
Abstract
The main goal in the influence maximization problem (IMP) is to find k minimum nodes with the highest influence spread on the social networks. Since IMP is NP-hard and is not possible to obtain the optimum results, it is considered by heuristic algorithms. Many strategies focus on the power of the influence spread of core nodes to find k influential nodes. Most of the core detection-based methods concentrate on nodes in the highest core and often give the same power for all nodes in the best core. However, some other nodes fairly have the potential to select as seed nodes in other less important cores, because these nodes can play an important role in the diffusion of information among the core nodes with other nodes. Given this fact, this article proposes a new shell-based ranking and filtering method, called shell-based ranking and filtering method (SRFM), for selecting influential seeds with the aim to maximize influence in the network. The proposed algorithm initially selects a set of nodes in different shells. Moreover, a set of the candidate nodes are created, and most of the periphery nodes are removed during a pruning approach to reduce the computational overhead. Therefore, the seed nodes are selected from the candidate nodes set using the role of the bridge nodes. Experimental results in both synthetic and real data sets showed that the proposed SRFM algorithm has more acceptable efficiency in the influence spread and runtime than other algorithms.
Introduction
Social network analysis has many applications in diffusing ideas on social networks such as viral marketing, outbreak detection, epidemic spread, and word-of-mouth marketing, which is attracted by researchers in recent years.1–3 The information spread process tries to expand information among nodes as far as possible. 4 For example, in word-of-mouth marketing, a company can have extensive advertising on its products by selecting a set of influential people on social networks.5,6 One of the most important topics in information spreading is the influence maximization problem (IMP). The problem of selecting minimum influential nodes is known as the IM.6,7 Notably, IM was first proposed by Domingos and Richardson, and then, Kempe et al. formulated this problem by examining two independent cascade (IC) and linear threshold (LT) models. It is notable that these models still are popular and used by researchers in many applications.8–14
The optimum information spreading depends on the selected influential nodes on the networks. It plays an important role in the formation of behavioral patterns and opinions on the social networks, which can be used to determine the initial influential nodes, the optimum spread of the opinions for advertising, and improve the formation of the opinion models. 15 IM refers to the selecting k-influential nodes that together have the highest effect on other nodes in total.16,17 Theoretically and practically, the IMP provides new insights into the viral marketing,1,17–20 outbreak detection, 21 rumor monitoring, 22 identification of the social network leaders, and so forth.
Diffusion models are one of the important problems in the field of network science that are used to map the IMP to information diffusion in the real world. IC and LT models are two widely used models in the IMP.1,4,5 In the IC model, each edge has a probability of diffusion that each node independently activates the other node based on the probability of diffusion. In the LT model, each edge has a diffusion weight, and one node is activated if the total diffusion weight of the in-neighbors of the node is greater than the threshold. In IM, the function of the influence spread in the IC model and the LT is a NP-hard problem and it has submodularity and monotonicity properties.1,6
The IMP has recently been studied in many fields.23–28 However, provided algorithms in recent years have several important problems. For example, most of the recently proposed algorithms do not consider the different impact of core nodes in the influence spread process because some core and high-degree nodes cannot provide optimal influence. In addition, these algorithms do not use a pruning approach at initial steps for the periphery and weak nodes to reduce computational time. To resolve these difficulties, this article proposes a new algorithm for solving the IMP under the IC model, which is more efficient in terms of runtime and influence spread than the other recently developed algorithms. This method is called the shell-based ranking and filtering method (SRFM) algorithm that is based on the hierarchical selection of the seed nodes and entails two general steps: the SRFM algorithm first divides the G graph into different sections, and graph segmentation is performed by the k-shell algorithm. After discovering all shells and core, the nodes are prioritized, and a pruning approach to remove periphery nodes is performed. Then, a set of candidate nodes is selected based on the assortativity and the range of influence (ROI) measures. In the second step, the seed nodes are selected based on the topological criteria from the candidate set. Experimental results on the synthetic and real-world networks show that the SRFM algorithm has better performance than the basic and other recently proposed algorithms in terms of the influence spread and runtime time.
The main contribution of this research is presented as (1) a new algorithm based on the hierarchical selection of the seed nodes is provided, which increases the algorithm efficiency in terms of the spread rate. (2) The influence spread calculations in the periphery nodes are optimally ignored in this algorithm, which reduces the computational overhead. (3) This algorithm examines the role of the core nodes in the influence spread by the influence power and the ROI measures. A small number of nodes can play an important role in diffusion, which are identified using the influence power and the ROI measures.
