
Abstract
Language is critical to the effectiveness of marketing messages. Achieving a desired outcome requires arranging words to formulate a message (i.e., syntax), but this task is not trivial. The authors study the role of syntax in marketing communications by focusing on syntactic surprise (i.e., how unexpected the syntax of a message is). They introduce a measure that captures syntactic surprise, establishes its internal and external validity, and tests its effectiveness for marketing messages. In a series of studies that include field data and randomized field experiments from contexts such as donations, advertising, and product reviews, the authors show that a message's syntactic surprise is related to its effectiveness. This relationship follows an inverted U-shape, such that medium-syntactic-surprise messages are the most effective. The authors then conduct experiments on Facebook and Instagram to demonstrate how these findings can be used to write effective marketing messages. In collaboration with two independent companies, they show that ads for products, services, or jobs that are written with medium syntactic surprise result in higher click-through rates than ads written with low or high syntactic surprise.
Keywords
Consider a manager who is deciding whether to advertise a job ad with the message “Apply today to join a great team!” or with the message “Join a great team, apply today!” These messages use almost the exact same words and communicate an invitation to apply for the job, but they are differently formulated (i.e., use different syntaxes). Can the manager tell which message will be more successful in facilitating applications? How can the manager effectively and efficiently compare how these two messages are formulated and make a decision?
Syntax is the grammatical formulation of words in a sentence (Lowrey 2008), and formulating the right message for an intended purpose is not a trivial task. Companies face these types of challenges often due to their permanent presence on digital platforms. In fact, today's companies have many communication tools and channels at their disposal for spreading messages of various lengths and types. Beyond social media and traditional channels such as television, radio, or newspapers, companies can reach consumers through email, brand websites, blogs, and other venues. While marketers have to weigh various elements of a message—including text, pictures, and choice of channel—language is one of the most critical for effective communication (Berger et al. 2020; Berger, Moe, and Schweidel 2019; Hosman 2002). Consequently, marketing scholars have called for more research that incorporates developments in text analysis and natural language processing (NLP) to better understand the effects of language on consumer behavior (Humphreys and Wang 2018).
Prior research has investigated how various aspects of language influence the way consumers interact with, perceive, and evaluate brands (Carnevale, Luna, and Lerman 2017; Cheema and Patrick 2008; Leclerc, Schmitt, and Dubé 1994). The effect of language is well established across various marketing communication contexts. For example, research has shown that semantic content and linguistic style properties of customer product reviews impact retail conversion rates (Ludwig et al. 2013). Word choice influences the effectiveness of songs, movies, and news articles (e.g., Berger and Milkman 2012; Berger and Packard 2018; Eliashberg, Hui, and Zhang 2007; Humphreys and LaTour 2013). Relatedly, pronoun choice affects perceptions of closeness (Sela, Wheeler, and Sarial-Abi 2012) as well as consumer engagement with brand content, in terms of shares or likes (Labrecque, Swani, and Stephen 2020). Research has also shown that linguistic style, such as the use of figurative language, reflects sincerity (Kronrod and Danziger 2013) while the use of function words, irrespective of content, impacts how the recipient of a communication perceives the communicator (Ireland and Pennebaker 2010). Ludwig et al. (2013) tie the use of function words to conversion rates in online sales. Language even affects the impact of scientific articles (Warren et al. 2021). Scientific articles written using less clear, abstract, technical, and passive language are cited less and thus have less impact.
Among many language factors, syntax is particularly important in affecting the persuasiveness of a communication. Pogacar, Shrum, and Lowrey (2017) classify the linguistic devices used in persuasive communication and suggest that syntax influences the persuasiveness of outcomes by affecting message processing. Marketing research that examines syntax in the context of broadcasting and print advertising (e.g., Bradley and Meeds 2002; Chebat et al. 2003; Lowrey 1998, 2006) finds that high syntactic complexity in advertisement scripts leads to lower levels of ad recall and recognition in both broadcasting and print advertising, and to lower levels of persuasiveness in print advertising. Specifically, the use of negative grammatical transformations (i.e., changing a statement into its negative form; Jacoby, Nelson, and Hoyer 1982), passive voice (Lowrey 1998; Motes, Hilton, and Fielden 1992), and left-branching sentences (i.e., sentences in which the main clause comes first, followed by a subordinate clause that modifies or adds information about the main clause; Bradley and Meeds 2002; Lowrey 1998, 2006) have a negative impact on a message's persuasiveness. More recently, Ostinelli and Luna (2021) show that syntax influences a claim's persuasiveness by instantiating an illusion of fit. Relatedly, Pancer et al. (2019) show that the readability of a message drives consumer engagement on social media. These findings reveal that syntax affects message processing and, by extension, message outcome.
We build on and complement this body of work by taking an NLP approach (Nivre et al. 2016; Schuster and Manning 2016) to systematically analyze an aspect of syntax and introduce a measure to capture it. We study the average unexpectedness in the syntax of a message, which we label syntactic surprise (Henderson et al. 2016; Tribus 1961). We establish the validity of the measure introduced and compare it with relevant linguistic measures that have been covered by the marketing and linguistics literature. Furthermore, we investigate how the measure introduced is linked to the message's effectiveness (e.g., facilitate clicks on an ad, stimulate donations). Here, we argue that high-syntactic-surprise messages activate attention but are difficult to comprehend and thus cannot achieve their desired impact (Gibson 1998; Hosman 2002). Low-syntactic-surprise messages also cannot reach their desired impact, but for different reasons: they are easy to comprehend but do not activate attention (Gibson et al. 2019). Thus, we hypothesize an inverted U-shaped relationship between syntactic surprise and the message's effectiveness. We support this hypothesis with studies that investigate the proposed relationship in a variety of contexts, including donations, advertisements, and product reviews.
Our work contributes to the marketing literature on message communication by examining syntactic surprise with a novel approach and measuring it with a scalable and automated method. Our work expands the marketing field's understanding of the role of syntax in designing effective marketing messages. Practitioners can use our measure and insights to assess and improve the syntax of their communications. To make our approach more accessible, we used the findings to classify the range of syntactic surprise into categories of effectiveness. In addition, we developed a tool that calculates syntactic surprise so that practitioners can easily assess the syntactic surprise of their message with a pretrained machine learning model (details provided in a subsequent section).
Syntax and Syntactic Surprise
Syntax and Extracting Meaning
Language is processed word by word (Venhuizen, Crocker, and Brouwer 2019), which is referred to as sentence parsing (Kempen and Vosse 1992). Parsing is essential to derive meaning (Bates 1995; Futrell, Mahowald, and Gibson 2015). When parsing, people automatically assess the syntactic relationships between the words and extract the meaning of the sentence. The syntactic relationships between the words are referred to as dependencies (McDonald et al. 2013; Nivre 2005). For example, to comprehend the sentence “Amazon delivers diapers,” a person has to identify the dependencies among the three syntactic elements—the noun “Amazon” (the subject), the verb “delivers” (the action), and the noun “diapers” (the object). Here, the words “delivers” and “diapers” have a direct object (dobj) relationship, implying that “diapers” are the object of the delivery rather than “Amazon.” Meanwhile, the words “Amazon” and “delivers” have a nominal subject (nsubj) relationship (see Figure 1).

