
Abstract
Extreme response style (ERS) is a systematic tendency for a person to endorse extreme options (e.g., strongly disagree, strongly agree) on Likert-type or rating-scale items. In this study, we develop a new class of item response theory (IRT) models to account for ERS so that the target latent trait is free from the response style and the tendency of ERS is quantified. Parameters of these new models can be estimated with marginal maximum likelihood estimation methods or Bayesian methods. In this study, we use the freeware program WinBUGS, which implements Bayesian methods. In a series of simulations, we find that the parameters are recovered fairly well; ignoring ERS by fitting standard IRT models resulted in biased estimates, and fitting the new models to data without ERS did little harm. Two empirical examples are provided to illustrate the implications and applications of the new models.
Likert-type or rating-scale items are widely used in psychological inventories or questionnaires to measure personality, interest, or attitude. It is commonly observed that a respondent may consistently use only a few of the given options. In such cases, an observed response is a combination of a respondent’s attitude and response bias. The term response style indicates a systematic tendency to use a limited number of options. Research has suggested that response style is content independent and reflects different types of item functioning across respondents (Jackson & Messick, 1958; Johnson, 2003; Rorer, 1965).
Several response styles have been noted. Baumgartner and Steenkamp (2001) summarize seven important response styles: acquiescence, disacquiescence, net acquiescence, extreme response, response range, midpoint responding, and noncontingent responding. Among them, extreme response style (ERS) has attracted much research attention (Greenleaf, 1992; Hamilton, 1968; Van Vaerenbergh & Thomas, 2013; Weijters, Geuens, & Schillewaert, 2010). ERS denotes a systematic tendency to endorse extreme options. The opposite testing behavior, mild response style (MRS), denotes a systematic tendency to endorse middle options (Hurley, 1998). For example, in a 5-point agreement scale (1 = strongly disagree, 2 = slightly disagree, 3= neutral, 4 = slightly agree, 5 = strongly agree) or a 5-point satisfaction scale (1 = very dissatisfied, 2 = somewhat dissatisfied, 3 = neither satisfied nor dissatisfied, 4 = somewhat satisfied, 5 = very satisfied), Options 1 and 5 are considered as extreme options, whereas Options 2, 3, and 4 are considered mild options. Likewise, in a 4-point frequency scale (1 = never, 2 = seldom, 3 = often, 4 = always) or a 4-point performance scale (1 = poor, 2 = fair, 3 = good, 4 = excellent), Options 1 and 4 are considered extreme options, whereas Options 2 and 3 are considered mild options. These two terms are mutually exclusive (ERS and MRS cannot be observed at the same time on an item). That is, a strong tendency toward ERS means a weak tendency toward MRS, and vice versa. Thus, ERS is used throughout this study.
Hamilton (1968) reviewed a series of studies on ERS and concluded that ERS reflects respondents’ personality attributes. It is argued that respondents who frequently exhibit ERS have a motivation to achieve clarity, precision, and decisiveness in verbal statements (Johnson, Kulesa, Llc, Cho, & Shavitt, 2005); respondents who complete surveys quickly and are simplistic thinkers are most likely to exhibit ERS (Naemi, Beal, & Payne, 2009); ERS is not affected by the length of response options (Kieruj & Moors, 2010); and ERS is rather stable across time (Weijters et al., 2010). Literature has shown the relationship between ERS and individual- and society-level variables (Arce-Ferrer, 2006; Baumgartner & Steenkamp, 2001; Chen, Lee, & Stevenson, 1995; van Herk, Poortinga, & Verhallen, 2004). Because ERS causes undesired interference with the normal response process, test validity and inference are threatened (De Beuckelaer, Weijters, & Rutten, 2010). Within the framework of item response theory (IRT), it was found that ERS could contaminate the precision of latent traits targeted for measurement and could result in biased estimates of item parameters (Bolt & Newton, 2011; van Herk et al., 2004).
Outside the IRT framework, studies on ERS within the raw-score framework have been conducted in various ways. An intuitive strategy is to investigate the target latent traits and ERS using the same item responses but different scoring rubrics. For example, extreme options are counted as a measure of ERS (Johnson et al., 2005). Unfortunately, as documented in the literature, item characteristics and person measures are mutually confounded and cannot be separated within the framework of classical test theory (Embretson & Reise, 2000); thus, the measures of the target latent traits and ERS are not separable when the same item responses are used. Because the selection of items is less critical in the identification of ERS (De Beuckelaer et al., 2010), another strategy is to use heterogeneous items (in content) to investigate response styles, in which a sample of items is randomly selected from a wide range of scales such that contents and response styles are separated (Greenleaf, 1992; Weijters et al., 2010; Weijters, Schillewaert, & Geuens, 2008). For example, three items each are sampled from 10 scales. The major drawback of this strategy is that the target latent traits cannot be measured precisely with such a short test for each latent trait.
The following five issues deserve clarification. First, the identification of ERS requires a large number of items. The larger the number, the better the identification will be. For example, 16 items were used by Greenleaf (1992) for the identification of ERS. Second, the identification also requires a large number of options. Again, the larger the number the better the identification will be. For example, it is much easier to identify ERS with 7-point scales (1 = strongly disagree, 2 = disagree, 3 = somewhat disagree, 4 = neutral, 5 = somewhat agree, 6 = agree, and 7 = strongly agree) than 3-point scales (e.g., 1 = disagree, 2 = neutral, and 3 = agree). Third, there is no clear categorization for extreme responses. In the aforementioned 3-point scale, we may all agree that Options 1 and 3 are extreme responses. However, in the aforementioned 7-point scale, some may argue that Options 1 and 7 are extreme responses, whereas others may argue that Options 1, 2, 6, and 7 are extreme responses. Fourth, different categorizations of extreme responses (e.g., Options 1 and 7 vs. Options 1, 2, 6, and 7 in a 7-point scale) will lead to different results. It is thus recommended that different categorizations be adopted and the results be compared. Finally, our models should detach ERS from the target latent traits so that the “purified” latent traits are valid for comparison.
