
Abstract
Computing confidence intervals around generalizability coefficients has long been a challenging task in generalizability theory. This is a serious practical problem because generalizability coefficients are often computed from designs where some facets have small sample sizes, and researchers have little guide regarding the trustworthiness of the coefficients. As generalizability theory can be framed to a linear mixed-effect model (LMM), bootstrap and simulation techniques from LMM paradigm can be used to construct the confidence intervals. The purpose of this research is to examine four different LMM-based methods for computing the confidence intervals that have been proposed and to determine their accuracy under six simulated conditions based on the type of test scores (normal, dichotomous, and polytomous data) and data measurement design (p×i×r and p× [i:r]). A bootstrap technique called “parametric methods with spherical random effects” consistently produced more accurate confidence intervals than the three other LMM-based methods. Furthermore, the selected technique was compared with model-based approach to investigate the performance at the levels of variance components via the second simulation study, where the numbers of examines, raters, and items were varied. We conclude with the recommendation generalizability coefficients, the confidence interval should accompany the point estimate.
Introduction
Generalizability theory (G-theory) provides a conceptual framework and statistical procedures for evaluating the reliability of behavioral measurements such as test scores, performance evaluations, and survey ratings (Cronbach et al., 1963). A key feature of G-theory is that it allows the researcher to quantify the contribution of different sources of variance to overall measurement error. In assessment situations, common sources of variance include facets such as the particular sample of test questions the examinee responds to, the raters who evaluated those questions, the types of rating scales that were used, and the particular occasion under which the observations were obtained (Brennan, 2001; Shavelson & Webb, 1981). G-theory relies on analysis of variance techniques to partition test scores into the sources of variance that contribute to those scores. Variance components are estimated for each facet and are used as the basis for constructing indices of measurement error and score reliability. Once researchers understand sources of measurement error, they can make informed decisions to fine tune their measurement procedures (e.g., increase the number of test questions; decrease the number of raters).
One of the more common indices in G-theory is the generalizability coefficient, designated as rho-square (ρ2). Under certain conditions (e.g., a group of students responding to a sample of test questions), the generalizability index is analogous to Cronbach’s coefficient alpha (Brennan, 2001; Shavelson & Webb, 1981) and is often interpreted as a fixed-point estimate. However, in the absence of confidence intervals (CIs), a point estimate of generalizability coefficient can be misleading. To illustrate, in the field of medical education, a type of performance test known as an objective structured clinical examinations (OSCEs) is often used for evaluating medical students’ readiness for practice. G-theory is typically used to evaluate the quality of ratings from an OSCE, and the generalizability coefficient is the primary evidence for either accepting or modifying the exam administration procedures. If the point estimate of the generalizability coefficient is 0.85 where the 95% CI spans from 0.65 to 0.90, the decision makers may not be satisfied with the current procedures, assuming the minimum acceptable value is 0.70. Therefore, knowing CIs around a generalizability coefficient is practically beneficial for well-grounded evaluations.
Researchers have proposed methods for estimating CIs (or standard errors) of the variance components and generalizability coefficients obtained in G-theory (Brennan, 2006; Feldt, 1965). These methods can be classified as either model-based or empirically based. Model-based methods assume that scores are randomly, independently, and normally distributed (iid), while resampling relies on bootstrap or simulation techniques (Brennan, 2006, 2007; Brennan et al., 1987; Gao & Brennan, 2001; Moore, 2010; Othman, 1995; Tong & Brennan, 2006, 2007). The former requires complex mathematical deriving and, so far, have been developed only for straightforward measurement designs (e.g., p×i) but not for nested designs, for example (p× [i:r]; Almehrizi, 2020). Although the latter methods are straighforward to implement, selecting different bootstrap or simulation techniques as well as tuning their corresponding configurations (e.g., the facet sampled; number or sizes of the samples) often result in inconsistent results that can be challenging to reconcile. For instance, Tong and Brennan (2007) show that bootstrapping from person and item perspectives produce large discrepancies in CIs.
The purpose of the present study is to evaluate the effectiveness of various resampling methods for estimating standard errors and CIs in generalizability theory. We focus on resampling methods because they are likely to be accessible researchers and users, and are applicable to a broad range of measurement designs. This study builds on the work of Tong and Brennan (2007) by adapting new approaches from linear mixed-effect model (LMM) paradigm, such that the performance of the corresponding CIs can be investigated.
