
Abstract
Aims:
We describe a new approach to estimate the risks of hypo- and hyperglycemia based on the mean and SD of the glucose distribution using optional transformations of the glucose scale to achieve a more nearly symmetrical and Gaussian distribution, if necessary. We examine the correlation of risks of hypo- and hyperglycemia calculated using different glucose thresholds and the relationships of these risks to the mean glucose, SD, and percentage coefficient of variation (%CV).
Materials and Methods:
Using representative continuous glucose monitoring datasets, one can predict the risk of glucose values above or below any arbitrary threshold if the glucose distribution is Gaussian or can be transformed to be Gaussian. Symmetry and gaussianness can be tested objectively and used to optimize the transformation.
Results:
The method performs well with excellent correlation of predicted and observed risks of hypo- or hyperglycemia for individual subjects by time of day or for a specified range of dates. One can compare observed and calculated risks of hypo- and hyperglycemia for a series of thresholds considering their uncertainties. Thresholds such as 80 mg/dL can be used as surrogates for thresholds such as 50 mg/dL. We observe a high correlation of risk of hypoglycemia with %CV and illustrate the theoretical basis for that relationship.
Conclusions:
One can estimate the historical risks of hypo- and hyperglycemia by time of day, date, day of the week, or range of dates, using any specified thresholds. Risks of hypoglycemia with one threshold (e.g., 80 mg/dL) can be used as an effective surrogate marker for hypoglycemia at other thresholds (e.g., 50 mg/dL). These estimates of risk can be useful in research studies and in the clinical care of patients with diabetes.
Introduction
Kovatchev et al. 1 introduced a transformation of the glucose scale to achieve a (nearly) symmetrical distribution and demonstrated a high correlation of the Low Blood Glucose Index with subsequent risk of severe hypoglycemia. 1,2 Monnier et al. 3 reported a relationship between risk of hypoglycemia and the magnitude of the percentage coefficient of variation (%CV) for glucose; in contrast, the risk of hyperglycemia was related to the mean and SD of glucose values, but only minimally to the %CV. Qu et al. 4 and Inzucchi et al. 5 have made similar observations. Swinnen et al. 6 noted that the rates of hypoglycemia depend on the arbitrary choice of glucose level used as the criterion for hypoglycemia.
Principle of the present method
If glucose data were subject to a “Gaussian” or “normal” distribution, then one could accurately predict the probability of hypoglycemic or hyperglycemic events if we knew the true population mean and SD. However, the distribution of glucose values is usually non-Gaussian, 1,7 the exact nature of the distribution is unknown, and one is subject to random sampling errors in the sample mean and sample SD. 8 In the present study, we propose to use simple nonlinear transformations of the glucose scale to achieve an approximation to the Gaussian distribution, which in turn permits estimation of the risks of hypo- or hyperglycemia using any desired threshold. 9 This principle should be applicable to both continuous glucose monitoring (CGM) and self-monitoring of blood glucose when sufficient data are available.
Materials and Methods
Box 1 provides an overview of the proposed method. We first evaluate whether the glucose distribution is consistent with a Gaussian distribution. If not, we attempt to transform the glucose scale to achieve a nearly Gaussian distribution. One can then estimate the probabilities of hypo- or hyperglycemia below or above any arbitrary threshold. 9 These estimates can be compared with the empirically observed rates for the same dataset. One can evaluate the robustness or stability of results by considering the uncertainties in the mean and SD 8,9 and in the nature of the transformation used for the glucose scale.
Box 1. Simplified Schematic of the Proposed Method to Estimate the Probabilities of Hypo- or Hyperglycemia Using Any Desired Threshold
1. Compute Sample Mean, Sample SD (s), Skew, and Excess Kurtosis of glucose distribution or subsets of the distribution by date, time of day, day of week
2. Perform tests of gaussianness
a. Test whether Skew and Excess Kurtosis are statistically significantly different from zero
b. Wilk–Shapiro test
c. Evaluate gaussianness using one or more graphical methods (e.g., Normality Plot, Q-Q plot, probit plot, or “inverse error function of cumulative frequency distribution” [erf −1(cfd)] vs. glucose)
3. Apply log and root transforms of the form:
4. Retest for gaussianness: Identify the optimal values for c, or c and n, to achieve as close to a Gaussian distribution as possible
5. Select desired thresholds for hypo- and hyperglycemia
6. Compute expected probability of glucose below or above the specified thresholds
7. Compare the calculated values for risks of hypo- and hyperglycemia with the empirically observed frequencies of hypoand hyperglycemia using the same thresholds
8. Evaluate robustness of results: consider the uncertainty due to random sampling variability in the sample mean (SEM) and in the sample SD, [SE(s)], and due to the uncertainties in the values for c and n. Consider alternative types of transformations to achieve gaussianness.
