
Abstract
In material science and engineering, the estimation of material properties and their failure modes is associated with physical experiments followed by modeling and optimization. However, proper optimization is challenging and computationally expensive. The main reason is the highly nonlinear behavior of brittle materials such as concrete. In this study, the application of surrogate models to predict the mechanical characteristics of concrete is investigated. Specifically, meta-models such as polynomial chaos expansion, Kriging, and canonical low-rank approximation are used for predicting the compressive strength of two different types of concrete (collected from experimental data in the literature). Various assumptions in surrogate models are examined, and the accuracy of each one is evaluated for the problem at hand. Finally, the optimal solution is provided. This study paves the road for other applications of surrogate models in material science and engineering.
Introduction
Human lives are full of artificial materials; however, concrete is the most common man-made material used in construction. Three basic ingredients of concrete are water, cement, and aggregate. However, many natural and artificial additives are used to impose specific characteristics on concrete, such as high strength or durability. Determination of the impact of various ingredients on the properties of concrete was always one of the challenges in material science. This research field is typically supported by large experimental programs coupled with data analysis and postprocessing the findings.
More specifically, predicting the mechanical properties of concrete mixes can help improve our understanding of their behavior and may lead to the development of robust design codes and standards. Developing such predictive models is not new, and the application of simple statistical models in terms of linear and nonlinear regression analysis goes back to a hundred years. 1 These models aimed to provide an analytical formula to determine the unknown parameters affecting the relationship between concrete strength and its ingredients or environmental variables.
With the development of machine learning (ML) algorithms, many researchers have adapted one or more techniques for concrete strength prediction. The two main objectives were as follows: (1) develop a practical relation that can assist practitioners in analysis and design, and (2) compare the accuracy and performance of various ML algorithms. This study will not dive into the pool of hundreds of articles on the application of ML in concrete mix and concrete structures. Multiple state-of-the-art review articles have discussed this topic more in detail.2–4 Several researchers have compared and contrasted ML algorithms in prediction of concrete strength: Young et al. 5 compared artificial neural network (ANN), decision trees, and support vector machines (SVM); DeRousseau et al. 6 compared regression trees, random forest (RF), and boosted trees; Cook et al. 7 applied ANN, SVM, RF, and several hybrid models; and Abuodeh et al. 8 used deep ML techniques.
With too many applications of ML in the prediction of concrete compressive strength, there is not yet any application of polynomial chaos expansion (PCE), † Kriging, and their family in this field. PCE is capable of capturing the stochastic relation for complex and nonlinear systems using homogeneous orthogonal polynomial basis functions, 9 and thus is a good candidate to be used in material science. Berveiller et al. 10 used PCE to update the long-term creep strains in concrete structures.
Kriging (also known as Gaussian process modeling/regression) 11 is an efficient surrogate model for problems with high nonlinearity. Hoang et al. 12 used Kriging for modeling compressive strength of high-performance concrete with only seven input parameters and compared the results with ANN and SVM. Verma et al. 13 compared several kernel-based methods, including Kriging, to predict the compressive strength in a small data set of only 50 samples and 4 input parameters. Afshoon et al. 14 proposed a combined method of Kriging with U-learning function and K-means clustering to predict the concrete fracture energy using a limited number of inputs. Asteris et al. 15 compared Kriging with ANN, multivariate adaptive regression splines, and minimax probability machine regression in the prediction of concrete compressive strength. The input variables include only seven variables, and more than a thousand experimental data have been used.
Aside from application-oriented articles, several major studies compared the performance of surrogate models, including PCE 16 and Kriging. Hadigol and Doostan 17 provided a state-of-the-art review on least-squares PCE with various sampling strategies. Luthen et al. 18 provided a comprehensive survey on sparse PCE methods, including benchmark problems.
On the contrary, due to fast development of information technology, a large amount of information has been collected in many branches of material science, which necessitates the application of big data management. The term “big data” has been used for in 1970s in an article related to atmospheric and oceanic soundings to point out to large amounts of collected data for that project. However, its concept has been altered in the past two decades, and nowadays it mainly refers to data that surpass the processing capacity of conventional data management systems and software tools to capture, store, manage, and analyze. The big data research can be tackled in different ways 19 : (1) collection, storage, and management, (2) data analytics, and (3) data sharing and collaboration. Material science data analytics to develop surrogate models sometimes is beyond the capacity of a single computer, and thus, parallel computing and collective mining are required.
Omran and Chen 20 conducted a comprehensive research on the application of big data in various aspects of construction-related research area. They reported that the big data has a low percentage of articles related to concrete and construction materials, and thus, this research field requires more attention.
Torre et al. 21 discussed the PCE as an ML regression and its application for big data analytics. Grasedyck et al. 22 and Kishore Kumar and Schneider 23 discussed various low-rank approximation (LRA) techniques, and Udell and Townsend 24 explained the effectiveness of low-rank models in big data science. On the contrary, big data is always challenging to be used in conjunction with ML and surrogates models. 25 van Stein et al. 26 proposed an optimally weighted cluster Kriging for big data regression. In this approach, several Kriging models built on disjoint subsets of the data are properly weighted for the predictions. Kleijnen and van Beers 27 proposed a simple one-shot design founded on the nearest neighbors of the new database to handle the hyperparameters in Kriging models of big data.
