
Abstract
The K-nearest neighbor (KNN) classifier is one of the simplest and most common classifiers, yet its performance competes with the most complex classifiers in the literature. The core of this classifier depends mainly on measuring the distance or similarity between the tested examples and the training examples. This raises a major question about which distance measures to be used for the KNN classifier among a large number of distance and similarity measures available? This review attempts to answer this question through evaluating the performance (measured by accuracy, precision, and recall) of the KNN using a large number of distance measures, tested on a number of real-world data sets, with and without adding different levels of noise. The experimental results show that the performance of KNN classifier depends significantly on the distance used, and the results showed large gaps between the performances of different distances. We found that a recently proposed nonconvex distance performed the best when applied on most data sets comparing with the other tested distances. In addition, the performance of the KNN with this top performing distance degraded only ∼20% while the noise level reaches 90%, this is true for most of the distances used as well. This means that the KNN classifier using any of the top 10 distances tolerates noise to a certain degree. Moreover, the results show that some distances are less affected by the added noise comparing with other distances.
Introduction
Classification is an important problem in big data, data science, and machine learning. The K-nearest neighbor (KNN) is one of the oldest, simplest, and accurate algorithms for patterns classification and regression models. KNN was proposed in 1951 by Evelyn and Hodges, 1 and then modified by Cover and Hart 2 KNN has been identified as one of the top 10 methods in data mining. 3 Consequently, KNN has been studied over the past few decades and widely applied in many fields. 4 Thus, KNN comprises the baseline classifier in many pattern classification problems such as pattern recognition, 5 text categorization, 6 ranking models, 7 object recognition, 8 and event recognition 9 applications. KNN is a nonparametric algorithm. 10 Nonparametric means either there are no parameters or fixed number of parameters irrespective of size of data. Instead, parameters would be determined by the size of the training data set, although there are no assumptions that need to be made to the underlying data distribution. Thus, KNN could be the best choice for any classification study that involves a little or no prior knowledge about the distribution of the data. In addition, KNN is one of the laziest learning methods. This implies storing all training data and waits until having the test data produced, without having to create a learning model. 11
Despite its slow characteristic, surprisingly, KNN is used extensively for big data classification, this includes the work of Refs.,12–16 this is due to the other good characteristics of the KNN such as simplicity and reasonable accuracy, since the speed issue is normally solved using some kind of divided-and-conquer approaches. Slowness is not the only problem associated with the KNN classifier, in addition to choosing the best K-neighbors problem, 17 choosing the best distance/similarity measure is an important problem, this is because the performance of the KNN classifier is dependent on the distance/similarity measure used. This article focuses on finding the best distance/similarity measure to be used with the KNN classifier to guarantee the highest possible accuracy.
Related work
Several studies have been conducted to analyze the performance of KNN classifier using different distance measures. Each study was applied on various kinds of data sets with different distributions, types of data, and using different number of distance and similarity measures.
Chomboon et al. 18 analyzed the performance of KNN classifier using 11 distance measures. These include Euclidean distance (ED), Mahalanobis distance, Manhattan distance (MD), Minkowski distance, Chebychev distance, Cosine distance (CosD), Correlation distance (CorD), Hamming distance (HamD), Jaccard distance (JacD), Standardized Euclidean distance, and Spearman distance. Their experiment had been applied on eight binary synthetic data sets with various kinds of distributions that were generated using MATLAB. They divided each data set into 70% for training set and 30% for the testing set. The results showed that the MD, Minkowski distance, Chebychev distance, ED, Mahalanobis distance, and Standardized Euclidean distance measures achieved similar accuracy results and outperformed other tested distances.
Mulak and Talhar 19 evaluated the performance of KNN classifier using Chebychev distance, ED, and MD, distance measures on K divergence distance (KDD) data set. 20 The KDD data set contains 41 features and 2 classes, the type of data of which is numeric. The data set was normalized before conducting the experiment. To evaluate the performance of KNN, accuracy, sensitivity, and specificity measures were calculated for each distance. The reported results indicate that the use of MD outperform the other tested distances, with 97.8% accuracy rate, 96.76% sensitivity rate, and 98.35% specificity rate.
Hu et al. 21 analyzed the effect of distance measures on KNN classifier for medical domain data sets. Their experiments were based on three different types of medical data sets containing categorical, numerical, and mixed types of data, which were chosen from the University of California, Irvine (UCI) machine learning repository, and four distance metrics including ED, CosD, Chi-square, and Minkowsky distances. They divided each data set into 90% of data as training and 10% as testing set, with K values ranging from 1 to 15. The experimental results showed that Chi-square distance function was the best choice for the three different types of data sets. However, the CosD, ED, and Minkowsky distance metrics performed the “worst” over the mixed type of data sets. The “worst” performance means the method with the lowest accuracy.
Todeschini et al.22,23 analyzed the effect of 18 different distance measures on the performance of KNN classifier using eight benchmark data sets. The investigated distance measures included MD, ED, Soergel distance (SoD), Lance–Williams distance, contracted Jaccard–Tanimoto distance, Jaccard–Tanimoto distance, Bhattacharyya distance (BD), Lagrange distance, Mahalanobis distance, Canberra distance (CanD), Wave-Edge distance, Clark distance (ClaD), CosD, CorD, and four locally centered Mahalanobis distances. For evaluating the performance of these distances, the nonerror rate and average rank were calculated for each distance. The result indicated that the “best” performance was the MD, ED, SoD, Contracted Jaccard–Tanimoto distance, and Lance–Williams distance measures. The “best” performance means the method with the highest accuracy.
Lopes and Ribeiro 24 analyzed the impact of five distance metrics, namely ED, MD, CanD, Chebychev distance, and Minkowsky distance in instance-based learning algorithms. Particularly, 1-nearest neighbor (1-NN) classifier and the Incremental Hypersphere Classifier, they reported the results of their empirical evaluation on 15 data sets with different sizes showing that the Euclidean and Manhattan metrics significantly yield good results comparing with the other tested distances.
Alkasassbeh et al. 25 investigated the effect of Euclidean, Manhattan, and a nonconvex distance due to Hassanat 26 distance metrics on the performance of the KNN classifier, with K ranging from 1 to the square root of the size of the training set, considering only the odd K's. In addition, they experimented on other classifiers such as the Ensemble Nearest Neighbor classifier 17 and the Inverted Indexes of Neighbors Classifier. 27 Their experiments were conducted on 28 data sets taken from the UCI machine learning repository, the reported results show that Hassanat distance (HasD) 26 outperformed both of MD and ED in most of the tested data sets using the three investigated classifiers.
Lindi 28 investigated three distance metrics to use the best performer among them with the KNN classifier, which was employed as a matcher for their face recognition system that was proposed for the NAO robot. The tested distances were Chi-square distance, ED, and HasD. Their experiments showed that HasD outperformed the other two distances in terms of precision, but was slower than both of the other distances.
Table 1 provides a summary of these previous studies on evaluating various distances within KNN classifier, along with the best distance assessed by each of them. As can be seen from the mentioned literature review of most related studies, all of the previous studies have investigated either a small number of distance and similarity measures (ranging from 3 to 18 distances), a small number of data sets, or both.
Comparison between previous studies for distance measures in K-nearest neighbor classifier along with “best” performing distance
Comparatively our current study compares the highest number of distance measures on a variety of data sets.
Contributions
In KNN classifier, the distances between the test sample and the training data samples are identified by different measures. Therefore, distance measures play a vital role in determining the final classification output. 21 ED is the most widely used distance metric in KNN classifications; however, only few studies examined the effect of different distance metrics on the performance of KNN, these used a small number of distances, a small number of data sets, or both. Such shortage in experiments does not prove which distance is the best to be used with the KNN classifier. Therefore, this review attempts to bridge this gap by testing a large number of distance metrics on a large number of different data sets, in addition to investigating the distance metrics that are least affected by added noise.
The KNN classifier can deal with noisy data; therefore, we need to investigate the impact of choosing different distance measures on the KNN performance when classifying a large number of real-world data sets, in addition to investigate which distance has the lowest noise implications. There are two main research questions addressed in this review:
Which is the “best” distance metric to be implemented with the KNN classifier? Which is the “best” distance metric to be implemented with the KNN classifier in the case of noise existence?
We mean by the “best distance metric” (in this review) is the one that allows the KNN to classify test examples with the highest precision, recall, and accuracy, that is, the one that gives best performance of the KNN in terms of accuracy.
