
Abstract
The chiropractic clinical competency examination uses groups of items that are integrated by a common case vignette. The nature of the vignette items violates the assumption of local independence for items nested within a vignette. This study examines via simulation a new algorithmic approach for addressing the local independence violation problem using a two-level alternating directions testlet model. Parameter values for item difficulty, discrimination, test-taker ability, and test-taker secondary abilities associated with a particular testlet are generated and parameter recovery through Markov Chain Monte Carlo Bayesian methods and generalized maximum likelihood estimation methods are compared. To aid with the complex computational efforts, the novel so-called TensorFlow platform is used. Both estimation methods provided satisfactory parameter recovery, although the Bayesian methods were found to be somewhat superior in recovering item discrimination parameters. The practical significance of the results are discussed in relation to obtaining accurate estimates of item, test, ability parameters, and measurement reliability information.
Keywords
Introduction
The National Board of Chiropractic Examiners (NBCE) is an independent third-party testing agency for the chiropractic profession. It was incorporated in 1963 and began administering its first examinations in 1965. Prior to the formation of the NBCE, each state chiropractic licensing board created and administered its own battery of licensure examinations. As a consequence, licensure testing for the chiropractic profession and standards for entry-level chiropractic licensure varied considerably from state to state. Presently successful completion of the NBCE examinations comprised of four separate parts is required for licensure across all of the United States, thereby providing the chiropractic profession with a single pathway to licensure (for additional details, see online Supplementary Appendix A).
One key component of the chiropractic clinical competency examination is the use of groups of items that are integrated by a common case vignette. The nature of the vignette items, however, violates the defining item response theory (IRT) assumption of conditional independence or local independence for items. This assumption basically states that the conditional probability of observing a particular response pattern given a latent trait value equals the product of the conditional probabilities of the items. The violation of this assumption is referred to as local dependence. Stated another way, local dependence implies that the only thing causing items to covary is the modeled latent trait(s). As items in a test should not be related to each other, having items nested within a vignette is a potential source of local dependence. Not accounting for these dependencies can lead to biased estimates of items, test, and ability parameters and even overestimation of measurement reliability (Sireci, Thissen, & Wainer, 1991; Wainer & Wang, 2000).
The purpose of this article is to introduce a new computational estimation algorithm based on the widely used two-level unidimensional testlet response theory (TRT) model (Wainer, Bradlow, & Wang, 2007). Although past research has suggested that the TRT model is ideally suited for obtaining parameters estimated in settings with local dependence, the estimation process can be computationally challenging due to the strong nonlinear coupling of examinee and item parameters. The newly proposed estimation approach seeks to address this issue and contribute to the literature by introducing a computationally efficient algorithm that can be used in practical measurement settings. To accomplish the purposes of this article, a number of simulations using data based on realistic data scenarios were conducted and scrutinized.
The remainder of the article is organized in the following way. The next section presents an overview of the literature on the estimation of tests containing testlet structure. This is followed by a description of the proposed computational approach. Next, complete details on the simulation design, the analyses, and the procedures used to examine the proposed computational approach are described. This is followed by a description of results obtained from analyses of the simulated data. Finally, a discussion of the implications of the findings is provided.
Overview of the Literature
Recent developments in educational and professional testing have provided support for the use of complex test items that often include group of items united by a common stimulus (Attali, 2011). Examples of such complex test items include ones containing a subset of so-called scaffolded or broken down tasks in one larger task that provide an opportunity to elicit more responses as well as situations when test-takers are provided with more information to complete an item (Bergner, Choi, & Castellano, 2019; Wolf et al., 2016). Wainer and Kiely (1987) proposed a name for such complex items, calling them “testlets.” Testlets are commonly used to boost testing efficiency in situations that examine an individual’s ability to understand some sort of stimulus (e.g., a reading passage, an information graph, a musical passage, or a table of numbers; Wainer et al., 2007). Other complicated situations include examinations where the local independence between the items of different testlets holds, but the assumption of within-testlet independence is violated due to the presence of within-testlet residual dependency in responses. Although attempts to develop a comprehensive, inclusive model for various types of dependent items date back some 30 years (Fray, 1989), the debate on how best to account for dependency in the test in a holistic final score continues to date. A main reason for this debate is that when items are united by a single prompt, they inevitably violate the assumption of local independence, which is a fundamental assumption for IRT models (De Boeck & Wilson, 2004).
To account for such potentially complex tests with dependencies in responses, De Boeck and Wilson (2004) suggested three different approaches to modeling the vector of
A number of other approaches to account for tests with dependencies in responses have also been proposed in the extant literature. For example, Fischer (1989) proposed a generalization of the logistic linear model with relaxed assumptions in the context of violation of stochastic independence for tests when testlets are formed. In the model, called a hybrid model, it is possible to estimate changes even if the responses do not have a common latent trait. Verhelst and Glas (1995) also proposed two dynamic generalizations of models that relax the assumption of local stochastic independence. In the first approach, they proposed a special case of a log-linear model with added parameters based on the Rasch model, while for the second approach they applied a framework from mathematical learning theory (Sternberg, 1963).
Other models proposed to handle settings with possible local dependency include the rating score model (Andrich, 1978), the partial credit model (Masters, 1982), the generalized partial credit model (Muraki, 1992), and the graded response model (Samejima, 1969). Following this strand of research, Culpepper (2014) presented an overview of different sequential item response models applicable to tests constructed using items with violation of local independence, specifically those allowing multiple attempts of an item. He demonstrated how these models for repeated attempts could be applied within the Rasch modeling framework, introducing attempt-specific parameters as a strategy to account for the differences in probability of providing correct response during the repeated attempts. Although advantageous, this modeling framework was never extended beyond the Rasch model to other models such as the 2-parameter- and 3-paramater-logistic models, that are often used by operational testing programs to explain the responses collected from test takers. Another limitation with these approaches is the computational complexity needed to solve the problem can be quite demanding. This is the reason Li, Li, and Wang (2010) indicated that “some relatively simple methods to detect local dependency and measure the magnitude of the testlet effect” (p. 22) need to be urgently developed. Given that to date no broader computationally efficient approach for addressing the problem has been suggested, this article proposes a new computational algorithm that is based on the estimation of parameters via the two-level unidimensional TRT model (Wainer et al., 2007).