Visualization of Dependencies in the Examples “Amazon Delivers Diapers” and “Amazon Delivers Fast.”
Syntactic Surprise
People parse sentences automatically when they are exposed to spoken or written communication. They are able to do so because they have acquired implicit knowledge of statistical patterns in language use (i.e., expectations of which dependencies will follow any given syntactic element they encounter; Bridgwater, Kyröläinen, and Kuperman 2019). People begin comprehending a sentence before processing it in full, mainly by making plausible inferences about what will follow next and updating their inferences as they go (Levy 2008). For example, people's past language experience generally leads them to anticipate a direct object relationship (i.e., the object “diapers”) after a verb (Wilson and Garnsey 2009). If this expectation is met, surprise is low. By contrast, high surprise would entail that this expectation is violated (Henderson et al. 2016). Consider the second example in Figure 1, “Amazon delivers fast,” where the adverbial modifier relationship (i.e., the adverb “fast” after “delivers”) is less expected than the direct object relationship in the previous example (the object “diapers”). Whereas both sentences are grammatically correct, the second example (“Amazon delivers fast”) features higher syntactic surprise than the first example (“Amazon delivers diapers”). Taken together, syntactic surprise is the unexpectedness of the syntactic element occurring (e.g., object: diapers vs. adverb: fast) given the previous syntactic element (e.g., verb: delivers) that the individual encountered in the sentence.
For another illustration, refer to the opening example about the choice between two possible ads, “Apply today to join a great team!” or “Join a great team, apply today!” Once again, although both sentences are grammatically correct and use almost the same words to communicate the invitation to apply for a job, they are formulated differently (see Figure 2). Here, the first sentence features lower syntactic surprise than the second one.

Visualization of Dependencies in Two Possible Ads.
The Role of Syntactic Surprise in a Message's Effectiveness
In general, the brain automatically focuses on stimuli that are unexpected (i.e., high surprise; Egner, Monti, and Summerfield 2010). Paying more attention to unexpected stimuli makes sense from a learning perspective: unexpected events require more attention to process thoroughly to maximize learning (Schmidhuber 2009). The positive relationship between surprise and attention has been observed with various types of stimuli. In processing language, attention (as measured by brain activation in functional magnetic resonance imaging [fMRI] scans) is high when people encounter unexpected words (Willems et al. 2016). In processing visual stimuli, attention (as measured by eye movements) is more frequently directed at high-surprise areas of images (e.g., areas with different colors or color gradients; Lin, Fang, and Tang 2010). Similarly, in processing auditory stimuli, people pay more attention (as measured by magnetoencephalography [MEG] activity) when they encounter high-surprise sounds (i.e., high-frequency spectra sounds) (Armeni et al. 2019). Relatedly, unusually spelled brand names are more memorable (Lowrey, Shrum, and Dubitsky 2003) and may command more attention (Song and Schwarz 2009). Conversely, low-surprise (expected) stimuli lead to a lower activation of attention, which then fosters the perception that the encountered material is uninteresting or boring (Milne and Herff 2020; Williams 1977). Milne and Herff (2020) for example, find that sounds that are too predictable are perceived as boring, while in the context of chatbot conversations, Csáky, Purgai, and Recski (2019) find that low-surprise dialogues are perceived as more boring.
These results may seem to suggest that high syntactic surprise is desirable—that an increase in syntactic surprise attracts more attention to the marketing message. We suggest, however, that higher attention (due to higher syntactic surprise) comes at the cost of higher processing difficulty (Del Prado, Kostić, and Baayen 2014; Futrell, Gibson, and Levy 2020; Lowder et al. 2018). As a result, the relationship between high syntactic surprise and message outcome is not linear. Let us explain.
Recall that comprehending a sentence is an incremental, dynamic process (Frazier and Fodor 1978). As people encounter a sentence, they need to store the words, the relationships between the words, and their expectations of what will follow in their working memory until they can correctly comprehend the sentence (Futrell, Gibson, and Levy 2020; Gibson 1998; Swets et al. 2007). Working memory is the cognitive resource that enables any type of processing (Just and Carpenter 1992). Working memory capacity is limited, and once people reach its limit, they cannot summon additional capacity for the task (Baddeley and Hitch 1974; Ellenbogen and Meiran 2008; Hudson Kam and Chang 2009). A low-surprise, highly expected dependency is effortlessly processed (Linzen and Jaeger 2014), but a high-surprise, less expected dependency consumes greater working memory capacity (Degaetano-Ortlieb and Teich 2019; Van Schijndel and Schuler 2013). If the resources required to process high surprise exceed the limits of working memory, then processing ability diminishes nonlinearly. Reducing surprise lessens the working memory capacity load and thereby eases the burden on the sentence-processing mechanism (Hale 2003, 2006, 2011).
On that basis, we expect syntactic surprise to have a positive effect on attention and a negative effect on working memory capacity. Thus, we hypothesize a nonlinear, inverted U-shaped effect of syntactic surprise on the effectiveness of a marketing message. Specifically, we argue that medium-syntactic-surprise messages are more successful in achieving their intended outcomes compared with their low- and high-surprise counterparts. This expectation aligns with the literature about syntactic complexity and its impact on the effectiveness of marketing communications, at least in terms of advertising (Lowrey 1998) and slogans (Bradley and Meeds 2002; for an overview, see Meeds and Bradley [2007]).
In the following section, before we test the hypothesized inverted U-shaped effect of syntactic surprise on the effectiveness of a marketing communication, we introduce and validate a measure of syntactic surprise and embed it into a general model that can be applied in various marketing contexts. We compare this measure of syntactic surprise with various linguistic measures to establish its internal and external validity.
Measurement of Syntactic Surprise
In what follows, we first briefly explain the origins of syntactic surprise. Then, we describe how we mathematically formalize and then estimate syntactic surprise by training a long short-term memory (LSTM) neural network on a large, publicly available corpus.
Origins of the Measure Introduced
Information theory aims to differentiate signal from noise in a communication. For example, one of the pioneers of this field, Shannon (1948), studied language to understand redundancy in it by way of capturing how much information is carried by each letter in a text. Information theory focuses on identifying the value of information through its unexpectedness. Unexpectedness has taken various labels such as information content, self-information, surprise, or entropy (e.g., Abou Jaoude 2017; Tribus 1961). We use the label “surprise” following the intuition of Tribus (1961). Generally, surprise refers to the amount of information carried in an event. Measures of surprise quantify the spread of the data such that if surprise is low, the data tend to concentrate around the same value, and information carried is low. In contrast, if surprise is high, the data tend to have a high spread with low-likelihood events occurring, and information carried is high (Feldman and Friston 2010; Gibson et al. 2019, Horstmann 2015; Horstmann and Herwig 2016).
Mathematical Definition of Syntactic Surprise
To model the sentence-parsing process, let D be a set of 47 syntactic dependencies defined by universal dependency grammar (Universal Dependencies 2019) and di a dependency with index i of the set D. The likelihood of a sequence of dependencies



