
Abstract
BACKGROUND:
Dental health issues are on the rise, necessitating prompt and precise diagnosis. Automated dental condition classification can support this need.
OBJECTIVE:
The study aims to evaluate the effectiveness of deep learning methods and multimodal feature fusion techniques in advancing the field of automated dental condition classification.
METHODS AND MATERIALS:
A dataset of 11,653 clinically sourced images representing six prevalent dental conditions—caries, calculus, gingivitis, tooth discoloration, ulcers, and hypodontia—was utilized. Features were extracted using five Convolutional Neural Network (CNN) models, then fused into a matrix. Classification models were constructed using Support Vector Machines (SVM) and Naive Bayes classifiers. Evaluation metrics included accuracy, recall rate, precision, and Kappa index.
RESULTS:
The SVM classifier integrated with feature fusion demonstrated superior performance with a Kappa index of 0.909 and accuracy of 0.925. This significantly surpassed individual CNN models such as EfficientNetB0, which achieved a Kappa of 0.814 and accuracy of 0.847.
CONCLUSIONS:
The amalgamation of feature fusion with advanced machine learning algorithms can significantly bolster the precision and robustness of dental condition classification systems. Such a method presents a valuable tool for dental professionals, facilitating enhanced diagnostic accuracy and subsequently improved patient outcomes.
Introduction
Oral health is an integral component of overall well-being, often serving as a window to general health conditions. Despite advancements in dental care, conditions such as caries, calculus, and gingivitis continue to affect a large portion of the population [1–4]. Traditional methods for diagnosing these conditions typically rely on the clinical expertise of dental professionals [5, 6]. While effective, these approaches are time-consuming and subject to human error [7, 8]. The advent of machine learning technologies, particularly deep learning, offers an opportunity to automate and improve the accuracy of dental diagnoses. This article elucidates the multi-layered importance of accurate classification in dental conditions.
One of the foremost benefits of accurate classification lies in enabling early diagnosis [9, 10]. Timely identification of dental issues like caries or gingivitis can lead to immediate intervention, preventing the escalation of these conditions into more severe forms [11]. Early treatment often mitigates the need for complicated procedures like root canals or tooth extractions, ultimately preserving the patient’s oral health. Classification algorithms can assist dental professionals in devising treatment plans tailored to individual conditions [12, 13]. A nuanced understanding of the specific dental issue at hand allows for more targeted therapies, leading to quicker and more effective treatment outcomes. In a healthcare setting, resources such as time, equipment, and skilled personnel are often limited. Accurate classification algorithms can streamline the diagnostic process, freeing up dental professionals to focus on treatment planning and patient care [14, 15]. This optimization translates into better resource allocation within healthcare facilities. The automation or semi-automation of classification processes can reduce healthcare expenditures substantially [16, 17]. By minimizing the time needed for diagnosis, automated systems enable healthcare practitioners to concentrate on other high-priority tasks, thereby reducing overall costs. Data derived from accurate classification can inform public health initiatives. This information can guide strategies aimed at reducing the prevalence of dental conditions in specific demographics or geographic locations. Human error is an inevitable aspect of any manually-executed process [18]. Automated classification, underpinned by machine learning algorithms, offers a level of consistency that minimizes the likelihood of diagnostic errors. In an era where telehealth is becoming increasingly prevalent, accurate classification algorithms can be integrated into virtual healthcare platforms [19]. These systems can provide preliminary diagnoses, enabling more effective remote consultations and treatment planning. For communities with limited access to dental care, automated classification systems can offer preliminary diagnoses. These can guide local healthcare providers in delivering initial treatments, bridging the gap in accessibility. Classification data is invaluable in research settings. It can help in the development of new treatment methods or the refinement of existing ones, thereby pushing the boundaries of dental healthcare. Accurate classification also empowers patients with the knowledge needed for informed decision-making. Understanding their dental conditions in detail allows patients to actively participate in treatment planning.
Convolutional Neural Networks (CNNs) have shown promise in medical imaging, yet their application in dental condition classification is still an emerging field [20]. Furthermore, many existing studies focus on individual dental conditions and employ a single type of CNN model, overlooking the potential of model ensembles and feature fusion techniques. However, dental diagnostics pose unique challenges such as varied presentation across patients and the need for high-resolution feature detection [21]. The complexity increases when dealing with a comprehensive set of dental conditions, necessitating the development of more robust and reliable classification systems. The integration of multiple CNN models and feature fusion methods could offer an innovative solution to these challenges, thus forming the basis for our research. The accurate and reliable classification of dental conditions offers a myriad of benefits that extend from individual patient care to broader healthcare system improvements. As machine learning technologies continue to advance, the role of automated classification in dental healthcare is poised to become increasingly significant, promising a future where dental conditions are diagnosed more quickly, treated more effectively, and managed more efficiently. However, classification of dental conditions using images presents a range of challenges that span technical, data-related, and clinical issues [22]. Some dental conditions are rarer than others, leading to an imbalance in the dataset. This imbalance can bias the classification model towards more prevalent conditions. Accurate annotation or labeling of dental images require specialized knowledge, making it labor-intensive and time-consuming. Obtaining proper consent for using dental images in a dataset can be challenging but is necessary for ethical research. Some dental conditions share similar visual traits, leading to inter-class confusion. Even if a model demonstrates high accuracy, there can be resistance from dental professionals in adopting machine learning-based approaches due to a lack of trust or understanding. Transitioning from research setting to a large-scale, real-world application presents challenges in scalability and reliability. Understanding and addressing these challenges are critical steps towards developing a reliable and clinically useful classification system for dental conditions using images.
The aim of this study is to fill these gaps by exploring an integrative approach that leverages both deep learning models and multimodal feature fusion techniques. This is to achieve comprehensive and reliable classification of six common dental conditions. As machine learning technologies continue to evolve, their potential impact on dental healthcare is becoming increasingly significant. However, the adoption of these technologies is not without challenges, ranging from data imbalances and annotation difficulties to issues of clinical trust and scalability. This study addresses these challenges, marking a step toward more efficient and reliable dental healthcare solutions.
Materials and methods
The data
The table provides an exhaustive overview of the Dental Condition Dataset, which was accessed from Kaggle (URL: https://www.kaggle.com/datasets/salmansajid05/oral-diseases, accessed on 2023/07/20). This dataset comprises a total of 11,653 images across six different dental conditions: calculus, caries, discoloration, gingivitis, hypodontia, and ulcers (Table 1).