9. Display the observed and predicted risks of hypo- or hyperglycemia for a given subject for the entire dataset or versus time of day, day of the week, date, or other variables of interest (e.g., Fig. 2), or compare observed and predicted risks for multiple subjects (e.g., Fig. 3)
One can examine the nature of the glucose distribution by calculating the mean, SD, Skew (a measure of asymmetry), and Kurtosis (a measure of curve shape—“pointiness” or flatness)
9
–14
. One can then transform the data using various nonlinear transformations, for example, the log transform after first applying a linear translation to the original glucose scale
or the root transform
For example, if n=2, this would be the square-root transformation of (Glucose+c).
We seek to find values of the constants (c in Eq. 1 or c and n in Eq. 2) that will result in as nearly symmetrical a distribution as possible. For a Gaussian distribution, Skew and Excess Kurtosis should be zero. If the distribution is skewed to the right, as usually the case for glucose, Skew will be positive. If the distribution is skewed to the left, as usually the case for log(Glucose), Skew will be negative. By plotting Skew and Excess Kurtosis versus c and n and estimating the values the values of c and n that result in Skew and Excess Kurtosis as close to zero as possible, one can identify the parameters for the transformations (Eq. 1 or 2) that result in a nearly Gaussian distribution. Alternatively, one can use the Wilk–Shapiro test 10 and/or other criteria to optimize the approximation to gaussianness. Once the best values for the constants in a transformation have been determined, one can recalculate the mean, SD, Skew, and Excess Kurtosis for the transformed glucose values and repeat tests for gaussianness. Several graphical methods are also available to compare an observed distribution with a Gaussian distribution. These include the Normality Plot or a Q-Q plot, 11,12 the probit plot, 13 or a plot of “inverse error function” of the cumulative frequency distribution (cfd), [erf –1(cfd)] versus Glucose or G′. 14
After identifying a transformation such that the transformed glucose data are nearly Gaussian, it becomes possible to estimate the percentage of observations that fall below or above any arbitrary threshold using standard tables and equations for a Gaussian distribution
11,14
(cf. Supplementary Data available online at
To evaluate the robustness of the method, to consider the effects of random sampling errors in the sample mean and sample SD, one can repeat the above calculations and reconstruct the profiles for probability of hypo- or hyperglycemia (e.g., vs. date or vs. time of day) using two plausible values for the Mean combined with two values for the SD, resulting in four combinations of parameters: the two values for the Mean could be selected as
The SE of the sample mean is
This approach makes it possible to evaluate the effects of uncertainty and random sampling errors in the sample mean and sample SD. However, this does not provide protection from errors that arise from a systematically non-Gaussian distribution. One can evaluate the robustness of results with respect to this potential source of error by repeating the calculations using the untransformed glucose values (assuming that the glucose distribution were Gaussian), using the log transformation with c=0 (i.e., assuming that the glucose values were log-normally distributed), and using an intermediate case where one assumes that the values for log10(Glucose+c) are normally distributed, using the value of c that minimizes Skew. Results for profiles of risk of hypo- and hyperglycemia can then be compared by displaying them simultaneously versus date, time of day, or other variables of interest.
Another approach to evaluation of the robustness of results would be to consider alternative methods for calculation of the sample mean and sample SD. These values
We have evaluated the performance of this method using illustrative data from 64 subjects with type 1 diabetes and 17 subjects with type 2 diabetes using either an insulin pump or multiple daily injections, 17 comparing the observed risks of hypo- and hyperglycemia with those calculated using the present approach using four thresholds (50, 80, 180, and 250 mg/dL). We examined the relationships between observed rates of hypoglycemia <50 mg/dL and observed rates <80 mg/dL, and between observed rates of hyperglycemia >250 mg/dL and >180 mg/dL. We also evaluated the relationship of %CV of glucose with the observed rates of hypoglycemia at two threshold levels (<50 and <80 mg/dL).
