
Abstract
Random item effects item response theory (IRT) models, which treat both person and item effects as random, have received much attention for more than a decade. The random item effects approach has several advantages in many practical settings. The present study introduced an explanatory multidimensional random item effects rating scale model. The proposed model was formulated under a novel parameterization of the nominal response model (NRM), and allows for flexible inclusion of person-related and item-related covariates (e.g., person characteristics and item features) to study their impacts on the person and item latent variables. A new variant of the Metropolis-Hastings Robbins-Monro (MH-RM) algorithm designed for latent variable models with crossed random effects was applied to obtain parameter estimates for the proposed model. A preliminary simulation study was conducted to evaluate the performance of the MH-RM algorithm for estimating the proposed model. Results indicated that the model parameters were well recovered. An empirical data set was analyzed to further illustrate the usage of the proposed model.
Keywords
Introduction
Likert-type items are ubiquitously utilized in education and psychology to measure traits that cannot be observed directly. Item response theory (IRT) models, such as the rating scale model (RSM; Andrich, 1978a, 1978b) and the partial credit model (PCM; Masters, 1982), are routinely applied in practice to analyze item-level responses with more than two categories. These polytomous IRT models depict the relationships between observed item responses, person latent traits (e.g., attitude, and academic proficiency), and item properties (e.g., item location). For example, the RSM specifies the log-odds of conditional probabilities that the response of a person

where
Random item effects IRT models, which consider that item effects/parameters random, have received much attention for more than a decade (e.g., De Boeck, 2008; Janssen et al., 2000; Van den Noortgate et al., 2003). Theoretically, it is reasonable that an IRT model treats item parameters as random variables. As the generalizability theory (G-theory; Shavelson & Webb, 1991) states, items in a measurement scale can be viewed as a random sample of an item universe (i.e., the population of items). Therefore, distributional assumptions regarding item effects need to be made if generalized conclusions are to be drawn for more items (Briggs & Wilson, 2007). IRT models are also recognized as special cases of the generalized linear mixed model (GLMM; Chalmers, 2015; De Boeck & Wilson, 2004; Rijmen et al., 2003) so that random item effects IRT models become natural extensions of conventional IRT models.
The random item effects approach also has substantive advantages in many practical settings. For example, in large-scale international survey studies, different nations would use a common measurement scale but it is not uncommon to observe that item characteristics vary across nations (e.g., De Jong et al., 2007; De Jong & Steenkamp, 2010; Fox & Verhagen, 2010; Rijmen & Jeon, 2013). In this context, random item effects IRT models can serve as a general tool for studying the issue of measurement invariance (Meredith, 1993), which is also known as differential item functioning (DIF; Holland & Wainer, 2012), across nations (De Boeck, 2008; Muthén & Asparouhov, 2018). Automated item generation, where hundreds of items are created as random “clones” from item families (Geerlings et al., 2011; Glas & van der Linden, 2003), is another area where the random item effects IRT models apply. The random item effects perspective allows understanding the heterogeneity within item families, identifying problematic items, and empowering test assembly. In addition, random item effects IRT models can be also desired in scenarios where the number of persons for item calibration is relatively small. This is because they generally require estimating fewer parameters than their fixed item effects counterparts.
Based on what item effects are random, the random item effects IRT models can be categorized into two types. In the first type, the item effects are random over items; while in the second type, the item effects are made random over persons or clusters. A well-known example of the first type is the random item effects Rasch model introduced in Van den Noortgate et al. (2003). While considering both person and item effects random, the binary item responses are cross-classified by persons and items. In other words, the random item effects Rasch model is essentially a generalized linear model with crossed random effects. The logit that a person

with
The basic model presented in Equation 2 was extended to the two-parameter logistic (2PL) model (e.g., Janssen et al., 2000; Van den Noortgate et al., 2003), the three-parameter logistic (3PL; e.g., Johnson & Sinharay, 2005; Van den Noortgate et al., 2003) model, and generalized partial credit (GPC; e.g., Johnson & Sinharay, 2005) model. Janssen et al. (2000) proposed a hierarchical IRT model for dichotomously scored items in criterion-referenced measurement. The hierarchical IRT model assumes the difficulty and discrimination parameters of items are both random effects and are drawn from certain normal distributions. Effects of items that measure the same criteria would share a common mean and variance. Johnson and Sinharay (2005) considered the 3PL (Birnbaum, 1968) and the GPC (Muraki, 1992) models so that the difficulty, discrimination, asymptote (for the 3PL model), and step (for the GPC model) parameters of items are all treated as random effects.
