
Abstract
Abstract
In current biomedicine, omics technologies drive systems-oriented modes of research to achieve a more holistic and personalized view of health and disease. This shift in scientific approach co-occurs with an era of biocapitalism characterized by markets for biomaterial (e.g., DNA, cells, and tissues) as exploitable resources, high-throughput technologies as tools, and “Big Data” as currency. Prediagnostics and genomics-based analyses successfully entered the public domain more or less unfiltered, offering numerous business opportunities envisioning individuals to contribute to the health sector by providing biomaterial and data as well as by using technology, thus becoming participants and informed coproducers of health. Exploring strengths and weaknesses, as well as opportunities and threats by S.W.O.T. analysis, we highlight some chances, pitfalls, and biases of this sector from a bioscience ethics stance. We conclude that the shift from diagnostic to predictive interpretation of data that comes along with integrative biology seems to escape the general and sometimes the experts' awareness. Moreover, rapid translation into products for the global health market is based on marketable views on health and disease that in turn affect basic research through, for example, funding policies and the research questions being asked. Along with this, biological reductionism is revived fuelling simplified understandings of the genotype phenotype relationship in terms of biology and the human dimension in a broader sense, as well as visions of achieving human perfection through novel biotechnologies.
Science may be described as the art of systematic over-simplification
—the art of discerning what we may with advantage omit. (Popper, 1982)
Introduction
In this review, we try to trace recent and current developments in biomedical research changing the art of science as it used to be in fundamental ways. Scientists' quest for causation of experimentally reproducible facts is changed into a predictive enterprise. The objective of this article is to provide the reader with some insights into the phenomena that have been collectively labeled “Big Data” and how they might have an impact on the field of biomedical research from a bioscience ethics perspective.
Transformation of biomedical research—at crossroads
After the major accomplishment of sequencing the complete human genome, within the framework of Human Genome Project-Read (“HGP-Read”) nominally completed in 2004, the postgenomics era now has been succeeded by the age of Big-Data-Centrism, prone to revolutionize science and medicine. As Big Data, commonly characterized by the “three Vs”: volume, variety, and velocity (Ward and Barker, 2013), has become a key human and financial resource due to its potential to speed up social and scientific innovations, biomaterials (e.g., DNA, cells, and tissues) have become a highly valuable currency, adding another “V” for value (EC, 2014, adopted in 2018). This shift in scientific approach co-occurs with an era of biocapitalism characterized by vast markets for biomaterial as exploitable resources (Rajan, 2006).
Moreover, the field of experimental biology has witnessed an industrial revolution triggered by the data abundance it generates (Leonelli, 2014). A great, and constantly rising, number of companies have thus prized the space of “health research.” As one of the first the Google-backed direct-to-consumer genetic testing company 23andMe promised revelations upon DNA analysis already in 2007. Currently, large consumer tech companies, such as Apple, Amazon, and Facebook as well as Google and its mother company Alphabet, determine the field (Sharon, 2016). For instance, Google's DeepMind announced bitcoin-style health record tracking, thereby shaping the health care sector (Hern, 2017). Access to the encoded treasures allow omics technologies, derived from Sanskrit OM “completeness and fullness” (Lederberg and McCray, 2001), as these research practices aim to decode from a cell's to potentially an entire organism's gene, protein, metabolite, or other entity in its totality.
This assessment of an entire entity intends to reveal a high-dimensional holistic picture, a “knowledge ecosystem” or “collective intelligence,” which ultimately—with the help of decoding algorithms, artificial and computational intelligence of some sort—should translate into integrative or systems biology (Micheel et al., 2012; Özdemir et al., 2009; Özdemir, 2013). Thereby, the genetic basis for human health as well as the pathology of disease to develop highly effective diagnostic tools and treatments suitable for the individual genetic makeup could be developed (NHGRI, 2010).
Recently, scientists announced the commencement of a 10-year-project called the Human Genome Project-Write (“HGP-Write”) aimed at chemically fabricating human DNA, potentially even manufacturing an entire human genome considered “ultrasafe” characterized by virus resistance, improved cancer resistance, and other useful traits such as improved genome stability (Boeke et al., 2016). Another goal stated is the engineering of organoids as well as transplantable organs suitable for cost-efficient and accelerated development of pharmaceutical products, for example, vaccines and drugs (Boeke et al., 2016).