The rest of this article is organized as follows. First, we review several existing IRT models. Second, we develop a new class of IRT models to account for ERS so that the resulting measures for the latent traits are valid for comparison. Third, we outline the parameter estimation procedures and computer software for the new class of models. Fourth, we present a series of simulation studies to examine the parameter recovery of the new class of models, evaluate the consequences of ignoring ERS by applying standard IRT models, and summarize our findings. Fifth, we give two empirical examples of an interpersonal conflicts scale and a civic education survey to illustrate the implications and applications of the new models. Finally, we present our conclusions and make suggestions for future studies.
IRT Models for ERS
One advantage of IRT is that person parameters and item parameters can be separated. Many IRT models have been proposed for analyzing Likert-type or rating-scale items, such as the partial credit model (PCM; Masters, 1982), the rating scale model (RSM; Andrich, 1978), and the graded response models (Samejima, 1969). For example, the PCM and RSM can be written, respectively, as
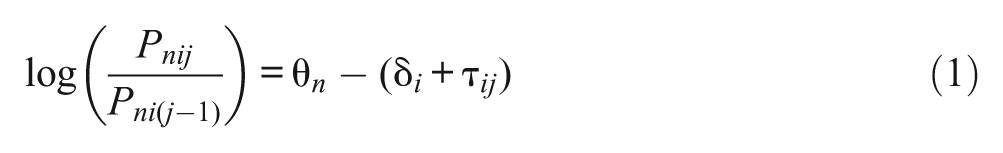
and
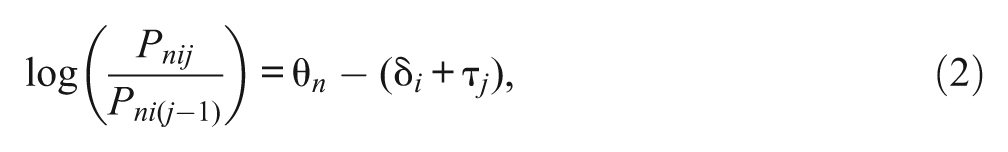
where Pnij and Pni(j − 1) are the probabilities of receiving scores j and j− 1 on item i for person n; θ n is the latent trait of person n; δ i is the overall difficulty of item i; τ ij is the jth threshold parameter (relative to δ i ) for item i (in the PCM), and τ j is the jth threshold parameter (relative to δ i ) for all items (in the RSM). In the PCM, RSM, and other standard IRT models, it is assumed that, conditional on item parameters, θ n is the only factor that determines the item responses. When response styles also play a role in item responses, such an IRT model becomes inappropriate.
Persons with different levels of ERS could be grouped into latent classes (Moors, 2008; van Rosmalen, van Herk, & Groenen, 2010). The PCM can be extended to accommodate latent classes:
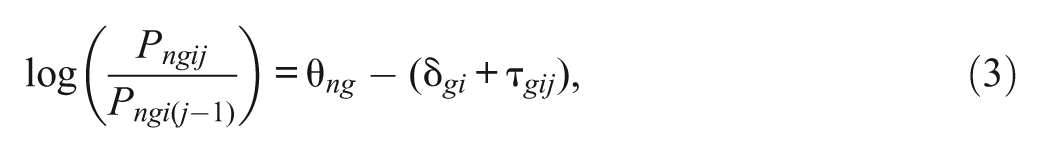
where g denotes the latent class membership. The labeling of the latent classes in the mixture PCM (Equation 3) can be determined by inspecting the threshold parameter estimates. It was frequently found that one latent class had a large distance between adjacent thresholds, whereas another latent class had only a small distance between adjacent thresholds (Rost, Carstensen, & von Davier, 1997; von Davier, Eid, & Zickar, 2007). The distance between adjacent thresholds represents the likelihood of exhibiting extreme responses; the larger the distance, the smaller the likelihood. Using the mixture PCM to investigate ERS should be done with caution because it may not always reveal true latent classes and may yield spurious latent classes (Alexeev, Templin, & Cohen, 2011).
The multidimensional nominal response model has been adopted to account for quantitative differences in ERS (Bolt & Johnson, 2009; Bolt & Newton, 2011; Johnson & Bolt, 2010). In the model, the log-odds of selecting option j over option R (the reference category) are defined as
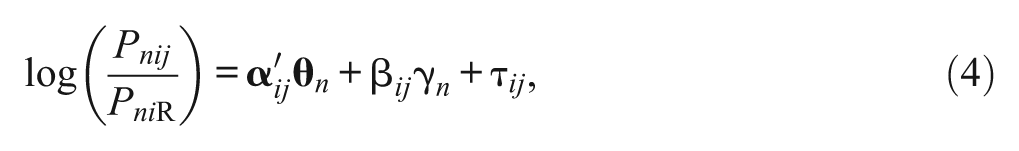
where Pnij and PniR are the probabilities of selecting options j and R on item i for person n, respectively;
Items may function differently for different persons. Johnson (2003) proposes a heterogeneous thresholds probit model for ordinal responses, in which a person can have his or her own thresholds. After constructing a symmetric space of latent responses and centering the thresholds across persons, distances between adjacent thresholds are obtained. The vector of the distances is assumed to follow a multivariate log-normal distribution. A person with a larger distance between adjacent thresholds exhibits ERS more frequently. Although this model portrays individual differences in exhibiting ERS, it does not quantify the tendency of persons to exhibit ERS.
In contrast to the cumulative IRT models for ERS, Javaras and Ripley (2007) adopt unfolding IRT models (Luo, 2001) to study ERS. Following the same idea of random thresholds across persons (Johnson, 2003), Javaras and Ripley develop a multidimensional unfolding model that allows thresholds to vary across persons. Group- or individual-specific thresholds are derived from a scalar parameter on common thresholds and a translation parameter. Although this model can quantify both acquiescence and ERS, the inherited ideal-point unfolding approach is not applicable when item response functions are cumulative (i.e., the higher the level of the latent trait, the higher the probability of endorsement). In practice, many Likert-type or rating-scale items are analyzed with cumulative IRT models. It is important to develop cumulative IRT models for ERS, which is the major purpose of this study.
