
Abstract
RGB-D cameras that can provide rich 2D visual and 3D depth information are well suited to the motion estimation of indoor mobile robots. In recent years, several RGB-D visual odometry methods that process data from the sensor in different ways have been proposed. This paper first presents a brief review of recently proposed RGB-D visual odometry methods, and then presents a detailed analysis and comparison of eight state-of-the-art real-time 6DOF motion estimation methods in a variety of challenging scenarios, with a special emphasis on the trade-off between accuracy, robustness and computation speed. An experimental comparison is conducted using publicly available benchmark datasets and author-collected datasets in various scenarios, including long corridors, illumination changing environments and fast motion scenarios. Experimental results present both quantitative and qualitative differences between these methods and provide some guidelines on how to choose the right algorithm for an indoor mobile robot according to the quality of the RGB-D data and environmental characteristics.
1. Introduction
In the last decade, visual odometry (VO) [1] has become very popular in robotics and the computer vision community. VO refers to the problem of recovering camera poses from a set of camera images. Before 2010, most VO methods used stereo cameras or monocular cameras (including perspective and omnidirectional) for motion estimation. From 2010 onwards, consumer-level RGB-D cameras became very popular in the robotics and computer vision community. RGB-D cameras can provide rich 2D and 3D information at the same time, which are well suited to solve the ego-motion estimation problem of an agent. In the past few years, several RGB-D visual odometry [2–5] estimation methods have been proposed. Existing RGB-D visual odometry methods have shown promising results with high accuracy. However, reliability is still an issue that prevents these methods from on board guidance of a fully autonomous vehicle. These methods may fail in different types of challenging scenarios as they process the sensor data in different ways. Understanding the accuracy changes/reductions of these methods with respect to different challenges is important, and helps us design a more robust motion estimation method for steering an autonomous vehicle.
This paper experimentally compares several real-time RGB-D visual odometry methods including Libviso2 [3], Fovis [4], DVO [5], FastICP [6], Rangeflow [7], 3D-NDT [8], CCNY [9], DEMO [10]. It should be noted that the study of this paper only focuses on visual odometry methods, and therefore various RGB-D V-SLAM algorithms [11], [12] are not considered. Besides, we consider motion estimation methods using data from RGB-D cameras only. Further comparison including inertial-aided methods [13] is not yet considered. The performances of these methods are studied in a variety of challenging scenarios such as in long corridors, illumination changing environments and fast motion scenarios. These scenarios involve low-quality features or featureless moments, which the existing method may or may not be able to handle. Experimental comparison of the aforementioned methods shows that the performance of each odometry estimation method depends on the quality of RGB-D data as well as environmental characteristics. Though some of these methods can obtain very good estimation in certain environments, none of them can perform very well in all environments. The experiment results provide some guidelines on how to use different visual odometry methods according to the quality of RGB-D data and environment characteristics.
The rest of this paper is organized as follows. In section II, we discuss the related work. Section III describes the selected representative odometry estimation methods. We validate the performance of each method by using real datasets in section IV and we conclude in section V.
2. Related work
Visual odometry is the process of estimating the ego-motion of an agent (e.g., vehicle and robot) using only the input of a single or multiple cameras attached to it. The term VO was coined in 2004 by Nister in his landmark paper [1]. VO is a particular case of structure from motion (SFM) in the computer vision community [14]. SFM is more general and tackles the problem of 3D reconstruction of both the structure of the environment and camera poses from a set of camera images. The final structure and camera poses are usually refined with an offline optimization process, whose computation time grows with the number of images. On the contrary, VO only focuses on estimating the 3D pose of the camera in real time. It is also worth mentioning another very popular topic in the robotics community: visual simultaneous localization and mapping (V-SLAM) [15], [16]. The goal of V-SLAM is to obtain a global, consistent estimate of the robot path. It keeps a track of a map of the environment. When the robot returns to a previously visited area, a loop closure will be detected that is used to reduce drift in both the map and camera path. Compared to V-SLAM, VO tries to recover the camera path incrementally, pose after pose. In some VO methods, local optimization methods (e.g., windowed bundle adjustment) may potentially be used to reduce the drift. In essence, VO only cares about the local consistency of the trajectory and map, while V-SLAM is concerned with global map consistency.
VO can be used as a front-end block for the V-SLAM algorithm. For a complete V-SLAM algorithm, some backend blocks such as loop-closure detection and graph optimization are still needed. Generally, V-SLAM is potentially much more precise, but is also more complex and computationally expensive. In recent years, RGB-D SLAM has also become very popular in the robotics community [17], [12]. The main difference between RGB-D SLAM and traditional V-SLAM is that RGB-D SLAM systems use both RGB and depth images from a RGB-D camera. In this paper, we mainly want to compare some motion estimation methods than can be potentially used on a small micro aerial vehicle (MAV). However, nowadays most V-SLAM and RGB-D SLAM algorithms cannot run in real time on computation-limited embedded computers. Therefore, in this paper we focus on real-time odometry methods that can be potentially used on a MAV.
