
Abstract
Acute hepatitis C virus (HCV) infection is usually asymptomatic, therefore, early diagnosis is rare. It may remain undiagnosed in individuals who progress to chronic infection, often until serious liver damage has developed. To incorporate the diagnosis of this viral disease in a multiple-diagnostic assay, we first analyzed by immunoinformatics the HCV subtype 1a polyprotein (specifically Core, E2, NS3, NS5A proteins) to select antigenic peptides to be tested initially by the Pepscan technique. Next, we performed the immunodiagnosis of HCV infection, using the Multiple Antigen Blot Assay (MABA). In 22 patients' sera included in this study, a 20-mer linear peptide belonging to the N-terminus of the worldwide conserved Core protein showed 100% sensitivity and specificity; other sequences showed different levels of antibody recognition. The use of MABA in combination with synthetic peptides as a source of multiple, specific, and nonexpensive antigens for other infectious diseases could represent a rapid, integrated, and inexpensive diagnostic methodology.
Introduction
S
HCV is an enveloped virus, composed by a positive sense RNA strand, classified in the Flaviviridae family (18). The envelope consists of two proteins (E1 and E2) that surround the nucleocapsid, which is composed of multiple copies of a small basic protein called core, containing the genomic RNA (16). After this genomic RNA enters the cytoplasm of the hepatocytes, the translation process occurs immediately, and the resulting polyprotein has 3,010–3,033 amino acids, depending on the virus genotype (7,15). This polyprotein is subsequently cleaved, yielding structural and nonstructural viral proteins (18). Initial cleavages release the individual envelope proteins (E1 and E2) and the capsid constituent protein (Core or C), located in the N-terminal region of the polyprotein. The remaining segment, containing viral enzymes or nonstructural proteins (NS2, NS3, NS4A, NS4B, NS5A, and NS5B), is released by viral proteases in subsequent cleaving events (12,13,30).
Effective evaluation and rapid and accurate diagnosis of HCV infection are extremely relevant in the control of the transmission and opportune treatment of infected patients. Exposure to the virus can be determined with high sensitivity and specificity with the currently available indirect serological assays that include multiple recombinant antigens from Core, NS3, NS4, and NS5 proteins (1,17). However, the diagnosis of HCV infection remains a subject of study because these assays are expensive, especially for developing countries. In this sense, searching for antigenic peptides derived from proteins traditionally used in current diagnosis kits can provide a less expensive alternative.
To select candidate diagnostic peptide epitopes, we analyzed the sequence of 2 structural (Core and E2) and 2 nonstructural (NS3 and NS5) proteins of 22 selected peptides that include several mutations found in the GenBank Database. We combined two sequential strategies known as the Pepscan (27) and MABA (Multiple Antigen Blot Assay) (21,22) methodologies, which have been successful in the identification of an antigenic sequence for hepatitis A virus (HAV) diagnosis (10). The first strategy consists of the synthesis of a library of peptides (possible antigens) in a Spot manner attached to a cellulose membrane support to subsequently be confronted with patients' sera. The most antigenic peptides were selected, subsequently synthesized in greater quantity and then explored by MABA.
Materials and Methods
Patient samples and ethical clearance
Twenty-two characterized sera with informed-consent signature were provided by the Laboratorio de Hepatitis y SIDA of the Departamento de Virología of the Instituto Nacional de Higiene “Rafael Rangel” (Ministerio del Poder Popular para la Salud-Venezuela). The diagnosis of hepatitis C patients was accomplished by serological third-generation tests, and those borderline cases were referred to INNO LIA HCV®, an enzyme immunoassay for verification of antibodies against specific proteins of the virus, and finally by polymerase chain reaction of the 5'NC. This study followed both the international and national standards on human experimentation, including the Declaration of Helsinki (World Medical Association, 2000) (29) and national regulations. This project has been evaluated and accepted by the Bioethics Committee of The Instituto de Medicina Tropical (IMT) of the Universidad Central de Venezuela.
Protein selection and prediction of B-cell epitopes
The HCV polyprotein subtype 1a (GenBank accession No. AGN33396.1), specifically Core, E2, NS3, and NS5A proteins, was selected for this immunoinformatic analysis. For the determination of possible linear B-cell epitopes, ANTHEPROT (8) was used, based on the physicochemical characteristics of amino acids, such as hydrophobicity (14), surface accessibility (3), and antigenicity (23). In the case of the NS3 protein, a crystallized structure (PBD: 1CU1) is available (31), which was used to locate the peptides selected by ANTHEPROT to adjust the epitopes. Crystallized structures are also reported for the NS5A protein [pdb: 1ZH1 (26) and 3FQM (19)]. Furthermore, peptides were additionally analyzed by multiple alignment with other polyprotein sequences (GenBank accession No. ABV46185.2, AGN33294.1, AEW90302.1, ACJ37189.1) using Muscle tool (
Bold and underlined residues correspond to mutations included by multiple alignment analysis.