Another way to quantify ERS is to classify item responses into two categories—extreme responses and nonextreme responses—and then fit a standard IRT model to the reconstructed data set (de Jong, Steenkamp, Fox, & Baumgartner, 2008). For the reconstructed data set, a latent trait denoting the tendency to perform ERS is measured. Although this approach is straightforward in assessing ERS and is easy to implement, it fails to yield measures of the target latent trait.
Different persons may have different perspectives on the given options. A person may consider the threshold between strongly disagree and disagree large, whereas another person might consider it small. To account for such a random nature, a random-threshold model and its extensions (Wang, Wilson, & Shih, 2006; Wang & Wu, 2011) have been developed, in which the threshold parameters in the RSM are treated as random effects:
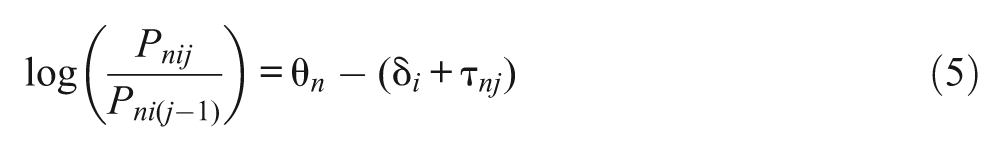
and

where τ
nj
is the jth threshold for person n and is assumed to follow a normal distribution with a mean of τ
j
and variance of

and

where τ nij is the jth threshold of item i for person n; and the other variables have been defined previously. Although the random-threshold RSM (Equations 5 and 6) and the random-threshold PCM (Equations 7 and 8) may be used to describe response styles across persons, they do not directly quantify the tendency toward ERS.
Two conclusions can be drawn from reviewing the aforementioned models. First, treating thresholds as random effects can account for response styles. Second, it is desirable to have an index to directly quantify the amount of ERS for individual persons. To achieve these goals, a class of IRT models for ERS is developed in this study.
Formulation of the New ERS Models
To account for the tendency toward ERS across persons, we revise Equations (5) and (7) as

and
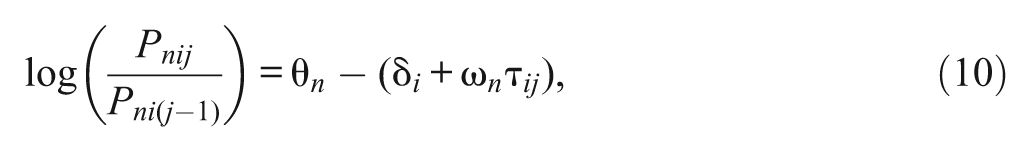
where ω
n
is a weight parameter of respondent n on thresholds and is assumed to follow a log-normal distribution with a mean of zero and variance of
Figure 1 exhibits the effects of different ω values on the response probabilities of a four-point item. When ω = 1, the item response functions are equivalent to those in the PCM, so they can be treated as a reference. When ω = 0.5, the shape of the item response functions becomes narrower, such that the probabilities of scoring 1 or 4 (extreme options) become larger than they are when ω = 1. On the other hand, when ω = 2, the shape of the item response functions becomes wider, such that the probabilities of scoring 1 or 4 become smaller than they are when ω = 1. When ω is increased to 5, the probability of extreme responses approaches zero. Apparently, a smaller ω value indicates a stronger tendency to exhibit ERS.
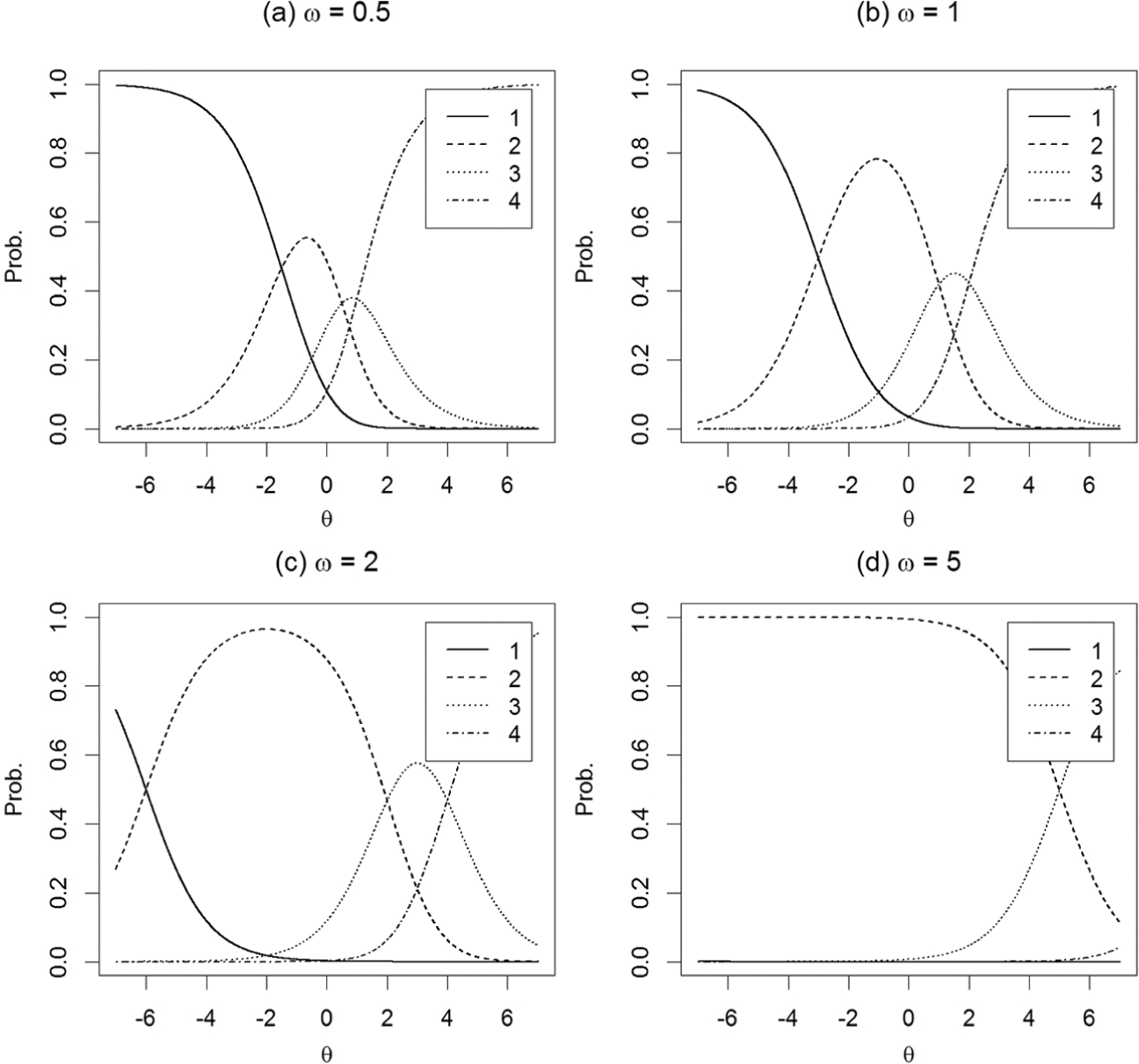
Item response functions for persons with different ω values in a hypothetical four-point item (α = 1, δ = 0, τ1 = −3, τ2 = 1, and τ3 =2).
