
Abstract
BACKGROUND:
The emergence of deep learning (DL) techniques has revolutionized tumor detection and classification in medical imaging, with multimodal medical imaging (MMI) gaining recognition for its precision in diagnosis, treatment, and progression tracking.
OBJECTIVE:
This review comprehensively examines DL methods in transforming tumor detection and classification across MMI modalities, aiming to provide insights into advancements, limitations, and key challenges for further progress.
METHODS:
Systematic literature analysis identifies DL studies for tumor detection and classification, outlining methodologies including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and their variants. Integration of multimodality imaging enhances accuracy and robustness.
RESULTS:
Recent advancements in DL-based MMI evaluation methods are surveyed, focusing on tumor detection and classification tasks. Various DL approaches, including CNNs, YOLO, Siamese Networks, Fusion-Based Models, Attention-Based Models, and Generative Adversarial Networks, are discussed with emphasis on PET-MRI, PET-CT, and SPECT-CT.
FUTURE DIRECTIONS:
The review outlines emerging trends and future directions in DL-based tumor analysis, aiming to guide researchers and clinicians toward more effective diagnosis and prognosis. Continued innovation and collaboration are stressed in this rapidly evolving domain.
CONCLUSION:
Conclusions drawn from literature analysis underscore the efficacy of DL approaches in tumor detection and classification, highlighting their potential to address challenges in MMI analysis and their implications for clinical practice.
Introduction
Medical imaging plays an indispensable role in the diagnosis and treatment of various diseases. Usually, Magnetic resonance imaging (MRI), Computed tomography (CT), Positron emission tomography (PET), and Single-photon emission computed tomography (SPECT) modalities are commonly practised in the medical field. These modalities offer complementary facts about the shape and features of various organs and tissues inside the frame, the human body being scanned. However, reading and integrating facts from several imaging modalities may be difficult because of differences in imaging protocols, image resolution, and noise elements. Analyzing multimodality medical images with multiple modes through conventional Machine learning (ML) methods necessitates the creation of capabilities manually, which is restricted by the intricacy and variety of medical data.
Physicist Alan Cormack [1] hypothesized that scanning a body from multiple angles could best extract the information it contained, although this study was not performed with the limitations of computers at the time [2]. Multimodality tomography in the field of diagnostic imaging originated in 1966 with the first prototype of CT-SPECT, which acquired images of the patient’s breast [3]. Although closely related, both functional (SPECT and PET) and morphological tomographic images (CT and MRI) were developed independently. Godfrey Honsfield is undoubtedly the central figure in the development of CT, as he developed a prototype and built the first CT for clinical use [4]. Few medical discoveries have received such immediate and enthusiastic acceptance. Hounsfield and Cormack jointly received the Nobel Prize in Medicine in 1979. In the era of the 1990 s, there was a growing realization among individuals that the incorporation of both morphological and functional information held a significant and deep-seated significance, prompting individuals to give more serious contemplation to the necessity of this amalgamation. To solve this problem, two approaches have been adopted: images acquired at different times are fused using digital image manipulation techniques, or images acquired simultaneously are automatically merged [5].
The problem with method selection in clinical diagnostic imaging is that the highest-sensitivity methods have relatively low resolution, while the high-resolution methods have relatively low sensitivity. In recent years, the idea of using multiple models in combination has gained popularity, and researchers have realized that great advantage can be gained by using the complementary capabilities of different imaging modalities together. The amalgamation of different imaging models can result in a synergetic effect, wherein the combined output surpasses the individual contributions of each model, thus enhancing the overall efficacy and efficiency of the imaging process [6]. The idea of combining imaging technologies went mainstream with the advent of the first successful commercial fused devices. The first fused PET-CT device, developed in 1998 by Townsend and colleagues in collaboration with Siemens Medical, became commercially available in 2001. Time magazine named “Biograph” one of the “Inventions of the Year” in 2000, and it was a success. By 2003, all major medical device manufacturers, including General Electric (GE), Philips, CTI, and Siemens, had PET-CT. Integrated devices are available. In the following years, PET-CT sales grew so rapidly that by 2006, there were virtually no sales of standalone PET devices [7]. All PET cells were part of a multimodality system. The next wave of innovation is in PET-MRI-fused devices, which promise improved patient safety and imaging capability over PET-CT. Although research on PET-MRI devices began with PET-CT, the economic and engineering challenges of combining the two modalities slowed development, and the first commercial PET-MRI prototype for a human-scale hybrid scanner was released by 2007 [8–10]. With the rise of hybrid technology, these new instruments have created a wave in probe design and development as investigators continuously discover new ways to maximize the clinical benefits of hybrid instrument technology [11, 12].
In healthcare facilities, the primary responsibility of analyzing medical images is predominantly fulfilled by individuals who possess specialized training and expertise in the form of radiologists and physicians. However, given the wide variation in pathology and the potential fatigue of human experts, researchers and clinicians have begun to take advantage of computer-assisted interventions. The velocity at which advancements are being made in the realm of computational medical image analysis may not be commensurate with the rapidity at which medical imaging technology progresses; nevertheless, with the advent of ML technology, notable enhancements are being witnessed within this domain in applying ML, finding, or learning information features that best describe the information. Regularities or patterns in data play an important role in various tasks in medical image analysis. Traditionally, meaningful or task-relevant features were designed mostly by human experts based on their knowledge of the target domains, making it difficult for non-experts to exploit ML techniques for their studies [13]. In the meantime, attempts have been made to learn sparse representations based on predefined dictionaries, potentially learned from training samples. Many fields of science are concerned with the parsimonious representation of data, a fundamental problem in many sciences. The simplest explanation of a given observation should be preferred over a complicated one. Spatial-inducing penalization and dictionary learning have demonstrated the validity of this approach for feature representation and feature selection in medical image analysis [14–18]. It should be noted that the sparse representation or dictionary learning methods described in the literature still find informational patterns or routines embedded in data with a shallow architecture, thus limiting their symbolic power. However, with auto features engineering, Deep learning (DL) [19] overcomes this constraint. Instead of manually extracting features, DL requires only a set of data with minimal pre-processing if necessary and then discovers a representation of the information in a self-taught manner [20]. Therefore, the computer took over humans’ feature engineering burden, allowing non-experts to effectively use ML for their research and DL applications, particularly in medical image analysis.
DL networks are specifically designed to acquire knowledge and extract hierarchical data representations. The underlying motivation behind pursuing DL lies in its inspiration drawn from the intricate structure and function of the human brain. The ultimate objective of DL is to create its resemblances to the cognitive and reasoning processes exhibited by humans. Recently, DL has gained considerable attention and popularity within the scientific community and in various other domains. Aside from medical practice, DL is utilized extensively in domains such as computer vision, natural language processing, speech recognition, and reinforcement learning. DL has demonstrated exceptional performance in various tasks, such as image classification, object detection, machine translation, and sentiment analysis. These notable accomplishments have propelled DL to the forefront of research and established it as a potent tool for tackling complex problems across numerous disciplines [21].
DL publicizes complex structures within high-dimensional data, making it well-suited for applications in medical image analysis. Litjens et al. [22] thoroughly surveyed DL in medical image analysis. Lundervold et al. [23] focus on MRI images, and Liu et al. [24] on ultrasound images. Here, we discuss DL-based analysis of images in MMI. Recent advances in ML, particularly DL, are helping to identify, classify, and quantify patterns in medical images. Central to these advances is leveraging hierarchical feature representations learned only from data rather than hand-designed features based on domain-specific knowledge. DL is fast becoming state of the art, increasing efficiency in various medical applications [25].
Extracting complex features from medical images using DL models, such as convolutional neural networks (CNNs), You Only Look Once (YOLO), and recurrent neural networks (RNNs), leads to better segmentation, registration, and classification outcomes. The creation of automated systems with computer-aided methods for disease diagnosis and treatment planning has also been revolutionized by DL, which may result in less work for healthcare personnel and better patient results. Our earlier ML and DL research, published in esteemed journals, has already examined these techniques across various fields, including computer vision, natural language processing, medical image analysis, segmentation, and classification. Along with automated medical image analysis and computer-aided diagnosis and prediction, enhancing the accuracy and efficiency of existing methods [21–34]. [26–39].
DL-based approaches are currently considered a promising alternative for analyzing multiple modalities of medical images [40–43]. Compared to single images, multi-modal images help to extract features from different views and bring complementary information, contributing to better data representation and discriminatory power of the network. As pointed out in Ref. [44], The CT image can diagnose muscle and bone disorders, such as bone tumors and fractures, while the MR image can offer a good soft tissue contrast without radiation. Functional images, such as PET, lack anatomical characterization while they can provide quantitative metabolic and functional information about diseases. MRI dependence on variable acquisition parameters, such as T1-weighted (T1), contrast-enhanced T1-weighted (T1c), T2-weighted (T2) and Fluid attenuation inversion recovery (Flair) images can furnish this work with supplementary information. T2 and Flair are suitable to detect the tumor with peritumoral oedema, while T1 and T1c are to detect the tumor core without peritumoral oedema. Therefore, applying multi-modal images can reduce the information uncertainty and improve clinical diagnosis and segmentation accuracy [45]. Several widely used multi-modal medical images are described in Fig. 1.

The multi-modal medical images, (a)–(c) are the commonly used multi-modal medical images and (d)–(g) are the different sequences of brain MRI [40].
This article has enlightened DL-based architectures such as CNNs and YOLO based Models, Siamese Networks, Fusion-Based Models, Attention-Based Models, and Generative Adversarial Networks (GANs) for multimodal medical image (MMI) analysis. We discuss recent developments in DL-based techniques and models for analyzing medical images from multiple modalities while highlighting potential research directions for future work. We exemplify specific applications of DL-based approaches, such as tumor detection and characterization, and provide background literature on disease progression tracking. Due to the diversity of the field, as we cannot cover all aspects of multimodal imaging, we will specifically focus on commonly used multimodality medical imaging modalities in this article while describing the use of the DL role in tumor detection and classification. The article highlights the higher performance gained by DL-based medical imaging analysis in the most used multimodality imaging techniques, such as PET-CT, SPECT-MRI, SPECT-CT, Ultrasound-photoacoustic, PET-MRI, and CT-MRI, while specifically focusing PET-CT and PET-MRI for tumor detection and classification. Moreover, we draw researchers’ attention to the advantages and limitations of such approaches compared to traditional ML-based techniques. Analyzing multimodalities, images have seen various generations. The approaches for MMI analysis are categorized as conventional methods, ML, and DL, as depicted in Fig. 2.

Three generations of MMI analysis.
Novel ML, AI, and specifically DL concepts are highlighted in this article regarding multimodalities medical image analysis. This article contributes in several ways regarding multimodal medical image analysis. This article contributes a survey of current state-of-the-art DL-based methods in MMI analysis for tumor detection and classification, including recent developments and trends. Our survey pindown gaps and challenges in the present literature, such as limitations of existing models and techniques, areas where more research is needed, and challenges related to data availability, interpretability, and generalizability. We focus on providing guidance on best practices for DL-based approaches for MMI analysis, including recommendations for preprocessing, model architecture, and evaluation metrics. The article can also highlight benchmark datasets that are commonly used for evaluating models in the field. This article provides an accessible and comprehensive introduction to DL-based MMI analysis and is a valuable educational resource for researchers and practitioners new to the field. By identifying gaps and challenges and highlighting best practices and benchmark datasets, this review article can help guide future research efforts in the field toward areas of greatest need and potential impact.
The survey is organized as follows: Section 2 provides background knowledge of commonly used multimodal medical imaging modalities, their familiar usage/ clinical applications, motivation, the objective of this survey and an introduction to the utilization of DL in MMI analysis. Section 3 covers the proposed survey search strategy and study selection criteria. Section 4 reveals the multimodal image classification and segmentation and some common challenges faced in multimodal medical image segmentation. Section 5 concerns the related survey of DL architectures in MMI analysis for tumor detection and characterization. Section 6 is about results comparison and discussion. Common challenges, future directions and emerging trends are highlighted in Section 7. Finally, Section 8 provides the concluding remarks of this survey. An overview of our survey articles is shown in Fig. 3.

Organization of the survey paper.
Several imaging modalities are used in medical imaging, having their own strengths and limitations. The choice of imaging modality used to acquire patient medical images for disease diagnosis depends upon the patient’s condition, the target of patient organs for imaging, and the availability of imaging modalities. Multiple imaging modalities are utilized to acquire necessary information about a patient’s anatomy, physiology, and pathology. Each imaging modality offers distinct advantages and is commonly used in clinical scenarios.
Multi-modal medical imaging uses multiple imaging techniques to capture patient anatomy or pathology information, which is about Two whole-body PET-CT studies of a 68-year-old male undergoing treatment for small cell lung cancer [46]. Each imaging modality presents unique acumens into specific aspects of the body, such as structure, function, metabolism, or blood flow. It demands the unification of images acquired with unique modalities such as MRI, CT, PET, SPECT, ultrasound, and others. Healthcare providers can better grasp the patient’s condition and make more accurate diagnoses by integrating several modalities.
Utilizing multi-modal medical images offers several advantages in clinical practice and research. It gives further information regarding the architecture, physiology, metabolism, and function of tissues or organs. Combining these models considerably improves the assessment process by providing a more thorough and accurate patient health assessment. Consequently, this integration of different models effectively augments diagnostic capabilities, thus rendering healthcare systems more efficient and effective in their implementation.
One prevalent application of MMI lies in its utilization to identify and describe a wide range of diseases. In the oncology domain, for instance, the combination of MRI and PET scanning holds great potential in accurately pinpointing and staging tumors. This is accomplished by simultaneously visualizing anatomical structures and metabolic activity, enhancing the precision of diagnostic procedures [47–49]. Likewise, merging CT and SPECT images can prove immensely valuable in cardiovascular disease, facilitating healthcare professionals in obtaining highly detailed and comprehensive information about vascular and myocardial perfusion. As a result, this enables a more effective diagnosis and evaluation of such afflictions.
