
Abstract
A widely applicable procedure of examining proximity to unidimensionality for multicomponent measuring instruments with multidimensional structure is discussed. The method is developed within the framework of latent variable modeling and allows one to point and interval estimate an explained variance proportion-based index that may be considered a measure of proximity to unidimensional structure. The approach is readily utilized in educational, behavioral, and social research when it is of interest to evaluate whether a more general structure scale, test, or measuring instrument could be treated as being associated with an approximately unidimensional latent structure for some empirical purposes.
Keywords
Educational, behavioral, and social science research is frequently based on or utilizes multiple-component measuring instruments (e.g., tests, scales, inventories, self-reports, questionnaires, surveys, test batteries, testlets, or subscales; McDonald, 1999). Part of the reason for their high popularity in these and cognate disciplines is their widely appreciated feature of providing multiple converging pieces of information about underlying latent constructs of main interest (e.g., Raykov & Marcoulides, 2011). A major activity routinely recommended to engage in prior to using these instruments is the examination of their latent structure (e.g., Mulaik, 2009). While that of unidimensionality is frequently desirable, empirical research in these sciences oftentimes evolves within settings where primarily for validity-related reasons an instrument under consideration may not possess a (strictly) unidimensional latent structure. Under those circumstances it is important for a scholar to be in a position to evaluate the degree to which its latent structure may be close to, or alternatively far from, unidimensional, with the view of possibly employing the instrument in the former case as approximately unidimensional for some substantive purposes in its applications.
Over the past couple of decades, essential unidimensionality has received considerable interest by educational and behavioral scientists (e.g., Reise, 2012; cf. Nandakumar, 1991). Much of this research has developed within the framework of the increasingly popular bifactor model (e.g., Reise et al., 2010). This model stipulates that each of a given set of observed variables loads on a “global” factor and in addition on a “local” factor related only to an appropriate subset of variables, with the global and local factors assumed uncorrelated for identification purposes (see also Eid et al., 2017; Eid et al., 2018; for additional discussions of model identification and related issues). The bifactor model may be seen as being highly structured due to having one or more local factors, which are often deemed of a lesser subject-matter relevance than the global (overall) factor loading on all manifest measures. These complexity-related properties of the model seem to limit though its applicability to situations where its restrictive multifactorial structure is plausible for a given study and/or analyzed data set. In addition, the bifactor model reflects a particular multidimensional structure, with a single possibly dominant dimension relating to all observed variables, whereas the question of proximity to unidimensional structure is relevant in principle with any multidimensional structure. However, as advocated for in the remaining discussion, the conceptual idea underlying the bifactor model can also be utilized in empirical settings where it is of interest to address the potentially highly relevant issue of proximity to unidimensional structure for an instrument associated with a latent structure more complex than that of unidimensionality.
The present note is concerned with the question of how one could evaluate the extent to which a multicomponent measuring instrument with two or more underlying factors possesses a latent structure approximating unidimensionality. The following discussion is initially concerned with a latent variable modeling (LVM; B. O. Muthén, 2002) procedure for point and interval estimation of an index quantifying empirically and theoretically important aspects of the “distance” between a two-dimensional and a unidimensional latent structure. The extant measurement literature does not seem to have addressed this issue to a sufficient extent, and therefore, this article aims to contribute to closing that gap in relation to evaluation of the discrepancy between unidimensionality and a more general latent structure of a multicomponent instrument (observed variable set). The LVM method described below is readily and widely applicable in research with measuring instruments that owing to various validity-related reasons—for example, construct underrepresentation (e.g., Messick, 1995)—possess in particular a two-dimensional latent structure, that is, one characterized by two factors rather than a single factor. The described approach is straightforwardly extended, however, to cases with more than two underlying factors, and is illustrated using a pair of examples with empirical and simulated data.
Notation and Assumptions
This article makes extensive use of the popular confirmatory factor analysis framework (e.g., Bollen, 1989). Suppose X1, X2, . . ., Xk (k > 2) denote the k (approximately) continuous components of a given measuring instrument; that is, their number is finite and fixed beforehand, like these k manifest variables that are thus not sampled from a potentially infinite pool of measures (or approach such a pool). For example, the measures X1, X2, . . ., Xk can be the k subtests in a test battery, k testlets within an overall test, or k subscales of a psychometric scale. We advance also the frequent assumption that the instrument is utilized with (an appropriate sample from) a studied single-level, single-class population, that is, a population with no clustering effects and consisting of a single as opposed to multiple latent classes (e.g., Raykov et al., 2016; see also the “Conclusion” section).
