
Abstract
Introduction:
Artificial intelligence (AI) platforms such as ChatGPT and Bard are increasingly utilized to answer patient health care questions. We present the first study to blindly evaluate AI-generated responses to common endourology patient questions against official patient education materials.
Methods:
Thirty-two questions and answers spanning kidney stones, ureteral stents, benign prostatic hyperplasia (BPH), and upper tract urothelial carcinoma were extracted from official Urology Care Foundation (UCF) patient education documents. The same questions were input into ChatGPT 4.0 and Bard, limiting responses to within ±10% of the word count of the corresponding UCF response to ensure fair comparison. Six endourologists blindly evaluated responses from each platform using Likert scales for accuracy, clarity, comprehensiveness, and patient utility. Reviewers identified which response they believed was not AI generated. Finally, Flesch–Kincaid Reading Grade Level formulas assessed the readability of each platform response. Ratings were compared using analysis of variance (ANOVA) and chi-square tests.
Results:
ChatGPT responses were rated the highest across all categories, including accuracy, comprehensiveness, clarity, and patient utility, while UCF answers were consistently scored the lowest, all p < 0.01. A subanalysis revealed that this trend was consistent across question categories (i.e., kidney stones, BPH, etc.). However, AI-generated responses were more likely to be classified at an advanced reading level, while UCF responses showed improved readability (college or higher reading level: ChatGPT = 100%, Bard = 66%, and UCF = 19%), p < 0.001. When asked to identify which answer was not AI generated, 54.2% of responses indicated ChatGPT, 26.6% indicated Bard, and only 19.3% correctly identified it as the UCF response.
Conclusions:
In a blind evaluation, AI-generated responses from ChatGPT and Bard surpassed the quality of official patient education materials in endourology, suggesting that current AI platforms are already a reliable resource for basic urologic care information. AI-generated responses do, however, tend to require a higher reading level, which may limit their applicability to a broader audience.
Introduction
The recent surge in popularity of artificial intelligence (AI) chatbots, notably OpenAI's ChatGPT and Google's Bard, marks a transformative era in various fields, including medicine. These AI platforms have specifically garnered interest in the urology community for their ability to streamline administrative tasks and support clinical decision-making, among other capabilities. 1 –3 Of particular interest, however, is the potential role for AI chatbots in urologic patient education.
It is important to evaluate the quality of health information provided by these platforms as patients are increasingly turning to the internet for health guidance. This is especially true for sensitive topics, many of which are urological. 2,4 Furthermore, online information available for prevalent urologic conditions such as benign prostatic hyperplasia (BPH) and erectile dysfunction has been found to be of poor quality. 4 –6
Since patients are increasingly using AI chatbots for health information, it is important to critically evaluate their responses as misinformation could lead to inaccurate self-diagnosis or to delay in seeking necessary medical attention. 7 –10 For these reasons, we sought to evaluate the quality of AI-generated responses in endourology, which encompasses some of the most common urologic conditions such as kidney stones and BPH.
Several recent studies have evaluated the appropriateness of ChatGPT's responses to urologic patient questions, while no such studies exist for Bard. 11 –17 These studies have yielded mixed results, with ChatGPT providing accurate information for some queries, but not others. While informative, a major drawback to these studies is that most evaluate ChatGPT without comparison with a validated benchmark. This is a significant limitation as without a benchmark, it is difficult to discern ChatGPT's usefulness given the availability of other, potentially more useful, patient education resources.
Given these limitations, our objective was to blindly compare the quality of AI-generated responses against established questions and answers found in patient education documents issued by the Urology Care Foundation (UCF), the official patient-facing organization of the American Urological Association (AUA). 18
We also sought to provide the first evaluation of Bard's ability to answer urology patient questions. We believe that including Bard is essential as newer platforms are rapidly entering the chatbot landscape and it remains unclear which AI platform will emerge as the most utilized in the future.
Together, we provide the first study to blindly compare AI-generated responses to common endourology patient questions from ChatGPT and Bard against traditional information sources.
Methods
Question identification
The UCF website was queried for endourology-focused patient education resources. All question-and-answer documents related to kidney stones, ureteral stents, BPH, and upper tract urothelial carcinoma (UTUC) were identified. Questions and answers were extracted verbatim, but images were excluded. Duplicate questions were only included once. Questions were classified as related to symptoms, etiology, diagnosis, treatment, prevention, or general/other common concerns.
