
Abstract
Modern organizations typically store their data in a raw format in data lakes. These data are then processed and usually stored under hybrid layouts, because they allow projection and selection operations. Thus, they allow (when required) to read less data from the disk. However, this is not very well exploited by distributed processing frameworks (e.g., Hadoop, Spark) when analytical queries are posed. These frameworks divide the data into multiple partitions and then process each partition in a separate task, consequently creating tasks based on the total file size and not the actual size of the data to be read. This typically leads to launching more tasks than needed, which, in turn, increases the query execution time and induces significant waste of computing resources. To allow a more efficient use of resources and reduce the query execution time, we propose a method that decides the number of tasks based on the data being read. To this end, we first propose a cost-based model for estimating the size of data read in hybrid layouts. Next, we use the estimated reading size in a multi-objective optimization method to decide the number of tasks and computational resources to be used. We prototyped our solution for Apache Parquet and Spark and found that our estimations are highly correlated (0.96) with the real executions. Further, using TPC-H we show that our recommended configurations are only 5.6% away from the Pareto front and provide 2.1 × speedup compared with default solutions.
Introduction
The size of data is growing exponentially. 1 Since huge volumes of data are difficult to be stored on model first load later fashion, organizations end up storing all the raw data on a distributed file system (e.g., HDFS*) or cloud storage (e.g., Amazon S3 † ). In addition, they have their own data pipelines to process the raw data, and store them into very wide tables2,3 by using hybrid layouts,4,5 which have built-in support for projection and selection operations, helping in reading data more efficiently from the disk.6,7
There are several available hybrid layout implementations, such as: Optimized Record Columnar (ORC), ‡ Parquet, § and CarbonData.** All of them follow the same physical structure as shown in Figure 1. Data are stored into multiple horizontal partitions, known as stripes in ORC, row groups (RGs) in Parquet, and blocklets in CarbonData; each horizontal partition stores its data column-wise, which is beneficial for projection. Statistics about the data are stored in each partition, and they may help on filtering partitions. Further, hybrid layouts support dictionary encoding for compressing repetitive values of individual columns. The dictionary can also be used to filter partitions.

Structure of hybrid layouts.
Further, high-level languages (e.g., Apache Pig, †† Hive, ‡‡ etc.) are used to write analytical queries for getting business insights from the processed data. These analytical queries are executed on distributed processing frameworks (such as Hadoop §§ or Spark***), which process data in parallel on multiple machines to speed up the analysis. As mentioned earlier, hybrid layouts allow to read less data from the disk. However, this is not thoroughly exploited by distributed frameworks when deciding the number of tasks ††† for processing the data. They always decide the number of tasks based on the total table size and not on the portion of the table being read. This leads to the over-provisioning of tasks, where many tasks remain idle—without any data to process, but still present extra overhead (e.g., initialization time, garbage collection). Further, the idle tasks also waste the computational resources that are assigned to them. The latter is not considered even in the area of cloud computing,8–11 where computational resources are decided based on the total data size. This leads to wastage of resources and money.
Motivational example
Let us assume that we have the processed data stored in a hybrid layout, which contains four RGs. Let us further assume that we are executing an analytical query with a filter operation, which only satisfies two RGs. The distributed processing frameworks process the data in parallel by dividing them into multiple partitions (for simplicity, we assume that one partition is equal to an RG). By default, a distributed framework would create four tasks. However, two of them would remain idle (c.f. Fig. 2a), and yet would read extra metadata from the disk and would require extra initialization time. This would increase the makespan—execution time. Further, in terms of computational resources, four executors ‡‡‡ would be required to execute all these tasks in parallel. However, in an ideal scenario, based on the amount of data read (c.f. Fig. 2b) only two tasks with two executors would be enough. The latter would help in saving computational resources and reduce the makespan.