This endeavor has become feasible through the contemporary gene-editing tools CRISPR (clustered regularly interspaced short palindromic repeats)-Cas9, zinc-finger nucleases, mitochondrial transfer, and transcription activator-like effector nucleases, which is already successfully used in various fields of bioengineering (Sander and Joung, 2014; Šlesingerová, 2018). Moreover, 3D bioprinting, with the potential future possibility to construct 3D tissues or even organoids, along with other breaking technologies and their applications such as artificial intelligence (AI), robotics, the Internet of Things, autonomous cars, nanotechnology, biotechnology, quantum computerization, and thus virtual reality and clouds, data analytics, and mining appear as achievable as never before (Olesh, 2016).
At the same time, standard operational procedures of good scientific practice such as the strict practice of peer reviewing before publishing results is shaken up by the real-time online publishing of results, sometimes even on digital social platforms such as on Twitter & Co (The Economist, 2016). Thus, the “V” for velocity when too speedy endangers the control of the peers of the scientific community over what is scientifically sound versus speculative.
Hence, undeniably, research currently faces itself at a crucial crossroad, with cutting-edge science and life-altering technologies at hand, which could significantly affect our future when it comes to health and disease. As improved technologies become available and scientific efforts have shifted from genome description, DNA mapping, and sequencing, to reprogramming and repairing on a genetic and molecular level, “life-editing” appears to become a feasible option in the biomedical field. Thus, the concept of power over life—known as biopower, a notion initially introduced by Michel Foucault in the 1970s—spurs the vision of governing bodies through biotechnology and total surveillance as a cultural phenomenon of our era (Šlesingerová, 2018). Biopower, however, entails numerous inevitable ethical, legal, and social implications, and challenges, in particular so with regard to autonomy, privacy, property rights, and potential harm through exploitation, as we will outline hereunder.
Moreover, the question remains, how the gap between omics laboratory practices and public health actions as well as clinical medicine benefitting society can be bridged. Thereby, it has been suggested that Big-Data-Centrism and the promise of a more holistic picture of health is defined by social, biological, and political determinants, which rule postgenomics life sciences (Dove and Özdemir, 2013); Kickbusch, 2015; Özdemir, 2013; Rose, 2009; Šlesingerová, 2018; Wynne, 2011).
Mind the gap—living lab
Another phenomenon of our decade impacting biomedical research is that citizens aspire to actively participate in their health and/or disease management as informed patients and thereby often as researchers themselves (Tutton and Prainsack, 2011). Movements such as “quantified self” count numerous engaging life-loggers, who desire to keep track of their vitals on a regular basis with the goal to enhance their personal health and performance capability (Quantified Self Labs, 2015). They rely on new technologies—tracking devices, smart phones, and an exponentially growing number of mHealth applications—to evaluate their health status. Some use these technologies primarily for their personal benefit and growth, for instance by changing their conditioned behavior with “carrots and sticks.” Indeed, gadgets such as a Pavlok device, which when triggered zaps its user with an electric current from 50 to 450 V are in use as “sticks” (Behavioral Technology Group, 2017).
Others enrich the community as citizen scientists, contributing to Big-Data-driven research, for instance by sharing their results from direct-to-consumer genetic tests and other research tools and kits, such as Apple's ResearchKit, which allows researchers to conduct medical studies on iPhones (Sharon, 2016). These data points related to the human body, revealing biomedical parameters as well as behaviors and their correlations for an extended period of time, hold incredible potential for science, moreover so, since this trend seemingly bypasses extensive proposal writing and ethics committee assessment (Vayena and Gasser, 2016).
Analytical methods (“algorithms”) through computational social science and biomedical Big Data research advances quickly, whereas limitations of technological capabilities decrease, which can be seen best when following the developments in AI. That so far a still limited scope of regulations is in place has been highlighted with studies such as the incident known as “Facebook-Cornell-Study,” where researchers from Cornell, Kramer et al. (2014), teamed up to study “emotional contagion” on the social network Facebook, omitting to ask the unknowing participants for an “informed consent,” a core principle of human research ethics.
