
Abstract
This study aimed at finding the kernel structure common to three different value taxonomies in European languages (Dutch with 641 values and 634 participants, Austrian with 496 values and 456 participants, and Spanish with 566 values and 532 participants). Values from those three taxonomies were translated into English, thus forming the basis for the connections between the taxonomies. Using the common values between the three pairs of languages, factor structures resulting from a principal components analysis (PCA) were pairwise compared based on congruence coefficients after Procrustes rotation. Moreover, PCA was applied to a set of 139 values that was common to the three taxonomies. Furthermore, a joint matrix of values was formed with 1,703 values and 1,622 participants. Using only the common values after translation into English, this matrix was compressed to a set with 413 values and 1,622 participants, which was subjected to simultaneous components analysis (SCA). The different procedures ultimately led to a common structure with five value components, each specified in four facets. Those value components are Interpersonal Relatedness, Status and Respect, Commitment and Tradition, Competence, and Autonomy.
People from different cultures are often understood to entertain different values, meaning that those people distinguish themselves from each other by valuing objects, events, and ideas in different ways. For example, people from individualistic cultures tend to value well-known brand names and traveling to new places more than people from collectivist cultures (Sun, Horn, & Merritt, 2004). Human morality, concerned with right and wrong, is probably guided by both personal values and cultural values (Vauclair et al., 2015). To a significant group of youth in Nigeria, for example, to be successful is now a function of money and personal connections rather than merit and hard work (Aghedo, 2015; Willot, 2011).
It is of great importance to map out values of different people and of different cultures, to find out about their commonalities and about what distinguishes them, and to know of the mechanisms that are implied with certain values being endorsed. The study of values has a long history (e.g., Dukes, 1955), but catalogs of values that may claim full coverage of the field, are hard to find. Studies of values that assume a certain coverage of the field are, for example, Rokeach (1973) and Schwartz (1992; Schwartz et al., 2012).
During the last two decades, research on values has been dominated by Schwartz and colleagues (Schwartz, 1992; Schwartz & Bilsky, 1987, 1990; Schwartz & Boehnke, 2004; Schwartz et al., 2012). Studies with the Schwartz’s 10 Basic Values, as, for example, measured through the Schwartz Value Survey (SVS), in many different cultures have provided an impressive amount of information about the usefulness of their value system in those cultures (e.g., Schwartz, 1994a; Schwartz & Bardi, 2001; Schwartz & Boehnke, 2004; Schwartz et al., 2001; Schwartz & Sagiv, 1995). Recently, the system was refined into 19 Basic Values (Schwartz et al., 2012), with additional value constructs distinguished within the original underlying dimensional system. There are, however, two types of problems with this research. One relates to the coverage of the value domains by those 10 or 19 value constructs, and the other relates to the preponderate etic nature of the approach. Taxonomic work does not fare well by theoretical preconceptions (Sneath & Sokal, 1973), and Schwartz’s value system is based indeed on insights and theoretical notions of the author(s). Moreover, the application of the instruments measuring the value constructs in different cultures runs the risk of blindness for cultural specific (emic) characteristics of value systems (cf. Cheung, Van de Vijver, & Leong, 2011).
The etic approach aims at universality of established models and tries to investigate whether certain models or instruments apply across the cultures under investigation. Rokeach (1973) and Schwartz (1992) have worked from this perspective, and have assumed a universal, culturally independent, structure of values. An emic approach would, however, focus more on analyses of values in specific cultural contexts. The appreciation of cultural effects on values has, for example, been expressed in Shweder (2001; cf. McAdams & Pals, 2006), who argues that Central Europe and the United States mainly orient by ethics of Autonomy, whereas Africa and Asia orient much more by the ethics of Community and Divinity: group related and spiritual values are differentiated to a larger extent in the latter continents. From these considerations, it may be expected that even within Europe, considering the more individualist Northern and Central part of the continent as compared with the more collectivist Eastern part, the value systems of different countries and cultures will show marked differences.
In the present study, we aim at a balance between emic and etic perspectives, taking optimal advantage of the emic perspective in taxonomic coverage of the semantics of values, and by allowing a more etic perspective in structuring the domain of values. Recently, a number of studies on values have been performed according to the psycho-lexical approach (De Raad, 2000), to be conceived of as indeed a combined etic-emic approach (see Cheung et al., 2011). The psycho-lexical approach assumes that all value conceptions important for speakers of a language sooner or later will be reflected in that language and will thus be part of its lexicon; those value conceptions are identifiable in a tangible repository of that language, such as a dictionary (Goldberg, 1981). This approach is particularly apt for studying values. If one wants to know what people find important in their lives, it seems obvious that one should ask them or, less obtrusively, find records of what they apparently found important. Values should essentially be derived from people’s personal orientations in life. Constructing a system of values theoretically, and imposing that system upon people, leaves little room for individually felt issues of importance. The psycho-lexical approach studies people’s views and orientations and considerations of importance, assuming that such information has become a sedimentation in the lexicon of the language in the form of concepts and expressions that are used to convey their meanings.
Although the psycho-lexical approach uses general agreed upon rules for the identification of values in a lexicon (which is a sort of etic feature), the approach always starts with the full lexicon (i.e., dictionary) of a particular language or culture, thus allowing for specific cultural aspects to be contained in the selection (emic feature). The psycho-lexical approach has been applied to the study of personality traits in many languages with great success (cf. De Raad, 2000). Aavik and Allik (2002) were the first to apply the psycho-lexical principles to the study of values. Similar subsequent studies were performed by Renner (2003), De Raad and Van Oudenhoven (2008), and Morales-Vives, De Raad, and Vigil-Colet (2012). Each of those studies gave evidence of value domains or sub-domains that were underrepresented in the Schwartz system, for example, concepts emphasizing the importance of aesthetics; in addition, it was found that certain domains of values specified by Schwartz were overrepresented in comparison with the different psycho-lexically derived systems (e.g., security). De Raad and Renner (2011) compared the psycho-lexically derived values in Dutch and Austrian German (henceforth referred to as Austrian) and showed that those two value structures differed in terms of cultural specifics on one hand. On the other hand, it was possible to find a common structure to those different languages that was unlike the system provided in, for example, the SVS.
A striking difference between the Schwartz system of values and, in particular, the psycho-lexically derived Dutch and Spanish value systems is most visible in the available (published) two-dimensional circular representations. All these three systems provide circumplex representations that show some commonality in terms of the two dimensions. In the system described by Schwartz (1992), Schwartz et al. (2012) system, Self-Enhancement (e.g., achievement, power) versus Self-Transcendence (e.g., benevolence, universalism) forms one dimension, which more or less resembles the pro-individual (e.g., ambition, goal-orientation) versus pro-social (e.g., helpfulness, kindheartedness) dimension in De Raad and Van Oudenhoven (2008) and the corresponding dimension (e.g., success and popularity vs. tolerance and forgiveness) in Morales-Vives et al. (2012). The Conservatism (conformity, tradition) versus Openness to Change (self-direction, stimulation) dimension in Schwartz (1992) more or less resembles the second dimension in Dutch (e.g., order and duty vs. joy and adventure) but does not agree with the second dimension in Spanish (e.g., cultured and education vs. romance and love). Moreover, the distribution of the value domains around the Schwartz (1992) circumplex is clearly different from the distributions of the same value domains in the two psycho-lexically derived circumplexes.
Numerous studies have been made to identify values that are common to different cultures and countries during the last few decades, especially through the use of Schwartz’s (1992) system of values. Although that system has been refined (Schwartz et al., 2012), by specifying some facets for existing value-types, it is a thoroughly constructed but essentially fixed framework. The power of the psycho-lexical approach is in the identification of the full range of hundreds of values in a language, thus freely tapping into the specifics of a culture. Specific salient values in a single culture or language will have relatively more difficulties to travel across the borders; the inclusion of different cultures or languages, each with its own salient characteristics, allows accumulation of values with small cultural densities, and provides a richer context for the comparison with, for example, etic findings.
