
Abstract
Recent Multirobot systems (MRS) are moving from theoretical considerations and from development and research centres to the area of practical applications. The solutions to real practical problems bring new challenges which are derived from actual requirements, while they are also interesting from theoretical point of view. One of the interesting areas of investigation is the problem of distributed data processing by limited computing and communication performance of individual components in MRS.
In this article, the authors try to demonstrate, using a simple example, the possibilities of distributed solution of classification tasks.
Such questions as:
To what extent it is appropriate to distribute the tasks among individual elements of the system and to what extent to minimalize the requests on the communication subsystem? Is it more appropriate, in the design concept of distributed data processing, to use a data fusion system, features fusion or decision fusion? are not universally solvable.
Therefore, we refrain from the analytical analysis and the choice of appropriate level of information fusion, but in four different scenarios we focus on solving ‘voice command recognition’ – we would like to show the advantages and disadvantages of individual approaches. The experiments described and the results achieved are based on simulation experiments and verified by experimental and demonstrative MRS.
1. Introduction
The need for interaction between robots and humans became evident at the birth of robotics when writer Karel Čapek used the term “robot” in his drama for the first time and Isaac Asimov defined three fundamental rules of robotics.
A type of human-robot interaction is given by two basic elements-communication medium and the communication form. The media are primarily derived from the three human senses-sight, hearing and touch [1]. There are two types of human-robot interaction- unimodal and multimodal interaction. For the most reliable communication between robot and human, multimodal interfaces are used these days. In those interfaces for the interaction the principles of multiple senses, most often hearing and sight, are used [2,3]. In general, unimodal interaction, mainly based on recognition of acoustic signals has lower requirements for technical equipment and computational complexity.
So, as the problems relating to human-robot interaction grow into a number of heterogeneous interacting elements [4], many new questions have arisen with regard to the definition of MRS and the control of not only one robot, but a group of robots [5,6]. There are many applications where it is necessary to control effectively bigger groups of robots. These tasks include, for example, the task of terrain exploration, supervision of protected buildings with mobile agents and so on. It is worth noting that in many applications the use of MRS instead of one robot it can bring an important increase in solution quality and alternatively the increase of system robustness.
It is obvious that in the process of information processing by a group of robots, some stages of data processing are performed autonomously and in other stages robots can collaborate [7,8,9]. In this case it is important to know and use principles not only from the field of distributed data processing, but also from collaborative data processing.
The rate between the amount of cooperation and independent work of robots is not possible to generally determine as it depends on the character of the solved problem, the technical equipment and mostly the applied solution method. In tasks where the information is recorded by a group of robots distributed in the terrain and is collaboratively processed, the communication subsystem requirements decrease with the increase in distributed data processing and vice versa.
The rate of distributed data processing also influences the principle of information fusion used [10,11]. Information fusion during the information processing and evaluation can be used in various steps of the processing chain [12]. Information fusion is a process in which the data is collected from autonomous items for attaining bigger accuracy and increasing evaluation quality in comparison with using only one item. The collected information should have at least similar content for the possibility of common processing and evaluation [13]. The information recording item can be a sensor from the wireless sensor network [14], when we use MRS, the term item is understood as a mobile autonomous robot (MAR) with the ability of recording and pre-processing of data, and the ability of communication.
Information fusion can be divided into three levels of information processing: data fusion, features fusion and decisions fusion. Data fusion is a method in which the MARs record the information and send it further for central processing. Another fusion level for information processing is the features fusion method, where the part of the processing chain is performed distributedly in each of MAR. Each MAR independently creates parameters of recording data and only those parameters are sent for central processing. The level where the whole recorded information processing and evaluation is performed in each MAR is named decisions fusion. After information evaluation, the MAR sends only the decision.
From those three fusion levels the rate of distributed data processing is the biggest in decisions fusion and the lowest in data fusion. The requirements for communication subsystems are growing with the decreasing of distributed processing, so in the case of data fusion, the requirements for communication subsystems are the biggest from those three fusion levels.
2. Experimental Multirobot System “Georges”
Multirobot experimental systems consist of autonomous mobile robots with the ability to scan pre-selected physical quantities, process them and communicate with each other, as well as with the supervisory system. They have been developed for the purpose of verification algorithms from field surveying and area mapping, tracking moving targets and speech-based human-robot interaction.

