
Abstract
A commonly encountered problem in wireless sensor networks (WSNs) applications is to reconstruct the state of nature, that is, distributed estimation of a parameter of interest through WSNs' observations. However, the distributed estimation in autonomous clustered WSNs faces a vital problem of sensors' selfishness. Each sensor autonomously decides whether or not to transmit its observations to the fusion center (FC) and not be controlled by the fusion center (FC) any more. Thus, to encourage cooperation within selfish sensors, infinitely and finitely repeated games are firstly modeled to depict sensors' behaviors. Then, the existences of Nash equilibriums for infinitely and finitely repeated games are discussed. Finally, simulation results show that the proposed Nash equilibrium strategies are effective.
1. Introduction
Wireless sensor networks (WSNs) have increasingly attracted attention due to their wide range of applications, such as industrial control and monitoring, home automation, military surveillance, environment monitoring, and health care. WSNs usually comprise a large number of small-size and energy-limited sensor nodes [1–7]. Different from traditional WSNs with fully cooperated nodes [8], some WSNs consist of selfish and autonomous nodes. In such WSNs, the selfishness nature of nodes that manage to achieve their own aims is considered to be common. In other words, all the nodes are not willing to cooperate and accomplish the network task. However, such noncooperation can deteriorate the network performances.
Specifically for the traditional distributed estimation problem [8, 9], nodes are required to cooperate fully and estimate a scalar parameter under the inherent limitations, such as limited energy and limited network bandwidth. In a practical WSN, these limitations impose a constraint on the design of estimation methods. Generally, the main goal is to save the total energy while achieving given estimation performance under these limitations. For example, in recent literature, the distributed estimation problem in the presence of attacks is discussed and joint estimation schemes of the statistical description of the attacks and the parameter to be estimated are proposed to deal with the attacked observations [10]. Additionally, a novel distributed estimation method based on observations prediction is focused on, and the innovations of sensors' observations are locally predicted and transmitted to the fusion center (FC) [11]. These recent advances usually assume all sensors are selfless and can be controlled by the FC arbitrarily.
However, in autonomous WSNs with selfishness, nodes may not be willing to cooperatively estimate a parameter at the cost of consuming their own limited battery resource. Therefore, each node autonomously decides whether or not to transmit its observations to the FC and not be controlled by the FC any more. Consequently, nodes will not be of their best interest to transmit their observations to the FC. It will deteriorate the network estimation accuracy of the interested parameter and this selfish rejection of transmitting eventually impairs the nodes' own interest. Hence, to encourage cooperation within selfish nodes and improve the final estimation accuracy, it is necessary to design rules and punishment mechanisms to self-enforce nodes' behaviors.
It is noted that such rules and punishment mechanisms usually are modeled as repeated games, in which the selfish nodes know when and how to cooperate in order to obtain potential interests over multiple periods. For example, the repeated game model has been adopted for packet forwarding problems in ad hoc networks. In [12, 13], the interactions of nodes' forwarding and rejection are modeled as repeated games. In [12], as a punishment strategy, a generous tit-for-tat (TFT) is proposed to enforce the nodes to cooperate. Meanwhile, in [13], three learning algorithms for different information structures are proposed to achieve the desired efficient cooperation equilibrium. Additionally, the repeated game model has been applied to address selfish behavior in the media access control (MAC) problem of sensor networks. For example, in [14], a contention window select game (CWSG) is defined, and a penalizing mechanism based on repeated games is proposed to prevent nodes' noncooperation.
We propose two simply repeated games instead of the extensive game [15] to meet the given estimation performance requirement. Different from the decentralized method [16–18], our game-theoretic approach is distributed and each node is selfish. To avoid the selfishness of nodes, a grim trigger strategy and the tit-for-tat strategy for the infinitely repeated estimation game are introduced in which each sensor is voluntarily cooperative. Meanwhile, multiple subgame-perfect Nash equilibriums for the finitely repeated estimation game are discussed to depict the cooperation behaviors.
Our main contributions are shown as follows: (1) the two kinds of repeated game models for distributed estimation in WSNs have been formulated: the infinitely repeated estimation game and the finitely repeated estimation game, respectively; (2) their Nash equilibriums and subgame-perfect Nash equilibriums are simply proposed; and (3) some conclusions of strategies have been verified to be effective in simulations.
2. System Model
2.1. Distributed Estimation Problem
Let us consider a distributed WSN with an FC as shown in Figure 1. This sensor network consists of K selfish nodes to observe a physical phenomenon θ (a scalar parameter of interest), such as temperature and moisture of soil. The nodes are selfish in the sense that the FC does not dictate to the local nodes any scheduling policies. Instead, all the local nodes choose their transmission policy by themselves to selfishly maximize their interest. Within, the network channel is assumed to be error-free and can be implemented by orthogonal time/frequency/code division multiple access (TDMA/FDMA/CDMA).

