
Abstract
The authors develop an attribute-based mixed-membership model of consumers’ preference for stockkeeping units in store assortments. The model represents the underlying “topics of interest” that drive shopping behaviors as probability distributions over product attributes. It overcomes several limitations of latent Dirichlet allocation topic models and is particularly useful for making preference predictions in large and frequently changing store assortments. The authors apply the proposed model to investigate topics driving browsing and purchase activities in an online deal marketplace of fashion products and explore how preference structures evolve over time. They find commonalities and differences in the topics that drive the browsing and purchase stages of online shopping processes. In general, browsing covers a broader range of product attributes than purchases. Consumers tend to browse products of premium positioning and/or deep discounts in the deal marketplace, but when purchasing, they tend to gravitate toward lower-tiered products at their original prices and modest depths of discounts. The authors illustrate how insights from the proposed model can be utilized to profile consumers based on their price preferences and to improve personalized product recommendations. They show that the model's performance is particularly strong in predicting preferences for new products that are not in the existing assortment.
Keywords
Many retailers carry large and frequently changing assortments. With the development of e-commerce, the assortment size of a typical online store or marketplace is even larger and growing steadily. Unlike for consumer-packaged goods, consumers hardly ever buy the same item multiple times in many other types of merchandise, such as clothes, footwear, bags, jewelry, fashion accessories, video games, music, movies, books, and electronics. Therefore, retailers selling such merchandise need to frequently update their assortments. In addition to large assortment sizes, the frequently changing nature of their assortments makes it difficult to predict consumers’ preferences and to make effective merchandising decisions.
The general approach proposed in the marketing literature to studying consumers’ purchase decisions in fairly large assortments is to translate individual stockkeeping units (SKUs) into relevant product attributes, and then model purchase decisions as driven by preferences for those product attributes (e.g., Fader and Hardie 1996; Ho and Chong 2003; Inman, Park, and Sinha 2008; Sinha, Sahgal, and Mathur 2013). As well articulated in the seminal work by Fader and Hardie (1996), an important advantage of modeling consumer preferences for product attributes is its ability to make preference predictions for new products that have yet to be included in the assortment. Nonetheless, prior SKU-level models were mostly constructed at the product category level. They were not meant to incorporate cross-category dependencies of purchase behaviors in the entire store assortment.
Recent developments in topic models for natural language processing have offered new tools for handling the scale of retail assortments. An analogy can be drawn between words and documents studied by natural language processing to purchased products (or SKUs) and a consumer's purchase history record in retailing data. Based on this analogy, Jacobs, Donkers, and Fok (2016, 2021) have adopted the latent Dirichlet allocation (LDA) topic modeling approach to studying purchase behaviors concerning the entire store assortments and investigated the underlying topics (which they called “motivations”) that drove purchase decisions. Their approach provides rich insights on consumers’ preference structures in terms of plausible motivating factors. For example, in the context of online grocery products, Jacobs, Donkers, and Fok (2016) identified underlying “motivations” such as a preference for ecofriendly products or low-fat products.
Nonetheless, the LDA models have several limitations which hinder their ability to assist managerial decisions facing many retailers, especially those with frequently changing assortments. The most serious limitation is that they cannot provide preference predictions for products that do not exist in the calibration data of existing assortments. In this study, we propose an attribute-based mixed-membership (ABMM) model, which is better suited for frequently changing store assortments. The proposed model is related to the LDA topic model framework but incorporates the idea of decomposing individual products (SKUs) into managerially relevant product attributes. It formulates the underlying topics as probability distributions over product attributes instead of individual products. We adopt the terminology “topic” from the natural language processing literature. A “topic” is similar to the underlying interest, need, objective, or goal that drives consumers’ shopping behaviors. Our model offers several advantages over LDA models in capturing consumer preferences in large store assortments. First, it is capable of making preference predictions for new products that are not in existing assortments, which is particularly important for retailers with frequently changing assortments. Second, unlike LDA models, which cannot incorporate the impact of time-varying marketing-mix variables, our model is able to do so because a marketing-mix variable can be treated as a product attribute in the model. Third, whereas LDA models ignore similarities among products sharing common attributes, our model explicitly captures such similarities. For example, in the context of fashion products, a consumer may have a strong preference for a particular brand or color and thus is likely to buy different clothes of the same brand or color repeatedly, which would be reflected in our attribute-based topic model. Fourth, the topics revealed by our model are clearly defined by managerially relevant product attributes and offer directly actionable insights for retail managers. In contrast, the meaning of an identified “topic” or “motivation” from an LDA model needs to be inferred from the commonality of products that are loaded on the same topic, and thus it is subject to interpretation and ambiguity. 1 Finally, our model can handle data sparsity better than LDA models, because its estimation relies on co-occurrence of product attributes in a shopping basket. In contrast, estimations of LDA models rely on co-occurrence of individual products in a shopping basket, which is less frequent than co-occurrence of product attributes.
The managerial focus of our research is to study the preference structures that drive consumers’ browsing and purchase activities for the entire store assortment of an online retailer. We thus construct a model of both browsing and purchase activities, in which topics for driving browsing and purchasing can be different, yet related. We apply the proposed model to data from an online deal marketplace for fashion products. Fashion retailers face unique challenges when it comes to assortment management. Consumers rarely buy the same item more than once, and their preferences tend to evolve over time. Certain fashion products have particularly short lifespans. These so-called “fads” need to be replaced frequently (e.g., Sproles 1981). Therefore, fashion retailers need predictive models that can be adapted to frequently changing store assortments. Our attribute-based topic model provides a solution to address this need by taking advantage of the fact that although consumers’ preferences for individual products are frequently changing, their preference structures at the product attribute level are more enduring. Many consumers have favorite brands and colors across product categories. The apparel categories that they favor also tend to be stable. For example, some women prefer pantsuits while others prefer power dresses, even though both categories are considered formal workwear.
In the context of deal-oriented fashion e-commerce sites, some questions are particularly relevant. For example, are consumers drawn by prestigious brands on deep discounts or low absolute prices regardless of the original prices and percentage discounts? Do consumers browse and purchase different products, and if so, what kind of products tend to draw consumers' interest in browsing, and what products tend to be converted into purchases? How does shopping experience influence consumers’ fashion preferences? How do consumers differ in their preference structures and evolution patterns? Our model will reveal easy-to-interpret and directly actionable “fashion topics of interest” that drive shoppers’ browsing and purchase activities and the time-varying patterns of their relevance to each individual. These insights can be utilized to make various merchandising decisions and product recommendations by online retailers or marketplace operators.
We make two main contributions in this study. First, we propose an ABMM model at the SKU level for inferring consumers’ preference structures in large and frequently changing store assortments, which overcomes several limitations of previous models for large assortments. We demonstrate that the proposed model outperforms benchmark models in its predictive power in both estimation and holdout data, and that it is particularly powerful in predicting preferences for new products not in existing assortments. Second, our study reveals novel insights on the underlying preferences driving consumers’ browsing and purchase activities in an online deal marketplace for fashion products and how they evolve with shopping experiences. The proposed model can be utilized to improve a variety of merchandising decisions. We illustrate its managerial value through an application of personalized product recommendations and demonstrate that recommendations based on our model substantially outperform those based on benchmark models.
Relevant Literature
Our research builds on several streams of prior literature. On the methodology front, our proposed model is related to previous developments in (1) assortment and SKU-level modeling and (2) topic models in machine learning developed for natural language processing, which have also been applied by marketing academics. In terms of the substantive area, it is related to the literature on online shopping and purchase behaviors. Next, we provide a brief review of each stream of research and outline how our study compares with the prior literature.
Assortment and SKU-Level Modeling