To describe the ERS-PCM, we simulated a data set of 1,000 persons and 40 six-point items following the ERS-PCM, with

Scatter plots of the θ and log(ω) values, the mean and SD of raw item scores, and the number of extreme responses (#ER) of a simulated data set.
Although the ERS-PCM (Equation 10) shares a common feature with the random-threshold PCM (Equation 7), they have very different conceptualizations. In both models, thresholds are treated as random effects to account for the interaction between persons and items. In the random-threshold PCM, there are as many as J− 1 random effects to account for the interaction (see Equation 8), whereas in the ERS-PCM there is only one random effect, ω. The J− 1 random effects in the random-threshold PCM have to be compared with the target latent trait to describe their impacts, whereas a person’s ω value in the ERS-PCM can directly account for his or her tendency toward ERS.
Generalization of the ERS-PCM is straightforward. For example, like many IRT models, one can incorporate a slope parameter into the ERS-PCM:
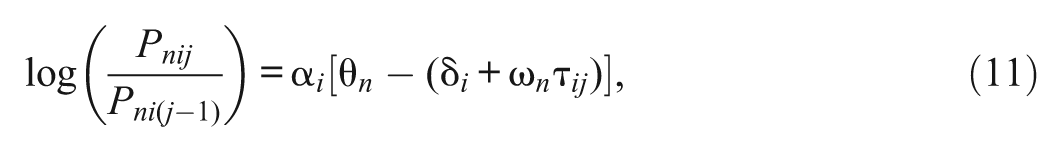
where α i denotes the discrimination power of item i with respect to θ, and the other variables have been defined previously. Equation (11) is referred to as the ERS model with generalized partial credit modeling (ERS-GPCM). When ω n = 1 for all persons, the model simplifies to the generalized PCM (Muraki, 1992).
In the aforementioned ERS models, the target latent trait θ is unidimensional. In practice, a person may be requested to respond to multiple scales, each measuring a latent trait (or a scale with multiple subscales, each measuring a latent trait). Although these scales can be analyzed one at a time, it has been shown that such a consecutive unidimensional approach is less statistically efficient than the multidimensional approach where all scales are analyzed jointly (Adams, Wilson, & Wang, 1997; Cheng, Wang, & Ho, 2009). To implement the multidimensional approach, Equations (10) and (11) can be extended as

and

where subscript s indexes scales (s = 1, . . ., S). The θ and ω variables are assumed to be independent, but the θ s variables can be correlated, and the ω s variables can also be correlated. In Equations (12) and (13), each person receives a ω value on each scale to depict his or her ERS tendency on that scale. These two models can be simplified by constraining a common ω value for each person across scales:
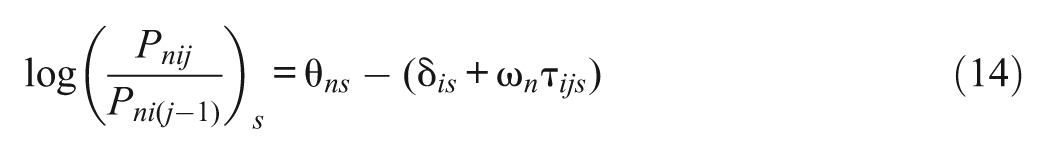
and
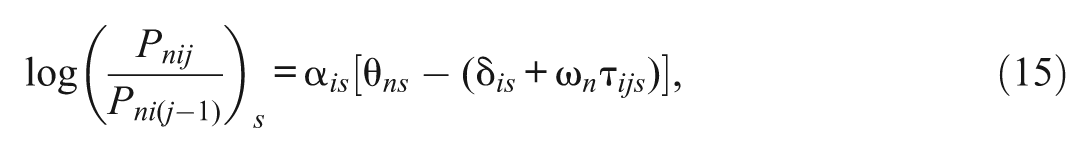
where ω n does not have subscript s, indicating a person has a single ω value to describe their ERS tendency. This kind of constraint is also imposed in the unfolding IRT models developed by Javaras and Ripley (2007).
Covariates can be added to account for the variations in the random effects, which is referred to as latent regression because the criterion variables are latent rather than observed (Adams, Wilson, & Wu, 1997). Apart from θ, ω can be regressed on a set of covariates. Because ω
n
follows a log-normal distribution, let ζ
n
≡ log(ω
n
) and

where
Parameter Estimation
The ERS-PCM and its variations (e.g., Equations 11-16) belong to nonlinear mixed models. The parameters can be estimated by using marginal maximum likelihood estimation methods, which have been implemented in the computer program SAS NLMIXED (SAS Institute, 1999). In addition, recent years have witnessed a rapid development in Bayesian estimation with Markov chain Monte Carlo (MCMC) methods and the popularity of the freeware WinBUGS (Spiegelhalter, Thomas, Best, & Lunn, 2007) on IRT models (Curtis, 2010). In this study, we adopt WinBUGS for parameter estimation. In Bayesian estimation, a statistical model and prior distributions of model parameters are specified to yield a joint posterior distribution. Because the joint posterior distribution is often very difficult to obtain, MCMC methods thus come into play. After a sequential sampling, the posterior distribution of each parameter is formed. Its mean and SD are reported as the point estimate and corresponding standard error of the parameters.
