
Abstract
Temporal and phonological predictability in children’s literature may support early literacy acquisition. Realization of predictive structure in caregiver prosody could guide children’s attention during shared reading, thereby supporting reading subskill development. However, little is known about how predictive structure is realized prosodically during child-directed reading. We investigated whether speakers use word intensity to signal predictive metric and rhyme structure in child-directed and read-alone productions of The Cat in the Hat (Dr. Seuss, 1957), by modeling maximum intensity (dB) of monosyllabic words as a function of metric strength, rhyme predictability, and a set of control parameters. In the control model, intensity increased with lower lexical frequency, capitalization, first mention, and likelihood of a syntactic boundary. Metric structure predicted word intensity beyond these control factors in a hierarchical manner: words aligned with beat one in a 6/8 metric structure were produced with highest intensity, words aligned with beat four were produced with intermediate intensity, and words aligned with all other beats were produced with the lowest intensity. Additionally, phonologically predictable rhyme targets were reduced in intensity. The effects of meter and rhyme were not moderated by the presence of a child audience. These results demonstrate that predictability along multiple dimensions is encoded during reading of poetic children’s literature, and that metric structure is realized hierarchically in word intensity. Further, the manner by which predictability is encoded in word intensity differs from that previously reported for word duration in this corpus (Breen, 2018), demonstrating that intensity and duration present nonidentical prosodic information channels.
1 Introduction
Two common features in children’s literature across languages are the presence of a strong metrical framework, and the use of rhyming phrases (Burling, 1966; Noel Aziz Hanna, Lindner, & Dufter, 2002). The temporal and phonological predictability created by these features may support the purported benefits of these texts for literacy acquisition (Goswami, 1999, 2011; Huss, Verney, Fosker, Mead, & Goswami, 2011); early children’s literature is typically heard before it is read, and temporal and phonological predictability guide the allocation of attention to important moments in the auditory stream (Astheimer & Sanders, 2009, 2011; Breen, Dilley, McAuley, & Sanders, 2014; Fitzroy & Sanders, 2015). However, little is empirically known about how meter and rhyme in children’s literature are instantiated in spoken productions of these texts, which is a necessary precursor to understanding how such structures might guide perceptual or literacy learning in young listeners.
Breen (2018) recently demonstrated that the metric and rhyme structures of The Cat in the Hat (Dr. Seuss, 1957) are realized in the duration and temporal spacing of words in child-directed and read-alone productions of the text. Prominence in speech is imparted through several prosodic correlates however, with duration, intensity, fundamental frequency (F0), and formant structure classically thought to be the most important (e.g., Bolinger, 1958; Fry, 1958; Jenkins, 1961; Lehiste, 1970; Lieberman, 1960). Multiple more recent studies directly comparing the relative contributions of acoustic correlates during continuous natural speech suggest that duration and intensity in particular are the strongest predictors of prominence under these conditions (Kochanski, Grabe, Coleman, & Rosner, 2005; Kochanski & Orphanidou, 2008; Silipo & Greenberg, 2000). Therefore, in the present paper we examine the effects of meter and rhyme in The Cat in the Hat on the intensity of words in continuous child-directed and read-alone productions, and compare the results to previous findings of impacts on word duration (i.e., Breen, 2018).
Multiple studies have demonstrated that increased intensity imparts prominence in speech. Increased intensity for more prominent syllables has been observed for isolated and continuous speech in which prominence is subjectively assessed by a listener (Kochanski et al., 2005; Silipo & Greenberg, 2000; Streefkerk, Pols, & Bosch, 1999) or defined by the conversational context (Breen, Fedorenko, Wagner, & Gibson, 2010), and for metronome-synchronous speech in which prominence is objectively defined as syllabic alignment with a metronome click (Boutsen, Brutten, & Watts, 2000; Kochanski & Orphanidou, 2008). Intensity variation similarly signals metric structure during expressive musical performance, with greater intensity indicating greater metric strength. Importantly, intensity in expressive music performance imparts metric strength in a hierarchical manner: metric structures that involve three levels of strength (e.g., 6/8 meter) are produced with three corresponding levels of intensity (Drake & Palmer, 1993). It is unclear whether intensity in continuous speech imparts metric prominence in a similarly hierarchical manner, or only in a binary manner. The strongly hierarchical metric structure of The Cat in the Hat is reflected in hierarchically produced word duration (Breen, 2018), suggesting that it may also be signaled through hierarchical modulation of produced word intensity.
Predictability in speech also modulates the production of words, as more predictable words are typically acoustically reduced relative to less predictable words (Aylett & Turk, 2004; Gregory, Raymond, Bell, Fosler-lussier, & Jurafsky, 1999; Jurafsky, Bell, Gregory, & Raymond, 2001). Moreover, predictability-related reduction is preferentially realized in word intensity, such that more predictable words are produced with lower intensity regardless of whether they are repeated in the local context (Lam & Watson, 2010). In contrast, local word repetition is preferentially associated with shortened word duration (Lam & Watson, 2010). Most stanzas in The Cat in the Hat are written such that the first line ends with a rhyme prime (e.g., “all” in (1) below), and the second line ends with a rhyme target (e.g., “fall” in (1)). This structure causes the stanza-final rhyme target to be both phonologically and semantically predictable, which should cause the rhyme targets to be reduced during production. Breen (2018) observed equivalent word duration but lengthened inter-word-onset intervals for predictable rhyme targets relative to rhyme primes in The Cat in the Hat, which may be interpreted as a reduction of the rhyme target. However, the temporal characteristics alone do not conclusively support this interpretation. Given that predictability-related reduction is preferentially realized in word intensity (Lam & Watson, 2010), we predict that word intensity will be reduced for rhyme targets relative to rhyme primes in The Cat in the Hat.