To deal with sales response or consumer demand/choice at the SKU level, models proposed in the marketing literature have essentially adopted two approaches. The first approach explicitly contains SKU-specific intercept terms to capture preference for a SKU (e.g., Guadagni and Little 1983). A key limitation of this approach is that the number of parameters to be estimated grows proportionally to the number of SKUs, and thus it cannot accommodate even a fairly small assortment well. The second approach is to define and parameterize the preference for a SKU as the sum of preferences for each of its product attributes. A seminal work taking this approach is Fader and Hardie (1996). They propose a multinomial logit model of product choice using a set of product attributes that parsimoniously characterizes a large number of SKUs in a category. Their model prevents explosion in the number of parameters. Moreover, it enables preference predictions for new products that are new combinations of product attributes in the model and provides valuable insights for identifying line extension opportunities.
Many studies have followed this general approach and extended it to incorporate other aspects of consumer decisions. For example, the model proposed by Ho and Chong (2003) captures the impact of consumers’ attribute-level experience and product-specific experience. Inman, Park, and Sinha (2008) develop a model that identifies product attributes driving switching versus repeat purchase behaviors, respectively. Rooderkerk, Van Heerde, and Bijmolt (2013) accommodate substitution patterns between SKUs by incorporating attribute-level similarity in their model. Sinha, Sahgal, and Mathur (2013) use an attribute-based approach to modeling sales of 3,000 SKUs of wine products and develop a decision support system based on it. Researchers have also utilized factor model structures in this line of pursuit. For example, Sinha et al. (2005) develop a factor-analytic choice model which captures a large number of SKUs in the soup category by a few latent factors. Singh, Hansen, and Gupta (2005) use a factor structure to capture cross-category correlations in attribute preferences and to deal with the scalability problem. In the operations management literature, research on assortment management has focused on developing heuristics that can solve discrete allocation optimization problems of sizeable assortments. Kök, Fisher, and Vaidyanathan (2008) provide a comprehensive review of operations management research on this topic.
Attribute-based models can be scaled up to handle a large number of products and to make preference predictions for new products, which is an inspiration for our ABMM model for store-level assortments. By adopting the mixed-membership modeling approach, our proposed model provides more flexibility in capturing preference structures as combinations of product attribute levels with varying degrees of relevance and heterogenous preferences among individual consumers. 2 In addition, compared with category-level models—which, by construction, focus on a given category and thus do not capture co-occurrences of purchases across product categories—our model incorporates interconnections in consumer preferences across categories (and other attributes), which can provide valuable insights for cross-selling, product recommendations, and assortment management at the store level.
LDA Topic Models
As mentioned previously, LDA topic models were originally developed for natural language processing in the computer science field. They are unsupervised Bayesian learning algorithms mainly used to extract latent “topics” by relating the words under a topic (for details, see Blei, Ng, and Jordan [2003]). There have been a growing number of applications of the LDA modeling framework in the marketing literature, primarily adopted to understand latent dimensions extracted from rich text data (e.g., Ansari, Li, and Zhang 2018; Dew, Ansari, and Li 2020; Liu and Toubia 2018; Tirunillai and Tellis 2014; Toubia et al. 2019). For example, Liu and Toubia (2018) study consumers’ content preferences in online search queries. They develop a hierarchical LDA model that allows topics in search queries to be semantically related to topics in search results.
LDA topic models have also been adopted to model purchase decisions in store-level assortments. Jacobs, Donkers, and Fok (2016) apply the LDA framework to study shopping baskets in an online grocery store and to identify the underlying “motivations” that drive the purchases. Their model outperforms several benchmark methods such as collaborative filtering and Dirichlet-multinomial mixtures in its predictive capability. Jacobs, Fok, and Donkers (2021) extend their previous model by including effects of shopping-trip-specific time indicators and incorporating temporal correlations in topic relevance using a correlated topic model with a vector autoregression formulation, which allows consumers’ preferences to change over time. They apply the extended model to study purchase decisions in an offline hardware store. Despite the improvement, their approaches share the limitations of LDA models when studying consumers’ preferences in frequently changing store assortments, as discussed previously. In this study, we propose a new mixed-membership topic model that overcomes these limitations. A prominent distinction of our proposed model with LDA models is that it formulates topics as distributions over product attributes and thus is capable of making preference predictions for new products that are not in the calibration data. In addition, we study the underlying “topics” driving both browsing and purchase activities in an online fashion retailing context. Our analyses reveal novel insights about connections and differences of preference structures driving these two types of shopping activities and how they evolve with consumers’ shopping experiences. Table W1 in Web Appendix A summarizes key features of the aforementioned studies that employ SKU-level models and compares ours with theirs.
Online Browsing and Purchase Behaviors
Our research is also related to the literature on online browsing and purchase behaviors. Prior research has extensively examined online shopping and purchase processes and/or decision outcomes. For example, Bucklin and Sismeiro (2003) study online users’ browsing behaviors on a website and find that a visitors’ propensity to continue browsing is affected by the depth of a given site visit and the number of repeat visits. Montgomery et al. (2004) focus on the navigation paths of online browsing behaviors and show that a user's past path information reflects their goals and is crucial in predicting a subsequent path. Moe (2006) examines the varying decision rules in online browsing and purchase stages within a given product category using attribute-based models of consideration set formation and choices, which identify the most relevant attribute(s) at each stage. Shi and Zhang (2014) investigate how online shoppers’ usage experiences with various decision aids influence the evolution of their store visit and purchase spending decisions over time.
In contrast, the substantive focus of our study is to identify the underlying product interests (which we call “topics”) that drive online browsing and purchase activities in large and frequently changing store assortments. Online shopping processes can be distinguished between the browsing and purchase stages. Moe (2003) characterizes web navigation sessions as knowledge-building, searching, browsing, and buying visits and shows that these types of visits differ in purchase likelihood and responsiveness to marketing messages. The online browsing and purchase stages can be linked conceptually to the broader framework of the purchase funnel as well as to the consideration set formation and purchase/choice stages, which have been modeled extensively in previous studies using scanner panel data (e.g., Gilbride and Allenby 2004; Hauser and Wernerfelt 1990; Roberts and Lattin 1991). 3 We expect that consumers exhibit broader product interests in the browsing stage than in the purchase stage. Therefore, the number of product attribute levels driving browsing activities is likely to be higher than that for purchase activities.
Model Formulation and Estimation
Our model is built on the mixed-membership modeling framework (for a comprehensive overview, see Airoldi et al. [2014]), which also includes LDA models. The basic premise of the model is that consumers browse or purchase certain products in a shopping session driven by a mixture of latent topics of interest. Figure 1 illustrates the main components of our model. The observed data of a consumer in a given shopping session are the products browsed and those purchased, if any. Each product is transformed into specific values defined by a set of product attributes. Topics are formulated as probability distributions over those product attributes. The topics have different degrees of relevance in driving shopping activities of a given consumer. Therefore, a consumer's preference structure is represented by individual-specific topic relevance probability distributions over the topics (for browsing and purchase activities, respectively), in combination with the nature of identified topics. We allow topics relevant to a consumer's browsing and purchase activities to be different but also related to each other.
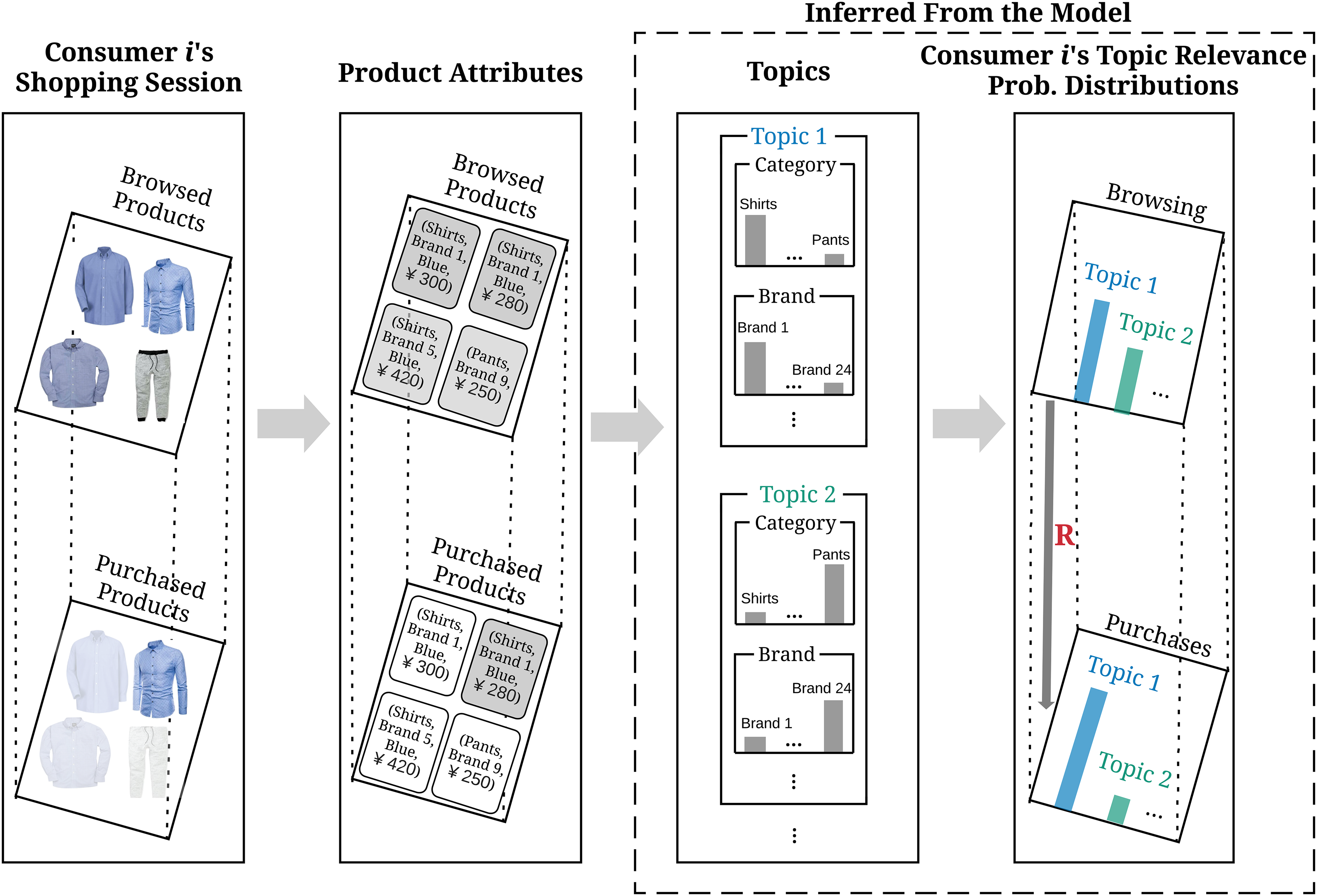
Main Components of the Proposed Model.
Formally, let i denote a consumer, i ∈{1, …, I}, and j denote a product (i.e., a SKU) in the store assortment, j ∈{1, …, J}. A shopping session is a visit to the online store during which a consumer browses certain products and possibly purchases some or even all of them. For each consumer i, we observe Si sessions in total. The set of products browsed by consumer i in session s, s = 1, …, Si, is denoted by
In the rest of this section, we first describe the product attribute space and how topics are defined on this space, followed by the topic relevance distributions and the link between topics driving browsing activities and those driving purchase activities. We then present our method of identifying the optimal number of topics in a model and estimation techniques.
Product Attribute Space
To capture consumers’ preferences over product attributes, we represent each product/SKU
Topics: Probability Distributions over Product Attributes
As stated previously, a novelty of our model is that topics are characterized by probability distributions over product attributes (instead of over individual products as in LDA models). Each topic m ∈ {1, 2, …, M} is characterized by a set of distributions involving A + D individual probability distributions: A probability mass functions each for a discrete product attribute, and D probability density functions each for a continuous product attribute. Within topic m, a discrete product attribute ca is represented by a categorical distribution over its attribute levels, denoted by the |ca|-dimension probability vector
Distributions over continuous product attributes under topic m are captured by probability density functions with specifications chosen based on the measurement of each attribute. A positive product attribute without upper limits, d1, such as the original price and days listed in the store, is assumed to follow a Gamma distribution:
How Topics Drive Shopping Activities: Topic Relevance Distribution Probabilities
Like in an LDA model, the browsing of a product j in a given session s by consumer i is assumed to be driven by a given topic, denoted by