Results
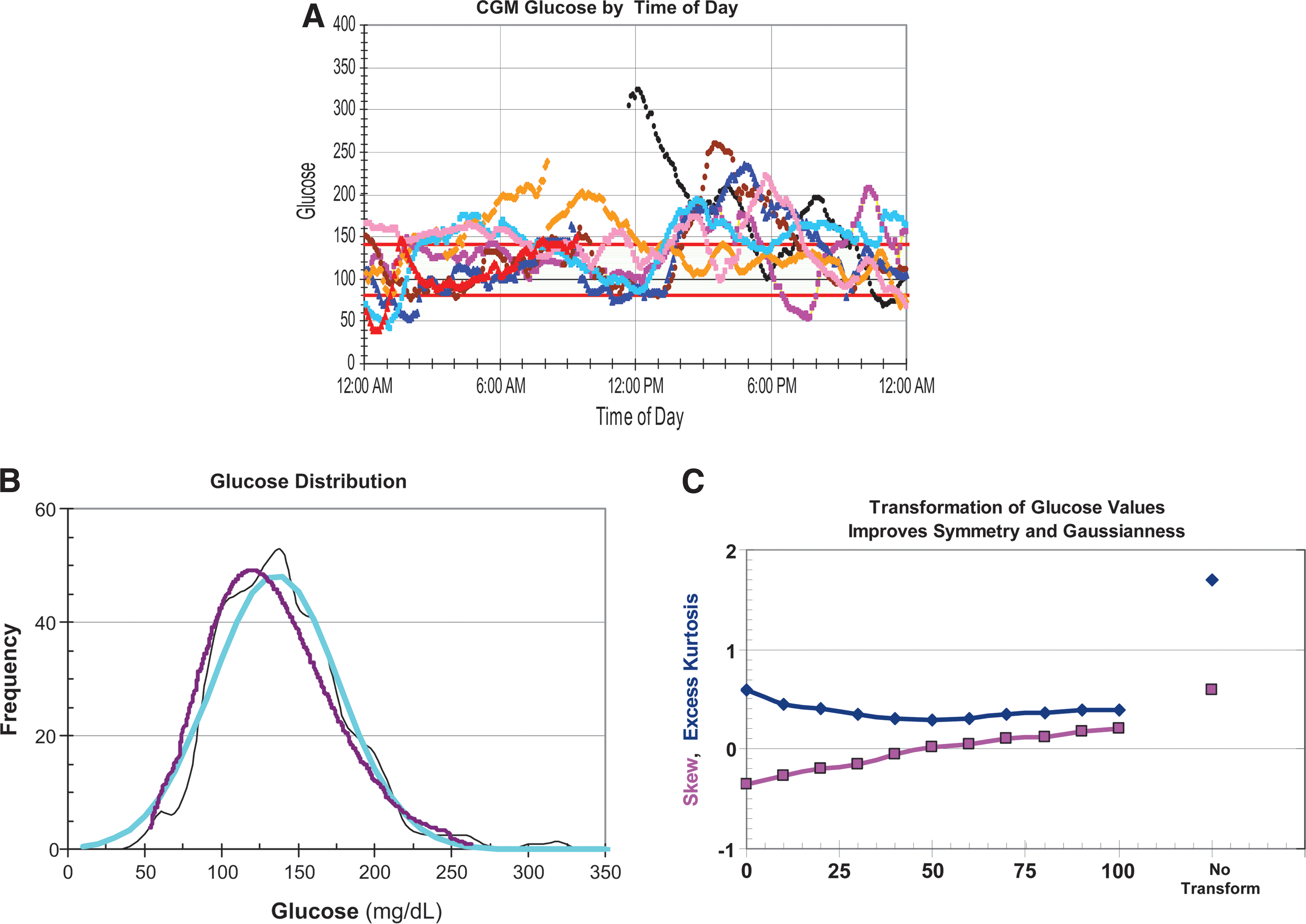
Figures 1 and 2 show results from analysis of CGM data from a single subject. Figure 1A shows representative CGM tracings for a subject for a period of 1 week aligned by time of day as shown in Rodbard et al. 17 However, it is difficult to estimate the risk of hypoglycemia by time of day from this type of “glucose profile”. Figure 1B shows the observed, moderately asymmetrical glucose distribution (frequency histogram) (black curve). A Gaussian distribution with the same mean and SD (blue curve) would systematically overestimate the frequency of hypoglycemia but underestimate the frequency of hyperglycemia. If one transforms the glucose scale so that the glucose distribution becomes more symmetrical, here using log10(Glucose+50 mg/dL), fits a Gaussian distribution to the transformed glucose values, and then redisplays the distribution on the original glucose scale, one can obtain a better approximation to the observed data, especially in the hypoglycemic range (red curve). Figure 1C shows the values for Skew and Excess Kurtosis for the original glucose data (before transformation) and shows how these values change systematically as one adjusts the value of c in the log transformation (Eq. 1). This enables us to identify the value for c that minimizes Skew: c=50 mg/dL in the present example. (In the author's experience with multiple datasets, a value of c between 30 and 50 mg/dL often results in considerably improved symmetry of the glucose distribution.)
