
Abstract
We investigated auditory gaydar (i.e., the ability to recognize sexual orientation) in female speakers, addressing three related issues: whether auditory gaydar is (1) accurate, (2) language-dependent (i.e., occurs only in some languages, but not in others), and (3) ingroup-specific (i.e., occurs only when listeners judge speakers of their own language, but not when they judge foreign language speakers). In three experiments, we asked Italian, Portuguese, and German participants (total N = 466) to listen to voices of Italian, Portuguese, and German women, and to rate their sexual orientation. Our results showed that auditory gaydar was not accurate; listeners were not able to identify speakers’ sexual orientation correctly. The same pattern emerged consistently across all three languages and when listeners rated foreign-language speakers.
1 Introduction
A widely shared belief among lay people is that gaydar enables us to recognize the sexual orientation (henceforth SO) of others by means of different cues, including non-verbal behavior (e.g., Rule, 2017; Woolery, 2007), facial characteristics (e.g., Rule, 2017; Kendig & Maresca, 2004), and—most importantly for the aims of the present research—voice (e.g., Gaudio, 1994; Valentova & Havlíček, 2013). Accordingly, simply listening to a person’s voice for a few seconds should enable listeners to identify the speaker’s SO, in much the same way as talking on the phone would enable one to guess the sex (e.g., Bachorowski & Owren, 1999) or age (e.g., Skoog Waller, Eriksson, & Sörqvist, 2017) of a conversation partner. In the present study, we focused on auditory gaydar, targeting female speakers; we investigated its accuracy and whether the language of both speakers and listeners influenced this voice-based recognition process.
1.1 Auditory Gaydar
Gaydar research has shown that people draw inferences about others’ SO on the basis of minimal cues such as face (e.g., Rule, Macrae, & Ambady, 2009), body shape body motion (e.g., Johnson, Gill, Reichman, & Tassinary, 2007), and voice (e.g., Munson, 2007). Research on auditory gaydar has specifically investigated whether a listener can recognize speakers’ SO just by hearing their voice. However, the majority of studies on auditory gaydar have focused on male speakers and provided mixed results concerning accuracy. Some studies have suggested that people do correctly recognize SO from vocal cues (Gaudio, 1994; Linville, 1998; Rieger, Linsenmeier, Gygax, Garcia, & Bailey, 2010; Valentova & Havlíček, 2013), even when listening to limited information such as single words or phonemes (e.g., vowels; see Tracy, Bainter, & Satariano, 2015). In contrast, other research has shown that although listeners consistently and systematically perceive speakers as either gay or heterosexual, depending on how they sound, this categorization does not always match the speaker’s self-defined SO (Munson, McDonald, De Boe, & White, 2006; Smyth, Jacobs, & Rogers, 2003). Moreover, a “straight-categorization bias” has emerged in many studies: people tend to judge the majority of targets as heterosexual, and perceive as gay only those individuals who deviate obviously from the “heterosexual” norm and expectations (Lick & Johnson, 2016; Sulpizio et al., 2015). In addition, while some studies have suggested that actual differences in gay and heterosexual male speech exist (see Linville, 1998), others have simply shown that specific acoustic cues, for instance, the sibilant /s/, are linked to SO perception and gay male voice stereotypes (Mack & Munson, 2012; Rácz & Shepacz, 2013).
An important limitation of the research on auditory gaydar is that it has mostly focused on male speakers, providing little information on how categorization of SO works with female speakers. One may argue that findings for male voices can be generalized to female voices. However, research on visual gaydar indicates that individuals are more accurate in judging women’s than men’s SO (Brewer & Lyons, 2017; Lyons, Lynch, Brewer, & Bruno, 2014; Tabak & Zayas, 2012). At the same time, it is commonly believed that people are better at recognizing gay men than lesbian women using voice cues (Fasoli, Hegarty, Maass, & Antonio, 2018) and, when judging SO, they are more prone to label a man as gay than to label a woman as lesbian (Lyons et al., 2014).
There are few published papers on gaydar for female targets involving voice. Research by Rieger et al. (2010) provided evidence for accurate gaydar, showing listeners were able to distinguish between lesbian and heterosexual women simply by listening to the speaker’s voice. In another study by Munson et al. (2006; see also Munson, 2007), participants were asked to listen to short recordings of single words and to judge speakers’ SO on a Likert scale. Results showed that listeners judged lesbian speakers, on average, as more lesbian than heterosexual ones, but their data also revealed huge variance in the perception of lesbian women’s voices. This suggests that the difference between lesbian and heterosexual women might not be clear-cut, but driven by a sub-sample of female speakers that sound stereotypically lesbian (see Kachel, Simpson, & Steffens, 2017). In this regard, the seminal work by Moonwoman-Baird (1997) is particularly relevant. This author investigated lesbian speech and found a link between intonation and conformity to gender role. In particular, she suggested that lesbian speakers tend to engage in a more monotone speech pattern that somehow “deviates” from stereotypical heterosexual female speech.
The existing studies investigating acoustic characteristics of lesbian and heterosexual English women’s speech have reported differences in formant frequencies; specifically, they have shown that lesbian women produce lower formant frequencies than heterosexual women (F1 of /ε/ and F2 of /oυ/ in Munson et al., 2006; F2 of /u/ and /ɑ/ in Pierrehumbert, Bent, Munson, Bradlow, & Bailey, 2004). With regard to pitch, there is less agreement in the literature (e.g., Munson et al., 2006; Pierrehumbert et al., 2004; Rendall, Vasey, & McKenzie, 2008; Van Borsel, Vandaele, & Corthals, 2013; Waksler, 2001). For instance, Van Borsel et al. (2013) found lower pitch and less pitch variation in lesbian compared to heterosexual women, whereas Rendall et al. (2008) and Waksler (2001) reported no significant difference in pitch and pitch variation, respectively. Recent research by Kachel, Simpson, and Steffens (2017) investigated German female speakers and found no differences between lesbian and straight women with respect to the fundamental frequency and vowel space dispersion of their voices. However, differences emerged within the lesbian group. Interestingly, variation among lesbian voices was related to two factors: how lesbian speakers self-perceived in terms of gender roles (i.e., as more masculine/feminine), and the extent of their contact with people of different gender and SO (e.g., male or female friends, lesbian or straight friends). For instance, those women who self-perceived as more feminine had a higher median F0 in their speech, indicating that the way they conformed to gender stereotypes affected their speech patterns. Also, more contact with other lesbian women was associated with a higher F1 of /a:/ and lower F2 of /i:/, potentially indicating that lesbian speakers assimilate vocal cues from other people.
More research on female auditory gaydar is needed. There are many differences between male and female voices due to biological and physiological features (e.g., the morphology of the larynx, Titze, 1989, and sex-related hormones, Dabbs & Mallinger, 1999); these differences impact on sound production (e.g., pitch variation is larger in females than in males) biological and physiological features might lead to differences in how male and female voices can signal SO. Moreover, some phonetic cues are likely learned and may thus mirror social and/or cultural gender-related norms (e.g., smaller or larger differences between male and female pitch; van Bezooijen, 1995). In addition, voices seem to be processed in distinct ways depending on the sex of the speakers. For instance, testing English-speaking participants, Strand and Johnson (1996) showed that listeners perceive a fricative sound either as /s/ or /ʃ/ depending on whether the speaker is male or female (see also Johnson, Strand, & D’Imperio, 1999). Thus, it is hard to justify generalizing from research on gaydar for male voices to female voices.
