
Abstract
The conventional discrete-choice model of demand assumes that consumers are fully informed about every available product alternative. This assumption is at odds with the large body of literature studying incomplete information and the role of the consumer's “evoked set” or “consideration set.” The author develops a novel empirical discrete-choice demand model derived from an underlying theory of consumers' rational inattention. The model distinguishes between factors that shift demand through the utility function, such as prices and product attributes, and factors that shift demand through the consumer's information “evaluation costs.” The author conducts an empirical case study of the laundry detergent category. Using a set of exclusion restrictions based on retail promotional instruments, specification tests select the rational inattention model over the conventional full-information discrete-choice model. Exploiting the launch of Tide Pods midway through the sample, the author demonstrates the role of evaluation costs for the measured value creation from a new product. A conventional discrete-choice model always assigns positive incremental consumer value from new products. However, the rational inattention model developed herein finds a decrease in overall consumer welfare from the new Tide Pods’ entry, with the increased friction in information associated with the larger choice set offsetting the potential gains from higher match value.
Discrete-choice random utility models revolutionized the empirical brand-choice literature by offering a method to estimate demand for differentiated products and to measure value creation to consumers (e.g., Guadagni and Little 1983; McFadden 1974, 1978, 1981). The canonical full-information random utility maximization models (FI-RUM) assume that each consumer considers all of the product variety supplied at the point of sale and has complete information about prices and the objective product benefits and attributes. These assumptions are at odds with a parallel literature dating back to the 1960s that has studied the information frictions that limit consumer choices at the point of sale. Limited product awareness, the cognitive effort required to recall product information, and the costly effort from browsing and deliberating at the point of sale may cause consumers to base their purchase decisions on a more limited “evoked set” or “consideration set” (e.g., Howard and Sheth 1969; Wright and Barbour 1977). In practice, consumers may only consider as few as two to eight product alternatives at the point of sale, often a small fraction of the variety supplied (e.g., Bronnenberg, Kim, and Mela 2016; Hauser and Wernerfelt 1990; Honka 2014; Moorthy, Ratchford, and Talukdar 1997; Newman and Staelin 1972; Punj and Staelin 1983; Ratchford, Talukdar, and Lee 2007). Unfortunately, consumers’ information sets and consideration sets at the point of sale are typically unobserved to the researcher.
I develop a novel formulation of the discrete-choice demand model that is consistent with consumer product/price uncertainty and endogenous information acquisition subject to “evaluation costs.” Unlike the FI-RUM, the framework distinguishes between consumers’ preferences and the costs associated with the gathering of choice-related product/price information at the point of sale.
Formally, I propose the subjective prior rational inattention (SP-RI) empirical model of consumer demand. The SP-RI empirical demand model extends the rational inattention (RI) discrete-choice theory model of Matĕjka and McKay (2015) and Fosgerau et al. (2020) to make it amenable to empirical estimation and welfare measurement. In the RI formulation of discrete choice, the consumer forms a prior belief at the start of a trip and then optimally acquires product/price information before purchase subject to evaluation costs measured by information-theoretic Shannon (1948) entropy. The randomness in consumer choices arises from the posterior incompleteness of the product and price information gathered. The challenge for empirical estimation of the RI model is that the prior belief structure is typically unobserved to the researcher. The first key result of the current research consists of an existence theorem of a latent subjective prior belief that is coherent with the RI theory. I use this result to devise an empirical estimator of the SP-RI model that can be applied to standard brand-choice data sets without assuming a functional form for the consumer's prior belief structure.
I rely on exclusion restrictions to demonstrate the empirical value of the SP-RI model over standard FI-RUM approaches. I exploit the incidence of exogenous retail promotion variables that shift consumers’ consideration by facilitating product and price information at the point of sale without generating direct consumption utility (e.g., Allenby and Ginter 1995; Mehta, Rajiv, and Srinivasan 2003; Terui, Ban, and Allenby 2011). For many consumer packaged goods (CPG) brands, the majority of their sales are associated with some kind of promotion, ranging from in-store displays to feature advertising in a weekly circular (e.g., Blattberg and Neslin 1989). The established wisdom in the literature is that these promotional tools are designed purely to inform consumers and reduce evaluation costs. For instance, point-of-sale displays “are placed near the merchandise they refer to so that customers know its price and other detailed information” (Levy, Weitz, and Grewal 2019, p. 436). Even though some of this information may already be on the label of the product or its packaging, the display “can quickly identify for the customer those aspects likely to be of greater interest” (Levy, Weitz, and Grewal 2019, p. 436). Similarly, free-standing displays are used “primarily to attract customers’ attention and bring them into a department” (Levy, Weitz, and Grewal 2019, p. 437). Feature advertising in local newspapers primarily communicates product/price information, unlike the potential for genuine, utility-shifting branding in higher-engagement media such as television. These exclusion restrictions allow me to test the SP-RI model against the conventional FI-RUM.
