
Abstract
This paper investigates how French signals prominence in prosody in the post-verbal domain of sentences with two objects or two adjuncts that vary in information status and prosodic length. The information status of particular interest here is dual focus, defined as the presence of two foci in a mono-clausal sentence, but other information states are investigated as well. The controlled production experiment we report on allows for a detailed examination of prosodic prominence. High boundary tones at the end of non-final prosodic phrases are pervasive, as has been documented in many studies before the present one. An important but less documented result is the variation in different prosodic curs, in particular in the number and position of high tones, as well as the particular scaling relationship between them, providing a powerful tool for the expression of (dual) focus. We also report on a perception experiment with our data, showing a clear tendency for French listeners to select the intended context question, recognizing dual focus better than other information states. Overall, this article provides elements of answers as to why French prosody is so difficult to pin down, and why contradictory results and analyses have been proposed for this language.
1 Introduction
This article investigates phonetic and phonological prominence in French, with a special emphasis on mono-clausal sentences containing a so-called “dual focus”; that is, sentences that answer interrogatives containing two “wh”-phrases. We understand phonetic prominence as an F0 raise, and phonological prominence as a high tone, at a local point in a sentence that signals prosodic highlighting of a word or a phrase (phrasal tone, boundary tone). Despite the growing body of experimental work on the interaction between prosody and information structure in French, the realization of dual focus is rarely examined. Yet this strikes us as an important issue given that mainstream prosodic theories typically disallow two main prosodic heads within one prosodic domain (see Gussenhoven, 2004; Selkirk, 1995; Truckenbrodt, 1995, as well as Kabagema-Bilan, López-Jiménez, & Truckenbrodt, 2011, and Wang & Féry, 2017 for an explicit formulation of the conflict). So, the issue comes down to understanding how phonetics and phonology cope with two foci within a single sentence, especially compared to single focus or to wide focus. The present study should also be understood as an extension of our previous work on post-verbal given constituents (see Destruel & Féry, 2019), where we showed that objects and adjuncts behave differently in this position: objects are phrased together with the preceding verb, but adjuncts are phrased independently, a difference in behavior that is reflected in the prosodic correlates.
Given this backdrop, the specific goals of our study on French are (a) to examine how prominence is realized in post-verbal sequences with two objects versus two adjuncts; (b) to provide empirical data on dual focus via a newly conducted production experiment; (c) to test whether French listeners are able to identify the context in which a sentence was produced; and (d) to compare the results with other types of focus (broad, initial, and final focus), as well as what is known about dual focus realization in other languages, notably English, German, and Mandarin.
The remainder of the introduction provides some background information relevant to our empirical study: focus and givenness, dual focus, and prior research on French prosody. Section 2 presents the study, detailing our research questions and hypotheses, methods, and reporting on the results. Section 3 discusses individual variation in our data. Section 4 presents and reports on the perception study designed to test whether listeners could identify the intended focus structure of our target sentences. Section 5 relates the results to the literature on information-structure and prosody in French, as well as cross-linguistic results in the prior research on dual focus. Section 6 concludes.
1.1 Focus and givenness
In this paper, we follow Krifka (2008), Rooth (1992), and Schwarschild (1999), whereby the notion of focus is taken to be a universal information-structural category that evokes a set of (explicit) alternatives that the speaker takes to be salient in the context. Focus is most commonly diagnosed in question–answer pairs, where it corresponds to the answering element associated with the “wh”-word in the congruent question. Thus, in (1), “Mary” is taken to be the focus of the sentence. In Germanic languages, prosodic prominence is realized on a lexically stressed syllable.
(1) Q: Who baked brownies? A: [
The notion of givenness is defined as “already mentioned in the context,” since this is the only kind of givenness occurring in the production experiment reported below.
In German and English, the given elements display reduction of pitch range in the pre-focal region of the sentence, deaccenting or compression in the post-focal region of the sentence; see Ladd (1980, 2008) for English, as well as Féry and Kügler (2008) and Kügler and Féry (2017) for German, among others. In French, compression is also used for expressing givenness, but it may be less systematic than in the Germanic languages, and also confined to entire prosodic phrases, see next section.
1.2 Background on French prosody
Lexical stress does not exist in French. Thus, a core question concerns where and how prominence is exactly realized—if at all. 1 Prior work on French has shown that syntax-based strategies are frequent for expressing focus and givenness, especially those involving phrasing, with clefts being the device used by default, especially when focus falls on the grammatical subject (Clech-Darbon, Rebuschi, & Rialland, 1999; Destruel, 2013; Hamlaoui, 2009; Lambrecht, 1994). Nevertheless, scholars note that information structure does influence prosody. Post-focal compression is optionally found in corrective contexts (Welby, 2006), but is rarely found in information focus (Vander Klock, Goad, & Wagner, 2018).
The phonological analysis of the prosodic pattern of French is subject to different interpretations. Most studies on prosody assume that an important prosodic constituent of French is what we call a “prosodic phrase” (henceforth, Φ-phrases), or “phonological phrase” (Post, 2000). 2 As far as phonetic correlates of prominence are concerned, all researchers find a rising tonal excursion in the non-final position of a sentence (Hirst & Di Cristo, 1996; Rossi, 1980). Opinions differ, however, as to how to analyze the final rise; certain scholars argue that it should be analyzed as a pitch accent (Astésano, Bard, & Turk, 2007; Beyssade, Marandin, & Rialland, 2003; Delais-Roussarie, 1995; Delais-Roussarie, Rialland, Doetjes, & Marandin, 2002; Portes, Beyssade, Michelas, Marandin, & Champagne-Lavau, 2014), while others argue that it is a demarcative tone, thus a boundary tone (Fónagy, 1979; Vaissière, 1980), or a phrasal tone (Féry, 2014), or both a pitch accent and a boundary tone (Jun & Fougeron, 2000).
Moreover, several authors also assume an optional phrase-initial prominence in the prosodic phrase, that is also realized with a pitch excursion (see D’Imperio & Michelas, 2010; Dohen & Loevenbruck, 2004; Jun and Fougeron, 2000; Post, 2000, among others). The exact location of this initial high tone is variable: it can be initial, or on the second or third syllable (see Welby, 2006). It also varies along different dimensions: it can be rhythmical or marking information structure (see Di Cristo, 1998; Pasdeloup, 1990; Rossi, 1980). A number of authors assume that it delimits the beginning of the focused constituent (see German & D’Imperio, 2016).
Finally, our recent research has supplemented prior findings by investigating the phenomenon of F0 “compression” (i.e., a reduction of pitch range) in post-focal sequences. Destruel and Féry (2015, 2019) showed that while compression does occur in French, it mostly affects entire Φ-phrases: when given, only post-verbal adjuncts were phrased separately from the verb, thus being optionally realized with a compressed register, objects were not or insignificantly so. Taken together, these findings suggest that, although French resorts to prominence in information-structural contexts, it does so quite differently from Germanic languages; see O’Brien (2019) and Fanselow (2016) for an overview on the correlates of information structure in Germanic languages. Vander Klok et al. (2018) proposed that the difference between English and French realization of givenness lies in the semantics of focus. They propose that the reason for the difference in prosodic compression of a given constituent is to be found in the semantic and/or pragmatic content of the focus operator. French can only focus entire clauses, whereas English can focus any constituents. Post-focal constituents are not compressed because they are obligatorily part of the larger focus that encompasses entire sentences. We return to this proposal in section 5.
1.3 Dual focus: issue and evidence across languages
The main issue arising in connection with the realization of two foci in a single sentence is that, if every focus comes with its own prosodic head, two foci should correspond to two prosodic heads in a single intonation phrase. But can two equally prominent foci co-exist in one intonation phrase? Indeed, if this is the case, it would conflict with the “Culminativity Principle” (Hyman, 2006), which requires a single and obligatory head per prosodic constituent—thus one per intonation phrase—or the formation of additional prosodic phrases that change the prosodic and tonal relationship of the sentence.
The past literature often presumed a negative answer, assuming that if two foci have to co-exist in one intonational phrase, one is more prominent than the other, resulting in a sequence of a subordinated secondary accent and a primary nuclear accent (Jackendoff, 1972; Truckenbrodt, 1995). Although empirical studies only exist for a few languages—that is, English, German, and Mandarin (see Eady, Cooper, Klouda, Mueller, & Lotts, 1986; Kabagema-Bilan et al., 2011; Wang & Féry, 2015, 2017)—these languages are shown to react differently to this conflict and to display different strategies as to how they realize dual focus. For instance, based on careful phonetic analyses, English and Mandarin allow two heads in a single prosodic domain of the size of an Intonation Phrase, while German adds the possibility of changing the phrasing, signaled by changes in the F0 and by duration. Yet these studies converge on the overall observation that the resulting prosodic structure of dual focus sentences amounts to more than just concatenating two single foci—the upcoming focus having a clear influence on how the first focus is realized, especially in the post-focal region. Anticipating our results slightly, we will see that this is not systematically the case in French. Although phrasing is prevalent in this language, information structure does not change it in any significant way. Section 2 presents the experimental study we conducted to try and overcome the lack of a systematic study on French with respect to the prosodic correlates of prominence and phrasing.
2 Production experiment
2.1 Materials and participants
The written scripted material used to elicit production consisted of question–answer pairs. The experimental sentences contained two post-verbal sequences that varied according to their constituents, either two objects as in (2), or two adjuncts as in (3).
(2) [SV + object + object] (SVOO) Jean-Marie a envoyé [un colis] [à ma sœur].
“Jean-Marie sent a package to my sister.”
(3) [SV + adjunct + adjunct] (SVAA) Jean-Marie l’a envoyé [par la poste] [à Toulouse]
“Jean-Marie sent it via the post office to Toulouse.”