We further posit in the remainder the validity of the common factor model for the above k components (e.g., Mulaik, 2009). That is, the following model, denoted M0, is assumed to be true (correct) for them:

where
As indicated earlier, this article will be concerned primarily with model M0 when q = 2, which for convenience we will refer to as a “two-dimensional latent structure,” but its method is directly extended to more general models with q > 2 along the lines of the following discussion (see the “Conclusion” section). A version of model M0 with k = 10, q = 2, and m = 5 observed measures per factor is depicted in Figure 1; this model will be of particular interest in the illustration section. In addition, we would argue that using robust estimation the method outlined next can be in general applied in a trustworthy way also in empirical studies involving items with at least five to seven categorical response options (e.g., Rhemtulla et al., 2012; see also Raykov & Marcoulides, 2016). Thereby, as alluded to earlier, the approach discussed below is applicable with no cross-loadings as free parameters in the matrix Λ (e.g., Figure 1), as well as alternatively with such cross-loadings, as long as the initial model M0 and model M1 defined in the following section are identified (e.g., using loading or latent variance fixing at 1 or appropriate covariance fixing at 0; this identifiability assumption, possibly after suitable parameter restrictions, is made for all models used in the article).
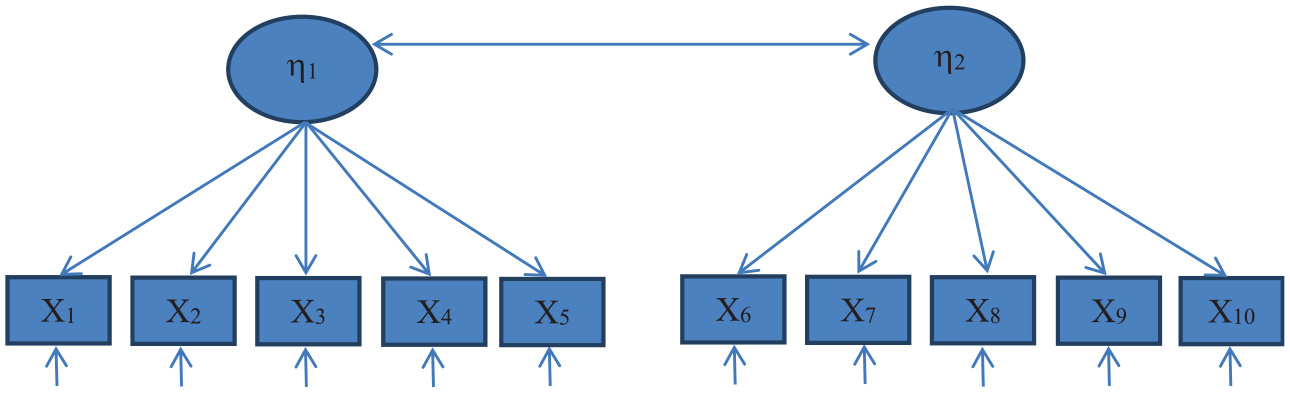
Model M0, for k = 10, q = 2, and m = 5 indicators per factor (short one-way arrows represent the unique factors that are not additionally symbolized to avoid graphical clutter).
A Latent Variable Modeling Procedure for Examining Latent Structure Proximity to Unidimensionality
Prior Research
The general issue of latent structure proximity to unidimensionality has received considerable attention in the methodological and substantive literature over the past several decades. In the context of a bifactor model for example, Raykov and Pohl (2013) discussed a proportion-explained variance-based index as a possible measure of essential unidimensionality. (As indicated earlier, a bifactor model is defined as one where each manifest measure is related to a pair of factors—a global factor that loads on all observed variables and a local factor loading only on a subset of them including the measure; for example, Reise, 2012; see also, Eid et al., 2017; Eid et al., 2018.) This index was defined as the proportion of observed overall scale variance attributable to the global factor (see Equation 2 for a formal definition), and due to some of its characteristic features it is also of relevance to the present article.
