
Abstract
The analysis of large-scale multimodal data has become very popular recently. Image captioning, whose goal is to describe the content of image with natural language automatically, is an essential and challenging task in artificial intelligence. Commonly, most existing image caption methods utilize the mixture of Convolutional Neural Network and Recurrent Neural Network framework. These methods either pay attention to global representation at the image level or only focus on the specific concepts, such as regions and objects. To make the most of characteristics about a given image, in this study, we present a novel model named Multilevel Attention Networks and Policy Reinforcement Learning for image caption generation. Specifically, our model is composed of a multilevel attention network module and a policy reinforcement learning module. In the multilevel attention network, the object-attention network aims to capture global and local details about objects, whereas the region-attention network obtains global and local features about regions. After that, a policy reinforcement learning algorithm is adopted to overcome the exposure bias problem in the training phase and solve the loss-evaluation mismatching problem at the caption generation stage. With the attention network and policy algorithm, our model can automatically generate accurate and natural sentences for any particular image. We carry out extensive experiments on the MSCOCO and Flickr30k data sets, demonstrating that our model is superior to other competitive methods.
Introduction
Generating image description is a more complex task than traditional computer vision tasks, for example, image classification,1,2 image retrieval,3,4 object detection, and recognition.5,6 People's interest is growing in solving a more “end-to-end” task of generating more detailed descriptions of images in terms of natural language. Owing to its essence, image captioning has been regarded as the bond between image content understanding and natural language expression. Image captioning models are required to recognize objects, attributes, activities, and relationships, and then transfer them to semantic accurate and fluent sentences. Thereby, image captioning can be useful in many applications, such as image understanding, visual question answer, and multimedia retrieval. Image captioning can transmit information and bring convenience to people, which has shown great significant research value in real life.
Benefiting from the exemplary developments of deep neural networks in sequence generation, the encoder–decoder framework has become mainstream in image captioning and the methods based on this framework have achieved gratifying results.7–11 Unlike traditionary template-based and retrieval-based approaches, the encoder–decoder models usually employ Convolutional Neural Network (CNN) to encode the input images into a feature vector and Recurrent Neural Network (RNN) to decode the feature vector into a complete natural language sentence. Certainly, encoder and decoder can be any foundational model. 12 Furthermore, to improve the encoder–decoder framework, the attention mechanism has been introduced in image captioning and has become a significant part. The descriptions of the image can be more real and articulate with the attention mechanism.10,13,14
Nevertheless, current attention models often treat the image as a set of regions and only focus on relevant regions by probabilities.11,15,16 In other words, only a few local regions are correlative when predicting the next word. However, the isolated regions may also have details that can be valuable for generating processes, such as color, quantity, category, and types. Besides, many models merely utilize global feature representation or treat objects and regions individually to generate sentences at the image level, making the model miss some objects. In addition, as Ranzato et al. 17 mentions, the RNN-based model has a particular degree of inconsistency between training and testing, which can cause an accumulation of errors called exposure bias.
Aiming at the aforementioned challenges, we present a Multilevel Attention Networks and Policy Reinforcement Learning (MANPRL) model to handle them. Specifically, we design a multilevel attention network to take full advantage of the global and local feature and take objects and regions on board instead of considering them separately. Our multilevel attention network contains a region attention network and an object attention network. In our region attention network, we use the CNN to extract global region features and divide them into independent regions as local region features. Then, we multiply them with the hidden state of the previously generated word and process the output with a visual attention mechanism. At the same time, we utilize Faster R-CNN
6
to capture objects features, which is a pretrained image detection model, then we perform average global pooling on all object features. The results are regarded as our global object feature and each object feature is regarded as local object feature. Similarly, we multiply them with the hidden state of the previously generated word and feed the output to the region attention model. After that, we use a concatenation operation to combine two visual features. Finally, to solve the exposure bias problem, we employ a policy gradient (PG) optimization to handle the concatenated visual feature to generate words. In summary, the essential contributions of our work are shown as follows:
Unlike current attention-based image captioning methods considering objects and regions in images individually, we take them into account simultaneously, which can capture elements that are easily overlooked in an image. Therefore, our model can extract relevant information as much as possible. We utilize a global-local attention mechanism separately for objects and regions to balance the role of global and local information in sentence generation. Our model preserves sufficient context information through this attention mechanism, which improves the performance of sentences generated finally. We evaluate our model on the MSCOCO and Flickr30k data sets. The experimental results reveal that our approach outperforms the compared baselines.
