
Abstract
Corpus linguistics has developed significantly as a branch of applied linguistics in recent times, in relation to the possibilities of employment in research both in linguistics and in related disciplines. This field of study, furthermore, aims at assaying and describing the salient characteristics of a language by questioning collected and stored data on computer support, in the most applicable way. Considering the proposed definition, it was decided to use the methodology of collection, archiving, and interrogation, specific of corpus-based analysis, within the language educational practices for teaching Italian as L1 and L2. For the purposes of experimentation, a working group of 30 Italian teachers was set up that was aimed at students from different educational orders, and specific training was proposed, within a course organised by Centro Interculturale della Città di Torino. At the end of the course, the teaching staff were able to use the operative modalities of the corpus linguistics with regard to the collection and analysis of the linguistic productions of the students, questioning the corpora with respect to the linguistic uses. In conclusion, the corpora were used as a tool for linguistic analysis and to suggest interventions on error analysis, proving effective both for teachers and for learners. Actually, all the linguistic productions have been used as a basis for the linguistic research proposed to the learners. Teachers were offered a questionnaire about experimentation and the results were positive, as these showed how corpus linguistics can contribute to a significant awareness of learners about the language and learning goals.
Keywords
Introduzione alla ricerca
La linguistica dei corpora si è sviluppata come branca della linguistica applicata, nel corso degli ultimi anni, in modo significativo, in relazione alle possibilità di impiego nella ricerca nelle scienze del linguaggio e nelle discipline affini (Freddi, 2014). La linguistica dei corpora, infatti, “mira ad analizzare e descrivere le caratteristiche salienti di una lingua interrogando, nel modo ritenuto più opportuno, i dati raccolti su supporto informatico” (Fratter e Lo Duca, 2009: 11). In particolare: […] corpus linguistics is an area of applied linguistics that uses computer technology to analyze large collections of spoken and written texts, or corpora, which have been carefully designed to represent specific domains of language use, such as informal conversation or academic writing. Since the early 1990s, researchers have become increasingly interested in applying the findings of corpus-based studies to second and foreign language education, and some […] have argued that corpus linguistics could revolutionize language teaching by fundamentally changing the way we approach materials design and curriculum development. (Keck, 2013: 1)
Alla luce della definizione proposta, si è deciso di utilizzare la metodologia di raccolta, archiviazione e interrogazione, caratteristica dell’analisi corpus-based (Prat Zagrebelsky, 2004), all’interno delle pratiche didattiche per l’insegnamento dell’italiano come L1 e come L2 (Giacalone Ramat et al., 2003), accogliendo le proposte di Aston (2001), Flowerdew (2009) e Pérez-Paredes (2020).
Ai fini della sperimentazione si è costituito un gruppo di lavoro composto da 30 docenti di italiano come L1 e L2, di diversi ordini di istruzione, e si è proposta una formazione specifica, all’interno di un corso di aggiornamento professionale organizzato dal Centro Interculturale di Torino 1 , in collaborazione con il Dipartimento di Scienze Umane e dell’Innovazione per il Territorio, dell’Università degli Studi dell’Insubria.
Terminato il corso, il personale docente ha potuto sfruttare le modalità operative caratteristiche della linguistica applicata per quanto concerne la raccolta e l’analisi delle produzioni linguistiche degli studenti, interrogando i corpora a lezione, rispetto agli usi linguistici, in merito alla trattazione degli argomenti previsti dalla programmazione didattica.
In conclusione, l’analisi corpus-based è stata utilizzata come strumento per l’analisi linguistica e per suggerire interventi relativi all’analisi degli errori (Cattana e Nesci, 2004), dimostrandosi efficace sia per i docenti che per gli apprendenti (Togini-Bonelli, 2001). L’insieme delle produzioni realizzate dagli studenti, infatti, è stato impiegato come corpus per le ricerche linguistiche proposte ai gruppi classe, e, a differenza dei materiali comunemente adoperati in glottodidattica, si è rivelato autentico e privo della matrice soggettiva, caratteristica di una produzione individuale (Dewaele, 2011). In particolare, sulla base delle proposte di Aston (2001), Flowerdew (2009) e Pérez-Paredes (2020), si è deciso di formare il personale docente con l’obiettivo di trattare le produzioni dei propri apprendenti come corpora linguistici e di attivare modalità laboratoriali che permettessero differenti livelli di analisi e di interrogazione. Oltre alla dimensione dell’errore, infatti, i corpora sono stati utilizzati: as an empirical component of lectures, student assignments and projects; to determine the meaning of words and identify differences in usage between synonymous lexical items; to study lexical collocations; to focus on linguistic evidence that either supports or contradicts the prescriptive grammar rules. (Osipova, 2018: 274)
Dopo due mesi dalla fine del percorso, agli insegnanti è stato proposto un questionario relativo alla percezione della sperimentazione e i risultati di carattere percezionale si sono rivelati positivi, mostrando quanto la linguistica applicata possa contribuire a una consapevolezza significativa degli apprendenti rispetto ai fatti della lingua e alle potenzialità glottomatetiche.