According to the above-discussed literature survey, the application of PCE and Kriging is immature in material science. In addition, the available research is mainly simple applications on various databases with a limited number of input variables. Such a database is not challenging for PCE and Kriging, as their central promise is to handle complex and nonlinear models. Therefore, this study aims to provide a comprehensive application of PCE, Kriging, their combination (i.e., polynomial chaos Kriging), as well as canonical LRA in material science. More specifically, we explore the application of these four surrogate models to predict the compressive strength of concrete mixes with normal aggregates and reclaimed aggregates with a large number of input variables. To the best of the author's knowledge, such research has not been conducted before.
The Theory of Surrogate Models section provides a short and high-level review on the theoretical underpinning of the applied surrogate models. The Description of Database section describes the database and the basic relationship among the input parameters. The Results and Discussion section discusses the results of surrogate models, and finally, the Conclusions section summarizes the research findings.
Theory of Surrogate Models
Surrogate models (i.e., the meta-models) are models used to approximate the actual response of the models (either analytical or numerical). The commonly used meta-models are PCE,28,29 Kriging,30,31 canonical LRAs,32,33 and high-dimensional model representation.34,35 This section provides a high-level review of the underpinning theory of these methods.
Polynomial chaos expansion
The fundamental idea behind the PCE is to expand the model response onto basis consisting of multivariate polynomials, which are orthogonal with respect to the joint distribution of the input variables.
36
Consider an M dimensional random vector with independent components
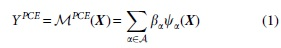
where
The standard scheme can be modified in the form of the hyperbolic truncation scheme by using the parametric q to define the truncation:

where by using q = 1, the hyperbolic truncation yields to the standard truncation scheme in Eq. (2). For
The initial computational model,

where the error
The expansion coefficients can be computed using multiple techniques, such as the least angle regression (LAR), least-squares regression, orthogonal matching pursuit (OMP), and Bayesian compressive sensing (BCS).
40
The LAR algorithm uses low rank truncation schemes and aims to find coefficient vectors with only a few nonzero entries (i.e., sparse solutions), while the other coefficients are set to zero.
41
The LAR algorithm can be formulated by expanding the least-square minimization and adding a penalty term
