
Abstract
Choosing the right parameter configurations for recurring jobs running on big data analytics platforms is difficult because there can be hundreds of possible parameter configurations to pick from. Even the selection of parameter configurations is based on different types of applications and user requirements. The difference between the best configuration and the worst configuration can have a performance impact of more than 10 times. However, parameters of big data platforms are not independent, which makes it a challenge to automatically identify the optimal configuration for a broad spectrum of applications. To alleviate these problems, we proposed MonkeyKing, a system that leverages past experience and collects new information to adjust parameter configurations of big data platforms. It can recommend key parameters, which have strong impact on performance according to job types, and then combine deep reinforcement learning (DRL) to optimize key parameters to improve job performance. We choose the current popular deep Q-network (DQN) structure and its four improved algorithms, including DQN, Double DQN, Dueling DQN, and the combined Double DQN and Dueling DQN, and finally found that the combined Double DQN and Dueling DQN has a better effect. Our experiments and evaluations on Spark show that performance can be improved by ∼25% under best conditions.
Introduction
In recent years, traditional computing models in the era of big data have gradually failed to meet performance and efficiency requirements, resulting in some excellent big data processing platforms, such as Hadoop, 1 Spark, 2 and Storm. 3 The execution engines of big data platforms have evolved into efficient and complex systems with multiple configurable parameters, and the impact of parameters may vary from applications or clusters. Besides, users can adjust parameters according to specific application requirements.
Related experiments have shown that choosing the right parameter configurations can greatly improve the performance of an application, and improper selection may significantly degrade the performance, and increase the average operating cost by 2–3 times, and in the worst case by 12 times. 4 The default parameter configurations cannot meet the performance requirements of big data platform users, so researchers have done a lot of work to find the optimal parameter configurations for applications and clusters. Obviously, it is impossible to check the impact of different values of all tunable parameters on performance, as their combination is nondeterministic polynomial time-hard. In the past, we used expert experience and manual operations to adjust parameters to improve performance, but it was expensive and time-consuming.
Currently, there are two main ways to tune the configuration parameters of big data analytics platforms. First, parameters can be manually adjusted by trial and error. 5 Although it is intuitive and effective, the inefficiency and time-consuming due to large parameter space and complex interactions between parameters cannot be ignored.
Second, some researchers have proposed a cost-based performance modeling method to tune parameters of Hadoop platform. 6 However, the underlying implementation mechanisms vary widely among platforms, so we cannot use this method directly on other platforms. At the same time, cost-based modeling is a white-box approach that requires an in-depth understanding of the internal structure of systems. And using a cost-based model to capture system complexity due to the inclusion of the software stack and hardware stack 7 is very difficult. Therefore, it is a challenging task to adjust a wide range of big data analytics platform applications by automatically searching all possible parameter configurations.
For the complexity of big data platforms, complex business configurations, cumbersome manual configuration, and error-prone problems all become the vital issues. 8 Different users have different requirements for parameter configuration, which makes the above problems more prominent. Our solution is to be able to predict the efficiency of subsequent system execution through machine learning algorithms and finally convert it into a regression problem. Traditional machine learning can be used to regress and optimize parameters. However, there are some problems. For example, algorithms rely heavily on the amount and quality of training data. In big data platforms, it is difficult to generate enough sample data for training because sample acquisition comes at the expense of time and cost.
In this article, we study reinforcement learning (RL) techniques because RL is a subfield of machine learning related to decision-making and action control. 9 RL is a way to simulate interactive learning between agent and environment. It only receives some good or bad feedback every time it takes action. Through these accumulated feedbacks, it can adjust and optimize actions and finally iteratively generate the optimal strategy. In recent years, with the advancement of deep neural network (DNN) technology, the combination of deep learning (DL) and deep reinforcement learning (DRL) has achieved good results in many real and complex environments, such as DeepMind's Atari results10,11 and AlphaGo. 12 Inspired by these results, we study deep Q-network (DQN) algorithm and propose using a DRL technique that combines Double DQN 13 and Dueling DQN 14 to dynamically train optimal parameter configuration to improve job performance.
The contributions of our work are summarized as follows:
For the explosion problem of parameter combination, we can select the key parameters for different jobs that have an impact on performance by using a feature selection technique called LASSO. For the parameter optimization problem, we leverage DRL techniques to dynamically tune parameters and verify their versatility through experiments. For the problem of recurring jobs, we have designed a historical information base to save job running information, so as to effectively recommend suitable parameters for different workloads.
The rest of the article is organized as follows. Background and motivation are shown in the Background and Motivation section. Preliminary will be listed in the Preliminary section. The specific design ideas of MonkeyKing will be proposed in the MonkeyKing Design section. The implement will be given in the Implementation section. Experimental methodology and results are given in the Experiments and Evaluation section. Discussion is shown in the Discussion section. The related work is discussed in the Related Work section. Finally, the conclusions are summarized in the Conclusion section.
Background and Motivation
In this section, we show the importance and challenges of choosing the best parameter configurations. We also present the feasibility of DRL in parameter tuning.
Big data platforms have received more and more attention, but they have hundreds of configurable parameters, and the setting of parameters is complicated, which hinders the popularity and application of big data platforms to a certain extent. In general, the performance-related parameters of big data platforms can be divided into several different types, such as runtime environment, shuffling behavior, compression and serialization, memory management, execution behavior, and network. There are also complex interactions between different types of parameters. A single tuning technology is not suitable for solving such problems, and a huge search space makes the use of trial and error unrealistic. In addition, jobs running on big data platforms are also rich in types such as WordCount, Sort, PageRank, machine learning tasks, and image processing tasks. 15 The dependency analysis of parameters for each job type is also extremely complex.
Parameter optimization is an important branch of performance optimization for big data platforms. However, developing high-performance computing using big data platforms is not straightforward. If parameter configurations are not properly set, the job may be executed for a long time, and the benefits of big data platforms as fast calculation engines cannot be fully demonstrated. For resource parameters, if set too low, the cluster resources may not be fully utilized and the operation will be very slow. If set too large, the queue does not have enough resources to provide, which can cause various exceptions. 16 In general, choosing the right resource parameters for big data analytics platform has the following challenges.
The explosion of parameters search space
Big data platforms have hundreds of configurable parameters so far, and each parameter has at least two tunable values, which causes the parameter space to explode exponentially, and its impact cannot be examined in detail. The large parameter space and the complex interactions between parameters make it impossible to manually adjust parameters through trial and error.
The selection of key parameters
The total parameters' number of big data platforms has reached hundreds of thousands, but not all parameters are suitable for tuning, and only a small number of parameters affect performance. We cannot directly determine which parameters have an impact on performance. It is unwise to randomly select parameters or adjust all parameters. To this end, we have specifically proposed a method of selecting key parameters.
The diversity of applications
The demand for applications for the amount of resources on big data platforms varies by their diversity. In other words, parameters that affect performance of the current application do not necessarily apply to other applications at the same time. Therefore, before resource parameter allocation, we also need to separately analyze the impact of parameters on different types of applications.
The reuse of historical information
Repetitive analysis jobs are typically performed on big data platforms, 17 so the reuse of historical information is particularly important. If important information can be extracted from historical information, the efficiency of subsequent analysis will be greatly improved and the cost will be reduced.
In previous research and work, most researchers only focused on parameter optimization. Of course, parameter optimization is necessary and important, but the work of parameter selection cannot be ignored. For instance, as one of the most popular big data platforms, Spark has over 180 parameters, more than 150 of which are configurable parameters, it is not easy to pick out the parameters that have strong impact on cluster performance. We used to rely on expert experience and other scholars' recommendations, which are effective but not very accurate. For big data platforms, different cluster environments and workloads have different sensitivity to parameters. Even with expert recommendation, it takes time and cost. Therefore, we need a simple and efficient algorithm that can recommend the required parameters in a short time.