Sensor networks with selfish nodes.
As shown in Figure 1, where two virtual cluster heads (CHs) and (
It is assumed that the observation of node k at time t is described as

Here, we review a key result from [16] concerning the distributed estimation problem in cooperative WSNs. It is assumed that a set of indicator variables (binary observations) will be spontaneously transmitted by local nodes and the classical maximum likelihood estimator (MLE) [16] is adopted at the FC. According to Proposition
The problem in distributed estimation arises because these selfish nodes have their own authorities to decide whether to transmit the binary information at each estimation stage. The FC can not make unilateral decisions and dictate nodes' behaviors. For example, in [17, 18], the decentralized power optimization schemes of the observation flow through solving Karush-Kuhn-Tucker (KKT) systems are not suitable for the autonomous WSNs any more. It is naturally assumed that all the nodes selfishly optimize their own interest, such as maximizing their energy efficiency.
It is worthwhile underlining that interactions among nodes happen not just once but repeatedly many times. Different from the extensive form game in [19], this special class of extensive form games, called repeated games, can explain why ongoing estimation tasks produce behavior very different from those observed in the one-time interaction in [19]. Additionally, it is worth mentioning that the extensive form game in [19] is assumed that all the nodes are required to cooperate fully. In other words, the refined Nash equilibrium in [19] is not suitable for depicting nodes' selfishness and autonomy. Meanwhile, due to the punishment mechanisms in [12, 13], the estimation problem in autonomous WSNs will be reformulated as a repeated game to depict the autonomy and then improve local nodes' energy efficiency.
2.2. Repeated Game
The repeated game theory is considered as a formal framework to model a multiplayer sequential decision making process. The model of repeated games has two versions: the horizon may be finite or infinite. It is noted that the results in the above two cases are different. Thus, in order to apply the model of repeated games in distributed estimation problems, an appropriate horizon (finite or infinite horizon) is required to be determined. In the following, some concepts of a repeated game are firstly introduced. Then, we formulate the distributed estimation system into an appropriate repeated game.
The stage game G is the basic component of a repeated game and can be represented by the three elements
Definition 1.
The infinitely repeated game of the set of players is N, the set of terminal histories is the set of infinite sequences the player function assigns the set of all players to every proper subhistory of every terminal history, the set of actions available to player i after any history is each player i evaluates each terminal history
The formal description of finite repeated games is very similar to the definition of infinite repeated games and can be defined as the following.
Definition 2.
For any positive integer T, the T-period finitely repeated game of
3. Repeated Estimation Game
It is noted that the CRLB varies inversely to the parameter K and depends also on these parameters in the distributed estimation problem, such as θ, τ, and σ [16]. In other words, the estimation performance of the MLE depends on the parameters like K, θ, τ, and σ, and so forth. The energy of selfish nodes is supplied by battery once exhausted and they can not charge up. Therefore, parameter K varies with the times of estimation task. Additionally, it is usually assumed that the physical phenomenon is stable and the same MLE is adopted at each stage of the multiple estimation tasks.
To improve and maintain the performance of the MLE as long as possible, K selfish nodes should live as long as possible. However, the cooperation problem among selfish nodes in sequential estimation tasks has not been introduced in the traditional estimation methods. Meanwhile, the repeated games can deal with the problem of nodes' survival, in which the selfish nodes know when and how to cooperate in order to evenly keep the selfish nodes alive over many periods [20]. Thus, the following repeated estimation game is introduced to explore the impact of nodes' selfishness on the estimation performance.
3.1. Stage Game
To be concrete, in the case of the estimation problem, we need to review several notions, namely, a stage game, the game history, and the strategy of a player. The stage game usually consists of a set of players, a set of actions, and a payoff function for each player. Thus, the set of players for the stage game is

Assume all these nodes are rational and aim at maximizing the cluster's interest. Thus, the set of players is the two clusters and the clusters' strategies space can be defined as
According to results in Section 2.1, a certain number of nodes
Players' payoff function can be given as

3.2. Infinitely Repeated Game
It is well known that a strategy of a player in infinitely repeated games should specify an action of the player for every sequence of outcomes. For the case of the estimation problem, a grim trigger strategy is defined as follows:


A grim trigger strategy for a repeated estimation game.
Another strategy (the tit-for-tat strategy, labeled as TFT) is shown in Figure 3. The strategy can be described in a very compact way: start by cooperating and then do whatever the other player did on the previous iteration.
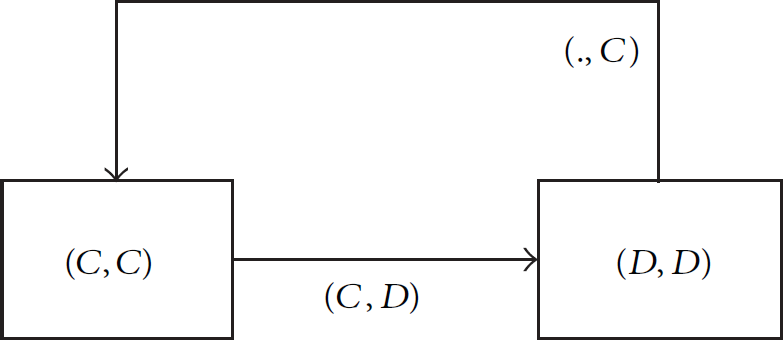
The tit-for-tat strategy for a repeated estimation game.
Now, suppose each player has selected a strategy
Proposition 3.
For the infinitely repeated estimation game, strategy profile (Grim, Grim) is a Nash equilibrium if and only if
Proof.
Suppose that player

while for adhering to “D,” its corresponding payoffs are


3.3. Finitely Repeated Game
The strategy space for repeated games is difficultly illustrated even if the game is repeated just
Payoff of the repeated estimation game.

The repeated estimation game
Payoff of the reduced two-stage game.


Sum of the two stage-game payoffs.
For example, after (
Since a player's preferences in the game of the initial round do not change when we add a constant to his payoffs, hence, the set of Nash equilibriums in the reduced estimation game is the same as the stage game (namely, the game of the initial round). It is a general result of finitely repeated game equilibriums as follows [21] and its proof is ignored here.
Lemma 4.
For the finitely repeated game
As shown in Table 1, the two players' sets of actions are the same and their preferences have the following characteristics:

In other words, there are multiple Nash equilibriums in the one-shot stage game of the finitely repeated estimation game:
Within, the first strategy denotes that the 1st player's first move is to play C and its second move is to play C after every possible history, and the 2nd player's first move is to play D and its second move is to play D after every possible history. The average payoff for the first strategy is
According to Proposition 3 and Lemma 4, the Nash equilibriums of the proposed repeated estimation game deal with the problem of nodes' selfishness and maintain nodes' actions evenly. It is noted that the MLE [16] can be extended into nonideal channels [22]. Meanwhile, nonideal channels have no effect on the proposed game due to nonadditional information exchange among nodes. Thus, the results can be applied onto the nonideal channels.
4. Simulation Results
In this section, simulation results are obtained by Matlab.
The players' actions for the infinitely repeated estimation game: cooperation.
A similar simple energy dissipation model is adopted for nodes' radio hardware [9]. In this model, 
As shown in Figure 5, strategy profile (Grim, Grim) is adopted and the two clusters choose the “C” strategy. It is noted that strategy profile (Grim, Grim) is Nash equilibrium under the condition of these parameters (γ, α, β, and ρ), which coincides with Proposition 3. Additionally, according to the definition of the stage game in Section 3.1, there are

Sensors' residual energy for the infinitely repeated estimation game: cooperation.
To show the effectiveness of the SPNEs for the finitely repeated estimation game, strategy “

