
Abstract
In this article, the phenomenon of scientist cooperation in the scientist cooperation network is studied from the perspectives of information spread and link prediction. By mining the information in the scientist cooperation network, analyzing the cooperation has been generated and discovering potential cooperation opportunities. It helps to build a richer cooperation network with more content. Information spread can reflect the inner laws of network structure formation, and the link prediction method can retain the integrity of network information to the maximum extent. First, the real network is abstracted by analyzing its structure as well as node attributes into a simulated network. Second, the process of information spread in the cooperation network is simulated by improving the traditional SIS model. Some improvements are made to the link prediction algorithm for the impact brought to the network by information spread. Finally, the experimental results in the scientist cooperation network show that the hybrid weighted link prediction algorithm combining node attributes and spread factors can improve the accuracy of link prediction and provide suggestions for scientists to find partners. The comparative experiments on simulated and real networks not only validate the effectiveness of the propagation model in the scientist cooperation network, but also verify the accuracy of the hybrid weighted link prediction algorithm.
Introduction
In the era of rapid development of the internet, it is easier to find and meet more suitable partners. Internet records detailed personal information about scientists, and the possibility of cooperation between scientists who do not know each other is greatly increased. Scientists relying only on information exchanges in small circles to find partners are far from keeping up with the development of the era, and Karlovčec et al had done a detailed study of cross-disciplinary cooperation in the process of scientists' cooperation. 1 Therefore, information mining of scientist network can not only help scientists to seek more suitable partners, but also promote the development of cross-field achievements and create new sparks.
In previous studies, researchers have investigated the characteristics of network propagation and the structure of networks in many social networks. Tang et al proposed a dynamic friend network with clustering and community features and a propagation model based on interest attributes. 2 Based on the study of the propagation process of failures, Wang et al found the two factors affecting the propagation of cascading failures, 3 and proposed a preferential attachment strategy to improve the robustness of interdependent networks against cascading failures. 4 Ma and Zhu proposed a novel rumor propagation model by taking into account the subjective judgment and diverse characteristics of individuals. 5 Wang and Qin proposed a novel method of finding and expanding the core communities in bipartite networks. 6 Cui and Wang proposed an algorithm to detect one-mode community structures in bipartite networks, and to deduce which one-mode community structures are weighted. 7
Zhu and Ma investigated how contact differences and individual similarity affect the rumor propagation process in complex heterogeneous networks. 8 Ren and Wang studied the epidemic spreading in time-varying community networks. 9 Yao and Gao proposed an SE2IR rumor propagation model with hesitation mechanism based on the actual situation of investor networks. 10 Wang et al provided two new strategies for epidemic prevention and controlled by representing different fractional rates of incubation and invasion periods. 11 Hosni et al proposed an HISB model by analyzing personal and social behaviors in social networks. 12 Liu et al used the characteristic infected cluster size to investigate the inhomogeneity of the epidemic spreading in static and dynamic complex networks. 13 Gebhart and Funk studied the emergence of higher order structures in collaborative networks. 14 Hui et al studied the statistical properties of the network by constructing a weighted network of scientific cooperation. 15
Zhou and Wang considered the difference in the sizes of the infected clusters in the dynamic complex networks, and the normalized entropy based on infected clusters was proposed to characterize the inhomogeneity of epidemic spreading. 16 Wang et al explored the propagation of multimessages by considering their correlation degree. 17 Ren and Wang studied cooperation in prisoner's dilemma game. 18 Fewer studies have been conducted to address the spread of information in collaborative networks of scientists. In fact, the publication of an article by a scientist and the resulting emergence of a collaborative authorship of scientists are similar to the process of information spread. When information about a certain research field appears in the limelight, the country needs talents to conduct in-depth research on a phenomenon or a technology, which contributes to the phenomenon of cooperation.
We can view this process as the process of information spread and use the idea of spread to analyze the phenomenon of cooperation.
It takes a long time for a scientist to go from finding a coauthor to successfully copublishing an article. Therefore, in the context of information spread in cooperation network, we analyze this phenomenon in depth. We propose the conjecture that multiple attributes of nodes affect the spread of information, improve the traditional propagation model, and construct a new simulation model to simulate the phenomenon of scientists' cooperation, which paves the way for the proposed hybrid link prediction algorithm.
Among the researches in the field of link prediction algorithms, a large part of the research is based on the form of node similarity. In the network, each node pair obtains a value according to the link prediction algorithm. For instance, the similarity index is based on local information, specifically, common neighbors, Salton Index, Jaccard coefficient, local path index, and preferential attachment are similarity indices defined using local information in the network. In addition, there are many similarity indices based on global information, such as the Matrix Forest Index, Katz Index, and Leicht–Holme–Newman Index. These similarity indices are described in detail in Lü and Zhou. 19
In recent years, the research enthusiasm for link prediction algorithms has continued to rise, but there are still many problems to be solved. Among them, there is less research on the attributes of nodes themselves and the influence of spread factors on the network. The influence of information spread data on network structure has always been a relatively active field in data mining. Researchers conduct research on information related to information spread and use mathematical formula derivation to infer network structure changes.20–28 The use of information spread is not just limited to the study of the influence of network structure, but also applied to many other fields. In our previous research, through the study of spread data, we successfully carry out the division of communities.
Tran et al simultaneously detected the community structure and network contagion between individuals in studying the activities of individuals to infer the underlying network and found coherent communities. 29 Therefore, it is possible to improve the link prediction algorithm by using the data of information spread.
From the analysis of previous work, the attributes of individuals in the scientist cooperation network are the basis for discovering the cooperation of scientists, and the factors of information spread in the network are important factors affecting the cooperation of scientists. Therefore, in this article, a link prediction algorithm based on the attributes of nodes is first proposed by studying the attributes of nodes for the scientists' cooperation network. Second, the spread factors are added to the link prediction based on node attributes after the successful simulation of scientists' cooperation by the joining cooperation related psychology and scientists personal attributes of SIS propagation model, and the hybrid weighted link prediction algorithm based on information spread factors and node attributes is proposed. Finally, the two algorithms are applied to the real scientist cooperation network to complete the validation of the model.
In this article, we investigate the phenomenon of scientists' cooperation in detail from several aspects, reflect the phenomenon of scientist cooperation network in the form of propagation, and reveal the evolution of the intrinsic structure in the cooperation network by link prediction.
Problem Description and Research Framework
In this article, we introduce node attributes and information spread influencing factors to construct link prediction models to identify potential scientists' cooperation by studying a scientist cooperation network. In reality, in addition to the existing cooperative relationship between scientists, scientists can also build an invisible cooperative relationship by studying the spread of information in the network. Cooperation network is constructed by using scientists as nodes and constructing connected edges with relationships between scientists who collaborate on publications. In the simulated network, first, the cooperation phenomenon existing in the scientist cooperation network is simulated by an improved information propagation model, and second, a single similarity index based on node attributes and a similarity index based on information spread factors are proposed.