1.2 Language Dependency and Ingroup Specificity
A second important limitation of the previous literature concerns the fact that the literature on auditory gaydar—for both male and female speakers—has mostly focused on native English speakers and listeners. There are a few exceptions: Rácz and Shepacz (2013) found that listeners judged Hungarian male speakers with high frequency sibilants as more likely to be feminine (and potentially gay). Valentova and Havlíček (2013) tested SO recognition of Czech men from both facial and vocal cues. They found that heterosexual women and gay men were able to distinguish gay from heterosexual male speakers; however, since the mean ratings for both groups of speakers were below the midpoint of the scale, this result can be interpreted as a tendency to judge all speakers on the heterosexual side of the sexuality spectrum with variation in terms of “prototypicality.” As suggested by the “straight categorization bias” phenomenon (Lick & Johnson, 2016), individuals tend to assume everyone is heterosexual until this assumption is somehow disconfirmed. Since disconfirmation seems to be primed by gender typicality (Lick & Johnson, 2016; see also Fasoli, Maass, & Sulpizio, 2016), these results can be interpreted as reflecting the fact that gay-sounding individuals are perceived to be less “normative” or “prototypical” and therefore are less likely to be labeled as “heterosexual” (see Smith & Zarate, 1992). This is in line with Sulpizio et al. (2015), who investigated the categorization of SO in Italians and Germans: it was found that male speakers were perceived as either heterosexual or gay, but independently of the SO they identified with. Moreover, there was a tendency to categorize the majority of speakers as heterosexual. Interestingly, a similar pattern emerged in the two languages, regardless of whether listeners judged speakers of their own or the foreign language. The authors concluded that voice-based categorization of SO reflected listeners’ expectations of how gay voices typically sound, regardless of the language they speak. Note that these studies were conducted with male speakers. Hence, it is crucial to extend this research to female speakers, in order to further establish whether the voice-based categorization of SO is a cross-language and cross-national phenomenon. Moreover, examining whether listeners make assumptions about foreign speakers’ SO will contribute to extend the literature on voice-based intersectionality, that is, when multiple social categories (SO and nationality) are simultaneously salient. Indeed, voice can convey information on intersecting social categories (Levon, 2014, 2015; see also Pharao, Maegaard, Møller, & Kristiansen, 2014) studying how listeners categorize individuals speaking different languages, we can examine whether nationality may interfere with SO voice-based judgments. Indeed, speaking a different language leads to categorizing the speaker as a foreigner. Thus, two social categories, namely SO and nationality, would be salient at the same time. The present research aims to shed light on whether voice conveys SO information above and beyond nationality, which has important consequences for social interactions and discrimination (see Fasoli, Maass, Paladino, & Sulpizio, 2017; Rakic, Steffens, & Mummendey, 2011).
Therefore, the current study examined whether auditory gaydar for female speakers is language-dependent (that is, whether it occurs in English, but not in other languages) and whether it is ingroup-specific (that is, whether listeners recognize SO only in individuals who speak the same language and belong to the same group as themselves or can also recognize it in individuals who are native speakers of a foreign language). With regard to language-dependency, the vocal expression of SO may be conveyed by single phonemes—with vowels being particularly informative, at least in American English (Munson et al., 2006; Tracy et al., 2015) —and is thus necessarily constrained by the linguistic parameters of any given language (e.g., type and number of vowels, degree of vowel reduction). If individuals use their stereotypes of how lesbian women sound to make their gaydar judgments, these language constraints may affect both SO expression and detection in different languages. However, voice-related stereotypes may vary across languages, implying that different acoustic cues are used in different languages to express (and to interpret) SO (see Zimman, 2013). Moreover, inter-linguistic variability may be grounded in cultural differences, as the construal of gender and SO varies greatly across cultures (Podesva, Roberts, & Campbell-Kibler, 2001). Therefore, by conducting a multi-linguistic investigation we can make comparisons across languages and extend our findings to languages other than English. Analogous results would speak to the generalizability of the process underlying acoustic gaydar. In contrast, a cross-linguistic difference would suggest that this process is a by-product of a specific language or cultural context.
The question of ingroup-specificity (also called “language specificity”; see Sulpizio et al., 2015) is an intriguing and particularly important issue. To understand the mechanisms underlying the voice-based recognition of SO, we need to investigate whether and how listeners detect the SO of foreign speakers. To our knowledge, only two published studies have investigated this issue. Valentova, Rieger, Havlicek, Linsenmeier, and Bailey (2011) compared American and Czech participants’ evaluations of targets shown in short videos. They found participants were better able to recognize targets’ SO when targets used speakers’ own (rather than another) native language. By contrast, in a comparison of Italian and German participants, Sulpizio et al. (2015) found that participants were overall rather inaccurate in recognizing the SO of speakers who spoke their own and different languages. Yet, there was remarkable agreement among listeners, such that some speakers were considered to sound clearly stereotypically gay or straight—a judgment that was largely independent of the speakers’ actual SO. This agreement was found both within and across languages, suggesting that the judgments of native and foreign-language listeners converge to a large degree. However, neither of these studies included female speakers.
2 Overview
The aim of the present research was to provide answers to three related and currently unresolved research questions. First, are listeners able to recognize the SO of women only by hearing their voices, suggesting that there is auditory gaydar for female voices? Second, does voice-based categorization of SO occur in a similar way in different languages (i.e., language-dependency)? Third, do listeners recognize the SO of women who speak their own language only (i.e., ingroup-specificity)? To answer these questions, three studies on different languages, namely Italian, Portuguese, and German, were conducted. We asked participants of each language to listen to voice samples of self-identified heterosexual and lesbian women and to rate the speakers’ SO. Each participant listened to speakers of her/his own and of the two foreign languages under consideration. We measured SO perception as a continuous variable. This type of assessment allowed us to test accuracy (see Munson et al., 2006), but, at the same time, to make a more nuanced assessment that could better reveal any straight categorization bias (i.e., the tendency to judge speakers as heterosexuals; Sulpizio et al., 2015).
The three languages under consideration here differ at multiple levels. First, they belong to two different linguistic groups: Italian and Portuguese are Romance languages, whereas German (like English) is a Germanic language. Second, these languages differ with respect to their phonological system (having different numbers of vowels and consonants) and phonetic realization, with German having a larger degree of flexibility and greater tendency to phonological reduction than Italian and Portuguese (Bertinetto & Bertini, 2012). This difference may be quite important for auditory gaydar, given that vowels have been found to be particularly relevant cues for SO (e.g., Smyth et al., 2003; Sulpizio et al., 2015). Previous research on male voices has shown that the acoustic information exploited by listeners to categorize speakers’ SO shows inter-linguistic variability in this respect (see Sulpizio et al., 2015). Therefore, although our primary goal was to investigate the accuracy of auditory gaydar within and across languages, we also explored the relation between listeners’ judgments and acoustic information, since this might contribute to our understanding of the process underlying voice-based categorization of speakers’ SO.
3 Method
3.1 Speakers and Recordings
Nine Italian (five heterosexuals and four lesbians), 10 Portuguese (five heterosexuals and five lesbians), and 10 German female speakers (five heterosexuals and five lesbians) were recorded. Speakers were all Caucasian and of similar age across samples: Italians (M = 23.87, SD = 2.36), Portuguese (M = 21.60, SD = 5.68), Germans (M = 24.00, SD = 2.00). Speakers were all native speakers of the respective language. To avoid potential confounds due to regional accents, speakers were selected from one region within each country: Italian speakers were from Veneto, German speakers were recruited in East-Westphalia, and Portuguese speakers were from areas around Lisbon.
All speakers were recruited through the researchers’ contacts, advertisements placed on university bulletin boards, and LGBT associations. To avoid any influence on production during recording, speakers were not informed about the aims of the research, nor was any reference made to SO. Participants were only told that the purpose of the study was to record materials for future studies. To avoid any suspicion, speakers contacted through LGBT associations were told that we were recruiting non-student participants by contacting different cultural associations in town (see Sulpizio et al., 2015 for the same procedure). German and Portuguese speakers received 5 Euro as reimbursement for their participation in the study.
Speakers entered the lab at the university and were seated in front of a computer, while a list of 20 sentences was presented. They were then invited to read the sentences aloud in their native language, and to do so in a natural way. Their voices were recorded using PRAAT (Boersma & Weenink, 2007). Sentences were all recorded at the same time and in the same order. Speakers were instructed to pause between sentences. Two of the recorded sentences were used as stimuli (“The dog ran in the park”; “The English course will start on Monday”). 1 These sentences were chosen as they had neutral content with regard to SO and a similar syntactic structure in all languages.
After the recording, speakers were asked to complete a questionnaire including different scales and demographic information, such as gender, age, and SO. SO was rated on a Likert scale ranging from 1 (exclusively heterosexual) to 7 (exclusively homosexual). Speakers who reported a value above the scale midpoint (i.e., 5 or above) were considered self-identified lesbians; those reporting a value below the midpoint (i.e., 3 or below) were considered self-identified heterosexuals (for a similar procedure, see Sulpizio et al., 2015). 2 Finally, speakers were fully debriefed about the aims of the recordings. Approval to use the audio materials was obtained from all speakers.