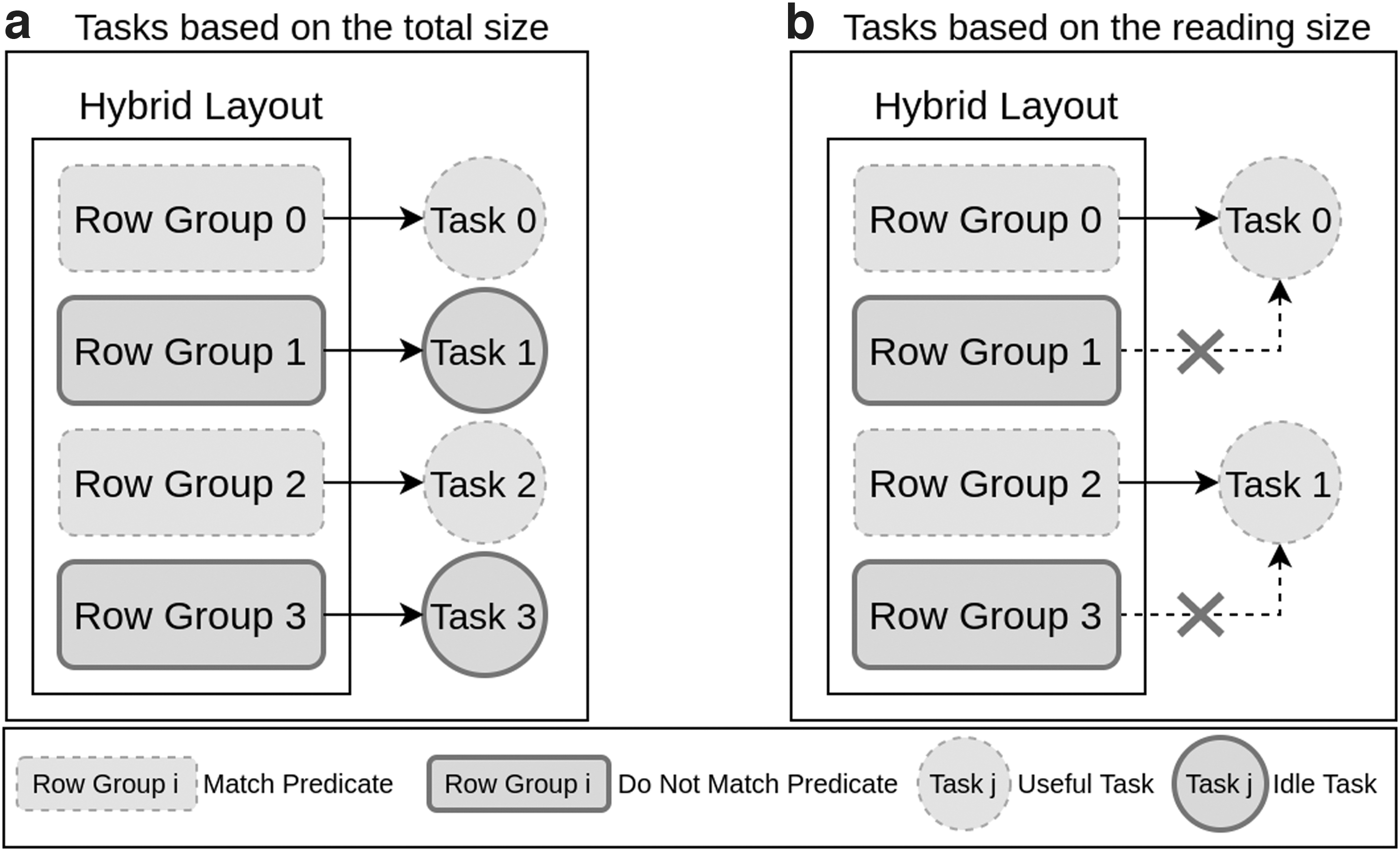
Parallelism for hybrid layouts in distributed processing frameworks.
As argued earlier, we need to decide the number of tasks based on the actual data read from the disk. To do that, we first need to estimate the read size, which can be done by utilizing our cost model presented in Munir et al. 12 The cost model estimates the scan, projection, and selection sizes for hybrid layouts.
In this article, we extend it further to estimate the makespan of the query implementing a query based on the estimated reading size. Thus, we design a framework that takes a user query and data statistics as inputs to estimate the reading size, and then through a multi-objective optimization method 13 decide the number of tasks and executors.
After configuring the number of tasks and executors, the query would be automatically submitted to a distributed processing framework. We implemented our approach for Parquet and Spark to show its applicability in real scenarios. The main contributions of this work can be summarized as follows:
– We extend the cost model for hybrid layouts presented in Munir et al.
12
to estimate the makespan of a query. – We propose a framework based on a multi-objective optimization method
13
that using our extended cost model, configures the number of tasks and executors for a given query. – We prototype our approach on Parquet and Spark to show its benefits. – We report the results of our extensive evaluation with the TPC-H
§§§
benchmark.
The remainder of this article is organized as follows: In the Related Work section, we discuss the related work. In the Cost Model for Hybrid Layouts and Our Approach sections, we present the cost model and the architecture of our approach. In the Multi-Objective Optimization section, we discuss a multi-objective method to find the number of tasks and executors. In the Experimental Results section, we present our experimental results and finally, in the Conclusions section, we conclude the article.
Related Work
Estimating number of tasks
There are research works14,15 for Hadoop, which estimate the number of mappers and reducers tasks. In Nghiem and Figueira, 14 the elbow curve technique is used to find the trade-off between the number of tasks and execution time. This helps to find the right number of tasks where execution time is minimized. Similarly, Verma et al., 15 utilize a multi-objective approach for estimating the number of tasks by considering a deadline constraint. Both these approaches do not consider the amount of data read, while estimating the number of tasks. These works only estimate the tasks based on the available number of machines and some objectives (such as deadline). As previously argued, the amount of data read is an important factor in deciding the number of tasks.
Resource provisioning in cloud
There have been extensive research works8–11 by cloud community on resource provisioning. There is also a survey 16 on energy-efficient techniques for big data analytics, which are divided into five categories. One of them (i.e., energy-aware resource allocation) focuses on deciding the number of machines to execute a given query with the aim of saving energy. These works from both cloud computing and energy-efficient big data analytics focus more on deciding the number of machines to process an application. They aim at saving energy and computational resources, which indirectly leads to cost savings. However, they make these decisions without considering the reading size. Our approach could help them to decide resource provisioning at a more granular level and overall, it can help these works to achieve their goals more efficiently.
Tuning configurable parameters
There are research works17–19 to tune the configurable parameters of distributed processing frameworks. 19 proposes a trial and error approach to tune the configuration parameters of Spark. This work finds the optimal values for these parameters, based on the trial and error approach. Similarly, Gounaris and Torres 18 propose a methodology to profile the impact of different parameter pairs on benchmarking applications, by applying a graph algorithm to create complex candidate configurations. These configurations are checked in parallel and then, the best performing one is chosen. In Davidson and Or, 20 the shuffle performance in Spark is improved by controlling the total number of shuffle files. This approach consolidated multiple shuffle files into one based on the available cores. This helps in improving the execution time of the shuffle phase. 17 profiles the bottlenecks (i.e., JVM, GC, serialization, etc.) of TPC-H queries, and parameters are manually configured to avoid the bottlenecks. This significantly increases the query performance.