Method
Model Notation and Specification
To illustrate the approach, let us consider
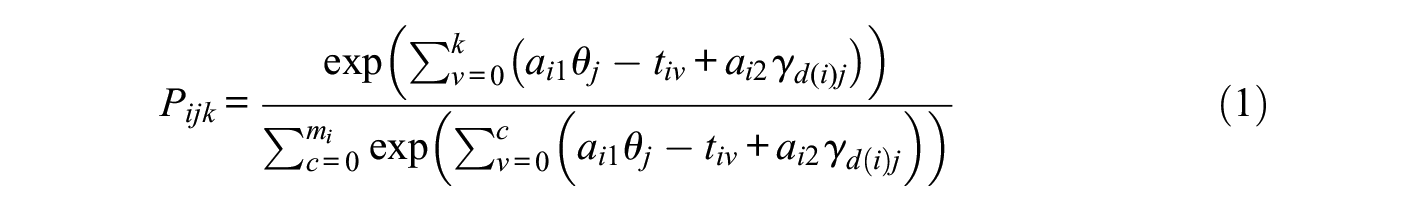
where
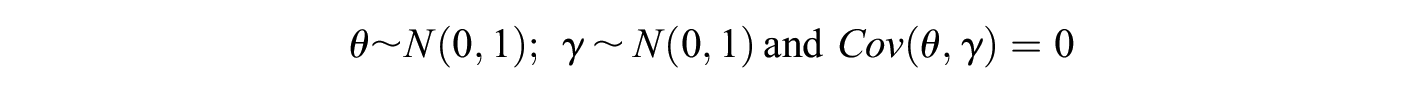
An alternating direction approach is adopted to decouple the examinee ability–related parameter

where the primed parameters are the testlet-level counterparts. The testlet item scores are obtained by summing up the scores in each constituting item. The testlet item categories are obtained in the same fashion.
More generally, during the alternating direction testlet TRT fitting, after obtaining the examinee ability parameter
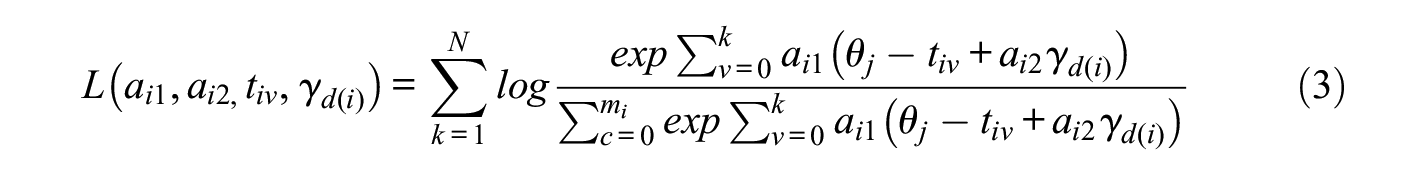
with
With successful decoupling, the above equation becomes a relatively straightforward mathematical system that can be solved using standard numerical approaches. Similarly, after the parameters
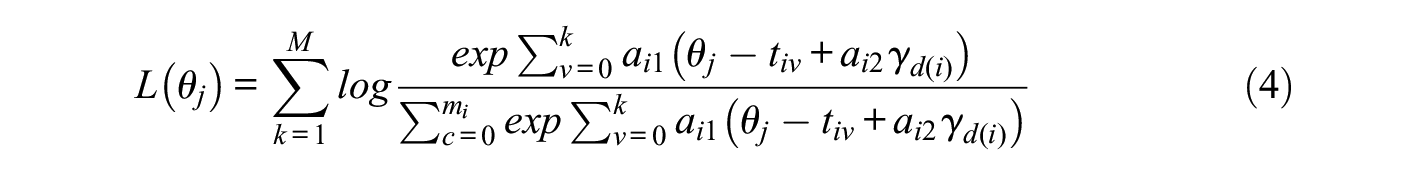
with
Monte Carlo Data Simulation and Analytic Strategy
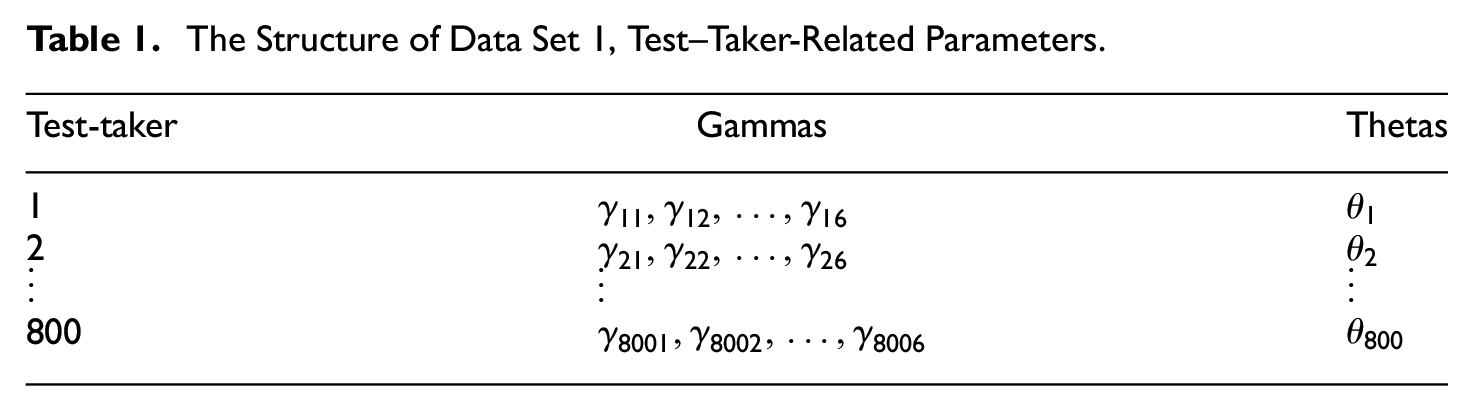
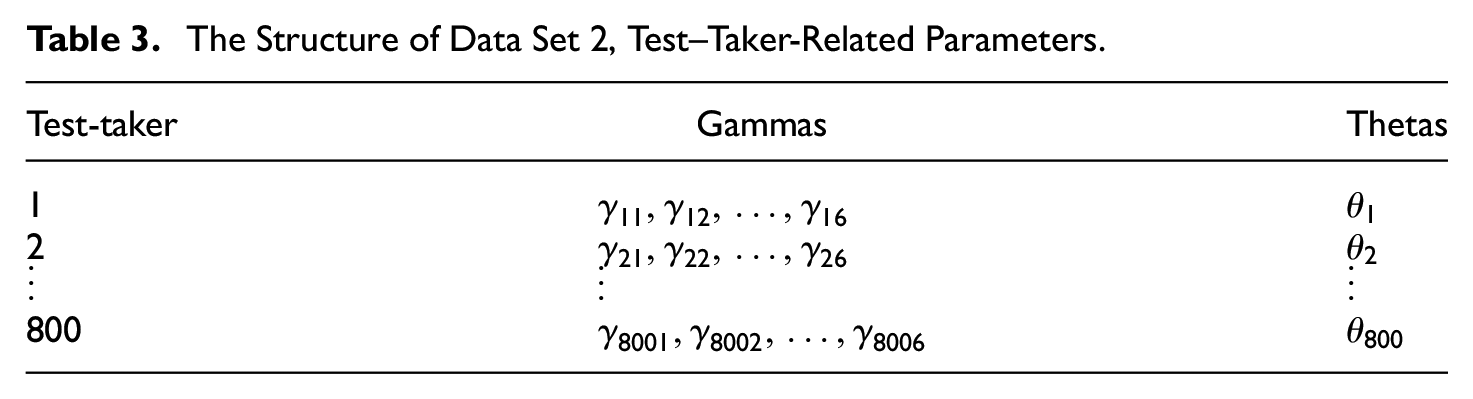
To systematically evaluate the performance of the proposed approach, simulated data using Monte Carlo techniques were analyzed under a variety of design conditions. The goal is to develop a computational approach using the likelihood function that will allow for an estimation of the parameters in the testlet model without loss of precision or reliability. Two simulated datasets were constructed and examined. The first contained synthetic data for 800 test-takers examined on 6 