The resampling methods are based on a two-step cycle where the “resampling” strategy is followed with the step of “estimating” models. For example, a new data set sampled (i.e., bootstrapped) from the original data set is fed into a G-theory model, and model parameter estimates, as well as relevant statistics calculated from the estimates, are recorded and aggregated. This iterative, two-stage process continues until a vector of the statistic of interest is formed. There are multiple computational algorithms for estimating variance components from G-theory. The more common methods include: analysis of variance using expected mean square (EMS) equations (Cornfield & Tukey, 1956); Henderson’s Method 1 and Method 3 (Henderson, 1953); minimum norm quadratic unbiased estimation (Rao, 1970). More recent approaches rely on maximum likelihood (ML) estimation, including full information ML for handling missing data and unbalanced designs, as well as restricted maximum likelihood (REML) within a LMM framework. LMMs, also known as a hierarchical linear models or as multilevel modeling, subsumes a class of statistical models specified for analyzing designs with clustering or nested structures (Raudenbush & Bryk, 2002) well suited for many complex measurement designs. Modeling in G-theory can be viewed as an instance of building an LMM according to a G-theory design (Brennan, 1992). Jiang (2018) adopted a software package called lme4 (Bates et al., 2015), a library specifically for analyzing LMMs in the R program (R Core Team, 2021) to handle variance component estimation in G-theory; similar works can be found in Huebner and Lucht (2019). The present article follows Jiang’s (2018) approach to variance component estimation, and uses bootstrap and simulation techniques from LMM paradigm to construct CIs around generalizability coefficients.
The bootstrap and simulation techniques from LMM paradigm are not identical to the traditional resampling strategy. Instead of resampling from the original responses, many LMM bootstrap and simulation techniques first estimate the model, and then use the model to generate new data sets that are further fed to the same model. At each iteration, feeding models with fresh data points produces a set of new parameter estimates. As a set of the parameter estimates can be used to obtain a generalizability coefficient, M sets of the parameters estimates can produce M generalizability coefficients for constructing CIs.
In this article, four mainstream LMM-based techniques are selected for evaluation: (1) parametric bootstrap (PB), (2) semiparametric bootstrap (SPB), (3) nonparametric bootstrap (NPB), and (4) posterior simulation (PS). To demonstrate the differences among the techniques, it is necessary to define the terms of LLMs. If
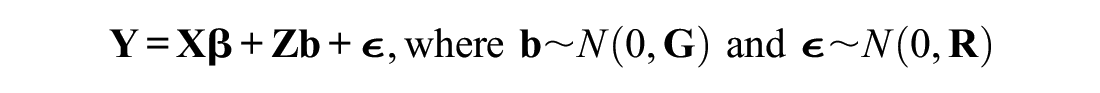
where
PB: (1) Fit the original LMM to the data to obtain the
SPB: (1) Fit the original LMM to the data to obtain the
NPB: (1) Match
PS: (1) Fit the original LMM to the data to obtain the
To summarize without the mathematical terms, PB utilizes the initial LMM to generate new data points that are further used to construct models, such that multiple sets of parameter estimates for each effect can be obtained. SPB is akin to PB except that the data generation process does not rely on the initial LMM but rather on a fixed-effect model rebuilt from the LMM’s residuals. NPB draws rows from the original data sets to form a new data set, estimate a new model with the data set, and repeat the process. PS derives posterior distributions for each parameter and samples from the distributions to form sets of parameter estimates. More details regarding PB to PS can be found in Davison and and Hinkley (1997), Gelman and Hill (2006), as well as Shang and Cavanaugh (2008).