The second type of random item effects IRT models allows the item effects to be random over persons or clusters (e.g., countries), and are often adopted in cross-national studies (e.g., De Jong et al., 2007; De Jong & Steenkamp, 2010; Rijmen & Jeon, 2013). For an item
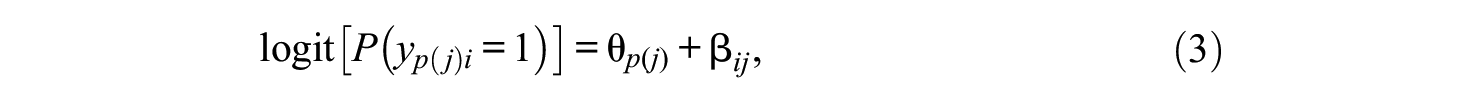
where
An issue that has been of substantive interest and needs more investigation with random item effects IRT models is how person characteristics (e.g., gender) and item features (e.g., if an item is reservedly worded) explain differences in the person latent variable(s) and the item properties (e.g., item location). De Boeck and Wilson (2004) introduced the explanatory item response models (EIRM) to simultaneously model the impacts of person-related and item-related covariates and the item response process. A widely-used example of EIRM is Fischer’s (1973) linear logistic test model (LLTM), which specifies the item location parameter as a weighted sum of multiple item features. However, in practice, the person latent variable and the item location parameters may not be fully explained by the covariates considered, leaving room for the inclusion of random residuals. Several explanatory random item effects models have been proposed for dichotomous data, including the explanatory multidimensional multilevel random item response model (EMMRIRM; Cho et al., 2013) and additive multilevel item structure (AMIS; Cho et al., 2014), while the models have not yet been extended to polytomous response data.
The present study focuses on the first type of random item effects model (i.e., models whose random effects vary over items.) To extend the utility of the random item effects approach and EIRM to more contexts, this study introduces an explanatory multidimensional random item effects RSM for polytomous items. The proposed model considers both person and item effects as random and allows the impacts of person-related and item-related covariates to be studied simultaneously. The proposed model is formulated under a novel parameterization of the nominal response model (NRM; Bock, 1972, 1997; Thissen & Cai, 2016; Thissen et al., 2010). The new parameterization unifies a series of divided-by-total (Thissen & Steinberg, 1986) polytomous IRT models, allows for straightforward multidimensional extensions of these models, and has been implemented in widely-used IRT software packages, including flexMIRT (Cai, 2017), IRTPRO (Cai et al., 2011), and OpenMx/ rpf (Pritikin & Falk, 2020). In addition, as Falk (2021) noted, the new parameterization facilitates Monte Carlo simulation studies since it allows for easy simulating a greater variety of category response functions that are reasonable. With the original parameterization, varying one of the item parameters may make other parameters unrealistic and lead to impractical category response functions. To estimate the proposed model, a new variant of the Metropolis-Hastings Robbins-Monro (MH-RM) algorithm designed for estimating latent variable models with crossed random effects (Cai, 2008, 2010a, 2010b; Chung & Cai, 2021; Huang, 2021) is applied.
The remainder of this article is organized as follows. The “Nominal Response Model” section presents the fixed item effects RSM as a constrained case of the NRM based on a novel parameterization (Thissen & Cai, 2016; Thissen et al., 2010). The “Proposed Modeling Approach” section proposes an explanatory multidimensional random item effects RSM and illustrates the new variant of the MH-RM algorithm for parameter estimation. The “Simulation Study” section presents a preliminary simulation study for evaluating the performance of the MH-RM algorithm for estimating the proposed model. The “Empirical Example” section analyzes an empirical data set and uses the proposed model to answer research questions that are of substantive interest. The “Conclusion and Discussion” section summarizes this study and discusses future research directions.