Evolution of Topic Relevance Distribution Vectors
Prior research shows that online purchase behaviors evolve with consumers’ experiences with an online store (e.g., Shi and Zhang 2014). To capture how each consumer's preference structure may change over time, we model the topic distribution vector

In addition, we incorporate potential variety-seeking or inertia behaviors in the model. Using the product attribute “brand” as an example, as a consumer becomes more familiar with a given brand, their interest may switch to other brands, which would lead browsing activities to exhibit variety seeking. In contrast, other consumers may gravitate toward the brand(s) that they become more familiar with, and their browsing activities would exhibit inertia. Our model allows both variety seeking and inertia with the following specification. Following Ho and Chong (2003), we operationalize familiarity with a certain attribute level in a session, Fisal, as the logarithm of the number of times consumer i had browsed attribute level l (e.g., brand B1) of the attribute ca (e.g., brand) before session s. falm is the coefficient for Fisal. The behavior pattern revealed depends on the nature of a topic and the sign of the relevant coefficients falm's in Equation 2. Suppose that brand B1 has a high distribution probability in topic 1, then fbrand1,topic1 > 0 indicates that familiarity with brand B1 would increase the relevance of topic 1, which suggests inertia behavior around brand 1; in contrast, fbrand1,topic1 < 0 would reveal variety-seeking behavior regarding brand B1. In general, positive coefficients of “own attribute levels” indicate inertia, positive coefficients of “cross attribute levels” and negative coefficients of “own attribute levels” indicate variety seeking, where “own” and “cross” are in terms of attribute levels with high versus low loadings on a given topic. We incorporate variety seeking and inertia of all discrete product attributes in the model. 5
A drawback of including these attribute-level familiarity variables in αism is that, as the numbers of product attributes and attribute levels increase, the model is likely to suffer from overfitting. We address the potential overfitting problem by adopting the variable selection and regularization method LASSO (Tibshirani 1996). This method automatically determines the relevant attributes in Fisal. Following common practice, we impose double exponential (Laplace) priors on falm to induce sparsity on the parameters (Gelman et al. 2013, p. 368).
We further incorporate correlations between topics at the session level by specifying that the consumer-specific vector
Likelihood Functions of Browsing Activities
Let Choose For each of the Choose topic Choose each product attribute in Choose level l of discrete attribute ca, l ∼ Categorical|ca|( Choose Choose
The probability that topic m drives the browsing of

Linking Browsing and Purchase Activities
Browsing a product may not lead to purchasing it, but a purchase must be preceded by browsing, which implies that the underlying preference structures driving browsing and purchasing are innately different in some ways yet also interconnected. To capture the similarities and differences in the preference structure that drives the two types of shopping activities, we adopt the hierarchically dual LDA formulation developed by Liu and Toubia (2018). Our application of this formulation involves two premises. First, purchase and browsing activities share the same set of potential topics but are subject to different mixtures of topic relevance probability distributions even within the same session. Second, the relevance of topics driving purchases can be reinforced or weakened by topics that are relevant to browsing activities in the same session.
Formally,

We put a Normal prior on each element in

The data-generating process for each of the products purchased by consumer i in session s, denoted by

We summarize the key notations of the proposed model in Table 1. In addition, a graphical model representation of our model is presented in Web Appendix B.
Summary of Notations in the Proposed Model.

