
Abstract
In the medical field, computed tomography (CT) is a commonly used examination method, but the radiation generated increases the risk of illness in patients. Therefore, low-dose scanning schemes have attracted attention, in which noise reduction is essential. We propose a purposeful and interpretable decomposition iterative network (DISN) for low-dose CT denoising. This method aims to make the network design interpretable and improve the fidelity of details, rather than blindly designing or using deep CNN architecture. The experiment is trained and tested on multiple data sets. The results show that the DISN method can restore the low-dose CT image structure and improve the diagnostic performance when the image details are limited. Compared with other algorithms, DISN has better quantitative and visual performance, and has potential clinical application prospects.
Introduction
Larger doses of radiation can cause harm to the human body. When patients absorb more than the normal dose of X-ray radiation, metabolic abnormalities will be caused, and even cancer and other diseases [1]. With the widespread use of medical CT, the potential risk of radiation dose in patients cannot be ignored. However, dose reduction leads to decreased photon density and increased noise in the scan, necessitating the development of denoising methods to ensure image quality and retain the clinical information contained within [2]. Therefore, reducing the scan dose while obtaining high-quality LDCT images is a challenging task that requires the use of advanced methods and techniques.
To improve the quality of CT images, researchers have proposed a variety of image denoising methods that can be categorized into three types: projection domain processing before reconstruction, iterative reconstruction processing during reconstruction, and post-processing after reconstruction. Projection domain methods include bilateral filtering [3] and structural adaptive filtering [4], but these methods may lead to image edge blurring and detail structure loss. The method based on iterative reconstruction (IR) first initializes the image and then updates the initial value through the forward projection operation to gradually approach the real target image. The commonly used methods include total variation (TV) and its variants [5, 6], and dictionary learning [7, 8]. Both methods require the use of raw projection domain data, which is hard to obtain in practical studies, increasing the research difficulty. Compared with other techniques, image post-processing techniques can be used to process LDCT images directly and can be easily combined with existing clinical procedures. Traditional image post-processing algorithms include improved BM3D method [9–12], non-local means method [13, 14], partial differential equation (PDE) method [15–17], dictionary learning [18], wavelet transform [19], etc. Although these operators can reduce noise to some extent, they often result in excessively smoothed or erroneous LDCT images after denoising. This is because these traditional methods may not fully consider the complex and diverse noise characteristics of LDCT images, resulting in compromised image details and important pathological information.
Using the nonlinear mapping ability of deep convolutional neural networks, some methods based on deep learning have obtained better results in reducing LDCT image noise. Chen et al. [20] proposed a neural network with an encoder-decoder structure (REDCNN) for LDCT images. Fan et al. [21] designed a quadratic auto encoder (Q-AE) network using secondary neurons and auto encoders, which effectively improved the denoising effect of LDCT images. Kang et al. [22] proposed a method for the study of deep convolutional neural networks for the reconstruction of LDCT images using directional wavelets. However, these methods still have the problem of processing noise while maintaining image details. Liang et al. [23] proposed the EDCNN algorithm in 2017, whose core idea is to use convolutional neural networks to extract edge information in images and fuse this information together through dense connections to achieve efficient and accurate LDCT image denoising. Jiang et al. [24] proposed FSNet using a novel hybrid convolutional and adaptive aggregation approach for LDCT image denoising by learning frequency separation networks, and achieved better performance. The method proposed by Gholizadeh-Ansari et al. [25] uses a CNN architecture that includes perceptual loss and edge detection layers. The perceptive loss layer used the pre-trained VGG-16 network to calculate the feature similarity between the reconstructed image and the corresponding NDCT image as a measure of image quality. The edge detection layer is designed to preserve the edges and important structures in the reconstructed image and prevent over-smoothing. Li et al. [26] introduced a novel LDCT denoising algorithm which is based on deep convolutional neural network and multi-scale feature fusion, which can be used to effectively remove noise from LDCT images while retaining more detailed information. Generative adversarial network (GAN) has great application potential and can bring more accurate and efficient solutions for LDCT image processing. Wolterink et al. [27] proposed a novel LDCT image denoising algorithm based on GAN. The algorithm relies on the generative power of GAN to produce realistic high-quality LDCT images by learning the mapping relationship between LDCT images and NDCT images through adversarial learning. Yang et al. [28] designed a GAN algorithm based on Wasserstein distance and perceptual loss for LDCT image denoising. The algorithm employs GAN to achieve high-quality LDCT image reconstruction, which effectively reduces the noise level of LDCT images. Geng et al. [29] proposed a medical image denoising algorithm using content-noise complementary learning under GAN networks. The algorithm achieves the operation of processing both noise and content information under the same network structure through two modules: the noise module and the content module, thus improving the effectiveness of medical image denoising. Han et al. [30] proposed an LDCT image denoising network using a dual encoder single decoder. The network learns the feature representations of LDCT images and high-dose CT images separately by using a dual encoder model, and combines them to reconstruct low-dose CT images. Marcos et al. [31] proposed a GAN network with the introduction of the SE module and CBAM module. The enhanced attention module is used to preserve the structural details of LDCT images. However, the training process of GAN is usually unstable and may produce artifacts inconsistent with NDCT. The proposal of the multi-domain network also provides a new possibility for LDCT image denoising. Lyu et al. [32] proposed a two-domain network, U-DuDoNet, to add artifacts in the sinogram and image domains using U-Net to directly model the artifact generation process to remove CT image noise. Yin et al. [33] presented a region progressive three-dimensional residual convolution network DP-ResNet, which designs networks in the sinusoidal domain, filtered back projection domain and image domain to achieve denoising. In recent years, researchers have tried to apply transformer to medical image denoising. Wang et al. [34] proposed a Transformer-based LDCT image denoising method CTformer. Different from the traditional CNN-based method, CTformer adopts pure Transformer structure to avoid convolution operation, making the model more efficient and easy to optimize.
Although the CNN-based low-dose CT noise reduction method has achieved satisfactory results, due to its abstract mapping function fitting process and lack of intuitive interpretation, two problems are proposed: (1) How to use the physical model to make the designed LDCT noise reduction network interpretable. (2) How to improve the model’s ability to maintain low-frequency smoothing and reconstruct high-frequency details. Therefore, for the denoising task of LDCT images, it is necessary to explore a new strategy to better utilize the unique characteristics of physical models and CT images and combine physical models with deep learning.
In the image denoising task, it has undergone an evolution from model-driven to data-driven. The advantage of model-driven is that it is easier to explain and can denoise single samples, but its shortcomings are also obvious, that is, it relies heavily on prior estimation. If the prior estimation is inaccurate, there will be obvious problems. At the same time, the algorithm design is difficult and the robustness is poor. The biggest problem of data-driven is unexplainable, which is actually to fit an end-to-end mapping through a large amount of data, but this mapping is expressed as a neural network. The quality of data-driven results depends heavily on the rationality of network design. If we can combine data-driven and model-driven, we can solve the inherent unexplainable problems in deep learning, and make full use of data features to make the whole model more reasonable and have better generalization ability. Therefore, a new strategy needs to be explored in image denoising tasks to better combine data-driven and model-driven. To solve these problems, we fully consider the physical model of the task when designing the network, and build a reasonable network according to the corresponding relationship of the physical model. We propose a purposeful and interpretable decomposition iteration strategy network (DISN) for LDCT denoising. The method shown in this paper resulted in good noise reduction on the 2016 NIH AAPM Mayo Clinic LDCT dataset [35], the piglet dataset [36] and the clinical dataset. The main salient points in this paper are the following: DISN based on decomposition iteration is a new architecture for the interpretability of LDCT denoising networks. Since there is a certain correlation between noise/artifact and inherent information, in order to preserve the edge/texture in the iterative process, we use the Hessian matrix to realize the frequency distribution of the image and decompose the LDCT image into low and high frequency, which effectively improves the ability of the model to maintain low frequency smoothing and reconstruct high frequency details. For the decomposed high frequency and low frequency information, the corresponding network is designed respectively, and in order to better process the obtained low frequency content features and the processed high frequency texture features, a fusion network is also designed. To verify the capability of the LDCT image denoising network, several data sets were used, including the 2016 NIH AAPM Mayo Clinic LDCT dataset, piglet data with different radiation doses, and clinical data. After verification, the proposed DISN has good noise suppression and edge detail protection ability.
