
Abstract
In this study, an artificial neural network (ANN) model is presented in order to predict the tenacity and hairiness of carded cotton yarns. Fiber measurement values generated by using a high-volume instrument (HVI) and an advanced fiber information system (AFIS) were used in the ANN model as input parameters. The radial basis function neural network (RBFNN) was used as ANN structure. The best RBFNN model was determined by analyzing the effect of epochs and the number of neurons on prediction performance. By using this ANN structure, the comparison between the performance of predicting yarn properties from HVIs and from AFISs was carried out. In the study, four different yarn counts (Ne20, Ne24, Ne30, and Ne40) for 10 different blends were applied. Each yarn count was spun at 4.34αe twist factor. In this study, the model presented a good rate of accuracy for predicting yarn tenacity and hairiness by using HVI and AFIS fiber values. The study showed that there was no significant difference between the accuracy of predicting these yarn properties from HVI fiber measurement results and those from an AFIS by using the RBF. From the results, it was noted that the performance of predicting yarn hairiness was better than that of predicting yarn tenacity. Also, this study could provide researchers with exclusive information on how to select the most appropriate ANN architecture and how to evolve the model for testing.
Keywords
Introduction
Knowledge of the relationship between performance and characteristic parameters of yarns made from given fibers assists the producers to arrange the technological processes. This will allow a producer to make an informed decision that accounts for the required quality of the yarn at the best price. So, modeling and predicting yarn properties by putting forward the relationship between the fiber and the yarn properties are two of the most remarkable subjects for textile researchers. Many statistical 1–9 and mathematical 9–16 models have been developed to address prediction accuracy and general applicability. Mathematical models are usually based on certain idealized assumptions, so their success potential is mainly limited by the viability of these assumptions. In recent years, neural networks have been shown as efficient alternatives to first principle models due to their ability to describe highly complex and nonlinear problems in many fields of engineering. 17
Artificial neural networks (ANNs) have received much attention recently. Like their biological counterparts, ANNs learn from experience, generalize, and perform abstraction. They have been taught with suitable training sets to perform well in a wide range of applications. An ANN is a network of simple processing elements that can exhibit complex global behaviors, determined by the connections between the processing elements and element parameters. These elements are known as neurons. An artificial neuron is a mathematical function conceived as a simple model of a real (biological) neuron. In an ANN structure, firstly, a set of input connections brings in activations from other neurons; secondly, a processing unit sums the inputs and then applies a nonlinear activation function; finally, an output line transmits the result to other neurons. An ANN is also a nonparametric estimation technique. It does not make any distributional assumptions regarding the underlying variable. Instead, it presents a formula with a set of unknown parameters and lets the optimization routine search for the parameters that are best fitted to produce the desired results. 18 Different learning types of neural networks are used in modeling studies. However, the most common classifications are made as supervised and unsupervised learning networks. A supervised learning network contains pairs of input and output data. There is a selected output dataset for each input dataset. In this type of learning, the key point is that the desired output of the network is known for each input dataset. Hence, the weights of the network can be modified. Supervised neural networks are typically used to solve function approximation, using examples of the function in the form of input-output pairs. In unsupervised learning, the output is not known. The learning is simply carried out by using input data. 19
ANNs consist of a large class of different architectures. However, most research related to predicting yarn properties focuses on the use of multilayered perceptron neural networks (MLPNNs) trained by back-propagation learning algorithms. Numerous applications of MLPNNs in developing models of predicting yarn properties have been reported. 20–33 Zeng et al. 20 presented the prediction models of air-jet spun yarn tenacity based on nozzle pressure, nozzle design and spinning speed. They used two techniques, namely, numerical simulation and the ANN model, and compared these models in respect to prediction accuracy. They concluded that the predicted and experimental values of yarn tenacity were relatively similar. Babay et al. 21 developed a linear regression model and an ANN model to predict cotton yarn hairiness from fiber properties measured by an high-volume instrument (HVI) system. They achieved good prediction accuracy by using the ANN model. Dayik 8 reported a prediction model of cotton yarn strength from fiber properties measured by an HVI system. Furferi and Gelli 22 studied the prediction of strength of different yarn compositions. Majumdar and Majumdar 9 used a linear multiple regression algorithm, a mathematical model, and an ANN model to predict the breaking elongation of ring-spun cotton yarns from fiber properties measured by an HVI system. They found that the prediction accuracy was best for the ANN model followed by the statistical and mathematical models, respectively. Gharehaghaji et al. 23 researched the prediction performance of ANN and multiple linear regression models for breaking elongation and breaking strength of cotton-covered nylon core yarns. They considered the count of core part, the count of sheath part, and the twist factor as input data and an MLPNN as the ANN structure. They found that the prediction performance of the ANN model was better than that of the linear model. Yadav and Kothari 24 presented a prediction study on air-jet textured polyester yarn properties, which included instability, physical bulk, and tenacity. They compared prediction performance of the MLPNN with the regression model based on the response surface design. They concluded that the mean square errors in MLPNN were higher in number than the number of errors that occurred in the response surface design model. Beltran et al. 25 predicted yarn neps, unevenness, tenacity, elongation at break, and thin and thick places of worsted yarn by using a MLPNN and a special program named Sirolan Yarnspec. They obtained better prediction accuracy using the MLPNN than with the Sirolan Yarnspec. Ramesh et al. 26 studied the prediction of breaking elongation and breaking load of air-jet spun yarn. In the study, blend, yarn count, and front and back nozzle pressures were considered as input data. Ramesh et al. achieved a good prediction performance. Shanbeh et al. 27 predicted the breaking strength and mass irregularity of cotton rotor-spun yarns containing cotton fiber recovered from the ginning process. They developed an ANN model by using rotor diameter, rotor speed, naval type, and yarn count as input data. Desai et al. 28 developed an ANN model to predict cotton yarn tenacity and unevenness from fiber properties measured with an HVI system. They compared the predicted output data with the actual data using statistical analyses. Ureyen and Gürkan 29,30 compared the ANN and linear regression models for predicting ring-spun yarn hairiness, unevenness, and tensile properties by using ANN model including back-propagation algorithm. Khan et al. 31 developed an MLPNN model to predict the hairiness of worsted yarns. Cheng and Adams 32 predicted yarn strength and presented the relationship between yarn strength and fiber properties by using ANN model including back-propagation algorithm. Mwasiagi et al. 33 tried to predict the elongation of ring-spun yarn from fiber properties. It is obvious from this discussion that the MLP type of neural networks have been used often. However, MLPNNs have some disadvantages, such as slow training speed, local minimal convergence behavior, sensitivity to the randomly selected initial weight values, and difficulty in explicit optimum network configuration. 18 To solve the problems in all mentioned investigations, an radial basis function neural network (RBFNN), which is another ANN architecture, is proposed by many researchers from different engineering fields. 18 An RBFNN has only one hidden unit, while an MLPNN has one or more hidden layers. The output layer of an RBFNN is linear, while the output layer of an MLPNN is nonlinear. 18 These characteristics provide RBFNNs with advantages, such as simple architectures, fast training speeds, near-optimal solutions, and easy optimization of topology. 18 Therefore, an RBFNN has been used extensively in systems modeling and prediction studies for many different engineering applications. 18,34–43
When the aforementioned studies are considered in respect to input and output data, it can be noted that most researchers have concentrated on the prediction of yarn tenacity and elongation from HVI fiber measurements, whereas fewer investigations on predicting yarn properties from AFIS fiber measurements have been conducted.
The focus of this study is to predict the tenacity and hairiness values of carded yarn from HVI and advanced fiber information system (AFIS) fiber measurements by using the RBFNN modeling method and comparing the performance of predicting yarn properties from HVI fiber measurement values with those of AFIS fiber measurement values.