Number of Topics
The number of topics (M) in mixed-membership models is a hyperparameter. It is typically prespecified to a certain value before the estimation of a model (e.g., Blei, Ng, and Jordan 2003), and the optimal number of topics is determined by comparing alternative models based on predictive performance measures such as deviance information criterion or Watanabe–Akaike information criterion (WAIC). In addition to being computationally expensive, this approach tends to favor models with a large number of topics, which would lead to overfitting of the data (Sharif-Razavian and Zollmann 2008). To overcome these problems, we adopt a Bayesian nonparametric method called the hierarchical Dirichlet scaling process (HDSP), which assumes an infinite number of topics a priori and identifies the number of relevant topics in a parsimonious way through the model estimation process (Kim and Oh 2017; Okui 2020; Paisley, Wang, and Blei 2011; Teh et al. 2006). Recently, Boughanmi and Ansari (2021) used this approach to infer the number of themes in a mixed-membership representation of music albums in the topic space. Details of our implementation of the HDSP method are provided in Web Appendix C.
Estimation
We use Markov chain Monte Carlo (MCMC) techniques to estimate the parameters in the model. Specifically, we use the no-U-turn sampler variant of Hamiltonian Monte Carlo (HMC) developed by Hoffman and Gelman (2014). This sampling method explores a high-dimensional posterior distribution exhibiting high autocorrelations over the MCMC draws much more efficiently than the Gibbs sampler and Metropolis algorithm (Gelman et al. 2013). The implementation is done in the software Stan (Stan Development Team 2018). We parallelize calculations of the log-likelihood across 12 processors using the reduce_sum function in Stan, which speeds up the sampling process of HMC significantly. Estimation of the proposed model takes 159.8 hours when using 12 (Intel Xeon W-2295) 3.0 GHz processors. Web Appendix D provides details of prior specifications in the proposed model. Synthetic data tests show that our estimation procedures recover the parameters well (details are provided in Web Appendix E). We include the Stan codes of model estimation in Web Appendix F.
Empirical Setting and Data
Institutional Background
We apply the proposed modeling framework to data from an online deal marketplace based in China that specializes in fashion products. It was launched in April 2013 as a marketplace for merchants to sell products at discounted prices for limited periods. Via the company's mobile app, consumers can view detailed information on available products, such as their picture, brand, product descriptions, the original price and sale price, and days listed on the app, in addition to placing orders. This marketplace operates exclusively through its mobile app and does not have a web presence. Online deal marketplaces are an ideal context for the purpose of our research because products sold in such venues are usually available for only a limited period, and thus the assortment is frequently changing.
Data Description
Our data set contains individual consumers’ browsing and purchase records with detailed timestamps of their activities and information on all products offered on the marketplace from August 2013 to July 2014, spanning a total of 53 calendar weeks. The products in our data were from the inventory management database, which only included products that were featured on the selling pages. Information on each product (SKU) included its category, brand name, color, target users (such as men or women 7 ), original price, 8 sale price, and days listed on the app by a given time point. We eliminated a small number of SKUs that were browsed fewer than ten times in the entire data period, which yielded a total of 7,557 unique SKUs for model estimation and follow-up analyses.
We define a browsing session as a period of continuous browsing activities separated by no more than one hour of inactivity (similar to Schweidel and Moe [2016]). We use data of the first 45 weeks for model estimation and data of the last eight weeks for holdout validations. We use the holdout data set to assess the predictive performance of the proposed method and compare it with several benchmark models. We keep consumers who had at least three browsing sessions in the estimation data set in order to identify consumer-specific parameters, which leads to 1,329 consumers who had a total of 18,744 browsing sessions, 2,426 of which resulted in purchases. Of those consumers, 309 of them appeared in the holdout period.
Table 2 summarizes the full data set and the two sub–data sets. Of the 1,672 unique SKUs in the holdout data set, 753 appeared in the estimation data, and 919 did not exist in the estimation data, which reflects the frequently changing nature of the focal online store's assortment. This enables us to examine the model's ability to predict preference for SKUs in the existing assortment as well as new products not in the estimation data. We use the following product attributes in the analyses: category, brand, gender of the target consumer (“gender” hereinafter), and color, which are discrete; and the original price, depth of discount, and days listed, which are continuous. The brand names are recoded into B1, B2, …, B24 for confidentiality reasons. The depth of discount is computed based on a product's sale price and original price and measured as a percentage of the latter. “Days listed” is the number of days by time t since a product first appeared on the app, and this information was visible to consumers. Table 3 provides more details of the product attributes used in our analyses. In terms of the number of SKUs, the largest category was Tees & Knits (16.1%), followed by Loafers & Other Casual Shoes (11.6%), Shirts & Blouses (11.6%), Jackets & Blazers (9.1%), and Pants (8.3%). A brand appeared in 12.1 categories on average, and 63.5% of the SKUs were products for women. As for product colors, the most common one in terms of percentage of SKUs was Black (21.6%), followed by Blue/Navy (19.1%), White/Off-White (12.4%), Red (8.3%), and Gray (8.1%).
Description of the Estimation and Holdout Data Sets.

Description of Product Attributes.

Table 4 presents descriptive statistics of the browsing and purchase activities of the 1,329 consumers in the estimation data. We use the number of categories browsed, the number of categories purchased, the cumulative spending prior to the current session, and product-attribute-level familiarity variables to capture consumers’ prior shopping experience. The familiarity variables are omitted in Table 4 due to the large number of them. Coefficients of variation show that there were large variations across consumers, especially in their prior purchase activities and total spending.
Descriptive statistics of the Estimation Data.

