
Abstract
This study proposes a novel bioinspired metaheuristic simulating how the coronavirus spreads and infects healthy people. From a primary infected individual (patient zero), the coronavirus rapidly infects new victims, creating large populations of infected people who will either die or spread infection. Relevant terms such as reinfection probability, super-spreading rate, social distancing measures, or traveling rate are introduced into the model to simulate the coronavirus activity as accurately as possible. The infected population initially grows exponentially over time, but taking into consideration social isolation measures, the mortality rate, and number of recoveries, the infected population gradually decreases. The coronavirus optimization algorithm has two major advantages when compared with other similar strategies. First, the input parameters are already set according to the disease statistics, preventing researchers from initializing them with arbitrary values. Second, the approach has the ability to end after several iterations, without setting this value either. Furthermore, a parallel multivirus version is proposed, where several coronavirus strains evolve over time and explore wider search space areas in less iterations. Finally, the metaheuristic has been combined with deep learning models, to find optimal hyperparameters during the training phase. As application case, the problem of electricity load time series forecasting has been addressed, showing quite remarkable performance.
Introduction
The severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is a new respiratory virus, causing coronavirus disease 2019 (COVID-19), first discovered in humans in December 2019, that has spread across the globe, having reportedly infected >4 million people so far. 1 Much remains unknown about the virus, including how many people who may have very mild, asymptomatic, or simply undocumented infections and whether they can transmit the virus or not. 2 The precise dimensions of the outbreak are hard to evaluate. 3
Bioinspired models typically mimic behaviors from the nature and are known for their successful application in hybrid approaches to find parameters in machine learning model optimization. 4 Viruses can infect people and these people can either die, infect other people, or simply recover after the disease. Vaccines and the immune defense system typically fight the disease and help to mitigate their effects while an individual is still infected. This behavior is typically modeled by an SIR model, consisting of three types of individuals: S for the number of susceptible, I for the number of infectious, and R for the number of recovered. 5
Metaheuristics must deal with huge search spaces, even infinite for the continuous cases, and must find suboptimal solutions in reasonable execution times. 6 The rapid propagation of the coronavirus along with its ability to cause infection in most of the countries in the world impressively fast has inspired the novel metaheuristic proposed in this study, named coronavirus optimization algorithm (CVOA). A parallel version is also proposed to spread different coronavirus strains and achieve better results in less iterations.
The main CVOA advantages regarding other similar approaches can be summarized as follows:
Coronavirus statistics are not currently known with precision by the scientific community and some aspects are still controversial, like the reinfection rate.
7
In this sense, the infection rate, the mortality rate, the spreading rate, or the reinfection probability cannot be accurately estimated so far, due to several issues such as the lack of tests for asymptomatic people. However, the current state of the pandemic suggests certain values, as reported by the World Health Organization (WHO).
8
Therefore, CVOA is parametrized with the actual reported values for rates and probabilities, preventing the user from performing an additional study on the most suitable setup configuration. CVOA can stop the solutions exploration after several iterations, with no need to be configured. That is, the number of infected people increases over the first iterations; however, after a certain number of iterations, the number of infected people starts decreasing, until reaching a void infected set of individuals. The coronavirus high spreading rate is useful for exploring promising regions more thoroughly (intensification), whereas the use of parallel strains ensures that all regions of the search space are evenly explored (diversification). Another relevant contribution of this study is the proposal of a new discrete and of dynamic length codification, specifically designed for combining long short-term memory (LSTM) networks with CVOA (or any other metaheuristic).
There is one limitation to the current approach. Since there is no vaccine currently, it has not been included in the procedure to reduce the number of candidates to be infected. This fact involves an exponential increase of the infected population in the first iterations and, therefore, an exponential increase of the execution time for such iterations. This, however, is partially solved with the implementation of social isolation measures to simulate individuals who cannot be infected during a particular iteration.
A study case is included in this work that discusses the CVOA performance. CVOA has been used to find the optimal values for the hyperparameters of an LSTM architecture, 9 which is a widely used model for artificial recurrent neural network (RNN), in the field of deep learning. 10 Data from the Spanish electricity consumption have been used to validate the accuracy. The results achieved verge on 0.45%, substantially outperforming other well-established methods such as random forest (RF), gradient-boost trees (GBT), linear regression (LR), or deep learning optimized with other metaheuristics. The code, developed in Python with a discrete codification, is available in the Supplementary Material section (along with an academic version in Java for a binary codification).
Finally, the need to further study the performance of well-established fitness functions 11 is acknowledged. However, given the relevance that this pandemic is acquiring throughout the world and the remarkable results achieved when combined with deep learning, this study is shared with the hope that it inspires future research in this direction.
The rest of the article is organized as follows. Related Works section discusses related and recent studies. The methodology proposed is introduced in Methodology section. Hybridizing Deep Learning with CVOA section proposes a discrete codification to hybridize deep learning models with CVOA and provides some illustrative cases. A sensitivity analysis on how populations are created and evolved over time is discussed in CVOA Sensitivity Analysis section. The results achieved are reported and discussed in Results section. Finally, the conclusions drawn and future study suggestions are included in Conclusions and Future Works section.
Related Works
There are many bioinspired metaheuristics to solve optimization problems. Although CVOA has been conceived to optimize any kind of problems, this section focuses on optimization algorithms applied to hybridize deep learning models.
It is hard to find consensus among the researchers on which method should be applied to which problem, and, for this reason, many optimization methods have been proposed during the past decade to improve deep learning models. In general, the criterion for selecting a method is its associated performance from a wide variety of perspectives. Low computation cost, accuracy, or even implementation difficulty can be accepted as one of these criteria.
The virus optimization algorithm was proposed by Liang and Cuevas-Juárez in 201612 and later improved by Liang et al. 13 However, as many other metaheuristics, the results of its application are highly dependent on its initial configuration. In addition, it simulates generic viruses, without adding individualized properties for particular viruses. The results achieved indicate that its usefulness is beyond doubt.