A total of 32 questions and answers from UCF, spanning topics on kidney stones (n = 12), ureteral stents (n = 7), BPH (n = 7), and UTUC (n = 6), were included in the study (Table 1).
Common Endourology Questions Extracted from Urology Care Foundation Patient Education Materials
BPH = benign prostatic hyperplasia; UTUC = upper tract urothelial carcinoma.
Generation of AI responses
The UCF questions were inputted into ChatGPT 4.0 and Bard on October 10, 2023, and responses were recorded. A new session was created for each query to negate the influence of prior responses on novel output. For each question, the word count of the verbatim UCF response was calculated. Both platforms were instructed to limit the generated response to within ±10% of the word count of the corresponding UCF question to ensure a fair comparison between UCF and the AI chatbots.
Response evaluation
Six endourology fellowship-trained urologists (M.G., W.A., J.A.K., A.J.Y., R.K., and K.G.) evaluated responses from each of the three modalities through a survey that blinded the reviewer to the response source (Supplementary Fig. S1). The response order was randomized for each question. All reviewers indicated that they had not previously viewed the relevant UCF documents. Quality was assessed using 5-point Likert scales for accuracy, comprehensiveness, and clarity, similar to prior studies (Fig. 1). 2
Evaluation instruments for responses to common questions in endourology.
Additionally, evaluators rated patient utility using the Global Quality Scale (GQS), which assigns a score from 1 to 5. 13,19 Treatment-related questions were further evaluated using Section 2 of the DISCERN instrument, which provides a score between 5 and 35 based on a series of questions related to the quality of information on treatment choices. 2 Reviewers also identified which of the three responses they believed was not AI generated.
To assess readability, validated measures, including the Flesch–Kincaid Reading Ease Score (FKRE) and Flesch–Kincaid Grade Level (FKGL), were calculated for each response. 20 The FKRE calculates a reading score from 0 to 100, where higher scores indicate text that is easier to read, while the FKGL assigns a reading level from “5th grade” to “College Graduate.”
Statistical analysis
Quality and readability measures were compared using T-tests or one-way analysis of variance (ANOVA) for continuous variables and chi-square tests for categorical variables. Multivariate logistic regression was performed to assesses whether ChatGPT or Bard was a predictor of high ratings (score ≥4) of each quality outcome when compared with UCF after controlling for the question category and type. Intraclass correlation coefficient (ICC) values were calculated to assess the degree of inter-rater reliability for ratings of accuracy, comprehensiveness, clarity, patient utility, and DISCERN score.