Finally, the two single similarity indices are coupled to propose the hybrid weighted similarity index, and the relative optimal algorithm is formed by evaluating the accuracy of the algorithm to determine the weights of the two metrics. In the end, the prediction of the cooperation relationship in the scientist cooperation network is successfully performed, which provides a reference for scientists to seek partners in the future.
Cooperation Spread Model of Scientists Based on Multifactor Coupling
Modeling of the spread dynamic model
We select the classical SIS model as the base model. 30 The traditional model divides the population within the epidemic range of infectious diseases into the following three categories: state S (Susceptible), which refers to people who do not have the disease but lack immunity. These nodes are susceptible to infection after contact with infected persons. State I (Infective), which refers to a person who has contacted an infectious disease and can spread to members of state S.
In the process of information spread, there are some similarities between the spread of information and the spread of diseases. In the SIS model, the spread of information usually refers to the fact that after the information has spread for some time, the information spreads again in the network because of certain factors. In the scientist cooperation network, there is a high probability that scientists will continue to be involved in writing articles in the field after they have been involved in collaborating on articles in that field. Nowadays, people have more ways to access information independently. The spread of information is no longer limited to a small area, and two people who did not know each other may become friends by chance through the accident of information in the internet. The same phenomenon exists in the scientist cooperation network.
Theoretically, any two scientists in the world have a certain probability of cooperation, and it is easier to produce collisions of thinking. Therefore, it is very meaningful for us to predict the future cooperation of scientists. In the traditional SIS model, both the propagation rate β and the recovery rate γ are static, but information spread in the network is affected by numerous factors. So, we improve the traditional propagation model to make the process of propagation closer to the real scientists' cooperation spread effect. This paves the way for the subsequent validation of our weighted hybrid link prediction algorithm in a simulated network.
Dynamic rate of change
When information about a field of research appears in the public eye, each article is published with a ranking of its authors. This ranking is defined by the degree of contribution to the article, with the more contributing scientists being ranked higher. We define this as the scientist's degree of involvement
To characterize this variability in the degree of activity, we define the activeness of the scientist (the extent to which scientists have been affected by the field) as
The weight value of the article published by the qth author is labeled as vq in Equation (2), and its weight value increases as q increases.
The number of
R in Equation (4) represents the set containing all the keywords in the research field where this information is located, and
To better match the actual situation of information spread in the scientist cooperation network, we analyze the effects of scientists' own attributes and group effects on information spread. The effects of scientists' own attributes include the average influence of scientists' neighboring nodes. The influence of group effects includes the huddle effect and field heat effect. In our previous experiments, we studied the influence of incentive mechanism on information spread behavior and established a model of spread based on incentive mechanism in Nian et al. 31 Based on the analysis of the human search phenomenon, a new propagation model was proposed in Nian and Diao. 32 Also, in this article, to be more consistent with the actual process of cooperation situation in the scientist cooperation network, the dynamic propagation rate is redefined as a better response to the spread of information in the scientist cooperation network. As shown in Equation (6).
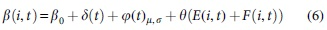
In Equation (6), 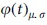 corresponds to the field heat effect.
corresponds to the field heat effect.
In Equation (7),
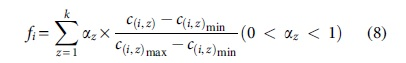
In Equation (8),
In the scientist cooperation network, information about the cooperation spreads through the network, and people's interest and state of mind change over time. The huddle phenomenon arises when information about a research field first appears among the networks and many scientists are curious about the emergence of a new field. We define this as the huddle effect. An online survey showed that the majority of respondents believed that the phenomenon of online huddle was widespread and indicated that they had participated in online huddles. However, with the passage of time and the spread of news, this effect will slowly fade over time and will no longer have a large fluctuating effect on the spread of information. In the dynamic propagation rate, we define it as Equation (10), where a and b are constants.
When a research field first appears in the public view, the field is still at a low level of enthusiasm. More and more people are involved in the research in the field when national policies are gradually improved, and the field will have a peak of enthusiasm after a period of time. When the field of research is hot, scientists will also want to use this opportunity to understand the development prospects of the field of research, and will be more willing to participate in research related to the field of information.
After a period of time, after the field heat reaches its peak, the field may reach a saturation of relevant research in the field, and the field heat returns to a plateau, we refer to this as the topic effect.
33
In the dynamic propagation rate, we define it as Equation (11).
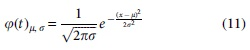
In the process of spread, the recovery rate of nodes is also affected by group effects as well as individual behavior. In the process of scientists collaborating on an article, some of the scientists who have already collaborated on an article will be involved again in collaborating on an article in the field. Over time, some scientists will have a stronger desire to go deeper into cooperation in the field and they will be more interested in this field.
However, with the influence of the topic effect, some scientists will be less enthusiastic in this field, and the novelty level brought by the huddle effect will gradually decrease. The scientists may participate in cooperation about other fields and focus on other new fields. Therefore, the recovery rate of a node is also dynamic and consists of four components, including the huddle effect, the field heat effect, the average influence of the scientist's neighbor nodes, and the activeness of the scientist. Therefore, we define the dynamic recovery rate as shown in Equation (12), where
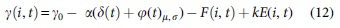
We bring Equation (5), Equation (9), Equation (10), and Equation (11) into Equation (6) and Equation (12) to obtain the dynamic propagation rate [Eq. (13)] and dynamic recovery rate [Eq. (14)].

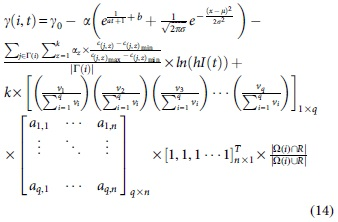
Construction of the improved spread dynamic model
In the scientist cooperation network, a node that has published an article in the field of information will influence a node that has not published a related article with a dynamic propagation rate β, so that the node knows about the information of cooperation and has a certain probability of being influenced to publish articles in the related field. After successfully publishing an article, the node changes from the S state to one of the q I states (Different I states indicate that articles are published with different ranks of authors, and q represents the number of coauthors in an article). When some node wants to publish again, the node changes to S state again and reengages in the process of publishing a new article. Therefore, we choose the SIS model to simulate the process of scientists' cooperation. The traditional propagation dynamic formulation of SIS is shown in Equation (15).
The description of the differential formula based on the improved SIS model is shown in Equation (16).
We bring the dynamic propagation rate of Equation (13) and the dynamic recovery rate of Equation (14) into Equation (16) to obtain the final spread dynamic model [Eq. (17)].