Summary statistics and entropy distribution of dental condition images in the Kaggle oral diseases dataset
Summary statistics and entropy distribution of dental condition images in the Kaggle oral diseases dataset
For each dental condition—calculus, caries, discoloration, gingivitis, hypodontia, and month ulcers (Fig. 1)—the table enumerates the number of samples available, the range of image sizes, as well as the minimum and maximum entropy values of image intensity. Entropy in this context serves as a measure of image complexity, which can be indicative of the presence and severity of certain dental conditions. Additionally, the table categorizes the images into those with low and high entropy based on a threshold value of 5. For intensity (grayscale) images, the maximum entropy occurs when all 256 gray levels are equally likely, leading to an entropy of log2(256) = 8. Categorizes the images based on their entropy values, using a cut-off point of 5. Images with entropy values below 5 are labeled as “Low Entropy”, whereas those above 5 are labeled as “High Entropy”. In the case of calculus, 68 images are classified under low entropy, and 1,228 under high entropy. This table serves as an invaluable resource for understanding the diversity and complexity of the dataset, thereby facilitating researchers in developing dental condition classification models that are both accurate and reliable.
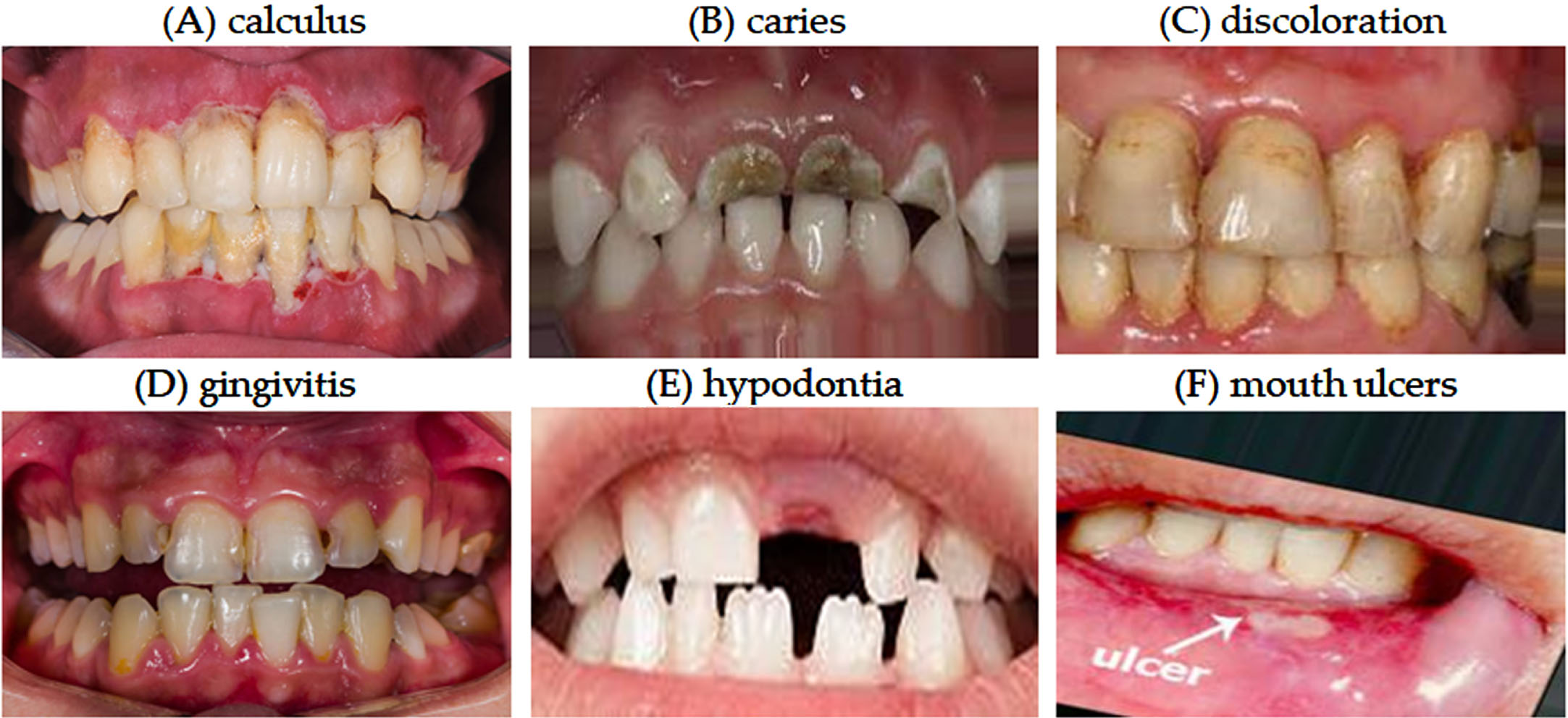
A visual guide to common dental conditions.
Creating deep learning models for image classification becomes particularly challenging when dealing with varying image sizes and differing entropy values across the dataset. Hence, different image sizes mean that a uniform input size must be decided upon, requiring resizing or cropping operations. These can inadvertently remove or distort significant features. Varying sizes can also make the task computationally expensive, especially if larger images require down sampling, which can be resource-intensive. Down sampling larger images or up sampling smaller ones can lead to a loss of crucial information, potentially affecting the model’s ability to accurately classify the condition. Meanwhile, images with low entropy often have less complexity and fewer features to extract, which could make it difficult for the model to learn robust, discriminating features for classification. High-entropy images may contain a lot of noise or unnecessary details that can mislead the model, requiring additional filtering or feature selection steps. Different entropy levels could require varying levels of computational power for effective feature extraction, complicating the design of a one-size-fits-all model architecture.
Addressing these challenges often involves a mix of sophisticated preprocessing techniques, data augmentation strategies, and adaptive or ensemble model architectures to create a deep learning model robust enough to handle the complexities introduced by varying image sizes and differing entropy values.
Figure 2 outlines the research workflow for this study, which encompasses two distinct modeling approaches for dental condition classification. The steps are detailed as follows.
Step 1: Loading Six Condition Images: We import image data corresponding to six dental conditions: calculus, caries, discoloration, gingivitis, hypodontia, and ulcers.

Research workflow for dental condition classification using deep learning.
Step 2: Image Preprocessing: The images undergo several preprocessing steps, including resizing, normalization, and data augmentation, to optimize them for deep learning models.