Le potenzialità dell’analisi corpus-based nella glottodidattica
La linguistica dei corpora, come si è visto nel paragrafo precedente, è una branca della linguistica recente, nonostante sia possibile individuarne alcune specificità già nel passato, in quanto l’archiviazione di fonti linguistiche per l’interrogazione costituisce un aspetto diffuso fin dall’antichità (McEnery e Wilson, 1996). In effetti, si tratta di “un ramo della linguistica che ha conosciuto in questi ultimi anni uno straordinario sviluppo” (Fratter e Lo Duca, 2009: 11). Zagrebelsky la descrive come un “approccio recente allo studio dei fenomeni linguistici che si basa sulla raccolta e sull’osservazione di usi linguistici autentici con l’ausilio del computer” (Prat Zagrebelsky, 2004: 22) . In merito a quest’ultima affermazione, si ricorda che: […] l’uso della tecnologia nella didattica delle lingue moderne prende il nome di ‘glottotecnologia’, e rientrano all’interno della casistica tutti i sussidi e i dispositivi hardware e software in grado di migliorare, perfezionare e ottimizzare l’evento del corso di lingua. Si intendono glottotecnologie i ‘nuovi media’, gli strumenti che i docenti utilizzano nella redazione dei sillabi, dei curricoli e delle programmazioni, così come i dispositivi di registrazione e di riproduzione audio-visiva, la LIM, la lavagna luminosa e gli apparecchi intelligenti – smart – come smartphone, smart TV, smart PC e tablet. Come emerge dalla casistica abbozzata, la lista non può essere considerata definitiva, visti i progressi continui della tecnologia in rapporto all’accessibilità dei prodotti da parte delle agenzie formative, degli insegnanti e, naturalmente, dei corsisti. La relazione che lega la didattica dell’italiano L2 e, più in generale, la didattica delle lingue moderne alle glottotecnologie è da rilevare nell’ambito delle teorie psicolinguistiche e linguistico-acquisizionali degli ultimi sessant’anni. (Nitti, 2018b: 40)
Se, però, si considera un corpus come una raccolta di materiali linguistici ai fini della consultazione per mezzo di attività diversificate di interrogazione, non solo attraverso supporto informatico, è possibile cogliere elementi di analisi corpus-based per quanto concerne l’interrogazione di qualsiasi repertorio lessicografico e di molte edizioni critiche fondate sui testi, nonostante le modalità di fruizione possano spaziare dalla linguistica alla filologia e alla critica testuale (Chernyavskaya, 2017). In linea di principio, però, si tratta di un “approccio empirico, induttivo, che parte dai dati per giungere a generalizzazioni di qualche tipo, e che si pone pertanto in netta antitesi rispetto ad approcci più mentalistici, basati sull’introspezione del grammatico e sulla competenza del parlante nativo” (Fratter e Lo Duca, 2009: 11). Al di là di considerazioni così nette, è possibile identificare nella linguistica dei corpora un modus operandi finalizzato alla ricerca di carattere quantitativo e soggetto all’organizzazione dei dati linguistici (Bennett, 2010; Reppen, 2010).
Tali premesse metodologiche e, ancor più nello specifico, tali impostazioni epistemologiche possono essere significativamente utili ai fini linguistico-educativi e glottodidattici, perché permettono di raccogliere e classificare i materiali linguistici attraverso una modalità scientifica, organizzandoli a seconda del tipo di trattazione didattica desiderata.
A differenza dei formati didattici tradizionali, la proposta di analisi corpus-based in classe consente di superare l’attaccamento emotivo ai testi, da parte degli studenti, e di sfruttarli a seconda di criteri maggiormente oggettivi. È possibile, dunque, svincolarsi dalla matrice affettiva e dal significato di una produzione testuale stricto sensu per apprezzarne in maniera approfondita la struttura (Riccio, 2016). Capita spesso, infatti, che un apprendente non possa beneficiare dell’occasione delle fasi di correzione, in merito ad un testo autoprodotto, in quanto si sente giudicato, lasciando emergere le defezioni caratterizzate dall’attivazione del filtro affettivo. Si tratta di un meccanismo originato da un dispositivo inconscio dell’individuo, una “difesa psicologica che la mente erge quando si agisce in stato di ansia, quando si ha paura di sbagliare, si teme di mettere a rischio la propria immagine, e così via” (Balboni, 1999: 42).
Si è detto precedentemente che l’aspetto più significativo dell’analisi corpus-based applicata alla linguistica educativa e alla glottodidattica è rappresentato dal modus operandi della linguistica dei corpora: […] per lavorare sui dati linguistici la prima operazione da fare è raccoglierli secondo criteri definiti, cioè, appunto, costruire un corpus. Il quale, dunque, si configura come una sorta di banca dati, normalmente costituita da testi scritti o orali, completi o parziali, scelti sulla base della loro rappresentatività (rispetto al tipo di lingua da analizzare) e degli scopi del ricercatore (a cosa deve servire la ricerca). (Fratter e Lo Duca, 2009: 11)
Nel caso dell’azione didattica, pertanto, gli scopi del ricercatore confluiranno nell’oggetto della trattazione, a scopo puramente valutativo o con finalità di lavoro sul materiale linguistico. Le produzioni dei corsisti, dunque, divengono input linguistico a tutti gli effetti e costituiscono una ricchezza per l’intero gruppo classe. La stessa operazione di organizzazione del materiale linguistico, inoltre, può essere portata a termine dai corsisti, i quali tratteranno le produzioni non tanto come elementi caratteristici del proprio vissuto personale, bensì come estratti linguistici a uso didattico. A partire da questa modalità di lavoro, sarà possibile intervenire sugli errori, classificandoli a seconda di tassonomie (Nitti e Facchetti, 2019), ricercare usi di parole, collocazioni sintagmatiche e sintattiche, usi verbali, anche senza avvalersi di applicativi sofisticati. Un classico elaboratore di testi, infatti, attraverso la funzione di ricerca, può rintracciare l’occorrenza delle parole e, se provvisto di un contatore, può calcolarne la frequenza.