De Raad and Renner (2011) succeeded in finding a joint value structure based on the common values in the Dutch and Austrian systems that is of interest theoretically. It is a five-factorial structure, of which the first two factors seem to represent the more generic dimensions of communion and agency (Bakan, 1966), called Communal Existence (friendliness, love, connection, cooperation, forgiving) and Realization of Potential (self-determination, independence, self-respect, emancipation), respectively. A third factor, called Rules of Conduct, covers duty, order, discipline, realism, and so forth, all values that are important in realizing goals of any kind, whether being communal or agentic. The last two dimensions, called Spirituality and Pride and Reputation, represent transcendental values on one hand (faith, religion, generosity, nationalism) and materialistic values on the other hand (wealth, success, property, career).
In this article, we investigate the relations between three psycho-lexically derived value systems, in Dutch, Austrian, and in Spanish, thus extending the previous two-language comparison. We do so following different psychometrical routes. The three value structures each represent full catalogs of values for a language, including values that are most apt for cross-cultural communication and values that are considered culture specific. We compare the three value structures, which were retrieved through principal components analysis (PCA), pairwise, by considering the congruence coefficients between the corresponding value factors. Moreover, we merge the three “emic” data sets on the basis of values that are common to two or three languages, thus yielding a large data set that contains all the information of the individual sets. We aim at establishing the common structure across the three data sets on the basis of the cross-lingually shared values, while allowing the non-shared values to entertain relations with the factors describing the common structure, and we try to indicate how the common structure is related to the three individual structures. For the identification of this common structure that is related to the individual structures, we use simultaneous components analysis (SCA), a PCA-related technique. Such a study should give further insight into their common ground and in their distinctions. The three languages or cultures differ in important respects and form a good representation of the broader differences between cultures in Europe in general. The study is expected to give further evidence of the power of the psycho-lexical approach in revealing the most important dimensions of values across languages, and it is taken as a further test of the five-factorial structure to which De Raad and Renner (2011) concluded earlier.
The Cross-Cultural Triangle
Spanish, Austrian, and Dutch form the triangle. These three pertaining countries differ in several respects. Hofstede (1980, 1991) performed a massive study leading to dimensions of national culture in which four clusters of values were found that distinguish countries from each other. The dimensions on which the countries are clustered are Power Distance, Individualism, Masculinity/femininity, and Uncertainty Avoidance. Of the three present countries, Austria scores lowest on Power Distance and Spain highest; The Netherlands score highest on Individualism, while Spain and Austria are more collectivistic; Austria scores highest on Masculinity and The Netherlands lowest, and Spain and Austria score higher on Uncertainty Avoidance, and The Netherlands lower.
In the domain of morality, some studies have recently been performed taking a somewhat shifted version of this cultural triangle as field of comparison, namely, with German data instead of Austrian, next to Dutch and Spanish. De Raad, Van Oudenhoven, and Hofstede (2005) studied terms of abuse in these three countries (cf. Van Oudenhoven et al., 2008) because possible differences were considered to reflect differences in moral expressiveness, in accordance with the dimensional differences described above. In the consanguine field of virtues, Van Oudenhoven, De Raad, Carmona, Helbig, and Van der Linden (2012) examined the relative influence of these three nations on the formation of virtues. Cross-national differences between Germany and The Netherlands on one hand, and Spain on the other hand, for example, had a greater influence on the importance ratings of virtues than religion.
We used value descriptive data from Austria (ratings on 496 values), The Netherlands (641 values), and Spain (566 values). Renner (2003), De Raad and Van Oudenhoven (2008), and Morales-Vives et al. (2012) have published the details on the structuring of these three independently developed value taxonomies. The original raw data sets were used for the present comparison. The main questions are to what extent the three value resources have the same structure and what are their differences. A special focus will be on the possibility to identify the five-factorial model hypothesized in De Raad and Renner (2011).
Method
The problem with comparing such independently developed taxonomies, as we have here, is that the seemingly incompatible has to be made compatible. In all three sets, both the values and the participants differ from each other. To find common ground for the comparison, the three lists of values were translated into English as the common language. This involved translation and back-translation into the language most familiar to all authors. To identify common descriptors, first we looked for common values for each pair of languages, using the English and the three other languages as much as possible, supported by translation-dictionaries. Second, we looked for values that were common for all three languages, following the same process.
Materials
The materials are briefly described here; for further details, we refer to the original publications. In all three sets, the value vocabularies used for collecting ratings had been constructed from a full listing of value descriptors as selected from comprehensive dictionaries or databases. The final sets of values that we used were carefully selected as the most relevant and practically useful terms available in the three lexicons.
Dutch
A data set consisting of self- and other-ratings (of the same person) from 634 participants (416 females) on 641 values was used. The average age was 35 years, ranging from 16 to 87; and just over 90% had a higher education. 1 Participants were instructed to indicate for each value to what extent they were guided by the value in behavior and decisions.
For the selection of values, a computerized database of the Dutch language was used. Two expert judges removed words that clearly could not serve as a value description. Next, three judges made a first selection using the definition that a value is “what people find important,” giving priority to nouns. The resulting list of words was rated by 12 judges on the extent to which those words could be considered as value descriptors. The combined ratings were used for the final selection. In the process of selection, words were removed that had synonyms that referred to specific ideologies or religious convictions (e.g., Communism or Christianity) and to specific sexual orientations (e.g., bisexuality). The procedure led to a final list of 641 descriptors.
Austrian
A data set consisting of self-ratings from 456 participants (350 females) on 496 values was used. Of the participants, 442 were from Austria and 14 from Germany; the average age was 29.8 years, ranging from 17 to 68; and just over 84% had a higher education. Participants were instructed to indicate the extent to which the value descriptors formed personal guiding motives in their lives.
To identify value descriptors, two judges checked a German dictionary to find nouns and adjectives that possibly described personal or societal values, taking into account the following definition of values: concepts expressed by nouns or adjectives that represent “guiding principles” in an individual’s life, expressing personal or societal objectives, motives, or interests that are stable over time. Next, those concepts were removed that were attitudes rather than values (e.g., specific confessions) or “regionalisms.” The resulting list of words was rated by six judges on their suitability to express a human value. These ratings were used for the final selection. In the process of selection, Angleitner and Ostendorf’s (1994) personality taxonomy was consulted to find terms that had been overlooked and to exclude terms that rather expressed emotions, dispositions, or roles. The procedure led to a final list of 496 descriptors.
Spanish
A data set consisting of self-ratings from 532 participants (419 females) on 566 values was used. The average age was 22 years, ranging from 18 to 50 years. All had higher education. Participants were instructed to rate each value on the extent to which it was important for them and to which they were guided by that value.
For the selection of values, an online database of the Spanish language was used from which those words were removed that clearly did not express human behavior or thoughts and words that clearly did not describe values. Next, three judges decided which words from the thus reduced database could be used to describe values, using the criterion of values describing “what people find important,” and words were removed when the three judges agreed that they were not values. The resulting list of words was rated by eight judges on the extent to which the words described values. These ratings were used for making the final selection. During a last check, two judges remove some synonyms. This procedure provided a final list of 566 descriptors of values.