PF, physicochemical profiles; TS, tertiary structure.
Peptide synthesis on cellulose paper
Twenty-two peptides were manually synthesized using the Spot technique as described previously (10,27) on a Whatman® 50 cellulose paper. After the peptide sequences were assembled, the side-chain protecting groups were removed with two cleavage solutions for 30 min and 3 h, respectively, without agitation. Solution I consists of 90% trifluoroacetic acid (TFA), 5% ultrapure water, 3% triisopropylsilane (TIPS) and 1% phenol and 1% dichloromethane (DCM). Solution II consists of 50% TFA, 2% ultrapure water, 3% TIPS, 1% phenol, and 44% DCM. The reagents were from Iris Biotech and Sigma-Aldrich chemical grade.
Immunoassay with cellulose-bound peptides (Pepscan)
The dry paper with the “spots” of peptides was blocked with phosphate-buffered saline containing 0.05% Tween-20 (PBST) and 5% nonfat dry milk. Peptides were tested with a pool of four hepatitis C patients' sera (diluted 1:250 each). Horseradish peroxidase (HRP)-conjugated anti-human IgG (Santa Cruz Biotechnology) was used as the secondary antibody and developed with a solution of Luminol SuperSignal™ West Pico substrate (Thermo Scientific). The output chemiluminescent signal was recorded using ChemiDoc® Bio-Rad equipment.
Solid-phase peptide synthesis
Based on the results obtained with the cellulose-bound peptides, those that showed antibody recognition were synthesized by a manual solid-phase Fmoc strategy in polypropylene syringes fitted with a polyethylene porous disk (2,4,9). The first amino acid was coupled manually as follows: 2-chlorotrityl resin (0.4 mmol, 1.0 mmol/g) was washed with DCM (3 × 1 min) and swelled in DCM for 15 min (2 × 15 min). Fmoc-aa-OH (1 equiv) and N,N-diisopropylethylamine (DIPEA) (3 equiv) were sequentially added to the resin, and the mixture was allowed to react for 90 min. Next, a capping step with methanol (MeOH)-DCM-DMF-DIPEA (5:40:40:15; 2 mL) was carried out. The rest of the synthesis was carried out using 2-(1H-Benzotriazole-1-yl)-1,1,3,3-tetramethylaminium tetrafluoroborate (TBTU) as a coupling reagent and DIPEA as a base. Fmoc removal was performed with 20% 4-methylpiperidine-DMF (1:4; 1 × 5 min, 1 × 10 min). Washings between deprotection and coupling were carried out with DMF (3 × 0.5 min) and DCM (3 × 0.5 min), using 2 mL of each solvent.
Peptides were synthesized with and without incorporation of stearic acid at the N-terminal end of the sequence. The fatty acid coupling was carried out using 15 M excess of this acid activated with N,N′-Diisopropylcarbodiimide (DIC)/hydroxybenzotriazole (HOBt) in DCM. Then, the complete peptides were cleaved from the support by using TFA (95%)/TIPS (2.5%)/ultrapure water (2.5%) for 3 h. Characterization and purity were evaluated by Electrospray Ionization Time-of-Flight (ESI-TOF) mass spectrometry and high-performance liquid chromatography, respectively.
Analysis of peptides antigenicity by the MABA
The simultaneous antigenicity of the synthetic peptides was analyzed by a special dot blot assay developed in our laboratory known as MABA (21,22). A rectangle of nitrocellulose (NC) paper (Bio-Rad) was cut and soaked in distilled water. The wet paper was located on an acrylic template (Miniblotter® 20SL) for its sensitization by the introduction of 60 μL of different peptide preparations (20 μg/mL in pH 9.6 carbonate-bicarbonate buffer) in each parallel groove. In addition, during immobilization on the membrane, a normal control human serum (HS) was included in two of the parallel marginal lanes as an internal control of the reaction in each strip. This control should always react in the presence of the secondary antibody. The peptide solutions were removed by washing, and blocking was achieved by immersing the NC in 5% nonfat milk in PBST. Once the NC was blocked, 2 mm-width-strips were cut perpendicular to the channels, and each strip thus contained a row of square spots corresponding to the different antigens. Strips were immersed individually in the troughs of an incubation tray in the serum (diluted 1:100 in blocking solution) of a larger sample of hepatitis C patients' sera (including the four ones previously used in Pepscan). In this preliminary study, we had access to sera from 22 hepatitis C patients. Four negative sera and one no-serum control (No-SC) were included. The reaction was detected separately with two secondary antibodies. The first one consists of goat anti-human IgG peroxidase (1:15,000; Santa Cruz Biotechnology), which was developed using the Luminol SuperSignal (West Pico Chemiluminescent Substrate) and recorded in a ChemiDoc Bio-Rad equipment. The second one consists of anti-human IgG alkaline phosphatase (1:15,000; Sigma) using a combination of nitro blue tetrazolium chloride (NBT) and 5-bromo-4-chloro-3′-indoly phosphate p-toluidine salt (BCIP) as chromogenic substrate.