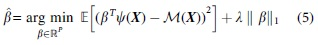
where
On the contrary, the OMP is an iterative algorithm that minimizes the approximation residual at each iteration by solving this equation 40 :
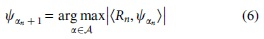
where Rn is the approximation residual for a polynomial basis with n elements. Once the basis element
Last but not least, in the BCS algorithm, a vector
Kriging
Kriging was introduced by Sacks et al.
31
in which the model response
where
The common types of Kriging include simple, ordinary, and universal. The first two are special cases of universal Kriging. The universal Kriging aims to find the best linear unbiased predictor while minimizing the mean square error of the prediction. For
where the covariance matrix
Taking the partial derivative of the log-likelihood function with respect to

The correlation function (i.e., kernel or covariance function),
Canonical LRAs
Using the same notation as of PCE in the Polynomial Chaos Expansion section, the canonical rank (i.e., a rank-one function of
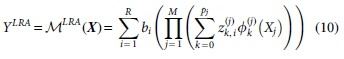
where
Description of Database
Various types of concrete have different applications and properties, such as normal strength, reinforced, high strength, roller compacted, and asphalt concrete. In this study, two databases are examined, that is, DB1: conventional concrete with additives, and DB2: reclaimed asphalt pavement aggregate concrete. 44 DB1 is traditionally used for many ML applications and includes the main ingredients of concrete with natural aggregate and few additives. The main reason to use DB2 is that a reclaimed aggregate is different from the virgin/natural one by having an extra layer of asphalt around it. This layer restrains, forming a perfect intermolecular bond between the aggregate and the mortar paste.
DB1 is primarily adapted from Yeh
45
with 425 samples (a subset of original database), with 7 input parameters, and one output (i.e., compressive strength),
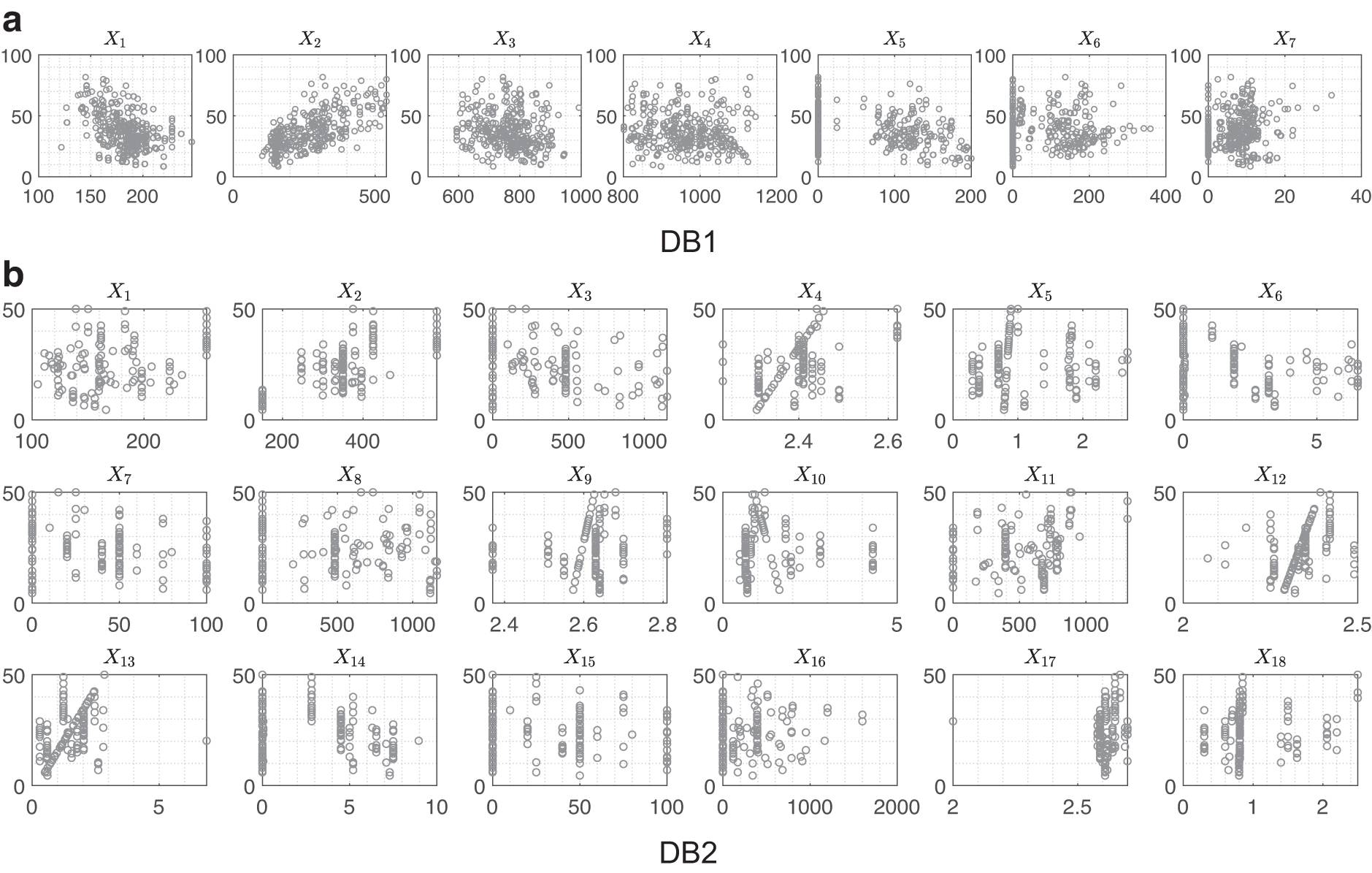
Input–output scatter plot.
On the contrary, the second database (i.e., DB2) includes 128 samples with up to 18 input parameters and one output (i.e., compressive strength),
The selected 18 input parameters are:
Results and Discussion
This section discusses the application of PCE, Kriging, and LRA surrogate models on two databases reviewed in the previous section.
Database 1 (
)
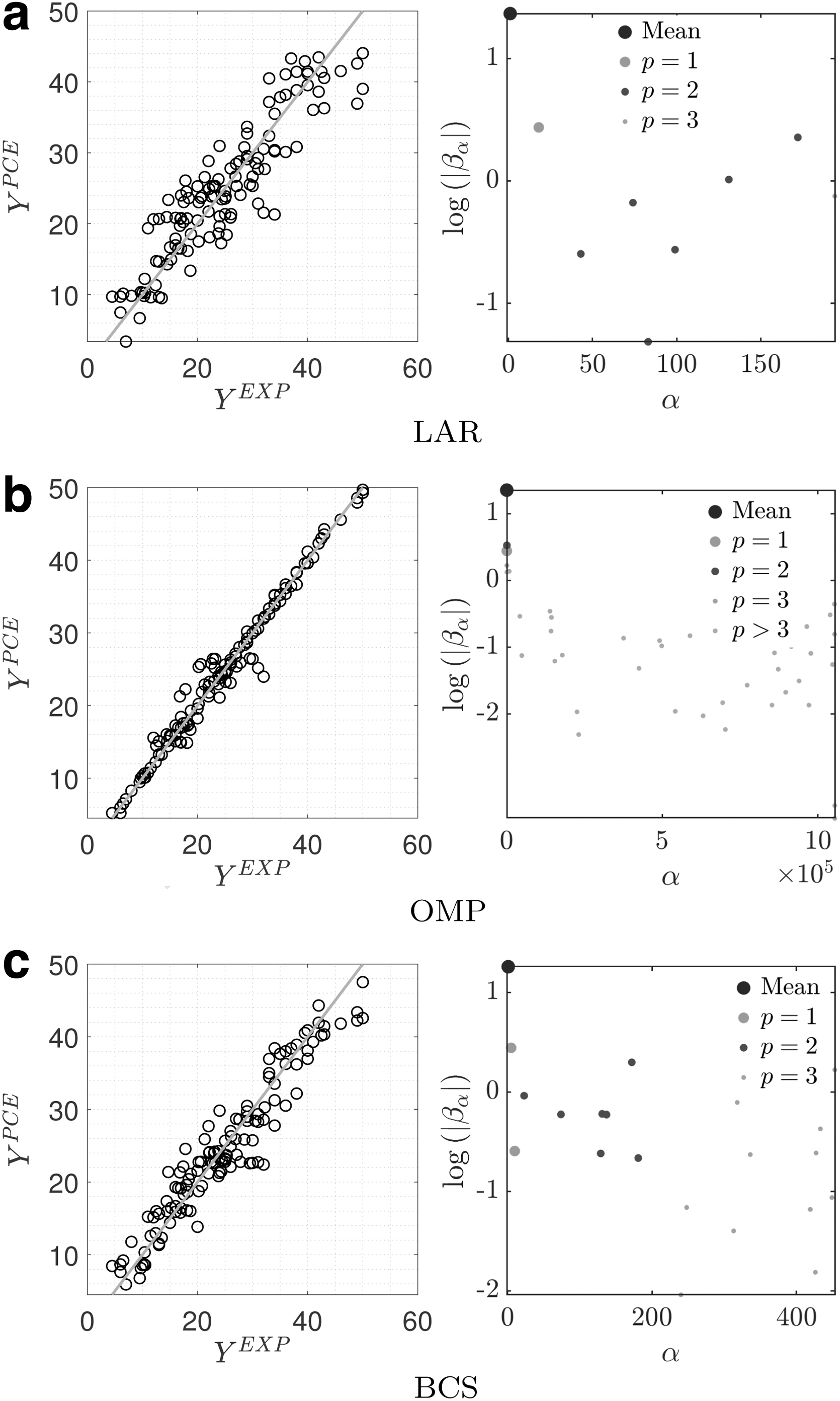
Figure 2 presents the developed PCE surrogate models using two techniques: LAR and OMP. In each case, the predicted output,

Developed surrogate models for concrete DB1 using PCE including nonzero coefficients. LAR, least angle regression; OMP, orthogonal matching pursuit; PCE, polynomial chaos expansion.
