
Abstract
This note highlights and illustrates the links between item response theory and classical test theory in the context of polytomous items. An item response modeling procedure is discussed that can be used for point and interval estimation of the individual true score on any item in a measuring instrument or item set following the popular and widely applicable graded response model. The method contributes to the body of research on the relationships between classical test theory and item response theory and is illustrated on empirical data.
Keywords
The past several decades have seen increased interest in the connections between item response theory (IRT) and item response modeling on one hand, and factor analysis and classical test theory (CTT) on the other (e.g., Takane & de Leeuw, 1987; Zimmerman, 1975; see also Raykov, Dimitrov, Marcoulides, & Harrison, 2017; Raykov & Marcoulides, 2017, and references therein). Their important relationships are highly useful for a deeper understanding of both methodologies and additionally facilitate substantially their well-informed applications. Recently, Raykov et al. (2017) highlighted and illustrated the links between IRT and CTT by discussing an item response modeling procedure for point and interval estimation of the individual true scores on each item in a measuring instrument or set consisting of binary or binary scored measures. The present note extends their procedure to the more general case of homogeneous polytomous items, and is concerned with instruments or item sets following the popular and widely used in educational and behavioral research graded response model (GRM; Samejima, 1969, 2016).
Point and Interval Estimation of Individual True Scores on Ordinal Polytomous Items
Background, Notation, and Assumptions
For the aims of this article, we assume that a set of ordinal polytomous items are given, with each having r response categories that are designated 1, 2, . . ., r (r≥ 2), and note that the following procedure is directly applicable in case of different numbers of responses across items. (The item invariance in these numbers is inconsequential for the method outlined in the sequel, entails no limitation of generality, and is assumed in this discussion merely for the sake of convenience.) We symbolize the items by Y1, Y2, . . ., Yk (k > 1) and presume that they are the components of a considered unidimensional multi-item measuring instrument or item set, such as a psychometric scale or test (referred to as “instrument” below; these may be items that are for instance used in a partial scoring setting or represent the responses on Likert-type questions). 1 We stipulate that the instrument has been administered to a sample of independent subjects from a studied population that is not a mixture of two or more latent classes (cf. Raykov, Marcoulides, & Chang, 2016). Last, we posit that the GRM is valid in the population for these items, and will designate by θ the underlying latent trait or ability (latent dimension) being evaluated by them.
Point Estimation of Item-Specific Individual True Scores
Following CTT, the true score Tij of the ith examined individual on the jth item is the expectation of his or her pertinent item score (treated as a random variable, at his or her given level of the underlying ability or trait θ as in the rest of this section):

