
Abstract
Machine-to-machine (M2M) networks could be connected by a wide range of wireless technologies (e.g., Bluetooth, WiFi, RFID). Due to some factors (e.g., mobility of machines, limited communication range), it is hard to maintain the connectivity of the network, that is, the network is disconnected and it is a specific application of delay tolerant networks (DTN). Communication in such network often needs nodes working in a cooperative way. However, due to selfishness, nodes have no incentive to help others. Therefore, if the source requests help from other nodes, it needs to pay certain fees to them. The main goal of this paper is to explore efficient ways for the source to maximize the average delivery ratio when the total fees are limited. First, we mathematically characterize the average delivery ratio under different policies. Then we get the optimal policy through Pontryagin's maximum principle, and prove that the optimal policy conforms to the threshold form when the fees that other nodes require satisfy certain conditions. Simulations based on both synthetic and real motion traces show the accuracy of our model. Through extensive numerical results, we demonstrate that the optimal policy obtained by our model is the best.
1. Introduction
At present, Machine-to-machine (M2M) networks have emerged as an innovative topic and are undergoing rapid development [1]. In particular, M2M networks could be connected by a wide range of wireless technologies (e.g., Bluetooth, WiFi). Due to the limited communication range, mobility of machines or other factors, it is hard to maintain the connectivity of the M2M networks. On the other hand, the concept of delay tolerant networks (DTN) has been proposed to support many new networking applications, where the end-to-end connectivity cannot be assumed [2]. Therefore, M2M networks can be seen as a specific application of DTN. In order to provide communication services in such disconnected networks, nodes in DTN communicate through a store-carry-forward way. In particular, when the next hop is not immediately available for the current node, some relay nodes will store the message in their buffer, carry the message along their movements, and forward the message to other nodes when a new communication opportunity is occurring [2].
By abuse of language, we will use node and machine alternately in this paper. It is easily to see that the store-carry-forward communication mode needs nodes working in a cooperative way. In particular, the source (one specific machine) may need other nodes serving as relays to forward message to the destination (another machine). In the real world, machines may be vehicles, smart phones, and so on. Though nodes in M2M networks can communicate with each other without human intervention, they can be manipulated by human, too. Therefore, peoples’ social behavior (e.g., selfishness) can have certain impact on communication. Due to the selfish nature, nodes have no incentive to help others [3, 4]. To make these nodes be cooperative, some incentive policies are necessary. This paper adopts the fees-based incentive policy, that is, the source has to pay certain fees to other nodes if it requests help from them. The fees may be real or virtual currency, by which nodes can buy certain services (e.g., downloading files) from others. Moreover, these fees may be varying with time. In fact, the buffer space or the forwarding ability can be seen as goods. The event that the source requests help from other nodes can be seen as that the source buys certain goods from them, so the message transmission process can be seen as the commodities trading process, and nodes want to maximize its income in this process. Therefore, nodes may adjust the price of their goods according to the market state. For example, if the remaining lifetime of message is shorter, nodes may guess that the source is eager to transmit the message as soon as possible, so they may guess that their goods (e.g., buffer space, the forwarding ability) are important for the source. In this case, they may increase the price. In addition, if the remaining lifetime of the message is long, nodes may guess that the source may be not eager to transmit the message quickly and is not willing to pay more fees. In this case, they may help the source with only a fewer fees. Therefore, the fees that the ordinary nodes require may be varying with time. If the source has enough fees and can make every node be cooperative, the message will be transmitted according to the classic epidemic routing (ER) algorithm [5], but it has to pay more fees. As the buyers, the source may be not willing to pay more fees, for example, it may think that it is not economical [6]. Therefore, when the total fees are limited, how to maximize the probability that the destination gets message before the message deadline is a very important problem.
Note that our work is similar to the packet purse model (PPM) of credit-based incentive policy, in which nodes can get certain nuggets (denoted by fees in our work) from the source if they help the source [6]. Therefore, the fees in our work can be seen as nuggets in the PPM model. However, state of the art works about the PPM model have some differences with our work. First, most of them do not consider the case that the fees that nodes require may be varying with time. In addition, they do not study how to use the limited nuggets efficiently. For example, supposing that node j is willing to help the source by charging m nuggets at time
On the other hand, our work is similar to the optimal control problem of ER algorithm in DTN, which is a popular topic recently, and there are some good works in this field, such as [7, 8]. However, they do not consider the selfishness nature of nodes. For the selfishness behavior, there are some works, which evaluate its impact on the routing performance [3, 4]. However, none of these works considers the optimal control problem. In addition, the selfishness behavior in those works is not varying with time and is denoted by a simple way. In particular, they use the probabilistic way to denote the selfishness behavior. For example, node i is willing to help node j with probability q.
