
Abstract
With the development of generative adversarial networks (GANs), more and more researchers apply them to image inpainting technologies. However, many existing approaches caused some inpainting images to be unclear or even restore failures due to a failure to keep the consistency of the inpainted content and structures in line with the surroundings. In this article, we propose the Improved Semantic Image Inpainting Method with Deep Convolution GANs, which can resolve this inconsistency. In the proposed method, we design a patch discriminator and contextual loss to jointly perform the accuracy and effectiveness for image inpainting. In addition, we also designed a consistency loss based on deep convolutional neural networks to constrain the difference between the generated image and the original image in the feature space. Our proposed method improves the details and authenticity effectively for the inpainting images. We evaluate our proposed method on two different datasets, and the result shows that our proposed method achieves state-of-the-art results.
Introduction
Semantic image inpainting is defined as the utilization of the available visual data to repair the large missing region. 1 It is a very meaningful and challenging work that repaired parts must be fully matched with the original content while being semantically consistent and coherent with the context. Image inpainting plays an important role in practical applications, such as the recognition of occluded objects, the completion of medical images, and the restoration of cultural relics.
Many works have been studied on image inpainting; most conventional inpainting methods are based on searching for similar textures 2 or patches 3 from the undamaged image parts, or matching the patch offset 4 to complete the images. However, these methods using basic characteristics of the images are only suitable for completing some large scenes with less detail or symmetrical patterns, but the results of the traditional methods can also not be well adaptive for arbitrary shapes of missing pixels. License plate images or human faces contain abundant details, so it is hard to complete the corrupted regions only with pattern information of the undamaged part.
The conventional inpainting methods can only fill small corrupted patches. Straying out of the fence of using the image itself, 5 proposed to search for the available similar information from the external database to complete the images instead of using the uncorrupted parts. However, the amount of the data in the database is limited, which is usually difficult to match the required scenes and details accurately.
With the development of deep learning, the results of deep architecture based image inpainting become more realistic and more convincing. Approaches based on deep convolution networks 6 and generative adversarial network (GAN) 7 are getting more attention than ever, which transforms the image inpainting into the conditional image generation problem.
The introduction of adversarial networks can make the generated pixels consistent with existing pixels. References8–14 employ the idea of a generative adversarial network to resolve the high-level image recognition and low-level pixel synthesis issues, which also can tackle the problem of arbitrary missing shapes or large missing parts.
However, there are still some unresolved problems when using these methods. For instance, only the fixed part of the image could be completed when inpainting the missing pixel with arbitrary shapes, and inpainting for other parts will be distorted and blurred. In addition, the checkerboard artifacts caused by deconvolution layers when training GANs can also have a bad influence in the reality of generated images.
In this article, to improve the problem that local inpainting results are distorted and blurred in existing methods, we employ a patch discriminator
12
to estimate the probability of authenticity of the local part inpainting, and we completed images with more complete and true details will be obtained. In addition, we design a special contextual loss to optimize the vector z to ensure the consistence between generated image and ground-truth. The main contributions of this article are summarized as follows:
We propose a deep convolutional GAN (DCGAN) based image semantic inpainting network, which will upgrade the input random vector z on a specific dataset to regenerate the original image and to perform accurate inpainting. The proposed framework consists of a novel discriminator, namely a patch discriminator (PD), which can pay more attention in corrupted patches in the original image. In addition, a contextual loss is designed to guarantee the quality of generated images. Two publicly available datasets are used for our experiments. And the results show that our proposed method can achieve the state-of-the-art results and obtain much more realistic images.
Related Works
Image inpainting
The method of image inpainting can be roughly divided into two categories. The first one is the traditional method for completing low-level features of the images. The other one is the deep network based method, which can learn image features and complete the corrupted images with GANs to generate conditional images.
Traditional approaches15,16 take the smoothness between pixels as the major consideration to complete the images, which are crucial to the image inpainting with a small missing part or tiny noise compensation, but they are not very ideal when the missing part is large. Barnes et al. 3 proposed a method to find the most similar patch in the undamaged area and to match the damaged area with it.