During this very controversial experiment, not only the behavior of users was analyzed without their knowledge, but also the users' newsfeed was manipulated. Later on, the editor-in-chief of PNAS published an “Editorial Expression of Concern and Correction” (Verma, 2014), stating as follows:
Obtaining informed consent and allowing participants to opt out are best practice in most instances under the US Department of Health and Human Services Policy for the Protection of Human Research Subjects (the “Common Rule”). Adherence to the Common Rule is PNAS policy, but as a private company Facebook was under no obligation to conform the provisions of Common Rule…It is nevertheless a matter of concern that the collection of data by Facebook may have involved practices that were not fully consistent with the principles…
Despite all ethical concerns, the study results reveal that the analysis of social networks between individuals offers a large potential for predictive analytics. Other digital records such as phone and e-mail contacts between people offer similar options. As a private company, Facebook used to regularly conduct/possibly still conducts experiments on users, which is consistent with their Data Use Policy, but not necessarily best scientific practice (Verma, 2014), hence the lines become easily blurred for anyone reading about such studies and results.
In the European Union data protection is considered a fundamental right and many categories of information are protected as personal data despite their public nature (European Parliament and Council, 1995). As a basis, Article 8 of the European Convention on Human Rights grants a right to respect for one's “private and family life, his home and his correspondence” and hence values privacy as part of human dignity (ECHR, 2016, updated in 2018). The respective directive used to regulate all research activities regardless of funding within the EU. The recently published EU General Data Protection Regulation along with the ePrivacy Regulation (EC, 2018) has replaced it in 2018.
At the same time the higher the number of data points of one's record is the easier it becomes to identify the owner as an individual (de Montjoye, 2015). This holds the danger of exposing vulnerabilities, for example, a person's HIV status or psychiatric conditions, which has been shown in numerous studies (Christl and Spiekermann, 2016; Duhigg, 2012).
Along with these developments, concepts of health and disease have shifted toward a more integrative perspective on biological complexity, for example, informing current state-of-the-art cancer treatments and efforts regarding health literacy and prevention of disease have been pushed. At the same time, ambiguous and outdated concepts such as “race” were reintroduced in an effort to appreciate human diversity (Yudell et al., 2016).
As this era in biomedicine utilizes omics technologies, this results in a rather systems-oriented mode of research. Nonhypothesis-driven investigations of biomaterial aim to reveal biomarkers as causative factors for certain conditions and diseases in an individual, thus encouraging N-of-1-trials and so-called “small-data” trials (Schork, 2015). Hence, this holds the promise that a more holistic and at the same time personalized view of health and disease can be achieved. This scientific trend requires a reductionist approach at the same time although, since meta-analysis ideally results in the selection of biomarkers in form of a certain single nucleotide polymorphism (SNP). As before, reductionism comes with vast limitations, and science still cannot account all the variables, potentially leading to falsifications or false positives.
Therefore, now the bias more often lies within the technological application and its potentials as well as limitations. Thus, this era still imposes to find the needle in the haystack, only in a bigger haystack as enormously large sets of data are assessed.
Just like legal frameworks, there needs to be ethical principles to assure privacy and other fundamental aspects and in response research communities have developed ethical guidelines and for instance the Secretary's Advisory Committee on Human Research Protections has developed draft guidance on the use of data collected from the Internet (Vayena and Gasser, 2016).
As a consequence, biomedical research has become a multidimensional and multistakeholder process, involving researchers, institutional review board administrators, industry representatives, regulators, ethicists, journal editors, and research subjects (Vayena and Gasser, 2016), so all pillars of society: academia, industry, policy makers, and consumers/patients. This is in line with the “three pillars” that sustain us all, the determinants of scientific thought: biological, social, and political (Özdemir, 2013).
It has been stated by Kolker et al. (2016) that currently the health care sector is lagging behind in incorporating strategies employed by many major industries and their businesses (e.g., Amazon, Apple, IBM, and Facebook) to create superior products and services for them. Exploring strengths and weaknesses, as well as opportunities and threats by S.W.O.T. analysis, we highlight some chances, pitfalls, and biases of this sector from a bioscience ethics stance.
Methodology—Process of Composing the S.W.O.T. Matrix
S.W.O.T. analysis is a strategic planning technique for businesses to differentiate between beneficial or risky issues in the context of further developing the enterprise. More generally applied (Madsen, 2016), the S.W.O.T. technique allows to structure a theme into a clear matrix and to distinguish between positives and negatives at one glimpse (rather than just composing a list of advantages and disadvantages). The analytical matrix aims to identify key factors and structures them into internal factors (strengths and weaknesses of any subject, in this case Big Data generated by biomedical research and in the health context) as well as external factors (opportunities and threats of the same subject). S.W.O.T. is a method of categorization and, therefore, has innate weaknesses.