To showcase the SP-RI demand model and the estimator, I conduct an empirical case study of the new Tide Pods product entry into the laundry detergent category. I use the Nielsen-Kilts household panel database, comprising laundry detergent category purchases from 2006 to 2016. As in previous work (e.g., Allenby and Ginter 1995; Mehta, Rajiv, and Srinivasan 2003; Terui, Ban, and Allenby 2011), I find that the inclusion of promotional variables in a standard FI-RUM improves fit and produces positive and statistically significant effects, which I interpret as reduced-form evidence for rational inattention. The full SP-RI model is selected over the FI-RUM in a series of model specification tests. The effects of consideration shifters in the SP-RI model are statistically and economically significant. Furthermore, I find substantial differences in the utility-coefficient estimates from the SP-RI model and the FI-RUM model, where the FI-RUM overestimates the magnitudes of almost all the utility parameters. For instance, the FI-RUM model overestimates the price sensitivity by 18%, the Tide brand coefficient by 44%, and the Gain brand coefficient by 65%. I attribute the bias of the utility-coefficient estimates of the FI-RUM to the omission of the promotional variables that are correlated with the corresponding price and brand variables. I find that the implied optimal average margins from the SP-RI model are 24% higher than those of the FI-RUM model, suggesting that the FI-RUM understates pricing power.
Finally, I explore the consumer-welfare implications of the SP-RI's distinction between preferences and evaluation costs. The canonical FI-RUM with unbounded support for the random utility (e.g., logit and probit) mechanically predicts that consumer welfare is strictly increasing in the number of product variants supplied at the point of sale (e.g., Berry and Pakes 2007; Fan and Yang 2020; Petrin 2002). This property is at odds with the commonly observed behavioral finding that too many alternatives can cause consumers to make bad choices (e.g., Bertrand et al. 2010; Broniarczyk, Hoyer, and McAlister 1998; Chernev and Hamilton 2009; Iyengar and Lepper 2000; Iyengar, Huberman, and Jiang 2004). In contrast, increasing product variety in the SP-RI framework increases the costs and complexity of choosing from a larger choice set, potentially leading to ex post inferior choices.
Returning to the empirical application, I measure the value creation to consumers from the launch of Tide Pods. Under the FI-RUM, I find that the launch of Tide Pods increased the nationally projected aggregate consumer surplus by $125 million per year. However, under the SP-RI, I find that the launch of Tide Pods reduced the nationally projected aggregate consumer surplus by $41 million per year, with heterogeneity in the sign of the welfare change across individual consumers. Intuitively, the new Pods offered a lower price-to-value ratio than the average incumbent detergents, and their launch increased the cost of information. The managerial relevance of this result is quite striking and might explain the subsequent decline in Tide Pods’ market share from 6.9% to 3.9% between 2014 and 2016.
The current research contributes to an emerging literature on discrete-choice RI (Caplin, Dean, and Leahy 2019; Fosgerau et al. 2020; Matĕjka and McKay 2015) by establishing a bridge between discrete-choice RI theory and empirical work. This article is the first to derive the empirical analog of RI, the SP-RI demand model, and a corresponding estimator. Key to my approach is the existence proof of a consumer's prior consistent with the demand model without needing to specify a specific functional form for those beliefs. Several recent papers have implemented variations of the SP-RI model and estimator developed in the present research (e.g., Bhattacharya and Howard 2022; Brown and Jeon 2020; DeDad et al. 2021; Natan 2021; Porcher 2020). 1
This article also contributes to the empirical literature on choice models with consideration sets and search (e.g., Honka 2014; Kim, Albuquerque, and Bronnenberg 2010; Mehta, Rajiv, and Srinivasan 2003; Morozov 2021) by offering a less computationally demanding model and estimator. Most approaches specify the consideration set as an additional random variable, imposing the computational burden of deriving the likelihood over all possible consideration sets. Some approaches also typically require observing the browsing and search process. The SP-RI model also provides a structural microfoundation that rationalizes the reduced-form consideration-and-purchase likelihood of Bronnenberg and Vanhonacker (1996).
This work is also related to consumer choice models with Bayesian learning (e.g., Crawford and Shum 2005; Erdem and Keane 1996). The SP-RI model does not require parametric assumptions about consumer beliefs, and it can be applied to the standard brand-choice data sets. However, it cannot accommodate the choice patterns of strategic experimentation because the consumer does not plan out future choices when making the current choice in the SP-RI model.
The remainder of the article is organized as follows. I first provide an illustrative example of the choice context being modeled. Following this, I develop the SP-RI discrete-choice and consumer-welfare evaluation framework. Next, I apply the proposed SP-RI discrete-choice and consumer-welfare evaluation framework to a case study on the addition of more alternatives to consumers’ set of alternatives—namely, Tide Pods’ introduction to the market in 2012. I close with conclusions.
An Illustrative Example of the Subjective Prior Rational Inattention Discrete Choice
This section illustrates the choice context and the SP-RI model being developed using a toy example. A consumer wants to buy one laundry detergent item that would deliver the highest consumption utility among what is available in the aisle. Assume that only three different detergents are available. The consumer instantly perceives the presence of three different options, but they do not know the consumption-utility value that each alternative would deliver.
Suppose first that the consumer does not have a prior consumption experience with any of the detergents, nor does the store have any promotion going on. Suppose the consumer is endowed with a subjective prior belief that each detergent's consumption utility is independent and equally likely to be 3 (good), 2 (neutral), or 1 (bad) with probability 1/3. 2 If the consumer makes a choice at this stage, it will be completely random with probability 1/3 because all three detergents are indifferent to the consumer in this stage. Such a random choice is not likely to be optimal for the consumer. To distinguish the detergents and obtain information about the consumption-utility value of each detergent, the consumer must engage in product/price research by reading labels, comparing prices, and so on. In the optimal strategy, the consumer would end up with some noisy information from the costly price and attribute research.
To fix ideas, assume further the true consumption utility of detergents {A, B, C} are {2, 2, 3}, respectively. When the cost of information is given by the Shannon (1948) entropy differences that I formally introduce in Equation 5, the probability of the consumer choosing detergent