DRL is an end-to-end perception and control system with strong versatility. Its learning process can be described as: (1) at each moment, agent interacts with environment to obtain a high-dimensional observation and uses DL to perceive observation to obtain a specific state feature table; (2) evaluating the value function of each action based on the expected reward, and mapping the current state to the corresponding action through a certain strategy; (3) Environment reacts to this action and gets the next state. By continuously cycling the above process, the optimal strategy for achieving the goal can be finally obtained. The DRL principle framework is shown in Figure 1.
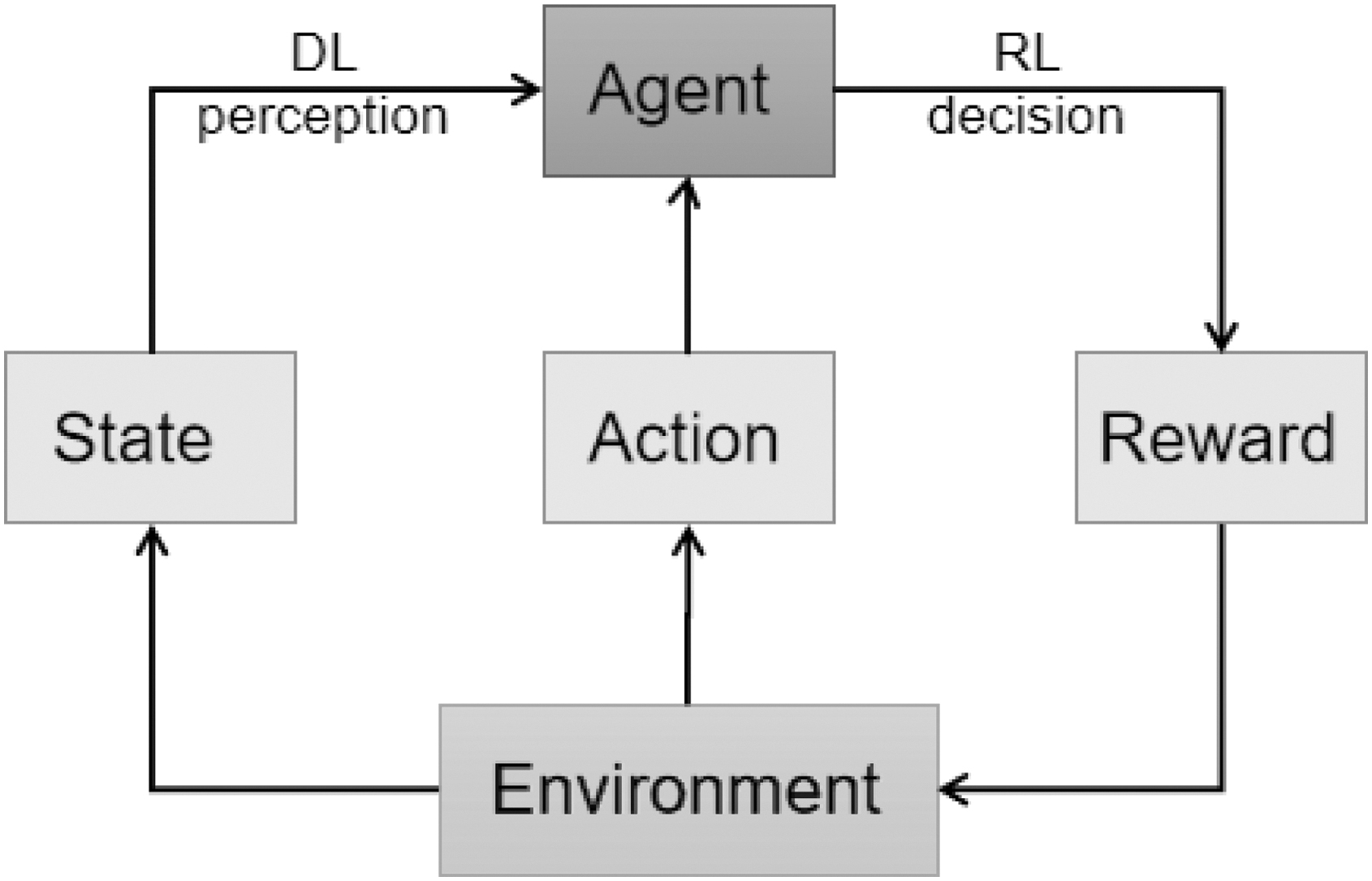
DRL principle framework. DRL, deep reinforcement learning.
With the continuous development of RL technology, many areas have successfully applied RL and made good progress. Mnih et al. 18 used recent advances in training DNNs to develop a novel artificial agent, termed a DQN, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end RL. AuTO 19 is an end-to-end automated traffic optimization system based on RL that collects network information, learns from past decisions, and performs operations to achieve operator-defined goals. Hansen 20 presented a novel definition of the RL state, actions and reward function that allows a DQN to learn to control an optimization hyperparameter. Ma et al. proposed ANANKE, 21 a scheduling system addressing these challenges. It extends the state-of-the-art in portfolio scheduling for data centers with a reinforcement-learning technique and proposes various scheduling policies for managing complex workflows. Yan et al. 22 developed CAPES based on Lustre file system, a model-free DRL unsupervised parameter adjustment system driven by DNN, which aims to find the optimal value of tunable parameters in computer systems. Yan et al. 22 used DQN to establish a parameter tuning system, which effectively proves the contribution of DQN to parameter optimization, but they mainly focus on the hyperparameter optimization of machine learning algorithms.
Based on the current research status of parameter optimization and DRL technology, in our strategy, DQN-based algorithms are used to automate parameter tuning to improve job performance.
Preliminary
In this section, we mainly introduce the working principle of MapReduce for big data platforms and several principles of DRL technologies.
MapReduce
MapReduce is a parallel scalable computing model with good fault tolerance, mainly for batch processing of massive offline data. MapReduce consists of a JobTracker and a TaskTracker. JobTracker is responsible for resource management and job control, and TaskTracker is responsible for running tasks.
In Map phase, the input file is split into splits, and each split is used as input to a map task. The intermediate result of input data processed by the map stage is written to the memory buffer and determines which partitioner the data is written to. When the written data reaches the threshold of memory buffer, a thread is started to write the data in the memory to the disk. During the data writing process, the MapReduce framework sorts the keys. In Reduce phase, when all map tasks are completed, each map task forms a final file, and the file is divided by region. Before reduce task starts, it will start a thread to get the map result data to the corresponding reduce task and continuously merge the data to prepare for the data input of reduce. After all the map tasks are completed, the reduce task is started, and the output is finally stored in Hadoop Distributed File System.
Deep Q network
For the problem of large state set size, just like our parameter tuning, DQN is a good solution. The basic idea of DQN comes from Q-Learning. But the difference with Q-Learning is that its Q value is calculated by a neural network called Q network. The optimal action-value function
Multiple Q values can be obtained by multiple experiments in state s. When the number of experiments tends to infinity, this expected value tends to the true
The input of DQN is the state vector corresponding to our states, and the output is the action value function Q of all actions in this state. The main skill used by DQN is experience replay, which saves the rewards and status updates obtained by each interaction with the environment for the subsequent update of the target Q value. There is an error in the target Q value obtained by experience replay and the Q value calculated through the Q network, and a loss function Li can be introduced to minimize the error. It can be expressed as:
where yi is expressed as shown in Eq. (5). When calculating the value of yi, the parameter
Double deep Q network
The target Q value of DQN is directly obtained by greedy algorithm. Although the maximum value can quickly make the Q value close to the possible optimization target, it is easy to cause over estimation, and the final algorithm model has a large bias. To solve this problem, Double DQN achieves the problem of eliminating overestimation by decoupling the selection of the target Q value action and the calculation of the target Q value. The structure of Double DQN is shown in Figure 2.

The structure of Double DQN. DQN, deep Q-network.
In double deep Q-network, it is no longer directly looking for the maximum Q value in each action in the target Q network, but first finding the action corresponding to the maximum Q value in the current Q network.
Then use this selected action
Dueling deep Q network
With the help of Double DQN, we solved the problem of overestimation of the DQN algorithm, and the convergence of DQN can also be improved by using Dueling DQN.