The previous questions were partially answered by the aforementioned studies; however, most of the reviewed research in this regard used a small number of distances/similarity measures and/or a small number of data sets. This study investigates the use of a relatively large number of distances and data sets, to draw more significant conclusions, in addition to reviewing a larger number of distances in one place.
Organization
We organized our review as follows. First in KNN and Distance Measures section, we provide an introductory overview to KNN classification method and present its history, characteristics, advantages, and disadvantages. We review the definitions of various distance measures used in conjunction with KNN. Experimental Framework section explains the data sets that were used in classification experiments, the structure of the experiments model, and the performance evaluations measures. We present and discuss the results produced by the experimental framework. Finally, in Conclusions and Future Perspectives section, we provide the conclusions and possible future directions.
KNN and Distance Measures
Brief overview of KNN classifier
The KNN algorithm classifies an unlabeled test sample based on the majority of similar samples among the KNNs that are the closest to test sample. The distances between the test sample and each of the training data samples are determined by a specific distance measure. Figure 1 shows that a KNN example contains training samples with two classes, the first class is “blue square” and the second class is “red triangle.” The test sample is represented in green circle. These samples are placed into two dimensional feature spaces with one dimension for each feature. To classify the test sample that belongs to class “blue square” or to class “red triangle,” KNN adopts a distance function to find the KNNs to the test sample. Finding the majority of classes among the KNNs predicts the class of the test sample. In this case, when k = 3, the test sample is classified to the first class “red triangle” because there are two red triangles and only one blue square inside the inner circle, but when k = 5, it is classified to the “blue square” class because there are two red triangles and only three blue squares.
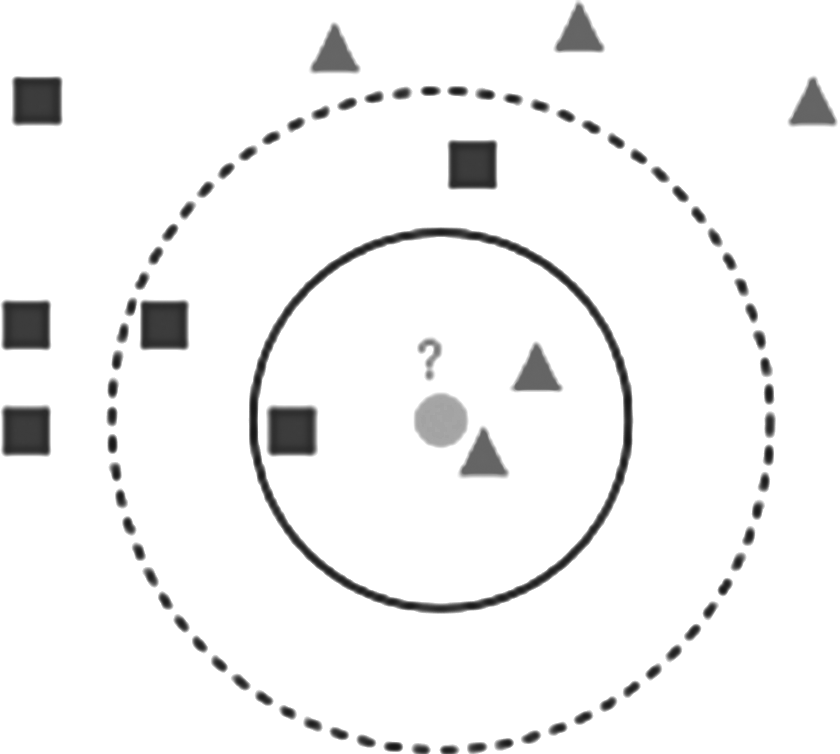
An example of KNN classification with K neighbors K = 3 (solid line circle) and K = 5 (dashed line circle), distance measure is ED. Each triangle represents a training example with two features (x, y), which belongs to class 1. Each square represents a training example with two features (x, y), which belongs to class 2. The gray circle represents a test example with two features (x, y), which belongs to an unknown (?) class, and the KNN needs to predict its class based on the ED distance. ED, Euclidean distance; KNN, K-nearest neighbor.
KNN is simple, but proved to be a highly efficient and effective algorithm for solving various real-life classification problems. However, KNN has got some disadvantages that include the following:
How to find the optimum K value in KNN Algorithm?
High computational time cost as we need to compute the distance between each test sample and all training samples, for each test example we need O(nm) time complexity (number of operations), where n is the number of examples in the training data and m is the number of features for each example.
High memory requirement as we need to store all training samples O(nm) space complexity.
Finally, we need to determine the distance function that is the core of this study.
The first problem was solved either by using all the examples and taking the inverted indexes, 29 or using ensemble learning. 30 For the second and third problems, many studies have proposed different solutions depending on reducing the size of the training data set, those include and not limited to Refs.,31–35 or using approximate KNN classification such as those in Arya and Mount 36 and Zheng et al. 37 Although some previous studies exist in the literature that investigated the fourth problem (see Related Work section), in this study we attempt to investigate the fourth problem on a much larger scale, that is, investigating a large number of distance metrics tested on a large set of problems. In addition, we investigate the effect of noise on choosing the most suitable distance metric to be used by the KNN classifier.
The basic KNN classifier steps can be described as follows:
Training phase: The training samples and the class labels of these samples are stored, no missing data allowed, no non-numeric data allowed.
Classification phase: Each test sample is classified using majority vote of its neighbors by the following steps:
Distances from the test sample to all stored training samples are calculated using a specific distance function or similarity measure. The KNNs of the test sample are selected, where K is a predefined small integer. The most repeated class of these KNNs is assigned to the test sample. In other words, a test sample is assigned to the class c if it is the most frequent class label among the K nearest training samples. If K = 1, then the class of the nearest neighbor is assigned to the test sample. KNN algorithm is described by Algorithm 1.
We provide a toy example to illustrate how to compute the KNN classifier. Assuming that we have three training examples, having three attributes for each, and one test example as given in Table 2.
Training and testing data examples
Noisy data
The existence of noise in data is mainly related to the way that has been applied to acquire and preprocess data from its environment. 38 Noisy data are a corrupted form of data in some way, which leads to partial alteration of the data values. Two main sources of noise can be identified: first, the implicit errors caused by measurement tools, such as using different types of sensors. Second, the random errors caused by batch processes or experts while collecting data, for example, errors during the process document digitization. Based on these two sources of errors, two types of noise can be classified in a given data set 39 :
Training and testing data examples with distances
Training and testing data examples with distances
Class noise occurs when the sample is incorrectly labeled due to several causes such as data entry errors during labeling process, or the inadequacy of information that is being used to label each sample.
Attribute noise refers to the corruptions in values of 1 or more attributes due to several causes, such as failures in sensor devices, irregularities in sampling, or transcription errors. 40
The generation of noise can be classified by three main characteristics 41 :
The place where the noise is introduced: Noise may affect the attributes, class, training data, and test data separately or in combination.
The noise distribution: The way in which the noise is introduced, for example, uniform or Gaussian.
The magnitude of generated noise values: The extent to which the noise affects the data can be relative to each data value of each attribute, or relative to the standard deviation, minimum, maximum for each attribute.
In this study, we add different noise levels to the tested data sets to find the optimal distance metric that is least affected by this added noise with respect to the KNN classifier performance.
Distance measures review
The first appearance of the word distance can be found in the writings of Aristoteles (384 AC–322 AC), who argued that the word distance means, “It is between extremities that distance is greatest” or “things which have something between them, that is, a certain distance.” In addition, “distance has the sense of dimension [as in space has three dimensions, length, breadth and depth].” Euclid, one of the most important mathematicians of the ancient history, used the word distance only in his third postulate of the Principia 42 : “Every circle can be described by a centre and a distance.” The distance is a numerical description of how far apart entities are. In data mining, the distance means a concrete way of describing what it means for elements of some space to be close to or far away from each other. Synonyms for distance include farness, dissimilarity, and diversity, and synonyms for similarity include proximity 43 and nearness. 22
The distance function between two vectors x and y is a function d(x, y) that defines the distance between both vectors as a non-negative real number. This function is considered as a metric if it satisfies a certain number of properties 44 that include the following:
When the distance is in the range [0,1], the calculation of a corresponding similarity measure s(x, y) is as follows:
We consider the 8 major distance families that consist of 54 total distance measures. We categorized these distance measures following a similar categorization done by Cha. 43 In what follows, we give the mathematical definitions of distances to measure the closeness between two vectors x and y, where x = (x1, x2, …, xn) and y = (y1, y2, …, yn) having numeric attributes. As an example, we show the computed distance value between the example vectors v1 = {5.1,3.5,1.4,0.3}, v2 = {5.4,3.4,1.7,0.2} as a result in each of these categories of distances reviewed here. Theoretical analysis of these various distance metrics is beyond the scope of this study.