The structure of the rest of the article is presented hereunder. Related Studies section reviews some basic and new studies in the IMP. The Proposed Method section describes our proposed method. Experimental Results and Analysis section presents the experimental results to evaluate the SRFM algorithm. Finally, in Conclusion and Future Directions section some conclusions are reached.
Related Studies
There are some survey articles related to the IMP.10,29,30 This section reviews the algorithms presented in recent years. Maghami and Sukthankar proposed the hierarchical influence maximization (HIM) algorithm, which creates a local network for each node consisting of its neighbors and neighbors of neighbors. 31 In this algorithm, influential nodes are transferred to the next level of the hierarchy. Then, influential nodes select based on a convex optimization technique. This algorithm is not fast because it uses convex optimization. Kitsak et al. proposed the k-core algorithm to identify the influential nodes using their position in the network. 32 The k-core algorithm divides the network into different layers and shows that nodes in the same layers have the same influence spread. This algorithm is fast, but it does not have a suitable performance for selecting seed set in all networks.
Narayanam et al. proposed the SPIN algorithm based on game theory. 33 The ShaPley value based influential nodes (SPIN) algorithm improves the runtime of the basic greedy algorithm, 6 but it does not provide an approximation guarantee. Therefore, the accuracy of the influence spread of the SPIN algorithm is lower than the greedy algorithm. Goyal et al. introduced a new model of credit distribution to find that the probability of selecting edges with different methods has a different effect on the selection of influential nodes. 34 Goyal also demonstrated that the credit distribution model for the IMP is an NP-hard problem.
Wang et al. proposed the maximum influence arborescence (MIA) scalable algorithm. 35 This algorithm was developed to avoid using unsuitable Monte Carlo simulation for online social networks due to its extremely low performance in large-scale networks. The MIA algorithm calculates the influence spread on the arborescence structure with an efficient recursion with suitable runtime. Since the MIA algorithm needs to store the data structure related to the local influence of each node, it likely has a high memory overhead. Therefore, Jung et al. proposed the influence ranking and influence estimation (IRIE) algorithm, which uses iterative computations to calculate the influence spread of the out-neighbors of each node, and during the computation steps, it does not require to store data structures. It has the low memory overload. 36
Chen and colleagues studied the time criterion in the IMP. 37 They also revealed that the IMP has a submodularity property in the time-delayed IC model. Cheng et al. introduced the StaticGreedy algorithm to improve the runtime of the NewGreedyIC algorithm. 38 The algorithm calculates the influence spread using the reachable nodes. Although this algorithm is fast, it does not provide an approximation guarantee. In addition, Morone et al. proposed the Collective Influence algorithm to choose the influential nodes with optimal percolation. 39 The algorithm locally calculates the influence spread in a circle of radius l (direct neighbors) for each node. The runtime of the algorithm is not suitable for the large-scale social networks.
Zhang et al. presented the VoteRank algorithm, which is based on the voting criterion. 40 In this algorithm, influential nodes are selected based on the voting ability of the neighbors of nodes. Although this algorithm is fast, it does not have acceptable accuracy for the influence spread. Therefore, Nguyen et al. introduced the ProbDeg algorithm that determines the effect of multihops on the IMP. 41 The algorithm is fast but does not ensure optimal approximation. Then, Zareie and Sheikhahmadi proposed the hierarchical k-shell (HKS) algorithm, which calculates the spreading capability of nodes based on of their locations and degrees as well as neighbors' information. 42 Also, this algorithm attempts to assign a hierarchal index for each node. The selection of seed nodes in this algorithm is not optimal because it ignores relations in high-density regions.
After that, Sun et al. developed the reversed local path (RLP) algorithm, which calculates the ability of the influence spread of the nodes using the local path. 43 The RLP algorithm can efficiently find influential nodes that can activate the localized target nodes. Localized target nodes are a set of nodes with high connections. Liu et al. presented the local index rank (LIR) algorithm. 44 LIR can detect the influential nodes using the local index and node degree criteria. The algorithm has a suitable runtime, but it does not have appropriate accuracy for the influence spread.