In Figure 3, Dueling DQN attempts to optimize algorithm by optimizing the structure of neural network. It considers dividing the Q network into two parts. The first part is only related to state s and has nothing to do with action a to be used. This part is called value function and is written as
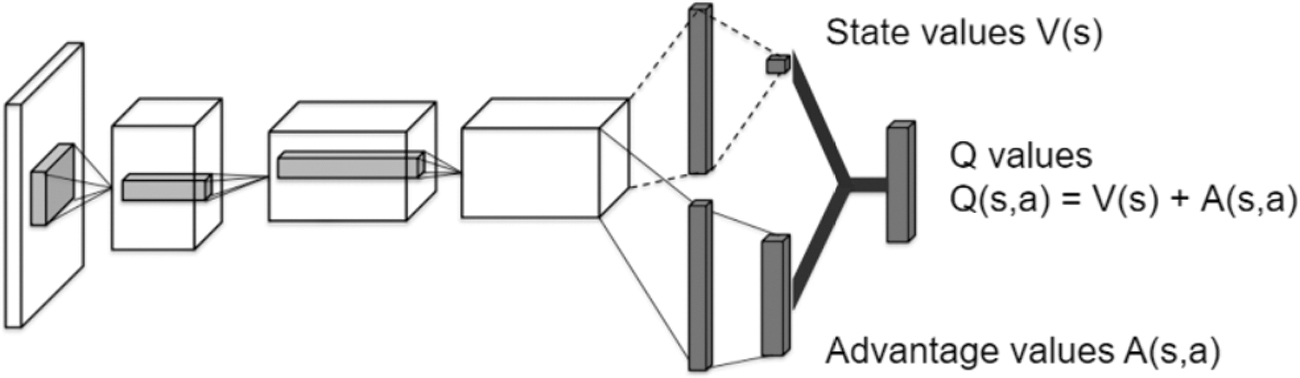
The structure of Dueling DQN.
where
MonkeyKing Design
In this section, a parameter optimization system named MonkeyKing is proposed for modeling the performance as it is a key component in an auto-tuning system. Next, we will elaborate and analyze objective function, overall design, the two important modules and so on.
Objective function
We analyzed various performance indicators for performance and noted that job completion time (JCT) can directly and effectively reflect whether performance has improved. The perfect thing is that we can get JCT directly from the log information generated by the submitted job. From this, we can dedicate the goal to minimize the JCT that satisfies the constraints under a given set of configuration parameters. Considering the general situation that users want performance improvement while ensuring CPU utilization, we have added CPU utilization constraints.
We are committed to optimizing performance by adjusting big data platforms' configuration parameters. First, we need to define the objective function. The objective function can be described by a formula as:
where P denotes the performance of big data platforms, c represents the valid value of a given set of configuration parameters, u is the CPU utilization of jobs, F indicates a function of P about c and u,
Overall design
Referring to Figure 4, MonkeyKing consists mainly of three modules: Parameter Selection Module, Parameter Tuning Module, and historical information base. MonkeyKing is a combination of both parameter selection and parameter optimization. We first select the key parameters that have a great influence on performance from the original parameter set through Parameter Selection Module and then deliver them to Parameter Tuning Module. When a workload is running, it will generate corresponding parameter configuration information and job log. The environment based on DQN algorithm interacts with parameter configuration and log information in the cluster to obtain corresponding actions, states, and rewards. At the same time, the calculation results of these two modules will be saved in the historical information base.
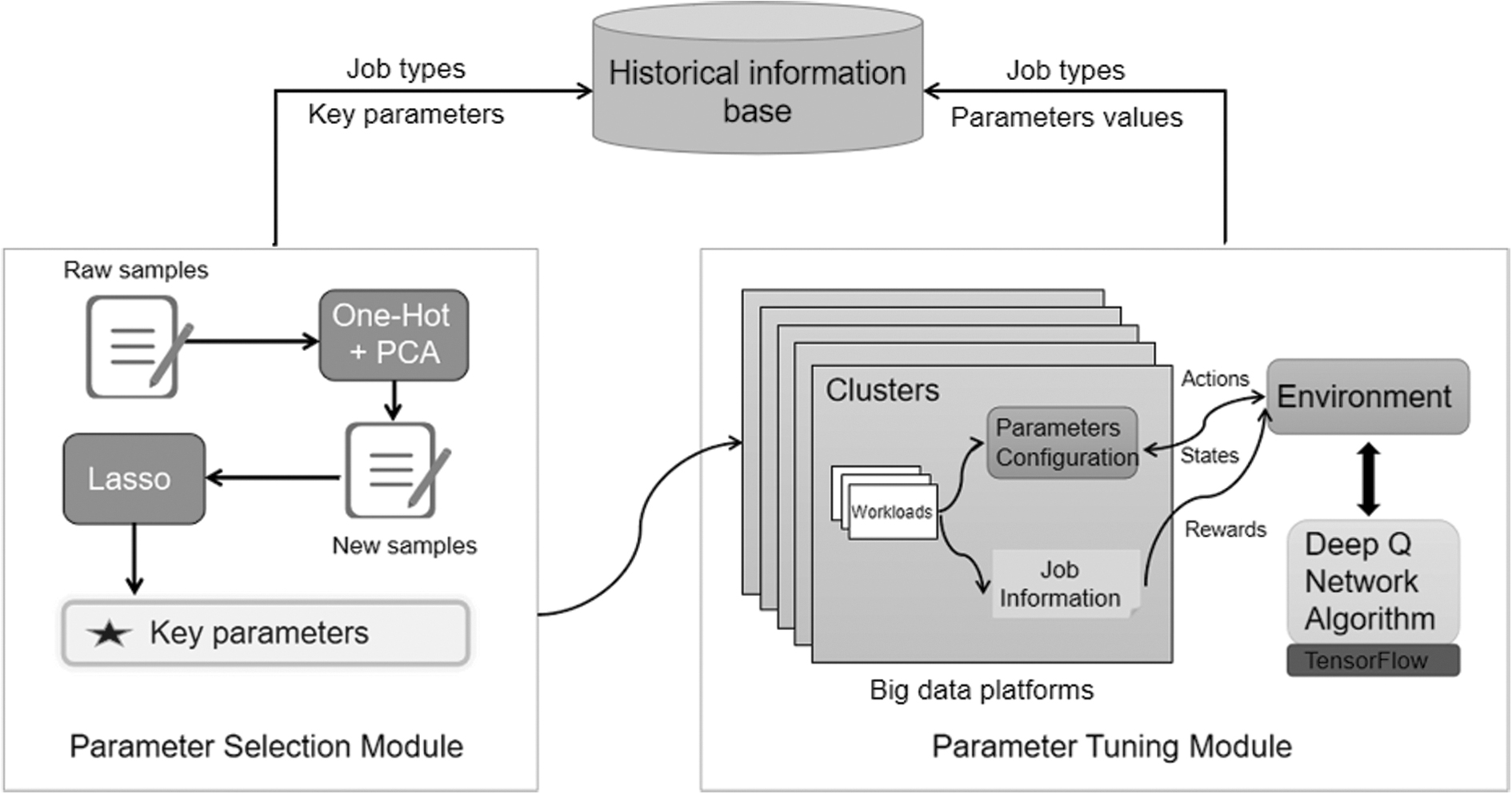
The overview of MonkeyKing.
Parameter selection module
First, we pay attention to the parameter selection section because this work is done before parameter optimization. We cannot and do not have to study all the parameters because this is a dimensional disaster problem, and only a subset of parameters actually affects performance. Our goal is to determine this minimal subset that has a strong impact on the performance of big data platforms with hundreds of tunable parameters for diversity job types and job sizes. Filtering out parameters that are not related to performance or have a weak impact on performance, leaving important parameters not only reduces the difficulty of learning tasks but also allows subsequent tuning learning processes to build models on only a small number of parameters. This is very helpful in mitigating dimensional disasters.