One of the most extended metaheuristics used to improve deep learning parameters is genetic algorithms (GAs). Hence, an LSTM network optimized with GA can be found in Chung and Shin. 14 To evaluate the proposed hybrid approach, the daily Korea Stock Price Index data were used, outperforming the benchmark model. In 2019, a network traffic prediction model based on LSTM and GA was proposed in Chen et al. 15 The results were compared with pure LSTM and autoregressive integrated moving average, reporting higher accuracy.
Multiagents systems have also been applied to optimize deep learning models. The use of particle swarm optimization (PSO) can be found in Liu et al. 16 The authors proposed a model based on kernel principal component analysis and back propagation neural network with PSO for midterm power load forecasting. The hybridization of deep learning models with PSO was also explored in Fernandes-Junior and Yen 17 but, this time, the authors applied the methodology with image classification purposes.
Ants colony optimization (ACO) models have also been used to hybridize deep learning. Thus, Desell et al. 18 proposed an evolving deep RNNs using ACO applied to the challenging task of predicting general aviation flight data. The study in ElSaid et al. 19 introduced a method based on ACO to optimize an LSTM RNNs. Again, the field of application was flight data records obtained from an airline containing flights that suffered from excessive vibration.
Some articles exploring the cuckoo search (CS) properties have been published recently as well. In Srivastava, 20 CS was used to find suitable heuristics for adjusting the hyperparameters of another LSTM network. The authors claimed an accuracy superior to 96% for all the data sets examined. Nawi et al. 21 proposed the use of CS to improve the training of RNN to achieve fast convergence and high accuracy. Results obtained outperformed those than other metaheuristics.
The use of the artificial bee colony (ABC) optimization algorithm applied to LSTM can also be found in the literature. Hence, an optimized LSTM with ABC to forecast the bitcoin price was introduced in Yuliyono and Girsang. 22 The combination of ABC and RNN was also proposed in Bosire 23 for traffic volume forecasting. This time the results were compared with standard backpropagation models.
From the analysis of these studies, it can be concluded that there is an increasing interest in using metaheuristics in LSTM models. However, not as many studies as for artificial neural networks can be found in the literature and, none of them, based on a virus propagation model. These two facts, among others, justify the application of CVOA to optimize LSTM models.
Methodology
This section introduces the CVOA methodology. Thus, Steps section describes the steps for a single strain. Remarks for a Parallel CVOA Version section introduces the modifications added to use CVOA as a parallel version. Suggested Parameters Setup section suggests how the input parameters must be set. Pseudocodes section includes the CVOA pseudocodes.
Steps
Each infected individual has a probability of dying (
The individuals who do not die will cause infection to new individuals (intensification). Two types of spreading are considered, according to a given probability (
(a) Ordinary spreaders. Infected individuals will infect new individuals according to a regular spreading rate (
(b) Super-spreaders. Infected individuals will infect new individuals according to a super-spreading rate (
There is another consideration, since it is needed to ensure diversification. Both ordinary and super-spreader individuals can travel and explore very different solutions in the search space. Therefore, individuals have a probability of traveling (
Deaths. If any individual dies, it is added to this population and can never be used again.
Recovered population. After each iteration, infected individuals (after spreading the coronavirus according to the previous step) are sent to the recovered population. It is known that there is a reinfection probability (
New infected population. This population gathers all individuals infected at each iteration, according to the procedure described in the previous steps. It is possible that repeated new infected individuals are created at each iteration and, consequently, it is recommended to remove such repeated individuals from this population before the next iteration starts running.
Remarks for a parallel CVOA version
It must be noted that it is very simple to use CVOA in a multivirus version since it can be implemented as a population-based algorithm, when considering the pandemic as a set of intelligent agents each of them evolving in parallel. In contrast to trajectory-based metaheuristics, population-based metaheuristics enhances the diversification in the search space.
For this case, a new variable must be defined, strains, which determines the number of strains that will be launched in parallel. Each strain can explore different regions and can be differently configured so that each of them intensifies with their own rates.
Several considerations must be done for this case:
Every strain is run independently, following the steps in the previous section.
A wise strategy must be followed to generate PZs for each strain. For instance, it is suggested the generation of PZs is evenly spaced or, at least, with high Hamming distances. That way, the exploration of distinct regions of the search space is facilitated (diversification).
The interaction between the different strains is done by means of dead and recovered populations, which must be shared by all the strains. Operations over these populations must be handled as concurrent updates. 24
New infected populations, on the contrary, are different for each strain and no concurrent operations are required.
This version may help to simulate different rates for different strains. That way, if there is any initial information about the search space, some strains could be more focused on diversification and some others on intensification.
Depending on the hardware resources and how busy they are, every strain may evolve at different speeds. This situation should not pose any problems since it is known that the pandemic evolves at different rates and starts at different time stamps depending on region of the world.
Last, another application can be found for this parallel version. CVOA simulates an SIR model and consequently, any other global pandemic can be modeled by using the specific rates. Different pandemics could be run in parallel.
Suggested parameters setup
Since CVOA simulates the COVID-19 propagation, most of the rates (propagation, isolation, or mortality) are already known. This fact prevents the researcher from wasting time in selecting values for such rates and turns the CVOA into a metaheuristic quite easy to execute.
However, it must be noted that the current rates are still changing and it is expected they will vary over time, as the pandemic evolves. Maybe these values will not be stable until 2021 or even 2022. The suggested values have been retrieved from the World Health Organization 25 and are discussed hereunder:
(a)
(b)
strains. This parameter should be adjusted according to the size of the problem and the hardware availability, and it is difficult to suggest a value suitable for all situations. But a tentative initial value could be 5, in an attempt to simulate one different strain per continent. Therefore,
Pseudocodes
This section provides the pseudocode of the most relevant functions for the CVOA, along with some comments to better understand them.