In both the following simulation studies and empirical examples, θ is constrained as N(0, 1) for model identification. Because ω is a weight parameter ranging from zero to positive infinity, it is assumed to follow a log-normal distribution. The mean of the log-normal distribution is set at zero for model identification, and the variance
Simulation Studies
Design
Two simulation studies were conducted. Study I focused on the parameter recovery of the ERS-GPCM. There were three independent variables: (a) sample size: 250, 500, 1,000, and 2,000; (b) test length: 20 and 40 rating-scale items; and (c) number of categories per item: 4 and 6. It was a 4 × 2 × 2 design. θ was generated from N(0, 1) and ω from log-normal (0, 0.42). The item slope parameters were generated from log-normal (0, 0.32), and item difficulty parameters were generated from uniform (−2, 2). The threshold parameters for the 4-point items were set at −0.6, 0, and 0.6 for each item, and −0.8, −0.4, 0, 0.4, and 0.8 for the 6-point items. Because of the lengthy computation time (approximately 20-40 hours per replication), each condition had 20 replications.
Study II focused on the consequences of model misspecification. It had two conditions: (a) the ERS-GPCM was fit to GPCM data (without ERS) and (b) the GPCM was fit to ERS-GPCM data (ERS ignored). Other settings included 40 six-point items answered by 1,000 persons, and
Analysis
The following priors were used in WinBUGS: N(0, 10) for the item difficulties and threshold difficulties, log-normal (0, 1) for item slopes, and gamma (1, 0.1) for the inverse of
Results
Study I
Tables 1 and 2 summarize the bias and RMSE values for 4- and 6-point items, respectively. The item parameter estimates for the overall difficulties and thresholds were seriously biased in small sample sizes (N = 250); fortunately, when the sample size or test length increased, the estimation gradually improved. It appeared that
Bias and RMSE in Item Parameters for the ERS-GPCM in 4-Point Items in Simulation Study I.

Note. RMSE = root mean square error; ERS = extreme response style; GPCM = generalized partial credit modeling.
Bias and RMSE in Item Parameters for the ERS-GPCM in 6-Point Items in Simulation Study I.
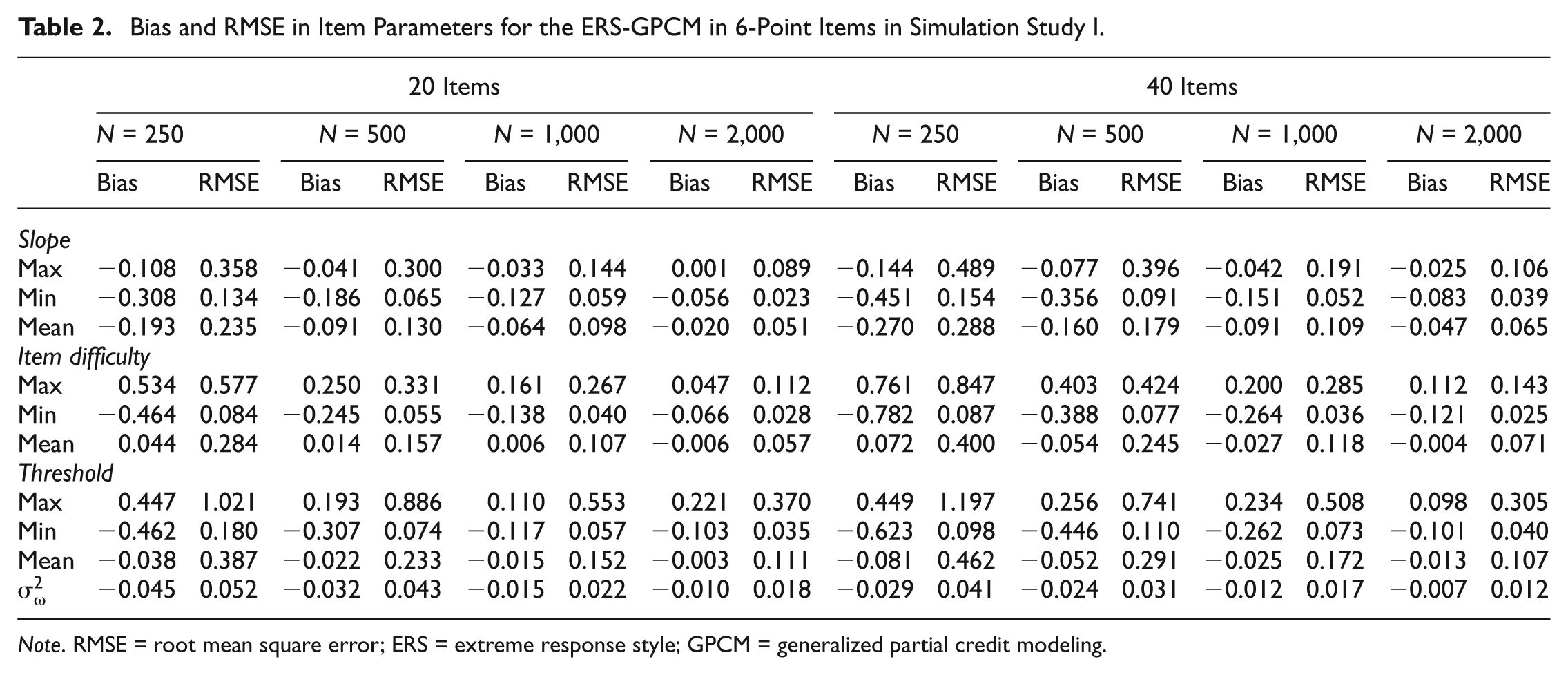
Note. RMSE = root mean square error; ERS = extreme response style; GPCM = generalized partial credit modeling.
Study II
Table 3 summarizes the bias and RMSE values when the GPCM and ERS-GPCM were fit to 6-point items. When
Bias and RMSE in Item Parameters for the GPCM and ERS-GPCM in 6-Point Items in Simulation Study II.