Step 3: Model 1 - CNNs Transferred Learning: For the first model, we employ five well-established CNN architectures: EfficientNetB0, MobileNetV2, InceptionV3, ResNet50, and ResNet101.
3.1 Validation of Performance: Key performance metrics such as accuracy, recall, precision, and the Kappa index are evaluated for each CNN model.
3.2 Obtained Models: The trained models are saved for potential future use, including ensemble methods.
Step 4: Model 2 - Fusion Extracted Image Features: In this step, we merge features extracted from the fully connected layers of the various trained CNN models into a fused feature matrix.
4.1 Training SVM and Naïve Bayes Classifiers: The fused feature matrix is used to train classifiers based on Support Vector Machines (SVM) and Naïve Bayes algorithms.
4.2 Validation of Performance: Validation of Performance: The classifiers are evaluated on the basis of accuracy, recall, precision, and the Kappa index.
4.3 The resulting trained classifiers are saved for future deployment or further research.
By following this structured workflow, the research aims to build robust and reliable models for classifying dental conditions using deep learning and feature fusion techniques. This structured approach aims to develop robust and effective models for the classification of various dental conditions.
In the realm of deep learning, effective preprocessing of images is an essential preliminary step that enhances the performance of the models. This study employs a series of preprocessing techniques on the dental condition images to prepare them for the Convolutional Neural Networks (CNNs) used later in the research. Below are the key preprocessing steps implemented.
Resizing: Given that the images in the dataset come in various sizes, they are resized to a uniform dimension as 300×300 pixels. This is necessary to ensure that all the images can be fed into the neural network which expects input of a consistent shape.
Normalization: Normalization is carried out to scale the pixel values of the images. In this study, pixel values are scaled to the range [1]. Normalizing the data helps the model to converge more quickly and improves the accuracy of the classifications.
By incorporating these preprocessing steps, the images are conditioned for optimal performance when subjected to deep learning algorithms. This not only accelerates the training process but also contributes to achieving a higher accuracy in the classification of dental conditions. Figure 3 illustrates the entropy correlation between input and post-preprocessing images. The relative change in entropy values ranges from –6.24% to 14.68%. Notably, the entropy values remained almost constant and demonstrated a strong linear correlation after the input images were resized to 300×300 and underwent normalization.

The correlation of entropy between input and post-preprocessing images.
Transferred learning is a machine learning technique where a model developed for a particular task is reused as the starting point for a model on a second task. This is especially valuable in the field of deep learning where training models from scratch requires substantial computational resources and data. This study leverages the power of transferred learning by employing pre-trained Convolutional Neural Networks (CNNs) to serve as the foundation for dental condition classification. For this study, five popular CNN architectures were selected due to their proven track record in image classification tasks. These architectures are EfficientNetB0, MobileNetV2, InceptionV3, ResNet50, and ResNet101. The five CNN architectures were chosen based on their distinct characteristics and proven effectiveness in image classification tasks. EfficientNetB0 is known for its balance of accuracy and efficiency, MobileNetV2 for its lightweight structure suitable for mobile applications, InceptionV3 for its inception modules that help in capturing information at various scales, and ResNet50 and ResNet101 for their deep residual learning framework that addresses the vanishing gradient problem. This diverse selection was intended to ensure robust and comprehensive feature extraction.
Each of these models has unique advantages in terms of computational efficiency, feature extraction capabilities, and overall performance, making them suitable candidates for dental image classification. Each pre-trained CNN model is fine-tuned for the specific task of classifying dental conditions. This involves modifying the final layers of each network to adapt to the six-category classification problem at hand, i.e., calculus, caries, discoloration, gingivitis, hypodontia, and ulcers. The models are trained using a labeled dataset, with the lower layers frozen to retain their pre-trained features and the upper layers trained to adapt to the new dataset. Three optimizers were utilized to compare their effects on the learning process and performance of the CNN models. These optimizers are Stochastic Gradient Descent with Momentum (SGDM), Adaptive Moment Estimation (ADAM), and Root Mean Square Propagation (RMSprop). Each has its own strengths and weaknesses, making it crucial to evaluate their impact on the dental condition classification task. The 10-fold cross validation was applied to evaluate the performance of CNN models. This ensures a fair evaluation of each model’s performance on previously unseen data, thereby giving an accurate measure of its generalizability. The training was conducted with the following hyperparameters, including epoch size 10, batch size 5, and learning rate 0.001. These hyperparameters were chosen based on preliminary experiments and literature recommendations to optimize both training speed and model performance.
Fusion extracted image features, SVM, and naïve bayes
Fusing extracted image features from multiple Convolutional Neural Networks (CNNs) can improve the performance of a classifier. The fusion of features from different CNN models was performed using a simple concatenation strategy without assigning explicit weights. This approach was chosen to maintain the originality and integrity of features extracted by each model. Regarding redundancy and correlation, preliminary tests were conducted to assess the complementarity of the features. The idea is to take advantage of the diverse strengths of different architectures for better feature representation. We forward-pass each preprocessed image through each of the five CNNs. Extract the feature vectors from the fully connected layers (also called dense layers, or sometimes the bottleneck layers) just before the output layer. These are high-level features for each image. Concatenate the extracted features from each CNN model horizontally to create a single, longer feature vector for each image. For example, if EfficientNetB0 outputs a 128-length vector and MobileNetV2 outputs a 64-length vector, the concatenated vector for a given image would have a length of 128 + 64 = 192.
Training SVM (support vector machine)
The Support Vector Machine (SVM) is a supervised machine learning algorithm widely used for classification tasks, as well as regression. The algorithm aims to find the optimal hyperplane that best separates data points belonging to different classes in a multi-dimensional feature space. In simpler terms, a hyperplane is a subspace one dimension less than its ambient space. For instance, in two dimensions, a hyperplane is a line, while in three dimensions, it is a plane. In higher dimensions, it becomes a multi-dimensional structure. The “margin” is defined as the distance between the closest points (support vectors) from different classes, and the SVM seeks to maximize this margin. This ensures the best possible separation between different classes of data. SVMs are capable of handling a large number of features, making them useful for text classification, image recognition, and other high-dimensional tasks. They are less sensitive to outliers than other methods like logistic regression, as they maximize the margin by focusing on support vectors that lie closest to the decision boundary. The algorithm’s focus on margin maximization can make it effective in cases where the classes are imbalanced. While SVMs have many merits, it’s important to remember that they are not a one-size-fits-all solution. Depending on the nature of the data and problem, other algorithms might be more appropriate.