In the current study, we test the hypotheses that hierarchical metric structure and rhyme predictability in The Cat in the Hat are realized in produced word intensity during aloud reading. We assess the influence of metric strength and rhyme predictability on word intensity in a corpus of child-directed and read-alone productions of The Cat in the Hat (Breen, 2018), while controlling for intrinsic word characteristics, font emphasis, and local repetition. We predict that metrically stronger words will be produced with higher intensity, and that, similar to prior findings in expressive musical performance, hierarchical metric structure will be realized as hierarchically produced word intensity. We further predict that predictable rhyme targets will be produced with reduced intensity relative to rhyme primes.
2 Method
2.1 Participants
The current study analyzed recordings from the The Cat in the Hat production corpus, originally published by Breen (2018). Recordings from 17 young adult (age 18–35 years) Mount Holyoke students were analyzed in the current study; these are the same 17 participants included in final analyses in Breen (2018). All participants identified as female and were self-reported native speakers of American English, defined as speaking English in the USA since at least age five. All participants were compensated for their time with research participation credit for Psychology courses.
2.2 Stimuli
Participants read The Cat in the Hat (Dr. Seuss, 1957) aloud from a hardcover copy of the text. The Cat in the Hat is a 61-page illustrated book written primarily in anapestic (i.e., weak-weak-STRONG) tetrameter. The Cat in the Hat is a common early text for native speakers of American English; a recent survey of infant book reading habits in English-speaking countries asked parents to list the five books they read most often to their 0–3 year old children, and The Cat in the Hat was the 16th most frequently named book across all ages and the 8th most frequently named by parents of 2 year olds (Hudson Kam & Matthewson, 2017). It consists of 1625 words (1576 monosyllabic words, 236 unique lexemes) organized primarily into 70 stanzas, with each stanza containing two lines of four anapests each (as in (1)). The first line in each stanza ends with a rhyme prime and the second line ends with a phonologically predictable rhyme target. In addition, there are six single anapestic lines in the text. In two cases, these single lines rhyme internally (e.g., “And then Something went
“Put me down!” said the fish. “This is no fun at all! Put me down!” said the fish. “I do
2.3 Procedure
Participants were randomly assigned to read The Cat in the Hat aloud in its entirety in one of two locations: to an audience of preschool students (4–5 years old) in a quiet classroom (n = 8), or alone in a quiet room (n = 9). Participants were provided with a copy of the book in advance and asked to read it through at least once prior to the recording session to ensure familiarity. In both environments participants read the book while seated and holding the book in their hands, and turned the pages on their own. All participants’ productions were digitally recorded using a head-mounted microphone (Shure SM10A) connected to a pre-amplifier (Rolls MP13 Mini-mic) plugged into the motherboard audio input of a laptop (in the classroom) or desktop computer (in the quiet room). Production recordings were digitized at 44,100 Hz with 16-bit resolution. Participants were given no specific instructions on how to read the text, other than to read it aloud. All participants provided informed consent before taking part in the study, and parents of the children who listened to the readings provided written assent for their child’s participation.
2.4 Acoustic measures
Word and silence boundaries (Figure 1) were identified in the production recordings by automatic force-alignment with the text in Praat (Boersma & Weenink, 2001) using the Prosodylab-Aligner (Gorman, Howell, & Wagner, 2011), which relies on the Hidden Markov Model Toolkit (Young & Young, 1993). Automatic force-alignment results were inspected in Praat, and word and silence boundaries were manually adjusted when the automatic alignment was incorrect. As shown in Figure 1, linearly-spaced intensity (dB) contours were calculated for each production recording automatically in Praat by squaring amplitude values then convolving them with a 32 ms Gaussian window, which kept pitch-synchronous intensity variations to less than 0.00001 dB (Boersma & Weenink, 2001). Word intensity was defined as the parabolically-interpolated maximum of the intensity contour occurring within each word. Multisyllabic words were excluded from further analyses, because the unstressed syllables in these words have reduced intensities for reasons unrelated to metric structure (Fry, 1955). Disfluent and incorrect word productions were manually identified and excluded from further analyses, resulting in a loss of 473 out of 26,792 possible monosyllabic word productions (1.77%). The remaining maximum intensity values of correctly-produced monosyllabic words were centered and scaled to standard deviation units (i.e., converted to z scores) separately for each participant.