3.2 Listeners and Gaydar Judgments
Three different samples, comprising 308 Italians, 101 Germans, and 186 Portuguese, respectively, were recruited. Data from Portuguese and German listeners were collected in the lab, while those from Italian participants were collected by means of an online survey. Overall, 646 participants completed the survey. Non-native speakers (n = 20) of the respective languages and participants who had encountered technical problems (n = 42) were excluded from the analyses. Since the number of participants who did not identify as heterosexual (n = 75) was not balanced across countries, these participants were also excluded from the analyses. To ensure that participants had actually listened to all audio samples when responding to the online survey, we excluded responses from those participants (n = 43) who took less than nine minutes to complete the study (the minimum time frame necessary to listen to all the audio files and provide answers). The final sample consisted of 466 heterosexual participants (193 males, Mage = 25.69, SD = 9.71): 266 Italians, 75 Germans, and 125 Portuguese.
All participants completed a survey created using Qualtrics. They were instructed to wear headphones 3 and to listen to the voices of different speakers. For each speaker, an audio file including two sentences, presented in a counterbalanced order across participants, was used. The audio file appeared on the survey page and participants had to click on it to start listening to that speaker’s voice. Participants were exposed to one audio file at a time and could listen to it as many times as they wanted. Audio stimuli were presented in three blocks, with each block including sentences produced by all speakers of one of the languages. In the first block, speakers spoke the language of the participant; in the other blocks, speakers of the two foreign languages were presented in a counterbalanced order across participants. After listening to both sentences by each speaker, participants had to rate her SO using a 6-point Likert scale from 1 (completely heterosexual) to 6 (completely homosexual). Next, participants’ level of homophobia was measured by asking them to complete the Attitudes Toward Lesbians scale (ATL; Herek, 1998; α ranging from .70 to .93 across countries); the scale required participants to indicate their agreement with 10 items (e.g., “Female homosexuality is wrong”) on a scale from 1 (completely disagree) to 7 (completely agree).
At the end of the experiment, participants provided demographic information (gender, age, native language, and SO) and reported the number of homosexual people they knew. In addition, we asked them to indicate whether, and to what degree, they knew the foreign languages used in the experiment (using a proficiency scale from 0 = I don’t know the language to 4 = excellent). Afterwards, they estimated the number of speakers of each language who were lesbian by choosing a number between 0 and 9 for Italian speakers, and between 0 and 10 for Portuguese and German speakers. Finally, they were debriefed, thanked, and dismissed.
3.3 Acoustic Analyses
With respect to the acoustic features of speakers’ voices, we focused mainly on the segmental level of speech (i.e., vowels and consonants) but also included speaking rate, mean pitch, and pitch range of the utterance, which are suprasegmental features. We selected those acoustic features that had already been reported in the literature as (potentially) relevant for the recognition of female and male speakers’ SO (e.g., Munson et al., 2006), including pitch and pitch variation (Van Borsel et al., 2013).
We considered the following features for vowels: duration (in ms), F0, F1, and F2 (all Fs in Hz) (Italian vowels: /a/, /e/, /i/, /o/, /u/; Portuguese vowels: /a/, /ã/, /e/, /ê/, /i/, /o/, /u/; German vowels: /a/, /a:/, /e:/, /ε/, /i/, /I/, /o/, /o:/, /u:/). For the sibilant fricative /s/, we considered: duration (in ms), center of gravity (in Hz), skewness, and kurtosis. Acoustic measures and acoustic analyses were done using the PRAAT software (Boersma & Weenink, 2007) and custom-written scripts. Formants were measured at vowel midpoint. Acoustic measures were extracted from all the relevant occurrences in the recorded materials. 4 Finally, we considered speaking rate. Speaking rate was measured as the ratio between total sentence duration and the number of syllables in the sentence.
4 Results
4.1 Preliminary Analyses
On average, participants indicated that they knew five lesbian people (M = 5.51, SD = 6.99), with no significant differences across countries, F(2, 407) < 1, p > .9. Moreover, the samples reported low levels of negative attitudes toward lesbians (M = 1.71, SD = 0.87), with no significant differences between countries, F(2, 459) = .87, p = .42, ηp2 = .004. Finally, participants reported an overall very limited knowledge of the two non-native languages. 5
4.2 Main Analyses
This section is divided into three distinct parts. We first describe participants’ overall ratings of SO and their estimation of the number of lesbian speakers in the voice sample. Second, we analyze SO accuracy and categorization bias within and across languages. Third, we report acoustic analyses that help us understand which cues influenced listeners’ impressions in the three languages.
4.2.1 Participants’ SO judgments and estimations
Judgment of SO
Overall, participants reported low SO ratings both for heterosexual (M = 2.90, SD = 0.63) and lesbian speakers (M = 3.05, SD = 0.65). Both ratings reflected a bias towards the heterosexual side of the spectrum with a range significantly below the scale midpoint (3.50), ts < -14.85, ps < .001. Furthermore, although the two means were on the heterosexual side of the scale, they were significantly different from each other, with lesbian speakers judged on average as less heterosexual than heterosexual speakers, t(465) = −5.91, p < .001.
Estimation of number of lesbian voices
Participants greatly underestimated the number of lesbian speakers they had actually listened to; they believed they had listened to only eight rather than 14 lesbian speakers, M = 7.71, SD = 4.98, one-sample t(447) = −26.73, p < .001. Reliable underestimates were found for speakers of all nationalities (Italian, German, and Portuguese, all ts < -2.0 and all ps < .001). The number of speakers identified as lesbians by participants positively correlated with ratings of SO, r(448) = .45, p < .001, indicating, unsurprisingly, that the higher the estimate of lesbian speakers in the voice sample, the higher the likelihood that listeners would judge individuals as lesbian.
This underestimation of lesbian speakers also emerges in the ratings for single speakers. To test whether speakers (regardless of their actual SO) received consistent ratings across participants, we looked at each speaker separately, using perceived SO as the dependent variable and comparing the mean ratings to the scale midpoint (3.5). If perceived as clearly straight or lesbian, a speaker should be consistently judged above or below the scale midpoint, respectively. As shown in Figure 1, the large majority of speakers (76%) were perceived as heterosexual. Of the 15 heterosexual speakers, 13 (87%) were reliably classified as heterosexual (i.e., with a mean evaluation that was significantly below the midpoint). Of the 14 lesbian speakers, only two (14%) were correctly identified as lesbian (i.e., with a mean rating significantly above the midpoint). If we use less strict criteria (i.e., targets rated on average, not on the midpoint of the scale), four speakers (29%) were identified as lesbian, which still represents a minority of the lesbian speakers. Hence, these first analyses suggest an overall tendency to perceive speakers as heterosexual; only a few speakers were clearly perceived to be lesbian (see Figure 1).

Ratings of Italian, Portuguese, and German speakers’ SO as a function of participants’ native language. Stars (and points) indicate speakers that were significantly perceived either as heterosexual or lesbian (* <.05; ** <.01; *** <.001). Higher values on the y-axis indicate perceived lesbianism, lower values perceived heterosexuality.
4.2.2 Mean SO ratings of Italian, Portuguese, and German speakers as a function of listeners’ nationality
We ran a linear mixed effects model (Baayen, Davidson, & Bates, 2008) with SO ratings as the dependent variable and listeners’ nationality (German vs. Italian vs. Portuguese, with German as reference level), speakers’ language (German vs. Italian vs. Portuguese, with German as reference level), and speakers’ SO (heterosexual vs. lesbian, with heterosexual as reference level) as fixed factors; the model included all main effects and interactions of fixed effects; participants’ age and gender were also included as covariates. Random intercepts for participants and speakers were included as well as by-participant random slopes for listeners’ nationality and speakers’ SO (but not their interaction because the model failed to converge), and by-speaker random slopes for speakers’ language. The model was fitted in R software using the lmerTest package (Kuznetsova, Brockhoff, & Christensen, 2013). Note that the inspection of random intercepts is informative regarding possible participant bias in scale use (i.e., whether participants tend to rate all targets as heterosexual or lesbian); in contrast, the inspection of random slopes is informative regarding participants’ accuracy in judging speakers’ SO, (i.e., whether they can accurately categorize who is lesbian and who is straight).