testlets with 5 items within each testlet, and the second contained synthetic data for 800 test-takers examined on 5 testlets and 20 items within each testlet. A complete itemized structure of the two generated data sets is presented in Tables 1 to 4.
The Structure of Data Set 1, Test–Taker-Related Parameters.
The Structure of Dataset 1, Item-Related Parameters.

The Structure of Data Set 2, Test–Taker-Related Parameters.
The Structure of Dataset 2, Item-Related Parameters.

On generating the synthetic data sets, the next step was to recover the parameters using Bayesian methods via Markov Chain Monte Carlo (MCMC) estimation and using the generalized maximum likelihood estimation (GMLE) method.
Bayesian Estimation
Considering the vector of

where “…” correspond to the hyper-parameters used in prior distributions. The prior distributions of
Given an old sample
The fully updated
Generalized Maximal Likelihood Estimation
Maximal likelihood approaches estimate model parameters that maximize the likelihood function, given examinees overall matrix of responses Y. This can be specified as follows:
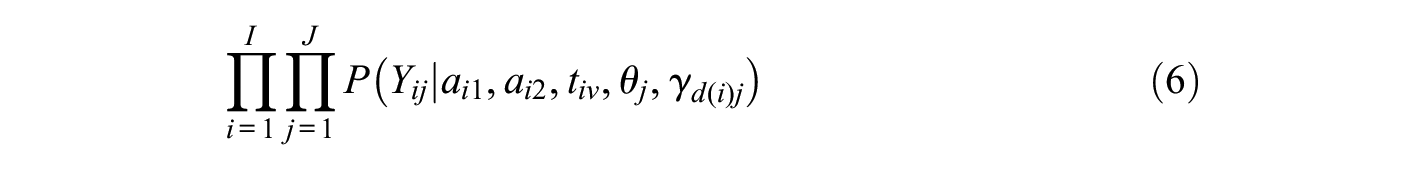
or equivalently as,

Numerically, the iterative gradient descent method is usually adopted to find optimal model parameters:
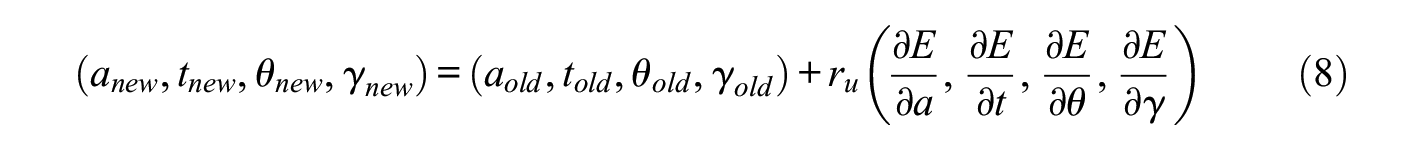
where
Because of the complexity of
The following steps summarize the algorithm implemented:
1. Generate
2. Find
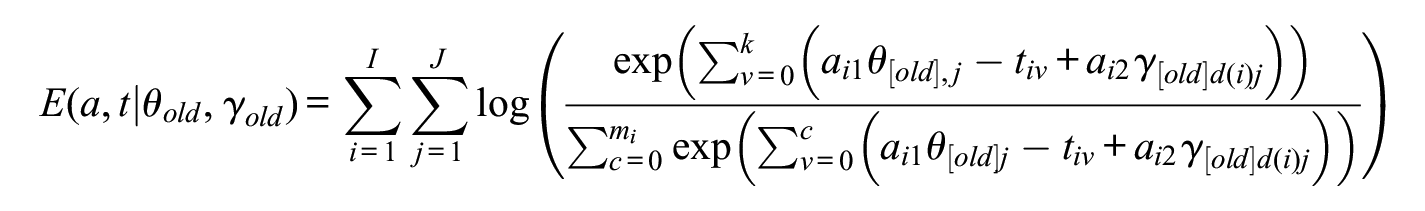
using the gradient descent method.