The parameter selection module mainly includes parameter data processing and feature selection using LASSO. In this module, we skillfully combine some existing high-efficiency technologies, such as One-Hot coding technology, principal components analysis (PCA) dimensionality reduction technology, and LASSO feature selection technology. The details of this work are shown in the Parameter Selection Module in Figure 1.
Parameter tuning module
The parameter optimization problem of big data platforms is obviously a parameter combination problem, which results in a large parameter search space. For this reason, we apply DRL techniques, including four DQN frameworks. Previous work has been performed to apply DRL techniques to hyperparameter optimization, thus improving the efficiency of algorithms. However, we cannot directly apply this approach to big data platforms because there are hundreds of parameters in big data platforms that are inconsistent in type.
DRL formulation of parameter tuning
Markov decision process
Each parameter of Spark has a certain range of variation, so state space can be set as a set of all valid values of key parameters. Action space includes actions that can adjust key parameters, and reward is performance improvement after executing Spark job. It is represented by JCT in our application scenario. Agent is in the environment. At time t, a certain state st takes action at to reach the next state
State space
The state space contains all the states in the parameter tuning scenario. For parameters, we can use their valid values to represent state. Since we also consider different workloads, we should also include information such as job type and job size. It can be expressed as: (para1, para2, …, paraN, Jtype, Jsize).
Action space
The action space is a combination of all the actions we can take. The processed parameter values are all numeric types. For each numeric parameter, we can take three adjustment actions: increase, decrease, and unchanged. So we use the action space containing these three actions to describe the transition between states.
Rewards
Rewards are feedback to the agent on how good its actions are. The reward can be obtained after the completion of a job. At time step t, the value of reward depends on the ratio of the completion time
Historical information base
We found that to get the running information of jobs, it is often necessary to run jobs repeatedly, but it is time-consuming. If we can extract the running information of jobs and save it to a database, we can query the database when needed, which can improve efficiency and usability. For the problem of parameter tuning, we need properties such as job type, parameter information, and completion time. Therefore, we have designed a historical information base to store the key parameters and parameter weights (the degree of impact on performance) calculated by the parameter selection module and the optimal values of the key parameters calculated by the parameter optimization module. The detailed design of the database is shown in Table 1. After each job runs, the relevant job type, parameter name, parameter value, and weight are saved in the database. N is the number of parameters. For key parameters, the database stores the optimized values, and the non-key parameters store the default values. Once values changes, the original information of the database is overwritten with new values.
Design of historical information base
The above content introduces the main design ideas of MonkeyKing. In the following part, we will conduct experiments based on the system on Spark platform.
Implementation
In this section, we mainly introduce the specific module design and implementation in the previous section.
Data preprocessing
The step of parameter data preprocessing needs to be completed before the feature selection, and the purpose of data preprocessing is to normalize the parameter data. This is necessary because parameter values are not always contiguous and not all digital data but contains many categorical values. In our proposed solution, first convert all functions to “virtual” variables using One-Hot encoding 23 and then normalize the data.
One-Hot encoding is proposed because most of the algorithms are calculated based on the metrics in the vector space, to make the nonpartial relationship variable values have no partial order and the distances to the dots are equal. 24 Using One-Hot coding, the value of the discrete feature is extended to the European space. A certain value of the discrete feature corresponds to a certain point in the European space, which makes the distance calculation between the features more reasonable. After the One-Hot encoding of the discrete features, the features of each dimension can be regarded as continuous features.
Although One-Hot coding solves the problem that classifiers cannot handle attribute data well, it expands the feature to some extent. When the number of categories increases, the feature space becomes very large. In this case, PCA 25 can generally be used to reduce the dimensions. And the combination of One Hot encoding and PCA is also very useful in practice. PCA is one of the most widely used data reduction algorithms. Its main idea is to map the n-dimensional features to the k-dimension. This k-dimensional is a new orthogonal feature, also called the principal component, which is a k-dimensional feature reconstructed on the basis of the original n-dimensional features.
The job of PCA is to sequentially find a set of mutually orthogonal coordinate axes from the original space. The selection of new coordinate axes is closely related to the data itself. Wherein, the first new coordinate axis selection is the direction with the largest variance in the original data, and the second new coordinate axis selection is the plane orthogonal to the first coordinate axis, so that the variance is the largest, and the third axis is the first one. The variance of the plane orthogonal to the two axes is the largest. By analogy, n coordinate axes can be obtained. In this way, most of the variances are included in the first k axes, and the subsequent axes contain almost zero variance. The remaining axes can then be ignored, leaving only the first k axes with most of the variance. In fact, this is equivalent to retaining only the dimensional features that contain most of the variance, while ignoring the feature dimensions containing the variance of almost zero, to achieve dimensionality reduction of the data features.
After using PCA for dimensionality reduction, the data dimensions will reduce from n to k, which is
Parameter selection with LASSO
After adopting the PCA techniques of the previous section, we will consider how to exact the most key parameters from the preliminary set of features.
As we known, linear regression is a statistical method that can be used to determine the strength of the relationship between one or more dependent variables and each of the independent variables. The relationship between the independent variable and the dependent variable can be modeled based on the weight of a linear predictor function estimated from the data. The most common method of fitting a linear regression model is the ordinary least squares (OLS), which estimates the regression weight by minimizing the residual squared error. 26 We could use OLS to determine important parameters, but it has two significant drawbacks in high(er) dimensional settings. First, OLS estimate has low deviation but high variance, and the high variance reduces the prediction and variable selection accuracy of the model. Second, OLS estimates that it is difficult to interpret the number of features because it never removes irrelevant features.
To avoid high variance and irrelevant features disturbance problems, we use a regularized version of the least squares method called LASSO, which reduces the effects of unrelated variables in linear regression models by penalizing models with large weights. Compared with other regularization and feature selection methods, LASSO's main advantage lies in its interpretability, stability, and computational efficiency. 27 There is also practical and theoretical work supporting its effectiveness as a consistent feature selection algorithm. 28
LASSO works by adding the
As with the usual regression scenarios, we construct a set of independent variables (X) and a dependent variable (Y) based on historical data obtained from previous job logs. In our application scenario, X is the parameter of the Spark platform, and Y is the corresponding JCT. First, a high penalty is set in the LASSO algorithm, and the weights of all features are zero. Then reduce the penalty in small increments, gradually distinguish between nonzero weights and zero weights, and sort according to the values.
To avoid the disaster of dimensional explosion and to DL methods, we reduce the number of parameters as much as possible. We analyzed and summarized all configurable parameters, filtered some parameters that could not be adjusted. First, we use the PCA to reduce some dimensions. Then, we take LASSO algorithm into the remaining parameter candidate set. The two stages can not only reduce the overall dimension calculation but also obtain more accurate key parameters. Finally, we selected the smallest candidate parameter set that affected performance. In our Spark application scenario, we selected 55 adjustable parameters from all spark platform parameters, which were reduced almost half dimensions after PCA algorithm. And after the LASSO algorithm, a total of 14 key parameters were selected as the parameters that seriously affected the JCT of Spark platform. We can conclude that the PCA step improves the performance and the LASSO technology is very sufficient to select key parameters relevant to JCT in cases.
Experiments and Evaluation
In this section, we verify the effectiveness of MonkeyKing on a 10-node Spark cluster, including one master node and nine slave nodes. Each node has also the same software stack: Ubuntu 14.04.3, Spark 2.2.0, Hadoop 2.7.2, Hibench 7.0, Java 1.8.0, and Scala 2.11.4. Two kinds of hardware configurations existed in the cluster. In the parameter tuning module, we used several different DRL algorithms, including DQN, Double DQN, Dueling DQN introduced in the system design section, and the combination of Double and Dueling DQN. Next, we will introduce benchmark, evaluation metrics, experimental results and analysis, and so on.