where θi is this person’s ability or trait level, Yij their observed score on the item, and ε(·) symbolizes expectation with respect to the pertinent propensity distribution of possible item scores (i = 1, . . ., n, with n denoting sample size and j = 1, . . ., k; Lord & Novick, 1968). Since, Yij is a discrete random variable, its expectation is (e.g., Casella & Berger, 2002)
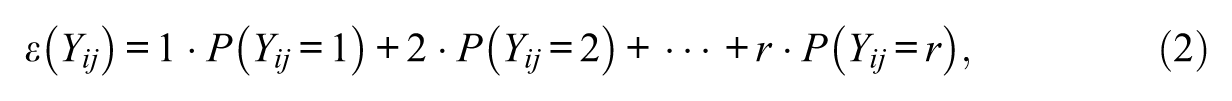
where P(·) denotes probability (and a dot is used to symbolize multiplication, as in the remainder of the section). According to the GRM (cf. de Ayala, 2009),
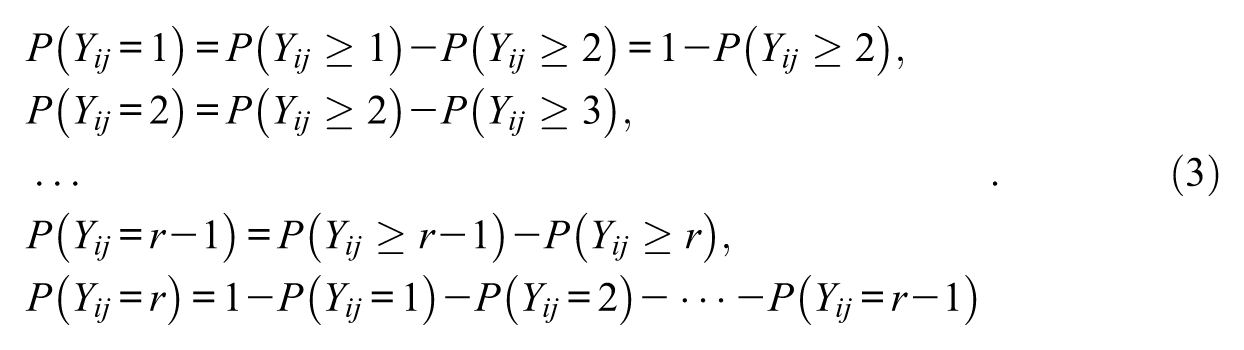
In Equations (3), P(Yij≥m) are the probabilities of responding in category m or higher, which are of main modeling interest and are parameterized in the GRM as follows:
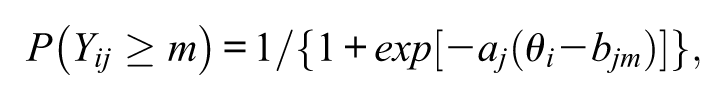
with exp(·) denoting exponentiation, aj an item discrimination parameter, and bjm a cut-point that can be thought of as a difficulty parameter associated with a response in category m or higher (m = 2, 3, . . ., r). That is, these probabilities can be viewed as formally satisfying the two-parameter logistic model with an item-specific discrimination parameter and r−1 additional parameters associated each with the corresponding ordered category of the item (second through last), whereby P(Yij > r) = 0 is presumed (“Stata Item Response Theory Manual,” 2015; cf. Samejima, 1969, 2016). In the rest of the article, for simplicity of reference the latter r−1 quantities are called “item difficulty parameters.”
Hence, from Equations (1) through (3) it follows that the true score of the ith individual on the jth item is (cf. de Ayala, 2009)
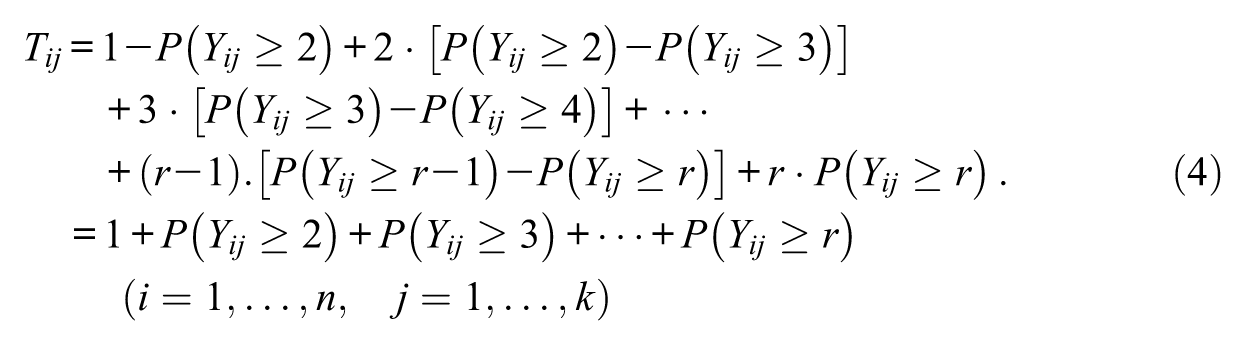
Therefore, after fitting the GRM to a given data set on ordinal polytomous items (and finding it plausible), the point estimates of the individual true scores on any of the k items under consideration are obtainable from Equation (3) as
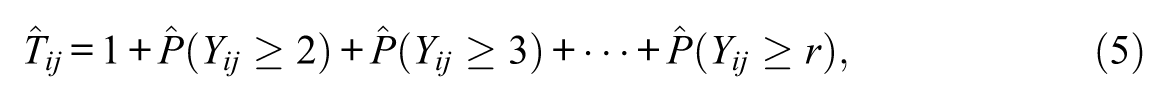
where a hat is used to denote estimate of the quantity underneath, as in the remainder of this note, and
Interval Estimation of Item-Specific Individual True Scores
Equation (5) only provides point estimates of the individual persons’ true scores on any item in an instrument or item set under consideration, with no information regarding the instability of these estimates. To resolve this issue, all estimated item discrimination and difficulty parameters are treated next as known, for instance, from prior calibration or application of the marginal maximum likelihood estimation method (e.g., Reckase, 2009; see also Raykov et al., 2017), as is nearly routinely proceeded with in corresponding IRT applications. In this way, by utilizing the delta method (e.g., Raykov & Marcoulides, 2004), we can furnish the following approximate standard error (SE) for the item-specific, individual true score in Equation (5) (cf. Raykov et al., 2017):
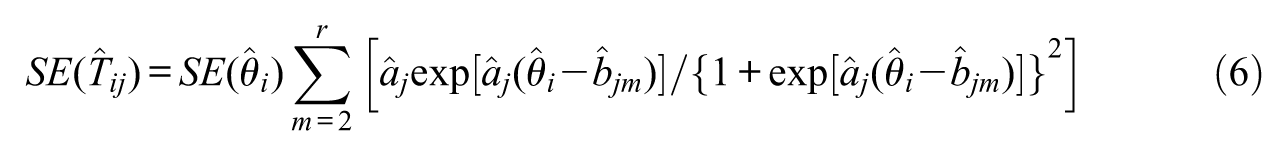
(i = 1, . . ., n, j = 1, . . ., k). (A standard error appearing in Equation 6 is by definition the positive square root of the pertinent approximate variance resulting from the delta method; e.g., Casella & Berger, 2002.)