1. Materials and methods
1.1 Materials
Fiber properties measured by using HVI and AFIS 38 and the dataset for RBFNN modeling
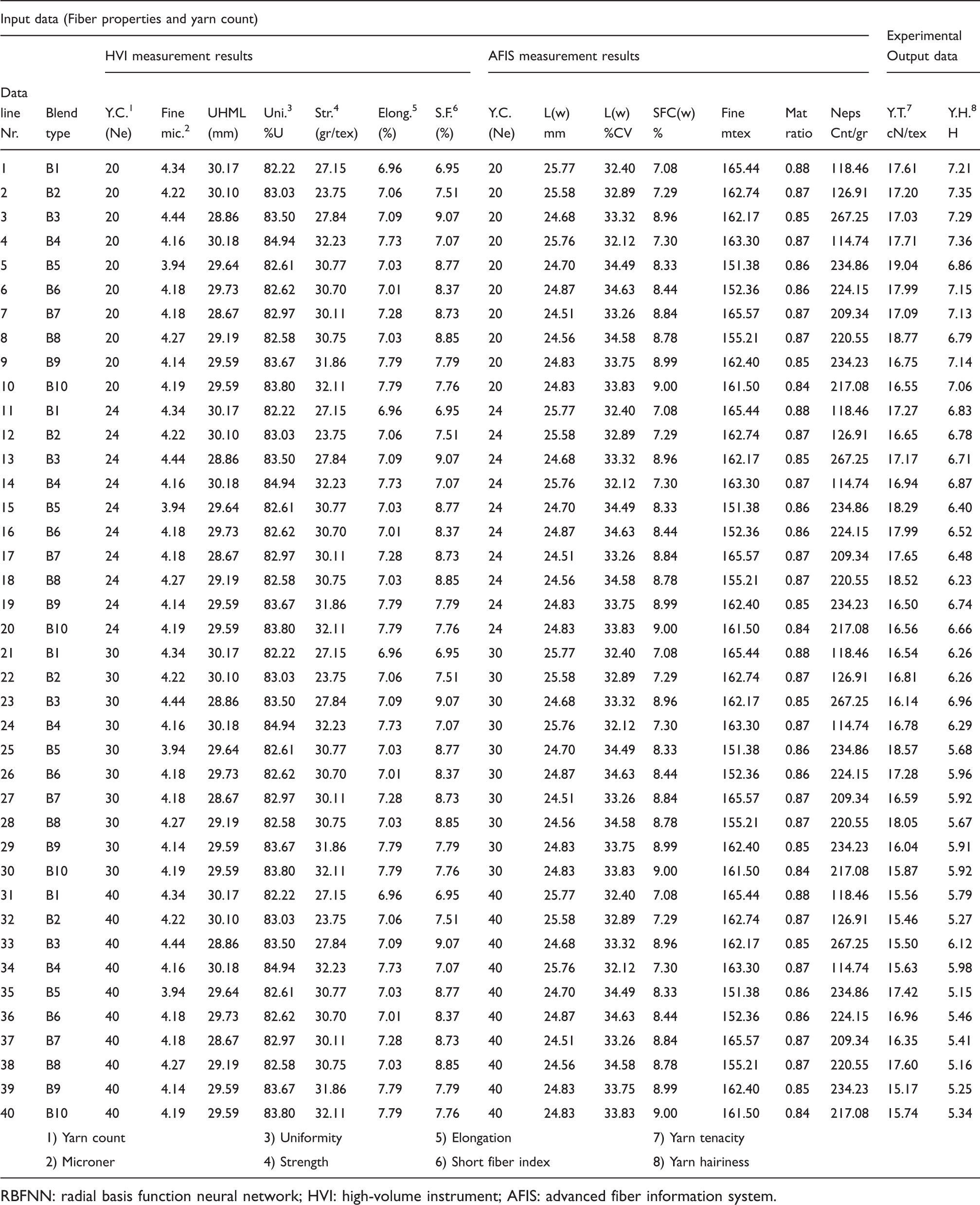
RBFNN: radial basis function neural network; HVI: high-volume instrument; AFIS: advanced fiber information system.
1.2 Method
This section contains two main parts. In the first part, information about the RBFNN is presented. In the second part, the implementation of the RBFNN in this study is explained.
1.2.1 RBFNNs
In this study, RBFNNs are used as the ANN structure. Overall neural network structures, RBFNNs have proven to yield successful results in function approximation type problems. 18,34–43
RBFs were first used to solve multivariable interpolation problems.
45
RBFNNs could be seen as a sensible alternative to the mentioned attempts to use complex polynomials for function approximation. The schematic diagram of the RBFNN for one output is given in Figure 1.
45
Schematic diagram of the radial basis function neural network for one output.
45
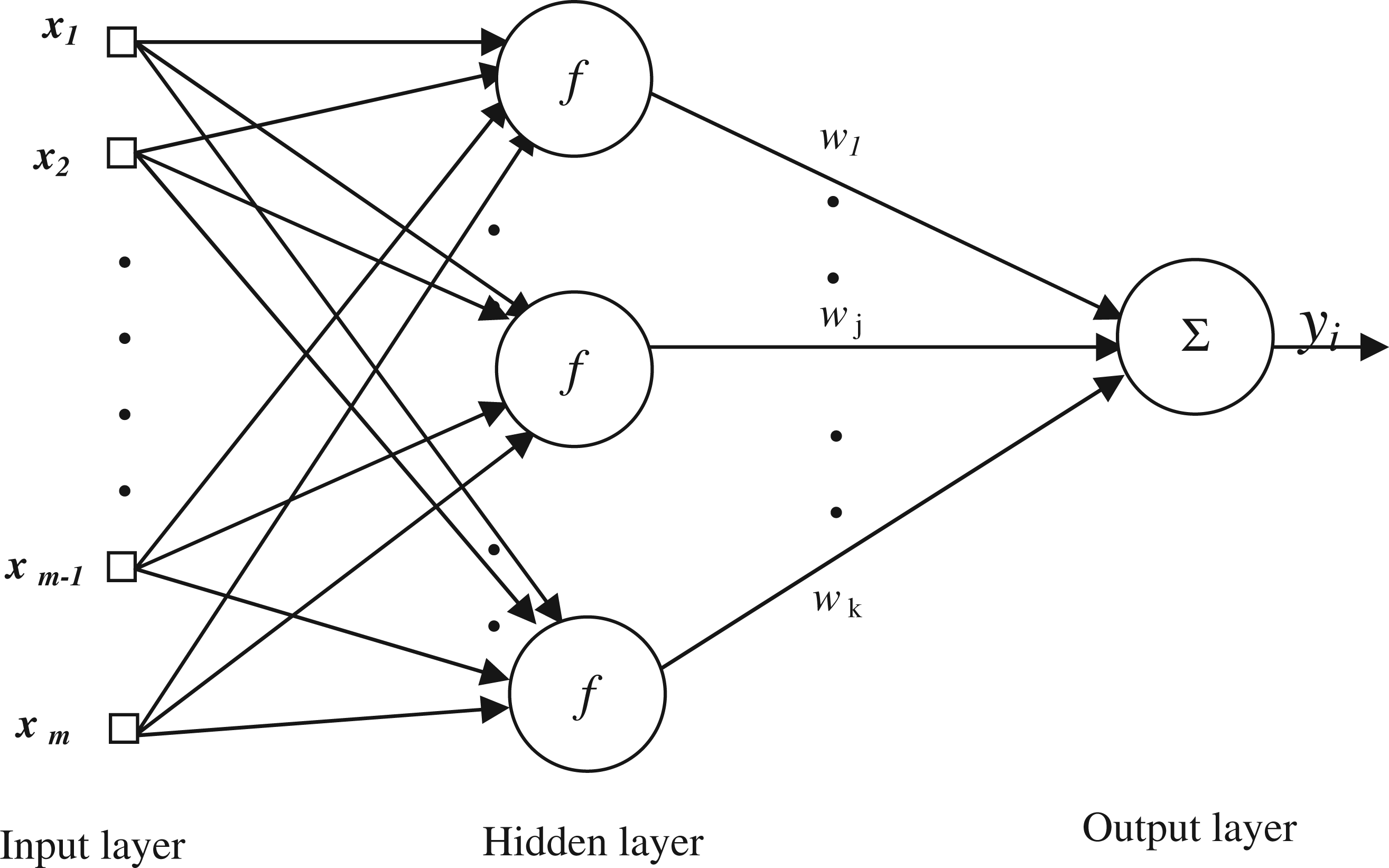
The RBFNN structure contains three layers: the input layer, the hidden layer, and the output layer. The input layer is made up of source nodes that connect the structure to its environment. The hidden layer carries out a nonlinear transformation from the input space to the hidden space. The third layer, the output layer, provides the response of the network to the activation pattern applied to the input layer. 45 There is only one hidden layer that uses neurons with RBF activation functions. A function is called RBF if its output depends on the distance of the input from a given stored vector. Different functions such as multiquadrics, inverse multiquadrics, and biharmonics could be used as a RBF. 39
The commonly used RBFNN function is the Gaussian function. The Gaussian function approaches 0 for large distance, r, values. Thus, even for the input patterns that are different from all teaching patterns, the learning will be still simple to predict. Additionally, the Gaussian function can generate beneficial results without the use of shortcut connections between the input and output layers.
