Particle filtering (PF) algorithm has found an increasingly wide utilization in many fields at present, especially in nonlinear and non-Gaussian situations. Because of the particle degeneracy limitation, various resampling methods have been researched. This article proposed an improved PF algorithm combining with different rank correlation coefficients to overcome the shortcomings of degeneracy. By simulating iteration operation in Matlab, it discovers that the proposed algorithm provides better accuracy than sequential importance resampling, Gaussian sum particle filter, and Gaussian mixture sigma-point particle filters in Gaussian mixture noise.
Introduction
Since Gordon's research1 in 1993, particle filtering (PF) algorithm also known as sequential Monte Carlo (SMC) method has become a recent technique to perform filtering and smoothing for nonlinear and non-Gaussian systems. This methodology has been adopted in various fields, including signal processing, navigation, target tracking, robotics, image processing, control, wireless communications, and economics.2,3
PF algorithms have already been implemented to deal with multiple integrals in fields of statistics and physics as early as the middle 1950s, and have been drawn into fields of automation around the 1970s. Limited by the particle degeneracy and calculation speed then, the method was unvalued. Gordon et al.1 implemented sequential importance resampling (SIR) while they proposed the bootstrap filter. It is an appropriate solution of the particle degeneracy phenomenon. Although the SIR algorithm is advantageous, it has limitations. Much research on the improved algorithms from a different perspective has been done and made some progress. Doucet and Johansen2 proposed that various particle methods could be reinterpreted as different instances of sequential Monte Carlo methods. Pitt and Shephard proposed the auxiliary particle filter,4 which introduced instrumental variable to correct the particle weights according to the likelihood. van der Merwe et al. proposed the unscented particle filter (UPF)5 The algorithm takes advantage of the unscented transformation and the unscented Kalman filter to achieve the proposal distribution. The sigma-point particle filter (SPPF) uses a sigma-point Kalman filter (SRUKF or SRCDKF) for proposal distribution generation and is an extension of the original UPF.5 They also proposed the Gaussian mixture SPFFs (GMSPPF) in Ref.6 Kotecha and Djuric7 applying the Gaussian distribution instead of the posterior probability density, which is called the Gaussian particle filter (GPF), avoided the resampling step. Similarly in Ref.,7 they proposed the Gaussian sum particle filter (GSPF) based on the GPF.8
Initially, particle filter was called the bootstrap filter, which is a powerful tool for Bayesian state estimation in nonlinear systems. The key idea of this algorithm is to construct the posterior density function of the state variables by a set of random samples (particles) with associated weights recursively. After decades of research carried out by many scholars, there are a variety of PF algorithms. Almost all of them consist in three important operations: particle propagation, weight computation, and resampling. Particle propagation means that the generation of particles and weight computation amount to the generation of particles and assignment of weights, whereas resampling replaces one set of particles and their weights with another set.9 More details are given in the following section.
Correlation coefficient is defined and used quite frequently in statistics or mathematical analysis. It is a measure that determines the degree of two arrays' variation tendency. There are several types of correlation coefficients that are perhaps the most widely used: the Pearson's linear correlation coefficient (Pearson's r), Spearman's rank-based coefficient (Spearman's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document}), and Kendall's concordance coefficient (Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}). In addition to the three coefficients mentioned, Xu et al. introduced a new correlation coefficient named order statistics correlation coefficient, which is based on order statistics and rearrangement inequality.10 Pearson's r is a measure of the linear associations between two variables. Spearman's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document} and Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document} are two special cases of rank correlation coefficient, which is a measure of the ordinal association between rankings of different ordinal variables, where “ranking” is the assignment of the range in order of numeric value. Although Pearson's r has fast computation speed, its performance in some nonlinear cases is unsatisfactory. In contrast, neither Spearman's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document} nor Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document} can be implemented as fast as Pearson's r, but even so, their “ranking” property makes them suitable in a nonlinear situation. Xu's order statistics correlation coefficient is a moderate measure that combines the advantages of the coefficients mentioned to achieve a reasonable speed while being well performed in both linear and nonlinear situations.