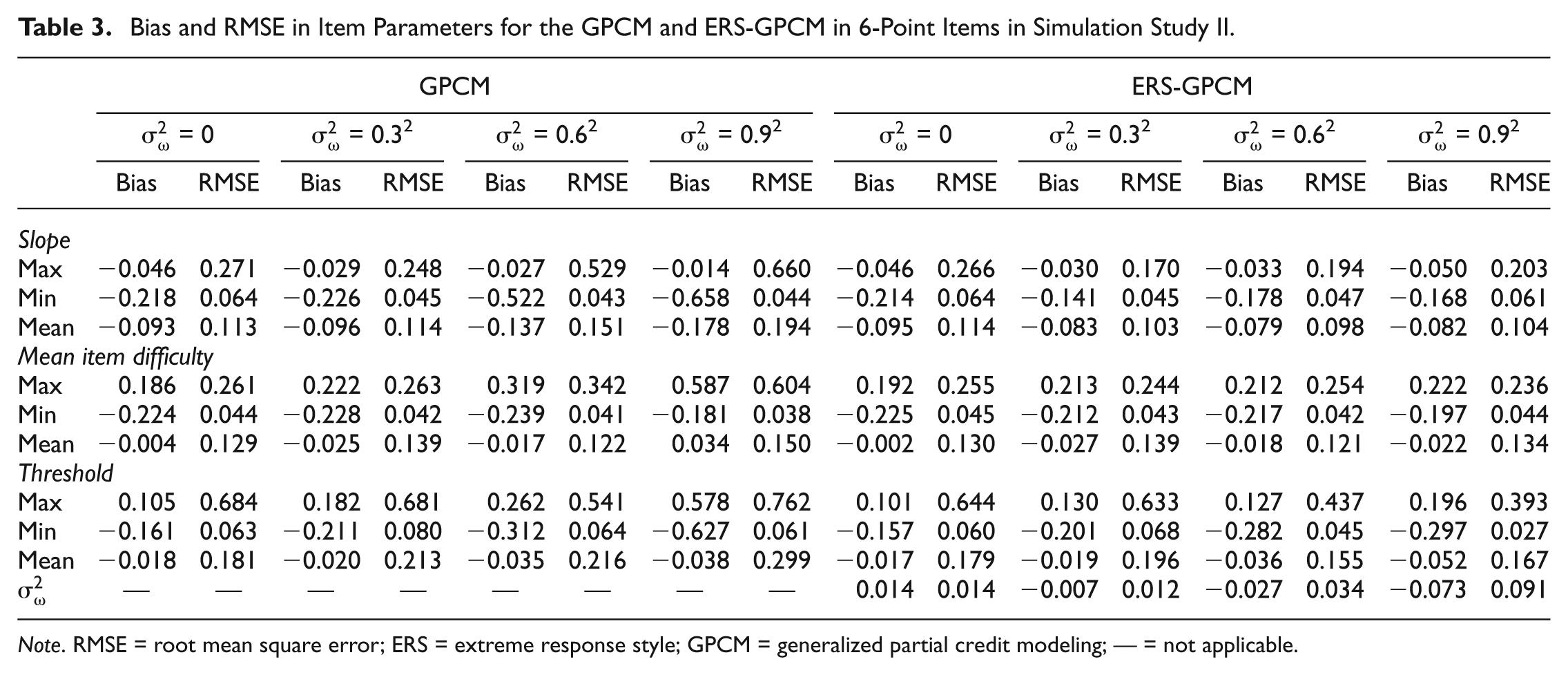
Note. RMSE = root mean square error; ERS = extreme response style; GPCM = generalized partial credit modeling; — = not applicable.
Of the 20 replications, the DIC favored the GPCM 15, 0, 0, and 0 times, respectively, when
Two Empirical Examples
Example I: Interpersonal Conflicts
Lo (2001) developed a scale to measure interpersonal conflicts, which consisted of 20 seven-point items: 1 = strongly unconfident, 4 = neutral, 7 = strongly confident. After removing a few invalid cases with unknown demographic variables, 982 students were kept in the analyses. Six IRT models were fit: (a) PCM, (b) ERS-PCM, (c) ERS-PCM-c, (d) GPCM, (e) ERS-GPCM, and (f) ERS-GPCM-c. The ERS-PCM-c and the ERS-GPCM-c included gender (male = 0 and female = 1) and number of siblings as the covariates of ω (see Equation 16).
The DIC values for the six models were 67,170, 64,946, 64,830, 67,063, 64,896, and 64,798, respectively, suggesting the ERS-GPCM-c had the best fit. In other words, adding slope parameters and covariates was useful. In the ERS-GPCM-c, the test reliability was 0.82; the estimates and standard errors (in parentheses) for the regression coefficients κgender and κsibling on ω were 0.001 (0.082) and −0.187 (0.028), respectively, and the residual variance was 1.098 (0.107). Thus, it can be concluded that these students showed different degrees of ERS; no gender difference was observed regarding ERS, but the number of siblings was a significant predictor of ERS: the more siblings one had, the more likely he or she would endorse extreme responses. This might be because a teenager with more siblings has more experience with interpersonal conflicts, so that his or her endorsement would be more highly differentiated.
Table 4 lists the raw responses of nine students and their θ and ω estimates. Students 19, 771, and 790 all had the same mean item score of 2.80, a very different SD of 1.28, 1.64, and 2.65, respectively, and a very different number of extreme responses (options of 1 and 7) of 4, 6, and 18, respectively. Because their mean item scores were identical, their θ estimates were expected to be very similar under the GPCM: −1.47, −1.54, and −1.70, respectively. Because Student 790 tended to choose extreme options (in this case, many 1s), it was very likely that his or her true θ value was not as low as the mean raw score indicated. So the ERS-GPCM-c gave this student an upward estimation on θ from −1.70 to −1.32. To be balanced, the ERS-GPCM-c gave Student 19 a downward estimation on θ from −1.47 to −1.66.
Students’ Response Patterns and the Estimates for θ and ω (SE in Parentheses) in Example 1.