Lp
where p is a positive value. When p = 2, the distance becomes the ED. When p = 1, it becomes MD. Chebyshev distance (CD) is a variant of Minkowski distance, where p = ∞. xi is the ith value in vector x and yi is the ith value in vector y.
MD: The MD, also known as L1 norm, Taxicab norm, rectilinear distance, or City block distance, which was considered by Hermann Minkowski in 19th-century Germany. This distance represents the sum of the absolute differences between the opposite values in vectors.
CD: CD is also known as maximum value distance,
45
Lagrange,
22
and chessboard distance.
46
This distance is appropriate in cases when two objects are to be defined as different if they are different in any one dimension.
47
It is a metric defined on a vector space where distance between two vectors is the greatest of their difference along any coordinate dimension.
ED: Also known as L2 norm or Ruler distance, which is an extension to the Pythagorean theorem. This distance represents the root of the sum of the square of differences between the opposite values in vectors.
L1
LD: LD is represented by the natural log of the absolute difference between two vectors. This distance is sensitive to small changes since the log scale expands the lower range and compresses the higher range.
where ln is the natural logarithm, and to ensure that the non-negativity property and to avoid log of 0, 1 is added.
CanD: CanD is introduced by
48
and modified by Lance and Williams.
49
It is a weighted version of MD, wherein the absolute difference between the attribute values of the vectors x and y is divided by the sum of the absolute attribute values before summing.
50
This distance is mainly used for positive values. It is very sensitive to small changes near 0, where it is more sensitive to proportional than to absolute differences. Therefore, this characteristic becomes more apparent in higher dimensional space, respectively, with an increasing number of variables. The CanD is often used for data scattered around an origin.
SD: The SD,
51
also known as Bray–Curtis, is one of the most commonly applied measurements to express relationships in ecology, environmental sciences, and related fields. It is a modified Manhattan metric, wherein the summed differences between the attribute values of the vectors x and y are standardized by their summed attribute values.
52
When all the vector values are positive, this measure take value between 0 and 1.
SoD: SoD is one of the distance measures that is widely used to calculate the evolutionary distance.
53
It is also known as Ruzicka distance. For binary variables only, this distance is identical to the complement of the Tanimoto (or Jaccard) similarity coefficient.
54
This distance obeys all four metric properties provided by all attributes that have non-negative values.
55
KD: Similar to the SoD, but instead of using the maximum, it uses the minimum function.
MCD: Also known as average Manhattan, or Gower distance.
NID: NID is the complement to the intersection similarity and is obtained by subtracting the intersection similarity from 1.
JacD: The JacD measures dissimilarity between sample sets, it is a complementary to the Jaccard similarity coefficient
56
and is obtained by subtracting the Jaccard coefficient from 1. This distance is a metric.
57
CosD: The CosD, also called angular distance, is derived from the cosine similarity that measures the angle between two vectors, where CosD is obtained by subtracting the cosine similarity from 1.
DicD: The DicD is derived from the dice similarity,
58
which is a complementary to the dice similarity and is obtained by subtracting the dice similarity from 1. It can be sensitive to values near 0. This distance is a not a metric, in particular, the property of triangle inequality does not hold. This distance is widely used in information retrieval in documents and biological taxonomy.
ChoD: It is a modification of ED,
59
which was introduced by Orloci
60
and to be used in analyzing community composition data.
61
It was defined as the length of the chord joining two normalized points within a hypersphere of radius 1. This distance is one of the distance measures that is commonly used for clustering continuous data.
62
BD: The BD measures the similarity of two probability distributions.
63
SCD: SCD is mostly used with paleontologists and in studies on pollen. In this distance, the sum of square of square root difference at each point is taken along both vectors, which increases the difference for more dissimilar feature.
MatD: MatD is the square root of the SCD.
HeD: HeD also called Jeffries–Matusita distance
64
was introduced in 1909 by Hellinger,
65
it is a metric used to measure the similarity between two probability distributions. This distance is closely related to BD.
SED: SED is the sum of the squared differences without taking the square root.
ClaD: The ClaD also called coefficient of divergence was introduced by Clark.
66
It is the squared root of half of the DivD.
NCSD: The NCSD
67
is called a quasi-distance.
SquD: SquD also called triangular discrimination distance. This distance is a quasi-distance.
PSCSD: This distance is equivalent to Sangvi χ
2
distance.
DivD:
ASCSD: Also known as symmetric χ
2
divergence.
AD: The AD, also known as average Euclidean, is a modified version of the ED,
62
wherein the ED has the following drawback, “if two data vectors have no attribute values in common, they may have a smaller distance than the other pair of data vectors containing the same attribute values,”
59
so that, this distance was adopted.
MCED: In this distance, the sum of squared differences between values is calculated and, to get the mean value, the summed value is divided by the total number of values wherein the pairs values do not equal to 0. After that, the square root of the mean should be computed to get the final distance.
SCSD:
KLD: KLD was introduced by Kullback and Leibler,
70
it is also known as Kullback–Leibler divergence, relative entropy, or information deviation, which measures the difference between two probability distributions. This distance is not a metric measure, because it is not symmetric. Furthermore, it does not satisfy triangular inequality property, therefore, it is called quasi-distance. Kullback–Leibler divergence has been used in several natural language applications such as for query expansion, language models, and categorization.
71
where ln is the natural logarithm.
JefD: JefD,
72
also called J-divergence or KL2-distance, is a symmetric version of the KLD.
KDD:
TopD: The TopD,
73
also called information statistics, is a symmetric version of the KLD. The TopD is twice the Jensen–Shannon divergence. This distance is not a metric, but its square root is a metric.
JSD: JSD is the square root of the Jensen–Shannon divergence. It is half of the TopD, which uses the average method to make the K divergence symmetric.
JDD: JDD was introduced by Sibson.
74
VWHD: The so-called Wave-Hedges distance has been applied to compressed image retrieval,
75
content-based video retrieval,
76
time series classification,
77
image fidelity,
78
finger print recognition,
79
etc. Interestingly, the source of the “Wave-Hedges” metric has not been correctly cited, and some of the previously mentioned resources allude to it incorrectly as given by Hedges.
80
The source of this metric eludes the authors, despite best efforts otherwise. Even the name of the distance “Wave-Hedges” is questioned.
26
VSD: VSD is defined by three formulas, VSDF1, VSDF2, and VSDF3 as the following:
MSCSD:
MiSCSD:
AvgD: AvgD is the average of MD and CD.
KJD:
TanD
81
:
PeaD: The PeaD is derived from the Pearson's correlation coefficient, which measures the linear relationship between two vectors.
82
This distance is obtained by subtracting the Pearson's correlation coefficient from 1.
where
CorD: CorD is a version of the PeaD, where the PeaD is scaled to obtain a distance measure in the range between 0 and 1.
SPeaD:
HamD: HamD
83
is a distance metric that measures the number of mismatches between two vectors. It is mostly used for nominal data, string, and bit-wise analyses, and also can be useful for numerical data.
HauD:
where h(x, y) = maxxi∈x minyi∈y||xi – yi||, and ||⋅|| is the vector norm (e.g., L2 norm). The function h(x, y) is called the directed HauD from x to y. The HauD(x, y) measures the degree of mismatch between the sets x and y by measuring the remoteness between each point xi and yi and vice versa.
CSSD: The CSSD was used for image retrieval,
84
histogram,
85
etc.
where
WIAD: WIAD was designed for species abundance data.
86
MeeD: MeeD depends on one consecutive point in each vector.
MotD:
HasD: This is a nonconvex distance introduced by Hassanat
26
where
As can be seen, HasD is bounded by [0,1]. It reaches 1 when the maximum value approaches infinity assuming the minimum is finite, or when the minimum value approaches minus infinity assuming the maximum is finite. This is shown in Figure 2 and the following equations.
By satisfying all the metric properties, this distance was proved to be a metric by Hassanat. 26 In this metric no matter what the difference between two values is, the distance will be in the range of 0 to 1. So the maximum distance approaches the dimension of the tested vectors; therefore, the increase in dimensions increases the distance linearly in the worst case.