An alternative approach to essential unidimensionality was discussed in Nandakumar (1991) and based on the consequential assumption of the number of observed binary items increasing without bound (see also Stout, 1987, 1990). That earlier approach is not of concern for the aims of this article, however, since the former possesses arguably very limited applicability in contemporary empirical research. The reason is that its above asymptotic assumption with respect to number of observed components is violated in all present-day educational and behavioral studies, which in addition oftentimes utilize measures that are not binary or binary scored as assumed by that approach (see also Raykov & Marcoulides, 2018a). Furthermore, unlike that past research, this note is concerned with the setting where the number k of nonbinary measures is finite and prefixed (typically up to a few dozens at the most). As explicitly stated in the preceding section, in the current article this number of used components, k, is not increasing or approximating in any sense a set of items with an unbounded number of elements that are only of relevance for the setup underlying Nandakumar’s (1991) work (see also Stout, 1987, 1990).
Returning to the setting of concern to this note, as described before (see previous section), in order to outline the procedure of relevance in the remainder let us denote by g the global factor in a bifactor model assumed for a multicomponent measuring instrument under consideration, and by f1, . . ., fr (r > 0) its local factors (e.g., Figure 1 in Raykov & Pohl, 2013; cf. above Equation 1 as well as Figure 2). The earlier mentioned proportion-explained variance-based index, denoted by
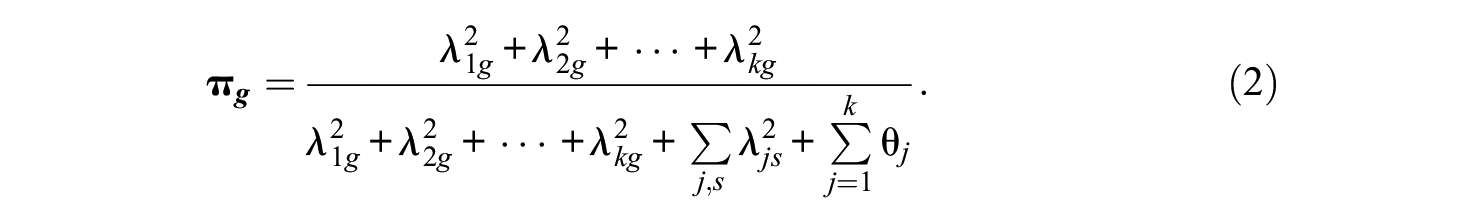

Model M1, for k = 10, q = 2, and m = 5 indicators of the “local” factor (short one-way arrows represent the unique factors; cf. Figure 1).
In Equation 2, λ
jg
are the observed measure loadings on the global factor g, λ
js
are those on the respective local factors f1, . . ., fr, and θ
j
are the unique factor variances (residual variances) (j = 1, . . ., k, s = 1, . . ., r; we note that in general some of the loadings on a local factor may be additionally assumed vanishing; see below). That is,
Model Comparison, Testing, and Relation to Studying Proximity to Unidimensionality
In the context of proximity to unidimensional structure, we would like to make several important points before proceeding further. First, the question of proximity does not necessarily imply the need for relative model testing in most empirical settings where this query is raised. That is, whenever an applied researcher asks a question about proximity to unidimensional structure, he or she is in effect primarily interested in quantifying the “distance” between unidimensionality on one hand and the latent structure of an instrument under consideration (observed variable set) on the other hand. It is this specific question that the present article is concerned with and in this sense complements the voluminous literature on model comparison (see also next). Second, we would like to argue that the question of model testing, particularly, of a more complex model relative to that of unidimensionality, is not nearly as relevant then—if at all—owing to the fact that test statistics are affected potentially to an intolerable degree by sample size. In these cases, as is well known, the associated p-value is not sufficiently informative. For this reason, one needs alternative and complementary quantities, such as effect size measures, in order to conduct a more informed model comparison. To respond to this need, the present article is dealing with an application of what may be seen as an effect-size measure, namely, the index
How to Quantify Proximity to Unidimensional Structure—A Useful Proposal
The above cited research, despite being focused on the bifactor model, provides as indicated earlier a useful approach to quantification of proximity to unidimensionality. In particular, based on that prior work, we propose employing (a) the index
Therefore, in order to make it possible to utilize the above index

where

In Equation 4, all loadings on the first factor κ1—which can be conceived of as a global factor here—are free parameters and denoted by γj1 (j = 1, . . ., k). Furthermore, the second factor κ2—conceived of as a local factor—loads only on the same m observed measures that the factor η2 in model M0 loads on. (That is, in the second column of Γ only γ12, . . ., γm2 are free parameters.) Moreover, in model M1 all cross-loadings that are present in M0 (if any) are retained as loadings of the factor κ2. Last, all loadings of the factor η2 in model M0 are also loadings of the factor κ2 in M1, while all observed measures load on the global factor κ1. A special case of model M1, with k = 10, q = 2, and m = 5 indicators of the local factor, which corresponds along the lines of this discussion to the initial model M0, is depicted in Figure 2 (compare with Figure 1) and will be of particular interest in the illustration section, where it will be employed in an instrumental fashion in its data examples.
