
Abstract
This note is concerned with evaluation of location parameters for polytomous items in multiple-component measuring instruments. A point and interval estimation procedure for these parameters is outlined that is developed within the framework of latent variable modeling. The method permits educational, behavioral, biomedical, and marketing researchers to quantify important aspects of the functioning of items with ordered multiple response options, which follow the popular graded response model. The procedure is routinely and readily applicable in empirical studies using widely circulated software and is illustrated with empirical data.
Keywords
Item response theory (IRT) has been enjoying impressively high popularity across the educational and behavioral sciences for more than a half century (e.g., van der Linden, 2016). While a great deal of applications of IRT have occurred in achievement and educational testing settings in its early years, over the past several decades IRT has been utilized increasingly more often also in behavioral, biomedical, and marketing research (e.g., Embretson & Reise, 2000; Raykov & Calantone, 2014; Zhang & Petersen, 2018). A setting frequently employed in that research is concerned with the evaluation of typical performance rather than maximal performance, for instance, when requesting multiple raters, teachers, judges, or councilors to rate each member of an examined group of patients, students, respondents, clients, customers, persons, or cases (e.g., Nering & Ostini, 2010). In particular, the widely used Likert-type items (often referred to as “Likert items”) tend to be employed under those circumstances, which represent perhaps the most prominent example of ordinal discrete measures in the educational, behavioral, and social sciences (e.g., Samejima, 2016).
Likert items typically contain at least three ordinal answer options. Due to their feature of ordinality, these items are associated with a substantively meaningful ordering of their response alternatives. Within one of the most frequently employed unidimensional IRT models for such items, the graded response model (GRM; for example, Thissen & Steinberg, 1988), each item is characterized by as many category characteristic curves (CCCs) as there are answers possible on it. The CCCs display graphically relevant characteristics of the item (e.g., Raykov & Marcoulides, 2018), but as curves stretching over an infinite continuum, they contain limited information about an important property of the functioning of the item. This feature is well known with binary/binary scored or dichotomous items (with no guessing) and is reflected in their difficulty parameter (e.g., Reckase, 2009). The latter parameter represents the item location and permits researchers to easily compare items in terms of their “position” along a studied latent trait or ability dimension. For this reason, the item difficulty parameter is often referred to as a location parameter (cf. van der Linden, 2016).
Bearing this insightful and useful interpretation of the difficulty parameters of dichotomous items in mind, it is intriguing to examine ways in which a parameter with similar properties could also be associated with Likert items possessing more than two ordinal response options. Such a parameter would have the feature of contributing markedly to the possibility of comparing different Likert items. This may become especially relevant in settings where individual teachers, councilors, raters, or judges are to be compared with each other based on their ratings of a set of studied persons (units of analysis or cases). The reason is that a location parameter of this kind would provide important information about the degree to which there may be agreement, or lack thereof, among the raters. Finding subsequently a trustworthy explanation of the agreement or the sources of disagreement (in particular, if considerable) may be a key activity in developing improved ways of evaluating students, patients, respondents, cases, or clients in the educational, behavioral, biomedical, and marketing sciences using multicomponent measuring instruments containing polytomous items.
Recently, Zhang and Petersen (2018) proposed as a location parameter for an ordinal item with multiple response options the intersection point of the CCCs for its lowest and highest response categories (see next section for its definition). Their approach can be seen as a useful generalization of the dichotomous item setup to that with more than two answer alternatives. This is because in the special case when an item has only two response options, that location parameter becomes identical to the item difficulty parameter which as mentioned is a location parameter for a binary or binary scored item. 1 Zhang and Petersen were concerned, however, only with the fairly restrictive rating scale model (RSM) that assumes the same number of categories for all items, identical discrimination parameters across them, and invariance of the differences in category difficulty parameters (e.g., Raykov & Marcoulides, 2018; Stata Item Response Theory Reference Manual, 2021). Furthermore, they did not describe a straightforward way of evaluating the degree of uncertainty associated with the estimation of location parameters for items following that model. This uncertainty is a major aspect of the estimation process and essential for a credible comparison among different items (teachers, raters, clinicians, councilors, or judges) if the latter is to be affected to a limited extent by sampling error. For this reason, one may well argue that point and interval estimation of location parameters and functions thereof, if possible with a single command of widely circulated software, would be very useful and helpful for empirical scholars, especially for more general and widely applicable polytomous item models.