3. Obtain
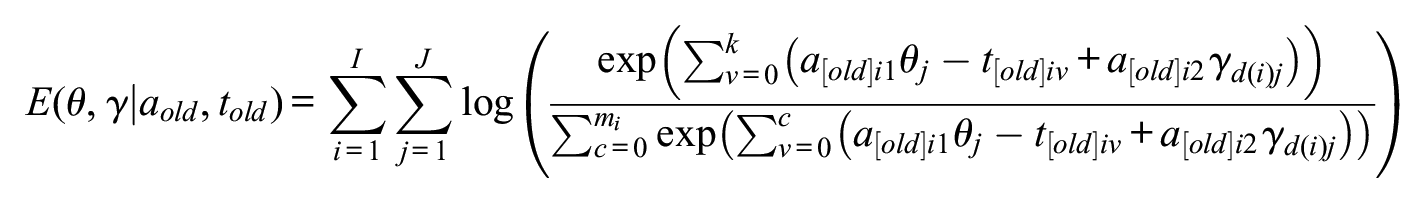
4. Set
5. Repeat steps 2 and 3 until convergence is attained.
The TensorFlow Platform
In the fields of mathematics and physics, tensors are large-dimension geometrical objects that describe linear relations between vectors, scalars, and other tensors. Accordingly, tensors can be considered as merely generalizations of scalars and vectors: a scalar is a zero-rank vector, and a vector is a first-rank tensor. The need for higher rank tensors comes when more than one direction is required to describe physical or other properties. In statistics, tensors can be quite helpful when the examined data are multidimensional and require tedious calculations.
TensorFlow was originally developed by researchers and engineers working on the Google Brain Team within Google’s Machine Intelligence organizational group for the purpose of conducting machine learning and deep neural network research. TensorFlow is basically an open-source software platform for dataflow programming. The platform provides an interface that can be used to express complex machine learning algorithms and enables the implementation and execution of such algorithms. The system is quite flexible and can be effectively used to express a wide variety of algorithms, particularly those required in machine training and neural network models (Abadi et al., 2015).
The system uses an increasingly powerful form of computational learning with very impressive accuracy. Any computation that can be expressed as a computational flow graph can in principle be computed on the TensorFlow platform. For the purpose of completing the analyses necessary for this study, TensorFlow was used to calculate the complex derivatives in the likelihood functions. All calculations were conducted on the Cloud, which also afforded any additional needed computational power. The Python source code needed to estimate the testlet models examined in this study using TensorFlow is included in the online Supplementary Appendix B.
Results
The overall parameter recovery solutions produced by the MCMC and the GMLE estimation methods were in general successful. In terms of estimated item parameters, overall item difficulties were recovered much better than item discriminations. In terms of test–taker-related parameters, the recovery was outstanding using both methodologies. Detailed results of the parameter recoveries are presented in Tables 5, 6, and 7 for Dataset 1 and in Tables 8, 9, and 10 for Dataset 2. Figures 1 to 4 display graphical visualizations of parameter recovery results for Dataset 1, while Figures 5 to 8 display similar graphical visualizations of parameter recovery for the second dataset.
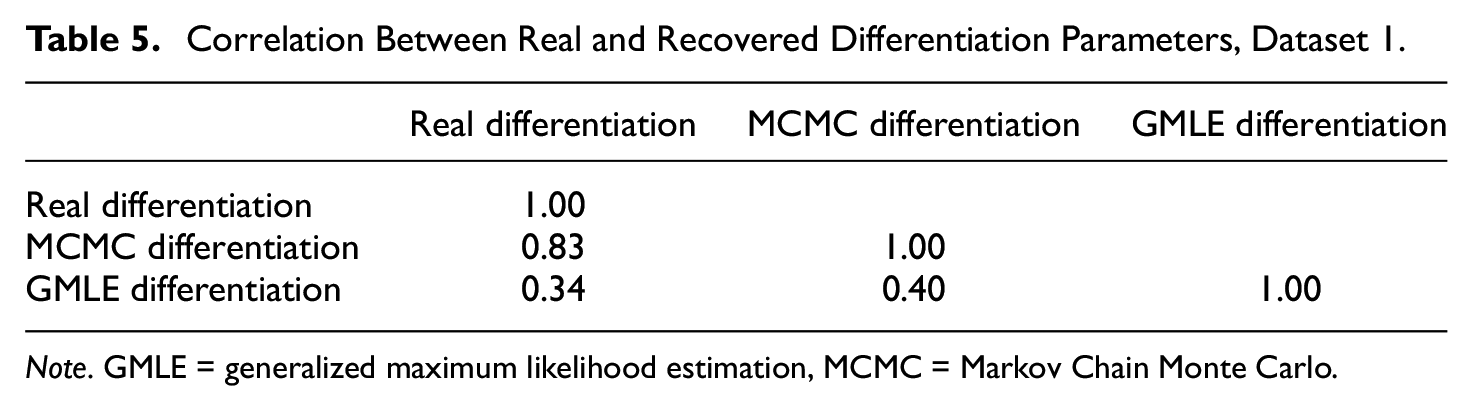
Correlation Between Real and Recovered Differentiation Parameters, Dataset 1.
Note. GMLE = generalized maximum likelihood estimation, MCMC = Markov Chain Monte Carlo.
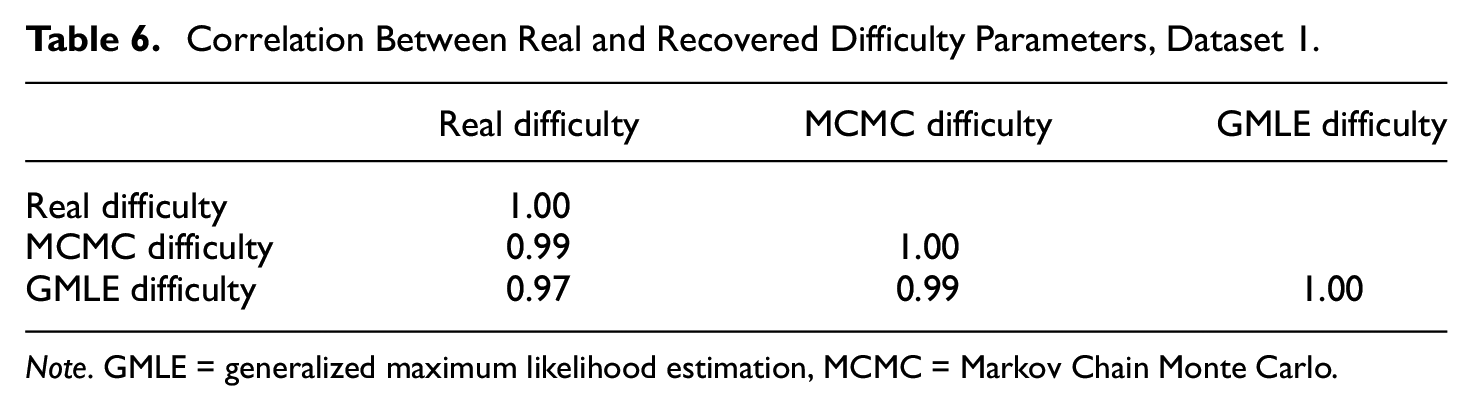
Correlation Between Real and Recovered Difficulty Parameters, Dataset 1.