Benchmark
HiBench is a big data benchmark suite that helps assess speed, throughput, and system resource utilization of big data frameworks. 29 The frameworks it supports are: HadoopBench, SparkBench, StormBench, FlinkBench, and GearpumpBench. HiBench has a total of 19 test directions, which can be roughly divided into 6 test categories: micro, ml (machine learning), sql, graph, websearch, and streaming. We select four kinds of benchmarks from the HiBench benchmark suite, including WordCount, Sort, PageRank, and Kmeans. These workloads are easy to understand and represent a true Spark application with a wide range of applications.
Competing methods
Because of the resilient distributed dataset and localization technology of the Spark platform, there are fewer existing works to tune Spark parameters than Hadoop platform. They adopt different underlying execution mechanisms. For example, Starfish 30 is specially designed for Hadoop platform and optimized by combining with the system framework, not only parameters tuning system. For fairness, we compared MonkeyKing with two methods, including C5.0 decision tree, 31 and exist rule of thumb native Spark recommendations from industry leaders. 32 These methods are chosen because they are the state-of-the-art in the relevant areas, that is, C5.0 is very efficient multiclassification method of traditional machine learning.
The default parameters value of native Spark is designed to afford all kinds of applications, which cannot be used to compare different applications. To have a fair comparison to MonkeyKing, we select the better parameters value for different type workloads based on gounaris2018methodology. This adaption significantly enhances the performance of native Spark. For C5.0 comparison, first, sampling was conducted on the parameter space, and 50 parameter lists were generated for each application to be used for testing. Each of parameter list was tested three times. However, the biggest problem is that in the process of collecting training data, which parameter values need to be further explored. Since the parameter space is huge, sparse sampling is selected at this time. In particular, it is necessary to search the space of different parameter subsets in detail, and to collect data evenly and randomly within the range of different.
All methods are implemented on Spark2.2.0 platform: DQN, Double DQN, Dueling DQN, and MonkeyKing are implemented using tensorflow, 33 C5.0 is taken from its authors, and parameters setting of native Spark is taken from the study of Gounaris and Torres. 32
Evaluation metrics
In the experiment, we chose computational performance as an evaluation metric. The performance aspect is mainly reflected by comparing JCT. If JCT is greatly reduced, then MonkeyKing is proved to be available. It is judged whether MonkeyKing is valid by comparing the parameters obtained by the comparison algorithm with the default determination of parameters configuration in terms of performance improvement. For comparison of several different algorithms, we chose convergence as a criterion.
Experimental results and analysis
Parameter selection for spark
Spark currently has more than 150 configurable parameters. 34 We studied Spark's 175 configurable parameters, analyzed and summarized the 10 categories listed in Table 2, and excluded a total of 120 unneeded parameters based on the classification results. In addition, based on the adjustment recommendations of other researchers, we finally selected a candidate subset of 55 parameters.
Classification of Spark configuration parameters
Then, we collect the obtained 55 parameter-related parameter data as raw data samples in the historical data information and input them to the parameter selection module for different job types. After data preprocessing and feature selection, we finally get the weight of each feature, that is, the degree of impact on performance of Spark jobs. Due to space limitations, we only show the first 14 parameters as representative in Table 3.
The effect of parameters on different workloads
From the results in Table 3 and Spark tuning guide recommendations, 2 we compiled 10 parameters that have the strongest impact on Spark performance as experimental objects.
Convergence test
To demonstrate the convergence of MonkeyKing, we run 10 times for 4-type application by the same workloads with the same data size on MonkeyKing. The different applications are as follows. The sort application is 320 MB data size. The WordCount application is 3.2 GB. The PageRank application is 3.6 GB. The K-means application is 3.6 GB. Figure 5 shows the JCT for different applications by MonkeyKing in a single heterogeneous cluster. The results demonstrate that MonkeyKing achieve better convergence trend for different applications in heterogeneous environments.
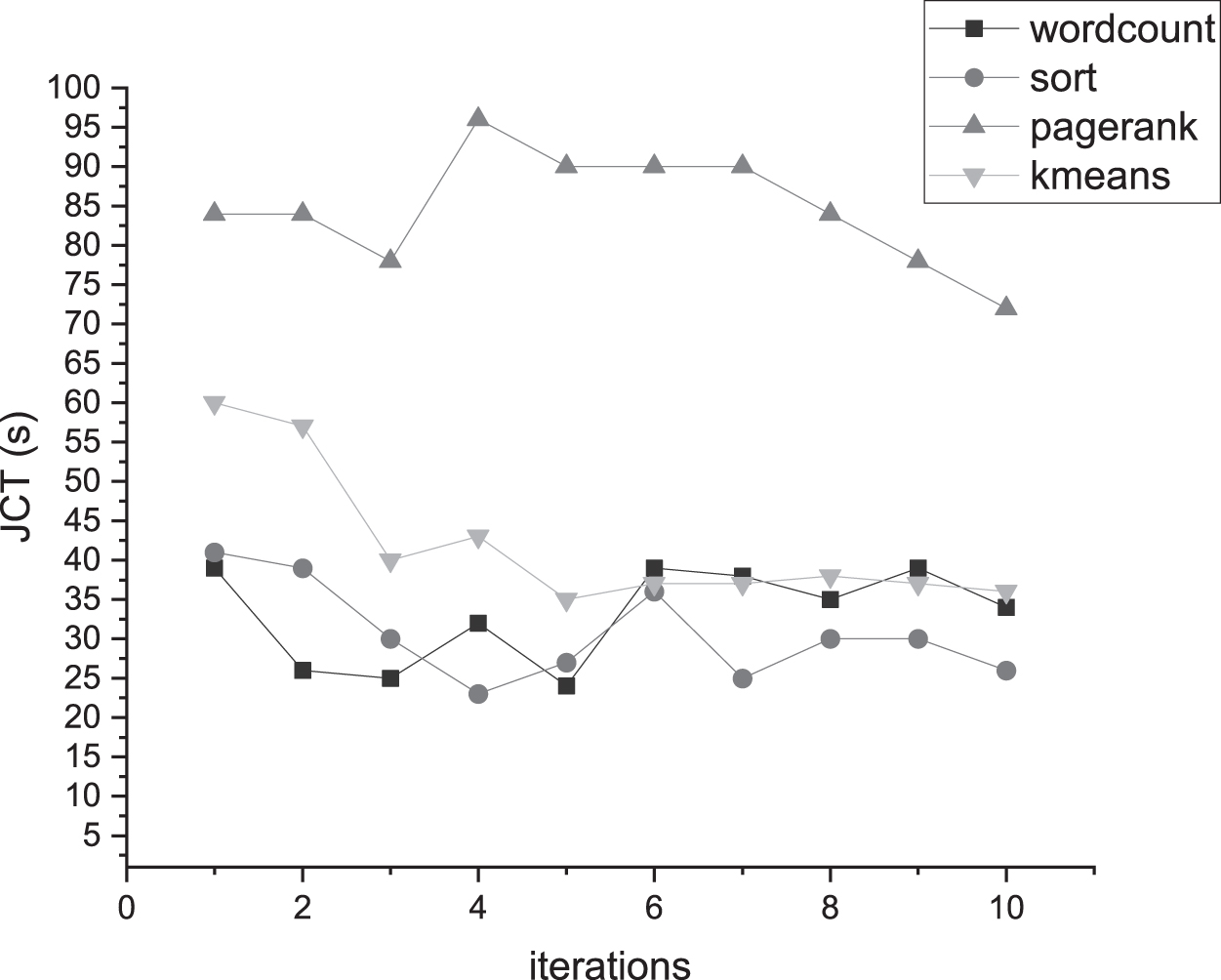
Learning curves of different workloads.