Training Data: GUM Corpus
To train the model, we used the Georgetown University Multilayer (GUM) corpus, which features the highest ratings among academics for learning universal dependencies (https://universaldependencies.org/). The corpus comprises 150,824 tokens that have been annotated and cross-checked by linguists with the correct dependencies. The corpus is particularly useful because it contains a wide range of sentences from myriad and diverse sources, including news stories, fiction, forum discussions, academic writings, and everyday conversations (Table WB1 in Web Appendix B). Training on a general corpus ensures that the resulting measure of syntactic surprise can be employed in a broad set of marketing messages.
An Example of the Assessment of Syntactic Surprise
Refer back to the opening example about the choice between two possible ads (Figure 2), “Apply today, to join a great team!” or “Join a great team, apply today!” Applying the syntactic surprise measure to these examples reveals that the first ad (Ad 1) features a syntactic surprise of 2.16 while the second ad (Ad 2) features syntactic surprise of 2.51. We test the performance of these ads in a randomized field experiment on Instagram in Study 6a. In the following section, we first aim to establish the validity of the syntactic surprise measure and then differentiate between values of syntactic surprise in terms of what they mean for a message’s effectiveness, such that the measure can be used to decide which version of the ad will be more effective.
Validation of the Syntactic Surprise Measure
To establish the internal and external validity of the measure introduced, we follow Berger et al. (2020) and Cook and Campbell (1979), who discuss key questions and measures of validity. Table 1 summarizes the validation methods and data sets we use and Table 2 provides an overview of studies with the main validation results.
Overview of Internal and External Validation Methods.

Overview of Studies.

Internal Validity
Construct validity
We start by establishing the construct validity of the syntactic surprise measure (i.e., ensuring that the measure captures what it is supposed to measure). Recall that the GUM corpus represents a myriad and diverse array of English words (Figure WC1 in Web Appendix C depicts the distribution of syntactic surprise in the GUM corpus). Relying on the GUM corpus, we used a holdout sample to show that the accuracy of the syntactic surprise measure does not falter when using unseen data. Specifically, we tested whether the LSTM model for predicting the next syntactic element performs well on a randomly selected, unseen data set of 20% of the GUM corpus. The model reaches an accuracy of 44.6% on the unseen data, which is comparable to the 45.0% on the training data, providing support for construct validity of the measure (for further details on convergence, see Web Appendix A). Note that the level of accuracy reached by the model represents a considerable improvement to the random baseline, which has an accuracy of only 2.1%.
Discriminant and/or convergent validity
As previously discussed, marketing literature has studied the role of language complexity (e.g., Bradley and Meeds 2002; Lowrey 1998, 2006). Therefore, we first compared the syntactic surprise measure with the following complexity measures: Flesch–Kincaid grade, Gunning fog index, Simple Measure of Gobbledygook (SMOG) index, difficult words, type/token ratio, and rarity.
Second, to establish that syntactic surprise is a unique aspect of syntax, we compared the syntactic surprise measure with other relevant syntactic measures: passive voice, average dependency distance, closeness centrality, and longest shortest path. Marketing literature has shown that the use of passive voice impacts the persuasiveness of a marketing message (Lowrey 1998; Motes, Hilton, and Fielden 1992). Meanwhile, the linguistics literature has found that average dependency distance (Hudson 1995; Liu 2008; Liu, Xu, and Liang 2017), longest shortest path, and closeness centrality (Oya 2010) impact message processing. An increase in each of these measures requires more working memory capacity to process the sentence.
Finally, we wanted to establish that the syntactic surprise measure does not simply capture conceptual differences (e.g., differences in meaning and style) that arise from differences in syntax. To this end, we focused on content measures that the literature has linked to message persuasiveness, such as linguistic style, concreteness, use of pronouns, and emotion. We explain the background of the included content measures in Web Appendix D. Table 3 shows a full list of complexity, syntactic, and content measures.
To establish discriminant and/or convergent validity, we calculated the correlation between the syntactic surprise measure and the three aforementioned types of measures: (1) complexity measures (i.e., Flesch–Kincaid grade, Gunning fog index, SMOG index, difficult words, type/token ratio, and rarity), (2) syntactic measures (i.e., average dependency distance, closeness centrality, longest shortest path, and passive voice) and (3) content measures (i.e., concreteness, functions words, pronouns, etc.). At the first step, we calculate these correlations in the GUM corpus. The correlations (Tables 4, 5 and 6) show that the syntactic surprise measure does not highly correlate with measures of complexity, syntax, and content. We replicate these analyses and provide further evidence with the publicly available field data sets used in Studies 1 and 2 (see Table 2 for an overview of studies). The results on discriminant/convergent validity of the syntactic surprise measure using these studies are in Tables WB3–WB5 (Study 1) and Tables WB7–WB9 (Study 2) in Web Appendix B. The results here show that the correlations between syntactic surprise and measures of complexity, syntax, and content are low, providing additional evidence that syntactic surprise is a unique aspect of language.
Overview and Definition of Relevant Linguistic Measures.