The players' actions for the finitely repeated estimation game:
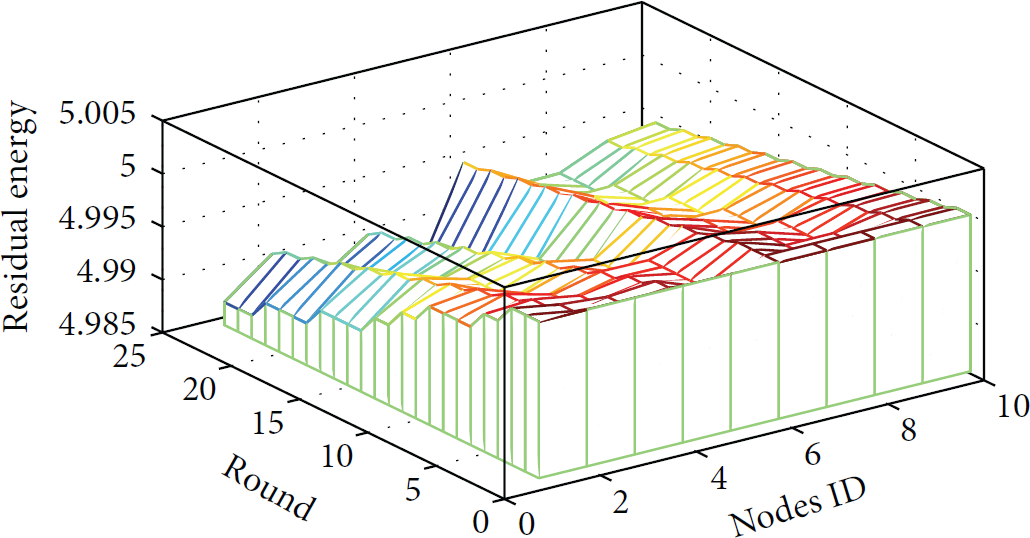
Sensors' residual energy for the finitely repeated estimation game:
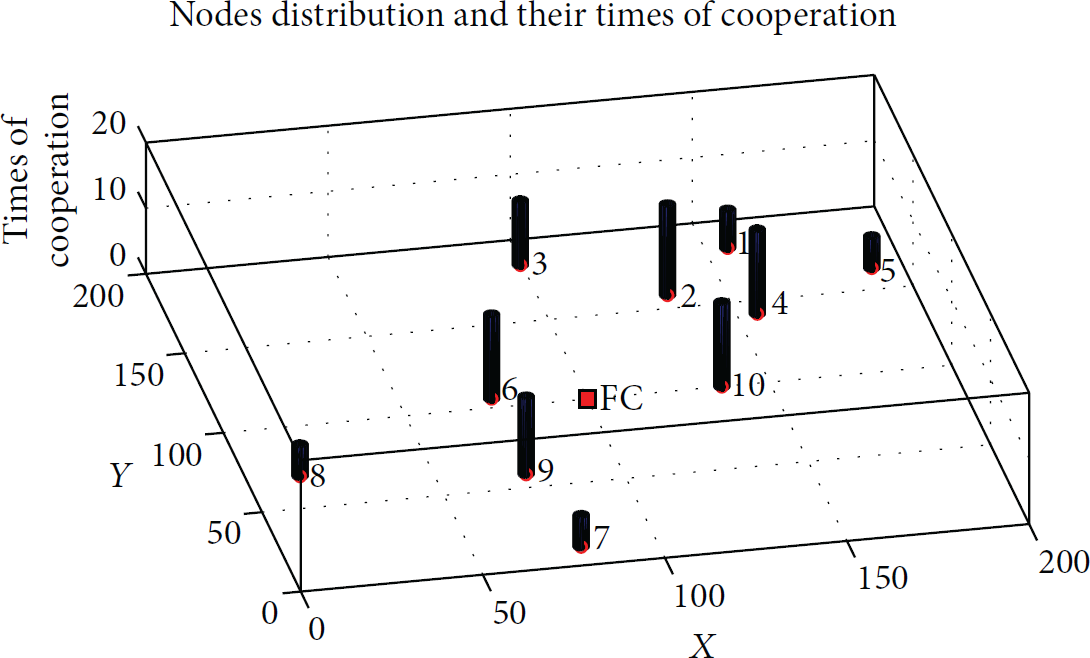
Moreover, sensors' times of transmissions or cooperation are depicted in Figure 9. Whether it is the infinitely repeated estimation game or the finitely repeated estimation game, there are more times for these sensors (

The players' times of transmissions or cooperation: infinitely and finitely repeated estimation games.

The players' payoffs: infinitely and finitely repeated estimation games.
5. Conclusions
In this paper, we focus on the repeated game for distributed estimation in WSNs. The two kinds of repeated estimation games (infinitely and finitely repeated estimation games) are investigated. Their existences of Nash equilibriums are simply proven. Particularly, the profiles (Grim, Grim) and (TFT, TFT) for the infinitely repeated estimation game and some SPNEs for the finitely repeated estimation game are discussed in detail. Finally, some simulation results show that some Nash equilibriums of the proposed infinitely and finitely repeated game are efficient.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by National Natural Science Foundation, China (61403089, 61162008, and 61573153), Program for Guangzhou Municipal Colleges and Universities (1201431034), Guangdong Science & Technology Project (2013B0104) and Guangzhou Education Bureau Science and Technology Project (2012A082), and Guangzhou Science and Technology Foundation (nos. 2014J4100142, 2014J410023).