Currently, visual odometry methods mainly use three kinds of cameras for motion estimation, namely stereo cameras, monocular cameras and RGB-D cameras. Stereo VO methods try to recover the camera trajectory using consecutive images from two cameras, while monocular VO methods try to recover the camera motion through only one (perspective or omnidirectional) camera. The advantage of stereo VO is that it can get absolute depth information through the triangulation algorithm by using the calibrated baseline. The disadvantage is that stereo VO will become monocular VO when the distance to the observed scene is much further than the length of the baseline of the stereo camera. For monocular VO methods, a shortcoming is that there is an unknown absolute scale problem in the estimation. For more details of traditional VO methods, the interested readers are referred to visual odometry tutorials [2]. From 2010 onwards RGB-D cameras became very popular since they can simultaneously provide RGB and depth images at a high frame rate, which also do not suffer from the unknown scale problem of monocular VO if the depth information is available. Since then, several RGB-D visual odometry estimation methods have been proposed by using visual data and/or depth data. These methods can be roughly divided into three categories according to what kind of data are mainly used, namely image-based methods, depth-based methods and hybrid-based methods. It should be noted that this is just a kind of rough classification. In fact, all of the methods use depth information. The difference is that for the image-based methods, they almost still follow the traditional stereo VO or monocular VO pipeline (which compute the depth values from triangulation), but use the depth information from depth images; for the depth-based methods, they only use depth information from depth images for motion estimation without using any RGB information; for the hybrid-based methods, they do not exactly follow the pipeline of traditional VO methods, but try to use both RGB and depth information in different ways to improve the robustness and accuracy of motion estimation.
The first category is
The second category is
The third category is
3. Examined Odometry Estimation Methods
As described in Section II, existing visual odometry methods can be roughly divided into three categories according to what kind of sensor data are used. Here, we select eight representative real-time odometry estimation methods and compare them by using the real datasets. Note that there are also some excellent methods [31],[21],[28] that can estimate the camera motion accurately, but we have not selected them because they are either too slow or they depend on a powerful GPU. The selected methods are shown in Table 1. In the following, the selected methods are briefly described.
Selected RGB-D visual Odometry Methods

3.1 Image-based Methods
Many odometry estimation methods proposed in the past several years are based on visual information. Here, we select three representative methods since they use the image information in different ways. RGB-D cameras like the Kinect are monocular vision systems. If one wants to use them to estimate the motion by using image data only, it is necessary to know external information to solve the unknown scale problem. In fact, the selected methods here all use depth information. However, since they depend on much information from RGB images, we call them image-based methods.
3.1.1 Libviso2
Libviso2 [3] is a fast algorithm for computing the 6 DOF motion of a moving mono/stereo camera. For the stereo version of libviso2, the key idea is to extract robust sparse features, find the feature correspondences, get the depth information through triangulation and finally minimize the

The monocular version assumes that the camera is moving at a known and fixed height over ground and uses this constraint to estimate the unknown scale. In order to use libviso2 with RGB-D cameras, we actually change the RGB-D camera into a virtual stereo camera using the depth information. We create a virtual camera using the depth information of each pixel with a fixed baseline. If the RGB pixels do not have depth information, we discard them. We then feed both RGB images of the real camera and virtual camera into libviso2 to calculate the odometry.
3.1.2 Fovis
Fovis [4] is a visual odometry method that estimates the 3D motion of a camera using a source of depth information for each pixel. It first detects FAST features in each image. Then, the depth corresponding to each feature is extracted from the depth image. Features that do not have an associated depth are discarded. After that, each feature is assigned an 80–byte descriptor. Features are then matched across frames by comparing their feature descriptor values using a mutual-consistency check. Then, the inliers are detected by computing a graph of consistent feature matches and using a greedy algorithm to approximate the maximal clique in the graph. Finally, the motion estimate is computed from the matched features in three steps. First, it uses Horn's absolute orientation method to provide an initial estimate by minimizing the Euclidean distance between the inlier feature matches. Then, the motion estimate is refined by minimizing feature
3.1.3 DVO
In contrast to sparse feature-based methods, dense visual odometry [5] methods want to fully exploit both the intensity and the depth information provided by RGB-D sensors. Dense visual odometry uses all colour information of the two consecutive images and the depth information of the first image. This approach is based on the photo-consistency assumption, which means a world point p observed by two cameras is assumed to yield the same brightness in both images.

where τ(ξ,X) is the warping function that maps a pixel coordinate X ∈ ℜ2 from the first image to a coordinate in the second image given the camera motion ξ ∈ ℜ6. The goal is to find the camera motion ξ that minimizes the
3.2 Depth-based Methods
There are also many people working on motion estimation using only depth data. Actually, this is widely studied in computer graphics where it is necessary to register different views of scans to reconstruct an object or environment. Many excellent registration algorithms have been proposed in the past decades, such as the 3D point-based method [32], plane-based method [21] and 3D Normal Distribution Transform [22]. Most of these registration algorithms are very accurate, but are usually slow and computationally expensive. Here, we select two methods that are very fast to run in real time. One is the FastICP method which mainly uses the point cloud for motion estimation. The other one is Rangeflow, which only uses depth image for motion estimation.
3.2.1 FastICP
The Iterative Closet Points (ICP) algorithm was proposed by Besl and McKay in 1992 [33] to solve the 3D rigid shape registration problem. The classical pairwise rigid registration problem can be described as: given a set of source points X = {xi,i = 1, …, n} and Y = {yi,i = 1, …, n}, we want to find the optimal transformation by minimizing the

where
The key concept of the standard ICP algorithm can be summarized in two steps: 1) the alignment is fixed, a set of closest corresponding points Y is computed. 2) the 3D point correspondences are fixed, compute a transformation which minimizes distance between corresponding points. Iteratively repeating these two steps typically results in convergence to the desired transformation. According to [34], the following six steps influence the performance of ICP:
Select a subset of points in one or both point clouds.
Match these points to samples in the other point cloud.
Weigh the corresponding pairs appropriately.
Reject certain pairs by some strategies.
Assign an error metric.
Minimize the error metric.
In this paper, ethzasl-icp-mapping [6] developed by Pomerleau is chosen for comparison because it mainly focuses on robotic applications. This fast ICP follows the standard ICP pipeline as described in [34].