Li et al. proposed the Hierarchy based Influence Maximization (HBIM) algorithm, which divides the information diffusion into levels, and finds influential nodes in each level based on random walk to calculate the belonging coefficient. 45 The greedy algorithm is better than the HBIM algorithm in terms of influence spread. Xin et al. proposed the heterogeneity-oriented (HO) centrality to find the influential nodes. 46 The algorithm uses two criteria of the spread rank and activity rank in this centrality to find the influential nodes for immunization. Talukder et al. introduced the KRIM algorithm under the LT model. 47 In the KRIM algorithm, the nodes activation process ends with the concept of influence decay.
Qiu et al. proposed the Partition-Heuristic-Greedy (PHG) algorithm that uses the community detection method and greedy algorithm. 48 This algorithm achieves excellent stability in influence spread. Beni and Bouyer presented the top-k influential nodes selection based on community detection and scoring criteria in social networks (TI-SC) algorithm to improve the spread of the DegreeDiscount algorithm. 14 The algorithm selects the seed nodes using a community detection method and a scoring measure. The main advantage of the algorithm is that it uses a scoring system and thus selection of the seed nodes is closer to the real world. However, it takes a long time to run on the large-scale graphs.
Ding et al. provided the D-greedy algorithm under the realistic independent cascade (RIC) model for the IMP. 49 The main advantage of the algorithm is that the IMP under the RIC model is suitable for analyzing the real-world problems. Aghaee and Kianian proposed Group of Influential Nodes (GIN) algorithm that creates different groups of graph nodes and by using the Expected Diffusion Value selects influential nodes. 50 In some social networks, the greedy algorithm has a better influence spread than the GIN algorithm. The GIN algorithm has a good efficiency.
The Proposed Method
In the IMP, the position of a node on the core and other shells is important on the selection of seed nodes in social networks. In the proposed SRFM algorithm, the seed nodes are, therefore, selected from the core and other important nodes based on their position. The SRFM algorithm has two main steps: (1) hierarchical selection of the initial seed nodes and (2) selection of the final seed nodes.
Hierarchical selection of the initial seed nodes
In this step of the algorithm, the graph G = (V, E) is initially divided into different parts. The graph shells are specified by the modified k-shell algorithm. In the modified k-shell algorithm, nodes with degree 1 are initially removed from the graph G and placed at a depth of 1 of shell 1. By removing the nodes with degree 1, another node with degree 1 is created in the graph, which is placed in depth 2 of shell 1, and this process continues until the new degree 1 node is not created in the graph. Then, nodes with degree 2 are removed from the graph G and placed at the depth 1 of shell 2. By removing the nodes with degree 2, other nodes with degree 2 are possibly created in the graph, which are placed at a depth of 2 of shell 2, and this process continues until there is no node with degree 2 in the graph. The overall process of the k-shell algorithm continues until all nodes are placed in related shells. For example, in Figure 1, nodes with similar colors are placed in the equal shells.