Results
Peptide selection
To select sequences with antigenic potential, four proteins were analyzed by ANTHEPROT software and peptides of 20-mer with high values of hydrophilicity, solvent accessibility, and antigenicity were chosen. Fifteen peptides were selected based on their physicochemical profiles; four of them belong to the Core protein, two to E2, four to NS3, and five to NS5A. The E2 protein showed a less hydrophilic and antigenic sequence. However, 20-mer peptides with the higher possible values were selected. Figure 1 represents an example of sequence analysis, together with the ANTHEPROT profile of the Core protein and the selected peptides.

ANTHEPROT physicochemical profiles based on the primary structure of the core protein peptide numbers are the same in spot synthesis.
The X-ray structure of the NS3 protein is currently available (PDB: 1CU1), which allowed us to determine if sequences selected by primary structure predictions by ANTHEPROT are exposed in the tertiary structure. This analysis showed that all selected peptides are well structured and the two sequences selected in the protease domains are exposed. However, one of the peptides of the helicase domain was discarded, as it was not exposed to solvents.
The reported crystallized structures of the NS5A protein were not considered in this study. The possible epitopes obtained by the ANTHEPROT analysis cannot be located in the three-dimensional (3D) structures as they are completely different sequences. The sequence used in this study is of recent date (2014), while the 3D structures were reported in 2005 and 2009. We propose to use them in the future to predict possible B epitopes based on structure.
Finally, even when the polyprotein of genotype 1a of HCV is conserved, there are several available sequences, which is the reason why a multiple alignment was utilized to include some possible mutations. All 22 selected sequences are summarized in Table 1, as well as their selection criteria.
Solid phase peptide synthesis and testing on cellulose paper (Pepscan)
To experimentally determine the antigenicity of selected peptides, the 22 sequences in Table 1 were synthesized on a functionalized cellulose paper in a spot manner. Three chemical control spots, numbered 23, 24, and 25, were added as a repetition of peptides 9, 17, and 4, respectively. When the membrane with peptides was exposed to a pool of four hepatitis C patients' sera, antibody recognition was observed for peptides 1, 3, 2, and 4, in decreasing order of signal intensity, corresponding to the N-terminal end of the Core (Fig. 2).