3.2.2 Rangeflow
This method uses the so-called range flow constraint to calculate the frame-to-frame motion estimation [7], [25], [35]. It assumes a 3D point X (measured in the depth camera's coordinate system) is captured at pixel position x = (x,y)T in depth map Zt. This point undergoes a 3D motion ΔX which results, first, in an image motion Δx between frames, and second in a change of the depth ΔZ of the 3D point captured at this new image location x + Δx. Thus, the range flow constraint is formulated as

In this paper, our implementation of the range flow odometry estimation method is based on [35]. This method utilizes a weighted least-squares minimization of the difference between the measured rate of change of depth at a point and the rate predicted by the so-called range flow constrain equation. It assumes that most of the surface is smooth enough that local tangent planes can be constructed and that the motion between frames is smaller than the size of most features in the range image. This method does not depend on detecting and matching of high-level features in the range images.
3.3 Hybrid-based Methods
Odometry estimation methods based on both image and depth information have become very popular in recent years. The most commonly used idea is first using 2D image features to obtain an initial guess and then using point registration methods (such as ICP, NDT) to refine the estimation. There are also some people who try to combine image-based error metrics and depth-based error metrics into one integrated error metric, then optimize the integrated error function to find the optimal transform [28], However, these methods depend on a powerful computer for complex optimization. Here, we choose three real-time RGB-D visual odometry methods for comparison.
3.3.1 Realtime NDT
Andreasson [8] proposes a real-time local visual feature boosted NDT method for RGB-D odometry estimation. The key idea is to detect 2D visual features and find corresponding regions from the previous frame to current frame and then use RANSAC to find a consistent alignment. After that, the geometrical information around the selected features is efficiently utilized as an input to a fast 3D-NDT-D2D method [22] to refine the transformation. Instead of computing the 3D-NDT representation of the full depth images, this method only considers the immediate local neighbourhoods of each of the detected local visual features points. By doing so, the number of Gaussian components can be substantially decreased. Thus, the whole estimation process can be calculated in real time.
3.3.2 CCNY
Dryanovski [9] from the City College of New York (CCNY) proposes a fast visual odometry method based on visual features and depth information. The key idea of ccny_rgbd visual odometry is to align 3D features against a global 3D feature map. They first compute the locations of sparse features in the RGB image and their corresponding 3D coordinates in the camera frame. Then, they align the 3D features against a global 3D features map expressed in the fixed coordinate frame using a modified ICP method. After calculating the transformation, the global 3D feature map is updated using a Kalman filter. Any features from the incoming image that cannot be associated are considered to be new features in the global 3D feature map. To guarantee constant time performance, they bound the number of 3D feature in the global 3D feature map. Once the map size is bigger than a threshold, the oldest features are dropped. Since this method does not need 2D feature descriptor computation and feature correspondence matching, it saves a lot of computation. Besides, by performing alignment against a global 3D feature map instead of only the last frame, this method can significantly reduce the drift of the pose estimation.
3.3.3 DEMO
Zhang [10] proposes a depth enhanced monocular odometry (DEMO) method. The difference of this method to other RGB-D visual odometry methods is that it considers both features with and without depth information. Most RGB-D visual odometry methods drop the image features that do not have a depth value. However, this paper thinks even those features without depth are still useful for motion estimation. In this method, first, visual features are tracked using the KLT method. Depth images are then registered using the estimated motion. Visual features are associated with a depth value using the registered point cloud. If a visual feature does not have corresponding depth value from the point cloud but has been tracked for longer than a certain distance, then its depth value will be calculated through triangulation using the first and the last image frames. By doing so, they have three different kinds of visual features; one is visual feature with depth from depth image, the other one is visual features with depth from triangulation and the third is feature with no depth information. They use these three kinds of features to calculate the frame-to-frame relative transformation. After this, they use a local bundle adjustment (BA) method to refine the estimation. Finally, they combine the high frequency frame-to-frame motion estimation with the low frequency refined motion estimation and generates the integrated motion transform as the final odometry estimation.
4. Experiments and analysis
In this part, we first compare the accuracy of each method by using the TUM RGB-D dataset 1 which has accurate ground truth for evaluation [36]. Then, in order to evaluate robustness, we also record some datasets in very challenging environments, such as long clear corridors, structured and cluttered environments, dramatic illumination changing environment, etc. Then, we validate the performance of each algorithm on an Asus UX31E Ultrabook (Quad-core 1.7GHz CPU and 4GB Memory) running ROS fuerte and PCL1.7. The RGB-D sensor is Asus Xtion Pro Live which records the RGB-D image at 15Hz with 640×480 resolution.