The aim of the present note is to respond to this need by describing a readily employed procedure for evaluation of a location parameter of each item in a given set of ordinal discrete measures that follow the popular GRM (e.g., Thissen & Steinberg, 1988). In the remaining discussion, we outline a latent variable modeling-based approach to point and interval estimation of the corresponding intersection point of the lowest and highest CCCs for such an item (see next section). The method is directly utilized with popular software and permits examining or testing of various hypotheses about relative location of items (or judges, raters, councilors, clients, cases) adhering to the model.
Background, Notation, and Assumptions
In the rest of this article, we assume that a set of k polytomous items are given, denoted
In the following discussion, of key relevance will be the item CCCs (e.g., Reckase, 2009). These represent the extension of the popular concept of item characteristic curve (ICC) in the dichotomous item case to that of polytomous items. However, unlike the ICCs, the CCCs are not all monotonically increasing and may be decreasing or consisting of parts that are increasing or decreasing. For a given item and response category on it, the pertinent CCC is the probability, as a function of the underlying trait (denoted as usual θ), of responding in that category. In particular, within the GRM this probability Pq(θ) of answering with the qth category on the item
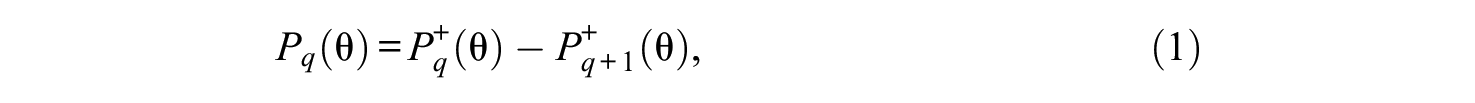
where
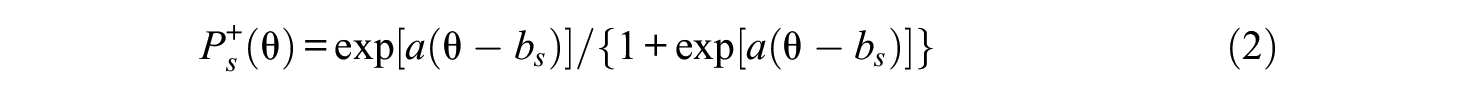
is the probability of responding with category s or higher on the item, a is its discrimination parameter that is assumed positive in what follows, bs the difficulty parameter associated with the item and its sth category (2 ≤s≤r), and exp(.) is the exponential function (i.e., the function e(.)). In addition,
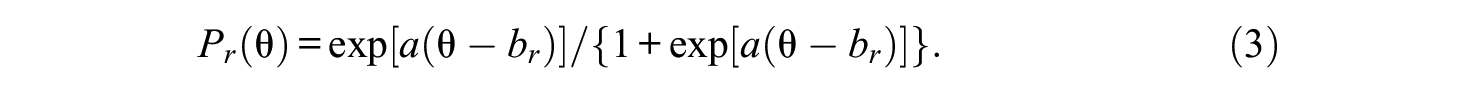
This probability, along with that of the lowest category, will play an instrumental role in the following discussion.