Sul piano prettamente teoretico “se l’obiettivo del ricercatore è quello di descrivere una lingua, poniamo l’italiano contemporaneo, allora il corpus da raccogliere dovrà essere rappresentativo dell’intera lingua, e dunque contenere al suo interno esempi di tutte le varietà che costituiscono oggi il variegato repertorio linguistico degli italiani” (Fratter e Lo Duca, 2009: 11). L’analisi corpus-based applicata in glottodidattica, tuttavia, prevede obiettivi certamente meno ambiziosi e più circostanziati; è possibile, infatti, verificare la presenza di un errore o rintracciare un uso linguistico sia di nativi che di non nativi, anche a seconda di una prospettiva docimologica. Secondo Serragiotto, infatti, la valutazione è concepita: come momento di un processo trasparente, unitario e globale che si sviluppa entro un contesto didattico e coinvolge numerosi attori; come esito di un processo di costruzione sociale delle competenze del discente; come punto di arrivo di un processo di apprendimento individuale e di gruppo; come azione regolata in modo intenzionalmente scientifico da parte dell’insegnante allo scopo di testare le abilità linguistiche dello studente e comparare i progressi che egli ha compiuto sia al livello di performance comunicativa sia della singola abilità (Serragiotto, 2016: 12).
In aggiunta a quanto detto, occorre notare che “l'importanza dei corpora in prospettiva glottodidattica emerge quando corpora bilanciati […] vengono utilizzati come testimoni dell'uso della lingua […]. Usare […] corpora bilanciati, o comunque ‘filtrati' come gli archivi dei giornali, permette di far notare aspetti quantitativi (enucleare le parole e le strutture più frequenti della lingua target e dare ad esse la priorità nell’insegnamento) e aspetti qualitativi, collocazionali” (Corino, 2014: 234–235).
Un’altra potenzialità didattica dell’analisi corpus-based riguarda la trascrizione del parlato, che in glottodidattica prende comunemente il nome di dettato. Scrivere sotto dettatura rappresenta una delle abilità integrate più discusse nella storia della glottodidattica moderna. Se fino agli anni Novanta in Italia si abusava della dettatura, soprattutto all’interno della scuola primaria (Nitti, 2019), oggi il dettato configura un’abilità integrata di pari dignità rispetto alle altre, soprattutto in riferimento ai contesti extrascolastici, dove può capitare di dover compitare e di trascrivere il parlato. La scrittura, d’altronde, è definita in linguistica come codice secondario, “avente cioè per contenuto l’espressione di un altro codice” (Facchetti, 2007: 14). Scrivere sotto dettatura, quindi, oltre che un compito di realtà (Allen, 2012), configura un’abilità da non sottovalutare soprattutto nei contesti di insegnamento di italiano come lingua seconda, laddove la corrispondenza grafema-fonema rischia di non risultare semplice da praticare, da parte di un apprendente non nativo. A questo proposito, è possibile ricavare un corpus a partire da audioregistrazioni, autodettature, dialoghi di un film o di videoregistrazioni di eventi comunicativi in contesti reali. Così, l’analisi corpus-based “may help teachers to design language analysis activities that engage students in explorations of texts that are more immediately relevant to their own lives” (Keck, 2013: 3).
La possibilità di lavorare sui corpora può incidere sullo sviluppo della competenza comunicativa degli apprendenti in quanto si analizza la lingua all’interno delle situazioni comunicative. In effetti, in glottodidattica: […] la competenza comunicativa può essere suddivisa in diverse sottocompetenze: linguistica, capacità di usare correttamente la lingua; sociolinguistica, capacità di comprendere e sfruttare le dimensioni di variazione della lingua; pragmatica, capacità di raggiungere uno scopo o di comprenderlo attraverso la lingua; internazionale, capacità di rispettare i rituali di comunicazione; testuale, capacità di produrre e recepire differenti tipi e generi di testi; culturale, capacità di sciogliere i nessi culturali della lingua, specificatamente rivolti alla realtà comunicativa di riferimento. (Nitti, 2019: 41)
Questa intersezione di sottocompetenze rappresenta l’obiettivo di molti corsi di lingue moderne, poiché si concepisce la lingua come un prodotto umano in riferimento alle situazioni comunicative, agli scopi della comunicazione e alle caratteristiche dei parlanti (Gotti, 1991).
Se le dimensioni della testualità e del piano formale della lingua sembrano beneficiare maggiormente dell’analisi corpus-based da parte degli apprendenti, per via del lavoro sulle produzioni testuali, non bisogna tuttavia trascurare la possibilità della ricerca di elementi sociolinguistici, culturali e interazionali. D’altronde, la stessa competenza testuale identifica la: […] capacità da parte del ricevente di instaurare relazioni fra gli elementi sulla base della conoscenza di schemi cognitivi globali […], di integrare il senso degli enunciati connettendo il detto al non detto […], di riconoscere il tipo di testo e le sue peculiarità e stabilire sulla base di tutti questi elementi un sistema di attese che facilita il processo di interpretazione. In altre parole, per sapere se un enunciato costituisce una frase, ci basta far ricorso alla nostra competenza linguistica, mentre per decidere se una sequenza di frasi costituisce un testo è necessario conoscere il contesto e affidarsi anche ad elementi extralinguistici. La competenza testuale, insieme a quella sociolinguistica e pragmatica, integra quella linguistica stricto sensu per formare la più generale competenza comunicativa. (Palermo, 2013: 29)
La ricerca
Come si è visto nei paragrafi precedenti, l’obiettivo di questa ricerca riguarda la possibilità di modellizzare interventi didattici rivolti allo sviluppo della competenza comunicativa attraverso l’analisi corpus-based, rendendo de facto l’insegnamento della lingua e l’analisi degli errori una pratica laboratoriale.