Employing the standard error in Equation (6) and the true score estimate in Equation (5) with the monotone transformation-based procedure using the logistic function in Raykov and Marcoulides (2011, chapter 7; after a suitable initial linear transformation, see below and Appendix B), we finally obtain for each person and item a confidence interval (CI) of his or her true score on the jth item:

where Tij,lo(α) and Tij,up(α), respectively, denote the lower and upper limit of the 100(1 −α)% CI for the true score of the ith examined person on the item (0 < α < 1; i = 1, . . ., n, j = 1, . . ., k).
The item-specific individual true score estimate in Equation (5) as well as its associated standard error in Equation (6) and CI in (7) are readily obtained using widely circulated statistical software, such as Stata and R (e.g., Raykov & Marcoulides, 2017; see also the Mplus source code for examining the plausibility of the GRM, which is provided in appendix 1 of Raykov et al., 2017). The source code needed for the point estimation of the item-specific individual true scores and the associated approximate standard error (Equations 5 and 6) is supplied in Appendix A to this note, and the R-function for the construction of the true score CI (7) is found in Appendix B.
The applicability and utility of the discussed true score estimation procedure is demonstrated next on empirical data.
Illustration on Data
For the purposes of this section, we make use of a data set from an anxiety study that is available with a download from www.ssicentral.com of the (student version of the) IRT software IRTPRO (Cai, Thissen, & du Toit, 2017). The data set results from k = 5 ordinal polytomous items with r = 5 response options each that were administered to n = 514 persons and asked about their feelings of being calm, at ease, tense, regretful, or nervous (e.g., du Toit, 2003). For the sake of illustration and ease of reference, the aims of the present discussion, and without loss of generality these items might be thought of in the remainder as being possibly indicative of the trait Generalized Anxiety.
We commence by examining the plausibility of the GRM. To this end, as in Raykov et al. (2017), we use confirmatory factor analysis for the five categorical items and apply the popular latent variable modeling software Mplus for fitting the pertinent single-factor model to them (L. K. Muthén & Muthén, 2017; see appendix 1 in Raykov et al., 2017, for the needed source code and notes to it). The overall goodness-of-fit indices of the GRM fitted thereby are nonsignificant and suggest that it is a tenable means of data description and explanation: Pearson chi-square value = 1682.251, degrees of freedom (df) = 3090, associated p value (p) = 1; and likelihood ratio chi-square value = 837.822, df = 3090, p = 1. 3 In addition, the individual item R 2 indices range between 32% and 71%, and thus none of them can be seen as indicating potentially serious “local” violations of model fit. With these global and “local” goodness-of-fit results, we may conclude that the GRM is plausible for the analyzed data set.
Next, we obtain the point estimates of the individual Generalized Anxiety trait levels, that is, the above values
Individual True Score Estimates on Each of k = 5 Anxiety Items (for the First 10 Subjects, in Stata Format).

Note. Tj = individual true score on the jth item (j = 1, . . ., 5, in the order “calm,”“atease,”“tense,”“regretful,” and “nervous”; subject identifier given in left-most column).
In the second step of the procedure of this article, employing these individual true score estimates and based on Equation (6), we furnish the standard errors associated with each of the 514 individual true scores (estimates) on any of the five items. This is accomplished with the following nine lines in the Stata code in Appendix A (after the pertinent comment line). These standard errors for the first 10 respondents are presented in Table 2.
Standard Errors for the Individual True Score Estimates in Table 1 (for the First 10 Subjects, in Stata Format).