Note: LIWC = Linguistic Inquiry and Word Count.
Correlations Between Syntactic Surprise and Complexity Measure—GUM Corpus.

Notes: Darker shading in this table indicates strong correlation, lighter shading indicates weaker correlation,and no shading indicates no correlation.
Correlations Between Syntactic Surprise and Syntactic Measures—GUM Corpus.

Notes: Darker shading in this table indicates strong correlation, lighter shading indicates weaker correlation,and no shading indicates no correlation.
Correlations Between Syntactic Surprise and Content Measures—GUM Corpus.

Notes: Darker shading in this table indicates strong correlation, lighter shading indicates weaker correlation,and no shading indicates no correlation.
Causal validity
According to Berger et al. (2020), causal validity is the degree to which a construct actually causes the proposed outcome. Berger et al. suggested controlling for alternative explanatory factors in the model to ensure causal validity in textual data. They also recommended conducting experimental studies with random assignment. We followed both suggestions. First, in Studies 1 and 2, we show that including the measures listed in Table 3 (see Tables 8 and 9) alongside other study-specific measures or a measure of variance in syntactic surprise (see Tables WB6, WB7 for Study1, and WB14 for Study 2) did not change the results. Second, we also ran randomized field experiments in Studies 3 and 4 to provide evidence of causal validity.
External Validity
To establish external validity for syntactic surprise (i.e., that the findings apply to phenomena outside of the main data set, the GUM corpus), we conducted Studies 1–4.
Generalizability
Studies 1–4 confirm that the results are not specific to a data set, generalize to different contexts (e.g., ads, product reviews, donations), and hold for different text lengths. Tables 7–12 demonstrate that our findings are generalizable to a variety of marketing contexts.
Impact of Syntactic Surprise on Donation Likelihood.

*p < .1. **p < .05. ***p < .01.
Notes: Standard errors are in parentheses.
Inclusion of Relevant Linguistic Measures (Complexity Measures, Syntactic Measures, and Content Measures).

*p < .1. **p < .05. ***p < .01.
Notes: Standard errors are in parentheses.
Inclusion of Relevant Linguistic Measures (Complexity Measures, Syntactic Measures, and Content Measures).

*p < .1. **p < .05. ***p < .01.
Notes: Standard errors are in parentheses.
Impact of Syntactic Surprise of Customer Reviews on Review Helpfulness.