The main contribution of this paper is to study the optimal routing problem in such complex application. In particular, we propose a unifying framework through a continuous time Markov process, which can be used to evaluate the total fees that the source pays. Then based on the framework, we formulate an optimization problem. Through Pontryagin's maximum principle, we explore the stochastic control problem, and we prove that the optimal policy conforms to the threshold form in some cases. By comparing the simulation results with the theoretical results, we show that our theoretical framework is very accurate. We compare the performance of the optimal policy with other policies through extensive numerical results and find that the optimal policy obtained by Pontryagin's maximum principle is the best.
The rest of this paper is organized as follows. In Section 2, we briefly present some related works, and we describe the network model in Section 3. In Section 4, we first present the theoretical framework, and then formulate the optimal control problem. In Section 5, we introduce the simulation and numerical results. Finally, we conclude our main work in Section 6.
2. Related Work
In the past few years, many routing protocols have been proposed in DTN, but most of them need certain prior knowledge of the network, or they can obtain such knowledge through some online learning processes, such as the works in [9–11]. In some applications, there may be no enough time to learn, so these algorithms have certain shortage. On the other hand, ER algorithm does not need any prior knowledge about the network and can be used in many environments. For this reason, this algorithm is still a very popular topic. However, it works in a flooding way, so it wastes much energy and suffers from poor scalability in large networks. At present, many policies have been proposed to reduce its overhead. Among them, there are probability forwarding policy [12], hop-based forwarding policy [13], and so forth. These algorithms try to achieve big delivery ratio and relatively low transmission cost. Generally speaking, big delivery ratio is obtained at the expense of more cost. Therefore, how to accurately evaluate both strengths and limitations of these algorithms is very important. Some works use the simulation manner [14], but recently, theoretical manner is more popular. The performance of ER algorithm based on the sparsely exponential graph is studied in [15] and then the problem is explored again with heterogeneous nodes in [16]. The authors in [17] get the generic theoretical upper bounds for the information propagation speed in large-scale mobile and intermittently connected network, and then the work in [18] explores the information propagation speed in bidirectional vehicular delay tolerant network. The work in [19] studies the performance of two-hop relay routing under limited packet lifetime. Performance of the ER routing when the contention exists is explored in [20].
Most routing algorithms in DTN need nodes working in a cooperative way, so the selfishness behavior can have important impact on the performance. Panagakis et al. evaluate the impact of selfishness through simulation in [21]. There are also some works, which study the impact of nodes’ selfishness behavior by theoretical method, such as [3, 4]. The work in [22] is the first to propose the social selfishness behavior in DTN and proposes a user-centered routing policy, which is adaptive to the selfishness nature. Specially, the social selfishness behavior means that nodes are more willing to help the one with whom they have certain social ties (e.g., citation relation). The work in [23] studies the impact of the social selfishness behavior on ER algorithm and finds that ER algorithm is very robust to the social selfishness behavior. Then they study its impact on multicasting in DTN [24].
Because ER algorithm has certain shortage, there are some works, which begin to consider the optimal control problem. The optimal control problem of two-hop routing algorithm based on discrete time model is studied in [7], and this work proves that the optimal forwarding policy conforms to the threshold form. Then the work in [8] explores the problem again with a continuous time Markov process. The work in [25] proposes an optimal activation and transmission policy, and then the work in [26] proposes an energy-efficient optimal beaconing policy. Above works try to maximize certain objective function under some constraints, but the work in [27] study the trade-off between the delivery delay and energy consumption in DTN that uses two-hop relaying method. This work is different from our work in certain aspects. First, the work in [27] is an optimization problem without constraint. Second, the energy consumption within given time is fixed. In particular, it is a special case of our work when PR(t) (see the definition in next section) is a constant. Third, that work uses the two-hop routing method, which is too simple. There are also some works, which consider the optimal control of ER algorithm with SIRD model, in which nodes carrying message (e.g., virus) may exist from the network [28, 29].
3. Network Model
In this paper, we assume that there are one source node S, N ordinary nodes and one destination node D, so the network totally has
To make the destination get message quickly, S requests help from the ordinary nodes. If one ordinary node (e.g., j) gets message, it can forward message to other node. Due to the selfishness nature, S has to pay certain fees to j every time j forward message to other node. Therefore, considering the cost constraint, S needs to control the behavior of itself and the ordinary nodes. In this paper, we assume that both S and the ordinary nodes have the same forwarding policy. In particular, any node carrying message forwards message to other ordinary nodes with probability