We note that neither the objects nor the adjuncts are assumed to be intrinsically right-dislocated. 3 Both types of constituents are taken to be in their canonical post-verbal position as parts of the main clause. It is important to bear in mind that a right-dislocated object necessarily implies the presence of a clitic on the verb, whereas a right-dislocated adjunct has no clitic resumption whatsoever. Thus, it cannot be excluded that a given adjunct was right-dislocated in the speech of some informants, while that was impossible in the case of the object, since the sentence with a post-verbal object never contained an additional clitic pronoun. In other words, the question of whether the adjunct was realized as a right-dislocated element is not a primary concern. For now, we concentrate on the prosodic phrasing rather than on the syntactic structure of the sentences.
For each of the experimental sentences in (2) and (3), two additional factors were manipulated, Focus Type and Constituent Length (of the focused element). Focus Type had four levels, illustrated in (4) for SVOO sentences. Thus, focus was tested (a) on the whole sentence “
(4) a. [ “Jean-Marie sent a package to my sister.” b. Jean–Marie a envoyé [ c. Jean–Marie a envoyé [ d. Jean–Marie a envoyé un colis [
The second factor, Constituent Length, had two levels: the post-verbal elements were either both short (i.e., three or four syllables) as in (5a–b), or both long (i.e., six or seven syllables) as in (5c–d).
(5) a. Short objects: Jean–Marie a envoyé [ b. Short adjuncts: Jean–Marie l’a envoyé [ c. Long objects: Jean–Marie a envoyé [ “Jean-Marie sent an important package to his British neighbour.” d. Long adjuncts: Jean–Marie l’a envoyé [ “Jean-Marie sent it in the middle of podunk Argentina without really doing it on purpose.”
To ensure that participants would interpret the experimental sentences with the intended information status on the target constituent(s), the different focus conditions were triggered via an explicit, congruent question. To illustrate for SVOO sentences, the AF condition (4a) was triggered via the broad question (6a), the DF condition with a question like (6b) such that the two “wh”-words were always separated, the IF condition via (6c), and finally the FF condition via the question in (6d).
(6) a. AF: “What happened?” b. DF: “What did Jean-Marie send and to whom?” c. IF: “What did Jean-Marie send to my sister?” d. FF: “To whom did Jean-Marie send a package?”
For each condition in this 2 x 4 x 2 design, we created four lexicalizations, which were pseudo-randomized with 20 fillers (~ 1:3 ratio) into two experimental lists (see Appendix I for all experimental material). Thus, each speaker uttered half of the 64 experimental sentences, and we obtained a total of 512 expected sentences (16 x 32), excluding fillers. However, some sentences had to be discarded. Indeed, one lexicalization of two long adjuncts was wrong in the IF condition (eight sentences): the object was not cliticized but appeared as an additional post-verbal constituent. Moreover, 17 sentences altogether contained disfluencies in the post-verbal domain in different conditions and lexicalizations. In sum, a total of 487 sentences entered the statistical analysis.
Sixteen female native speakers of Standard French (aged between 23 and 45) participated and were compensated monetarily for their time.
2.2 Recording procedure and analysis
Participants met a native speaker of French in a quiet laboratory space where they sat in front of a microphone and were given a handout that contained the experimental list to be read. The version of the handout given to the participants only contained the target sentences, and this to ensure that they paid attention to the question posed by the experimenter. Participants were encouraged to repeat the recording whenever they felt they made a mistake or produced an unnaturally or improperly read sentence. The recording took about approximately an hour per participant. They were recorded at a sampling rate of 22.05 kHz with a 16-bit resolution with a head-mounted Shure microphone. The experimental sentences were extracted and saved as separate files.
The data was then automatically annotated for the words of interest by using the automatic phonetic alignment tool EasyAlign (Goldman, 2011). The phonetic correlates of phrasing investigated were F0 and duration. To obtain measurements on the target phrase, we used the script ProsodyPro (Xu, 2013). To extract continuous F0 contours, the vocal cycles were first calculated by Praat and then hand-checked for errors such as double-marking or pitch period skipping. While checking for spurious vocal pulse markings, segmentation labels were also added to mark the syllable boundaries. The duration of F0 periods was converted into F0 values automatically by ProsodyPro. The vocal pulse marking, segment labels, and F0 values were saved in separate text files for each utterance. In the next step, ProsodyPro calculated the highest and lowest F0 values as well as the duration of each syllable. For the graphical display of the intonational contours, the F0 values were smoothed using a trimming algorithm (Xu, 1999).
The data from our two dependent variables, F0max (discussed in section 2.6.1) and duration (see section 2.6.2), were log-transformed prior to statistical analysis in order to improve normality, and then analyzed using generalized linear mixed-effects regressions implemented with the lme4 library in the R environment (GPL-2j GPL-3, v.3.3.3; R Core Team, 2017). For the F0max variable, the measuring point considered for our analysis corresponds to the one value of the F0 maxima measure taken on each constituent.
In all analyses, Participant and Lexicalization were included as random-effects. The three fixed factors—Post-Verbal Sequence (OO, AA), Length (short, long), and Focus Type (IF, FF, DF, AF)—were treatment-coded prior to analysis. For Focus Type, DF was always the baseline. To find out whether the fixed factors had an effect on the dependent variables in the prosodic marking of dual focus, we first built a full model that included the maximal random-effect structure (RES) justified by the data and the theoretical assumptions (i.e., random intercept and slopes by-item and by-participant for the fixed effects of interest, as well as their interaction), the main effects of the three fixed factors, the two-way interactions between each of the three fixed factors, and the three-way interaction between all of them. Thus, the full model had the following structure: Maximal RES + Post-Verbal Sequence * Length * Focus Type. Then, in a stepwise fashion, we pruned off any non-significant interaction from the model, as long as the higher-order one was not significant either. We report on the final model by presenting estimates, standard errors and t-values, with any t-value exceeding 1.96 considered statistically significant with p < .05. P-values were obtained by likelihood ratio tests of the final models.
2.3 Research questions and hypotheses
Our study seeks to answer the following research questions:
2.4 Results
2.4.1 F0 results
Before reporting on the statistical analysis, the results are illustrated via four figures, representing the pooled normalized F0 results of all speakers for the test sentences per Length and Focus type. Thus, the plotting points represent pooled averaged measurements on each constituent (subject, verb, post-verbal constituent 1, and post-verbal constituent 2), with 10 measurements for each syllable per constituent (as provided by ProsodyPro). Figure 1 shows SVOO sentences in the short (left panel) and long condition (right panel).
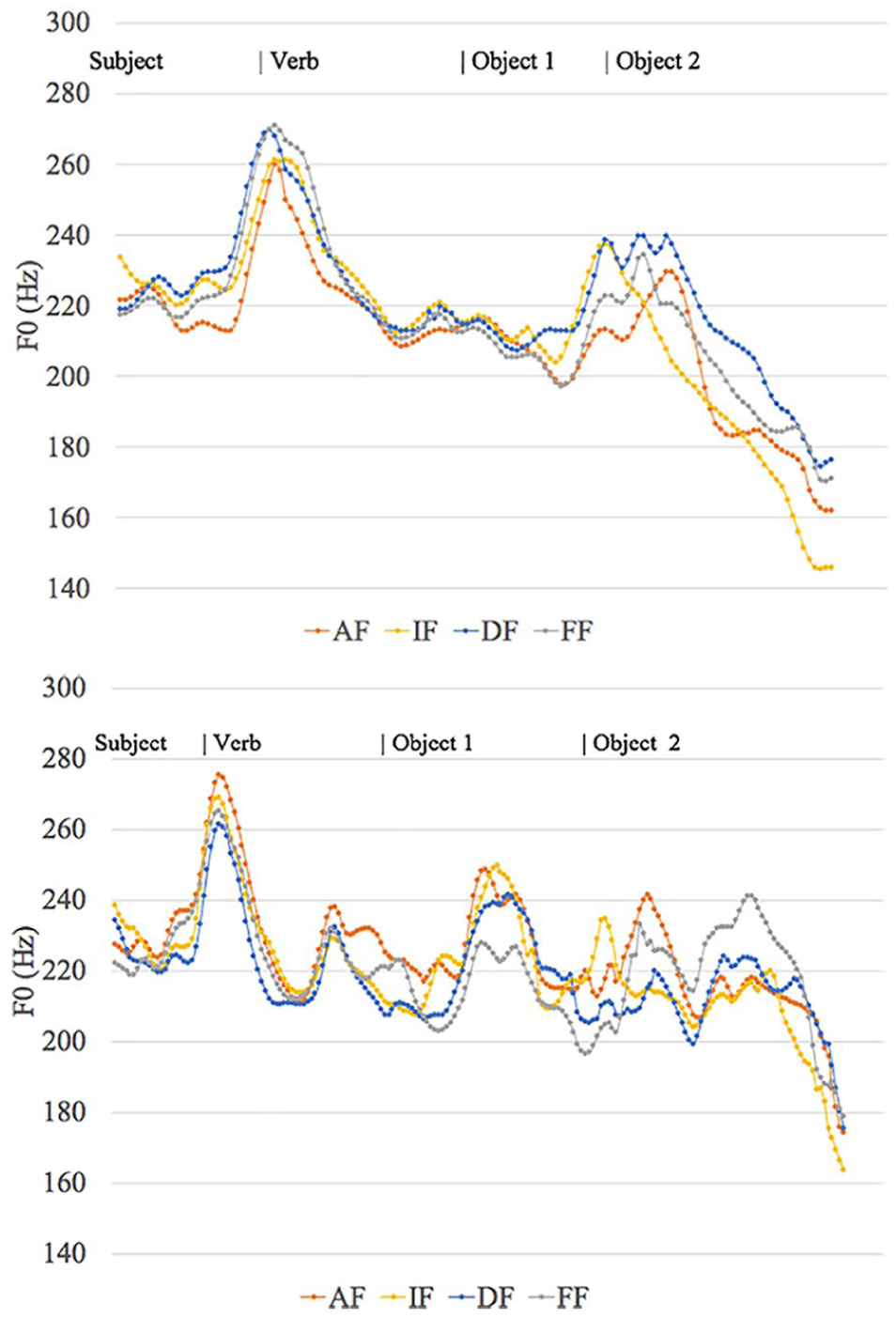
Pooled normalized intonational contours per focus condition for the SVOO sentences with two short objects (top) and two long objects (bottom).