The remainder of this article is constructed as shown below. The second part reviews the knowledge related to LDCT image noise reduction, and introduces the DISN framework in detail, including the use of the Hessian matrix to decompose the image, the design of low frequency network and high frequency network after decomposition, the network design of high frequency and low frequency information fusion. The third part gives the specific experimental design and relative comparison experiment. Finally, we will discuss the related issues of LDCT image noise reduction in the fourth part, and make a summary of this paper.
Methods
Noise reduction model
The LDCT image denoising model can be represented as a reflection projection process from LDCT image X to NDCT image Y:
T denotes the nonlinear degradation process from the NDCT image Y to the corresponding threshold LDCT image X. The denoising process can be transformed into the mapping f:
In LDCT image denoising tasks, it is usually assumed to be a linear model, which can be expressed as:
In this model, X denotes a noisy LDCT image, B denotes a clean CT image to be recovered, and N denotes noise. We can develop state-of-the-art denoising networks by learning the resulting mapping from noisy images to potentially clean images.
However, as CT images can be made up of low and high frequency information, in this work we make use of an alternative composition of images, whose model can be expressed as:
Decomposition iteration idea is integrated into the LDCT image denoising process to learn in the DISN process rather than a simple linear combination of the noisy image and the denoised clean image. DISN is an iterative framework with n iterations summarized in the following steps:
In considering the forward problem, we assume the existence of a mapping such that:
That is, the input to the network is the low-dose CT image I to be processed, and the input image is first decomposed into low and high frequency information. However, in this process, we iterate by using the residuals, so there is:
In the initial condition, ΔI0 = I. For the current residual image ΔI n , the residual components ΔL n , ΔH n can be decomposed using the image decomposition.
In considering this task from an inverse problem perspective, this paper argues that there exists a mapping such that:
The input of the network is the processed low and high frequency information, and the output of the network is the image after noise reduction in the DISN process, and F (·) is the network that fuses low-frequency information and high-frequency information.
Because of the large difference between low and high-frequency information, we designed a sub-network, L (·) for the low-frequency network dealing with low frequency information and H (·) for the high frequency network dealing with high-frequency information, respectively. Then refine the low and the high frequency information L
n
, H
n
by adding these residual components.
With infinite iterations, n→ ∞ when ΔI n → 0 such that the LDCT images converge to the NDCT images. Based on the whole decomposition iteration strategy, we propose a purposeful and interpretable decomposition iteration network (DISN), which is a new, specific LDCT noise reduction method aiming to improve the detail fidelity instead of blindly designing or using a deep CNN architecture. The whole process is shown in Fig. 1.

The proposed decomposition iterative strategy (DISN) pipeline for LDCT denoising.
This study combines a physical model and explores a decomposition iteration strategy suitable for low-dose CT image denoising. In this study, the image denoising is carried out in an iterative manner, and the image is decomposed into high-frequency and low-frequency parts, and the multi-stage denoising effect is realized by image difference. First, the low-dose CT image is decomposed into a high-frequency part and a low-frequency part using the Hessian matrix. The high frequency part mainly contains the details of the image, and the low frequency part contains the overall structure and background information. Then, the deep learning network is used to denoise the high-frequency part to restore the details and remove the noise. Using deep learning network to the low frequency part. It is processed separately to improve the clarity of the overall structure and the accuracy of the background information. Finally, the noise reduction processed.
In the CT image decomposition stage, we use the Hessian Filter method. the Hessian matrix, a filter based on the second-order gradient information of an image, was early applied to tasks such as edge detection and corner point detection in computer vision. Since Hessian Filter is very sensitive to noise, this method is also widely used in LDCT image denoising, usually by extracting the high-frequency part of the image (i.e., noise), then filtering it using Hessian Filter to eliminate the high-frequency noise, and finally obtaining the low-frequency part and reconstructing it with the original image. The Hessian matrix is determined by the image’s partial derivatives in the horizontal and vertical directions are determined as:
The Hessian matrix is represented in Eq.(11). as a symmetric matrix of second-order partial derivatives, where I
xx
, I
yy
, and I
xy
(I
yx
) denote the horizontal, vertical, and mixed second-order partial derivatives of x. The maximum eigenvalue of the Hessian matrix can be used to describe the intensity of the edges of image structure and has a good measurement capability in terms of residual images, which can effectively improve the image detail fidelity. It should be noted that the calculation of the Hessian matrix requires needs to use its second derivative, which can be obtained by applying some specific filters.
Characterize image detail fidelity using the maximum eigenvalue of the Hessian matrix, which is usually calculated using the eigenvalue decomposition. The eigenvalue and the corresponding eigenvector of the Hessian matrix represent the magnitude and direction of the curvature of the point in a given direction, respectively. The Hessian matrix in Eq.(12). is a real symmetric matrix, so the relationship between the eigenvalues (λ1> λ2), trace tr(H(x)) and determinant |H(x)| can be deduced using the knowledge of linear algebra. A real symmetric matrix has many important properties, among which are that all its eigenvalues are real and the eigenvectors are orthogonal. These properties make it easier to perform eigenvalue decomposition to obtain the eigenvalues and eigenvectors of a Hessian matrix.
For a pixel in an image, its Hessian matrix is 2×2, so there must be two eigenvalues.
Since only a pixel-by-pixel gradient is required, this Hessian filtering process can be accelerated using the specific convolution in (12).
More generally, λ is an algebraic combination of the second-order gradients of x and λ ∝ ∑i=-1,0,1 ∇ x i , where ∇ denotes the gradient extractor through (12).
The Hessian filter takes the high frequency information portion of the original image and then subtracts it from the original LDCT image to obtain the low frequency information of the image.
To fully extract the features in LDCT images, the designed DISN consists of three sub-networks, namely, low frequency network L net , which processes low frequency information, high frequency network H net , which processes high frequency information, and fusion network F net . The DISN is an iterative framework in which each sub-network shares parameters at different stages. In this section, we introduce the network architectures of the low frequency network, the high frequency network, and the fusion network.
Low frequency network architecture
We designed the low-frequency network architecture to adequately train to extract low-frequency content features. The architecture consists of multichannel residual blocks (MCRB) and multiscale residual blocks (MSRB). As shown in Fig. 2, the number of sub-blocks consisting of multichannel residual blocks and multiscale residual blocks we set is 3. The multiscale residual block first acquires multiscale features using Pooling operations with different kernel sizes and step sizes, and then fuses and feeds all scales into the Conv + PReLU and Conv + PReLU + Conv layers with the original input signal to learn the residuals. MSRB can learn features at different scales and fuse all different features to learn the main features. In addition, we use a multi-channel residual block to process the important low-frequency information, which consists of multiple channel attention modules and residual blocks. The shallow information is extracted first, and then the information is channelized by three channel attention modules to obtain the important low-frequency information. The information obtained from all channel attention modules is fused and fed into the Conv + PReLU + Conv layer with the original input signal to learn the residuals as a way to learn the processing results of low-frequency information.

(a) Low frequency network architecture (b) MSRB module (c) MCRB module.
In order to improve the training effect and fully extract the high-frequency content features, we deeply studied the design of the network architecture. Finally, we successfully constructed a unique high-frequency network architecture. The core of the architecture is a cascaded multi-block network composed of three residual structures, represented by a gray box, as shown in Fig. 3. First, the entire network performs preliminary processing of the input data through the Conv layer, with the aim of extracting initial information. This layer plays an important role in the network, which can quickly and effectively filter out useful features from the original data. Then, the network enters the first residual structure block. This structural block is composed of several different layers, which are carefully designed to capture and transmit feature information. The design of this residual structure is inspired by the residual learning idea in deep learning, which optimizes network training through skip connections. Then, the network will experience another cycle of residual structure blocks. In this process, the network further improves its ability to extract high-frequency information by learning residuals. This design allows the network to better understand and extract high-frequency details in the input signal. Finally, after multiple residual structure processing, the network performs the final extraction process through the Conv + PReLU + Conv layer. The design goal of this layer is to accurately extract and optimize high-frequency information. In this way, the network completes the task of fully extracting high-frequency content features from the input signal. In general, our designed high-frequency network architecture can effectively extract and optimize high-frequency content features through a multi-block cascaded residual structure and an accurate Conv layer. This design idea has achieved remarkable results in the process of network training, which provides higher accuracy and efficiency for our model in dealing with high-frequency information.