It is worthwhile emphasizing that model M1 is neither identical to model M0 nor equivalent to it. The sole purpose of considering M1 is to introduce a model that (a) is as close as possible to M0, and at the same time (b) accounts for the factor interrelationship in M0 by the loadings of the global factor in M1 on the observed measures that in M0 load on its second factor, η2. At the same time, model M1 could be considered a bifactor model if in the definition of the latter it is included that some factor loadings may be (additionally) equal to 0. (We note that within their general definition, and as indicated earlier, bifactor models may differ in the extent to which they are restricted, permitting in particular further loadings to vanish; e.g., Gibbons & Hedeker, 1992; Hyland, 2015; Reise et al., 2010.) These loadings would then be those of the factor κ2 in M1 on the manifest measures, that in M0 load on its factor η1 (e.g., Figure 1 in Raykov & Pohl, 2013; see also Figures 1 and 2 in the present article). With this in mind, we can view M1 as the closest to M0 bifactor model, that is, a bifactor model that approximates maximally the two-factor model M0 of initial concern.
The benefit of considering model M1 lies in the fact that based on the preceding developments we can revisit the earlier mentioned proportion-explained variance-based index
When the IPU is salient in an empirical study, that is, the global factor dominates to a substantial extent the local factor in a pertinent model M1, one may argue that with its dominance in terms of explained observed variance its global factor κ1 makes the local factor κ2 in effect superfluous (see also below). In those cases, for certain empirical and substantive purposes one could consider the instrument consisting of the above components
The next section presents a couple of applications on empirical and simulated data of the described method for examining the proximity of the latent structure underlying a multicomponent measuring instrument to a unidimensional structure.
Illustration of Unidimensional Proximity Evaluation Procedure on Empirical and Simulated Data
We commence here with the consideration of an empirical example involving a study of one of the most widely used scales in behavioral and social research, the Positive and Negative Affect Schedule (PANAS; Watson et al., 1988; Watson & Tellegen, 1985). Although affect might be construed along a circumplex structure with positive and negative affect forming polar opposites (e.g., Russel, 1980; Warr, 1990), the PANAS questionnaire is known to represent a two-dimensional instrument with weakly correlated factors for positive and negative affectivity, respectively (see also, Tellegen et al., 1999, for a discussion of the dimensionality of affect). Therefore, aggregating items that reflect positive and negative affectivity in order to form an index of overall affectivity (after appropriate recoding of “inverse” items) need not be legitimate, as it could incur substantial loss of information since proximity to unidimensionality may be a far from tenable hypothesis (and in fact unidimensionality was not originally intended for the PANAS instrument; cf. Watson et al., 1988).
In this context, we analyze next the 10 (= 2 × 5) items of the international PANAS short form using publicly available data from U.S. (n = 346) respondents found at https://osf.io/a5pze (Anvari & Lakens, 2019). This scale has been developed with the aim of maximizing cross-cultural comparability, and is oftentimes referred to as the I-PANAS-SF instrument (Thompson, 2007). In the following analyses, we wish to examine the proximity of its latent structure to that of unidimensionality. In line with the preceding discussion, we first fit the single-factor model of (strict) unidimensionality (i.e., model M0 with q = 1), which is found to be associated with poor fit: chi-square value (χ2) = 330.816, degrees of freedom (df) = 35, p value (p) = .0, and root mean square error of approximation (RMSEA) = .156 with a 90% confidence interval (CI) being [.141, .172]. When fitting model M0 with two correlated factors, however (see Figure 1), the resulting overall fit indices suggest a tenable model: χ2 = 43.425, df = 34, p = .129, and RMSEA = .028 (90% CI = [.000, .051]). The factor correlation estimate is thereby .045, which additionally indicates that the data are not close to supporting a (strictly) unidimensional latent structure. Fitting then model M1 with a global and a local factor (see Figure 2) yields also tenable and markedly better fit indices relative to M0: χ2 = 34.764, df = 30, p = .251, RMSEA = .021 (90% CI = [.000, .048]). (The Mplus input file that can be used for this purpose is provided in Appendix A.) Table 1 contains its parameter estimates along with their standard errors, t values, and p values. 2
Parameter Estimates in Model M1 for the Empirical Data Example (Used Software Presentation Format).