Analyses
We applied three procedures in comparing the Dutch, Austrian, and Spanish value structures, the first involving inspecting hierarchies of factors from the three languages, the second implying pairwise (language by language) comparisons of the three structures, and the third was about finding the common structure to the three and about the relation of this common structure to the individual structures. Especially, the first two procedures were used to allow decisions on the appropriate number of value factors that would represent best the individual structures and that would form the best choice for a tripartite comparison. The second and the third of the procedures needed to be based on the set of values that was common to the two languages involved or common to the three languages. The second procedure of comparison involved factoring the three full data sets and calculating congruence coefficients between the corresponding factors based on the selection from the matrix of loadings for the common values (after translation) per pair of languages. The third procedure, involving the tripartite situation, aimed at finding the structure common to the three sets of values.
To have a good view on the three value sets, and to facilitate decisions about the number of factors to be selected for the comparisons, we started with an analysis of the hierarchy of value factors in the three languages as they emerge in factor solutions with a small number of factors to factor solutions with a larger number of factors. Decisions about the numbers factors are based on the eigenvalue patterns, on the interpretability of factors, on the hierarchical position of factors, and on pairwise comparisons of the structures from the three languages.
Results
Three Hierarchies of Factors
All three data sets were factor-analyzed using PCA (on the associated correlation matrix), followed by Varimax rotation. Varimax rotation was used to enhance independent interpretability of the factors. In all three cases, factor structures with two up to seven factors were extracted. We considered the first differentiation of interest among factors a solution with two factors. The reason to extract up to seven factors was an earlier comparison between the Dutch and Austrian value structures that did not give much substance of interest beyond seven factors. Moreover, the Spanish structure provided a seven-factor structure (Morales-Vives et al., 2012).
For the three languages, the first 10 eigenvalues, expressed as percentages of explained variance, are given in Table 1, together with their totals. Based on the scree test, the three lists of eigenvalues indicated that indeed at best six or seven factors might make sense to define the final structures.
The First 10 Eigenvalues in Terms of Percentages of Variance Explained for the Three Languages.
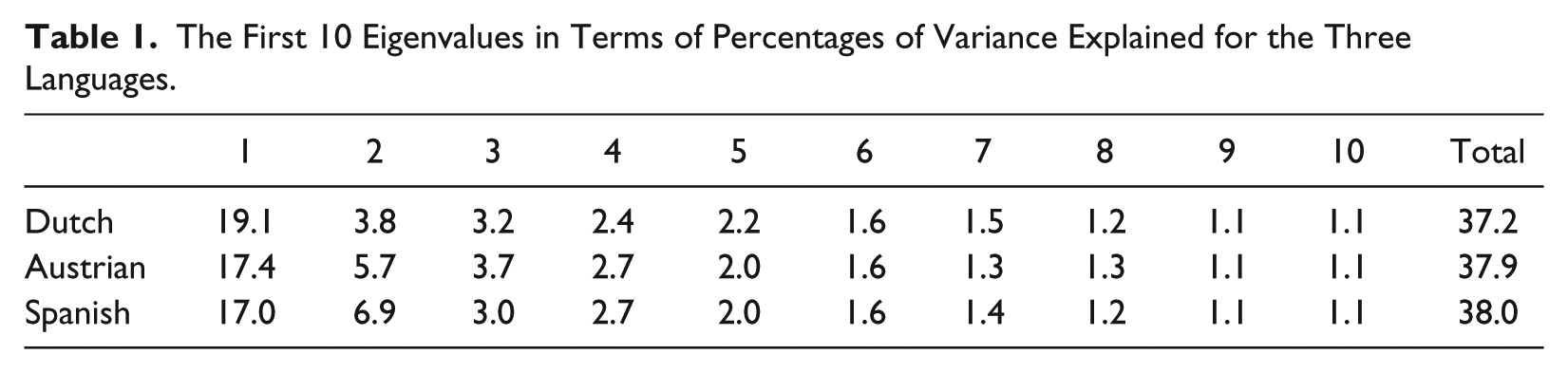
A further indication of the usefulness of factors is given through the inspection of the emergence of factors as they appeared in the three sets of six solutions. The Figures 1, 2, and 3 give only the factors from solutions with two to five factors. In the text, we sometimes also refer to solutions with six and seven factors. In these three figures, the various factors were identified by a number, indicating the level of extraction followed by the order of appearance (after Varimax rotation). For example, in Figure 1, the Factor 4/2 is the second factor of the four-factor solution. For each factor, a maximum of the five highest loading distinct values are given in their English translation, to represent its content. For Factor 4/2 of Figure 1, for example, those five values are accuracy, thoroughness, discipline, conscientiousness, and industriousness; this means that the second factor of the four-factor solution represents values of organization and achievement. Also a figure is given representing the number of values loading at least .40 on a factor. The number of values loading on the Austrian Factor 5/5 is pretty small, but there is an additional 10 values with loading between .30 and .40 on that factor. Between the adjacent levels of factor-extraction, the correlations between the factors are given. These correlations are to be understood as congruence coefficients between factors from different levels of extraction based on factor-scores. Only correlations of .40 or higher are given.

Dutch components-hierarchy and relations to SCA components.
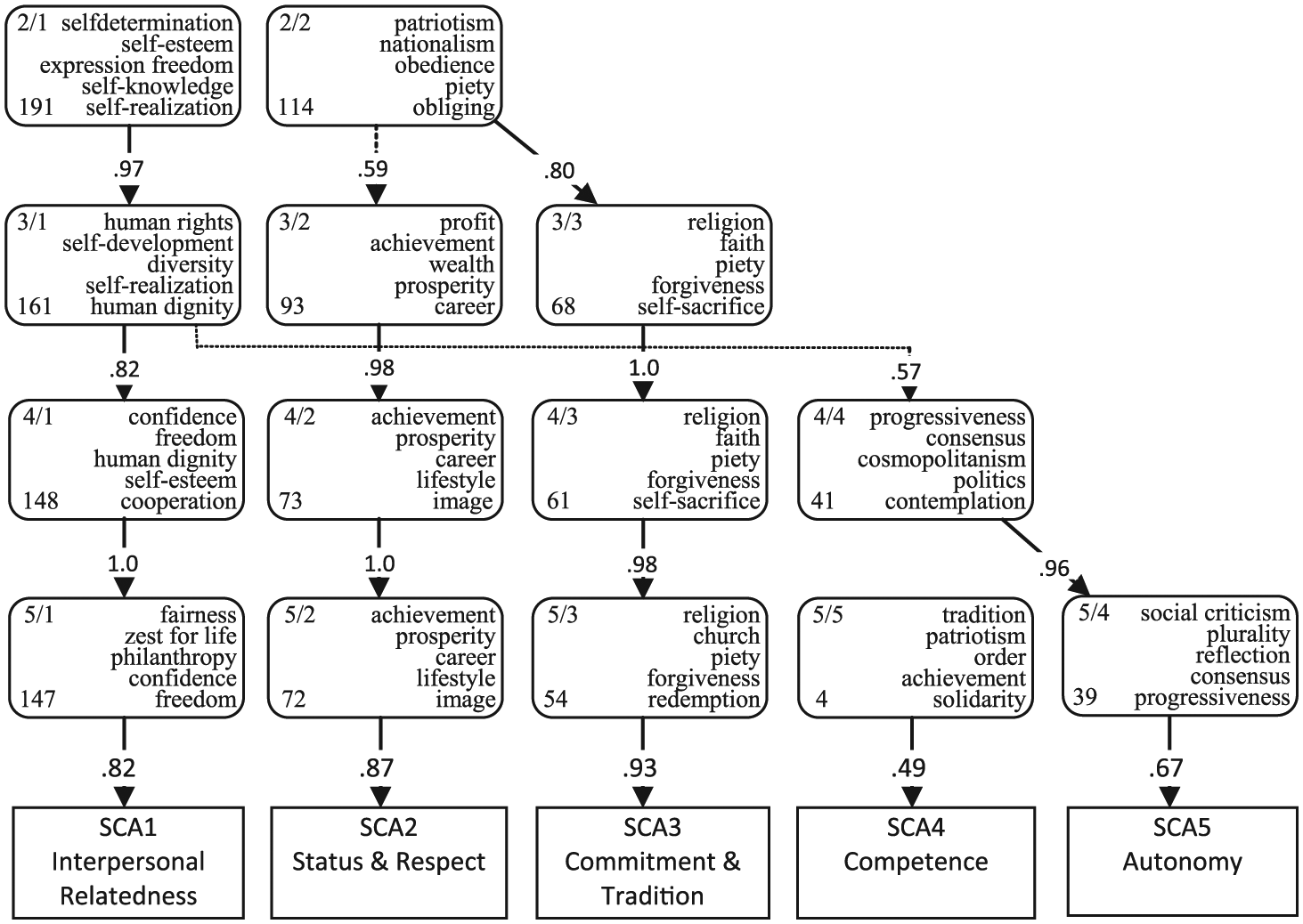
Austrian components-hierarchy and relations to SCA components.
