
Abstract
The article assesses the developments in automated phenotype pattern recognition: Potential spikes in classification performance, even when facing the common small-scale biomedical data set, and as a reader, you will find out about changes in the development effort and complexity for researchers and practitioners. After reading, you will be aware of the benefits and unreasonable effectiveness and ease of use of an automated end-to-end deep learning pipeline for classification tasks of biomedical perception systems.
In 2016, we published a study on Automated phenotype pattern recognition of zebrafish for high-throughput screening. 1 The central contribution was a classifier to distinguish four different fish lines (Fig. 1) of hatched zebrafish larvae at 72 h postfertilization with respect to their phenotypical features. Back then (Spring 2015), the study was carried out within a 4-month project, and an average accuracy of 89% was achieved. Looking past the small-scale data set (1057 samples in four classes), and the handcrafted feature approach, the addressed biomedical visual classification task is just as relevant today. 2 Thus, inspired by Andrew Karpathy's blogpost* on reproducing the article on Backpropagation applied to handwritten zip code recognition on Modified National Institute of Standards and Technology dataset, 3 we revisited our study on automated phenotype pattern recognition to find out what has changed during the past years in terms of methodology in biomedical vision tasks.

Exemplary samples of the four zebrafish classes: Wild type (top left), 1-phenyl 2-thiourea (top right), homozygous rx3 Mutant (bottom left), and Kita HRAS (bottom right).
Introduction: 6 Years Ago
Before the AlexNet 4 revolution caught on and got widespread traction, a computer vision pipeline, so ours, followed a three-step approach of data loading, feature extraction, and finally pattern recognition. To put things into perspective, let us shortly recapitulate the specifics of the 2016 setup. Image acquisition was handled by two cameras in orthogonal pose (transversal and sagittal view), directed at a cuvette that holds the zebrafish.
Let us take a closer look on the different classes in Figure 1: The top left image represents the wild-type zebrafish, with a natural pigmentation pattern and all developmental features in place. The top right image contrasts the wild type by a reduced pigmentation due to the 1-phenyl 2-thiourea (PTU) treatment, the effects on the pigmentation strength can vary so differentiation can be ambiguous. The bottom left shows a homozygous rx3 (retinal homeobox gene 3) mutant in which the development of the eye segment is suppressed, which is easily spotted by a human. The bottom right features a transgenic kita proto-oncogene with protein product (HRAS) sample, 5 which develops an amplified pigmentation phenotype, especially on the yolk bag. Apparently, pigmentation phenotype expression is crucial for classification; however, the individual fish lines express a broad spectrum of pigmentation intensity within themselves. Finally, the larvae's pose has an impact on how well the features can be assessed by a human or a computer vision system.
Feature extraction was carried out based on handcrafted features and heavily relying on biomedical expert domain knowledge. Usually done manually, classifying different zebrafish types is a hard and tiring undertaking. Feature extraction had to be carried out specifically for each class, following multiple processing and extraction steps, leading to features based on the level of pigmentation (Fig. 2) for PTU and kita-HRAS (kita-driven protein), or the eye segment formation (homozygous rx3 Mutant). For pattern recognition we have been using support-vector networks 6 in a binary classification setting, separating wild type versus variant, while we had to optimize for two control variables: The fault-tolerance and the Radial Basis Function-Kernel. Everything was implemented in MATLAB and OpenCV. Performance has been 89.0% and has been reported as classification accuracy (Table 1).