Method
This study consists of two simulation studies, while the first one investigates CIs at the level of generalizability coefficient and the second one further examines CIs at the variance component level with references. The first one follows the general design of the simulation study conducted by Tong and Brennan (2007). The data generation process was completed [or conducted, or executed] for normal, dichotomous, and polytomous responses. The sample sizes were set to
For normal data, responses for the p×i×r design were generated on the basis of Equations 1 and 2. Equation 1 shows that an observed score,
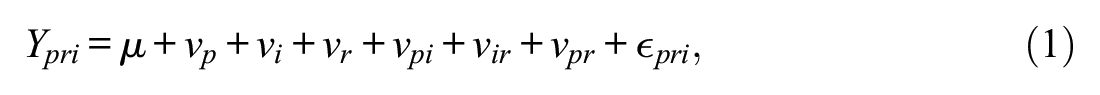
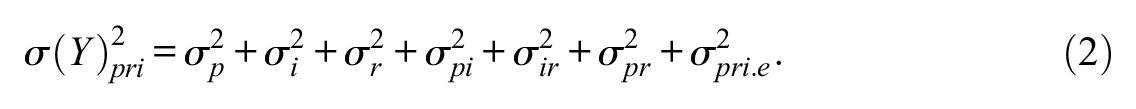
Similarly, observed scores and variances for the p× [i:r] design were generated using Equations 3 and 4.
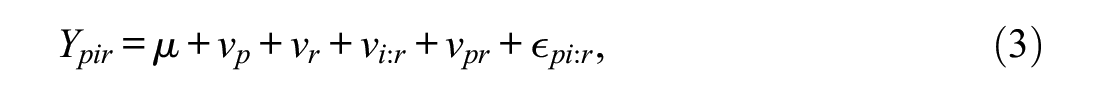
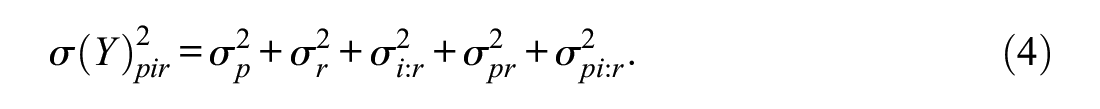
For dichotomous data, Equations 1 to 4 were again used for the two designs, respectively. If the simulated score exceeded 1, a response of 1 was assigned; otherwise, a response of 0 was assigned to create dichotomous responses. As the parameter values for variance components for dichotomous data were not readily available in the simulation process, 5000 data sets were produced and their
For polytomous data, the normal distributions in Equations 2 and 4 were replaced by binominal distributions. To illustrate,
True Parameters for the Simulation Study.

Note. Na = not applicable.
After obtaining true parameter values of variance components by either directly copying from the original values or averaging the simulated values, the true generalizability coefficient can be calculated using Equations 5 to 7. Note that

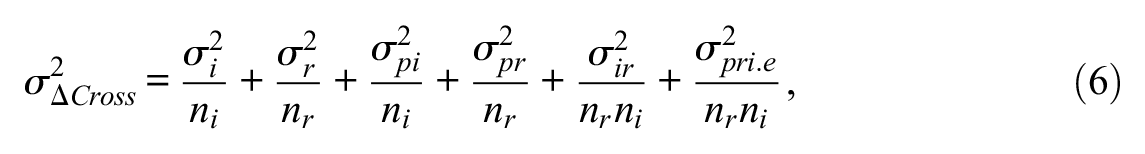
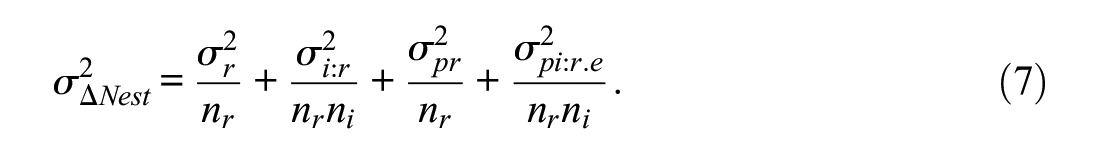
Each of the p×i×r and the p× [i:r] designs involved 1,000 replications. That said, 1,000 arrays of size 100 × 20 × 2 were generated. For each of the bootstrap techniques, 500 bootstrapping samples were drawn within each of the 1,000 replications. Within each replication, a 95% CI was constructed and the true generalizability coefficient was investigated to see if it was covered within that CI. The primary outcome measure is the coverage rate, which is defined as the proportion of replications that a CI contains the true generalizability coefficient. A secondary outcome is the mean standard deviation of the generated generalizability coefficients from the resampling techniques (i.e., the average dispersion of the resampled statistics).