This can settle the problem of large missing images, but its completion ability is limited when the missing region has arbitrary shapes, which leads to unsatisfying results. Deng et al. 17 proposed a geometric model based image inpainting algorithm. This method is useful to complete face details, but it is also suitable for inpainting smaller patches.
The GAN-based methods acquire more accurate results than other deep network based methods. The work by Pathak et al. 8 is the first work to employ the deep learning network to deal with the image inpainting problem, in which the context encoder (CE) is proposed. It combines the structure of Encoder-Decoder and GANs. In the process of Encoder-Decoder, the structure learns the image characteristics and generates the predicted picture of the image area to be completed.
Meanwhile, it uses the adversarial loss 7 of GANs to judge whether the predicted picture comes from the training set or the prediction set. When the image content of the generated predicted picture matches with ground truth, the GANs discriminator cannot judge where the predicted picture comes from. However, CE considers the structure of holes only during training but not the inference stage. It results in an image that is blurry, especially when the missing part has arbitrary shapes.
Yeh et al. 1 takes the structure of the hole into consideration during the inference stage, and it reaches a clearer state when the missing region has different shapes. After training the adversarial network, it searches for the closest encoding of the damage images with the images in the latent space and feeds the encoding into the generator to reconstruct images.7,18
Generative adversarial networks
This section covers the basics of related technologies of GANs. GANs was first proposed by Goodfellow et al.
7
in 2014, and it is divided into two parts: the generator (G) and the discriminator (D). The generator takes a random vector
Besides, many variants are proposed. Radford et al. 19 proposed DCGAN, in which deep convolutional networks are utilized to replace the conventional network structure of G and D. This makes the training of GANs more stable. Arjovsky et al. 20 proposed Wasserstein GAN (WGAN), which makes an improvement in the loss function of GANs, solving the problem of model collapse.
Gulrajani et al. 21 improved the continuity restriction of WGAN, which pays attention to the gradient vanishing and exploding problem. It converges faster than standard WGAN and generates higher quality samples. GANs adopts an unsupervised training method and is widely used to generate high-quality images,22,23 semi-supervised learning, 24 image blending, 25 and image super-resolution. 26
Among all the variants of GANs, this article adopts the structure of DCGAN. Specifically, we employ PD, which takes only a small region around the completed area as input. PD can help completing the missing part with high resolution so that we can get more reliable results. We conduct experiments on two benchmark databases of different topics for training and testing to ensure that the proposed network structure can have better image inpainting effects in different scenarios.
Proposed Method
The illustration of our proposed framework is shown in Figure 1. In our work, we utilize the DCGAN 19 as the basic inpainting module. Specifically, we transform the original inpainting task into a conditioned image generation task by upgrading the random vector z according to the loss function we design, which is the input of generator of DCGAN.

The proposed inpainting framework.
In addition, we add a well-designed PD working together with the original global discriminator in DCGAN, to align the generated image with real images both locally and globally. To keep the semantic information in generated images, we also design a contextual loss to supervise the process of inpainting, which is proved to be a very effective and efficient loss function for this specific task. The earlier mentioned modules will be introduced elaborately in the following.
PD and the inpainting network
It is well known that DCGAN can perform image generation on various types of data, yet details of missing patches are not very satisfying.
To deal with this disadvantage and to pay more attention to the missing part of the corrupted images, we build a PD to focus more on the semantic relevance between the patch and the whole image with convolutional neural networks (CNNs) that compress the images into small feature vectors. This PD works hand in hand with the original global discriminator in DCGAN to jointly perform supervision when inpainting.
Specifically, the PD is based on a CNN, which compresses the image patches into feature vectors, and in this case, it represents the probability that the completed patches are real. The outputs of both discriminators are fused together by a concatenation layer that predicts a continuous value corresponding to the probability of the completed image being real. A sigmoid activation function is used so that this value is in the [0,1] range and represents the probability that the generated result is true.