Effectiveness test with different DRL algorithms
In the choice of specific algorithms, we are mainly based on DQN because it has developed into a very mature technology and contains various DQN variants. We finally chose several popular frameworks: DQN, Double DQN, Dueling DQN, and the combination of Double and Dueling DQN. The initial sample data size used in the experiment was 200. The minimum CPU utilization
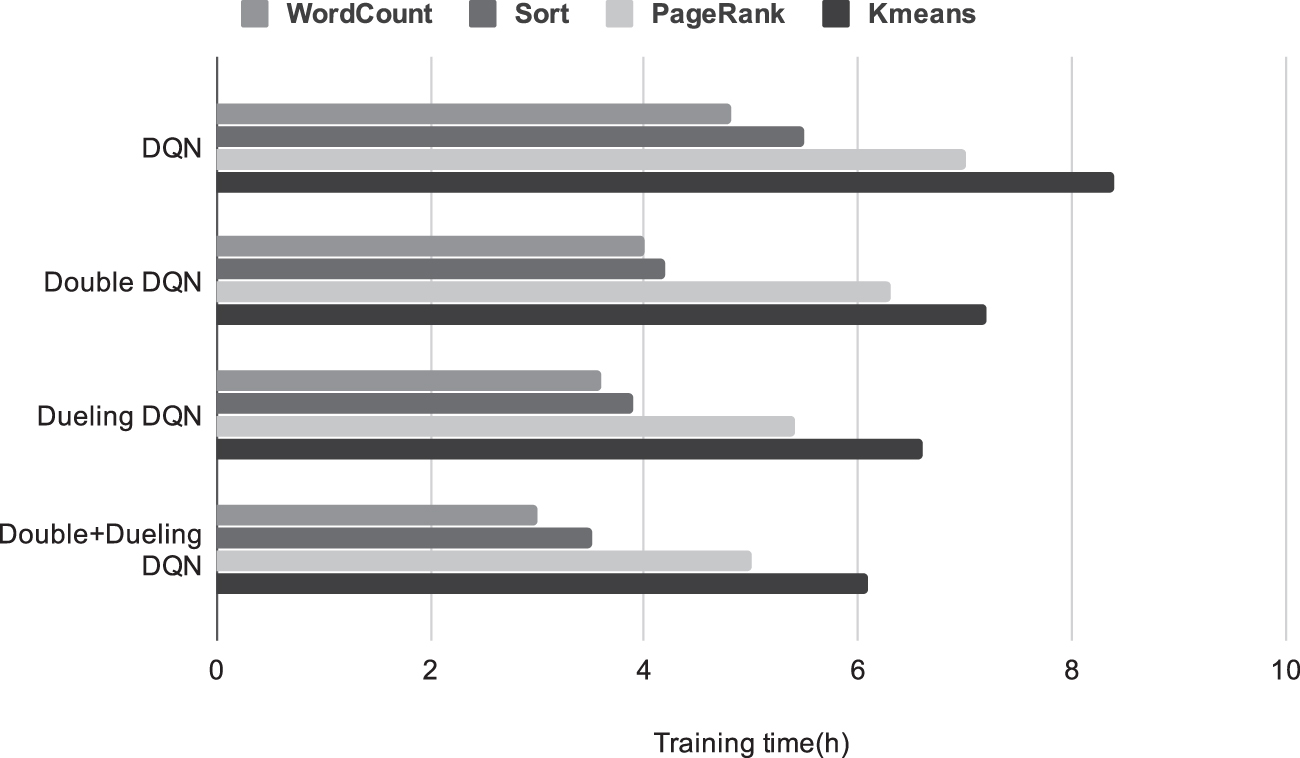
Comparison of four DQN algorithms.
This is because Double DQN solves the problem of overestimation in DQN, and Dueling DQN improves the network structure, so this method converges faster than the other three. The experimental results of MonkeyKing are represented by this combination algorithm.
We leverage MonkeyKing to calculate the optimal configuration of the above parameters. Then, we represent the change in performance by comparing the JCT under the parameter configuration recommended by our approach with the JCT under the default parameter configuration. Affected by limited cluster resources, we may not be able to achieve the best value recommended by the industry, we can only find a set of optimal configurations based on existing resources.
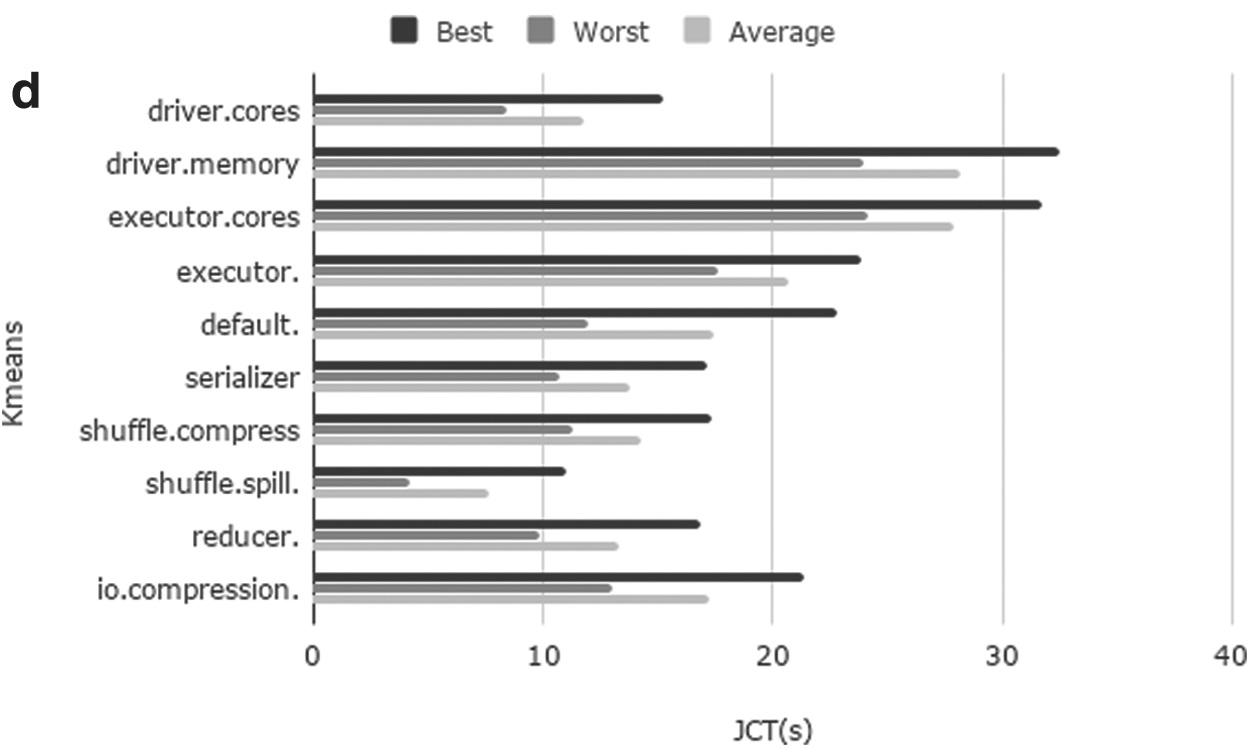
Impact analysis of different key parameters
MonkeyKing can prove that parameter tuning is important and necessary. This can be seen in the single parameter tuning results. We tuned 10 parameters to determine their impact on job performance, respectively. Figure 7 compares various JCTs achieved by MonkeyKing with 10 parameters, respectively. The Figure 7a-d shows the performance of Wordcount, Sort, PageRank, and K-means, respectively. Based on Figure 7, we further analyzed performance improvement of different parameters impacting, respectively. Figure 8 shows that parameter tuning is useful. We can see that the impact of these 10 parameters on performance is roughly in the range of 6%–36% from results. Besides, the impact of the same parameter on different types of jobs is different. The results demonstrate MonkeyKing achieve shortest training time than other DRL approaches in heterogeneous environments. This is due to the fact that the MonkeyKing adopts the double DQN and dueling DQN composition framework to speed up training time.