The model showed a main effect of listeners’ nationality (F = 7.65, p < .001) and a significant interaction between listeners’ nationality and speakers’ language (F = 11.81, p <.001). No further effect reached significance (all Fs < 2.8, ps >.09). Moreover, the inspection of the model intercept revealed that, on average, heterosexual speakers were rated somewhat in the middle of the scale. (Intercept: German speakers rated by German listeners: 3.15. For the other two groups, the following average ratings can be estimated by the intercept as follows: Italian speakers: 3.15+ (-0.03) = 3.12; Portuguese speakers: 3.15+ (-0.02) = 3.13.) The inspection of random intercepts indicates that individual intercepts varied between 1.55 (3.15+(-1.6), which was the minimum value reported) and 4.24 (3.15+1.09, which was the maximum value reported), with the median being 3.22 (3.15+0.07). These values suggest that there is a large degree of variability among participants, with some participants showing a bias toward homosexuality and other participants showing a bias toward heterosexuality; however, since both medians are below the scale midpoint and only 97 (out of 466) participants have a random intercept higher than the scale midpoint, the overall tendency suggests that only a few subjects have a stronger bias toward homosexuality.
The absence of any effect of speakers’ SO (F = 1.54, p >.2) indicates that, overall, listeners are not able to accurately infer speakers’ actual SO. The inspection of the random slopes allows us to look at the extent to which the overall mean estimates mirror individual judgments. The inspection of the estimated ratings suggests that participants were quite heterogeneous in the way they judged the speakers’ SO, with the central tendency (i.e., the estimate of the fixed effect) being a weak representation of the inter-individual variability. More interestingly, estimated judgments for both heterosexual and lesbian speakers were distributed across the complete range of the response scale, suggesting a certain degree of independence between the speakers’ SO and the listeners’ perception; moreover, the predominance of estimated values at the lower end of the scale suggests a bias toward heterosexuality.
As highlighted before, the model yielded a significant interaction between speakers’ nationality and listeners’ language (see Figure 2). This interaction was further inspected by separately looking at the three speakers’ languages: Italian speakers were rated as more lesbian by German listeners than by Italian listeners (beta = −0.22; st. err. = 0.08, t = −2.61, p = .009) and Portuguese listeners (beta = −0.29, st. err. = 0.09, t = −3.09, p =.002), but no difference emerged between Italian and Portuguese listeners (t = −1.01, p > .3). Portuguese speakers were rated as less lesbian by Portuguese listeners than by German (beta = 0.39, st. err. = 0.09, t = 4.07, p <.001) and Italian listeners (beta = 0.45, st. err. = 0.09, t = 6.25, p <.001), but no difference emerged between German and Italian listeners (t < 1, p >.5). Finally, German speakers were rated similarly by all three groups of listeners (German vs. Italian listeners: t < 1, p >.7; German vs. Portuguese listeners: t = −1.54, p >.1; Italian vs. Portuguese listeners: t = −1.64, p >.09).

Mean ratings of Italian, Portuguese, and German speakers’ SO as a function of participants’ native language. Bars indicate standard errors.
Finally, to check whether there was agreement in the ratings provided by different listeners, we examined intra-class correlations (ICC) obtained from the model, using the rpt function in the rptR package. The ICC for the speakers’ random factor was .06, p <.001, 95% CI from .02 to .08. Overall, the low values of ICC reveal low agreement among listeners, suggesting listeners found it difficult to assess the SO of lesbian speakers, and indicating that the remaining self-identified lesbian speakers were reliably misclassified as heterosexual.
4.3 Acoustic Analyses
4.3.1 What acoustic features do differentiate voices of straight and lesbian women?
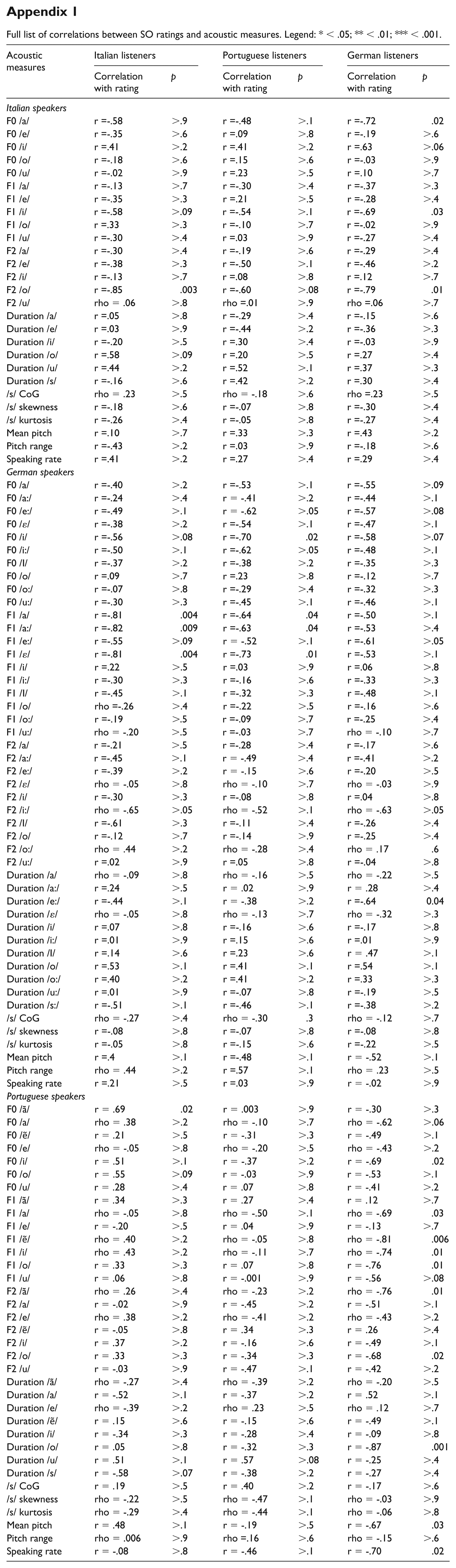
We explored whether the acoustic features of the heterosexual and lesbian voices differed, by running a Wilcoxon test within each language and for each acoustic feature. The results showed that, in all languages, there are very few differences: for Italian speakers, heterosexual and lesbian voices differed for speaking rate (Mheterosexual = 0.16 vs. Mlesbian= 0.19, W = 0, p = .01); for German speakers, heterosexual and lesbian voices differed for the F2 of /u:/ (Mheterosexual = 1430 Hz vs. Mlesbian = 1035 Hz, W = 23, p = .03); for Portuguese speakers, heterosexual and lesbian voices differed for the F1 of /ã/ (Mheterosexual = 552 Hz vs. Mlesbian = 711 Hz, W = 1, p = .01) and the F1 of /ẽ/ (Mheterosexual = 609 Hz vs. Mlesbian = 439, W = 23, p = .01). Note that these differences must be considered with great caution: they emerged from exploratory analyses and no corrections for multiple comparisons were applied.