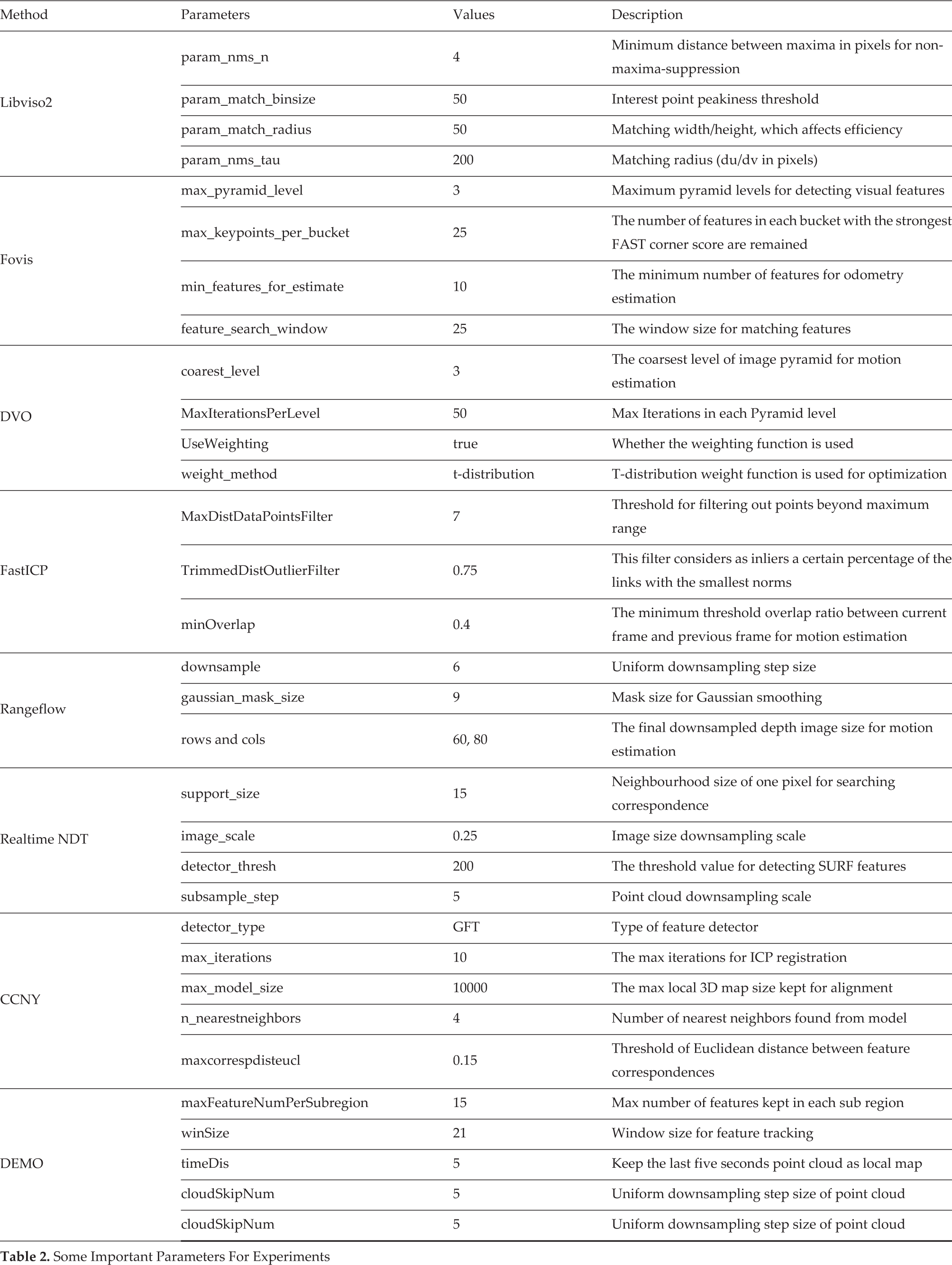
It should be noted that all the methods evaluated in this paper are sensitive to the choice of parameters, which might influence the final accuracy and timing results. From our experience, for a certain dataset better results may be achieved for a method if its parameters are carefully tuned according to that specific dataset. However, this same set of parameters may work undesirably for another dataset. Here, we only select the RGB-D fr2/desk dataset for tuning all the parameters of each method. The reason that we choose this dataset is that this dataset has relative rich visual and geometric features which are good for all the examined methods. Besides, this dataset is also the easiest dataset of all the datasets used in this paper. We carefully tune all the parameters for each method based on the RGB-D fr2/desk dataset. Some important parameters are listed in Table 2. However, since we want to get a general comparison of these methods, we do not tune the parameters again for the rest of the test datasets. The parameters of each method are kept the same in all tests.
Some Important Parameters For Experiments
4.1 Accuracy Comparison using Benchmark Dataset
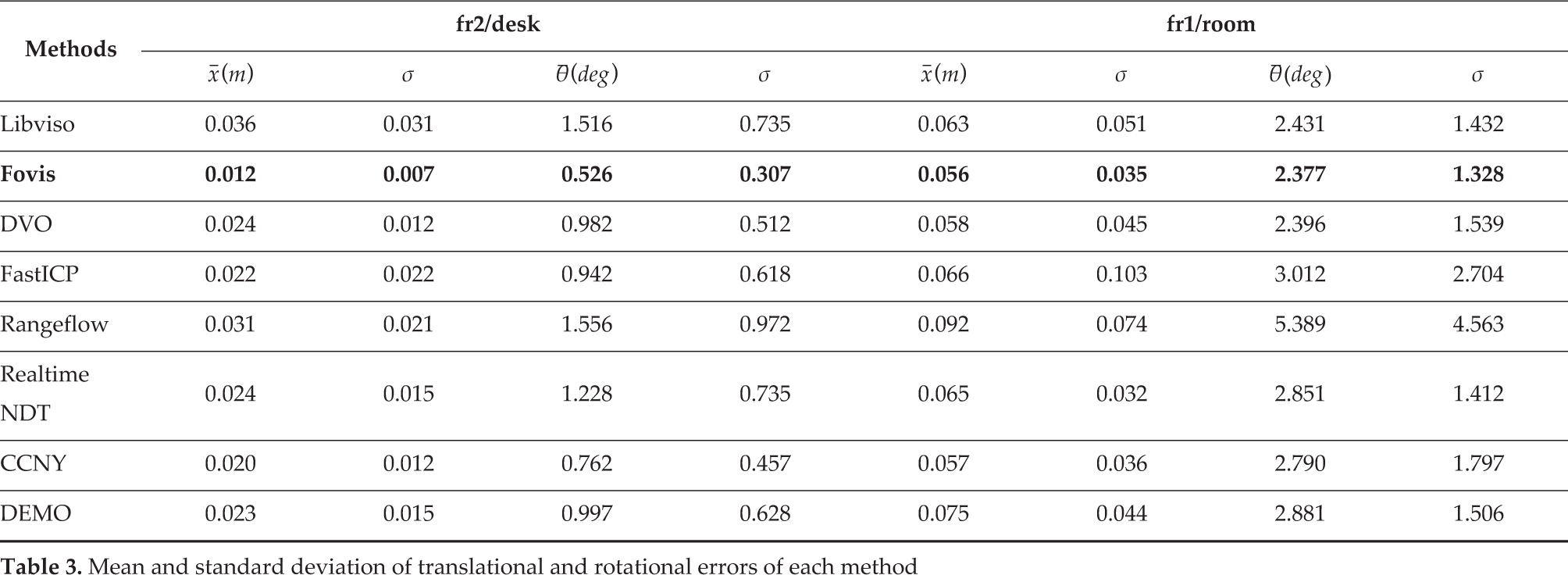
In this section, we use TUM RGB-D datasets to test the estimation accuracy of each method. The dataset contains the colour and depth images along with the ground-truth trajectory. The data are recorded at full frame rate (30 Hz) and sensor resolution (640×480). The ground-truth trajectory is obtained from a high-accuracy motion-capture system with eight high-speed tracking cameras (100 Hz). Here, we choose two datasets to evaluate the accuracy of each method. The experimental results are shown in Table 3.