Multirobot system “Georges”.
2.1 Autonomous Robot Description
The multirobotic system Georges consists of several identical units – autonomous robots. Each robot consists of two electronic systems (modules) ‘Brain’ and ‘Body’. Both modules are managed by their own control unit, but they work together in a master-slave configuration. The power source, lithium-ion battery, is common for both systems.
2.1.1 Body Module
The task for this module is the movement of the robot itself. The robot uses DC motors to move. They are controlled by H bridges, which are switched by a microcontroller with an AVR core. Specifically it is a processor Atmega8, which is able to change direction, velocity and to enact a sudden stop of the motors. Apart from the MCU, MOSFET drivers and motors, there is an interface for communication with the master module. A communication protocol was developed using the UART interface.
2.1.2 Brain Module
From the name of this module's purpose is obvious, that it is the controlling part of the robot. The computing performance is centralized in this module. The base consists of a microcontroller with a Cortex-M3 core. In this application an MCU STM32F103CB was used, by STMicroelecronics corp. The microcontroller has 128 kB of programmable flash memory and 20 kB of static RAM memory. The maximum CPU's performance is 1.25 DMIPS/MHz, while the maximum core frequency is 72 MHz. From this specification it is clear that implemented algorithms do not require too much memory and computing performance. For division and multiplication of the hardware components, divider and multiplier are used (implemented in the MCU). The processor uses a wide range of programmable peripherals. Peripherals used, along with a brief description, are listed in Table 1.
Used peripherals.

The maximum sampling rate of ADCs is 1 Msps at 12 bit resolution. In this application, the sampling rate 16 ksps was used, which also corresponds to the cutoff frequency of anti-aliasing filters (fc = 8 kHz). As a DA converter two timers were used. The first timer generates the pulse width modulation (PWM) and the other one changes the duty cycle of the PWM. Detailed specifications of all peripherals are available in the datasheet [LIT].
3. Recognition Algorithm
This MRS contains four identical MARs, with the possibility of autonomous behaviour. MARs are placed in the monitoring area. Suppose, that every robot senses acoustic signals via integrated microphones (Figure 2). An acoustic signal is sensed in various conditions, when signal-to-noise ratio (SNR) is changing. The MRS operator commands are sensed by each robot, which identifies the beginning of the operator commands. Those robots which identify the speech beginning are the active robots (AR). Only the robots which identify the beginning of the operator's commands are involved in the classification process. We suppose that all the robots detected the speech beginning correctly.

Block diagram of robot George.
In Figure 3 we can see the individual robots of the MRS assigned as MRk, dk represents the distance of k-th robot from the speaker. Suppose the acoustic signal, received by the sensors of individual robots, is:
Multirobot system.

where
ak is a parameter, which expresses the attenuation of signal generated by the speaker. It is dependent on the distance between the sensor and the speaker dk.
τk is time delay of the acoustic signal on the way between the sensor of k-th robot and the speaker.
ek(t) is white Gaussian noise interference, with zero mean value; ek(t)=N(0, σ).
Further, suppose, that every robot in the system senses the acoustic signal Sk(t) continuously, and based on short-time energy and zero crossing rate, it evaluates the beginning of commands. If the robot evaluates the beginning of speech, the robot senses signal Sk(t) and converts it into a discrete equivalent and saves gained samples. During discretization, the following parameters were set:
Sampling frequency 16 kHz, Binary word length of every sample is 12 bit.
Individual commands do not exceed a duration of 1024 ms. In order to clearly describe the used methods, as well as to evaluate performed experiments, the following signification is used.
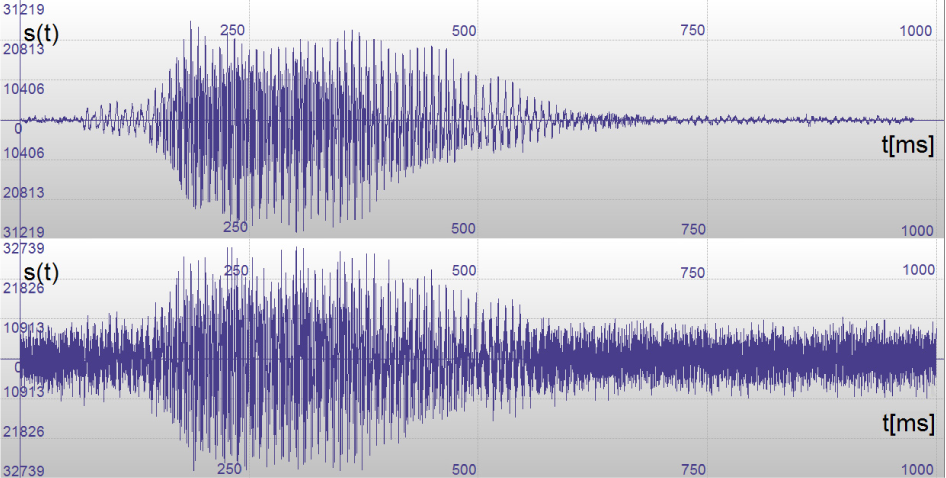
Single s(t) without noise a) and with applied noise of SNR = 10 dB.
Continuous acoustic signal is marked as s(t).