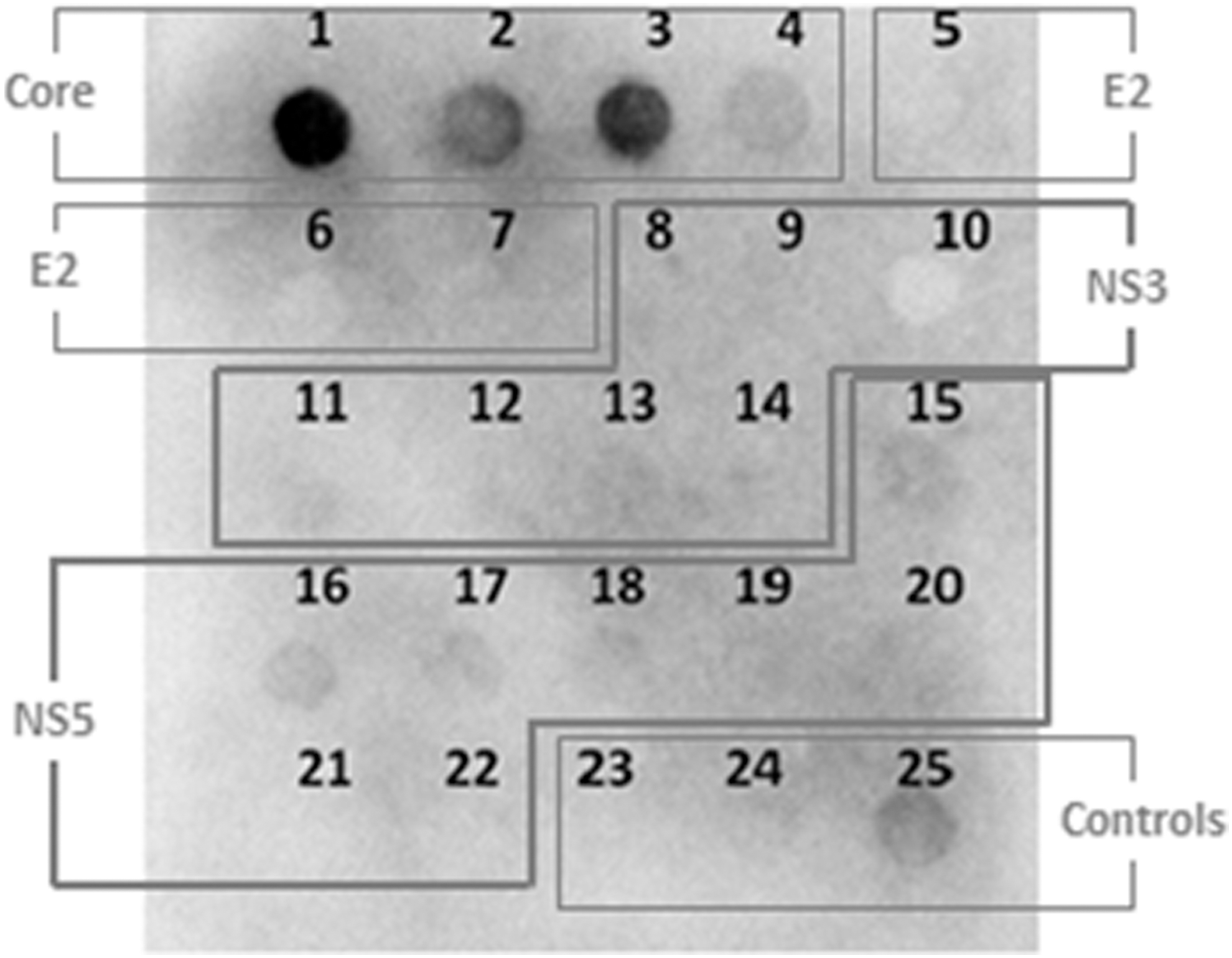
Peptide reactivity against a pool of sera using Pepscan methodology.
Other sequences, such as spots 11, 13, 15, 16, 17, 18, and 24 (a repeat of spot 17) of nonstructural proteins, showed slight antibody recognition. However, since we are looking for potent antigens, these peptides were discarded for the time being. No recognition was observed by selected sequences from the structural protein E2, which is not surprising since its values of hydrophilicity, solvent accessibility, and antigenicity were the lowest ones of those observed in the immunoinformatic analysis (data not shown). These results suggest that the Core molecule, which is a highly conserved basic protein, is the most antigenic under our study conditions.
This technique allowed us to reduce the selected peptides to those corresponding to spots 1, 2, 3, and 4 for a larger scale synthesis on resin, with and without incorporation of stearic acid at the N-terminus, to be tested against a total of 22 hepatitis C patients' sera by MABA.
Multiple antigen blot assay
Eight peptides were tested by MABA, corresponding to sequences selected by Pepscan (spots 1–4) and their analogs with stearic acid (Table 2). Peptide IMT-2052 (spot 1 in Pepscan) showed antibody recognition by all 22 infected patients' sera included in this preliminary study. Most of signals corresponding to this peptide were strong using both enzymes, the anti-human IgG peroxidase and anti-human IgG alkaline phosphatase. Its stearic acid analog to IMT-2052 resulted with recognition values of 16/22 (Fig. 3A, B). Other peptides showed different degrees of antibody recognition ranging from 13/22 to 0/22, as summarized in Table 2.

Antigenicity of synthetic peptides evaluated by MABA by sera of 22 hepatitis C patients and 5 negative controls using
IMT, Instituto de Medicina Tropical; MABA, multiple antigen blot assay.
Discussion
In previous studies, we have combined immunoinformatic analysis, Pepscan methodology, and MABA technique in the discovery of antigenic peptides for immunodiagnosis of hepatitis A infection (10). In this study, sequences of two structural and two nonstructural proteins of HCV were analyzed in combination with structural analysis of NS3 protein. Twenty-two sequences, most of them of 20-mer, were selected for their synthesis on a cellulose membrane.