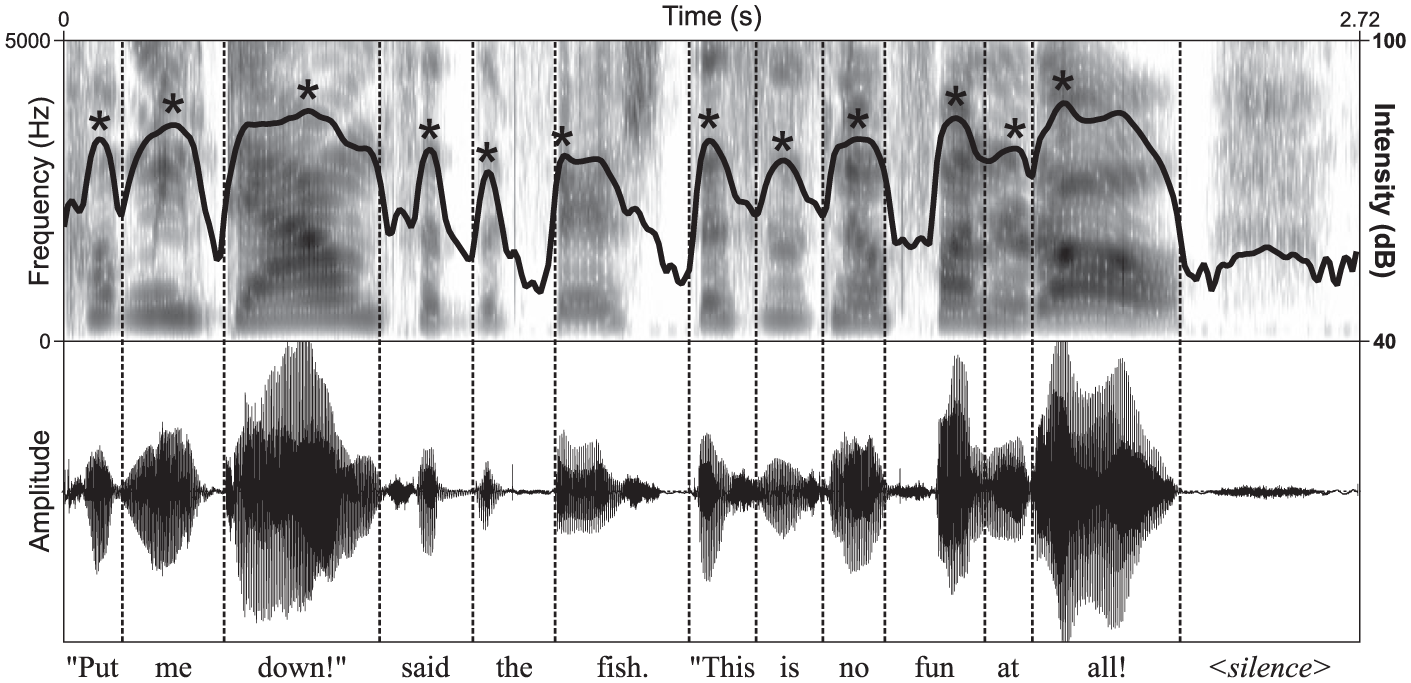
Word intensity measurement. An excerpt from one The Cat in the Hat production is plotted as a time–frequency spectrogram (top) and as a time domain waveform (bottom). Identified word and silence boundaries are plotted as dashed vertical lines. The smoothed intensity contour generated for this excerpt is plotted in black over the spectrogram, with the parabolically-interpolated maximum intensity for each word indicated with an asterisk.
2.5 Data analysis
We analyzed the standardized maximum intensity of correctly-produced monosyllabic words using linear mixed-effects regression modeling implemented in the lme4 package (Bates, Mächler, Bolker, & Walker, 2014) within R (R Core Team, 2015; RStudio Team, 2014). Data and analysis scripts can be downloaded from https://doi.org/10.17605/OSF.IO/XGY4T. We predicted maximum word intensity as a function of metric strength, rhyme predictability, linguistic control factors (number of phonemes, lexical frequency, word class, font emphasis, intra-stanza repetition, and syntactic boundary strength), and presence of a child audience.
Metric strength was defined by beat position in a 6/8 metric hierarchy (Figure 2), with beat 1 of each measure assigned metric strength level 3 (strong), beat 4 assigned metric strength level 2 (intermediate), and beats 2, 3, 5, and 6 assigned metric strength level 1 (weak). The first stressed syllable in each stanza was considered beat 1 of the first measure of that stanza. This metric parsing is in agreement with previous linguistic metric descriptions of The Cat in the Hat as anapestic tetrameter in terms of stress placement (Nel, 2004), but adopts a musical perspective of metric phase in that the first stressed event in a phrase likely represents the start of a larger metric unit (i.e., a measure) with any preceding unstressed events considered anacrustic (Lerdahl & Jackendoff, 1983). Rhyme predictability was coded as 1 for verse-final rhyme target words (e.g., “fall” in (1)) and 0 for all other words.

Regression predictors. Word intensity was modeled using linear mixed-effects regression with within-subjects factors of metric strength in a 6/8 metric structure (MS), rhyme predictability (RP), number of phonemes (#P), lexical frequency (LF), word class (WC), font emphasis (FE), intra-stanza repetition (ISR), and syntactic boundary strength (SBS). Lexical frequency values are rounded to the nearest tenth for clarity. See text for details.
To account for effects of basic word and text characteristics on produced intensity, several linguistic control factors were included in the regression models (Figure 2). The 1576 monosyllabic words in The Cat in the Hat were annotated using the Medical Research Council (MRC) Psycholinguistic Database (Coltheart, 1981) for number of phonemes (range = 1–6, M = 2.54, SD = 0.75) and lexical frequency as assessed by Kučera-Francis (K-F; Francis & Kučera, 1982) norms (log-transformed K-F frequency; range = 0–11.16, M = 7.37, SD = 2.31). For words that did not have raw K-F frequencies (n = 18), the K-F frequency of the singular or infinitival form of the word was substituted if available. There was no K-F frequency available for the word “plop”, so it was excluded from further analyses. The 1575 analyzed monosyllabic words were also annotated for syntactic word class (open, n = 540; closed, n = 1035), font emphasis (normal font, n = 1550;
Our regression approach was to first create a fully saturated control model containing all linguistic control factors as both fixed effects and random slopes over participant. Before being entered into the model as either a fixed effect or random slope, continuous predictors were centered and categorical predictors were recoded such that the sum of factor levels for each contrast was equal to zero. We then refined the control model by removing each fixed effect individually in order of ascending t magnitude, and using a likelihood ratio test to compare model fit with and without the fixed effect to justify its continued inclusion. The control model included only fixed effects that significantly increased model fit.