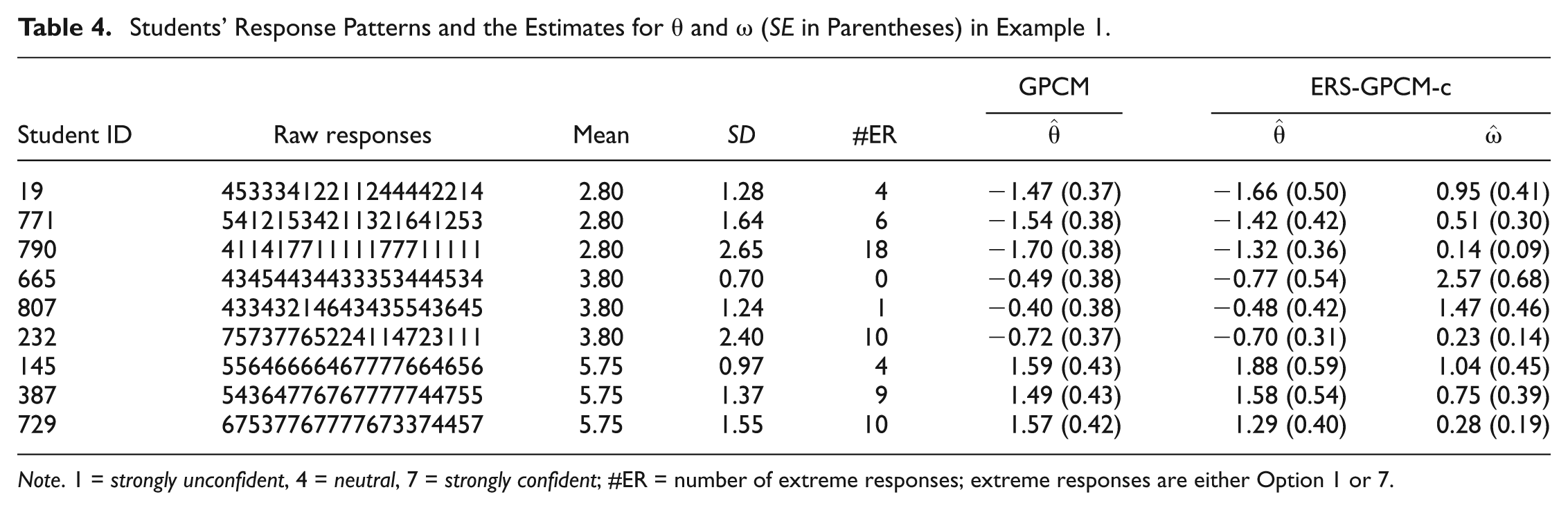
Note. 1 = strongly unconfident, 4 = neutral, 7 = strongly confident; #ER = number of extreme responses; extreme responses are either Option 1 or 7.
The case of Students 145, 387, and 729 was the opposite. Among the three students, Student 145 exhibited the least ERS (
Figure 3 describes the relationship of the θ estimates obtained from the ERS-GPCM-c and GPCM. Some variations were found. The difference in the θ estimates between models ranged from −0.95 to 0.93, with a mean of −0.0004 and an SD of 0.22. The correlation was 0.97, which was reasonable because only 30% of students had a ω estimate that was statistically significant.

Relationship in the θ estimates between the ERS-GPCM-c and GPCM of Example 1.
Example II: ICCS 2009
The International Civic and Citizenship Education Study (ICCS) surveyed students’ preparation in undertaking the role of citizens. In 2009, in addition to the common instrument, ICCS included regional modules for Europe, Latin America, and Asia. The Latin American module had a scale measuring students’ perception of government and law. That scale consisted of three subscales measuring students’ attitudes toward authoritarianism in government (9 items), corrupt practices in government (6 items), and disobeying the law (11 items). Students were asked to indicate their level of agreement with the statements (1 = strongly disagree, 2 = disagree, 3 = agree, 4 = strongly agree). A higher score denoted a greater degree of acceptance of a specific undemocratic activity. Because these three subscales were moderately to highly correlated (Schulz, Ainley, & Fraillon, 2011), we adopted the multidimensional approach to analyze them simultaneously (Cheng et al., 2009). We followed the normal practice of fitting the ICCS data with the family of Rasch models (Schulz et al., 2011). As pointed out in the official report, the correlations among the target three latent traits were rather strong, ranging from 0.72 to 0.86. Thus, the multidimensional form of the partial credit model (MPCM) and the multidimensional form of the ERS-PCM (MERS-PCM; Equation 14) were fit. A total of 5,626 cases in Mexico were analyzed. WinBUGS was used to calibrate the parameters.