This study was exempt from institutional review board evaluation as it was deemed nonhuman subjects research.
Results
Each of the six reviewers evaluated 96 potential patient queries, generating 576 unique assessments across UCF, ChatGPT, and Bard. On average, ChatGPT responses scored the highest across all quality assessments, while UCF scored the lowest in each category (Fig. 2). For accuracy, mean ratings of UCF, ChatGPT, and Bard were 3.48, 3.79, and 3.58, respectively. These differences were significant between ChatGPT and UCF (p < 0.001) as well as ChatGPT and Bard (p = 0.014), but not between UCF and Bard.
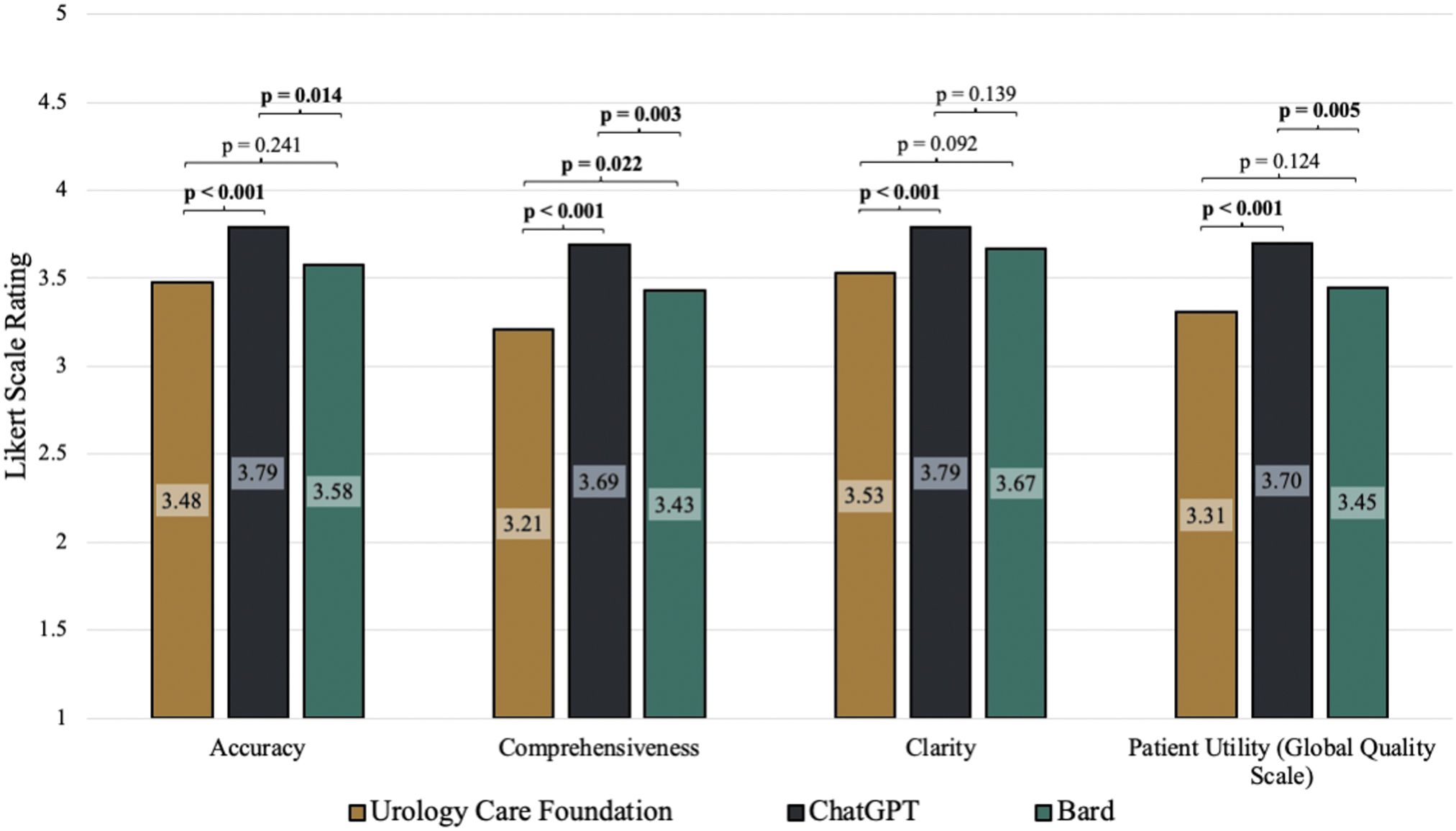
Mean accuracy, comprehensiveness, clarity, and patient scores by response source.
For comprehensiveness, mean ratings of UCF, ChatGPT, and Bard were 3.21, 3.69, and 3.43, respectively, and each group was significantly different from each other, p < 0.05. For clarity, mean ratings of UCF, ChatGPT, and Bard were 3.53, 3.79, and 3.67, respectively. ChatGPT responses were significantly different than UCF responses (p < 0.001), while other comparisons were not significant.
For patient utility, mean ratings of UCF, ChatGPT, and Bard were 3.31, 3.70, and 3.45, respectively. The differences between ChatGPT and UCF/Bard were significant, both p < 0.01, while the difference between UCF and Bard was not significant.
Upon subanalysis, these trends in quality remained consistent across questions related to kidney stones, ureteral stents, BPH, and UTUC, in which ChatGPT responses were always rated highest and UCF responses were rated the lowest (Table 2). Treatment-related responses generated by ChatGPT received higher total DISCERN scores than UCF or Bard, but these differences were not significant, except for questions related to UTUC. Furthermore, inter-rater reliability was generally high for quality ratings across all questions, with the median ICC value being 0.845 (interquartile range [IQR]: 0.772–0.920).
Response Quality Outcomes for Urology Care Foundation, ChatGPT, and Bard
p-Values derived from one-way ANOVA. Accuracy, comprehensiveness, clarity, and patient utility scores ranged from 1 to 5; Section 2 DISCERN scores have a possible range from 5 to 35. DISCERN scores not collected for the ureteral stent category. Significance set to p < 0.05 (shown in bold and * for reference).
ANOVA = analysis of variance; GQS = Global Quality Scale; STD = standard deviation.
On multivariate analysis, a ChatGPT-generated response was predictive of scores ≥4 for accuracy (odds ratio [OR] = 2.381), comprehensiveness (OR = 3.844), clarity (OR = 2.129), and patient utility (OR = 2.900) when compared with UCF, all p < 0.001 (Table 3). Compared with UCF, a Bard-generated response was predictive of comprehensiveness (OR = 1.937) and patient utility (OR = 1.668), both p < 0.05, but not accuracy or clarity.