Function CVOA
This is the main function and its pseudocode can be found in Algorithm 1. Four lists must be maintained: dead, recovered, infected (the current set of infected individuals), and new infected individuals (the set of new infected individuals, generated by the spreading of the coronavirus from the current infected individuals).
The initial population is generated by means of the patient zero (PZ), which is a random solution.
The number of iterations is controlled by the main loop, evaluating the duration of the pandemic (preset value) and whether there is still any infected individual. In this loop, every individual can either die (it is sent to the dead list) or infect, thus enlarging the size of the new infected population. This infection mechanism is coded in function infect (see Function infect section).
Once the new population is formed, all individuals are evaluated and whether any of them outperforms the best current one, the latter is updated.
Function infect
This function receives an infected individual and returns the set of new infected individuals. Two additional lists, recovered and dead, are also received as input parameters since they must be updated after the evaluation of every infected individuals. The pseudocode is shown in Algorithm 2.
Two conditions are evaluated to determine the number of new infected individuals (use of
Function newInfection
Given an infected individual, this function generates new infected individuals according to the spreading and traveling rates. This function also controls that the new infected individuals are not already in the dead list (in such case, this new infection is ignored) or in the recovered list (in such case, the
The effective generation of the new infected individuals must be carried in the function replicate, whose pseudocode is not provided because it depends on the codification and the nature of the problem to be optimized. This function must return a set of new infected individuals, according to the aforementioned rates. Specific information on how this codification and replication is done for LSTM models is provided in Hybridizing Deep Learning with CVOA section.
The pseudocode for the described procedure can be found in Algorithm 3.
Function die
This function is called from the main function. It evaluates all individuals in the infected population and determines whether they die or not, according to the given
Function selectBestIndividual
This is an auxiliary function used to find the best fitness in a list of infected individuals. Its peudo code is given in Algorithm 5.
Hybridizing Deep Learning with CVOA
This section describes the codification proposed for an individual, to hybridize deep learning with CVOA. The term hybridize is used in this context as the combination of two computational techniques (deep learning and CVOA) so that the best hyperparameter values are discovered. This strategy is very common in machine learning for optimizing models during the training process.32–34
Hence, the individual codification shown in Figure 1 has been implemented to apply CVOA to optimize deep neural network architectures.
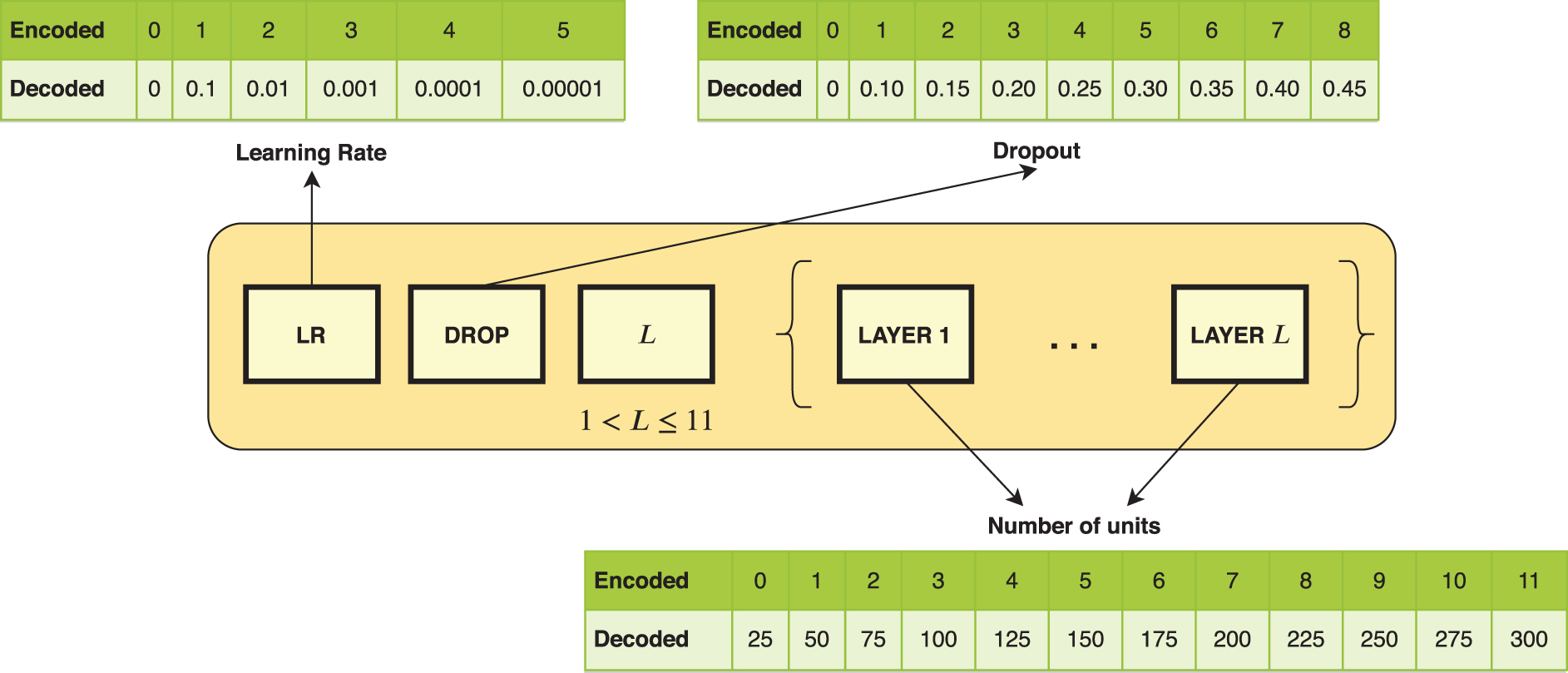
Individual codification for hybridizing deep learning architectures using the proposed coronavirus optimization algorithm.
