
Abstract
Two concepts of particular relevance for educational and psychological measurement research using the popular structural equation modeling methodology are revisited—saturated model and (just) identified model. The distinction is emphasized between a saturated model on the one hand and an identified model on the other. It is shown that a saturated model need not be identified (and thus need not be just identified). Within that context, it is stressed that for a given set of observed variables there may be more than a single saturated model. To avoid possible confusion, a proposal is made to use the concept of “the saturated model” as referring only to the model with unconstrained variances, covariances, and means for a given set of manifest measures and to make references to “a saturated model” whenever any of the possible set of saturated models for these observed variables is meant.
Over the past several decades, the structural equation modeling (SEM) methodology has been increasingly used in the educational, behavioral, social, and biomedical sciences. Its high popularity in these and cognate disciplines is in part based on the possibility to account for measurement error in independent variables, fit complex multivariable models, and evaluate various postulated effects (e.g., Raykov & Marcoulides, 2006). A major issue in applications of SEM is that of model identification, that is, the unique estimability of all model parameters for a given set of observed variables. (The use of unique estimability here includes the case of uniqueness up to a sign reversal; e.g., Millsap, 2001.) A structural equation model that is not identified is typically of little empirical relevance if any. Special care is therefore needed in utilizations of SEM to ensure that a considered model is identified, and a large mathematically rigorous body of literature has been devoted to this topic (e.g., Albert, 1944a, 1944b; Anderson & Rubin, 1956; Hayashi & Marcoulides, 2006, and references therein; Kaplan, 2008; see also Ledermann, 1937).
Model identification in general has two aspects, existence and uniqueness, and they can have major implications with respect to model fitting. For this article, of special importance is the widely appreciated fact that the fit of a considered structural equation model is evaluated via comparison with a particular model that reproduces perfectly the analyzed data (covariance matrix and means) and thus represents a useful benchmark against which the performance of the former model is typically quantified. More generally, researchers often make specific assumptions for existence and focus mainly on the uniqueness aspects of a fitted model. For example, existence within the context of factor analysis implies that a factor decomposition exists for a given number of factors, whereas uniqueness assumes it is the only factor decomposition possible (Hayashi & Marcoulides, 2006).
In this context, two frequently used concepts in SEM applications are those of a “saturated model” and of a “just identified” model. A just identified model can be defined as an identified model that has zero degrees of freedom, whereas a saturated model can be defined as a model that has zero degrees of freedom (see below). A considerable part of the SEM literature, however, especially in empirical educational and psychological research, often does not seem to have treated these two concepts differently. Yet their distinction is quite important, since using them interchangeably can lead to consequential theoretical and empirical confusion, with potentially misleading substantive conclusions.
To counteract such possible confusion, the present note shows that a saturated model need not be (just) identified, and thus the two concepts should be kept in general separately. This demonstration also draws attention to a related fact that in our view is not sufficiently widely appreciated among some empirical behavioral and social researchers. Accordingly, for a prespecified set of observed variables, there need not be just one saturated model based on them. With this in mind, we make the proposal that (a) for any given set of manifest variables, the concept of “the saturated model” be reserved for a particular saturated model, viz., the one with unconstrained (unstructured) measure variances, covariances, and means; and (b) the reference “a saturated model” be used when the pertinent statement would be correct for any saturated model for that set of observed variables.
A Saturated Model Need Not Be Just Identified
Following a widely adopted definition, a structural equation model is just identified if it is (a) identified and (b) associated with zero degrees of freedom (cf. Bollen, 1989). An identified model can be categorized as being globally or locally identified. Global identification implies that all model parameters are identified and is typically of interest when model identification is of concern. Global identification can be seen as a prerequisite for drawing inferences about the parameters of a model under consideration. When a model is not globally identified, it is possible that some of its parameters are identified and permit testing of a section of the model (a situation at times referred to as partial identification; Hayashi & Marcoulides, 2006; Hershberger & Marcoulides, 2012).
For the aims of this article, we refer here to the widely adopted definition of a saturated structural equation model as one with zero degrees of freedom, that is, having as many parameters as there are data points to which it is fitted (see Agresti, 2002, for the case of categorical data analysis). Perhaps due to the rather frequent reference in the literature to the likelihood ratio test for model fit in SEM as a test of a considered model against a saturated model, the implication seems to be widespread among some empirical educational and psychological measurement researchers that a saturated model is an identified model with zero degrees of freedom. While the latter part of the last statement is correct, the first is not.
In this section, we use one of the simplest possible examples to demonstrate that a saturated model need not be identified (and thus not just identified). To this end, consider the model defined by the following p = 3 equations, for p observed zero-mean variables y1 through y3:

with the assumptions of η being a zero-mean factor with unit variance, which is uncorrelated with the zero-mean error terms (residuals) ε1 through ε3, and λ1 through λ3 being positive factor loadings. This confirmatory factor analysis model is indirectly involved in many SEM applications in the behavioral and social sciences, when use is made of a latent construct (here η) with a triple of indicators (y1 through y3).
For our demonstration purposes in this section, we assume that (a) λ1 = λ2 = λ, say; (b) the error variances of the first two indicators are identical, that is, Var(ε1) = Var(ε2) = θ say, where Var(.) denotes variance; as well as that (c) there is a nonzero covariance (free parameter) of the first and second residuals, as well as of the second and last residuals, that is, Cov(ε1, ε2) = φ > 0, and Cov(ε2, ε3) = ψ > 0 say, with Cov(.,.) denoting covariance. We assume also that θ and θ3 = Cov(ε3) are sufficiently larger than φ and ψ, so that the implied covariance matrix by this model, denoted Σ below, is positive definite, that is, Σ > 0 (e.g., Raykov & Marcoulides, 2008; this choice of the four error variances and covariances can obviously be made without loss of generality of the following argument; proof that such a choice is possible, can be obtained from the authors on request).
As can be readily counted, the model defined in this way—which we will refer to as Model 1 below for simplicity—has q = 6 parameters and thus zero degrees of freedom because there are p(p+ 1)/2 = 6 variances and covariances of the p = 3 observed variables to which it is fitted. (Without loss of generality, we may assume the manifest measures being trivariate normal; furthermore, due to the zero-mean y variables, it is sufficient to fit this model to the covariance structure.) Therefore, Model 1 is saturated.
However, despite being saturated, Model 1 is not identified (and hence not just identified; this is also an example where the so-called t-rule—see Bollen, 1989—is satisfied but this fact does not guarantee model identification). The reason Model 1 is not identified is that it is not possible to uniquely estimate its 6 parameters, for any given positive definite matrix of size 3 × 3 (which is taken as the covariance matrix of the variables y1 through y3). To see this, we examine the covariance matrix Σ implied by Model 1, which we obtain using straightforward rules of covariance algebra on Equations 1 (due to symmetry, we present next only its main diagonal and elements below it; e.g., Raykov & Marcoulides, 2006):

Although the q = 6 nonredundant elements of Σ are structured in terms of the same number of 6 parameters, their unique estimation is not possible. In particular, it is not possible to uniquely estimate the factor loadings λ and λ3. Indeed, suppose we change λ to λ/c, with a constant c > 1, and at the same time λ3 to (cλ3). These changes can be compensated completely, that is, without altering the implied covariance matrix Σ, by appropriate changes of the remaining parameters of Model 1. Indeed, the following choice (transformation) of correspondingly altered error variances and covariances accomplishes this complete reproduction of Σ (ψ remaining unchanged, i.e., being identically transformed)
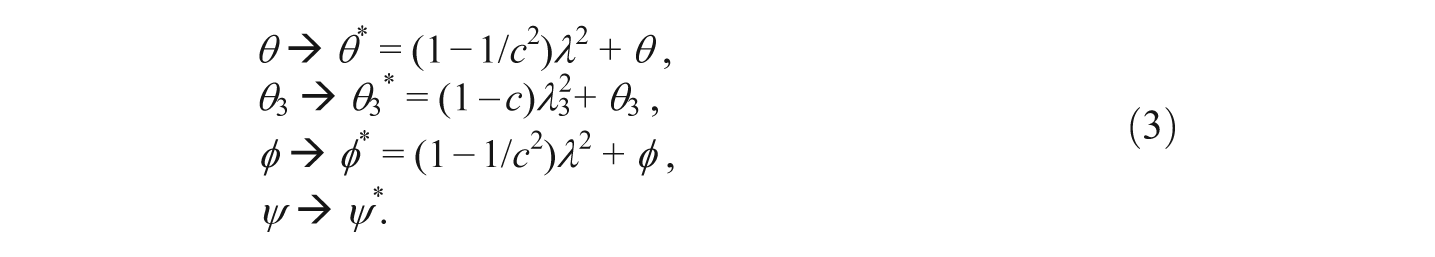
That is, by exchanging the model parameters θ through ψ with θ* through ψ*, respectively, as defined in (3), the covariance matrix Σ is unaltered—thus compensating for the changes λ to λ/c and λ3 to (cλ3). Since the latter changes and those in (3) can be made in infinitely many ways, due to the choice of c being possible in infinitely many ways, Model 1 is not identified, that is, its parameters cannot be uniquely estimated given a particular data set.
Hence, Model 1 that is defined by Equations (1) (and its following discussion) represents an example of a saturated model that is not identified, and thus not just identified. Therefore, the two concepts “saturated model” and “just identified model” need to be handled carefully and differentially. In particular, whenever the concept of a saturated model is used, one needs in our view to clarify whether an identified saturated model is meant or a nonidentified saturated model is so (see also next section).
The preceding discussion also allows indicating more than a single saturated model for the three considered observed variables. For instance, another saturated model for these measures y1 through y3 is the same as Model 1 but with free factor loadings (i.e., λ1≠λ2) yet equal error covariances instead (i.e., φ = ψ), as can be readily ascertained. This simple example shows that when talking about a saturated model, in our opinion one may also need to specify completely the particular model meant rather than use merely the reference “saturated model.” In the next section, we will refer to yet another saturated model, for any given set of observed variables, which we find merits special attention.
A Proposal for Use of the Concept “the Saturated Model”
In view of the preceding discussion indicating (a) in general multiplicity of saturated models for a given set of observed variables y1 through y p (p > 1) as well as emphasizing (b) the fact that a saturated model need not be identified, we propose to reserve the reference “the saturated model” for a special saturated model (see below), and otherwise use the reference “a saturated model” whenever any saturated model for that set of measures is meant.
That special saturated model is the one (a) parameterizing only the variances, covariances, and means of the measure set y1 through y p and (b) with no restrictions imposed on any of its parameters. This model can alternatively be readily defined by the introduction of a dummy variable for each measure, which loads 1 on the latter and is associated with zero error variance (and thus zero error term; e.g., Jöreskog & Sörbom, 1996; Raykov, 2001):

where
In deference to Model 2, we propose to reserve the reference “a saturated model” (or “saturated model”) for any other model based on the observed variable set y1 through y p , which is saturated. In this way, we submit that discussions in the empirical behavioral and social research literature will gain in precision and uniformity that will contribute significantly to enhancing the clarity of author–reader communication.
Footnotes
Authors’ Note
Thanks are due to an anonymous referee for valuable critical and suggestive comments on an earlier version of this note.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.