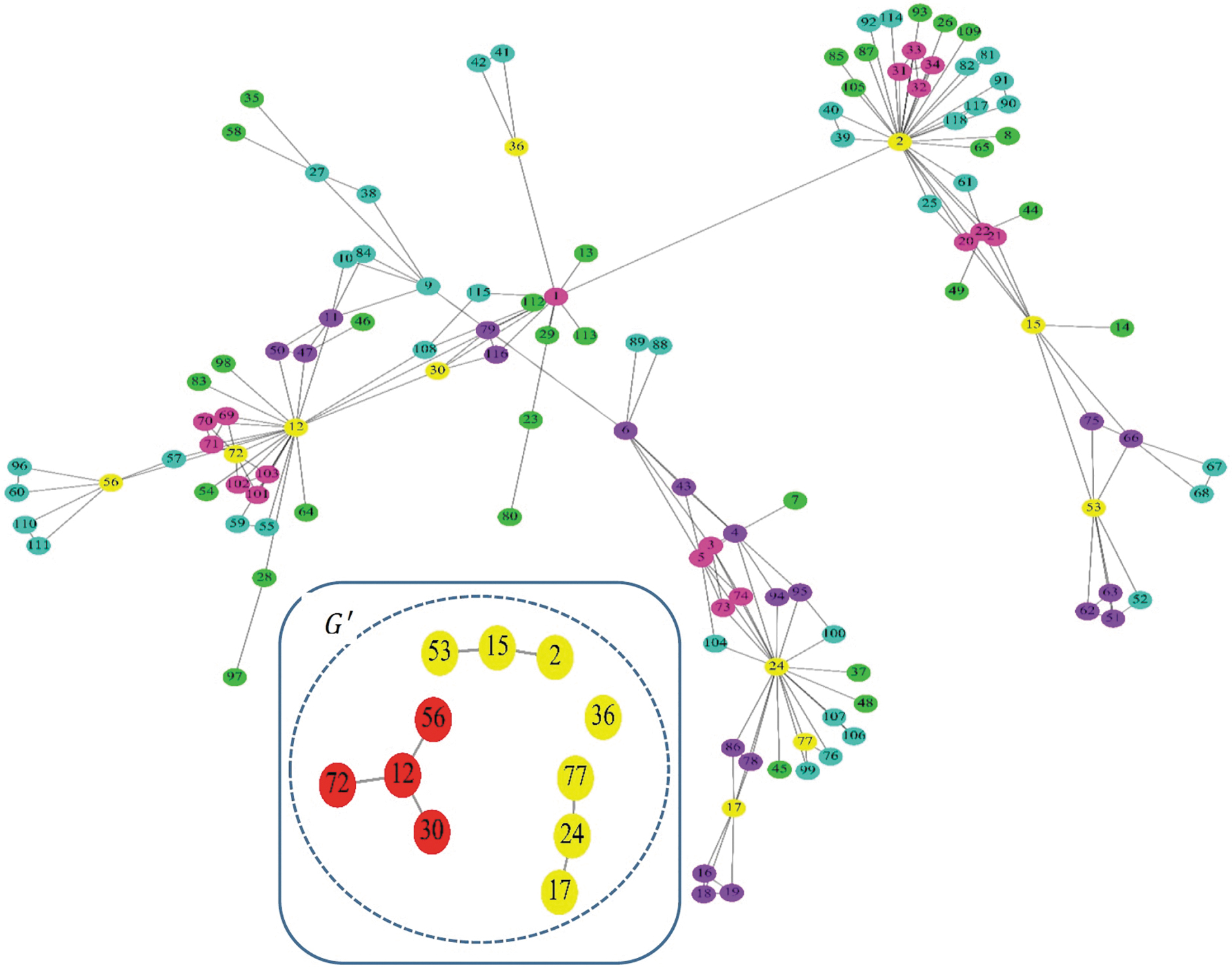
The result of improved K-shell on Santa Fe Scientists Collaboration. Nodes of the same color are in the same shell and the subgraph
According to Table 1, all the nodes in this Network are identified by the shell depth. After detecting all the shells, based on the remaining edges between the core nodes, the graph
Separation of nodes based on the depth and shell in the Santa Fe Scientists Collaboration Network
where  represents the assortativity criterion changes after removing the node
represents the assortativity criterion changes after removing the node 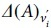 criterion is small. In other words, it has less changes by deleting the node
criterion is small. In other words, it has less changes by deleting the node 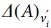 experiences many changes and
experiences many changes and 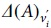 increases in this case. After calculating
increases in this case. After calculating
Definition 1. The ROI: For the graph
where k is the size of a set of the seed nodes and
Definition 2. The CC set:
Therefore, Algorithm 1 shows the creating of the CC set. First, the graph
where ns is the number of the graph shells and Ad is defined according to equation (6).
where
where
Hence, Algorithm 2 is proposed to produce the PC set by the SRFM algorithm. In lines 4–6, the nodes inside the
Selecting the final seed nodes
After creating the CC and PC sets, the CG set must be generated to select the seed nodes. Accordingly, the CG set is produced according to the following equation:
At next, for each node vi in the CG set, equation (9) is calculated. Then the k node with the highest

where
Therefore, Algorithm 3 is introduced for the second step of the SRFM algorithm. The CG set is generated in line 2. In lines 3–5, the criterion
Time complexity analysis
The time complexity analysis in the SRFM algorithm consists of two steps. In the first step, time complexity refers to the hierarchical selection of the initial seed nodes. The time complexity for this step is O(m), where m is the number of the edges in the graph. In the second step, time complexity represents the selection of the final seed set that is
Experimental Results and Analysis
In this section, we use 10 networks (2 synthetic networks and 8 real networks) with different sizes and categories to evaluate the effectiveness and efficiency of SRFM compared with the other 7 well-known algorithms. Moreover, the fundamental features for these networks are given in Table 2.