As is shown in Figure 1, each individual is composed of the following elements. The element LR encodes the learning rate used in the neural network algorithm. It can take a value from 0 to 5 and its corresponding decoded values are 0,
The element DROP encodes the dropout rate applied to the neural network. It can take values from 0 to 8 that correspond to 0,
The element L of the individual stores the number of layers of the network. It is restricted to
The proposed individual codification has a variable size. Thus, its size depends on the number of layers indicated in the element L. Consequently, a list of elements (LAYER 1, …, LAYER L) are also included in the individual, which encode the number of units (neurons) for each network layer. Each of these elements can take values from 0 to 11, and their corresponding decoded values range from 25 to 300, with a step of 25.
PZ generation
The PZ, as it has been described previously, is the individual of the first iteration in the CVOA algorithm. After the hybridization proposed, a random individual is created considering the codification already defined.
In first place, a random value for the learning rate of the PZ is generated. Specifically, a number between 0 and 5 is generated randomly in a uniform distribution. Such limits are indicated in Figure 1, according to the possible encoded values of the learning rate element. The same process is carried out to produce a random value for the dropout element. In such case, a random number between 0 and 8 is generated.
In second place, a random number of layers are generated for the element L of PZ. Such number of layers is a random number between 2 and 11. Note that the first layer is reserved for the input layer of the neural network, as it has been discussed before.
In last place, for each one of the L layers, a random number of units is generated between 0 and 11, covering the possible encoded values for the number of units previously defined (Fig. 1).
Infection procedure
The infection procedure described here corresponds to the functionality of
The first step is to determine the element L of the infected individual that will be mutated. The probability of such mutation that occurs has been set to
If the element L (the number of layers of the network) changes, then the elements encoding the different layers within the individual (LAYER 1, …, LAYER L) must be resized accordingly. Such resizing process is explained in Individual Resizing Process section.
The second step is to determine how many elements of the individual will be infected. If the
As third step, once the number of infected elements of the individual is determined, a list of random positions is generated. For example, if three positions of the individual must be changed, then the random positions affected could be, for instance, referred to the elements {DROP, LAYER 2, LAYER 4}.
Finally, the selected positions of the individual are mutated. Such mutation is described in Single Position Mutation section.
Individual resizing process
When an individual is infected at the position of the element L, the list of elements that encodes the number of units per layer (LAYER 1, …, LAYER L) must be resized accordingly.
In the case that the new number of layers after the infection is lower than its previous value, then the last leftover elements are removed. For instance, if the initial individual is
In the case that the new number of layers after the infection is higher than its previous value, the new random elements are added at the end of the individual. For instance, if the initial individual is
Single position mutation
The process carried out to change the value of a specific element of an individual is described in this section.
First, a signed amount of change
Once the amount of change is determined, the new value for the infected element is computed. If its previous value is V, then the new value after the single position mutation will be
CVOA Sensitivity Analysis
This section discusses several aspects about the sensitiveness of CVOA to different configurations. Hence, Sensitivity to the Number of Strains section evaluates the evolution of the populations for a different number of strains. Sensitivity to the Parameters section assesses the performance when other well-known viruses are modeled. Finally, Sensitivity to the Social Distancing Measures section provides information about R0 and how it varies when social distancing measures change.
Sensitivity to the number of strains
This section provides an overview on how populations evolve over time and how the search space is explored, when a different number of strains are used.
A binary codification has been used, with 20 bits, to conduct this experimentation. A simple fitness function has been evaluated,
According to Suggested Parameters Setup section, the following configuration has been used:
Every experiment has been launched 50 times and, on average, the optimum value was found during the iteration number 13, 6, and 3, for 1, 4, and 8 strains, respectively.
Figure 2 illustrates the evolution of the new infected population over time, for 1, 4, and 8 strains. The number of new infected people increases exponentially during the first
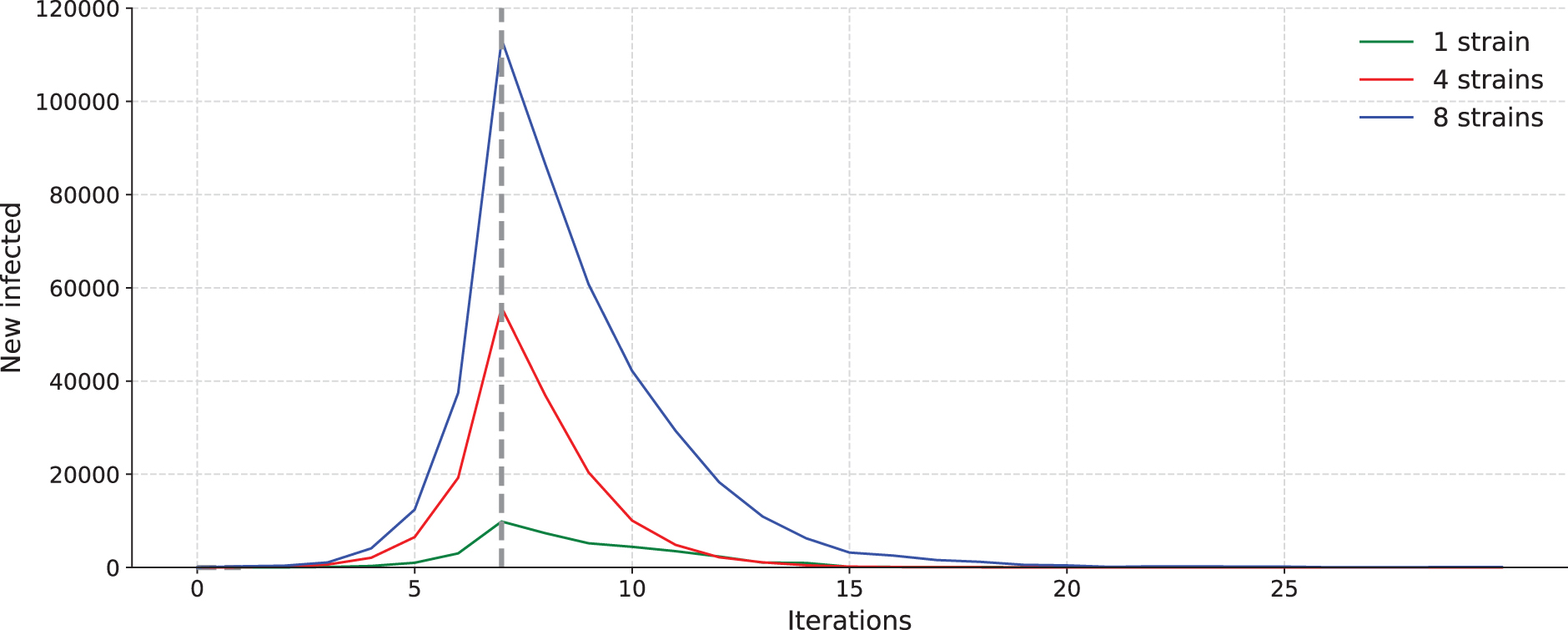
Number of new infected individuals for a 20-bit binary codification execution, with 1, 4, and 8 strains.