For instance, it does not prioritize the elements and aspects within one of the four major categories (hence, weak opportunities may appear to balance strong threats). Furthermore, there is an element of subjectivity as we identified and selected factors that according to our practical experience as basic researchers have profound impact regarding ethics in the field of biomedical research. Also, we decided to avoid differentiating between nonprofit and for-profit applications for Big Data because of the increasingly blurred lines between these two as indicated by rapid translation of research into (high-throughput) applications and of applications into products.
Results and Discussion
S—strengths: new era—new possibilities
One advantage of the utilization of new technologies and Big-Data-Centrism in biomedical research is the possibility for less in vitro and in vivo experimentation. Disease modeling, computational tools, and visualization technologies can compensate to a certain extent and virtual physiological human models and decision support services for individualized therapies lead toward personalized medicine (WHO, 2016). One successful example is the “p-medicine” project, which aimed to develop and promote the use of technology to personalize medicine and meet societal needs (p-medicine, 2015). This project also addresses data integration with health information systems, biobanks, genetic databases, and medical imaging systems, and works in interoperability issues.
Hence, personalized treatments become more feasible as large amounts of different types of data are assessed on individual patients (eCancer News, 2015). Virtual models of disease could in the future be used to test therapies with these models (WHO, 2016), as has also been acknowledged by the former European Commission's Directorate-General Information Society and Media (EC-DG INFSO, 2008), now known as Digital Single Market:
Major diseases like cancer, neurological and cardiovascular diseases are complex in nature involving environmental, life style, ageing and genetic components. One of the future challenges is to integrate the knowledge of all these different components into robust and fully reliable computer models and “in silico” environments that will help the development and testing of new therapies for better prediction and prevention tools in healthcare.
Moreover, precision medicine, as a more holistic approach that aims to optimize time and dose schemes of drug treatments based on a patient's genetic makeup, lifestyle, environment, and other factors, has come to the attention of various stakeholders as another strength (Allesandrini et al., 2016).
One more plus side of omics technologies is that their application allows a nonhypothesis-driven approach, taking into account the nonlinear dependencies of biological systems, which are characterized by robustness and redundancies (Klein et al., 2013). Controversially, at the same time, when filtering for biomarkers, individual genes and SNPs, this might lead to a reductionist notion and in the worst case to an oversimplification of causation and biological complexity (Barnes and Dupré, 2009).
With Big Data, scientific research has also developed into more of a team-play league, since a number of experts from different fields, for example, science and bioinformatics, but more and more often large multi- and transdisciplinary consortia collaborate. In addition, awareness about the advantages of sharing over not sharing results is rising (Friend and Norman, 2013).
As a result, research involving other genome-related projects (e.g., the International HapMap Project to study human genetic variation and the Encyclopedia of DNA Elements, or ENCODE, project) is now characterized by large-scale, cooperative efforts involving many institutions, often from many different nations, working collaboratively. The era of team-oriented research in biology is here. (NHGRI, 2010)
As an effect, the costs for certain analyses have been lowered significantly, as for instance DNA sequencing has become significantly less expensive in only a decade (NHGRI, 2016). Owing to the low costs, a huge number of Citizen Science projects and start-ups have evolved such as, for example, “SNPedia,” a wiki investigating human genetics or, for example, “uBiome,” a sequencing-based clinical microbiome screening test, providing detailed and accurate information about one's gut health. Moreover, co-participation models of prevention and treatment offers a real chance to improve health affordably with greater patient satisfaction (WHO, 2016).
W—weaknesses: privacy versus confidentiality versus security
Although there is an ethical obligation to protect personal data (Vayena and Gasser, 2016), the question of ownership is not always so simple. The protection of the human subject is the overarching goal agreed on by all expert bodies, but the sensitivity of the information and potential harm of disclosure is often subjected to the underlying conflict of interest, in use of data versus protection of the human being as a private individual. Human protection strategies should encompass data minimization (only the necessary amount of data is collected) and purpose specification (neglecting nonhypothesis-driven approaches and favoring a clear hypothesis, which defines the kind of data that should be collected) as well as a justified purpose for data collection (NDG, 2016).