*p < .1. **p < .05. ***p < .01.
Notes: Standard errors are in parentheses.
Predictive ability
Studies 1–4 also establish that the inverted U-shaped relationship between syntactic surprise and message effectiveness holds for different accounts of message effectiveness, such as donation likelihood, review helpfulness, and click-through rates (CTRs). Tables 7–12 demonstrate that even though the studies use different measures of effectiveness, they all provide the same conclusive evidence for the predictive ability of the syntactic surprise measure.
Robustness
Finally, for robustness, we used tenfold cross-validation methods on the GUM corpus and found that the average holdout accuracy is 44.4% with a standard deviation of .9%.
Study 1: The Role of Syntactic Surprise in Donation Likelihood in the Persuasion for Good Data Set
Method
Study 1 uses the publicly available Persuasion for Good data set that was collected and made available by Wang et al. (2019). In this experimental data set, participants on the Amazon Mechanical Turk platform were randomly assigned to an experimental role in which one participant was a “persuader” and the other was a “persuadee.” In each randomly assigned pair, the persuader's goal was to get the persuadee to donate money (part of their task earnings from the study) to a good cause (i.e., Save the Children Charity). The data set includes information about whether the persuadee donated, along with the transcript of the conversation and various individual difference measures for the persuader and the persuadee.
This data set contains 1,017 pairs of persuaders and persuadees, with 1,017 transcribed conversations and 10,600 utterances by the persuaders. Fifty-four percent of “persuadees” made a donation. The dependent variable is whether a persuadee made a donation (0 = no donation, 1 = donation). In the data set, the average syntactic surprise of the different persuaders’ communications ranged from 1.64 to 3.09, with a mean value of 2.17 (SD = .18). Figure WC2 in Web Appendix C shows the distribution of syntactic surprise in the data set.
Results
We tested the hypothesized effect of syntactic surprise. We ran a logistic regression with donation likelihood as the dependent variable, and syntactic surprise and syntactic surprise squared as independent variables. We controlled for the number of syllables per word (
According to a likelihood ratio test, the model that included the quadratic term of syntactic surprise fits the data better than the model that did not (χ2 = 13, p < .001). As the results in Table 7 show (Model 3, Column 3), syntactic surprise is positively and significantly related to donation likelihood (β = 19.78, p = .001), whereas syntactic surprise squared is negatively and significantly related to donation likelihood (β = −4.55, p = .001). This result indicates that, as predicted, the effect of syntactic surprise on donation likelihood follows an inverted U-shape, with an optimal donation likelihood reached at a syntactic surprise of 2.2.
To provide further evidence on the internal and external validity of the syntactic surprise measure, we (1) ran models with syntactic surprise and the measures of complexity, syntax, and content and (2) calculated correlations between syntactic surprise and these measures. The inverted U-shaped relationship between syntactic surprise and donation likelihood remained robust after including these measures (for all coefficients, see Table 8 and Table WB17 in the Web Appendix). The correlations between syntactic surprise and measures of complexity, syntax, and content were low (Tables WB3–WB5 in Web Appendix B), providing additional evidence that syntactic surprise is a unique aspect of language. The results support the findings reported previously using the GUM corpus.
Robustness Tests
Note that, in the context of this study, language choices are made strategically by the persuader, and their effectiveness depends on the interaction partner (persuadee). To test the robustness of the findings, taking into account the interactive nature of the data set, we include variables that take individual differences between persuader and persuadee into account as in Wang et al. (2019), such as their age, income, education, employment, and personality traits. Table WB6 in Web Appendix B displays the results and confirms that the findings are robust when individual difference measures are added. Table WB7 shows that the results also remain robust to including a measure for variance in syntactic surprise.
Discussion
Study 1 provides the evidence for the internal and external validity of the syntactic surprise measure and the hypothesis that medium-syntactic-surprise messages are more effective than low- or high-syntactic-surprise messages. This study demonstrates the role of syntactic surprise in the likelihood of donating from participants’ earnings in the experiment. In the next study, we use field data on the helpfulness of product reviews to supply further evidence.
Study 2: The Role of Syntactic Surprise in the Helpfulness Ratings of Amazon Reviews
Method
Study 2 investigates the effect of syntactic surprise on the helpfulness of Amazon reviews. We used the Amazon customer reviews data set from Ni, Li, and McAuley (2019)—specifically the five-core version, which contains reviews for which the product and the reviewer have at least five reviews each. We used the full sample of Amazon reviews from the six largest product categories (i.e., Books, Movies and TV, Electronics, CDs and Vinyl, Kindle Store, and Apps for Android) for the period 1997–2014. We cleaned the review texts so that they did not contain, for example, any HTML tags or hyperlinks. We removed reviews without review text, without review titles, and reviews not written in English. The final data set contains 13,707,894 reviews (97% of the original raw data) of 556,577 products by 961,588 reviewers. For each review, we recorded the number of times the review was voted “helpful” or “unhelpful.” Of these, 7,340,820 of the reviews had at least one vote.
We then calculated syntactic surprise for each review, which ranged between 1.00 and 8.31, with an average value of 2.06 (SD = .26). Figure WC3 in Web Appendix C shows the distribution of syntactic surprise in the final data set, and Table WB8 in Web Appendix B reports correlations between variables in the model.
Results
We measured a review's helpfulness as its ratio of helpful votes to total votes. Given the multilevel structure of the data (i.e., multiple reviews can be written by the same reviewer), we estimated a hierarchical linear regression model with a reviewer random intercept, wherein review helpfulness served as the dependent variable, and syntactic surprise and syntactic surprise squared served as independent variables. We included the same controls as in Study 1. Excluding these controls from the model does not impact the results. According to a likelihood ratio test, the model that included the quadratic term of syntactic surprise fits the data better than the model that did not (χ2 = 35,111, p < .001). The estimation results provide support for the hypothesized inverted U-shaped relationship between syntactic surprise and review helpfulness (Table 10), with an optimal review helpfulness reached at a syntactic surprise of 1.9. The results of the main model (Table 10, Column 3, Model 3) show a positive, significant relationship between syntactic surprise and review helpfulness (β = .38, p < .001) as well as a negative, significant relationship between syntactic surprise squared and review helpfulness (β = −.10, p < .001).
As in Study 1, we compiled additional evidence for our measure's internal and external validity by (1) incorporating the linguistic variables on complexity, syntax, and content into the model (for all coefficients, see Table 9 and Table WB18 in the Web Appendix) and (2) calculating correlations between syntactic surprise and these measures. The low correlations between syntactic surprise and measures of complexity, syntax, and content (Tables WB9–WB11 in Web Appendix B) provide further evidence that syntactic surprise is a unique aspect of language.
Robustness Tests
We tested the robustness of the results using varying model assumptions (linear regression model, fractional logistic regression, logistic regression, and negative binomial regression). We also tested alternative definitions of the dependent variables (number of helpful votes and unhelpfulness ratio). The results held across all models and were robust to these alternative specifications. We report all results in Tables WB12 and WB13 in Web Appendix B. Table WB14 shows that the results also remain robust to including a measure for variance in syntactic surprise.
Discussion
The findings from Study 2 support the validity of the syntactic surprise measure and the hypothesis that medium-syntactic-surprise messages are more effective than their low or high counterparts in the context of review helpfulness ratings. Next, we validate the findings in randomized field experiments conducted on Facebook in collaboration with two independent companies. In Studies 3 and 4, we validate our prior findings by manipulating syntactic surprise of marketing messages to show that syntactic surprise systematically impacts message effectiveness, as captured by CTRs.
Study 3: Impact of Syntactic Surprise on CTRs in Facebook Ads (Beauty Salon)
Method
We collaborated with marketing professionals at a beauty salon to write six ad copies that varied in their syntactic surprise (for the ad copies, see Table WB15 in Web Appendix B). The syntactic surprise of the ad copies ranged between 1.65 and 2.70, with an average value of 1.99 (SD = .30). All six ad copies had the exact same ad layout and were shown alongside the same image to Facebook users during Fall 2021. In a between-subjects design, each Facebook user only saw one of the ads that was selected randomly and presented once. In total, six ads achieved 67,967 impressions and led to 149 clicks on the ads (CTR = .22%). The recorded CTR may seem low; however, we attribute it to the niche product being advertised (i.e., permanent tattooed eyebrows).
Results
First, we ran a logistic regression, with CTR (0 = no click, 1 = click) as the dependent variable, and syntactic surprise and syntactic surprise squared as independent variables. We included the same controls as in Study 1. Excluding these controls from the model does not impact the results. According to a likelihood ratio test, the model that included the quadratic term of syntactic surprise fit the data better than the model that did not (χ2 = 4.63, p = .031). The estimation results in Table 11 confirm the hypothesized inverted U-shaped effect of syntactic surprise on CTR, with an optimal CTR reached at a syntactic surprise of 2.2. The results of the main model revealed a positive, significant effect of syntactic surprise (β = 9.29, p = .031) and a negative, significant effect of syntactic surprise squared (β = −2.07, p = .039) on CTR. These results lend further predictive validity to the measure by showing that the syntactic surprise measure has the expected effect on another meaningful outcome variable, here CTR (Berger et al. 2020).
Impact of Syntactic Surprise on CTR.

