
Abstract
Introduction:
Automated skills assessment can provide surgical trainees with objective, personalized feedback during training. Here, we measure the efficacy of artificial intelligence (AI)-based feedback on a robotic suturing task.
Materials and Methods:
Forty-two participants with no robotic surgical experience were randomized to a control or feedback group and video-recorded while completing two rounds (R1 and R2) of suturing tasks on a da Vinci surgical robot. Participants were assessed on needle handling and needle driving, and feedback was provided via a visual interface after R1. For feedback group, participants were informed of their AI-based skill assessment and presented with specific video clips from R1. For control group, participants were presented with randomly selected video clips from R1 as a placebo. Participants from each group were further labeled as underperformers or innate-performers based on a median split of their technical skill scores from R1.
Results:
Demographic features were similar between the control (n = 20) and feedback group (n = 22) (p > 0.05). Observing the improvement from R1 to R2, the feedback group had a significantly larger improvement in needle handling score (0.30 vs −0.02, p = 0.018) when compared with the control group, although the improvement of needle driving score was not significant when compared with the control group (0.17 vs −0.40, p = 0.074). All innate-performers exhibited similar improvements across rounds, regardless of feedback (p > 0.05). In contrast, underperformers in the feedback group improved more than the control group in needle handling (p = 0.02).
Conclusion:
AI-based feedback facilitates surgical trainees' acquisition of robotic technical skills, especially underperformers. Future research will extend AI-based feedback to additional suturing skills, surgical tasks, and experience groups.

Introduction
Training surgeons need high-quality feedback to accelerate their training process while minimizing harm to patients. Currently, most surgical feedback is provided by attending surgeons inside the operating room in a stressful and high-stake environment. The opportunities to receive surgical feedback are highly limited by the caseload of the training hospital, duty hour restrictions, and the bandwidth of the attending surgeons. 1 Multiple studies have suggested that surgical residents feel they do not get enough feedback during training, 2 which leads to a feeling of insufficiency to perform surgery autonomously immediately following residency or even fellowship training. 3
In addition, the threshold to provide feedback, the content of feedback, and the timing of feedback vary greatly between attending surgeons, which results in heterogeneity in the quality of surgical training. Other factors, such as the interpersonal relationship between the mentor and the mentee, may exaggerate this heterogeneity.
Automation of surgical assessment and feedback can serve as a novel method to provide objective, timely, and personalized feedback independent of the aforementioned limitations. It can supplement traditional surgical training, allow surgical residents to receive targeted feedback, and improve surgical skills outside the operating room safely and efficiently.
Although multiple studies have automated surgical assessment using artificial intelligence (AI)-aided algorithms, 4 –7 few have reported on AI-driven automation of surgical feedback and evaluation of its effectiveness.
We previously developed an AI-based algorithm to assess suturing skills using live surgical videos. 8 In this study, we aim to further develop an algorithm to automatically provide feedback for robotic suturing skills and measure the efficacy of AI-based feedback on a robotic suturing task. We hypothesize that AI-assisted feedback can improve participants' robotic suturing technical skill scores compared with the control group. We also hypothesize that participants who initially perform worse can benefit more from the AI-assisted feedback than participants who initially perform well.
Materials and Methods
Participants and study design
Under institutional review board approval (no. HS-17-00113), 42 undergraduate and medical students without any prior robotic surgical experience were recruited by institutional email lists and posters displayed around the campus to complete a simulated suturing task on a da Vinci robotic system (Sunnyvale, CA). The task was a modified dry-laboratory model to simulate vesicourethral anastomosis (VUA) during the robot-assisted radical prostatectomy.
The study was designed as a two-round repetition of the same suturing task over a 1-hour session (Fig. 1). To ensure consistency in preparation, every participant was required to familiarize themselves with the robotic system by completing a standardized suturing pad task (i.e., around the world). Upon commencement, all participants were introduced to the VUA procedure. A standardized script was utilized to provide a consistent orientation. To further ensure clarity and precision, a VUA model was displayed, guiding participants on the specific suturing locations and the sequential order to be followed. Then participants were randomized to a control group or a feedback group and video-recorded while completing the two rounds (R1 and R2) of exercise. Participants were assessed on needle handling and needle driving domains from a previously validated tool (End-To-End Assessment of Suturing Expertise [EASE]), 9 and feedback was provided via a visual interface after R1 (Fig. 2).