Mean and standard deviation of translational and rotational errors of each method
We use the relative pose error and absolute pose trajectory error metric [36] to measure the drift and global consistency of the visual odometry system, respectively. We calculate the ratio of pixels in the image that contain a valid depth compared to the total number of pixels in the image to estimate the quality of the point cloud. We compute the average and standard deviation of the grey-scale-pixel values of the RGB image as a measurement of the amount of light available in the image, which is a simple way to estimate the quality of an image.
The first dataset is freiburg2/desk. For this sequence, the RGB-D data are recorded in a typical office scene with two desks, a computer monitor, chairs, etc. The Kinect is moved around two tables so that the loop is closed. The average translational and angular velocity are 0.193m/s and 6.338 deg/s respectively. The mean intensity changes from 73.1 to 153.8, and the standard deviation changes from 76.1 to 42.1. However, the depth coverage changes from 85.3% to 53.9%. Therefore, the RGB information is good while the depth information is not very good. The mean and median relative pose error of each method is shown in Table 3 and the absolute pose trajectory error of each method is shown in Fig. 1. From the results, we can see that Fovis gets the best accuracy. Besides, the image and depth combined methods also obtain very good and similar results. The reason that visual information-based methods are good is that they can accurately and robustly detect and match feature correspondences since the RGB information is very good and the motion is relatively slow in this dataset.
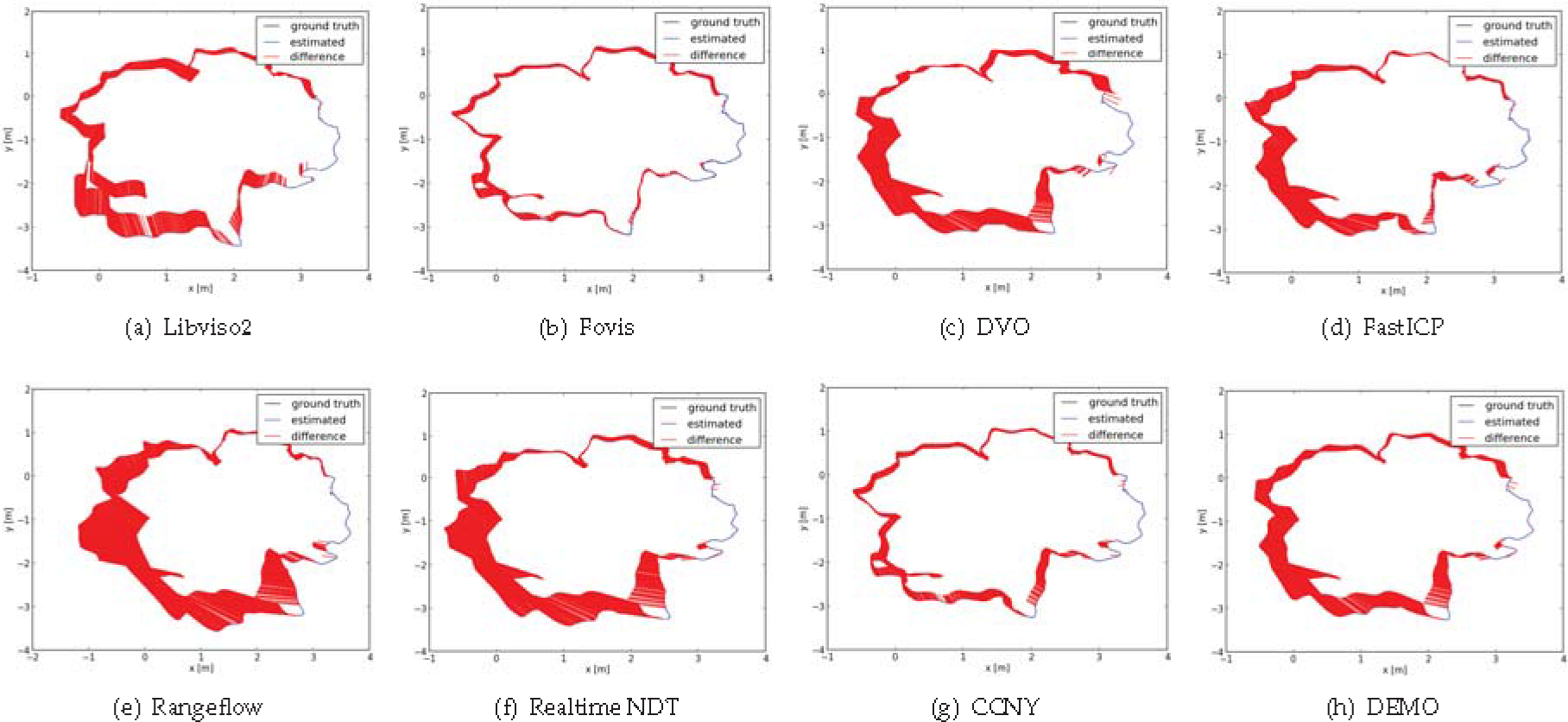
Absolute Pose Trajectory Error
The second dataset is freiburg1 room. In this dataset, the sequence is filmed along a trajectory through a typical office. It starts with the four desks but continues around the wall of the room until the loop is closed. The depth coverage changes from 83.8% to 54.9%. The mean intensity changes from 169.5 to 77.8 and standard deviation changes from 101.6 to 41.8. The experiment results are also shown in Table 3. In this dataset, there are some fast rotations. The average translational velocity is 0.334 m/s and the average angular velocity is 29.882 deg/s, which is much faster than the freiburg2/desk dataset. Therefore, it is a little bit difficult for sparse feature-based methods. The advantage of the visual feature-based method is not that obvious in this dataset, as you can see the mean translation and rotation error of depth-based methods are similar to visual information-based methods. In this dataset, the Rangeflow method gets the worst performance. The potential reason for this is that the fast motion of the camera breaks the small motion assumption of this method. The sampling rate is not fast enough to ensure a small relative motion between two consecutive frames. Generally for DVO and Rangeflow, a fast sampling rate is good for odometry estimation.
4.2 Robustness Validation in Challenging Environments
In this part, we collect some datasets in different kinds of environments to test the robustness of each method. Though it is quite easy to get ground truth in outdoors (highly accurate GPS) and small indoor environments (Motion Capture System, such as Vicon), it is very difficult to obtain accurate 6DOF ground truth in large indoor environments. Since it is very hard to obtain ground truth in large indoor environments, the camera is started and stopped at the same position. Therefore, we can use loop-closing error to evaluate the estimation performance of each method to some extent. We define the loop-closing error as the gap between the two ends of a trajectory output compared to the total length of the trajectory. The loop-closing errors of each method are shown in Table 4. Note that in Fig. 2–Fig. 5, the trajectory is projected onto the x − y plane. Therefore, if the x, y errors in the figure are very small but the loop-closing error is very big, this means there is a big drift in z coordinates. In order to show the clear differences between each method, an experimental video can be found at https://www.dropbox.com/s/561itmojn1cka1c/IJARS.mp4?dl=0.
Loop-closing error