Nominal Response Model
In this section, the parameterization of the NRM proposed by Thissen et al. (2010) and Thissen and Cai (2016) is briefly introduced to facilitate the understanding of the proposed model.
A Novel Parameterization of NRM
The NRM was originally designed for item responses with no pre-determined orders (Bock, 1972, 1997). Thissen et al. (2010) and Thissen and Cai (2016) presented a novel parameterization of the NRM and showed that the NRM is best treated as a template for polytomous IRT models. Adopting the new parameterization, an NRM specifies the probability that person
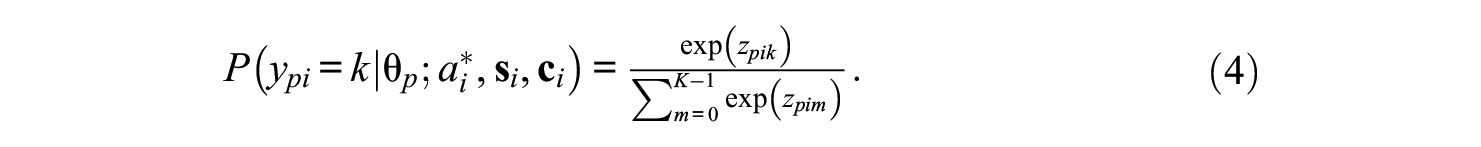
In Equation 4,

in which

As pointed out in Thissen et al. (2010) and Falk (2021), elements in
A major benefit of adopting this novel parameterization is that it allows for straightforward multidimensional generalizations of the NRM and its special cases by expanding the scalar latent variable and the associated overall slope into vectors.
RSM as a Constrained NRM
As shown in Thissen et al. (2010) and Thissen and Cai (2016), several well-known divided-by-total (Thissen & Steinberg, 1986) polytomous IRT models, including the RSM, the PCM, and the GPC model (Muraki, 1992), can all be viewed as constrained cases of the full-rank NRM. To formulate an RSM under the new parameterization, three constraints need to be imposed: (a) the overall slopes are restricted to be equal across items,
If the person latent variable

The threshold parameters are

Proposed Modeling Approach