Point and Interval Estimation of Polytomous Item Locations
As in Zhang and Petersen (2018), a location parameter of a polytomous ordinal item is defined as the projection on the underlying latent continuum of the intersection point of (a) the CCC for its lowest category, that is, the one denoted (scored) by 1, with (b) the CCC for its highest category, that is, that designated by r. Therefore, by definition, the item location parameter is the position θ l on that underlying ability dimension θ, which has the property

Based on the developments in the last section, in particular Equations 1 through 3, from Equation 4 one obtains for the GRM:
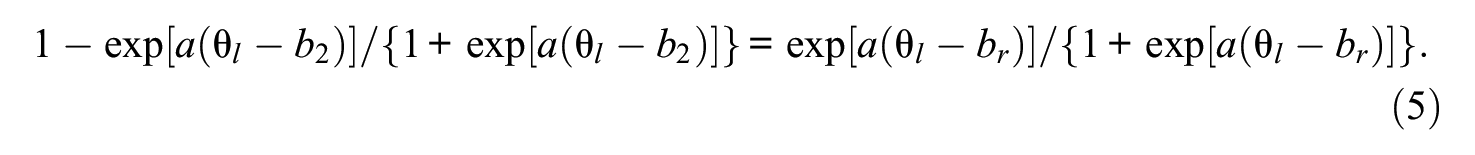
After some direct algebra, the solution of Equation 5 in terms of the unknown θ l is found to be

That is, for a polytomous ordinal item following the GRM, its location parameter is the average of the difficulty parameters associated with its highest category and the lowest above the reference category.
As discussed in detail in Zhang and Petersen (2018), the interpretation of the location parameter for a given item is as that point on the underlying latent continuum that is, informally speaking, representative of the “middle part” of the set of its CCCs. More concretely, from two items with differing location parameters, the one whose parameter is to the right has the property that at any fixed trait or ability level, (a) its lowest categories tend to be more likely to be endorsed than the same categories of the other item, while (b) its highest categories are less likely to be endorsed than those categories of the other item. (The exact relationship is determined by the shape and location of the individual CCCs associated with the two items; e.g., Raykov & Marcoulides, 2018. We note in passing that as can be readily observed, this interpretation is applicable to and remains valid also in the binary/binary scored item case, that is, with r = 2 item response options, which setup as indicated earlier is a special case of the general setting underlying this note and not of concern in the remainder.)
Based on Equation 6, when using the maximum likelihood (ML) method for fitting the GRM, the ML estimator of the location parameter for any item is the average of the resulting ML estimators for the difficulty parameters of its second lowest and highest categories. This estimator relationship is quite useful both theoretically and empirically, and follows from the well-known invariance property of ML (e.g., Casella & Berger, 2002). Point estimation of the item location parameter (as well as of linear and nonlinear functions of such parameters) is thereby easily carried out with the widely circulated software Stata, in effect with a single command, when using its IRT module (e.g., Raykov & Marcoulides, 2018, Chapter 11; see the appendix for that Stata command). The source code needed thereby is provided in the appendix (see, for example, Line 5 for the Calm item say). Furthermore, and no less importantly, interval estimation of the item location parameter, as well as functions of such parameters, is accomplished by the same command. This is achieved by employing thereby internally the popular delta method (e.g., Raykov & Marcoulides, 2004; Stata Base Reference Manual, 2019) and is thus readily available to a researcher as a by-product of that command.
We demonstrate in the next section the discussed procedure for evaluation of polytomous item location parameters using empirical data.
Procedure Application on Empirical Data
To illustrate the applicability and utility of the outlined estimation method, we will utilize a data set from an anxiety study that is available with a download from www.ssicentral.com of the IRT software IRTPRO (Cai et al., 2017; cf. Raykov et al., 2019). The study employed k = 5 Likert-type questions with r = 5 response options each, which were administered to n = 514 patients. The questions asked about their feelings of being calm, tense, regretful, at ease, or nervous, and specifically whether they experienced them never, rarely, occasionally, frequently, or always (scored in this order as 1 through 5, respectively; cf., for example, duToit, 2003; recoding of the item categories was carried out where needed by the original authors before making the data set publicly available). Granted the method illustration goals of this section, these questions may be thought of as indicative of the trait Generalized Anxiety (GA).