Similarly, Figure 2 illustrates SVAA sentences where post-verbal adjuncts are either both short (left) or both long (right).
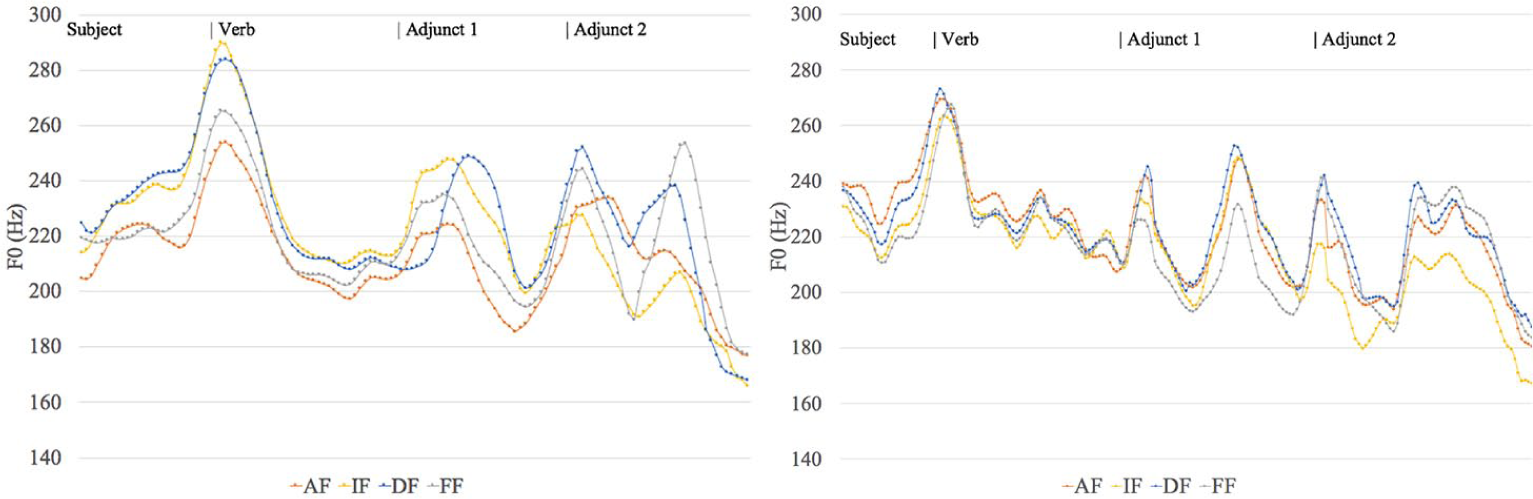
Pooled normalized intonational contours per focus condition for the SVAA sentences, with two short adjuncts (left) and two long adjuncts (right).
Visual inspection of Figures 1 and 2 does not lead to a straightforward interpretation, yet some important generalizations can be made. First, some properties of the tested sentences did not vary much:
A striking property is that the subjects and the beginning of the verbs were realized in the same way in all conditions, except in the short adjuncts where the different focus conditions triggered different height on the subject and verb. In the other conditions, the variation in the pitch contours began at the boundary of the verb and was most obvious on the post-verbal constituents.
A non-final constituent always bears a final high tone. This high tone was present in all focus conditions, and thus it seems to be dependent on phrasing rather than on information structure (Research question 1). 4 There may be a difference in the way the first post-verbal constituent was phrased relatively to the verb, but not in the way the two constituents were phrased relatively to each other: they were always in separate prosodic phrases as testified by the ubiquitous high boundary tone at the end of the first post-verbal constituent (see also the pitch tracks in Figures 3–5 for illustrations).
When the constituent was long, there was also an additional high tone. We discuss these additional high tones in section 3.1.
All speakers realized the sentences as declaratives: all of them ended in a low tone (or in some instances at mid-level; see Figure 1a for an example). In cases where the last constituent was subject to compression (see section 3.3), the first constituent ended with a falling contour.
A further common property is that the IF condition often triggered post-focal compression. In Figures 1 and 2, the final contour of the yellow line is always lower than in the other conditions. As for the FF condition, it did not regularly trigger a higher contour on the focused constituent; it did in the long OO and in the short AA, but in the other cases it resembles the AF and DF conditions.
Second, a couple of other obvious differences arose across the different conditions, the first and most important one being the number of high tone peaks in each constituent and their position (see section 3.1 for more detail), and the second being the height of the high tones (see statistical analysis just below). For instance, the first post-verbal constituent always reached the highest value in the IF condition, and the second post-verbal constituent was sometimes the highest one in the FF condition.
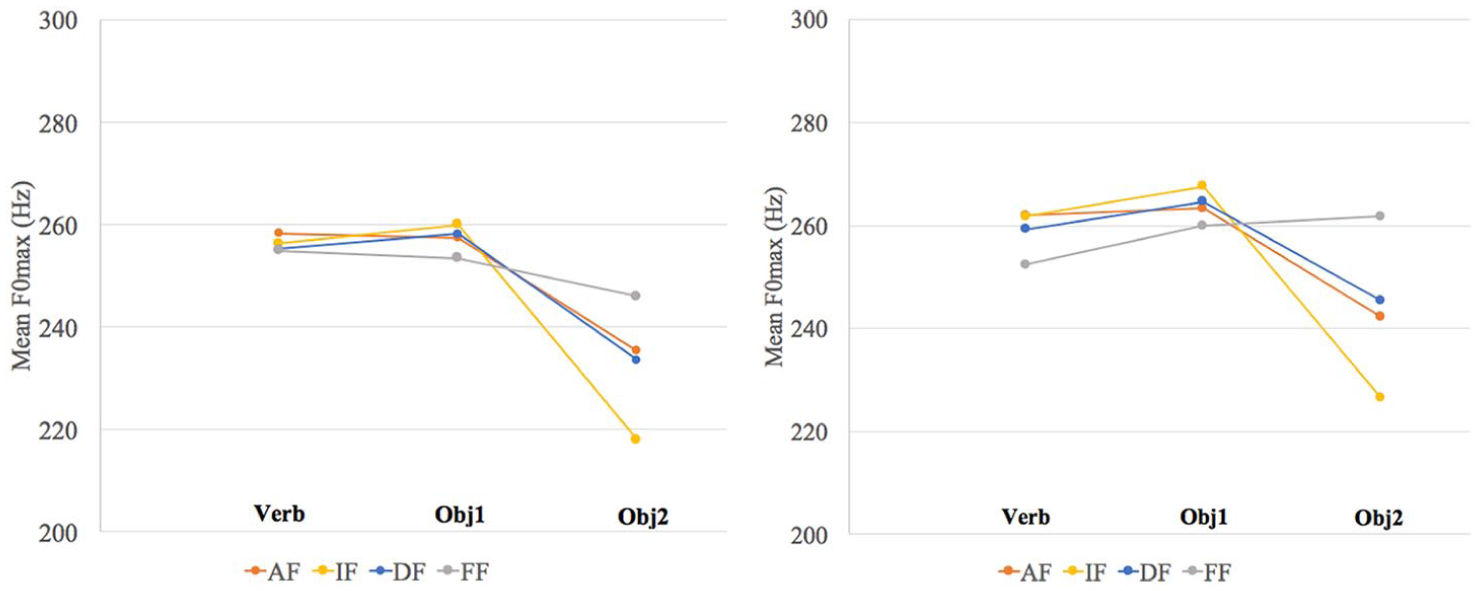
Pooled normalized means for F0max per focus condition for the SVOO short and long sentences (left and right, respectively).
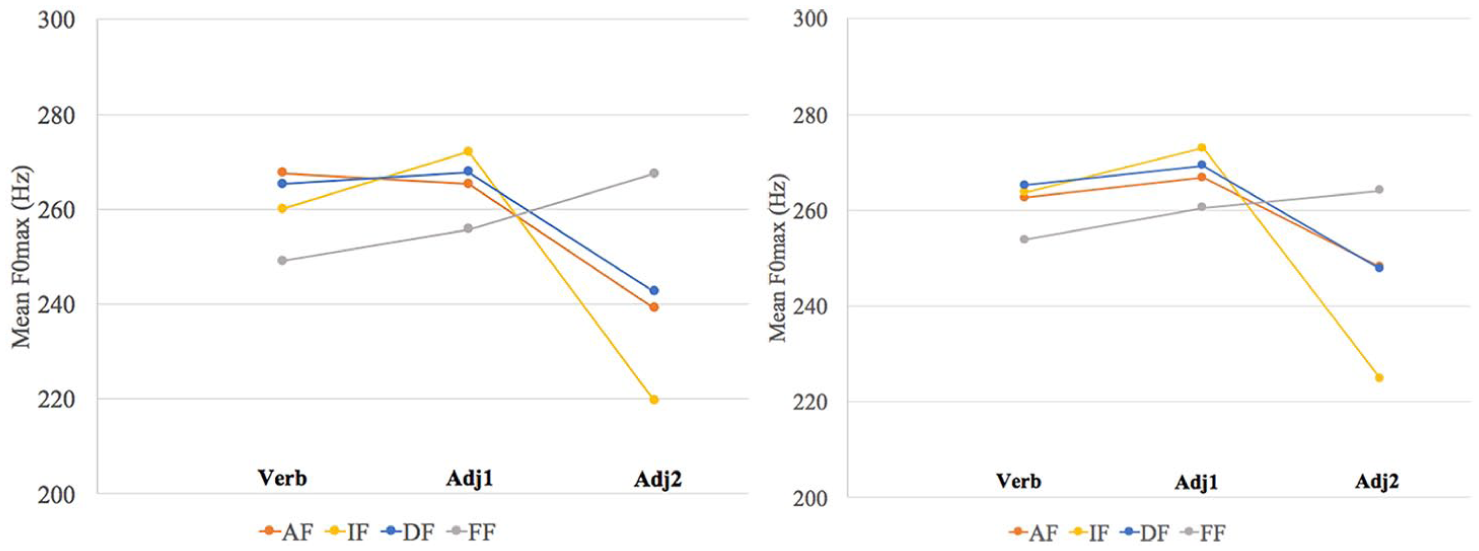
Pooled normalized means for F0max per focus condition for the SVAA short and long sentences (left and right, respectively).