This article is organized as follows. In Preliminaries section, we present the definitions and background information of the traditional PF algorithm and the four correlation coefficients mentioned. In the Proposed Methods section, we introduce a new method by combining the traditional PF algorithm and different correlation coefficients. In Simulation section, we present a numerical simulation using Matlab. And finally, discussions and conclusions are stated in Discussion section.
Preliminaries
This section is divided into two parts, which introduce the traditional PF algorithm and different correlation coefficients, respectively.
PF algorithm
For nonlinear and non-Gaussian systems, PF algorithms provide a practical and effective framework to perform filtering and smoothing for dynamic systems. General state space models can be described in the forms of hidden Markov models (HMMs) as follows:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{x_k} \,= \,f \, ( {x_{k - 1}} , {v_k} ). \tag{1}
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{y_k} \,= \,h \, ( {x_k} , {w_k} ). \tag{2}
\end{align*}
\end{document}
Equation (1) is the process equation and [Equation (2)] is the measurement equation. In the mentioned equations, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k = 1 , 2 , \cdots$$
\end{document} is a discrete time series; the hidden state vector of the system xk satisfies \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${x_k} \in { \mathbb{R}^n}$$
\end{document} at time k, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_k} \in { \mathbb{R}^m}$$
\end{document} is the measurement vector produced by the system; \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$f \left( \cdot \right)$$
\end{document} denotes the state space function or system transition function under the Markovian hypothesis and associated with the state variables iteration; \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$h \left( \cdot \right)$$
\end{document} denotes the system measurement (observation) function associated with the series of measurements \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left( {{y_1} , {y_2} , \cdots } \right)$$
\end{document}; vk is the system process noise; and wk is the measurement noise. It is worth noting that both Gaussian and non-Gaussian noises can be applied here.
For state estimation problems, what we are actually concerned about is finding an appropriate estimator of xk. Based on Bayesian statistics and sequential Monte Carlo framework, the PF algorithm can be seen as a method for solving the Bayesian estimation problem. The state space variable xk can be regarded as a random variable with certain distribution \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{x_k}} \right)$$
\end{document}. To find the distribution \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{x_k}} \right)$$
\end{document}, we have to calculate the posterior distribution \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{x_k} \vert {y_{1:k}}} \right)$$
\end{document}. Applying the Bayes rule, we can obtain
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
p ( { x_k } { \rm { \vert } } { \kern 1pt } \, { y_ { 1 \,: \,k } } ) \,=\, { \frac { p \, ( { y_k } { \rm { \vert } } \, { x_k } ) \;p \, ( { x_k } { \rm { \vert } } { \kern 1pt } \, { y_ { 1 \,: \, } } _ { k - 1 } ) } { p \, ( { y_k } { \rm { \vert } } { \kern 1pt } \, { y_ { 1 \,: \,k - 1 } } ) } } , \tag { 3 }
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{y_k} \vert {x_k}} \right)$$
\end{document} is obtained through the measurement Equation (2) and the distribution \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{y_k} \vert {y_{1:k - 1}}} \right)$$
\end{document} is thought as a normalizing constant. Lastly, we have the Chapman–Kolmogorov equation:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
p \, ( {x_k}{ \rm{ \vert }}{y_{1:}}_{k - 1} ) \,= \int {p ( {x_k}{ \rm{ \vert }}{x_k}_{ - 1} ) \;p} ( {x_{k - 1}}{ \rm{ \vert }}{y_{1 \,: \,}}_{k - 1} ) \,dx{{ \kern 1pt} _{k - 1}}. \tag{4}
\end{align*}
\end{document}
The probability density \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{x_k} \vert {x_{k - 1}}} \right)$$
\end{document}, also known as the transition density, can be obtained with the system model [Equation (1)]. A prediction-update procedure is formed using Equations (3) and (4). This provides us a way to obtain the posterior probability density function (PDF) of the state, recursively.