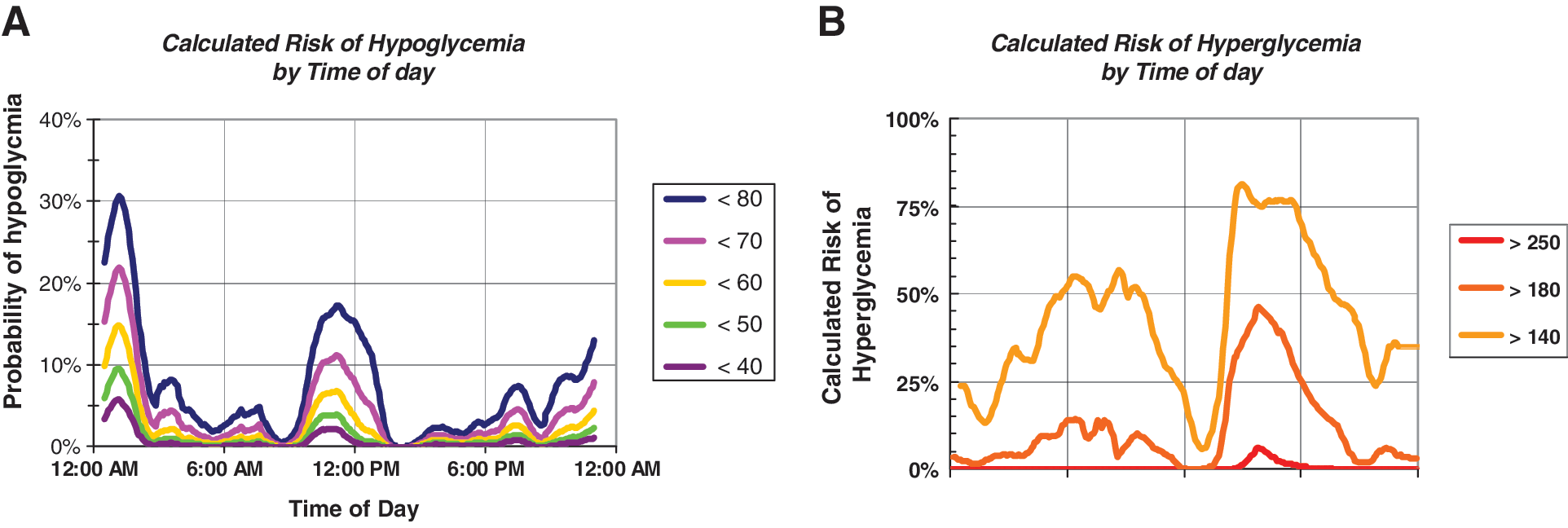
Calculated probabilities of hypoglycemia and hyperglycemia by time of day, based on the assumption that glucose has a Gaussian distribution and using the observed values for sample mean
Estimation of the risk of hypo- and hyperglycemia based on a Gaussian distribution for glucose (G) or a transformed glucose value (G ′)
After achieving a Gaussian or nearly Gaussian distribution for glucose (or for a transformed glucose scale), it becomes possible to estimate the probability that a glucose value would be observed below or above any specified threshold.
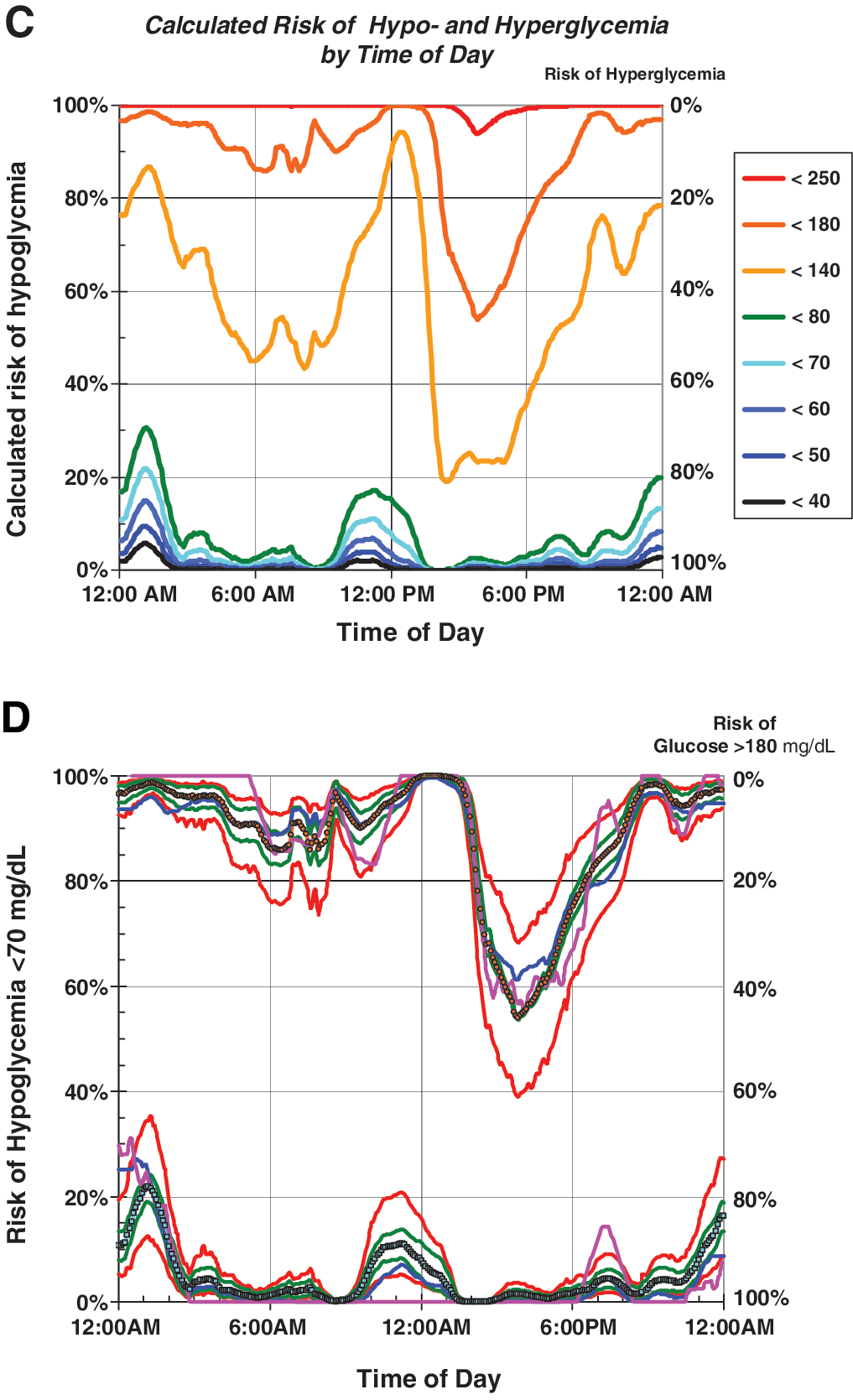
The calculation can be performed using just two instructions in Microsoft® (Redmond, WA) Excel using Eqs. S1 and S2 (compare Supplementary Data, Appendix). Figure 2A and B shows the calculated probabilities of hypoglycemia and hyperglycemia, respectively, by time of day. One can calculate risks using any arbitrary threshold, including thresholds for which only a few events (or none at all) have been observed. Risks can also be displayed by date or day of the week. The risks of hypo- and hyperglycemia can be displayed simultaneously in one compact graph (Fig. 2C) by inverting the curves for hyperglycemia: rather than showing the expected percentage of glucose values above a given threshold (e.g., glucose >180 mg/dL) (Fig. 2B), one can show the expected percentage of values below the same threshold (glucose<180 mg/dL). This method of display (Fig. 2C) is closely related to the “stacked bar chart” for display of the observed percentages of glucose values within a specified series of ranges of glucose. 18,19
