
Abstract
Multiclass classification and feature (variable) selections are commonly encountered in many biological and medical applications. However, extending binary classification approaches to multiclass problems is not trivial. Instance-based methods such as the K nearest neighbor (KNN) can naturally extend to multiclass problems and usually perform well with unbalanced data, but suffer from the curse of dimensionality. Their performance is degraded when applied to high dimensional data. On the other hand, model-based methods such as logistic regression require the decomposition of the multiclass problem into several binary problems with one-vs.-one or one-vs.-rest schemes. Even though they can be applied to high dimensional data with L1 or L p penalized methods, such approaches can only select independent features and the features selected with different binary problems are usually different. They also produce unbalanced classification problems with one vs. the rest scheme even if the original multiclass problem is balanced.
By combining instance-based and model-based learning, we propose an efficient learning method with integrated KNN and constrained logistic regression (KNNLog) for simultaneous multiclass classification and feature selection. Our proposed method simultaneously minimizes the intra-class distance and maximizes the interclass distance with fewer estimated parameters. It is very efficient for problems with small sample size and unbalanced classes, a case common in many real applications. In addition, our model-based feature selection methods can identify highly correlated features simultaneously avoiding the multiplicity problem due to multiple tests. The proposed method is evaluated with simulation and real data including one unbalanced microRNA dataset for leukemia and one multi-class metagenomic dataset from the Human Microbiome Project (HMP). It performs well with limited computational experiments.
Introduction
Multi-class classification and feature selections are commonly encountered in many biological and medical applications, especially in genomic and metagenomic studies. Those data usually have high-dimensions, small-sample size, and unbalanced classes, and features (genes) may be highly correlated. It is not trivial to detect disease associated genes and evaluate the predictive powers under the multi-class classification framework, Machine learning for multiclass (and more general multilabel) classification has received increasing attention in many areas.1–4 In current literature, all machine learning methods roughly fall into two different categories: instance-based and model-based learning. Instance-based learning (IBL) such as the k-nearest neighbor (KNN) 5 predicts the class of a sample with unknown class by considering the classes of k-nearest neighbors. It is more robust for data with unbalanced classes and is efficient for multiclass classification with a small number of features. However, its predictive accuracy is seriously degraded when there is a large number of irrelevant features because of the curse of dimensionality. On the other hand, model-based learning methods such as support vector machine (SVM) and logistic regression are mainly designed for binary classification. They are designed to separate two different classes as far as possible without considering the intra-class distances. Multi-class problems are often dealt by combining binary classifier outputs, such as one class against the other (one vs. one) or one class against the rest (one vs. rest). However, this may lead to over-fitting and poor predictive accuracy especially when sample size is small, since we need to estimate either c(c - 1)n/2 or (c - 1)n parameters for problems with c classes and n features. It also produces unbalanced classification problems with one vs. the rest rule even if the original multiclass problem is balanced.
Instance-based leaning only takes into account the minimal distance, while model-based learning incorporates maximizing the interclass distances (eg, maximizing the margin in SVM). It is natural to integrate the instance-based and model-based methods and maximize the interclass distances while minimizing the intraclass distances. While there are some efforts in this direction, 6 they only consider the labels of neighborhood instances as additional features for logistic regression. They do not fully take advantage of the robustness of instance-based learning for unbalanced classes and continue to have the same drawbacks of estimating too many parameters and creating unbalanced classes in multi-class classifications, even if the original problem is balanced.
A fundamental aspect of feature (variable) selection for high dimensional data is to derive interpretable results. Earlier approaches for feature selection7–9 were based on filtering to select a subset of features, independent of the statistical learning methods. However, filtering methods, which examine each feature in isolation and ignore the possibility that groups of features, may have a combined effect that does not necessarily follow from the individual performance of features in the group. 10 In addition, they result in multiplicity problems due to multiple comparisons. The more recent L1 and L p based penalized statistical learning approaches perform variable selection as part of the statistical learning procedure.11–16 However, they are mainly designed for binary classification and can only select independent features. However, highly correlated features may function together and it is very important to select highly correlated genes in biological research.
There are two difficulties when dealing with multiclass problems with high dimensional data: small sample size and unbalanced classes. In this paper, we propose a novel approach through integrating instance-based and model-based learning to overcome both difficulties encountered in multiclass classification with high dimensional data. Our proposed approach combines the k-nearest neighbor (KNN) and a model-based binary classifier and simultaneously maximizes the interclass distance and minimizes the intraclass distance. It is robust for unbalanced classification and can classify multiclasses simultaneously without creating unbalanced classes. It also estimates a fewer number of parameters (only the same as the number of features) and can simultaneously select features and predict multiclasses with simple parameter regulation. Moreover, the proposed method can identify highly correlated features for multiclass classification and overcome both the problem of multiplicity with statistical tests and the problem of failing to identify correlated features with L1 and L p penalized statistical learning methods. We evaluate the performance of our proposed method through simulation and the publicly available microRNA expression and metagenomic data sets. The proposed method is robust across data-sets and efficient for feature identification and pheno-type prediction.
Methods
A general multiclass classification problem may be simply described as follows. Given n samples, with normalized features, D = {(x1, y1), …, (xn, yn)}, where xi is a multidimensional feature vector with dimension m and g classes with class label yi∈ C = {c1, …, cg}, find a classifier f(x) such that for any normalized feature vector x with class label y, f(x) predicts class y. Given two samples xi. and xj, we introduce a general weighted distance functions for KNN learning as follows:



Loglikelihood Based Approach for Weight Estimation (KNNLog)
Now, the goal is to choose optimal w with small intra-class distance and large interclass distances simultaneously and automatically identify features relevant to multiple classes. We proposed an integrated KNN and constrained logistic regression (KNNLog) approach for sparsef parametric estimation, which forces the irrelevant features to zero. The problem can be formulated as a constrained linear programming (LP) as follows:
Subject to
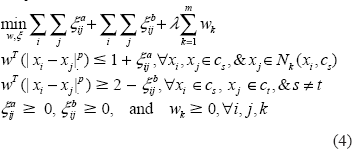
While we can solve Equation 4 with some LP software such as linprog in MATLAB, and lpsolve in C (http://lpsolve.sourceforge.net/5.5/), there are limitations with the LP approach. It could not scale both in terms of time and memory for problems with large number of examples and variables. The number of constraints will increase with O(n
2
) for a problem with the number of samples n. Even though efficient algorithms exist, handling a large number of constraints is still challenging. We therefore propose an efficient log-likelihood based approach for weight estimation. Since we would like to maximize the intra-class distance and minimize the inter-class distance, we first define an augmented distribution for the intra-class and inter-class distances with the truncated logit function of logistic regression. Letting h = 1 be the class of intra-class distance D
r
(w, x
i
, x
j
, p) and h = 0 represent the class of inter-class distances D
e
(w, x
i
, x
j
, p), we define the probabilities:


The likelihood for the intra-class and interclass distances is

Taking the negative log likelihood and drop the constant, we have the following error function:

Equation (8) is a much simpler negative log likelihood with nonnegative constraints. It can be solved efficiently, even if the problem is one of both large sample size and high dimension. Let


Based on Equation (10) and w
k
≥ 0 ∀ k = 1, …, m, we implement a standard conjugate gradient method
17
with nonnegative constraints. Because E is a convex optimization with a convex constraint, a global optimal solution is guaranteed theoretically. The global minimum of E is reached if, for each element w
k
, either (i) w
k
> 0 and
Computational Results
Simulation data
The purpose of our first simlation is to show that the proposed method can predict the class labels with high accuracy and identify the class associated features correctly even if there is a high correlation among the features. The simulated dataset is randomly generated with input dimension m = 1000 and only the first 10 features are relevant to the classes. All other features are random noise generated from N(0, 1). We first generate the input data of 5 classes with the sample size of 10, 20, 30, and 50 for each class from 5-dimensional multivariate normal distributions with different means and a variance-covariance matrix
We analyze this simulation data with the proposed approach and show that our method can identify the features 1-5 and 6-10 simultaneously. The free parameters k, p, and λ are determined through leave-one-out Jackknife test with the training data only. We simulate the experiments 100 times for each of the different sample sizes and count number of correctly identified features in Table 1. Table 1 indicates that KNNLog correctly identified all 10 features with at least 76% accuracy and correctly chose 6 out of 10 features in all 100 simulations with a sample size of n = 10 for each class. As the sample size n increases, the accuracy for selecting the true features also increases. KNNLog identified all 10 features with at least 93% accuracy and 6 out of 10 features with 100% accuracy with the sample size of n = 50. In addition, KNNLog selected features 1 and 6, 2 and 7, 3 and 8, 4 and 9, and 5 and 10 simultaneously with the same accuracy, even if they are exactly the same. Therefore, KNNLog can identify highly correlated features simultaneously without encountering the multiplicity problem with statistical tests. Moreover, the average number of selected features is also closer to the true number 10, when the sample size increases as shown at the bottom of Table 1. The prediction errors with KNNLog are 0.046, 0.04, 0.041, 0.034 with the sample size of 10, 20, 30, and 50 respectively, compared to the much larger prediction errors (0.41, 0.32, 0.25, and 0.20) using KNN without feature selection as shown in Figure 1. In addition, we also compare the performance of our KNNLog with random forests (RF). Random forests (RF) is a classification algorithm that uses an ensemble of unpruned decision trees, each of which is built on a bootstrap sample of the training data using a randomly selected subset of variables.
18
Figure 1 shows that KNNLog has similar test errors with a different sample size. It also has better performance than random forests (RF) which has the prediction errors of 0.104, 0.063, 0.06, and 0.037 respectively, especially when the sample size are small. Finally, unlike KNNLog which can identify highly correlated features, RF can only select independent features, the average number of features selected with RF are 3.8, 4.2, 4.5, and 4.8 respectively.
Average prediction. Frequencies of correctly identified features with different sample sizes.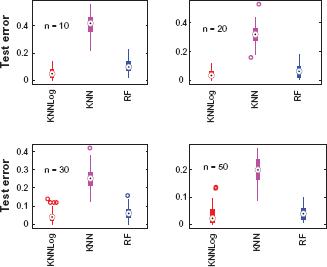