However, the posterior PDF \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{x_k} \vert {y_{1:k}}} \right)$$
\end{document} is usually hidden and cannot be easily obtained. And, therefore, as alternative to the posterior PDF, we draw N random samples (particles) \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left\{ {x_k^i} \right\} _{i = 1}^N$$
\end{document} with associated weights \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left\{ { \omega _k^i} \right\} _{i = 1}^N$$
\end{document}. As the number of samples (particles) increases, the estimates become close to the functional description of the PDF. Thus we get the sample-based posterior PDF approximately:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\hat p \, ( {x_k}{ \rm{ \vert }}{ \kern 1pt} {y_{1 \,: \,}}_k ) \,= \mathop \sum \limits_{i = 1}^N { \omega _k^i \delta \, ( {x_k} - x_k^i ) } , \tag{5}
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\delta \left( \cdot \right)$$
\end{document} is the Dirac delta function that is defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\delta ( x ) \,= \,\begin{cases} + \infty , x \,= \,0 \\ 0 , \ \ \,\,\,\,\, \, x \neq 0.\end{cases} \tag{6}
\end{align*}
\end{document}
The idea of sequential importance sampling (SIS) is the basis of PF algorithm. We choose an important distribution such that it factors similarly to the posterior density
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
q ( {x_k}{ \rm{ \vert }}{ \kern 1pt} {y_{1 \,: \,k}} )\, = \,q \, ( {x_k}{ \rm{ \vert }}{x_{1 \,}}_{: \,k} , {y_{1 \,: \,k}} ) \,q ( {x_{k - 1}}{ \rm{ \vert }}{y_{1 \,: \,k - 1}} ) , \tag{7}
\end{align*}
\end{document}
It has been proven that using the SIS method mentioned alone may lead to the particle degeneracy problem. That is to say, after a few iterations, most of the particle weights reduce close to 0, only one weight increases close to 1. This makes it a waste of computing resources and causes the algorithm to become invalid. To avoid this phenomenon, PF needs another step, referred to as resampling.
Normally, the measurement of particle degeneracy is the effective sample size:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ N_ { e { \kern 1pt } f { \kern 1pt } f } } = \frac { 1 } { { \sum \nolimits_ { i = 1 } ^N { { { ( \omega _k^i ) } ^2 } } } } . \tag { 12 }
\end{align*}
\end{document}
During each time step, the posterior distribution is resampled: N particles are chosen from the approximated posterior density. With this procedure it is assured that particles with small or negligible weight will be discarded, whereas particles with more weight will multiply. The code for complete PF algorithm is shown in Algorithm 1.
As described in the Introduction section, correlation coefficients provide a measure of the strength and direction of the linear relationship between two time series. We depict the definitions and structures of several different correlation coefficients hereunder.