Baldacci and Golfarelli 21 have proposed a cost model for Spark, which helps to estimate the cost of different query plans and decide the best one. Nevertheless, they assume that the number of tasks and executors are fixed. This work is complementary to ours and would optimize the overall query plan, once data are read from the disk and available for the first task. As discussed earlier, these existing works do not explicitly consider the degree of parallelism. Their main aim is to fine tune a cluster of distributed processing frameworks or find an optimal query plan. Our approach can further help them to improve the query execution time, by configuring the degree of parallelism and computational resources.
Cost Model for Hybrid Layouts
In Munir et al.,
12
we did not consider configuring the number of tasks and machines, but we focused on choosing different storage layouts based on their reading and writing cost. Thus, we extend the cost model to consider new factors (e.g.,
Parameters of the cost model
Our cost model for hybrid layouts relies on a wide range of statistical information that is summarized in Table 1, containing system constants, data statistics, workload statistics, and hybrid layout variables. We assume that the constants that depend on the configuration of the environment (e.g.,
Parameters of the cost model
Extra 4 bytes are considered for variable length columns.
RG, row group.
Physical format of hybrid layouts
As shown in Figure 1, hybrid layouts divide the data into multiple RGs [estimated by using Eq. (1)], and each RG contains a subset of rows [estimated by using Eq. (2)]. In each RG, hybrid layouts store data column-wise and its size can be estimated by using Equation (3). Moreover, hybrid layouts also store metadata (e.g., min-max statistics) for each RG inside either the header or footer section, which can be estimated by using Equation (4). The size of actual data and metadata are further used in Equation (5) to estimate the total size of the file.
Estimating number of tasks
Modern distributed processing frameworks decide the number of tasks based on the total file size (which is the size of the actual data without metadata) and the partition size [estimated by using Eq. (6)]. Moreover, the degree of parallelism depends on the number of executors. All tasks cannot be executed at once, if the number of executors is less than the total number of tasks. Thus, we need multiple rounds/waves to finish the query [estimated by using Eq. (7)]. Further, we can calculate the number of executors active in the last wave by using Equation (8). In addition, each partition contains one or more RGs, which can be estimated by using Equation (9).
Estimating makespan
In this article, we focus on read-only analytical queries, to estimate the amount of data read for their first operation and based on that, we try to find the best partition size to control the number of tasks. Given the simplicity of a file system (far from that of a DBMS), only three operations need to be considered: scan, projection, and selection. These three operations can be generalized to selection sorted and selection unsorted, because scan and projection operations are just the extreme cases of selection unsorted with selectivity factor (SF) of 1 (i.e., they read all RGs).
Data read estimation
As mentioned earlier, hybrid layouts help to read only the referred columns and their size can be estimated by using Equation (10). In addition, they use the available metadata (e.g., min-max statistics) to filter some RGs. If selection is applied on sorted data, the average number of read RGs can be calculated directly based on the SF as shown in Equation (11) (we add one to handle the effect of position variation inside the RGs, because hybrid layouts read the whole RG even if there is only one matching row
5
). However, for selection of unsorted data, the expected number of read RGs can be estimated by using Equation (11) (borrowed from bitmap indexes
22
).
Types of partitions
Distributed processing frameworks process data by dividing them into multiple partitions, where each partition is processed in a separate task. For selection unsorted, every task processes a full partition except the last task, whose partition might not be completely full, as shown in Figure 3a. Equations (12) and (14) indicate the number of full and last partitions. Thus, for unsorted data, any partition has the same probability of containing data. However, selection sorted guarantees that we read full partitions, except for, potentially, the first (from where selection starts) and last one (where selection ends), because requested data will not start just at the beginning and finish just at the end of a partition. To reflect this, we always have two partial partitions [Eq. (13)] and the number of full partitions depends on the number of RGs to be read [Eq. (12)]. Importantly, note that all other partitions will, nevertheless, read their metadata to determine that no data match the predicate [Eq. (15)]. Figure 3b exemplifies these partitions. It should be noted that the number of partitions and the number of RGs inside each partition are important factors for deciding the correct number of tasks and have direct impact on makespan estimation.
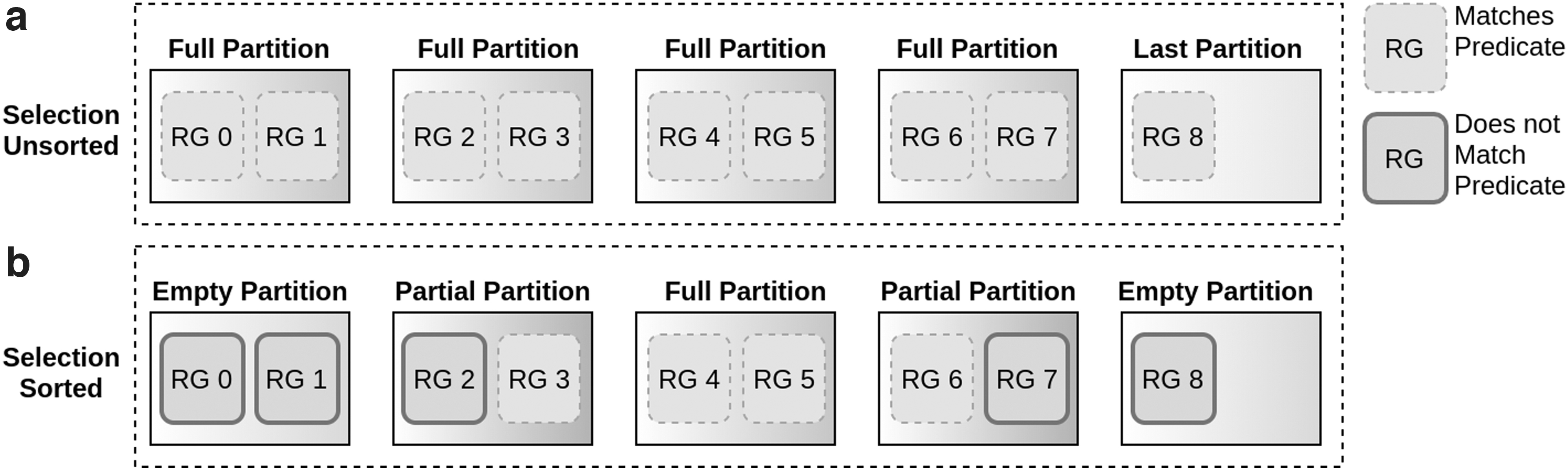
Type of partitions in selection sorted and unsorted.