Before training the SVM model, divide the dataset into training and testing sets. A commonly used 10-fold cross validation for evaluation. In many real-world scenarios, the data is not linearly separable in its original feature space. The kernel function is employed to map the original feature space into a higher-dimensional space where it becomes linearly separable. The Radial Basis Function (RBF) is a commonly used kernel function in SVM. The Sequential Minimal Optimization (SMO) algorithm is often used for the optimization phase of SVM. SMO breaks down the primary optimization problem into smaller problems that are solved analytically, instead of using numerical optimization techniques. This makes the training process more efficient.
By following these steps, we are able to train an SVM model that is well-suited for classification tasks, particularly when one is dealing with high-dimensional data or data that isn’t easily separable in its original feature space.
Training naïve bayes
The Naïve Bayes classifier is another type of supervised machine learning algorithm, primarily used for classification tasks. It is based on Bayes’ theorem, with the key assumption that each feature in the data set is independent of the other features when classifying the output. While this assumption (of feature independence) is often not fully accurate in real-world applications, the Naïve Bayes classifier has proven to be effective and robust for a variety of tasks, including text classification, spam filtering, and sentiment analysis. The algorithm is easy to understand and implement, making it accessible for people who are new to machine learning. Naïve Bayes algorithms are computationally efficient, requiring a single pass through the training data. This makes them suitable for real-time and online prediction tasks. While the assumption of independence between features is rarely true in real life, it simplifies calculations and often works well enough in practice for classification tasks. Naïve Bayes can be easily extended to multi-class classification problems.
As with SVM, the first step in training a Naïve Bayes classifier is to prepare the dataset. Split the dataset into training and testing sets, often using 10-fold cross validation, to facilitate model evaluation post-training. Naïve Bayes assumes that the features used for classification are independent of each other, given the class variable. This simplifies the calculation of individual feature probabilities, which can be easily estimated from the training data. The Naïve Bayes classifier works by calculating the posterior probability of each class, given a set of features. The class with the highest posterior probability is chosen as the output label.
Steps for training Naïve Bayes are listed followings. Preprocess the data, which may include normalization, handling missing values, and feature selection. Split the dataset into training and testing sets, commonly using 10-fold cross validation. For each class C and each feature f, calculate the likelihood P(f|C) using the training set. Use Bayes’ theorem to find the posterior probability P(C|f1, f2,..., fn) for each class. Train the model using the calculated probabilities based on the training set. Evaluate the model’s performance using the testing set.
By following these steps, one can train a Naïve Bayes model suitable for classification tasks. Despite its simplicity and the somewhat naive assumption of feature independence, Naïve Bayes often performs remarkably well in practical applications.
Validation of performance
To thoroughly assess the effectiveness of the developed models, Model 1 refers to the CNNs with transfer learning, while Model 2 denotes the approach involving SVM with feature fusion. A more detailed description of each model is provided in sections 2.4 and 2.5, respectively. Both Model 1 and Model 2 are evaluated using a comprehensive set of performance metrics. These metrics aim to provide a multi-faceted view of each model’s predictive power and reliability. Here are the specific metrics as below.
Accuracy is a widely used metric that provides a general measure of a model’s performance as Equation (1). It is calculated as the ratio of correctly classified samples to the total number of samples. While straightforward, it is important to note that high accuracy alone does not guarantee a well-performing model, especially if the dataset is imbalanced.
The Kappa statistic is used to assess the agreement between the predicted and actual classifications, while accounting for random chance as Equation 2. A Kappa value closer to 1 indicates better agreement and, consequently, a more reliable model. Where P0 is the relative observed agreement, and P
e
is the hypothetical probability of chance agreement. The Kappa statistic provides an adjustment for the accuracy by accounting for correct classifications occurring by random chance.
Recall Rate, also known as sensitivity, the recall rate measures the ability of the model to correctly identify positive cases within the actual positive classes as Equation (3). A high recall is crucial for medical applications, as failing to identify a condition could have serious consequences.
Precision measures the proportion of true positive predictions among the total predicted positives. High precision indicates that the false positive rate is low, which is particularly important in a clinical setting to avoid unnecessary treatments or interventions.
These metrics, obtained using 10-fold cross-validation, provide a comprehensive understanding of model performance, allowing us to evaluate both the strengths and weaknesses of our models from multiple angles. Each of these metrics offers a different perspective on the model’s capabilities, making it essential to consider all of them for a holistic evaluation. By doing so, the study aims to ensure that the developed models are not only accurate but also reliable and clinically applicable.
The primary aim of this research was to investigate the utility of advanced machine learning algorithms and feature fusion in classifying six dental conditions. This section details the performance metrics of two models evaluated in this study.