Note. GMLE = generalized maximum likelihood estimation, MCMC = Markov Chain Monte Carlo.
Correlations Between Real Parameters and Recovered Proficiency, Dataset 1.

Note. GMLE = generalized maximum likelihood estimation, MCMC = Markov Chain Monte Carlo.
Correlation Between Real and Recovered Differentiation Parameters, Dataset 2.
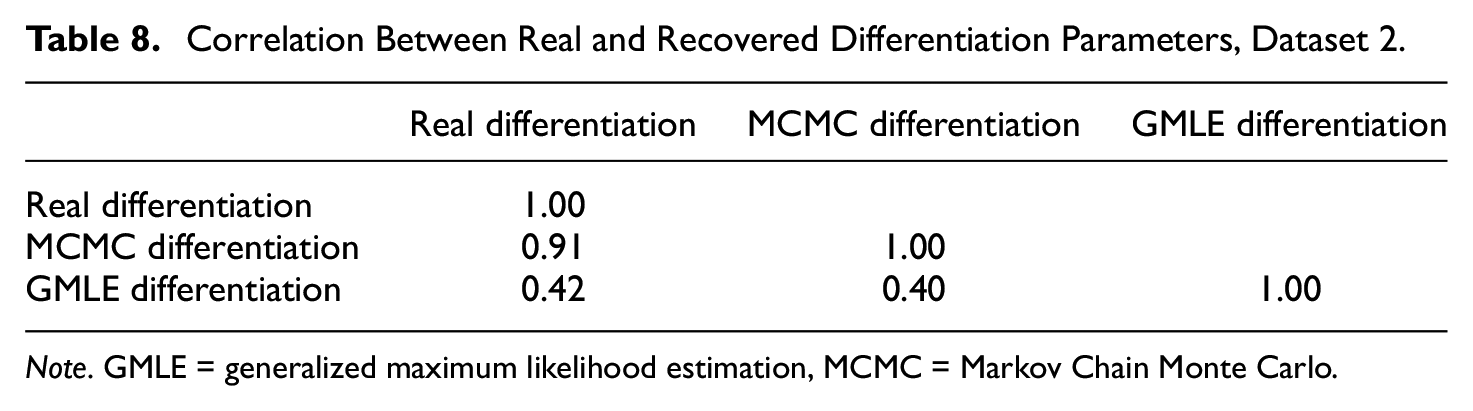
Note. GMLE = generalized maximum likelihood estimation, MCMC = Markov Chain Monte Carlo.
Correlation Between Real and Recovered Difficulty Parameters, Dataset 2.
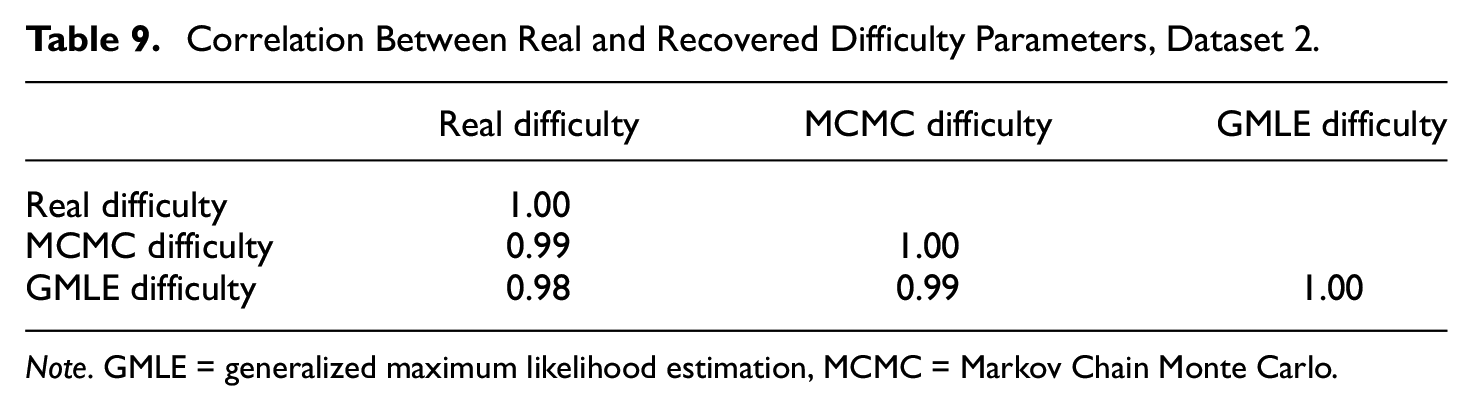
Note. GMLE = generalized maximum likelihood estimation, MCMC = Markov Chain Monte Carlo.
Correlations Between Real Parameters and Recovered Proficiency, Dataset 2.

Note. GMLE = generalized maximum likelihood estimation, MCMC = Markov Chain Monte Carlo.

Comparison between real differentiation parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 1.

Comparison between real difficulty parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 1.

Comparison between real overall ability (theta) parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 1.

Comparison between real secondary ability (gamma) parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 1.