During this Pepscan, we used amino acid solutions four times less concentrated than previously used to synthesize 20-mer peptides on paper (10). Even when the lowest concentration of amino acid solutions was used, strong signals were observed for spots 1–4, all of them from Core protein, highlighting its relevance in the immunodiagnosis of hepatitis C infection.
It was precisely spot 1 that exhibited the strongest antibody recognition by Pepscan, and it was the peptide that showed the highest sensitivity when synthesized and tested by MABA. Peptide IMT-2052 had a recognition frequency of 22/22, 100% of sensitivity, while sequences of peptides IMT-2054, IMT-2053, and IMT-2055 showed sensitivities of 59%, 30%, and 0% by MABA, respectively, which aligns with the signal intensity observed by Pepscan. The 100% IMT-2052 recognition frequency will lead us to confirm these high values of sensitivity and specificity and to determine the positive and negative predictive values through epidemiological studies in the general population.
It has been reported that peptides containing bulky and hydrophobic side chains may bind better to solid plastic surfaces of certain enzyme-linked immunosorbent assay (ELISA) plates (25). As mainly hydrophobic interactions are responsible for adsorption to the surface of PVC plates as well as NC paper, we may assume that the use of fatty acids will provide the conjugate with the necessary hydrophobicity (11). In an attempt to optimize the MABA technique and improve peptide adhesion to NC paper, we synthesized antigenic peptides with the incorporation of stearic acid at N-terminus. However, we obtained better antibody recognition with those peptides without the hydrophobic tail, possibly due to a decrease in peptide solubility caused by the incorporation of a fatty acid composed of 18 carbon atoms, which is 2 carbons greater than palmitic acid that is typically used. Fortunately, peptide IMT-2052 seems to have good adhesion to NC paper and the incorporation of a hydrophobic tail is not necessary to reach 100% sensitivity.
Other controls have been recently incorporated to the MABA technique, such as the normal control HS. This control consists in the immobilization of a serum as a source of immunoglobulin in the first and last lanes of each strip, which should always react in the presence of the secondary antibody. In addition, a No-SC was used, which consists of a strip not exposed to serum such that only a reaction with the HS should be observed. These controls behaved as expected, and all signals were reproducible with both enzymes.
MABA has been a useful technique, which permits us to simultaneously test all peptides against the same serum at the same time, reducing possible variations in study conditions for different antigens. This low-cost technology requires very small concentrations of antigens and very small volumes of serum (6 μL), resulting in the identification of molecules (peptides) at a low cost per patient ($0.006 per MABA vs. $0.129 per conventional ELISA) (21). Furthermore, as the peptide synthesis becomes more widespread, its costs decrease in comparison with the use and production of purified or recombinant antigens.
Peptide IMT-2052 from the N-terminus of Core protein is an interesting region of study for the design of inexpensive diagnosis tests, which makes it more accessible for developing countries. It must be said that the major goal of our research group is the development of a multidiagnosis kit based on MABA technique and synthetic peptides, where this sequence can join others of public health relevance to be adapted and implemented for particular populations where coinfections are frequent (5,20).
Conclusions
HCV infection is usually asymptomatic and it often remains undiagnosed until serious liver damage has developed. To prevent its transmission and the development of cirrhosis and hepatic cancer, it is critical to have rapid, effective, and inexpensive diagnostic methods that can be incorporated into routine procedures in health centers in endemic areas. In this work, we report the integration of a sequence analysis of the HCV polyprotein subtype 1a (including structural and nonstructural viral proteins), followed by a spot synthesis (Pepscan) of chosen peptides. This strategy allowed the selection of four peptide sequences from the very conserved Core protein, highlighting its relevance in the immunodiagnosis of viral hepatitis C infection. These four peptides showed different levels of antigenic recognition by MABA, with the peptide 1MSTNPKPQRKTKRNTNRRPQ20 (IMT-2052) being the most antigenic, with a sensitivity and specificity of 100% utilizing sera from 22 hepatitis C patients. Further epidemiological studies with a larger sample size are necessary. Finally, we conclude that this peptide, with just twenty residues, is a low-cost alternative for prevalence studies and early diagnosis of hepatitis C infection.
Footnotes
Acknowledgments
This work has been partially supported by grants G-2005000387, 201100413, 2007001425, F-2005000122, and 20122001311 from FONACIT-Venezuela, as well as Grand Challenges Explorations grant funding number OPP1151004.
Author Disclosure Statement
No competing financial interests exist.