46
A Gaussian function in which the output of the j
th hidden unit can be written as
45,46
σ
i
is the width of the RBF at the i
th hidden unit,
ci
is the center of RBF at the i
th hidden unit (ci
∈ ℜ1×n
),
j is index of the number of hidden units.
k is the maximum number of hidden units,
i is index of the number of input data,
n is the number of input variables,
m is the size of dataset, and

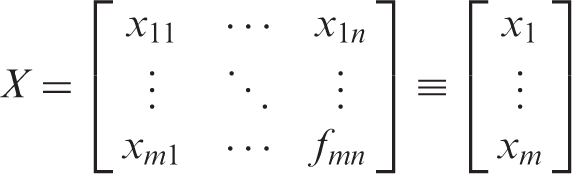
In this case, the distance between the ith
data and j
th centers could be written as

So, 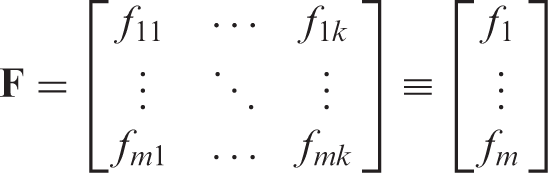
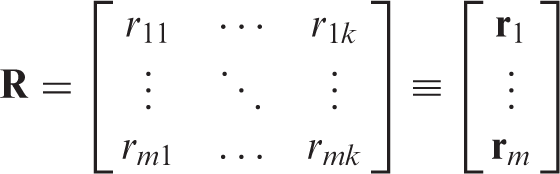
From equation (1), the generated values of fij
is written in the matrix form as follows
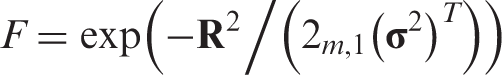
The RBF that is computed by the j
th hidden unit using equation (1) is maximum, when the input vector xi
is close to the center cj
of that unit. The output of an RBFNN can be computed as a weighted sum of the hidden units
45
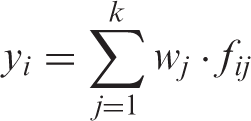
One of the most important factors affecting the prediction performance of a RBFNN model is the number of neurons because they form the main construction of the RBFNN model. Many methods such as evolutionary algorithms 40,41 and k-fold cross-validation were proposed to determine the number of neurons and their centers. 42 In our study, a three-fold cross-validation (3CV) method has been used. The method is explained in detail in Section 1.2.4, “Determining the training and testing dataset”.
1.2.2 Implementing the RBFNN method for modeling
In this method, the yarn tenacity and hairiness values, which were experimentally measured by using USTER tensorapid and Uster tester 3, respectively, were predicted using the RBFNN method. The RBFNN design process involved six steps. These were
1. Determining the input and output dataset from experimental values 2. Determining the training and testing dataset 3. Normalization and renormalization of the data 4. Training 5. Testing the models 6. Determining the best model 7. Creating the stages of modeling, as shown in Figure 2. Schematic representation of the modeling study.
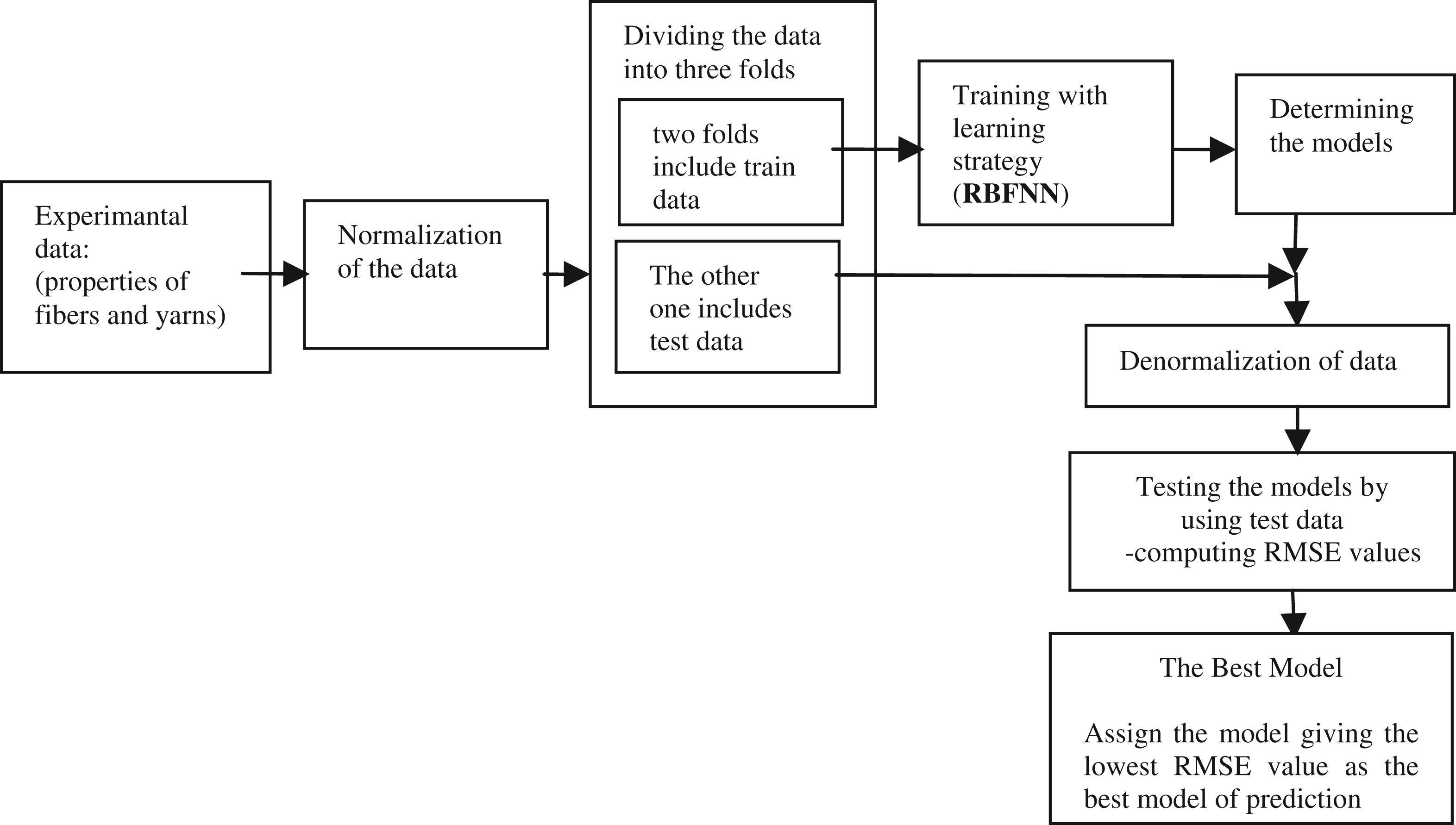
1.2.3 Determining the input and output dataset from experimental values
The four prediction cases for radial basis function neural network modeling

The dataset for the RBFNN modeling was formed by considering the four cases. Table 1 shows the dataset.