Another area where MMI finds its application is in the realm of image-guided intervention and surgical planning, a crucial component of contemporary medical practice. The amalgamation of preoperative imaging data produced by various imaging modalities such as CT, MRI, and PET give surgeons more power with a comprehensive understanding of the target region and its surrounding anatomy. This augmented visualization enhances the precision and safety of surgeries and furnishes invaluable assistance in meticulously planning these interventions. Moreover, the versatility of multimodal imaging transcends the boundaries of the operating room and extends its influence on the evaluation and monitoring of treatments, playing a pivotal role in gauging the efficacy and progression of interventions over time. By capturing and scrutinizing the dynamic alterations transpiring in the target regions post-treatment, multi-modal imaging empowers healthcare providers with the necessary insights to make well-informed decisions regarding patient care and fine-tune treatment strategies accordingly. Consequently, the integration of MMI into clinical workflows confers numerous advantages, heralding a medical revolution and significantly enhancing patient outcomes.
The integration and analysis of MMI often involve advanced image registration, fusion, and data analysis techniques to effectively combine and extract meaningful information from different modalities. Image segmentation is pivotal in healthcare because it significantly impacts precise information extraction. Accurate and precise multimodal image segmentation is critical for clinical diagnosis, treatment planning, and monitoring of various illnesses, including tumor detection, categorization, and progression tracking.
Medical imaging paradigms in multimodal healthcare vary depending on clinical needs, with no ideal solution. PET-CT combines metabolic and anatomical data, valuable for cancer staging, neurological, and cardiovascular diseases. PET-MRI enhances tumor detection, and SPECT-CT offers precise localization. Various multimodal techniques like ultrasound-photoacoustic imaging, and Positron Emission Tomography-Magnetic Resonance Spectroscopy (PET-MRS) aid in tumor characterization. PET-MRS is utilized in tumor detection to provide comprehensive insights into metabolic and molecular processes within tissues. While PET offers functional imaging by detecting the distribution of radiolabeled tracers, MRS provides biochemical information by measuring the concentrations of metabolites. Together, PET-MRS enhances tumor detection by correlating metabolic changes with tissue characteristics, aiding in diagnosis, treatment planning, and monitoring of therapeutic responses [50]. Clinical applications, advancements, and challenges are discussed, emphasizing ongoing research to refine and expand techniques’ utility, particularly with the integration of DL methods. The evolving landscape of multimodal imaging continues to shape diagnostic approaches, improving patient care across various medical fields [51–60]. Some common multimodality imaging techniques and their familiar uses are shown in Table 1.
Common multimodality imaging techniques and their familiar uses
Common multimodality imaging techniques and their familiar uses
As previously said, medical imaging is crucial in diagnosing, prognosis, therapy, and monitoring numerous diseases and medical conditions. While traditional medical image analysis methods have demonstrated some effectiveness, they often heavily rely on the laborious and subjective process of manually extracting features and implementing manual algorithms. Unluckily, this approach is prone to time-consuming work, subjectivity, and human error. Nonetheless, with the rise of DL, medical image analysis has experienced significant advances, leading to the birth of automated algorithms capable of more accurate interpretation of complicated medical images [61]. The MMI approach acquires complementary and comprehensive insights into a patient’s condition. However, due to these data sets’ inherent complexity, heterogeneity, and high dimensionality, effectively harnessing the potential of MMI data presents a substantial challenge [62–64].
DL techniques have demonstrated immense potential in effectively tackling these challenges and have exhibited exceptional performance in many tasks in analysing medical images [65]. These groundbreaking methods can extract intricate patterns and establish intricate relationships from multimodal imaging data, ultimately enhancing accuracy in diagnosis, treatment planning, and patient prognosis. The primary objective of composing this all-encompassing review article is to provide readers with a comprehensive and exhaustive overview of recent advancements in DL-based MMI analysis methods. By conducting thorough investigations into integrating and amalgamating diverse imaging models, this review seeks to meticulously demonstrate and elucidate how DL algorithms can efficiently harness copious amounts of supplementary information from various modes, thereby augmenting the overall accuracy and resilience of medical image analysis.
Moreover, it is important to note that this comprehensive review article aims to delve deeply into the multifaceted challenges that arise in MMI analysis. The aim is to meticulously examine and deliberate upon these challenges to fully comprehend their intricacy and multifaceted nature. One of the main obstacles to MMI analysis lies in the inherent heterogeneity of the data, which presents a significant obstacle in integrating and interpreting the data. The wide-ranging diversity and variability within the data makes it arduous to effectively analyze and draw meaningful conclusions. Furthermore, the explainability of DL models presents another puzzling issue in MMI analysis. Understanding the underlying mechanisms and decision-making processes of DL models is crucial for their effective and responsible deployment in medical imaging. Overall, this review article aims to shed light on these problems faced in tumor detection and classification in the MMI field and give insight into potential remedies and possibilities for the future.
Objectives
The primary objectives of this review article on DL-based approaches for MMI analysis are twofold. The initial goal of this essay is to offer a thorough review of the cutting-edge DL methods utilized in MMI analysis. This paper will go deeply into the subtle aspects involving the amalgamation and fusion of several imaging modalities, including, but not limited to, MRI, CT, PET, and ultrasound imaging, to broaden our awareness and expertise in this field. The article aims to present a detailed understanding of how DL can effectively analyze MMI by examining the advancements in DL architectures, algorithms, and training strategies.
Secondly, the review article addresses the challenges and limitations of MMI analysis specifically around tumor detection and classification. It will go through the intrinsic heterogeneity and unpredictability of multimodal imaging data, which presents difficulties for data collection, fusion, and analysis. By highlighting these challenges, the article aims to inspire further research and innovation in developing solutions to overcome them and to encourage the creation of standardized benchmarks and datasets for MMI analysis.
Furthermore, the article outlines potential future directions and emerging trends in DL-based MMI analysis and improving patient outcomes. It will explore avenues for incorporating domain knowledge into DL models, leveraging transfer learning techniques to adapt models to domains and diseases, and integrating clinical data for a holistic analysis. By presenting these future directions, the article aims to provide researchers and practitioners with insights and guidance to advance the field further and drive improvements in MMI analysis.
DL-based MMI analysis
DL-based multimodal imaging has shown incredible promise in various clinical applications across medical specialities. This game-changing technology effectively uses deep neural networks (DNNs) great potential to completely examine and seamlessly integrate data from various imaging modes, substantially improving diagnosis accuracy and providing critical insights into the area of medical practice. Implementing this unique technique might benefit health sectors such as neuroimaging, cancer imaging, and cardiovascular imaging.
It has greatly impacted many medical domains in molecular imaging, musculoskeletal imaging, gastrointestinal imaging, lung imaging, ophthalmology, dentistry, maxillofacial imaging, obstetrics, and gynecology. This technology can transform how many diseases and disorders are diagnosed and tracked, ultimately improving patient outcomes and worldwide healthcare services. Researchers and practitioners are encouraged to use the meticulously compiled and voluminous evaluation literature displayed in Table 2 to get a comprehensive overview of the existing body of literature and research relevant to DL techniques employed in multimodal imaging.
Various exercises of DL-based MMI analysis
Various exercises of DL-based MMI analysis
Multimodal imaging has substantially improved the evaluation of heart function, notably by combining data from echocardiography, MRI, and CT scans. This comprehensive approach gives doctors a full view of the patient’s heart condition and allows them to make better-educated treatment decisions [66]. Moreover, DL technology in cancer imaging has provided new opportunities for researchers to examine PET-CT and PET-MRI data, allowing for observing molecular processes and malignant tumors. A recent study conducted by Laquan Li et al. (2020) proposed a novel method that utilizes full convolutional networks (FCN) to accurately segment tumors from PET-CT images, further showcasing the potential of DL in this field [55].
Neurotransmitter imaging: Utilizing multimodal molecular imaging can facilitate examining neurotransmitter activity and its correlation with neurological disorders. Orthopedics: DL models integrate MRI and CT data to enhance the evaluation of musculoskeletal injury, skeletal health, and surgical planning. Mouchess Maria et al. (2006) employed multimodal imaging techniques to evaluate tumor progression and bone resorption in mouse models of neuroblastoma. They could monitor tumor growth and bone loss by implanting luciferase-expressing human neuroblastoma cells in the femur using radiography, bioluminescence, micro-CT, and MRI. The administration of zoledronic acid inhibits tumor growth and prevents bone loss, while high-resolution MRI can detect distant metastases [67]. Liver disease assessment: The application of multi-modal medical imaging, based on DL, in liver disease assessment employs intricate algorithms. These algorithms can integrate and analyze data from diverse imaging techniques, enhancing accuracy and diagnostic capabilities. Xue Zhongliang et al. (2021) solved the predicament of liver lesion segmentation by utilizing a deep CNN in combination with multi-modal PET and CT scans. They proposed a model that could improve the interaction between features in different models, merge feature maps with varying resolutions, and introduce a similarity loss function to ensure consistency. This model surpassed the performance of baseline techniques in liver tumor segmentation and exhibited greater accuracy [68]. The detection of lung cancer is significantly enhanced through the analysis of combined PET and MRI scans using DL algorithms [56]. Monitoring fetal development is effectively carried out by utilizing ML-based and DL-based multimodal ultrasound and MRI data, thus providing comprehensive insights into fetal development, and detecting abnormalities during pregnancy [69]. Clinical practice transforms by implementing DL-based multimodal imaging, improving diagnostic accuracy, treatment planning, and patient care across various medical specialities. Anticipated advancements in DL algorithms and imaging technology are poised to augment its clinical application further.
DL has a significant role in tumor detection and classification across diverse multimodal imaging modalities. Analyzing multimodal data with DL models enhances diagnostic accuracy, facilitates personalized treatment plans, and enables early detection, thereby revolutionizing cancer management and improving patient outcomes. M. Attique Khan et al. (2020) [70] studied automated brain tumor classification using DL, which addresses radiologists’ challenges. The method incorporates contrast stretching, DL feature extraction, joint learning, and feature fusion. They validated their study on BraTS datasets and achieved high accuracies: 97.8%, 96.9%, and 92.5% for BraTS2015, BraTS2017, and BraTS2018, respectively.
G. Murtaza et al. (2020) [71] performed a study on DL-based breast cancer classification. Their review focuses on the DL-based classification of breast cancer using various medical imaging modalities. It systematically analyzes 49 studies, covering imaging modalities, datasets, preprocessing techniques, neural network architectures, and performance metrics. The review highlights challenges and future research directions in this domain, serving as a valuable resource for both beginners and advanced researchers in multimodality medical imaging. A study by EliasHossain et al. (2022) [72] proposes a strategy for brain tumor segmentation using 3D Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) scans with 3DU-Net Design and ResNet50. The ResNet50 achieved 98.96% accuracy, and the 3DU-Net scored 97.99%. Additionally, image fusion and a specific loss function improved segmentation accuracy. The models were validated using various metrics and integrated into a web server for practical deployment in healthcare settings.
In constructing this all-encompassing survey article, we meticulously adhered to the guidelines explicitly delineated in the Preferred Reporting Project for Systematic Review and Meta-Analysis (PRISMA) Methodology, ensuring a methodical and thorough literature review. This particular approach establishes a uniform and standardized framework, promoting transparency, precision, and the ability to replicate the implementation of the systematic review. We embarked upon an extensive and all-encompassing investigation into the existing body of literature, undertaking a meticulous and thorough examination of the esteemed academic search engine Google Scholar, and employed a range of carefully chosen search terms to procure enlightening and groundbreaking future research findings pertaining to the highly specialized and intricate domains of tumor segmentation, and categorization with a particular emphasis on various facets of multi-modal imaging, thereby ensuring the integration of diverse and exhaustive future research outcomes into perspectives on this intricate and pivotal subject matter. The search query encompasses a variety of terms, including but not limited to “deep learning,” “convolutional neural networks,” and “machine learning.” In addition, it incorporates abstract keywords such as “lesion,” “cancer,” and “tumor,” along with the concepts of “segmentation,” “classification,” “multimodal imaging,” “multimodal therapy,” “PET-CT,” “SPECT-CT,” “PET-MRI,” multimodality image analysis,” “PET-CT in multimodality imaging,” “tumor detection using PET-MRI imaging,” and similar terms for other modalities. The primary objective of this query is to delve into the intricate and nuanced connections between these advanced computational techniques and their potential applications within the realm of medicine. Figures 4 and 5 show the year-wise distribution of the chosen literature on DL-based tumor detection, lesions segmentation, and classification approaches. Figure 5 articles distribution is based on a Google Scholar query upon all the articles mentioning the words “Deep learning” and specific modality, i.e., “PET-CT”. Figure 6 depicts the most often practiced technique distribution, Fig. 7 shows the Region-wise distribution of the selected research papers. Several efficient methods have been proposed for MMI analysis, and survey papers in the literature have reviewed the recent work on DL techniques for multimodal imaging, as presented in Table 3.

DL-based approaches for tumor detection and classification focus on PET-CT, PET-MRI, and SPECT-CT multimodalities.