512 samples microsegment of signal s(t) without noise a) and with applied noise of SNR = 10 dB.
Sampled signal, limited to 16 384 samples, will be taken as a vector and named as a data vector, marked as

where k is robot's number.
After the signal is processed by FFT, Mell operations, 256 cepstral coefficients will be obtained. They are supposed to be a feature's vector with 256 components, marked as
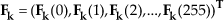
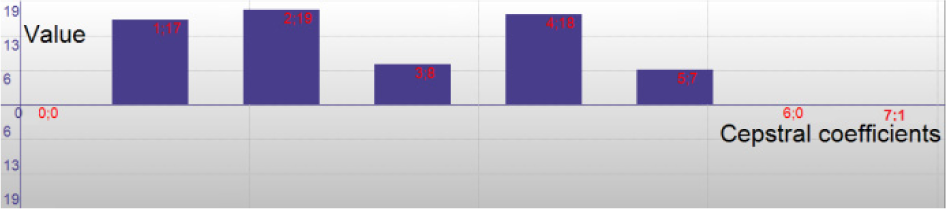
Cepstral coefficients of “go” command microsegment.
By the Euclidean distance between two vectors we mean the length of the path connecting them in the Euclidean plane, the distance between points (x1, y1) and (x2, y2) which is given by the Pythagorean theorem [15].
The feature's pattern vector for “go” command is defined as:

Similarly, it is valid for other commands such as: “back”, “left”, “right” and “stop”. The commands patterns are stored in the memory.
Finally, a decision vector is defined:

as Euclidean distance between features vector
Because the identified beginning of commands can vary slightly in individual robots, it is necessary to move individual vectors Sk to eliminate their mutual time delay. This is called the process of time-alignment.
In this process of time-alignment it is necessary to select one reference robot (RR). It can be the robot with the largest signal energy Sk(i) or a pre-selected reference robot. Based on the mutual correlation function between the reference robot vector and every other robot, which has recognized the beginning of the command, it is necessary to determine the time shift, where the mutual correlation function reaches its maximum. After the determination of time shift, we need to adjust the individual vectors so that their beginnings correspond to the beginning of the speech. In practical application, the mutual correlation function was calculated only from the first 2048 components of vectors for the shift -100 do 100, so with the sampling rate 16 ksps, it refers to the time interval 〈-6.5 ms,6.5 ms〉. The time-alignment process is performed in every robot autonomously, based on its own sampled vector

Steps of acoustic signal processing.
Relative to the number of robots in the area, the computing performance of each of them and the bandwidth of transmission channel, via which the robots communicate, it is possible to continue on different scenarios during the process of data acquisition and data evaluation. The choice of the most appropriate scenario is dependent on the end user's preferences – short response time, low transmission requirements, low computing requirements, etc. In our design, we decided to simulate system behaviour in four different scenarios, where each of them is optimized for different end user preferences.
4. Testing of an Algorithm Using Information Fusion
4.1 Scenario 1: Data Fusion
In this case, the system is centralized and focused on each robot's computational cost reduction. It is composed of M robots evenly distributed within the area, while one of them, RR, is superior to the others. Its purpose is to evaluate the data sent by other robots, see Figure8.