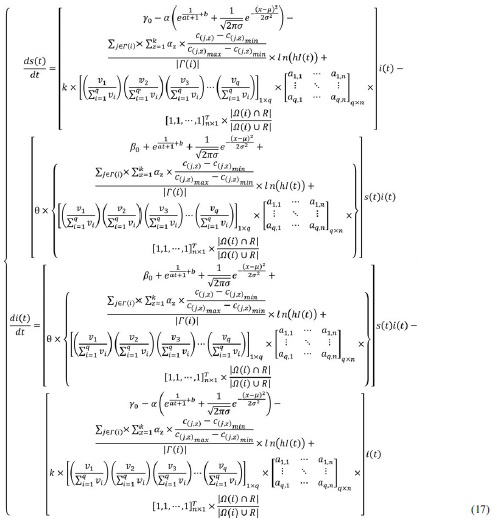
where
where N is the total number of nodes in the network, S0 is the number of susceptible infectors in the network, and I0 is the number of infected individuals in the network. It is calculated as the number of nodes infected in the network at the moment t = 0 with propagation probability as
where
Definition of Similarity Index in the Scientist Cooperation Network
If we want to use the similarity between nodes to perform link prediction, we must set a premise that the greater the similarity between two nodes, the greater the probability of the existence of connected edges between nodes. This section constructs a new similarity index by looking at the properties of the scientist cooperation network. In the prediction model of the scientist cooperation network, we first calculate the prediction accuracy of this metric for the cooperation network using the similarity index based on node attributes. Second, we calculate the prediction accuracy of this index for the cooperation network using the similarity index based on information spread factors. Finally, the hybrid weighted index based on node attributes and spread factors is constructed by combining the attribute similarity index as the base indicator with the proposed similarity indicator based on information spread factors. The three similarity indexes are described in detail in this chapter.
Similarity index based on the node attributes
The degree of similarity of the preexisting attributes between scientists influences the search and matching of partners. Similar research fields and similar institutions, as well as the same job titles, represent the common pursuit of research areas among individuals. Therefore, individuals with similar attributes have a higher probability of connection and they are more likely to produce cooperation in the scientist cooperation network. In contrast, scientists with lower degrees of similarity have a relatively lower probability of cooperation. In this article, attribute similarity is defined as the number of common attribute labels shared between nodes. Based on this, we propose a formula for calculating the similarity index based on node attributes, as shown in Equation (20).
where
Similarity index based on information spread factors
The SIS model which takes into account the psychological effects and personal attributes of scientists involved in the process of cooperation is used to simulate the process of information spread in the network. After the information spread in the network, the nodes will be infected with several states because the nodes are infected with different degrees of information. We put the nodes infected with different states into different sets and only consider the nodes in the same set that have a higher degree of similarity to each other. If there is no infection of a state, the similarity index is 0.
To quantify the degree of similarity of nodes in the same set, we define the value of the spread factors as
Hybrid weighted similarity index for information spread factors based on node attributes
On the basis of the similarity index of node attributes, we consider the information spread factor, and construct the hybrid weighted similarity index for information spread factors based on node attributes to predict the cooperation relationship. Compared with the traditional single-link prediction index in the prediction of scientists' cooperation, the mixed weighted similarity index takes not only the nodes' own attribute information, but also the evolution in the network from a global perspective into account. We calculate the probability of collaboration between scientists from different perspectives to provide more accurate predictions. The calculation is shown in Equation (22).
Simulation Experimental Design and Analysis
Data set division method
First, the known connected edge E is divided into two parts: the training set ETand the test set EP. Only the information in the training set can be used when calculating the fractional values, obviously
To test and compare the performance of the link prediction algorithm based on spread factors, a portion of the simulated network needs to be selected as the training set for information spread. Since information is spread according to its neighboring nodes, the information cannot be spread to the set of unconnected nodes if the delineated training set is not connected. Combining the properties of propagation, we need to ensure that the training set remains connected after sampling. The specific process of dividing the test set and training set is as follows.
In this experiment, 90% of the edges in the simulated network are used as the training set EP, and 10% of the edges are used as the test set EP. The number of edges in EP is calculated from the number of edges in the simulated network, which we denote as
We select a randomly connected edge e in the network and delete the connected edge e.
We need to determine whether the network after deleting this connection is fully connected. If the answer is yes, we put this connecting edge into the test set. If the answer is no, we put it back again and return to step 1.
Repeat steps 2–3 and monitor the number of edges in EP. When the number of edges is equal to
Evaluation index
There are various measures of the accuracy of link prediction algorithms, and the common ones are AUC,
35
accuracy,
36
and ranking score.
37
In this article, AUC is chosen as a measurement tool for the accuracy of link prediction algorithms, and the AUC
38
is calculated as follows.
AUC can be understood as the comparison of the probability of a high score calculated by the link prediction algorithm for a randomly selected edge in the test set versus a randomly selected edge among nonexistent edges. So, the degree to which AUC is greater than 0.5 measures the degree to which the algorithm is more accurate than the method of randomly selecting connected edges.
Experimental simulation and analysis
Construction of cooperation simulation network for scientist
After analyzing the crawled scientist cooperation network, we construct a virtual network model. The goal is to construct a simulated network
By observing the real scientist cooperation network, we can find that the scientist cooperation network is characterized by small-world phenomenon and scale-free property, and the degree distribution of the network obeys power-law distribution. However, the underlying small-world and scale-free networks cannot reflect the distribution characteristics of node attributes. Therefore, we construct the simulation network. The process of building the simulation network is shown below.
1. A network structure containing N nodes without concatenated edges is constructed, and each node follows the six virtual attributes of the real scientist cooperation network: research area, current institution, current title, number of publications, number of citations of published articles, and number of years of research time. These attributes are used for later studies.
2. The similarity of attributes between all nodes in the network is calculated and the values of similarity are ranked. The formula for calculating the similarity y between nodes is shown below, where
3. Connected edges are created based on observing the sparsity of connected edges in the real network. We consider the possibility of cooperation between scientists in similar research fields and scientists in different fields in the real network. So, we add random edges to the set of edges with high similarity and randomly select a certain proportion of edges to be connected. We simulate the cooperation phenomenon in the real scientist network by controlling the proportion of similarity-linked edges and random-linked edges.
We use the above steps to construct the simulated network with the number of nodes N = 3000 and N = 6000, and visualize the network with Gephi software. We can see more intuitively the similarity between the simulated network and the real network by the visualized graph. In Figure 1, the same color of the nodes represents the nodes with high similarity to the research field and the institutions they belong to. The neighbors of some nodes are also marked with different colors to simulate the cooperation of some scientists who have produced collaborative relationships in the real network. Nodes of the same color represent groups of scientists who have had collaborative relationships. Figure 2 shows the cooperation of the real network. It can be found that there are some scientists who collaborate in the same field and the similarity between them is relatively high.

Cooperation of nodes in the simulated network.

Cooperation of some nodes in the real network.
There are some scientists who collaborate across fields and the similarity between them is relatively low. Therefore, it is found that the phenomenon of cooperation in the simulated network can be well represented in the network of scientists' cooperation by comparison. Figure 3 shows the degree distribution of the simulated network graph and the real scientist cooperation network with a power-law distribution. We conclude that the constructed network is consistent with the small-world and scale-free characteristics embodied in the real network.