Le domande che hanno guidato l’indagine erano relative alla possibilità di formazione del personale docente in merito alla linguistica dei corpora, applicata alla glottodidattica, e alle modalità di valutazione del percorso formativo in termini di percezione dell’apprendimento e dell’insegnamento.
Il campione
I docenti che hanno partecipato all’indagine presentano profili diversificati. La compilazione del questionario ha permesso di evidenziare come la maggior parte degli informanti abbia un’età superiore ai 45 anni (58%) e sia in servizio per un periodo superiore ai 10 anni (65%). Per quanto concerne il titolo di studio, la quantità di diplomati (8%) è minore rispetto a quella dei laureati (92%). In merito agli ordini di istruzione, il 43% dei docenti insegna nella scuola primaria, il 34% nella secondaria di primo grado e il 23% nella scuola secondaria di secondo grado. Inoltre, per quanto concerne la disciplina insegnata, il 78% insegna italiano come L1, mentre il 22% come L2.
È opportuno evidenziare come i docenti di italiano L1, accanto al compito di insegnare la lingua, abbiano anche l’onere di insegnare la letteratura, soprattutto all’interno della scuola secondaria di primo e di secondo grado, limitando pertanto le ore dedicate esclusivamente alla lingua.
Il percorso di ricerca
Ai fini della formazione del personale docente, si è valutato che: […] per quanto riguarda l’aspetto puramente procedurale, l’analisi e la ricostruzione del materiale linguistico presuppone l’adozione di alcuni strumenti, essenzialmente di carattere lessicografico e lessicologico […], ad esempio corpora, dizionari, enciclopedie, manuali, abituando lo studente ad adottare il modus operandi proprio dell’attività di ricerca. Un elemento significativo della didattica basata sui testi e sui documenti, siano questi antichi o contemporanei, riguarda l’affinamento dello spirito critico del discente rispetto alle fonti che utilizza e alle possibilità di incorrere in forme diverse di mistificazione, di plagio e di falsificazione. (Facchetti e Nitti, 2019: 93)
Tale contestualizzazione delle pratiche didattiche ha reso necessario l’affinamento delle competenze del personale docente in merito ad alcune delle possibilità offerte dall’analisi corpus-based nell’ambito della formazione linguistica. Gli obiettivi del corso di formazione, relativo a questa ricerca, hanno riguardato un’introduzione breve alla disciplina, la trattazione della dimensione della testualità, a livello glottodidattico, e alcuni esempi di possibili attività da condurre in classe con i propri discenti, sia a livello teorico che operativo.
Il corso di formazione, della durata di 30 ore, ha previsto non solamente l’approfondimento di elementi di linguistica dei corpora e di trattamento dei testi, ma anche la ripresa di alcune delle linee fondamentali della glottodidattica, dal momento che non tutti i docenti erano in possesso delle medesime competenze iniziali.
Si è scelto di presentare attività connesse con le produzioni in classe degli studenti, individuando, a titolo esemplificativo, elementi linguistici quali usi verbali, impiego degli articoli, ricorrenza di determinate parole o sintagmi radicali, analisi della frequenza del lessico, ricerca delle collocazioni sintagmatiche forti (Gaskell e Cobb, 2004), d’altronde: […] these resources are increasingly drawing upon corpus analysis tools to provide additional information about collocation, the tendency of words to co-occur with other words, and phraseology, the tendency of words to occur in particular grammatical patterns. […] Corpus analysis tools, such as concordancing programs, allow teachers and students to view several examples of a key word in context and to study how this context impacts word meaning. These tools are particularly well suited for investigating the multiple senses of a single word, the subtle differences in the use of seemingly synonymous words, and the positive and negative connotations of particular phraseologies. (Keck, 2013: 1–2)
Oltre al lavoro sulle produzioni degli studenti, si sono raccolti e trattati alcuni dati linguistici prodotti dagli stessi docenti durante l’attività di formazione, attraverso la registrazione dei dialoghi, prodotti dagli insegnanti, nel corso delle esercitazioni di gruppo, consentendo di trascrivere il parlato audioregistrato e di analizzarlo per ricercare elementi specifici. L’adesione alla realtà, dunque, ha rappresentato un obiettivo linguistico-educativo della proposta formativa: […] l’esegesi delle fonti e l’analisi linguistica costituiscono due modalità privilegiate, soprattutto nell’ambito della società contemporanea, caratterizzata da un alto tasso di fruizione di testi digitali, per verificare l’autenticità delle informazioni e la loro attendibilità. L’utilità pratica, rivolta al mondo extrascolastico, della ricerca linguistica e della documentazione non dovrebbe, pertanto, essere trascurata dalle agenzie formative. (Facchetti e Nitti, 2019: 93)
Il questionario glottodidattico
L’analisi delle pratiche didattiche richiede l’adozione di strumenti specifici finalizzati all’inquadramento di fenomeni talvolta molto articolati. La branca di studio più vicina, alla quale la linguistica applicata ed educativa si riconducono prioritariamente per l’analisi dei fenomeni linguistici è la sociolinguistica.