1.2.4 Determining the training and testing dataset
In the modeling study, some of the experimental data was used for training, and the other experimental data was used for testing. Many methods in literature proposed this to select data for training and testing. In this study, a k-fold cross-validation method was applied to select training and testing data for many epochs (epoch refers to each trial and error for decreasing the mean square error (MSE) of the ANN in the batch processing mode) in many numbers of neurons because this method was used successfully in previous applications. 39–41 k-fold cross-validation is a technique to develop the holdout method. In this method, the data set is separated into k subsets, and the holdout method is repeated k times. Each time, one of the k subsets is considered as the test set and the other k - 1 subsets are incorporated to create a training dataset. Then in order to predict accurately, the average error corresponding to k trials is computed. Each data point is included in a test set definitely once and is included in a training set k - 1 times. The variance of the resulting estimate is reduced as k is increased. A variant of this method is to randomly divide the data into a test and training set k times. The advantage of doing this is that we can independently choose how large each test set is and how many trials one averages. 47,48
Three randomly chosen folds for the three-fold cross-validation method
Table 3 was generated from Table 1, and the numbers in Table 3 refer the line numbers of experimental data in Table 1.
Training and test datasets for the three-fold cross-validation method

1.2.5 Normalization and renormalization of the data
The purpose of the normalization of the data is to prevent the higher values to weigh down the influence of lower values and to maintain the symmetry of the activation function. In this study, linear normalization was used. All values in a variable were divided by its maximum value to be normalized to the same range values [0, 1]. After training was performed, normalized network outputs were renormalized back to their original values.
1.2.6 Training
The purpose of an RBFNN model is to carry out a nonlinear function approximation. For this reason, firstly, W, σ, and C are determined by using a supervised learning algorithm. Therefore, the sum squared is minimized by a gradient descent method.
49
For this purpose, equation (8)
49
was used

Firstly, all center values were selected randomly, making sure that all of the center values were in the input range. The spread of the jth
center c
j
is denoted as σ
j
and it is mainly related to the number of RBF functions. The σ vector is given as
Equation (10) provides an acceptable initial spread in which σ
j
increases as the number of input variables increases or the number of hidden units decreases. Initially, all w values were selected randomly. So, the gradient descent learning for the three parameters can be given as
43


1.2.7 Testing the RBFNN models
Testing of the trained ANN requires the inputs of the test set be presented to the RBFNN. The measured output of the test set is compared to the output produced by the RBFNN in order to see if the RBFNN’s output is acceptable. If the output produced by the trained RBFNN is correct within accepted error ranges, the RBFNN can then be used in modeling the dataset.
The prediction performance is analyzed by using the root mean square error (RMSE) for only single output RBFNN works, which is given as
49
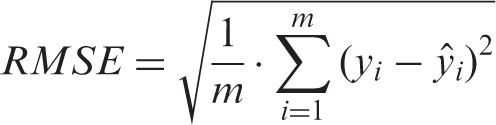
In this study, the best model that gives the minimum RMSE is determined by comparing RMSE values of the test data.
2. Results and discussion
The results of modeling study are presented in two main stages. These are
Determining the models: This stage contains the following studies:
– Computing RMSE values of each application – Determining the mean RMSE values of a given epoch – Determining the minimum mean RMSE value in a given neuron – Determining the best RBFNN model for a given case Testing the RBFNN model
After these stages, the RBFNN model was compared with the model developed by using linear regression analysis.
Figure 3 shows the stages of modeling studies for case 1 as an example.
The stages of modeling studies for case 1.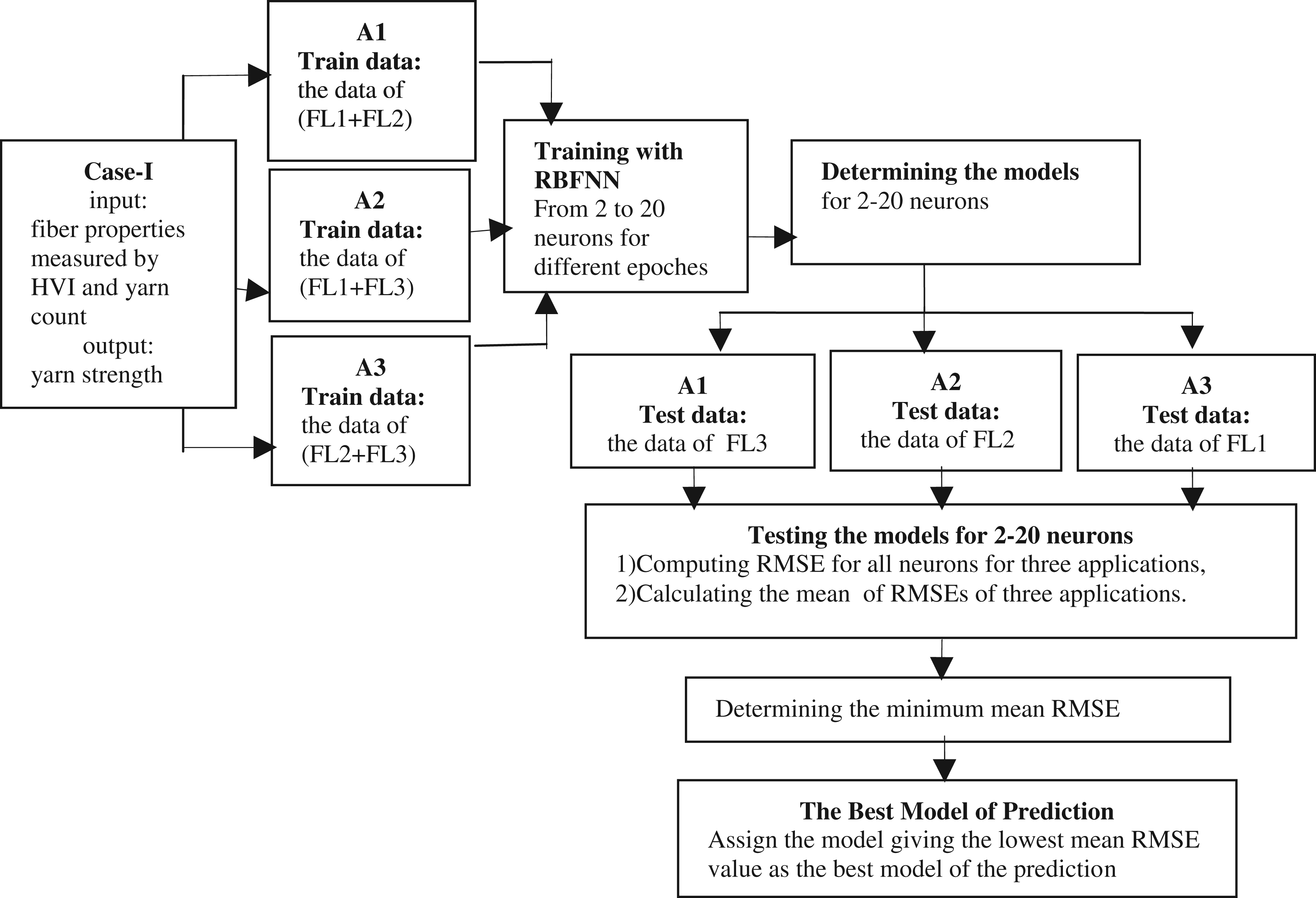
2.1 Determining the models with RBFNN
2.1.1 Computing RMSE values of each application
For determining the prediction models, test and train RMSE values of each three applications were computed in different epochs for a given neuron. As an example, Table 5 presents the parameters selected for the modeling study of case 1. Figure 4 shows the test RMSE and train RMSE values of application 2 (A2) in many epochs of two neurons for case-I.