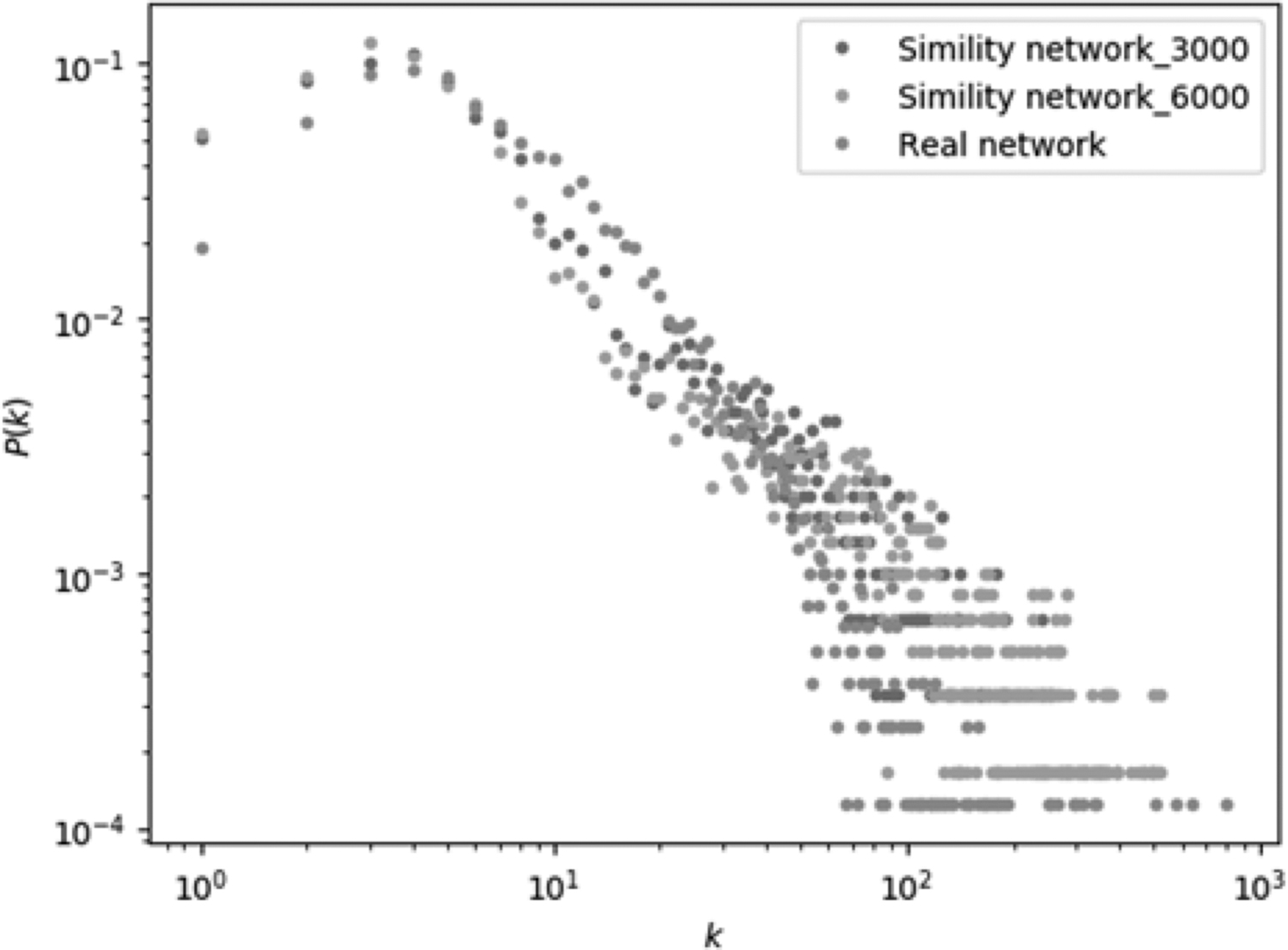
Degree distribution of the real and simulated networks.
Simulating information spread in the network
After the test set and training set are divided, the multifactor-coupled scientist-based collaborative propagation model is simulated in the training set, and the simulation process is shown in Figure 4. Figure 5 shows the information infection density plot after simulating the propagation in the training set network. Since there are certain articles with more collaborating authors, we select the top four subauthors for simulation and statistics after observing the real network. Thus, we divide the authors into first, second, third, and fourth authors according to their cooperation, corresponding to the I1, I2, I3, and I4 states of the nodes. The remaining scientists who are not involved in information spread (no publications related to this field), the state of these nodes is S. Scientists will publish different articles with different ranks of authorship. Thus, in the simulation experiment, each node will be infected with one or more states.
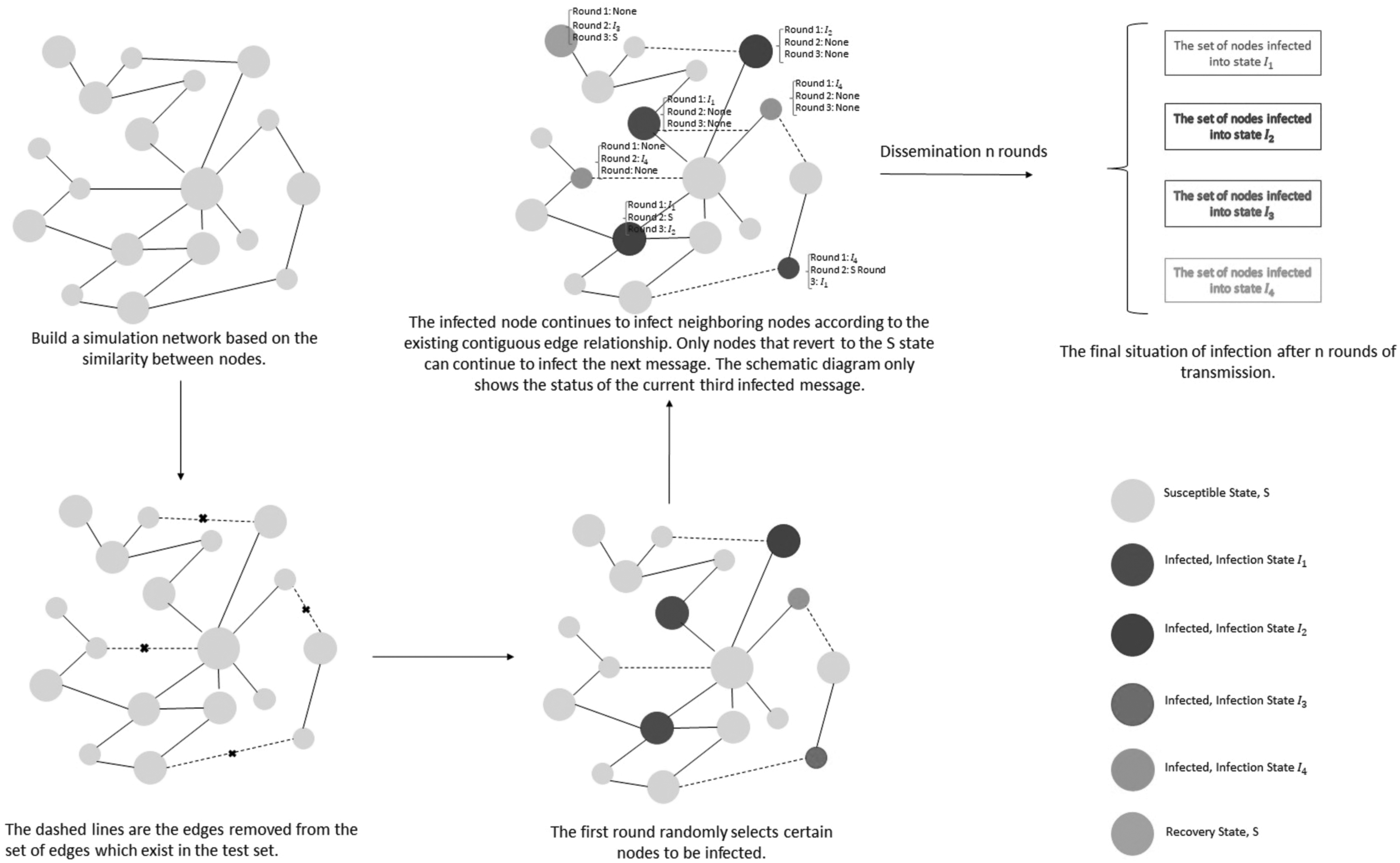
Schematic diagram of simulated information spread in the training set.