The second simulation study (1) varies the facet levels of a fully crossed design to create different conditions, (2) utilizes the best technique from the four candidates, (3) calculates the coverage rate as the first simulation study yields, and (4) compares its variance component estimates with a model-based approach based on Satterthwaite’s solution (Smith, 1982). Specifically, the sample sizes were set to
Results
Table 2 contains the coverage rates of the first simulation study. To illustrate, the first cell in the table (0.9516) indicates that for continuous (normal) data, the true generalizability coefficient for the p×i×r design was covered by the CIs produced by PB about 95% of the time. It is apparent from Table 2 that PB outperformed the other three methods in all conditions. However, for polytomous response data, the coverage rates for PB dropped, particularly for the p× [i:r] design where coverage rates fell to about 81%. However, all methods performed less well with polytomous data, with huge decrements for methods SPB, NPB, and PS. In general, neither SPB, NPB, or PS was practically trustable as their coverage rates were far below 0.95, leaving a firm belief that these CIs were either drifted far from the target or spanned overly narrow ranges.
Coverage Rates of the Simulated Confidence Intervals (CIs) for Each Simulated Condition.

Note. PB = parametric bootstrap; SPB = semiparametric bootstrap; NPB = nonparametric bootstrap, PS = posterior simulation.
The average standard deviations are listed in Table 3 showing the variability of the coefficients resampled by the selected methods. Consistently, generalizability indices generated by PB spanned a wider range than those of other methods. These findings support the reasoning that the CIs for methods SPB, NPB, and PS were too narrow such that the true generalizability coefficient was left out of the range in many replications. The average standard deviations were larger for the p× [i:r] design than for the p×i×r design.
Mean Standard Deviations of Generalizability Coefficients Across Simulated Conditions.

Note. PB = parametric bootstrap; SPB = semiparametric bootstrap; NPB = nonparametric bootstrap, PS = posterior simulation.
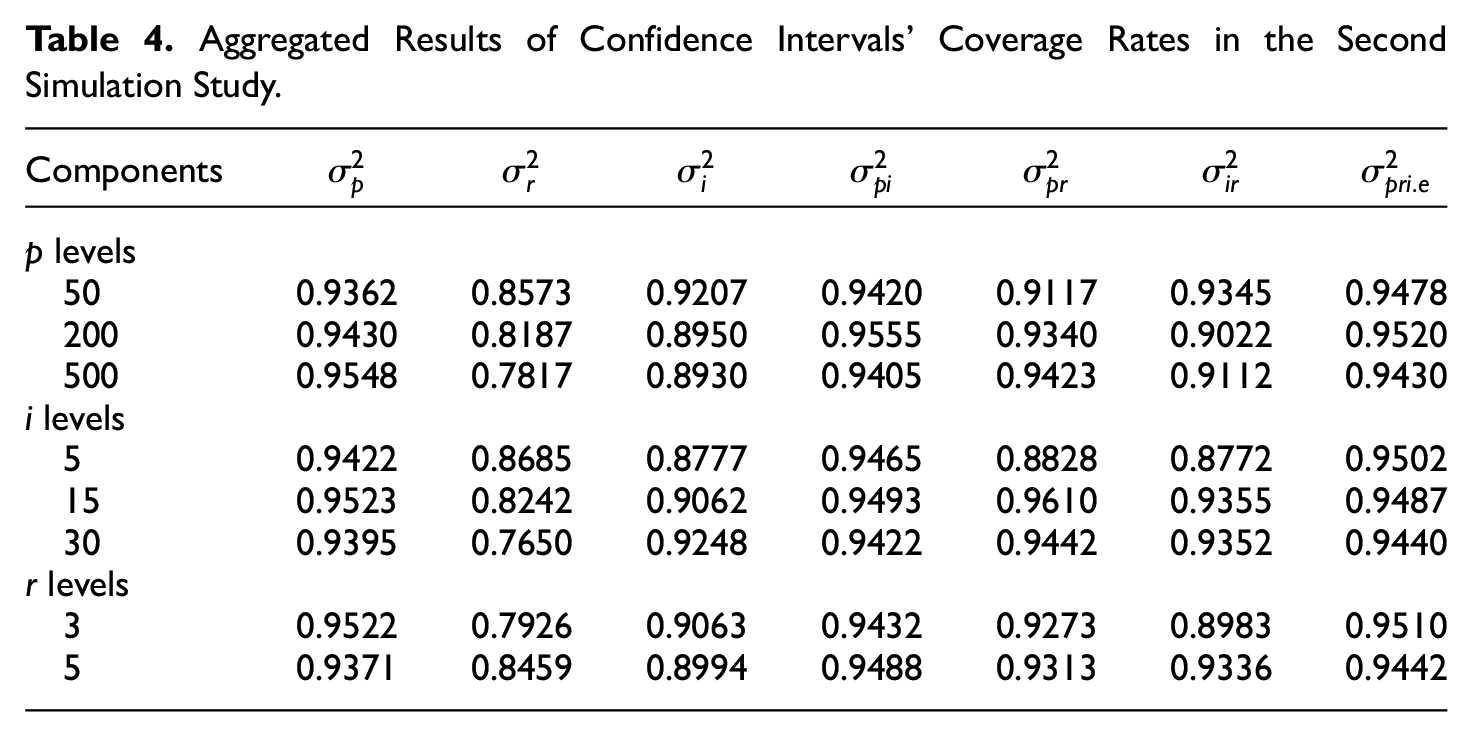
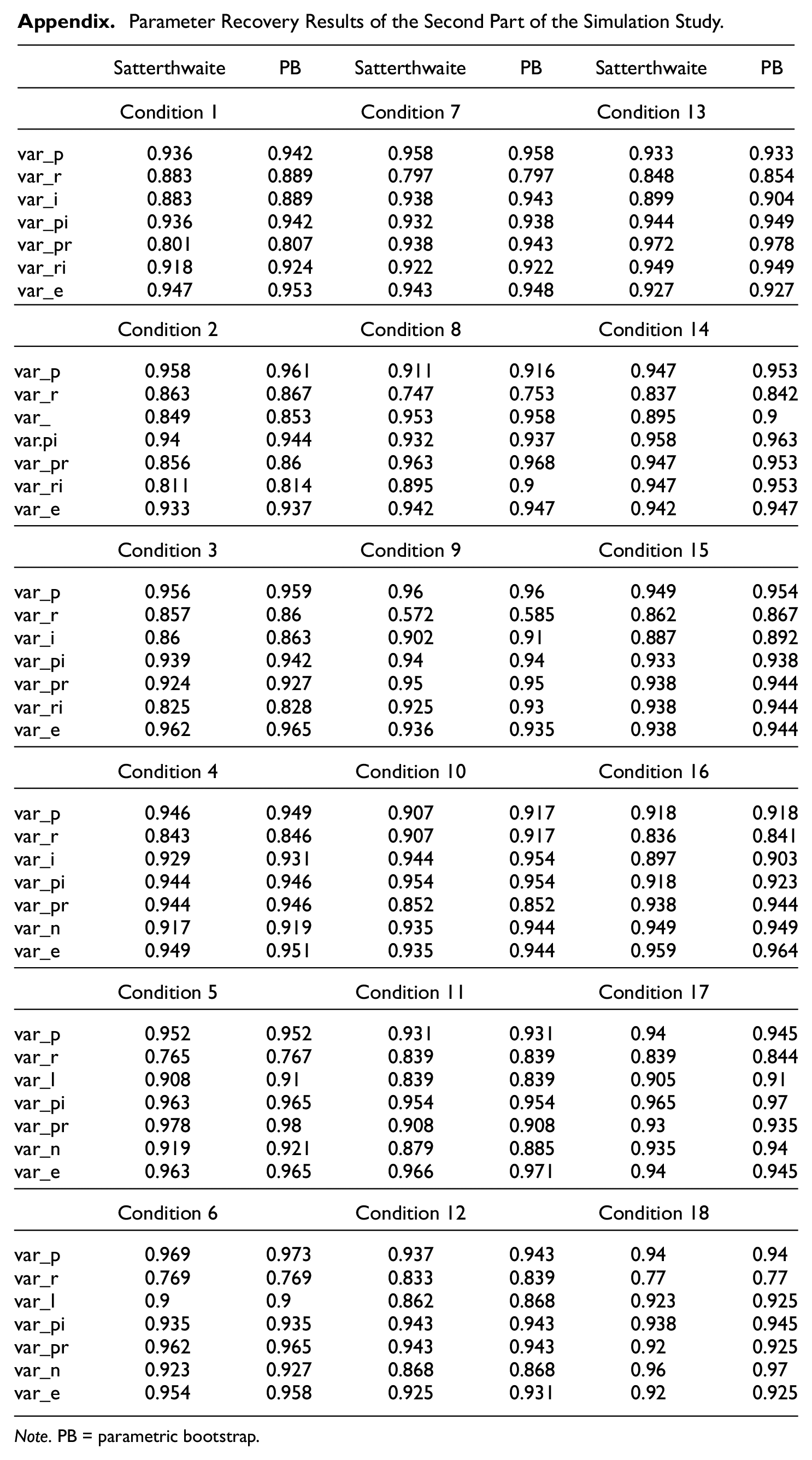
The complete results of the second simulation study are listed in the appendix. As PB outperformed other methods, it was used to compared with Satterthwaite’s approach. In all conditions, the coverage rates yield by PB are slightly higher than those by Satterthwaite’s approach: The differences across all random effect components are less than 0.01. It concludes that, in addition to generating appropriate CIs for generalizability coefficient, PB can reproduce the accuracy yielded by model-based approaches at the levels of variance components; this emphasizes the advantages of the proposed approach over model-based approaches: the capacity of producing accurate CIs at both levels.