Multivariate Logistic Regression Analysis for High Ratings of Quality Outcomes
A high rating was defined as a score of 4 or 5 on the 5-point Likert scales of accuracy, comprehensiveness, clarity, and patient utility. Significance set to p < 0.05 (shown in bold and * for reference).
CI = confidence interval; OR = odds ratio; Ref = reference; UCF = Urology Care Foundation.
When asked to identify which of the three responses to a particular question was not AI generated, 54.2% of responses indicated ChatGPT, 26.6% indicated Bard, and only 19.3% correctly identified it as the UCF response (Fig. 3). For readability, mean FKRE scores were the highest for UCF and lowest for ChatGPT (UCF = 63.60 ± 10.97, ChatGPT = 25.69 ± 9.66, and Bard = 49.83 ± 15.68), p < 0.001.

Frequency in which UCF, ChatGPT, or Bard responses were selected when evaluators were asked: “Which response do you think was not AI generated?” AI = artificial intelligence; UCF = Urology Care Foundation.
AI-generated responses were also more likely to be classified at an advanced reading level, while UCF responses showed improved readability (college or higher reading level: ChatGPT = 100%, Bard = 66%, and UCF = 19%), p < 0.001 (Fig. 4).

Flesch–Kincaid Reading Grade Level ratings by response source.
Discussion
As AI platforms become more mainstream, it is likely that these chatbots will be increasingly used to answer patient health care questions. We blindly evaluated AI-generated responses to endourology patient questions against UCF materials and found that ChatGPT, and to a lesser extend Bard, surpassed the quality of official patient education information. Moreover, our results suggest that readers were unable to distinguish between human-generated and physician-generated output. However, we also found that AI-generated responses were more likely to be classified at an advanced reading level than UCF materials.
A key finding in our study was that ChatGPT outperformed UCF and Bard on all quality metrics. It is difficult to contextualize these results as there are few similar endourology-related studies—none of which compare ChatGPT with an established benchmark. Among these studies, results are varied. One study found that ChatGPT elicited misinformation related to BPH, while in a different analysis, ChatGPT correctly answered 95% of urolithiasis-related questions. 12,16 While these studies are informative, the utility of AI compared with existing patient education resources is unclear without a benchmark.
Of note, one study adopted a similar methodology to our analysis, in which they reported no significant differences in accuracy or understandability between ChatGPT 3.5 responses and UCF materials on men's health. 10 While this study covered a different subject, it suggests that ChatGPT can provide comparable responses to urologic questions when compared with UCF. However, our study even showed ChatGPT to have superior quality than UCF. One explanation for this discrepancy is that our study used ChatGPT 4.0—the more advanced model.
ChatGPT also generally outperformed Bard on quality. While we did not identify any other similar urology-focused studies, studies in other specialties have similarly affirmed that ChatGPT provides more accurate and understandable responses to patient questions than Bard. 21,22 We also found that while the Bard score was slightly higher than UCF across all quality domains, these differences were only significant for comprehensiveness. These findings suggest that Bard may be comparable with UCF's quality, but in their current iterations, ChatGPT 4.0 is a superior AI platform than Bard for urology patient education.
Our study also found that reviewers were rarely able to identify physician-created responses such as those from UCF. Perhaps the simplest explanation is that evaluators assumed that the highest quality answer was least likely to be AI generated, thus explaining why ChatGPT was selected as the non-AI-generated response in most cases. Nonetheless, in a prior study that asked respondents to identify whether medical advice was written by ChatGPT 3.5 or clinicians, survey takers correctly identified the human response in most cases. 23
Accordingly, we hypothesized that our evaluators would correctly identify human-generated responses more frequently and at least in 33% of cases based on random chance. Yet, UCF responses were only selected in 19% of cases on average. Collectively, our study suggests that with the advancement of AI, text generated by AI chatbots may be becoming less distinguishable from human-written text.