In this section, an explanatory multidimensional random item effects RSM based on the new parameterization is proposed. The measurement model, which specifies the probability of selecting a response option as a function of the person and item latent variables, is introduced first. The person latent variables represent the latent constructs that a test aims to measure. The level of the item latent variable reflects the deviation of an item from the average item location. Then the structural models are presented, which connect the person-related and item-related covariates with person and item latent variables through regression equations.
Measurement Model
Adopting the novel parameterization, the probability that person
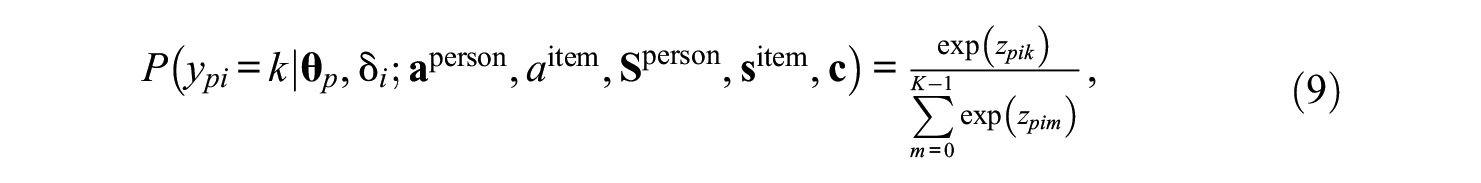
where the linear predictor is
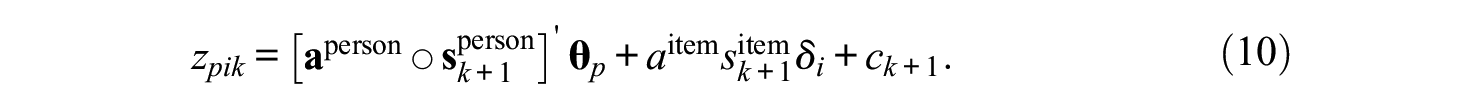
The item responses are cross-classified by persons and items. Therefore, like the random item effects model presented in Equation 2, the first two terms of Equation 10 capture the person and item random effects, respectively. Specifically, in Equations 9 and 10,
Restrictions on the scoring function matrix associated with person latent variables
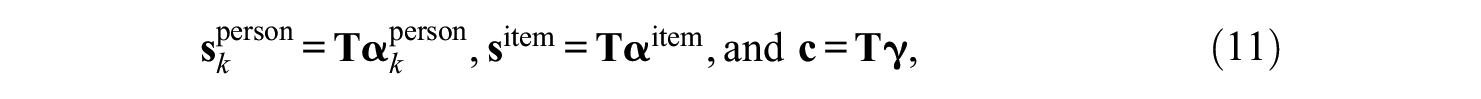
where
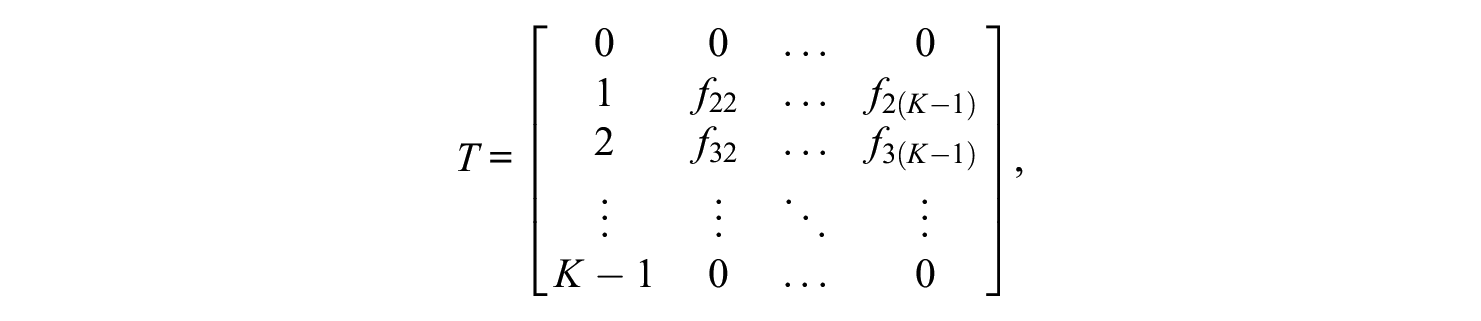
in which
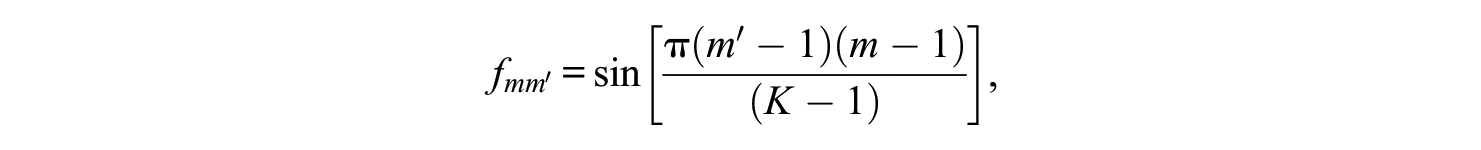
so that the second to last columns of
To formulate the proposed model as an RSM type model,
Structural Model
Two regression equations for the person and item latent variables are defined, respectively, incorporating person-related and item-related covariates:


Equation 12 models the relationships between person-related covariates and the person latent variables.