Diagram of density change of information infection in the training set.
The authorship of articles published as first, second, third, and fourth author derived from the simulation propagation is put into the sets C1, C2, C3, and C4. We get the nodes infected with different states and put the nodes infected with the same state into the same set after the end of the simulation spread.
It can be seen from the information infection density diagram that all simulated infections have a tendency of first increasing and then decreasing, and then becoming stable after a period of time. This is because in the process of scientists' cooperation at the beginning, the high level of interest in the involvement of everyone in the publication of articles will reach a peak in the number of cooperations within a certain period of time due to the rise of a certain research area. After a period of time, scientists' cooperation becomes less influenced by the group effect, and thus, the share of individual scientist's influence becomes larger. Therefore, the situation of thesis cooperation gradually tends to be relatively stable.
Figure 6 shows the statistics of real network cooperations. Among the real scientist cooperation network, the research in related fields is still high due to the fact that most of the crawled scientists and published articles belong to communication- and computer-related fields. For the scientist cooperation network, the time span of scientists' cooperation to publish articles is long, and it may take a year or more from prepreparation to publication, and so, there is a certain delay in response to the information. Therefore, the cooperation trend that we observe for real networks is still on the rise. However, every research field will eventually be replaced by other new scientific technologies. So, we have reason to believe that after a few years, the number of publications related to this field will fall back to a relatively stable value in a fluctuating range.
Statistical chart of real network cooperation.
Comparison of algorithm performance in the simulation network
Prediction of cooperation relationship based on similarity index of node attributes
Before information spread, the fraction of connected edges between nodes in a simulated network with 3000 nodes is calculated using a similarity index based on node attributes. The distribution of attribute similarity values is shown in Figure 7.
Using the AUC evaluation index, 672,400 independent comparison experiments are conducted and 10 sets of experiments are done to take the average. Finally, the AUC value is calculated by using the similarity index of node attributes, and the result is 0.7645.
Prediction of cooperation relationship based on similarity index of information spread factors
After the simulation of network spread, the infection situation set of nodes is collected. We use the similarity index based on information spread factors to calculate the edge score between nodes in the simulation network with 3000 nodes. The average AUC is 0.6545, and the prediction effect of this algorithm needs to be improved obviously.
Prediction of cooperation relationship based on a mixed weighted similarity index of node attributes and information spread factors
After the infection situation set of nodes is collected, how to add spread factors to the link prediction algorithm is the focus of our thinking. In this article, only this case of similarity between nodes in the set of infections with the same state is considered. Combined with the observed distribution of attribute similarity values, we consider the value of the weight occupied by the spread factors (
We conducted 672,400 independent comparison experiments and monitored the variance of the accuracy during the experiments, thus ensuring that the experimental calculation error is within a reliable range. By adjusting the parameter
It is found by Figure 8 that we can find the relatively optimal value to improve the prediction accuracy of the link by adjusting the values of

Distribution of attribute similarity values in the simulation network.
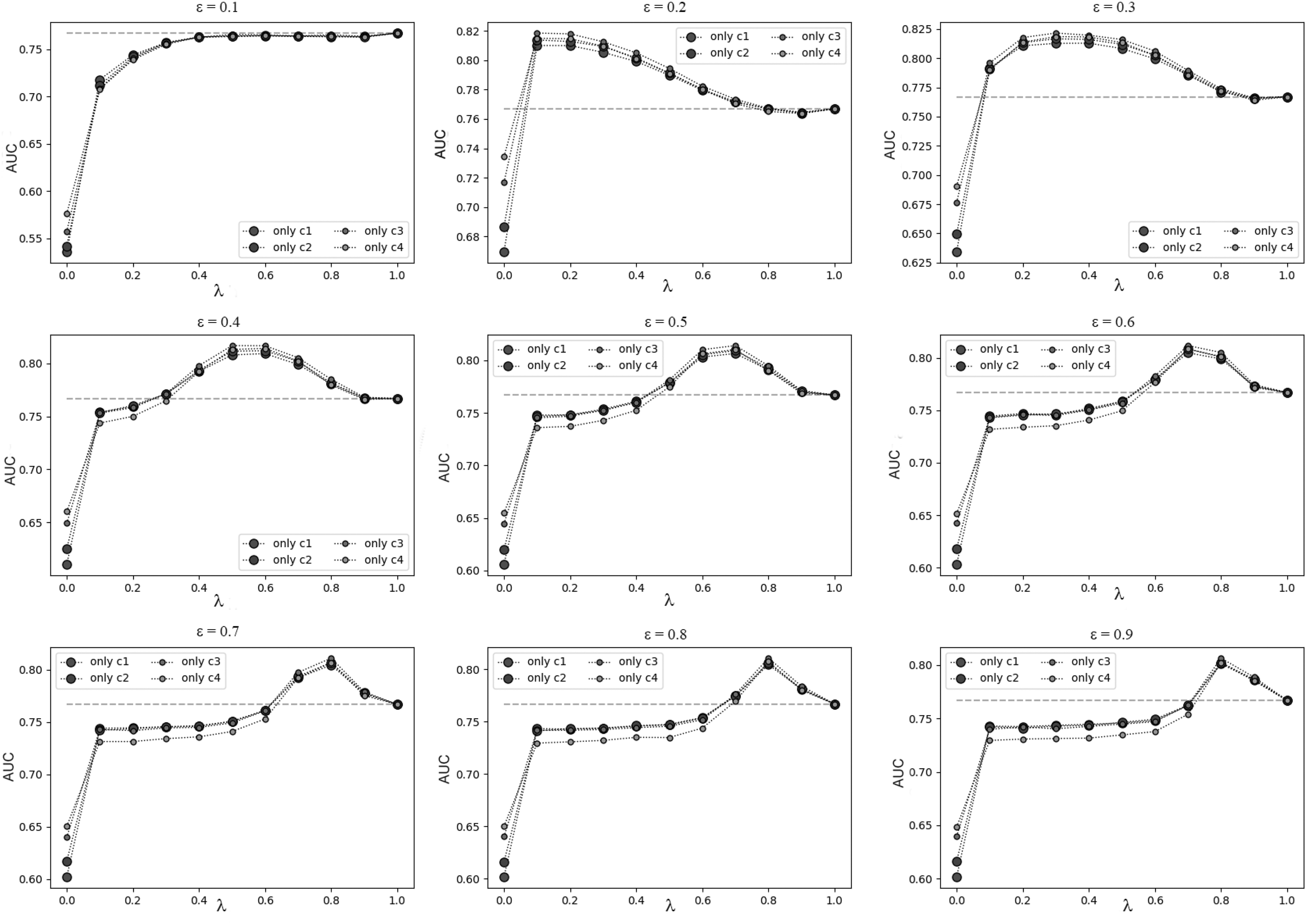
The direction of AUC variation in the simulation network.