Cost estimation
The total cost of a task depends on four factors: initialization cost, I/O cost, CPU cost, and networking cost. The initialization cost is constant and can be determined according to the execution environment. The I/O cost depends on the amount of data read within a task and the disk bandwidth. We do not consider CPU cost due to its negligible impact compared with I/O cost (existing works4,5 already proved that this is enough to capture the execution trend). Finally, we do not need any shuffling, 4 because we focus only on the first operation loading data and therefore, the networking cost for shuffling is considered to be zero.
However, there might be some cases when partition size goes beyond the chunk size and it may require some chunks to be transferred over the network. There are two solutions to handle this scenario. The first one is to define a maximum limit on the partition size and always keep it less than the chunk size. The second is to use an existing approach,
23
which transfers data in advance to avoid idle cycles on the processing machines. The approach to be used should be chosen based on the business requirements. Our approach would work fine for cloud storage (e.g., Amazon S3), as soon as it accesses the whole file together as an object (not in partitions). Thus, distributed processing frameworks can create a partition without worrying about going beyond the chunk size and data locality.
There is still a networking cost for metadata [Eq. (16)], because current solutions require to sequentially transfer metadata to all other executors before they start processing the data. Typically, it is read and transferred by the master or driver executor.
Each partition has an initialization cost, which is a constant, and an I/O cost (which depends on metadata and the amount of data read inside the partition). As shown in Figure 3, full partitions read all matched RGs inside a partition, and their cost can be estimated by using Equation (17). Equation (18) estimates data read from partial partitions, and Equation (19) determines its cost. Equation (20) reads the data left in the last partition, and Equation (21) deals with its cost. The other partitions just read metadata and its cost is in Equation (22).