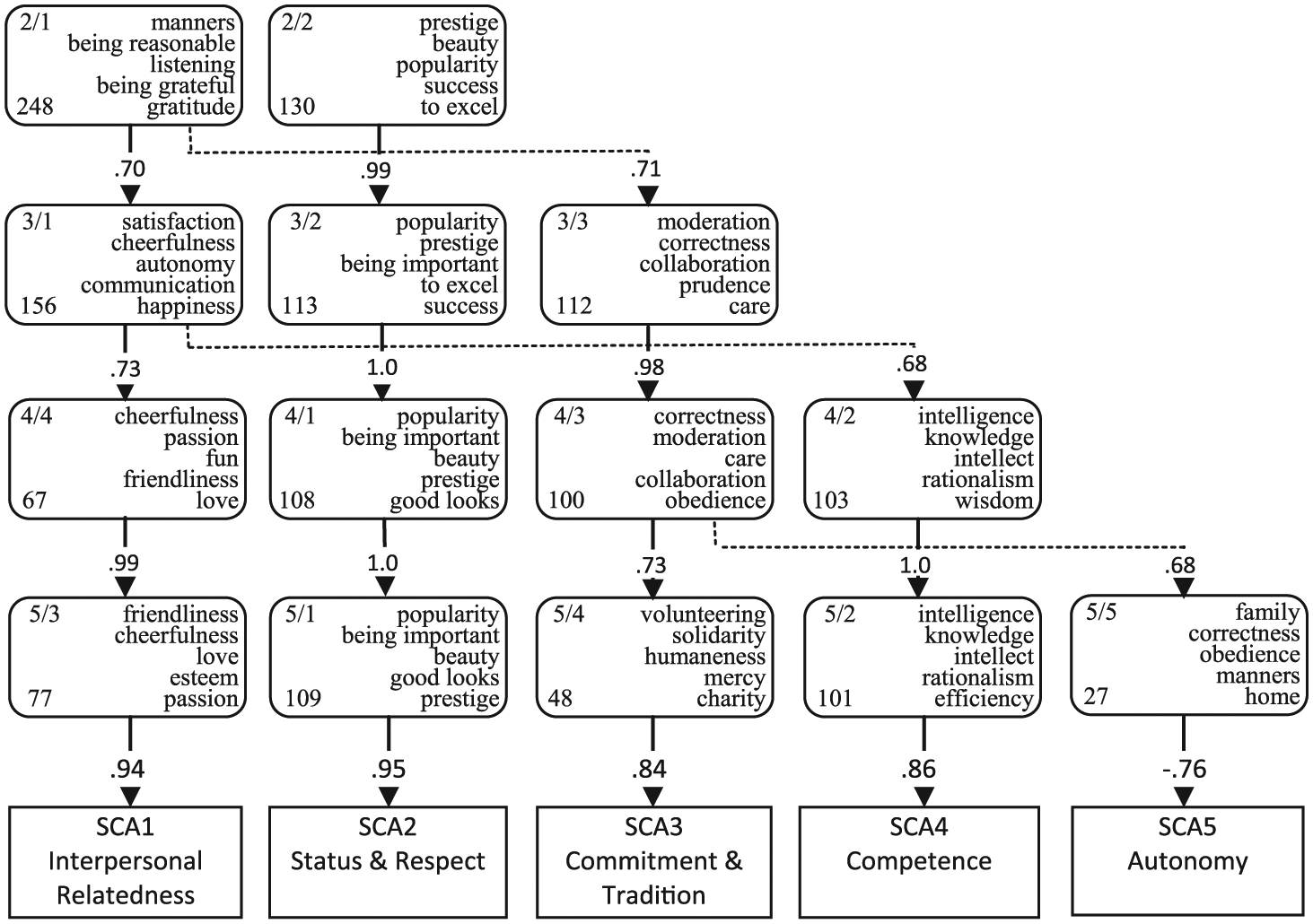
Spanish components-hierarchy and relations to SCA components.
The various value factors depicted in Figures 1, 2, and 3 were all reasonably well interpretable. Although additional variance was explained with each additional factor in the next solution, most of the kernel meanings of the additional factors throughout the hierarchy were already contained in factors at a previous level, as indicated by the correlations between the factors of adjacent levels. For example, in Figure 1, Factor 2/2 correlates .91 with Factor 3/2, which in turn correlates .92 with Factor 4/1, which in turn correlates 1.0 with Factor 5/1. This means that those factors have virtually the same meaning, as can be read in the pertaining sets of five values representing each of those factors. The Factor 2/2 in Figure 1, referring to Interpersonal Relatedness, is also obtained in the other three levels of extraction. After a differentiation into five factors, for all three languages certain factors remained virtually identical at the levels not given in the figures, namely, with six and seven factors.
Also, for all three languages, there was a further splitting into more specific factors that seemed to cover related domains of values across the languages. The values described by the Dutch Factor 5/4 (chastity to religion, Figure 1) and the Austrian Factors 5/3 (religion to redemption, Figure 2) and 5/5 (tradition to solidarity, Figure 2), all tapped into values related to tradition and morality. Yet, the differentiation into more specific values at levels with six and seven factors, diverged. Dutch Factor 5/4, for example, split into 6/2 (forgiveness to chastity) and 6/5 (spirituality to religion). Austrian Factor 5/3 split into 6/5 (religion to Christianity) and 6/2 (nationalism to duty), and Austrian Factor 5/5 split into 6/6 (anarchism to revolution) and, also, into 6/2 (nationalism to duty). The Spanish Factor 6/6 had only a very few values with loadings just above 0.30. For these reasons, it seemed wise to focus on structures with no more than five factors.
For further arguments concerning the appropriate number of factors with a cross-cultural capacity, we turned to the sets of value descriptors that were common to Austrian, Dutch, and Spanish, both pairwise and in the tripartite situation.
Pairwise Comparisons: Congruencies
After the translation of the values from the three sets into English, for each pair of languages the common values could be established. Dutch and Austrian had 194 values in common, Dutch and Spanish had 291 in common, and Austrian and Spanish had 185 in common. We calculated congruencies between the pairs of languages and for each of the six sets of factor solutions (with two to seven factors). For the comparison of Austrian with Dutch, the 194 rows with loadings were selected from the respective full matrices with loadings for the values common to the two languages, and congruence coefficients were calculated for all levels of factor-extraction between the corresponding factors. For the comparison of Austrian with Spanish and Spanish with Dutch, the same procedure was followed using the 185 and 291 sets of values, respectively. In all cases, the congruencies were calculated after rotation of the one structure in the comparison with the other and vice versa after which the congruencies were averaged. Table 2 contains those averaged congruencies.