In LAR, the polynomial degrees are selected by a degree-adaptive polynomial chaos method, which varies from 3 to 15. A same method is used in OMP with degree varying from 5 to 95. In both LAR and OMP, the hyperbolic truncation scheme corresponding to
There are multiple metrics to evaluate the performance of a surrogate model. Sudret
16
proposed the LOO metric to be used for PCE and Kriging, which is formulated as follows:
where
On the contrary, Daneshvar et al. 58 collected more than 10 error metrics that can be used to compare the initial database and the predicted one. It includes mean bias error, root mean-squared error (RMSE), mean absolute percentage error (MAPE), coefficient of determination, and Willmott's index.
Some of these error metrics are computed for all the surrogate models based on DB1 and are tabulated in Table 1. As seen, the error metrics from the OMP algorithm are twice better than LAR. This is also intuitive from scatter data in Figure 2. This figure also shows the distribution of the expansion coefficients, which are eventually used to develop the meta-model. The LAR-based model has only 18 nonzero (NNZ) coefficients, while the OMP-based one includes 78 coefficients. This indeed increases the accuracy of the OMP-based model for this specific database.
Comparison of the relative error for all surrogate models based on DB1
LAR, least angle regression; LOO, leave-one-out; LRA, low-rank approximation; MAE, mean absolute error; MAPE, mean absolute percentage error; MBE, mean bias error; OMP, orthogonal matching pursuit; PCE, polynomial chaos expansion; R2, coefficient of determination; RMSE, root mean-squared error; WI, Willmott's index.
Figure 3 presents the results of Kriging using the two-correlation family: exponential and Gaussian. The correlation function (also called kernel function),
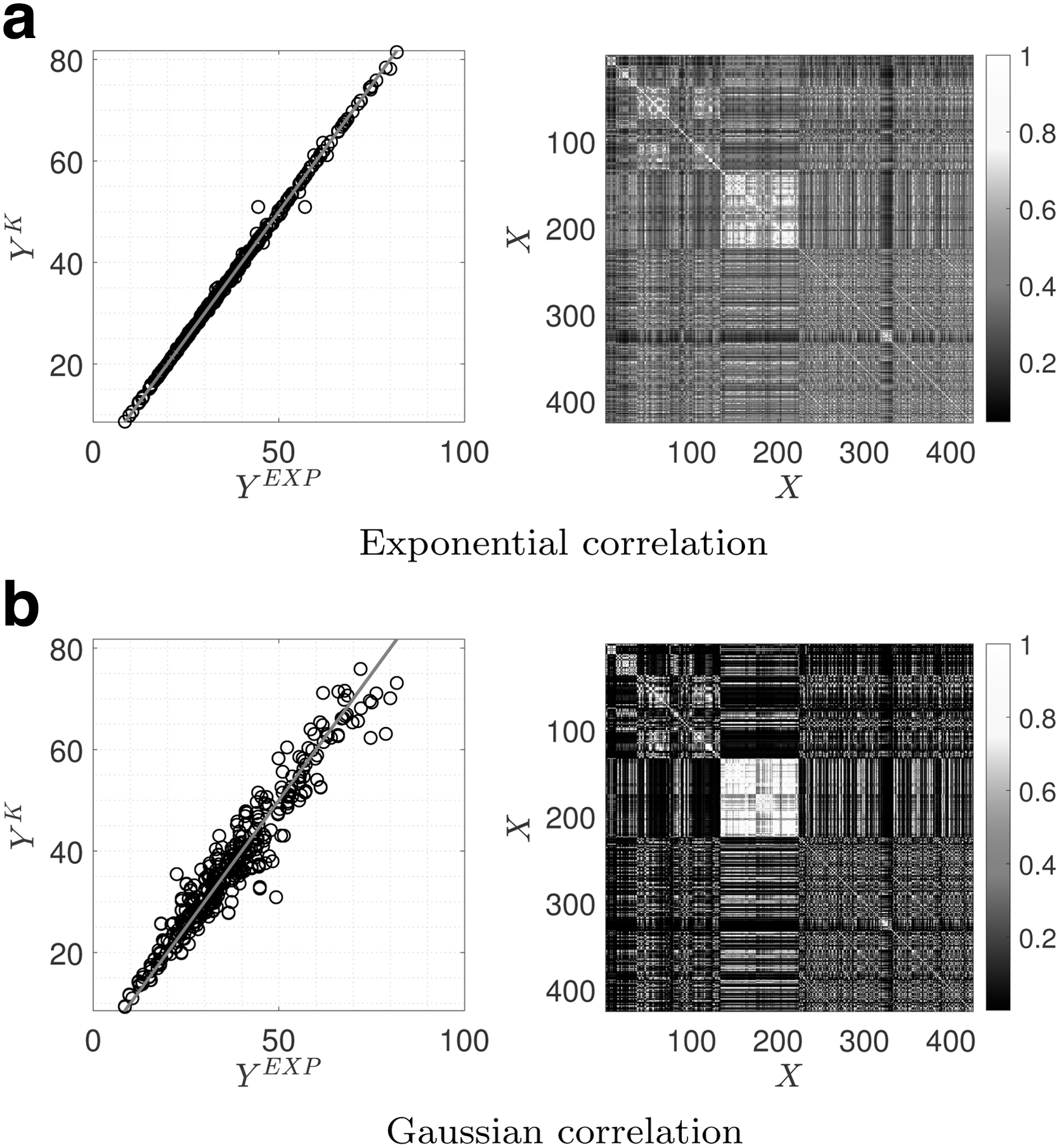
Developed surrogate models for concrete DB1 using Kriging including correlation matrix.