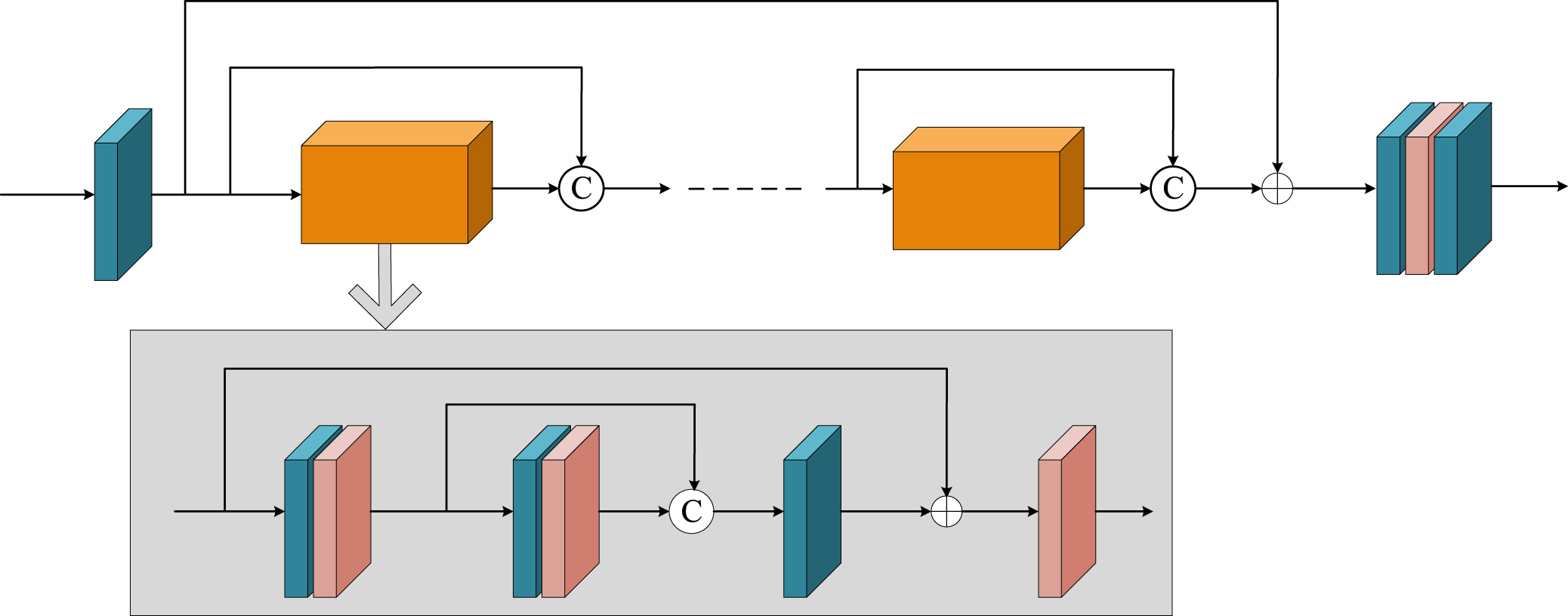
High frequency network architecture.
Most of the existing fusion methods treat channel and pixel features in the same way when dealing with image features. However, this method may not fully consider the importance of different parts of the image and different types of information. Therefore, we design a unique fusion network (as shown in Fig. 4), which is mainly composed of local residual learning, channel attention module and pixel attention module. The local residual learning part allows the network to establish multiple local residual connections, which enables the network to better focus on the important information in the image and ignore some less important information. In this way, the network can focus more on dealing with effective information that has a greater impact on the results. The introduction of the channel attention module and the pixel attention module provides the network with additional flexibility, enabling it to adjust the processing method according to different tasks and input images. These modules can extend the representation ability of Convolutional Neural Network, making the network more flexible and effective in processing different types of image information.
Fusion network architecture.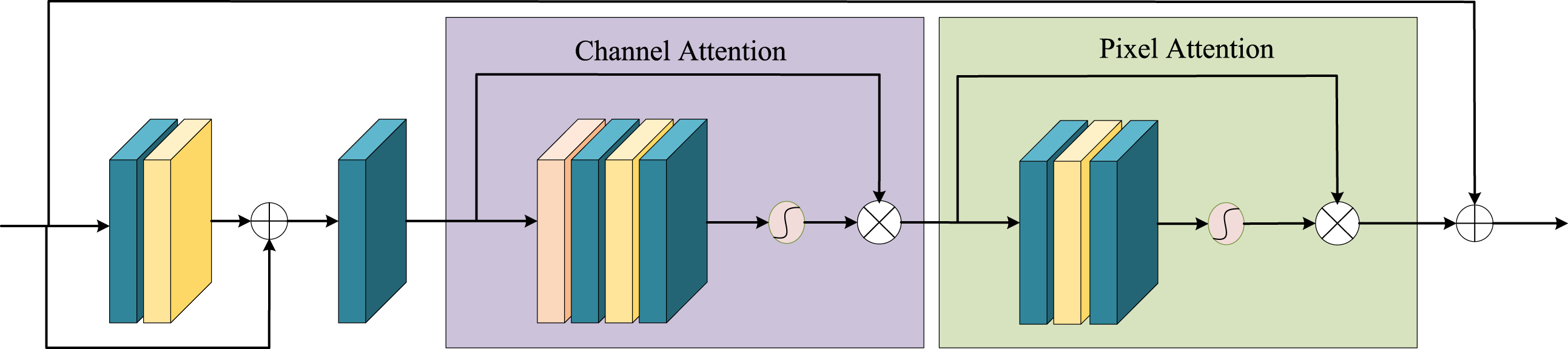
To train a DISN network for LDCT image denoising, we can apply supervision on the NDCT image and the denoised image LDCT after N iterations. The L1 loss function, also known as mean absolute error (MAE), is a measurement method that measures the difference between two vectors. It calculates the average absolute value of the difference between the predicted value and the true value. The L1 loss function is more robust to outliers. When the L1 loss function is used, the predicted results of the model tend to be closer to the median of the true value. Therefore, we use L1 loss to train the final DISN.
In this section, we test performance and generality of proposed denoising method by validating it on different datasets. Specifically, we choose the Mayo dataset, the Piglet dataset and the clinical dataset for our experiments. As can be seen in Fig. 5, different types of medical images have different noise characteristics. The CT images in the Mayo dataset are scanned using a thin-layer technique with high voxel resolution, and the Mayo low-dose CT dataset has a lower scan dose and is louder relative to noise compared to conventional CT scans. The Piglet dataset contains CT image data from five piglets born less than 24 hours after birth, with different application scenarios and the same type of noise compared to the human CT dataset. The noise of the clinical dataset is more expressive compared to the simulated dataset noise. During the training process, we utilized a data augmentation strategy of randomly cropping patches. Specifically, we set the patch size to 60×60 with a sliding interval of 60 pixels for both the input batch of LDCT images and the corresponding target batch of NDCT images. We experimented with several parameter combinations and ultimately chose the following parameters: an Adam optimizer was used to optimize the network weights during training, with an initial learning rate α of 0.0002, a batch size of 6, and two exponential decay factors β1 = 0.5 and β2 = 0.999. We performed 500 training iterations to converge the model with 3 epochs. Our network model was developed using the PyTorch framework and implemented on an Intel (R) Core (TM) i9-10900X CPU @3,10 GHz; 32 GB RAW, GPU NVIDIA RTX A5000. Although patch-based training was employed, the proposed network can handle images of any size. All test images are directly fed into the network without decomposition.

LDCT images of different data sets.