Experimental Framework
Data sets used for experiments
The experiments were done on 28 data sets that represent real-life classification problems, obtained from the UCI Machine Learning Repository. 87 The UCI Machine Learning Repository is a collection of databases, domain theories, and data generators that are used by the machine learning community for the empirical analysis of machine learning algorithms. The database was created in 1987 by David Aha and fellow graduate students at UCI. Since that time, it has been widely used by students, educators, and researchers all over the world as a primary source of machine learning data sets.
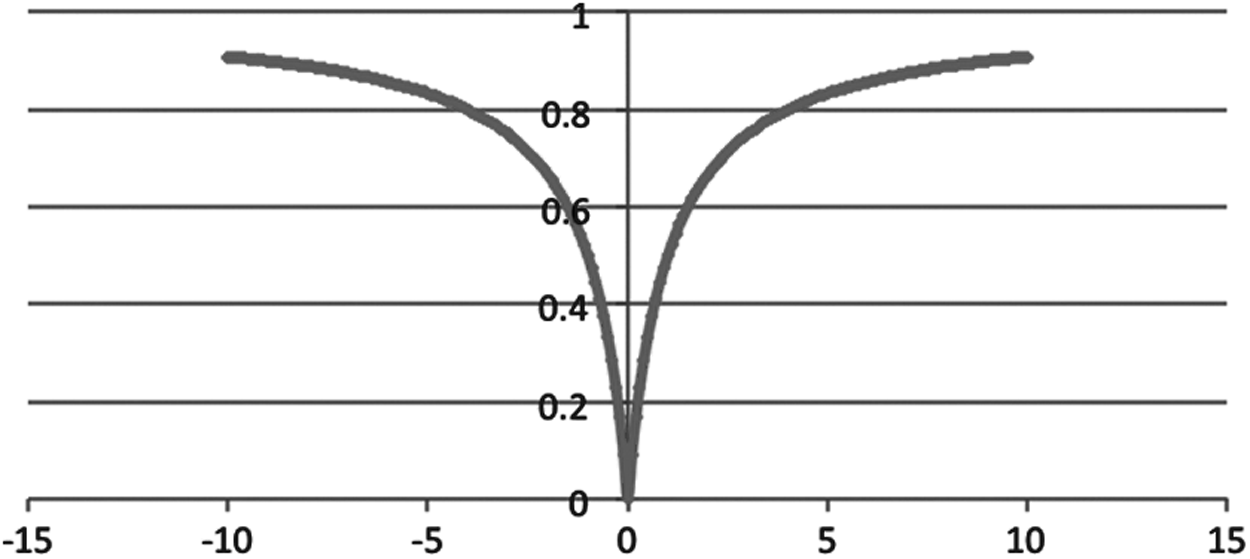
Representation of HasD between the point 0 and n, where n belongs to [−10,10]. HasD, Hassanat distance.
Each data set consists of a set of examples. Each example is defined by a number of attributes and all the examples inside the data are represented by the same number of attributes. One of these attributes is called the class attribute, which contains the class value (label) of the data, whose values are predicted for testing the examples. Short description of all the data sets used is provided in Table 5.
Description of the real-world data sets used (from the UCI machine learning repository)
BCW, Breast Cancer Wisconsin; #C, number of classes; #E, number of examples; #F, number of features; Max, maximum; Min, minimum; QSAR, quantitative structure activity relationships.
Experimental setup
Each data set is divided into two data sets, one for training and the other for testing. For this purpose, 34% of the data set is used for testing and 66% of the data set is dedicated for training. The value of K is set to 1 for simplicity. The 34% of the data, which were used as a test sample, were chosen randomly, and each experiment on each data set was repeated 10 times to obtain random examples for testing and training. The overall experimental framework is shown in Figure 3. Our experiments are divided into two major parts:

The framework of our experiments for discerning the effect of various distances on the performance of KNN classifier. 1-NN, 1-nearest neighbor.
The first part of experiments aim to find the best distance measures to be used by KNN classifier without any noise in the data sets. We used all the 54 distances that were reviewed in Distance Measures Review section.
The second part of experiments aim to find the best distance measure to be used by KNN classifier in the case of noisy data. In this study, we define the “best” method as the method that performs with the highest accuracy. We added noise into each data set at various levels of noise. The experiments in the second part were conducted using the top 10 distances, those that achieved the best results in the first part of experiments. Therefore, to create a noisy data set from the original data set, a level of noise x% is selected in the range of (10%–90%), the level of noise means the number of examples that need to be noisy, the amount of noise is selected randomly between the minimum and maximum values of each attribute, all attributes for each examples are corrupted by a random noise, the number of noisy examples is selected randomly. Algorithm 2 describes the process of corrupting data with random noise to be used for further experiments for the purposes of this study.
Performance evaluation measures
Different measures are available for evaluating the performance of classifiers. In this study, three measures were used: accuracy, precision, and recall. Accuracy is calculated to evaluate the overall classifier performance. It is defined as the ratio of the test samples that are correctly classified to the number of tested examples,
To assess the performance with respect to every class in a data set, we compute precision and recall measures. Precision (or positive predictive value) is the fraction of retrieved instances that are relevant, whereas recall (or sensitivity) is the fraction of relevant instances that are retrieved. These measures can be constructed by computing the following:
True positive (TP): The number of correctly classified examples of a specific class (as we calculate these measures for each class).
True negative (TN): The number of correctly classified examples that were not belonging to the specific class.
False positive (FP): The number of examples that are incorrectly assigned to the specific class.
False negative (FN): The number of examples that are incorrectly assigned to another class.
The precision and recall of a multiclass classification system are defined by
where N is the number of classes, TPi is the number of TP for class i, FNi is the number of FN for class i, and FPi is the number of FP for class i.
These performance measures can be derived from the confusion matrix. The confusion matrix is represented by a matrix that shows the predicted and actual classification. The matrix is n × n, where n is the number of classes. The structure of confusion matrix for multiclass classification is given by
This matrix reports the number of FPs, FNs, TPs, and TNs that are defined through elements of the confusion matrix as follows:
Accuracy, precision, and recall are calculated for the KNN classifier using all the similarity measures and distance metrics discussed in Distance Measures Review section, on all the data sets described in Table 5, this is to compare and assess the performance of the KNN classifier using different distance metrics and similarity measures.
Experimental results and discussion
For the purposes of this review, two sets of experiments were conducted. The aim of the first set is to compare the performance of the KNN classifiers when used with each of the 54 distances and similarity measures reviewed in Distance Measures Review section without any noise. The second set of experiments is designed to find the most robust distance that affected the least with different noise levels.
Without noise
A number of different predefined distance families were used in this set of experiments. The accuracy of each distance on each data set is averaged for 10 runs. The same technique is followed for all other distance families to report accuracy, recall, and precision of the KNN classifier for each distance on each data set. The average values for each of 54 distances considered in the article are summarized in Table 6, where HasD obtained the highest overall average.
Average accuracies, recalls, and precisions over all data sets for each distance
Bold values signify the best performance, which is the highest accuracy, precision or recall.
HasD obtained the highest overall average.
AD, Average distance; ASCSD, Additive Symmetric χ 2 ; AvgD, Average (L1, L∞) distance; BD, Bhattacharyya distance; CanD, Canberra distance; CD, Chebyshev distance; ChoD, Chord distance; ClaD, Clark distance; CorD, Correlation distance; CosD, Cosine distance; CSSD, χ 2 statistic distance; DicD, Dice distance; DivD, Divergence distance; ED, Euclidean distance; HamD, Hamming distance; HasD, Hassanat distance; HauD, Hausdorff distance; HeD, Hellinger distance; JacD, Jaccard distance; JDD, Jensen difference distance; JefD, Jeffreys distance; JSD, Jensen–Shannon distance; KD, Kulczynski distance; KDD, K divergence distance; KJD, Kumar–Johnson distance; KLD, Kullback–Leibler distance; LD, Lorentzian distance; MatD, Matusita distance; MCD, Mean Character distance; MCED, Mean Censored Euclidean distance; MD, Manhattan distance; MeeD, Meehl distance; MiSCSD, Min symmetric χ 2 distance; MotD, Motyka distance; MSCSD, Max symmetric χ 2 distance; NCSD, Neyman χ 2 distance; NID, Non Intersection distance; PCSD, Pearson χ 2 distance; PeaD, Pearson distance; PSCSD, Probabilistic Symmetric χ 2 distance; SCD, Squared chord distance; SCSD, Squared Chi-Squared; SD, Sorensen distance; SED, Squared Euclidean distance; SoD, Soergel distance; SPeaD, Squared Pearson distance; SquD, Squared χ 2 distance; TanD, Taneja distance; TopD, Topsoe distance; VSD, Vicis symmetric distance; VWHD, Vicis-Wave Hedges distance; WIAD, Whittaker's index of association distance.