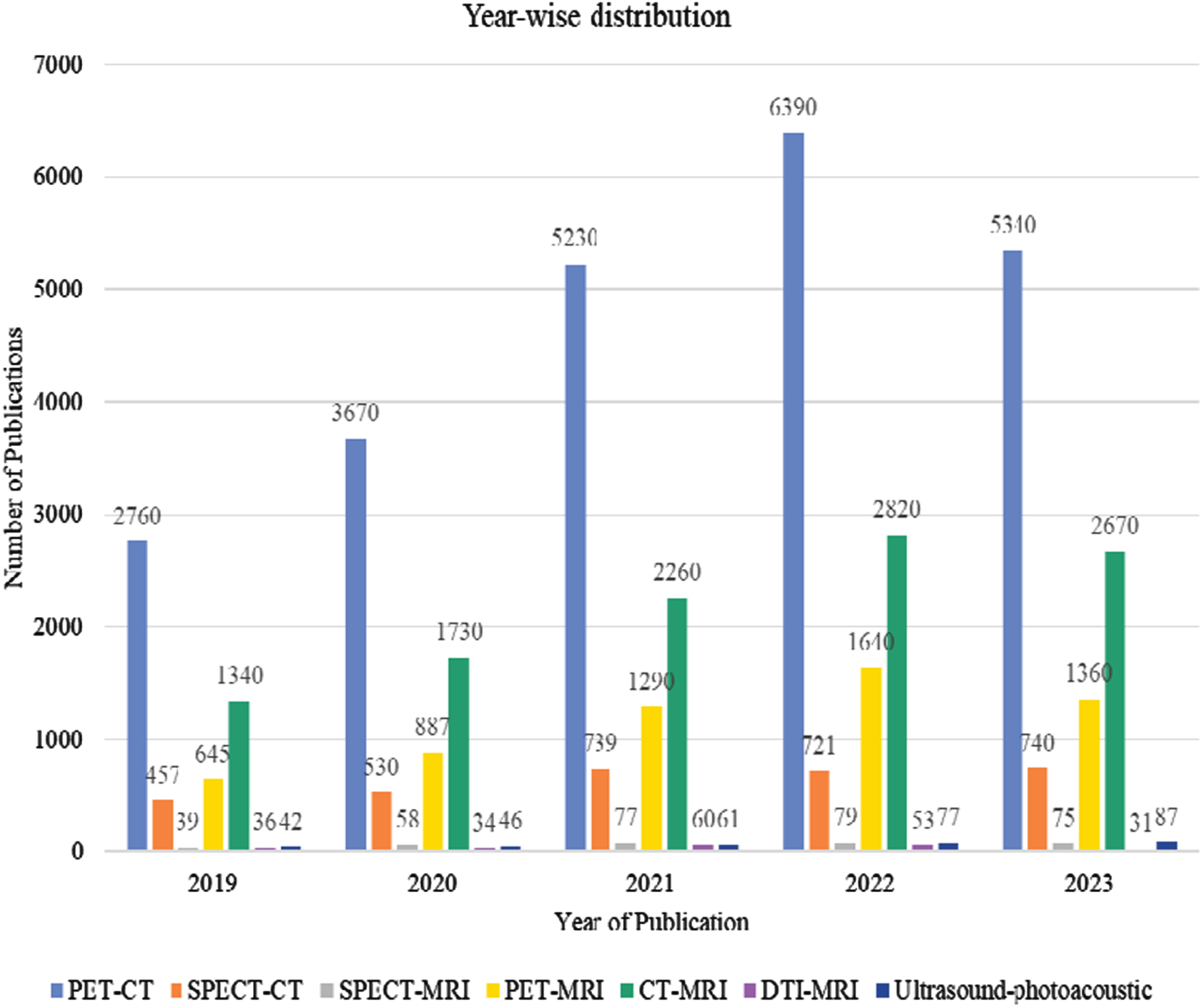
Year-wise distribution of the reviewed literature is based on google scholar query upon all the articles mentioning word “Deep learning” and specific modality i.e., “PET-CT”.
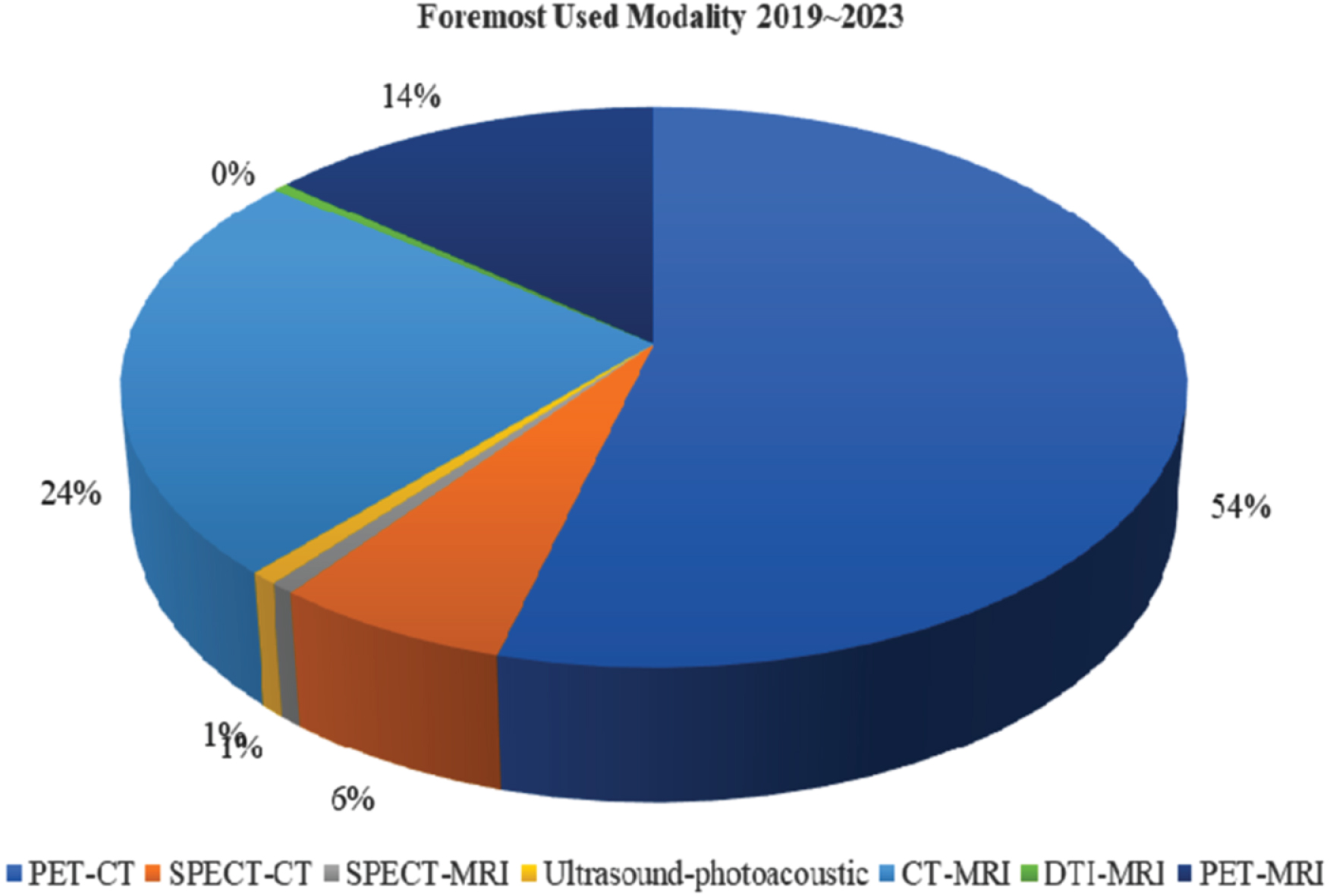
Most often practiced technique.
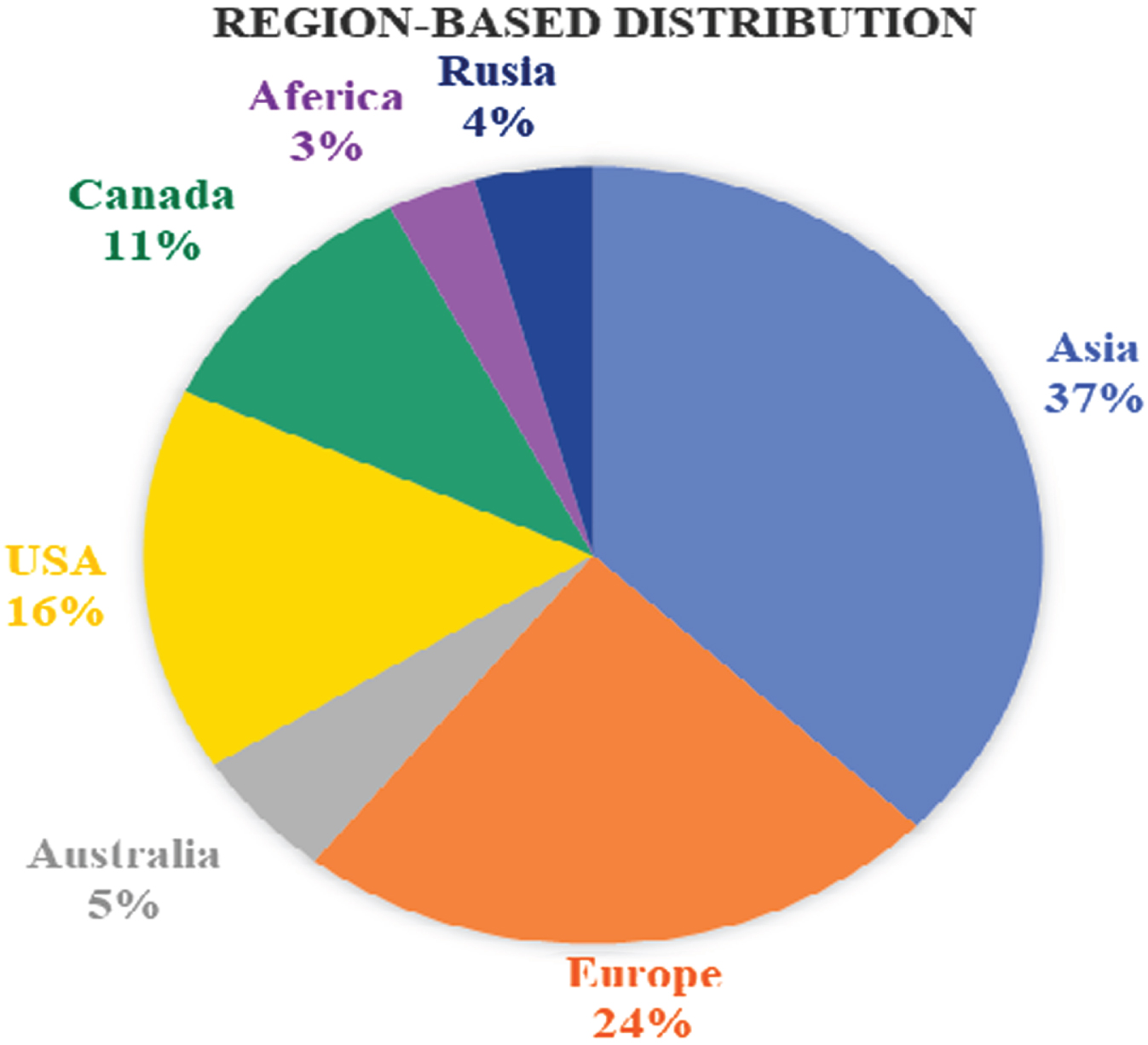
Region-wise distribution of the selected research papers.
Summary of related survey articles MMI analysis
This survey discusses key parameters used to explore recent studies on tumor detection, classification and key aspects of image analysis i.e., image segmentation in multimodalities imaging. Table 4 describes the parameters used to explore the reviewed studies, which are classified into five categories: architecture design, dataset characteristics, Tumor type, model performance (Perf.), and implementation (Imp.) code availability of the proposed study. Under the architecture design category, we discuss the backbone network, the shortcuts connection, convolution, and the attention mechanism used with the backbone model. We also consider loss functions such as distribution-based, region-based, or hybrid loss functions, and the optimizer during model training. Based on the architectural design, we classified the existing DL models into CNNs and YOLO based Models, Siamese Networks, Fusion-Based Models, Attention-Based Models, and Generative Adversarial Networks (GANs). These models are categorized and subdivided into several types, including CNN, FCN, SegNet, RNet, UNet, TSN, CSN, RSN, efusion, ARNN, LSTM, VGAN, cGAN, PGAN, InfoGAN and their variants. A summary of the classification of the reviewed literature is shown in Fig. 8.
Details of the parameter used to explore DL models
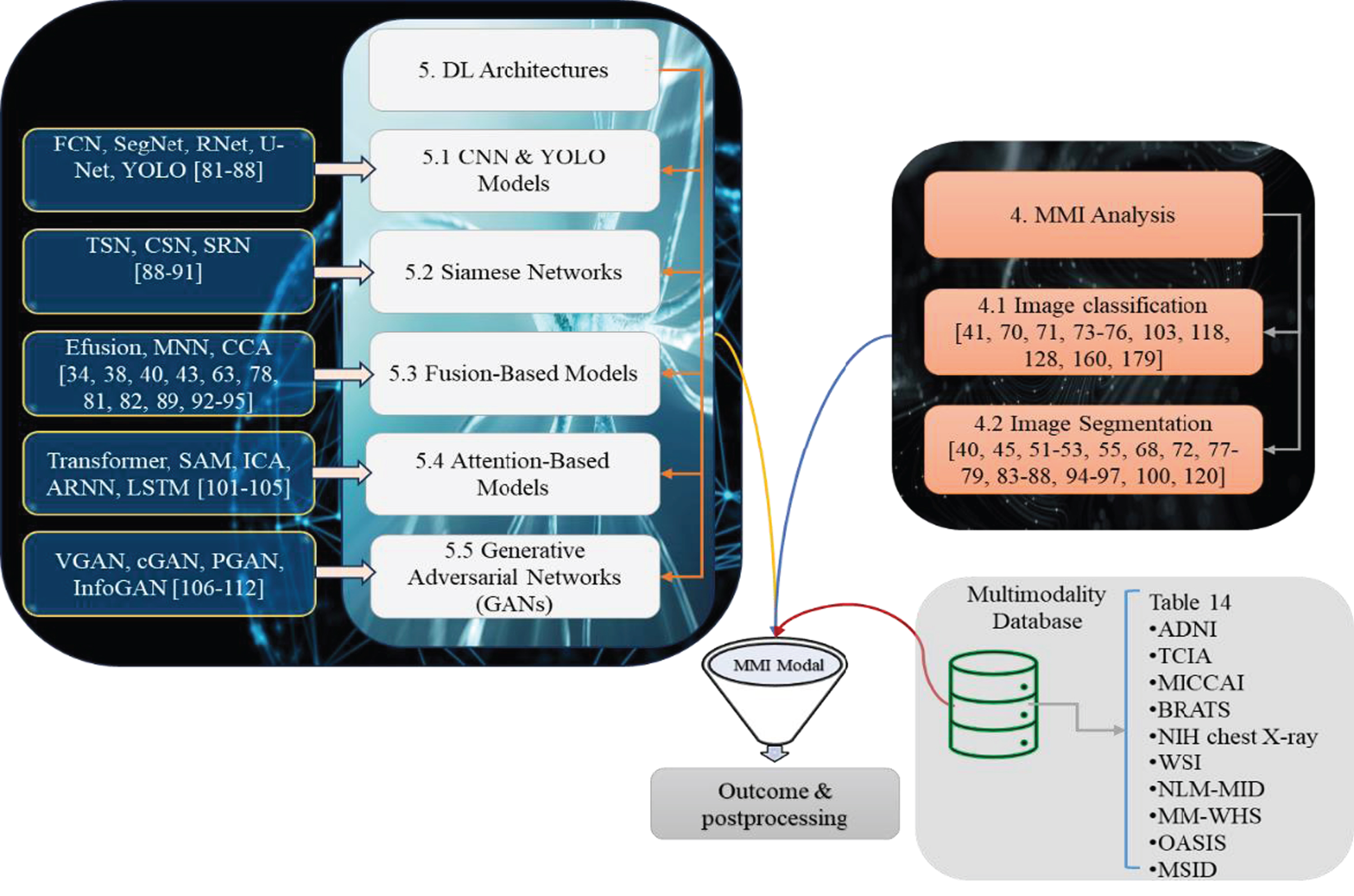
DL-based multimodality image analysis architecture.