The test and training root mean square error (RMSE) values of application-2 (A2) in two neurons for case 1. The parameters selected for the modeling study of case 1
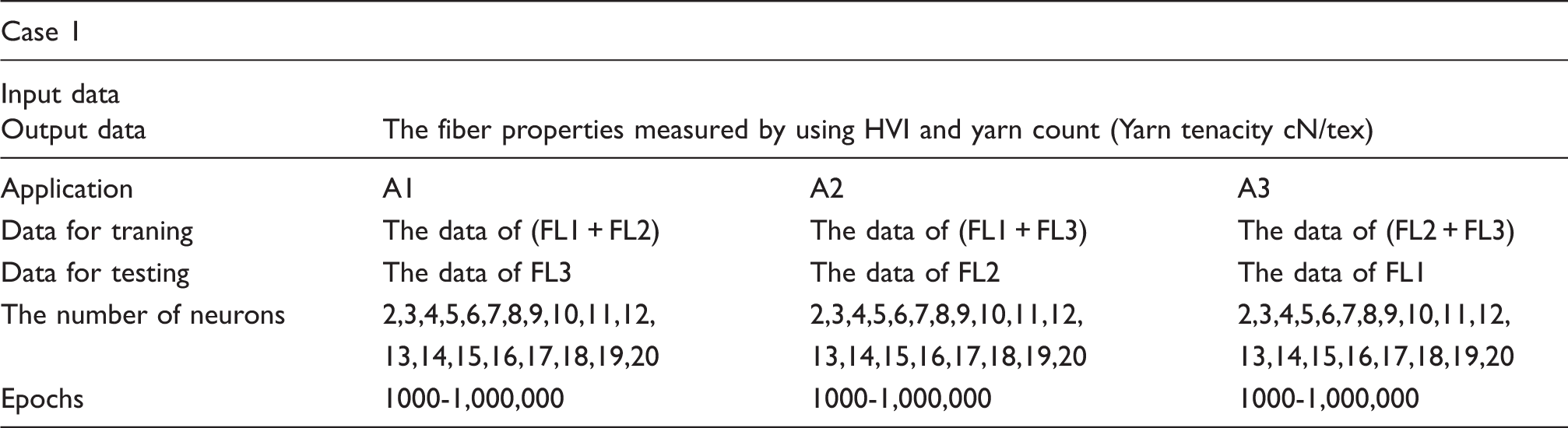
It was observed that the minimum TSTRMSE, the test RMSE, was achieved at epoch 200,000, and the test error started to level-off or increase after that epoch. The test RMSE value at that epoch was then determined to be the RMSE value for this application. The same computations were carried out to find RMSE values of each case corresponding to various neuron configurations. A similar observation was made for all of the other applications of all cases, and therefore, the results were noted up until the epoch value of 200,000.
2.1.2 Determining the mean RMSE values of a given epoch
The mean RMSE values were computed by considering the RMSE values of three applications in a given epoch of a given neuron. In equations (15) and (16), computing the mean RMSE value in 5000 epochs of two neurons for case 1 is presented as an example


where
TRNRMSE is the RMSE value for training data, TSTRMSE is the RMSE value for test data, the number of neurons, A1, A2, A3, is the application number, and Mean of TSTRMSE =
The mean test root mean square error (TSTRMSE) values of each epoch in two neurons for case 1

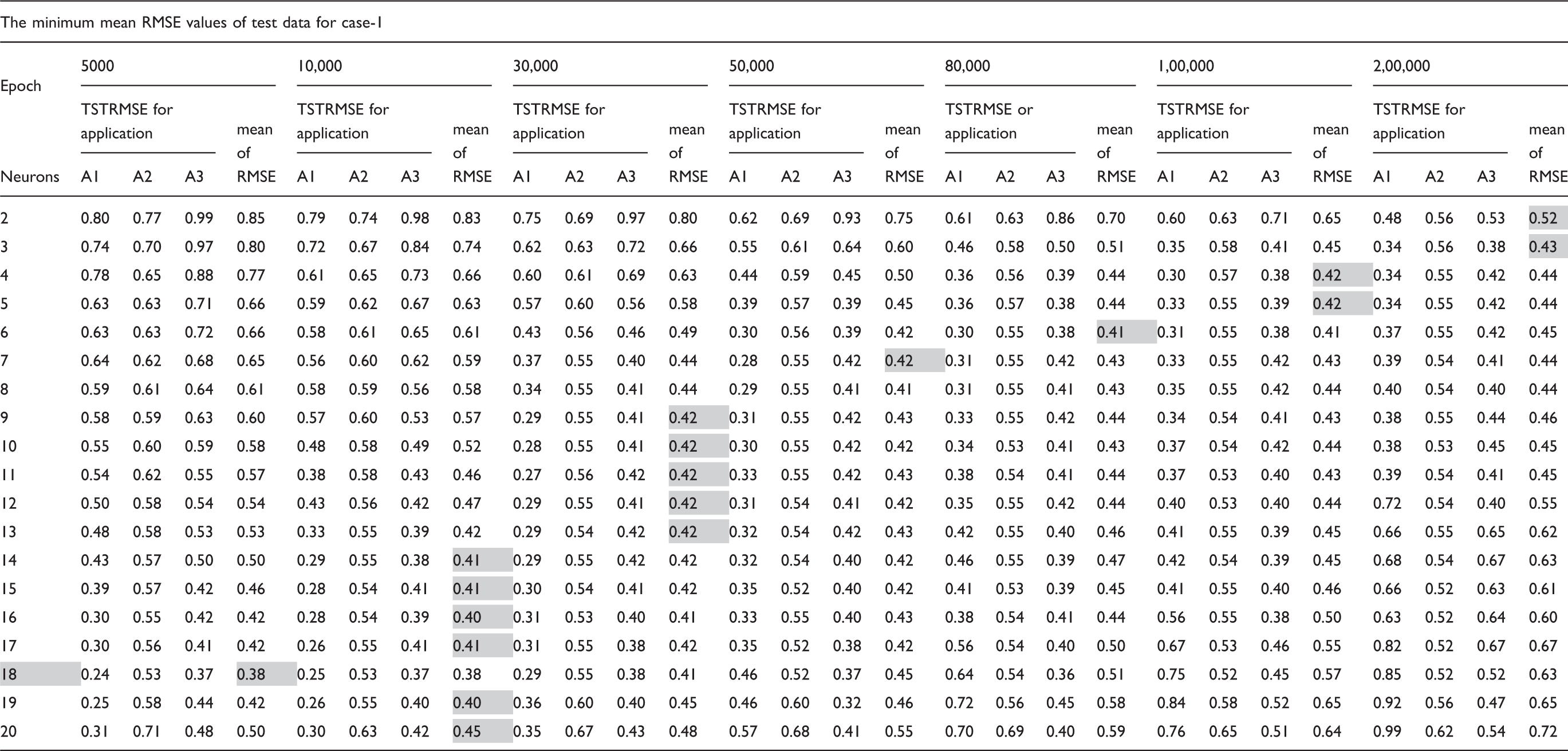
2.1.3 Determining the minimum mean RMSE value in a given neuron
The minimum mean of test root mean square error (TSTRMSE) values of all of the neurons for case 1
2.1.4 Determining the best RBFNN model for a given case
The best neuron, which represented the best prediction model, was determined by selecting the neuron giving the lowest minimum mean TSTRMSE values among all the neurons.