Define \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left( {{x_i} , {y_i}} \right)$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$i = 1 , 2 , \cdots , N$$
\end{document} to be two time series with length N. Rearranging pairwise the two time series with respect to the magnitudes of xi, we get two new series denoted by \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left( {{x_{ \left( i \right) }} , {y_{ \left[ i \right] }}} \right)$$
\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ {{x_{ \left( 1 \right) }} \le {x_{ \left( 2 \right) }}} \le \cdots \le {x_{ \left( N \right) }}$$
\end{document} are called the order statistics of x and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \left[ 1 \right] }} , {y_{ \left[ 2 \right] }} , \cdots , {y_{ \left[ N \right] }}$$
\end{document} the associated concomitants. Reversing the roles of x and y, we also define the order statistics of y and the corresponding concomitants that are denoted by \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \left( 1 \right) }} , {y_{ \left( 2 \right) }} , \cdots , {y_{ \left( N \right) }}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${x_{ \left[ 1 \right] }} , {x_{ \left[ 2 \right] }} , \cdots , {x_{ \left[ N \right] }}$$
\end{document}, respectively. Suppose xj is at the kth position in the sorted series \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${x_1} , {x_2} , \cdots , {x_N}$$
\end{document}, the number \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${1} \le {k} \le {N}$$
\end{document} is termed the rank of xj and is denoted by \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${p_j} \left( { = k} \right)$$
\end{document}. Similarly, we can get the rank of yj denoted by qj. Such operation of obtaining the ranks of all elements in a series is called ranking. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left( {{x_i} , {y_i}} \right)$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left( {{x_j} , {y_j}} \right)$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$i = 1 , 2 , \cdots , N$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$j = i + 1 , i + 2 , \cdots , N$$
\end{document} be two data pairs from the original time series. If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${p_j} - {p_i}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${q_j} - {q_i}$$
\end{document} have the same sign, we say that the two data pairs are concordant, otherwise, we say that they are discordant.11 Let P stand for the number of concordant pairs and Q the number of discordant pairs, it follows that \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$P + Q = N \left( {N - 1} \right) / 2$$
\end{document}. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\bar x$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\bar y$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\bar p$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\bar q$$
\end{document} be the arithmetic averages of x, y, p, and q, respectively, Pearson's correlation coefficient rP, Spearman's rho rS, and Kendall's tau rK are defined as follows:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ r_P } ( x , y ) \,= \, { \frac { \sum { _ { i = 1 } ^N ( { x_i } - \bar x ) ( { y_i } - \bar y ) } } { \sqrt { \sum { _ { i = 1 } ^N { { ( { x_i } - \bar x ) } ^2 } \sum { _ { i = 1 } ^N { { ( { y_i } - \bar y ) } ^2 } } } } } } , \tag { 13 }
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ r_S } ( x , y ) \,= \,1 - { \frac { 6 \sum { _ { i = 1 } ^N { { ( { p_i } - { q_i } ) } ^2 } } } { { N^3 } - N } } , { \rm and } \tag { 14 }
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ r_K } ( x , y ) \,= \, { \frac { 2 ( P - Q ) } { N ( N - 1 ) } } . \tag { 15 }
\end{align*}
\end{document}
As proposed by Xu et al.,10 the order statistics correlation coefficient can be defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ r_X } ( x , y ) \,= \, { \frac { \sum { _ { i = 1 } ^N ( { x_ { ( i ) } } - { x_ { ( N - i + 1 ) } } ) { y_ { [ i ] } } } } { \sum { _ { i = 1 } ^N ( { x_ { ( i ) } } - { x_ { ( N - i + 1 ) } } ) { y_ { ( i ) } } } } } . \tag { 16 }
\end{align*}
\end{document}
Proposed Methods
General state space models can be described in the forms of HMMs as follows:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{X_n} \vert ( {x_{n - 1}} \,=\, {x_{n - 1}} ) \sim f ( {x_n} \vert {x_{n - 1}} ) , \tag{17}
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{Y_n} \vert ( {x_n} \,=\, {x_n} ) \sim h \, ( {y_n} \vert {x_n} ) , \tag{18}
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$f \left( \cdot \right)$$
\end{document} denotes the system transition function or the probability density associated with the state variables iteration, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$h \left( \cdot \right)$$
\end{document} denotes the system observation function or the marginal density associated with the observations \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\{ {Y_n}\} _{n \ge 1}$$
\end{document}. The prior distribution of the process of the state variables \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\{ {X_n}\} _{n \ge 1}$$
\end{document} and the likelihood function are defined by Equations (1) and (2), respectively, that is,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
p ( {x_{1:n}} ) \,=\, \mu ( {x_1} ) \mathop \Pi \limits_{k = 2}^n \;f ( {x_k}{ \rm{ \vert }}{x_{k - 1}} ) \tag{19}
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mu \left( \cdot \right)$$
\end{document} is a PDF.