An issue, which cannot be ignored, is possible security breaches, as for instance even with encryption and controlled authorized access only, a secure virtual workplace and network might not exclude all types of data transfers, such as, for example, printing, downloading, and e-mailing (Shoffner et al., 2013). Along the same lines, Caldicott's review stresses that “in most cases, breaches or cyber-attacks are unwittingly facilitated by the behaviour of employees who can be classed as ‘non-malicious insiders’” (NDG, 2016, p. 12).
Such a breach in security can lead to the exposure of and thus harm toward vulnerable groups, manifested in practices of ancestry-, identity-, or race-based medicine (Roberts, 2011). In extreme cases, this might even pose a threat, when data are used to reify stereotypes (Bonham et al., 2018; Cooper et al., 2018). Although DNA is often denoted as the “code of codes,” “the holy grail,” “the blueprint,” or also as “the secret of life,” Alondra Nelson ascribes it a social power and a social life also, discussing the social and political aspects inherent in the topic, such as for instance the grappling with the unfinished business of slavery (Nelson, 2016). According to her investigation such social traumas can lead to major security issues.
There is no one-size-fits-all solution for the broad range of potential privacy issues, and the cases might include conflicting issues regarding privacy, confidentiality, security, sensitivity, and others. Therefore, an expert and review body should be implemented, which encompasses the various interest groups, such as, for example, consumer review board, participant-led review board, and personal data cooperative (Vayena and Gasser, 2016).
A major source of weakness lies within the core—the quality of data and analysis. In biology and biomedicine in particular, many different types of data often come from a variety of resources, as there are “myriads of epistemic communities within the life sciences with their own terminologies” and these sets of data “travel across research contexts” (Leonelli, 2014, p. 3). Thus, it is crucial to fully understand how data were gathered and analyzed, the algorithms behind the process, when used to generate knowledge.
O—opportunities: informed = empowered
A real opportunity lies in the education and training sector, as new technologies and applications make it a necessity to incorporate biostatistical concepts and input from other fields, for example, legal updates in the training of health care professionals (WHO, 2016). Clearly, skills to harness data-informed approaches have become more valuable (Kolker et al., 2016). The WHO survey has revealed that 71% of Member States of the European region already use eLearning strategies for educating their health professionals as 96% state that it improves access to educational content and to experts (WHO, 2016).
These sources are mostly accessible to patients also (EPF, 2015). For example, a survey of 1323 members of “PatientsLikeMe” using this online quantitative personal research platform showed that 72% found this opportunity helpful and 76% felt empowered to learn to understand their condition, 62% of patients even experienced improved quality of life, and 22% claimed that they needed less inpatient care since using the site. Moreover, 66% of health providers supported their patients' involvement in “PatientsLikeMe” and appreciated if they printed and brought their symptom summaries to medical appointments (Wicks et al., 2010). Eventually such platforms could lead to a number of real advantages, for example, better-informed decisions, a stronger evidence base, personalized treatment, and care, which would all be generating economic growth (EC, 2014, adopted in 2018).
T—threats: property does not equal property
Especially in omics research, multiple concepts of property pertain: real property (e.g., a blood sample) versus intellectual property (e.g., a gene patent) versus informational property (e.g., genetic code). This needs to be clarified and stated clearly before individuals participate in a Big Data centric science project. Otherwise, exploitation by the expanding translational industry is legal.
For instance, nutritional research has been developing toward “hard facts” as personal health status is defined and even quantified by the formula “genotype × phenotype × environment” (Ommen, 2013). As a purely statistical presentation of reality carries the danger of “wishful thinking” and limitations are often neglected, “small data”-trials are performed to show that individuals have individual characteristics and needs (Ommen, 2013).
To acquire a large cohort for these “small data” trials, the Nutrigenomics Organisation (NuGO), an association of universities and research institutions focusing on nutrition and genomics, has been formed. The involved parties have organized an open access cohort, mostly researchers themselves, where each individual provides and owns their own health data. This became a working strategy to provide both empowerment for individual health optimization and, brought together, a powerful open access cohort.
Most importantly, the NuGO organization has composed a Bioethics Guidelines Tool, which offers “compiled information about sensitive bioethical issues relevant for human nutritional sciences and nutrigenomics research” (NuGO, 2007). This research initiative may be considered best practice, as their guidelines among all valuable principles also state that “Wishes of individuals not to be informed should be respected” (NuGO, 2007). In most studies and commercial tests, one of the most sensitive issues is disclosure of (genetic) test results, as there might be adverse incidental findings, affecting the patients or test consumers as well as their relatives (in the case of genetics).