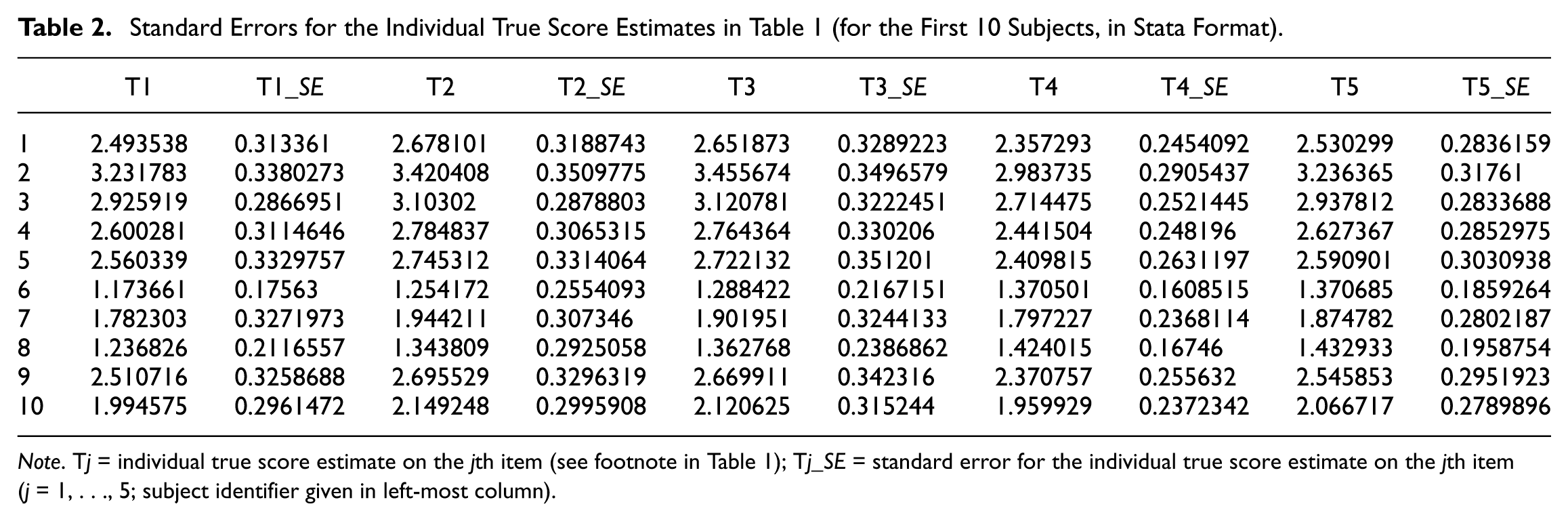
Note. Tj = individual true score estimate on the jth item (see footnote in Table 1); Tj_SE = standard error for the individual true score estimate on the jth item (j = 1, . . ., 5; subject identifier given in left-most column).
In the third step of the method discussed in this note, utilizing the R-function “ci.ordinal_polytomous_item_TS” in Appendix B with the true score estimates and their standard errors obtained as above, we finally furnish the 95% CIs for each of the 514 individual true scores on any of the five items. These CIs for the first 10 persons and first item are presented in Table 3.
Confidence Intervals at 95% Confidence Level for the Individual True Scores (for First 10 Subjects and First Item, “Calm,” in Stata Format).
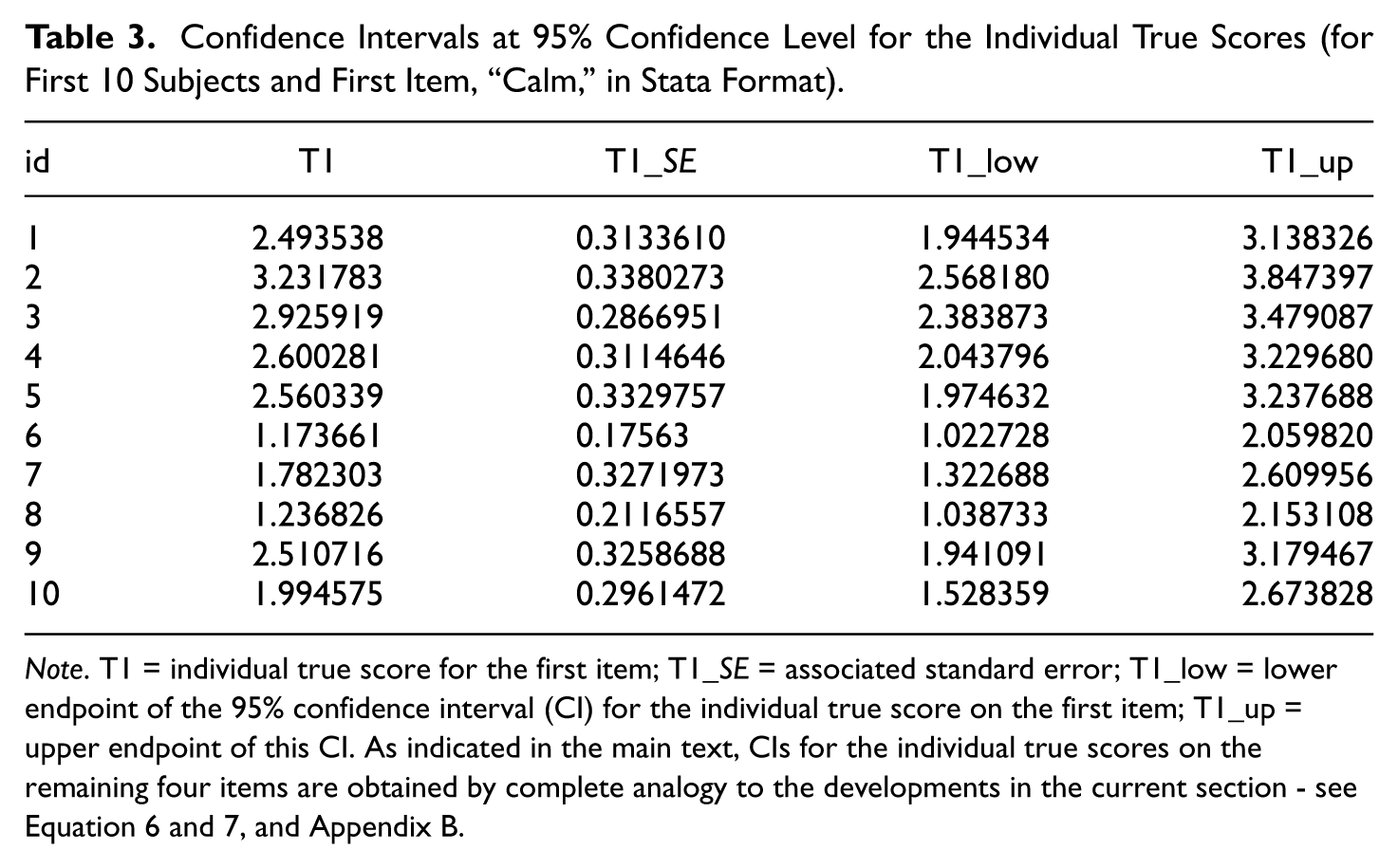
Note. T1 = individual true score for the first item; T1_SE = associated standard error; T1_low = lower endpoint of the 95% confidence interval (CI) for the individual true score on the first item; T1_up = upper endpoint of this CI. As indicated in the main text, CIs for the individual true scores on the remaining four items are obtained by complete analogy to the developments in the current section - see Equation 6 and 7, and Appendix B.
The individual true score CIs with respect to the remaining four items are obtained by complete analogy, using their earlier rendered true score estimates and associated standard errors.
Conclusion
In this note, we have discussed an extension of the true score point and interval estimation procedure in Raykov et al. (2017) to the case of ordinal polytomous items. The method has generalized their procedure to the setting of a unidimensional measuring instrument or item set adhering to the popular and widely applicable GRM, with that earlier procedure being a special case of the present one (when r = 2). We were similarly concerned here with an IRT modeling–based approach to point and interval estimation of individual true scores on each item in an item set under consideration that followed the GRM, and our goal was also to highlight and illustrate further important and useful links between IRT and CTT.