Model 1: Transfer learning of CNNs
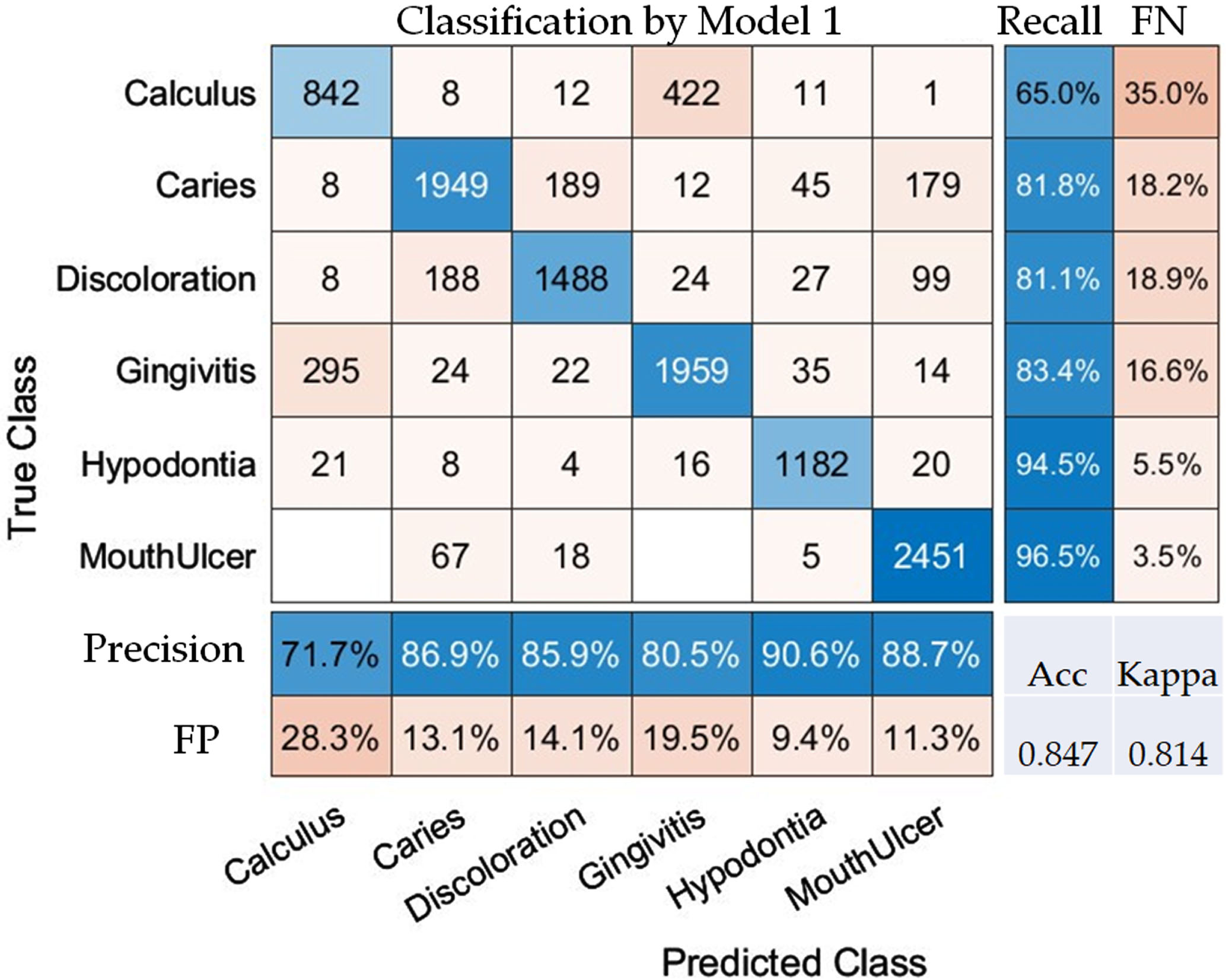
Here, we summarize the results of applying Convolutional Neural Networks (CNNs) with transfer learning to the dental condition classification task. Five CNN backbones were employed: EfficientNetB0, MobileNetV2, InceptionV3, ResNet50, and ResNet101. The performance of various Convolutional Neural Networks (CNNs) was evaluated using three different optimizers: SGDM, ADAM, and RMSprop. The metrics reported include recall rate, precision, accuracy, and Kappa for six dental conditions: calculus, caries, discoloration, gingivitis, hypodontia, and mouth ulcers (Table 2).
Comparative evaluation of convolutional neural networks and optimization algorithms in the automated classification of dental conditions using 10-Fold Cross-Validation. Note: Each cell represents the recall rate (precision), and “Acc” denotes Accuracy
Comparative evaluation of convolutional neural networks and optimization algorithms in the automated classification of dental conditions using 10-Fold Cross-Validation. Note: Each cell represents the recall rate (precision), and “Acc” denotes Accuracy
In Table 2, EfficientNetB0 with the SGDM optimizer achieved the highest accuracy (0.847) and Kappa index (0.814) among all the tested combinations. Specifically, the recall rate and precision for calculus were 0.650 and 0.717, respectively, while for caries, they were 0.818 and 0.869. When using the ADAM optimizer, the accuracy dropped to 0.796, and the Kappa index decreased to 0.751. The RMSprop optimizer yielded an accuracy of 0.810 and a Kappa index of 0.767.
MobileNetV2 with the SGDM optimizer led to an accuracy of 0.789 and a Kappa index of 0.743. Using ADAM, these metrics slightly improved to an accuracy of 0.798 and a Kappa index of 0.753. Conversely, RMSprop resulted in a decrease in performance, with an accuracy of 0.776 and a Kappa index of 0.730.
For InceptionV3, using SGDM led to an accuracy of 0.750 and a Kappa index of 0.697. ADAM further decreased both the accuracy (to 0.725) and the Kappa index (to 0.662). Employing RMSprop saw the metrics decline even further, with an accuracy of 0.689 and a Kappa index of 0.618.
With ResNet50, the SGDM optimizer resulted in an accuracy of 0.757 and a Kappa index of 0.704. ADAM yielded an accuracy of 0.737 and a Kappa index of 0.678. RMSprop led to a decrease in performance, with an accuracy of 0.705 and a Kappa index of 0.637.
Finally, ResNet101 with SGDM achieved an accuracy of 0.730 and a Kappa index of 0.670. Using ADAM led to an accuracy of 0.742 and a Kappa index of 0.686. RMSprop resulted in an accuracy of 0.703 and a Kappa index of 0.637.
In summary, among the CNNs tested, EfficientNetB0 paired with the SGDM optimizer yielded the highest accuracy and Kappa index. In contrast, InceptionV3 with RMSprop had the lowest performance based on these metrics.
This subsection focuses on models built using feature fusion, in conjunction with Support Vector Machines (SVM) and Naïve Bayes (NB) classifiers. Table 3 provides a detailed comparative evaluation of SVM and NB algorithms for the classification of various dental conditions. The results are presented in terms of recall rate, precision, accuracy (Acc), and the Kappa index. For each condition and algorithm, the recall rate is listed first, followed by the precision in parentheses. The use of 10-fold cross-validation reinforces the stability and reliability of the models. This validation technique offers a more accurate estimate of how the models will perform on unseen data, lending greater credibility to the comparative evaluation.
Comparative performance metrics of SVM and NB algorithms for classifying dental conditions, using 10-Fold Cross-Validation. Note: Each cell in the table represents the recall rate, followed by the precision in parentheses. “Acc” denotes accuracy
Comparative performance metrics of SVM and NB algorithms for classifying dental conditions, using 10-Fold Cross-Validation. Note: Each cell in the table represents the recall rate, followed by the precision in parentheses. “Acc” denotes accuracy
In the case of SVM, the use of 10-fold cross validation revealed impressive consistency. The average accuracy across all ten folds remained high, ranging from 0.921 to 0.923, while the Kappa index varied between 0.904 and 0.906. These stable and high metrics across multiple trials attest to the robustness and reliability of SVM for the automated classification of dental conditions.