4.3.2 What acoustic features do differentiate voices perceived to be those of straight or lesbian women?
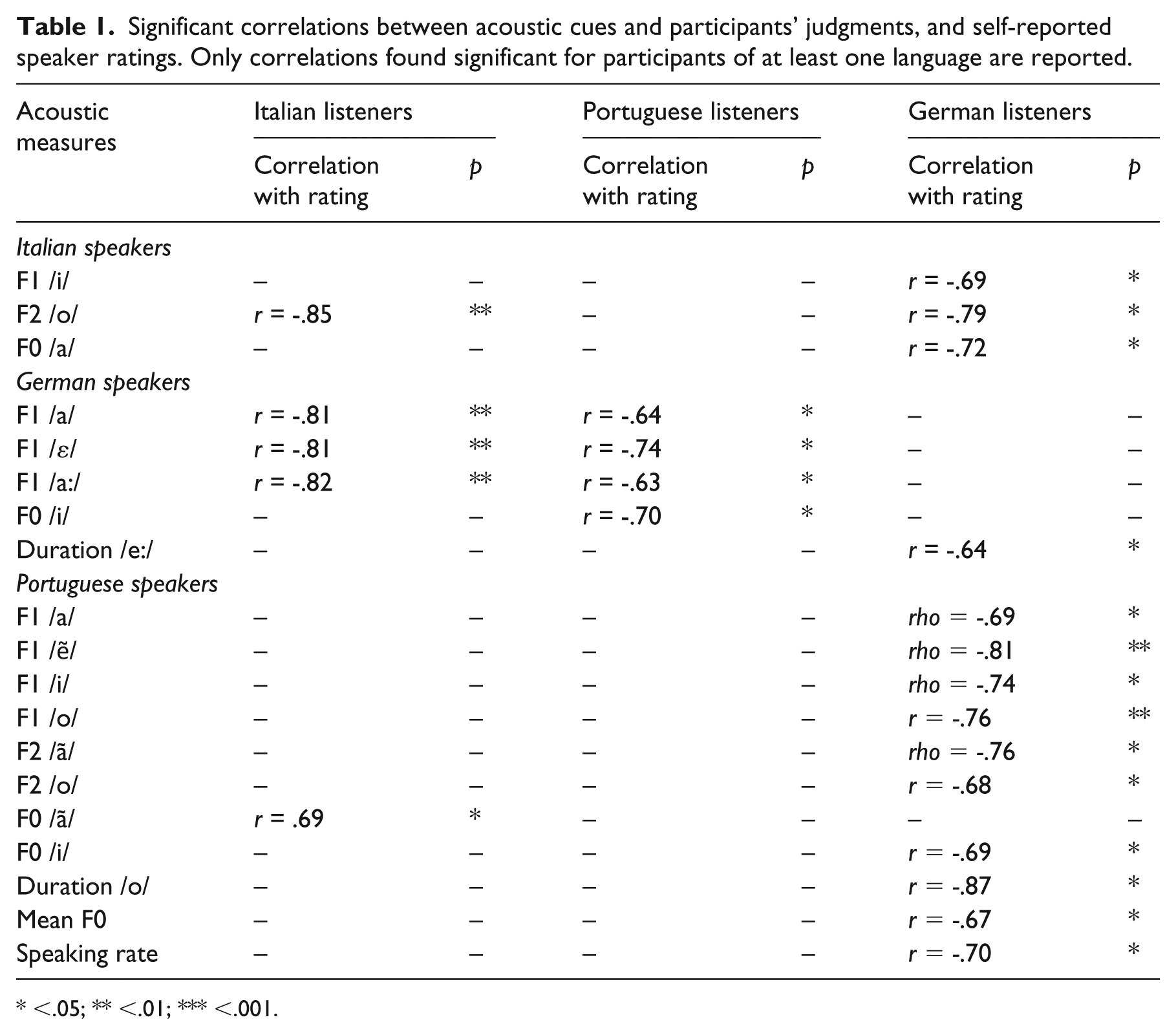
To explore which acoustic features participants associated with heterosexual- versus lesbian-sounding voices, correlation analyses were run between listeners’ judgments and all acoustic measures. When both measures had a normal distribution, Pearson correlations were calculated; in all other cases, Spearman correlations were run. Significant correlations between ratings and the acoustic features for listeners of each language are reported in Table 1 (for a full list of correlations, see Appendix 1).
Significant correlations between acoustic cues and participants’ judgments, and self-reported speaker ratings. Only correlations found significant for participants of at least one language are reported.
<.05; ** <.01; *** <.001.
4.3.3 Italian speakers
Italian and German listeners perceived speakers producing lower F2 of /o/ as more lesbian. In addition, German listeners perceived those speakers who produced lower F1 of /i/ and F0 of /a/ as more lesbian. No significant correlation between acoustic measures and perceived SO emerged for Portuguese listeners.
4.3.4 Portuguese speakers
Italian listeners associated speakers who produced higher F0 for /ã/ more strongly with lesbian SO. By contrast, Germans based their judgments on duration information (with more lesbian-sounding speakers producing shorter /o/ and speaking more slowly) and on formant frequencies for /o/, /i/, /a/, and /ã/. No significant correlation emerged for Portuguese listeners.
4.3.5 German speakers
German listeners perceived those speakers who produced shorter /e:/ as more lesbian. Italians associated being lesbian with greater vowel duration and perceived those speakers who produced lower F1 of /a/, /a:/, and /ε/ as more lesbian. The analyses of Portuguese listeners fully overlapped with those of Italian listeners as they used all the cues used by Italians plus the F0 of /i/.
5 Discussion
In this three-language study we investigated the existence of auditory gaydar for female speakers. We did so by investigating within- and across-language categorization by Italian, Portuguese, and German listeners. Taken together, our results provide initial answers to our three key research questions, namely: a) whether auditory gaydar for female voice is accurate; b) whether such auditory gaydar works similarly in the three languages under investigation (language dependency); and c) whether listeners categorize the SO of women speaking the same native language as themselves versus women who speak a foreign language in a similar way (ingroup specificity).
5.1 The Accuracy of Auditory Gaydar and the Perception of SO
Our data suggest that listeners were not able to distinguish lesbian from straight speakers. Indeed, our main analysis did not show any effect of speakers’ actual SO on listeners’ perception. This result is in contrast with results based on a t-test, showing a mean difference between ratings for straight and lesbian speakers. As shown in other research (e.g., Sulpizio et al., 2015), such differences are usually driven by a subgroup of speakers and therefore should be considered with caution when interpreting the data. The lack of interaction between actual SO and languages in our mixed model also suggests that this was the case, regardless of the language spoken by speakers or listeners. Hence, SO judgments were inaccurate independently of the language of speakers and listeners. In fact, across the three languages, some speakers were perceived as heterosexual or lesbian, but this occurred independently of their actual SO. For instance, German speaker S4 self-identified as heterosexual, but listeners from all three countries consistently tended to rate her as lesbian; similarly, Portuguese speaker S9 reported being lesbian, but was consistently perceived as heterosexual by Portuguese, Italian, and German listeners. Overall, 10 lesbian speakers (i.e., 72% of all lesbian speakers) were misidentified by listeners from at least two out of three nationalities.
However, our data confirmed that listeners endorsed a common strategy when judging speakers’ SO, namely they all showed a tendency to judge speakers as heterosexual. This bias was evident in our model, in participants’ estimation of the number of lesbian speakers they listened to, and in the descriptive analyses conducted on single speakers. The majority of speakers were rated on the heterosexual side of the continuum, and only a few of them were clearly perceived as lesbian. This result is in line with the straight categorization bias highlighted by Lick and Johnson (2016) for visual gaydar. Similar effects were also found in research carried out on male voices (Sulpizio et al., 2015).
Moreover, in line with what Kachel and colleagues called “dispersion inaccuracy” (Kachel, Simpson, & Steffens, 2018; see also Kachel et al., 2017; Sulpizio et al., 2015), we observed variability in the way speakers were perceived within both straight and gay/lesbian speaker groups—for example, average ratings given by Italian listeners to heterosexual speakers were between 2.4 to 3.6, and those given to lesbian speakers were between 2.4 and 3.8. Such variability suggests that “prototypicality” may play an important role in SO judgments. Indeed, those heterosexual or lesbian speakers who deviated from the heterosexual default were those likely to be labeled as lesbian. It is possible that how women adhere to gender roles and stereotypes (masculinity/feminity), rather than their actual SO, affects their speech and how they are perceived by listeners (see Kachel et al., 2017).
Finally, in line with recent research (Kachel et al., 2017), we did find that listeners’ consensus in rating female speakers’ SO was rather low, possibly indicating a general difficulty in recognizing SO on the basis of minimal vocal cues. This low consensus in ratings was not observed in prior research on male speakers (Sulpizio et al., 2015). This difference may reflect the fact that individuals have a clear idea of how gay men, but not how lesbians, sound. Research has indeed shown that men, but not women, believe their SO to be easily detected, although this varies depending on whether their voices are perceived as sounding gender-typical or atypical (Fasoli et al., 2018). Mass media has possibly created or reinforced such “gay voice” stereotypes. Male actors playing gay characters have been found to modulate their voices in order to match an effeminate gay stereotype (Cartei & Reby, 2012), and the audience prefers actors who emphasize vocal femininity when dubbing gay characters (see Fasoli, Mazzurega, & Sulpizio, 2017). On the contrary, lesbian characters have long remained invisible in mass media and voice has never played a specific role in their portrayal (see Ciasullo, 2001). This might explain why voice is more likely to play a role as a cue supposedly signaling men’s but not women’s SO (Barton, 2015) and why fewer stereotypes exist for lesbians’ voices (see Moonwoman-Baird, 1997).