Summary of eight real-world networks and two synthetic networks
CAIDA, Center for Applied Internet Data Analysis; PGP, Pretty Good Privacy.
Real-world networks
Here are the descriptions of the eight real-world data sets. All data sets are undirected. Data sets of these eight networks can be downloaded from the Konect website.*
Route views: This is the network of autonomous systems of the Internet connected with each other. 51
PGP: This network is the interaction network of users of the Pretty Good Privacy (PGP) algorithm. 52
Sister cities: The Sister cities network is an undirected network of cities of the world connected by “sister city” relationships, as extracted from WikiData. 51
As-22july06: The As-22july06 is a network of the structure of the Internet at the level of autonomous systems. 51
COND-MAT-2003: The COND-MA (1993–2003) collaboration network is from the e-print arXiv and covers scientific collaborations between author's articles submitted to Condense Matter that the data cover articles in the period from January 1993 to April 2003. 53
Center for Applied Internet Data Analysis: The CAIDA is the network of autonomous systems of the Internet connected with each other from the CAIDA project. 51
COND-MAT-2005: The COND-MA (1995–2005) collaboration network is from the e-print arXiv and covers scientific collaborations between author's articles submitted to Condense Matter that the data covers articles in the period from 1995-01-01 to April 2005-03-31. 51
Douban: The Douban network is a Chinese social networking service of a Chinese online recommendation site. 54
Synthetic networks
Here are the descriptions of the two synthetic networks, and the forest fire model is used to make synthetic networks. The power-low distribution property is important in the forest fire model. Synthetic networks are as follows:
Basic compared algorithms
The SRFM algorithm has been compared with seven baseline algorithms (i.e., TI-SC, PHG, LIR, ProbDeg, VoteRank, CI, and k-core). The list of baseline algorithms is described hereunder.
TI-SC: This algorithm is a community-based approach. It selects the seed nodes based on the special scoring system near to real-world ranking. 14
PHG: This algorithm is based on the community detection method and greedy algorithm. 48
LIR: Influential nodes are selected in the LIR algorithm using the criteria of local index and node degree. 44
ProbDeg: The ProbDeg determines the effect of multihops on the IMP. 41
VoteRank: In the VoteRank algorithm, influential nodes are selected based on the voting ability of the neighbors of one node. 40
CI: The CI algorithm locally calculates the influence spread in a circle of radius l for each node. 39
K-core: The k-core algorithm divides the network into different layers and shows that nodes in the same layers have the same influence spread. 32
Experiment setup
In this article, the SRFM algorithm is programmed in python language and is ran on a computer with 2.5GHz Intel Core i5 CPU-3230M and 16GB memory. Our proposed algorithm supports instances of the IC model. In this model, influence probability of each edge is
Experimental results
Quality
Quality in the IMP is the amount of the influence spread of seed nodes. The high influence spread of the algorithm indicates the high quality of the algorithm. We select seven distinct sets of seed users of size 1, 5, 10, 15, 20, 25, and 30 for 10 data sets. Figure 2 shows the amount of the influence spread of SRFM with state-of-the-art algorithms under IC models, where the x-axis represents the number of seed nodes. In contrast, the y-axis represents the overall influence spread. The results in real-world data sets and synthetic networks represent that the SRFM algorithm completely outperforms other state-of-the-art algorithms in terms of influence spread. Compared with the mentioned algorithms, the selected seed set by the SRFM algorithm has the largest influence spread.

Influence spread comparison in various data sets under independent cascade model.