As a first analytic step, one would wish to examine the plausibility of the unidimensionality hypothesis for the five items under consideration. To this end, confirmatory single-factor analysis of these measures that was conducted in Raykov et al. (2019; see Appendix 1 in that source and its Footnote 1) suggested its plausibility. In addition, as reported there, the individual R2 indices ranged between 32% and 71%, and thus none of them could be seen as indicating potentially serious “local” violations of the fitted model. As a follow-up step, a comparison of the information criteria associated with the GRM, RSM, partial credit model, and generalized partial credit model that are popular polytomous IRT models, which was also carried out in Raykov and Marcoulides (2018, Chapter 11, Table 11.1), showed that the GRM had the lowest Akaike information criterion (AIC) and Bayesian information criterion (BIC) indices. One may conclude therefore that the GRM, which underlies the preceding discussion in this note, is preferable as a means of data description and explanation.
With these prior findings in mind, the earlier described item location estimation procedure is now carried out, as indicated in the previous section using the Stata source code in the appendix (and involving marginal ML estimation; for example, Stata Item Response Theory Reference Manual, 2021). The resulting point and interval estimates of the location parameters of the five items under consideration are presented in Table 1 (which contains also point and interval estimates of a particular location parameter difference that is of interest and discussed below).
Item Location Parameter Estimates, SEs, and CIs
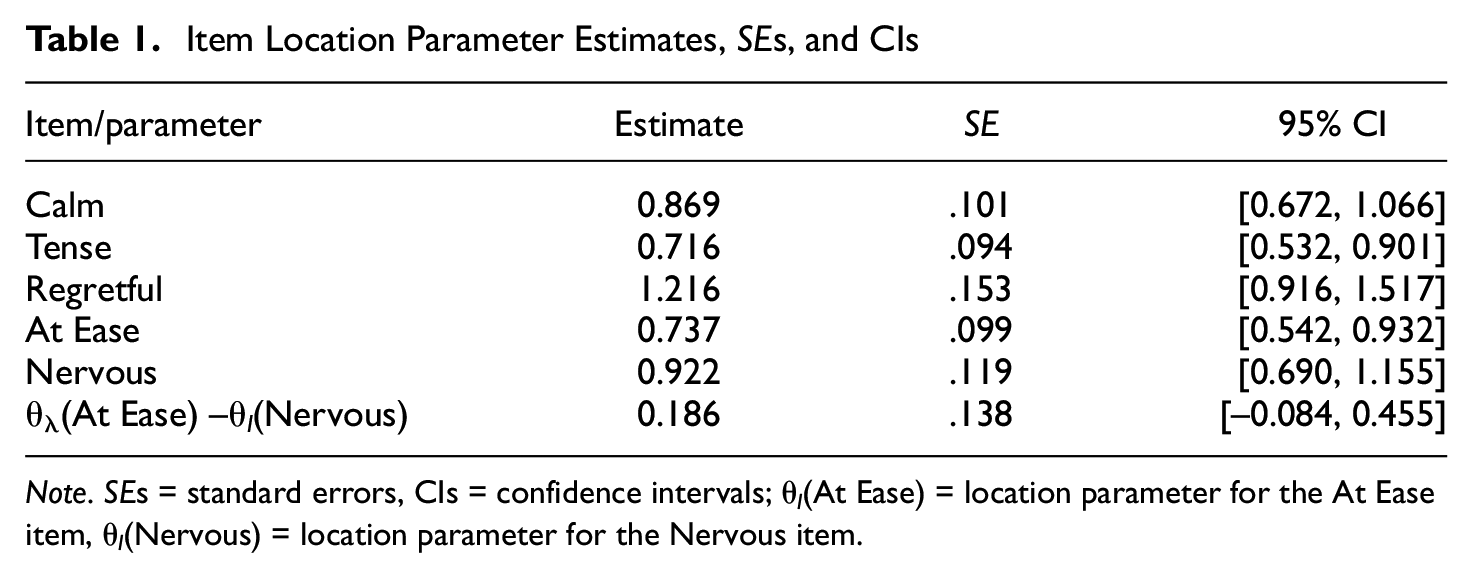
Note. SEs = standard errors, CIs = confidence intervals; θ l (At Ease) = location parameter for the At Ease item, θ l (Nervous) = location parameter for the Nervous item.