Given the statistics produced by Satterthwaite’s approach and PB are extremely similar, PB results are used here to describe the variability of the CIs in different conditions. On average, the coverage rates for
Aggregated Results of Confidence Intervals’ Coverage Rates in the Second Simulation Study.
Discussion
In a simulation of this kind, a coverage rate of 0.95 indicates an ideal approximation of the 95% CI. In all conditions, PB came closer to 95% than all other methods, while PS was the least accurate. When data responses were normal or dichotomous, it seems appropriate to use PB to obtain CIs for the estimated generalizability coefficients for the two types of designs studied here. Methodologically, PB mimics LMM’s properties to a maximal degree such that the resampling process is based on a structure consistent with the original mode. SPB does not integrate the random-effect components when performing bootstrapping and leaves the part of the information unused. NPB operates bootstrap techniques from the data side, instead of the modeling perspective; therefore, the unsatisfactory results were consistent with the findings in Tong and Brennan (2007). Finally, PS simulates parameters directly from posterior distributions, of which the dispersions seemed to be too conservative compared with other methods.
Most studies that have examined CIs or standard errors within the context of G-theory have focused on the variance components (e.g., Brennan, 2006, 2007; Tong & Brennan, 2007; Wiley, 2000), while this article addresses the issue from the level fo actual generalizability coefficients that aare computed from the variance components. Although there may be some risk in ignoring variance-level CIs, investigating CIs at the level of generalizability coefficients is desirable. One reason is that CIs for variance components do not directly inform the uncertainty of generalizability coefficients, as they cannot be converted to one another via simple or closed-form solutions. In addition, variance components are not by themselves useful for decision-making purposes, while generalizability coefficients are often interpreted as direct evidence for decision making. Also, Cronbach’s
Although Bayesian methods have been used in G-theory (Jiang & Skorupski, 2018; LoPilato et al., 2015), they were not addressed here for two reasons. First, Bayesian methods can be highly sensitive to prior distributions, leading a simulation design less controllable when varying the prior distributions becomes necessary. Second, Bayesian methods are computationally expensive and less used in practice.
Conclusions
G-theory provides an important framework for evaluating the quality of ratings and scores in performance testing. Point estimates of generalizability coefficients are not sufficient because the imprecision of those estimates is unknown to decision makers. The PB technique illustrated here appears to provide one useful way for evaluating the trustworthiness of generalizability coefficients, thus allowing decisions about a test’s design to be made with greater accuracy and confidence.
Footnotes
Appendix
Parameter Recovery Results of the Second Part of the Simulation Study.