In terms of dataset features, we reviewed the dataset’s public availability, as well as the study population, which includes total data size, training, testing, and validation data size, and is used to illustrate the usefulness of the suggested methodologies. The dataset’s heterogeneity in tumor structure, size, and location is also taken into account. We also evaluate the cross-testing feature, which accounts for the dataset’s high unpredictability and complexity. Data from a single or several sites are used in cross-testing. We label a data set as cross-testing if it comes from various centers and some of the data is utilized for training and some for testing. It is also being studied whether data augmentation and pre/post-processing approaches have been employed to improve tumor segmentation performance. The type of cancer or anatomical interest of the region is also summarized.
Evaluation measures such as dice similarity coefficient (DSC), intersection over union (IoU), sensitivity, precision, recall, and C-index were employed to describe model performance. The metrics DSC and IoU are used to assess the agreement between expected and actual results. The measurement measures accuracy, sensitivity, precision, and recall are used to calculate the segmentation model’s fraction of true positives and negatives. The C-index is used to examine the consistency between anticipated risk and survival status in a survival prediction task (Harrell et al., 1996). There is no gold standard for assessing model performance; instead, most models are assessed using a variety of criteria. DSC is a frequently used segmentation statistic that measures the similarity between forecasts and ground realities. As a consequence, we provided the DSC value in the comparison table, and the findings of additional diagnostic measures are also addressed while examining the research in the appropriate parts. Finally, we indicate if the proposed study’s implementation code is publicly available. The availability of implementation code as a foundation model improves repeatability and promotes the notion of transfer learning in order to construct more robust distribution models.
DL-based techniques have become effective for assessing clinical images from different modalities in recent decades. DL has intensified the quality and efficiency of medical image analysis by automatically learning key features from raw image data. DL has significantly improved Image Registration, Image Segmentation, and Image Classification [21–25].
Image classification
In recent years, there has been outstanding progress in DL-based image classification methods, signifying significant advancements in this domain. These methods have been effectively implemented in image classification tasks in multimodal medical imaging, yielding promising outcomes. One particularly noteworthy contribution in this field is the TransMed model, as proposed by Yin Dai et al. (2021), which specifically focuses on the classification of multimodal medical images. By capitalizing on the capabilities of CNNs and transformers, the TransMed model successfully addresses the existing limitations within this domain. The remarkable front of this model is its performance, which has far surpassed that of the CNN-based model, as demonstrated by two distinct data sets. TransMed’s achievements have significantly improved 10.1% and 1.9%, respectively. This exceptional accomplishment not only underscores the potential of the TransMed model but also instils optimism regarding its applicability to various tasks involving the analysis of medical images [73].
M Xiao et al. (2020) [74] addresses the challenges in diagnosing and classifying gliomas, the most common brain tumors. It introduces two convolutional neural network models: a 2D ResNet-based model for pathology image classification and a 3D DenseNet-based model for MRI image classification. These models achieved first place in the CPM-RadPath-2019 challenge for classifying different grades of gliomas. K Takahashi et al. (2022) [75] explore the utility of DL models in improving the accuracy of PET- CT image classification for breast cancer (BC). Using images with multiple degrees of PET maximum-intensity projection (MIP), DL models trained on 400 images showed promising results, outperforming radiologists in sensitivity and specificity.
Jiapeng Zhang et al. (2022) [76] introduces a DL-based method for classifying multiple organ-specific cancers using PET/CT images, aiming to assist radiologists in cancer screening. The proposed method incorporates a modality fusion module to fuse PET and CT images with segmented multi-organ information. Grayscale transformation and a double-level V-net are utilized for organ segmentation in low-dose CT images, addressing data annotation challenges and enhancing image context information. The classifier achieves an F-score of 82.3%, demonstrating its potential to aid radiologists in cancer screening across six classes.
Image segmentation
DL-based approaches have shown significant promise in improving the precision and efficiency of segmentation, marking an important milestone in the MMI field. It is worth noting that attention mechanisms have emerged as a notable breakthrough in this sector, promising to improve segmentation accuracy by selectively concentrating on pertinent characteristics. This promising aspect was underscored by the research conducted by Guo Zhe et al. (2019), who made a substantial contribution by introducing a supervisory MMI analysis method based on DL. Their study specifically concentrated on segmenting soft tissue sarcoma lesions using MRI, CT, and PET. Their investigation revealed that fusing different network levels can yield superior outcomes compared to solely analyzing single-modal images. This finding assumes paramount significance as it furnishes invaluable guidance for developing multi-modal image analysis techniques [45].
Multimodal medical image segmentation (MMIS) is a vital challenge in obtaining relevant information from several imaging data sources. Advances in this subject help to enhance clinical decision-making and provide a better knowledge of complicated biological and environmental events. MMIS pertains to the intricate and convoluted process of characterizing and delineating distinct anatomical structures or regions of interest that are visible in medical images produced using a variety of imaging modes. This complex endeavor necessitates the utilization of sophisticated image processing and analysis methodologies that aim to extract vast amounts of information-rich data from each pattern, followed by the harmonious integration of these data sets to generate precise and all-encompassing segmentation. The primary objective of MMIS is to enhance the accuracy and comprehensiveness of medical image analysis by harnessing the complementary advantages provided by different imaging models.
The endeavour of MMIS presents a formidable challenge due to the variations in image characteristics, intensity distribution, and spatial resolution observed across different modes. However, it also holds immense potential for harnessing each modality’s diverse and complementary information, thereby opening avenues for enhanced precision and adaptability in the generated segmentation outcomes. This perspective is fortified by the findings of earlier investigations [40, 77], which support the assertion mentioned earlier.
Several approaches have been developed for MMIS. One common approach is to perform modality-specific segmentations independently and then fuse the results using registration techniques to ensure spatial alignment. Another approach is to directly incorporate the information from multiple modalities into a unified segmentation framework by exploiting the similarities and differences in intensity patterns.
ML and DL techniques have also been effectively utilized in the field of MMIS, whereby they have demonstrated remarkable efficacy. These techniques leverage diverse and comprehensive information derived from various models to construct highly accurate models capable of classifying structures of interest with precision and accuracy. In particular, CNNs and other intricate architectures are frequently employed in these methods, as they can establish intricate nonlinear associations between input images and their corresponding segments [77–79]. The employment of ML and DL methodologies in MMIS has yielded significant achievements due to their ability to exploit the vast array of information accessible in different models. By virtue of these techniques, models can be trained to precisely and accurately segment structures of interest present in medical images. Furthermore, the performance of these models can be further augmented through the utilization of CNN or other advanced architectures, as they effectively assimilate the intricate nonlinear relationships between input images and their corresponding segments [77–79].
The segmentation outcomes derived from MMIS possess many practical and scholarly applications within clinical practice and research. These applications span a broad spectrum of disciplines, encompassing treatment planning, image-guided intervention, surgical navigation, disease diagnosis, and treatment response monitoring. In order to facilitate the process of quantitative analysis, accurate volumetric measurement, tracking of disease progression, and the effective utilization of computer-aided diagnostic systems, it becomes imperative to acquire precise and dependable segmentation results.
There is no doubt that the task of MMIS presents a formidable challenge, yet it undeniably holds paramount importance within medical imaging. This task capitalizes on the advantages of various imaging modalities to construct all-encompassing and exceptionally precise segments, which in turn provide invaluable aid in diagnosis, treatment planning, and patient management. The continuous advancement of sophisticated algorithms and technological innovations within this specific field has, without a doubt, played a significant role in propelling noteworthy progress in medical imaging, ultimately leading to enhanced levels of patient care and prognostic capabilities.
Common challenges in multi-modal medical image segmentation
Multi-modal medical image segmentation poses several challenges due to the complexities of integrating and analyzing data from multiple imaging modalities [40, 80]. Some of the key challenges include:
Related survey of multimodal DL architectures
In medical image analysis, numerous architectures of DL have been meticulously crafted to cater to the distinctive requirements of scrutinizing medical images procured through various modalities. These techniques and models, which are grounded in DL, have been painstakingly designed and implemented with the objective of unearthing the potential complexities found within vast collections of medical images. By seamlessly integrating multiple models within their framework, these techniques and models can extract information and insights, facilitating accurate and comprehensive analysis. In order to demonstrate the extensive range and profound nature of these multi-modal DL architectures, this article presents several noteworthy instances.
2D & 3D CNNs and YOLO based models
In this section, we will discuss the segmentation approaches that employ a DL model, specifically CNN and FCN, SegNet, RNet, U-Net, VNet, WNet and YOLO based models for tumor detection and classification. The advantages of CNNs over traditional ML models can be summarized as, (1) minimum preprocessing for input data requires. (2) automating the feature engineering (3) reducing the number of learnable parameters (Jose Dolz et al., 2018). It is one of the most often exploited DL models for the detection, classification, and segmentation model for medical images (J. Sun et al., 2021). 3D CNN was created to assess health images obtained from various modalities, such as MRI and CT. The fundamental benefit of using 3D CNNs is their capacity to immediately extract significant information about the spatial and temporal properties inherent in three-dimensional picture data. As a result, when compared to their two-dimensional counterparts, 3D CNNs have outperformed them. This performance improvement can be vividly exemplified through the notable work conducted by Mohammed Oves and his colleagues in the year 2023. Oves et al. successfully used DL technology to solve the complicated challenge of reliably identifying large-scale medical imaging data, including two-dimensional and three-dimensional pictures. The team’s proposed deep volume classification network showcases remarkable efficiency by skillfully amalgamating and integrating multiple depth features, culminating in highly commendable performance outcomes. Specifically, the area under the curve (AUC) value attained an impressive 93.66%, as the corresponding papers reported [81, 82] values.
Zhao et al. 2018, [83] presented 3D FCN for brain tumor segmentation, which included multi-task learning and feature fusion modules. In the multi-task learning module, VNet style architecture was used to extract high-dimensional characteristics from each imaging modality (PET-CT). The feature fusion module accepts the feature maps as input and executes feature re-extraction procedures using four convolution layers fusion networks. The proposed model’s performance was verified against State-of-The-Art (SOTA) VNet (Milletari et al., 2016 [84]), WNet (Xu et al., 2018 [85]), and fuzzy c-means clustering approaches using a lung cancer dataset of 84 patients. According to the results, the suggested co-segmentation approach achieved a DSC of 0.850 with classification and volume error values of 0.330 and 0.150, respectively.
YOLO has the ability to properly detect and accurately pinpoint the placement of objects inside an image or video frame. Tao Zhou et al., 2023 [86] proposed A Cross-modal Cross-scale Clobal-Local Attention YOLOV5 Lung Tumor Detection Model (CCGL-YOLOV5). They used stochastic gradient descent (SGD) with Localization Loss cost function for performance match. The CCGL-YOLOV5 model achieved an accuracy of 97.83%, a recall rate of 97.39%, an average accuracy of 96.67%, an F1 score of 97.61%, and a frames per second (FPS) of 98.59% on the multimodal lung tumor PET-CT data set. The experimental results demonstrate that the performance of the CCGL-YOLOV5 model in this study surpasses that of other conventional models. Moreau et al. 2021, [87] proposed UNet-based UNet BL and UNet FL models for breast cancer metastatic lesions segmentation and treatment response monitoring with longitudinal whole-body PET-CT scans as input. The baseline model UNet BL was trained on baseline PET-CT images for segmenting baseline lesions, while the follow-up UNet FL model was trained on four inputs: two for follow-up PET and CT, two for baseline PET, and output of UNet BL as baseline lesions segmentation. The proposed models were evaluated on the EPICURE seinmeta dataset consisting of 60 patients with 60 baseline and 104 follow-up images. The results explain that UNet BL and UNet FL achieved a mean DSC score value of 0.66 and 0.58, respectively.
Joonas Liedes et al. (2022) [88] study the the applicability of a convolutional neural network in detecting and auto-delineating Head and neck squamous cell carcinoma (HNSCC) from PET-MRI data. They employed a U-net model described in that was built using the TensorFlow Keras version 2.5.0 framework in Python version 3.7.10. The model was trained to identify the main tumor and any metastasis in the PET-MRI slices. In addition, models trained just with PET slices and models trained with augmented PET-MRI slices were created. The model based on PET-MRI attained a precision of 0.71 by employing a 9-pixel classification fidelity. It exhibited specificity and sensitivity values of 0.68 and 0.77, respectively. Conversely, the pure PET model displays a greater susceptibility to false positives, despite its sensitivity being comparable to that of the PET-MRI model. Models trained using augmented PET-MRI data yielded sensitivity, specificity, and precision values of 0.53, 0.77, and 0.65, respectively. The summary of the CNNs and YOLO-based network tumor detection models is presented in Table 5.
CNNs and YOLO architectures for tumor detection
CNNs and YOLO architectures for tumor detection
The Siam Network, a neural network architecture that has emerged as a viable solution for facilitating image registration and alignment of various modes, exhibits a distinct characteristic comprising two identical subnets. These subnets not only possess identical sets of weights but also possess the capability to encode two dissimilar images into fixed-length characteristic vectors. Leveraging this shared weighting scheme, the Siam network undertakes a comparative analysis of these characteristic vectors, thus enabling the determination of similarity between the two images.
