesions is improved (shown by the circles in Figs. 3(i) and 4(i)). On contrast, the proposed method exhibits better visual effect.
Three metrics are used to perform image quantitative analysis, which are peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and visual information fidelity (VIF) [32].
PSNR is expressed as the ratio between the maximum power present in the signal and the power of the of noise present in the signal. Mathematically, it is expressed as
SSIM gives a measure about the perceptual similarity between the denoised image and NDCT image. Mathematically SSIM is defined as follows:
VIF is a full-reference image quality metric that uses information theoretic criterion for image fidelity measurement, derived from a quantification of two mutual information quantities: one is the mutual information between the input and the output of the human visual system (HVS) channel when no distortion channel is present (called the reference image information), other is the mutual information between the input of the distortion channel and the output of the HVS channel for the test image(called the distorted image information).The mutual information quantifies the information that the brain could ideally extract from the reference image or the distorted image. VIF measures the quality of the distorted image by
Here, the distorted image is the denoised image and the reference image is the NDCT image. VIF value lies in the interval [0, 1], The larger the VIF value, the better the image quality. More details on VIF can be seen in [32].
The quantitative results of different methods are shown in Table 1, from which we can observe that the quantitative values of the denoised images by WGAN-VGG is the lowest, and the results produced by FFA have higher PSNR, SSIM and VIF, compared with the results of BM3D, CPCE-2D, DRL-E, MAP-NN and RED-CNN. This is thanks to the multi-level integration of FFA in depth. Since considering multiple depth levels and local multi-scale fusion, the proposed method AAFFA obtains the highest quantitative value. Especially when LDCT images have obvious streak artifacts and noise, the effect of the proposed AAFFA is more obvious. The PSNR of Fig. 2(a) has an increase of about 0.7 compared with FFA.
Quantitative results of typical images of different methods
The PSNR, SSIM and VIF values in the form of mean±std (mean value±standard deviations) for different denoising methods are given in Table 2, from which we observe the average PSNR values of the denoised images by different methods are in the following order: WGAN-VGG < BM3D < CPCE-2D < DRL-E < MAP-NN < RED-CNN < our method, which shows that our method can reduce noise and artifacts effectively; The average SSIM values of the denoised images by different methods are in the following order: WGAN-VGG < CPCE-2D < DRL-E < BM3D < MAP-NN < RED-CNN < our method, which illustrates that our method can better preserve the structure of the image. The average VIF values of the denoised images by different methods are in the following order: WGAN-VGG < BM3D < DRL-E < MAP-NN < RED-CNN < CPCE-2D < our method, which shows that the visual effect of our method is also the best compared with other methods.
The average quantitative results of different denoising methods
In addition, a Mann-Whitney U test is used to further analyze the denoising performance of different algorithms. The size of the test set is 880. The results of p-values have been showed in Table 3. Taking “PSNR value of RED-CNN” as an example, we assume that the denoising performance of RED-CNN and our algorithm has no difference in other aspects except the average level. We give original hypothesis H0: RED-CNN and our method have no significant difference in denoising performance, alternative hypothesis H1: RED-CNN and our algorithm have significant difference in denoising performance. Table 3 gives the results of Mann-Whitney U test. Among them, Asymp. Sig. (2-tailed)=0.000, which is significantly less than 0.05. Thus, RED-CNN and our method have significant difference in denoising performance.
P-Value by Mann-Whitney U test
To estimate the impact of each sub-module in AAFFA on denoising performance, we compare three networks with the proposed network to perform ablation study. The structures of the three networks are listed in Table 4. (1) FFA: the network has residual attention groups (RAGs) and the block in groups is single scale convolutional layer; (2) w/o A: the proposed network AAFFA with only the artifact channel removed; (3) w/o F: the proposed network AAFFA with only FEFB removed.
Components of different Networks for ablation studies
Components of different Networks for ablation studies
The quantitative values of four networks are shown in Table 5. Compared with FFA, the quantitative results of w/o A and w/o F have been significantly improved, which demonstrates that MRAG and FEFB block can help to improve the ability to extract multi-scale artifact features and the artifact channel can provide effective artifacts and noise information and strengthen the effect of artifact information to the backbone network. The proposed method AAFFA obtains the highest quantitative value, which fully shows that each sub-module has a certain contribution to the denoising performance of the network. Especially for LDCT images with strong noise and streak artifacts (Fig. 2(a)), AAFFA obtains an improvement of 0.2 in PSNR compared with w/o A, which shows the artifact channel has the ability of extracting artifact features.
The quantitative values of different networks for ablation studies
Table 6 gives the PSNR, SSIM and VIF scores of the test images in the form of mean±std (mean value±standard deviations). The Experimental results further show that the results by the size 256×256 are better than those by the size of 128×128.
The comparison experiment of patch size of the input image
The comparison experiment of patch size of the input image
This paper aims to improve the deep learning-based method’s artifact and noise extraction capabilities and obtain high-quality CT images suitable for radiologists’ diagnosis. To achieve this aim, (1) a local multi-scale feature fusion attention block is designed for extracting and fusing artifact features from coarse to fine, which combines local multi-scale feature fusion with global feature attention mechanism. The combined structure is beneficial to multi-scale artifact feature extraction; (2) a multi-level fusion architecture based on long-range skip connection and attention modules is introduced for artifact feature extraction. The shallower features enter the channel attention mechanism for better extraction of artifact features, and the deeper features are sent into the pixel attention for focusing on the artifact pixel information; (3) An artifact channel is proposed to provide rich artifact features and guide the extraction of artifact feature in backbone network. We evaluate our proposed method on a publicly available dataset of the 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge. The proposed AAFFA method increases the averaged PSNR/SSIM/VIF values from 43.4961/ 0.9595/ 0.3926 (LDCT) to 48.2513/0.9859/0.4589. The quantitative comparison of the proposed AAFFA method with BM3D, RED-CNN, DRL-E, WGAN-VGG, MAP-NN and CPCE-2D demonstrated the superior performance of the AAFFA method in terms of PSNR, SSIM, VIF. And subjective comparison shows the proposed AAFFA method is not only superior in removing artifacts but also the preservation of details.
However, there are some limitations of this study. First, due to the introduction of the U-net network, the block size of the input image is set to 256×256, which will obviously increase the network parameters, resulting in the batch size being set to 1. If the memory of the GPU allows, the batch size may be larger, so that the training of the network is more stable. Secondly, we only validated the AAFFA method with one dose level in this paper and it is worth further validating with lower radiation dose.
Footnotes
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China (No. 62001321), the Natural Science Foundation of Shanxi Province (No. 201901D111261, No. 202103021224274, No. 202103021224265), the Social and Economic Statistical Research Project in Shanxi Province (KY [2021]145) and Taiyuan University of Science and Technology Ph.D. Start-up Fund (20152020).