Estimation Results
Model Comparisons
We compare our model with three benchmark models. Benchmark Model 1 assumes that topic relevance distribution vectors for browsing and purchases in a session are independent (i.e., without the linkage via the matrix
We use the WAIC for model comparisons. WAIC (Watanabe 2010) is a fully Bayesian measure of out-of-sample predictive performance that considers the entire posterior distribution instead of conditioning on a point estimate. It is particularly desirable in our context, which involves models with hierarchical and mixture structures, and thus the number of parameters increases with the sample size (Gelman, Hwang, and Vehtari 2014). A lower WAIC indicates better predictive performance of a model. We compute and compare WAICs across models in the estimation and holdout data sets, respectively, and further separate out WAICs for existing versus new products in the holdout data.
By definition, new products in the holdout data did not exist in the estimation data. We can directly compute WAICs on all products in the holdout data for the proposed model and Benchmark Model 1, because they formulate topics over product attributes and thus can handle new SKUs. To compute WAICs in the holdout data for Benchmark Models 2 and 3, we assume that the probability of observing a new SKU equals the smallest probability among existing SKUs in the corresponding topic assignment, because the probability of observing a new SKU given a topic assignment must be smaller than the probability of observing any existing SKU given the same topic assignment.
Tables 5 and 6 present WAICs of the proposed model and benchmark models for browsing and purchase activities in the estimation and holdout data sets, respectively. Since Benchmark Models 2 and 3 are not designed to make preference predictions for new products, we expect their performance to be worse for new products in the holdout data. As shown in the tables, our model in general performs better than the three benchmark models in both the estimation and holdout data sets based on WAICs for the entire data set (browsing and purchases). In terms of the ability to predict browsing or purchase activities separately, the proposed model outperforms the benchmark models for both activities in the estimation data and also does so in the holdout data, with the exception that WAIC of Benchmark Model 1 is slightly lower than the proposed model for browsing activities. It is worth noting that the two attribute-based models (the proposed one and Benchmark Model 1) perform substantially better in predicting browsing and purchases in the holdout data than Benchmark Model 2, which is an LDA model, because of the former's ability to predict preferences for new products. In addition, compared with Benchmark Models 1 and 3, which do not account for the interconnections of topic relevance between browsing and purchases, the proposed model performs better in predicting purchase activities in both estimation and holdout data sets. 9
Model Comparisons: WAICs in the Estimation Data Set.

Model Comparisons: WAICs in the Holdout Data Set.

The model comparisons demonstrate the importance of incorporating the interconnections of topic relevance for browsing and purchase activities in our model, which enables it to do a much better job of predicting preferences for purchases than Benchmark Model 1. It enhances the model's ability to address the challenge brought about by sparsity of purchase occasions in the data, because it pools information in both purchase and browsing activities, the latter of which occurs more frequently. Compared with Benchmark Models 2 and 3, which use the LDA approach to representing topics, our attribute-based topic model can predict preferences for new products, which is a major advantage for retailers with frequently changing assortments.
Product attributes in the proposed model need to be defined at a high level so that they are applicable to all merchandise in the store. A potential modification of it is to apply the model at merchandise category level and to incorporate category-specific attributes. We have tested such category-level models in three categories: Jackets & Blazers, Pants, and Shirts & Blouses. Comparisons of WAICs in the estimation and holdout data sets indicate that these category-level models perform substantially worse than the proposed store-level model in predicting browsing and purchase activities in each category (details of the models and comparison results are reported in Web Appendix G). The main reason is that co-occurrences of product attributes in a shopping basket are much sparser in category-level data than in store-level data, which severely hinders the reliability of parameter estimates and predictive power of the category-level topic models. In addition, the proposed store-level model incorporates associations in preference structures across categories, which cannot be captured by the category-level models. In conclusion, we do not recommend implementing our proposed topic model to category-level data, especially when co-occurrences of product attributes are sparse.
We report estimation results of key parameters of the proposed model in Web Appendix H and focus on describing the substantive findings in the following subsections.
Topics
Our model identifies 14 topics based on the HDSP approach. In each topic, the distribution over a discrete attribute is represented by a probability vector over its attribute levels, the original price and days listed in the store are modeled using Gamma distributions, and the depth of discount (%) is modeled using Beta distributions. Figure 2 presents a heat map of the topics characterized by their estimated probability distributions of discrete product attributes (category, brand, gender, and color). Each row represents a topic, and each column represents a specific product attribute level, with heat colors indicating the expected probability of a given attribute level. The numbers in the last three columns represent the mean of days listed (in days), the original price (in 100 yuan), and depth of discount (%), respectively, of the distribution represented by each topic. Figure 3 presents the distribution plots of the three continuous attributes.

Heat Map of Topics.

Distributions of Continuous Attributes in Each Topic.
Figure 2 shows varied patterns in terms of how specific product attributes are related to the identified topics. Some topics are characterized by a single attribute level on most product attributes, such as Topic 2. Nonetheless, most other topics are characterized by attributes spanning across multiple levels of all physical attributes. Figure 3 shows that the distributions of the continuous attributes take on quite different shapes. The distribution of days listed is fairly similar across topics. All of them are highly right-skewed, which indicates that consumers prefer products that are newly listed on the deal marketplace in general. The distributions of the original price and depth of discounts show a high degree of variation in both shapes and means across topics, which reflects a wide spectrum of price preferences in this deal marketplace. The original price of a fashion product reflects its brand image and prestige (Groth and McDaniel 1993; Lee, Chen, and Wang 2015). While a couple of topics represent preferences for low original prices and high depth of discounts (e.g., Topics 10 and 12), others indicate the opposite preferences for high original prices and relatively low depth of discount (e.g., Topics 6 and 11). Some other topics capture preferences for low original prices and low discounts (e.g., Topics 5 and 13) or for high original prices and high depths of discount (e.g., Topic 1). As we illustrate subsequently, these findings offer the basis to segment consumers into different profiles of price preferences, which can assist a variety of merchandising decisions for a deal marketplace. To assist interpretations of the topics, in Table 7 we provide more details of the physical product attributes that characterize each topic.
Descriptions of the Identified Topics.