For NB, although it lagged behind SVM, the results from the 10-fold cross validation still indicated reasonably good performance. The average accuracy ranged from 0.891 to 0.893, and the Kappa index fluctuated between 0.867 and 0.869. The consistent outcomes across the ten folds suggest that while NB may not be as accurate as SVM, it remains a reliable algorithm for this classification task.
The application of 10-fold cross validation in these trials enhances the credibility of the findings, suggesting that SVM is the more reliable and accurate model for automated classification of dental conditions compared to Naïve Bayes.
Authors should discuss the results and how they can be interpreted from the perspective of previous studies and of the working hypotheses. The findings and their implications should be discussed in the broadest context possible. Future research directions may also be highlighted.
Comparisons between CNNs and SVM classifiers
The study undertook a detailed comparative analysis between various CNNs and SVM classifiers enhanced by feature fusion techniques. When analyzed using various optimization algorithms such as SGDM, ADAM, and RMSprop, CNNs generally outperformed SVMs in classifying a range of dental conditions. The effectiveness of an optimizer can be highly dependent on the specific use case and dataset. Therefore, experimenting with different optimizers and monitoring their performance on various datasets or tasks is often beneficial. In general, the choice of an optimizer may depend on the specific problem and dataset, making empirical testing essential. Regardless of the chosen optimizer, it is crucial to fine-tune hyperparameters such as the learning rate, decay factors, and momentum terms for optimal performance.
The 10-fold cross-validation results further supported the robustness of CNNs, as they consistently achieved higher accuracy and Kappa index scores. In particular, the CNN model using the ADAM optimizer showed promising results with an average accuracy exceeding 0.9. Conversely, while SVM classifiers were generally consistent, they lagged slightly in performance metrics, reaffirming the efficiency of CNNs in complex image classification tasks. Model 1 used EfficientNetB0 with the SGDM optimizer, while Model 2 employed an SVM classifier with fusion features.
Comparative performance metrics of Model 1 and Model 2 in dental condition classification. Note: Each cell in the table represents the recall rate, followed by the precision in parentheses. “Acc” denotes accuracy
Comparative performance metrics of Model 1 and Model 2 in dental condition classification. Note: Each cell in the table represents the recall rate, followed by the precision in parentheses. “Acc” denotes accuracy
In the context of classifying various dental conditions, Model 1 and Model 2 show distinct levels of performance across multiple metrics such as calculus, caries, discoloration, gingivitis, hypodontia, mouth ulcers, overall accuracy (Acc), and the Kappa index. Here are some key observations comparing the two models (Table 4). Model 2 has an overall accuracy of 0.923 and a Kappa index of 0.906, which are both significantly higher than Model 1’s 0.847 and 0.814, respectively (Fig. 4). In summary, Model 2 consistently outperforms Model 1 across almost all metrics and dental conditions. The results indicate that Model 2 is likely a more robust and reliable option for the automated classification of dental conditions (Fig. 5).
Confusion Matrix of Model 1 for Evaluating classification performance across various dental conditions. Note: FN and FP in the matrix represent false negative and false positive rates, respectively.
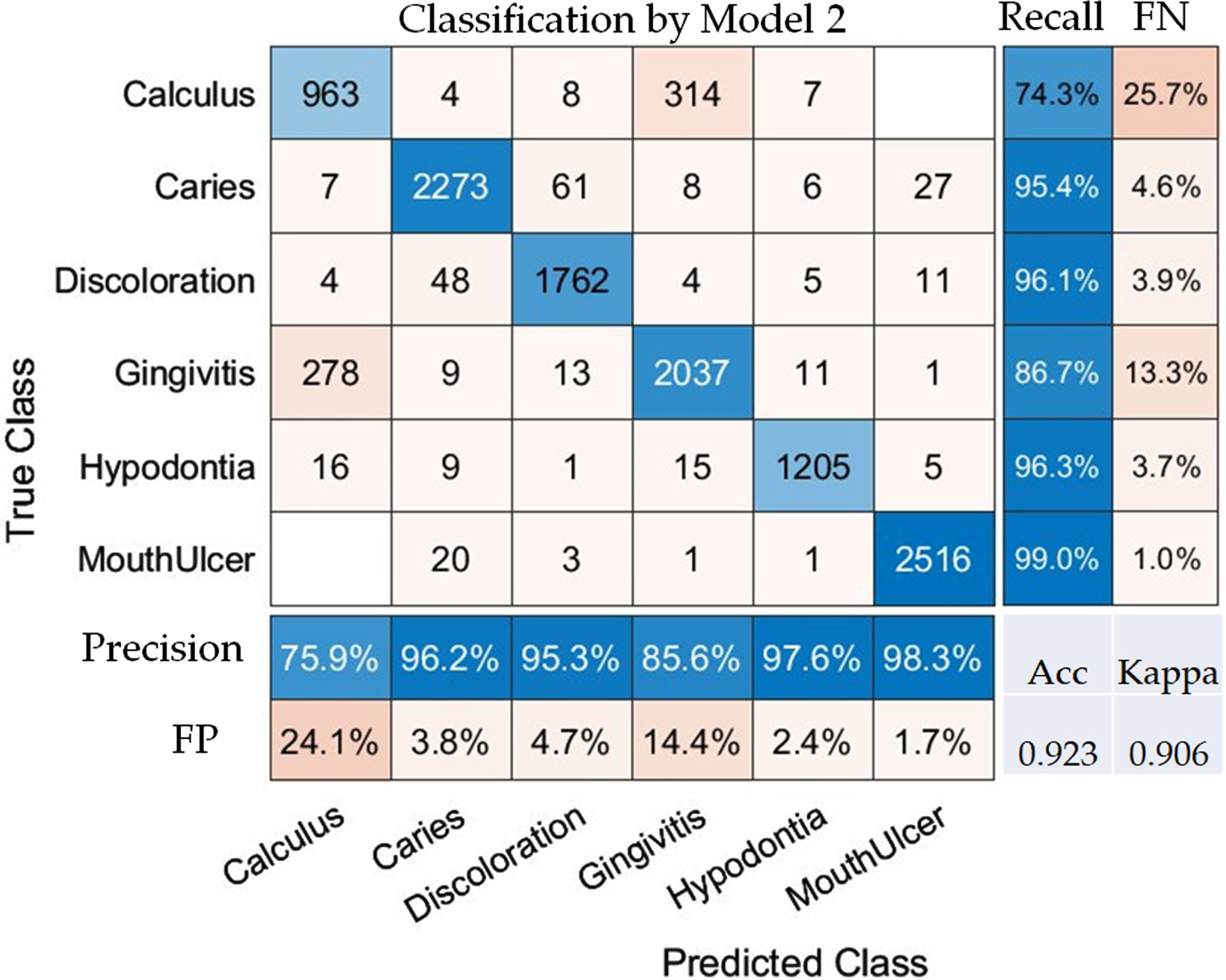
Confusion Matrix of Model 2 for Evaluating Classification Performance Across Various Dental Conditions. Note: FN and FP in the matrix represent false negative and false positive rates, respectively.