Identification Constraints
To identify the proposed model, a few constraints need to be imposed. Specifically, the person and item random effects are let to have unit variances. In other words, diagonal elements of
Free parameters in the proposed model include elements of the regression coefficient matrix
Estimation
A variant of the MH-RM algorithm (Cai, 2008, 2010a, 2010b; Chung & Cai, 2021; Huang, 2021) that implements a new sampling strategy for estimating latent variable models with crossed random effects is applied to estimate the explanatory multidimensional random item effects RSM introduced above. The MH-RM algorithm produces the maximum likelihood estimates (MLEs) of model parameters and is preferred in high-dimensional IRT settings (e.g., Chung & Cai, 2021; Falk & Cai, 2016; Monroe & Cai, 2014; Yang & Cai, 2014). The MH-RM algorithm makes use of the idea of data augmentation and combines the MH (Hastings, 1970; Metropolis et al., 1953) sampler with the RM (Robbins & Monro, 1951) Stochastic Approximation (SA) algorithm.
The MH-RM algorithm has two strong motivations: (a) Fisher’s (1925) identity, which states that the conditional expectation of the gradient of the complete data log-likelihood is equal to the gradient of the observed data log-likelihood, and (b) the RM algorithm, which is a root-finding algorithm designed for functions that are corrupted by noise. To illustrate how the two motivations facilitate the MLE, the iterative scheme of the standard MH-RM algorithm is outlined below first. Following the general scheme, the sampling strategy applied in the new variant of the algorithm to aid the estimation of crossed random person and random item effects is introduced. Readers that are interested in more technical details are referred to Cai (2008, 2010a, 2010b), Chung and Cai (2021), and Huang (2021).
Each iteration of the MH-RM algorithm consists of three steps: stochastic imputation, stochastic approximation, and Robbins-Monro update. With the MH-RM algorithm, the person and item latent variables/random effects are treated as missing data (Dempster et al., 1977). The missing data and the observed data (i.e., item response and covariates) form the complete data. In the first stochastic imputation step of each iteration, the MH sampler is applied to impute missing data (i.e., person and item random effects) so that the complete data are formed. In the stochastic approximation step, made possible by Fisher’s identity, the gradient vector and information matrix of the complete data log-likelihood are evaluated as an approximation of the observed data log-likelihood, which is more difficult to evaluate. In the Robbins-Monro update step, the RM algorithm is applied to update the model parameters, accounting for the missing data (i.e., noise) introduced in the stochastic imputation step.
In the stochastic imputation step of each iteration, a sampling strategy that couples the Metropolis-within-Gibbs algorithm with the alternating imputation posterior (AIP) algorithm (Cho & Rabe-Hesketh, 2011) is adopted. In this process, values of the person and item latent variables/random effects are simulated in alternation. Specifically, the person latent variables/random effects are imputed first, fixing item latent variables/random effects to the imputed values from the previous iteration. Direct simulating latent variables/random effects for persons from their conditional densities are not feasible. Therefore, a Gibbs sampler is constructed and combined with the MH algorithm. Then the item latent variables/random effects are simulated in the same manner, fixing the person latent variables/random effects to the imputed values obtained in the current iteration.
Simulation Study
To evaluate the performance of the MH-RM algorithm in terms of estimating the proposed explanatory multidimensional random item effects RSM, a simulation study was conducted. Data were simulated and analyzed with the popular IRT software flexMIRT (Cai, 2017).
Simulation Design
Item responses were simulated based on a five-category explanatory random item effects RSM presented in Equations 9, 10, and 12. For illustration purposes, the person latent variable
Manipulated factors considered in this simulation study were: (a) the number of persons, (b) the number of items, and (b) the variances of persons and item random effects. Specifically, the numbers of persons generated were 500 and 1,000, which aimed to reflect a relatively small and large sample size. The numbers of items simulated were 100 and 200. The numbers of persons and items were chosen to mimic real-world scenarios where a large number of persons are employed to evaluate an item pool that consists of a relatively small number of items. Another consideration is that, as mentioned, the random item effects approach can be ideal in situations where the sample size is too small to produce stable parameter estimates if conventional fixed item effects IRT models are adopted.