Table 7 shows the distances that obtained the highest accuracy on each data set. Based on these results we summarize the following observations.
The highest accuracy in each data set
The distance measures in L1 family outperformed the other distance families in five data sets. LD achieved the highest accuracy in two data sets, namely on Vehicle and Vowel with average accuracies of 69.13% and 97.71%, respectively. In contrast, CanD achieved the highest accuracy in two data sets, Australian and Wine data sets achieved average accuracies of 82.09% and 98.5%, respectively. SD and SoD achieved the highest accuracy on Segmen data set with an average accuracy of 96.76%. Among the Lp Minkowski and L1 distance families, the MD, NID, and MCD achieved similar performance with overall accuracies on all data sets: this is due to the similarity between these distances.
In inner product family, JacD and DicD outperform all other tested distances on Letter recognition data set with an average accuracy of 95.16%. Among the Lp Minkowski and L1 distance families, the CD, JacD, and DicD outperform the other tested distances on the Banknote data set with an average accuracy of 100%.
In Squared chord family, MatD, SCD, and HeD achieved similar performance with overall accuracies on all data sets, this is expected because these distances are very similar.
In Squared L2 distance measures family, SquD and PSCSD achieved similar performance with overall accuracy in all data sets: this is due to the similarity between these two distances. The distance measures in this family outperform the other distance families on two data sets, namely, ASCSD achieved the highest accuracy on the German data set with an average accuracy of 71%. ClaD and DivD achieved the highest accuracy on the Vote data set with an average accuracy of 91.87%. Among the Lp Minkowski and Squared L2 distance measures family, ED, SED, and AD achieved similar performance in all data sets: this is due to the similarity between these three distances. Also, these distances and MCED outperform the other tested distances in two data sets, Wave21 and Wave40, with average accuracies of 77.74% and 75.87%, respectively. Among the L1 distance and Squared L2 families, MCED and LD achieved the highest accuracy on the Glass data set with an average accuracy of 71.11%.
In Shannon entropy distance measures family, JSD and TopD achieved similar performance with overall accuracies on all data sets: this is due to similarity between both of the distances, as TopD is twice the JSD. KLD outperforms all the tested distances on Haberman data set with an average accuracy of 73.27%.
The Vicissitude distance measures family outperform the other distance families on five data sets, namely, VSDF1 achieved the highest accuracy in three data sets, Liver, Parkinson, and Phoneme with accuracies of 65.81%, 99.97%, and 89.8%, respectively. MSCSD achieved the highest accuracy on the Diabetes data set with an average accuracy of 68.79%. MiSCSD also achieved the highest accuracy on Sonar data set with an average accuracy of 87.71%.
The other distance measures family outperforms all other distance families in seven data sets. The WIAD achieved the highest accuracy on Monkey1 data set with an average accuracy of 94.97%. The AvgD also achieved the highest accuracy on the Wholesale data set with an average accuracy of 88.66%. HasD also achieved the highest accuracy in four data sets, namely, Cancer, Breast Cancer Wisconsin (BCW), Ionosphere, and quantitative structure activity relationships (QSAR) with average accuracies of 96.16%, 96.24%, 90.25%, and 82.57%, respectively. Finally, HamD achieved the highest accuracy on the Heart data set with an average accuracy of 77.14%. Among the inner product and other distance measures families, SPeaD, CorD, ChoD, and CosD outperform other tested distances in three data sets, namely, Balance, Iris, and Egg with average accuracies of 94.3%, 95.88%, and 97.25%, respectively.
Table 8 shows the distances that obtained the highest recall on each data set. Based on these results, we summarize the following observations.
The highest recall in each data set
The L1 distance measures family outperforms the other distance families in seven data sets, for example, CanD achieved the highest recalls in two data sets, Australian and Wine with 81.83% and 73.94% average recalls respectively. LD also achieved the highest recalls on four data sets, Glass, Ionosphere, Vehicle, and Vowel with 51.15%, 61.52%, 54.85%, and 97.68% average recalls, respectively. SD and SoD achieved the highest recall on Segmen data set with 84.67% average recall. Among the Lp Minkowski and L1 distance families, MD, NID, and MCD achieved similar performance as expected, due to their similarity.
In Inner Product distance measures family, JacD and DicD outperform all other tested distances in Heberman data set with 38.53% average recall. Among the Lp Minkowski and Inner Product distance measures families, CD, JacD, and DicD also outperform the other tested distances in the Banknote data set with 100% average recall.
In SCD measures family, MatD, SCD, and HeD achieved similar performance: this is due to similarity of their equations as clarified previously.
The Squared L2 distance measures family outperforms the other distance families on two data sets, namely, ClaD and DivD outperform the other tested distances on Vote data set with 91.03% average recall. PCSD outperforms the other tested distances on Wholesale data set with 58.16% average recall. ASCSD also outperforms the other tested distances on German data set with 43.92% average recall. Among the Lp Minkowski and Squared L2 distance measures families, ED, SED, and AD achieved similar performance in all data sets: this is due to similarity of their equations as clarified previously. These distances and MCED distance outperform the other tested distances in two data sets, namely, Wave21 and Wave40 with 77.71% and 75.88% average recalls, respectively.
In Shannon entropy distance measures family, JSD and TopD achieved similar performance as expected, due to their similarity.
The Vicissitude distance measures family outperforms the other distance families in six data sets. VSDF1 achieved the highest recall on three data sets: Liver, Parkinson, and Phoneme data sets with 43.65%, 99.97%, 88.13% average recalls, respectively. MSCSD achieved the highest recall on Diabetes data set with 43.71% average recall. MiSCSD also achieved the highest recall on Sonar data set with 58.88% average recall. VSDF2 achieved the highest recall on Letter recognition data set with 95.14% average recall.
The other distance measures family outperforms all other distance families in five data sets. Particularly, HamD achieved the highest recall on the Heart data set with 51.22% average recall. WIAD also achieved the highest average recall on the Monkey1 data set with 94.98% average recall. HasD also has achieved the highest average recall on three data sets, namely, Cancer, BCW, and QSAR with 96.08%, 38.33%, and 80.41% average recalls, respectively. Among the inner product and other distance measures families, SPeaD, CorD, ChoD, and CosD outperform the other tested distances in three data sets, namely, Balance, Iris, and Egg with 64.37%, 95.92%, and 97.72% average recalls, respectively.
Table 9 shows the distances that obtained the highest precision on each data set. Based on these results, we summarize the following observations.
The highest precision in each data set
The distance measures in L1 family outperformed the other distance families in five data sets. CanD achieved the highest precision on two data sets, namely, Australian and Wine with 81.88% and 74.08% average precisions, respectively. SD and SoD achieved the highest precision on the Segmen data set with 84.66% average precision. In addition, LD achieved the highest precision on three data sets, namely, Glass, Vehicle, and Vowel, with 51.15%, 55.37%, and 97.87% average precisions, respectively. Among the Lp Minkowski and L1 distance families, the MD, NID, and MCD achieved similar performance in all data sets: this is due to similarity of their equations as clarified previously.
Inner Product family outperforms other distance families in two data sets. Also, JacD and DicD outperform the other tested measures on Wholesale data set with 58.53% average precision. Among the Lp Minkowski and L1 distance families, the CD, JacD and DicD outperformed the other tested distances on the Banknote dataset with 100% average precision.
In SCD measures family, MatD, SCD, and HeD achieved similar performance with overall precision results in all data sets: this is due to similarity of their equations as clarified previously.
In Squared L2 distance measures family, SCSD and PSCSD achieved similar performance: this is due to similarity of their equations as clarified previously. The distance measures in this family outperform the other distance families on three data sets, namely, ASCSD achieved the highest average precisions on two data sets, Diabetes and German with 44.01% and 43.43% average precisions, respectively. ClaD and DicD also achieved the highest precision on the Vote data set with 92.11% average precision. Among the Lp Minkowski and Squared L2 distance measures families, the ED, SED, and AD achieved similar performance as expected, due to their similarity. These distances and MCED outperform the other tested measures in two data sets, namely, Wave21 and Wave40 with 77.75% and 75.9% average precisions, respectively. Also, ED, SED, and AD outperform the other tested measures on the Letter recognition with 95.57% average precision.