Taken together, although based on a small sample of speakers, our results show that listeners were rather reluctant to judge a speaker as clearly lesbian and only in few cases did judgments correspond to speakers’ self-identification. This is in line with Munson et al. (2006), who found overall low accuracy rates and a large overlap between heterosexual and lesbian English speakers, but in contrast with findings by Rieger et al. (2010), who reported accurate SO judgments of listeners exposed to speakers’ voices. It is worth noting, however, that the audio stimuli used by Rieger et al. (2010) consisted of a sentence taken from a speech about personal interests (and personal interests reported by female speakers correlated with listeners’ SO perception). Hence, the content of the audio stimuli may have affected the results. Our stimuli, instead, were neutral sentences (13 words) and therefore more similar to Munson et al.’s (2006) material, which consisted of three single unrelated words.
The current findings cast doubt on the existence of an accurate auditory gaydar for female voice. This result is in contrast with findings on facial features, where the detection of SO for female targets was found to be quite accurate and better than for male targets (Brewer & Lyons, 2017; Lyons et al., 2014; Tabak & Zayas, 2012). This raises the interesting question of whether different cues may have distinct communicative meanings as well as different weights in revealing personal information such as SO. Future research should compare SO accuracy and perception of both visual and vocal cues to understand whether they may play a different role in the SO categorization process.
The acoustic analyses, although exploratory and based on a small sample of speakers, provided additional information about speakers’ SO and listeners’ perception. In line with Kachel et al. (2017), and in contrast to Moonwoman-Baird (1997), who found that that the F0 range is associated with women’s SO), we did not find substantial differences between heterosexual and lesbian speakers in any of the three languages under consideration. This may speak to the difficulty of making accurate judgments: there is little information in the acoustic signal that listeners can use to accurately infer whether a voice belongs to either a heterosexual or a lesbian person. Nevertheless, some acoustic parameters were associated with the perception of SO. Differing from results reported by Moonwoman-Baird (1997), pitch range was not among these cues. Moreover, acoustic cues related to perceived SO were not those found to differ between heterosexual and lesbian speakers. This suggests that listeners were influenced by acoustic cues potentially related to their stereotypes about how lesbian women sound rather than by actual differences in voice. A close inspection of the results of the acoustic analyses shows that, across languages, some cues seem to be stereotypically perceived as more reliable than others. This is the case, for example, for F0 /a/ or F2 /o/, which were almost always negatively correlated with the perception of SO, both across listeners and speakers (see Appendix 1). Thus, one might speculate that these cues might be stereotypically perceived as more reliable indicators of female speakers’ SO. Note, however, that there are few significant correlations and this observation is based more on numerical directions than statistical results.
Taking only the significant results into consideration, acoustic analyses revealed heterogeneous results across languages. To identify SO of the speakers of their own language, Italian listeners used information about vowel formant frequencies, with lower frequencies for speakers perceived as more lesbian (for similar results in English-speaking women see Munson et al., 2006). In contrast, German listeners were found to also extract information from sound duration, with shorter sound duration for speakers perceived as more lesbian. Although preliminary, these results suggest that there is little (or no) consistency between the acoustic cues used by listeners to the different languages under investigation here; moreover, even when speakers of different languages used similar acoustic features at a micro-linguistic level, cross-linguistic overlap was almost always lacking. Apparently, listeners of different languages rely more on distinct acoustic cues to infer speaker SO. Interestingly, and in line with Waksler (2001), we found no relation between pitch and pitch range in speakers, and the perception of women’s SO among listeners.
When listeners categorize foreign speakers, the situation resembles that observed for same language speakers. In all cases, listeners tend to use either formant frequencies or duration information (or, more rarely, both) to categorize foreign speakers, although this acoustic information bears little resemblance to that used by native-language listeners (e.g., Italian listeners rate German speakers on the basis of first formant frequency; but German listeners do not, since they rate German speakers based on vowel duration). It is therefore likely that, when judging SO, listeners refer to the acoustic cues they use to categorize SO in speakers of their own language even when judging foreign speakers. This seems to suggest that the criterion they use for their own language is transferred to other languages.
5.2 Language Dependency and Language Specificity
Putting our findings regarding the acoustic correlates of SO and gaydar accuracy together, we are in a position to answer our second and third research questions—that is, the issue of language dependency (i.e., whether auditory gaydar works in some languages, but not in others) and that of ingroup specificity (i.e., how listeners categorize the SO of foreign speakers). Regarding language dependency, our study suggests that listeners in all three languages were not accurate when judging speakers’ SO. The main strategy they used seems to be the assumption of speakers’ heterosexuality and the tendency to label those who sound differently as lesbian, in line with the straight categorization bias and prototypicality assumption (Lick & Johnson, 2016.). The fact that listeners’ agreement in judging speakers’ SO was very poor and the fact that multiple and different acoustic cues influenced SO perception raises the possibility that our participants did not have a consistent idea of what a lesbian woman sounds like. This interpretation is further strengthened by the absence of any difference in judgments of the voices of actual heterosexual and lesbian speakers, which makes the recognition of speakers’ actual SO very difficult (see Kachel et al., 2017). Hence, future studies should investigate what underlying processes guide SO perception in the three languages, since different vocal cues appear to predict SO perception.
Finally, our research provides some indications regarding the ingroup specificity issue, namely whether auditory gaydar is specific to female speakers of the listeners’ own language. Since listeners were equally bad at judging speakers of their own and foreign languages, it is hard to say whether the process is language-specific or not. It may be that the process is similar across the languages under consideration, as shown for male speakers (Sulpizio et al., 2015), and that detection of female speakers’ SO is inaccurate and not specific to any language. Nevertheless, our findings provided evidence that a foreign language does not stop individuals from making inferences about foreign speakers’ SO, since listeners perceived some speakers as heterosexual and others as lesbian regardless of the language they spoke. Hence, listeners’ categorization strategies may be the same for all speakers. This tells us something about intersectionality and suggests that when inferring SO from voice, vocal cues related to nationality are not so relevant. If this is the case, social categories activated by voice may work independently of each other (e.g., being Italian does not in any way constrain perception of a person’s SO). It is also possible that which social category conveyed by voice is most salient varies across situations (e.g., a mating context). Thus, the nature of intersectionality conveyed by voice remains to be investigated.
An interesting additional finding that emerged from the cross-linguistic comparison concerns differences in the overall perception of heterosexuality for speakers of different languages. Among our (numerically limited) speaker samples, German voices were similarly rated by speakers of all nationalities, whereas Italian speakers were perceived as more lesbian-sounding by German and Portuguese listeners and Portuguese voices were judged more lesbian by German and Italian listeners. On the one hand, this result could be read as a tendency among Italian and Portuguese listeners to perceive speakers of their own language as more heterosexual-sounding overall. Indeed, there is research showing that individuals perceive speakers of their own language who have a standard accent more positively (Dragojevic, 2016); as heterosexuality is perceived as the norm, rating same language speakers as more heterosexual-sounding may represent an ingroup favoritism strategy or a tendency to judge the ingroup as more normative. On the other hand, it may be that individuals perceive languages differently and that some languages sound more “lesbian” or masculine than others. In this regard, previous research has shown that German listeners perceive Italian male speakers as sounding more gay than German speakers possibly because they sound less masculine (Sulpizio et al., 2015; see, e.g., Tanaka et al., 2010). In a similar vein, we might speculate that, to some listeners, some languages sound more masculine or more “lesbian” than others. Note, however, that the perception of languages is not an absolute and universal phenomenon, as the “masculinity/femininity” as well as “gay/lesbian” perception of a foreign language may be affected by the listener’s language and culture. With regard to gender typicality, research suggests that masculinity/femininity may be the key factor driving categorization of SO (Rieger et al., 2010; see also Lick & Johnson, 2016; Kachel et al., 2018).
5.3 Limitations and Future Directions
Although our research represents a step forward for the literature on auditory gaydar, it has some limitations that will have to be addressed by future research. The first and main limitation is the small sample of speakers, who might be unrepresentative of their nationality and SO; this implies that the present findings on both listeners’ judgments and acoustic measures should be generalized with caution to the entire population of lesbian and heterosexual speakers. Similarly, the sentences we used as stimulus material, although highly plausible in everyday conversations, are not representative of everyday discourse. Future studies should overcome these issues by using larger and more representative samples of speakers and materials.
A second limitation of our research concerns the fact that the results were based only on (self-identified) heterosexual participants. The small and unbalanced sample of sexual minority participants across languages in our study did not allow us to test potential differences. Future studies could investigate auditory gaydar in sexual minority participants, who might be more accurate due to more extensive experience (i.e., more frequent exposure to gays and lesbians) and/or increased motivation (see Shelp, 2002). Along these lines, it has been found that homosexuals are more accurate than heterosexuals in identifying targets’ SO when presented with pictures or short video clips (Ambady, Hallahan, & Conner, 1999; Shelp, 2002). Future research should examine whether this phenomenon also holds for voice-based categorization of SO.