We next added metric strength into the model as both a fixed effect and random slope over participant, coded using simple contrast coding with metric strength level 2 (intermediate; beat 4) as the reference level. This initial experimental model did not converge, so we iteratively removed random slopes in order of least variance explained until convergence occurred. To determine whether metric strength predicted word intensity variance beyond the control parameters, we used a likelihood ratio test to compare the initial experimental model to an updated version of the control model containing only those random slopes included in the initial experimental model. Additionally, to determine whether audience presence moderated the effects of metric strength on word intensity, we used a likelihood ratio test to compare the initial experimental model to a modified version of itself adding the interaction of metric strength and audience presence as a fixed effect. Next, to determine whether rhyme predictability accounted for additional unique word intensity variance, we added rhyme predictability to the model as a fixed effect and random slope over participant and used a likelihood ratio test to compare the result to the initial experimental model containing control factors and metric strength. To determine whether audience presence moderated the effects of rhyme predictability on word intensity, we used a likelihood ratio test to compare this final experimental model to a modified version of itself adding the interaction of rhyme predictability and audience presence as a fixed effect.
3 Results
3.1 Control model
The control model included number of phonemes, lexical frequency, word class, font emphasis, intra-stanza repetition and syntactic boundary strength as random slopes over participant, and lexical frequency, font emphasis, intra-stanza repetition and syntactic boundary strength as fixed effects (Table 1). Number of phonemes and word class were not warranted for inclusion in the control model as fixed effects (p’s > 0.3). Across individuals, higher word intensity was predicted by lower lexical frequency (β = −0.133, SE = 0.006, t = −22.542), presentation in a capitalized font (β = 0.784, SE = 0.065, t = 12.101), not being a repeat of recent material (β = −0.164, SE = 0.022, t = −7.567) and higher likelihood of being a syntactic boundary (β = 0.015, SE = 0.008, t = 1.888).
Control model. Variance estimates and standard deviations are shown for each random slope over participant included in the control model. β estimates, standard errors, and t values are shown for each fixed effect justified for inclusion in the control model, along with χ2 and p values from the likelihood ratio test justifying its inclusion. The regression equation for the control model is provided, with subscripts i and j indexing over words and participants respectively. #P: number of phonemes; LF: lexical frequency; WC: word class; FE: font emphasis; ISR: intra-stanza repetition; SBS: syntactic boundary strength.
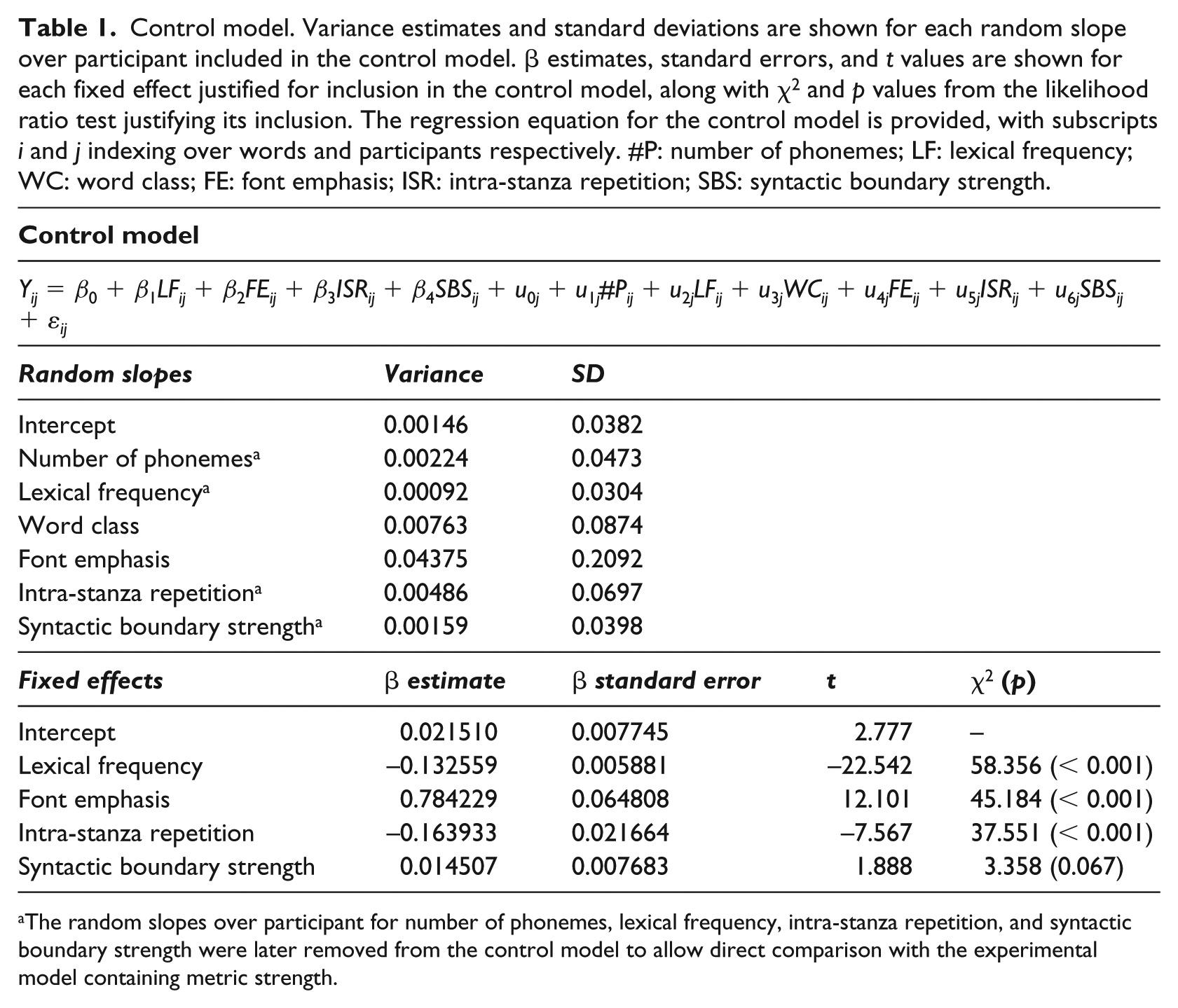
The random slopes over participant for number of phonemes, lexical frequency, intra-stanza repetition, and syntactic boundary strength were later removed from the control model to allow direct comparison with the experimental model containing metric strength.