Model 2 fuses extracted image features from all CNNs, possibly creating a richer, more comprehensive feature space that enables the SVM classifier to make better decisions. This fusion of features can capture a variety of aspects that a single CNN model might miss. Support Vector Machines are known for their robustness and can perform well on a wide range of classification problems. When combined with a rich set of features, SVM can outperform other algorithms. While transferred learning can be powerful, it’s not always the best option for every task. If the pre-trained CNNs in Model 1 were initially trained on data that is not sufficiently similar to the dental conditions dataset, the features extracted may not be optimal. The fusion of features in Model 2 could make the model more robust to variations in the data, thereby generalizing better to unseen examples. This is reflected in the higher accuracy and Kappa scores. Given these points, it’s evident that Model 2’s approach of fusing extracted image features and utilizing an SVM classifier offers a more robust and accurate solution for this specific task.
The factors influencing oral health and its early diagnosis through deep learning are manifold and demand a comprehensive, integrated approach for effective results [12, 24]. Lifestyle factors such as diet, oral hygiene, and even stress can substantially affect oral health, acting as either protective factors or risks. Moreover, medical and genetic factors, including underlying health conditions like diabetes or genetic predispositions to certain diseases, also play an indispensable role in the equation. These medical variables often interact in complex ways with lifestyle choices, making the need for personalized prevention and early diagnosis strategies more crucial than ever [25].
Deep learning can play a transformative role in this context [26, 27]. The quality and quantity of the data used are foundational elements for building effective models. Data from various sources, including clinical records, dental imaging, and patient-reported metrics, need to be integrated seamlessly for a holistic understanding. Feature selection and preprocessing are also essential steps that can significantly influence the performance of deep learning algorithms [28]. Beyond data considerations, algorithmic choices such as the type of neural network architecture, optimization methods, and loss functions can profoundly impact the model’s diagnostic capabilities [29, 30]. Additionally, computational power can be a limiting or enabling factor, especially when dealing with large and complex datasets that require real-time analysis. Interdisciplinary collaboration between dental experts, data scientists, radiologists, and even ethicists is another pivotal factor. These collaborations enable the nuanced tuning of deep learning algorithms to the specific needs and challenges of dental healthcare. They also help in developing ethical guidelines for data use, ensuring that patient privacy is maintained and that the models are unbiased.
By taking into account these diverse yet interconnected factors, there is a substantial opportunity to revolutionize oral healthcare [31–33]. The use of deep learning techniques can make diagnosis more precise, treatment more personalized, and prevention more proactive. This technological advancement can act as a catalyst for a more comprehensive and effective approach to oral health, ensuring that interventions are not just curative but also preventive.
Issues of misclassifications
In analyzing the confusion matrix for Model 2, we notice that the false positive (FP) rates for Calculus and Gingivitis are relatively high at 24.1% and 14.4%, respectively. Several factors could contribute to these elevated FP rates, and a deeper understanding of these factors is crucial for improving the model’s performance. The misclassification between Calculus and Gingivitis in the context of dental image classification can arise due to a variety of factors, some of which are specific to the medical domain (Fig. 6).
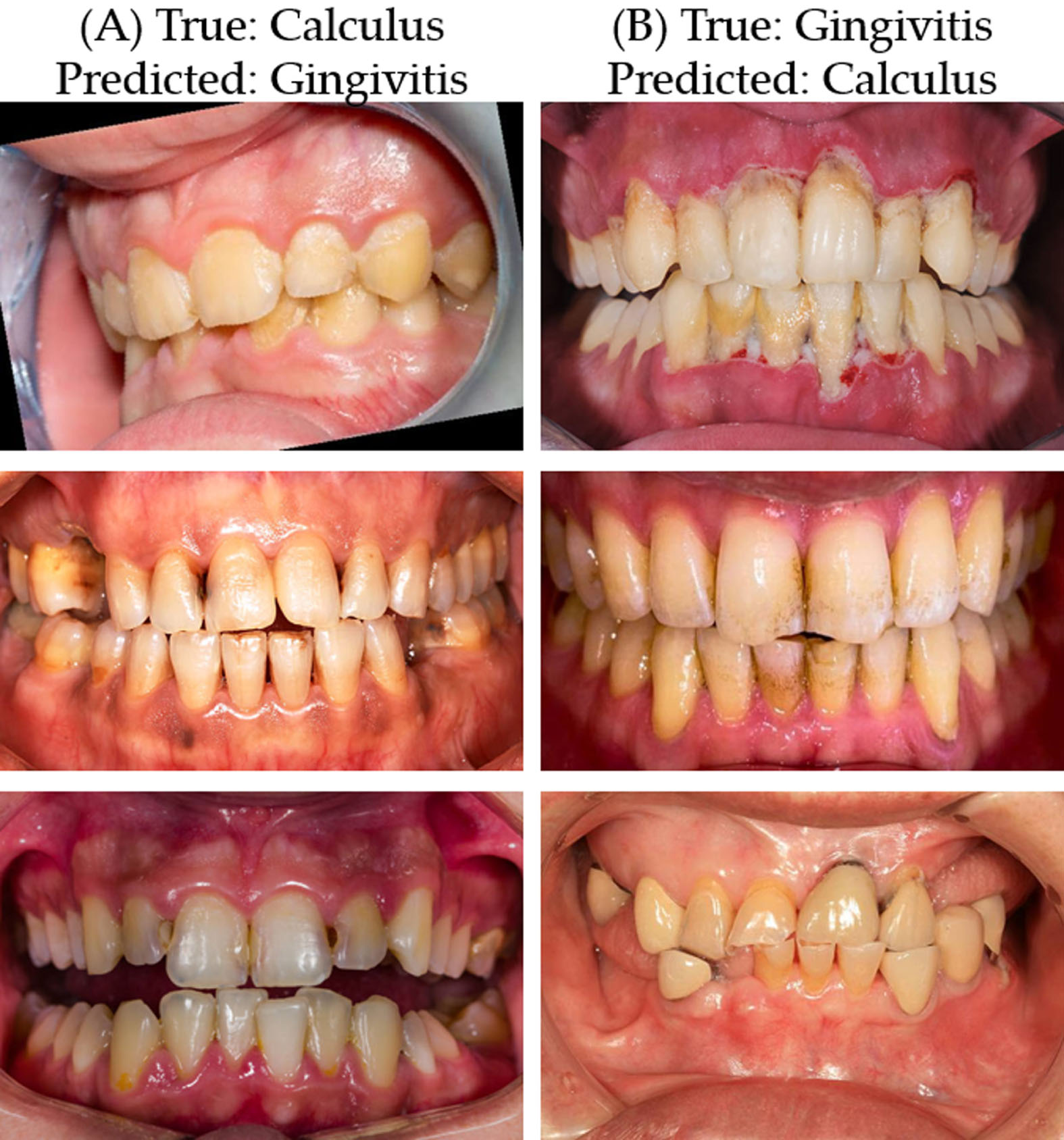
Examples of misclassification between calculus and gingivitis in Model 2. (A) Samples incorrectly classified as Gingivitis when the true condition is Calculus, and (B) Samples incorrectly classified as Calculus when the true condition is Gingivitis.