We have adapted the ordinary Kriging in these simulations, and thus,
Figure 4 presents the results of the surrogate models for DB1 using the LRA. The required hyperparameters for this method are as follows: the range of rank selection is set to be 1–20; and the range of the polynomial degrees is set to 6–20. Moreover, the rank and degree adaptation strategy are used in LRA. The accuracy of this surrogate model is less than PCE and Kriging, and it shows a larger dispersion. The cross-validation (CV) error (based on 10-fold CV) is 3.19 (not shown in the Table 1), and all other error metrics in Table 1 are worse than PCE and Kriging. This figure also illustrates the natural logarithm of
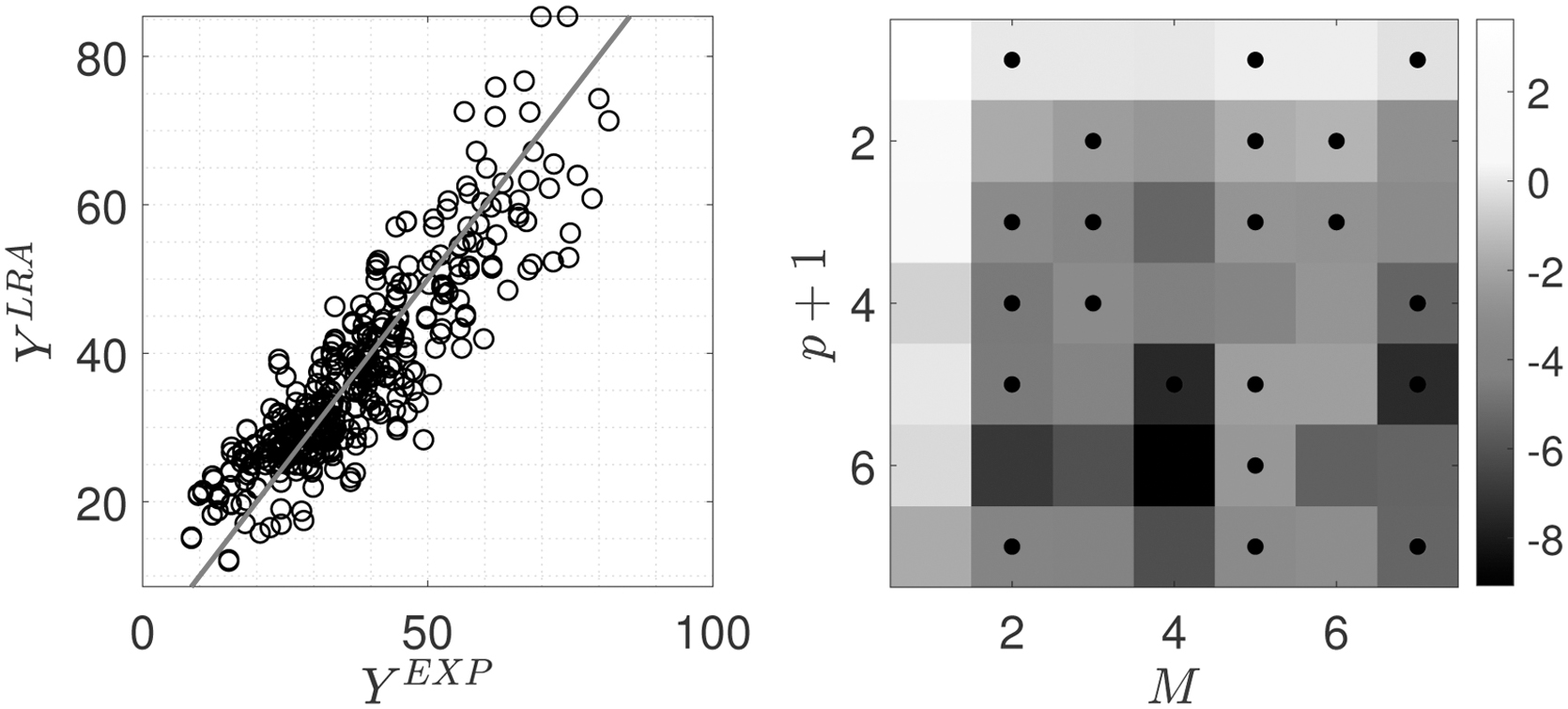
LRA-based surrogate models for concrete DB1 including the univariate polynomial coefficients. LRA, low-rank approximation.