3.2 Experimental models
As shown in Table 2 and Figures 3 and 4, position in a 6/8 metric hierarchy predicted word intensity such that metric strength level 3 (beat 1) was produced with highest intensity, metric strength level 2 (beat 4) was produced with intermediate intensity, and metric strength level 1 (beats 2, 3, 5 and 6) was produced with lowest intensity (level 3 vs. level 2: β = 0.322, SE = 0.058, t = 5.536; level 1 vs. level 2: β = −0.191, SE = 0.054, t = −3.554). Including metric strength in the regression model significantly improved model fit relative to an updated version of the control model containing the same control fixed effects and random slopes over participant, χ2 (11) = 1157.60, p < 0.001. Therefore, metric strength provides explanatory power for produced word intensity beyond that explained by intrinsic and contextual word characteristics alone. Model fit was not further improved by adding the interaction of metric strength and audience presence (p > 0.1), demonstrating that the effect of metric strength was not moderated by the presence of a child audience.
Initial experimental model containing metric strength. Variance estimates and standard deviations are shown for each random slope over participant included in the initial experimental model examining metric strength. β estimates, standard errors, and t values are shown for each fixed effect included in this model. The regression equation for the initial experimental model is provided, with subscripts i and j indexing over words and participants respectively. MS: metric strength; LF: lexical frequency; WC: word class; FE: font emphasis; ISR: intra-stanza repetition; SBS: syntactic boundary strength.

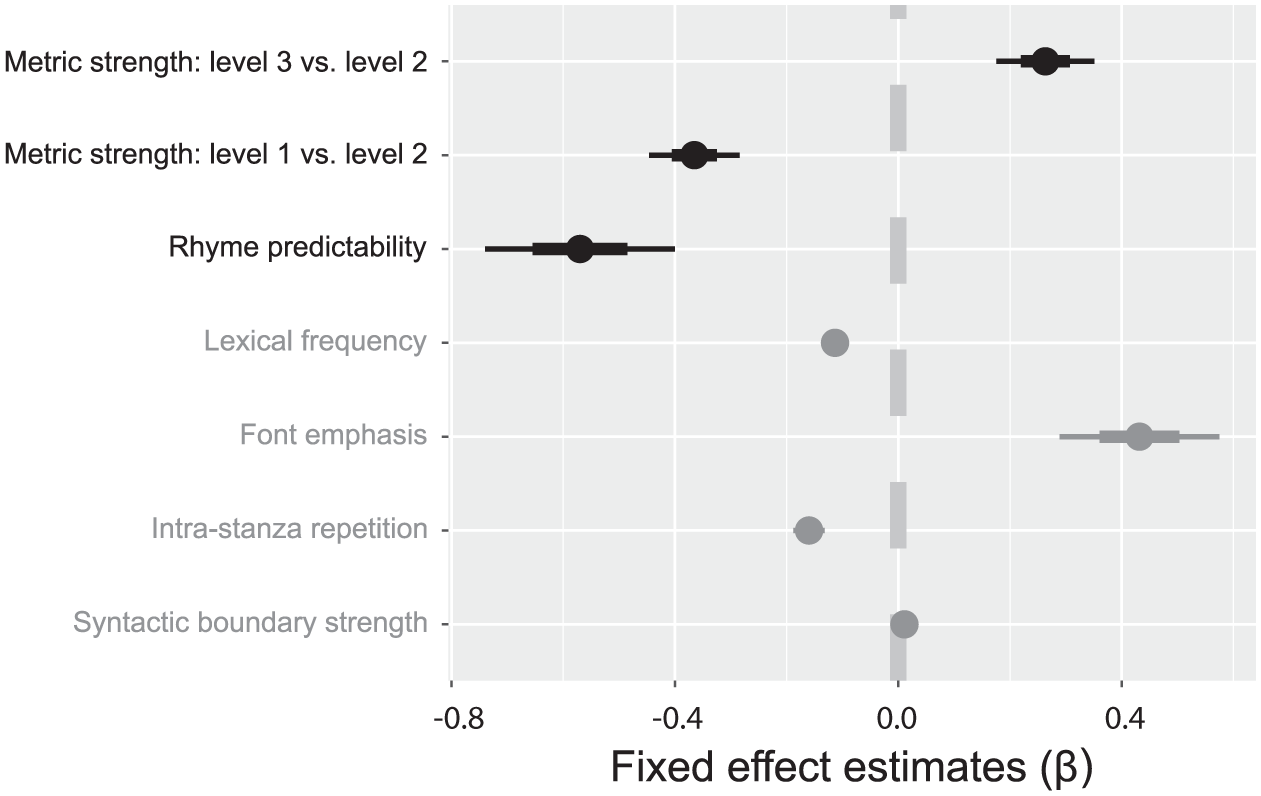
Fixed effect β estimates from final experimental model. Metric strength and rhyme predictability are highlighted in black, linguistic control factors are shown in grey. Thicker horizontal bars indicate one standard error, thinner horizontal bars indicate two standard errors.