Frequencies of correctly identified features with different σ2/σ1 ratios.

microRNA Expression Profiling for Leukemia
32 selected leukemia associated microRNAs and their relevance counts.


Normalized log-gene expressions for the 32 identified microRNAs in three different classes: left–-normal, middle–-AML, and right–-CLL.
Human metagenomic count data
KNNLog was applied to a 16S rRNA metagenomic dataset from 6 human body habitats, 25 external auditory canal (EAC), gut, hair, nostril, oral cavity (OC), and skin. This benchmark dataset excludes samples from communities that were transplanted from another subject or body site. Similar to Costello et al 25 it has 552 remaining samples. OTU count data are generated using Mothur package 24 (pubmed: 19801464) with the standard processing pipeline at a sequence similarity threshold of 97%. Since this is a highly unbalanced dataset dominated by one class (skin), which could create challenges for classification. We normalized the count data with proportion and arcsin transformation, 26 and then detect the body-site associated features and estimate the predictive powers with KNN. The data is split into training (2/3 of samples) and test (1/3 of samples. We estimate parameters λ, p and k using the leave-one-out Jackknife test with the training data only. To prevent bias from a specific partition, we repeat the partition 100 times, the relevance count is calculated by the number of times an OTU is selected in 100 permutations. The parameters with best predictive error are (λ*, k*, p*) are (50, 8, 1) respectively. The predictive performance for classification is shown in Table 4. Eleven selected OTUs with nonzero parameters are given in Table 5.
Predictive performance of the test data for each location.

Identified class associated OTUs with KNNLog.

The numbers in the parentheses are the relevance counts an OTU being selected. Table 4 shows that OC and Gut can be separated from other class perfectly, which is consistent with the result of Costello et al. We also achieved a predictive error of 0.07 (±0.005) with only 11 OTUs in Table 5, compared with the predictive error of 0.08 with 27 OTUs reported by Knights et al. 27 KNNLog performs very well even with this highly unbalanced dataset.
Conclusions
We have proposed a KNNLog method that combines instance-based learning (KNN) and model-based learning (logistic regression) for simultaneous feature selection and multi-class prediction. Unlike L1 and L p (P < 1) penalized methods, which can select only independent features, KNNlog can identify highly correlated features without encountering the multiplicity problem due to multiple tests. In addition, the proposed method can also identify features from data that different classes may have similar means, but are from different distributions, a task t-test fails. Finally, it is robust for unbalanced classification, and can classify multiple classes simultaneously without creating unbalanced classes. It also estimates fewer number of parameters (the same as the number of features) than both one-vs.-one and one-vs.-rest classification schemes, and is efficient for problem with small sample size and a large number of features. While KNNLog was evaluated with only a limited number of datasets, it shows that the integration of instance-based and model-based learning methods can improve the efficiency in both feature selection and multi-class prediction.
Funding
This work was partially supported by the 1R03CA133899 grant from the National Cancer Institute.
Author Contributions
Conceived and designed the experiments: ZL. Analysed the data: ZL. Wrote the first draft of the manuscript: ZL. Contributed to the writing of the manuscript: ZL, HB, MT. Agree with manuscript results and conclusions: ZL, HB, MT. Jointly developed the structure and arguments for the paper: ZL. Made critical revisions and approved final version: HB, MT. All authors reviewed and approved of the final manuscript.
Footnotes
Acknowledgments
We thank the Associate Editor and the two anonymous referees for their constructive comments, which improve this manuscript significantly.
As a requirement of publication author(s) have provided to the publisher signed confirmation of compliance with legal and ethical obligations including but not limited to the following: authorship and contributorship, conflicts of interest, privacy and confidentiality and (where applicable) protection of human and animal research subjects. The authors have read and confirmed their agreement with the ICMJE authorship and conflict of interest criteria. The authors have also confirmed that this article is unique and not under consideration or published in any other publication, and that they have permission from rights holders to reproduce any copyrighted material. Any disclosures are made in this section. The external blind peer reviewers report no conflicts of interest.