Average Congruencies Calculated for Two up to Seven Factors After Target Rotating the One Structure to the Other and Vice Versa.

Note. Decimal points are omitted.
We took a congruence of 0.80 as a point of orientation, but treated the congruencies in a relative sense. According to Haven and Ten Berge (1977), strict correspondence would assume a congruence level of 0.85 (cf. Lorenzo-Seva & Ten Berge, 2006). As the comparisons were sub-optimal (only partial, translatable data sets were used), we gave some rein to the congruencies and considered 0.80 a fair level to be indicative of similarity of factors; the more congruencies got below that level, the more the factors were considered dissimilar. Table 2 shows that when seven factors were rotated to a target, between two and, up to a maximum of, five factors could be considered relatively similar. With six factors, the sixth factor gave congruencies running from a low of 0.27 to 0.57, which confirmed the idea not to go beyond five factors. The suggested structure with five factors needs to be confirmed for recurrent content across languages.
Tripartite Values: Searching for Common Ground
For the tripartite situation, the goal was to find the structure of values that was common to the three structures of values and in such a way that information was also provided about the relations of the individual structures to the common structure. In the previous paragraph, the common sets of values for pairs of languages were 194, 291, and 185. To study the structure that is common to all three languages, one needs to find the values that are common to all those three languages. That number turned out to be 139, which is a rather small set of values. This set was found by selecting those values that were the same in the three languages based on their translations into English. Practically, we started with the common set of values from one of the three pairs of languages and selected those values in the third language set that had the same meaning as the common values identified in the first pair of languages. In exploratory analyses, different psychometric techniques may very well lead to results with different emphases. For this reason, we applied two different techniques.
First, we applied PCA to the set of 139 value variables that the three languages had in common. We used the value ratings on this set of 139 from the total group of 1,622 participants in three languages and employed it for PCA. It should be noted that such a PCA on the data set across all three languages jointly implies that one focuses both on the structure present between languages (i.e., at the culture-level) as well as the structures present within the languages (i.e., at the individual level; see, for example, Timmerman, 2006). This is a proper approach if the between and within structures are similar; if they differ substantially, the revealed structure offers little insight, as it is a mix of between- and within structures. The advantage of this procedure is that it aimed directly at the set of values common to the three languages and the problem is that only a relatively small set of values was ultimately used.
Second, we applied SCA (e.g., Kiers & Ten Berge, 1994) to a matrix that was the result of merging the three values sets of variables into one huge matrix, making use of both the set of values common to the three languages and the sets common to the three pairs of languages. That is, we merged the full three value data sets into one joint data set with 1,703 value variables and 1,622 participants. We used the translations into English from the pairwise comparisons, and in the process of merging, some more good translations turned out to be possible, finally resulting in 1,148 distinct value variables. Of these, 142 2 were common to all three languages, 413 were available in at least two languages, and 735 were available in just one language. We applied SCAs to both the set with 1,148 and the set with 413 value variables. An SCA focuses only on the structures present within the three individual languages. The problem with this procedure was the great amount of missing data that had to be dealt with; the advantage was that use could be made of many more value variables from the three languages. In each of the three separate taxonomies, the value variables were centered around the mean, thus ensuring that the between structures information was removed and subsequent component analyses only reflected within structures. Also, the variables were scaled to variance of 1, thus ensuring that differences in variation across the taxonomies were removed, and the joint analysis revealed the common correlation structure. This common structure can be directly compared with the individual taxonomy structures resulting from the PCAs.
PCA on the common set of 139 values
As this was a relatively small set of values, it was important to ensure that the 139 set of values was representative of the full three individual sets. To have an indication of the representativeness of the 139-set, we focused on the five-dimensional level. We extracted five factors on the full set of values in a language, extracted five factors on the basis of the small set of 139 values in that same language, both followed by Varimax rotation, and subsequently correlated these two different sets of five factors. Table 3 (left set of five columns) gives the correlations between the sets of factors in the three languages.
Correlations Between Factors Based on the 139 Values for the Individual Languages and for the Combined Set of Languages.

Note. Decimal points are omitted; correlations in bold are the highest correlations per row; all sets of five factors are ordered in terms of explained variance in both the rows and the columns.
The correlations in Table 3 show that there were substantial correlations between the factors based on the full sets of values (641, 496, and 566, respectively) and those based on the smaller (common) set of 139 values for the same language. The correlations in bold indicate that the relations were virtually on the basis of a one-to-one correspondence. These correlations were considered sufficient to take the set of 139 values as representing the three full sets of values rather well.
We followed two related routes to arrive at a structure of the 139 values, to be able to check the stability of the structure. Of the structures resulting from these two routes, the congruencies were calculated between the corresponding factors. For the first route, we produced three correlation matrices with the 139 values for the three languages, averaged the corresponding correlations, and subsequently factored the averaged correlations. This implies that we focus on the structure occurring within the sets. Principal components analyses were performed followed by Varimax rotation. Factor solutions with two to seven factors were inspected; five factors seemed to be best interpretable, with additional factors from the six- and seven-solutions forming further specifications of factors from the five-solutions.
For the second route, we took the raw value data sets restricted to the 139 value variables, combined the three sets of data, and subsequently factored those 139 value variables. Principal components analyses were performed on the combined values data set with ratings from a total of 1,622 participants, followed by Varimax rotation. This implies that we focus on the structure occurring both between and within sets. Different solutions were studied but again the solution with five factors turned out to be best interpretable.
To find out about the stability of the five factors across these related procedures, the congruencies were calculated between the two sets of five factors; the un-rotated congruencies were 0.94, 0.86, 0.85, 0.89, and 0.99, indicating that the two sets of factors bear the same interpretation. Both sets of five factors seemed to form a near perfect replication of the structure that was proposed by De Raad and Renner (2011) with the factors called Self-Direction, Virtue, Pleasure, Spirituality, and Pride and Reputation.
Table 4 consists of a set of marker items for the established five-factorial structure based on the combined sets of data for the 139 values. These were the highest loading values on the five factors.
Marker Items for Five Factors Based on Combined Sets of Data for 139 Values.

Table 3 (second set of five columns) also contains the correlations between the factors based on the full sets of the individual languages and the factors based on the 139 values with the combined data sets. The highest correlations per row (in bold) indicate, with a few exceptions, a relatively close one-to-one correspondence between the factors. This suggests that the between and within structures are similar, implying that those value dimensions are useful both to characterize the countries, as well as the inhabitants within the countries.
Differences between the three languages
An interesting corollary of the second procedure to factor the data set with 139 values was that differences in means based on the three groups of participants could be calculated. Table 5 gives the results.
Mean Component Scores per Language (Spanish, Austrian, and Dutch).

The Austrian participants apparently scored higher on average, especially in comparison with the Dutch participants, on values emphasizing self-direction, liberty, and individualism. Also, the Austrian participants scored higher on values emphasizing pleasure and commitment, and also on values emphasizing spirituality (especially in comparison with the Spanish). Although Spain is generally considered to be a religious country, the Spanish participants were from Catalonia, which is one of the least religious regions of Spain. The Spanish participants scored higher on values emphasizing virtue, especially in comparison with the Austrian participants. Differences like these could somehow be related to differences described by Schwartz (1994b) who tabulated Nation scores on seven culture-level value-types (Conservatism, Intellectual Autonomy, Affective Autonomy, Hierarchy, Mastery, Egalitarian Commitment, and Harmony). However, those types, although to some extent seemingly covering the same value semantics, each have different emphases in comparison with the contents of the present factors of values. For example, Schwartz’s Hierarchy (with values such as wealth, power, influence, authority) and Mastery (with values such as success, ambition, independent, and daring) seem to overlap with the present fifth factor, describing values of pride and reputation (wealth, career, reputation, comfort). Also, Affective autonomy (with values such as pleasure and exciting life) seems to be related to the present third factor (Pleasure). Yet, the different sets of value groupings do not precisely match. Moreover, the clearest differences in Schwartz (1994b) are found between geographically rather remote countries such as Malaysia versus Switzerland (on Conservatism), and Switzerland versus Singapore (on Intellectual autonomy).