In linea generale, la sociolinguistica indaga i principali assi di variazione della lingua (Berruto, 2004), ovvero la facoltà che ha un sistema linguistico di cambiare riguardo allo spazio (diatopia), al periodo temporale (diacronia), al canale della comunicazione (diamesia), al tipo di evento comunicativo (diafasia) e ai gruppi sociali implicati nell’interazione (diastratia). Tuttavia, non risulta semplice separare in modo netto tutti questi assi di variazione, tanto che alcuni teorici ne hanno talvolta ridisegnato la segmentazione, proponendo un approccio globale, soprattutto per quanto riguarda la diastratia e la diafasia (Dufter e Stark, 2002). Le variabili, in effetti, si articolano come rete fitta di relazioni e contraddistinguono le pratiche discorsive e testuali rispetto agli eventi della comunicazione (Marazzini, 2010). In aggiunta a quanto detto, la sociolinguistica, oltre alle dimensioni di variazione, indaga anche le modalità di ricerca privilegiate in linguistica sul piano epistemologico (Alfonzetti, 2017), concentrandosi, in particolare, sulla raccolta e sull’analisi dei dati, sui questionari e sulle interviste. In effetti, il questionario stricto sensu è considerabile un debito che la sociolinguistica stessa ha contratto nei confronti delle altre scienze sociali, in particolare la sociologia e l’etnologia (De Marco, 2010). L’indagine linguistica, però, ha a che vedere con la descrizione e con la classificazione degli usi linguistici rispetto alle comunità o ai gruppi di parlanti: […] a sociolinguistic interview is a particular kind of social occasion: it is a naturally bracketed spate of activity in which particular kinds of actions and behavior are expected […]. Those expectations provide a framework for interpreting what is said, e.g., for interpreting a question as seeking a particular kind of information. Furthermore, the relationship of those expectations to the interpretive processes guiding all social interaction can be made more or less explicit within an utterance. It seems clear that what those being interviewed by a sociolinguist expect (at least initially) is an agenda in which one person (thought of as ‘the interviewer’) asks questions that they are to answer. Awareness of this agenda provides a dominant frame within which what is said is understood, and specific utterances may display their relevance to this frame. (Schiffrin, 1993: 249–250)
In merito all’indagine relativa alle pratiche glottodidattiche, comunemente, “si utilizzano questionari di carattere sociolinguistico per analizzare le interlingue o le lingue degli apprendenti e dei docenti, la percezione degli usi linguistici e le pratiche per l’insegnamento della lingua” (Nitti, 2018a: 34).
Inoltre, come accade per qualunque strumento impiegato ai fini della ricerca, il questionario è fondato sulle caratteristiche dell’indagine stessa e sui fenomeni che si intendono studiare. A questo proposito, il disegno di questa ricerca riguarda la possibilità di utilizzare l’analisi corpus-based come formato didattico privilegiato per l’insegnamento della lingua italiana rivolto a nativi e a non nativi. Per riuscire a rispondere alle domande che hanno orientato la ricerca, è stato predisposto un questionario ed è stato individuato come campione rappresentativo l’insieme dei partecipanti che hanno preso parte al progetto formativo, al fine di analizzarne la percezione dell’azione didattica: “all’interno dei contesti didattici, infatti, il campione e la popolazione generalmente coincidono e sono generalmente stabiliti a priori” (Nitti, 2018a: 34). Uno dei limiti dell’attività di ricerca, che pare opportuno mettere in rilievo, riguarda l’affidabilità dei dati raccolti attraverso il questionario glottodidattico (Nitti, 2018a). Capita sovente, infatti, che i docenti intervistati si sentano giudicati e che forniscano rappresentazioni non del tutto aderenti alla realtà e questo limite deve essere considerato ai fini dei risultati che provengono dall’elaborazione dei dati.
Giacché un questionario per l’analisi della resa e dell’efficacia delle attività di insegnamento intende rilevare gli aspetti che riguardano la bontà di un’azione didattica, si è deciso di suddividerlo in varie sezioni per riuscire a valutare gli aspetti legati all’organizzazione dei corsi, alle competenze e alle caratteristiche del personale docente, ai diversi profili di apprendente e al tipo di corso e di sillabo di lingua italiana. Inoltre, dal momento che la struttura di un questionario può essere più o meno rigida (Hudson, 1998), inserendo domande con risposte fissate a priori – chiuse – o quesiti aperti di carattere prettamente qualitativo, si è valutato, in relazione alla facilità di analisi dei dati, di inserire quesiti a scelta multipla, corredati di uno spazio per le note libere alla fine di ogni sezione, qualora gli informanti avessero voluto inserire alcune considerazioni non inoltrate all’interno delle risposte precedenti (Nitti, 2018a).
Un questionario semistrutturato, in effetti, avrebbe comportato tempi decisamente maggiori per la compilazione e avrebbe implicato una difficoltà di analisi più ampia, a causa dell’organizzazione delle risposte in tassonomie definite, nonché un tasso maggiore di interpretazione, durante la fase di analisi (Enghels et al., 2020). Difatti, “un’indagine molto libera necessita di tempi più dilatati per il trattamento dei dati, perché occorrerà considerare tutte le risposte e indicizzarle a seconda di descrittori di ampia portata” (Nitti, 2018a: 36).
Per quanto concerne la struttura, il questionario riporta, oltre al titolo dell’indagine, un frontespizio all’interno del quale sono chiarite le modalità di compilazione, le leggi che disciplinano la privacy in Italia, la responsabilità scientifica della ricerca, le modalità di trattamento e di divulgazione dei dati, con l’indicazione della sede congressuale per la disseminazione, ovvero il Colloque VALS-ASLA 2020, organizzato dall’Université de Neuchâtel, e i tempi necessari alla compilazione, non superiori ai 20 minuti. Un questionario più lungo avrebbe potuto comportare tempi di compilazione più dilatati, rischiando di invalidare i dati a causa della dispersione: […] in linea generica, un questionario non dovrebbe mai essere troppo lungo, poiché gli informanti tenderebbero a produrre risposte casuali e devianti rispetto alla realtà; un range di 20-30 domande pare essere ragionevole, così come un intervallo di 15–20 minuti necessari alla compilazione. (Nitti, 2018a: 36)
La prima sezione del questionario, successiva al frontespizio, contempla una batteria di 4 quesiti relativi alle informazioni socio-anagrafiche dei docenti (disciplina insegnata, ordine di istruzione, anni di servizio, contesto territoriale), mentre la seconda sezione è rivolta alle specificità degli apprendenti, contando altre 6 domande.