Figure 2A shows the experimental results of the Sister cities data set which we can observe significant gaps of influence spread value between the SRFM algorithm and other algorithms. The k-core and LIR algorithm show the worst performance in Figure 2A. Figure 2B shows the influence spread of the SRFM algorithm in the PGP data set. In Figure 2B, SRFM is better than PHG, VoteRank, and TI-SC on the PGP network. Figure 2C shows that the influence spread of the SRFM algorithm in the COND-MAT (1993–2003) is the best. The k-core algorithm shows the worst performance in the COND-MAT-2003 data set. Figure 2D shows the influence spread of the SRFM algorithm in the CONDMAT-2005 data set which we see that the influence spread values of TI-SC, PHG, and VoteRank algorithms are lower than the SRFM algorithm. Figure 2E shows the influence spread of the SRFM algorithm in the CAIDA data set which the SRFM algorithm outperforms other algorithms. Likewise, PHG, TI-SC, and VoteRank algorithms have the same influence spread value shown in Figure 2E. Figure 2F shows the influence spread of the SRFM algorithm in the As-22july06 data set. The SRFM algorithm is superior to the VoteRank, PHG, and TI-SC algorithms shown in Figure 2F. Also, the k-core algorithm shows the worst performance in Figure 2F. Figure 2G shows that the influence spread of the SRFM algorithm in the Douban data set. The influence spread values of the PHG, TI-SC, and VoteRank algorithms are the same as the SRFM algorithm in this data set. Finally, Figure 2H shows the influence spread of the SRFM algorithm in the Route views data set. When k is 1, 10, and 15, the influence spread values of the PHG and VoteRank algorithms are the same as the SRFM algorithm. In Figure 2G and H, the influence spread of the compared algorithms is rather close when k is small values. We can observe significant gaps of influence spread value between the SRFM algorithm and other algorithms shown in Figure 2I. Figure 3J shows the influence spread of the SRFM algorithm in the M-FO120 data set. As can be seen in Table 3, SRFM is the best algorithm.
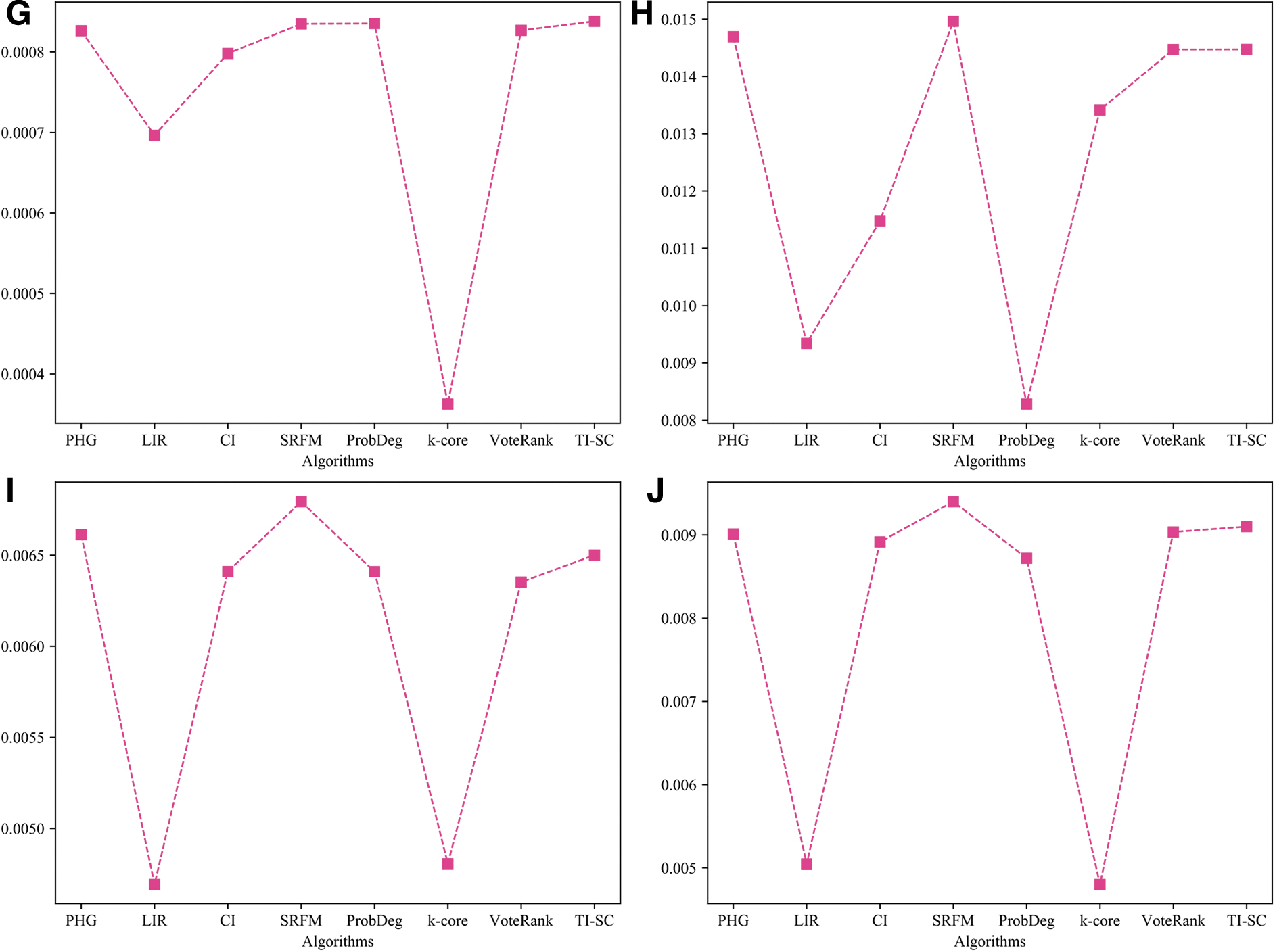
The influence spread over social network nodes comparison in various data sets under independent cascade model for |k| = 30,
The average number of influence spread in k = 1, k = 5, k = 10, k = 15, k = 20, and k = 30 on eight real-world data sets and two synthetic networks
The highest value of each row is bolded.