We used five metrics to compare and analyze the post-experimental images. Structural similarity based on the structural difference (SSIM) [37], peak signal-to-noise ratio (PSNR) based on pixel grayscale difference, gradient similarity deviation (GMSD) [38] based on gradient change, feature similarity metric measure (FSIM) [39] based on feature difference, and multiscale pixel domain implementation metric (VIFS) [40] based on visual perception is used. SSIM calculates the product of luminance similarity, contrast similarity, and structural similarity, and then predicts the local image quality at a certain location. The higher the SSIM, the higher the similarity of the denoised image to the reference image. The FSIM combines the similarity of the phase coherence map and the gradient magnitude map between the reference image and the processed image. VIFS is to extract information of different frequencies on multiple scales of the image, and then use this information to calculate the similarity between images, to obtain the similarity evaluation index. As with SSIM, the higher the FSIM and VIFS values, the better the image quality. The GMSD represents the similarity between the reference image and the processed image in terms of the gradient magnitude map at the pixel level, and the GMSD score is lower for good processing. The implementation of these metric methods procedures is based on their official code, and their parameters are set according to the recommendations of the documentation.
Experimental details
The dataset used in this section is the Mayo CT dataset. Paired NDCT images and corresponding 25% -dose CT (LDCT) images from 10 patients were taken, where quarter-dose data were simulated by adding Poisson noise to the full-dose projection data. The image size is 512×512 and the data format is DICOM. Therefore, the network model uses LDCT images as input and NDCT images as supervised images. The dataset was segmented before training, and the CT images of 9 patients (812 pairs) were randomly selected as the training set, and the images of the remaining 1 patient (83 pairs) were used as the test set. By dividing the data in this way, we can ensure that there is enough data in the training set for network learning, but also be able to evaluate and validate the model’s abilities to generalize on a separate test set. In the context of visual effectiveness and quantifiable assessment, we compared the residual-based REDCNN [20], edge-based EDCNN [23], quadratic self-encoder QAE [21], transformer-based CTformer [34], physical model-based CNCL [29], GAN network-based WGAN_VGG [28], and multi-scale architecture of MSFLNet [26]. For a fair comparison, all methods use the configurations recommended in the corresponding papers.
Qualitative assessment
In the qualitative evaluation, these methods showed different degrees of noise suppression ability. As can be seen in Figs. 6∼8, we selected three representative CT images from the test set, and all CT images in the axial view are shown in the [–160HU, 240HU] window to visually analyze several representative denoising results, Fig. 6 and 7 are CT images of the abdomen, and Fig. 8 is a CT image with a lesion. To show the noise reduction effect more clearly, we zoomed in on the region of interest (ROI), as shown in Fig. 9. Although REDCNN has a certain effect on noise suppression, the processing results over-smoothed the image details. EDCNN pays attention to preserving image edge information, effectively avoiding the information loss caused by image edge blur, but in some complex edge regions, the denoising effect is limited to a certain extent, resulting in sharpening and false edges in the restored image. Although QAE can restore low-dose CT images better, it relies too much on high-frequency information, which leads to a bit of blurring in detail processing after noise reduction, and the whole image looks a bit smooth and introduces artifacts. CT former removes most of the global features and local relationship information of LDCT images by learning CNCL effectively removes the noise and artifacts in LDCT images, but there are problems of image smoothing and loss of details, etc. MSFLNet can learn the high frequency detail information of LDCT images through multi-level feature extraction and fusion, and has better restoration ability, but compared with the image clarity, some details of processing are still lacking. Our DISN has the best noise reduction effect compared to these algorithms, and achieves better results in artifact removal and tissue detail protection. This experimental result shows that our decomposition-based iterative denoising strategy has a strong noise and artifact removal capability. In conclusion, DISN has excellent capabilities in removing noise and artifacts and restoring image details and textures.
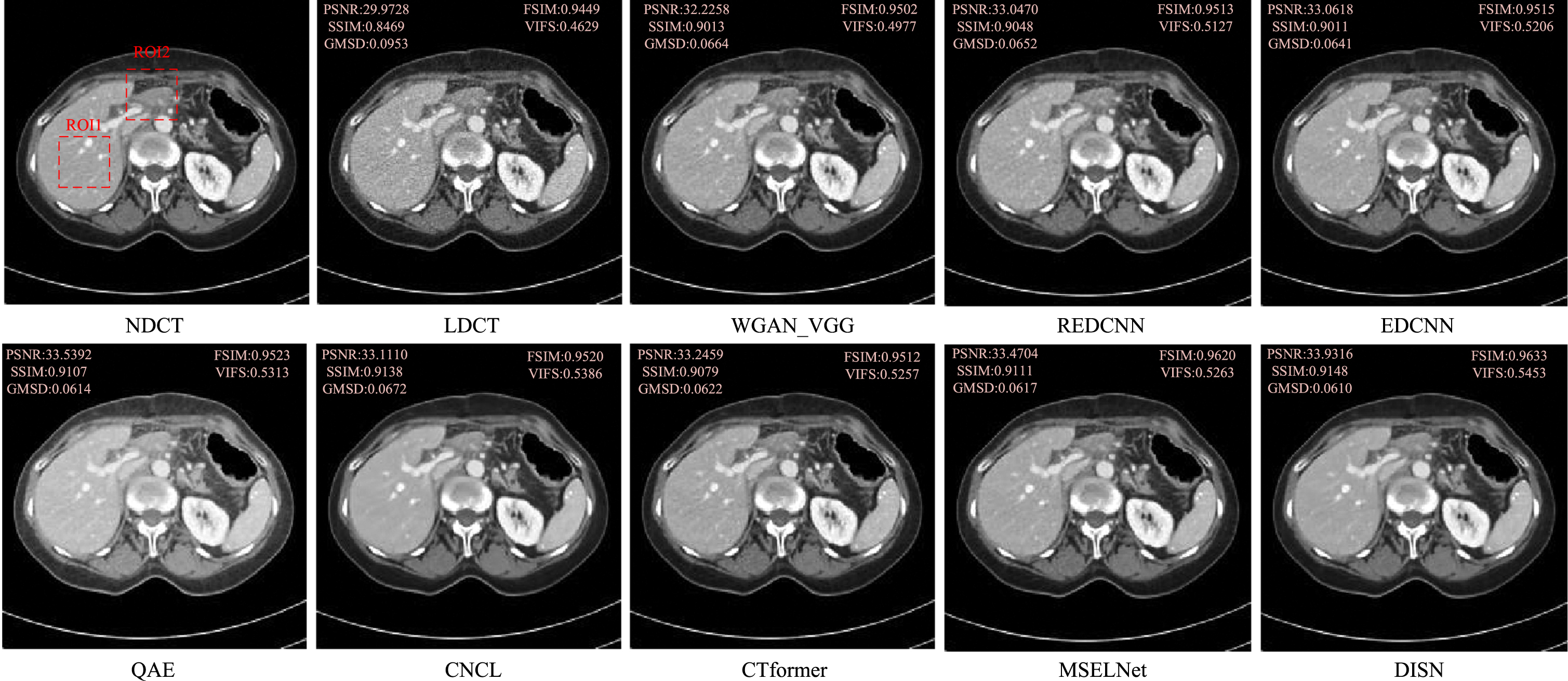
The noise reduction results of sample 1 in AAPM data set are visually displayed.