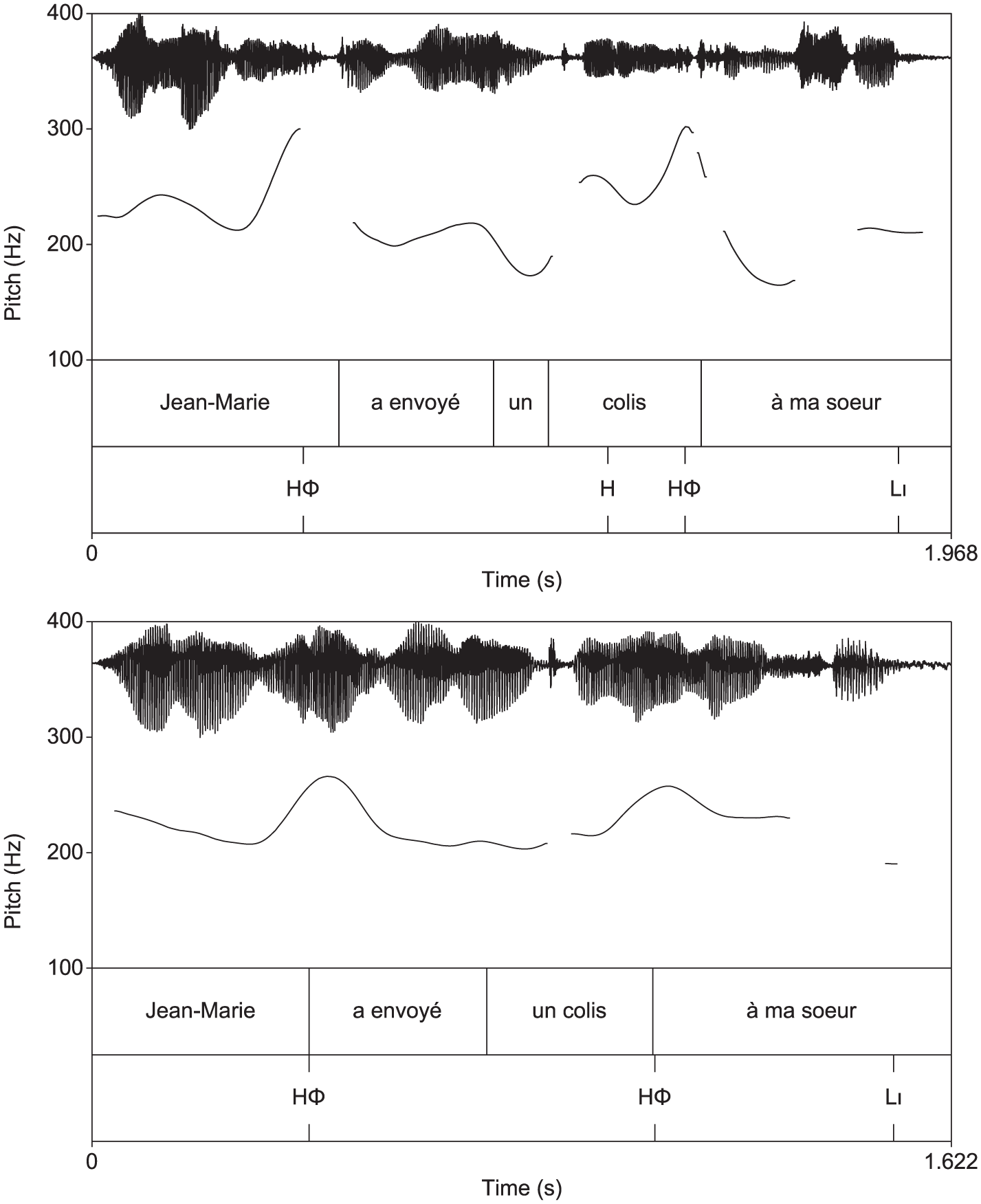
A high tone on the first syllable of colis “package” and another one on the second syllable of the same word. This sentence ends at a mid-level, rendering the word sœur “sister” prominent (top). A high tone on the last syllable of colis and a final falling contour on sœur (bottom).
Turning now to our statistical analysis, a first result concerns
A second result concerns the effect of Constituent Length, and more specifically
The third and last result for F0 height concerns
First, we discuss the results for SVOO sentences, illustrated visually in Figures 3 and 4, which represent the pool normalized F0max means for the VP domain with the two panels representing a different length condition for each sentence type (short PVS on the left, long PVS on the right).
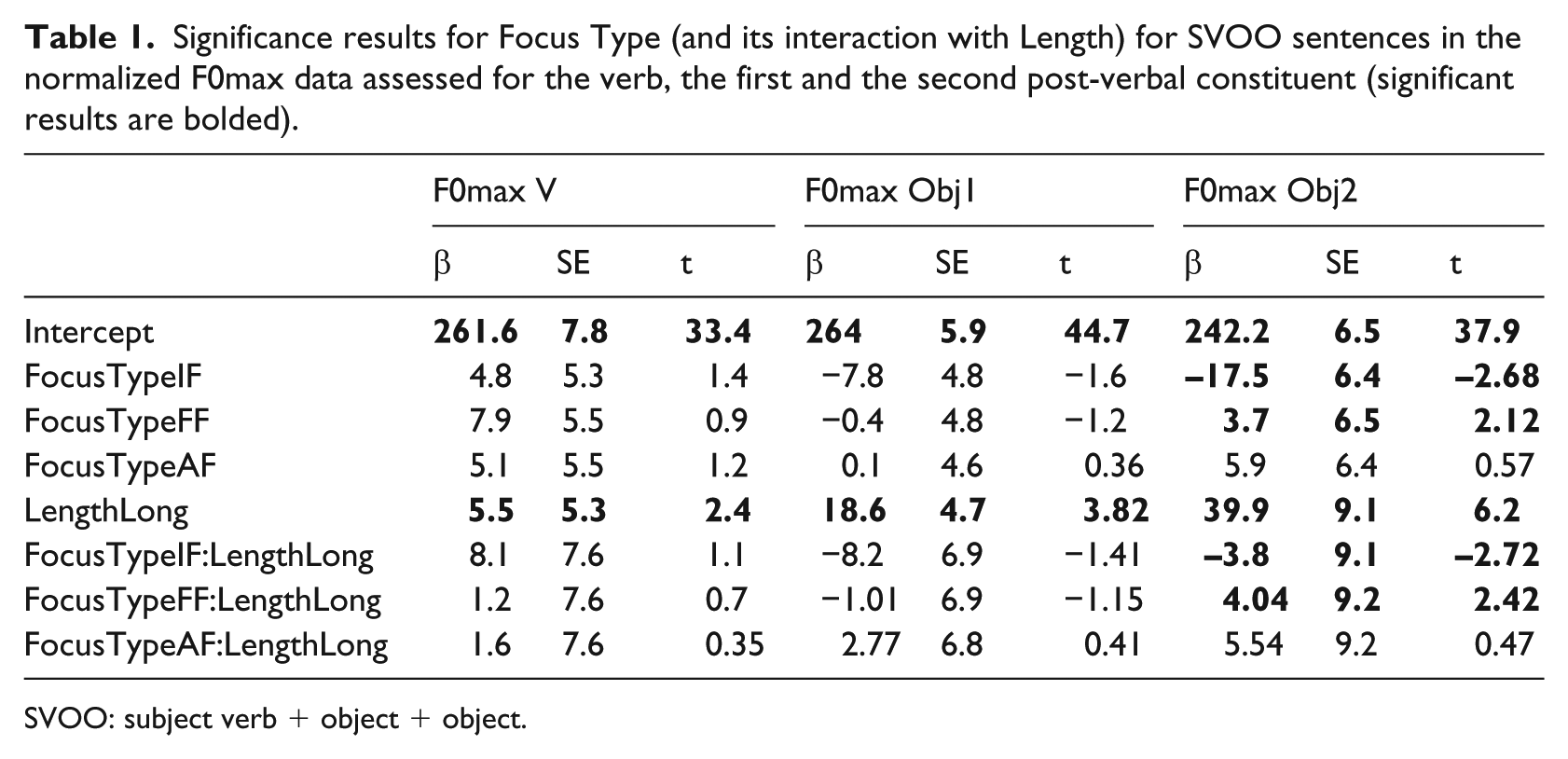
Statistically, Table 1 shows the results of mixed-effect linear regressions ran on the normalized F0max data for the verb, the first and the second post-verbal object, with full models including RES + Focus Type * Constituent Length. Again, the DF condition served as a baseline and was compared to the other conditions: AF, IF and FF.
Significance results for Focus Type (and its interaction with Length) for SVOO sentences in the normalized F0max data assessed for the verb, the first and the second post-verbal constituent (significant results are bolded).
SVOO: subject verb + object + object.