The remainder of this study is organized as follows. Related works are summarized in Related Work section. In Approach section, we introduce an outline of the proposed model MANPRL. Next, we elaborate the details of MANPRL in Experiments section. We also conduct extensive ablation studies by comparing with different models. Finally, Conclusion section shows the conclusion and future work.
Related Work
Generating descriptions for images has a long research history. In this section, we describe a variety of existing image captioning methods and divide these methods into three main types, including template-based, retrieval-based, and novel caption generation methods. 18 The template-based methods 19 first generate a predesigned sentence template with blank slots, then fills them with information such as objects, attributes, actions, and relationships of objects in images.20–22 Template-based methods can generate proper image descriptions with fixed lengths. In retrieval-based approaches, as the name suggests, descriptions are retrieved from all standard descriptions. One way is to find the visually similar image and transfer corresponding descriptions to the query image before retrieving.11,23 Another way is to retrieve descriptions from a multimodal embedding space of all candidate descriptions.24,25 The size of the preconstructed sentence storage limits the retrieval-based methods. In recent years, with the development of deep neural networks in image captioning, abundant novel methods have been introduced.26–28 Kiros et al. 26 learn a joint text-image embedding space for generating descriptions. Mao et al. 27 and Vinyals et al. 11 regard the image captioning task as a seq2seq task. They use CNN to capture visual features and RNN to decode the feature into sentences. Lu et al. 16 introduce an adaptive encoder–decoder framework with new “visual sentinel” mechanism. Karpathy and Fei-Fei 8 exploit an alignment model to generate image captions and their locations at the same time. Yang et al. 29 merge retrieval-based and generation-based methods with dual Generator GAN. The aforementioned methods accept all the information of the picture when generating words. These methods are not efficient, which costs more time to train.
Recently, the attention mechanism has become an important part of image captioning task. Xu et al. 10 put forward two image captioning methods with different attention mechanism, which can learn a latent alignment from word and image region. You et al. 13 integrate semantic concept into hidden states with different methods. Wu et al. 30 inject high-level concepts into a CNN-RNN framework as semantic attention to improve image captioning performance. Wu et al. 31 use a review module to capture the global concepts into fact vectors with attention mechanism. Introduce a novel approach to bridge the gap between vision and language domains add textual concepts to enriching the image features. Liu et al. 32 introduce a novel approach to bridge the gap between vision and language domains add textual concepts to enriching the image features. Yao et al. 33 construct variants of architectures by feeding high-level attributes from images to complement image representation for image captioning. Zhao et al. 34 proposes a style memory module designed to explicitly memorize the style knowledge learned and a decomposing sentence algorithm that separates style-related part from stylized sentence. Li et al. 35 encode image group into a context-aware feature by combining self-attention and group image visual features. However, the common attention method simply applies a single-level attention mechanism for image information, and our approach considers multiple levels of image information.
Reinforcement learning (RL) is another approach to boost the performance of image captioning, which aims to generate sequential actions defined by a policy through maximizing the accumulative forthcoming rewards. 36 Liu et al. 37 propose a new PG and new metric called SPIDEr. SPIDEr is a linear combination of semantic propositional image caption evaluation (SPICE) 36 and consensus-based image description evaluation (CIDEr). 38 Rennie et al. 39 propose a self-critical sequence training (SCST) model based on the reinforce algorithm, which chooses its test-time output as a “baseline” to normalize the rewards and weaken the variance generated during the training phase. Zhang et al. 40 employ an actor-critic model for image captioning. Bahdanau et al. 41 apply a token-level critic network to generate reward and an actor network to give policy. Ren et al. 42 present a “policy network” to predict actions for generating the next word and a “value network” to predict rewards by evaluating all possible sentences. Liu et al. 43 utilize a word-level policy network and a sentence-level network collaboratively to generate captions with multilevel reward function.
Approach
In this section, we explain our proposed model in detail. First, we present the overall framework briefly. Then, we expound the encoding process of images to generate two types of features, that is, region feature and object feature. Then, we introduce region attention network and object attention network, respectively. Finally, we give a state of our RL method based on the policy method to generate captions.