Relations of Topic Relevance for Browsing Versus Purchase Activities
The interconnections of topic relevance for browsing and purchases are captured by the matrix
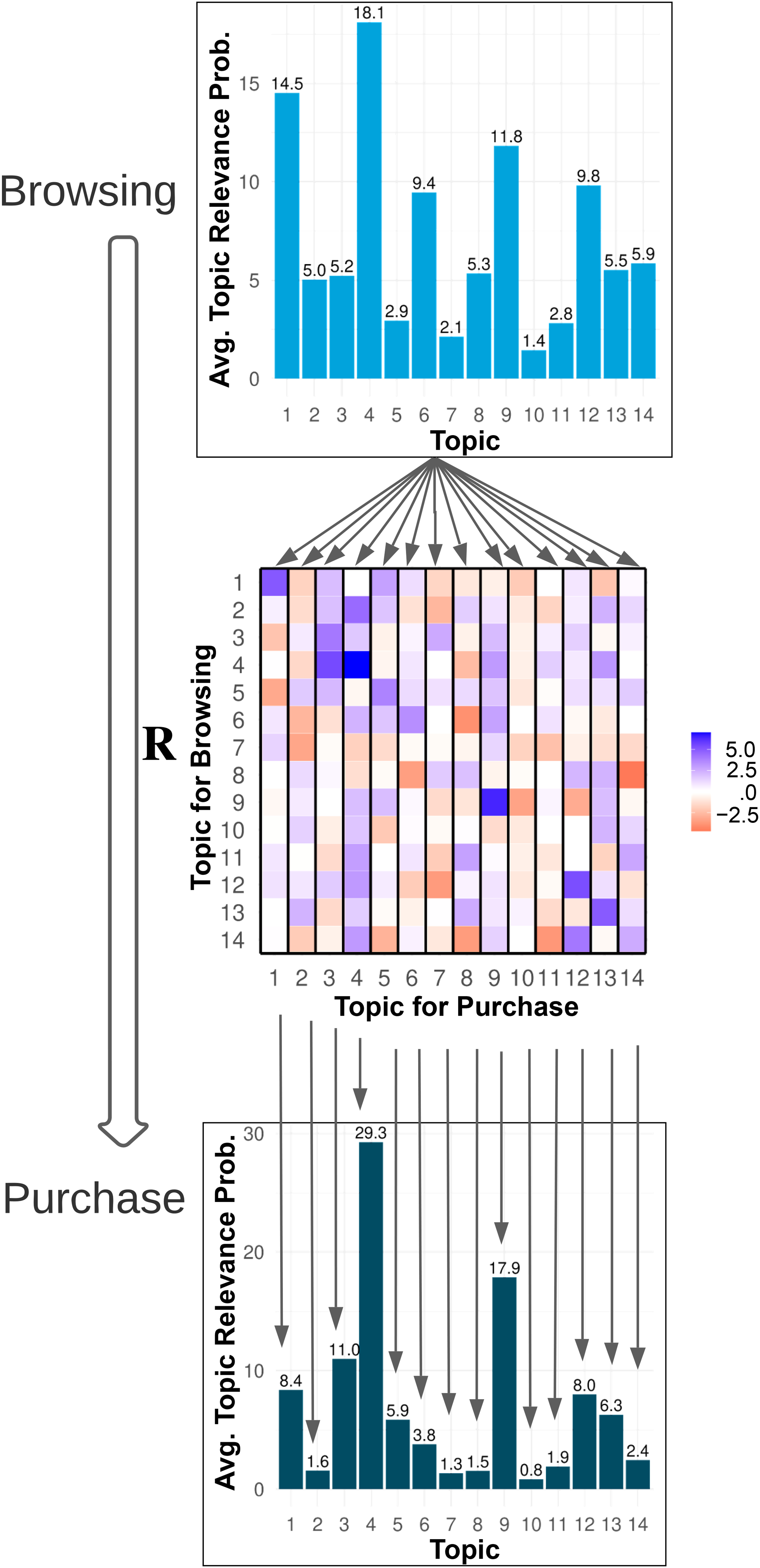
Relations of Topic Relevance for Browsing Versus Purchase Activities.
We further examine the similarities and differences of topics driving these two stages. In the top and bottom panels of Figure 4, the length of each bar represents the average relevance probability of each topic for browsing and purchases, respectively. As the figure shows, some topics play a prominent role in driving both browsing and purchase activities, such as Topic 4, which is characterized by multiple attribute levels within a discrete attribute and low original prices and lower depth of discounts. Nonetheless, browsing and purchases are not necessarily driven by the same topics. For example, Topic 1, which is characterized by high original prices and deep discounts, is more relevant in driving browsing than purchases across all consumers. In contrast, Topic 3, which is characterized by lower original prices and deeper discounts, is more relevant in driving purchases than browsing across all consumers.
To compare the breadth of attribute levels between browsing and purchases, we compute normalized entropies 10 for each discrete product attribute based on the weighted average probabilities across attribute levels (weighted by topic distribution probabilities for a given session and consumer). For each of the continuous attributes, we compute the weighted mean and standard deviation weighted by the corresponding topic distribution probabilities. Table 8 presents the results. In general, the entropies for browsing are larger than those for purchases, indicating that consumers tend to browse a broader set of products than what they end up purchasing. The weighted standard deviation of the original price for browsing is also larger than that for purchases, which speaks to the same phenomenon. There is not much difference in the weighted standard deviations of days listed and depth of discount between the two stages. Interestingly, the weighted means of original prices and depth of discounts of topics driving browsing are substantially higher than those driving purchases, suggesting that, in general, consumers tend to be attracted by products of premium positioning and/or deep discounts on the deal marketplace in their initial search processes but gravitate toward products of lower tiers of original prices and modest depth of discounts for purchases.
Entropy of Distribution Probabilities of Discrete Attributes and Weighted Mean and Standard Deviation of Continuous Attributes.