Despite their high quality, AI responses were more likely to be classified at an advanced reading level than UCF materials. These findings are not unique; several other studies have found that ChatGPT-generated text often shows poor readability. 2,10,24 A head-to-head comparison of AI chatbots also similarly found that ChatGPT required a higher reading level than Bard. 21
The American Medical Association and National Institutes of Health recommend that patient education materials should be written in a sixth- to eighth-grade reading level—which happens to be the reading level for most UCF responses in our study. 3
This may seem like a major issue for AI-generated materials, which tended to be at a college reading level. However, AI chatbots enable the user to adjust the readability of the output. For example, Shah et al. added the prompt “Explain it to me like I am in sixth grade” to improve the readability of ChatGPT responses related to men's health. Interestingly, when comparing ChatGPT output with and without the prompt, the response quality was found to be similar.
Therefore, AI readability may be less of a concern as responses can be modulated using user input to produce more readable output that may not experience a decrease in quality. Still, an important caveat is that if users do not request a readability modification, default responses from AI chatbot passages may show limited accessibility. Accordingly, it may be preferable for the developers of AI platforms to ensure that chatbots automatically respond at an appropriate reading level for the general public when queried with health care-related questions.
Almost three-quarters of Americans seek medical advice online and acknowledge that this information influences their medical decision-making. 25,26 Inaccurate or biased online health care information can lead to inaccurate self-diagnosis and delays in treatment, among a host of other adverse outcomes.
With the rising popularity of AI chatbots, it was important to question whether AI-generated patient education was appropriate. We demonstrate that AI platforms such as ChatGPT and Bard are useful for endourology-related questions and that ChatGPT may even be superior to existing resources in some cases.
Research on these AI platforms provides insights into how urologists could integrate emerging AI technologies into their practice. Our results suggest that it is conceivable that AI platforms could be used to create new patient education content that is later refined by urologists.
This would be advantageous as existing patient education materials are often confined to information on the most common questions for each urologic condition. Given that AI chatbots can theoretically respond to a seemingly infinite number of unique queries, this would allow for rapid development of more specific information on urologic diseases.
Looking ahead, organizations such as the AUA may have the opportunity to play a larger role in how AI impacts patients. For instance, OpenAI recently announced the introduction of custom GPTs that allow users to create a tailored version of ChatGPT that is optimized for specific topics or tasks. 27 The AUA could feasibly develop a custom patient education GPT that is trained specifically on AUA-vetted information, ensuring that the material provided is relevant, accurate, and up to date.
This study is not without limitations. First, the most obvious limitation to our study is that our AI queries may be unrealistic as it is unlikely that users would ask for a response of a specified length. However, if urologists used AI to generate de novo patient education materials, this scenario may be more realistic. Regardless, the reason for our methodology is that prior studies have demonstrated that AI chatbot output length is often significantly longer than physician-generated responses to the same question. 10,28
Therefore, we believe that equalizing response length with UCF was important as it allowed for a fair comparison of quality across all platforms. Furthermore, if certain responses were consistently longer or shorter than the other options, our survey takers may have associated these responses with a particular platform—thus biasing their ability to identify the non-AI-generated response.
Second, ChatGPT and Bard results are known to fluctuate across points in time as these technologies advance. To limit these stochastic implications, we asked all questions on a single date. Third, we utilized UCF materials as they are widely trusted and created by the AUA. Nonetheless, UCF may not accurately reflect the quality of all urologic patient education resources.
Last, all quality outcomes were subjectively evaluated, resulting in potential bias. However, we attempted to mitigate this risk by including six evaluators, exceeding those in most prior studies of AI response quality in urology, which typically used two to three reviewers.
Conclusions
In a blind evaluation, AI-generated responses from ChatGPT and Bard surpassed the quality of endourology patient education materials from UCF. Furthermore, expert urologists were unable to distinguish between AI-generated and human-generated responses. Together, our results suggest that AI platforms may be a reliable resource for basic urologic care information.
However, AI responses tended to require a higher reading level, meaning that AI-generated text may need to be modified to improve its readability to make it more accessible to a broader audience. Future studies should explore how patients perceive the usefulness and accessibility of AI-generated patient education materials.
Footnotes
Authors' Contributions
C.C. was involved in conceptualization, methodology, formal analysis, investigation, data curation, writing—original draft, writing—review and editing, and visualization. K.G. and J.K. were involved in conceptualization, methodology, investigation, writing—original draft, and writing review and editing. R.K. and A.Y. were involved in conceptualization, investigation, and writing—original draft. M.L. was involved in writing—original draft, and writing—review and editing. B.G. was involved in methodology, data curation, and project administration. W.A. was involved in conceptualization, investigation, and supervision. M.G. was involved in conceptualization, methodology, investigation, writing—original draft, writing—review and editing, supervision, and project administration.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.
Supplementary Material
Supplementary Figure S1
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.