Database 2 (
)
This section presents the results of surrogate models using database 2, which includes a larger set of input variables with a smaller sample size. In this experimental program, the ratio of the number of samples to input parameters is about 7 (which is one-tenth of the previous example, DB1). The hyperparameters in database 2 are similar to those reported for database 1.
Figure 5 presents the developed PCE surrogate models using three techniques: LAR, OMP, and BCS. Again,
Developed surrogate models for concrete DB2 using PCE including nonzero coefficients. BCS, Bayesian compressive sensing.
Table 2 summarizes all the error metrics associated with DB2 and three surrogate models. Again, the error metrics from the OMP algorithm are two to three times better than LAR and BCS. More specifically, the LOO error for LAR is 0.034, while it is 0.201 for both OMP and BCS. The scatter data points in Figure 5 also confirm this conclusion. The distribution of the expansion coefficients shows that the OMP-based model has 43 NNZ coefficients, while the LAR-based and BCS-based models have 9 and 21 coefficients, respectively. This is indeed one of the objectives of the LAR algorithm to develop the surrogate models with minimum possible polynomial coefficients. One should note that the range of
Comparison of the relative error for all surrogate models based on DB2
BCS, Bayesian compressive sensing.
Figure 6 illustrates the results of Kriging using the four-correlation family: exponential, Gaussian, linear, and Matérn-5/2, in which the first two models have been explained already. The linear correlation function is defined as follows:
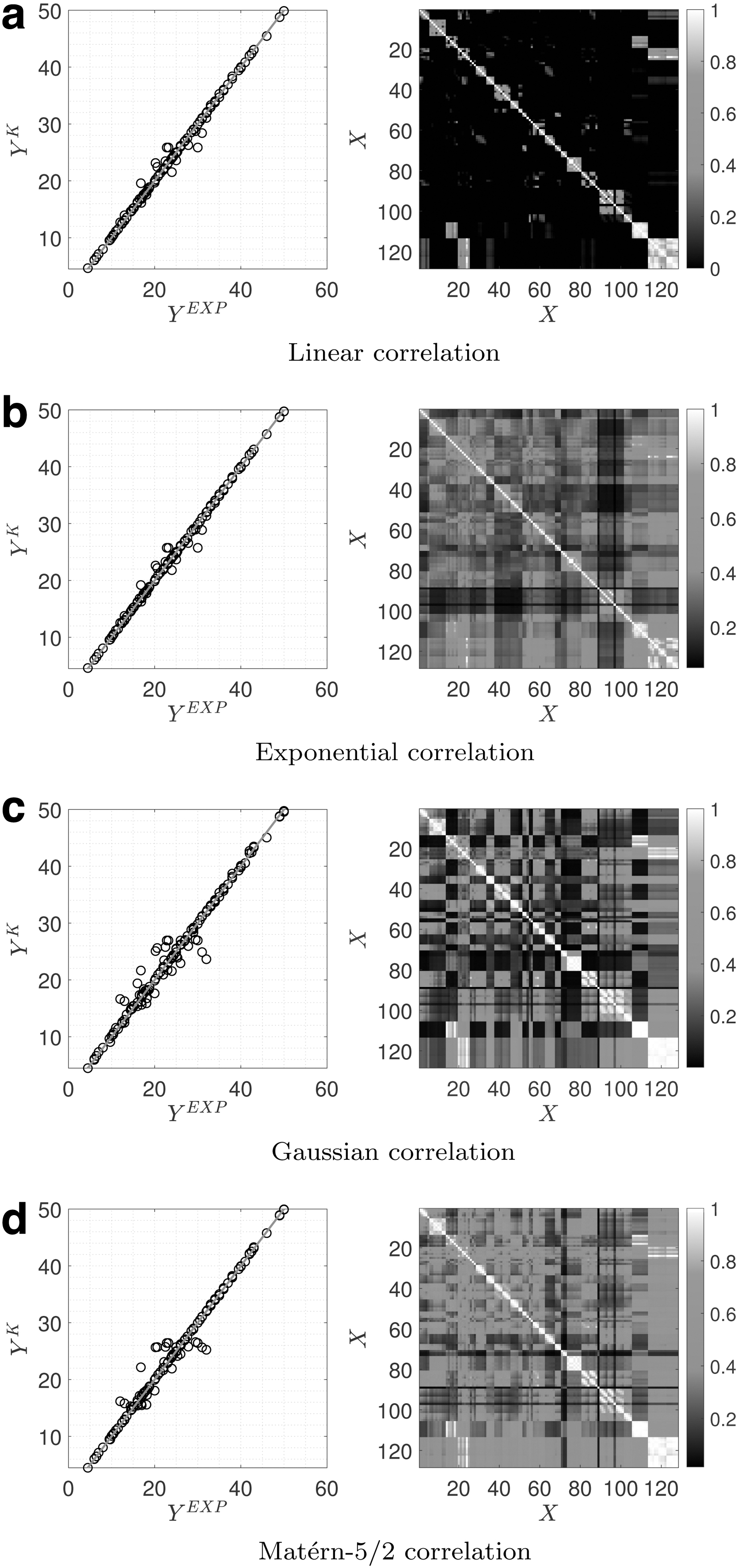
Developed surrogate models for concrete DB2 using Kriging including correlation matrix.
where v is a shape parameter and is considered 5/2 in this study. For
According to Figure 6, the linear model presents less correlation compared with the other three, while the Matérn-5/2 presents a higher correlation. Based on Table 1, the performance of various correlation function models depends on the interpretation of the error metrics. The classical metrics point to linear and exponential functions as the superior models, while the LOO presents contrarily (i.e., better performance for Gaussian and Matérn-5/2 models). This can be explained by checking Figure 6a–d. The majority of data points have nearly exact predictions based on the Gaussian and Matérn-5/2 models, while there are few outliers with larger errors.