SCA on the joint set of values
Although SCA was applied to both the joint sets with 1,148 values and 413 values, we had more interest in the smaller set with 413 values. This smaller set would increase the connectivity between the languages and reduce the amount of missing data. The SCA applied to the full set with 1,148 values produced a structure with components that turned out to be strongly colored by highest loading language-specific variables. Moreover, although in the individual PCAs quite similar amounts of variance were explained with a fixed number of components (five, for example), the SCA five-component solution based on the 1,148 set of values explained 23.5% of the variance in the joint data set and only 18.5% of the variance of the Austrian value variables while it explained 25.4 in the Spanish data set and 24.9 in the Dutch data set. So, the common SCA solution on the full set of 1,148 variables did not do a very good job in explaining the information in the Austrian value data set.
Of the different possible SCA variants (e.g., De Roover, Ceulemans, & Timmerman, 2012), we used the SCA model with equal cross-products (SCA-ECP; see Timmerman & Kiers, 2003). In this model, the components within each individual value structure are orthogonal (i.e., uncorrelated and with the variance of each component equal to one), thus ensuring a sound comparison between the common structure, as revealed through the SCA-ECP, and the individual structures, as revealed through the PCAs. For more details on the application of this technique, see, for example, De Raad, Barelds, Timmerman, De Roover, Mlačić, & Church (2014).
A problem with performing the SCA-ECP analysis was formed by the large amounts of missing data due to the fact that large amounts of value variables were missing. To deal with this problem, we used iterative imputation (De Roover et al., 2012; Kiers, 1997) through which the component scores, the loadings, and the missing data were estimated jointly, which means that the model itself was used for the missing data estimation.
The application of SCA to the smaller set of 413 values gave the following percentages of explained variance for the first 10 components: 16.4, 3.9, 3.2, 2.6, 1.9, 1.1, 1.1, 1.1, 0.8, and 0.9. This configuration suggests no more than some four or five components to retain. We analyzed solutions with two to seven components after Varimax rotation to get a view on the hierarchical relations among the different solutions and to see whether the various components were well interpretable and not too narrow or too specific. The hierarchy, given in Figure 4, shows a stable patterning of components from a high level to a low level of abstraction. At each level, a relatively new and distinct component emerged, namely, Component 3/1, correlating relatively low (0.54) with 2/1 at the higher level, and Components 4/1, 5/5, 6/6, and 7/6. The other components remained virtually the same across the various levels, as indicated by many almost perfect correlations between factors from adjacent levels of extraction. All components at all levels were well interpretable. Components 6/6 and 7/6, however, seemed to be rather specific and did explain only little amounts of variance. A five-solution seemed to come close to what was expected. For this reason, we accepted the five-component solution as the optimal one to be used for further analyses. This five-solution explained 28.0% of the variance of the common set, 26.6% of the Austrian part, 28.1% of the Spanish part, and 28.5% of the Dutch part.
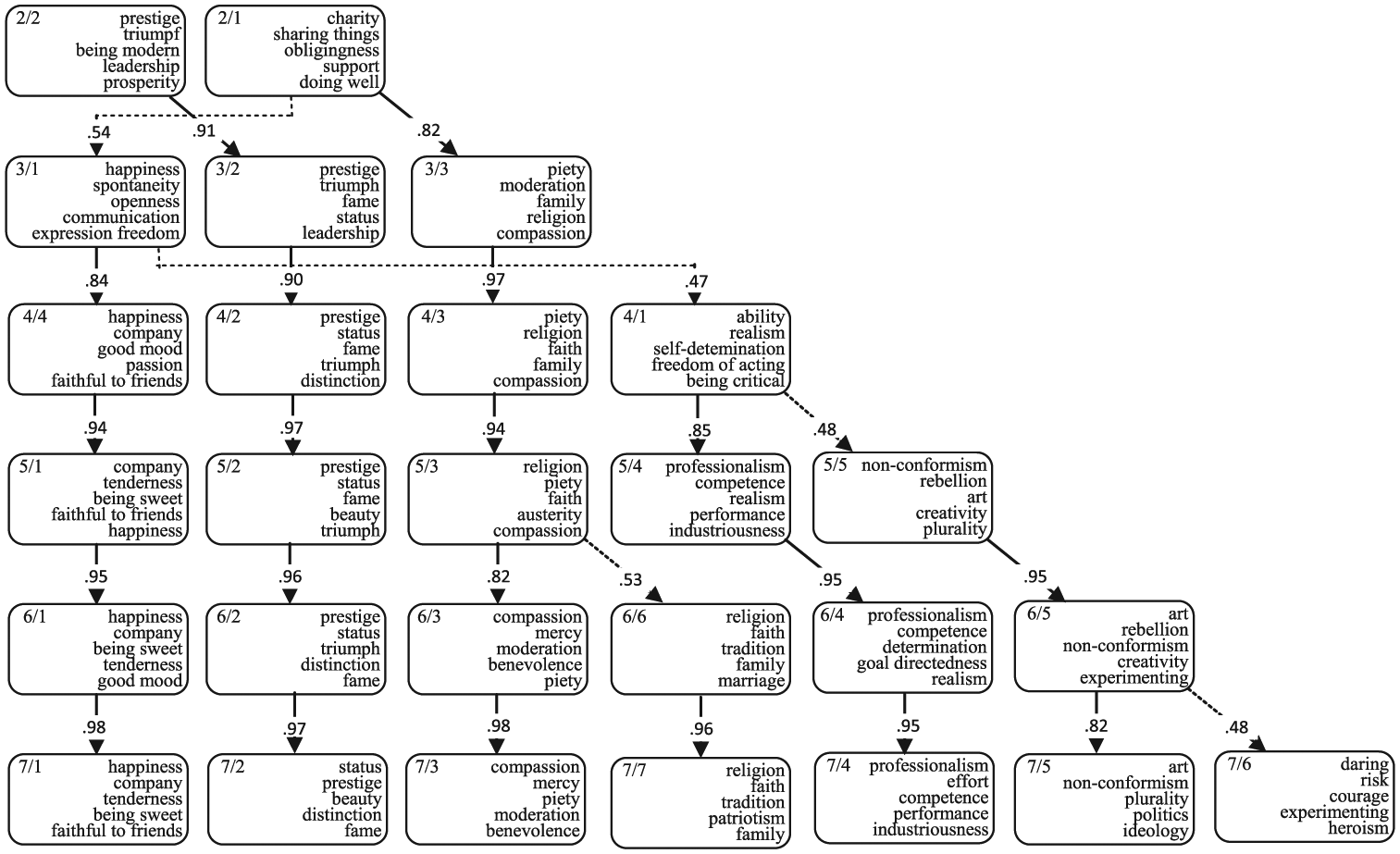
Emergence of SCA components at subsequent levels of extraction.