The snapshot of the network at time
Nodes in the network can communicate with each other only when they come into the transmission range of each other, which means a communication contact, so the mobility rule of nodes is critical. In this paper, we assume that the occurrence of contacts between two nodes follows a Poisson distribution. This assumption has been used in wireless communications many years. At present, some works show that this assumption is only an approximation to the message propagation process, and they reveal that nodes encounter with each other according to the power law distribution [30]. However, they also find that if you consider long traces, the tail of the distribution is exponential. In addition, the work in [31] shows that individual inter-meeting time can be shaped to be exponential by choosing an approximate domain size with respect to given time scale. Moreover, there are also some works, which describe the intermeeting time of human or vehicles by Poisson process and validate their model experimentally on real motion traces [32, 33]. According to these descriptions, the exponential intermeeting time is rational in some applications, and we assume that the intermeeting time between two nodes follows an exponential distribution with parameter λ. Simulations based on both synthetic and real motion traces show that our theoretical framework based on such assumption is very accurate. The list of commonly used variables can be seen as in Table 1.
The list of commonly used variables.

4. Optimization Formulation
4.1. Theoretical Framework
Let

Symbol

Therefore, we can get the expectation of


Note that

There are

Further, we can obtain

Let

Let


Then, we have
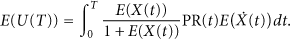
4.2. Optimal Control
Our object is to solve the following optimization problem:

Symbol C denotes the maximal fees that the source can pay, and T is the maximal lifetime of the message. The controlling variable is


Note that at time t,
The transversality conditions are shown as follows:

Then according to Pontryagin's maximum principle ([34, Page 109, Theorem 3.14]), there exist continuous or piece-wise continuously differentiable state and costate functions, which satisfy

This equation between the optimal control parameter p and the Hamiltonian H allows us to express p as a function of the state (X, F, U) and costate (
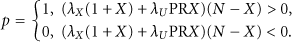
The total number of ordinary nodes is N, so we have
Below, we will prove that when the function of PR(t) satisfies certain conditions, the optimal policy has a simple structure. The conditions are: PR(t) is nondecreasing with time t; it is differentiable; it is nonnegative. In fact, the maximal lifetime
Theorem 1.
If the
Proof.
This theorem means that the source requests help with probability 1 before time h, but it stops requesting help after time h. We simply use
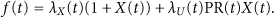
Therefore, we have

If

Then based on (14) and
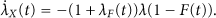
In fact, we have

From (22), we can see that
Now, we assume that
Combined with (19), we have,

Note that we have proved that
If
Because
In summary, for time h, if
In fact, Theorem 1 means that if PR(t) satisfies certain conditions, the optimal policy has a bang-bang structure. In particular, the source will require help from others with probability 1 before certain threshold, and then stop. In addition, the value of the threshold is denoted by h.
5. Simulation and Numerical Results
5.1. Model Validation
In this section, we will check the accuracy of our framework by comparing the theoretical results obtained by our model with the simulation results. We run several simulations using the opportunistic network environment (ONE) [35] based on both synthetic mobility model and realworld-based scenarios. For the synthetic mobility trace, we use the famous random waypoint (RWP) mobility model [36], which is commonly used in many mobile wireless networks. There are totally 500 nodes, and all nodes move according to the RWP model within a 10000 m × 1000 m terrain with a scale speed chosen from a uniform distribution from 4 m/s to 10 m/s. The communication range is 10 m. Moreover, the source and destination nodes are randomly selected among these nodes. For the realworld-based scenarios, we use a real motion traces from about 2100 operational taxis for about one month in Shanghai city collected by global position system (GPS) [37]. The location information of the taxis is recorded at every 40 seconds with the area of 102 km2. We randomly pick 500 nodes from this trace, and the source and destination nodes are randomly selected among these nodes, too.
The first metric is the total fees that the source pays to the ordinary nodes under different forwarding policies. The source may forward message with any probability, that is, the value of

Simulation and numerical results comparison of total fees with RWP mobility model.