Thus far, I have assumed that all three detergents are homogeneous before engaging in costly information acquisition. Now suppose detergent B is featured in the store, which would shift the consumer's prior belief but not the true consumption utilities. Say, for example, the consumer's prior belief about detergent B's consumption utility is now adjusted to the following: 1 with probability 1/4, 2 with probability 1/4, and 3 with probability 1/2. The probability of choosing detergent B then becomes

The logit shape of the choice probability is inherited from the shape of Shannon (1948) entropy, but the degree of incomplete information about consumption utilities is also affected by the unit information cost term. The role of the unit information cost can be best understood by considering the two extremes. If the term approaches 0, the product/price research becomes free, and the consumer learns all the detergents’ consumption-utility value precisely. They would then choose detergent C with probability 1 regardless of the γ magnitude. By contrast, if the term approaches infinity, implying that the product/price research becomes extremely expensive, the consumer does not engage in any product/price research. Then, the promotion effect γ would be the only factor that affects the purchase probability.
The SP-RI Empirical Framework of Discrete Choice and Consumer-Welfare Evaluation
In this section, I develop the main empirical framework of subjective prior rational inattention (SP-RI). The section is divided into three parts. The first part develops the SP-RI model of the consumer's purchase decision. The setup and exposition in the subsection mostly follow Matĕjka and McKay’s (2015) Lemma 1 and Corollary 1, 3 but with modifications on the interpretation of the prior belief and the definition of the information-cost function, explained in detail subsequently. The second and third parts are entirely novel to the literature. The second part establishes the SP-RI discrete-choice model as an empirical framework of consumers’ discrete choice. The third part then develops the SP-RI discrete-choice demand model as a framework of consumer-welfare evaluation.
Discrete Choice Behavior Under Subjective-Prior Rational Inattention
On each shopping trip, a consumer faces the choice set of products,
Comparison of Welfare Calculations.