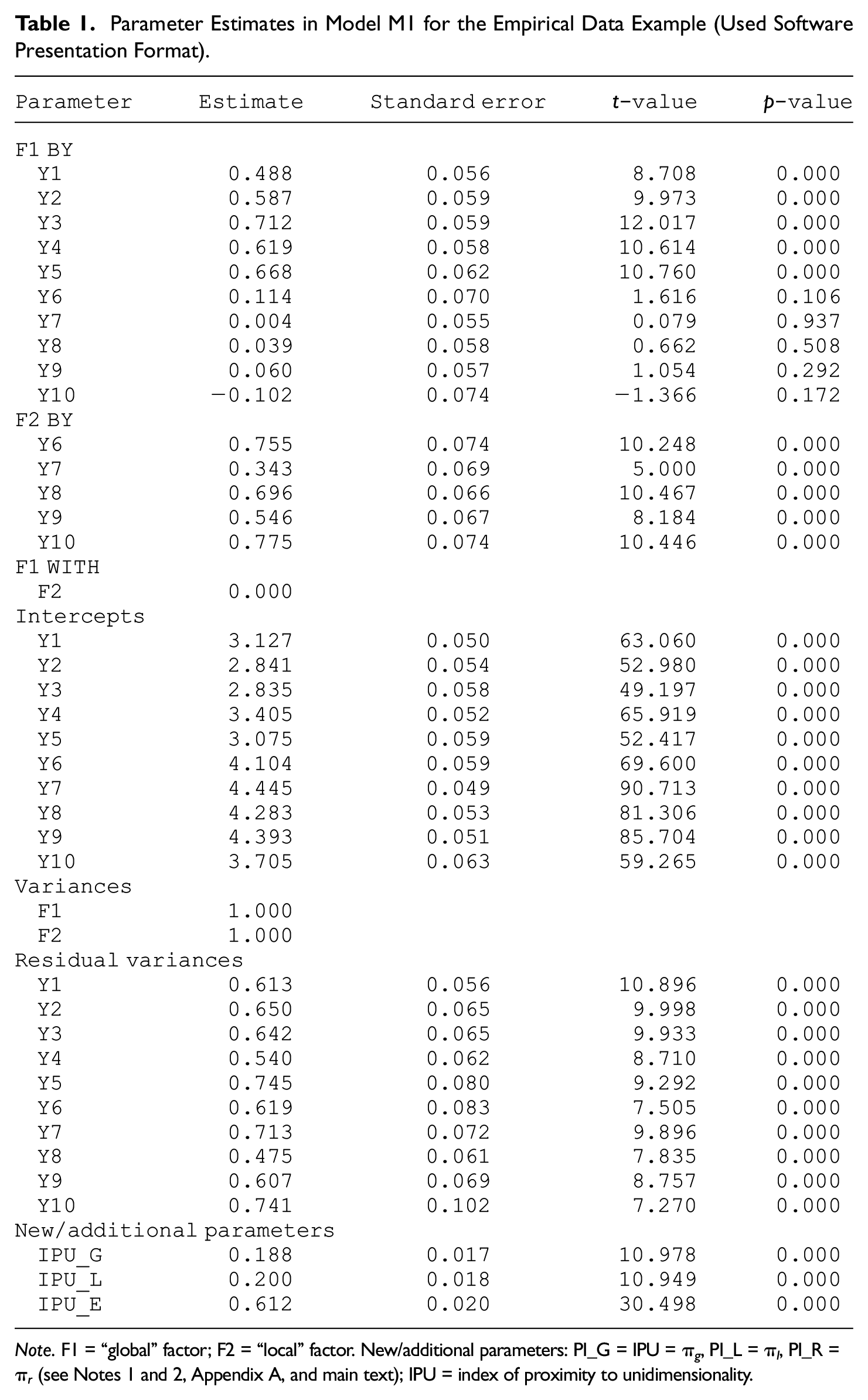
Note. F1 = “global” factor; F2 = “local” factor. New/additional parameters: PI_G = IPU = π g , PI_L = π l , PI_R = π r (see Notes 1 and 2, Appendix A, and main text); IPU = index of proximity to unidimensionality.