Simulation and numerical results comparison of total fees with Shanghai city mobility model.
From these results, we can see that the average deviation between the theoretical and the simulation results is very small. For example, the average deviation is about 2.92% for the RWP mobility model, and 4.01% for the Shanghai city motion trace. In addition, Figure 3 shows that the source has to pay more fees if it adopts the policy of Case 2. In fact, when it adopts the policy of Case 1, nodes can get message timely, when the fees that the ordinary nodes required is less. However, if it adopts the policy of Case 2, many nodes can get message when the time t is bigger, so the source has to pay more fees to them.
Then based on the same settings, we explore the average delivery ratio in Figures 4 and 5, respectively. These results also show that the average deviation between the theoretical and the simulation results is very small.

Simulation and numerical results comparison of average delivery ratio with RWP mobility model.

Performance comparison of different policies with Shanghai city mobility model.
To further check the accuracy of the model, we want to explore the performance when the number of nodes is different. In particular, we assume that there are 300 and 600 nodes, respectively. For simplicity, we only consider Case 1, that is, the value of

Simulation and numerical results comparison when the number of nodes is different.

Performance comparison when the number of nodes is different.
All of the above results demonstrate the accuracy of our theoretical framework. For this reason, we can use the numerical results obtained by our theoretical framework to evaluate the performance of different policies.
5.2. Performance Analysis with Numerical Results
In this section, all of the numerical results are obtained by our theoretical framework based on the best fitting for the Shanghai city motion trace.
First, we evaluate the performance of the optimal policy, which is the threshold form. For comparison, we consider three other cases. Case 1:

Performance comparison of different policies when the maximal message lifetime is different.
Now, we let the maximal message lifetime T be 10000 s, and the value of C increase from 1 to 200. Other settings remain unchanged, and we can obtain Figure 9. This result shows that the optimal policy is best when the total fees are limited, too. On the other hand, when the total fees reach about 100, the average delivery ratio is about 1. This means that the source only needs to pay limited fees.

Performance comparison of different policies when the total fees are different.
The number of ordinary nodes may have certain impact on the routing performance. At present, we only consider the optimal policy obtained from (17). We let the value of C be 50, and the maximal message lifetime increase from 0 s to 10000 s. Other settings remain unchanged. Based on these settings, we can obtain Figure 10 when N equals to 200, 600, and 1000, respectively.

Average delivery ratio of the optimal policy when the value of N is different.
The result in Figure 10 shows that if the number of ordinary nodes is bigger, the performance is better. As shown above, the message transmission process can be seen as the commodities trading process. The event that the source requests help from other nodes can be seen as that the source buys certain goods from them. The price of the goods is increasing with time. Therefore, it is good for the source to buy more goods early. However, when the number of ordinary nodes is smaller, the goods are limited, so the source cannot buy many goods early. Therefore, if the number of ordinary nodes is bigger, the performance is better.
On the other hand, as shown in Theorem 1, the source will stop requesting help at certain time. In particular, the optimal policy satisfies:

Optimal policy when the value of N is different.
In the above simulation and numerical results, we define: PR(t) = 3(

Optimal policy with different function.
6. Conclusions
Due to the mobility of nodes and many other factors, it is hard to maintain the connectivity in M2M networks. Therefore, the store-carry-forward communication mode is an important message propagation way. Such communication mode needs nodes working in a cooperative way. Due to the selfishness nature, nodes may ask for some fees (denoted by PR(t)) from the source, which may be varying with time. For example, when the message stays in the network a long time, the ordinary nodes may think that its remaining lifetime is shorter, so they may ask for more fees from the source. In this paper, we propose a unifying framework to evaluate the total fees that the source pays under different forwarding policies. Then based on the framework, we study the optimal control problem. In particular, we prove that the optimal forwarding policy conforms to the threshold form when PR(t) satisfies certain conditions. Simulations based on both synthetic and real motion traces show the accuracy of our theoretical framework. Numerical results show that the optimal forwarding policy obtained by (17) is the best one.