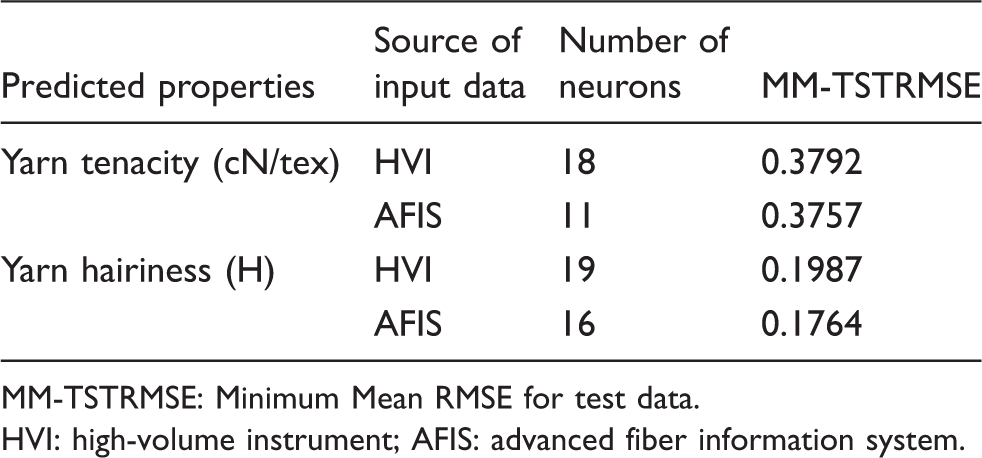
Table 7 presents RMSE values for case1, which is the prediction of yarn tenacity by using HVI fiber measurement results and yarn counts. A detailed analysis of this table leads to the conclusion that the best RBFNN model for case1 is the one with 18 neurons (hidden layers), given the minimum RMSE value.
For the other three cases, a detailed RMSE table like Table 6 was built. Upon analysis of the tables, the best networks for these cases have been determined. Figures 4 and 5 summarize these tables for four cases. Figures 5 and 6 show the minimum mean RMSE values and the number of neurons corresponding to them on the prediction of yarn tenacity and on the prediction of yarn hairiness, respectively.
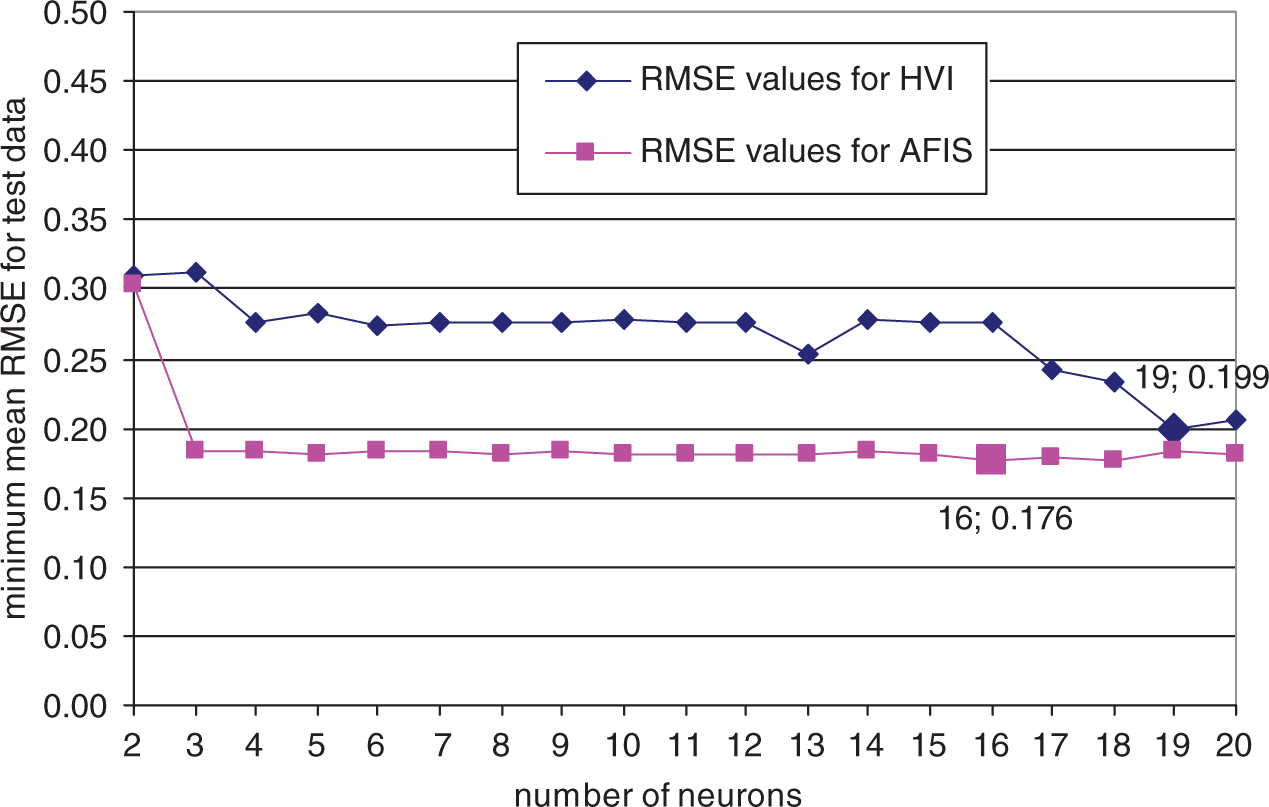
The minimum mean root mean square error (RMSE) values of test data for predicting yarn tenacity model. HVI: high-volume instrument; AFIS: advanced fiber information system. The minimum mean root mean square error (RMSE) values of test data for predicting yarn hairiness model. HVI: high-volume instrument; AFIS: advanced fiber information system.
The best radial basis function neural network model for each of the four cases
MM-TSTRMSE: Minimum Mean RMSE for test data. HVI: high-volume instrument; AFIS: advanced fiber information system.
It is seen from Figures 4, 5, and 6 and Table 8 that the predicting performance of HVI and AFIS fiber measurements for yarn hairiness is better than the predicting performance for yarn tenacity.
Figure 5 illustrates that the minimum mean TSTRMSE values of predicting yarn tenacity from HVI and AFIS fiber measurement are close but are received in different numbers of neurons.
When Figure 6 is analyzed, it shows that the minimum mean TSTRMSE value of predicting yarn hairiness from AFIS fiber measurements and yarn counts is a bit smaller than that from HVI fiber measurements and yarn counts.
2.2 Testing RBFNN model
The dataset for testing of the selected radial basis function neural network models
HVI: high-volume instrument; AFIS: advanced fiber information system.
The root mean square error (RMSE) values of unseen test data in the best radial basis function neural network models for the four cases

HVI: high-volume instrument; AFIS: advanced fiber information system.
Figures 7 and 8 show the predicted and measured yarn tenacity and yarn hairiness, respectively.
The predicted and measured yarn tenacity values. HVI: high-volume instrument; AFIS: advanced fiber information system. The predicted and measured yarn hairiness values. HVI: high-volume instrument; AFIS: advanced fiber information system.