On the contrary, the surrogate models based on linear and exponential models do not have such outliers, but their overall prediction is a bit less than the two others. The classical error metrics are based on the majority vote, and thus, they prioritize the linear and exponential models. Finally, for the ordinary Kriging models,
Figure 7 illustrates the results of the surrogate model for DB2 using the LRA. While the accuracy of this surrogate model is less than PCE and Kriging, there is no large gap as we observed for the previous example (Fig. 4). The CV error is 11.3 (not shown in the Table 1) and all other error metrics in Table 1 are worse than PCE and Kriging (except BCS-based PCE). The natural logarithm of
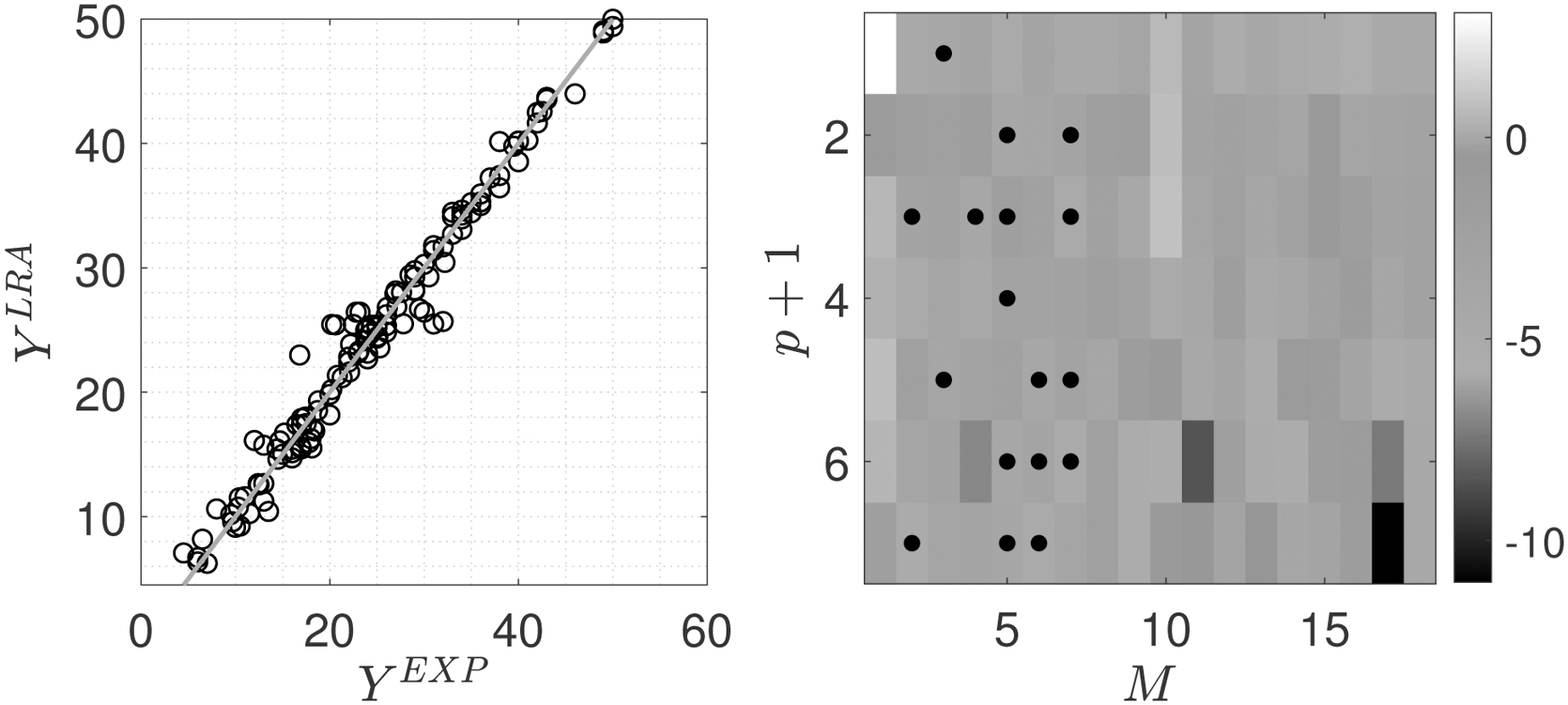
LRA-based surrogate models for concrete DB2 including the univariate polynomial coefficients.
Conclusions
In this study, several surrogate models were trained to investigate their capability in predicting the mechanical properties of materials (in our case, the compressive strength of normal and reclaimed aggregate concrete admixtures). For this purpose, three methods, including the PCE, Kriging (i.e., Gaussian process), and canonical LRA, are used to find the optimal architecture for the meta-models. The two databases used in this study are essentially different in the number of samples and input random variables. The first one (DB1) is a low-input, large-sample size database, while the second one (DB2) is high-input, small-sample size. A total of seven error metrics were also used to compare the performance of the surrogate models.