These costs of all partitions help to estimate the total cost of all tasks using Equation (23), which is used in Equation (24) to estimate the average cost of a task. It should be noted that the cost of the last partition is only applied for selection unsorted and it is considered separately when estimating the total makespan. Thus, we do not consider its cost here.
Estimating makespan
As discussed earlier, each task processes different amounts of data and thus, some tasks can finish earlier compared with others. Likewise, each executor can finish their assigned tasks at different times. Thus, we should estimate makespan based on the executor that is processing the largest stack of tasks (e.g., in Fig. 4, Executor 0 and Executor 1 are the ones with the largest stack). This can be done by estimating standard deviation among tasks and using it further for estimating the overall makespan of an operation.
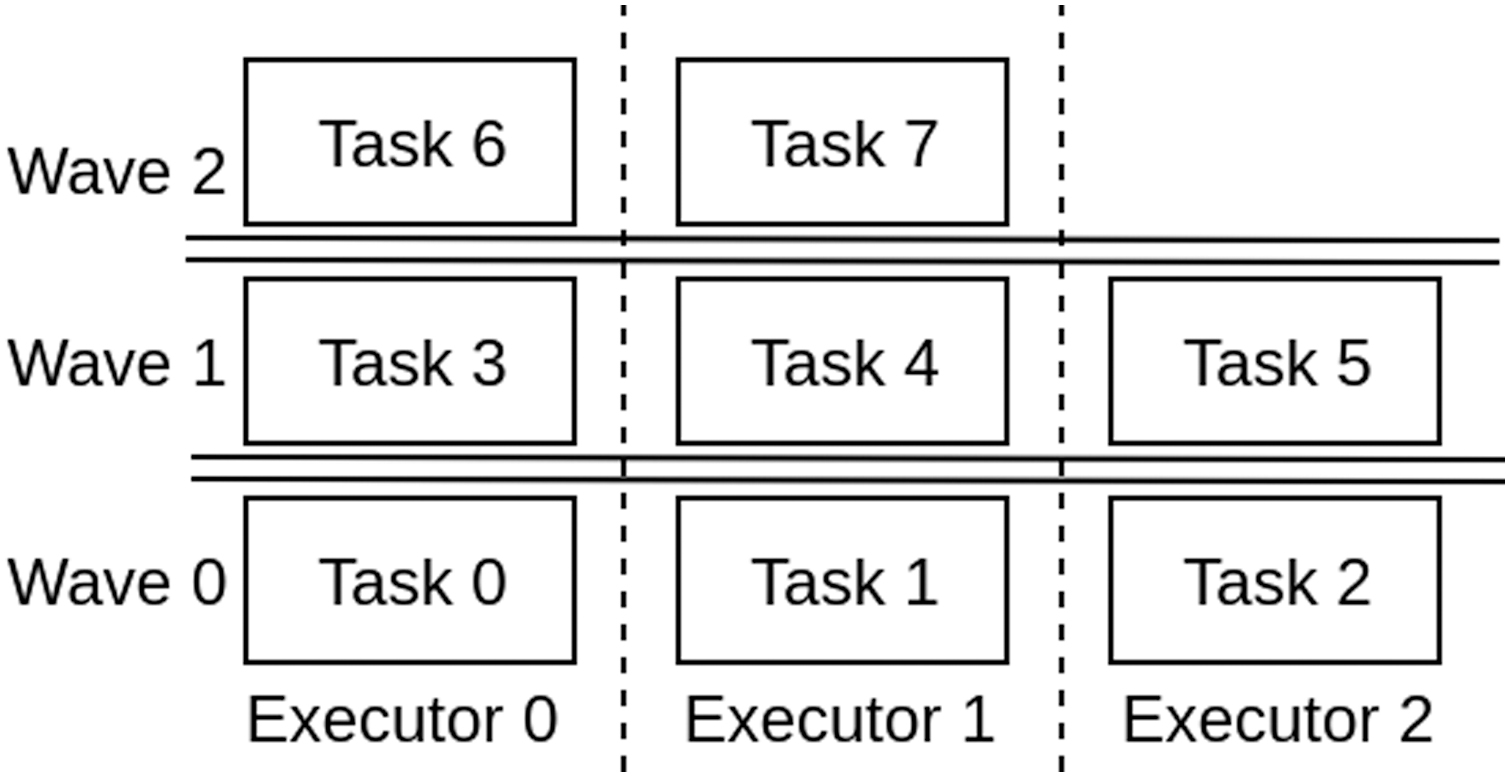
Execution of tasks.
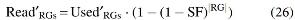
For standard deviation, first we need to estimate the number of RGs inside full partitions, using Equation (25). It is further used in Equation (26) to estimate the actual read RGs based on the SF.
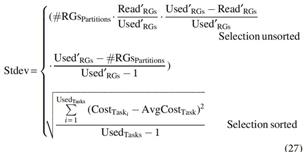
Finally, we use hypergeometric distribution
24
for selection unsorted to estimate the standard deviation of a full partition in Equation (27), based on the read RGs. Hypergeometric distribution estimates the standard deviation of choosing a subset of items without replacement from the total available items. This is similar to our case where we are also trying to select RGs (i.e.,
Finally, we estimate makespan for an operation by using Equation (28). There are two scenarios based on the number of executors active in the last wave. In the first scenario, there is only one executor in the largest stack. In this case, the last task is processing
In the second scenario, the makespan depends on metadata transfer, the average cost of a task, the number of executors running in the last wave, and their standard deviation. Thus, we need to estimate the expected maximum
25
of those by using the standard deviation as presented in Equation (28), which accounts for the standard deviation of the addition of tasks (i.e.,
Our Approach
In this section, we discuss our approach in detail. Figure 5 shows its architecture, which does not require any change in a distributed processing framework (i.e., it is fully transparent for users). The main function blocks of our architecture are the following ones:
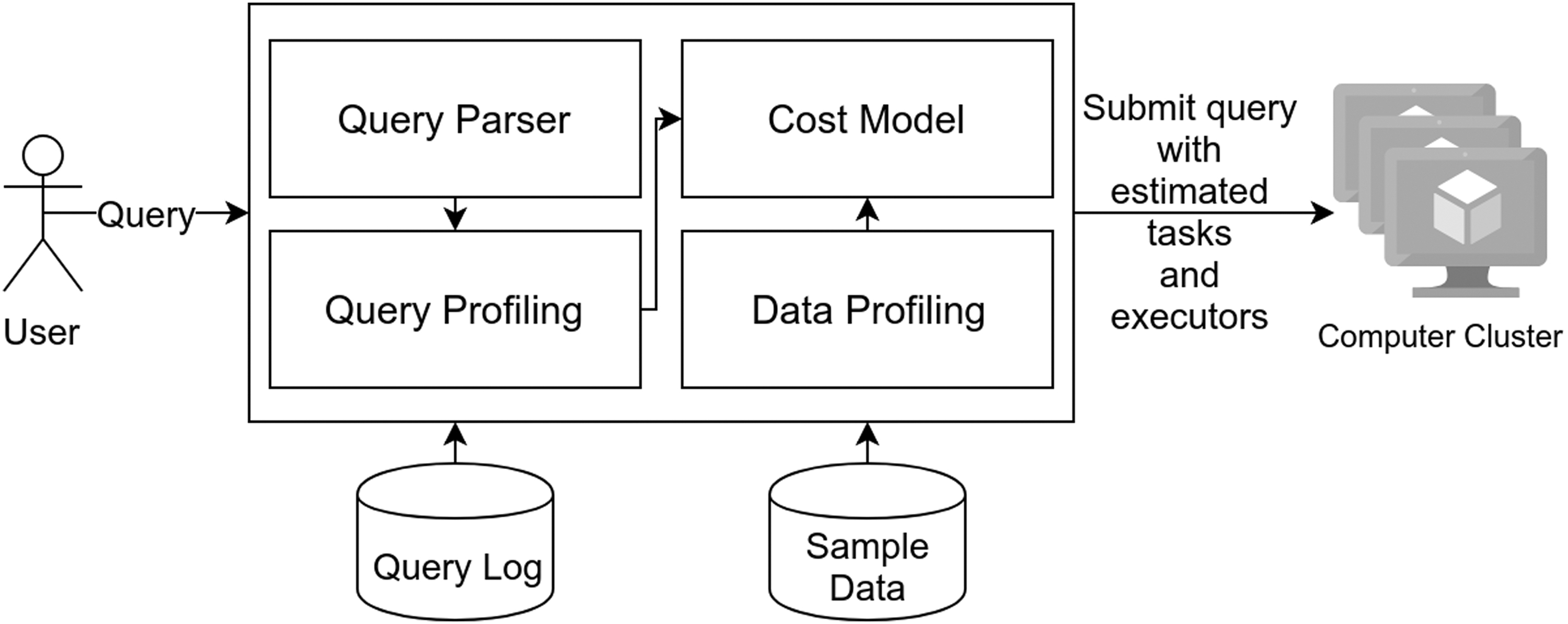
Architecture of our approach.