Notes: The table illustrates the differences in consumer welfare associated with the presence of additional Good, Neutral, and Bad, respectively, in the choice set, compared with the Baseline case with two Neutral alternatives. The proposed SP-RI welfare is calculated using Equation 12, and the FI-RUM welfare is calculated using the usual log-sum formula presented in Equation W5 of Web Appendix B.
Prior to purchase, the consumer collects product information and engages in deliberation prior to making their choice. Let
After acquiring the free information, the consumer may also engage in costly information acquisition and product deliberation to reduce their subjective uncertainty about the consumption utility vector
Prior to engaging in product deliberation, the consumer's ex ante unconditional probability of choosing j, defined by the expectation of the conditional choice probability against the consumer's prior belief 
The consumer adjusts the accuracy of the costly information that they obtain to maximize the expected value of {Gross benefit from choice − Information cost}. The accuracy of costly information corresponds to the shape of the conditional choice probability 
The information-cost function, 
The consumer solves the problem stated in Equation 4 by optimizing over the shape of the conditional choice probabilities, 

The following subsections explain how I address the challenge to establish the RI-discrete-choice model as an empirical framework. Before proceeding further, I provide a brief explanation of how the proposed SP-RI model differs from the extant discrete-choice RI theory models by Matĕjka and McKay (2015) and Fosgerau et al. (2020).
Key Innovation from Matĕjka and McKay (2015): Subjectivity of the Prior-Belief Distribution
The key innovation of the SP-RI framework is to introduce the subjectivity in the prior-belief distribution explicitly. In the extant RI-discrete-choice theory literature, the consumer's prior belief
I first illustrate why the state dependence of the consumption utilities may lead to identification failure from the empirical researcher's point of view. Suppose, in the context of the consumer-choice example presented previously, two different, equally possible states of the world wherein the consumption-utility value realizations are (2, 2, 2) and (2, 2, 4.2), respectively. Let us further assume that the unit information cost is 1. An empirical researcher, however, typically does not observe the underlying state of the world in consumers’ brand-choice context. Without knowing the underlying state in which the data are generated, the probability of choosing detergent 3 will look like .576 to an empirical researcher because
To establish the RI-discrete-choice model as an empirical framework readily applicable to observational choice data, I depart from such interpretation of the prior belief. I take the consumption-utility vector
I overcome this challenge by interpreting the prior belief
The interpretation of the prior belief is novel in the RI-discrete-choice literature. Thus, I refer to the proposed RI-based empirical framework as the subjective-prior rational inattention (SP-RI), emphasizing the subjectivity of the prior belief.
The SP-RI Empirical Model of Discrete-Choice Demand
In this subsection, I derive an empirically estimable version of the SP-RI-discrete-choice model developed previously. I use the optimal conditional-choice-probability expression in Equation 6, with suitable parameterizations on (
Recall that the conditional (on realized consumption utility 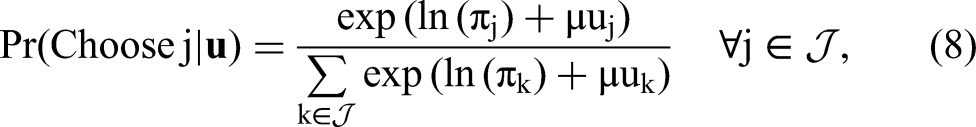

In practice, an empirical researcher typically does not observe a consumer's prior belief distribution,
(Existence of Subjective-Prior-Belief Distribution): Suppose the consumer solves an RI-discrete-choice problem described in the previous subsection. Let J ≥ 2 and let For each

See Appendix B for a more general version of the theorem and the proof.
Condition (i) is a condition that ensures any consumption-utility vector
Note that I assumed that every alternative must have a positive unconditional choice probability (i.e., πj > 0) for the following two reasons. First, zero unconditional choice probability cannot be distinguished from infinitesimal unconditional choice probability with only a finite number of choice samples in hand. Second, in the aggregate demand-estimation context, market-share-equation inversion does not apply when an alternative has zero choice probability, leading to identification failure. Requiring πj to be strictly positive is not the restriction necessarily imposed by the extant RI-discrete-choice theory literature. For example, Caplin, Dean, and Leahy (2019) allow for the zero unconditional choice probability and interpret the alternatives with zero unconditional choice probability as not included in the decision maker's consideration set. On the contrary, in the SP-RI model, higher πj is interpreted as a higher probability of product j being considered during the choice stage.
In Appendix B, I generalize the results presented thus far by adopting the generalized entropy information-cost function proposed in Fosgerau et al. (2020). Appendix B shows that any functional form of discrete-choice probability resulting from additive random utility maximization (ARUM) models, including but not limited to multilevel nested logit or probit, can be established as a likelihood resulting from a rationally inattentive consumer's choice.
The SP-RI-Based Consumer-Welfare Evaluation
Developing consumer-welfare evaluation frameworks when consumers make choices under incomplete information is an ongoing area of research (e.g., McFadden and Train 2019; Morozov 2021; Train 2015). This subsection derives the Hicksian compensating variation (CV) associated with the SP-RI to demonstrate the applicability of the model to welfare analysis and the measurement of value creation to consumers. To simplify the notation, I omit the consumer subscript; however, I discuss the incorporation of heterogeneity in the empirical application.
The true utility has the usual quasilinear-in-the-numeraire form:
I define the consumer-surplus function as follows:

Appendix A provides a formal derivation of the consumer surplus function, including the timing and aggregation argument that lead to the formula, Equation 12. The following example illustrates the proposed SP-RI-based consumer-welfare calculation and compares it with the FI-RUM-based consumer-welfare calculation, focusing on the possibility that consumer welfare may decrease when more alternatives are added to the choice set.
An Example of SP-RI Consumer-Welfare Evaluation
Using the same example presented previously, I next demonstrate how to calculate consumer welfare, defined as the net expected utility of engaging in the problem of choosing one detergent out of all available detergents. Suppose the unit information cost is $1, the store is offering no promotion, and the consumer has no prior experience with the detergents. Suppose the consumption utility of detergents {A, B, C} is now {2, 2, 1}. Then, the proposed welfare calculation using the formulas in Equation 12 with Equation 5 is as follows:

Next, I compare the analogous welfare calculation under the conventional FI-RUM model. Recall that the usual FI-RUM discrete-choice model with double-exponential distributed preference shocks generates the identical logit choice probability when the consumption-utility values of the detergents are the same. In comparing the two-goods case with the three-goods case, I assume that the consumers’ subjective prior beliefs are initialized in the same way that all the detergents are ex ante homogeneous before being affected by any promotions or engaging in the product/price research.
Table 1 summarizes the welfare calculations for the SP-RI and FI-RUM models. I consider four cases to compare the welfare calculations across different scenarios of available detergents in the aisle. The baseline rows consider the case with only two detergents with utility {2, 2}. The “‘good’ added,” “‘neutral’ added,” and “‘bad’ added” rows then consider the welfare calculations of {2, 2, 3}, {2, 2, 2}, and {2, 2, 1}, respectively.
As expected, the FI-RUM welfare increases with the addition of another choice alternative. In contrast, the change in SP-RI welfare associated with another choice alternative depends on the product. When a “bad” is added to the set of alternatives, the proposed SP-RI consumer welfare decreases to 1.763 from 2. In the calculation of Equation 14, the gross benefit decreases from 2 to 1.845 and the actual information cost increases from 0 to .081 by adding the “bad” with the consumption-utility value of 1; the gross benefit decreases and the information cost increases. The resulting consumer welfare in the SP-RI calculation may strictly decrease as a result of adding more alternatives.
When a neutral alternative is added to the choice set, the SP-RI-based consumer welfare is unchanged from the baseline, whereas the FI-RUM-based welfare increases by more than 15% = (3.099 – 2.693)/2.693. All else equal, one would not expect consumer welfare to change when the same neutral with uC = 2 is added to the choice set.
Application: Laundry Detergent Demand and Consumer-Welfare Effects of the Tide Pods Introduction
In this section, I estimate the laundry detergent demand using the SP-RI model and the FI-RUM model, run the specification tests for model selection, and compare their differing managerial implications. Then, I measure the consumer-welfare implications of the new Tide Pods laundry detergent products using the welfare formula based on the SP-RI model and the FI-RUM model, respectively.
Data
The data used are a combination of Nielsen-Kilts Homescan and Retail Measurement Services (RMS) data during the sample period of 2006–2016. Homescan data record all the CPG items purchased in the panel households, using the barcode scanner issued to each household, along with the identity of the store where purchased, if available. In addition, Homescan provides the panel projection weights that allows household-level choices to be projected to the entire U.S. population. RMS data record one-third to one-half of all U.S. CPG transactions. Homescan does not provide the set of alternatives that the participating households faced. Therefore, I matched Homescan shopping trip data that include any purchased laundry detergent with the RMS weekly sales using the store code and week information to construct the estimation data. Then, the stores that do not provide the display and feature information in RMS are dropped. The matching and cleaning process results in 170,968 choice observations with 17 million alternative observations. On average, each choice incidence had around 100 options. Further details about data matching and the cleaning procedure are relegated to Web Appendix E.
I classified the brands, product attributes, and scents by manually querying different Universal Product Code (UPC) databases for 10,911 laundry detergent UPCs in the database. The cleaning procedure resulted in 7 major brand dummies and 18 functional product attributes. The average per package price of the laundry detergents in the estimation sample is $8.91. There are 163 pods detergents in the database, of which 73 UPCs belong to the Tide brand. About 4% of the UPCs are displayed, and 8% of the UPCs are featured. Table 2 presents the summary statistics for the estimation data for price, in-store promotion, and brand indicators.
Descriptive Statistics of the Estimation Sample.