La terza sezione, composta da 10 quesiti, si concentra in maniera significativa sui risultati del formato didattico proposto durante il percorso di aggiornamento, in termini di valutazione delle pratiche formative e di gradimento delle attività di aggiornamento professionale.
Ogni domanda, inoltre, include il campo “non so/non rispondo/dato non disponibile” al fine di evitare la distorsione delle risposte e di permettere a ciascun informante di esprimere il proprio pensiero senza ricorrere alle etichette prestabilite all’interno del questionario.
Il questionario è stato inviato, dopo due mesi dalla fine del percorso formativo, via posta elettronica o link diretto, a tutti i docenti che hanno partecipato al corso di formazione, con un tasso di risposte pari al 98%.
Analisi dei risultati
All’inizio del percorso formativo si è domandato agli insegnanti quali potessero essere gli impieghi potenziali dell’analisi corpus-based rivolta alla didattica della lingua. Il campione si è espresso a favore dello scritto sia in ricezione che in produzione (Grafico 1).

La percezione delle potenzialità dell’analisi corpus-based nell’insegnamento della lingua.
Il Grafico 1 rende visivamente l’idea del preconcetto riguardo alle potenzialità dell’analisi corpus-based. In effetti, l’opinione del personale docente risulta viziata anche in riferimento alla tradizione didattica dell’italiano, schierata in molti contesti a vantaggio esclusivo della scrittura, soprattutto in produzione, nonostante la diffusione dei metodi comunicativi (Nitti, 2020). Uno dei motivi che hanno contribuito alla mancanza di apertura della didattica dell’italiano, soprattutto come L1, all’approccio comunicativo, riguarda, come si è visto in precedenza, la commistione della didattica della lingua e di quella della letteratura. Essendo la produzione letteraria essenzialmente scritta, la didattica della lingua si è spesso orientata allo sviluppo delle abilità di comprensione dello scritto. Lo stesso concetto di corpus, d’altronde, è concepito nella mente dell’insegnante come afferente allo scritto, fattore del quale si è tenuto conto nelle attività formative. Si sono presentati, dunque, esempi di analisi del parlato, coinvolgendo attivamente i partecipanti sia nella fase di registrazione che in quelle di trascrizione e di analisi. In effetti, […] teachers who are interested in applying corpus linguistics in their own classrooms have a number of options available to them. Teachers who are just beginning to learn about corpus linguistics themselves, or who do not feel they have enough time or resources to devote to corpus activities, can nevertheless draw upon a variety of corpus-based resources when planning lessons and designing materials, including corpus-based dictionaries, grammars, and language textbooks […]. Teachers can also take a more critical approach to evaluating existing language teaching materials, keeping in mind issues that corpus linguists have emphasized as important: frequency (e.g. when selecting target vocabulary); collocation and phraseology (e.g. teaching not only word meaning, but also important collocates and syntactic patterns); and register variation (e.g. highlighting key differences in the use of a particular feature in speaking and writing). A number of online tools also make it possible for language teachers to analyze collections of texts they plan to use in their classroom, to assess the difficulty of these texts, and to investigate how vocabulary words are recycled across an entire instructional unit […]. Teachers can also consult a variety of online corpora when preparing lessons and materials […]. In addition to consulting corpora themselves, teachers also have the option of introducing corpora to their students. (Keck, 2013: 2)
In merito alle abilità integrate, invece, nelle rilevazioni preliminari allo svolgimento del corso di formazione e aggiornamento, l’attenzione degli insegnanti era orientata soprattutto sul piano della traduzione, individuando come elemento saliente della linguistica dei corpora i repertori lessicografici di carattere contrastivo, ovvero i vocabolari di lingua (Grafico 2).

La percezione delle potenzialità dell’analisi corpus-based nell’insegnamento della lingua in merito alle abilità integrate.
Il Grafico 2 mostra la percezione delle potenzialità dell’analisi corpus-based rispetto alle abilità integrate. Come si può notare, lo sviluppo delle abilità integrate che prevedono l’oralità è fortemente sottostimato a favore delle attività di traduzione. Se è vero che gli insegnanti e gli studenti sono comunemente abituati a utilizzare i vocabolari, è certamente innegabile che le potenzialità della linguistica dei corpora in glottodidattica sono decisamente più significative (Sinclair, 2004). L’analisi dei fatti di lingua riguarda probabilmente l’attività più preziosa sul piano dell’insegnamento, ma la stessa raccolta dei dati e la trascrizione del parlato costituiscono un buon allenamento sia della competenza metalinguistica che delle abilità cognitive.
Dopo due mesi dalla fine del corso di formazione, è stato chiesto al personale docente quale attenzione avesse rivolto all’analisi corpus-based rispetto alla propria attività didattica, proponendo un questionario di gradimento del corso con alcune domande di carattere glottodidattico (cf. Il questionario glottodidattico).