The contents of the five Varimax rotated SCA components are given in Table 6. The components were labeled Interpersonal Relatedness, Status and Respect, Commitment and Tradition, Competence, and Autonomy. The components were each specified in four facets. Very small sets of values had high loadings on a component with loadings close to zero on the other components. Those small sets of values were nevertheless close to the heart of the meanings of the components and are indicated by 1+1+, 2+2+, 3+3+, 4+4+, and 5+5+, respectively. All the other values had high (primary) loadings on one component and also substantial (secondary) loadings on another component (and usually on no more than one other). The Interpersonal Relatedness component, for example, had as the fourth facet 1+5+ (“communication”), meaning that the values liberality, openness, and so forth, had primary loadings on Component 1 (Interpersonal Relatedness) and secondary loadings on Component 5 (Autonomy). In the facet 1+5+, Interpersonal Relatedness (1+) is blended with Autonomy (5+), producing the facet Communication. Similarly, Autonomy (5+) is blended with Interpersonal Relatedness (1+), producing the facet 5+1+ (Originality). Those two facets, Communication and Originality are closely related. In the same manner, 2+5+, Status and Respect mixed with Autonomy, and 5+2+, Autonomy mixed with Status and Respect, lead to the two related facets, Risky Engagement and Rebellion. The conceptual organization is thus fully empirically based and provides a coherent arrangement of conceptual distinctions among values and their facets.
SCA Components, Their Facets, and the Highest Loading Values.

Note. SCA = simultaneous components analysis.
Coverage of PCA Components by the SCA Components
To what extent do the SCA components reflect the contents of the PCA components in each of the three original full sets of values and the PCA components based on the common set of 139 values? To examine these questions, the SCA components were first correlated with each of the three sets of five factors based on the full sets of values per language. These correlations are given in the bottom part of the Figures 1, 2, and 3. They are all rather substantial, with a clear exception in the relation between SCA Competence and the Austrian Factor 5/5 (Figure 2).
The SCA components were also correlated with the five factors based on the common set of 139 values as presented in Table 4. Those correlations are given in the top panel of Table 7. The 139-based components, Self-Direction, Pleasure, Spirituality, and Pride and Reputation have their highest correlation with the conceptually related SCA components, Autonomy, Interpersonal Relatedness, Commitment and Tradition, and Status and Respect, respectively. Virtue related substantially with three SCA components.
Relations Between SCA and PCA Components Based on Unique Values per Language.
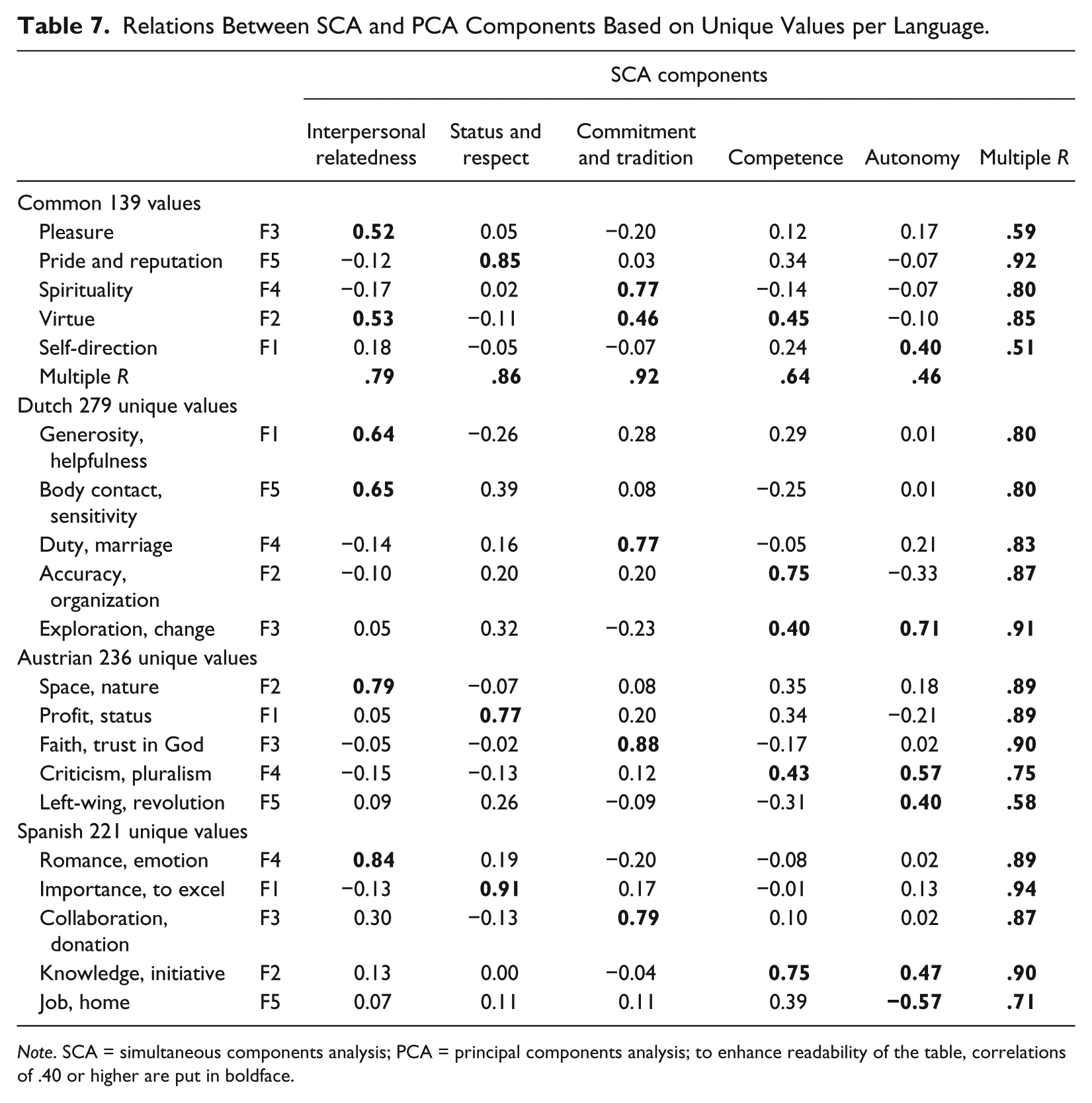
Note. SCA = simultaneous components analysis; PCA = principal components analysis; to enhance readability of the table, correlations of .40 or higher are put in boldface.
SCA Components and the PCA Components Based on Values Not Used in the SCA
To what extent do the SCA components reflect the language-unique values, those that were excluded from the SCA application? These are the values for which there were no clear equivalents in both the other two sets of values after translation into English. It is of interest to know what the contents are of those variables, and to know whether the SCA components had explained the information in the respective three data sets sufficiently.
The Dutch unique set contained 279 value variables, the Austrian set contained 236 values, and the Spanish 221. PCA was applied to each of the three language-unique value variable sets, and although the eigenvalue patterns did not suggest more than some three factors in all three cases, five factors were extracted to optimize the amounts of information in the matrices. Next, the five SCA components were correlated with the three sets of language-specific factors. Moreover, the SCA components were used in regression analyses, with the individual factors of the three language-unique sets as dependent variables. The results are given in Table 7. The last column of Table 7 with the multiple Rs summarizes the results pretty well. The information in the language-unique factors (each loosely characterized by just two highest loading values) seemed to be virtually exhausted considering the level of the multiple Rs. There were only a few exceptions, such as, for example, an apparent relatively strong presence of values referring to ideologies or life orientations (Austrian Factor 5, with lifestyle, being leftist, revolution, left-wing orientation, anti-authoritarianism). Those values are not well captured by the SCA components. The Dutch unique set did not yield a Status and Respect factor, while such a factor was clearly present using the full Dutch set of values. Apparently, the Dutch values describing Status and Respect were most contained in the common set of 413 values, and thus virtually exhausted by the SCA components on that latter set.