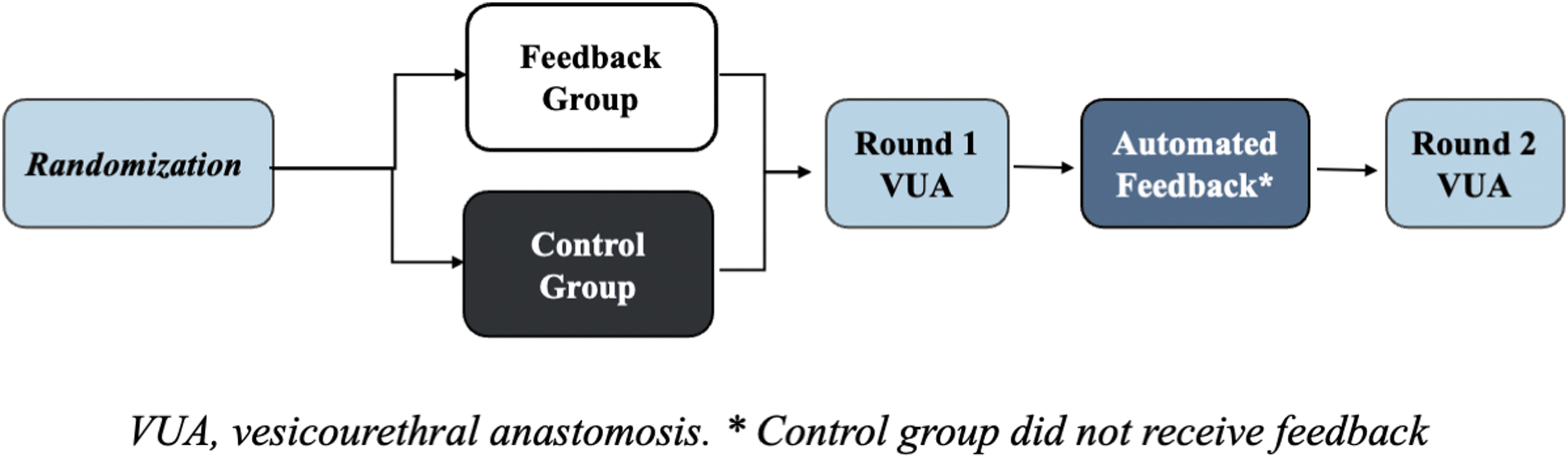
Study design.
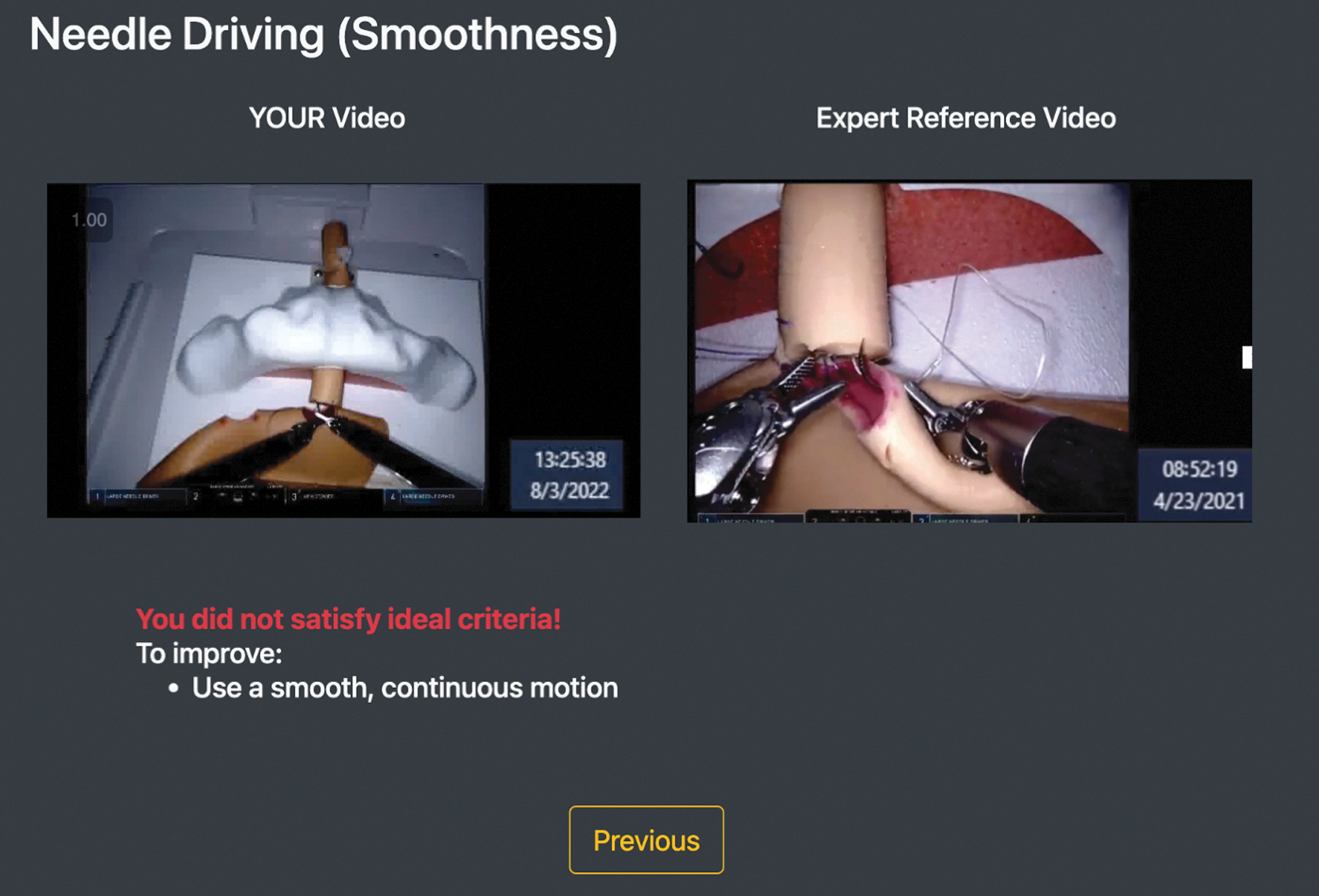
Video interface for the feedback group. The AI-based interface consisted of the assessment of their suturing performance for needle handling and needle driving. (1) Selected video clips from their task, which exemplified the assessment, (2) video examples of expert suturing (ideal skill), and (3) textual explanations of how to improve. AI = artificial intelligence.
For control group, participants were presented with randomly selected video clips from R1 as a placebo. For the feedback group, participants were informed of their AI-based skill assessment and presented with specific video clips from R1. The System Usability Scale (SUS) questionnaire 10 was filled out by the feedback group to analyze the participants' perceptions of the automated feedback system regarding its usefulness. Open-ended questions were also asked in the questionnaire to collect participants' suggestions for the system.
Design of automated feedback system
Underlying our automated feedback system was an AI algorithm that our team had developed in a previous study. 11 In the context of this study, the AI algorithm processed a video depicting the activity of each participant in the feedback group and returned the binary skill level (0 = low skill, 1 = high skill) of the needle handling and needle driving domains associated with all stitches performed by the participant. For example, if a participant performed eight stitches, then the AI algorithm would return eight binary skill assessments (for each domain). To achieve this in practice, the AI algorithm returned the probability, p, that a domain (e.g., needle handling for stitch 1) was performed with high skill.
We then introduced a threshold (
An example of a visual interface for a participant in the feedback group is shown in Figure 2. For both control and feedback groups, the interface rendered the domain being assessed as a title at the top: “Needle Handling” or “Needle Driving.” For the feedback group, a selected video from the participant's activity was rendered on the left with the caption “YOUR video.” A short example expert video showing the correct performance of the action specific to the domain was rendered on the right with the caption “Expert Reference Video.”