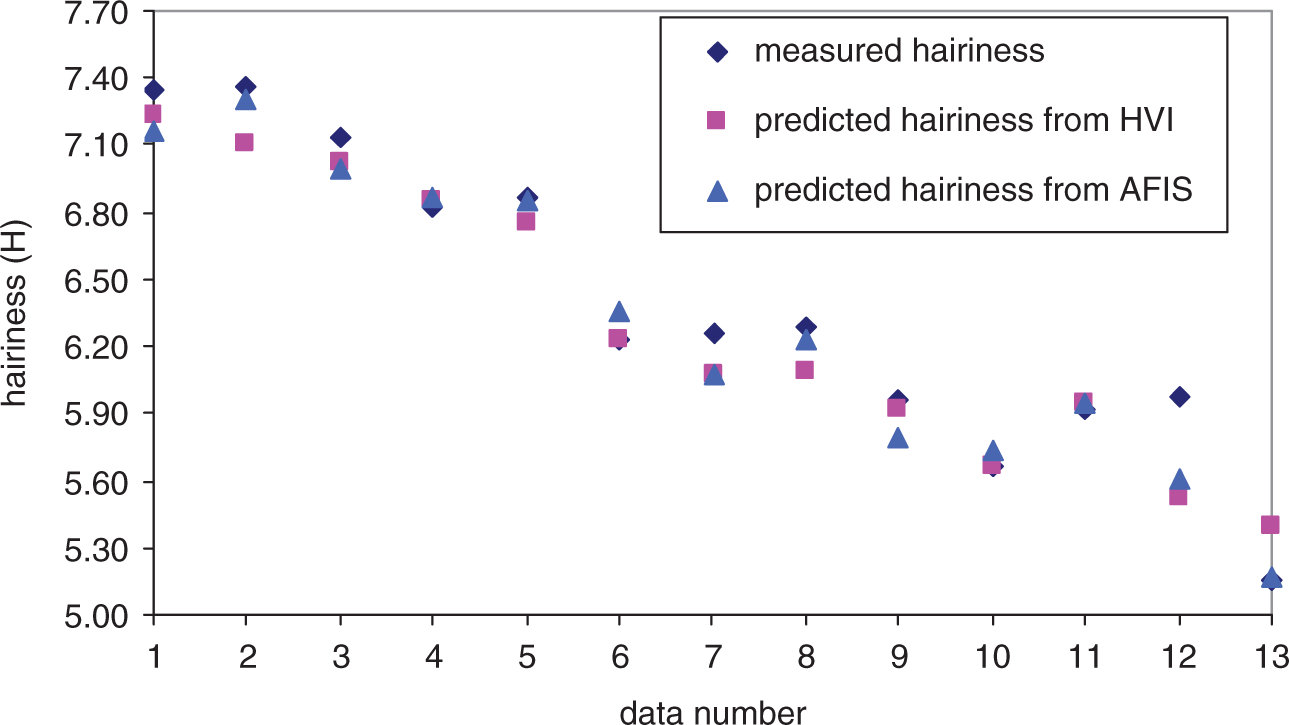
With a detailed analysis of the figures, it can be seen that the measured and predicted values are very close (well correlated) and the changes in curves of measured and predicted values are very similar in both of figures. So, it can be stated that there is no remarkable difference between HVI and AFIS fiber measurements in respect to the predicting performance for these four cases.
2.3 Determining the models by linear regression analyses
Linear regression develops the models that represent the relationship between a scalar variable y and one or more elucidatory variables shown, x. The case of one explanatory variable is called a simple linear regression. More than one explanatory variable is called a multiple linear regression. For this study, multiple regression models were selected because there was more than one independent variable.
44,49
In linear multiple regression, a simple model relates several independent variables to a dependent variable with a straight line given as
44,49
y is the predicted output (dependent variable),
xn
is the input data (independent variable),
n is the number of independent variables,
β0
is the y-intercept of the line,
βn
are the coefficients of the independent variables, and
ε is the random error component.
In this study, linear regression analyses were carried out using SPSS 16.0 program.
2.4 Determining the linear regression model by using the dataset of training
Statistical analysis results in linear regression analysis
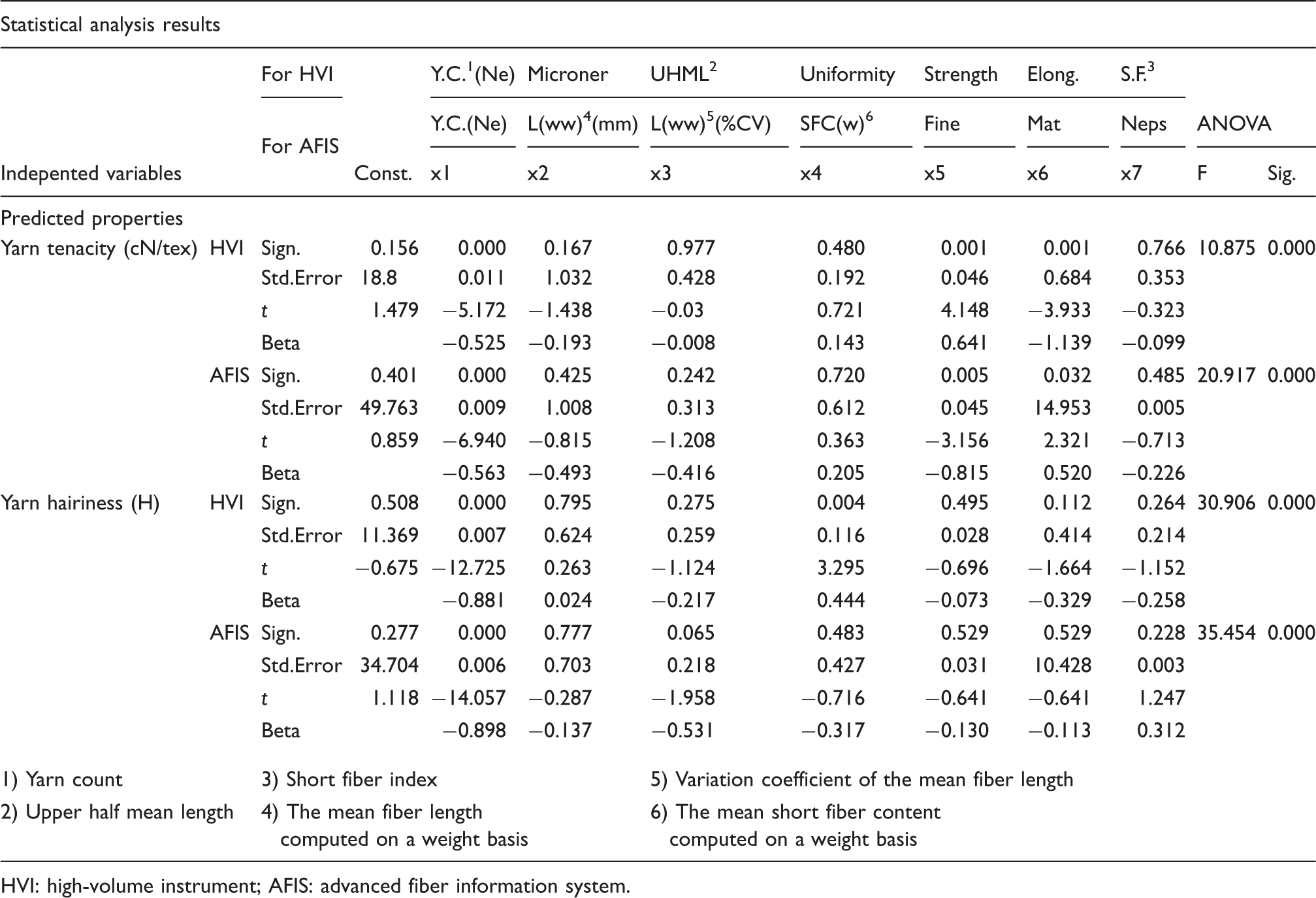
HVI: high-volume instrument; AFIS: advanced fiber information system.
The models obtained in linear regression analysis

HVI: high-volume instrument; AFIS: advanced fiber information system.
From the statistical analysis results in Table 11 and the regression equations in Table 12, it can be seen that the relationships between some fiber characteristics and yarn properties are contrary to expectation. For example, we found a negative effect between fiber elongation results in HVI and yarn tenacity and between mean length results in AFIS and yarn tenacity. The other example is that there is an unexpected negative effect between fiber diameter results in AFIS and yarn hairiness. In addition to the relationship between fiber characteristics and yarn properties, unexpected results were obtained in terms of impact of fiber characteristics on yarn tenacity and hairiness. For example, as known, fiber diameter in AFIS has very high effect on yarn hairiness. However, we found a low influence degree on yarn hairiness for this fiber characteristic. It is the well-known fact that there are very high autocorrelations among fiber properties. These autocorrelations can cause some illogical signs on significant variables of regression equations. Therefore, some of the highly correlated fiber properties should be excluded from the group of independent variables by pre-study before regression analysis. However, in RBFNN modeling, all independent variables were used without considering their autocorrelations between them. Same independent variables were selected for linear regression analyses to compare with RBFNN. Because of the reasons introduced above, the linear regression models achieved in this study can not be used to predict.