Test 1: Long Corridor Environment. The left part shows the approximate traversing trajectory when recording the dataset and some snapshots of the environment along the trajectory. We start from point A, then go along the corridors in counter-clockwise direction to place B, C D, E and finally go back to the start point again. The top right figure shows the projected trajectories of each odometry method on the map. The bottom right figure shows the 3D trajectory of each method. At place C and E, FastICP fails due to insufficient constraints in the moving direction. At place D, fovis fails due to repetitive features on the wall.

Test 2: Complex Environment. The left part shows the approximate traversing trajectory when recording the dataset and some snapshots of the environment along the trajectory. We start from place A, then go through doors to get to place B, C and D, then finally go back to start point A. The top right figure shows the projected trajectories of each odometry method on the map. The bottom right figure shows the 3D trajectory of each method. In this dataset, place A is a little bit cluttered and place B is close to the wall. Place C is long corridor and place D is a spacious area. Those areas pose different challenges for each odometry method.

Test3: Illumination changing Environment. The left part shows the approximate traversing trajectory when recording the dataset and some snapshots of the environment along the trajectory. We start from place A where the illumination is very good, then enter into a dark conference room to place B, and move counter-clockwise to place C and D, and finally go back to place A. The top right figure shows the projected trajectories of each odometry method on the map. The bottom right figure shows the 3D trajectory of each method. As you can see that when we enter into or exit the room, the illumination changes a lot. Most methods do not work well after arriving at place B except Rangeflow, FastICP and DVO. At place B, FastICP and Rangeflow both suffer from the degeneration problem as you can see a sudden orientation change occurred.

Test3: Fast motion scenario. The top part shows the projected trajectories of each odometry method on the floor map and some snapshots of the environment along the trajectory. The bottom figure shows the 3D trajectory of each method.
Test 1: long corridor environment. Very clear long corridors usually pose big challenges for visual odometry methods. In this experiment, the mean intensity of images changes from 164.5 to 59.4 and the depth coverage ratio changes from 90.9% to 79.3%. It seems that both RGB and depth information are very good. However, in this long corridor, the floors and walls are very smooth. There are many places where only small objects on the wall or door frames can be used to estimate the translation. Therefore, this environment is very challenging for both visual and depth-based method since there are only few visual features and geometry features. Fig. 2 shows the experimental results of different methods. As you can see, in this environment DVO has the best result, while Fovis fails before the robot enters into the last corridor section. It should be noted that Fovis does not output any estimation when the algorithm finds there are not enough feature correspondences. A very short failure in Fovis will only increase the drift of the odometry, which will not cause the whole estimation to totally fail. The FastICP method also has a similar failure detection technique. When the overlapping of two consecutive point clouds is too small or not enough point correspondences are available, FastICP will not output any results. Fovis's failure is due to many repetitive textures around the corner of the last corridor section, as shown in the top right picture in Fig. 2, where Fovis fails to detect and track features when the camera turns quickly around that corner. However, Libviso2 can still track the features successfully around that corner. It seems Libviso2's feature tracking method is more robust than Fovis. The reason why DVO can succeed is that it depends on the whole image information other than sparse visual features which are difficult to detect in this environment. Sometimes, though some sparse visual features can be detected, they may be discarded due to a lack of corresponding depth value. This is why the DEMO method is also better than other sparse visual feature-based methods. The FastICP method also fails to estimate the translation in the last corridor section. The reason for failure is that there are not enough constraints in the last corridor for the ICP method to estimate the translation.