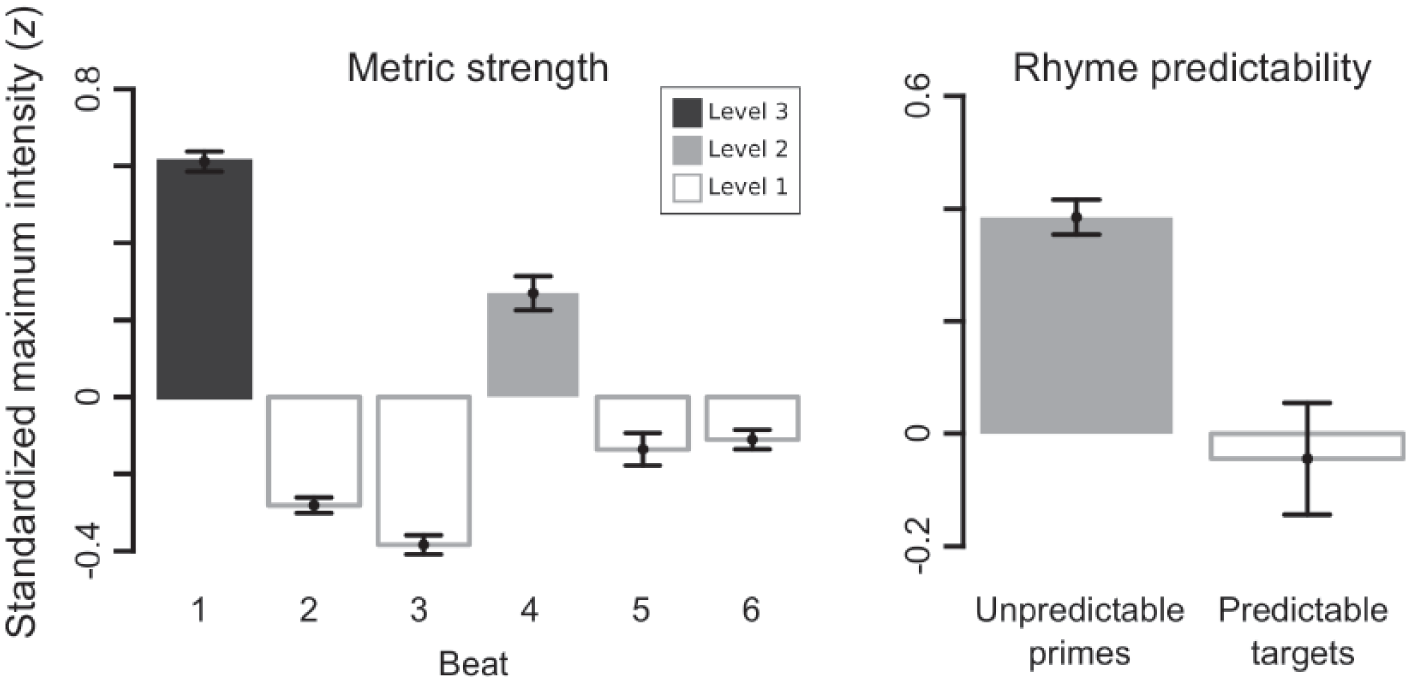
Standardized maximum word intensity as a function of position in a 6/8 metric hierarchy and rhyme predictability. Produced word intensity increased hierarchically with metric strength (left), and predictable rhyme targets were produced with lower intensity than other words, including phonologically similar but unpredictable rhyme primes (right). Note that all words that were not rhyme targets were coded as unpredictable in the regression models, but only unpredictable rhyme primes are shown here for clarity.
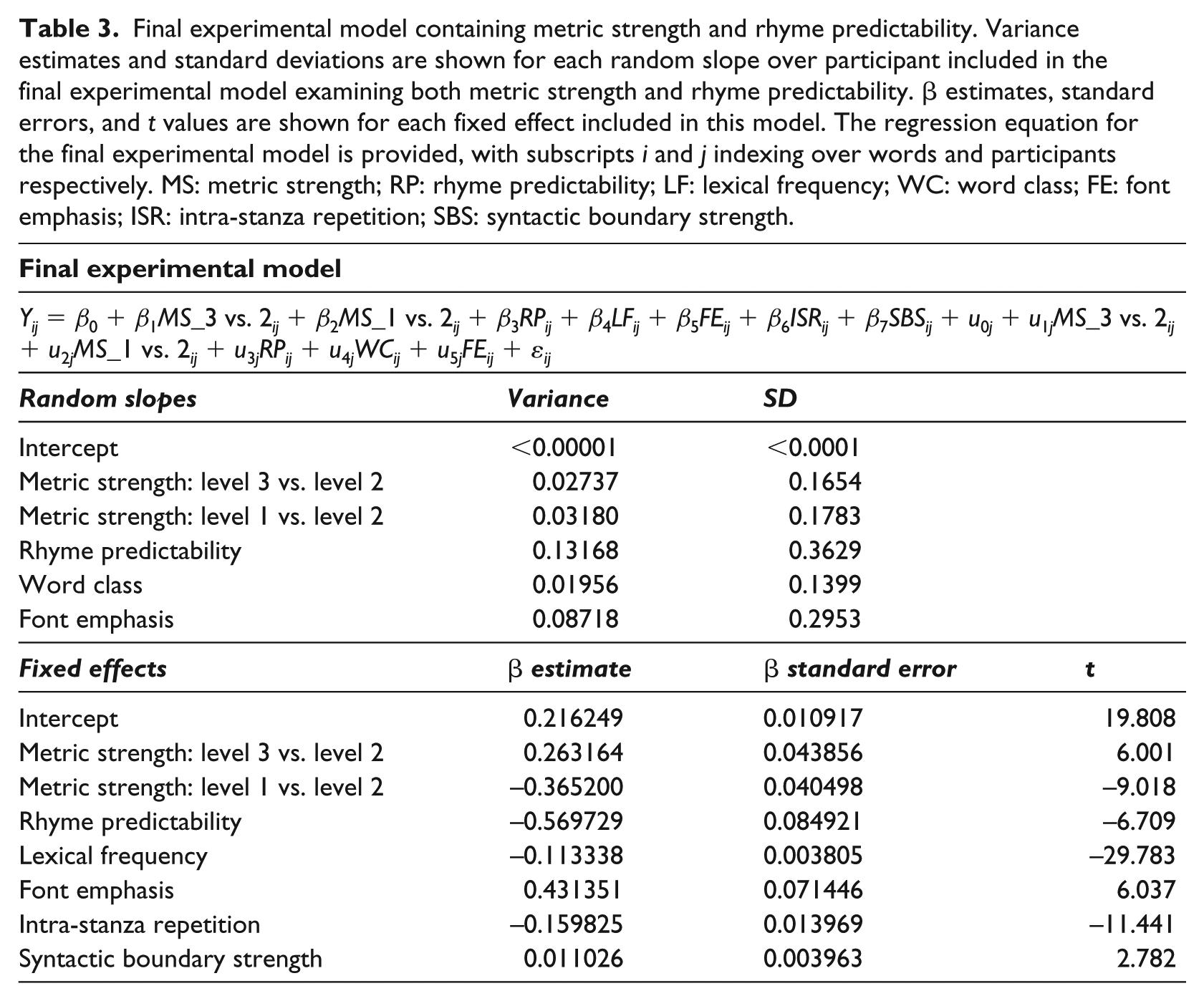
As shown in Table 3 and Figures 3 and 4, rhyme predictability predicted word intensity such that predictable rhyme targets (e.g., “fall” in (1)) were produced with lower intensity than other words, including metrically and phonologically similar rhyme primes (β = −0.570, SE = 0.085, t = −6.709). Adding rhyme predictability to the regression model significantly improved model fit relative to the initial experimental model containing control parameters and metric strength, χ2 (7) = 280.70, p < 0.001, demonstrating that rhyme predictability provides explanatory power for produced word intensity beyond that explained by intrinsic and contextual word characteristics and metric structure. Model fit was not further improved by adding the interaction of rhyme predictability and audience presence (p > 0.2), demonstrating that the effect of rhyme predictability was not moderated by the presence of a child audience.
Final experimental model containing metric strength and rhyme predictability. Variance estimates and standard deviations are shown for each random slope over participant included in the final experimental model examining both metric strength and rhyme predictability. β estimates, standard errors, and t values are shown for each fixed effect included in this model. The regression equation for the final experimental model is provided, with subscripts i and j indexing over words and participants respectively. MS: metric strength; RP: rhyme predictability; LF: lexical frequency; WC: word class; FE: font emphasis; ISR: intra-stanza repetition; SBS: syntactic boundary strength.
4 Discussion