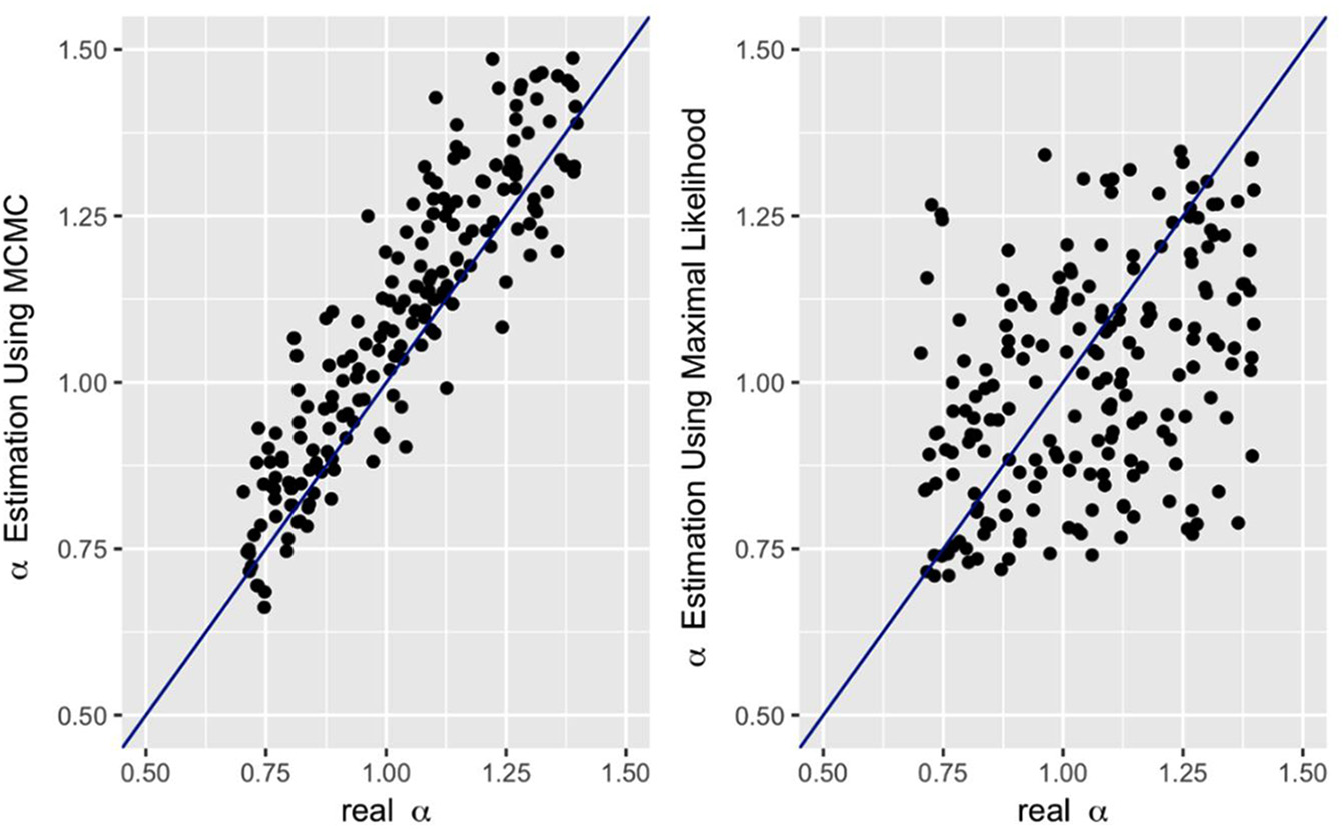
Comparison between real differentiation parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 2.
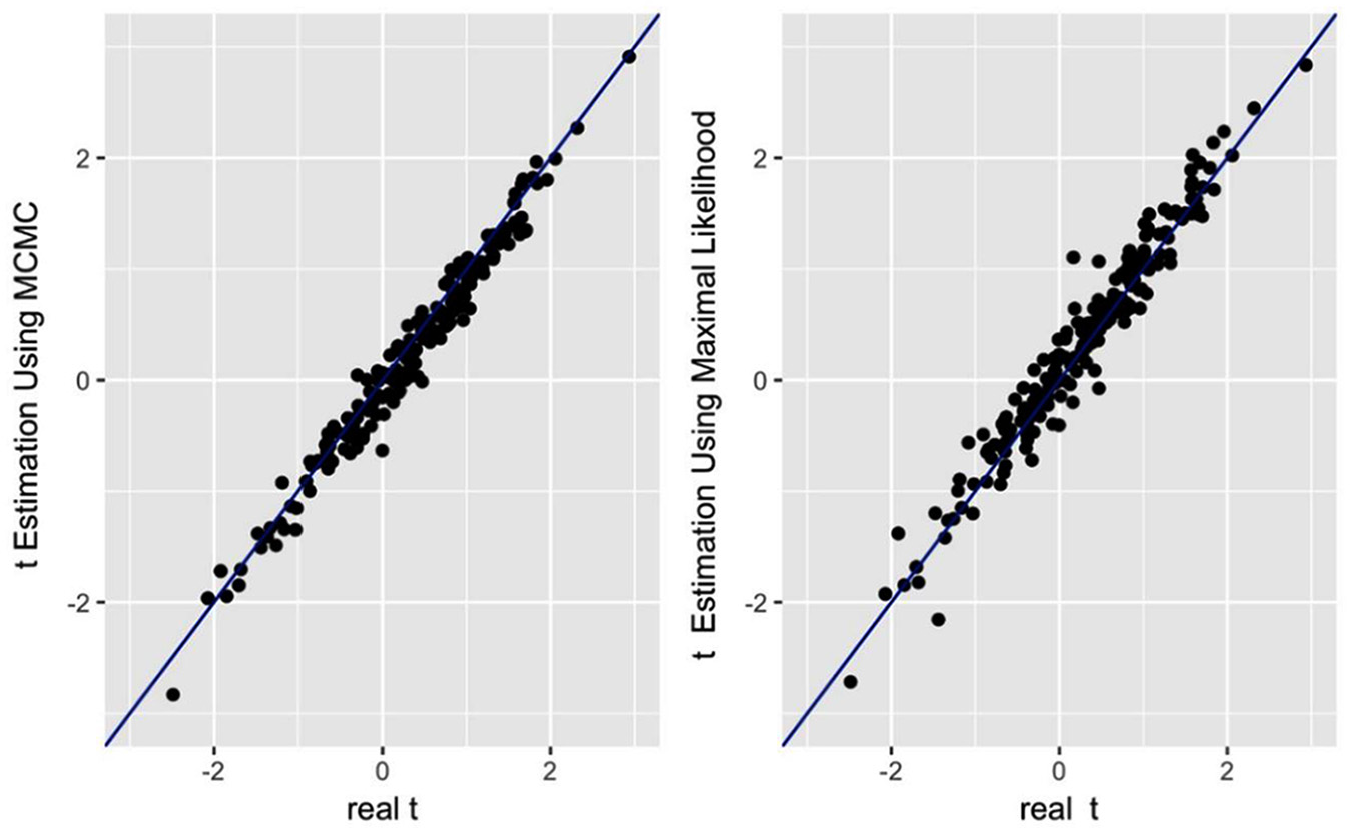
Comparison between real difficulty parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 2.