Correlation coefficients provide a measure of the strength and direction of the linear relationship between two time series. Some of the more popular correlation coefficients include Pearson's r, Spearman's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document}, Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}, and Goodman and Kruskal's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma$$
\end{document}. Pearson's r computes very fast, however, it may lead to a significant margin of error if non-Gaussian is involved in the model. The other three coefficients can be used under non-Gaussian condition with lower computation efficiency. Xu et al.10 proposed a novel measurement called order statistic correlation coefficient, which possesses wider scope and is more efficient.
This article proposes an improved PF algorithm based on different rank correlation coefficients. Different from the algorithm discussed in Ref.,12 the proposed PF methods apply several rank correlation coefficients in some selected iteration, which is dominated by a threshold \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${S_{t{ \kern 1pt} h{ \kern 1pt} r}}$$
\end{document}, and eliminate the Pearson correlation coefficients for the reason that it is deficient in non-Gaussian condition sometimes. This method may take into account both the efficiency of the calculation and the accuracy of the estimation.
SIS method causes the degeneracy phenomenon and provides estimates whose variance increases exponentially with the discrete time index n. Resampling techniques are effective methods to solve this problem. Besides, applying the proposed methods in this article can also refresh the particles weights.
In HMM mathematic framework, since the independent observations of the true state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \left\{ {{y_n}} \right\} _{n \, = \,m , \,m \, + \,1 \cdots l}}$$
\end{document} and the observations of the particles \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \left\{ {y_n^ \star } \right\} _{n \, = \,m , \,m \, + \,1 \cdots l}}$$
\end{document} vary together the method of correlation coefficient could be applied to check the synchronization of both variable series. Because of the complexity of the computational process of the rank correlation coefficient and normalization, we apply the method in some selected iteration, which is dominated by the judgment index \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${S_{t \,h \,r}}$$
\end{document}.
Let k denote the discrete time index of the iterations, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${X_k} = \{ {x_j}:j = k - L + 1 , \cdots , k \} $$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$X_k^ \star = \{ x_j^ \star \left( i \right): j = k - L + 1 , \cdots , k;i = 1 , \cdots , {N_s} \} $$
\end{document} denote the true state and a set of all particles in recent time from \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k - L + 1$$
\end{document} to k, respectively, where L is a constant specified in advance and Ns is the number of particles. Accordingly, by calculating with the system observation function [Equations (21) and (22)] hereunder, we obtain \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${Y_k} = \{ {y_j}:j \,= \,k - L + 1 , \cdots , k \} $$
\end{document} and
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
Y_k^ \star \,= \, \{ y_j^ \star \left( i \right): j \,=\, k - L + 1 , \cdots , k;i = 1 , \cdots , {N_s} \} ,
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{y_j} \,= \,h ( {x_j} , \,0 ) , \tag{21}
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
y_j^ \star ( i ) \,=\, h ( x_j^ \star ( i ) , \,0 ) . \tag{22}
\end{align*}
\end{document}
According to the definition of different rank correlation coefficients, we get the corresponding equations as follows.