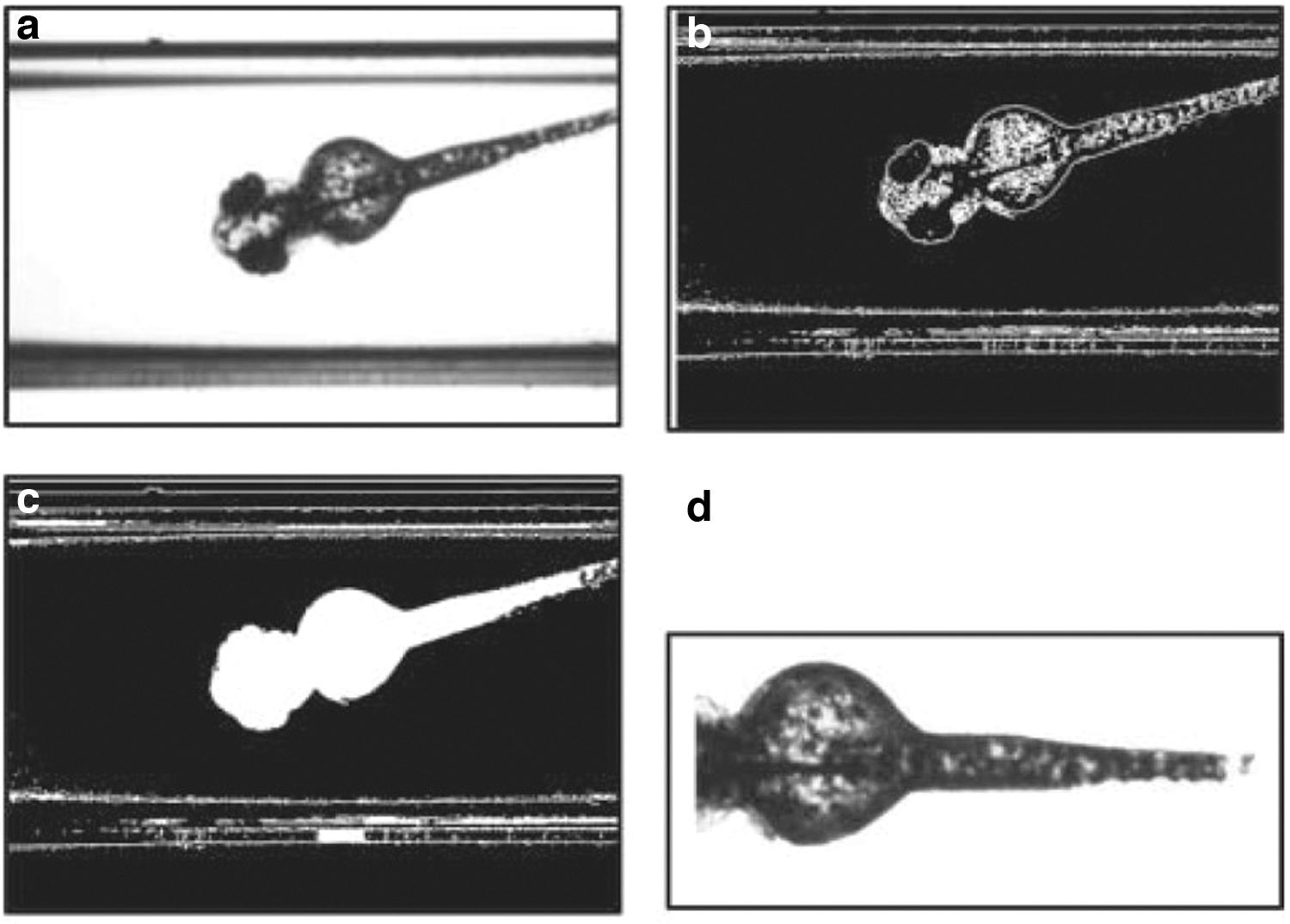
Feature extraction pipeline for the pigmentation level of the zebrafish larvae.
Average Accuracy Performance of the Binary Classifiers, Learned by a Support Vector Machine
Method: Now
We draw on an arsenal of matured and practice-proven deep learning methods. This revision does not intend to use the past performance as a benchmark that needs to be surpassed. We deliberately refrain from an extensive hyperparameter tuning. Quite the opposite, we want to reflect on what has changed, and is possible out of the box with the current plug-and-play approaches and methods, which we would opt for if asked to tackle the problem today. Now, neural network specification is supported by high-level scriptable Application Programming Interfaces, 7 bringing to the table everything that is necessary for training and developing a neural network, from architecture design, optimizers, loss functions, data loaders, and monitoring tools.
There are now a multitude of pretrained neural networks suitable for image classification, which come ready for deployment. 2 This reduces architectural design complexity and neural network training time, which might otherwise pose a barrier to implementation. It can be expected that the neural network will be able to have its way even with a multiclassification setting, arguably even benefitting from the multitask training, thus the output layer is designed as a dense layer with four nodes. This accommodates the neural network architecture for the task of classifying the same four classes as in 2016: Wild type, PTU, kita HRAS, and the homozygous rx3 mutant (Fig. 1).
In detail our deep learning pipeline † follows a transfer learning approach 8 provided originally as a demo by TensorFlow, ‡ which is based on python (3.9), tensorflow (2.7.0), tensorflow-hub (0.12.0). Thus, the time for setting up the pipeline is neglectable. Wherever possible we fall back to the default parameters given by the corresponding package and version. The only thing we could not default on was the choice of the feature extraction backbone, so we revert to the first thing that comes to mind, and a common choice for that matter: Inception_v3 § ,9 with a prepended normalization layer, and the optimizer where we go for the Adam optimizer. 10
For training early stopping 11 was used, with a patience of five, so we did not have to decide on how many epochs to train until convergence. A more difficult decision to make is on a training to validation split. Where we could utilize the whole data set for validation in 2016, as we could draw training samples online while setting up the imaging platform. To reach a fair comparison, we want enough training samples to be able to converge on a model with little prediction uncertainty. However, we judge the evaluation variance to be of even higher importance. Thus, knowingly sidelining the deep learning approach's performance we set the train-validation-ratio to 0.5. Notice that once the classes have been labeled, there is no further domain knowledge necessary to develop and operate the deep learning pipeline.