*p < .1. **p < .05. ***p < .01.
Notes: Standard errors are in parentheses.
Discussion
The results from Study 3 show that taking syntactic surprise into account improves the outcomes of marketing messages. The study also adds evidence for external validity by extending the results to a social media advertising context.
Study 4: Impact of Syntactic Surprise on CTRs in Facebook Ads (Fashion Brand)
Method
We collaborated with a fashion brand to write 17 ad copies that varied in their syntactic surprise (for the ad copies, see Table WB16 in Web Appendix B). The syntactic surprise of the ad copies ranged between 1.33 and 2.26, with an average value of 1.79 (SD = .25). All 17 ad copies had the exact same ad layout and were shown alongside the same image to English-speaking Facebook users in the United States during the summer of 2021. In a between-subjects design, each Facebook user only saw one of the ads that was selected randomly and presented once. Combined, the 17 versions achieved 247,339 impressions and led to 1,890 clicks on the ads (CTR = .76%).
Results
First, we ran a logistic regression, with CTR (0 = no click, 1 = click) as the dependent variable, and syntactic surprise and syntactic surprise squared as independent variables. We included the same controls as in Study 1. Excluding these controls from the model does not impact the results. According to a likelihood ratio test, the model that included the quadratic term of syntactic surprise fit the data better than the model that did not (χ2 = 6.3, p = .012). The estimation results in Table 12 confirm the hypothesized inverted U-shaped effect of syntactic surprise on CTR, with an optimal CTR reached at a syntactic surprise of 2.0. The results of the main model revealed a positive, significant effect of syntactic surprise (β = 4.47, p = .004) and a negative, significant effect of syntactic surprise squared (β = −1.13, p = .012). These results lend further predictive validity to the syntactic surprise measure by showing that it has the expected effect on another meaningful outcome variable, here CTR (Berger et al. 2020).
Impact of Syntactic Surprise on CTR.
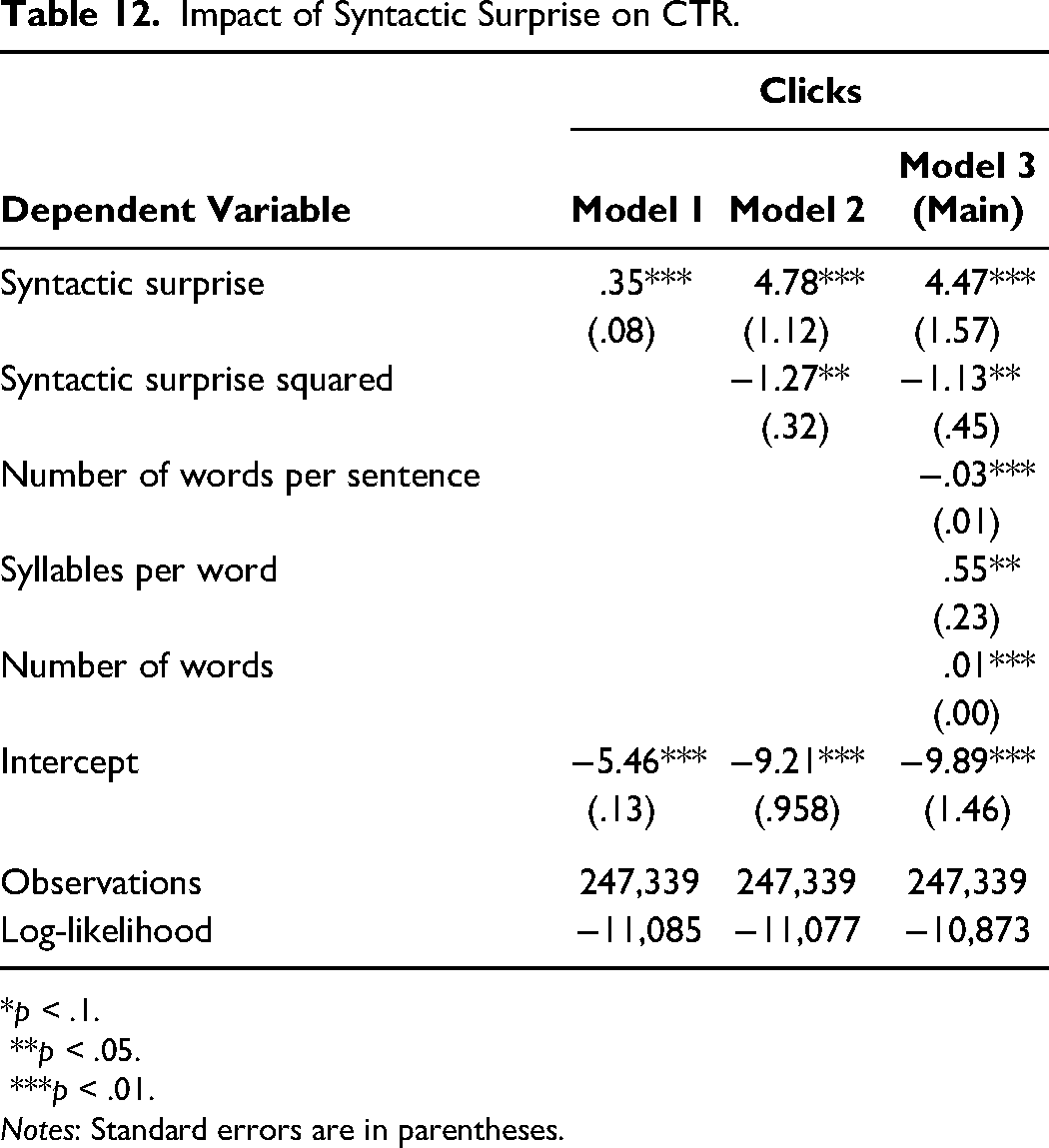
*p < .1. **p < .05. ***p < .01.
Notes: Standard errors are in parentheses.
Discussion
The results from Study 4 expand the results from Study 3. Taken together, these studies show that companies should take syntactic surprise into account to improve their messages and their outcomes. These studies also add evidence for external validity by extending the results to a social media advertising context.
Ranges of Syntactic Surprise
Across four studies using various types of data, we explored how marketing messages’ effectiveness is tied to syntactic surprise. All studies provide evidence for an inverted U-shaped relationship between syntactic surprise and effectiveness, with medium syntactic surprise being the most impactful across the observed range of settings. Next, we collectively analyzed the findings from the four studies to show how the measure of syntactic surprise can be used (i.e., by marketing professionals) to improve the effectiveness of various messages. To this end, we classified the range of syntactic surprise into four categories: optimal, effective, acceptable, and ineffective. Figure 3 illustrates these categories in each study.