In some cases, both Calculus and Gingivitis might occur in the same location, creating conflicting features that may be challenging to separate. Both Calculus and Gingivitis can produce color changes in the oral cavity. Calculus often appears as yellow or brown deposits on the teeth, while Gingivitis can cause the gums to become red and swollen. The color contrast between the affected areas and normal regions could be similar for both conditions. Both conditions frequently affect the gum line, either separately or even simultaneously. Calculus tends to build up near the gum line, and gingivitis primarily involves inflammation of the gums. This proximity could cause some overlap in the image features that a model uses to identify each condition. Both conditions often manifest with some degree of inflammation. While calculus itself is not a sign of inflammation, it can contribute to it, making it even harder to distinguish between the two based on visual cues.
Calculus and Gingivitis may present visually similar characteristics, such as color, texture, or shape, which might confuse the machine learning model. Both conditions often appear in close proximity to each other in dental images, which may make it challenging for the model to differentiate. If there are not enough diverse examples of Calculus and Gingivitis, the model might not learn the subtle differences between the two. Factors such as poor lighting, shadows, or blurring can interfere with the quality of dental images and hence affect classification. Variations in image quality, lighting, and angle can also affect the model’s ability to classify dental conditions accurately, potentially leading to higher FP rates. These similarities could contribute to a higher rate of false positives when a machine learning model like Model 2 attempts to classify images of dental conditions. Proper feature engineering, data augmentation, and more advanced classification algorithms may be required to improve the model’s ability to differentiate between these conditions accurately.
The layers in the CNN might not be sufficiently complex to capture subtle differences between the two conditions. Parameters like learning rate or regularization might not be well-tuned for this specific task, affecting model performance. The conditions could have unclear or overlapping clinical definitions, which might not be cleanly separable by a machine learning model. The decision thresholds set within the model for classifying these two particular conditions might not be optimal.
Hence, by addressing these potential factors, it may be possible to improve the model’s ability to distinguish between Calculus and Gingivitis, thereby reducing the rate of misclassification.
In conclusion, while both CNN and SVM classifiers offer high degrees of accuracy and reliability, SVM with fusion features holds a slight but significant edge. This study thus lays the groundwork for further research in this swiftly advancing area of study. This study set out to evaluate the effectiveness of CNNs and SVM in the automated classification of various dental conditions. By employing feature fusion techniques and optimization algorithms such as SGDM, ADAM, and RMSprop, the study found CNNs to outperform SVM classifiers consistently. The results were further validated through a rigorous 10-fold cross-validation process, which substantiated the stability and reliability of the CNN models. The study contributes to the existing body of literature by providing a comprehensive comparative analysis across multiple dental conditions and employing a variety of optimization algorithms. It thereby extends our understanding of how machine learning can be effectively utilized in medical image classification, specifically in dentistry. The importance of early detection via deep learning cannot be overstated. Accurate and timely diagnosis can significantly improve treatment outcomes and patient experiences, making the advancement of these models crucial for the future of dental care.
However, the study also highlighted the limitations of both CNN and SVM classifiers, including issues of misclassifications. While the developed models showed significant promise, they are not yet foolproof and should be used as supplementary tools to human expertise rather than as standalone diagnostic methods.
For future work, it would be beneficial to explore ensemble learning methods or more advanced CNN architectures to minimize the rate of misclassification. Additionally, the integration of these models into real-world clinical settings can be examined to evaluate their applicability and effectiveness in routine dental diagnosis. As we expand our research, a key area of focus will be the practical application of our findings in clinical settings. In the upcoming work, we aim to address how this deep learning tool can be seamlessly integrated into existing diagnostic procedures. The tool’s ability to quickly and accurately classify dental conditions could make it an invaluable adjunct to traditional diagnostic methods, aiding dentists in making more informed decisions. We anticipate that the tool’s ability to provide rapid and precise classifications will lead to earlier interventions, potentially mitigating severe dental issues and improving long-term oral health. Through these efforts, we aim to bridge the gap between advanced machine learning technologies and everyday clinical practice, ultimately enhancing the quality and efficiency of dental care.
Supplementary materials
Not applicable.
Author contributions
Conceptualization, S.-T.H.; methodology, S.-T.H.; software, S.-T.H. and Y.-A.C.; validation, Y.-A.C.; formal analysis, S.-T.H. and Y.-A.C.; investigation, Y.-A.C.; resources, S.-T.H.; data curation, Y.-A.C.; writing—original draft preparation, S.-T.H.; writing—review and editing, S.-T.H.; visualization, S.-T.H.; supervision, S.-T.H.; project administration, S.-T.H.; funding acquisition, S.-T.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional review board statement
Not applicable.
Informed consent statement
Not applicable.
Data availability statement
Dental Condition Dataset, which was accessed from Kaggle (URL: https://www.kaggle.com/datasets/salmansajid05/oral-diseases, accessed on 2023/07/20).
Footnotes
Acknowledgments
Not applicable.
Conflicts of interest
The authors declare no conflict of interest.