A third limit concerns the conceptualization of gaydar accuracy and the way in which we look at SO. In our study we used a Likert scale to test perceived SO, allowing for graded judgments, but still tested whether speakers fell above or below the scale midpoint (considering those above the midpoint as lesbian and those below the midpoint as heterosexual). In our understanding of gaydar, accuracy implies that a target is perceived as clearly gay/lesbian or as clearly straight. Conversely, other scholars consider a relative difference in ratings between heterosexual and homosexual targets as an indication of accuracy, independently of whether the means are at the homosexual pole of a Likert scale (e.g., Rieger et al., 2010). In our view of gaydar, a difference in mean ratings simply signals non-normativity (i.e., a target deviates from the assumed heterosexual norm) or non-prototypicality (i.e., the target is perceived as less prototypical of heterosexuality). This result could also represent uncertainty in judging the target as gay/lesbian (i.e., a difficulty in clearly labeling the target as such). Hence, results may be interpreted differently depending on the definition of gaydar accuracy. In our study, overall mean ratings revealed a small difference in the way the lesbian and straight speakers were perceived at the heterosexual end of the “spectrum.” This difference could be interpreted by some as “accuracy” but, in our view, it shows that among the lesbian speakers there are some that are heard to be non-prototypical and non-normative, making the group of lesbian speakers sound “less heterosexual.” Indeed, a more sensitive analysis (mixed model) did not find actual SO to be a predictor of perceived SO in our findings, suggesting that speakers were mostly judged as straight.
Finally, considering the recent interest in the acoustic features of lesbian and heterosexual speakers, further studies on the relationship between listeners’ categorization and acoustic information related to speakers’ voice are needed. These studies should not only involve a larger set of acoustic features, but also examine whether such features are under the voluntary control of speakers. Speakers of different languages, countries, and cultures may be differentially motivated to hide or display SO cues. Indeed, contextual factors and familiarity have been suggested as factors that may affect accuracy in SO recognition (Brambilla, Riva, & Rule, 2013) as well as variability in lesbian women’s speech (Kachel et al., 2017). Thus, the degree to which contextual variables and communicative intentions may affect SO recognition remains an interesting question for future investigation.
6 Conclusion
The present study provided some answers to the three questions that marked the starting point of our research. First, is auditory gaydar for female voices accurate? It seems it is not, given that most lesbian speakers are misidentified as heterosexuals and that actual speakers’ SO did not predict listeners’ judgments. Second, does auditory gaydar work in some languages, but not in others? The process of voice-based categorization of SO appears to be similar across the three languages considered here, as auditory gaydar inaccuracy was found for Italian, German, and Portuguese speakers. Third, how do listeners categorize the SO of foreign speakers? Our findings only provide evidence for a tendency of listeners to perceive speakers of their own language as more heterosexual-sounding, but they do not provide evidence for higher SO accuracy for speakers of own (versus other) languages.
To conclude, our study suggests that auditory gaydar does not work well for female voices, as the SO of speakers was poorly detected and mostly judged in line with a “hetero-norm” for voice: most women were perceived as heterosexual and some as lesbian, independently of their actual SO.
Footnotes
Appendix
Full list of correlations between SO ratings and acoustic measures. Legend: * < .05; ** < .01; *** < .001.
| Acoustic measures | Italian listeners |
Portuguese listeners |
German listeners |
|||
|---|---|---|---|---|---|---|
| Correlation with rating | p | Correlation with rating | p | Correlation with rating | p | |
| Italian speakers | ||||||
| F0 /a/ | r =−.58 | >.9 | r =−.48 | >.1 | r =−.72 | .02 |
| F0 /e/ | r =−.35 | >.6 | r =.09 | >.8 | r =−.19 | >.6 |
| F0 /i/ | r =.41 | >.2 | r =.41 | >.2 | r =.63 | >.06 |
| F0 /o/ | r =−.18 | >.6 | r =.15 | >.6 | r =−.03 | >.9 |
| F0 /u/ | r =−.02 | >.9 | r =.23 | >.5 | r =.10 | >.7 |
| F1 /a/ | r =−.13 | >.7 | r =−.30 | >.4 | r =−.37 | >.3 |
| F1 /e/ | r =−.35 | >.3 | r =.21 | >.5 | r =−.28 | >.4 |
| F1 /i/ | r =−.58 | >.09 | r =−.54 | >.1 | r =−.69 | .03 |
| F1 /o/ | r =.33 | >.3 | r =−.10 | >.7 | r =−.02 | >.9 |
| F1 /u/ | r =−.30 | >.4 | r =.03 | >.9 | r =−.27 | >.4 |
| F2 /a/ | r =−.30 | >.4 | r =−.19 | >.6 | r =−.29 | >.4 |
| F2 /e/ | r =−.38 | >.3 | r =−.50 | >.1 | r =−.46 | >.2 |
| F2 /i/ | r =−.13 | >.7 | r =.08 | >.8 | r =.12 | >.7 |
| F2 /o/ | r =−.85 | .003 | r =−.60 | >.08 | r =−.79 | .01 |
| F2 /u/ | rho = .06 | >.8 | rho =.01 | >.9 | rho =.06 | >.7 |
| Duration /a/ | r =.05 | >.8 | r =−.29 | >.4 | r =−.15 | >.6 |
| Duration /e/ | r =.03 | >.9 | r =−.44 | >.2 | r =−.36 | >.3 |
| Duration /i/ | r =−.20 | >.5 | r =.30 | >.4 | r =−.03 | >.9 |
| Duration /o/ | r =.58 | >.09 | r =.20 | >.5 | r =.27 | >.4 |
| Duration /u/ | r =.44 | >.2 | r =.52 | >.1 | r =.37 | >.3 |
| Duration /s/ | r =−.16 | >.6 | r =.42 | >.2 | r =.30 | >.4 |
| /s/ CoG | rho = .23 | >.5 | rho = −.18 | >.6 | rho =.23 | >.5 |
| /s/ skewness | r =−.18 | >.6 | r =−.07 | >.8 | r =−.30 | >.4 |
| /s/ kurtosis | r =−.26 | >.4 | r =−.05 | >.8 | r =−.27 | >.4 |
| Mean pitch | r =.10 | >.7 | r =.33 | >.3 | r =.43 | >.2 |
| Pitch range | r =−.43 | >.2 | r =.03 | >.9 | r =−.18 | >.6 |
| Speaking rate | r =.41 | >.2 | r =.27 | >.4 | r =.29 | >.4 |
| German speakers | ||||||
| F0 /a/ | r =−.40 | >.2 | r =−.53 | >.1 | r =−.55 | >.09 |