As predicted, hierarchical metric structure and rhyme predictability in The Cat in the Hat both modulated word intensity when reading the text aloud. Greater metric strength resulted in greater produced word intensity in a hierarchic manner, such that the metrically strongest words were produced with highest intensity, metrically intermediate words were produced with intermediate intensity and metrically weak words were produced with lowest intensity. Rhyme predictability resulted in clear acoustic reduction, as rhyme targets were produced with lower intensity than other words including rhyme primes. Both metric strength and rhyme predictability provided unique explanatory power for word intensity, accounting for variance beyond that accounted for by lexical frequency, font emphasis, intra-stanza repetition, and syntactic boundary strength. Further, these effects were unique from one another, with rhyme predictability providing explanatory power beyond that accounted for by metric strength and control factors. Neither the effect of metric strength nor the effect of rhyme predictability was moderated by the presence of a child audience.
The effects of intrinsic word and text factors, local repetition, and syntactic structure in The Cat in the Hat on produced word intensity were largely consistent with prior findings for produced word duration (Breen, 2018). Consistent with the duration findings of Breen (2018), produced word intensity increased with lower lexical frequency, higher likelihood of being a syntactic boundary, and font emphasis in the form of
The effects of metric structure and rhyme predictability on produced word intensity were not moderated by audience presence, indicating that a child audience is not necessary for these effects to emerge. Although the read-alone participants were not given any specific instructions on how to read the text, we speculate that because the experimental material is a highly familiar children’s book that participants likely had read to them as a child (Hudson Kam & Matthewson, 2017), they read it in a child-directed manner despite the absence of a child audience. Alternatively, it is possible that the realization of hierarchical metric structure and rhyme predictability in produced word intensity is independent of audience presence or composition; future work examining productions of multiple types of poetic texts with different audience compositions could test this empirically. Whether or not the realization of metric and rhyming structure in word intensity depends on the actual or imagined presence of a child audience, the prevalence of such structure in children’s literature (Burling, 1966; Noel Aziz Hanna et al., 2002) suggests that children are often exposed to these prosodic variations during child-directed reading.