Discussion
This study aimed at finding the structure of values that was common to three previously developed taxonomies of values in three languages, Dutch, Austrian, and Spanish. On the basis of an earlier comparison of the Dutch and Austrian value taxonomies, a five-factorial structure was expected, with the factors describing values emphasizing communal existence (e.g., friendliness, love, trust, pleasure), values emphasizing the realization of potential (e.g., self-determination, reflection, individualism, emancipation), values emphasizing rules of conduct (e.g., dutifulness, orderliness, sincerity, responsibility), values emphasizing spirituality (e.g., faith, religion, generosity, nationalism), and values emphasizing pride and reputation (e.g., success, property, achievements, career). The inclusion of a third taxonomy made the comparison drastically more difficult. The application of the same procedure of comparison as in the case of Dutch and Austrian now involved three pairwise comparisons, which would lead to three sets of findings describing the commonality of values. The pairwise comparisons were indeed performed, but primarily to help determining the appropriate number of factors.
To find the structure common to the three taxonomies, the same rules were applied to find common values: those values that were the same after translation into English. That set turned out to be rather small with only 139 values. Yet, the very fact that those 139 values were present in the three taxonomies indicates their cross-cultural importance. The combined data for those 139 values from the three taxonomies were subjected to PCA, resulting in a structure that seemed to form a confirmation of the expected structure, with Self-direction being related to Realization of Potential, with Virtue being related to Rules of Conduct, with Pleasure being (moderately) related to Communal Existence, and with Spirituality and Pride and Reputation both appearing with the same name. However, as the number of values that determined that structure was rather small, it remained uncertain whether that was indeed the ultimate and optimal kernel structure.
We used an alternative technique to enhance the connectivity between the three taxonomies and to increase the number of common values. This technique involved the use of both the pairwise connections with much larger numbers of common values and the tripartite connections. The three taxonomies were merged to form a matrix totaling 1,703 values and 1,622 participants. That matrix inevitably had large amounts of missing data. That amount of missing data was first reduced by identifying values with the same meaning for the different languages, ultimately resulting in a matrix with 413 values and 1,622 participants. That matrix still had relatively large amounts of missing data. We dealt with that problem through iterative imputation. The matrix was subjected to the PCA-related technique SCA-ECP, resulting in a five-factorial structure with the factors describing values emphasizing Interpersonal Relatedness, Status and Respect, Commitment and Tradition, Competence, and Autonomy.
These SCA components more or less confirmed the 139 common-values-based structure with the exception of Virtue in that structure. That factor was replaced by SCA Competence. As a matter of fact, the earlier Virtue factor was (moderately) related to SCA Interpersonal Relatedness, SCA Commitment and Tradition, and SCA Competence; therefore, the information contained in Virtue was well captured by the SCA components.
The five SCA components form the framework for an inclusive description of the differentiation of the domain of values. For an explicit description of the rich assortment of value meanings, each of the SCA components could be specified into four distinct facets, thus accommodating the many nuances in values in an intelligible way.
The emic aspect of the lexical approach is especially in optimizing a full account of all possible value descriptors relevant in a certain language or culture. There is little chance that value concepts relevant in a certain language do not pop up in the value vocabulary put together according to psycho-lexical procedures. This is undoubtedly one of the great advantages of this approach in which, under a taxonomic perspective, all possible value descriptors are considered for further scientific use. Taxonomic work is not well served by theoretical frameworks, which could easily function as an imposed etic. The collection of ratings on those values means that all, both more universal and more culture specific values, were found more or less interrelated. When merging the three different culturally determined value data sets on the basis of common values and establishing the structure based on the common core, the relations of the culture specific values with the common core were also expressed. This implies that strict culture specific value concepts do not exist. It is a matter of gradation.
When compared with Schwartz’s two-dimensional circumplex with the circular distribution of 10 or 19 value constructs, it becomes easy to identify and accommodate those value constructs in our newly developed framework. Some of Schwartz’s values seem to be somewhat broader than the present facets, some are narrower, and some are related to more than one distinct facet of the present system. Moreover, this new framework makes more faceted distinctions to which the value constructs of Schwartz are not directly related. The problem with systems like that of Schwartz is that the value constructs were largely based on facet-theoretical considerations, and the choice of the facets is up to the taste of the investigator. The main problem with Schwartz’s value system is, however, not in the coverage of the value domain. The main problem is in the lack of frames of reference by which the adequacy of that system may be evaluated. The present psycho-lexically based system may form such a frame of reference.
There are some other frames of reference that might be used for the purpose of evaluating the adequacy of value systems. The basic psychological need theory (e.g., Deci & Ryan, 2000), for example, claims a system with three basic psychological needs, namely, the need for relatedness, the need for competence, and the need for autonomy. The semantics of these three basic needs are easily identified in the present value factors Interpersonal Relatedness, Competence, and Autonomy, respectively. The need for relatedness has been described in terms of experience of intimacy and genuine connection with others, which conveys a central concern of the Interpersonal Relatedness facets. The need for competence refers to being effective and capable to achieve a desired outcome, which forms a nice abstract description of much of what is contained in the Competence value facets. The need for autonomy refers to self-determination, which relates to the facets of the Autonomy value factor (cf. Chen et al., 2015). Although needs are not the same as values (see, for example, Leuty, 2013), both have been defined in terms of preferences and desires or desired states (e.g., Allport, 1961; Rokeach, 1973; Schwartz, 1992), and the concepts have often been used interchangeably (e.g., Maslow, 1954). Two of the basic dimensions of both needs and of values are related to the fundamental pair describing modes of human existence, namely, Agency and Communion (Bakan, 1966). These Big Two have been found very useful in social cognition, where they were repeatedly empirically confirmed as the fundamental dimensions Competence and Warmth (cf. Fiske, Cuddy, & Glick, 2007).
The strength of this study on values is that it forms a most direct reflection of the central values as sedimented in the lexicon of the collective minds of a language community, in this case stretching to three different languages and their related cultures. The relevance of the value factors and their facets form a mirror of their functionality in daily lives of people, without being molded by theoretical considerations. For the presentation of the five value factors in Table 6, use is made of primary loading and secondary loading on factors, thus leading to this empirically based taxonomy of value concepts together with their facets. The clusters of values contained in each facet may allow for further conceptual distinctions.
Although the present results may form a good indication of the dimensions underlying the domain of values in Europe, it should be corroborated by similar lexical studies in a good representative set of languages to give it a Europe-covering status. The approach may ultimately include as many data sets as available. A study by De Raad et al. (2014) on 11 trait-taxonomies that were merged in the same way as the present three value structures has proven that. Each new language adds relatively specific information to the combined set, which specifics can be expressed in relation to what the data sets have in common. The approach will continue to be emic in content coverage and somewhat etic through the application of structuring procedure. Yet, it is not expected that more or new dimensions are recovered. What might be expected is that value factors and value facets obtain a fuller coloring of values.
The psycho-lexical approach to the study of values, as opposed to theoretical approaches, has the advantage of arriving at a full catalog of frequently used value descriptors. A problem is in the densities of words for the same values in the different countries. If in a certain language more words are used for a certain value, and thus more items of that type are included in the analyses, there is more chance that a strong factor may be found or even a new factor is revealed. Such a factor may carry bloated specificity. However, this problem is strongly reduced when focusing on value descriptors that are common to various languages, as in the present study.
Each of the three original value taxonomies gave rise to a differentiating system to describe values in detail. Those systems of value turned out to cover the same ground to a large extent. The language specific characteristics consisted most of densities of values with similar meaning; distinct language specific value clusters were not found. With the three psycho-lexical studies in remote languages or cultures in Europe, and with the delineation of the common framework, a firm empirical foundation is laid for a comprehensive system of values. This system with five dimensions and 20 facets is not only empirically based, but it is also easy to understand and logical in design. Both the dimensions and the facets are to be understood in terms of what ordinary people find important, not in terms of what is prescribed by mere theoretical considerations.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.