Besides the advancements in methodology and software tooling, hardware accelerators have played a major role in the success of deep learning. This is not the concern in this study, due to the transfer learning approach, thus the training was carried out on an Intel® Core™ i7-6820HQ Central Processing Unit (CPU)@ 2.70GHz, 2712 MHz, 4 Cores, 8 Logical Processors and 32.0 GB Random Access Memory (RAM).
Results: The Unreasonable Effectiveness
While one epoch took an average of 41 s, we reach our 2016 average accuracy performance after 4 epochs (∼2.5 min), achieving a validation accuracy of 89.0%.
The console output then looks like this:
Epoch 4/1000
17/17 [ = = = = = = = = = = = = = = = = ] - 36s 2s/step - loss: 0.3808 - acc: 0.8922 - val_loss: 0.4287 - val_acc: 0.8902
As we set up early stopping, our training automatically finished after 23 epochs with a validation accuracy of 94.70%:
Epoch 23/1000
17/17 [ = = = = = = = = = = = = = = = = ] - 45s 3s/step - loss: 0.0521 - acc: 1.0000 - val_loss: 0.2363 - val_acc: 0.9470
Proceeding naively, we out of the box have been able to sweep away our 2016 approach's performance and exceed it by ∼6% in validation accuracy, or seen from the other side, the error has been reduced by ∼50% (Table 2).
Final Accuracy Performance of the Multiclass Classification Setting, As Achieved By Our Deep Learning Pipeline
In 2022, this is not where one would end if set out to crunch a conventional approach's baseline. The generalization gap of ∼5% (see the light blue band in Fig. 3) after 23 epochs asks for further regularization such as Dropout 12 or adjusting the objective function. 13 Taking the small scale of the available data into account, data augmentation methods 14 is an obvious next step. Knowing, that we want to follow a data-driven approach to feature extraction and selection through a neural network—acquiring more data is a definite to-do-next.15,16 If interpretability is crucial for the application, there are heat-map approaches, and others that are fully developed for classification tasks within perception.

Training accuracy (upper lines) and validation accuracy (lower lines) over the epochs—as provided by tensorboard. The light lines are the real values, whereas the strong lines reflect the smoothed learning curves.
Discussion: So Now?
What has been changed and achieved within automated phenotype pattern recognition since we last looked (Table 3)?
Comparison of the Conventional Handcrafted Feature Extraction Approach and the End-to-End Deep Learning Approach to Automated Phenotype Recognition
An asterisk depicts evaluations that can be improved with available methods.
The key findings and what you should take away from this article are as follows:
The paradigm shift of an end-to-end data-driven pattern recognition by deep learning caught on conclusively. This is also reflected in automated phenotype pattern recognition and allows for automated adaptation and extension of phenotypical classification tasks. Whereas we would have to handcraft feature representations for each added phenotype, today we implicitly introduce further types by providing the associated training samples, in a dedicated directory, then even adding a node to the final layer of our neural network is realized seamless. The required programming skills are reduced to a bare minimum of setting up and running an integrated development environment and require no formal or academic training. Development of phenotype pattern recognition has become more accessible, as only little domain knowledge is necessary to group the samples, whereas it is no longer necessary for a human to understand the features that need to be extracted to best describe a specific phenotype. However, we would argue that at the latest with validation and continuous improvement of the model, domain knowledge remains as crucial as it has ever been. More difficult biomedical tasks are targeted,17–19
as phenotypical classification tasks require less development, free up research capacities, and by now scale seamless due to transfer learning. At the same time deep learning pipelines naively reach competitive performances, compared with handcrafted feature approaches. The notion of neural networks being compute and data hungry has been done away with, especially during training, as we were able to achieve satisfying performance on a CPU and without robbing the piggy bank to get our hands on the latest Graphics Processing Unit or even Tensor Processing Unit. Owing to transfer learning the number of required training samples is significantly reduced as we can limit ourselves to fine-tuning the last classification layer of our model. Besides label-efficient learning strategies are developed and constantly improving.
15
Footnotes
Acknowledgments
We thank our colleagues at the Institute for Automation and Applied Informatics, and especially Prof. Dr. Christian Pylatiuk who supervised the study on the baseline method from 2016.
Authors' Contributions
Conceptualization, investigation, data curation, and writing—original draft by M.S. Methodology and formal analysis by M.S. and M.R. Software and validation by M.S. and L.R. Resources, supervision, project administration, and funding acquisition by M.R. Writing—review and editing and visualization by M.S., L.R., and M.R.
Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.