Categorization of Ranges of Syntactic Surprise.
To define these categories, we started by determining an empirically realistic syntactic surprise range. Based on the GUM corpus, we defined a range of syntactic surprise within two standard deviations (SD = .51) from the mean of syntactic surprise (M = 1.98). We then defined the categories relative to this realistic syntactic surprise range (.96–3.00). Note that this realistic range represents syntactic surprise in 99.7% of all English communication, as represented by the GUM corpus.
Categories of Syntactic Surprise
Figure 3 depicts optimal syntactic surprise in dark green; this is the best value for the dependent variable in each study. Mathematically, it is the maximum of the fitted function in the regression models in Studies 1–4. Figure 3 shows that the value of optimal syntactic surprise varies from 1.9 to 2.2 across studies. This deviation can be a result of potentially noisy estimations of our regression models in Studies 1–4 or, alternatively, the result of differences between the contexts in the four studies (e.g., the type of involvement associated with the product advertised, the type of platform). Meanwhile, effective syntactic surprise is depicted in light green: messages in this range reach their goals within 5% of the maximum effectiveness that the message can reach within the previously defined range. Acceptable syntactic surprise is depicted in yellow: messages in this range reach their goals within 5%–20% of the maximum effectiveness. Lastly, ineffective syntactic surprise is depicted in red: messages in this range reach their goals with less than 20% of the maximum effectiveness.
Examining the syntactic surprise ranges across the four studies, we observe that a range between 2.1 and 2.2 is always effective in reaching its goals. Meanwhile, a syntactic surprise range between 1.9 and 2.1 or between 2.2 and 2.3 indicates an acceptably effective message. To illustrate this category further, consider Study 4, where we tested the effectiveness of a fashion brand's ads in a Facebook advertising context. Here, the syntactic surprise of Ad 17 (Table WB16 in Web Appendix B) was an acceptable 2.26 (the yellow zone in Figure 3) and the CTR was .94%. However, for an ad with optimal syntactic surprise (2.0), the obtained CTR (1.01%) would be 7.4% higher. By implication, and assuming all else is equal, the fashion brand could have produced a more effective ad by lowering the syntactic surprise. Lastly, all four studies showed that a message becomes ineffective when the syntactic surprise is less than 1.9 or greater than 2.3. To illustrate this point, consider Study 4 once again: The syntactic surprise of Ad 1 (Table WB16 in Web Appendix B) was an ineffective 1.33, and the CTR was .61%. However, for an ad with optimal syntactic surprise (2.0), the obtained CTR (1.01%) would be 66% higher.
Syntactic Surprise Calculator
To facilitate managers’ use of our findings, Figure 3 includes a summary of the ranges for all studies and visualizes the effective, acceptable, and ineffective ranges. To help practitioners implement the findings without modeling or machine-learning skills, we developed a syntactic surprise calculator (see Figure 4, Panels A and B). This tool can calculate the syntactic surprise of any text at the message and sentence level and then provide recommendations that align with the logic presented in Figure 3 using a temperature-based color-coding system. Figure 5 shows how the logic presented in Figure 3 was translated in the calculator into the temperature-based color-coding system that uses a scale from a too-unsurprising syntax to a too-surprising syntax. Using the tool, managers can revise their messages sentence by sentence until they reach the effective or acceptable range. Future work could develop tools that automate the process of revising messages to improve their syntax.

Illustration of the Syntactic Surprise Calculator and Its Output (Ad 6 in Study 3).

Translation of Ranges Color Coding into a Temperature-Based Color Coding Used in the Syntactic Surprise Calculator.
Studies 5 and 6: Modifying Syntactic Surprise to Increase CTRs on Facebook and Instagram
With the final set of studies, we wanted to demonstrate an application of the syntactic surprise measure to better understand its role in the effectiveness of marketing messages and provide additional support for the validity of the findings. Thus, we tested eight ads on Facebook and Instagram, where the ads featured only minor grammatical differences. These follow-up experiments on Facebook and Instagram mirrored the design of Studies 3 and 4. Each time, the ads were run in parallel on the same user groups as in Studies 3 and 4, and we ensured that users only saw one of the ads once. In each case, the ad with syntactic surprise in the effective range outperformed (in terms of CTR) the ad with syntactic surprise that was not in the effective range.
Study 5a: Fashion Brand Ad Tested on Facebook
The stimuli used here were based on Ad 11 in Study 4 (Table 13). In Study 5a, we introduced passive voice to Ad 11, which pushed the syntactic surprise into the effective range (increasing it from 1.86 to 2.02). Two versions were tested on Facebook: the original Ad 11 and its improved version were shown for 11,074 impressions in total, and these impressions led to 146 clicks. The CTR for the original Ad 11 was .92% while the CTR for the improved version was 1.6%. The difference in CTRs for the two versions was significant (p = .003).
Stimuli Used in Study 5.