As seen from the first five rows of Table 1, in the analyzed data set, the item Tense is located to the left of all other items, followed by the item At Ease, then by Calm, and by Nervous; furthermore, the item Regretful is located to the right of all items. Comparing next the item location parameter confidence intervals (CIs), upon observing that those of Tense and Regretful do not overlap, it may be suggested that in the studied patient population, the Regretful item is positioned to the right of the Tense item. (This is not meant to be a statistical test of the pertinent parameter relationship; see below.)
Moreover, if a researcher was interested to begin with (i.e., before analyzing the data) in examining a conjecture stating that the item At Ease say was located to the left of the item Nervous in the population, they could proceed by interval estimating the difference in their location parameters. (This is accomplished with the final part of the Stata source code in the appendix; see also Figures 1 and 2 for the CCCs associated with these two items).
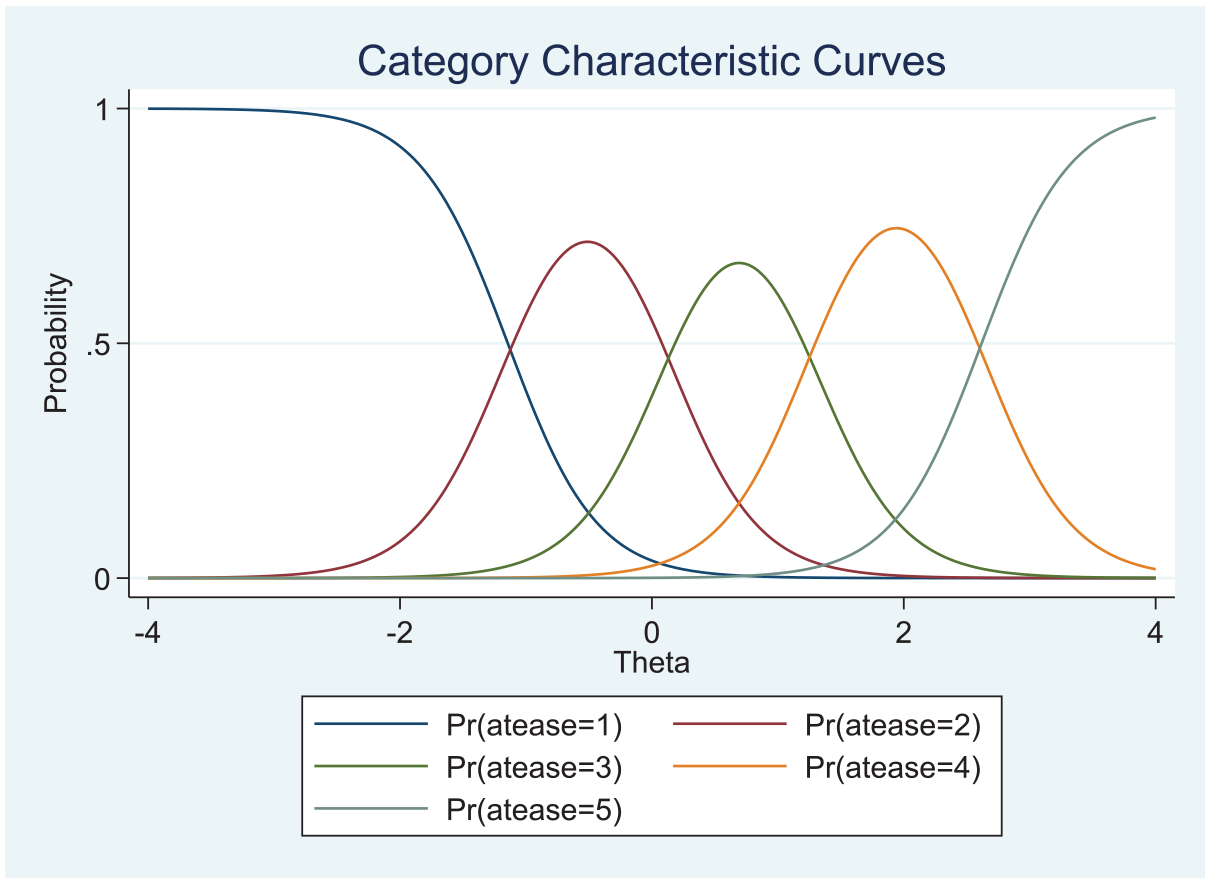
Category Characteristic Curves for the At Ease Item (Location Parameter Represented by the Projection on the Theta Continuum of the Intersection Point of the Lowest and Highest Response Category Characteristic Curves; See Also Table 1).