One can use several methods to evaluate the stability, robustness, and accuracy of the proposed method for estimating risk of hypo- and hyperglycemia. First, one can display the best estimates of the risks of hypo- and hyperglycemia graphically versus a variable of interest (e.g., time of day) as obtained using the present method and as observed empirically by counting “events” (Fig. 2D). Second, one can assess the effect of uncertainty in the mean glucose by showing the corresponding risks calculated on the basis of the (Mean+1 SEM) and the (Mean−1 SEM). Similarly, we can assess the magnitude of error likely to be introduced by random sampling error in the SD, using [
Analysis of a patient population
Utilizing data from 81 subjects using masked CGM for a period of 1 week 17 where the mean, SD, and observed rates of hypo- and hyperglycemia were available for each subject, we compared the predicted probabilities with the observed number of events for hypo- and hyperglycemia using multiple specified thresholds (Fig. 3). The correlation of predicted and observed rates for hyperglycemia at 180 and 250 mg were particularly good (both r=0.98). The correlation of observed and predicted rates for hypoglycemia at 80 mg/dL was fair (r=0.86), but the correlation using a threshold of 50 mg/dL was lower (r=0.65), in part because of a nearly 10-fold smaller number of observed events. These calculations were performed assuming that the original glucose distributions were Gaussian without transformation of the glucose scale. Better correlations might have been obtained if one were to optimize the symmetry of the distributions using transformations such as Eqs. 1 and 2 above.