Contextual loss
We designed a contextual loss to capture available information to fill the missing regions. The most straightforward choice will be conducting an l2 norm between the original image y and the generated image
Here, i is the pixel index, Wi denotes the importance weight at pixel location i, Ni indicates the neighboring pixels of location i, |·| denotes the cardinality of Ni, and M is the binary mask with a size equal to the corrupted hole of the image.
With this predefined importance matrix, we can perform weighted L2 norm loss as:
In addition, to fully incorporate the semantic information hiding beneath the original images, we design another loss term to make sure the generated images are similar to the real ones. Inspired by the discriminator of GANs, we construct our loss in the following formulation:
Here,
Note that every
Inpainting
As aforementioned, we aim at updating the random vector

Inpainting with and without blending.
Implementation details
The PD is constructed by a series of convolution layers and a fully connected layer. The fusion layer is actually a fully connected layer with 2048 nodes. And other parts of DCGAN remain the same, as depicted in Ref. 19 The details of PD can be found in Table 1.
Architectures of the patch discriminator
Conv., convolution.
Experiments
Datasets
In this article, two popular datasets are employed, namely the Celeb Faces Attributes (CelebA) Dataset 28 and the Street View House Numbers (SVHN) Dataset. 29
There are 202,599 face images that are coarsely aligned in CelebA dataset, and the images are cropped at the center to
The SVHN dataset consists of 99,289 images of house number. For the benefit of DCGAN, we resize them to
Base lines
To demonstrate the effectiveness of the out method, we compare our method with three states of the art: total-variation (TV) based approach, 16 low-rank (LR) based approach, 30 Globally and Locally Consistent Image Completion (GL) 12 and Semantic based completion method (SE). 31 Although such methods are good at propagating high-frequency texture details, they do not capture the semantics or global structure of the image. TV loss based methods take into account the smoothness property of natural images, which is useful to fill small missing regions or remove spurious noise. Holes in textured images can be filled by finding a similar texture from the same image.
Based on the method of matrix inpainting, an improved double-weighted truncated kernel norm regularization is proposed and used. The rows and columns of the matrix are given different weights, and the gradient descent method is used when the matrix is updated. Its initial mathematical expression is as follows:
where
Based on the GL inpainting method, it constructs a text encoding network with a double discriminant network, adds a local discriminator network, and introduces a mean square error loss function during network training and generated adversarial network loss function. The joint loss function is as follows:
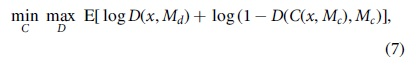
where Mc is the input mask, Md is a random mask,
An inpainting method is based on SE, which optimizes the input vector based on text loss and prior loss, and can repair large areas and arbitrary shapes of missing cases. The basic optimization expression is as follows:
where
The LR method is a relatively new and improved shallow method that has achieved good results. The missing part is completed through the idea of diffusion; whereas the GL and SE methods are two classic deep methods, both of which are based on the training of the generated adversarial network to generate new content for completing the missing parts. The CE approach employs a CNN that is trained with an adversarial loss. It was motivated by feature learning, but it did not fully describe how to handle arbitrary inpainting masks nor how to apply the approach to high-resolution images.
The larger the calculation result of the Peak Signal to Noise Ratio (PSNR), the smaller the image distortion. The value range of Structural Similarity Index (SSIM) is [0,1], and the larger the value, the closer the two pictures are. So, PSNR and SSIM are used as evaluation indicators of image completion results. The deep learning framework adopted in the experiment is TensorFlow 1.6.0. The device uses Intel Xeon(R) E5-2650 for CPU, Nvidia Titan Xp 12G for GPU, and 256G memory of 3200 MHz DDR4.
Visual analysis
We use two different shapes of masks: central block masks and random pattern masks
8
with
Inpainting with center block masks
It is worth noting that TV and LR-based methods cannot perform well with this kind of mask, so we only compare our methods with GL, which is shown in Figure 3.