Another threat is the fact that data analysis is somewhat cryptic for most of us as understanding underlying assumptions, algorithms, and the predictive nature of calculating probabilities and correlations rather than causality from large data sets easily slip the mind, which can lead to misconceiving data as facts. Particularly where results from data-intensive research inspire big business, such misconceptions may even have economic value. Some authors, therefore, call “for adopting and even mandating practices that rely on causation (and mechanisms)—and not just correlation [as] […] the harms of wrongful generalization or missed side effects are substantial” (Zarsky, 2018, p. 55).
The currently still limited understanding of the complexities of biology and environment that affect health and disease turns Big Data centric biomedical sciences extremely vulnerable to support oversimplified views, reductionist concepts, and pseudoscientific conclusions (Prainsack et al., 2014).
Although Table 1, the S.W.O.T. matrix, highlights some of the major chances and risks of current biomedical research, it can never be exhaustive. Its main intention is to evoke a discussion, which leads to the mapping out of a bioscientific ethics perspective encompassing the state-of-the-art research.
Matrix as Outcome of the S.W.O.T. Analysis
Conclusions
Biomedical research is transforming with data-intensive omics technologies and other Big-Data-centered applications. The question remaining although is whether this revolution actually has potential to empower its consumers/costumers/super-users or whether it exploits their biomaterial for purely economic reasons. The question seems to concern the individual more than society as a whole, because the focus shifts to the question of personalization and how these new developments can help ME to improve MY health and life (Kolker et al., 2016). Research has thus yet to shift to N-of-1-trials, as patient advocacy strives for greater autonomy, and self-governance and the participatory codesign movement in new product development have led to new realities in the beginning of the 21st century (Kolker et al., 2016).
Already, as a result, our society has developed well beyond the paternalistic physician focus, with patient associations and disease advocacy groups striving for better treatments (Vayena and Gasser, 2016). This is a chance for research and the application of precision medicine, but clearly needs to be guided by ethical principles. The vast amount of data entities that need to be encompassed are shown in Figure 1. A comprehensive investigation of these new complexities is provided by Prainsack (2017).
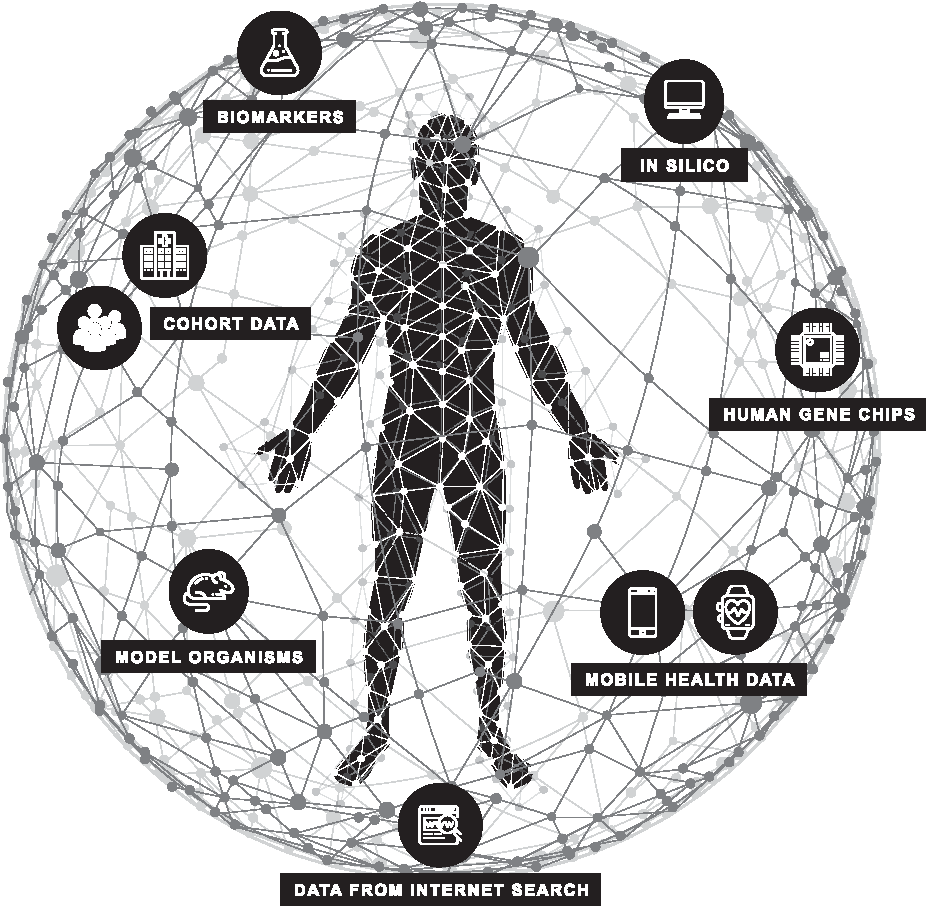
The current state-of-the-art of transformed biomedical research. With focus on the human being as a living lab in the center, the surrounding web of integrated biological/biomedical collective knowledge is portrayed. The available data compiled from different sources compose a health cloud of an individual (N = 1) and hence constitute gathered knowledge of health and disease of the digital being—a host of Big data.