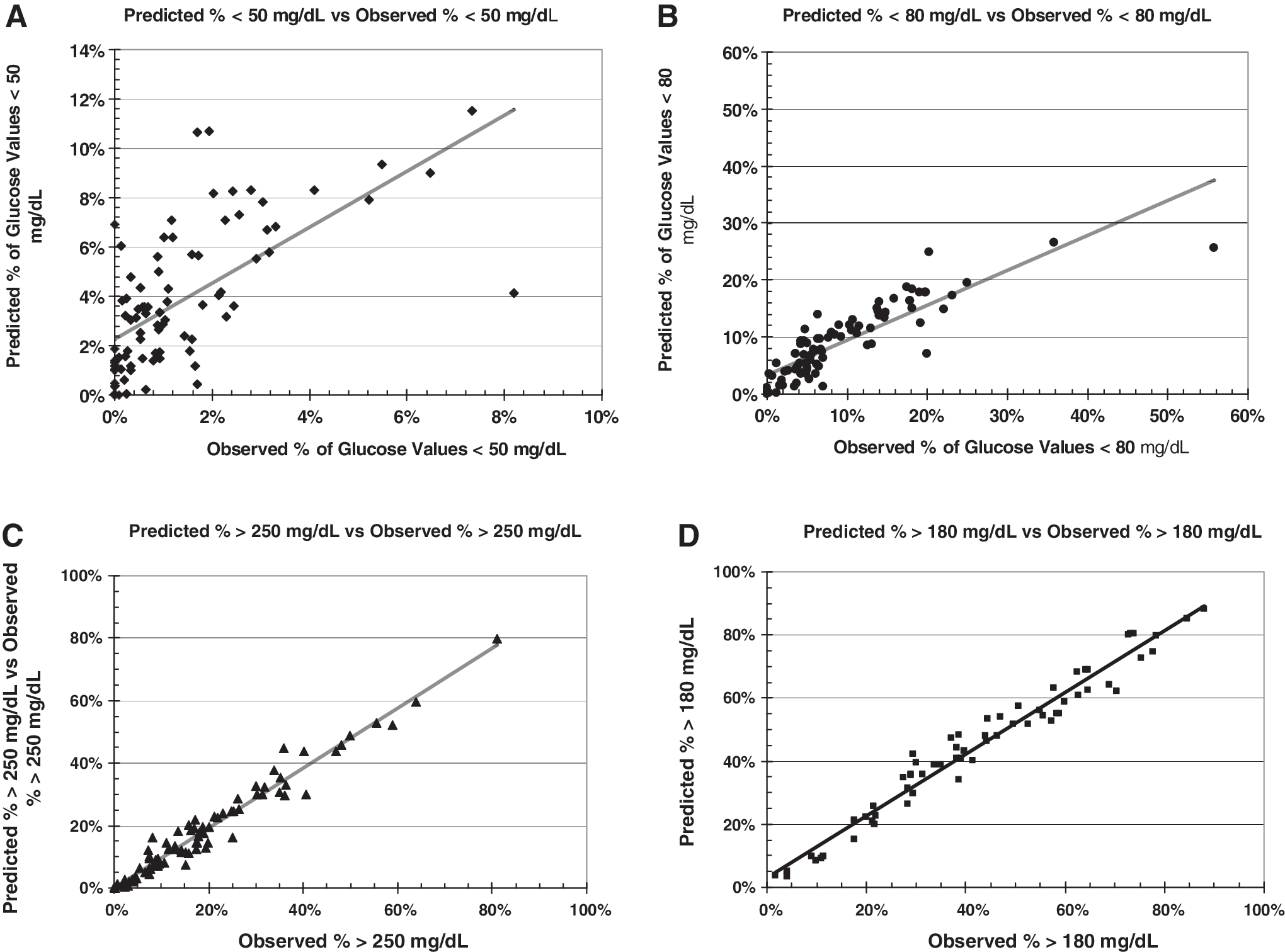
Correlation of calculated risks of hypo- and hyperglycemia assuming a Gaussian distribution (without transformation) (vertical axis) and observed risks (horizontal axis) based on observed events. Data are from Rodbard et al.