Comparisons with the GL method on center mask for CelebA dataset. CelebA, Celeb Faces Attributes; GL, Globally and Locally Consistent Image Completion.
Inpainting with random pattern masks
We compare our method with TV, LR, and GL, respectively, with a random pattern mask, which is shown in Figure 4.

Comparisons with other methods on random mask for CelebA dataset.
Inpainting with masks on SVHN dataset
We further perform experiments on the SVHN dataset, with the same setting on CelebA, which are shown as Figure 5 with center block masks and as Figure 6 with random pattern masks respectively.

Comparisons with the GL method on center mask for SVHN dataset. SVHN, Street View House Numbers.

Comparisons with other methods on random mask for SVHN dataset.
It can be seen in Figures 3–6 that our proposed method has achieved the best visual effects in each dataset.
Quantitative analysis
Usually, visual comparisons are straightforward and sufficient for inpainting tasks, but it is also important to provide some quantitative analysis for methods. Following previous work, we compare the PSNR values and SSIM 32 with several methods. The real images from the dataset are used as ground truth reference.
To illustrate the overall performance of the method, we take the average value of PSNR and SSIM obtained by the central mask and random mask, and the obtained value represents the final corresponding PSNR value and SSIM value of this algorithm. Table 2 provides the results on the CelebA datasets, and Table 3 provides the results on the SVHN datasets. We can see from the two tables that our method has higher PSNR and SSIM scores on both datasets.
The peak signal to noise ratio values (dB) and Structural Similarity Index on the Celeb Faces Attributes Datasets
GL, Globally and Locally Consistent Image Completion; LR, low-rank; PSNR, peak signal to noise ratio; SE, semantic-based completion method; SSIM, Structural Similarity Index.
The peak signal to noise ratio values (dB) and Structural Similarity Index on the Street View House Numbers Datasets
Discussion
Results on CelebA dataset
As we can see from Table 2, our proposed method achieved the best results on PSNR and SSIM respectively. Concretely, recovered parts by GL are not very consistent with the surrounding pixels, especially in colors. However, our method has a small shortcoming as well, which is the small artifact around the left eye part. It is probably caused by the not well-trained PD.
As for the random mask, all three comparisons are not performing very well, leading to blurring and noisy images. Due to a large number of missing points, TV and LR-based methods cannot recover enough image details, and the missing points are very discrete for GL to learn the pattern and to recover effectively.
Results on SVHN dataset
Images in the SVHN dataset are relatively simple, making it easier to recover the corrupted images. Results from all four methods verify that it is worth noting that the GL method performs badly under both mask settings. As a matter of fact, the recovered patches from GL always seem to have the same background color; when it comes to data with a different background color (such as green or blue), it cannot correctly recover the missing patch, which is mainly because of the insufficient inpainting power of the completion network in GL.
Overall discussion
To sum up, our proposed method shows promising inpainting results on both datasets and under both mask types, but there are some limitations as well. The DCGAN model in this article works well for relatively simple structures such as faces, but when it comes to representing complex scenes in the world, it will be less effective. Hence, replacing DCGAN with other generating models may lead to a better result when dealing with complex inputs, which will be studied in the future.
Conclusion
Aiming at the problem that the existing image inpainting method makes part of the image unclear or even the inpainting failure, we propose the Improved Semantic Image Inpainting Method with Deep Convolution GAN. Further, we construct a novel contextual loss, which takes the semantic information of pixels into consideration in a weighted matrix formulation. Experimental results show that our method achieves state-of-the-art results.
The input damaged image size has been manually cropped, the faces in each image are aligned, and the mask is manually set. However, in a real scene, the shape and size of the occluded or destroyed parts are uncertain, and the face is not necessarily aligned. Therefore, we plan to study the accurate detection of randomly missing regions and perform high-quality completion.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by Dongguan Polytechnic National Double High Plan for Major Group of Electronic Information Engineering Technology Special Funding under Grant No. ZXJCD002.