Query parser
The query parser takes a query as input and uses an existing parser (i.e., SparkSQL parser****) to validate its syntax. After validation, it generates the physical plan of the query as an XML and forwards it to the next module. The physical plan represents a tree that starts from input sources to the final output. It also highlights the operations, which can be pushed down to the storage layer.
Query profiling
The query profiling takes physical plan as an input and extracts pushdown operations from the plan. Hybrid layouts can only push down two operations: projection and selection. It is easy to extract referred columns from the physical plan. However, for selection, it is not possible to extract SF from the physical plan. To extract SF, the query log needs to be parsed for analyzing the old executions of the same query. Finally, this module passes the pushdown operations along with the required statistical information of operations to the cost model.
Data profiling
The data profiling module takes a sample of data and computes the statistical information listed in Table 1. We rely on an existing approach, namely the single-column profiling technique from Abedjan et al. 26
Cost model
The cost model is used to estimate the reading size for a given query. Typically, a query can have many operations that are linked together as a Directed Acyclic Graph. The operations are ordered based on their possibility of pushdown to the storage layer. Hence, the first operation is always a pushdown operation, which reads directly from the disk and impacts parallelism. The subsequent operations takes processed data from the first operation, which modern processing frameworks (e.g., Spark) always keep in memory.
The cost model uses a pushdown operation, workload, data statistics, and cluster configuration as inputs, which are used to estimate the makespan for a given partition size and the number of executors as presented in the Cost Model for Hybrid Layouts section. Our goal is to find the best partition size and the number of executors, which can be done by using a multi-objective optimization method described in the next section.
Multi-Objective Optimization
In this article, we focus on optimizing two objectives, which are contradictory to each other. These objectives are makespan of query and resource usage (i.e., number of executors) required to run the query. We would like to minimize both together. However, they are mutually contradicting, that is, if we want to reduce makespan, we require more computational resources. In the same way, if we want to save computational resources, we have to compromise makespan. Thus, we need to find a trade-off between them that satisfies user requirements and constraints.
The first objective function [i.e., MakeSpan (OperationType, PSize, UsedExecutors)] is based on the makespan estimation according to Equation (28) (as defined in the Cost Model for Hybrid Layouts section) for a given operation type, partition size, and the number of executors. Similarly, the second objective function [i.e.,
To avoid unfavorable or even impossible configurations, we need to add three constraints. First, Equation (29) guarantees that the partition size is always greater than or equal to the RG size and at the same time, we have enough partitions to utilize all assigned executors as shown in Equation (30). Finally, Equation (31) enforces the maximum number of executors.
Typically, there is no single optimum in a multi-objective optimization problem, but a Pareto front that contains many potentially optimal solutions depending on user prioritization of one objective or another (as shown in Fig. 6a). Thus, the user has to choose one configuration from the Pareto front to, in the end, execute the query at hand. Our framework †††† facilitates the user choice by reducing the many possible configurations to very few (belonging or close to the Pareto front), thus helping her to select one according to her preferences. As shown in Figure 6b, the position in the solution space does not determine the position in the configuration space, which hinders user's choice. In this case, our framework leaves only 2 (out of 35 possible solutions), which satisfy both objectives according to our estimations. When the user selects one of those two, the framework submits the query seamlessly to a processing engine by configuring the partition size and number of executors accordingly.
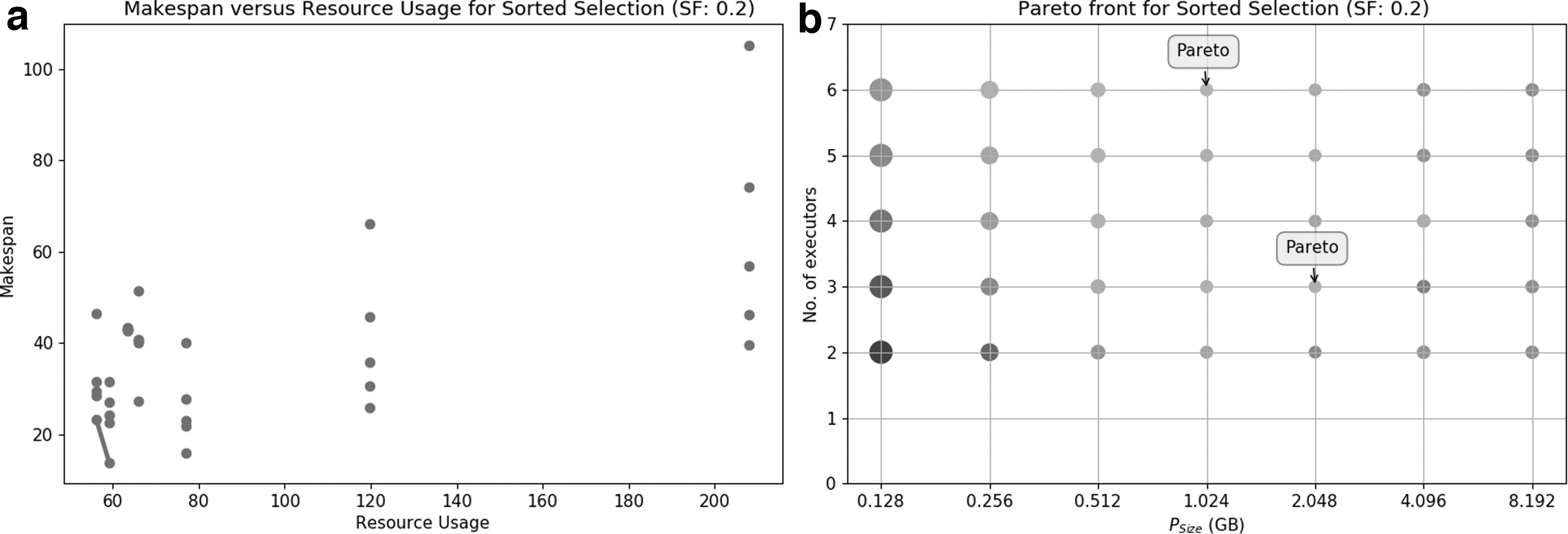
Pareto front for a selection (circle size represents resource usage, the bigger the more resources; and color represents makespan, red for high and green for low).