Centralized data fusion.
Each robot is capable of recording a single channel acoustic signal with a sample rate of 16 kHz and a resolution of 12 bits. After an identification of the beginning of voice activity, each robot obtains 16 384 samples, i.e.,1,024 ms. If k-th robot in a time of 100 ms since the last measured sample does not receive a vector
The reference robot has M vectors at its disposal from active robots R1, R2 … Rk. Using an arithmetic average it computes a resulting average vector application of Hamming window function FFT computation Mel filter bank application normalization classification
The results of the process are normalized Mel-frequency cepstral coefficients of the spoken command. These coefficients represent the components of a vector. A classification process then represents finding such a pattern from the reference set as to which vector of cepstral coefficients has a best fit Euclidean distance from the tested command vector. After a successful classification, the RR transmits the resulting command to all the other robots in the group.
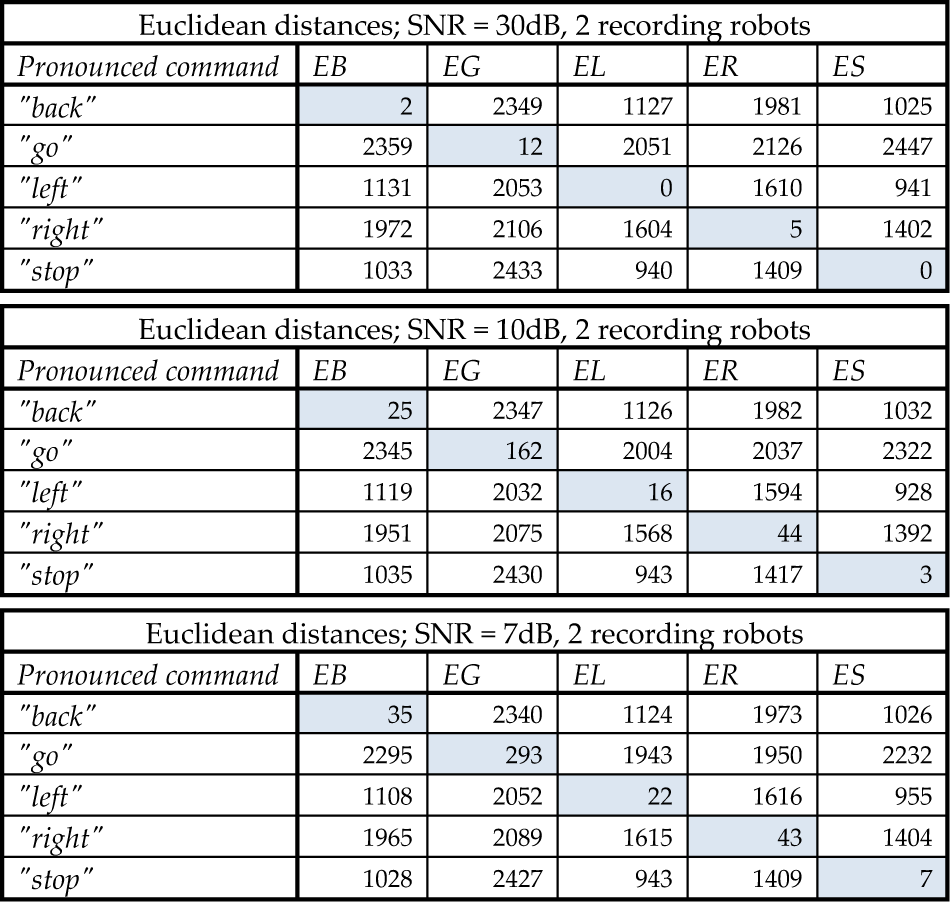
The results that we obtained by our experiments are shown in the following tables. They contain the Euclidean distances of the spoken commands compared to the reference commands. Table 2 contains the Euclidean distances obtained while recording a signal by two active robots.
Euclidean distances obtained while recording of the signal by two active robots – scenario 1.
In Table 3 the Euclidean distance of cepstral coefficients vector was computed from input signals recorded by four robots. The level of noise at which the commands were recorded is shown in the relevant part of the table.
Euclidean distances obtained while recording of the signal by four active robots – scenario 1.

According to expectations, the Euclidean distances after recording by multiple robots were lower in the case of equal commands and a similar noise level. This means that the more robots are recording the signal, the more reliable recognition we get. It is obvious that at a lower level of noise the advantages of the number of robots recording the signal at the same time will not reflect on the results. Such a condition, where the power of the noise reaches such a low value, very rarely occurs in real situations. The situation where the Euclidean distance depends on the number of robots and at the same time also on the level of noise is better visible on the graph shown in Figure 9. The experiments were conducted with different numbers of robots and at different levels of additive noise while the spoken “go” command was given. As we can see on the graph, the Euclidean distance decreases with the increase in the number of robots and the decrease in noise level.