The DIC values for the MPCM and MERS-PCM were 306,893 and 277,422, respectively, suggesting the MERS-PCM had a better fit. In the MERS-PCM, the test reliabilities for the three θ variables were 0.85, 0.84, and 0.82, respectively, whereas the test reliabilities in the MPCM were 0.89, 0.88, and 0.86, respectively, suggesting that ignoring ERS by fitting standard IRT models overestimates the precision of the measurement, which is consistent with the findings of previous simulation studies. The estimate for
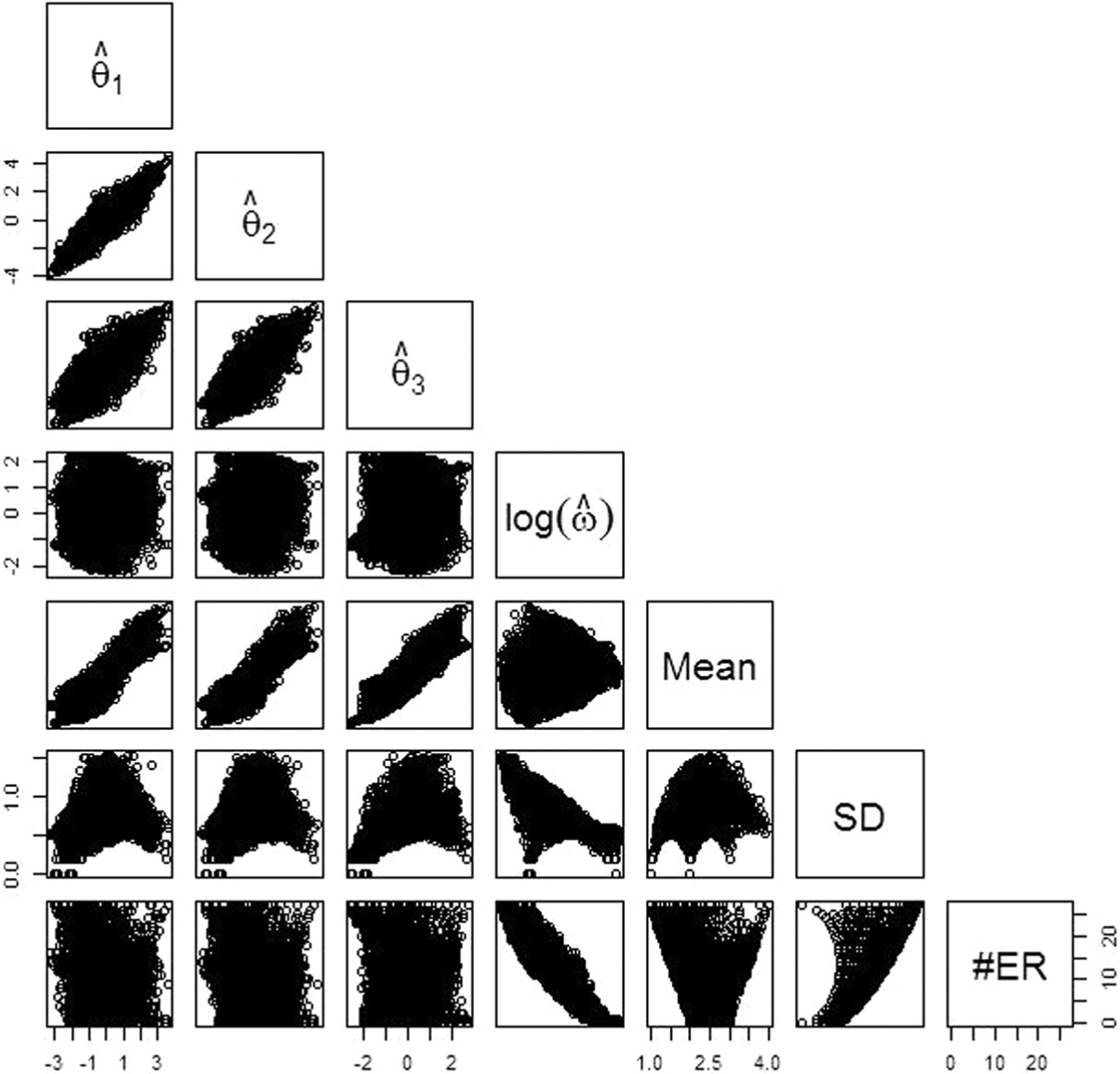
Scatter plots of the θ and ω estimates, the mean and SD of raw item scores, and the number of extreme responses (#ER) of Example 2.
The assumption of a common ω for ERS across the three subscales, as adopted in the MERS-PCM, can be relaxed by allowing a distinct ω for each subscale, as shown in Equation (12). This general and complicated model was fit to the data and compared with the MERS-PCM. Although the DIC preferred the complicated model, the practical difference between these two models was minimal. Specifically, in the complicated model the three ω estimates (in logarithm scale) were highly correlated (0.81 < r < 0.92), suggesting a single ω might be enough. The estimates for the item difficulties and thresholds obtained from the two models were almost perfectly correlated (r = 0.999); the largest difference in the test reliabilities of the θ variable for the three subscales obtained from the two models was as small as 0.01. Besides, on average, the standard errors for the three ω estimates in the complicated model were 55% larger than those for the single ω estimate in the MERS-PCM. In view of these results, the simpler MERS-PCM was kept.
Conclusion and Discussion
Respondents may exhibit different response styles when responding to Likert-type or rating-scale items. Some respondents may prefer extreme options, whereas others prefer middle options. To model this kind of personal preference, we developed a new class of ERS models where a random-effect variable is added to standard IRT models to account for the random widths between thresholds across respondents so that the degrees of ERS can be quantified. Two simulation studies were conducted to assess parameter recovery and the effect of model misspecification. The results showed that the parameters in the ERS models could be recovered fairly well using WinBUGS. Even when respondents did not exhibit ERS, fitting the ERS models still yielded good parameter recovery. In contrast, ignoring ERS by fitting standard IRT models yielded biased estimation, and the larger the variation of ERS the more serious the biased estimation. Moreover, ignoring ERS resulted in overestimated test reliability. Finally, the DIC appeared to be very powerful in selecting true models.
In the simulation study, we deliberately increased the test length to 20 or 40 items to yield a better estimation of ω. In general, the longer the test, the better the estimation of person parameters (i.e., θ and ω in this study). To gain a precise estimate for ω, either the test should be long or the number of options in each item should be large. Furthermore, compared with standard IRT models, the ERS models require a larger sample size for the parameter estimation, mainly because of the model complexity.
This study focuses on ERS and does not consider other types of response styles, which are left for future studies. For instance, previous studies have investigated acquiescent and disacquiescent response styles within the non-IRT framework (Johnson et al., 2005; Kieruj & Moors, 2010; van Herk et al., 2004; Weijters et al., 2008). Future studies can aim to develop IRT models to account for these response styles. Recently, researchers have developed IRT-based sequential decision models to describe response styles in which observed responses are regarded as branched outcomes of multiple response processes. For example, Böckenholt (2012) developed a branching IRT model for odd numbers of categories, in which three branching processes are posited in responding to Likert-type scales. For example, in responding to a 5-point Likert-type scale (strongly disagree, disagree, neutral, agree, and strongly agree), the sequential binary judgment involves: (a) endorsing the neutral opinion or not; (b) if the nonneutral opinion is preferred, choosing the direction of opinion (disagree vs. agree); and (c) expressing the intensity of the opinion (strongly or not). Similarly, Thissen-Roe and Thissen (2013) introduce a two-decision model to describe extreme response sets, in which the first and second stages of Böckenholt’s (2012) model are combined and the third stage is expanded to cover the neutral option. Although these approaches destroy the ordering of categories in Likert-type or rating-scale items, the response styles appear to be better examined. How these approaches would work on other response styles needs further investigation.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.