In a recent investigation by Ahmed Sabeeh Yousif et al. (2022), the authors acknowledge the pressing need for accurate disease diagnosis within medical imaging. More specifically, they concentrate on the crucial task of multi-modal image fusion and endeavor to introduce an innovative approach that successfully amalgamates two potent techniques: sparse representation and orthogonal matching pursuit (OMP) with Siamese convolutional neural network (SCNN) methods. By seamlessly integrating these methods, the researchers aspire to tackle several pivotal challenges, including the augmentation of pixel positioning, the refinement of sparse characteristics, and the mitigation of undesirable artifacts. Ultimately, their proposed approach strives to yield superior fusion outcomes within the medical imaging domain when juxtaposed with previously employed methodologies [89].
Zhaisheng Ding et al. (2021), [90] proposed a study on tumor detection from PET-MRI, a critical aspect of medical imaging. They introduce a novel framework that combines the local extrema scheme (LES) and a Siamese network to improve efficiency and overcome limitations in tumor detection. Through extensive experiments and analysis, the proposed approach demonstrates superior performance compared to existing methods, offering promising advancements in tumor detection within medical imaging. Ning Xiao et al. (2022), [91] proposed a Siamese Pyramid Fusion Network (SPFN) and introduced feature pyramid transformation to the Siamese convolution neural network to extract multi-scale information from the fusion of PET and CT images to detect lung tumors. Their findings concluded that the proposed fusion-based Siamese method has a particular competitive performance in the quality improvement and information retention of PET-CT. A summary of the Siamese network-based models is presented in Table 6.
Siamese Networks architecture models for tumor detection/classification
Siamese Networks architecture models for tumor detection/classification
A specially designed model based on fusion has been meticulously created to effectively merge and amalgamate the extracted information from various models, resulting in a substantial enhancement of the precision and reliability of medical image analysis. “Image fusion generates an informative composite image, which can promote the performance of subsequent computer vision tasks. In this domain, multimodal medical image fusion has drawn increasing attention due to its significant clinical applications, including tumor segmentation, cell classification, neurological research, and treatment strategies for recurrent high-grade gliomas” [92]. A novel DL-based multimodal medical image fusion method via a multiscale adaptive Transformer called MATR was proposed by Wei Tang et al. (2022), [92] for analysing SPECT-MRI images from the Harvard database. They adopted seven representative and state-of-the-art methods for qualitative and quantitative comparisons. On the whole, when compared with the proposed MATR, the other seven algorithms have several drawbacks. The multi-modal deep neural network (MDNN) is a renowned example of a fusion-based model that has received significant attention and accolades for its outstanding capacity to smoothly integrate numerous layers of varied modes inside the depths of neural networks. Many references have validated and supported this exceptional result, further consolidating its fame and relevance in medical image analysis [34, 38, 40, 43, 63, 78, 81, 82, 89, 93–95].
Lei Bi et al. (2021), [96] propose a recurrent fusion network (RFN) for automatic PET-CT tumor segmentation. Their recurrent fusion network (RFN) consists of multiple recurrent multi-modalities down sampling (RMD) and up sampling (RMU) processes, which are connected via interconnect link modules (ILMs) backed with ResNet, DenseNet and 3D-UNet. According to their statement, the considerable improvement (> 5% in DSC) of RFN to 3D-UNet suggests that RFN can alleviate this training initialization limitation for 3D-based FCNs. A. Kumar et al. 2019, [54] checked CNN with fused inputs (FSs), multi-branch (MB) and multi-channel (MC), and found that CNN had a significantly higher foreground detection accuracy (99.29%, p <; 0.05) than the fusion baselines (FS: 99.00%, MB: 99.08%, and TC: 98.92%) and a significantly higher Dice score (63.85%) than the recent PET-CT tumor segmentation methods. Sebastian Jinu et al. (2022) [97] proposed a novel technique for fusing PET-MRI images using the YUV color space and wavelet transform. The fusion aims to integrate complementary information from both modalities for enhanced diagnosis. Comparative analysis suggests that the Dmey wavelet at decomposition level 3 and the maximum fusion rule yield optimal results for brain tumor detection. Quality assessment confirms promising outcomes for medical image fusion. The summary of the Fusion network-based models is presented in Table 7 with added articles referenced as [98–100].
Fussion-based networks architecture models for tumor detection/classification
Fussion-based networks architecture models for tumor detection/classification
In the vast realm of medical imaging, attention-based models have been subjected to extensive research and development to concentrate on pertinent features prevalent effectively and selectively in images procured from a myriad of models. These intricate models harness the power of attentional mechanisms, allowing them to direct their focus toward specific areas within an image that encompasses the utmost informational value of a given task. Through the utilization of attention mechanisms, attention-based models have proven to be exceedingly efficacious in their ability to discern and prioritize the most germane and pivotal regions present in images, consequently leading to a noteworthy enhancement in the overall performance and precision of medical image analysis and interpretation [101].
M Fallahpoor et al. 2023, [102] conducted a comprehensive investigation focused on using AI and DL on PET-CT images and its use in oncology, neurology, cardiology, and other emerging medical fields. Their review underscores the power of DL in PET-CT imaging, with successful applications in lesion detection, tumor segmentation, and disease classification with special focus on Attention-based models. Xiao Yang et al. 2022, [103] present a multimodality relation attention network (MMRACR-net) for breast tumor classification that uses consistency regularization. A multi-modality relation attention module (MMRAM) and a classification consistency module (CCM) are included in the suggested network. The MMRAM investigates the correlation information between two modalities to learn the attentive aspect of each. The CCM provides classification consistency by reducing the classification difference between the diffusion-weighted imaging (DWI) and apparent dispersion coefficient (ADC) image modalities. The summary of the Attention-Based Models is presented in Table 8 with added articles referenced as [104, 105].
Attention-Based Networks architecture models for tumor detection/classification
Attention-Based Networks architecture models for tumor detection/classification
GANs are commonly employed in image-to-image translation, where their primary objective is to ease image conversion between discrete modes. The generator and the discriminator are the two subnets that comprise the base GAN. Together, the generator and discriminator produce the desired results. The generator performs a critical part in ensuring the effective translation process by creating an image that closely resembles the target mode. On the other hand, the discriminator has been explicitly taught to discriminate between the produced image and the genuine one. This complex interaction between the generator and discriminator enables GANs to efficiently produce visually cohesive and contextually accurate translations across various languages.
In the field of MMI analysis, GAN has become a strong and significant technology, demonstrating its potential and effect. GAN makes synthesizing realistic and coherent multimodal images possible, representing a significant achievement in the field. This accomplishment is made feasible by teaching the generator to create synthetic samples that are so reliable that they can almost be mistaken for real images. Additionally, discriminators are taught to distinguish between genuine and synthetic samples with skill, which adds to the overall effectiveness of this system. GANs have a wide range of uses in multimodal analysis, with numerous potential applications. Multimodal image synthesis, which entails the production of missing modalities to acquire a comprehensive and holistic perspective of a patient’s overall status, is one of the main uses of GANs in this context. The capacity to more thoroughly assess and evaluate a patient’s medical condition makes this capability very valuable. The enhancement of domain adaptability is another essential function of GANs. Domain-invariant expressions can be learnt by aiding knowledge transfer from one modality to another or from a source domain to a target domain using the power of GAN. This is incredibly helpful when data gaps exist across different imaging modalities, scanners, or agencies or when annotated data is lacking. To advance the MMI analysis field, overcoming these obstacles and creating links between other disciplines [106–108].
A. Liebgott et al. 2019, [109] used 2D Conditional GAN backed with preprocessing techniques contrast-limited adaptive histogram equalization (CLAHE), Histogram Matching (HM) and Gaussian blurring (GB) on PET-CT images. The average mean square error (MSE = 0.7107) score was achieved. The summary of the GANs-Based Models is presented in Table 9 with added articles referenced as [51, 53, 110–112].
GANs architecture models for tumor detection/classification
GANs architecture models for tumor detection/classification
Various research investigations have demonstrated the effectiveness of DL-based approaches in the analysis of MMI. These investigations propose that disease detection, segmentation, and classification precision have been enhanced under diverse imaging models. Comparisons with conventional techniques frequently emphasize the superior performance and potential to offer more comprehensive and personalized patient care in addressing the intricacies and disparities of MMI.
Based on our extensive review of literature sources and findings, it is evident that models such as U-Net, ResNet, DenseNet, and their multiple variants are widely used in the medical imaging field to accomplish tasks such as segmentation, detection, and classification. Nonetheless, the effectiveness of these models depends on the specific task being addressed, the dataset used, and numerous other factors that exert their influence.
From our findings 2D CNNs and YOLO based perform well on PET-CT data sets where Siamese Networks achieved good score on PET-MRI and CT-MRI datasets. Fusion and attention-based models are highly employed in PET-CT, SPECT-CT, and PET-MRI multimodality imaging analysis and results were superior in case of PET-CT, SPECT-CT. The GANs based models are mostly employed for PET-CT data set analysis according to our findings.
Most frequently used modalities and DL architecture in MMI analysis
According to our findings PET-CT is one of the most used multimodality imaging techniques in healthcare for tumor detection segmentation and classification compared to other, while Fusion and GAN based DL architectures are multimodality imaging analysis. Table 10 reveals some facts about different modalities and DL architecture with respect to published articles from 2019 to 2023.
Distribution selected articles on Multimodalities imaging and DL Architectures (2019–2023)
Distribution selected articles on Multimodalities imaging and DL Architectures (2019–2023)
Numerous research studies have documented substantial enhancements in the accuracy of multimodal image analysis utilizing DL in contrast to traditional approaches. As an illustration, in 2019, a study by Tohidul Islam et al. concentrated on the segmentation of brain tumors, where multimodal DL achieved an astonishing accuracy rate of 98%, surpassing the performance of traditional techniques [113]. The study also presented several compelling discoveries, some elaborated upon in Table 11.
DL based models’ tumors segmentation and performance (mean and standard deviation of a five-fold cross-validation) from various authors. The best results for each metric are shown in bold
DL based models’ tumors segmentation and performance (mean and standard deviation of a five-fold cross-validation) from various authors. The best results for each metric are shown in bold
DL methods that integrate data from diverse imaging modes are typically more advantageous compared to single-modal methods when it comes to performance and accuracy. In a comprehensive investigation conducted by Guo et al. (2018), scholars harnessed DL technology to identify soft tissue sarcomas by utilizing MMI, such as MRI, CT, and PET. To augment the process of segmentation, the researchers put forth an image fusion architecture, which is visually depicted in Fig. 9. Astonishingly, despite the potential challenges associated with robustness, the authors discovered that the most optimal outcomes were achieved by amalgamating information at the feature level [77]. Furthermore, the authors expounded on the efficacy of their proposed approach and showcased sample label maps that were generated by employing a type I fusion network that incorporated PET, CT, and T2 images (Fig. 10). As evidenced by the visualization, it becomes abundantly clear that the CNN model, which was trained on the accumulated data, effectively predicted the contour of the tumor area with exemplary precision.
Illustration of the structure for (a) type-i fusion networks, (b) type-ii fusion network and (c) type-iii fusion network. The yellow arrows indicate the fusion location [45].
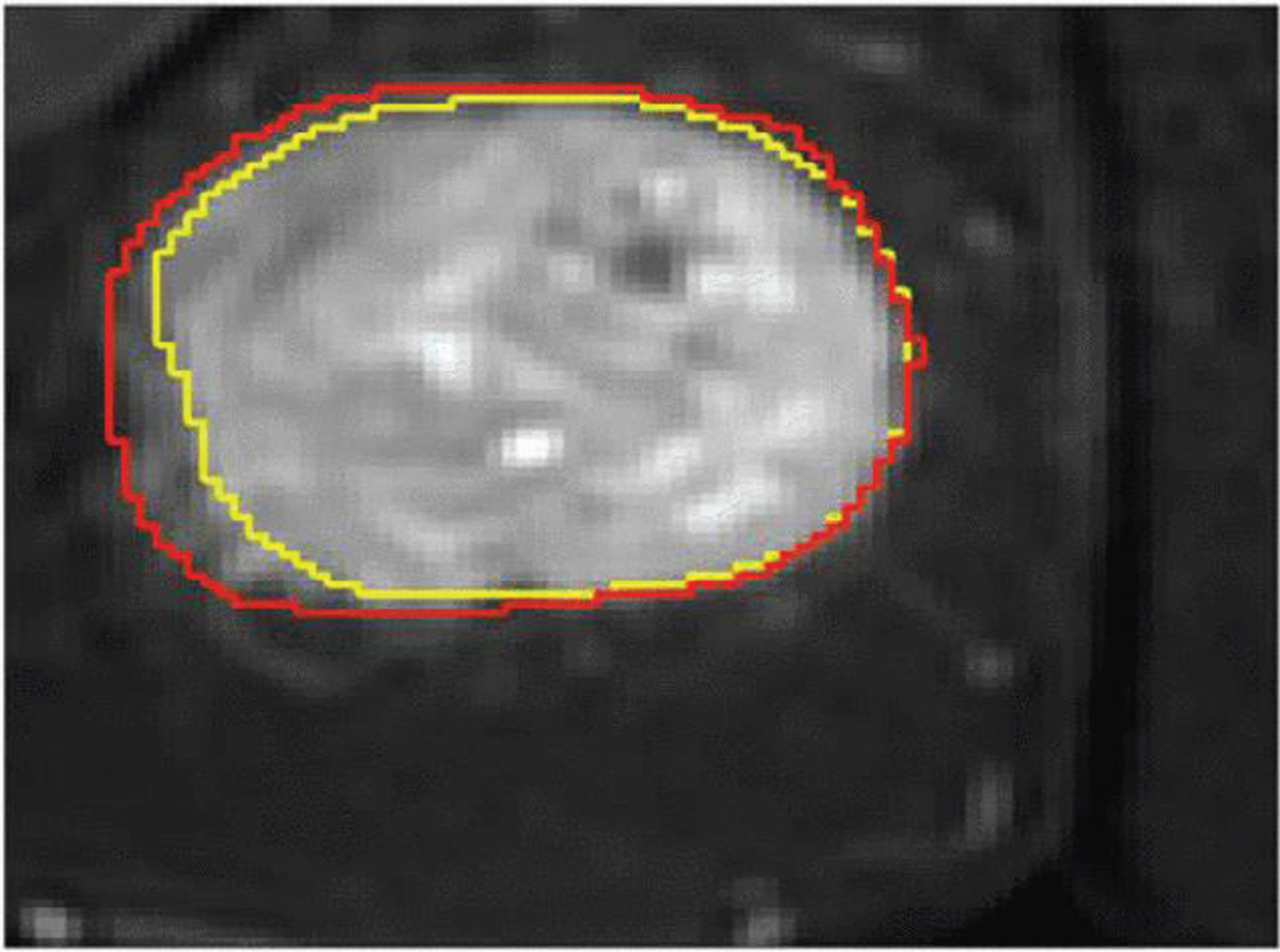
Contour line of the ground truth annotation (yellow line) and labelmap (red line) overlaid on the T2-weighted MR image from one randomly selected subject [77].