Notes: This table presents the descriptive statistics of the estimation sample. Except for “per pack price,” all other variables listed are indicator variables.
Empirical Specification of the Demand Models
I introduce the subscript i to denote different consumers with potentially heterogeneous tastes, where the choice set
Consideration shifters and unit-information-cost shifters as exclusion restrictions from consumption-utility value
Conventional wisdom in the extant marketing literature finds that in-store displays and features shift consumers’ consideration (sets) but do not generate direct consumption-utility (see, e.g., Allenby and Ginter 1995; Anderson and Simester 1998; Andrews and Srinivasan 1995; Bronnenberg and Vanhonacker 1996; Fader and McAlister 1990; Mehta, Rajiv, and Srinivasan 2003; Terui, Ban, and Allenby 2011; Zhang 2006). Simply plugging features and displays into a conventional FI-RUM as additional shifters in the deterministic utility index is at best a reduced-form, since such promotional variables are not expected to generate consumption utility. In contrast, under the SP-RI framework, I can specify these promotional variables as primitives in the unconditional-choice probability component of the model, πj, shifting only consumers’ consideration as opposed to consumption utility.
I also let a consumer's unit evaluation cost
Formally, let 

The formulations of the model primitives πi,js and μi also generate exclusions restrictions with which I can test the RI framework. Appendix B provides further arguments as to why the parametrizations in Equations 15 and 16 are sensible. Appendix B also discusses the parametrizations in the context of general discrete-choice probabilities beyond simple logit.
Consumption-utility specification
I define the “quality index” function, χi,j, introduced in Equation 11, as follows:

Purchase likelihood
I obtain the following conditional choice probability that consumer i chooses j:
Identification and estimation
Given the functional form of likelihood in Equation 18, identification of the utility parameters can be achieved in the proposed SP-RI framework because the true utility of a product is fixed and deterministic from the perspective of the researcher in this setup. The utility parameters (−β1,
Identification of the individual-product-specific random-effect term ηi,j follows the usual identification argument for the random coefficients/effects. In the model, the functional form of the conditional choice probability follows logit-like form, inherited from the shape of the information-cost function. Deviation of the observed choice and substitution patterns from logit form is attributed to unobserved preference heterogeneity, which is the source of identification of ηi,j's distribution.
I estimate the model using maximum simulated likelihood. Web Appendix A presents details of the consumers’ and researcher's information sets, interpretation of random effects, maximum simulated likelihood formulation, numerical optimization, and further discussion on the implementation details.
Model Selection and Estimation Results
Model selection: Specification test of SP-RI against FI-RUM
This subsection conducts specification tests between the proposed SP-RI model and the FI-RUM model. I compare three specifications: (1) the FI-RUM, (2) the popular reduced-form FI-RUM that includes promotional variables as linear utility shifters (e.g., Guadagni and Little 1983) but without the evaluation cost shifters, and (3) the SP-RI model with promotional variables specified as consideration shifters and demographics specified as evaluation cost shifters. For each model, I report the log-likelihood as well as two in-sample fit statistics, Akaike information criterion (AIC) and Bayesian information criterion (BIC). I also report the out-of-sample average hit rate for the holdout sample. 17
Table 3 reports the model fit measures for specifications 1–3. Specification 3, the SP-RI model that includes both the consideration shifters and evaluation cost shifters in the purchase probability, is selected by all four model-fit measures. The results of the specification tests presented here reconfirm the importance of incorporating the consideration shifters and evaluation cost shifters in the likelihood, where the SP-RI framework offers a microfoundation.
Model Specification Test Results.

Notes: ✓ = indicates that the corresponding variables are included in the purchase likelihood; G-L 1983 = Guadagni and Little (1983). AIC, BIC, and log-likelihood are calculated after scaling the panel-projection factor weights so that they sum to the number of choice observations. The estimation sample has 160,698 choices with a total of 15,989,188 alternatives. The holdout sample has 10,000 choices with a total of 994,378 alternatives.
Parameter estimates of the full SP-RI model
Table 4 summarizes the model-parameter estimation results of the full SP-RI demand model estimated using the entire sample of 170,698 choices. The effective magnitude of the utility parameters for predicting the conditional choice probability
Model-Parameter Estimates.