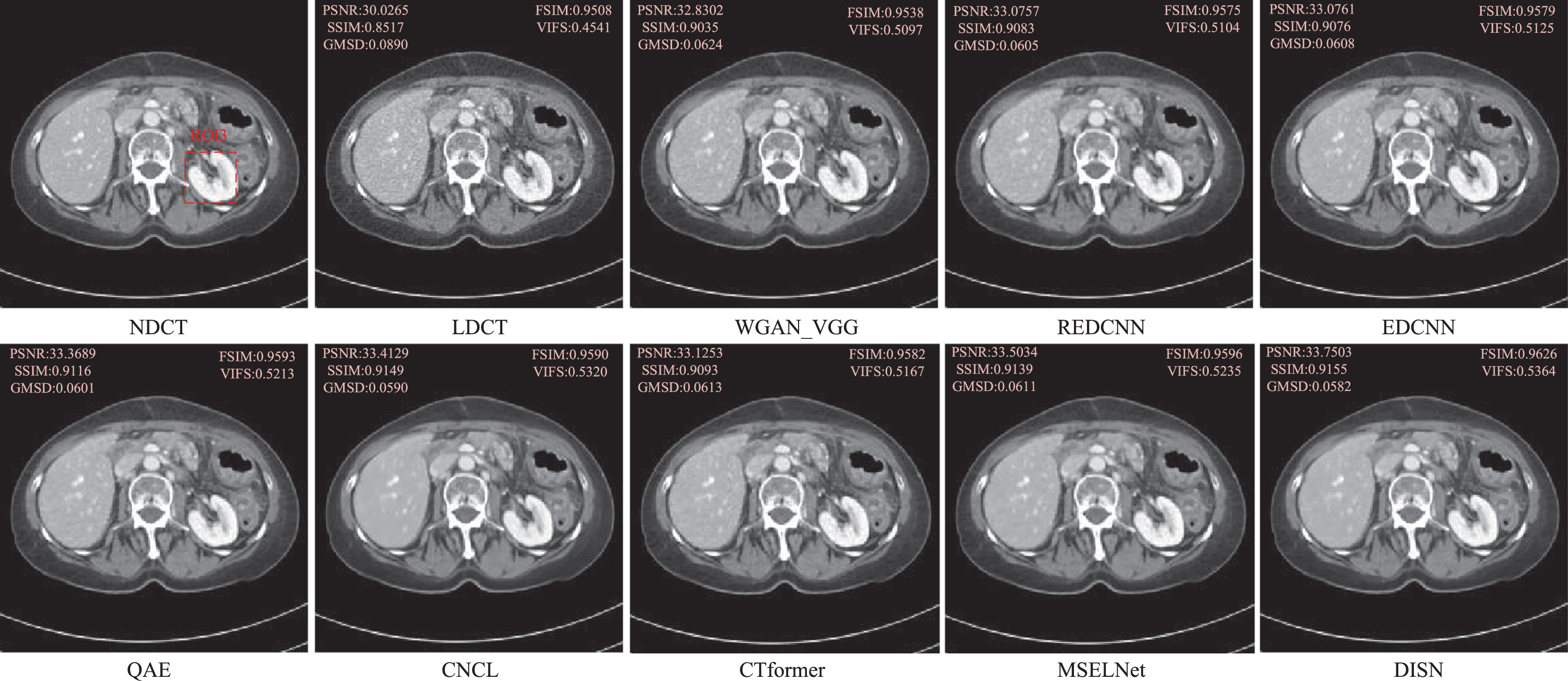
The noise reduction results of sample 2 in AAPM data set are visually displayed.
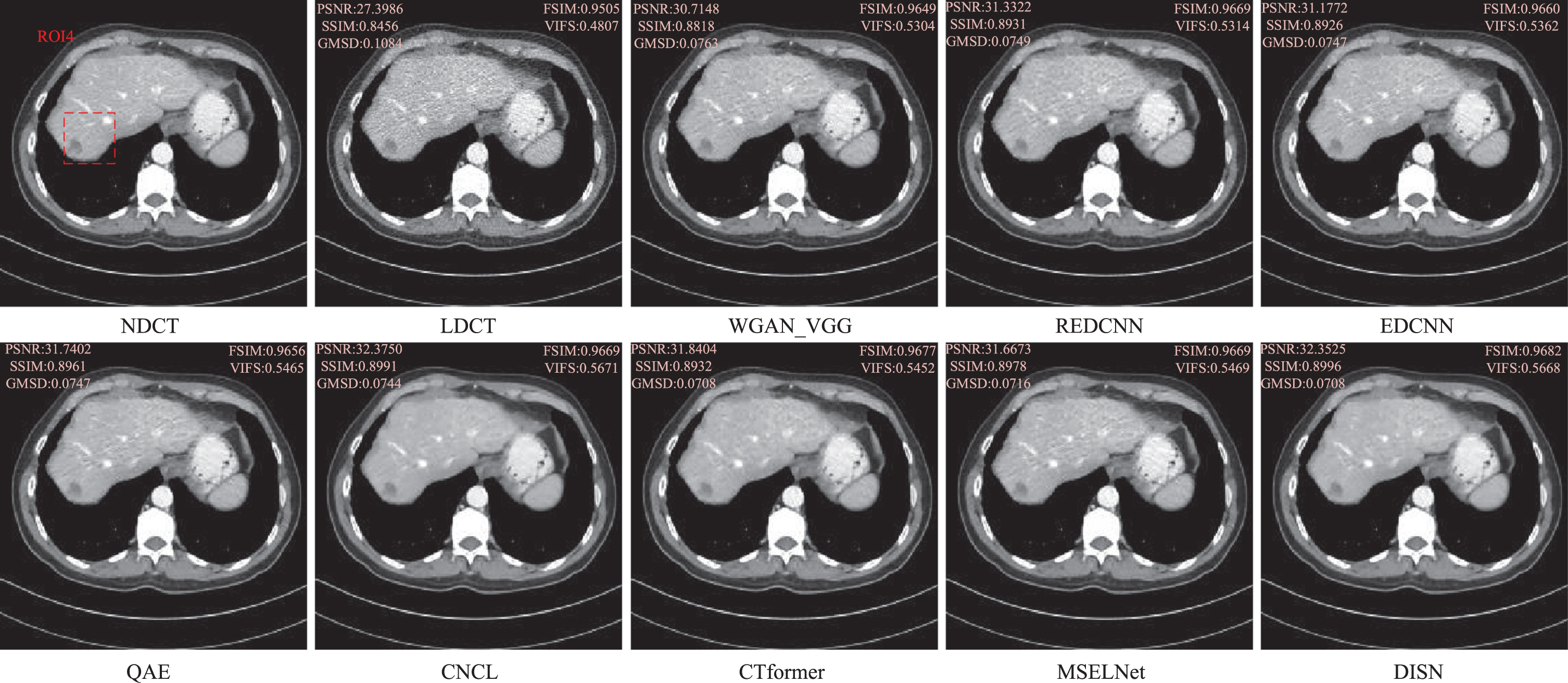
The noise reduction results of sample 3 in AAPM data set are visually displayed.
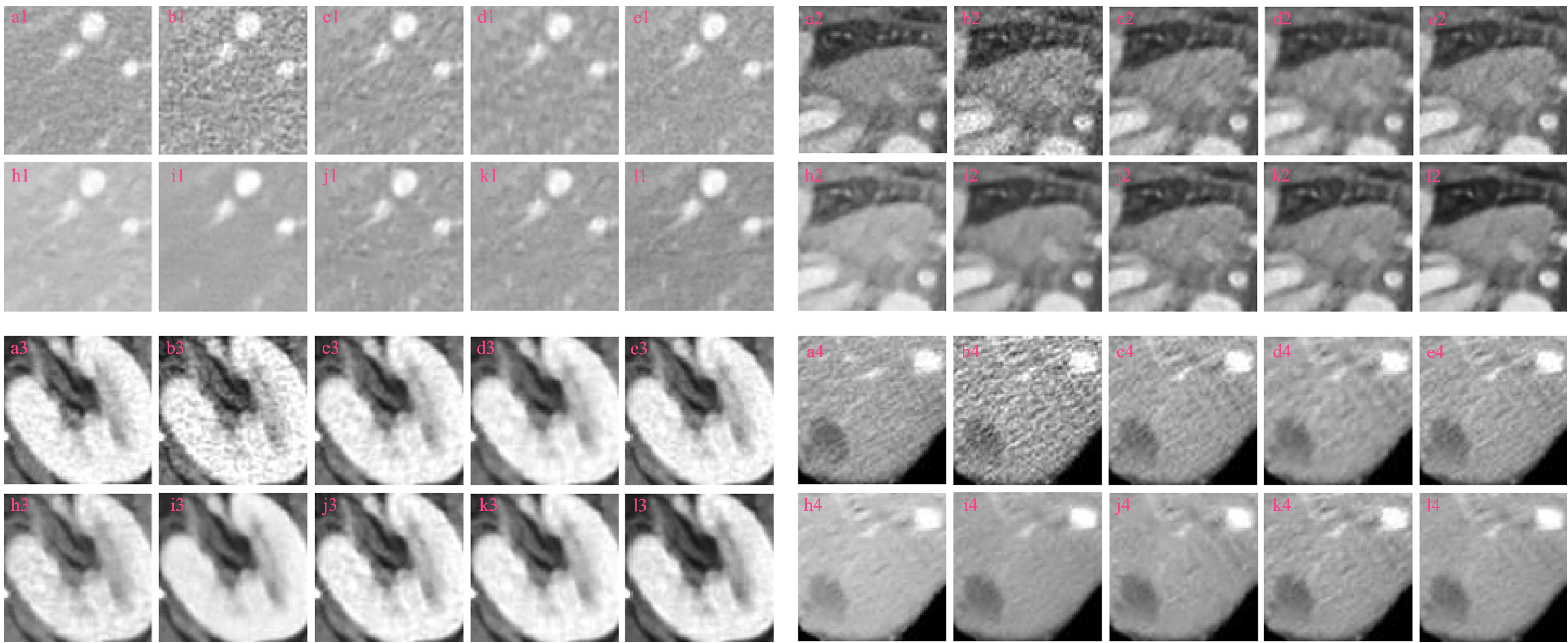
Magnification ROIs.