According to a study by Nahed Tawfik et al. (2021), [114] intramodality fusion improves performance in multimodality imaging. The article highlights the significance of combining images from various imaging modalities to enhance image quality and clinical applicability. It discusses how medical image fusion captures complementary information from modalities like MRI, PET, CT, etc., aiming to address their limitations. While existing fusion methods have shown promising results, the article emphasizes the need for further advancements to tackle emerging challenges. This comprehensive survey serves as a valuable resource for researchers in the field, laying the groundwork for developing more effective fusion techniques to improve medical imaging applications.
Manoj Diwakar et al., [115] introduced a novel method for multi-modality medical image fusion using shearlet domain processing. Input images undergo non-subsampled shearlet transform (NSST) decomposition, with base and detail layers fused using a local extrema (LE) approach and Co-occurrence filter (CoF). High-frequency components are fused using sum-modified Laplacian (SML) for edge preservation. The comparative analysis demonstrates superior edge preservation with the proposed method over existing techniques, validated through subjective and objective evaluations on multi-modal medical image datasets.
According to Niharika S.D Souza et al. (2024) [116] multiplexed graphs approach using a graph neural network, which enables task-informed reasoning to effectively fuse information from multiple modalities. Evaluation of benchmark datasets and clinical data for Tuberculosis treatment outcome prediction and autism spectrum disorder classification demonstrates robust performance improvements over state-of-the-art methods.
Accurate breast cancer prediction and prognosis is very important for treatment planning and quality life of patients. Integrating multi-modal data like genomics and pathology images enhances predictive accuracy. Existing approaches face challenges: the Kronecker product technique is computationally expensive, and methods often overlook modality-specific relations. To address these challenges, Honglei Liu et al. (2024) [117] propose an attention-based multi-modal network that efficiently captures both intra-modality and inter-modality relations without high-dimensional features. their method outperforms existing approaches in breast cancer prognosis prediction.
The application of DL has demonstrated remarkable efficacy in various tasks, including segmentation and lesion localization. In a recent investigation conducted by Guo Zhe et al. (2019), the primary objective was to accurately outline the lesion profile of soft tissue sarcoma, a significant challenge in medical imaging. The researchers discovered that DL-based segmentation surpasses other existing methods, particularly when utilizing multi-modal images and integrating fusion techniques into networks [45]. The investigation’s findings in Fig. 11 include performance comparisons obtained through several model combinations. Moreover, Fig. 12 visually presents the obtained results when executing the same task using a single-modal network. These visual representations further emphasize the benefits of DL-based segmentation in lesion contouring and localization. Extensive research has established that utilizing multi-modal images alongside fusion techniques in DL networks constitutes an effective approach to enhance the precision and accuracy of lesion segmentation, thereby facilitating improved diagnosis and treatment planning for patients afflicted with soft tissue sarcoma. The results of this study profoundly contribute to the field of medical imaging and underscore the potential of DL to enhance the clinical prognosis of sarcoma patients. Overall, DL-based segmentation technology has raised as a valuable practice in medical imaging, offering a promising avenue for further research and development in this domain.
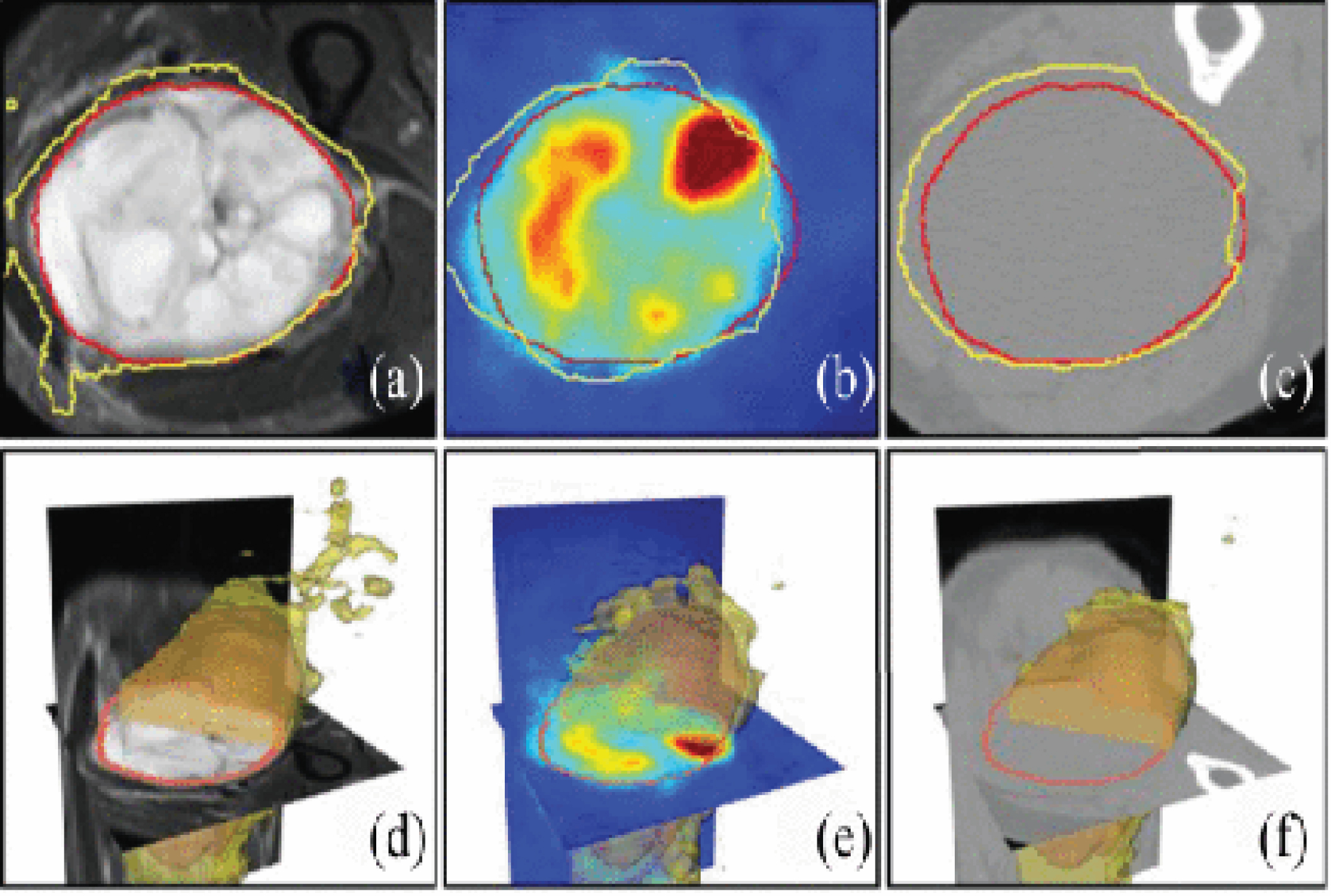
Contour line of the ground truth annotation (red line) and segmentation result (yellow line). (a) Single-modality network on T2. (b) Multimodality network on T2 + PET (Type-I). (c) Multimodalities network on T2 + PET+CT. (d)–(f) 3-D surface visualization of the segmentation results in (a)–(c) [45].
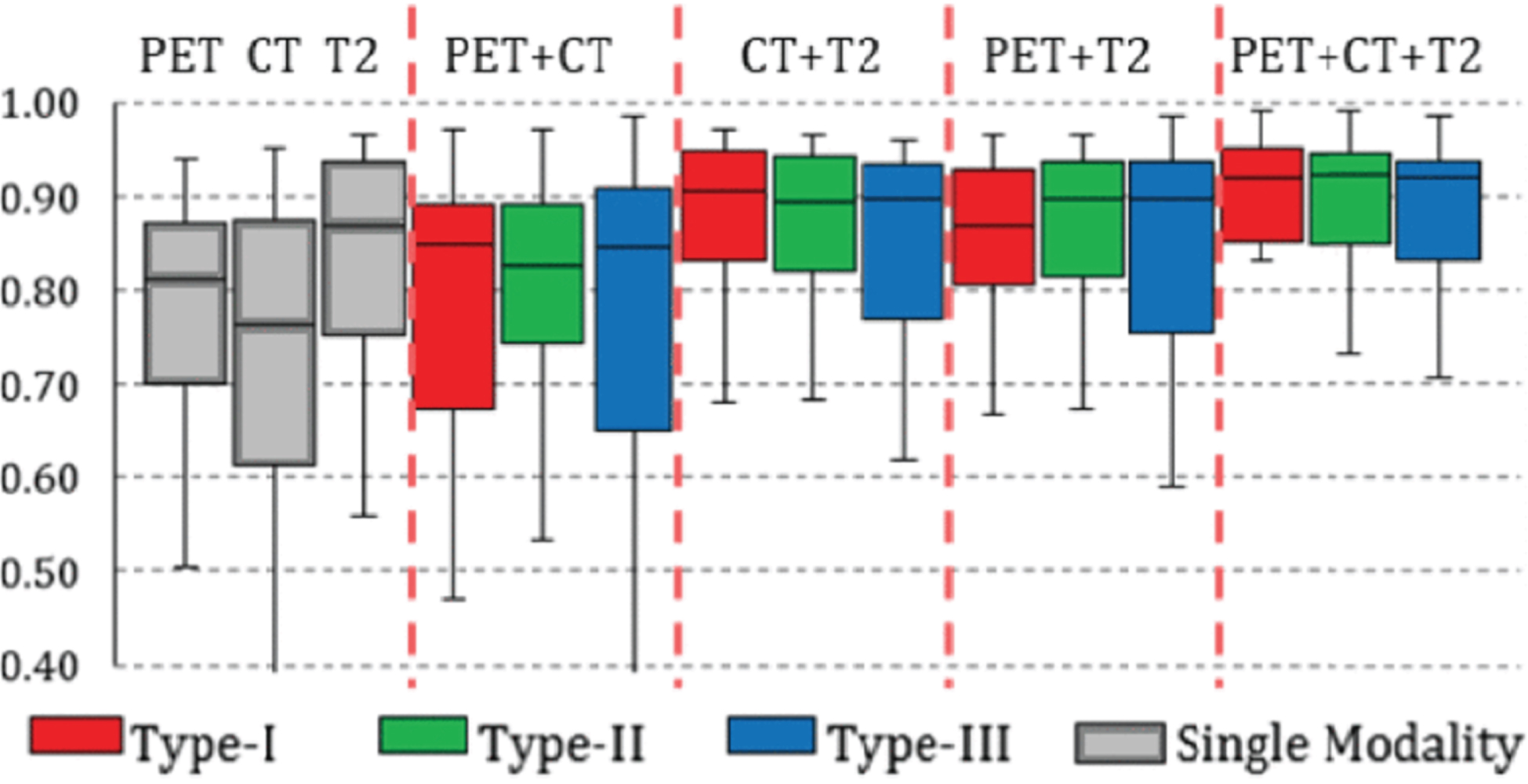
Box chart for the statistics (median, first/third quartile and the min/max) of the DICE coefficient across 50 subjects. Red box stands for network train and test on Type-I network, blue box stands for Type-II network, and green stands for Type-III. Performances of single-modality network are shown as gray boxes to the left for reference [45].
The selection of PET-CT, PET-MRI, and SPECT-CT modalities for the purpose of medical image analysis is contingent upon the precise clinical scenario, the requisite information, as well as the inherent merits and constraints associated with each model. Each individual model possesses distinct advantages and is typically determined based on the precise clinical investigation at hand.
PET-CT combines functional and anatomical information in a single scan and is excellent for cancer imaging, as it provides metabolic information (PET) along with detailed anatomical localization (CT). It is widely used for cancer staging, treatment planning, and monitoring. Very high radiation exposure due to the CT component is one of the shortcomings of this technology. It has limited soft tissue contrast compared to MRI. PET-MRI provides functional information (PET) and excellent soft tissue contrast (MRI) with no ionizing radiation exposure in the MRI component. It is an ideal technology for imaging soft tissues and neurological conditions. Longer scan times compared to PET-CT, limited availability and higher cost are the shortcomings of this technology. SPECT-CT combines functional information (SPECT) with anatomical localization (CT) and is widely used in nuclear medicine for various applications, including bone scans and myocardial perfusion imaging with lower radiation dose compared to PET-CT. Limitations: Lower spatial resolution compared to PET. Limited in soft tissue imaging compared to MRI. Selection Criteria: Cancer Imaging: For comprehensive cancer imaging, especially in staging and treatment monitoring, PET-CT is often preferred due to its ability to combine metabolic and anatomical information. Neurological Imaging: PET-MRI is valuable for neurological conditions where soft tissue contrast is crucial. It avoids ionizing radiation and provides detailed information about brain structures and functions. Bone Scans: SPECT-CT is commonly used for bone scans, providing functional information about bone metabolism along with precise anatomical localization. Soft Tissue Evaluation: In scenarios where soft tissue evaluation is a priority and ionizing radiation is a concern, PET-MRI may be preferred.
The ultimate determination hinges upon the clinical indications, the precise information requisite, and the equilibrium between the advantages and disadvantages of each paradigm. In various clinical scenarios, the progress in technology and the continuous investigation may sway individuals’ inclinations towards a particular model as opposed to another. It is of utmost importance for healthcare professionals to meticulously mull over the distinct prerequisites of individual patients when ascertaining the most suitable imaging model.