Results of interest for SVOO can be summarized as follows: overall, there is no significant difference between the F0max of the verb in any of the Focus Type conditions compared to DF. Furthermore, when comparing AF to DF, there are no distinct differences on either of the post-verbal constituents, and indeed when visually inspecting the bottom panels of Figure 3, AF and DF data look very similar. The effect of IF is seen, however, on the second post-verbal constituent when compared to the DF condition—the second object is significantly lower when it is given than when it is focused, and there is a significant interaction with the factor Length. Finally, comparing DF to FF, we do notice differences in the post-verbal domain as well. Indeed, the F0max of the second object in the FF condition is significantly higher than in DF, and there is a significant interaction with the factor Length.
Next, we discuss the results for SVAA sentences, as reported in Table 2 (see also Figure 4). Starting with the verb: the only condition that shows a significant difference on verb F0max with the DF condition is when the focus is final (FF). Indeed, the V F0max is much lower in the latter condition, speaking for cancelling the phrase boundary between the verb and a following adjunct when this adjunct is given. As for the post-verbal constituents, when visually inspecting the bottom panels of Figure 4, the data for AF and DF are again strikingly similar. But when comparing DF to IF, the effect of Focus Type is significant on the second adjunct, whereby its F0max is drastically lower in the latter condition. However, we do not find an interaction with the factor Length, suggesting that both short and long adjuncts behave similarly in that respect. Finally, comparing DF to FF, we see differences on both post-verbal constituents, with the F0max of the first adjunct being significantly lower and that of the second being significantly higher in the FF condition, but no significant interaction of Length and Focus Type.
Significance results for Focus Type (and its interaction with Length) for SVAA sentences in the normalized F0max data assessed for the verb, the first and the second post-verbal constituent (significant results are bolded).
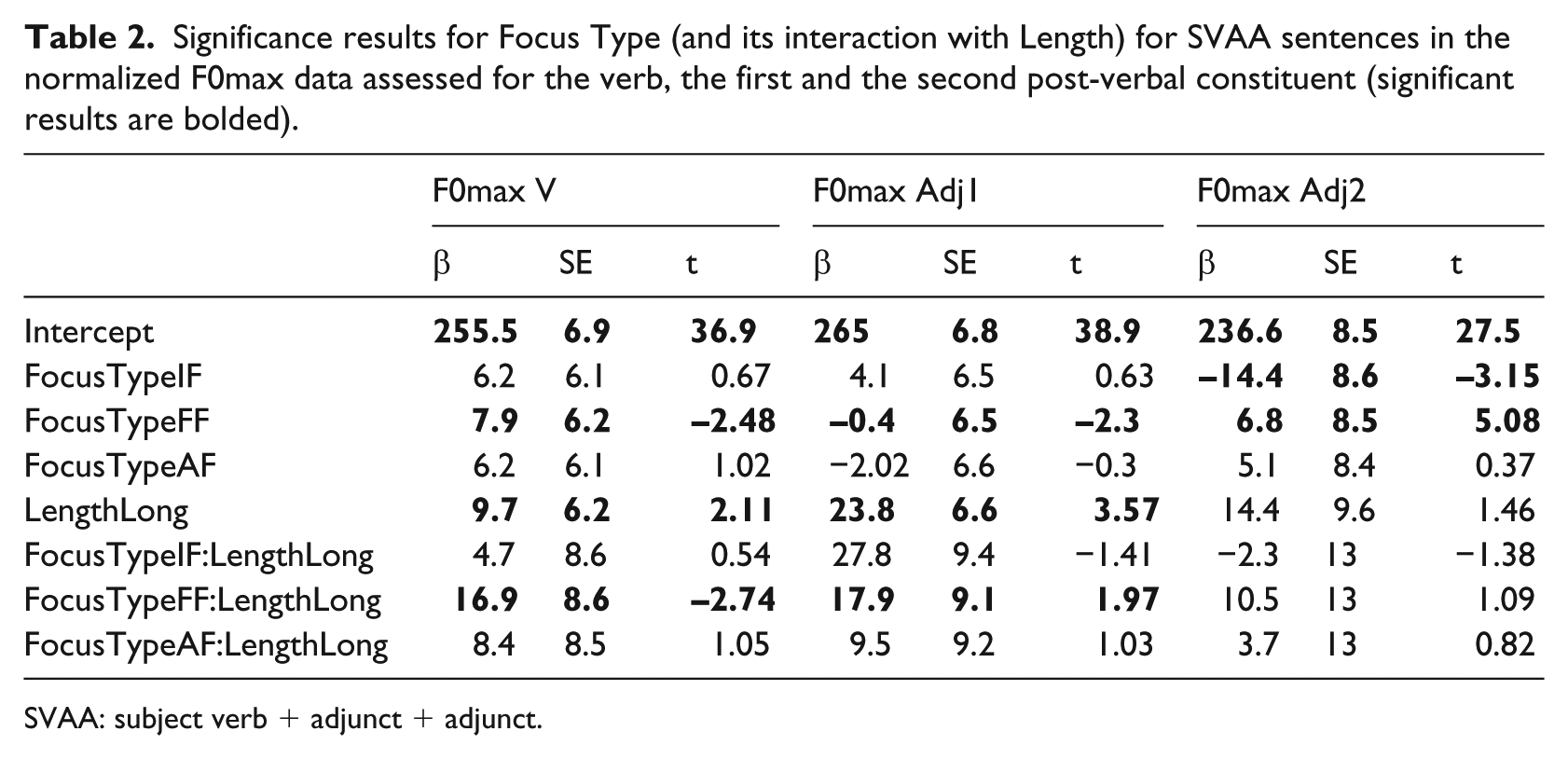
SVAA: subject verb + adjunct + adjunct.
2.4.2 Duration results
Similar to the analyses conducted for F0, we were interested in the effect of Post-Verbal Sequence and Focus Type on duration—our second dependent variable. We note that we did not analyze the effect of Constituent Length here since long constituents necessarily had a longer duration compared to short ones.
First, we examined
Second, we were concerned with
Concerning the
Results of the final model for the
Finally, results from the final model on the
In sum, these results suggest that duration is not significantly affected by the focus type encoded in the sentence but does vary according to the constituent that follows the verb along with its prosodic length.
3 Individual variation
It is important to note that the pooled normalized results (Figures 1–4) and the statistical analyses can obliterate the individual differences that may appear among speakers. Yet speakers use different strategies to realize focus prosodically, and cross-speaker variations appears pervasive in French. We address them in this section, as posited in research question 5, since, in our view, variation is one of the reasons why it is so difficult to account for French prosodic structure in simple terms. An understanding of the source of this difficulty can only be achieved by a careful survey of variation. In the following discussion, we focus on the factors that were most affected by variation: number and position of the high tones in the post-verbal constituents (section 3.1); tone scaling relationship between them (3.2); deaccenting of entire final phrases (3.3); and perceived breaks between the post-verbal constituents (3.4). In this section, 480 sentences were taken into consideration. From the expected 512 sentences, the same 25 mentioned in section 2.2. were discarded, and an additional 7 sentences were also removed because they contained hesitations between constituents that did not affected the statistical results but did affect the results of the individual variation.
3.1 Number and position of high tones in each post-verbal constituent
In the short constituents, there generally was one high tone per non-final constituent that lay on the last syllable of the constituent. This high tone is best analyzed as a prominent phrase boundary (see section 1 for references), and is annotated as HΦ in the following figures, to indicate that it is the boundary tone of a prosodic phrase. In some cases, however, there was an additional high tone earlier in the phrase, as illustrated in the top panel of Figure 5, where the first syllable of colis “package” has an additional high tone. Since this tone is not a boundary tone, we annotate it as H. This figure compares to the bottom panel of Figure 5 where there is only one final high boundary tone on the last syllable of colis. Both sentences were produced in the all-focus condition and both show the final LLι responsible for the final fall at the end of the sentence. 5
We found six additional high tones in the first post-verbal object in the AF condition, out of 32 realizations, thus in 19% of such sentences. In the DF and IF conditions, we found more additional high tones on the first constituent, 15 and 20 respectively; see Table 3 for a survey. In the FF condition, only two such tones were produced on the given first constituent. Additional high tones were also found in the second post-verbal constituent, though not as frequently as in the first one. Only in the FF condition did we count 12 additional high tones. In sum, focused constituents had more additional high tones than given ones.
Non-final high tones on the two constituents in sentences with two short objects.
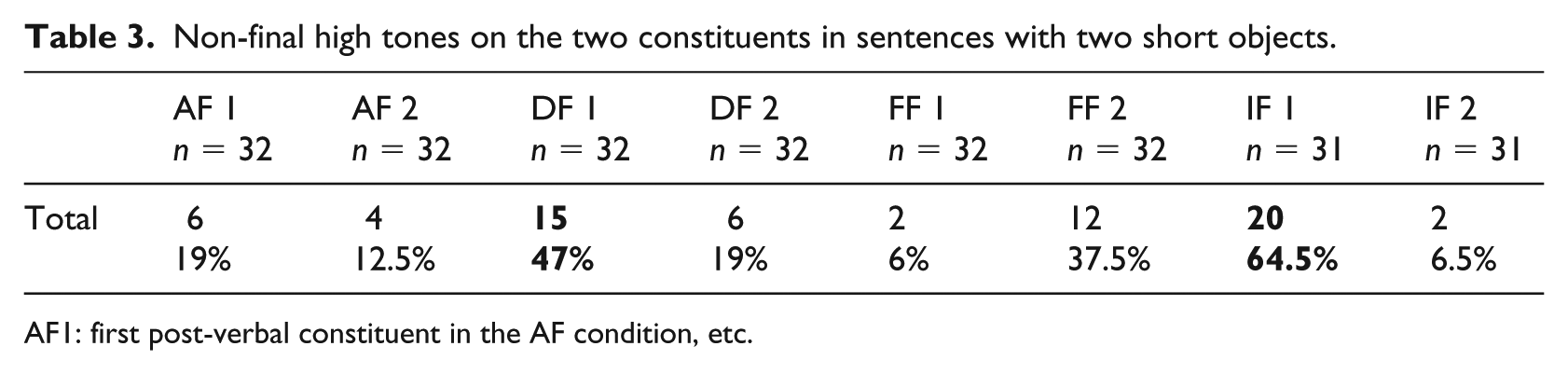
AF1: first post-verbal constituent in the AF condition, etc.