Texture information from CT images is very important for physicians when making a diagnosis. Texture can provide information about the microstructure and the tissue type within the tissue and can help physicians more accurately determine the nature and distribution of lesions. Therefore, it is crucial to suppress artifacts and recover texture and details in LDCT image noise reduction. Figure 10 show the difference images obtained by subtracting different denoised results from LDCT. Evidently, the artifacts (or details) residuals in these difference images can reflect the noise reduction performance of different methods.Among them, the more amount of artifacts (or details) in the difference images, the more amount of artifacts (or details) are suppressed (or damaged) in the noise reduction process. Our study finds that our proposed DISN has a strong noise artifact suppression ability and can suppress the noise to the maximum extent, so its denoising effect is more excellent than other methods.

Different methods are used to obtain difference images (Fig. 6).
To quantitatively analyze the effectiveness of different noise reduction methods, Table 1 lists the metrics of these methods for the test data set. The best values are shown in red and the second best values are shown in blue. From the table, DISN shows a more excellent performance in all objective metrics, especially in the two metrics in PSNR and SSIM, where there is a significant improvement. Specifically, WGAN_VGG and CNCL perform poorly in PSNR, while REDCNN and WGAN_VGG score lower in VIFS, which is consistent with excessive image smoothing and low contrast in visual judgment. Although CNCL is at a disadvantage in PSNR, its SSIM and VIFS values still rank second best. both QAE and CT Form CNN-based methods have some advantages. MSELNet performs best in the metrics of FSIM. Although DISN is not the best in the performance index of FSIM, it is not much different from the best MSELNet and performs best in the remaining evaluation indexes, which indicates that the method has the ability of both noise/artifact suppression and feature information retention, and its denoising result is close to the real NDCT image, and its performance is excellent.
Comparison with different algorithms on the Aapm Dataset
Comparison with different algorithms on the Aapm Dataset
The distribution characteristics of PSNR and SSIM for the different methods on the test dataset were compared by box-line plots, as shown in Fig. 11. The box line plot sums up the data set with five statistics (maximum, minimum, lower and upper quartiles, and median). Based on the width of the frame and the distribution range of PSNR and SSIM in Fig. 11, we can find that DISN has better robustness compared to other denoising methods. In terms of the grey line (median), the order of different denoising methods is as follows: (PSNR)WGAN < REDCNN < EDCNN < CNCL <CTformer < QAE < MSELNet < DISN,(SSIM)WGAN < EDCNN < REDCNN < CTformer < QAE < CNCL < MSELNet < DISN. DISN has the highest median, which confirms its best performance in terms of average quantization performance.
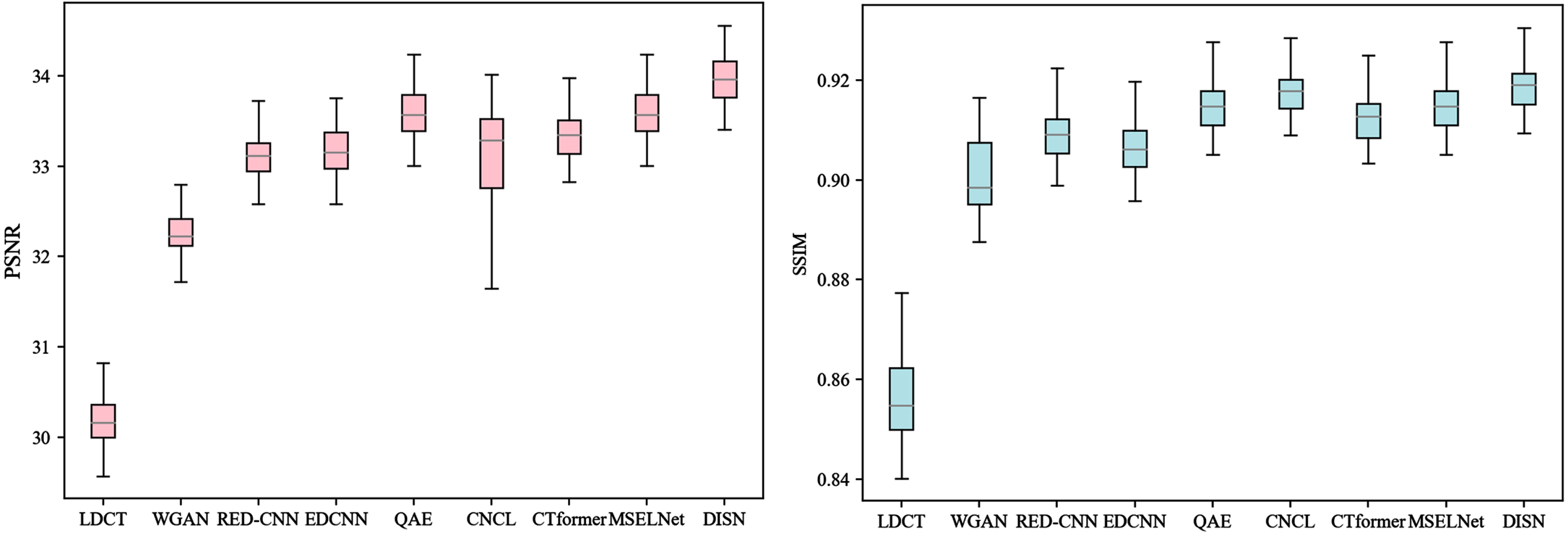
Boxplot of denoised results using different denoising methods on AAPM testing set.
To illustrate that physicians usually focus on the region of interest (ROI) related to medical diagnosis, we use PSNR and SSIM in the figure to quantify the performance of each method within the same ROI, as shown in Fig. 12. Comparing the PSNR of various methods within the same region of interest, it can be found that our proposed DISN is always in the lead and its performance is superior to other methods.
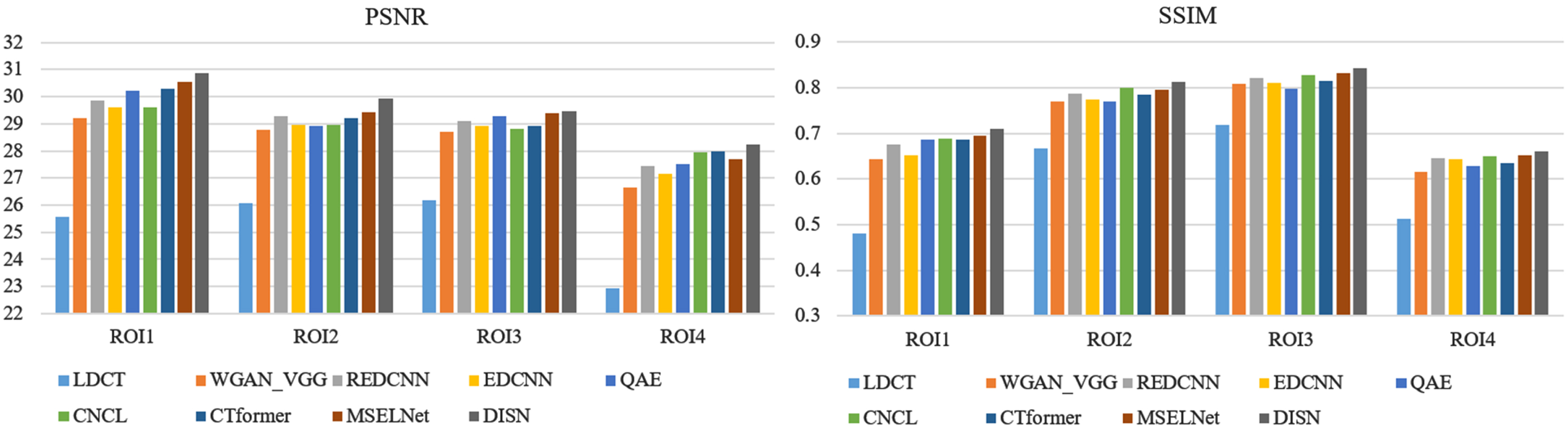
Histogram of ROI of denoised images obtained by different methods.