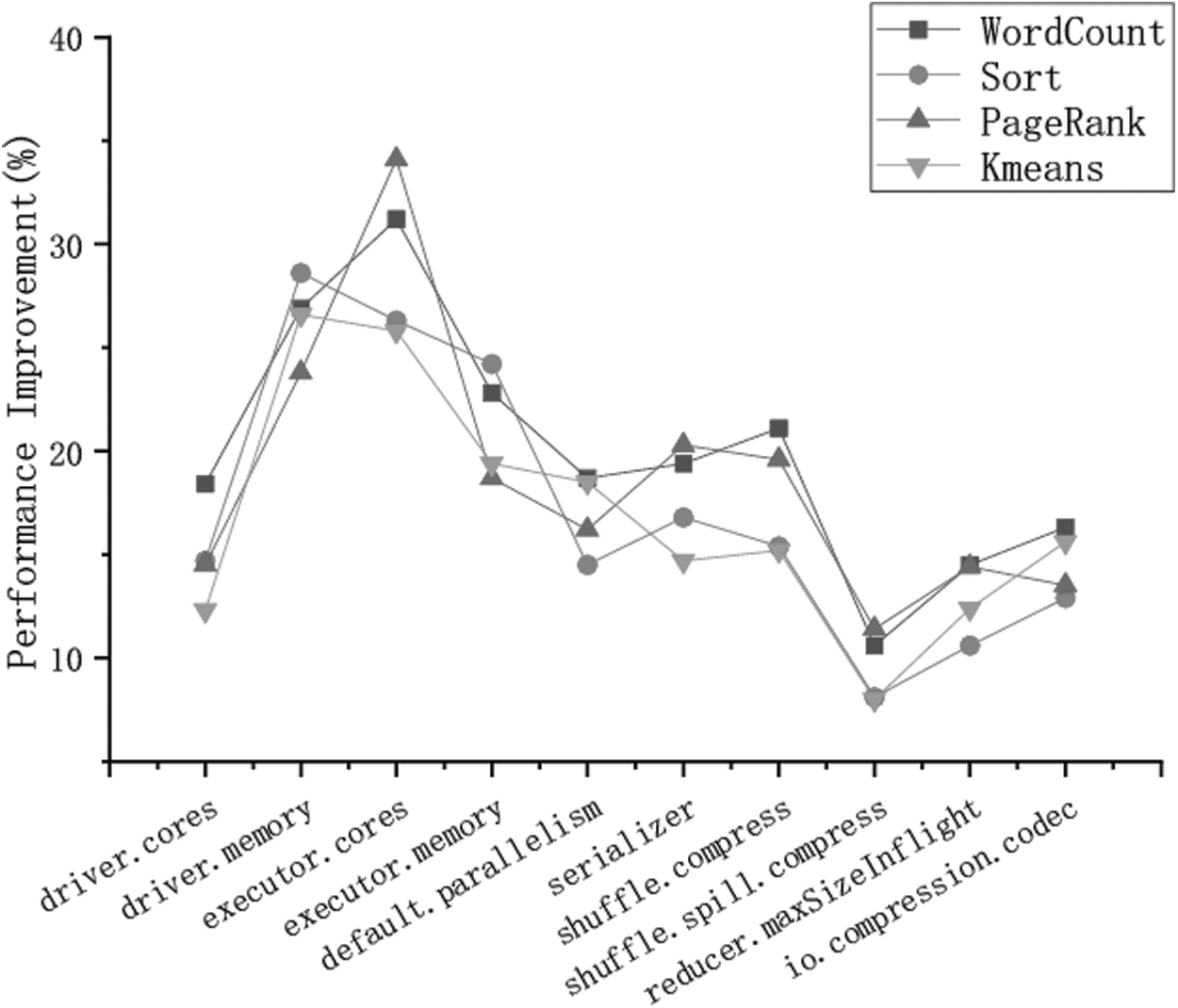
Performance improvement of single parameter tuning.
Effectiveness test with different approaches
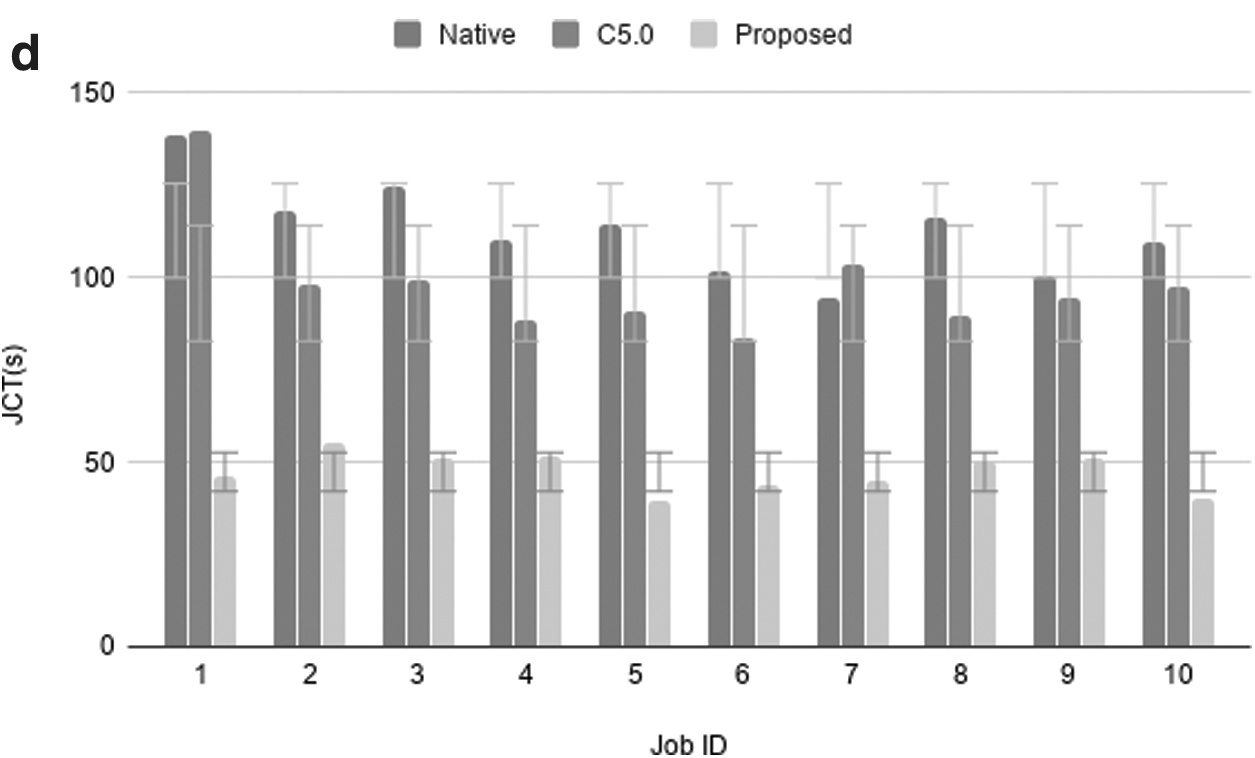
We mainly study parameter combination tuning because JCT is affected by multiple parameters at the same time. Experiments show that MonkeyKing can effectively adjust the combination of parameters and can significantly reduce JCT and improve performance. The performance results of four different types of job are shown in Figure 9. Figure 9a-d shows the performance of Wordcount, Sort, PageRank, and K-means, respectively. In this part of the experiment, we used the small job size of 1.2 GB. Spark clusters are affected by various factors, so there is no guarantee that the completion time of each job is exactly the same. For this reason, we also run all comparison experiments more than 10 times and label all standard deviation in the results figures. We also analysis the standard errors for all competing approaches with different applications. And Figure 10 shows that the MonkeyKing almost achieves all the best standard errors in different applications.

Standard errors of competing approaches with different applications.
We can draw a conclusion that WordCount performance increased by an average of 24.8%, Sort performance increased by an average of 19.7%, PageRank performance increased by an average of 18.5%, and Kmeans performance increased by an average of 21.7%. The results demonstrate that MonkeyKing achieve better performance improvement than other approaches in heterogeneous environments. We also find that C5.0 achieves slight performance improvement compared with the native approach. This is due to the fact that the main contribution of MonkeyKing relies on the DRL and adaptive configuration in heterogeneous environments.