The most interesting lexicalization is the one which has a disyllabic final word (à leur rival “to their rival”), the other three lexicalizations had a final monosyllabic word. Out of the eight utterances for the sentence containing the disyllabic word in the FF condition, an additional high tone was realized once on à “to,” twice on leur “their,” and three times on the first syllable of rival “rival.” Only two speakers did not add a high tone there. Similarly, the DF condition exhibited five additional high tones, all of them on ri- (of rival). In the other sentences, where the final word was monosyllabic, the last syllable was often longer in duration or the final word was pronounced with a rising-falling tone or with a mid-tone, all realizations being perceived as prominent. Some additional tones were present in these sentences too, usually on the preposition à or on the following possessive.
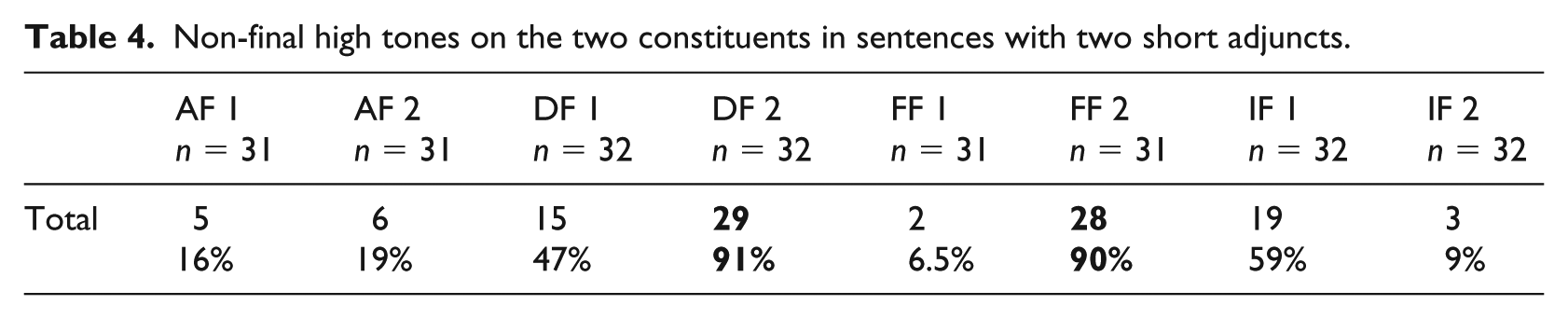
The results for sentences with two adjuncts (see Table 4) are partly similar to those with two objects (more additional tones in focused constituents), except for the fact that the additional high tones were altogether more numerous. This difference may correlate with the fact that there were more disyllabic final words in the sentences with adjuncts (and thus more space to realize an additional tone), or with the difference in phrasing between objects and adjuncts (Destruel & Féry, 2019).
Non-final high tones on the two constituents in sentences with two short adjuncts.
In sentences with long adjuncts, the post-verbal constituents under scrutiny mostly consisted of a prepositional phrase containing another (embedded) phrase, or of a noun and an adjective. They are thus syntactically and prosodically more complex than the sentences with two short constituents. The typical pitch contour has again a high boundary tone on each constituent, usually the last word, as a prominent HΦ boundary, but often also on the embedded constituent, as illustrated in Figure 6, a sentence with final focus. In this pitch track, there are several additional high tones. Downstep is interrupted on the last syllable of américain, suggesting that américain carries a more important boundary than collègue.
(8) Bernadette a présenté [son collègue [américain]] [à ma belle-sœur [canadienne]. “Bernadette introduced her American colleague to my Canadian sister-in-law.”
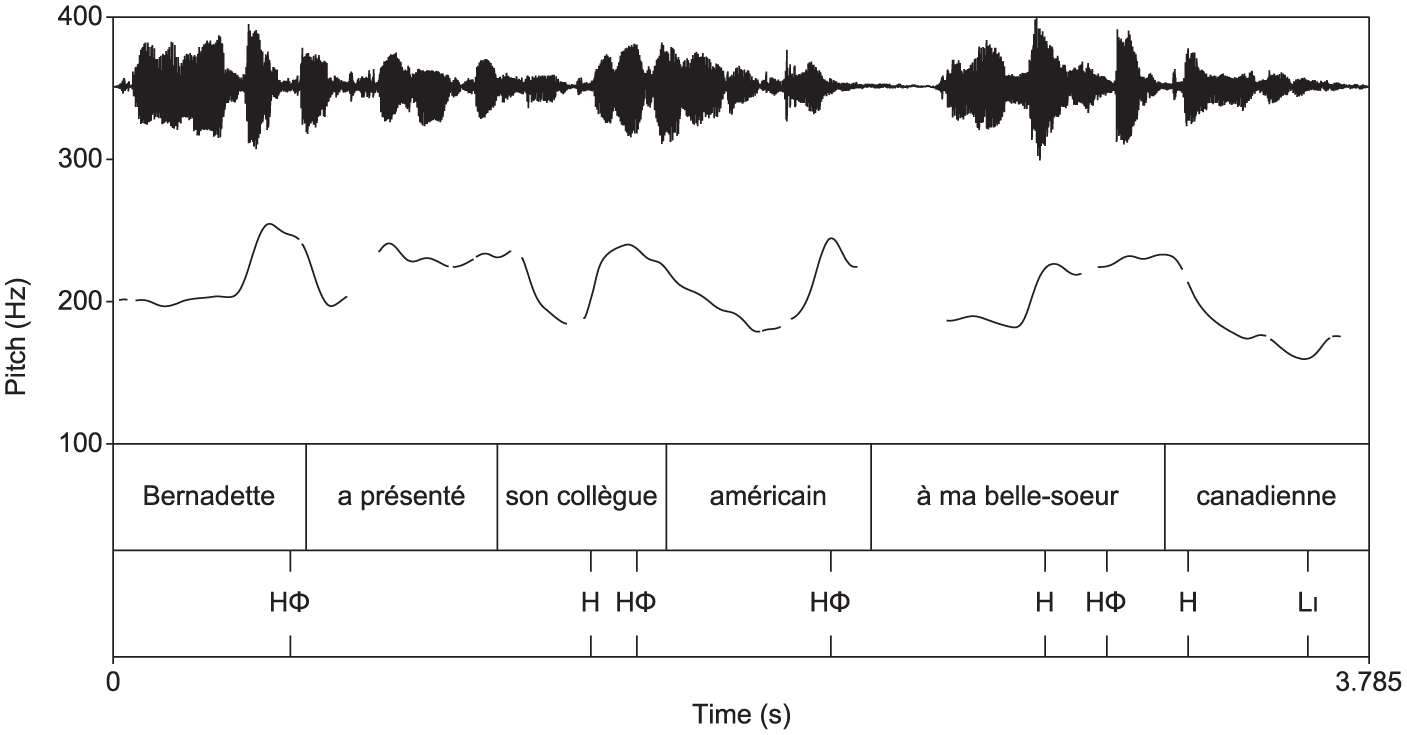
Additional high tones on a sentence with long objects.
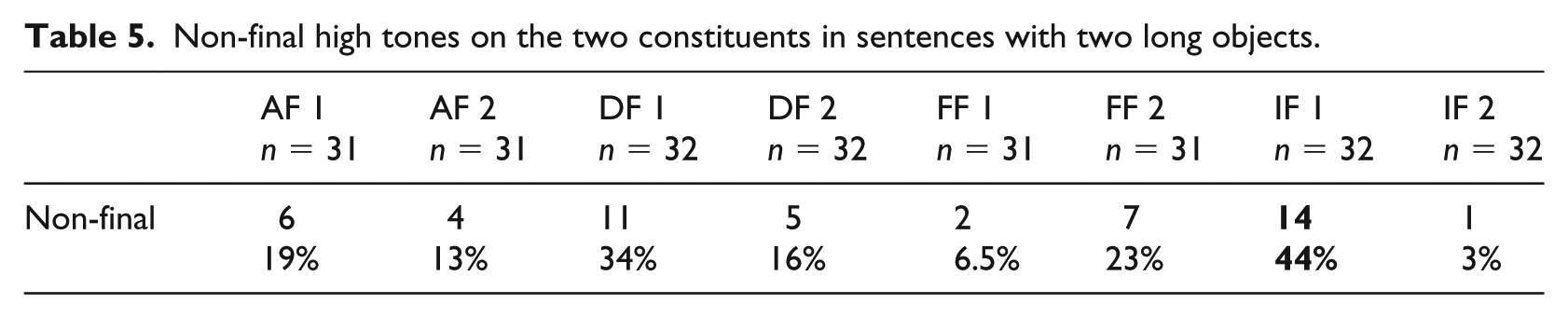
We also counted the additional high tones in the long sentences. Results, as reported in Tables 5 and 6, reveal here again a tendency to realize more non-final high tones in adjuncts than in objects, but also more in focused constituents than in non-focused ones.
Non-final high tones on the two constituents in sentences with two long objects.
Non-final high tones on the two constituents in sentences with two long adjuncts.