Il Grafico 3 mostra le attività più frequenti connesse con l’analisi corpus-based rispetto alla didattica dell’italiano, a seconda del ciclo e dell’ordine di istruzione. Non emergono differenze sostanziali fra l’insegnamento dell’italiano L1 o L2. Le attività con i vocabolari, contrariamente ai pregiudizi iniziali ben documentati nel Grafico 2, rappresentano una minoranza rispetto agli altri impieghi dell’analisi corpus-based. La consultazione delle banche dati costituisce uno degli elementi maggiormente trascurati dal personale docente, soprattutto in considerazione della difficoltà di reperimento di banche dati gratuite, della scarsa intuitività delle applicazioni, e della difficoltà d’uso connessa con le interfacce e con le grafiche, spesso percepite come inadatte al pubblico di studenti di qualsiasi ordine e grado (Corino, 2014). La stessa perplessità, d’altronde, è testimoniata anche in altre ricerche affini (tra gli altri, cfr. gli studi di Gavioli, 2001; McCarthy, 2008; Tsui, 2005). A questo proposito occorre notare che […] la grafica si riferisce alla qualità visiva del programma che si sta utilizzando; mentre l’interfaccia riguarda il rapporto fra utente e applicazione in termini di operatività […]. L’intuitività fa riferimento alla semplicità di uso di un’applicazione; trattandosi come molti indicatori di un parametro soggettivo, non è detto che quello che per un individuo è semplice, risulti semplice per un altro individuo (Nitti, 2018b: 42).
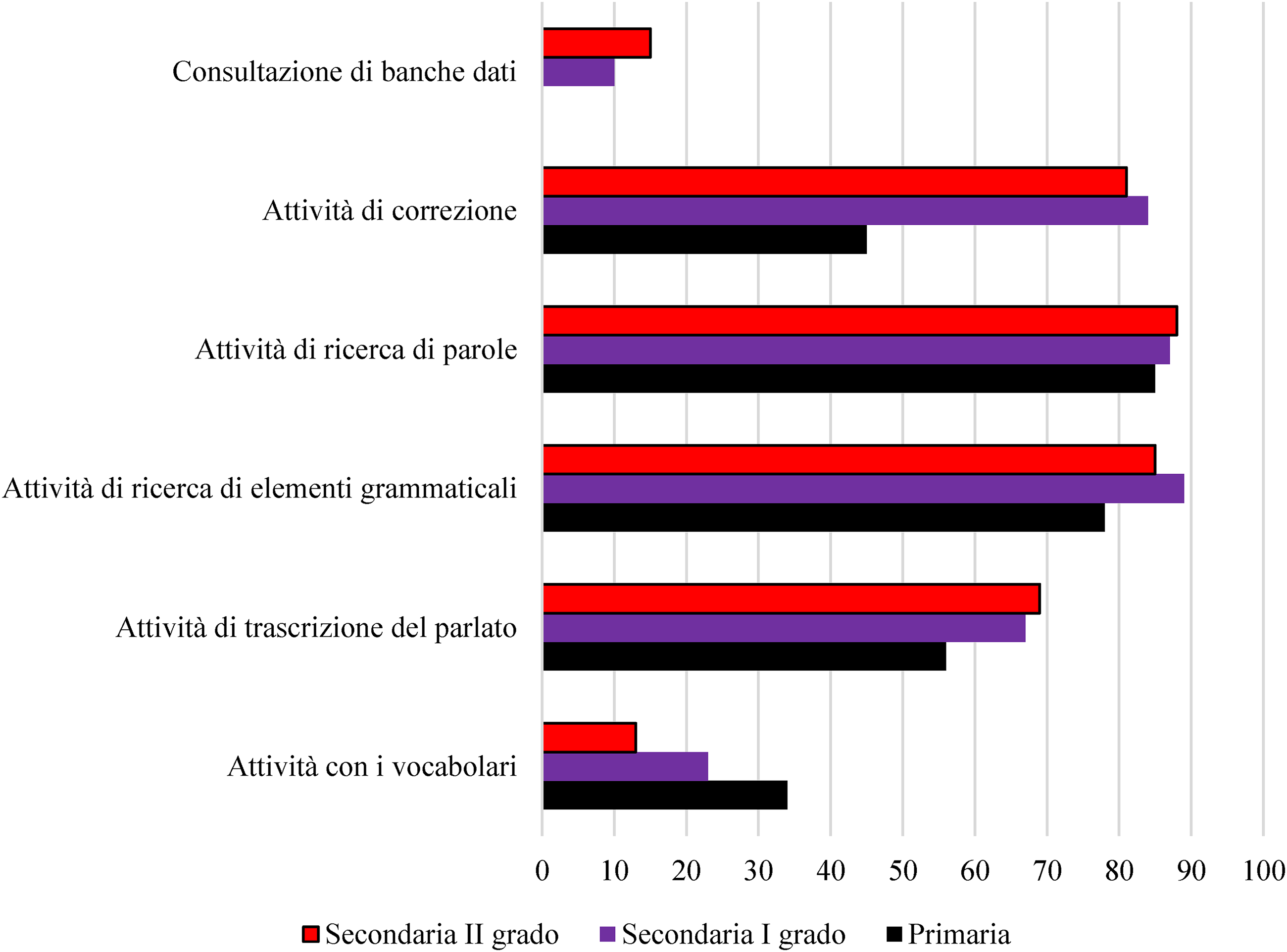
L’utilizzo della linguistica dei corpora nella didattica dell’italiano dopo il corso di formazione.
In merito all’analisi corpus-based da parte degli apprendenti, il personale docente ha dichiarato di apprezzare particolarmente il trattamento e la didattizzazione degli errori (James, 2013) e questo aspetto conferma i risultati di alcune ricerche affini (tra gli altri studi cfr. Khansir, 2008; Kokoreva, 2013; Leńko-Szymańska, 2017; Sosnina, 2017). Infatti, secondo il campione, l’analisi degli errori attraverso attività corpus-based avrebbe consentito agli studenti di svincolarsi dal filtro affettivo e di concepire il testo come prodotto linguistico, esaminandolo in maniera oggettiva e distaccata.