| Satterthwaite | PB | Satterthwaite | PB | Satterthwaite | PB | |
|---|---|---|---|---|---|---|
| Condition 1 | Condition 7 | Condition 13 | ||||
| var_p | 0.936 | 0.942 | 0.958 | 0.958 | 0.933 | 0.933 |
| var_r | 0.883 | 0.889 | 0.797 | 0.797 | 0.848 | 0.854 |
| var_i | 0.883 | 0.889 | 0.938 | 0.943 | 0.899 | 0.904 |
| var_pi | 0.936 | 0.942 | 0.932 | 0.938 | 0.944 | 0.949 |
| var_pr | 0.801 | 0.807 | 0.938 | 0.943 | 0.972 | 0.978 |
| var_ri | 0.918 | 0.924 | 0.922 | 0.922 | 0.949 | 0.949 |
| var_e | 0.947 | 0.953 | 0.943 | 0.948 | 0.927 | 0.927 |
| Condition 2 | Condition 8 | Condition 14 | ||||
| var_p | 0.958 | 0.961 | 0.911 | 0.916 | 0.947 | 0.953 |
| var_r | 0.863 | 0.867 | 0.747 | 0.753 | 0.837 | 0.842 |
| var_ | 0.849 | 0.853 | 0.953 | 0.958 | 0.895 | 0.9 |
| var.pi | 0.94 | 0.944 | 0.932 | 0.937 | 0.958 | 0.963 |
| var_pr | 0.856 | 0.86 | 0.963 | 0.968 | 0.947 | 0.953 |
| var_ri | 0.811 | 0.814 | 0.895 | 0.9 | 0.947 | 0.953 |
| var_e | 0.933 | 0.937 | 0.942 | 0.947 | 0.942 | 0.947 |
| Condition 3 | Condition 9 | Condition 15 | ||||
| var_p | 0.956 | 0.959 | 0.96 | 0.96 | 0.949 | 0.954 |
| var_r | 0.857 | 0.86 | 0.572 | 0.585 | 0.862 | 0.867 |
| var_i | 0.86 | 0.863 | 0.902 | 0.91 | 0.887 | 0.892 |
| var_pi | 0.939 | 0.942 | 0.94 | 0.94 | 0.933 | 0.938 |
| var_pr | 0.924 | 0.927 | 0.95 | 0.95 | 0.938 | 0.944 |
| var_ri | 0.825 | 0.828 | 0.925 | 0.93 | 0.938 | 0.944 |
| var_e | 0.962 | 0.965 | 0.936 | 0.935 | 0.938 | 0.944 |
| Condition 4 | Condition 10 | Condition 16 | ||||
| var_p | 0.946 | 0.949 | 0.907 | 0.917 | 0.918 | 0.918 |
| var_r | 0.843 | 0.846 | 0.907 | 0.917 | 0.836 | 0.841 |
| var_i | 0.929 | 0.931 | 0.944 | 0.954 | 0.897 | 0.903 |
| var_pi | 0.944 | 0.946 | 0.954 | 0.954 | 0.918 | 0.923 |
| var_pr | 0.944 | 0.946 | 0.852 | 0.852 | 0.938 | 0.944 |
| var_n | 0.917 | 0.919 | 0.935 | 0.944 | 0.949 | 0.949 |
| var_e | 0.949 | 0.951 | 0.935 | 0.944 | 0.959 | 0.964 |
| Condition 5 | Condition 11 | Condition 17 | ||||
| var_p | 0.952 | 0.952 | 0.931 | 0.931 | 0.94 | 0.945 |
| var_r | 0.765 | 0.767 | 0.839 | 0.839 | 0.839 | 0.844 |
| var_I | 0.908 | 0.91 | 0.839 | 0.839 | 0.905 | 0.91 |
| var_pi | 0.963 | 0.965 | 0.954 | 0.954 | 0.965 | 0.97 |
| var_pr | 0.978 | 0.98 | 0.908 | 0.908 | 0.93 | 0.935 |
| var_n | 0.919 | 0.921 | 0.879 | 0.885 | 0.935 | 0.94 |
| var_e | 0.963 | 0.965 | 0.966 | 0.971 | 0.94 | 0.945 |
| Condition 6 | Condition 12 | Condition 18 | ||||
| var_p | 0.969 | 0.973 | 0.937 | 0.943 | 0.94 | 0.94 |
| var_r | 0.769 | 0.769 | 0.833 | 0.839 | 0.77 | 0.77 |
| var_I | 0.9 | 0.9 | 0.862 | 0.868 | 0.923 | 0.925 |
| var_pi | 0.935 | 0.935 | 0.943 | 0.943 | 0.938 | 0.945 |
| var_pr | 0.962 | 0.965 | 0.943 | 0.943 | 0.92 | 0.925 |
| var_n | 0.923 | 0.927 | 0.868 | 0.868 | 0.96 | 0.97 |
| var_e | 0.954 | 0.958 | 0.925 | 0.931 | 0.92 | 0.925 |
Note. PB = parametric bootstrap.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Peking Univeristy Health Science Center under Grant BMU2021YJ010.