In Shannon entropy distance measures family, JSD and TopD achieved similar performance with overall precision in all data sets, due to similarity of their equations as clarified earlier.
The Vicissitude distance measures family outperforms other distance families on four data sets. VSDF1 achieved the highest average precisions on three data sets: Liver, Parkinson, and Phoneme with 43.24%, 99.97%, and 87.23% average precisions, respectively. MiSCSD also achieved the highest precision on the Sonar data set with 57.99% average precision.
The other distance measures family outperforms all the other distance families in six data sets. In particular, HamD achieved the highest precision on the Heart data set with 51.12% average precision. Also, WIAD achieved the highest precision on the Monkey1 data set with 95% average precision. Moreover, HasD yields the highest precision in four data sets, namely, Cancer, BCW, Ionosphere, and QSAR, with 38.35%, 95.62%, 58.12%, and 81.54% average precisions, respectively. Among the inner product and other distance measures families, SPeaD, CorD, ChoD, and CosD outperform the other tested distances in three data sets, namely, Balance, Iris, and Egg, with 68.95%, 95.85%, and 97.22% average precisions, respectively. Also, CosD, SPeaD, and CorD achieved the highest precision on Heberman data set with 38.87% average precision.
Table 10 gives the top 10 distances with respect to the overall average accuracy, recall, and precision over all data sets. HasD outperforms all other tested distances in all performance measures, followed by LD, CanD, and SCSD. Moreover, a closer look at the data of the average as well as highest accuracies, precisions, and recalls, we find that HasD outperforms all distance measures on four data sets, namely, Cancer, BCW, Ionosphere, and QSAR: this is true for accuracy, precision, and recall, and it is the only distance metric that won at least four data sets in this noise-free experiment set. Note that the performance of the following five group members (1) MCD, MD, and NID, (2) AD, ED, and SED, (3) TopD and JSD, (4) SquD and PSCSD, and (5) MatD, SCD, and HeD is the same within themselves due to their close similarity in defining the corresponding distances.
The top 10 distances in terms of average accuracy, recall, and precision-based performance on noise-free data sets
We attribute the success of HasD in this experimental part to its characteristics discussed in Distance Measures Review section (see distance equation in 8.13, Fig. 2), where each dimension in the tested vectors contributes maximally 1 to the final distance, this lowers and neutralizes the effects of outliers in different data sets. To further analyze the performance of HasD comparing with other top distances, we used the Wilcoxon's rank-sum test. 88 This is a nonparametric pairwise test that aims to detect significant differences between two sample means, to judge whether the null hypothesis is true or not. Null hypothesis is a hypothesis used in statistics that assumes there is no significant difference between different results or observations. This test was conducted between HasD and with each of the other top distances (Table 10) over the tested data sets. Therefore, our null hypothesis is “there is no significant difference between the performance of HasD and the compared distance over all the data sets used.” According to the Wilcoxon test, if the result of the test showed that the p-value is less than the significance level (0.05), then we reject the null hypothesis, and conclude that there is a significant difference between the tested samples; otherwise we cannot conclude anything about the significant difference. 89
The accuracies, recalls, and precisions of HasD over all the data sets used in this experiment set were compared with those of each of the top 10 distance measures, with the corresponding p-values given in Table 11. The p-values that were less than the significance level (0.05) are highlighted in bold. As given in Table 11, the p-values of accuracy results are less than the significance level (0.05) eight times, here we can reject the null hypothesis and conclude that there is a significant difference in the performance of HasD compared with ED, CanD, CosD, ClaD, SCSD, WIAD, CorD, and DivD, and since the average performance of HasD was better than all of these distance measures from the previous tables, we can conclude that the accuracy yielded by HasD is better than that of most of the distance measures tested. Similar analysis applies for the recall and precision columns comparing Hassanat results with the other distances.
The p-values of the Wilcoxon test for the results of Hassanat distance with each of other top distances over the data sets used
The p-values that were less than the significance level (0.05) are highlighted in boldface.
With noise
These next experiments aim to identify the impact of noisy data on the performance of KNN classifier regarding accuracy, recall, and precision using different distance measures. Accordingly, nine different levels of noise were added into each data set using Algorithm 2. For simplicity, this set of experiments conducted using only the top 10 distances given in Table 10 are obtained based on the noise-free data sets.
Figure 4 shows the experimental results of KNN classifier that clarify the impact of noise on the accuracy performance measure using the top 10 distances. x-axis represents the noise level and y-axis represents the classification accuracy. Each column at each noise level represents the overall average accuracy for each distance on all data sets used. Error bars represent the average of standard deviation values for each distance on all data sets. Figure 5 shows the recall results of KNN classifier that clarify the impact of noise on the performance using the top 10 distance measures. Figure 6 shows the precision results of KNN classifier that clarify the impact of noise on the performance using the top 10 distance measures. As can be seen from Figures 4–6, the performance (measured by accuracy, recall, and precision, respectively) of the KNN degraded only ∼20%, whereas the noise level reaches 90%, this is true for all the distances used. This means that the KNN classifier using any of the top 10 distances tolerates noise to a certain degree. Moreover, some distances are less affected by the added noise comparing with other distances. Therefore, we ordered the distances according to their overall average accuracy, and recall and precision results for each level of noise. The distance with highest performance is ranked in the first position, whereas the distance with the lowest performance is ranked in the last position of the order. Tables 12–14 give this ranking structure in terms of accuracy, precision, and recall under each noise level from low 10% to high 90%. The empty cells occur because of sharing same rank by more than one distance. The following points summarize the observations in terms of accuracy, precision, and recall values.
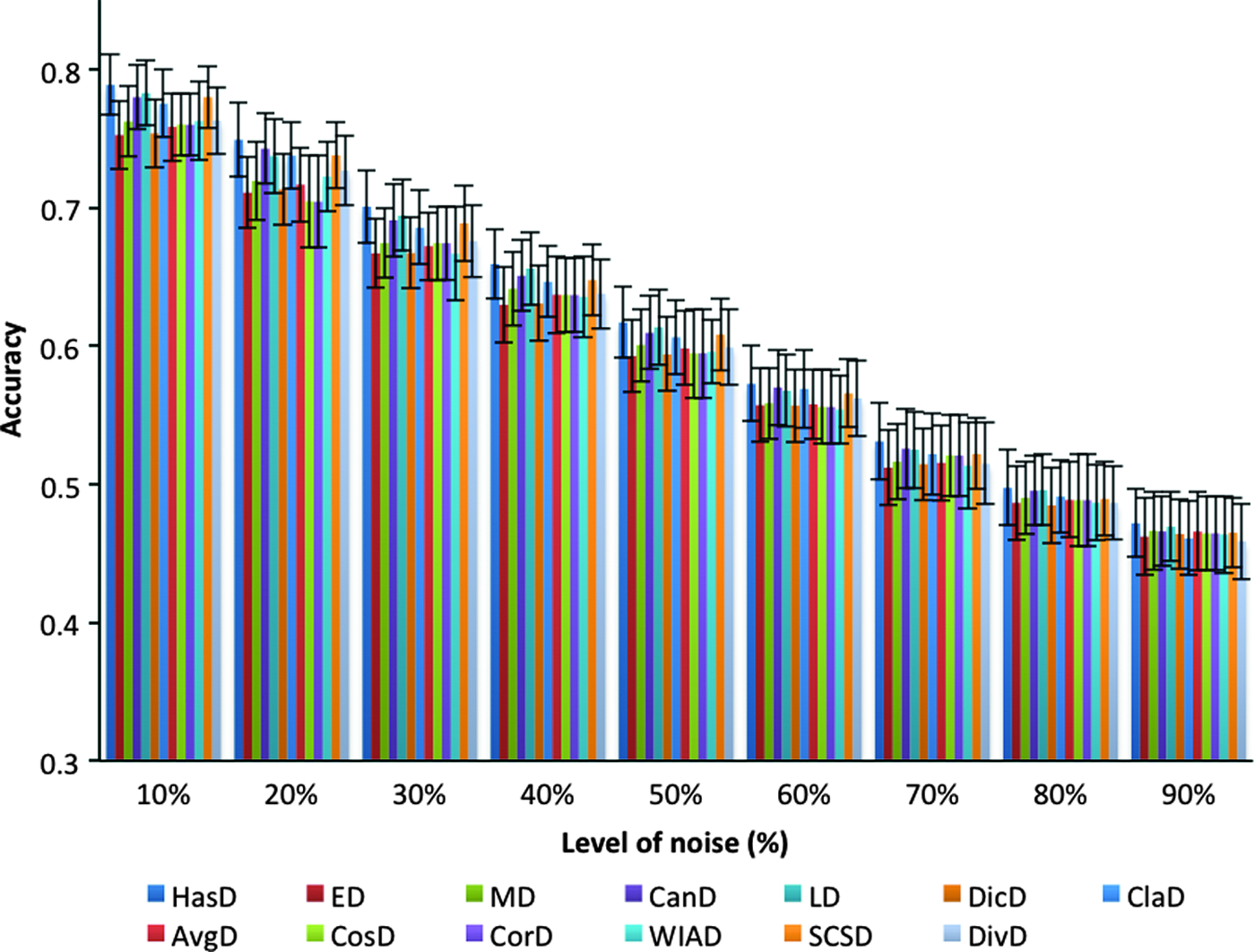
The overall average accuracies and standard deviations of KNN classifier using top 10 distance measures with different levels of noise. AvgD, Average (L1, L∞) distance; CanD, Canberra distance; ClaD, Clark distance; CorD, Correlation distance; CosD, Cosine distance; DicD, Dice distance; DivD, Divergence distance; LD, Lorentzian distance; MD, Manhattan distance; SCSD, Squared Chi-Squared; WIAD, Whittaker's index of association distance. Color images are available online.