2.5 Testing the linear regression model
Correlation of the coefficients of the radial basis function neural network (RBFNN) and the linear regression analysis for testing
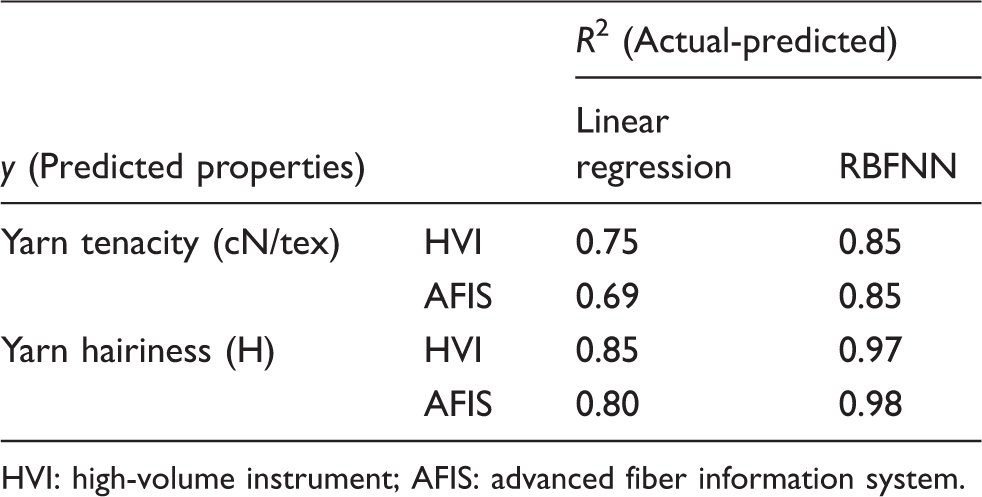
HVI: high-volume instrument; AFIS: advanced fiber information system.
Figures 9 and 10 show the comparisons between measured output data and output data predicted using the RBFNN and linear regression analysis.
Comparison between measured and predicted yarn tenacity values for HVI dataset. HVI: high-volume instrument; RBFNN: radial basis function neural network. Comparison between measured and predicted yarn tenacity values for AFIS dataset. RBFNN: radial basis function neural network; AFIS: advanced fiber information system.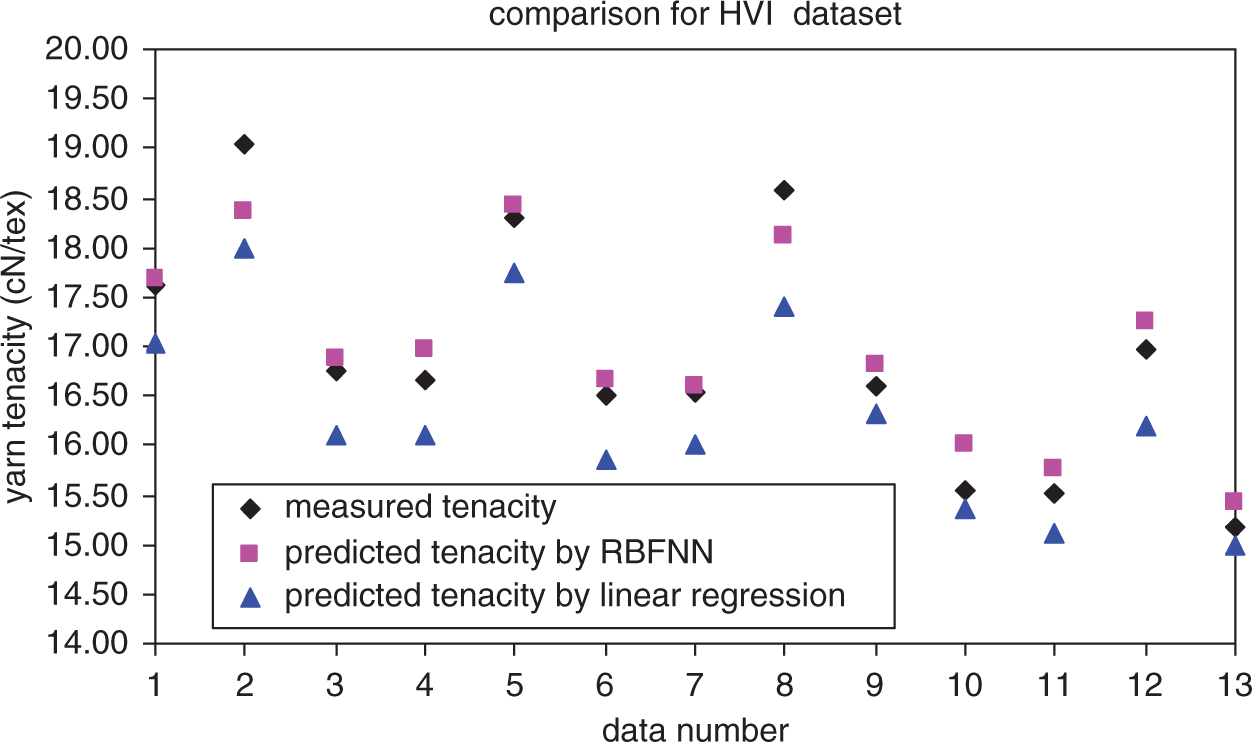

With a detailed analysis of both the HVI and AFIS datasets in these figures and Table 13, it can be noted that the prediction performances of yarn tenacity in RBFNN models are better than those in linear regression models. The information in Table 13 illustrates that the prediction performances of hairiness for both HVIs and AFISs are better than those of the yarn tenacity, similar to RBFNN analysis.
3. Conclusion
An ANN model was developed to predict the strength and hairiness properties of carded cotton yarn. Data generated by using HVI and AFIS fiber measurements were used in an ANN model as input parameters.
The model in this study, both AFIS and HVI input data, performed well at predicting the strength and hairiness properties of carded cotton yarn. For both fiber measurement systems, no significant differences between predicting yarn strength and yarn hairiness were observed.
The results from the ANN model showed that predicting the yarn hairiness is much more accurate compared to predicting the yarn strength. There are two explanations for this. First, as is commonly known, there is a high correlation between yarn hairiness and yarn count. Therefore, yarn count is an important parameter that affects yarn hairiness. The second, and much more important explanation, is the fact that there is an important relation between the coefficient of yarn twist, hairiness, and strength. Additionally, the relationship between the coefficient of twist and yarn strength is stronger than the relationship between the coefficient of twist and yarn hairiness. However, in this study, only one twist factor (4.34αe) for all yarns was considered. Therefore, tenacity values for all yarns were similar as seen Table 3.
Models can be used for in-house carded cotton yarn development to decrease yarn production cost and time. Also, the RBFNN model has been explained to help researchers who work in this field. This modeling study can be expanded to wider yarn count ranges, other yarn characteristics (e.g., uniformity or neps), different twist factors, and machine settings. Also, taking into account the same characteristics, similar modeling can be carried out for other cotton yarn types, such as combed yarns and open-end yarns.
Footnotes
Acknowledgments
We would like to thank everyone at Abalioglu Yem, Soya and Tekstil Spinning Mill, Denizli, Turkey for their support of our research on fiber measurements of HVIs and AFISs and yarn measurements on Uster systems. We would like to thank Sezai Tokat of Pamukkale University, Computer Engineering Department, in Turkey for his help with the ANN modeling system.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.