Underneath the videos, a textual explanation was given consisting of two components: (1) skill assessment textual feedback: “You did not satisfy ideal criteria!” or “Good work!” for low- and high-skill assessment, respectively, and (2) improvement suggestion such as “To improve: Minimize number of regrabs of the needle (<2 times)” for low skill or praise such as “You successfully: Regrabbed the needle fewer than 3 times” for high skill.
For the control group, the visual interface would render randomly selected video fragments from the participant on both left and right with the same caption: “YOUR Video (randomly selected).” No expert reference video would be provided. This was done to preserve the same layout of rendering two videos side-by-side. The interface version for the control group also did not render any textual explanation underneath the videos.
Feedback was provided for each assessed domain at a time. Participants could switch between the domains by clicking the “Continue” or “Previous” button at the bottom of the interface, as shown in Figure 2.
Validation of the automated suturing skill assessment
The ground-truth annotation of skill assessments of all suturing tasks was performed retrospectively by three blinded researchers (T.F.H., D.K., and J.A.L.) after standardized training. These scorers utilized EASE to assess needle driving and needle handling. The recorded suturing tasks were presegmented by the AI-based program and the manual rater would assign an EASE score to the clip after review. The ground-truth annotations (manual assessments) were later compared with AI-based assessments to calculate the area under the curve (AUC). We tested the performance of our previous published model 11 in this new data set with a total of 672 stitches (42 participants × 8 stitches × 2 rounds). The AUCs of needle handling and needle driving were 0.67 and 0.80, respectively.