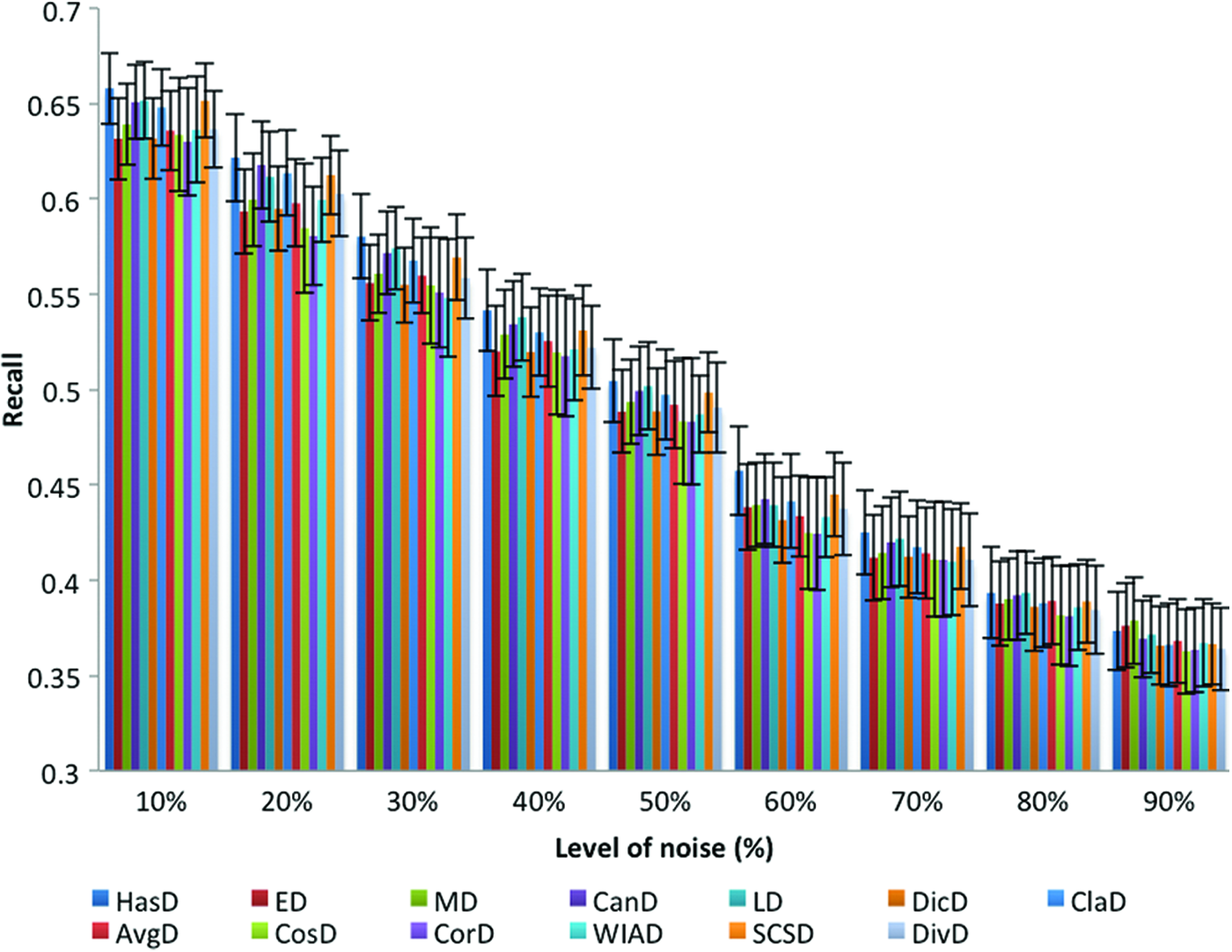
The overall average recalls and standard deviations of KNN classifier using top 10 distance measures with different levels of noise. Color images are available online.
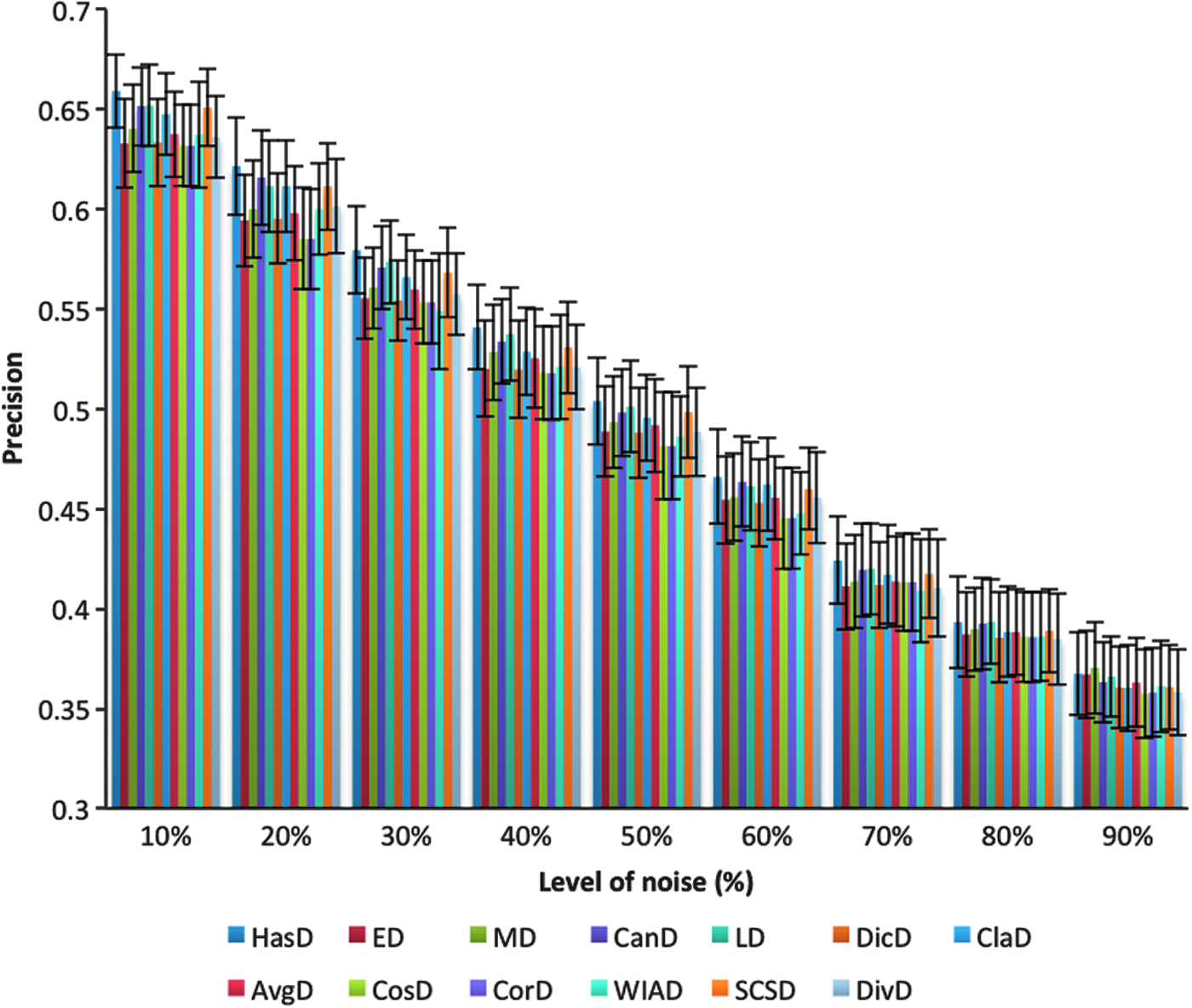
The overall average precisions and standard deviations of KNN classifier using top 10 distance measures with different levels of noise. Color images are available online.