Overview
The framework of our model MANPRL is recapitulated in Figure 1. The model contains a modality embedding process, a MANPRL method. In Modality Embedding section, we employ the pretrained deep CNNs and Faster R-CNN to obtain region features and object features individually. Then, our multilevel attention network is built to learn more effective attended visual features. It contains a region attention network and an object attention network, which is used to extract attended region feature and attended object feature, respectively, both by consideration of the global and local features. Finally, a policy reinforcement learning network is introduced to generate the corresponding caption.

The framework of MANPRL. CNN, Convolutional Neural Network; LSTM, long short-term memory; MANPRL, Multilevel Attention Networks and Policy Reinforcement Learning.
Modality embedding
In our model, we extract two types of features, that is, region visual feature and object visual feature, on which the global and local operations are conducted individually. Global features reveal a general view of the input image, whereas local features take the detail of small imaging factors into account.
Region feature
Region visual features allow models to focus on parts of the image. Similar to,
10
we use the conv5–4 layer of VGG-19 network to extract features. There are 14 × 14 regions of each image and every region is expressed as 512 visual feature channels, namely the region visual features can be represented as
Object feature
Benefiting from Faster R-CNN in object detection,
44
a pretrained Faster R-CNN
6
is used to extract object feature. We select top-10 ranked objects based on the classification confidence scores. Thus, the object visual features of an image can be expressed as
Multilevel attention network
Region visual features and object visual features are obtained by modality embedding mentioned earlier. The next step is to make the most useful of them. Inspired by the incredible result of attention mechanism in computer vision studies,8,45,46 we present a multilevel attention network, including region attention network and object attention network. Figure 2 describes the process of the region attention network, object attention network is depicted in Figure 3.

Region Attention Network.
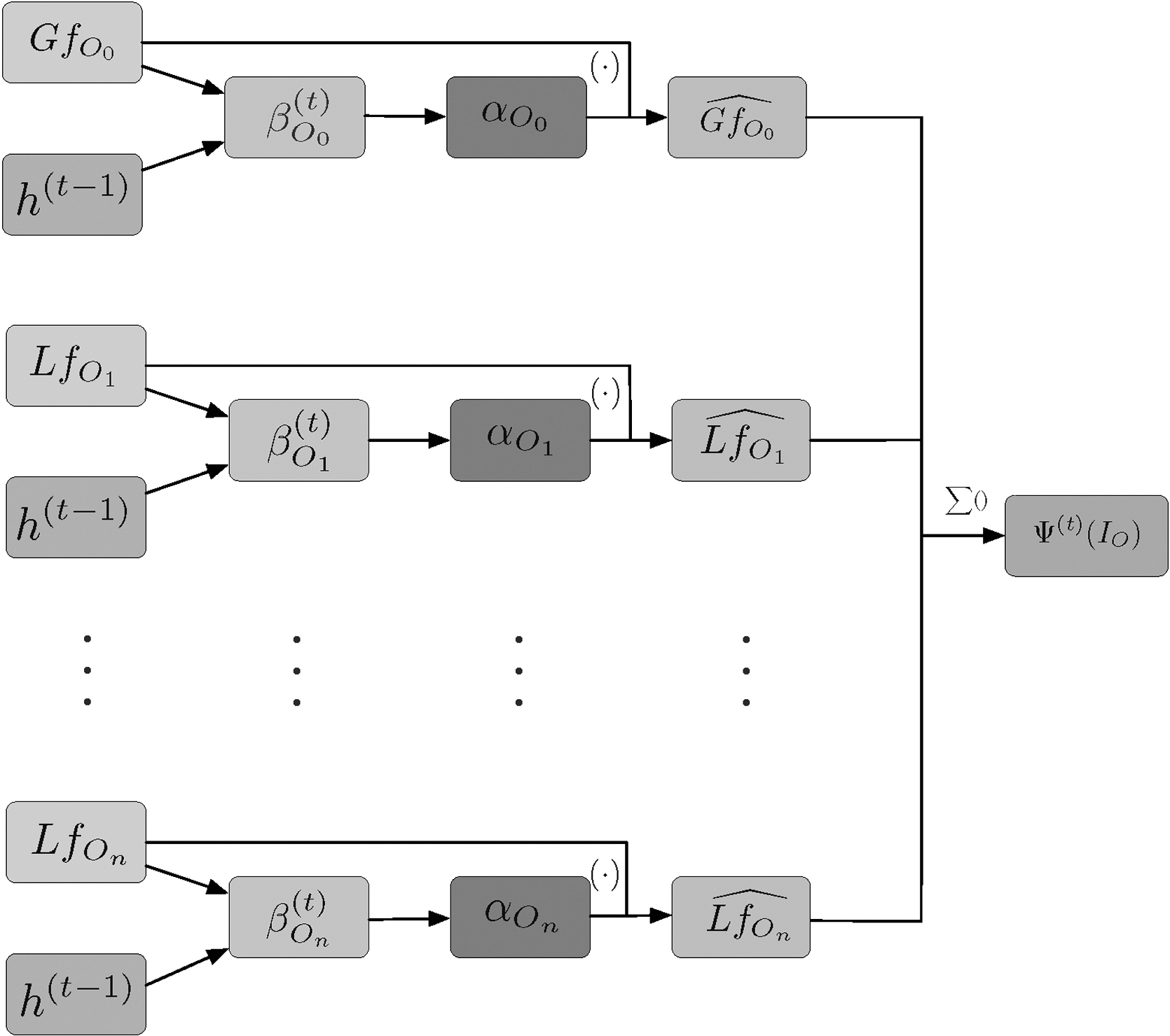
Object Attention Network.
Region attention network
First, given the region feature
In Eq. (1),
After parameter 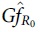 and local region feature could be obtained through multiplying attention weight with these two kinds of features. Summing up all these features, we get the attended region feature
and local region feature could be obtained through multiplying attention weight with these two kinds of features. Summing up all these features, we get the attended region feature
Object attention network
Considering the importance of objects in image description generation, we choose to use objects to enhance the accuracy of the description. As described in Figure 3, the final attended object features are calculated by weighted summing the n processed object features. Similar to the region attention process, the attended object feature can be obtained as the following formula:
Similar with the region attention network, the value
In Eq. (5),
After computing
Reinforcement learning
In image captioning task, the evaluation function is generally recall-oriented understudy for gisting evaluation (ROUGE), 47 bilingual evaluation understudy (BLEU), 48 or CIDEr. 38 It is difficult for traditional maximum likelihood estimation methods to directly learn such nondifferentiable evaluation functions, leading to deviations in training and testing. RL can solve this problem because it does not require feedback or the loss is differentiable and any evaluation function can be used for optimization learning.
We treat sequence generation as an RL problem. The long short-term memory (LSTM) is regarded as model's agent to generate captions, the action is to generate next word, the state is hidden unit in LSTM, the policy is θ. LSTM will stop generating words when the end-of-sequence token is detected. Our model's reward r is computed by CIDEr score, calculated by comparing the generated sentences with corresponding human-annotated sentences. Therefore, the goal of our model is to minimize
where
Then, we utilize the policy RL algorithm to compute the gradient
In practice, we use Monte-Carlo to sample
Mante-Carlo sampling has large randomness, which makes the final samples have huge differences and results in a high variance in the reward, especially in large search space such as our caption generation task. Adding baselines is one solution to this problem, which can constraint the reward to a restricted extent. Then Eq. (10) becomes the following:
Any function can be used for baseline b, only if it does not depend on the action ws. This conclusion can be derived from simple mathematics inference:
These proof equations show that baseline b reduces the gradient variance although does not influence the expected gradient. We chose the baseline is the reward obtained by the reinforcement algorithm with the current model under the inference algorithm used at test time. This baseline forced to improve the model's performance under the inference algorithm used at test time and encourages training/test time consistency similar to the maximum likelihood-based approaches. Applying the chain rule, the gradient can be expressed as
where st is the input features. In the text generation model, the gradient of
where
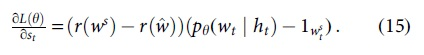
Image description generation
We treat description generation as a variable-length sequence generation problem, in which LSTM is widely adopted. Before feeding visual features to LSTM, we need to integrate two kinds of features. Equation (16) calculates the final visual vector for our multilevel attention network, where Concat means the concatenation function of the region visual features
Given image visual features I and the predicted sentences
where it, xt, ft, ot, and
Experiments
In this section, we conduct experiments to evaluate the performance of MANPRL. First, we go through the preparation of the experiment, including data sets, baselines and experiment setup. Then, evaluations are accomplished on MSCOCO and Flickr30k data sets to prove our proposed model. Finally, we analyze the effectiveness of the model with quantitative and qualitative evaluation results.