In this article, we do not focus on proposing a new multi-objective method, rather we focus on finding the best possible configuration (i.e., number of tasks and executors) for a given query. Thus, we use an existing multi-objective optimization approach, namely NSGA-II, 13 implementing genetic algorithms. It simply takes objective functions along with constrains as input, and it produces the Pareto front as an output.
Experimental Results
In this section, we discuss the setup and dataset used in our experiments. We also provide the results that validate the accuracy of the cost model and show the benefits of our approach.
Setup
We perform experiments on a five-machines cluster. Each machine has a Xeon E5-2630L v2 @2.40GHz CPU, 128 GB of main memory, and 1TB SATA-3 of hard disk, and it runs Hadoop 2.6.2 and Spark 2.1.10 on Ubuntu 14.04 (64 bit). In the cluster, we dedicated one machine for the HDFS name node and Spark master node together, and the remaining machines to data nodes for Hadoop and executors for Spark. We prototyped our approach for Apache Parquet 1.8.2. Table 2 shows the values of all environmental variables in our testbed. We also configured replication factor equals to the number of machines to have replicas on every machine, thus avoiding chunk transfer in the case of having partition size greater than the chunk size.
Values according to our environment
We also instantiated our cost model presented in the Cost Model for Hybrid Layouts section for scan, projection, and selection (both sorted and unsorted). Scan operation is just a selection unsorted with SF 1, referring all the columns of the table. Similarly, Projection is also a selection unsorted with SF 1 and based only on the referred columns. For Selection, we just need to give SF and it would work for both.
Results
As mentioned in Refs.,2,3 very wide tables are common in modern analytical systems, because of their advantages in processing compared with normalizing data into narrower tables. Nevertheless, to the best of our knowledge, there is no public benchmark available that consists of wide tables. Therefore, in this section, we first validate the accuracy of our cost model for makespan with a synthetic dataset of a very wide table. Further, we present the results to show the benefits of our approach to choose the best configuration for queries over the TPC-H denormalized schema.
Cost model validation
We generated a synthetic dataset of a very wide table with 1186 columns with different data types and 32 GB of size. We executed scan, projection with 10 referred columns, and selection with 0.2 SF to compare the real executions with our estimations. Figure 7 shows that comparison (notice that, we normalized the results, both real and estimation, like
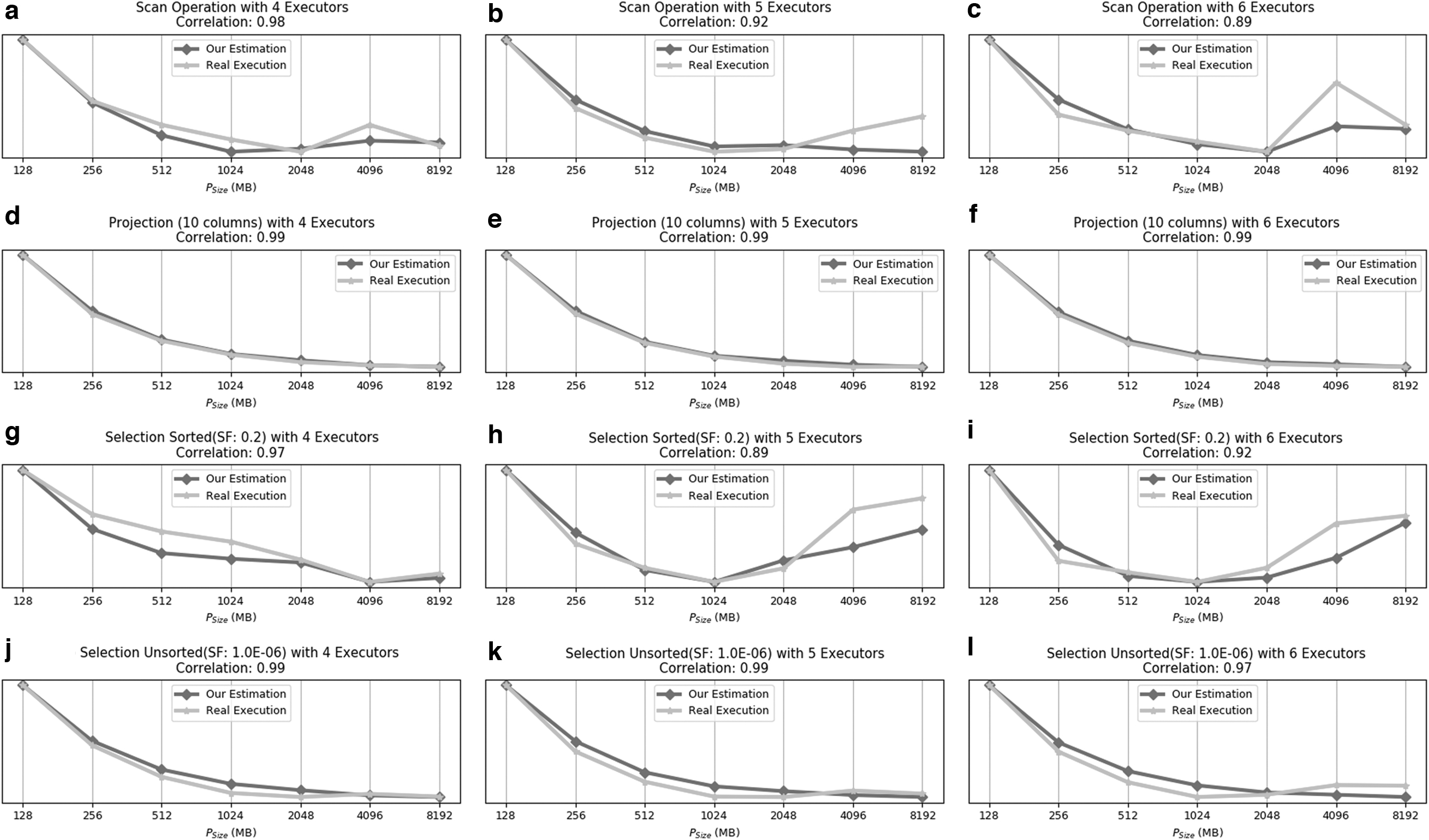
Validation of our estimation for makespan.
Figure 7a–c show the results for a scan operation with a different number of executors. Similarly, Figure 7d–f shows the results for a projection operation with a different number of executors. Finally, Figure 7g–i shows the accuracy of our estimations in comparison with the real executions for selection operation against sorted data. Figure 7j–l shows the results for selection operation against unsorted data. Observe that our estimations successfully capture the trends of real executions in almost all cases. Most of our predictions closely follow the real trends. In case of Figure 7c, h, and i, the divergences with the real trends are due to the different units used in our estimation. However, the trends are predicted correctly and suffice to find the optimal partition size. The only exception is Figure 7b, where we estimated a lower cost for large partition. Nevertheless, even in this case, our choice is still better than the default partition size.