The above results, along with the earlier discussion in this note, may suggest that an empirical scholar could be tempted to use model M1 in subsequent research with the I-PANAS-SF instrument. To examine further a possible rationale behind such a suggestion, we turn to the critical IPU estimate in this model (see Table 1), which is
For the interpretation of the above IPU estimate, we use now the informal guidelines provided by Raykov and Pohl (2013). (See in particular the discussion of the 70:20:10 interpretation guides offered there—accordingly, a global factor underlying an instrument under consideration may be viewed for some empirical purposes as dominating its local factors if it explains at least 70% of the variance in the analyzed set of observed variables; the remaining variance would then be explained by the local factors and residuals; for further details, we refer to the above-cited source.) With this in mind, we observe that the CI of the IPU,
In the second example, we employ simulated data to demonstrate further the utility and applicability of the discussed unidimensionality proximity estimation procedure. The benefit of using here simulated data derives from the observation that unlike the last example where the true structure was unknown, we have now access to the model having generated the data and can thus judge the degree to which the described IPU evaluation method leads to results consistent with that model’s features. More specifically, we utilize next multinormal data generated for n = 1,000 cases on k = 10 components using the following two-factor model (see Figure 1):
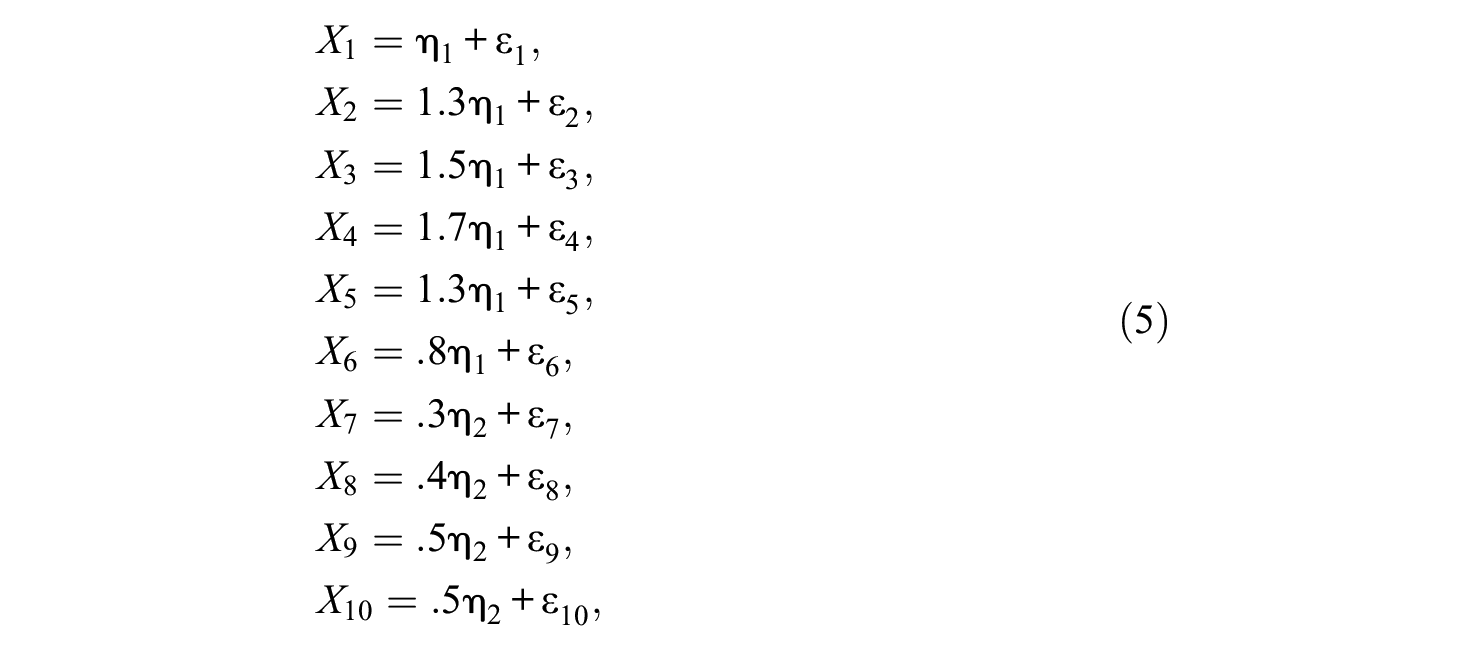
where η1 and η2 were standard normal random variables with correlation ρ = .55, while the error terms ε1 through ε10 were independent zero-mean normal variables with variance .3 each. (The Mplus command file used for data simulation is provided in Appendix B, including the seed employed, in order to facilitate replication of the following results; L. K. Muthén & Muthén, 2020.)