Evolution of Topic Relevance
The evolution of a consumer's preference structure is captured by the effects of time-varying covariates in Equation 2 (
The role of consumers’ prior shopping experience
Our model shows how the relevance of each topic is associated with a consumer's prior shopping experience at the focal deal marketplace. For example, as consumers browse or purchase more categories from the marketplace, Topic 6 (characterized by high original prices and low depth of discounts) becomes more relevant, while Topic 10 (characterized by low original prices and high depth of discounts) becomes less relevant. This suggests that consumers may gravitate toward more expensive products as they have been exposed to more categories, which provides another reason for online fashion retailers to encourage consumers to browse more categories in their stores early on.
Effects of product attribute familiarities
Estimation results show that familiarity with attribute levels also drives preference evolution. The effects of a consumer's prior exposure to different product attribute levels on the topic relevance reflect variety seeking, inertia, or loyalty in consumers’ browsing or purchase behaviors. We use the variable selection method LASSO to determine the relevant product attribute familiarity variables for each topic. Web Appendix I reports detailed estimation results. We find that variety seeking was the dominant pattern in both browsing and purchase activities, especially with regard to category and color. The tendency to switch away from prior exposure to the color black is particularly strong (as indicated by negative effects of familiarity with this color on relevance of topics with high loadings of the black color) in both browsing and purchases. Nonetheless, consumers showed loyalty to several brands (brands B1, B7, B12, and B18), as familiarity with these brands reinforces the relevance of topics with high loadings on them. The estimation results also reveal cross-category browsing patterns across sessions. For example, as consumers gained more familiarity with the category Shorts, they tended to become more interested in browsing Jackets & Blazers and Overcoats.
Seasonality
The quarter dummy variables in Equation 2 capture potential seasonality in the preference for products in the assortment. The results are consistent with the expected seasonality of fashion products. For example, Topic 10, which is characterized by women's black overcoats, is most relevant in Quarter 4 (October–December), while Topic 12, which is characterized by women's black and white/off-white tees and knits, is most relevant in Quarter 3 (July–September).
Model-Based Consumer Profiles According to Price Preference
Understanding consumers’ price preferences is particularly important for deal-oriented online retailers or marketplaces. Some consumers may be attracted by prestigious brands (which are of high original prices) on deep discounts, while others may be attracted by low absolute prices regardless of whether it is due to low original prices and/or deep discounts. How important is the brand prestige versus discounts? How do consumer preferences for the original price and depth of discounts vary in the browsing vs. purchase stages? Our model incorporates the original price and depth of discount as continuous product attributes. It reveals consumers’ preferences for the two distinct dimensions of prices in browsing and purchases, respectively, which enable us to answer these questions by constructing a consumer profile according to their price preferences.
We profile consumers into four types based on their preferences for the original price and depth of discount. We first compute the average topic distribution vector across shopping sessions for each consumer, and then compute averages of original price and depth of discount weighted by their topic distribution probabilities for browsing and purchases, respectively. Next, we classify each consumer into “high” or “low” based on whether their average original price or depth of discount is above or below the corresponding average value across all consumers. This leads to four profiles of consumers based on their price preference. Table 9 summarizes the profiles and presents the percentage of consumers belonging to each profile for browsing and purchases, respectively.
Profiles of Consumers Based on Their Price Preference.
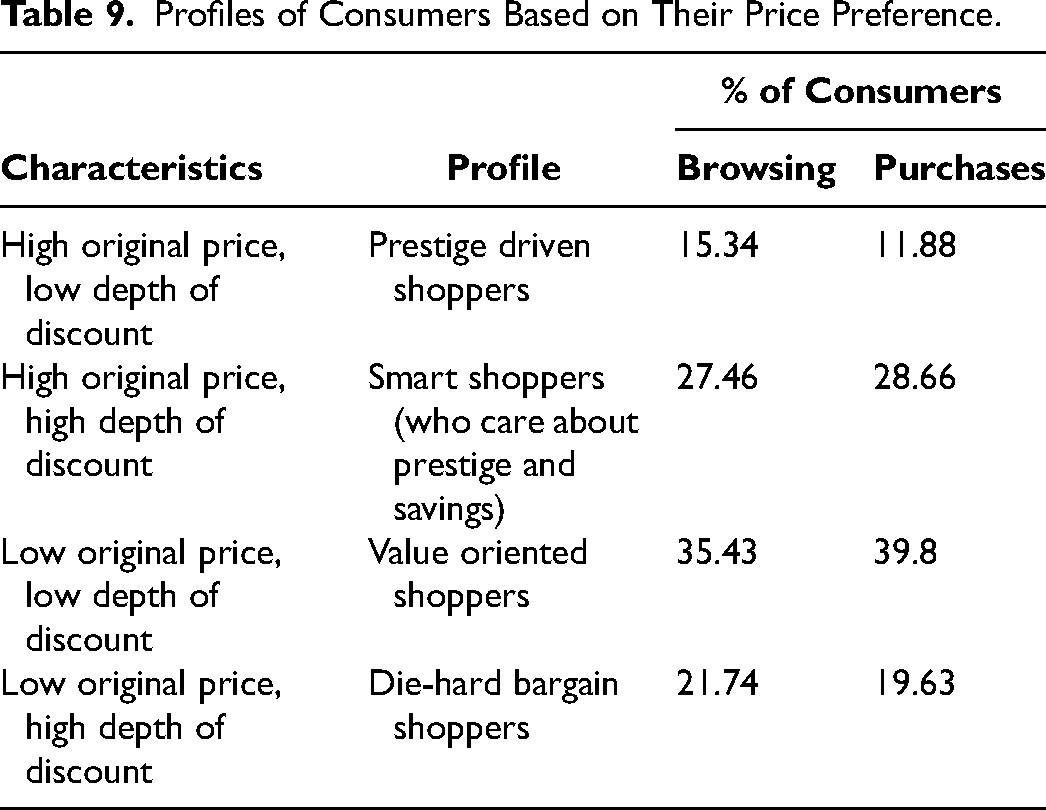
Table 9 shows that the majority of consumers on the focal deal marketplace belong to the middle two profiles in both browsing and purchases. The largest group is “value-oriented shoppers” who prefer products of low original prices but are not obsessed with high percentage discounts. The second largest group is “smart shoppers” who prefer prestigious brands with deep discounts. “Prestige driven shoppers” are the smallest group. Interestingly, more consumers belong to this group in their browsing behaviors than in purchases. Our analysis reveals that most consumers belong to the same profile for both browsing and purchases. Nonetheless, some customers show different profiles in their browsing and purchase activities. For example, 3.91% of consumers are value-oriented shoppers for browsing but die-hard bargain shoppers for purchases, while 5.64% of consumers are die-hard bargain shoppers for browsing but value-oriented shoppers for purchases. The individual differences provide valuable information for personalizing product offerings and communication messages based on each consumer's price preference for browsing versus purchases.
Our model provides a rich set of insights that can be used to assist or improve a variety of merchandising decisions, such as assortment planning, cross-selling, and designing personalized offerings. In the next section, we illustrate its managerial value through an application of personalized product recommendations.
Application: Personalized Product Recommendations
Personalized product recommendations have been widely used in e-commerce practices. A general challenge is the “cold start” problem of making recommendations for new products that do not exist in the model calibration data set/existing assortment. As discussed previously, LDA models of store assortments cannot make preference predictions for new products and thus are not designed to address this problem. Conventional collaborative filters rely on correlations of products purchased across users. They cannot address the problem either, because products not in the existing assortment by definition could not have been browsed or purchased by anyone previously. Solving the cold-start problem regarding new products is particularly relevant for retailers managing frequently changing assortments. For example, in our empirical application here, 55% of SKUs in the holdout data set were new products that did not exist in the calibration data set. Our model provides the basis for a solution to address this challenge.
A personalized product recommendation system identifies a certain number of products that are predicted to maximize a consumer's likelihood of the desired outcomes. In the empirical application, we set the goal to find a set of recommended products that maximizes a consumer's likelihood of browsing and purchasing. When applying our proposed model to derive the product recommendations, the basic idea is to find the optimal set of product attributes from combinations of available attributes in the assortment. Using the recommendation set of one product as an example, the said problem translates to maximizing the following likelihood over product attribute vectors:
Solving this optimization problem involves two challenges. First, some product attributes take discrete values, whereas other product attributes take continuous values, which prevents us from adopting gradient-based optimization methods to maximize the objective function. Second, exploring the large combinatorial space of discrete product attributes for the exact solution that maximizes the likelihood using conventional methods such as grid or random search is a formidable task in terms of computing time and resources. To address these two challenges, we adopt the Bayesian optimization (BO) method to find optimal product attributes. Details of our application of the BO technique are presented in Web Appendix J. It takes 4.4 hours to complete the BO computation based on the proposed model for all consumers in the sample when using 12 (Intel Xeon W-2295) 3.0 GHz processors. In real-world applications, the predictive model only needs to be estimated once in a while. The BO derivation of product recommendations can be done even faster by utilizing more processors for parallel computing.
We compare the performance of personalized product recommendations based on our model with those based on the three benchmark models described previously. For each method, we create consumer-specific recommendation sets of products that are most likely to be browsed and purchased and then compare them with a consumer's actual browsed and purchased products in the holdout data set. As a reminder, Benchmark Model 1 is an attribute-based topic model like ours except it does not consider interconnections of the topic distribution probabilities for browsing and purchases. We apply the same BO method to derive the recommended products for this model. Benchmark Models 2 and 3 are LDA models with topics formulated over individual products. For these two models, we first compute a consumer's likelihood of browsing and purchasing each product in the calibration data directly from the model and then identify the top-ranking products based on the predicted likelihood.
A recommendation set of size V contains the V highest-ranked products for a consumer. We vary the size V to allow different contexts of personalization applications (Jacobs, Donkers, and Fok 2016). In the empirical application, we examine V ranging from one to ten, because the number of recommended products in a single push hardly goes beyond the upper limit of ten (Zolaktaf, Babanezhad, and Pottinger 2018). For example, as of January 2022, jcrew.com (“Customers Also Love”) and gap.com (“Customers Also Liked”) recommend five products each time on their websites.
We assess the quality of a recommendation set by matching its content against products actually browsed and purchased by a consumer in the holdout data. Denote these products by
The quality of a recommendation set of size V can be measured by the number of products in the recommended set
In addition, we compare a frequently used performance measure in the machine learning literature, the F-measure, which combines precision and recall (Adomavicius and Tuzhilin 2005). Precision is the proportion of products in the recommendation list that match with products actually browsed/purchased in the holdout data, and recall is the proportion of products actually browsed/purchased in the holdout data that appear in the recommendation list. The precision and recall measures correct for the fact that recommendation set sizes may not be the same. Since these two measures of a given algorithm do not usually go in the same direction, the overall performance is often captured by the F-measure, a harmonic mean of precision and recall (Adomavicius and Tuzhilin 2005): [(recall−1 + precision−1)/2]−1, with a higher value indicating a better overall performance.
We present the average hit rate, ranking-weighted hit rate, and F-measure across all consumers for product recommendations based on our proposed model and the three benchmark models, for browsing and purchases, respectively, in Figures 5 and 6. We further separate out the performance for existing products (those that were present in the estimation data) and new products (those that only existed in the holdout data). Note that a given recommendation set may contain both existing and new products, but we separately tally and report the performance of the recommendation sets by these two groups of products. The two LDA models, Benchmarks 2 and 3, cannot make preference predictions for new products. Therefore, a priori, we expect their performance to be poor on all new product related measures. Moreover, as Figure 5 shows, even for existing products, our model and Benchmark 1, both of which are attribute-based topic models, yield substantially better performance in recommending products for browsing than the two LDA models. Moreover, recommendations based on our model outperform those by Benchmark 1 for browsing existing and new products in general. 11

Predictive Performance for Browsing.