*p < .1.
*p < .05.
***p < .01.
Notes: Choice observations = 170,698; sample size = 17 million;
The
The unit-information-cost parameter estimates
Comparing the estimates from the SP-RI model and the FI-RUM model, reported in Table W1 of Web Appendix B.2, I find that the FI-RUM model generates much larger magnitudes for almost all the estimated utility parameters. The FI-RUM model overestimates the price sensitivity by around 18%, the Tide brand coefficient by around 44%, and the Gain by around 65%, relative to the SP-RI model. 20 On the contrary, the popular Guadagni–Little specification that includes the in-store promotions as a part of consumption-utility shifter, reported in Table W2 of Web Appendix B.2, generates similar utility-coefficient estimates to the full SP-RI model. The differences in the effective magnitude of the utility coefficients between the SP-RI and FI-RUM models are likely due to the omitted variable bias in the FI-RUM specification that does not include the displays/features in its specification, reconfirming the importance of properly including the consideration shifters in the purchase likelihood.
The net effect of the upward bias in the parameter magnitudes on the implied pricing power, on the supply side, is negative: the FI-RUM understates the optimal contribution margins. I use the standard category pricing conduct, or multiproduct monopoly, to assess optimal contribution margins for a profit-maximizing retailer (e.g., Chintagunta, Dubé, and Singh 2003). The SP-RI model suggests the average optimal margins as $9.60 (brand-level joint pricing) and $7.65 (stockkeeping unit [SKU]–level individual pricing). In contrast, the FI-RUM model suggests $7.70 (brand-level joint pricing) and $6.21 (SKU-level individual pricing). The result demonstrates that biases incurred in the misspecified FI-RUM model may lead managers to suboptimal pricing decisions.
In summary, I systematically select the SP-RI model over the standard FI-RUM model using various in- and out-of-sample testing criteria. I also find that the FI-RUM overstates most of the marginal utility parameters, which, on net, understates the pricing power of a retailer that maximizes category profits. Next, I turn to the differing welfare implications of a new product launch under SP-RI versus FI-RUM.
Counterfactual Welfare Simulation Associated with Tide Pods’ Introduction
In 2012, Procter & Gamble successfully launched its Pods laundry detergent product to the market under the Tide brand name. I now measure the welfare implications of Procter & Gamble's launch of Tide Pods laundry detergent, comparing the results using the SP-RI-based welfare formula proposed in the previous section and the conventional FI-RUM-based welfare formula. 21
The CV is calculated as follows. Recall the consumer-choice model is estimated by pooling the pre– and post–Tide Pods introduction data. The model-parameter estimates
The “average per shopping trip” row in Table 5 summarizes the average CV per shopping trip. Note that average
Average and Annually Projected Compensating Variation per Shopping Trip Associated with Tide Pods’ Introduction.

Notes: This table presents the CV predictions from my SP-RI model and the FI-RUM model, respectively, associated with Tide Pods introduction. Standard errors of average per shopping trip are reported in parentheses, calculated using parametric bootstrap. The parametric bootstrap is conducted by redrawing the estimates from the estimators’ asymptotic distribution, of which the mean and standard error are reported in Table 4 and Table W1 of Web Appendix B.2, respectively, and then predicting CVSPRI and CVFIRUM for 500 times. The “annually projected” row is calculated using the subsample of the estimation data during 2012–2016, projected to the entire U.S. population using the Homescan panel-projection factors as sampling weights, and then annualizing. “Pods sales/year” and “detergent sales/year” rows are calculated using the total Nielsen RMS laundry detergent sales of 2012–2016, multiplied by 2.5 and then annualized.
Figure 1 illustrates the CV distribution associated with Tide Pods’ entry into the market. Each observation corresponds to each shopping instance in the estimation data. Note that adding Tide Pods laundry detergent to consumers’ choice set does not monotonically increase