Three combinations of variances of person and item random effects were simulated, which were
A total of
Evaluation Criteria
The bias and root mean square error (RMSE) were used to evaluate if the model parameters were well recovered. Specifically, for a generic model parameter

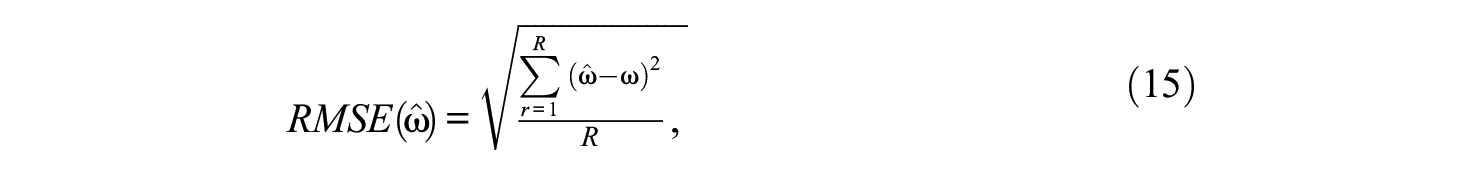
where
Simulation Results
Table 1 summarizes the biases for parameter estimates of the proposed model under various simulation conditions. As shown in the table, the slope parameter (
Biases for Parameter Estimates of the Random Item Effects Model

The slope parameter (
Table 2 shows RMSEs for parameter estimates of the explanatory random item effects RSM under all simulation conditions. Holding the number of persons constant, the RMSEs for conditions with 100 items were slightly larger than those for conditions with 200 items. For all equal variance and larger person variance conditions, the RMSEs for all parameters were all below .1 with four exceptions. For larger item variance conditions, the RMSEs for the slope parameter (
RMSEs for Parameter Estimates of the Random Item Effects Model

Note. RMSE = root mean square error.
Empirical Example
Data and Analysis
The proposed explanatory multidimensional random item effects RSM approach was applied to an empirical data set presented in Zhang et al. (2016). The data included responses of 312 persons to the abbreviated 18-item Need for Cognition (NFC) scale (Cacioppo & Petty, 1982). The sample consisted of 252 females and 59 males. The mean and standard deviation of the age were 19.95 and 2.72, respectively. The NFC scale measures the tendency of an individual to engage in and enjoy thinking. Each item of the NFC scale describes a cognitive activity (e.g., “I would prefer complex to simple problems.”) and has nine categories. Among the 18 items, nine are reversely worded (e.g., “Thinking is not my idea of fun”). Two person-related covariates, including gender and age, and one item-related covariate that indicates if an item is reversely worded were available.