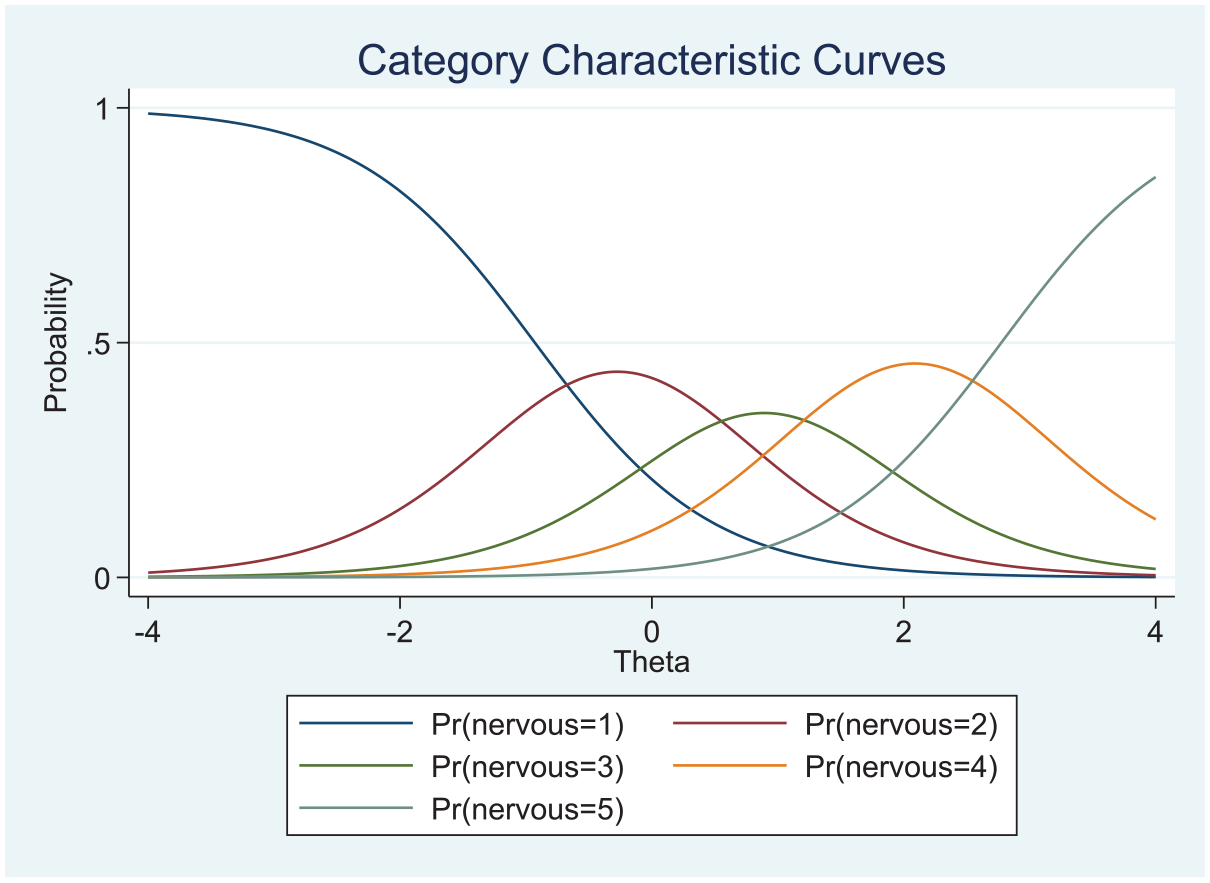
Category Characteristic Curves for the Nervous Item (Location Parameter Represented by the Projection on the Theta Continuum of the Intersection Point of the Lowest and Highest Response Category Characteristic Curves; See Also Table 1).