Compensating Variation Associated with Tide Pods’ Entry.
I also calculate the changes in the average gross benefit separately, which corresponds to the change of the first term in the consumer-surplus formula in Equation 12. The average gross-benefit change is still negative at −$.073/trip, implying that the difference of −$.026/trip can be attributed to the changes in the information cost. Therefore, I conclude that both the gross-benefit and information-cost change contribute to the negative average
The findings from the counterfactual consumer-welfare simulations presented in this subsection are consistent with popular press articles stating that the introduction of Tide Pods into the market did not unanimously benefit consumers, and that the new Tide Pods products were priced substantially higher even after considering their convenience. 23 Furthermore, just after one full year after its launch, the national market shares of Tide Pods began to drop sharply—they declined from 6.9% to 3.9% over the period 2014–2016. 24 The consistency of the consumer-welfare analysis results with the popular press and longer-term market shares pattern provide the face validity of the SP-RI-based consumer-welfare evaluation and pricing counterfactuals conducted. Numerous mechanisms may explain why the introduction of the new product harmed at least some consumers. Explaining the exact reason would require supplementing the purchase data with, for example, consumer surveys, which exceeds the scope of the present research.
Web Appendix A provides further discussion on implementation details, possible price endogeneity, and equilibrium responses of the competitors. Finally, Web Appendix D reports demand estimates and CV calculations from several additional specifications, including the specification in which demographics are interacted with prices to shift the consumption utility. I find that the key results are robust across all the specifications I compare, namely, the FI-RUM systematically predicts that launching Tide Pods increases value to consumers, whereas the SP-RI typically predicts negative total value, in spite of heterogeneity in the sign of the value created for different consumers.
Concluding Remarks
I propose a novel empirical framework for brand choice that allows for rationally inattentive consumers who make utility-maximizing choices at the point of sale under imperfect information about the choice set. In a case study of the laundry detergent category, I find that the SP-RI model fits the data better than a conventional random utility model (i.e., FI-RUM). I also find that the FI-RUM systematically overstates the magnitudes of the marginal utility parameters and understates the implied pricing power of a category-profit-maximizing retailer. I also demonstrate that the SP-RI model can potentially predict either welfare increases or decreases from the launch of new products, in contrast with conventional FI-RUM models, which always predict welfare increases. In my case study of the launch of Tide Pods, I indeed find that the consumer-welfare change is heterogeneous in its signs, and the average consumer welfare decreases slightly due to the trade-off of higher search and evaluation costs under the larger choice set.
An interesting direction for future research would consist of applying the SP-RI consumer-welfare-evaluation framework developed herein to contexts that may include, but are not limited to, composition of individual product attributes during new product development, product-line design, product curation of a category, SKU rationalization, pricing, and store choice.
Supplemental Material
sj-pdf-1-mrj-10.1177_00222437221110173 - Supplemental material for Rational Inattention as an Empirical Framework for Discrete Choice and Consumer-Welfare Evaluation
Supplemental material, sj-pdf-1-mrj-10.1177_00222437221110173 for Rational Inattention as an Empirical Framework for Discrete Choice and Consumer-Welfare Evaluation by Joonhwi Joo in Journal of Marketing Research
Footnotes
Difference of the SP-RI Framework from the Extant RI-Discrete-Choice Theory Models
The setup of the proposed SP-RI framework departs from the extant RI theory models in two aspects: the subjectivity of the prior-belief distribution and the definition of the information-cost function. The modifications allow an empirical researcher to not specify the complete shape of the consumer's prior belief, both in implementing the SP-RI discrete-choice model and in conducting the SP-RI-based consumer-welfare evaluation. In this appendix, I detail how the SP-RI framework differs from the extant RI theory models in those aspects.
Generalization of the SP-RI Empirical Framework to Any Discrete-Choice Probabilities and the Proof of Theorem 1
Acknowledgments
The author is grateful to his dissertation advisors, Jean-Pierre H. Dubé, Ali Hortaçsu, Pradeep K. Chintagunta, and Doron Ravid, for their guidance and support. The author thanks Bart J. Bronnenberg, Inyoung Chae, Tat Chan, Andrew Ching, Khai X. Chiong, Lawrence Y. Chung, Filip Matĕjka, Carl Mela, Sanjog Misra, Michael Grubb, Mingyu Joo, Irene Kim, Jun Hyung Kim, Kyeongbae Kim, Tongil Kim, Nanda Kumar, Nitin Mehta, Ram C. Rao, Brian Ratchford, Linda M. Schilling, Jinyeong Son, Kenneth Wilbur, and seminar participants at the University of Chicago, University of British Columbia Sauder School of Business, The University of Texas at Dallas Naveen Jindal School of Management, University College London School of Management, International Industrial Organization Conference 2017, INFORMS Marketing Science 2018, Econometric Society Asian Meeting 2019, and 2nd DFW Marketing Junior Symposium for suggestions and discussions. This article includes figures calculated or derived based on data from The Nielsen Company (US), LLC, Copyright 2018, provided by the Kilts Center for Marketing at the University of Chicago Booth School of Business. The conclusions drawn from the Nielsen data are mine and do not reflect the views of Nielsen. Nielsen is not responsible for, had no role in, and was not involved in analyzing and preparing the results reported herein.
Associate Editor
Brett Gordon
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.