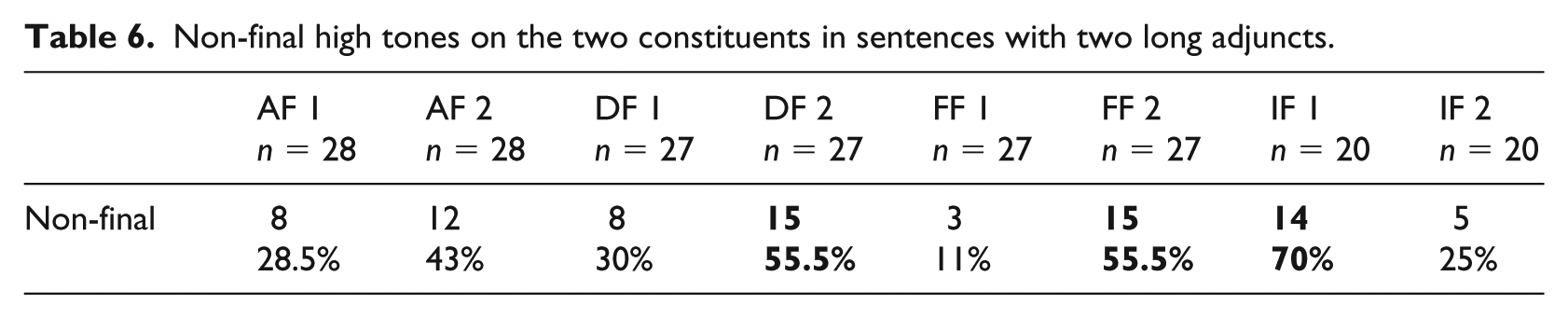
To sum up, the most frequent occurrences of an additional high tone happened in a focused constituent, thus in both constituents in DF, in the last one in FF, and in the initial one in IF, speaking for a cue of focus. Furthermore, more additional high tones were realized on the long constituents than in the short ones. Most interesting is that the high tone can appear in several locations, rather than in a single one, and speakers seem to behave quite freely with respect to which syllable they chose for hosting a non-final high tone.
3.2 Scaling relation between the two post-verbal constituents
Let us turn to pitch scaling, a correlate that is seldom considered in the literature on French prosody. We think it is a crucial cue in French that should be studied carefully. As in other better-studied languages, the height of high tones is an indicator of prominence, and even though a high tone does not have the same function as in Germanic languages, where it signals the head of a prosodic domain, it does render a word or a constituent prominent in French as well. And the higher it is, the more prominent it becomes. Inversely, givenness can decrease the height of a high tone. For these reasons, tonal scaling is a prosodic reflex of information structure; see, for instance, Kügler and Féry (2017) for post-focal downstep in German.
First, notice that a large downstep typically takes place between the subject and the verb, but none between the verb and the next constituent. Visual inspection of Figures 1 and 2 reveals a default downstep pattern in the two post-verbal constituents, except for DF and FF. In AF and IF, the second constituent is lower than the first one—even more so in the IF condition.
Turning to individual variation, in the sentences with short objects, most sentences presented downstep; see Table 7 for quantification. In the following, downstep means a lower F0max in the second post-verbal constituent than in the first one. The difference between the two must be of at least 5 Hz for counting as downstep, considering the highest F0 in both phrases. Surprisingly, downstep is also often found in the DF condition, as often as in the AF condition. Only the FF condition cancels downstep of the second constituent more often than in the other conditions. In this case, the highest tone is at the same level or higher as the highest tone of the first constituent in 18 cases (out of 31 cases). However, there is a difference in the amount of downstep in the different conditions.
Downstep of the second phrase relative to the first one in two short constituents.

In the case of two adjuncts, downstep also takes place in the IF condition (except in two cases). In the AF and DF conditions, downstep is less regular than in the sentences with two objects, as can be seen in the right-hand column of Table 7.
Results in Table 8 suggest that, in the long sentences, downstep is less frequent altogether, especially in the sentences with adjuncts, although it is not rare. It is again most frequent in the IF condition, and least frequent in the FF condition. In AF and DF, it is much less frequent than in the short sentences.
Downstep of the second phrase relative to the first in two long constituents.

These data suggest that tonal scaling across constituents is an important cue to focus and givenness—a cue probably as important as the presence of an additional tone early in the constituent. The length of the constituents also plays an important role: in the long conditions, downstep is less frequent than in the short conditions.
3.3 Deaccenting of entire final phrases
We call “deaccenting” or “compression” a realization in which an entire final constituent is realized with a low and flat contour. Compression can be considered an extreme case of downstep because the entire constituent is realized on a much lower level than the preceding one. Figure 7 illustrates the sentence in (9), realized in the IF condition. As is visible in the pitch track, the last word of the first post-verbal constituent poste “post office” has a falling contour; it is not downstepped relative to the preceding verb and is thus perceived as prominent.
(9) Jean-Marie l’a envoyé par la poste à Toulouse. “Jean-Marie sent it via the post-office to Toulouse.”
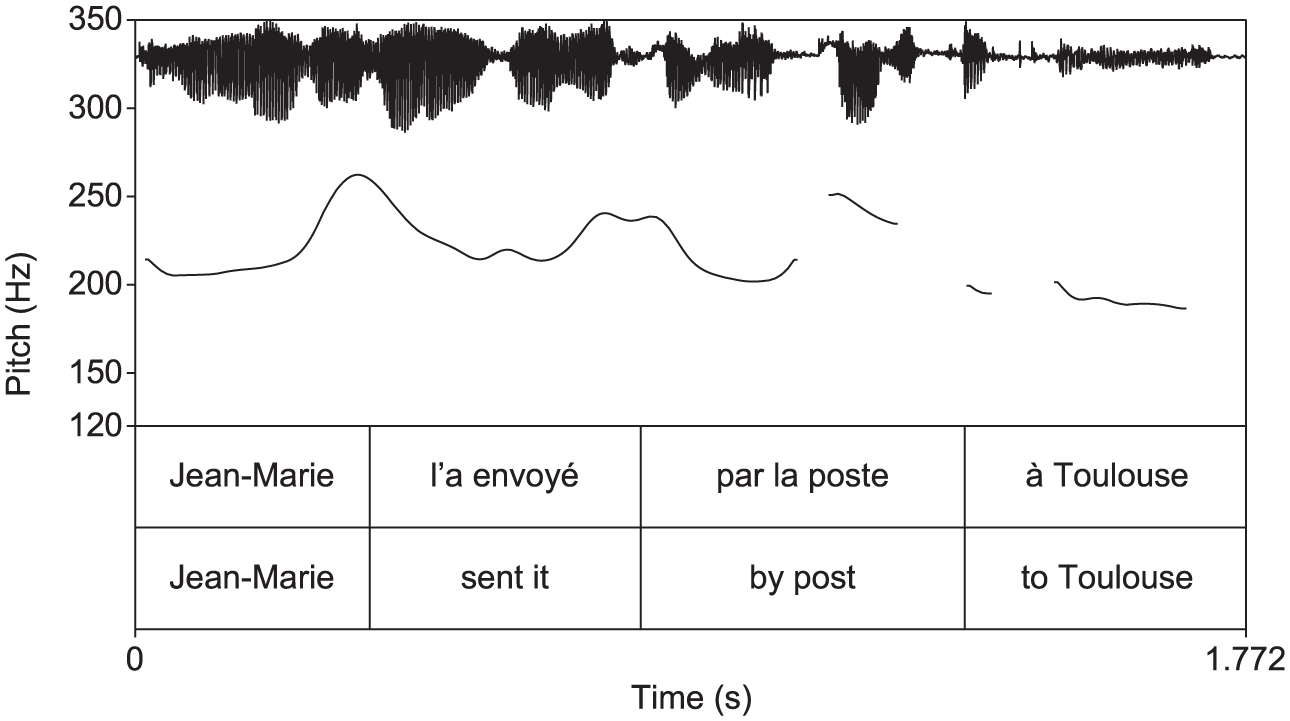
Deaccenting of a final constituent in the IF condition.
Compression of the final constituent was often present in the IF condition, but not always (59 times out of 114 possible contexts, thus 52%); see Table 9 for details. It is much more frequent in the short sentences than in the long ones, but there is no difference between objects and adjuncts.
Compression of the final constituent in the IF condition for all lexicalizations.

Interestingly, compressing the final constituent in other conditions than IF was not infrequent. It happened 16 times altogether: 6 times in AF, 7 times in DF, and even 3 times in FF. One speaker, as seen in Figure 7, compressed the final constituent especially often (nine times) who also often ended her focused constituent at mid-level. This speaker is one of two speakers who always compressed the last constituent in the IF condition. Six other speakers compressed one or two sentences each in IF. In sum, only 2 of the 16 speakers always compressed a final given constituent—most of the speakers did it optionally, but more often when the constituents were short than when they were long.
We conclude that, although this is the preferred context, compressing a second post-verbal constituent does not necessarily mark givenness. It may be the reflex of right-dislocation, which is itself not necessarily triggered by givenness.
3.4 Perceived breaks between the post-verbal constituents
The last factor subject to variation is an audible break between the post-verbal constituents. It is realized with a short silence, or a glottal stop or an extra high tone on the preceding final syllable, that is then also a bit lengthened. A break is realized a lot more often between long constituents than between short ones, and also more often after a focused constituent than in the AF constituent or before the final focus of FF, as can be seen from the numbers reported in Table 10.
Audible breaks between the two post-verbal constituents in all conditions.

Altogether, this strategy for marking phrasing was extremely frequent in our data, but with large differences among the conditions. The main differences appear between the short sentences (100 breaks total) and the long sentences (186 breaks total). However, among the short sentences, there is another divide between objects and adjuncts. There were more breaks between adjuncts than between objects, and, among objects, the most probable context for a break is after a focused constituent (DF and IF).
To sum up this subsection, the presence of a short break between the post-verbal constituents appears to be a further indication of focus.