It is worthwhile stressing at this point several limitations of the estimation approach of the present article. One is the requirement of large samples with respect to both persons and items, since it is instrumentally based on maximum likelihood estimation that is grounded in an asymptotic theory (see Raykov et al., 2017, for additional discussion on this general limitation, in particular with respect to number of items). Two, the discussed method rests on the assumption of the items following the GRM, and therefore, its application with an instrument or item set that is multidimensional is not recommendable (cf. Reckase, 2009). Three, we have assumed that the instrument or considered items are given, that is, prespecified, rather than sampled from a pool, population, or universe of items. Last, the procedure of this note makes extensive use of the delta method that is based on a linear approximation, and it is unknown to what extent its approximate validity may be generalizable to complex parametric functions representing expected observed scores (true scores) in models other than the GRM.
In conclusion, this note provides educational and behavioral scientists with a widely applicable procedure for estimation of individual true scores on any of the items in a unidimensional measuring instrument or item set adhering to the popular GRM, and contributes further to the body of research on the connections between IRT and CTT (e.g., Raykov et al., 2017, and references therein).
Footnotes
Appendix A
Appendix B
Acknowledgements
We are grateful to B. Muthén and L. Steinberg for valuable discussions on the graded response model. We are indebted to R. Raciborski for helpful and instructive comments on applications of the Stata IRT module.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.