Statistical analyses
A generalized estimating equation (GEE) was used to compare stitch performance between the feedback and the control group to adjust for data clustering within participants (i.e., each participant performed multiple stitches). In addition, participants from each group were labeled as underperformers or innate-performers, based on a median split of EASE scores from R1. Comparison between feedback and control group was performed in underperformers and innate-performers, respectively, as subgroup analyses. All statistical tests were 2-tailed other than specifically noted. In primary analysis, p < 0.05 was considered statistically significant. In subgroup analysis, p < 0.025 was deemed as statistical significance to adjust for type 1 error rate inflation resulting from multiple comparisons in subgroup analysis. Our sample size of 20 vs 22 can have >80% power in detecting a large effect size of Cohen's d = 1 with a two-sided t-test and a penalized α of 0.025 from subgroup analysis.
Our study has adequate power since a GEE model has higher power than a t-test with average score from multiple stitches. 12 PASS 2022 was used for power calculation and SPSS 24 was used for all other statistical analyses.
Results
Participant demographics
A total of 42 participants had a median age of 24 (interquartile range [IQR] 23–25), male/female 17/25, and undergraduate/medical students 8/34. There were no significant differences in demographic variables between feedback group (n = 22) and control group (n = 20)
Demographic and Baseline Performance Comparison Between the Feedback and Control Groups
Primary analysis
Observing the improvement from R1 to R2, the feedback group had a significantly greater improvement in needle handling skill (mean 0.30 vs −0.02, p = 0.018) compared with the control group, although the improvement in needle driving skill did not reach statistical significance between groups (mean 0.17 vs −0.40, p = 0.074) (Table 2).
End-To-End Assessment of Suturing Expertise Score Comparison Between the Feedback and Control Groups
CI = confidence interval.
Subgroup analysis in innate-performers and underperformers
All innate-performers (n = 22) exhibited similar improvement across rounds, regardless of feedback. In innate-performers, the mean EASE score improvement (from R1 to R2) of needle handling in the feedback group (n = 11) was 0.06 vs −0.08 in the control group (n = 11) (p = 0.24). The mean EASE score improvement (from R1 to R2) of needle driving in the feedback group was 0.05 vs −0.12 in the control group (p = 0.28). In contrast, in underperformers (n = 20), the feedback group (n = 11) improved more than the control group (n = 9) in needle handling (mean 0.60 vs 0.01, p = 0.02), although the improvement of needle driving did not reach statistical significance between groups (mean 0.27 vs 0.02, p = 0.08) (Fig. 3). A further breakdown of EASE scores of the innate-performers and underperformers is provided in Supplementary Tables S1 and S2.

Score improvement of innate-performers and underperformers. p Values in the figure represent the comparison of the improvement from round 1 to round 2 between the feedback group and the control group.
System Usability Scale
SUS was significantly correlated with R2 total EASE score after controlling for participants' R1 performance (n = 22, ρ = 0.40, p = 0.034, one-tailed). In underperformers, the correlation coefficient between SUS and R2 total EASE score after controlling for R1 performance was 0.43 (n = 11, p = 0.092, one-tailed). In innate-performers, there was no correlation between SUS and R2 total EASE score after controlling for R1 performance (n = 11, ρ = 0.01, p = 0.49, one-tailed). There was no difference in SUS between innate-performers (median 65, IQR 50–78) and underperformers (median 73, IQR 59–84, p = 0.53).
Feedback from participants
When asking the feedback group participants about their satisfaction level with the feedback system, they generally thought the system was correct, relatively easy to understand, trustful, and they were willing to make an adjustment based on the feedback given by the system, with an average score ranging from 3.96 to 4.67 (on a 5-point scale questionnaire) for different questions (Table 3). When asked to choose which component is most helpful for their performance in R2, 95.4% (21/22) chose “expert reference video,” 63.6% (14/22) chose “feedback text,” and only 4.5% (1/22) chose “their own video.” Finally, we asked for participants' suggestions to further improve the automated feedback system, and results are summarized in Table 4.
Participants' Satisfactory Level with the Automated Feedback System (n = 22)
Suggestions from the Participants for the Automated Surgical Feedback System
Discussion
Our results show that: (1) the AI scores align with human assessment, which proves the reliability of the present automated feedback system; (2) the feedback group improves more in specific domains of robotic suturing skills than the control group, which suggests the effectiveness of the present automated feedback system; and (3) underperformers and more receptive participants appear to benefit most from the feedback system, although further investigation is needed to confirm this finding.