Fitting first model M0 (with k = 10, q = 2, and m = 5 indicators per factor and no cross-loadings; see Figure 1) to the so-generated data set yields, as expected, tenable overall fit indices, since this model is identical in structure to that utilized in the simulation process: χ2 = 49.806, df = 34, p = .039, and RMSEA = .022 (90% CI = [.005, .034]). Like earlier, when fitting instead the model of (strict) unidimensionality—that is, the single-factor model M0 with q = 1—these fit indices are found to be clearly far from tenable: χ2 = 952.900, df = 35, p = .0, RMSEA = .162 (90% CI = [.153, .171]). The results indicate that the data do not comply with a (strictly) unidimensional latent structure, a correct conclusion since the latter seriously misspecified structure did not underlie the data generation process. Yet fitting model M1 (see Figure 2) to the simulated data set is associated with tenable fit indices: χ2 = 47.436, df = 30, p = .022, RMSEA = .024 (90% CI = [.009, .037]). (The Mplus command file for fitting model M1 is provided in Appendix A.) These findings suggest that model M1 (which is distinct from the model used in the data generation process) is plausible for the analyzed data set. Table 2 contains its parameter estimates along with their standard errors and associated t values as well as p values. (We note in passing that the individual measure R2 indices are correspondingly nearly identical in models M0 and M1.)
Parameter Estimates in Model M1 for the Simulated Data Example (Used Software Presentation Format).

Note. F1 = “global” factor; F2 = “local” factor. New/additional parameters: PI_G = IPU = π g , PI_L = π l , PI_R = π r (see Notes 1 and 2, Appendix A, and main text); IPU = index of proximity to unidimensionality.
As seen from Table 2, the estimate of the critical IPU quantity is
Conclusion
This note addressed the query of how one could ascertain whether a multidimensional multicomponent measuring instrument may be associated with a latent structure that is approximately unidimensional. A point and interval estimation procedure based on latent variable modeling was discussed, which can be used to evaluate the “distance” between a two-dimensional latent structure of a set of observed measures (instrument components) and a unidimensional structure (see also below). An IPU aimed at quantifying this distance, in the metric of proportion-observed overall variance attributable to a suitably defined global factor, was discussed as a measure of the discrepancy between two-dimensional and unidimensional latent structures. Due to its particular definition (see Equation 2), the IPU may also be viewed as an effect size measure of the “distance” between the latent structure underlying a given multicomponent measuring instrument and the corresponding unidimensionality structure. It was argued that when the IPU is deemed sufficiently large based on substantive considerations in a subject-matter domain, the instrument may be used as essentially unidimensional for certain empirical purposes (see illustration section for some informal interpretation guidelines of possible utility then).
While the discussion in this article evolved predominantly within the framework of a two-factor model with correlated factors (model M0 with q = 2; e.g., Figure 1), its approach is applicable as mentioned also in more general settings with a larger number of underlying factors. To this end, a suitable subset of q− 1 from these factors are formally reconceptualized as “local” factors in a bridging model (M1), following relevant substantive considerations, which factors are then assumed unrelated to the remaining, “global” factor in M1. The latter factor explains in M1 all original relationships of an appropriately chosen factor in M0 with the rest of the factors there, via this global factor’s loadings on their own indicators in M1 that are unaltered relative to M0 (e.g., Figure 2). The same index of proximity to unidimensionality in Equation 2 can then be used as a measure of the degree of approximation of the original latent structure by that of unidimensionality. 5
Several limitations of the procedure discussed in this article are worth indicating at this point. One, the note does not imply and is not meant to suggest that any measuring instrument’s latent structure can be approximated (well) by a unidimensional structure. It is for this reason that we discussed the IPU measure as applied within the bridging model M1. Two, the note does not mean to suggest that with its procedure one can identify the true model having generated a given data set in an empirical study. Three, while we argued in favor of using the IPU quantity π g in educational, behavioral, and social research, we do not imply that there ought to be hard and fast cutoffs for it, especially with respect to how to interpret its point and interval estimates in an empirical setting. We referred thereby to the preliminary guides offered in Raykov and Pohl (2013; specifically, the 70:20:10 relation between π g , π r , and π l , respectively) only as informal and tentative guidelines, rather than as such approaching a rule-of-thumb status. With this in mind, we leave to future research the examination of the degree to which they could be trustworthy as well as in particular the conditions under which they may be so. Four, we do not suggest that a conclusion in a given study that a used instrument may have approximately unidimensional structure would be valid for all purposes in its possible applications. In particular, one could imagine that for some of them, especially where it is relevant to capitalize on the discrepancy between the instrument’s actual latent structure and that of unidimensionality, it may not be