The realization of hierarchical metric structure in The Cat in the Hat as hierarchical word intensity demonstrates that during aloud reading of poetic children’s literature, multiple levels of acoustic prominence are signaled. This regular, hierarchically organized prominence could provide temporal guideposts for young listeners during joint reading, creating expectancies for certain moments in time to which children can then predictively attend (e.g., Fitzroy & Sanders, 2015; Jones, 1976). Such periodic guidance of temporal attention during joint reading could represent a mechanism by which highly metrical children’s literature leads to positive reading outcomes. Better ability to synchronize to an external auditory rhythm is associated with better phonological awareness and rapid automatized naming in pre-readers (3–4 years old; Woodruff Carr, White-Schwoch, Tierney, Strait, & Kraus, 2014); guided practice tracking auditory rhythms during joint reading could improve synchronization, and in turn improve these pre-reading skills. Further, in older (8–13 years old) typically-developing children and children diagnosed with dyslexia, the ability to perceive changes in intensity over time predicts sensitivity to intensity-defined metric structure, which further predicts phonological awareness and reading outcomes (Huss et al., 2011). This result suggests that accurate perception of hierarchical intensity structure plays a role in typical reading development, which could be facilitated by the periodic guidance of temporal attention during joint reading. Alternatively, increased intensity for metrically strong words could reflect speaker-centric factors such as greater speaker attention to metrically strong words (e.g., Arnold & Watson, 2015). Importantly, whether the metric strength effect reflects speaker-centric or listener-centric motivations, hierarchical prominence in the speech signal could still provide perceptual benefits to the listener.
The realization of hierarchical meter in The Cat in the Hat as hierarchical word intensity is consistent with previous report of its realization as hierarchical word duration and inter-word intervals (Breen, 2018). However, the pattern of metric prominence realized in intensity differs from that realized in duration. In the present study, word intensity was highest for beat 1 in a 6/8 metric parsing, intermediate for beat 4, and lowest for beats 2, 3, 5, and 6. Conversely, in Breen (2018), word duration and inter-word intervals were intermediate for beat 1 in a 6/8 parsing (called metric level 2 in the metric model inspired by Fabb & Halle (2008) employed by Breen), longest for beat 4 (called metric levels 3, 4, and 5), and shortest for beats 2, 3, 5, and 6 (called metric level 1). These findings demonstrate that although word intensity and word duration provide important and partially redundant information regarding prominence in speech, the information encoded on these two prosodic channels is not identical. In the same productions, word duration was aligned with the predictions of a linguistic model of rhythm in poetry (Fabb & Halle, 2008), whereas word intensity was aligned with previous observations of dynamics in expressive music performance (Drake & Palmer, 1993). Though it is possible that the observed dissociation between intensity and duration is unique to productions of poetry, which involves elements of linguistic and musical rhythm, previous reports that prominence in non-poetic contexts is best explained by a combination of intensity and duration (Kochanski & Orphanidou, 2008; Silipo & Greenberg, 2000) suggest that this dissociation may be a more general prosodic phenomenon. Further, these findings indicate that metric strength is realized in both word duration and word intensity, but that phrase structure is preferentially encoded in word duration, consistent with prior work (Wagner & Watson, 2010); in The Cat in the Hat, beat 4 in a 6/8 metric parsing often occurs at phrase-final positions, whereas beat 1 never does. Our metric strength results across the two studies could therefore be interpreted as a combination of two mechanisms: hierarchically increased duration and intensity with metric strength in a 6/8 structure, and an additional duration increase for phrase-final beat 4s.
The observed intensity reduction for highly predictable rhyme targets is consistent with prior findings that more predictable words are acoustically reduced relative to less predictable words (e.g., Jurafsky et al., 2001). Moreover, the contrast between the observed clear predictability-related reduction in intensity and the equivocal predictability effects on duration presented by Breen (2018) is consistent with prior findings indicating that predictability-related reduction is preferentially realized in intensity (Lam & Watson, 2010). There is no local perceptual benefit to a listener when a talker acoustically reduces a predictable word, as reduction reduces the effective signal-to-noise ratio of that speech element. Further, listeners do not preferentially allocate attention to predicted moments in speech when the information to be presented at that time is also completely predictable, reducing the signal to noise ratio even more at these times (Astheimer & Sanders, 2011). Nonetheless, highly predictable words are regularly communicated without error, suggesting that the system is robust to information loss at moments where information is highly predictable. It may be that listeners shift from a detailed, attentive perceptual strategy to a template-matching perceptual strategy when information is highly predicted, which would be both more efficient and more robust to reduced signal-to-noise ratio. Note that reductions in produced word intensity might be a result of either speakers being aware of and accommodating such a strategy by listeners or of a similar shift in strategy by the speaker during production without regard to the listener, but in both cases the communicative outcome is the same.
Collectively, the increased prominence with metric strength and reduction with rhyme predictability observed in the current study represent two methods by which predictability modulates produced word intensity. On one hand, temporal predictability, such as that provided by a regular metric framework, indicates when important information is likely to occur but not what that information will be. It is advantageous then for listeners to direct attention to these moments, maximizing the perceptual resources available to encode the unknown important information. It is in turn advantageous for talkers to impart prominence at these moments, both to attract listener attention and to increase signal strength. On the other hand, phonological and semantic predictability provide strong expectations regarding not only when important information will occur, but also what that information will be. Under these conditions it is less important for listeners to encode with high perceptual detail, instead only needing to encode with sufficient detail to confirm or disconfirm their expectations. In turn, talkers can take advantage of the lowered communicative demands of highly predictable information by reducing production effort for such words. Finally, the differences between how metric strength and rhyme predictability are realized in word intensity in the present study compared to in word and inter-word duration in Breen (2018) provide further evidence that intensity and duration provide important, but not identical, prosodic information channels during speech production.