Experiments and Analysis of the Real Network
To verify that adding information spread factors to the link prediction algorithm can improve the correctness of the accuracy of the link prediction algorithm in the real scientist cooperation network. In this section, the effectiveness of the proposed hybrid weighted link prediction algorithm combined with information spread is verified by statistical data of real network and link prediction algorithm in a simulation experiment.
As the data set of the existing cooperation network of scientists in the internet rarely contains the attribute information of scientists, it is impossible to use the attributes of scientists to analyze. Therefore, we use the internet as a huge carrier and the web crawler technology to obtain data sets with node attributes. This website mainly records the communication engineering scientists and computer related scientists from 1990 to the present part of the cooperation.
The contents of the crawl include the author's coauthors, the articles produced by the collaboration, the publication time of the article, the order of the authors of the cooperative articles, the author's personal information, including nationality, current affiliation, and research area. Some scientists only have the ID (a unique identification of a scientist) value of the node, but there is no record of the attribute of the scientist. So we sift through the data and finally analyze the attributes of 7747 scientists and 104,736 collaborations between these scientists.
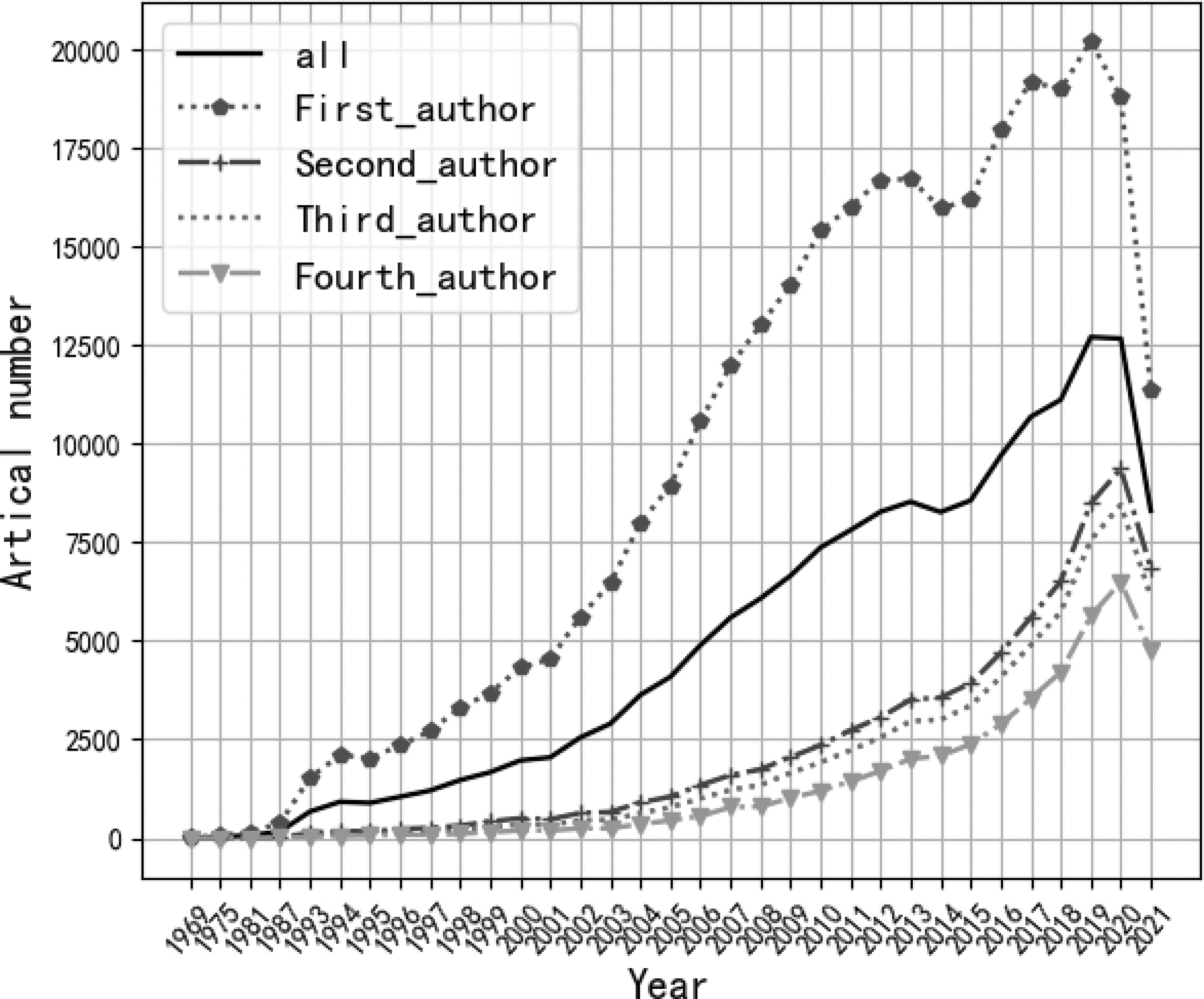
Figure 9 is a schematic diagram of the number of articles. The ordinate of the figure is the number of articles published, and the abscissa is the time when the articles are published. We can see when a certain event occurs by looking at the graph of the number of articles published. The number of articles published in the related field is sharply increasing, and then in the following years, the number of articles published increases more and more slowly and tends to fall back. By looking at the data in Figure 9, we can see that the number of publications fluctuates from year to year.

Trend in the number of articles.
After the concept of 3G network was introduced, a large number of scientists flocked to the field of wireless communication, and the number of publications increased substantially in the following years. On May 13, 2014, Samsung Electronics announced that it had pioneered the development of the first mobile transmission network based on 5G core technology. Therefore, we find that when the 5G wireless communication technology started to be proposed, the number of articles has increased substantially compared with the previous ones. This means that there are many scientists who are actively responding to the call to start researching about wireless communication technologies and collaborating to publish articles.