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ r_S } \mathop = \limits^ \Delta 1 - { \frac { 6 \sum { _ { i = j - L + 1 } ^j { { ( { y_i } - y_j^ \star ) } ^2 } } } { L ( { L^2 } - 1 ) } } , \tag { 23 }
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ r_K } \mathop = \limits^ \Delta { \frac { 2 ( P - Q ) } { L ( L - 1 ) } } , { \rm and } \tag { 24 }
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ r_X } \mathop = \limits^ \Delta { \frac { \sum { _ { i = j - L + 1 } ^L ( { y_ { ( i ) } } - { y_ { ( L - i + 1 ) } } ) { y_ { [ i ] } } } } { \sum { _ { i = j - L + 1 } ^L ( { y_ { ( i ) } } - { y_ { ( L - i + 1 ) } } ) { y_ { ( i ) } } } } } , \tag { 25 }
\end{align*}
\end{document}
where rS, rK, and rX denote the Spearman's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document}, Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}, and Xu's order statistics correlation. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left( {{y_i} , y_i^ \star } \right)$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$i = j - L + 1 , \cdots , j$$
\end{document}, be two time series of length L. Rearranging pairwise the two time series with respect to the magnitudes of yi, we get two new series denoted by \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left( {{y_{ \left( i \right) }} , y_{ \left[ i \right] }^ \star } \right)$$
\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$y_{ (i-L + 1)}\le \cdots \le y_{(i)} $$
\end{document} are called the order statistics of yi and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \left[ {j - L + 1} \right] }} , \cdots , {y_{ \left[ j \right] }}$$
\end{document} the associated concomitants.7P and Q denote the number of concordant and discordant pairs, respectively. Concordant means \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${p_b} - {p_a}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${q_b} - {q_a}$$
\end{document} have the same sign, where pa is the ordinal number of ya in the sorted time series \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \left( {j - L + 1} \right) }} , \cdots , {y_{ \left( j \right) }}$$
\end{document}, the parameters satisfy \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$a = j - L + 1 , \cdots , j , b = a + 1 , \cdots , j.$$
\end{document} Analogously, we get qa and qb from time series \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$y_i^ \star$$
\end{document}.
When calculated the rank correlation coefficients of the two time series, we take the exponential function with an adjustable parameter \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha$$
\end{document} to expand the numerical range of the mentioned results, not limited to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$-1 \le cc \le 1$$
\end{document}. For the purpose of simplifying the calculation, we take a threshold \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${S_{thr}}$$
\end{document} as reference, redistribute the weights using the proposed PF method for the condition of particle degeneration screened by the threshold. The proposed algorithm proceeds as follows.
Justification
Since the screening procedure affected by the threshold \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${S_{t{ \kern 1pt} h{ \kern 1pt} r}}$$
\end{document} behaves similarly to the resampling procedure essentially, the justification for the proposed PF method may rely on the result from Smith and Gelfand.13 They show that Bayes theorem can be implemented as a weighted bootstrap. Sampling from a continuous density function G(x) gives us a sample set
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\left\{ {x_k^ \star \left( i \right): i = 1 , 2 , \cdots , N} \right\}
\end{align*}
\end{document}
which is required from the PDF \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$L \left( x \right) G \left( x \right)$$
\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$L \left( x \right)$$
\end{document} is a known function.
The theorem states that a sample drawn from the discrete distribution over \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left\{ {x_k^ \star \left( i \right): i = 1 , 2 , \cdots , N} \right\} $$
\end{document} with probability mass \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$L \left( {x_k^ \star \left( i \right) } \right) / \sum \nolimits_{j = 1}^N L \left( {x_k^ \star \left( j \right) } \right)$$
\end{document} on \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$x_k^ \star \left( i \right)$$
\end{document} tends in distribution to the required density as N tends to infinity. If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$G \left( x \right)$$
\end{document} is identified with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \left( {{x_k} \vert {y_{1:k - 1}}} \right)$$
\end{document} (the prior) and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$L \left( x \right)$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$cc{e_k} \cdot p \left( {{y_k} \vert {x_k}} \right)$$
\end{document} (the likelihood), where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$cc{e_k}$$
\end{document} is the mentioned exponential transform of the corresponding correlation coefficient, then this theorem provides a justification for the proposed PF method.
Simulation
In order to verify the reliability and validity of the proposed method, we apply a well-known example of simulation that has been analyzed in many publications before.