Experiment setup
Data set and evaluation metrics
Our experiments are conducted on the famous MSCOCO-201422 and Flickr30k 49 data sets. MSCOCO data set is the largest data set for image captioning, which contains 82,783, 40,504, and 40,775 images in the train, validate, and test set, respectively. Each image has five corresponding sentences annotated in English by humans. We utilize the Karpathy split method, 8 which takes 113,287 images for training, 5000 images for validation and another 5000 images for testing. Flickr30k data set contains 31,000 images, which takes 1000 images for validation, 1000 images for testing, and the rest for training.
Generally, BLEU, 48 metric for evaluation of translation with explicit ordering (METEOR), 50 ROUGE, 47 and CIDEr 38 are standard evaluation protocols. BLEU is the most common and popular metric, which is only based on the precision of n-gram with a sentence-brevity penalty. The value of n is 1, 2, 3, 4, which corresponds to the performance of n number of grams, respectively. METEOR aims to solve inherent deficiencies in the BLEU metric, which employs WordNet to calculate the harmonic mean of unigram precision and recall between sentences. ROUGE is usually the evaluation standard for the automatic summary task. There are three evaluation criteria about ROUGE, namely ROUGE-N, ROUGE-L, and ROUGE-S. CIDEr is specially designed for image captioning tasks, which treats each sentence as a document and expresses it as the form of a Term Frequency Inverse Document Frequency vector. By calculating the weight of each n-tuple and the cosine similarity between the reference caption and the caption generated by the model, the consistency of the description can be measured.
Features and parameter setting
For any given image, we first resize them to 224 × 224. Then, ResNet101-based Faster R-CNN is adopted to obtain object features and VGG-19 is utilized to obtain region features from the resized images. We only choose words that appear more than five times in the training data set and our vocabulary size is 9485. Each word is embedded in a 1000-dimensional word embedding space.
Training details
We employ PyTorch to implement our models on 2 Tesla-V100. Adam optimizer is employed to optimize our proposed model for 200 epochs. The learning rate is initialized to
Baselines
We compare our model with attention-based methods, RL-based methods and some other methods under all metrics on the Karpathy test split to prove our method. We divide the compared models into three categories.
Attention-based models
Show-Attend-Tell 10 introduces two attention mechanisms to learn salient image regions separately. SCA-CNN 51 uses CNN-based encoder with spatial and channel-wise attention. Adaptive-Att 16 employs RNN-based decoder with a visual sentinel adaptive attention. Up-Down 52 introduces two LSTM layers, which has a top-down attention LSTM and Language LSTM.
RL-based models
SCST 39 employs a self-critical sequence training model for image captioning, which uses sentences generated at the test time as a benchmark to normalize rewards. PG-SPIDEr 37 optimizes a new metric with a linear mixture of SPICE and CIDEr by PG. Embedding-Reward 42 employs a “policy network” and a “value network” to generate captions together. Actor-Critic 53 adopts a self-critical n-step training to forecast words based on the actor-critic algorithm. StackCap 54 proposes a coarse-to-fine forecast framework, which has multiple LSTM-based decoders and complicated RL-based reward.
Other models
Variational autoencoder (VAE)
55
uses a variational autoencoder model based on an encoder–decoder architecture to learn images and associated labels or captions. Neural image caption (NIC)
11
proposes an image description generation architecture based on a deep recurrent network. Attributes-CNN
30
presents a method of integrating high-level concepts into the encoder–decoder architecture. CNN
Image captioning results
Quantitative analysis
We verify the performance of our model quantitatively based on two public data sets. Tables 1 and 2 are the experiment results on the MSCOCO and Flickr30k data sets. From these two tables, the following statements and analysis can be drawn.
Results on the MSCOCO data set
BLEU, bilingual evaluation understudy; CIDEr, consensus-based image description evaluation; CNN, Convolutional Neural Network; METEOR, metric for evaluation of translation with explicit ordering; NIC, neural image caption; PG, policy gradient; RNN, Recurrent Neural Network; ROUGE, recall-oriented understudy for gisting evaluation; SCST, self-critical sequence training; SPIDEr, a linear combination of SPICE and CIDEr; VAE, variational autoencoder.