Notes: We replaced the original brand name with FASHIONBRAND for confidentiality reasons.
Study 5b: Fashion Brand Ad Tested on Facebook
The stimuli used here were based on Ad 17 in Study 4 (Table 13). In Study 5b, we converted the passive voice in Ad 17 to active voice, pushing the syntactic surprise into an effective range (from 2.26 to 2.13). Two versions were tested on Facebook: the original Ad 17 and its improved version were shown for 19,242 impressions in total, and these impressions led to 156 clicks. The CTRs for the original Ad 17 and the improved version were .72% and .98%, respectively. The difference in CTRs for the two versions was marginally significant (p = .055).
Study 6a: Beauty Salon Ad Tested on Instagram
The stimuli (a job ad) tested in this study feature the opening example in this article (Figure 2). These stimuli were developed in collaboration with the beauty salon that we partnered with for Study 4 and were tested on Instagram. Ad 1 (displaying the text “Apply today to join a great team!”) had a syntactic surprise of 2.16, in the effective range, and Ad 2 (with the text “Join a great team, apply today!”) had a syntactic surprise of 2.51. The two versions were tested on Instagram and were shown for 21,516 impressions in total, leading to 240 clicks. The CTR for Ad 1 (Ad 2) was 1.55% (.85%). The difference in CTRs for the two ads was significant (p < .01).
Study 6b: Beauty Salon Ad Tested on Instagram
The stimuli used in this study were also developed in collaboration with the beauty salon that we partnered with for Study 4. The stimuli (an ad for a facial treatment) were tested on Instagram. Ad 1 (featuring the text “Take a beauty break to get a Hydrafacial!”) had a syntactic surprise of 1.62, while Ad 2 (displaying the text “Take a beauty break, get a Hydrafacial!”) had a syntactic surprise of 2.11—the latter in the effective range. The two versions were tested on Instagram and were shown for 16,750 impressions in total, leading to 286 clicks. The CTR for Ad 1 (Ad 2) was .80% (1.82%). The difference in CTRs for the two ads was significant (p = .0023).
Discussion
Taken together, Studies 5 and 6 provide evidence for the role of syntactic surprise in message effectiveness in the context of CTR. In Study 6 we replicate the findings of Study 5 in a different context (job ads) and a different platform (Instagram). Studies 5 and 6 also illuminate how managers can use the syntactic surprise measure. Once various ad copies have been created to communicate a desired message, managers can employ the syntactic surprise measure to assess which option is most likely to succeed based on its syntax.
General Discussion
Effective messages have various elements that make them successful (e.g., use of videos, photographs, information provided or the language used in the message). To bolster our understanding of successful messages, we focused on the fundamental element of language, and more specifically, syntax. Using NLP, we tested and validated a general approach to measure a distinct aspect of syntax—syntactic surprise.
First, we introduced a measure that captures syntactic surprise and established its internal and external validity. We then conducted four main studies (Studies 1, 2, 3, and 4) and four follow-up experiments (Studies 5a and 5b, Studies 6a and 6b) to validate the measure and to assess the role of syntactic surprise in various forms (i.e., experimental and field data), contexts (i.e., donations, advertising, and product reviews), and relevant outcomes (likelihood to donate and CTR). We found that syntactic surprise is a unique aspect of syntax that accounts for the effectiveness of marketing messages beyond previously established measures. In addition, we confirmed that the relationship between syntactic surprise and message effectiveness is inverted U-shaped: messages are most effective at a medium syntactic surprise level, but less effective at the low and high syntactic surprise levels. Through the field experiments in Studies 5 and 6, we demonstrate how managers can use the proposed approach and the insights to modify syntactic surprise of ads to increase CTRs significantly, improving the performance of ads on Facebook and Instagram. Relatedly, in an effort to replicate the results in a different context and thus add further external validity to the findings, we ran a study on Prolific in the context of hotel descriptions on Booking.com and customers’ willingness to pay. In this study, we examined the effect of the syntactic surprise of the description of the hotel on willingness to pay for the hotel. The ten hotel descriptions used in the study were scraped from Booking.com. The results replicate; we find that the syntactic surprise of the hotel descriptions has an inverted U-shaped effect on willingness to pay for hotels (Web Appendix E).
Our work also points to novel areas for future research. First, while we tested the effect of syntactic surprise on message effectiveness across various contexts and messages with different lengths, we did not establish any boundary conditions for this effect. Indeed, the findings applied to both short messages (e.g., Facebook and Instagram ads) and long messages (e.g., product reviews). Future research could apply this approach to other types of messages (e.g., slogans), as well as outcome variables such as message comprehension or recall. Second, further research may illuminate the interactions between individual syntactic structures, such as left-branching sentences (Bradley and Meeds 2002; Lowrey 1998, 2006), passive voice (Lowrey 1998; Motes, Hilton, and Fielden 1992), or the grammatical subject (Ostinelli and Luna 2021). Relatedly, there may be additive or interactive effects between syntactic surprise and the use of metaphors or explanatory language. Specifically, metaphors (i.e., figurative speech) impact cognitive resources in processing a message because they aid comprehension by making abstract notions concrete (|Landau, Meier, and Keefer 2010, 2018). Similarly, explanatory language can impact information processing by improving understanding (Genova et al. 2012). Future research can investigate syntactic surprise at the sentence level to understand this factor and various interactions at a more granular level. For example, the order of the sentences with respect to syntactic surprise may be relevant, as this may impact how working memory resources are used in processing the message. It would also be interesting to incorporate interactions with elements such as language, emojis, and pictures in the advertising context. Relatedly, there may be interactions with tone of voice and speed of speech if the communication is spoken.
To our knowledge, the current work is the first to introduce an automatic and scalable measure of syntactic surprise, built on universal dependency grammar, to the marketing literature. Today's consumers have more options and higher expectations, so marketers need more sophisticated tools to bolster their communication efforts. To that end, practitioners can use our approach to assess and improve the syntactic surprise of their messages. Our efforts join recent studies in marketing that have adapted advancements in NLP to support companies in developing marketing content. Reisenbichler et al. (2021), for instance, show that natural language generation can help companies create content for search engine optimization. Our approach can be used as a complement to such natural language generation tools. By assessing the syntactic surprise of generated text, practitioners can validate the effectiveness of their messages and better reach their communication goals.
Supplemental Material
sj-pdf-1-jmx-10.1177_00222429231153582 - Supplemental material for Creating Effective Marketing Messages Through Moderately Surprising Syntax
Supplemental material, sj-pdf-1-jmx-10.1177_00222429231153582 for Creating Effective Marketing Messages Through Moderately Surprising Syntax by A. Selin Atalay, Siham El Kihal and Florian Ellsaesser in Journal of Marketing
Footnotes
Acknowledgments
The authors thank Alex Bleier, Joshua J. Clarkson, Gizem Ceylan, Florian Dost, Daria Dzyabura, John R. Hauser, Marat Ibragimov, Ann Kronrod, Tetyana Kosyakova, Mirko Kremer, Don Lehmann, Tina Lowrey, Shasha Lu, Christian Schulze, and Cathy Yang for their valuable feedback and comments on the article. They also thank Andras Simonyi, Lily Shevchenko, and Nikita Varioshkin for their research assistance.
Associate Editor
Robert Meyer
Author Contributions
The authors are listed alphabetically and contributed equally.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.