Ranking of distances in descending order based on the accuracy results at each noise level
Ranking of distances in descending order based on the recall results at each noise level
Ranking of distances in descending order based on the precision results at each noise level
According to the average precision results, the highest precision was obtained by HasD, which achieved the first rank in the majority of noise levels. This distance succeeds to be in the first rank at noise levels 10% up to 70%. However, at a level 80%, LD outperformed HasD. Also, MD outperformed HasD at a noise level 90%.
LD achieved the second rank at noise levels 10%, 30%, 40%, 50%, and 70%. CanD achieved the second rank at noise levels 20% and 60%. Moreover, this distance achieved the third rank in the rest noise levels except at noise levels 50% and 90%. SCSD achieved the fourth rank at noise levels 10%, 30%, 40%, and 70%, and the third rank at a level of noise 50%. This distance was equal with LD at a noise level 20%. ClaD achieved the third rank at noise levels 20%, and 60%.
The rest of distances achieved the middle and the last ranks in different orders at each level of noise. CosD at level 80% was equal to WIAD in the result. This distance was also equal to CorD at levels 30% and 70%. These two distances performed the worst (lowest precision) in most noise levels.
Based on results given in Tables 12–14, we observe that the ranking of distances in terms of accuracy, recall, and precision without the presence of noise is different from their ranking when adding the first level of noise 10%, and it significantly varies when we increased the level of noise progressively. This means that the distances are affected by noise. However, the crucial question is, which one of the distances is least affected by noise? From the given results, we conclude that HasD is the least affected one, followed by LD, CanD, and SCSD. Good performance of the KNN achieved by these distances might be contributed by their good characteristics. Table 15 gives these characteristics of the top 10 distances in our analysis. All of these top 10 distances are symmetric, and we further provide input and output ranges and the number of operations.
Some characteristics of the top 10 distances (n is the number of features)
Precise evaluation of the effects of noise
To justify why some distances are affected either less or more by noise, the following toy Examples 1 and 2 are designed. These illustrate the effect of noise on the final decision of the KNN classifier using HasD and the standard ED. In both examples, we assume that we have two training vectors (v1 and v2) having three attributes for each, in addition to one test vector (v3). As usual, we calculate the distances between v3 and both v1 and v2 using both of ED and HasD.
As shown, assuming that we use k = 1, based on the 1-NN approach, and using both distances, the test vector is assigned to class 1, both results are reasonable, because V3 is almost the same as V2 (class = 1) except for the first feature, which differs only by 1.
Based on the minimum distance approach, using Euclidian distance, the test vector is assigned to class 2 instead of 1. However, the test vector is assigned to class 1 using the HasD, this makes the distance more accurate with the existence of noise. Although simple, these examples showed that the ED was affected by noise and consequently affected the KNN classification ability. Although the performance of the KNN classifier is decreased as the noise increased (as shown by the extensive experiments with various data sets), we find that some distances are less affected by noise than other distances. For example, when using ED, any change in any attribute contributes highly to the final distance, even if both vectors were similar, but in one feature there was noise, the distance (in such a case) becomes unpredictable. In contrast, with the HasD we found that the distance between both consecutive attributes is bounded in the range [0,1], thus, regardless of the value of the added noise, each feature will contribute up to 1 maximally to the final distance, and not proportional to the value of the added noise. Therefore, the impact of noise on the final classification is mitigated.
It is worth mentioning that the aforementioned experiments used the KNN classifier with K equal to 1, also known as the nearest neighbor classifier. In fact, the choice of distance metric might affect the optimal K as well. A K = 1 choice is more sensitive to noise than larger K values, because an unrelated noisy example might be the nearest to a test example. Therefore, a valid action with noisy data would be to choose a larger K; it would be of interest to see which distance measure handles this aspect best. We remark that choosing the optimal K is out of the scope of this review, and we refer to Hassanat
17
and Alkasassbeh et al.
25
However, we have repeated the experiments on all data sets using K = 3 and
The average accuracy of the top 10 distances over all data sets, using K = 3 and
In previous experiments, the noisy data have been used with the top 10 distances only. However, it would be interesting to see whether any of the other measures would handle noise better than these particular top 10 measures. Table 17 gives the average accuracy of all distances over the first 14 data sets, using K = 1 with and without noise. As given in Table 17, some of the top 10 distances still remain ranked the highest even with the existence of noise compared with all other distances, this includes HasD, LD, DivD, CanD, ClaD, and SCSD. However, interestingly, some of the other distances (which were ranked low when using data without noise) have shown less vulnerability to noise, these include SquD, PSCSD, MSCSD, SCD, MatD, and HeD. According to the extensive experiments conducted for the purpose of this review, and regardless of the type of the experiments, in general, the nonconvex distance HasD is the best distance to be used with the KNN classifier, with other distances such as LD, DivD, CanD, ClaD, and SCSD performing close to best.
The average accuracy of all distances over the first 14 data sets, using K = 1 with and without noise
Conclusions and Future Perspectives
In this review, the performance (accuracy, precision, and recall) of the KNN classifier has been evaluated using a large number of distance measures, on clean and noisy data sets, attempting to find the most appropriate distance measure that can be used with the KNN in general. In addition, we tried finding the most appropriate and robust distance that can be used in the case of noisy data. A large number of experiments conducted for the purposes of this review and the results and analysis of these experiments show the following:
The performance of KNN classifier depends significantly on the distance used, the results showed large gaps between the performances of different distances. For example, we found that HasD performed the best when applied on most data sets comparing with the other tested distances.
We get similar classification results when we use distances from the same family having almost the same equation, some distances are very similar, for example, one is twice the other, or one is the square of another. In these cases, and since the KNN compares examples using the same distance, the nearest neighbors will be the same if all distances were multiplied or divided by the same constant.
There was no optimal distance metric that can be used for all types of data sets, as the results show that each data set favors a specific distance metric, and this result complies with the no-free-lunch theorem.
The performance (measured by accuracy, precision, and recall) of the KNN degraded only ∼20% while the noise level reaches 90%, this is true for all the distances used. This means that the KNN classifier using any of the top 10 distances tolerates noise to a certain degree.
Some distances are less affected by the added noise comparing with other distances, for example, we found that HasD performed the best when applied on most data sets under different levels of heavy noise.
Our study has the following limitations, and future work will focus on studying, evaluating, and investigating these.
Although we have tested a large number of distance measures, there are still other distances and similarity measures that are available in the machine learning area that need to be tested and evaluated for optimal performance with and without noise.
The 28 data sets although higher than previously tested still might not be enough to draw significant conclusions in terms of the effectiveness of certain distance measures and, therefore, there is a need to use a larger number of data sets with varied data types.
The creation of noisy data is done by replacing a certain percentage (in the range 10%–90%) of the examples by completely random values in the attributes. We used this type of noise for its simplicity and straightforwardness in the interpretation of the effects of distance measure choice with KNN classifier. However, this type of noise might not simulate other types of noise that occur in the real-world data. It is an interesting task to try other realistic noise types to evaluate the distance measures for robustness in a similar manner.
Only KNN classifier was reviewed in this study, other variants of KNN such as Hassanat90–93 need to be investigated.
Distance measures are not used only with the KNN, but also with other machine learning algorithms, such as different types of clustering, those need to be evaluated under different distance measures.
Footnotes
Author Disclosure Statement
No competing financial interests exist.