17
for 81 subjects (64 with type 1 diabetes, 17 with type 2 diabetes, all receiving basal-bolus therapy with continuous subcutaneous insulin infusion or multiple daily injections, studied for 1 week with masked continuous glucose monitoring). Thresholds were
Potential use of surrogate markers for hypo- and hyperglycemia: correlation of risks of hypoglycemia at two thresholds (80 and 50 mg/dL) and of risks of hyperglycemia at two thresholds (180 and 250 mg/dL)
Figure 4A examines the relationship between the observed rates of hypoglycemia using two thresholds: <50 and <80 mg/dL. Figure 4B displays the relationship of observed rates of hyperglycemia using two thresholds: >180 and >250 mg/dL. There is a high correlation in both cases, confirming that the higher threshold (80 mg/dL) might be suitable for use as a proxy to estimate the risk of more severe hypoglycemia (50 mg/dL). The risk of events below 80 mg/dL can be measured much more accurately than the risk of events <50 mg/dL because of the much larger number of events when using the higher threshold (<80 mg/dL). Similarly, the risk of hyperglycemia using a threshold of >180 mg/dL can be regarded as a proxy for the risks of events at higher levels (e.g., >250, >300, or >400 mg/dL).
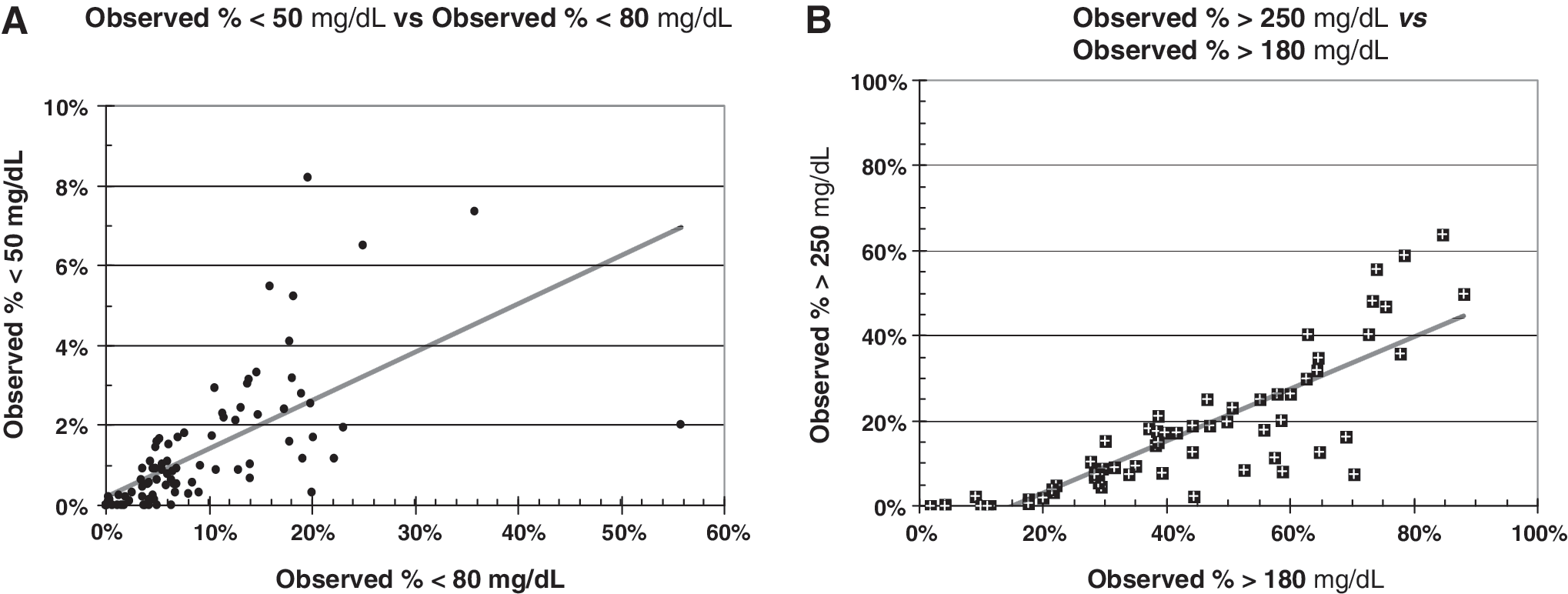
Use of surrogate markers for more severe levels of hypo- and hyperglycemia. Data are from Rodbard et al.
17
for 81 subjects (64 with type 1 diabetes, 17 with type 2 diabetes, all receiving basal-bolus therapy with continuous subcutaneous insulin infusion or multiple daily injections, studied for 1 week with masked continuous glucose monitoring).
Correlation of risk of hypoglycemia and %CV for glucose
Figure 5 shows the relationship between risk of hypoglycemia in the same 81 subjects (data of Rodbard et al.