The selection of a DL framework for the purpose of identifying and categorizing tumors in multimodal imaging is contingent upon various factors, such as the distinctive characteristics of the data, the intricacy of the undertaking, and the available resources. Different architectures have shown success in different scenarios. Here’s a brief overview of each type:
Convolutional Neural Networks: CNNs are well-suited for image-based tasks and have succeeded highly in tasks such as image classification and segmentation. They automatically learn hierarchical features from the input data, making them effective for capturing patterns in medical images. CNNs can be applied to each modality individually or to fused multimodal images for tumor detection and classification.
Siamese Networks: Siamese Networks are designed for tasks like image similarity and dissimilarity. They can be used for comparing and contrasting different regions within the same or across different modalities. Siamese Networks can be beneficial when comparing corresponding regions in multimodal images to identify tumor characteristics.
Fusion-based Networks: Fusion-based networks combine information from multiple modalities to enhance overall performance. They leverage complementary information from different modalities, improving the model’s ability to detect and classify tumors. When dealing with multimodal imaging, fusion-based networks can effectively combine PET, CT, MRI, or other modalities to provide a more comprehensive analysis.
Attention-based Models: Attention mechanisms allow the model to focus on specific regions of interest, improving interpretability and performance. It is useful for emphasizing relevant information in multimodal images for tumor detection. Attention-based models can be applied to highlight important features in each modality or guide the fusion process in multimodal tumor classification.
Generative Adversarial Networks: GANs can be used for generating synthetic data, potentially augmenting limited datasets in medical imaging. They may aid in enhancing the quality of images, which can be valuable for training more robust tumor detection models. GANs can be used for data augmentation or for generating realistic images that simulate various tumor characteristics.
Choosing the Best Model: The choice depends on the nature of the imaging data, the availability of labeled samples, and the specific requirements of the task. For multimodal imaging, fusion-based networks and attention-based models are often beneficial to leverage the complementary information from different modalities. Siamese Networks might be useful for tasks involving direct comparisons between regions or structures in different modalities. Data availability, computational resources, and interpretability considerations should also guide the selection. Ultimately, the “best” model depends on the specific context and requirements of the tumor detection and classification task in multimodality imaging. Experimentation and comparative evaluations on the specific dataset of interest are often necessary to determine which model performs optimally.
Clinical validity
The clinical effectiveness of DL models holds immense significance due to their pivotal role in determining their applicability and dependability. A study conducted by Yinhao Wu et al. (2022) focusing on the classification of skin cancer has shed light on the potential and practicality of DL in the field of clinical practice, thereby showcasing its viability. Nonetheless, it is imperative to highlight that further validation is indispensable to ascertain the strength and reproducibility of these models, especially when considering different cohorts of patients. The requirement for additional validation arises from the acknowledgment that the efficacy and effectiveness of the DL model can potentially vary across diverse patient groups, thereby necessitating a comprehensive evaluation and validation process to ensure its clinical utility [118]. Recent interest in AI, machine learning, and DL in cardiovascular medicine promises personalized care through advanced CV imaging applications [119]. DL models can simultaneously analyze diverse imaging modes, thereby enabling the enhancement of tumor diagnostic accuracy through the utilization of additional data furnished by each model. In the realm of oncology, the amalgamation of MRI and PET images serves to furnish a more thorough comprehension of tumor characteristics, exemplifying this phenomenon. For instance, DL algorithms can accurately delineate tumor boundaries across MRI, CT, and PET images, facilitating precise radiotherapy planning [120–124].
A study by Ahmed Hosny et al. (2022) [125] presents a comprehensive clinical validation strategy for DL models in segmenting primary non-small-cell lung nodules (NSCLC) tumors and lymph nodes from PET-CT images. It includes interobserver and intraobserver benchmarking, primary validation on multiple datasets, functional validation, and end-user testing. Results demonstrate improved segmentation accuracy over interobserver benchmarks, consistency with intraobserver benchmarks, and equivalent radiation dose coverage compared to expert segmentations. Despite variations across datasets, the models show potential clinical utility by reducing segmentation time and interobserver variability. This study highlights the importance of evaluating clinical utility beyond geometric segmentation metrics.
According to a study by Zhaoshuo Diao, et al. (2021) [126] focuses on enhancing the clinical validity of tumor delineation in PET-CT images. Existing segmentation methods often lack consideration for uncertainty and consume significant computing resources. To address this, the proposed evidence fusion network (EFNet) reduces uncertainty by separately outputting PET and CT results and fusing them through evidence fusion. EFNet simplifies the network architecture, achieving improved segmentation results and enhancing efficiency compared to existing methods. Experimental validation on soft-tissue sarcomas and lymphoma datasets demonstrates significant improvements in segmentation accuracy, enhancing the clinical utility of PET-CT imaging for tumor delineation.
DL algorithms can analyze large volumes of multimodal images rapidly, potentially reducing the time required for image interpretation. This can enhance workflow efficiency in clinical practice, allowing radiologists to focus more on complex cases or patient care. According to a study performed by Amirhossein Sanaat et al. (2021) [127] summarize that DL techniques, specifically CycleGAN, successfully synthesize full-dose PET images from low-dose scans, aiding in reducing radiation exposure and enhancing patient comfort. The study demonstrates comparable diagnostic quality and tumor detectability between synthesized and full-dose images, validating the efficacy of DL in PET-CT.
Bonardel Gerald et al. (2022) [128] evaluates the clinical validity of a DL-based denoising algorithm, SubtlePET, applied to PET/CT images acquired at reduced count statistics compared to regular acquisition. Phantom and patient images from three different PET-CT scanners were assessed. Results indicate that SubtlePET effectively denoised images acquired at reduced count statistics while maintaining lesion detectability and SUVmax values. The study suggests that SubtlePET could be applied in clinical practice for PET-CT acquisitions with reduced injected doses, aligning with European recommended injected dose guidelines, without compromising diagnostic confidence.
A study by Yngve Mardal et al. (2021) [129] focuses on evaluating the clinical validity of convolutional neural networks (CNNs) for automatically delineating gross tumor volumes (GTV) in head and neck cancer (HNC) patients using FDG-PET/CT images. By comparing CNN-generated delineations to manual ones by specialists and introducing new structure-based evaluation metrics, the study demonstrates the accuracy and reliability of CNN models in accurately identifying GTVs. Importantly, the study emphasizes the significance of PET/CT imaging in improving delineation accuracy, with PET/CT-based CNN models outperforming those based solely on CT images. Overall, the findings underscore the clinical utility of CNNs in enhancing tumor delineation in HNC patients, providing valuable insights for improving treatment planning and patient outcomes.
DL network computational demands
DL requires substantial computational and memory resources throughout the training and inference phases, but its accuracy remains high. To fulfil these resource demands, cloud computing has become a conventional technique despite presenting obstacles concerning data migration. To expedite the process of DL inference, specialized hardware solutions like ASICs (such as Google’s TPU and ShidianNao) and FPGA-based DNN accelerators have emerged, delivering exceptional energy efficiency.
In 2019, Chen Jiashi and her colleagues authored a publication that delves into the intricate discussions surrounding the application, implementation, and training of DL with edge computing. This comprehensive study addresses the numerous challenges in system performance, network technology, benchmarking, and privacy. The notion of edge computing, which is viewed as a very promising method with the ability to efficiently address the computational and low latency needs of DL on edge devices, is of great interest. Given this context, it becomes imperative to initiate an in-depth investigation into the various techniques employed to safeguard invaluable privacy concepts within the complex and intricate process of transferring substantial volumes of data between edge devices and the ethereal realm of the cloud. By meticulously examining these technologies, we can acquire invaluable insights into effectively alleviating privacy concerns and seamlessly integrating DL at the network edge. These earnest efforts will undoubtedly significantly contribute to advancing the field and pave the way for the widespread adoption of DL in edge computing environments [130]. An overview of the taxonomy of these strategies, with examples of various scenarios that will be described in further depth in Table 12.
Overview of selected studies on privacy-preserving inference
Overview of selected studies on privacy-preserving inference
Interpretability remains a concern. Some studies, like Saad Bin Ahmed et al. (2022) on explainable AI (XAI) in chest X-ray analysis, raise issues crucial for clinical acceptance. There is an overall lack of universally accepted quantitative evaluation metrics for XAI techniques, so additional research in this direction is needed [131].
Transfer learning
Transfer learning techniques, as discussed by Yi Li et al. (2023) in their review, enable knowledge transfer from one dataset to another, reducing the need for large, annotated datasets. In their work, they presented a unique multimodal dataset for glaucoma diagnosis and classification (GMNNnet) and proposed a new multimodal neural network of transfer learning with little training data for glaucoma diagnosis and classification. GMNNnet performs well in capturing complex glaucoma information from multiple modalities, offering promising results for accurate diagnosis and classification of glaucoma [132]. Parvin Razzaghi et al. (2022), Multimodal brain tumor detection using a multimodal deep transfer learning model approach significantly outperforms the comparable approaches. Their study shows that the multimodal feature encoder and multimodal domain adaptation technique successfully learn and transfer knowledge, as shown in Table 13 [133].
The comparison of reported DICE coefficients for various methods on the figshare dataset: Evaluation of base models with and without modality knowledge and adaptation techniques, using ResNet50 and U-Net as backbone frameworks for classification and segmentation in Base1. In Base2, data is input into the network without incorporating modality-specific information
The comparison of reported DICE coefficients for various methods on the figshare dataset: Evaluation of base models with and without modality knowledge and adaptation techniques, using ResNet50 and U-Net as backbone frameworks for classification and segmentation in Base1. In Base2, data is input into the network without incorporating modality-specific information
Transfer learning and domain adaptation approaches can assist models in overcoming the limitation of limited data by allowing them to harness information learnt from comparable datasets or modalities. These techniques have become instrumental in addressing challenges related to data scarcity, domain adaptation, and improving the generalization of DL models in MMI analysis. These strategies use information learned from previously trained models on one job or domain to enhance performance on a related task or domain with little data.
Benchmark data sets are frequently utilized to evaluate DL models in the domain of MMI, playing a pivotal and crucial role in assessing and comparing the performance of these models. The utilization of these data sets for this specific objective has been comprehensively explained and expounded upon in Table 14. These data sets encompass a vast array of medical imaging models and clinical applications, thereby presenting an invaluable and highly significant resource for developing and evaluating DL models in the realm of multi-modal imaging research. Scholars and researchers commonly depend on these data sets to gauge the effectiveness and accuracy of algorithms associated with many tasks, including but not limited to classification, segmentation, tumor and other disease diagnosis. Using these esteemed benchmark data sets, researchers can effectively and efficiently assess the strengths and weaknesses inherent in their DL models, refining and optimizing their performance meticulously and discerningly.
Benchmark datasets are commonly used for evaluating deep learning models for multimodality imaging
Benchmark datasets are commonly used for evaluating deep learning models for multimodality imaging
Using DL-based methods for MMI analysis has numerous potential advantages compared to traditional ML methods. The utilization of DL models allows for auto-learning and intricate feature extraction from medical images, eliminating manual feature engineering. This characteristic has proven exceptionally beneficial in medical imaging, where images often contain substantial noise levels and are influenced by various imaging artefacts. DL models can handle noise and variability, enhancing MMI task performance. Moreover, DL models can effectively integrate information from different imaging modes, improving accuracy and diagnostic performance.
This scholarly article extensively investigates the dynamic and ever-evolving landscape of DL in MMI tumor analysis. It uncovers DL significance and progress that has been made in this domain. Healthcare workers may merge information from many imaging techniques, such as MRI, CT, PET, and others, by leveraging the power of DL. This integration empowers the DL model to exhibit an elevated ability to provide accurate diagnosis of tumors. Undoubtedly, this emerging trend marks a substantial advancement in the field of MMI analysis, offering tremendous potential for more precise and comprehensive patient care.
Although DL-based MMI analysis methods have potential advantages over traditional machine learning-based methods, DL also has certain limitations. One limitation is that training DL models necessitates substantial amounts of labelled data, which can prove arduous to acquire when faced with rare diseases or multiple patterns. Another limitation to the computational robustness of DL models, they necessitate high-performance computing resources such as GPUs or TPUs, thereby incurring costs. Additionally, DL models can manifest difficulties in exploitability, rendering comprehension of the rationales behind their predictions challenging. Furthermore, deep-fitting models are harmed by overfitting and underfitting. Finally, DL models are often perceived as “black boxes” due to the demanding nature of understanding the underlying process through which predictions are made.
Main challenges in MMI analysis
MMI analysis presents challenges due to data heterogeneity, limited annotated datasets, and the need for interpretability. Integrating diverse imaging modalities while preserving their unique features is complex. Domain adaptation is required to handle variations between datasets. The lack of generalization and computational complexity are additional hurdles [62, 63, 80]. Some of the key challenges, as in Fig. 13, are as follows:

Challenges in multimodal medical image analysis.
Despite the promising potential of DL models in multimodality imaging, several challenges exist, including the need for large and diverse datasets for training, interpretability of DL-based predictions, and integration into existing clinical workflows. Additionally, DL models may encounter difficulties in handling data heterogeneity, variability in imaging protocols, and generalization to unseen patient populations.
Data quality and quantity
To achieve optimal performance, DL models necessitate substantial amounts of superior-quality data. Nevertheless, medical imaging datasets frequently suffer from limitations in both size and quality, resulting in overfitting and decreased generalization of models [30, 31, 34, 39, 40–43].
Explainability
The intricate nature of DL models presents a formidable challenge regarding their interpretability, rendering it arduous for clinicians to place trust in and comprehend their output. It is of utmost importance to develop techniques for visualizing and elucidating model output to surmount this predicament [140].
Standardization and reproducibility
Presently, the application of DL-based methods in medical image analysis lacks standardization, rendering it troublesome to compare the outcomes of diverse studies and replicate findings. A pressing need exists to standardize data collection, pre-processing, and model development robustly [141].
Clinical Translation: Despite the promising outcomes observed in research environments, the clinical translation of medical image analysis methods founded on DL remains nascent. Further investigations are warranted to authenticate the performance of these methods in clinical settings and address concerns about regulatory approval and integration with established clinical workflows.