Predictive Performance for Purchases.
The advantage of our model over the benchmark models is particularly strong when it comes to making recommendations for purchases, as shown by Figure 6. Although Benchmark Model 1 has the ability to make preference predictions for new products in theory, it shows poor performance in our empirical application. It is unable to predict purchases of any new products in all recommendation sets examined and of existing products in recommendation set sizes between 1–7. The reason is that Benchmark 1 treats the topic distribution vectors for browsing and purchases in a session independently. Although the flexibility allows Benchmark 1 to achieve a slightly better WAIC in predicting browsing in the holdout data than the proposed model (see Table 6), the sparsity of purchase data makes it ill-fitted to make predictions of purchases. In contrast, our model incorporates interconnections between the topic relevance for browsing and purchases, which enables it to enhance predictions for purchases by drawing on information in the browsing data. The current application further demonstrates the importance of incorporating interconnections of topic relevance in browsing and purchases and points to an opportunity to deal with the sparsity problem of purchase data by utilizing online browsing data. As to recommendations based on the two LDA models, Benchmark 2 is unable to hit any purchased products in the holdout data; Benchmark 3, which employs an autoregressive formulation of temporal correlations of topic relevance, does a decent job (yet still worse than our model) of recommending existing products for purchases, but it is unable to recommend any new products.
In addition to improved WAICs of purchases in the holdout data (as shown in Table 6), the current application shows that product recommendations based on our model offer a much closer fit with consumers’ preferences and would lead to substantially better purchase outcomes than those based on all three benchmark models. Since the product recommendation application uses only data in the calibration period to predict consumer preferences in the holdout period, the comparisons in this section are a better reflection of the practical value of our proposed model than WAICs.
Summary and Discussion
We have developed an attribute-based mixed-membership topic model for discovering online consumers’ preference structures in large and frequently changing store assortments from their browsing and purchase activities. The proposed model overcomes several limitations of LDA topic models for handling store assortments. A main advantage of our model is that it is capable of making preference predictions for new products not in the existing assortment and, thus, is particularly useful to retailers with frequently changing store assortments. In addition, our model can incorporate the influence of marketing-mix variables and other time-varying product attributes, which is an important improvement for assisting merchandising decisions. We demonstrate the managerial value of our model through an application of personalized product recommendations, and our model shows particularly strong performance over benchmark models in predicting purchases of new products in the holdout data. It offers a reasonable tool to address the cold-start problem of new products for personalized product recommendations, which is an important issue for retailers with frequently changing assortments.
The managerial focus of our research is to study consumer preferences in browsing and purchase activities in online deal stores/marketplaces of fashion products. Our empirical analyses reveal many novel insights of shopping behaviors in such venues. For example, we find that consumers’ preference structures tend to shift from the browsing to the purchase stage. In general, consumers tend to be drawn to products of premium positioning and/or deep discounts in the browsing stage, while their purchases tend to gravitate toward products of lower tiers of original prices and modest depths of discounts. Nonetheless, there are large variations across consumers. Drawing on the model estimation results, we profile consumers in the focal deal marketplace based on their price preferences, which provides valuable insights for modifying assortment compositions and designing personalized merchandising offerings.
The proposed model offers an effective tool for retail managers to discover underlying preference structures that could span seemingly dissimilar or unrelated product attributes without imposing a priori structures. In addition to its advantage in assisting personalized product recommendations, insights revealed by the model can be used to improve a variety of other merchandising decisions. For example, the revealed correlation patterns among product attributes are valuable input for creating new styles by recombining attributes from existing styles and modifying them in a way that is most likely to suit a consumer's taste. They can also be utilized by personal styling service providers to curate personalized product combinations that cater to each individual's preference. In addition, they can be very useful for retailers to devise cross-selling offerings. Furthermore, our model estimation results reveal detailed depictions of individual-specific preference structures and how they may evolve over time with consumers’ shopping experience in the store. For example, we find that certain topics became more prominent, while others became less prominent, in driving a consumer's shopping activities, as they had been exposed to more product categories in the store through either browsing or purchases. Such insights can help retail managers refine personalized targeting strategies based on a shopper's prior activities in their store.
Although our specific model formulation is developed to study browsing and purchase activities in an online store of fashion products, the modeling framework can be easily modified for other retail contexts. For example, offline retailers can simplify the model to focus on purchase outcomes, in which case the model does not need the hierarchical structure component. Retailers selling other types of merchandise can adjust the specific product attributes and their levels used in the model to fit the nature of their businesses.
Our study has several limitations that provide opportunities for future research. First, consumers’ preferences for fashion products can be influenced by social sources, such as social networks, news outlets, and fashion magazines. While our model captures the result of social influence as part of a consumer's preference structure, it cannot separate out the net effect of such influence due to a lack of data on these sources. If data on social influence sources are available, they can be incorporated into the topic relevance distribution vector of our model. We leave this as an important direction for future research. Second, although our model can make preference predictions for new products that did not exist in the estimation data/existing assortment, it requires that those new products be sufficiently mapped to the product attribute levels included in the calibration model. Therefore, the model is not well suited for predicting preference of products with drastically new attributes that are hard to relate to previous products or categories with frequent introductions of new product attributes. Third, while showing strong performance in addressing the cold-start problem of new products for personalized recommendations, our model cannot make reliable preference predictions of new customers/users. An important area of research endeavor is to develop more advanced models and algorithms that can simultaneously solve the “cold start” problems of new products and new users. Finally, our model is built on predetermined product attributes that are clearly defined and directly actionable by retail managers. Future research can expand insights from our model by using machine/deep learning techniques to identify unexpected product features that drive consumer preferences. This approach can be particularly useful for designing fashion products.
To conclude, we hope our study will stimulate more research on inferring consumers’ preference structures from complex assortment data and on advancing understanding of browsing and purchase behaviors in diverse e-commerce environments.
Supplemental Material
sj-pdf-1-mrj-10.1177_00222437221130722 - Supplemental material for Discovering Online Shopping Preference Structures in Large and Frequently Changing Store Assortments
Supplemental material, sj-pdf-1-mrj-10.1177_00222437221130722 for Discovering Online Shopping Preference Structures in Large and Frequently Changing Store Assortments by Min Kim and Jie Zhang in Journal of Marketing Research
Footnotes
Acknowledgments
This article is based on one of the dissertation essays of the first author. The authors would like to thank an anonymous e-commerce company for providing the data used in this research and Professor Lily Du of Xi’dian University for her help acquiring the data. They are also grateful for the valuable input from Bruno Jacobs, Michel Wedel, and Yogesh Joshi of the University of Maryland, and from seminar participants at the University of Maryland, National University of Singapore, Rutgers University, Vrije Universiteit, University of Technology Sydney, and Korea Advanced Institute of Science and Technology.
Associate Editor
Neeraj Arora
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The first author gratefully acknowledges financial supports of the American Statistical Association through its Doctoral Research Award in Marketing and the Marketing Science Institute through its Alden Clayton Dissertation Proposal Competition Award (Honorable Mention).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.