We also confirm the accuracy of our estimations with the real executions by using statistical correlation, which measures how well the cost model estimates are related to the real execution. In Figure 7, it can be seen that our estimations are highly correlated (i.e., overall Pearson correlation coefficient 0.96) to real executions.
Performance evaluation
In TPC-H, the widest table has only 16 columns and in TPC-DS, ‡‡‡‡ only 26. Hence, we follow 27 to generate a wide table by completely denormalizing all other tables in TPC-H against lineitem. The FROM clauses in all queries are consequently changed to the corresponding denormalized table. This results, for a scale factor 16 GB, in a denormailized table of 124 GB being generated for the evaluation. We have chosen six representative queries based on different projected attributes and SFs as shown in Table 3. The table shows the intervals of SF and the number of referred columns of each group of queries. The other queries follow similar access patterns to those selected.
Representative queries of TPC-H
As presented earlier, there is no optimal solution in a multi-objective optimization, but there are many best solutions referred to as Pareto front. The Pareto front of our estimation is denoted as
We compute the Euclidean distance between
In Figure 8, we show the Boxplot of the distances corresponding to Our Solution compared with the boxplot of the distances to Default Configurations. We are showing the results of the representative queries (chosen based on their referred columns and SFs) of TPC-H. It should be observed that the boxplots in Our Solution are smaller and closer to zero distance, which means that the solutions proposed (i.e.,

Comparison between our configurations and default ones for TPC-H.
We also compare the query execution time (i.e., makespan) of our approach with the default configuration (e.g., default partition size of 128 MB). As mentioned earlier, we have multiple solutions for a query and we took the minimum makespan among these solutions for comparison. Similarly, we have multiple default configurations and we took the average of their makespans. Figure 9a compares the makespan of TPC-H queries, which highlights the advantage of our approach over the default solutions. Likewise, we also present the speedup gain in Figure 9b, which is between 1.8 × and 2.5 × . On average, our approach provides 2.1 × speedup against the default configuration.

Speedup gain for TPC-H queries.
Conclusions
Hybrid layouts are widely used to store processed data in highly distributed Big Data systems to perform ad hoc analysis. These Big Data systems process data on a computers cluster by creating multiple tasks. Typically, they create tasks based on the total size of the table, rather than based on the reading size of the query. Moreover, always using the default configuration has a heavy impact on performance. Thus, we proposed a cost-based framework that utilizes a multi-objective approach to decide the number of tasks and executors for a given query based on the reading size. We prototyped our approach for Apache Parquet, evaluated it on TPC-H queries, and showed the improvement it provides.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research has been funded by the European Commission through the Erasmus Mundus Joint Doctorate “Information Technologies for Business Intelligence–Doctoral College” (IT4BI-DC).