Results on the Flickr30k data set
First, the results show our model surpasses the compared models on seven evaluation measures. Compared with traditional models, we consider corresponding regions and objects in the sentence and their roles in sentence generation from local to global. In other words, the features of the images our model learns are richer.
Second, we also found that more sophisticated attention models are better than simple attention models. Adaptive-Att and Up-Down obtain higher score than Show-attend-tell, SCA-CNN, CNN+Att. The possible reason is that the models considering more image details achieve good performance in the sentences generation process. This reflects that the complex model distinguishes the important level of information in the picture in generating sentences.
Third, most RL-based models have more satisfactory performance than others, which demonstrates that the RL algorithm solves the loss function mismatch problem by optimizing evaluation metrics directly. Other models are trained by maximizing the likelihood of each ground-truth word given the previous ground-truth words and the image using back-propagation. This creates a mismatch between training and testing time since at test-time, the model uses the previously generated words from the model distribution to predict the next word.
Qualitative analysis
To facilitate the comparison between our model and other comparison models, we generate some descriptions from randomly selected images. Figure 4 shows these descriptions and the corresponding images. The first green ones are ground-truth sentences. The soft-attention model and SCST model generate the blue ones (C1) and purple ones (C2), respectively. The last red ones are generated by our model, which is more accurate and naturalist. From those captions, we can observe that our model can detect some missed objects, similar to the first example, after generated “A man,” the others generated “in a suit,” whereas our model can generate “in a glasses and tie.” Intuitively, the sentences generated by our model are closer to ground-truth sentences for all examples.

Visualization of the generated sentences: The blue ones (C1) generated by the soft-attention model and purple ones (C2) generated by the SCST model. All samples are randomly selected. SCST, self-critical sequence training.
To make the multilevel attention network more intuitionistic, Figure 5 visualizes the weights of attention network learned by the multilevel attention network, from which we can see that although our attention mechanism basically covers the corresponding regions and objects, it is not completely consistent. Similar to the top example in Figure 5, the area of attention does not completely cover the area of the boy. The possible reason is that we only use a simple concatenation operation without considering their mutual cooperation in our multilevel attention network.

The visualization of multilevel attention.
Ablation study
To verify the effectiveness of different modules in our proposed model, we conduct ablation experiments without one of three parts at a time, respectively, for the ablation analysis. The three parts are object-attention network, region-attention network, and policy RL algorithm. The result on MSCOCO data set is presented in Table 3 and the result on Flickr30k data set is presented in Table 4. In Tables 3 and 4, “without OAN” represents no object attention network in re-train stage, “without RAN” represents no region attention network in re-train stage, and “without RL” represents no policy RL in re-train stage.
Performance of various combinations of model on MSCOCO data set
OAN, object attention network; RAN, region attention network; RL, reinforcement learning.
Performance of various combinations of model on Flickr30k data set
First of all, one can observe that all three components of the model play an essential role in the image captioning task. Second, policy RL algorithm has the greatest impact on the final results. Third, the performance improvement obtained through the object-network is not as influential as the region-network.
Conclusion
In this study, we present a novel model named MANPRL for image caption generation. Different from other methods, our model considers as much detail of images as possible from different views. We employ a multilevel attention network to explore the importance of regions and targets from local to global in the image features encoder stage. After that, a policy RL algorithm is adopted to overcome the exposure bias problem in the training phase and solve the loss-evaluation mismatching problem at the sentence generation stage. We conduct experiments on MSCOCO and Flickr30k data sets. The experimental results reveal that our model achieves better results on various metrics than the compared models, reflecting the effectiveness of our model. We also perform an ablation study on the MSCOCO data set, and the results show that the three components are beneficial for image captioning.
From the attention visualization laboratory of Qualitative Analysis, we can see that the effect of attention is not very accurate. In the future study, we will explore RL to guide attention mechanism to learn the connection between words and corresponding image details.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported in part by the National Natural Science Foundation of China (Grant Nos. U1636211, 61672081, 61370126, 62002068), the 2020 Tencent Wechat Rhino-Bird Focused Research Program, and the Fund of the State Key Laboratory of Software Development Environment (Grant No. SKLSDE-2021ZX-18).