Scalability of MonkeyKing
We also studied the relationship between job size and parameter tuning. 35 It can be inferred from the results that the larger the job size, the more obvious the effect of MonkeyKing performance improvement compared with the C5.0 and native Spark. Figure 11 shows the performance changes of the four benchmarks for different job sizes. In summary, with the increase of job size, the effect of performance improvement is more obvious. Figure 11a shows the optimization effect of WordCount; WordCount has 22.7% performance gain when the job size is 1 GB and 26.4% performance gain when the job size is 6 GB. Figure 11b represents the optimization effect of Sort benchmark. We can see that Sort has 20.6% performance gain when the job size is 1 GB and 25.5% performance gain when the job size is 6 GB compared with the native Spark. Figure 11c represents the optimization effect of PageRank, which illustrates that PageRank has 21.2% performance gain when the job size is 1 GB and 24.4% performance gain when the job size is 6 GB. Figure 11d shows the optimization effect of Kmeans. Kmeans has 20.7% performance gain when the job size is 1 GB and 22.9% performance gain when the job size is 6 GB. The C5.0 method also works in terms of scalability, but not as well as what the MonkeyKing achieved.

Discussion
In this section, we mainly discuss the specific contributions of this article and the direction that is worth studying in the future.
Parameters tuning
Parameter tuning is a very important research task in many aspects. For example, big data analysis platform, hyperparameter tuning in AutoML, compiler parameter tuning, and Database system parameter tuning. In the current very hot research field of AutoML, some current research methods mainly use learning-based method to study the automatic tuning of hyperparameters. Their goal optimize a learning algorithm to make the right parameters choice when faced with these network degrees of freedom.36–38 But in the field of big data analysis platform, the goal is to optimize the whole platform performance at runtime. The challenges are different for different scenarios. How to simultaneously leverage selecting a learning algorithm and setting its hyperparameters is a big challenge in AutoML research. Hundreds of configuration parameters have high dimensionality, naive exhaustive search is not feasible is a big challenge in big data analysis platform. Therefore, we cannot use “one-size fits all” approach to solve different challenges in different scenarios.
Performance optimization
In view of the performance optimization problem of Spark platform, this article improves from the perspective of parameter tuning and proposes a system called MonkeyKing based on DRL algorithm. Although the use of RL to solve optimization problems is not new, and even some researchers have made good progress on parameter optimization problems, the existing use of RL techniques to study parameter problems focuses on optimizing the hyperparameters of machine learning algorithms. The number of configuration parameters of Spark is not only hundreds but also includes different types. To this end, we define the Markov Decision Process that conforms to the Spark parameter optimization scenario.
Performance modeling
Specifically, we divide MonkeyKing into two key modules: parameter selection and parameter tuning. Compared with previous studies, in addition to applying RL techniques to solve Spark performance tuning, we have also added parameter selection work. Considering parameter selection is because other parameter optimization problems (such as hyperparameter optimization) do not involve a lot of parameters, and unlike Spark platform, only individual parameters will affect performance. At the same time, we also considered job type, obviously different types of jobs have different optimal configurations. In the parameter selection module, with the help of LASSO algorithm, we can recommend different parameter configurations for different types of jobs. In the parameter tuning module, we mainly apply the mature DQN framework in DRL technology. We have studied four frameworks: DQN, Double DQN, Dueling DQN, and the combination of Double DQN and Dueling DQN. The results show that the combination of Double DQN and Dueling DQN has better convergence.
Scalable space
We are pleased to apply DRL to Spark's parameter tuning and achieve acceptable results. It is worth mentioning that this technology can also be extended to the parameter optimization of other big data analysis platforms, such as Hadoop and Storm. Although the structure of each platform is not exactly the same, there are differences in parameters, the ideas provided by MonkeyKing are universal. Although MonkeyKing provides great convenience for our parameter tuning work, there are still some imperfections. For example, the system training time is too long, and the convergence of DQN needs to be improved. These issues are the work that we will study now and for some time to come.
Related Work
Much of the previous work on auto-tuning on big data analytics platform focused on choosing the best cost or performance design, which we describe in turn. The popularity of big data analytics platforms has made big data analysis fast and efficient. However, many default resource configurations are no longer sufficient for program developers. Therefore, many researchers have analyzed parameters to improve performance by modifying the configuration. At present, the parameter optimization of big data analytics platforms can be summarized in the following three aspects.
Cost-based optimization
Cost-based optimization refers to the performance cost required by calculating the various stages of task execution process, and the corresponding optimization scheme is obtained. Starfish 30 is a self-tuning system, which is based on cost modeling to search for the job configurations required for MapReduce workloads. But Starfish only works for Hadoop, and the mechanisms between other parallel distributed platforms and Hadoop are quite different. SBAC-PAD 201639 presented a novel Impala simulation framework that simulates the behavior of a complete software stack and the activities of cluster components (such as storage, networking, processors, and memory) using a shared-nothing parallel database architecture. Impala aims to bridge the gap between near real-time data analysis on the Hadoop stack to help IT professionals understand their performance behavior. AROMA 40 automates job configuration and resource allocation through leveraging a two-phase machine learning and optimization framework for heterogeneous clouds.
Performance-based optimization
Performance-based optimization is the monitoring of performance data or other data. By analyzing the monitoring results, performance bottleneck is obtained, and then, performance can be optimized. Alipourfard et al. 4 proposed CherryPick, a system that can adaptively mine the best cloud configuration for big data analysis, using Bayesian optimization to build performance models for various applications. While CherryPick is ideal for resource allocation issues for large applications. Lee and Jos 41 proposed an approach that avoids problems of previous self-tuning approaches based on performance models or resource usage; the proposed approach uses a fuzzy-prediction controller for self-optimization of the number of concurrent MR jobs. Shi et al. 42 discussed the impact of MapReduce and Spark on large-scale data analysis, where the impact of parameters on the platform is not much. Petridis et al. 43 studied some related parameters that have a significant impact on Shuffle and Compress phases of Spark and proposed a parameter tuning method based on trial and error. Bao et al. 44 used Latin hypercube sampling to generate effective samples in the high-dimensional parameter space, and multiple bound-and-search to select promising configurations in the bounded space suggested by the existing best configurations. Yigitbasi et al. 45 used the support vector regression model on Hadoop platform for auto-tuning. Although the algorithm works well, it is obvious that the trial and error method is time-consuming. Wang et al. 46 analyzed the shortcomings of cost-based modeling methods and proposed a new method based on machine learning to optimize Spark configuration. Wang et al. 47 proposed a speculative parallel decompression algorithm based on Apache Spark to extend parallelism and improve the decompression efficiency of large-scale data sets.
Heuristic-based optimization
The heuristic-based optimization method mimics the way machine learning is done, storing some good configurations in a certain number of experiments that have been run in the optimizer. Gopalan and Suresh 48 proposed an improved Hadoop Fair Scheduler delay scheduling and implementation in Hadoop. The proposed algorithm does not blindly wait for the local node, but first estimates the time to wait for the local node to use for job, and avoids waiting if the location is not possible within the predefined delay threshold while completing the same location. The authors present a heuristic approach to reducing the operational costs of virtual machines running Hadoop in the study of Shyamasundar et al. 49 Heuristics are simple and efficient, extending the number of Hadoop nodes based on the type and size of jobs submitted.
Conclusion
In this article, to solve the problems of key parameter selection and tuning for different job types of big data platforms and reuse of historical information, we propose a system called MonkeyKing. MonkeyKing mainly includes three parts: parameter selection, parameter tuning, and historical information base. First, the feature selection technique is used in parameter selection module to determine the parameters that have the strongest impact on performance of jobs, and then, DRL algorithms are selected in parameter tuning module to dynamically optimize parameters. At the same time, the historical information base will save the running information of jobs for subsequent reuse. In terms of the selection of key parameters, we conduct research on different job types, enabling our method to recommend relevant key parameters for different workloads. In terms of parameter tuning, we choose DQN structure and its four classic algorithms. We finally found that the combination of Double DQN and Dueling DQN is more convergent and the obtained parameter optimal value is more stable. The experimental results show that compared with the C5.0 and native parameter configuration, the recommended parameter configuration of MonkeyKing can effectively reduce JCT by ∼25%.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.