17
) versus the %CV for glucose (%CV=100

Relationships between percentage coefficient of variation (%CV) and risk of hypoglycemia using thresholds of glucose <80 mg/dL (black solid diamonds and black solid line) and <50 mg/dL (blue open circles and blue dashed line), for data for 81 subjects studied for 1 week using masked continuous glucose monitoring. 17 Highly significant correlations were observed (r=0.53 for a threshold of <80 mg/dL; r=0.49 for a threshold of 50 mg/dL).
Conclusions
The present study demonstrates that one can obtain reasonably reliable estimates of the historical risks of hypo- or hyperglycemia for any desired arbitrary glucose threshold by transforming glucose values to achieve a (nearly) Gaussian distribution. If we assume that the patient's pattern remains stable over time, then one can use retrospective data to predict future risks by time of day (Fig. 2) or day of the week for individuals and groups of subjects. The results can be insensitive to the choice of transformation for the glucose values, indicating robustness of the method (Fig. 2D). The present method can be used to estimate the risk of rare events (e.g., severe hypoglycemia), even when such events have not been observed.
There was excellent agreement between observed and calculated risks of hypo- and hyperglycemia using a large dataset, assuming a Gaussian glucose distribution for each subject (Fig. 3), with thresholds of 50, 80, 180, and 250 mg/dL. Even better correlations might have been obtained with use of nonlinear transformations of the glucose scale.
Surrogate markers for hypoglycemia
In view of the relative infrequency of severe hypoglycemic events (e.g., <50 mg/dL or lower thresholds), Rodbard et al. 20 suggested that there was a need for surrogate markers and further suggested that the frequency of glucose values below 100 mg/dL might be a useful surrogate for clinically significant hypoglycemia at lower thresholds (e.g., <70 or <50 mg/dL). The calculated patterns of risk for hypoglycemia often have a very similar shape for a wide range of thresholds (e.g., 40–80 mg/dL) (Fig. 2A). Figure 3 confirms these relationships between risks calculated with different thresholds, using data from masked CGM of 1-week duration, 17 where each data point represents a different study participant. These results support the use of the much larger (and thus more accurately and precisely measured) risks of glucose below 80 mg/dL as an effective surrogate marker to predict the risks of more severe hypoglycemia (e.g., for evaluation of the relative risk of hypoglycemia associated with different forms of therapy). 20
It would be desirable to conduct larger-scale studies to assess the performance of this approach applied to both CGM and self-monitoring of blood glucose specifically to examine the effects of differing categories of patients, differing types of treatments, differing amounts of data for each subject, and differing types of glucose distributions. The computational methods required are simple and can be readily implemented utilizing spreadsheets. However, it would be desirable to have these methods incorporated into fully automated software to reduce the risk of user errors. Furthermore, it would be desirable to compare the performance of the method proposed here with alternative methods for prediction of hypo- and hyperglycemia such as Low Blood Glucose Index, 2 High Blood Glucose Index, Hypoglycemia Index, Hyperglycemia Index, 15,16 GRADEHypoglycemia, GRADEHyperglycemia, 21 and %CV.
The present analysis emphasizes the critical importance of glycemic variability in determining the risks of hypo- and hyperglycemia and makes it possible to predict the relationships of the Mean, SD, and %CV of glucose to those risks. The Supplementary Data illustrate the interaction of the Mean and SD in determining the risks of hypo- or hyperglycemia. If there is a low Mean glucose and a large SD and hence a large %CV, the risk of hypoglycemia will be high. In contrast, if both the Mean and SD are high but with a low %CV, the risk of hypoglycemia will be relatively low. Similar kinds of statements can be made for the risk of hyperglycemia: a high Mean will generate a high frequency of hyperglycemia that is relatively insensitive to the magnitude of the SD. A lower mean could generate a high risk of hyperglycemia if the SD is large but not if the SD were small. These inferences can be demonstrated rigorously mathematically and follow directly from Eqs. S1 and S2 (cf. Supplementary Data). These calculations can be performed for any specified shape of the glucose distribution.
We have recently proposed 22 that the %CV may be the best parameter to use to characterize glycemic variability in view of the relative constancy of its percentiles irrespective of glycated hemoglobin or mean glucose levels, which avoids the strong dependency of SD and other measures on mean glucose level or glycated hemoglobin. The correlation of %CV with risk of hypoglycemia has been observed empirically (Fig. 5) in the present study, and by others. 3 –5,23 This relationship can be predicted theoretically irrespective of the glucose level chosen as the criterion for hypoglycemia (see Supplementary Fig. S1). These observations enhance the importance of %CV as a parameter to describe glycemic variability.
Footnotes
Author Disclosure Statement
The author has served as a consultant to the following: Amylin, DexCom, Halozyme, LifeScan, Merck, Roche Diagnostics, Sanofi, University of Colorado, and Walter Reed National Medical Center.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.