Figures 3 and 4 show the accumulated number of recovered people and accumulated deaths, respectively. Note that deaths and recovered individuals cannot be infected again (except for the individuals in the recovered list that can be reinfected with a given probability,
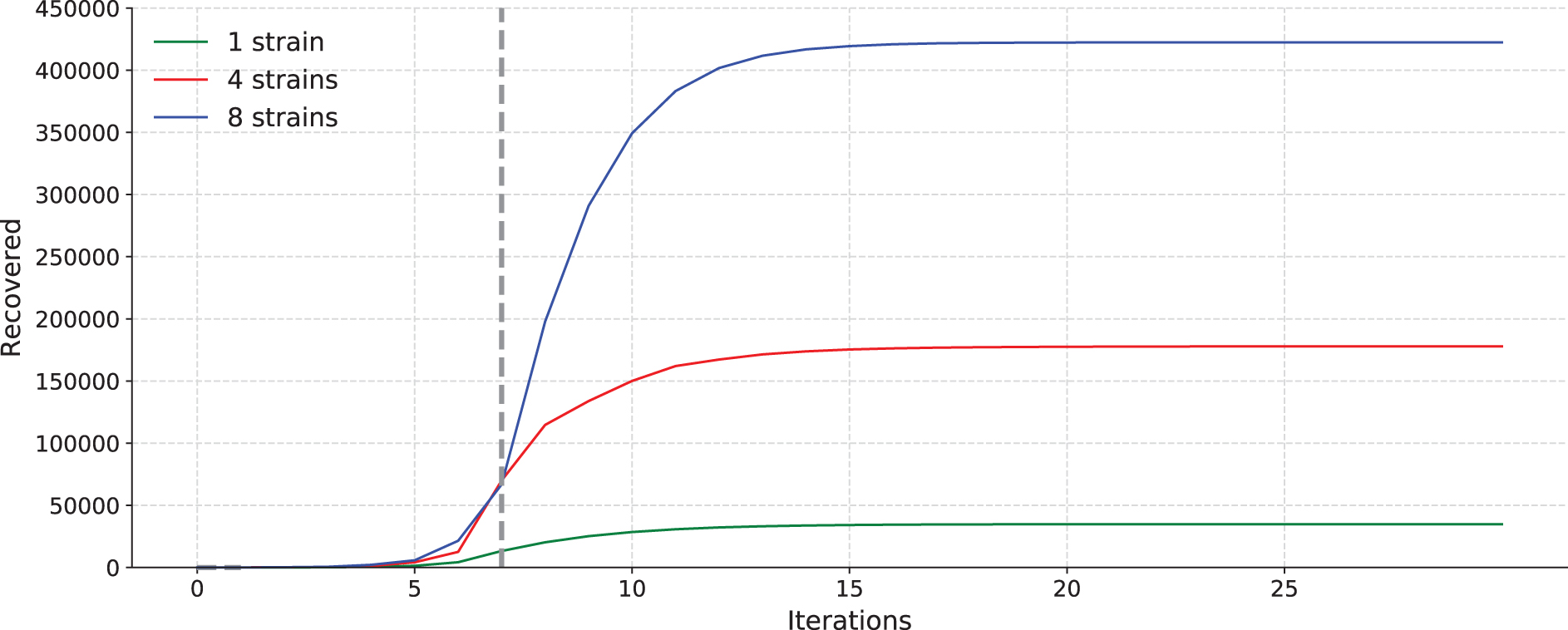
Total number of recovered people for a 20-bit binary codification execution, with 1, 4, and 8 strains.