meaningful to consider a test or scale under consideration as having approximately unidimensional structure, even if the associated IPU appears to be high. As always, substantive considerations are called for and of higher relevance while assessing (a) whether a particular empirical setting and research question(s) pursued warrant the consideration of a measuring instrument as effectively unidimensional when interpreting its IPU, and (b) for which analytic, modeling, or interpretation purposes this may be the case. Five, we do not imply that in any given empirical study a scholar will need to make a decision of sufficient proximity to unidimensionality, or lack thereof, for a used multicomponent instrument. Future studies with the same instrument (and population) may provide additional important information permitting then, rather than before them, drawing such a conclusion. In this context, we wish to also point out that we do not necessarily expect the described IPU evaluation procedure to allow one reaching an unambiguous decision in this respect in any single application or in a series of its applications with a particular measuring instrument. Six, we do not mean to suggest that the IPU discussed in this note is the only possible index (effect-size measure) that could be used when examining proximity to unidimensionality. In addition, as indicated earlier we have only considered the IPU as one possible complementary measure to model comparison that a researcher may as well be interested in during such an examination. Seven, we presumed throughout the article that the standard confirmatory factor analysis model M0 (Equation 1) is correct, or at least plausible in a given empirical study, which is basic for the entire preceding discussion. This implies that all prior work on exploring and confirming the latent structure of a multicomponent measuring instrument in question has been already conducted before considering an application of the procedure of this note, including exploratory and confirmatory analyses (factor analyses) if need be, which are recommended to be carried out on an independent sample(s) from the same studied population (e.g., Mulaik, 2009).
Moreover, we assumed the instrument components to be (approximately) continuous, and so the discussed IPU need not be meaningfully applicable when they are binary, binary scored, or highly discrete (e.g., with say three or four possible response options). As alluded to earlier, one may conjecture that the robust maximum likelihood (ML) method (e.g., L. K. Muthén & Muthén, 2020) may be used with components possessing at least five to seven possible categorical values, as in the empirical example of the previous section, unless some items possess excessive skewness like in cases with preponderance of floor or ceiling values (cf. Rhemtulla et al., 2012). Whereas the normality assumption is made when utilizing the discussed procedure with ML as in the second example of the illustration section, we point out that its use with an application of weighted least squares with large samples is possible under nonnormality of the (approximately continuous) components. In addition, we would submit that up to mild violations of normality may be handled then also by the robust ML method. With highly discrete items, an extension of the discussed IPU evaluation procedure or the development of a corresponding analogue may well be possible along the lines of Raykov and Marcoulides (2018b), which is beyond the confines of this article. Furthermore, as explicitly indicated earlier we assumed a single-class studied population. Therefore, we would like to raise caution that the proposed method—like all conventional, single-class statistical and measurement approaches—may be misleading when applied to samples from populations with substantial unobserved heterogeneity if the latter is not accounted for (cf. Raykov et al., 2016; Raykov et al., 2019). Relatedly, we presumed also no clustering effects in a studied population, but it may be suggested that minor such effects may be accommodated by the robust ML method especially with normality or under up to limited violations of it. Last but not the least, being based on ML or its robust version, or alternatively on the weighted least squares estimation method, the procedure of concern in this note is asymptotic (with respect to units of analysis rather than components), and thus, best applied with large samples. We encourage future research into possible guidelines as to when samples may be considered sufficiently large (and under which circumstances) in order for the underlying large sample theory to be viewed as having obtained practical relevance.
In conclusion, this article offers to educational, behavioral, and social scientists a readily and widely applicable procedure for evaluation of the degree to which the multidimensional latent structure of a studied multicomponent measuring instrument may be considered (well) approximated by a unidimensional structure for certain empirical purposes.
Footnotes
Appendix A
Appendix B
Appendix C
Acknowledgements
We are indebted to G. A. Marcoulides for helpful discussions on essential unidimensionality as well as instructive and critical comments on a prior version of the paper that have led to its substantial improvement. We are grateful to the editor and two anonymous referees for critical comments on an earlier version of the article. Thanks are also due to K. Bartz for valuable comments on evaluating measuring instrument dimensionality.
Authors’ Note
This research was in part carried out while T. Raykov was visiting GESIS—Leibniz Institute for the Social Sciences in Mannheim, Germany.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.