CI, Collective Influence; LIR, local index rank; PHG, Partition-Heuristic-Greedy; SRFM, Shell-based Ranking and Filtering Method; TI-SC, Top-k Influential nodes based on Scoring criteria and Community detection.
The influence spread is calculated based on the total data nodes for k = 30 in Figure 3 on real-world networks and synthetic networks. As shown in Figure 3, the influence spread of SRFM is better than other algorithms. We also analyze the average influence spread in k = 1, k = 5, k = 10, k = 15, k = 20, and k = 30 on real-world networks and synthetic networks in Table 3. As given in Table 3, we can easily find the SRFM algorithm is better than others.
Computational time
In this section, the running time of the SRFM algorithm is compared with that of the baseline algorithms. Table 4 gives the running time of different algorithms on the eight real-world networks and two synthetic networks. From the results, it is obvious that the running times of SRFM and k-core are lower than other compared algorithms. From the eight real-world data sets, SRFM is the best in Route views, Sister cities, and Douban data sets and k-core is the best in PGP, COND-MAT-2003, COND-MAT-2005, CAIDA, M-Fo115, and M-Fo120 data sets. However, as shown in Figures 2 and 3, k-core has the lowest quality in comparison with other algorithms, and it cannot provide any performance guarantee in terms of influence spread. Therefore, if we do not consider the k-core algorithm, our SRFM method in all data sets has the best computational time and performance compared with the rest. The SRFM algorithm is more time efficient than PHG, TI-SC, VoteRank, CI, and LIR algorithms.
Execution times on real-world networks and synthetic networks (all times are in seconds)
The lowest value of each row is bolded.
In synthetic networks, k-core is the best and SRFM in the second best in comparison with other methods. Nevertheless, the SRFM in both M-Fo115 and M-Fo120 synthetic networks has the best quality, whereas k-core algorithm has the lowest quality in these data sets.
Conclusion and Future Directions
In this article, we have presented a new algorithm for IMP, called SRFM. SRFM overcomes the low accuracy of the VoteRank, PHG, and TI-SC algorithms and the low efficiency of the CI and PHG algorithms based on the hierarchical selection of the seed nodes. The proposed algorithm examines the role of the core nodes and nodes within other shells in the influence spread and selection of the seed nodes. The influence spread calculations in the periphery nodes are optimally ignored in this algorithm, which reduces the computational overhead. Thus, the SRFM algorithm considers two main steps to improve the effectiveness of selected seed nodes: (1). Hierarchical selection of the initial seed nodes with aim to filter unimportant nodes and to reach a fast approach in detecting the CC and PC sets and (2). the final seed set selection from the CC and PC sets. Since the number of nodes in these sets is insignificant, they are quickly processed and the final seed set is selected. The experimental results on eight real-world networks and two synthetic networks proved that the SRFM algorithm outperforms other algorithms in terms of influence spread (quality). Correspondingly, the SRFM algorithm is the fastest algorithm in 50% of data sets and is the second best in other 50% data sets. Consequently, the SRFM algorithm is a trade-off between time and efficiency. As a future study, the SRFM algorithm can completely be extended to make a parallel processing in finding the CC and PC sets and seed node selection step.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.