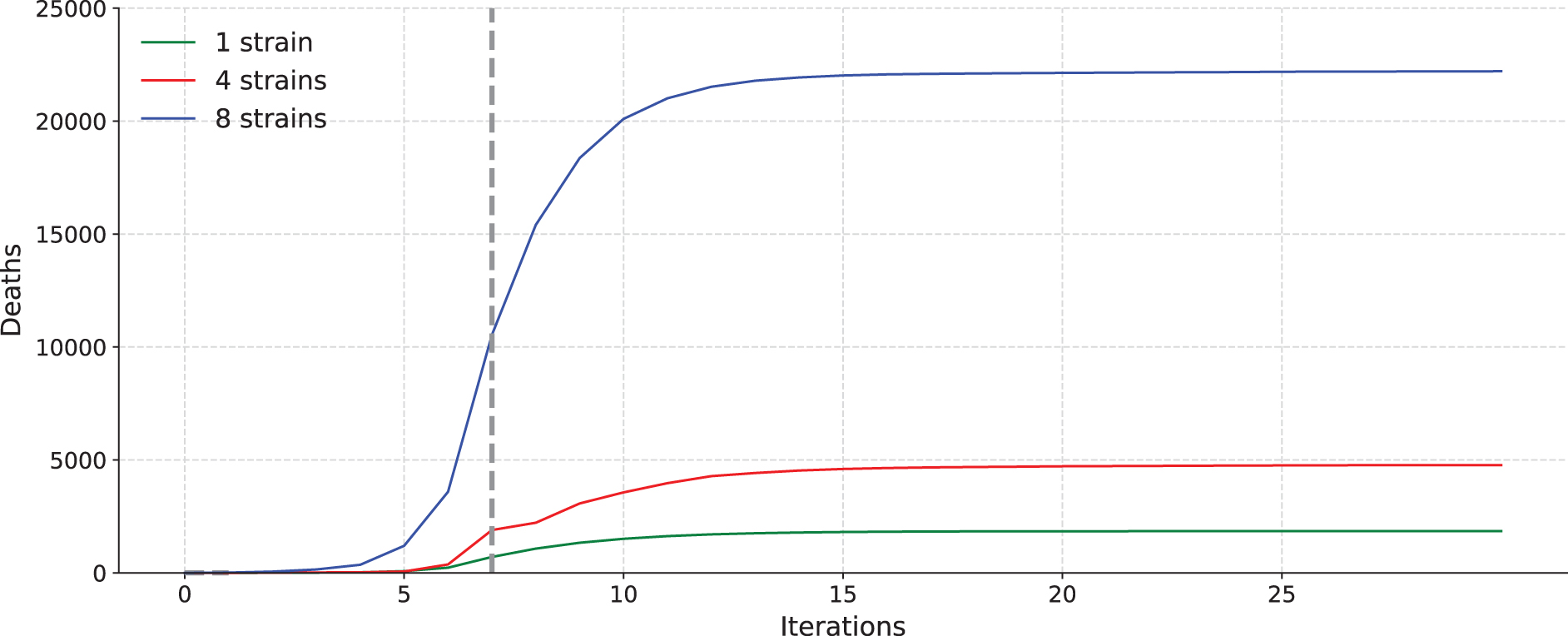
Total number of deaths for a 20-bit binary codification execution, with 1, 4, and 8 strains.
Four main conclusions can be drawn from the analysis of these figures:
The number of new infected individuals, accumulated recovered, and deaths is directly proportional to the number of strains.
The higher the number of strains, the lower the number of iterations that are required to reach the optimal value.
The number of individuals evaluated increases at each iteration on an almost linear basis, as the number of strains increases. In case no random numbers were generated, the relationship would be directly proportional, that is, four strains would evaluate four times the number of individuals than one strain would do.
To reach the optimum values, the search space explored is smaller as the number of strains increases. This is due to the generation of PZ evenly spaced, which makes easier to explore wider areas.
Sensitivity to the parameters
Several well-known viruses with deep impact in human beings' health are modeled in this section, to assess the CVOA robustness to different input parameter values.
Middle East respiratory syndrome (MERS), SARS, influenza (seasonal strains), and Ebola have been selected, with the parametrization given in Table 1. It is worth mentioning that the modeling of each virus requires much research and an approximate parametrization has been used, according to the references in the rightmost column.
Parametrization for other viruses
MERS, Middle East respiratory syndrome; SARS, severe acute respiratory syndrome.
All experiments have been conducted with 4 strains and 30 iterations. The viruses with vaccines have been simulated by using
Table 2 summarizes the percentage of search space explored and the best fitness found, on average. Codifications of 10, 20, 30, 40, and 50 bits have been used, with associated search spaces of length 1024, 1.05E+6, 1.07E+09, 1.10E+12, and 1.13E+15, respectively. Several findings are revealed:
CVOA performance with different configurations
COVID-19, coronavirus disease 2019; CVOA, coronavirus optimization algorithm.
CVOA finds the optimal values even for the longest codification (50 bits) and it is done by exploring a similar search space size as the other configurations do.
SARS is the second best parametrization, reaching remarkable fitness even for 50 bits. But it required the evaluation of a greater number of individuals and, therefore, the execution time was greater as well.
MERS obtained the poorest results in terms of fitness but it explored a smaller space search. This situation may be explained due to the low associated reproductive number (
Influenza has obtained slightly worse results in terms of fitness than CVOA but with less solutions explored. This configuration may be useful to obtain satisfactory results in a reduced execution time.
The high death fatality rate of Ebola prevents from exploring most of the search space. This fact makes difficult to visit optimal values. However, results for 40 bits are satisfactory in terms of fitness. For 50 bits, its use is discouraged considering the poor fitness value reached.
It can be concluded that variations in the input parameter values lead to results varying both in fitness and in execution time. This feature is very useful for the CVOA parallel version, since strains with different rates and probabilities can be simultaneously launched. That is, strains aiming at diversifying can be combined with strains aiming at intensifying.
Sensitivity to the social distancing measures
In this section, an analysis on how
Figure 5 illustrates how R0 varies for a 40-bit codification, with probabilities of isolation ranging from 0 to 1, and with 1, 4, and 8 strains. Quite similar behaviors have been achieved for all codifications.