4 Perception study
4.1 Methods
The perception experiment was conducted to assess whether French listeners make use of the differences in prosodic and phonetic realization to distinguish between different focus contexts. The experimental sentences elicited and recorded in the production experiment served as target items in this experiment—they were presented acoustically and in writing to the participants, together with the four questions corresponding to the four focus conditions tested (IF, FF, DF, AF). Only one of the questions was congruent with the sentence heard; participants had to select which one they thought was the appropriate one. An illustration of the test screen appears in Figure 8, where the questions correspond to dual focus, all focus, initial focus, and final focus, respectively; see also examples (4) and (6) for other sample stimuli.

A sample trial for dual focus in the perception experiment.
A total of 26 sentences from the short-short objects (7 sentences), short-short adjuncts (6 sentences), long-long objects (6 sentences), and long-long adjuncts (7 sentences) were used as experimental sentences in this study. All four conditions were included: there were six AF, six IF, six FF, and eight DF sentences. For each sentence, we chose 3 different realizations each, thus resulting in a set of 132 utterances. These were organized in 2 lists of 66 sentences each, along with fillers. The study was conducted online, on the free SoSciSurvey (<www.soscisurvey.de>) platform, and took approximately 20–30 minutes. A total of 79 French native speakers participated, but only 50 completed the entire study, the responses of whom we report in the next section.
4.2 Results
The results appear in Figure 9, which represents the percentages of responses for each Focus Type condition.
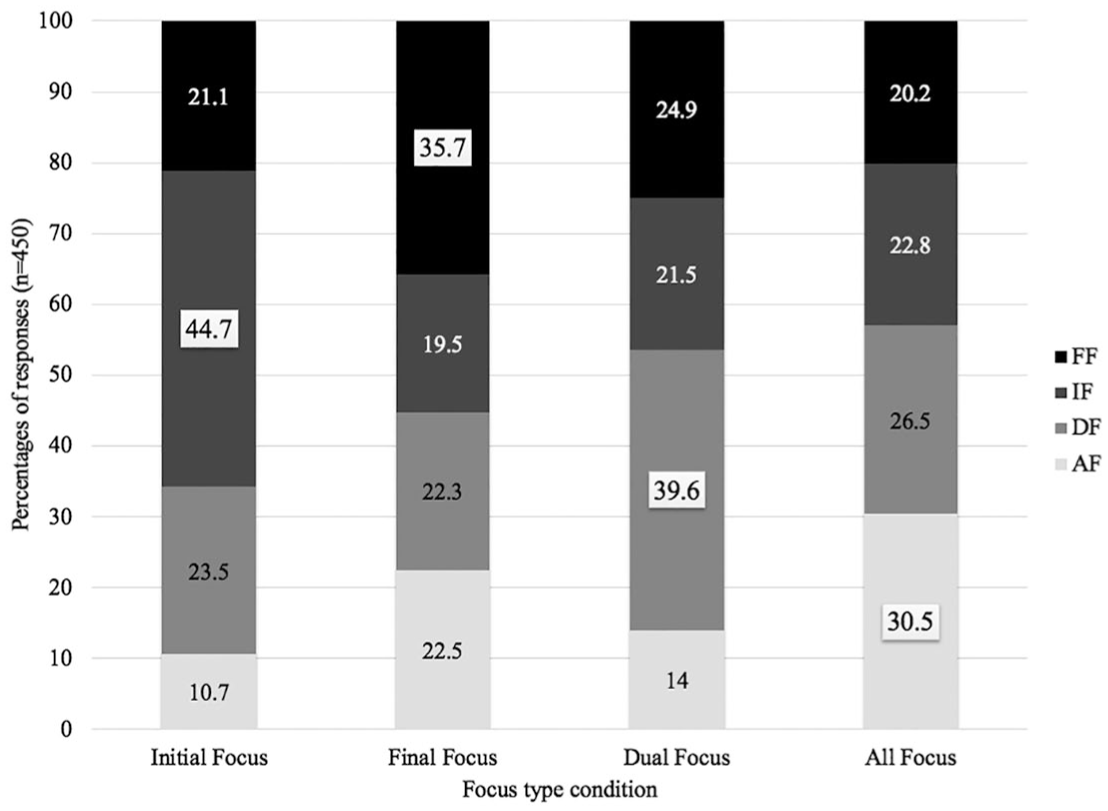
Results of perception study in percentages per Focus Type condition.
Visual inspection shows that in the Initial, Final, and Dual Focus conditions, speakers display a preference for the correct response, with the best results obtained for the IF condition (44.7% rate of correct responses). In the AF condition, on the other hand, percentages of responses are more evenly distributed across the four levels of responses. Statistically, we restricted our attention to the Focus Type condition of interest—Dual Focus—for which we examined whether the differences in the responses selected were significant. To do so, we ran a series of logistic mixed-effect models, each concentrating on two responses. Results revealed a significant effect of Response when comparing the rate of response between DF and IF (β =0.408, SE = 0.219, z = 1.86, p <.05), between DF and FF (β =0.449, SE = 0.224, z = 2.22, p <.05), and even more so when comparing DF and AF (β =1.477, SE = 0.347, z = 4.25, p <.001). This suggests that listeners tend to select the congruent question in DF Focus Type condition; that is, the question that contains two wh-words (see 6b). This is a welcome result because it also indicates that the speakers in our production study completed the task well, with the intended information structure.
We speculate that the post-focal compression that was realized by a number of speakers was decisive in the recognition of an initial focus, whereas the other conditions did not vary that much. This is especially obvious in comparison to results for the same experience conducted in German (see Wang & Féry, 2017), where the preference for the correct response is much larger in each condition. In German as well, initial focus elicited the best results, but the other conditions were also much better recognized than for French. We take these data to suggest that French speakers do use prosodic cues for communicating the information structural context, but that the prosodic cues are not strong enough to straightforwardly disambiguating the information-structural context in which the sentence occurred. This explains the mixed results of the perception experiment, especially when compared to a language where the prosodic cues are much stronger; that is, German.
5 Discussion
In this section, we provide elements of answers to the research questions formulated in section 2.4.
Research question 1:
Research question 2:
Research question 3:
Research question 4:
However, in comparison with the other languages for which experimental evidence exist for the realization of dual focus, our data suggests a clear difference from German and English; see Wang and Féry (2017) for German. The listeners in the latter language prove to be much more reliable at discriminating across the four focus types encoded in the (non)-congruent questions presented in the experimental task. Dual focus is often realized with a special phrasing eliciting a falling tone both on the initial and on the final focus, but, in French, phrasing was stable in all information contexts. There was no change in the direction of the medial boundary tone. In all focus conditions, the first post-verbal constituent was phrased independently from the second one, and the boundary between them was always rising, except in the cases of deaccenting of the final constituent (often in the IF condition, but not exclusively).
Moreover, Eady et al. (1986), who conducted the first production experiment investigation dual focus in English, showed that, in this language, the F0max and word duration of both focused words increased to the same degree as in the corresponding single focus conditions. Furthermore, both DF and IF conditions exhibited falling contours on focused words, and this differed from the FF and the AF conditions, which had initial rising contours. The main difference between IF and DF was that post-focal F0 was significantly lowered after an initial focus. According to Eady et al. (1986), the lack of post-focal F0 lowering in dual-focus sentences represents an anticipatory influence of the additional focus at the end of the sentence. In Mandarin (Wang & Féry, 2015), there was also less final compression after the first focus in dual focus than in initial focus. No such F0 lowering was found after the first focus in a dual-focus sentence in French.
Research question 5:
Even though we were unable to detect a stable prosodic indicator of focus, the fact that listeners were able above chance to indicate a correct congruency in the case of dual focus speaks in favor of acoustic cues in the signal beyond F0-max and obligatory final H-tones. However, these cues appear to be variable and optional, which relates to the less systematic congruency ratings compared to Germanic languages.
6 Conclusion
To the best of our knowledge, this article contributes the first experimental study on dual-focus for French—an information-structural condition that is largely lacking from the past literature on French prosody, and, more generally, scarcely investigated cross-linguistically. Even though we cannot exclude that our results may turn out to be specific to the type of sentences tested, some aspects of French prosody were distinctly revealed. Indeed, we found that a sequence of two foci does not display the same effects as corresponding single focus on each of them. We note that French differs from the other languages investigated so far in that the language does not change the phrasing of a focused constituent and does not appear to allow two equally prominent pitch accents to co-exist in one intonation phrase, as in German. In sum, our study brings to the forefront the importance of individual variation in French, suggesting that prominence can be achieved in different ways. It is important to keep in mind that French speakers may favor non-prosodic correlates for the communication of information structure, like cleft sentences, word order, and ellipsis, rendering the use of prosody marginal in some cases.
This study highlights the fact that the individual variation as to how to realize focus in French may partly explain the different interpretations that are found in the literature. French has a truly different type of prosodic structure: it has no lexical stress (like German) and of course no lexical tone (like Mandarin) and thus no designated syllable in a word or in a prosodic phrase for a pitch accent that can be realized with more prominence. There is thus no obligatory marking of focus, no obligatory correlate of focus. Rather, we found a very stable syntax-based phrasing and a multitude of different cues for indicating focal prominence. We could show in a perception experiment that listeners are aware of these different cues, although they do not perform as well as speakers of a language with obligatory cues for focus.
Footnotes
Appendix I. Reading material
Due to space restrictions, we only present here the material in condensed form, in French, and the English translation, for each of the four lexicalizations.
Acknowledgements
Thanks are due to Dominik Thiele, Sebastian Bredemann, Luise Kloß, and Johannes Messerschmidt for technical help, and Bei Wang for precious advice and comments, and review; to Annie Rialland for her review and help for the perception experiment, as well as to an anonymous reviewer; and, last but not least, to Frank Kügler, the editor of this special issue who gave us very helpful comments. We also benefited from conversations with Fatima Hamlaoui and Michael Wagner.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.