Verso un formato didattico innovativo
In questo contributo sono stati descritti i risultati di una ricerca sperimentale di ambito glottodidattico, relativa alle potenzialità di uso della linguistica dei corpora all’interno delle attività glottodidattiche. Il percorso di ricerca, scandito in diverse fasi, si è articolato attraverso un corso di formazione rivolto a docenti di lingua italiana. L’analisi dei dati provenienti dal questionario di gradimento del corso e di rilevazione delle pratiche glottodidattiche ha consentito di evidenziare gli impieghi d’uso della linguistica dei corpora non tanto come disciplina autonoma quanto come modus operandi per una trattazione scientifica della lingua. È proprio questo l’aspetto di maggior significatività della ricerca, ovvero il fatto di poter formare gli studenti a essere veri e propri ricercatori in merito alle questioni della lingua, sviluppando uno spirito critico e un atteggiamento di rigore e serietà nei confronti della ricerca. Tale prospettiva, difatti, ha consentito pienamente di incrementare la competenza metalinguistica (Peppoloni, 2018).
Uno dei limiti dell’indagine, tuttavia, riguarda le competenze digitali degli apprendenti, poiché “una volta raccolti, i testi vanno trasferiti su supporto informatico e resi disponibili ad essere interrogati […]. Una prima importante decisione da prendere riguarda il tipo di trattamento cui sottoporre, o non sottoporre, i testi costituenti il corpus” (Fratter e Lo Duca, 2009: 12). Un altro aspetto critico di questo studio di carattere esplorativo riguarda da un lato l’esiguità del campione e dall’altro la mancanza di soluzioni per valutare efficacemente i risultati in termini di performance da parte degli apprendenti. Infatti, trattandosi di ordini e cicli di istruzione differenti e di insegnamento dell’italiano come L1 e come L2 non è stato possibile uniformare le attività di testing e, d’altronde, questo aspetto non rappresenta un obiettivo dell’indagine, in quanto le domande di ricerca riguardano l’efficacia del percorso formativo e la percezione del corpo docente in merito all’azione didattica. Ciascun docente ha testato le competenze dei propri apprendenti, dopo le attività di analisi corpus-based, in autonomia, dichiarandosi soddisfatto all’interno del questionario. Un’espansione possibile di questa ricerca, dunque, potrebbe riguardare l’impiego di un campione su vasta scala e la valutazione dell’apprendimento a seconda di una prospettiva didattico-acquisizionale (Rastelli, 2009).
In conclusione, la ricerca, inserita all’interno degli studi di linguistica educativa, permette di confermare che la linguistica dei corpora costituisce una rivoluzione epistemologica, almeno a livello glottodidattico, scardinando le pratiche tradizionali comuni: […] possiamo rispondere alla domanda se veramente la linguistica dei corpora ha costituito una rivoluzione nella storia del pensiero linguistico e dare il nostro punto di vista in merito alla controversia se si tratti piuttosto di un insieme di metodi che di una disciplina indipendente. Per alcuni, infatti, si tratta semplicemente di un approccio allo studio di fenomeni linguistici nella misura in cui, per verificare un’ipotesi, si attinge dal corpus per reperire esempi che confermino, o eventualmente servano a confutare, una teoria […]. Noi riteniamo invece che la base empirica e i modi per comprenderla abbiano rivoluzionato la teoria linguistica su più fronti. Primo, dando origine a ipotesi innovative riguardo alla costruzione del significato e alla condivisione dello stesso nell’uso linguistico […]. Secondo, mostrando come grammatica e lessico siano state artificiosamente separate nella tradizione linguistica […]. Terzo, liberando l’apprendimento e l’insegnamento delle lingue da un’inclinazione normativa che pone un target fisso di grammaticalità a cui mirare, solitamente corrispondente alla figura idealizzata del parlante nativo, sostituendola con un orientamento probabilistico secondo cui anche la struttura grammaticale non è indipendente dalla variazione d’uso, anzi ne è soggetta, non è fissa e immutabile, bensì variabile. (Freddi, 2014: 112–113)
Al di là della portata innovativa dell’utilizzo dell’analisi corpus-based a lezione, è da rilevare che se il gruppo classe non è alfabetizzato sul piano informatico, non è in possesso delle competenze procedurali per l’utilizzo delle applicazioni e non dispone di una competenza metalinguistica adeguata, tale strategia può risultare controproducente: […] the use of corpus data in the classroom is not uncontroversial, however, as others have expressed skepticism concerning the relevance of corpora for language teaching. In some cases, corpus data, when divorced from its original context, may serve to confuse students, rather than help them to learn about the language. (Keck, 2013: 3)
Tuttavia, nel tentativo di rispondere alla domanda di Conrad (2000), riguardo al potenziale innovativo della linguistica dei corpora in merito all’insegnamento della grammatica e, in senso più ampio, delle lingue, i risultati di questo studio dimostrano che la strada è ancora lunga, ma che le prospettive future sono incoraggianti, dal momento che i soggetti che hanno preso parte alla formazione si sono dimostrati interessati e la percezione degli esiti della sperimentazione sono stati soddisfacenti. Pertanto, […] corpus linguistics has fundamentally changed our understanding of language use, and this, in turn, has led to changes in how we approach language education. Over the next few decades, it is likely that corpus-based findings will continue to inform the development of language teaching materials. The use of corpora in the classroom is also likely to increase, as teachers and students are given greater access to online corpora and text analysis tools. The major question to be explored is no longer “What relevance does corpus linguistics have for language teaching?” but rather “How can teachers and students most effectively make use of the corpus-based resources available to them?” Continued exploration of the use of corpora in a wide range of classroom contexts will no doubt help to refine our understanding of the variety of ways in which corpus linguistics might be applied to language pedagogy. (Keck, 2013: 4)
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.