Test 2: structured and cluttered environment: The second experiment is in a more complex environment. In this environment, sometimes there are very long corridors, sometimes there are cluttered rooms and sometimes there are very spacious rooms. We use this environment to check whether all the methods can adapt to the changes of environmental structure. The mean intensity of images changes from 173 to 47 and the depth coverage ratio changes from 88.7% to 47.0%. As you can see, the quality of both image and depth changes much more than the first experiment. Fig. 3 shows the experiment results. From the experiment results, you can see that Fovis has the smallest loop-closing error and Libviso2 also gets very good estimation. The pure depth-based methods, FastICP and Rangeflow, get similar loop-closing error, but both have a big drift. DVO works well on most occasions except around some turning points, where most algorithms become poor. The reason is that the passage is very narrow (less than 1 metre) and the quick turn happened at a place very close to a wall, where Xtion RGB-D cameras cannot attain good RGB and depth data since the fast motion and the minimum measurement range of Xtion is 80cm. Therefore, it is very difficult for most of the evaluated methods to estimate the transform accurately.
Test 3: Illumination changing environment. The third experiment is a conference room where there is a big desk and many chairs. In this experiment, dramatic illumination changes occur when the robot enters into and goes out of the conference room. The mean intensity changes from 169.2 to 3.5. The conference room is very dark where the intensity is just about 3.5~30, which is very challenging for visual-based methods. Fortunately, we can still get a good point cloud in this environment, where the depth coverage ratio changes from 71.5% to 90.1%. The experiment result is shown in Fig. 4. There is no doubt that depth-based methods will be better than visual-based methods in this environment. In our experiment, we found that Rangeflow achieves the best performance. To our surprise, dense visual odometry can still work almost all the time except in very dark areas (the mean intensity is less than 10). It seems that DVO is much more robust than sparse feature-based methods in this test. However, even depth-based methods achieve better results in this test, and they also encounter the degeneration problem. As you can see around place B in 4, both FastICP and Rangeflow slide far away from the true position.
Test 4: Fast motion scenario. This dataset is recorded in a typical office environment where there are many tables, desks and computers. Therefore, this environment has lots of very good geometric and textural features for motion estimation. When recording the data, we keep rotating the camera with a relatively fast speed. The experimental result is shown in Fig. 5. As you can see from the RGB images, there is an obvious motion blur. The loop-closing error of each method is also shown in Table 4. From the results, we can see that for relative fast motion, FastICP is better than the image-based method. The reason for this is that fast motion can cause motion blur (Asus Xtion RGB-D camera is a rolling shutter camera) which is very bad for feature detecting and matching while the point cloud is not too bad. This is why the RGB and depth combined methods can also get better results. In this test, the CCNY method gets the smallest loop-closing error. One reason for this is that it uses robust 2D visual feature detectors and 3D feature matching methods. Another reason why FastICP and CCNY are better than other methods is that both of them use frame to local map matching strategy. When there was a large motion, frame-to-frame or frame-to-keyframe based methods could not find good feature correspondences. However, since a local map is much bigger than one image frame, there are many more features or points to match, which makes it much better for fast motion. The NDT method is also better than image-based methods. That benefits from NDT using a two-stage optimization strategy. Though the fast motion decreases the estimation accuracy of the first stage, most of the time the second stage can refine the estimation of the first stage by using NDT registration on dense point clouds. However, if the motion is too fast, the first stage might be unable to achieve a good motion estimation. This means the initial guess of the second stage is not very good, and therefore the final estimation is sometimes still not very good.
4.3 Speed and CPU Usage Comparison
Besides the accuracy and robustness, the computational performance of each method is also very important, especially for the application on computation resources limited robot platform. We test the speed and CPU usage of each method using an Asus UX31E Ultrabook (Quad-core 1.7GHz CPU, 4GB Memory). Both RGB and depth images are of 640×480 size. The experimental results are shown in Table 5. In our experiment, all the tested methods can run in real time on our laptop. Most of them can run at more than 20Hz. It should be noted that Libviso2 and DEMO are multi-thread programs, while others are single-thread programs. In libviso2, one node is for feature matching and another node is for odometry estimation. While there are three nodes in DEMO, one is for feature tracking, another one is for depth processing and the third one is for odometry estimation. Out of all of the methods, Rangeflow has the best speed and the lowest CPU usage, which is also much faster than image-based methods. The reason why Rangeflow is so fast is that it only needs to compute the gradients of a down-sampled depth image without any feature detection and matching, which saves a lot of computation time. Besides, it is only a frame-to-frame estimation method, which does not use any image pyramid, keyframe, local-map or local BA techniques to improve robustness.
Computational performance on the Test2 Dataset

4.4 Analysis and Discussion
From the experiment results, it is clear that though some of the examined methods can achieve good results in specific environments, none of them can perform very well in all kinds of environments: they all have their own advantages and disadvantages.