Right now, the discussion evolves around data security, but it barely tackles the shift that constitutes the human being as a digital being and hence affects scientists' understanding of the human body as well as of the human condition and the research questions that are pursued. Recently, a Google teaser for internal use only has been leaked that frames the human being as a “data carrying ledger.” These data, as it is clearly stated, should be used to navigate the human being alias ledger through daily life, presenting various tailored temptations that the human being should indulge in The Verge (2018). An economical benefit in mind, this Google teaser portrays the epigenetic evolution of data generated and hosted by a person (as summarized in Fig. 1).
In fact, it has become taken for granted, that companies use algorithms to analyze large amounts of personal information and predict future behavior (Christl and Spiekermann, 2016), increasingly developing AI to make predictions. The personal data market has grown immensely and is controlled by data brokers (e.g., Acxiom and BlueKai) and the large data collectors (e.g., Google, Apple, and Facebook), which benefit by this ubiquitous digital tracking in the non-transparent manner in which it occurs. This shift toward individualistic consumerist behavior (and neoliberal self-responsibilization), and “data mining” as a phenomenon of biocapitalism, often results in deanonymization and reidentification of individuals (Christl and Spiekermann, 2016).
As a result, there is an actual peril that the human body is turned into a bioresource not only being studied for the purpose of understanding health and disease and hence for “all of us,” the collective welfare. Data on individual bodies also become a commodity in the rapidly growing El Dorado of health-related data applications for only “some of us” who gain in the era of biocapitalism, thus undermining solidarity (Prainsack and Buyx, 2017; Prainsack, 2017).
Recently, Char et al. (2018) emphasized the crucial importance to address ethics when implementing machine learning in the clinics since biases, such as racial or social biases inherent in the data could harm patients and violate social justice. Significantly, a commentary “envisioning the future of ‘big data’ biomedicine” and referring to the NIH Big Data to Knowledge (BD2K) program does not refer to ethics or inherent biases of data (Bui et al., 2017). However, as we outline here by using S.W.O.T. analysis, there is clearly a need for scientists to engage in the ethical dimensions of their research.
In a recent interview, Sheila Jasanoff* called for requiring students to “learn the moral dimensions of science and technology” regarding “frontier fields [like artificial intelligence] that have the potential to change not just individuals but the entirety of what it means to be a human being” (Todd Bergman, 2019). We would like to advocate here for re-introducing philosophy of science, epistemology, and ethics as integral parts of graduate science programs worldwide to “put the Ph. back into the Ph.D. education” (Bosch 2018). Others propose the profession of a health information counselor, to help patients with their diagnosis and decision-making (Fiske et al., 2018). These efforts aim to keep or rebuild the trust of the public in biomedical science, an issue of importance, which require governance solutions and institutional efforts (which warrant that research contributes to the public good (Adjekum et al., 2017).
One concern often raised in the context of governing research from an ethics perspective is that such an approach could jeopardize the freedom of research. However, freedom also entails responsibility and responsibility is based on values. Science is a main pillar for Responsible Research and Innovation in modern societies. Scientists, therefore, will have to engage—again—also in reflection on values and responsibilities as these are an important foundation for the freedom they need and claim (Felt et al., 2018). After all, “smart” innovation in the health sector will have to fit humans and not the other way round.
Footnotes
Acknowledgments
We thank the editor and all reviewers for their valuable input.
Author Disclosure Statement
The authors declare that no conflicting financial interests exist.
Abbreviations Used
*
Founding director of the Science, Technology and society program at Harvard Kennedy School of Government.