| F0 /a:/ | r =−.24 | >.4 | r = −.41 | >.2 | r =−.44 | >.1 |
| F0 /e:/ | r =−.49 | >.1 | r = −.62 | >.05 | r =−.57 | >.08 |
| F0 /ε/ | r =−.38 | >.2 | r =−.54 | >.1 | r =−.47 | >.1 |
| F0 /i/ | r =−.56 | >.08 | r =−.70 | .02 | r =−.58 | >.07 |
| F0 /i:/ | r =−.50 | >.1 | r =−.62 | >.05 | r =−.48 | >.1 |
| F0 /I/ | r =−.37 | >.2 | r =−.38 | >.2 | r =−.35 | >.3 |
| F0 /o/ | r =.09 | >.7 | r =.23 | >.8 | r =−.12 | >.7 |
| F0 /o:/ | r =−.07 | >.8 | r =−.29 | >.4 | r =−.32 | >.3 |
| F0 /u:/ | r =−.30 | >.3 | r =−.45 | >.1 | r =−.46 | >.1 |
| F1 /a/ | r =−.81 | .004 | r =−.64 | .04 | r =−.50 | >.1 |
| F1 /a:/ | r =−.82 | .009 | r =−.63 | .04 | r =−.53 | >.4 |
| F1 /e:/ | r =−.55 | >.09 | r = −.52 | >.1 | r =−.61 | >.05 |
| F1 /ε/ | r =−.81 | .004 | r =−.73 | .01 | r =−.53 | >.1 |
| F1 /i/ | r =.22 | >.5 | r =.03 | >.9 | r =.06 | >.8 |
| F1 /i:/ | r =−.30 | >.3 | r =−.16 | >.6 | r =−.33 | >.3 |
| F1 /I/ | r =−.45 | >.1 | r =−.32 | >.3 | r =−.48 | >.1 |
| F1 /o/ | rho =−.26 | >.4 | r =−.22 | >.5 | r =−.16 | >.6 |
| F1 /o:/ | r =−.19 | >.5 | r =−.09 | >.7 | r =−.25 | >.4 |
| F1 /u:/ | rho = −.20 | >.5 | r =−.03 | >.7 | rho = −.10 | >.7 |
| F2 /a/ | r =−.21 | >.5 | r =−.28 | >.4 | r =−.17 | >.6 |
| F2 /a:/ | r =−.45 | >.1 | r = −.49 | >.4 | r =−.41 | >.2 |
| F2 /e:/ | r =−.39 | >.2 | r = −.15 | >.6 | r =−.20 | >.5 |
| F2 /ε/ | rho = −.05 | >.8 | rho = −.10 | >.7 | rho = −.03 | >.9 |
| F2 /i/ | r =−.30 | >.3 | r =−.08 | >.8 | r =.04 | >.8 |
| F2 /i:/ | rho = −.65 | >.05 | rho = −.52 | >.1 | rho = −.63 | >.05 |
| F2 /I/ | r =−.61 | >.3 | r =−.11 | >.4 | r =−.26 | >.4 |
| F2 /o/ | r =−.12 | >.7 | r =−.14 | >.9 | r =−.25 | >.4 |
| F2 /o:/ | rho = .44 | >.2 | rho = −.28 | >.4 | rho = .17 | .6 |
| F2 /u:/ | r =.02 | >.9 | r =.05 | >.8 | r =−.04 | >.8 |
| Duration /a/ | rho = −.09 | >.8 | rho = −.16 | >.5 | rho = −.22 | >.5 |
| Duration /a:/ | r =.24 | >.5 | r = .02 | >.9 | r = .28 | >.4 |
| Duration /e:/ | r =−.44 | >.1 | r = −.38 | >.2 | r =−.64 | 0.04 |
| Duration /ε/ | rho = −.05 | >.8 | rho = −.13 | >.7 | rho = −.32 | >.3 |
| Duration /i/ | r =.07 | >.8 | r =−.16 | >.6 | r =−.17 | >.8 |
| Duration /i:/ | r =.01 | >.9 | r =.15 | >.6 | r =.01 | >.9 |
| Duration /I/ | r =.14 | >.6 | r =.23 | >.6 | r = .47 | >.1 |
| Duration /o/ | r =.53 | >.1 | r =.41 | >.1 | r =.54 | >.1 |
| Duration /o:/ | r =.40 | >.2 | r =.41 | >.2 | r =.33 | >.3 |
| Duration /u:/ | r =.01 | >.9 | r =−.07 | >.8 | r =−.19 | >.5 |
| Duration /s:/ | r =−.51 | >.1 | r =−.46 | >.1 | r =−.38 | >.2 |
| /s/ CoG | rho = −.27 | >.4 | rho = −.30 | .3 | rho = −.12 | >.7 |
| /s/ skewness | r =−.08 | >.8 | r =−.07 | >.8 | r =−.08 | >.8 |
| /s/ kurtosis | r =−.05 | >.8 | r =−.15 | >.6 | r =−.22 | >.5 |
| Mean pitch | r =.4 | >.1 | r =−.48 | >.1 | r = −.52 | >.1 |
| Pitch range | rho = .44 | >.2 | r =.57 | >.1 | rho = .23 | >.5 |
| Speaking rate | r =.21 | >.5 | r =.03 | >.9 | r = −.02 | >.9 |
| Portuguese speakers | ||||||
| F0 /ã/ | r = .69 | .02 | r = .003 | >.9 | r = −.30 | >.3 |
| F0 /a/ | rho = .38 | >.2 | rho = −.10 | >.7 | rho = −.62 | >.06 |
| F0 /ẽ/ | r = .21 | >.5 | r = −.31 | >.3 | r = −.49 | >.1 |
| F0 /e/ | rho = −.05 | >.8 | rho = −.20 | >.5 | rho = −.43 | >.2 |
| F0 /i/ | r = .51 | >.1 | r = −.37 | >.2 | r = −.69 | .02 |
| F0 /o/ | r = .55 | >.09 | r = −.03 | >.9 | r = −.53 | >.1 |
| F0 /u/ | r = .28 | >.4 | r = .07 | >.8 | r = −.41 | >.2 |
| F1 /ã/ | r = .34 | >.3 | r = .27 | >.4 | r = .12 | >.7 |
| F1 /a/ | rho = −.05 | >.8 | rho = −.50 | >.1 | rho = −.69 | .03 |
| F1 /e/ | r = −.20 | >.5 | r = .04 | >.9 | r = −.13 | >.7 |
| F1 /ẽ/ | rho = .40 | >.2 | rho = −.05 | >.8 | rho = −.81 | .006 |
| F1 /i/ | rho = .43 | >.2 | rho = −.11 | >.7 | rho = −.74 | .01 |
| F1 /o/ | r = .33 | >.3 | r = .07 | >.8 | r = −.76 | .01 |
| F1 /u/ | r = .06 | >.8 | r = −.001 | >.9 | r = −.56 | >.08 |
| F2 /ã/ | rho = .26 | >.4 | rho = −.23 | >.2 | rho = −.76 | .01 |
| F2 /a/ | r = −.02 | >.9 | r = −.45 | >.2 | r = −.51 | >.1 |
| F2 /e/ | rho = .38 | >.2 | rho = −.41 | >.2 | rho = −.43 | >.2 |
| F2 /ẽ/ | r = −.05 | >.8 | r = .34 | >.3 | r = .26 | >.4 |
| F2 /i/ | r = .37 | >.2 | r = −.16 | >.6 | r = −.49 | >.1 |
| F2 /o/ | r = .33 | >.3 | r = −.34 | >.3 | r = −.68 | .02 |
| F2 /u/ | r = −.03 | >.9 | r = −.47 | >.1 | r = −.42 | >.2 |
| Duration /ã/ | rho = −.27 | >.4 | rho = −.39 | >.2 | rho = −.20 | >.5 |
| Duration /a/ | r = −.52 | >.1 | r = −.37 | >.2 | r = .52 | >.1 |
| Duration /e/ | rho = −.39 | >.2 | rho = .23 | >.5 | rho = .12 | >.7 |
| Duration /ẽ/ | r = .15 | >.6 | r = −.15 | >.6 | r = −.49 | >.1 |
| Duration /i/ | r = −.34 | >.3 | r = −.28 | >.4 | r = −.09 | >.8 |
| Duration /o/ | r = .05 | >.8 | r = −.32 | >.3 | r = −.87 | .001 |
| Duration /u/ | r = .51 | >.1 | r = .57 | >.08 | r = −.25 | >.4 |
| Duration /s/ | r = −.58 | >.07 | r = −.38 | >.2 | r = −.27 | >.4 |
| /s/ CoG | r = .19 | >.5 | r = .40 | >.2 | r = −.17 | >.6 |
| /s/ skewness | rho = −.22 | >.5 | rho = −.47 | >.1 | rho = −.03 | >.9 |
| /s/ kurtosis | rho = −.29 | >.4 | rho = −.44 | >.1 | rho = −.06 | >.8 |
| Mean pitch | r = .48 | >.1 | r = −.19 | >.5 | r = −.67 | .03 |
| Pitch range | rho = .006 | >.9 | rho =.16 | >.6 | rho = −.15 | >.6 |
| Speaking rate | r = −.08 | >.8 | r = −.46 | >.1 | r = −.70 | .02 |
Acknowledgements
We would like to thank numerous psychology students for helping with the data collection and audio file annotation. We also thank Anne Maass and Francesco Vespignani for very helpful comments and discussions on some of the ideas proposed in the paper.
Funding
This study was supported by a grant from the Cassa di Risparmio di Trento e Rovereto entitled “Omofobia, stereotipi sessuali e informazioni veicolate dalla voce” [Homophobia, sexual stereotypes and information transmitted by voice] and by a grant from the German Research Foundation (COE 277).
Ethical Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed Consent
Informed consent was obtained from all individual participants included in the study.