Visual information-based methods are usually more robust and accurate than point cloud-based methods. However, they have the following disadvantages. First, the environments must have enough illumination. Second, the environments must have good texture features to be detected. Third, most of them discard the feature points that do not have depth information. Therefore, for spacious environments where depth information is not sufficient, most of them also cannot attain good estimation.
For depth information-based methods, the advantage is that they can be used in very dark environments. However, they also have some shortcomings. First, the effective measurement range of the RGB-D camera is very limited. Therefore, there are often not enough points with constraints in spacious areas like atria and long hallways, which often cause the degeneration problem. Second, the depth data of the consumer-level depth camera is very noisy. However, we still need to downsample it to reduce computation time. Therefore, the estimation accuracy of the point cloud-based method is not as accurate as visual information-based methods in most cases.
Methods that use both image and depth information usually they take advantage of both information types. Most times these methods work very well. However, most of them depend on good RGB images, and if they cannot find very good visual features most of them will obtain bad estimation results even if the depth is still very good. Therefore, the issue of how to use depth and image information more effectively and efficiently is still a problem.
By analysing the characteristics of each method and the RGB-D data, we can get some basic ideas on how to use the RGB-D camera for robust and accurate odometry estimation. If the RGB and depth information are both available and good, we think that we should use both kinds of information as much as possible for robustness consideration. If the RGB image has abundant features but very limited depth information, we should still consider how to use those features that do not have depth information. If the depth image has abundant geometric features but the RGB information is bad, we can depend on depth information-based methods. If both RGB and depth information are unavailable, we can only use other sensor information for short time prediction; for, example fusing visual odometry with IMU.
In addition, through analysing each method from theoretical and experimental aspects, we can also attain some important tips for using each method. Libviso2 was originally designed for stereo cameras, which follows a traditional stereo visual odometry pipeline. Its performance mainly depends on robust and accurate sparse visual feature detection and matching. It needs enough and accurate sparse feature correspondence to do triangulation and estimation. Another problem is that even when there are enough features, when the camera performs pure rotation the linear system to calculate the fundamental matrix degenerates. Therefore, when using libviso2 one should avoid motion that has pure rotation without translation. Though the estimation pipeline of Fovis is similar to libviso2, it has several techniques to make it more accurate and efficient than libviso2. Firstly, it uses an image pyramid to enable more robust feature detection at different scales. Secondly, it uses the keyframe technique to reduce short-scale drift. A shortcoming of Fovis is that it doesn't work well in environments with many repetitive features. DVO tries to use all of the dense visual information without detecting any sparse features; therefore, theoretically it can be more robust and accurate than sparse feature-based methods. However, in order to achieve this the relative motion between two consecutive image frames must be small enough. Even though DVO uses the image pyramid technique to make it more robust against large motion, it is still not good for large motion. Therefore, a higher sampling rate is better for DVO. This is almost the same for range flow-based methods, which are also direct motion estimation methods based on depth images instead of RGB images. In this paper, the rangeflow method is only a frame-to-frame estimation method, and is therefore fast but not accurate or robust. It does not use either image pyramids or keyframe techniques to improve robustness. The FastICP method constructs local maps to reduce the drift; however, the ICP-based method is still not very fast. A big problem for depth-based methods is that they both easily suffer from degeneration problems, which are very common in indoor environments. To achieve a good performance of rangeflow and FastICP, one should avoid making the camera only see a wall, especially during rotation, otherwise both of them will output the estimated results sliding away from the true position. For the realtime NDT method, it really depends on a good initial guess from sparse visual features. For the refine stage, a good segmentation is also very important. The CCNY method estimates the motion using 3D features, providing four kinds of feature detectors including ‘GFT’, ‘SURF’, ‘STAR’ and ‘ORB’. Most of the time we found that ‘GFT’ is the best choice for robustness and efficiency. Besides, the maximum iteration and model size of ICP registration really influences the speed and accurate of the estimation. The DEMO method is a little different from others since it tries to reconstruct features without depth values, while other methods directly discard those features. There are two important things that will influence the performance of DEMO: First, the maximum features number and searching window size for feature tracking, and secondly the local point cloud size and density. The performance of the DEMO method is almost the same as other sparse feature-based methods in rich visual feature environments with depth values, but it will outperform other methods in depth insufficient environments.
5. Conclusions
In this paper, a detailed analysis and comparison of several visual odometry methods using RGB-D cameras has been presented. Representative approaches were compared on real data from publicly available datasets and author-collected datasets in several challenging environments. As the experimental results show, the performance of each odometry estimation method depends on the quality of RGB-D data and the environment characteristics. The experiment results provide some guidelines on how to use different visual odometry methods.
If the environment has rich visual features and illumination is also good, we should generally consider image-based or hybrid-based methods since they are more robust than depth-based methods. However, for featureless or dark environments, depth-based methods are the best choices. More specifically, in environments with abundant texture features, if the image grey value is also good, Fovis is the best choice for accuracy and speed. If the illumination is relatively dark, DVO is the best choice since it works much better than sparse feature-based methods in bad illumination environments. If the illumination is very bad (Mean grey value is smaller than 10) or in featureless environments, then Rangeflow is the best choice since it is much faster than ICP-based methods. If there is no sufficient depth information, DEMO is better than other methods. For fast-motion scenarios, generally local map-based methods are better than others. The choice of the best algorithm depends on the quality of RGB-D data and the characteristics of the practical environment.
Footnotes
6. Acknowledgements
Research presented in this paper was funded by China Scholarship Council, NSFC under grant no.61040014, No. 61005085 and Fundamental Research Funds for the Central Universities under grant no.N120408002 and 2012QNA4024. The authors would also like to thank Sebastian Scherer for his valuable discussions and help.