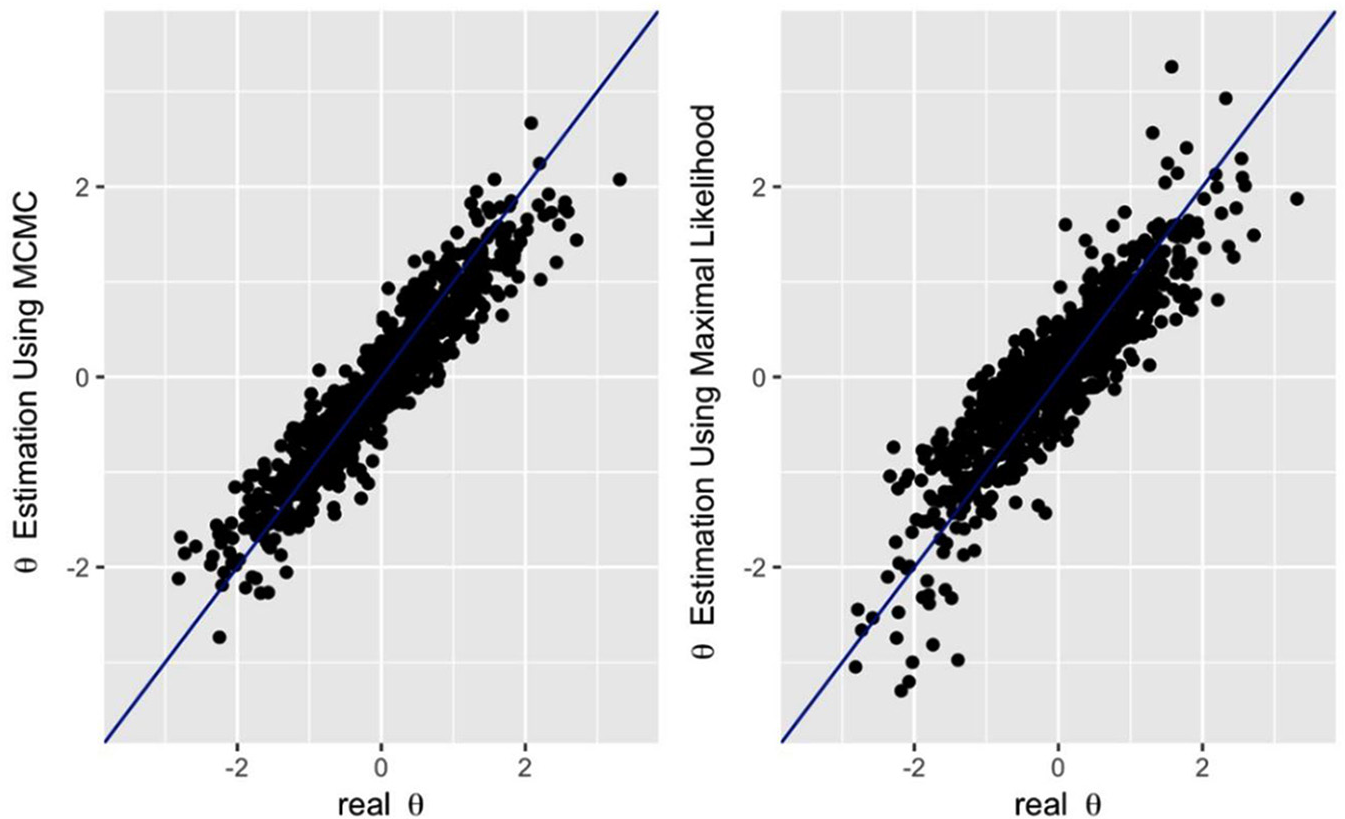
Comparison between real overall ability (theta) parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 2.
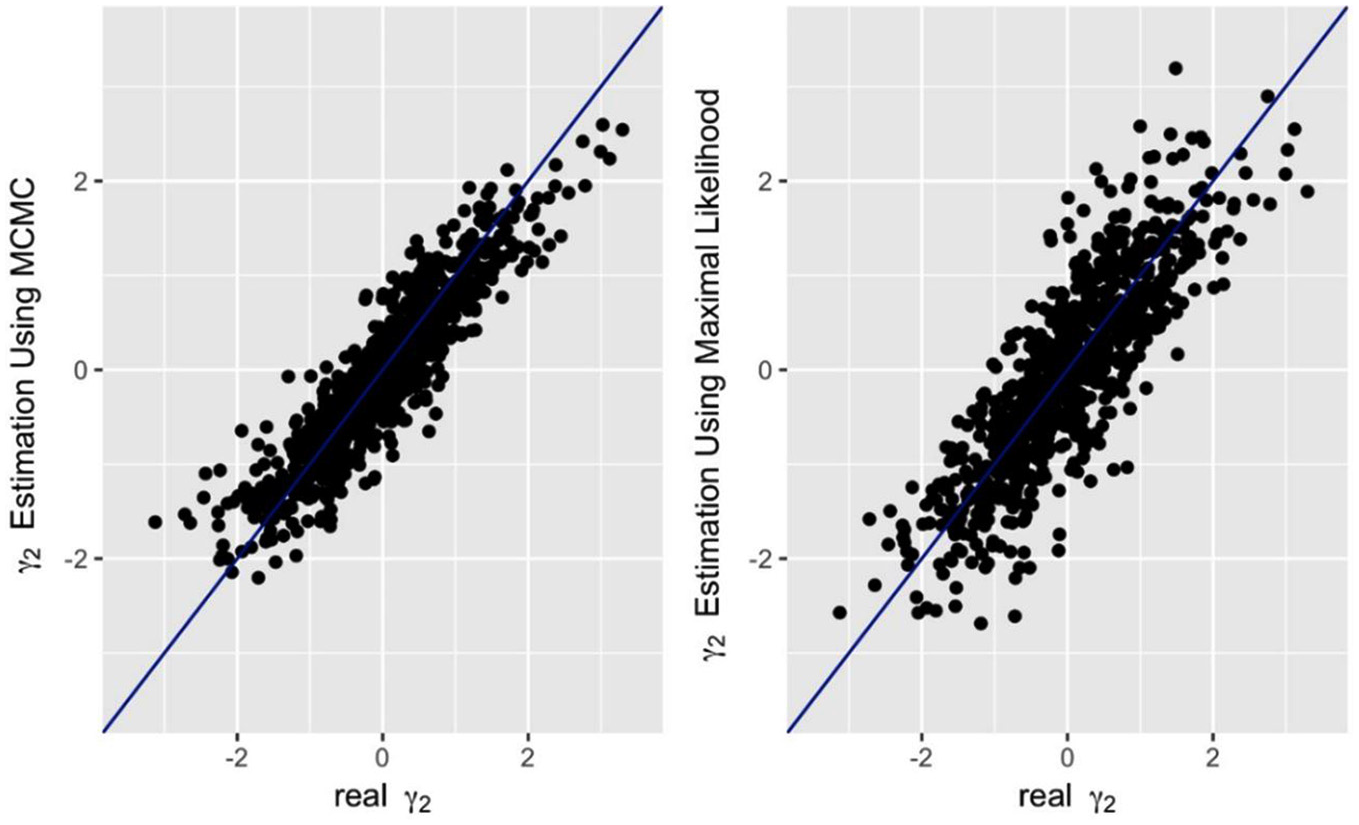
Comparison between real secondary ability (gamma) parameters and parameters recovered by Markov Chain Monte Carlo (MCMC) and generalized maximum likelihood estimation (GMLE), Dataset 2.
As can be seen by examining these results, it appears that both these methods did not perform well in recovering the item discrimination values (see Figures 1 and 4), although overall the MCMC was somewhat superior to GMLE in the recovery. The correlations between the sets of real parameters and the sets of parameters recovered by the MCMC were r = .83 for Dataset 1, and r = .91 for Dataset 2. In contrast, the correlations between the real parameters and the GMLE-recovered item-discrimination values were rather low at values of r = .34 for Dataset 1, and r = .42 for Dataset 2.
Item difficulties were recovered with much better success by both methods (see Figures 2 and 6). Specifically, the correlations between the real parameters and the MCMC-recovered parameters were r = .99 for Dataset 1, and r = .99 for Dataset 2. Similarly, for the GMLE-recovered parameters, the correlations were r = .97 for Dataset 1, and r = .98 for Dataset 2.
Test-taker-related parameters were also recovered well by both methods. The relationships between the real thetas and the MCMC-estimated thetas were r = .92 for Dataset 1, and r = .94 for Dataset 2, while for the GMLE-estimates parameters, the relationships were r = .89 for Dataset 1, and r = .87 for Dataset 2 (see Figures 3 and 7). Finally, for the gamma parameter recovery, the following correlation averages were obtained: for MCMC,
Discussion
When the NBCE made the decision to move away from classical test theory scoring and implement IRT-based operational scoring procedures, they were faced with a problem of the violation of model assumptions by some of the items in their licensure examination. Specifically, the problem emerged because key components of the chiropractic clinical competency examination involve the use of groups of items that are integrated by a common case vignette. Because of the nature of the vignette items, the IRT assumption of conditional independence or local independence for items is inevitably violated. In search of an alternative model to account for this consequential violation, a two-level unidimensional TRT model was implemented (Wainer et al., 2007). Because the application of such a model can be computationally demanding with increased numbers of items, a new computational estimation algorithm needed to be developed. The newly proposed estimation approach provides the necessary solution to address this issue and contribute to the literature by introducing a computationally efficient algorithm that can be used in practical measurement settings. To accomplish the