There is a tendency for the number of articles to decrease after the year 2000. Two reasons are analyzed as follows. One is that the number of articles published with wireless communication as the main content has decreased due to the impact of the global epidemic in 2020. The second point is that the wireless communication industry is steadily evolving and the discovery of new areas of relevance is becoming more difficult. This confirms that in the network of scientists' cooperation, the cooperation is influenced by the information spread factors.
Figure 10 provides a count of the number of authors who publish in different positions. By looking at the percentage of the number of each scientist who publish articles with the first seven authors, it is found that the majority of cases are involved in publishing articles as the first four scientists. Therefore, in the scientist cooperation network, only the nodes published by the previous four authors are selected as the nodes we consider to participate in information spread.
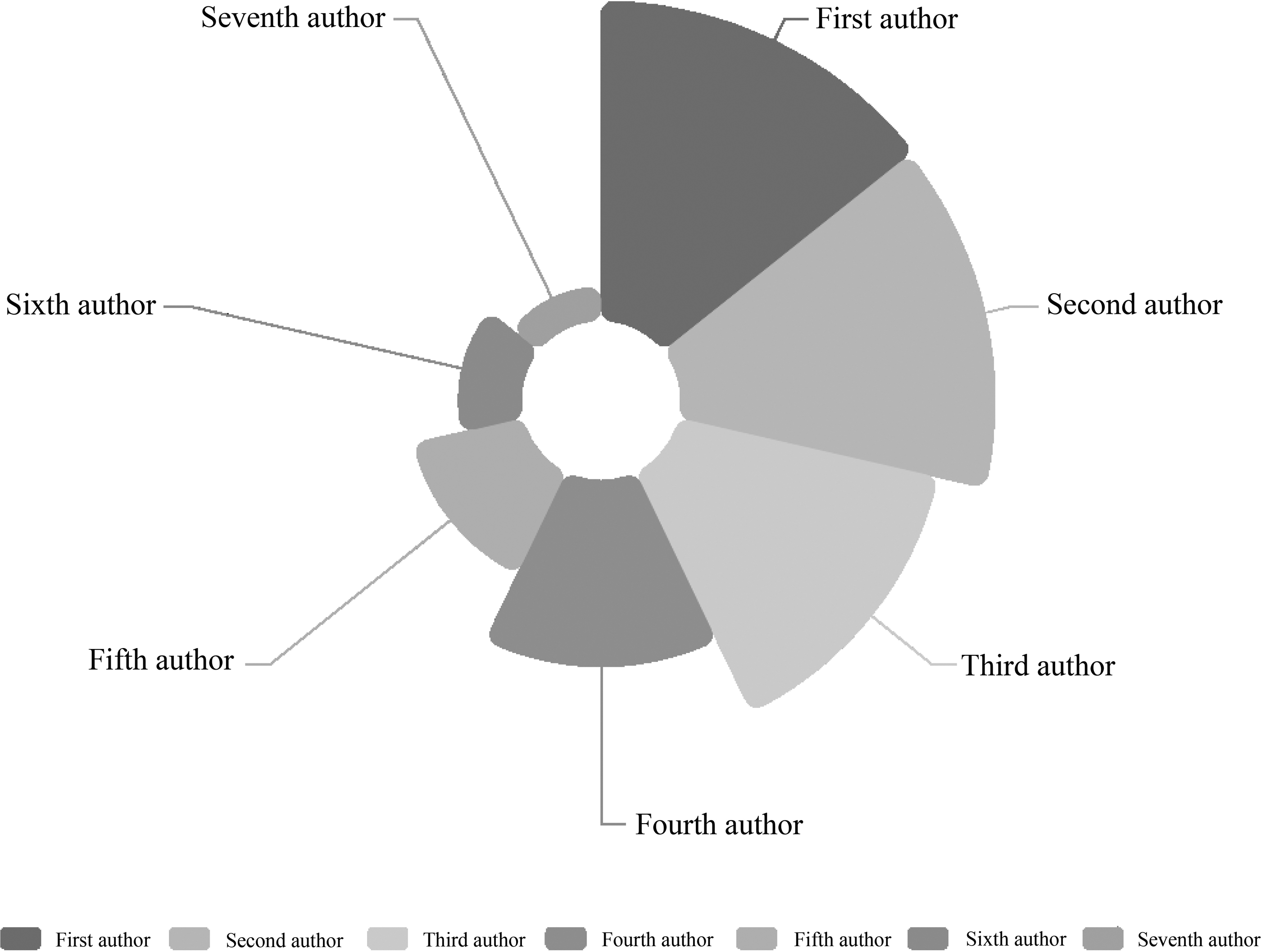
Percentage of the number of scientists who published in the previous seven positions.
Figure 11 is the distribution diagram of the attribute similarity values of the edges in the real scientist network calculated according to the similarity index based on the node attributes. It can be observed that the connected edges with attribute similarity values below 0.09 are around 91%. Therefore, the value of
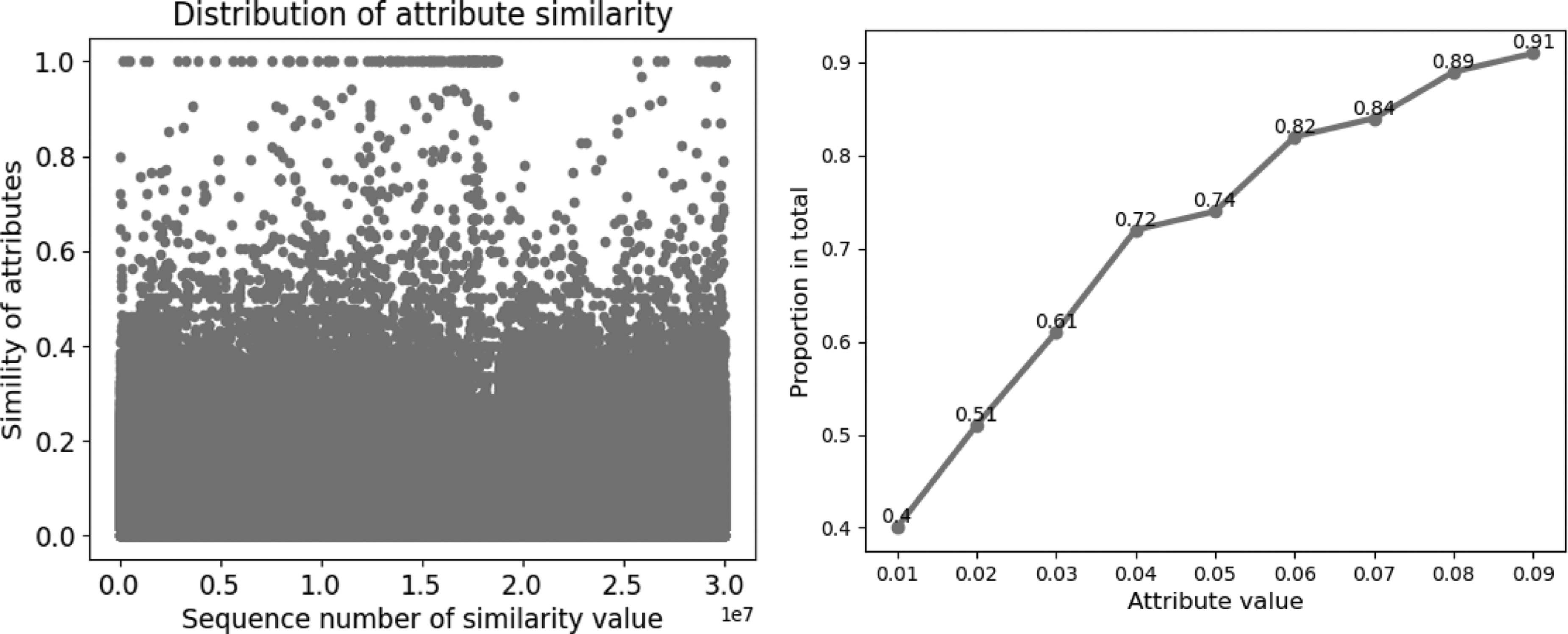
Distribution of the attribute similarity values in the real network.