Experimental details
We obtained a 512×512 piglet CT dataset with different dose ranges of 50%, 25%, 10% and 5% using a Discovery CT750 HD type GE scanner with 300 mAs as the normal dose. We selected 400 pairs of piglet images (tube currents of 150 mAs and 300 mAs, respectively) as training inputs and trained the model. To validate the applicability of the model on different dose datasets, we tested it on four different dose datasets, each containing 40 pairs of images. In evaluating the model performance, we compared the model with five state-of-the-art methods BM3D, REDCNN, EDCNN, QAE, and CT former. We have compared these methods in a comprehensive manner in both visual effectiveness and quantitative evaluation.
Qualitative assessment
In Fig. 13, we display the results of various methods of processing representative piglet sections, which were obtained at different doses of 50%, 25%, 10% and 5%. Since our dataset was trained based on 150 mAs LDCT images, the results obtained by the BM3D method were excessively smooth and the results obtained by the CNN-based method can keep some denoising ability when testing images from datasets with 150 mAs LDCT images and 75 mAs LDCT images. Specifically, the REDCNN, CT form, and QAE methods produce results with blurred details. The EDCNN method preserves edges and details but has inferior denoising performance, while the performance of the DISN network results are very similar to those of the respective NDCT images. The REDCNN method performs well when the test images are from LDCT images at 30 mAs, while our proposed DISN method is closer to the results of NDCT images relative to the other methods. However, when the images are heavily noise-contaminated (15 mAs), all methods fail to achieve satisfactory results, but then the conventional noise reduction method BM3D has some outstanding advantages.
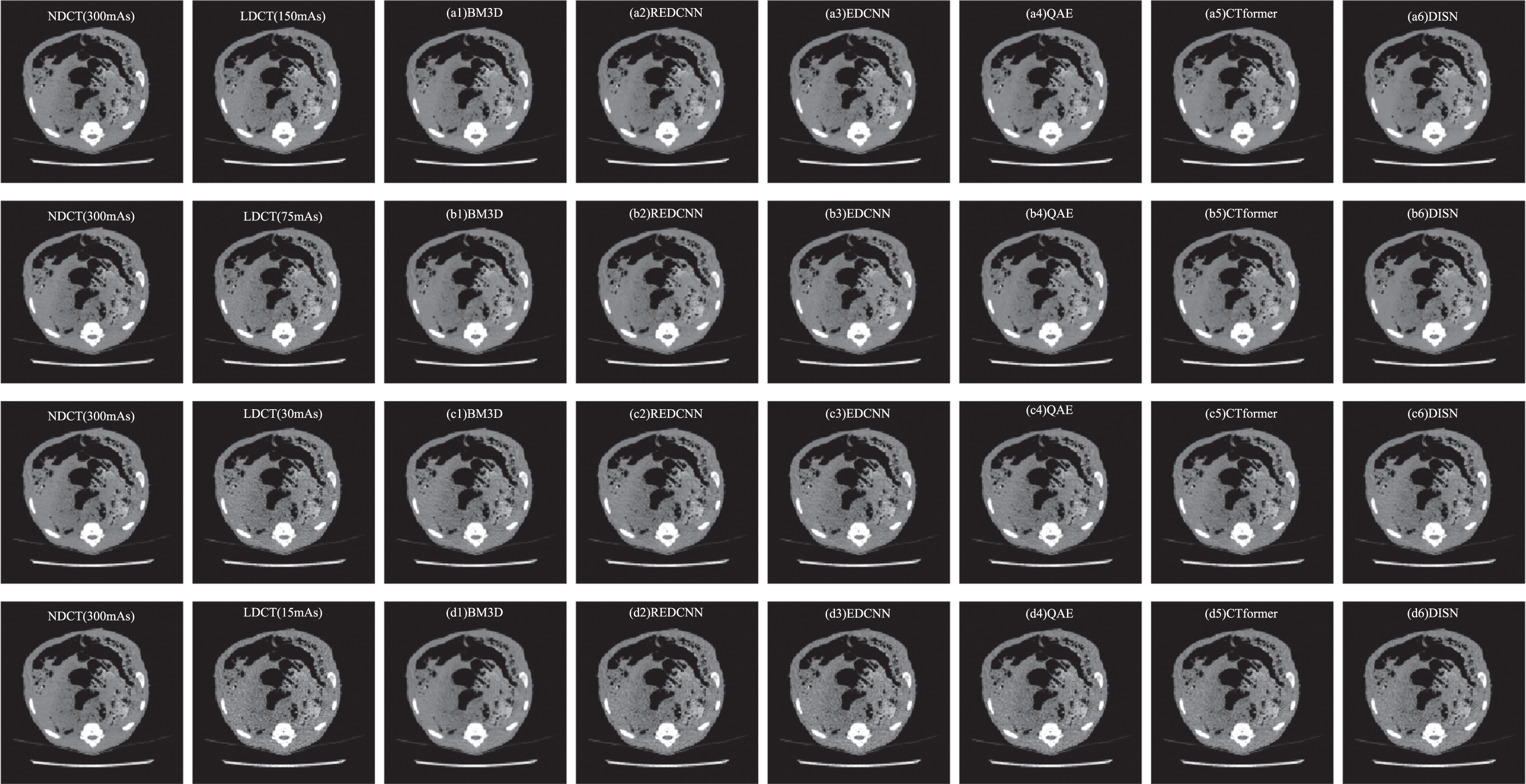
The noise reduction results of the sample in piglet data set are visually displayed.
The average quantitative properties achieved during robustness validation experiments on the whole Piglet dataset are shown in Table 2, where the best and second best values are shown in red and blue. At doses of 50% (150 mA) and 25% (75 mA), the best results for all metrics were achieved with our proposed DISN method. At a dose of 10% (30 mAs), both REDCNN and DISN methods showed good results in all metrics. At 10% dose and 5% dose, conventional denoising method BM3D has the advantage of being unconstrained by the training data set by adjusting the hyperparameters and has better quantitative metrics than the deep learning-based method.
Comparison with different algorithms on the Piglet Dataset
Comparison with different algorithms on the Piglet Dataset
Due to the more complex noise introduced under natural conditions, we performed robustness validation experiments on real clinical CT images and compared them with relevant comparison experiments. The dataset was approved by the hospital ethics committee. In this section, a representative slice is selected for validation, and two ROI regions from the slice, upper left and upper right, are selected for comparison, as shown in Fig. 14. In the LDCT image, there are severe noise and artifacts that have a significant impact on the observation of texture and lesion. The image after WGAN_VGG processing still has some noise. REDCNN and QAE can suppress noise and artifacts to some extent, but the processed image is blurred. Compared with CT former, EDCNN has more artifacts in the processed images, but the outline of the ROI lesion in the upper right corner is clearer. CNCL and MSELNet can produce better results, but the CNCL processed images still have obvious artifacts and the brightness needs to be improved. Therefore, DISN-processed images are easy to diagnose by physicians and have practical application value.