To our authors' knowledge, this is the first time that surgical feedback was provided by an automated AI algorithm. Multiple studies have used AI to aid surgical assessment in the past. 4 –7 This study represents a significant advancement following automated surgical assessment. While the surgical feedback system explored in this research remains relatively simple, the observed improvement in robotic surgical skills demonstrates its promising potential. As a proof of concept, this study underscores the value of AI-assisted feedback systems as an effective teaching tool in surgical training.
The progression of different suturing skill development (needle handling and needle driving) likely differs. In this study, we observed a statistically significant larger improvement in the feedback group than the control group in needle handling, although we only observed a borderline significant larger improvement in needle driving. This could be because the progress of needle handling is simpler and more direct, so significant changes can be observed immediately after receiving feedback. On the contrary, needle driving may require more practice. Another factor to consider in this study is that all participants are pure novices (no prior robotic suturing experience). The acquisition of needle driving technique requires multiple rounds of practice especially in this cohort of participants.
Our subgroup analysis shows that underperformers can benefit more from automated feedback, which is consistent with previous findings. 13 SUS shows that most of the participants favored our automated feedback system, and their usability score for the automated feedback system was positively correlated with their final performance, which suggests that the more receptive an individual is to the feedback (i.e., how useful they found it), the more efficacious the feedback appears to be.
Based on the survey results, it appears that the expert video, serving as a frame of reference for novice participants, plays a significant role in their learning process. The expert video provided in the study was a short clip to demonstrate specifically the deficient suturing skill of the participants. The textual feedback provided is also crucial, as 63.6% (14/22) participants chose “feedback text” extremely helpful for their performance. It assists novices in identifying essential aspects to observe in expert videos, ultimately fostering their learning process. Our ongoing research endeavors to examine the specific contributions of distinct feedback components within the AI system, aiming to optimize its effectiveness for trainees' skill development.
This study is clinically relevant. The AI-based feedback system can serve as a useful teaching tool to provide objective, individualized, and real-time feedback, increase opportunities to practice and improve outside the operating room, shorten the learning curve in real patients, and make feedback more equal across teaching centers. Presented here as a prototype, the current model shows promising results to accelerate the acquisition of robotic suturing skills of participants. We believe that AI-based feedback can complement human instruction, rather than replace it. It is especially beneficial considering a human teacher is not always readily available.
This study has its limitations. The feedback system is relatively simple, and the domains of evaluation cannot completely cover all techniques of robotic surgical suturing. The sample size is relatively limited. However, the study is the first step toward automated surgical feedback, providing a meaningful prototype that could then be further refined. The study cohort is complete novices, which limits the generalizability of the conclusions. It is conceivable that an ideal automatic feedback system should provide different levels of feedback (from the simplest to the most difficult) according to differing experience levels of participants. Future studies should include different cohorts to further refine the automated feedback system. Finally, this study only performed two rounds of suturing exercises. A prior study shows that spacing feedback can lead to better results, 14 and so, future studies can add multiple rounds of exercises and feedback to study the cumulative effect of AI-based feedback.
Conclusions
AI-based feedback facilitates surgical trainees' acquisition of robotic suturing techniques in specific domains. This study serves as a proof of concept to demonstrate the potential impact of automated feedback on surgical training. In the future, we envision that this AI-based feedback system can be applied to a broader range of domains, thereby making surgical training more accessible and effective.
Footnotes
Authors' Contributions
R.M.: writing—original draft and formal analysis. D.K.: conceptualization and methodology. J.A.L.: conceptualization, methodology, and data curation. R.K.: methodology and software. E.Y.W.: data curation and writing—review and editing. T.N.C.: data curation and writing—review and editing. S.C.: formal analysis. C.H.Y.: data curation and writing—review and editing. I.S.D.: data curation and writing—review and editing. T.F.H.: data curation and writing—review and editing. M.G.G.: writing—review and editing. X.H.: the study's design and supervision. A.A.: supervision and writing—review and editing. A.J.H.: supervision, conceptualization, fund acquisition, and writing—review and editing.
Disclaimer
The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author Disclosure Statement
A.J.H. reports financial disclosures with Intuitive Surgical, Inc. A.A. is a paid employee of Nvidia.
Funding Information
Research reported in this publication was supported by the National Cancer Institute of the National Institutes of Health under award no. R01CA251579.
Supplementary Material
Supplementary Table S1
Supplementary Table S2
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.