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ x_k } \,=\, \frac { { { x_ { k - 1 } } } } { 2 } + { \frac { 25 { x_ { k - 1 } } } { 1 + x_ { k - 1 } ^2 } } + 8 \cos ( 1.2 ( k - 1 ) ) + { v_ { k - 1 } } , \tag { 26 }
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ y_k } \,= \, { \frac { x_k^2 } { 20 } } + { n_k } , \tag { 27 }
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${n_k} \,\sim \,N \left( {0 , 1} \right)$$
\end{document} is zero mean Gaussian random variables. The initial state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${x_0} = 0.1 ,$$
\end{document} number of particles \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${N_s} = 50$$
\end{document}, and the adjustable parameter \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha = 10$$
\end{document}. The simulation step \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k = 100$$
\end{document}. The process noise distribution vk is a Gaussian mixture given by
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
p ( {v_k} ) = \in N ( v;0 , \sigma _{v1}^2 ) + ( 1 - \in ) N ( v;0 , \sigma _{v2}^2 ) , \tag{28}
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\varepsilon = 0.8$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sigma _{v1}^2 = 1$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sigma _{v2}^2 = 10$$
\end{document}, that can model the heavy-tailed distributions well.
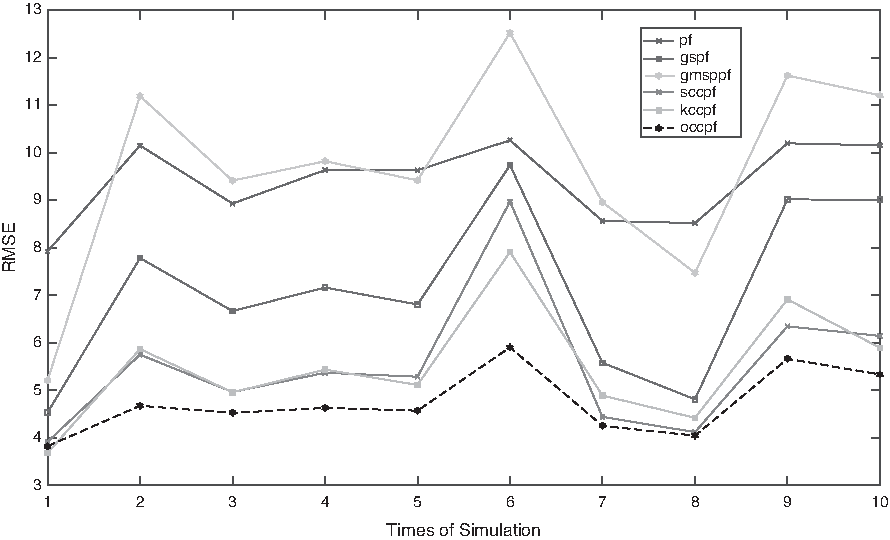
The simulation algorithm was coded using Matlab, and the program was performed on an Inter Core i5-4570 PC of 3.2GHz and 4GB memory. Average results of 1000 random Monte Carlo (MC) simulation runs are shown in Table 1. Average time (AvgT) required for processing 1000 iterations is also summarized in it. We use the root mean squared error (RMSE) to quantify performance of different algorithms. RMSE values of 10 random MC simulation runs of different algorithms are plotted in Figure 1. In Table 1 and Figure 1, Spearman correlation coefficient particle filtering (SCCPF), Kendall correlation coefficient particle filtering (KCCPF), and order statistic correlation coefficient particle filtering (OCCPF) denote the SMC method combining with Spearman's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document}, Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}, and order statistic correlation coefficients, respectively.
RMSE of PF, GSPF, and GMSPPF, and proposed algorithms for 10 random simulation runs. GMSPPF, Gaussian mixture sigma-point particle filters; GSPF, Gaussian sum particle filter; PF, particle filtering; RMSE, root mean squared error.