Graph of dependencies of Euclidean distances from the number of the robots and noise level.
The given scenario puts quite high computational requirements on the communication subsystem, due to the amount of the transmitted data from RR to other participants and vice versa. Load distribution during the classification is uneven, which results from a centralized system architecture. There is, however, a reduction of computational requirements for individual robots and the transfer of the requirements to the RR.
4.2 Scenario 2-Features Fusion
The data processing is, similar to the previous case, centralized and it is focused on reducing computational requirements on the communication subsystem. The MRS contains k robots distributed in the area, while one of the robots is again a RR, which is superior to the others. It aims to evaluate the data sent by other robots, see Figure 8.
As mentioned before, each active robot is capable of recording a single channel audio signal with a sample rate of 16 ksps and a resolution of 12 bits. After identification of the beginning of voice activity, each robot performs the time-alignment and calculation of Mel-frequency cepstral coefficients. These processes are fully described in the previous scenario. Each robot then transmits obtained data to the reference robot in the defined way (TDMA = assigned time slots). The RR has at its disposal M characteristic vectors, while each contains 256 components. The RR then computes a Euclidean distance matrix in the following form:

The rows refer to the number of commands (N) and the columns refer to active robots (M).
In the next step the components of each row are summed and they are divided by the count of the active robots M. Then we get the decision vector
As with the previous scenario, we also present the tables that represent the results of the experiments.
Euclidean distances obtained while recording of the signal by two active robots-scenario 2.

Euclidean distances obtained while recording of the signal by four active robots-scenario 2.

Compared to the previous scenario, there has been a reduction of the communication subsystem load, however, on the other hand there has been an increase of computational requirements on the individual robots. Thus, such a system has even more load distribution between individual elements of the system. The role of the final decision is, however, still in the hands of the RR.
4.3 Scenario 3: Features Fusion
The following scenario is only a slight modification of scenario 2, while the main difference is that each active robot calculates its own decision vector
The main difference from previous scenarios is therefore only an increase of the level of distributed data processing and the reduction of the communication subsystem load. Although at the same time there are imposed higher requirements on the memory subsystem of the robots, as each robot must keep all the patterns of the spoken commands in the memory. However, the resulting values of the Euclidean distances are unchanged compared to scenario 2.
In the case where the number of coefficients N is smaller than 256, we will encounter the lower load of the communication subsystem compared to other scenarios. At the same time there is also a more equal distribution of computational load between individual robots.
4.4 Scenario 4: Decisions Fusion
In this case each robot calculates the Euclidean distance from the set of patterns, selects the command with the lowest Euclidean distance and transmits the result to the RR (in addition to the sequence number of selected command, it is appropriate to also transmit a Euclidean distance). The RR based on M received partial decisions selects the most suitable command. The selection can be realized based on:
the highest number of similar decisions the minimal Euclidean distance
In this case low requirements are placed on the communication subsystem with relatively uniform computational load on individual robots. The computational requirements for each element of the system are, however, not significant compared to the previous scenarios.
Considering that using the given algorithm all robots achieved the right decision, the Euclidean distances in the tables for scenario 4 should match with the tables for scenario 2 and 3. If any of the robots recognize the command differently compared to the other robots in the group, its result would not be taken into account and therefore it would not affect the value of the Euclidean distance. In that case we would be achieving better results in scenario 4 than in the previous two scenarios. The other option of how to modify this scenario is the exclusion of the results of that robot which achieved the highest Euclidean distance in its decision about the best fit spoken command. Thus, we achieved the results that can be seen in the following tables.
Euclidean distances obtained while recording of the signal by two active robots – modified scenario 4.

Euclidean distances obtained while recording of the signal by four active robots – modified scenario 4.

5. Conclusion and Future Work
In each scenario the same acoustic signals were used so the scenarios can be compared in conclusion. In Figure 10 it is visible as the increasing SNR influences the accuracy of classification, which is represented by the component of the vector

Scenario comparison when using various SNRs.
From the graph in Figure 10 it is obvious that we reached the lowest Euclidian distance in scenario 1.
Different approaches can be compared in terms of communication subsystem load. In Figure 11 the load when one active robot sends the necessary data to the RR using five model commands is shown. Communication subsystem load in this case is independent from noise level and it is indicated in bits.

Load of the communication subsystem.
From the results it is obvious that scenario 1, which reaches the best results in recognition, burdens the communication subsystem the most from the given scenarios. The valuation of other scenarios is also possible to read from the graphs in the Figure 10 and Figure 11. To select the appropriate scenario it is necessary to consider the solution reliability, distributed data processing level, requirements for the memory subsystem of the robots and also the communication subsystem requirements.
The work presented in the article pointed to how it is possible to increase the reliability of classification with the appropriate information fusion rate. Next we would like to continue with the command recognition problem, improve the used algorithm and incorporate DTW, speaker identification and so on. After those modifications the improved algorithm could be used, for example, for detection task of speaker position with MRS or many other tasks.
Footnotes
1
These modules are not shown in the block schematic