purposes of this article, a number of simulations using data based on realistic data scenarios were conducted and scrutinized. Although the specific models themselves are not entirely new, the approach to computation and the development of the algorithms for estimation are novel. To estimate the various testlet models examined in this study, we used the TensorFlow platform. To the best of our knowledge, this study is the first application of such a powerful platform for psychometric work. Through increased computational power, the platform enabled the analysis of complex likelihood functions that to date have proved to be computationally intensive and extremely time consuming. For example, it took as much as 15 hours for one MCMC chain to converge while the GMLE analyses took only about 1 hour. Another shortcoming of the Bayesian method is its inability to parallelize the analysis (i.e., to divide the computation and compute different parts using different computers) as the MCMC chain requires all parts to be run at the same time. By gaining the computational power through the use of the TensorFlow platform, we were able to compare without much difficulty the quality of estimation between the MCMC and GMLE approaches.
Overall our results indicated that apart from the estimation of the item discrimination values, the parameter estimates recovered by both examined methods were very similar. Although the MCMC estimation showed some minor supremacy over the GMLE approach, the longer time needed to arrive at these estimates can sometimes be rather excessive. Given the tendency of the MCMC approach to overestimate the test-takers with lower abilities and underestimate the test-takers with higher ability, using the GMLE that provided more unbiased estimates may ultimately be the better option. Indeed, the parameter estimates obtained from the GMLE estimation approach may even serve as starting values for the MCMC, which will save the “burning” time and will aid the model converge much faster.
In conclusion, we believe the proposed approach to be extremely valuable in helping researchers tackle parameter estimation in complex tests with dependencies in responses with more power and accuracy than ever before. At the same time, we acknowledge that more work and thinking needs to be done regarding improved efficiency in implementation of these approaches.
Supplemental Material
Online_Appendix – Supplemental material for A Two-Level Alternating Direction Model for Polytomous Items With Local Dependence
Supplemental material, Online_Appendix for A Two-Level Alternating Direction Model for Polytomous Items With Local Dependence by Igor Himelfarb, Katerina M. Marcoulides, Guoliang Fang and Bruce L. Shotts in Educational and Psychological Measurement
Footnotes
Authors’ Note
Guoliang Fang is now affiliated with Colorado State University Global, CO, USA.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.