From the analysis of this figure, several conclusions are drawn:
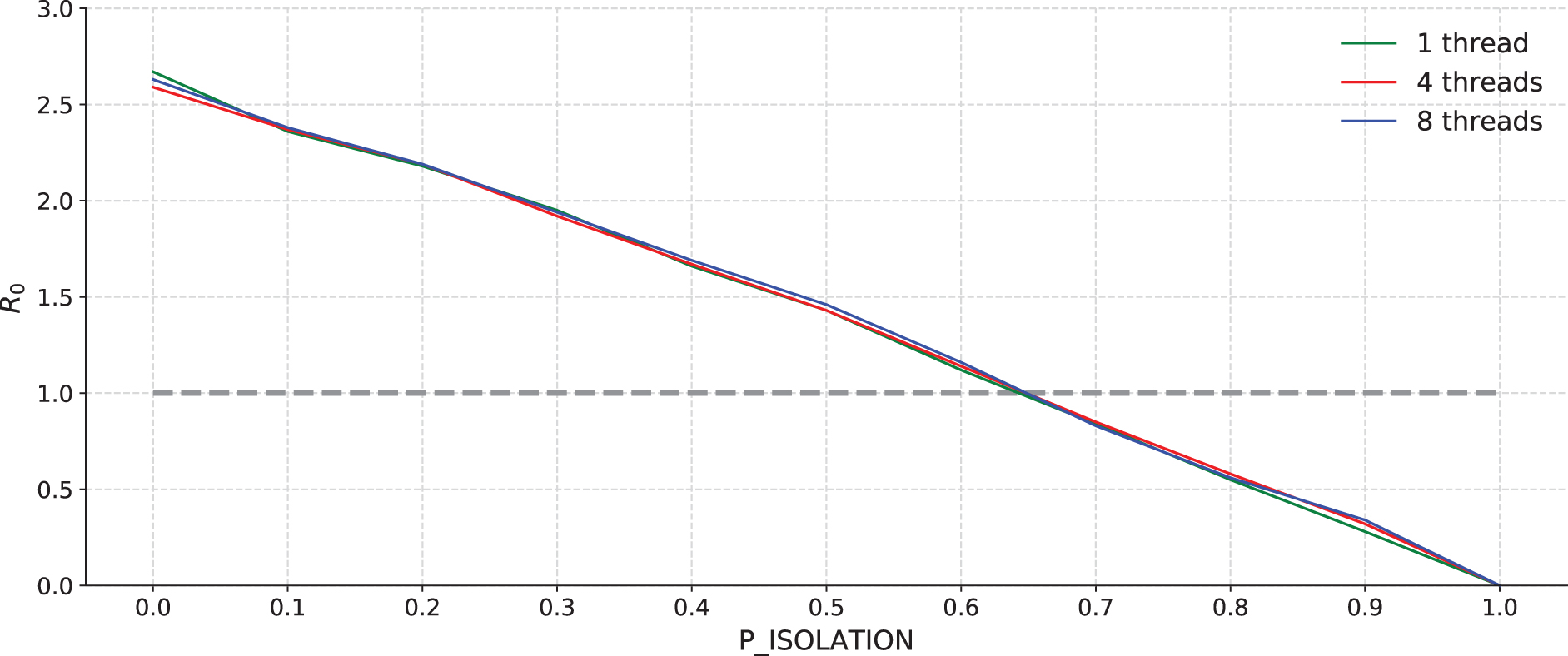
R0 sensitivity to
R0 is linear and inversely proportional to
The same negative slope is shown, with variations no higher than 10E−2 on average for all codifications and number of strains.
R0 is <1 with
Results
This section reports the results achieved by hybridizing a deep learning model with CVOA. Study Case: Electricity Demand Time Series Forecasting section describes the study case selected to prove the effectiveness of the proposed algorithm. Data Set Description section describes the data set used. Performance Analysis section discusses the results achieved and includes some comparative methods.
Study case: electricity demand time series forecasting
The forecasting of future values fascinates the human being. To be able to understand how certain variables evolve over time has many benefits in many fields.
Electricity demand forecasting is not an exception, since there is a real need for planning the amount to be generated or, in some countries, to be bought.
The use of machine learning to forecast such time series has been intensive during the past years. 41 But, with the development of deep learning models, and, in particular of LSTM, much research is being conducted in this application field. 42
Data set description
The time series considered in this study is related to the electricity consumption in Spain from January 2007 to June 2016, the same as used in Torres et al.. 43 It is a time series composed of 9 years and 6 months with a 10-minute sampling frequency, resulting in 497,832 measures.
As in the original article, the prediction horizon is 24, that is, this is a multistep strategy with
Performance analysis
This section reports the results obtained by hybridizing LSTM with CVOA, by means of the codification proposed in Hybridizing Deep Learning with CVOA section, to forecast the Spanish electricity data set described in Data Set Description section.
LR, decision tree, GBT, and RF models have been used with parametrization setups according to those studied in Galicia et al.44,45 A deep neural network optimized with a grid search (DNN-GS) according to Torres et al. 43 has also been applied. Another deep neural network, but optimized with random search (DNN-RS) and smoothed with a low-pass filter (DNN-RS-LP), 46 has also been applied. Furthermore, CVOA has been combined with DNN (DNN-CVOA), using the same codification as in LSTM.
These results along with those of LSTM, and combinations with GS, RS, RS-LP, and CVOA, are summarized in Table 3, expressed in terms of the mean absolute percentage error. It can be observed that LSTM-CVOA outperforms all evaluated methods that have showed particularly remarkable performance for this real-world data set. In addition, DNN-CVOA outperforms all other DNN configurations, which confirms the superiority of CVOA with reference to GS, RS, and RS-LP.
Results in terms of MAPE for LSTM-CVOA compared with other well-established methods
Bold indicates the best results for the proposed method in the article (LSTM-CVOA).