Three research questions that are of substantive interest were asked:
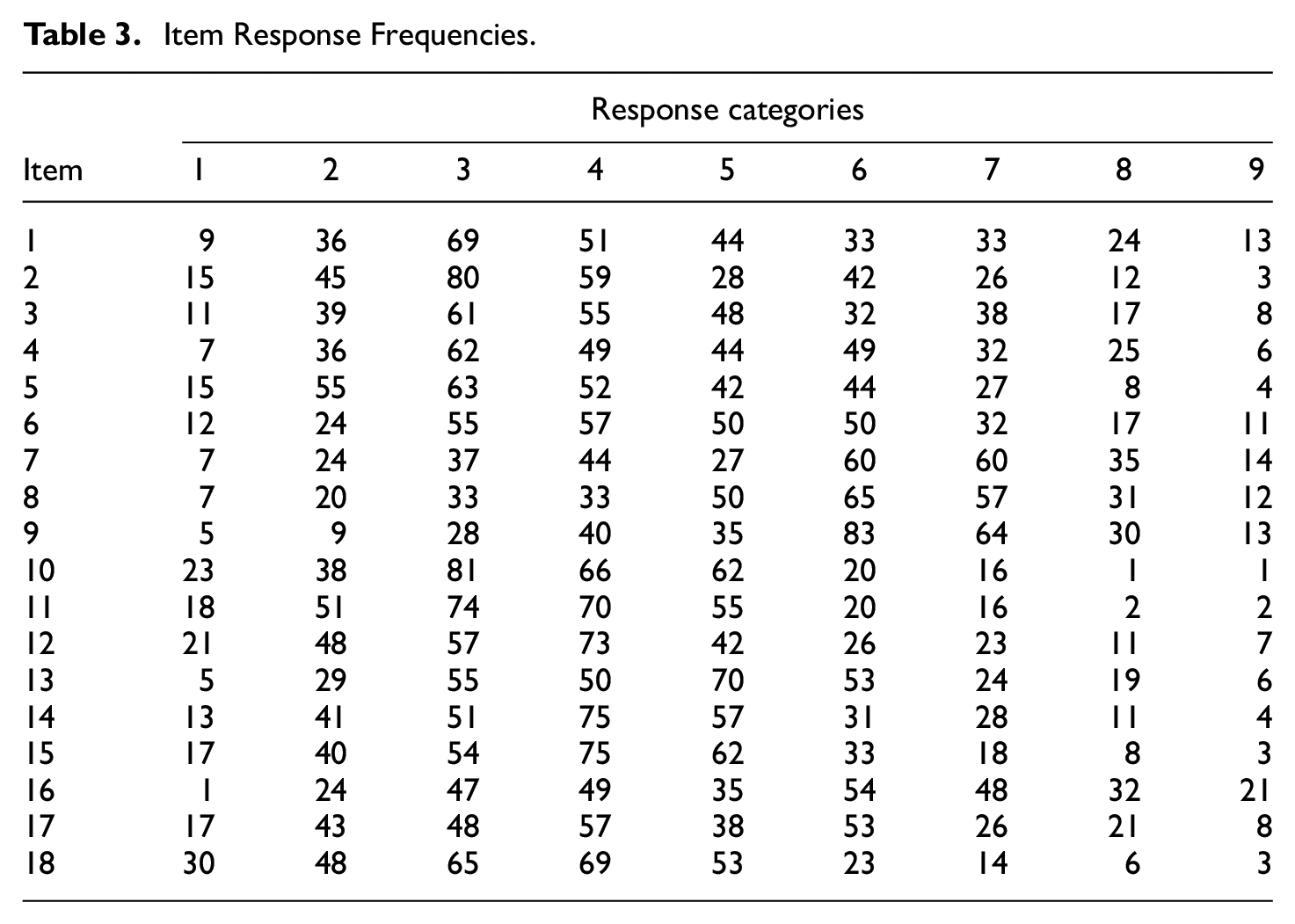
Based on the frequencies of item responses (shown in Table 3), categories 1 and 2 were collapsed into one category due to the low frequency of category 1, and categories 8 and 9 were combined as well due to the low frequency of category 9. Thus, a seven-category explanatory random item effects RSM, which included a unidimensional person latent variable and a unidimensional item latent variable, was applied to fit the data. In addition, persons’ gender and their standardized age were incorporated as predictors of the person latent variable. The item type indicator was utilized as the predictor of item latent variable. The analysis was conducted using flexMIRT (Cai, 2017). The syntax is presented in the appendix.
Item Response Frequencies
Results
The estimates of the slopes associated with person and item latent variables were .44 (.02) and .31 (.01), respectively. These estimates indicated that compared with the item locations, the persons had more variation in the tendency of engaging in and enjoying thinking. Estimates of the second to the last elements of the
Estimates of the two regression coefficients associated with gender and age were .07 (.09) and .04 (.06). Neither of the two estimates was significant, indicating that there was no difference between the female and male groups in their tendency to engage in and enjoy thinking, and age is not a significant predictor of the tendency. The estimated regression coefficient for the item type is −.17 (.35). This insignificant estimate indicates that if an item is reversely worded has no impact on its location.