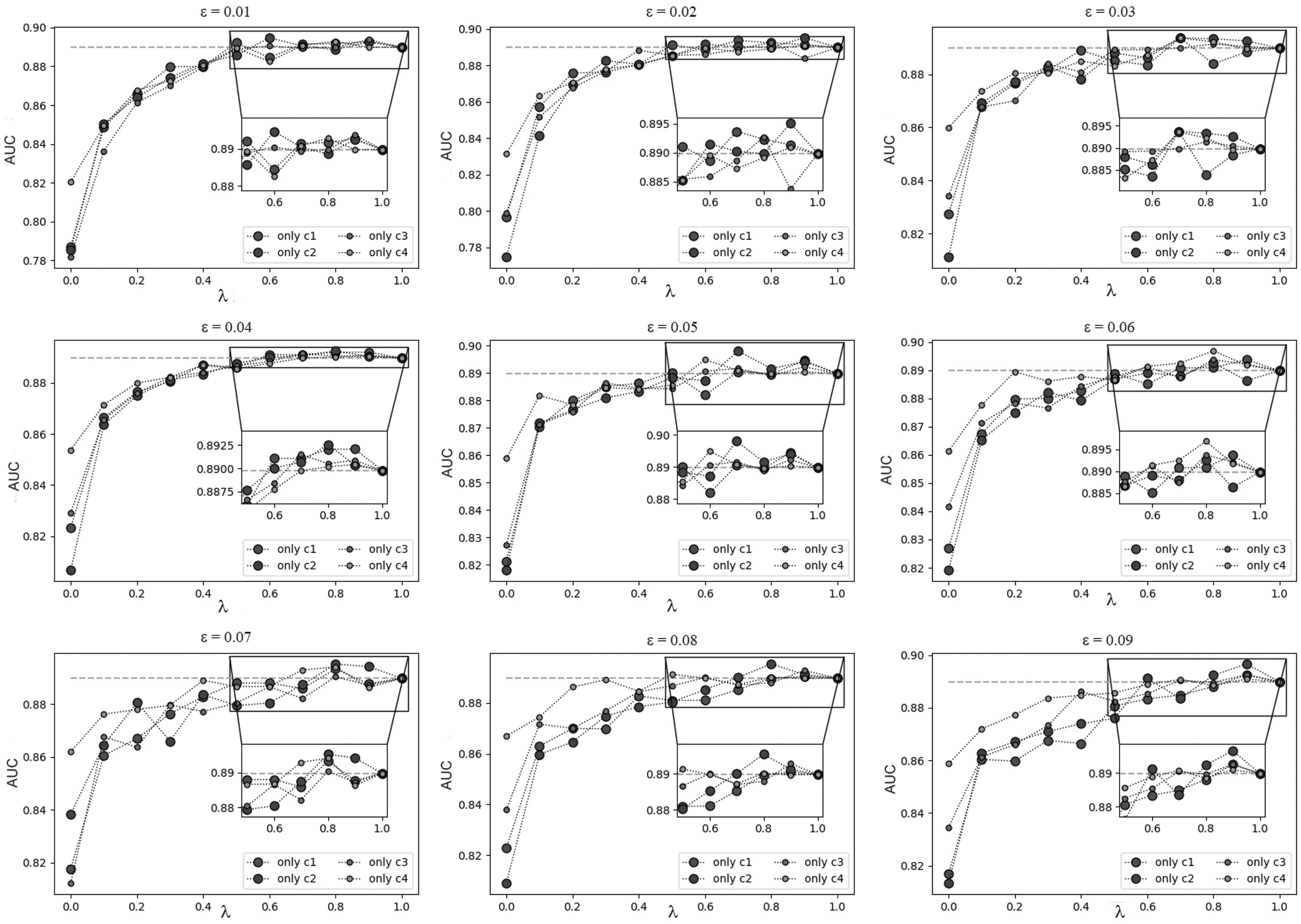
Trend diagram of AUC changes in the real network.
When the value of
Although the improvement is not as large as that of the simulation network, it is because in the scientist cooperation network, the composition of the network and the formation of cooperation are not only affected by the attributes of the nodes, but also affected by many other factors, which also reflects the complexity of the network. However, through experimental analysis, it can be found that in the process of cooperation between scientists, the objects of cooperation between scientists tend to be close to their own research fields, and authors who have published articles with a higher ranking among previous scientific research results.
Conclusion
This article studies the spread of information on the scientist cooperation network and the characteristics of the information in the process of spread. We add the influence of the information on the nodes in the network after the information spread into the link prediction algorithm, and design the hybrid weighted similarity index for information spread factors based on node attributes. It is proved that adding propagation factors into the link prediction algorithm will improve the accuracy of the link prediction algorithm, which has a certain theoretical significance and practical value for scientists to seek the recommendation of partners and predict cooperation.
In this article, a simulation network with small-world and scale-free characteristics is first constructed, and the improved SIS model is used to simulate the phenomenon of scientists' cooperation on the simulation network. The simulated cooperation is then further statistically and analytically analyzed, and the statistical results are added to the link prediction algorithm. We find that the accuracy of link prediction is improved by adding the information propagation on the network to the algorithm of link prediction. In the real network, the proposed idea is verified by analyzing the node attributes of the scientist cooperation network and the situation of the cooperation.
In the process of future research, the accuracy and universality of link prediction algorithms should be verified in networks with other characteristics. How to add the influencing factors of information spread into the link prediction algorithm and improve the accuracy of the link prediction algorithm is also a work that needs to be carefully studied in the future.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research is supported by the National Natural Science Foundation of China (No. 61863025), the Program for International S&T Cooperation Projects of Gansu province (No. 144WCGA166), the Program for Longyuan Young Innovation Talents, and the Doctoral Foundation of LUT.