Table of algorithms used, root mean squared error, mean, variance, and average time required (averaged over 1000 Monte Carlo runs)
It is shown that the performance of the proposed algorithms is better than the PF, GSPF, and GMSPPF, whereas the three proposed algorithms perform similarly. KCCPF's extra time consumption is due to the computational complexity of Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}. Despite the long simulation time of KCCPF, we retain this result. The reason for this is that the simulation accuracy of KCCPF is acceptable. With simulation time similar to GMSPPF, the simulation accuracy of KCCPF is much higher than that of GMSPPF. Furthermore, we are also expected to shorten the calculation time of Kendall's \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document} in the following study. With similar computation time spent, SCCPF and OCCPF achieved more accuracy than other algorithms. It is also worth noting that OCCPF has lowest RMSE variance.
Conclusions
In this article, a new particle filter algorithm combing with different rank correlation coefficients is proposed. Unlike other resampling methods, we used several nonlinear correlation coefficients to calculate the weights of resampled particles. Different rank correlation coefficients are introduced to measure the variation tendency between the particles and the state and, therefore, obtain the particle weights. This has two advantages. First, setting an appropriate threshold can ensure the efficiency of the algorithm as a whole. Second, the selection of nonlinear correlation coefficient can avoid the failure or divergence of linear correlation coefficient in some specific situations. Compared with the PF, GSPF, and GMSPF algorithms, the proposed method has better performance of estimation accuracy, under the condition of consuming about the same computation time. Moreover, the computational complexity of the proposed algorithm is lower than that of GSPF and GMSPF, which can be reflected by time consumption in Gaussian mixture noise.
Footnotes
Acknowledgment
This study was supported by the National Natural Science Foundation of China (grant no. 51277080).
Author Disclosure Statement
No competing financial interests exist.
Abbreviations Used
References
1.
GordonNJ, SalmondDJ, SmithAFM. Novel approach to nonlinear/non-gaussian bayesian state estimation. IEE Proceedings F (Radar and Signal Processing). 1993; 140:107–113.
2.
DoucetA, JohansenAM. A tutorial on particle filtering and smoothing: Fifteen years later. In: CrisanD, RozovskyB (Eds.): The Oxford Handbook of Nonlinear Filtering. Oxford, United Kingdom: Oxford University Press, 2011. pp. 656–704.
3.
ArulampalamMS, MaskellS, GordonN, ClappT. A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking. IEEE Trans Signal Process. 2002; 50:174–188.
4.
PittMK, ShephardN. Filtering via simulation: Auxiliary particle filters. J Am Stat Assoc. 1999; 94:590–599.
5.
van der MerweR, DoucetA, de FreitasN, WanE. The unscented particle filter. In: LeenTK, DietterichTG, and TrespV, (Eds.): Advances in Neural Information Processing Systems, Vol. 13, 2001, pp. 584–590. 14th Annual Neural Information Processing Systems Conference (NIPS), Denver, CO, November 27 to December 2, 2000.
6.
van der MerweR, WanE.Gaussian mixture sigma-point particle filters for sequential probabilistic inference in dynamic state-space models. In 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP'03), Vol. 6, pp. VI–701–704, April 2003.
7.
KotechaJH, DjuricPM. Gaussian particle filtering. IEEE Trans Signal Process. 2003; 51:2592–2601.
8.
KotechaJH, DjuricPM. Gaussian sum particle filtering. IEEE Trans Signal Process. 2003; 51:2602–2612.
9.
LiT, BolicM, DjuricPM. Resampling methods for particle filtering: Classification, implementation, and strategies. IEEE Signal Process Mag. 2015; 32:70–86.
10.
XuW, ChangC, HungYS, et al.Order statistics correlation coefficient as a novel association measurement with applications to biosignal analysis. IEEE Trans Signal Process. 2007; 55:5552–5563.
11.
KendallMG.A new measure of rank correlation. Biometrika. 1938; 30:81–93.
12.
HaomiaoZhou, ZhihongDeng, YuanqingXia, MengyinFu. A new sampling method in particle filter based on pearson correlation coefficient. Neurocomputing. 216(Suppl C): 208–215, 2016.
13.
SmithAFM, GelfandAE. Bayesian statistics without tears: A samplingresampling perspective. Am Stat. 1992; 46:84–88.