For both databases, the Kriging model outperformed PCE and LRA. It is found that the performance of the Kriging model has a direct relation to the selected correlation function. For DB1, the exponential function provided better performance considering all the error metrics. However, in DB2, decision-making really depends on the selected error metric. This is evident from Figure 8, which proposes a coupled decision-making criterion using parallel plots.
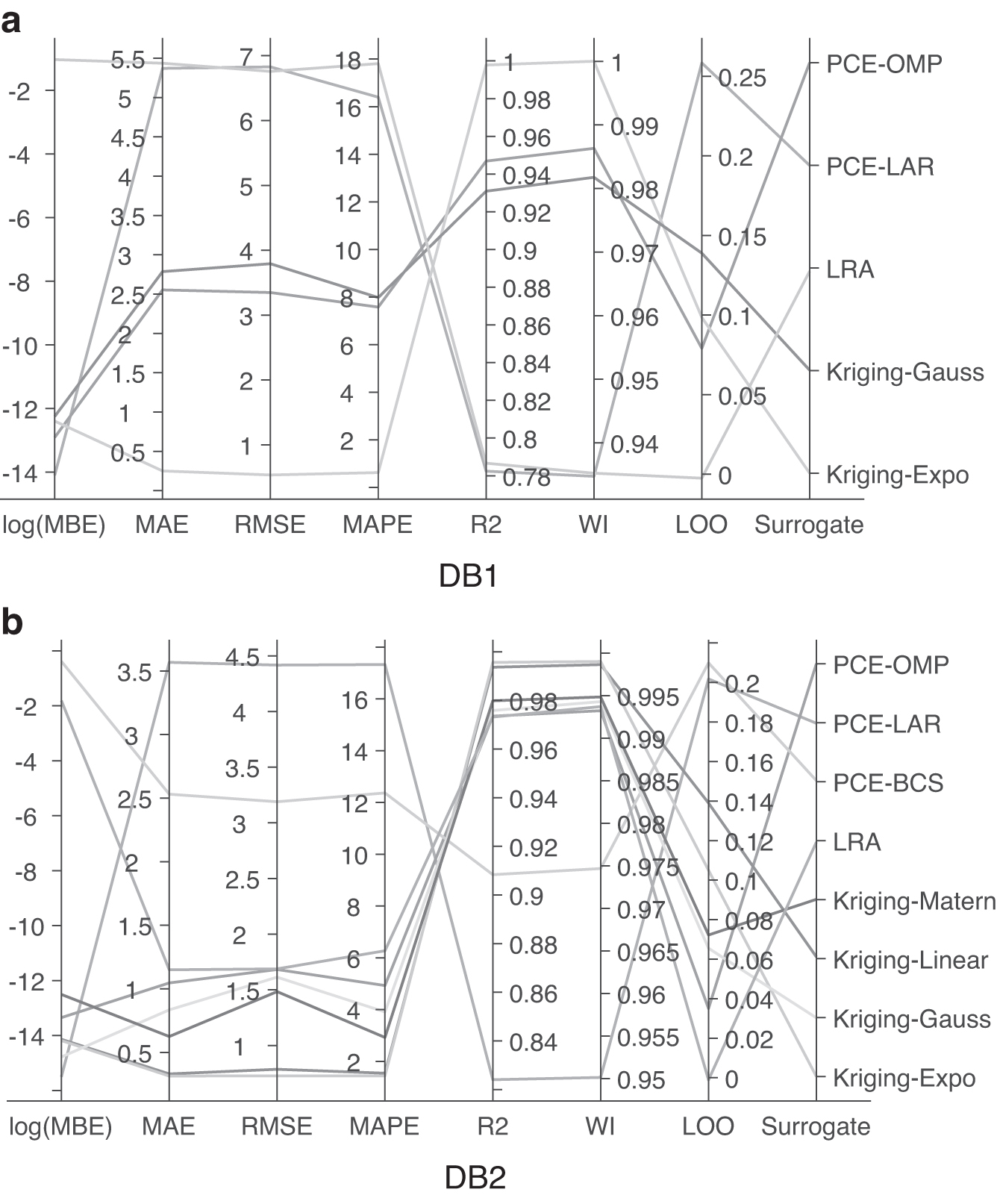
Coupling of various error metrics in decision-making toward the optimal surrogate model. LOO, leave-one-out; MAE, mean absolute error; MAPE, mean absolute percentage error; MBE, mean bias error; R2, coefficient of determination; RMSE, root mean-squared error; WI, Willmott's index.
The accuracy of LRA method is less than the PCE and Kriging methods. Specifically for DB1, it causes a relatively large dispersion in the predicted data. Finally, comparing different PCE algorithms, it shows that OMP outperforms both the LAR and BCS methods. However, it has more expansion coefficients compared with the other two methods.
In conclusion, it is recommended to consider the Kriging model as the primary choice of surrogate model when it comes to problems in material science, including the prediction of the mechanical properties of concrete and asphalt mixtures. This study is based on only two databases for concrete, and further research is required to generalize the findings in this study. The performance of PCE, Kriging, and LRA can be compared with other conventional ML algorithms such as ANN, SVM, and RF. A similar idea can be also used in nano- and microscales to characterize the impact of material ingredients on their response behavior. For the larger databases, it is beneficial to compare the computational time from different meta-models with various assumptions as hyperparameters.
Footnotes
Authors' Contributions
G.M. and M.A.H.-A.: Conceptualization (equal), writing—original draft (equal), formal analysis (equal), and writing—review and editing (equal).
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.