Multimodal image registration
Multimodal image registration is indeed a critical challenge in the application of multimodal medical imaging. When we acquire Images from different modalities (MRI, CT, PET, etc.) they are aligned together in multimodal imaging techniques, which enables accurate comparison and fusion of information. Inaccurate registration can lead to misalignment of anatomical structures or features, compromising the quality and reliability of subsequent applications like image fusion, segmentation, or quantitative analysis. Therefore, robust and accurate multimodal image registration techniques are very important for the effectiveness and reliability of multimodal medical imaging. Advancements can be made in multimodal image registration by advancing DL for various modalities, integrating biomechanical models, enabling real-time registration, quantifying uncertainty, and incorporating artificial intelligence. Robust frameworks should be developed, and methods must be validated for clinical use to address challenges and improve accuracy in medical imaging applications [142–144].
Future directions and emerging trends
From the literature we presented on the role of DL in MMI analysis, we identified some emerging trends and provided some insight into future directions for research development in this field. Some of them are presented below, and we hope that this information will serve as a guide for future researchers. An overview of this guidance and emerging trends can be found in.
Incorporation of domain knowledge
The incorporation of domain knowledge is a critical part of MMI analysis, where medical practitioners’ experience and domain-specific information may be used to improve the accuracy and interpretability of DL models. This integration ensures that the models align with medical principles and constraints, making the analysis more clinically relevant and reliable [145]. Several ways domain knowledge can be incorporated include:
Designing Task-Specific Architectures: Domain experts can guide the design of DL architectures tailored to specific medical image analysis tasks. For example, understanding anatomical structures and disease characteristics can inform the development of specialized organ segmentation or lesion detection networks [146].
Annotating Training Data: Domain experts can annotate training data, providing accurate and detailed labels that capture clinically significant features. High-quality annotations are essential for training robust models that generalize to new data.
Feature Selection and Extraction: Medical knowledge can aid in identifying relevant features and modalities that are most informative for the task at hand. This can reduce the dimensionality of the data and enhance model efficiency.
Loss Function Design: Domain knowledge can inform the choice and formulation of loss functions, emphasizing clinically relevant metrics and penalizing errors that may have more severe consequences in medical practice.
Interpretability and Explainability: Domain knowledge can be used to develop interpretability techniques, allowing clinicians to understand the model’s decisions and gain insights into how the analysis aligns with medical expertise.
Handling Uncertainty: Medical domain knowledge can help address uncertainties in multimodal data and model predictions, common in real-world medical scenarios.
Validation and Clinical Adoption: Involving domain experts in the validation process and clinical adoption of DL models ensures that the analysis aligns with medical best practices and meets the needs of healthcare professionals [147].
DL models can become more accurate, reliable, and clinically relevant by incorporating domain knowledge into MMI analysis. Collaboration between AI researchers and medical experts is essential to bridge the gap between cutting-edge technology and real-world medical applications, leading to improved patient outcomes and enhanced healthcare practices.
Explainable AI
Interpretation and explication within the realm of artificial intelligence, or the field of XAI, constitutes an indispensable domain that devotes its attention to advancements in techniques and frameworks that furnish lucid and comprehensible elucidations for the determinations and prognostications of AI systems. In intricate artificial intelligence models, such as DNN, the internal mechanisms are frequently regarded as enigmatic, rendering it arduous to apprehend the modus operandi employed by the model in drawing inferences. This lack of transparency can serve as a conspicuous impediment, especially in vital sectors such as healthcare, finance, and autonomous systems, where users necessitate assurance in the decision-making processes of AI.
XAI’s primary objective is bridging the chasm between the intricacy of AI models and human comprehension by furnishing substantial explications for the outcomes produced by the model. This enables users, including researchers, clinicians, regulators, and end users, to acquire insights into the rationales behind AI predictions and a more profound discernment of how AI arrives at specific determinations. The research endeavors in developing the XAI model will augment the reliance and acceptance of multi-modal analysis in clinical practice [45, 148].
Integration of clinical data
The primary objective of medical image analysis methods founded on DL is to amplify patient treatment outcomes. The amalgamation of clinical data into medical image analysis necessitates the fusion of patient-specific information (including medical history, laboratory findings, and clinical evaluations) and data from diverse imaging techniques. This combination is critical in improving the precision and contextual knowledge of medical picture interpretation, allowing healthcare providers to make better-educated diagnoses, treatment regimens, and prognoses. By incorporating clinical data, a multi-modal analysis approach transforms an all-inclusive strategy that fosters personalized and patient-centric healthcare decisions. To accomplish this objective, such analysis must be integrated with the processes associated with clinical decision-making, including treatment planning and monitoring [149].
Explainable and interpretable DL models
The creation of AI algorithms that can offer reasonable explanations for their predictions and actions is referred to as explainable and interpretable DL models. The inner workings of classic DL models, such as DNNs, can be complicated to read, resulting in a “black-box” scenario in which it is unknown how the model arrived at a given solution. Explainable and interpretable DL models seek to overcome this issue by providing human-readable explanations for their results. This means that, besides providing predictions, the model may give insights into which elements or patterns in the input data influenced the choice. Explainable and interpretable DL models can improve MMI analysis performance by offering insights into how the model integrates input from many imaging modalities. Clinicians can discover possible mistakes or biases and fine-tune the model by determining which characteristics or modalities are most significant in generating predictions. This openness allows for better decision-making and higher trust in AI-driven analysis, leading to more accurate and trustworthy patient diagnoses and treatment plans [150].
Federated learning
Federated learning (FL) is a decentralized approach to model training that enables collaboration across multiple institutions without sharing patient data centrally. Each institution trains its model locally on its own data, and only model updates, rather than raw data, are shared with a central server. This approach addresses data privacy concerns, as patient data remains secure within each institution’s boundaries. FL encourages collective intelligence by incorporating knowledge from several sources, resulting in more robust and accurate models while protecting data privacy. FL tackles data privacy, but most focus on unimodal data. Multimodal FL emerges for enhanced system performance, explored in this survey as cited here [151].
Meta-learning
Meta-learning, sometimes called “learning to learn,” is a promising technique that teaches models how to learn from various tasks or domains, helping them quickly adapt to new tasks or data distributions with less data. Meta-learning may be used in MMI analysis to create models that generalize successfully across multiple imaging modalities and medical situations [152]. The model becomes more resilient and may effectively adapt to new modalities or patient groups by learning common representations or characteristics from varied tasks, even when data is limited. Meta-learning approaches could increase MMI analysis’s efficiency and accuracy, making it a vital area of study with the potential to improve patient care and speed medical discoveries. Advances in multimodal fusion techniques will enable better data integration from many imaging modalities. According to a proposed methodology by Aishik Konwer et al,. (2023) [153], in medical imaging, not all modalities are consistently available. They propose a meta-learning approach to enhance modality-agnostic representations, improving brain tumor segmentation even with limited data.
Generative models
Generative models play an important role in MMI analysis by generating synthetic data that closely matches real medical pictures. GANs, which consist of a generator and a discriminator network, are one of the most well-known generative model architectures. GANs may be utilized in MMI analysis to solve data scarcity by generating more samples for underrepresented modalities or expanding the training dataset [154, 155]. Furthermore, GANs present modality translation, which allows them to transform pictures from one modality to another, enabling cross-modality analysis and correlation. Researchers may use generative models to extend datasets, improve model generalization, and investigate multiple imaging modalities without requiring substantial data collection and annotation. These models have a significant capacity to improve the accuracy and robustness of medical image analysis, impacting customized medicine and patient care. Nonetheless, ensuring the quality and precision of the produced pictures in this sector remains a constant issue.
Limited data availability is a challenge in medical imaging. Train DL models using Augmentation Generative Adversarial Nets for Multimodality imaging with limited data can be a choice as discussed in a study by Chaobin Xu et al. (2024) [154]. The proposed Scarce Data Augmentation Generative Adversarial Nets (Scarcity-GAN) tackles data scarcity by selecting similar features from extra datasets, enhancing defect detection. The model, incorporating an Encoder-Decoder framework and Fusion Patch-Embedding module, accurately locates defects. Extensive experiments demonstrate Scarcity-GAN’s superiority in performance and generalizability over state-of-the-art models, suggesting GANs’ potential for training DL models with limited data in medical imaging.
Clinical integration of AI models
Healthcare professionals can benefit from AI-driven diagnostic assistance, treatment planning, and patient monitoring by integrating AI into clinical settings [156]. AI models may help with illness detection and diagnosis, individualized therapy suggestions, and timely treatment response. Clinical integration also entails dealing with data privacy, governance, and regulatory compliance issues. Building confidence in AI-driven healthcare applications requires ensuring patient data is securely handled and utilized responsibly. Ultimately, successful clinical integration of MMI analysis empowers healthcare professionals with powerful AI tools, leading to improved patient outcomes, more efficient healthcare processes, and better healthcare delivery [157–159].
Multi-task learning
The employment of multi-task learning (MTL) entails training DL models to concurrently execute multiple interconnected tasks by utilizing a shared set of parameters. MTL uses shared knowledge between tasks to improve the model’s performance on each task instead of training different models for each task. The utilization of MTL within the realm of MMI analysis allows for the meticulous examination of distinct imaging modes or the execution of various tasks, such as image segmentation, classification, and registration, all within a unified framework. The model is able to extract more flexible and generalized representations from multi-modal input through the joint acquisition of knowledge from numerous tasks and data [160].
MTL possesses numerous advantages in medical image analysis, including heightened efficiency, mitigated risk of overfitting, and amplified generalization capabilities. It can also be particularly useful when dealing with limited annotated data for individual tasks. In conclusion, multi-task learning is an influential technology that can amplify the capabilities of DL models in the domain of MMI analysis, thereby facilitating the production of more precise and comprehensive outcomes. Furthermore, it expedites the advancement of AI-driven solutions in healthcare. As suggested by Huihui Yu et al. (2024) [161] Novel self-supervised multi-task learning framework improves representations, outperforming state-of-the-art methods on Chest X-ray datasets.
Uncertainty estimation
The measurement of indeterminacy in the analysis of multimodal interaction encompasses the assessment of the indeterminacy connected to forecasts made by models of AI. In healthcare situations, indeterminacy assumes a pivotal function due to medical data’s fundamental intricacy and variability. Indeterminacy is comprised of two primary categories: 1) stochastic indeterminacy and 2) epistemological indeterminacy [162, 163].
In MMI analysis, uncertainty estimation becomes particularly valuable when dealing with limited or noisy data, domain shifts between different imaging modalities or patient populations, and ambiguous cases. AI models may give confidence intervals for predictions by measuring uncertainty, allowing healthcare practitioners to make better-informed judgments, highlight situations that require additional evaluation, and prevent potentially misleading outcomes. Uncertainty estimation is a judgmental component in constructing dependable AI systems for medical image processing, enhancing the reliability and safety of AI-powered clinical applications, and improving patient care [164–166].
Other emerging technologies
Healthcare textiles are an emerging technology that comes in a variety of shapes and functions [167]. This emerging technology of healthcare textiles in multimodality imaging can enhance patient comfort, reduce infection risks, minimize artifacts, and integrate smart technologies, leading to improved imaging performance and diagnostic accuracy.
Quantum machine learning (QML) enhances healthcare by optimizing drug discovery, genomic analysis, and medical imaging processes [168]. The utilization of QML can improve multimodality imaging through enhanced image reconstruction, automated segmentation, and personalized treatment planning.
Conclusion
This review article comprehensively investigates recent advancements in MMI analysis methods based on DL. These techniques surround tumor detection, segmentation, and classification. The article explores specific DL models and techniques for analyzing diverse medical image models while emphasizing their strengths and limitations compared to conventional ML methods.
Moreover, this review article also introduces specific instances where DL-based methods have been employed in MMI analysis, such as disease classification. The findings of these applications have been succinctly summarized. The use of MMI plays an essential role in improving knowledge, diagnosis, and treatment of a variety of diseases. By amalgamating information from distinct imaging modes, clinicians and researchers can better comprehend the patient’s condition, enhancing patient management and prognosis.
Researchers are presently exploring future directions and emerging trends to surmount the hurdles encountered in this field. Explainable and interpretable DL models strive to enhance AI models’ transparency, enabling clinicians to navigate the problem-solving process more effectively. Furthermore, integrating patient-specific data with multimodal imaging data through clinical data integration further enhances AI-driven analysis, facilitating more personalized and context-aware healthcare decisions.
Transfer learning techniques aid in utilizing knowledge acquired from existing models to enhance the performance of models when data sets are limited in availability. Generative models permit data augmentation and pattern transformation, effectively addressing the challenge of insufficient data and facilitating the analysis of diverse models. On the other hand, meta-learning focuses on constructing models that can quickly adapt to new tasks or patterns with less data, increasing the model’s generalizability.
As the domain of DL-based MMI analysis continues to advance, the amalgamation of these principles will persistently shape the trajectory of AI-driven healthcare. AI models will steadily enhance their accuracy, interpretability, and applicability in clinical settings by identifying and addressing difficulties, exploring fresh methodologies, and embracing emerging trends. This will help patients and healthcare workers.
A comprehensive examination of analytical methods in MMI based on DL is an extremely crucial and indispensable resource for individuals involved in the research field, practitioners, and decision-makers. This review presents the remarkable progress in the field and emphasizes the pressing need for further research, validation, and incorporation of ethical considerations, particularly as these technologies move towards broader clinical adoption. In essence, the combination of DL technology with MMI has the potential to completely transform healthcare by providing more precise, rapid, and personalized diagnostic and treatment options. Given this, it is of utmost significance that all pertinent stakeholders possess a comprehensive understanding and delve into the significance and influence of this integration.
Footnotes
Acknowledgments
We gratefully acknowledge the support received for this work from the following funding sources: This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (2021-0-00755, Dark data analysis technology for data scale and accuracy improvement). Furthermore, this work was partially supported by the National Research Foundation of Korea (NRF), funded by the Korean government (MSIT) (No. RS-2023-00243034).
I acknowledge the use of ChatGPT (https://chat.openai.com/), which helped refine my work’s academic language and accuracy [![]() ].
].
Figures Copyright Permissions
Some of the figures are reused from published articles online. Copyright permissions to reuse these figures are obtained under License Number 5742810476253 from IEEE Explorer.