Conclusion and Discussion
This study contributes to the IRT literature by introducing an explanatory multidimensional random item effects RSM for polytomous items. The proposed model adopted a novel parameterization of the NRM, which facilitates extending commonly known polytomous IRT models to their multidimensional versions. The proposed model allows for studying the relationships between covariates that are of interest with latent variables, such as the relationship between gender and the person’s personality, and the relationship between item features and item locations. A variant of the MH-RM algorithm designed for estimating latent variable models with crossed random effects was used to estimate the proposed model. A simulation study was conducted to evaluate the performance of the MH-RM algorithm in terms of parameter recovery with a popular IRT software flexMIRT (Cai, 2017). The simulation results indicated that the model parameter estimates were well recovered. The slope parameter and regression coefficient associated with the person latent variable and elements of
The proposed explanatory multidimensional random item effects RSM considers item locations random over items and can be applied in many practical settings, such as the automatic item generation. As illustrated in the “Proposed Modeling Approach” section, the proposed random item effects RSM requires estimating a smaller number of model parameters (compared with the fixed item effects RSM). Therefore, it can also be desired in scenarios where the number of persons is relatively small to obtain stable estimates of model parameters.
The present study enhances the idea that the full-rank NRM is best treated as a flexible template and promotes the understanding of the novel parameterization proposed by Thissen et al. (2010) and Thissen and Cai (2016). The flexibility of the full-rank NRM template allows for straightforward extensions of unidimensional polytomous IRT models to multidimensional models. It also makes it possible to design models for specific purposes by imposing constraints on model parameters. In addition, this paper facilitates the interpretations of outputs of popular IRT software packages that implement this parameterization.
However, the present study evaluated the proposed model in a unidimensional person latent variable setting and under a relatively small number of conditions. Therefore, it is recommended that the proposed model be evaluated in a more general multidimensional person latent variable case, and under a broader range of simulation conditions, such as different sets of item parameters, multiple combinations of numbers of persons and items, and multiple person-related and item-related covariates, to facilitate decision-making in empirical studies. In addition, the present study focused on the RSM and developed its random item effects counterpart. Future studies can adopt this novel parameterization of the NRM to extend other polytomous IRT models (such as the GPC model) to their random item effects versions.
Footnotes
Appendix
Sample flexMIRT syntax for estimating the explanatory multidimensional random item effects RSM
<Project>
Title = “Empirical Data Analysis”;
Description = “Zhang et al., 2016 Data”;
<Options>
Mode = Calibration;
Rndseed = 1234;
Algorithm = MHRM; // The MH-RM algorithm is applied to estimate the model.
Processors = 4;
ProposalStd = 2.2;
ProposalStd2 = 2.4;
InitGain = 0.1;
Stage1 = 20000;
Stage2 = 1000;
SavePRM = Yes;
SaveMCO = Yes;
SaveSCO = Yes;
Score = EAP;
<Groups>
%Gr%
File = “LongData.dat”;
Varnames = id, gender, age, item, res, rw; // Variable names in the data set
Select = res; // The variable res consists of item responses.
Dimensions = 2; // The proposed model included a person dimension and an item dimension.
Between = 1; // Item responses are cross-classified by the person and item dimensions.
Cluster = id; // The variable id indicates persons.
Block = item; // The variable item indicates items.
Code(res) = (1,2,3,4,5,6,7,8,9),(0,0,1,2,3,4,5,6,6); // The nine-category items are recoded.
Ncats(res) = 7;
Model(res) = Nominal(7); // The model is specified as an NRM with seven categories.
Crossed = Yes;
Covariates = gender, age, rw; // Two covariates are incorporated in the model.
L2covariates = 2; // The first two covariates are to be regressed to the person latent variable.
<Constraints> // Constraints are imposed to the full-rank NRM.
Fix Gr, (res),ScoringFn; // The alpha vector/scoring functions are fixed.
Fix Gr, (res),Intercept(1); // The first element of gamma vector is fixed to zero.
Value Gr, (res), Intercept(2), 0.2; // Assign a starting value to the 2nd element of gamma.
Value Gr, (res), Intercept(3), 0.2;
Value Gr, (res), Intercept(4), 0.2;
Value Gr, (res), Intercept(5), 0.2;
Value Gr, (res), Intercept(6), 0.2;
Free Beta(1,1); // Allow the regression coefficient to be free estimated.
Value Beta(1,1), 0.2;
Free Beta(1,2);
Value Beta(1,2), 0.2;
Free Beta(2,3);
Value Beta(2,3), 0.2;
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.