CVOA, coronavirus optimization algorithm; DNN, deep neural network; DNN-CVOA, CVOA has been combined with DNN; DNN-GS, DNN optimized with a grid search; DNN-RS, DNN optimized with random search; DNN-RS-LP, DNN smoothed with a low-pass filter; DT, decision tree; GBT, gradient-boosted trees; LR, linear regression; LSTM, long short-term memory; LSTM-CVOA, CVOA has been combined with LSTM; LSTM-GS, LSTM optimized with a grid search; LSTM-RS, LSTM optimized with random search; LSTM-RS-LP, LSTM smoothed with a low-pass filter; MAPE, mean absolute percentage error; RF, random forest.
Another relevant consideration that must be taken into account is that the compared methods generated 24 independent models, each of them for every value forming h. So, it would be expected that LSTM-CVOA performance increases if independent models are generated for each of the values in h.
These results have been achieved with the following codification: {4,0,8}{9,7,2,7,2,7,10,7}. The decoded architecture parameters are listed below:
Learning rate: 10E−04.
Dropout: 0.
Number of layers: 8.
Units per layer:
Finally, Figure 6 depicts the first 5 predicted days versus their actual values, expressed in watts.
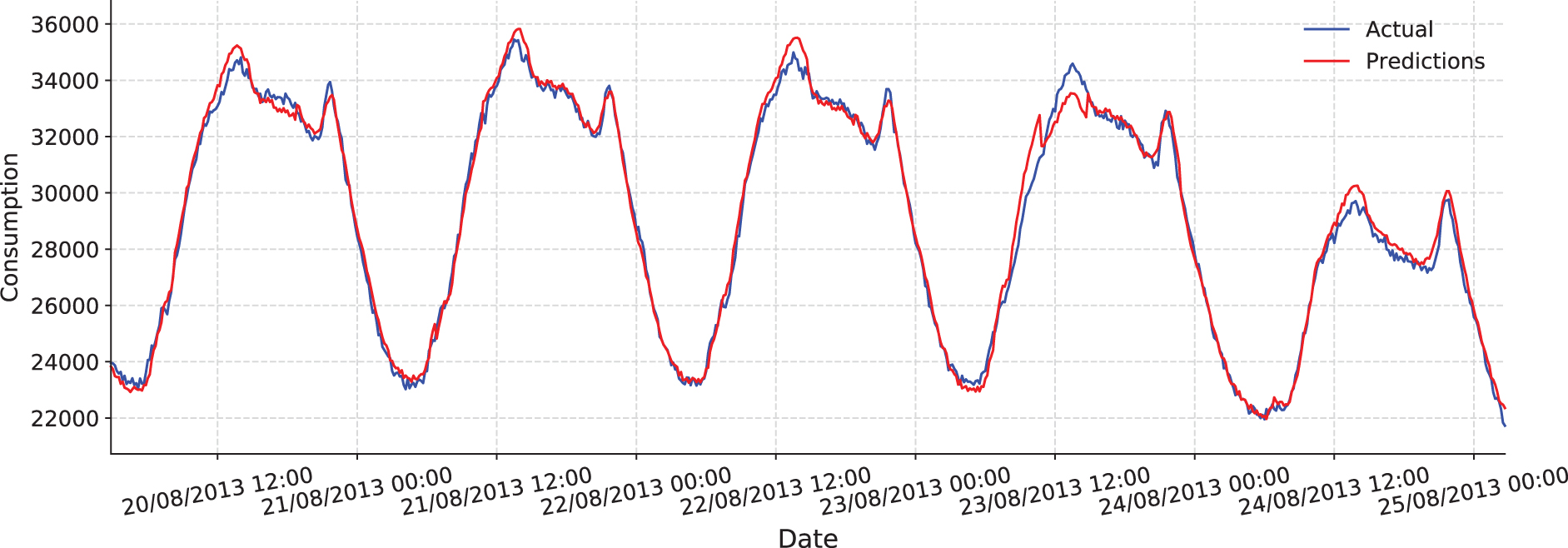
Actual versus predicted values for the first 5 days in the test set (in W).
Conclusions and Future Studies
This study has introduced a novel bioinspired metaheuristic, based on the COVID-19 pandemic behavior. On the one hand, CVOA has three major advantages. First, its high relation to the coronavirus spreading model prevents users from making any decision about the input values. Second, it ends after a certain number of iterations due to the exchange of individuals between healthy and dead/recovered lists.
In addition, a novel discrete and dynamic codification has been proposed to hybridize deep learning models. On the other hand, it exhibits some limitations. Such is the case for the exponential growth of the infected population as time (iterations) goes by.
Furthermore, a parallel version is proposed so that CVOA is easily transformed into a multivirus metaheuristic, in which different coronavirus strains search for the best solution in a collaborative way. This fact allows to model every strain with different initial setups (higher
Additional experimentation must be conducted to assess its performance on standard F functions and find out the search space shapes in which it can be more effective.
As for future study, some actions might be taken to reduce the size of the infected population after several iterations, which grows exponentially. In this sense, a vaccine could be implemented. This case would involve adding to the recovered list, at a given
Another suggested research line is using dynamic rates. For instance, the observation of the preliminary effects of the social isolation measures in countries such as China, Italy, or Spain suggests that the
For the multistep forecasting problem analyzed, it would be desirable to generate independent models for each of the values that form the prediction horizon h.
Finally, further research has to be conducted to assess the CVOA performance when applied to other fields and combined with other networks.
Footnotes
Supplementary Material
Along with this article, an academic version in Java for a binary codification is provided, with a simple fitness function in a GitHub repository (https://github.com/DataLabUPO/CVOA_academic). The master branch includes a simple implementation, whereas the sets branch provides an optimized version with a command line interface. In addition, the code in Python for the deep learning approach is also provided, with a more complex codification and the suggested implementation, according to the pseudocode provided (![]() ).
).
Author Disclosure Statement
No competing financial interests exist.
Funding Information
The authors thank the Spanish Ministry of Economy and Competitiveness for the support under project TIN2017-88209-C2.