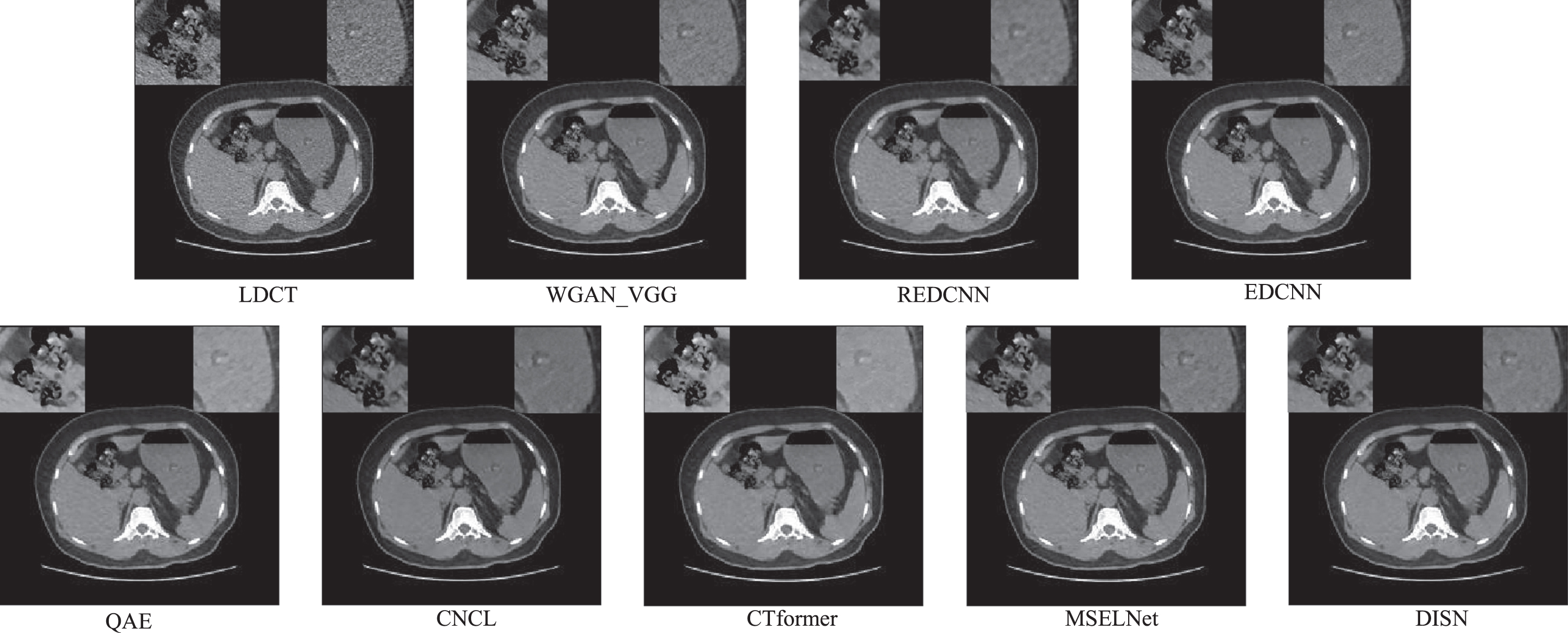
The noise reduction results of the sample in clinic data set are visually displayed.
In LDCT image noise reduction, it becomes particularly important to suppress artifacts and recover texture details. Figure 15 show the difference images obtained by subtracting different denoised results from LDCT. Evidently, the artifacts (or details) residuals in these difference images can reflect the noise reduction performance of different methods. Among them, the more amount of artifacts (or details) in the difference images, the more amount of artifacts (or details) are suppressed (or damaged) in the noise reduction process. Our study finds that our proposed DISN has a strong noise artifact suppression ability and can maximize noise suppression.

Different methods are used to obtain difference images (Fig. 14).
Number of iterations
We had the number of iterations of DISN models set to 3, 4 and 5 and evaluated their quantitative performance. The experimental results demonstrate that the performance of the DISN model does not improve greatly with increasing the number of iterations, but adds to the number of parameters and training time. Considering the above conditions, the number of iterations of the DISN model is finally set to 3.
Fusion network
By doing 3 iterations, we consider the impact of the fusion network on the whole network. Instead of directly summing the high-frequency information and low-frequency information after obtaining them, our network adds a fusion network to process this information. We selected another representative slice from the Mayo dataset and enlarged the ROI region for better comparison. As can be seen in Fig. 16, if the high-frequency information and low-frequency information are directly summed, the obtained image has some blurring and the details are not obvious.
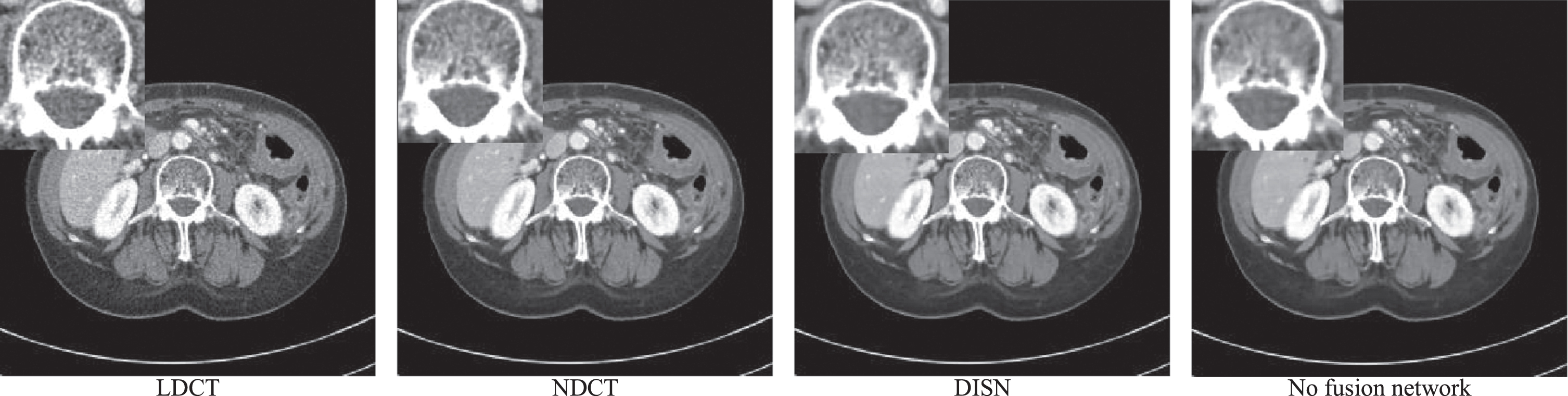
The effect of fusion network on noise reduction of LDCT image.
In this study, we proposed a new LDCT image denoising algorithm, interpretable decomposition iterative network (DISN). The algorithm uses a physical model to design a low-dose CT noise reduction network and improves the model’s ability to maintain low-frequency signals and high-frequency details. The purpose is to suppress noise and artifacts caused by radiation dose reduction on CT images. This method solves the blind design or use of deep neural network architecture, combines data-driven and model-driven, solves the unexplained problems inherent in deep learning, and makes full use of data features to make the whole model more reasonable and has better generalization ability. In order to preserve the edge/texture in the iterative process, this paper uses the Hessian matrix to realize the frequency distribution of the image, and designs the corresponding low frequency, high frequency and fusion network. Experiments show that this method can effectively remove the noise and artifacts in CT images, maintain the integrity of CT image structure and pathological information, and improve the diagnostic performance of CT images. Compared with the existing mainstream algorithms, the visualization effect and quantitative indicators of the algorithm are significantly improved, and it has certain generalization ability. However, this method still has some shortcomings. Since the noise in LDCT is distributed over the entire spectrum, if the frequency of the entire noise can be calculated, the accuracy of noise extraction can be improved, thereby further improving the noise reduction ability of LDCT. Although this method has certain interpretability, it still needs to combine the traditional denoising method with the network to design a more accurate and credible method.
Funding
National Nature Science Foundation of China under Grant (61801438), Postgraduate Education Innovation Project of Shanxi Province (2022Y582), the Research Project Supported by Shanxi Scholarship Council of China under Grant 2021-111.
Footnotes
Acknowledgments
We would like to thank the editors and reviewers for their reviews that improved the content of this paper.
Conflict of interest
The authors declare no conflicts of interest.
Data availability
The basic data for the results of this paper can be found in the references.