As a result, the last row of Table 1 shows the corresponding item location difference estimated at .186, with a standard error of .138 and a 95% CI of [−0.084, 0.455]. This suggests that there is not sufficient evidence in the data to warrant rejection of the identity hypothesis of the location parameters for the At Ease and Nervous items.
Conclusion
This note was concerned with location parameters for polytomous ordinal items. Based on the developments in Zhang and Petersen (2018) for the restrictive RSM, who proposed as such a parameter the projection on the latent continuum of the intersection point of the characteristic curves for the lowest and highest response categories on a considered item, the present article outlined a widely and easily applicable procedure accomplishing routine point and interval estimation of this parameter for items following the more general and popular GRM. The method can also be directly used for point and interval estimation of linear and nonlinear functions of such parameters. The procedure provides important information to educational, behavioral, biomedical, and marketing researchers interested in polytomous item comparisons, in particular those involved in evaluating differences and similarities in teacher, rater, or councillor judgments of examined students, patients, respondents, cases, or clients. The approach followed in the note can also be considered a generalization of the item location (difficulty) parameter in the widely used binary or binary scored (dichotomous) item setting to the case with more than two response options, with that setting being a special case for two response alternatives of the preceding developments in the article.
The specific contributions of this note, in particular relative to the work by Zhang and Petersen (2018), are the following. One, with the preceding discussion, we enable applied educational and behavioral researchers, working with polytomous items, to routinely and easily point and interval estimate location parameters of such items as well as linear and nonlinear functions of them. Two, we accomplish this by using a single straightforward command (in a widely circulated software; see Line 5 in the Stata code provided in the appendix, for the Calm item say). Three, the approach of this note is relevant for a markedly less restrictive and more generally applicable IRT model, the GRM, which permits different items to have different discrimination parameters and number of response categories, unlike the RSM that was the only model considered by Zhang and Petersen (2018). In addition, the GRM does not impose restrictions on the difficulty parameters as does the RSM (e.g., Stata Item Response Theory Reference Manual, 2021). Four, unlike the developments in Zhang and Petersen (2018) that necessitate an iterative application of a numerical minimization routine to estimate the location parameter—for items following the more restrictive RSM—we derive an explicit, closed-form expression in Equation 6 for the location parameter of the more general polytomous items following the GRM. The use as in the present note of this explicit solution for the item location parameter enhances the likelihood of reduced numerical inaccuracies in the final estimates.
Several limitations of the discussed estimation procedure are worth pointing out. One is the requirement of large samples with respect to persons (cases). The reason is that the approach is grounded in the framework of latent variable modeling and ML estimation, which are themselves based on an asymptotic statistical theory (van der Linden, 2016). Furthermore, the method hinges on the assumption of the items in question following the GRM. Hence, its use with a measuring instrument or item set that is multidimensional cannot be recommended (cf. Reckase, 2009). In addition, it was assumed at the outset that the considered items are given, that is, prespecified, which limits the procedure application to settings where no inferences are sought with respect to larger pools or universes of items. Last but not least, the procedure employs the widely used delta method, which is based on a linear approximation in the vicinity of the population parameter vector (cf. Raykov & Marcoulides, 2004).
In conclusion, this note provides educational, behavioral, biomedical, and marketing scientists with a widely and easily applicable procedure using popular software for point and interval estimation of location parameters for polytomous ordered items complying with the popular GRM in empirical applications of IRT and modeling.
Footnotes
Appendix
Acknowledgements
The authors thank G. A. Marcoulides and L. Steinberg for valuable discussions on item response theory and the graded response model. They also thank the Editor and two anonymous Referees for valuable comments and criticism on an earlier version of the paper, which have contributed considerably to its improvement.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.